После
описания таблиц выполняется последний
этап проектирования
— разработка взаимосвязи между Таблицами,
составляющими
одну БД
СКЛАД. Результатом
выполнения этого этапа будет
схема, называемая логической
структурой БД СКЛАД (см.
рис, 4.2).
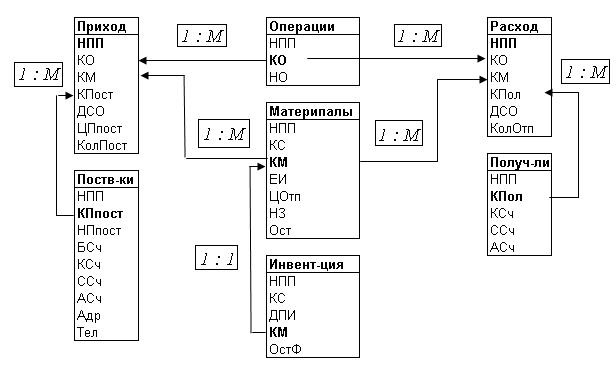
Рис. 4.2. Логическая
структура БД СКЛАД
Как
отмечалось выше, при создана формы
связи между таблицами: «один ко многим»
и «сдан к одному».
В
схеме данных связь между
таблицами
устанавливается на основе
общего
поля, которое
в одной из таблиц обязательно является
ключевым,
то
есть содержит уникальное, неповторяющиеся
значения, и поэтому представляет сторону
«один»; а в другой таблице оно будет
полем
связи, значения
которого могут повторяться, и поэтому
оно обозначает
сторону «многие».
Смысл
логических отношений между таблицами
(описан в разделе 4.2.2)*
Материалы — Приход;
Материалу — Расход;
Инвентаризация — материалы;
Поставщик — Приход;
Получатель — Расход;
Операции — Приход;
Операции — Расход.
Разработкой
схемы данных заканчивается проектирование
таблиц БД
так ютшщсм1ттй «бумажный», этап их
создания. Схему данных полезно
согласовать с пользователем, после чего
можно приступить непосредственно к
созданию БД
См
приложения
5. Создание базы данных склад
Создание
реляционной БД СКЛАД осуществляется в
полном соответствии
с ее структурой, разработанной в
результате проектирования
и определенной составом таблиц и их
взаимосвязями.
БД
создается как новая,
то
есть «с нуля», что определяет стадии ее
формирования:
-
формирование
структуры таблиц; -
загрузка таблиц;
-
создание
межтабличных связей.
5.1. Формирование структуры таблиц
На
этой стадии по материалам
проектирования
формируется состав
полей и задается их описание.
Однако
прежде чем приступить к этой работе
необходимо создать
файл базы данных, так как все реляционные
таблицы хранятся в одном файле.
5.1.1 Создание файла бд склад
1. Сразу
после запуска ПП ACCESS
открывается первое диалоговое
окно Создание
БД
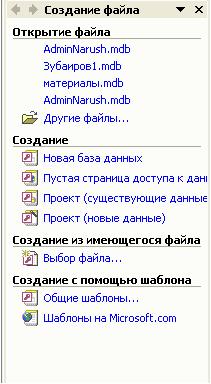
Рис.
5.1. Окно Создание
БД
Если по какой-либо
причине окно не выводится, то следует
выполнить команду Файл
→ Создание
или воспользоваться кнопкой создать
базу данных на панели инструментов.
-
В окне СОЗДАНИЕ
базы данных выбрать закладку Новая
база данных. -
В появившемся
окне Файл
новая база данных
(рис.5.2.) следует выбрать палку для
размещения файла (по умолчанию файл
будет сохранен в папке Мои документы
— воспользуемся ею) или создать свою,
затем задать имя файла новой базы данных
— СКЛАД и нажать кнопку Создать
(тип файла по умолчанию имеет значение
База данных,
что придает файлу расширение .mdb).
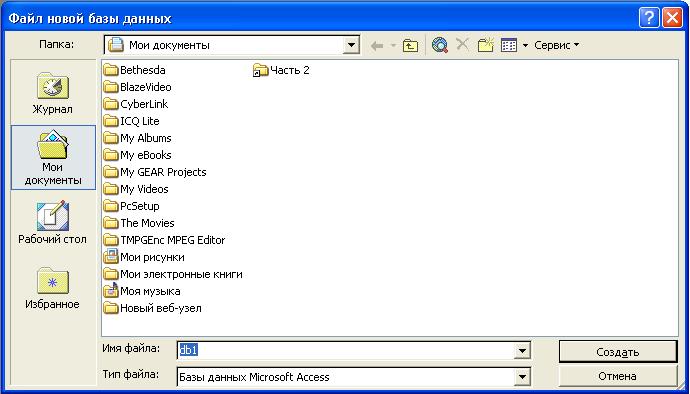
Рис. 5.2. Окно Файл
новой базы данных
-
В
результате выполнения команды Создать
открывается окно СКЛАД: база
данных
(рис. 5.3)
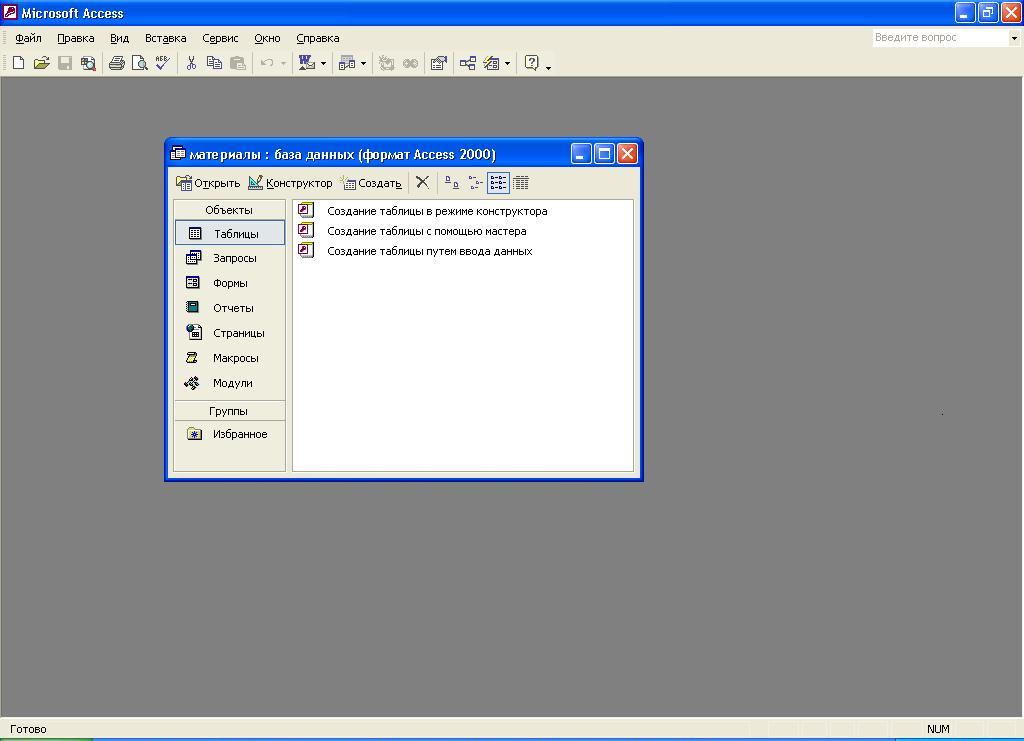
Рис.
5.3. Окно Базы
данных СКЛАД
Именно
с этого окна начинается работа с любыми
объектами базы
данных, в том числе и с таблицами.
5.1.2. Создание структуры таблиц бд
На
этом этапе по каждой таблице задается
состав полей, определяется
последовательность их размещения,
выделяется ключевое поле
и дается описание свойств полей.
1.
Для создания новой таблицы в окне Базы
данных СКЛАД
(рис.5.3)
необходимо выбрать вкладку Таблицы
и
нажать кнопку
![]()
Создать.
В
результате открывается окно Новая
таблица
(рис.5.4),
в котором
представлены режимы создания таблиц.
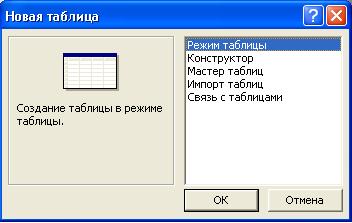
Рис.
5.4. Окно Новая
таблица
Не
рассматривая особенности каждого
режима, выберем Конструктор.
Он
является основным способом создания
таблиц, так как
отличается наглядностью и, позволяет
пользователю самому указывать
параметры всех элементов таблицы.
2.
Выбранный режим Конструктор
открывает
окно Таблица
1: таблица
(рис.5.5).

Рис.
5.5. Окно Конструктора
таблицы —
Таблица
1: таблица
Окно
Конструктора таблицы напоминает
графический бланк, удобный
для создания и редактирования структуры
таблиц. Первоначально
он пуст.
В
верхней части бланка должен; быть
представлен перечень всех полей
(гр. «Имя поля»), их типы (гр. «Тип данных»)
и подсказки к полям
(гр. «Описание»); последние не являются
обязательными к заполнению.
Нижняя
часть бланка содержит список свойств
поля, выделенного
или заполняемого в верхней части.
Некоторые из свойств уже заданы по
умолчанию, однако их можно изменить.
Теперь
подробно опишем порядок формирования
структуры таблиц
БД СКЛАД.
Очередность
создания таблиц значения не имеет.
Поэтому рассмотрим
их в той последовательности, в которой
они разрабатывались
на этапе проектирования.
Начнем
с главной таблицы — Материалы.
Описание ее
структуры представлено в разделе 4.2.
Поле
НПП
*
В первую ячейку гр. «Имя поля» окна
Конструктора таблицы (Таблица
1: таблица) введем
имя поля — НПП.
• Для
того чтобы задать тип
поля надо
щелкнуть мышью в соответствующей
ячейке гр. «Тип данных», что приведет к
появлению
символа списка
![]()
справа
в выбранной ячейке. Щелкнув по этой
кнопке, раскроем список
типов данных и выберем в нем нужный
Счетчик
(рис.5.6а).
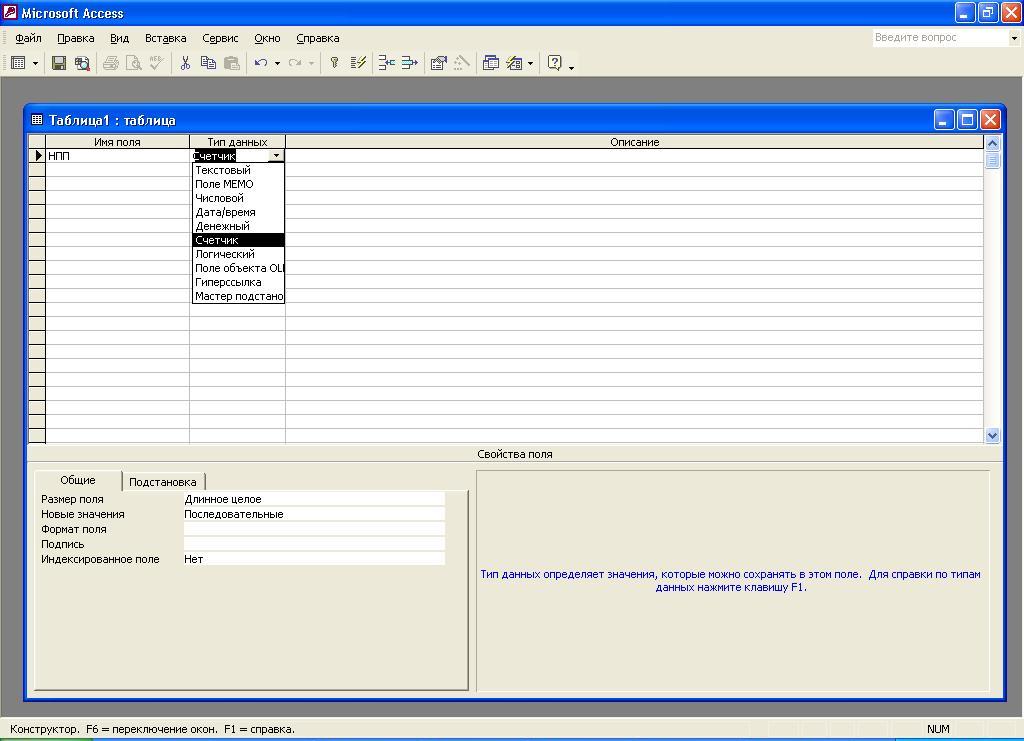
Рис.5.6а.
Окно Конструктора таблицы со
спискам типов данных
После
щелчка по выбранной позиции — счетчик
это
сообщение переносится в ячейку гр. «Тип
данных», которая
соответствует полю НПП.
Одновременно с этим занесением в нижней
части бланка (раздел «Свойства
поля») на
вкладке Общие
автоматически
появляется список свойств
полей типа счетчик
(рис.
5.6б).
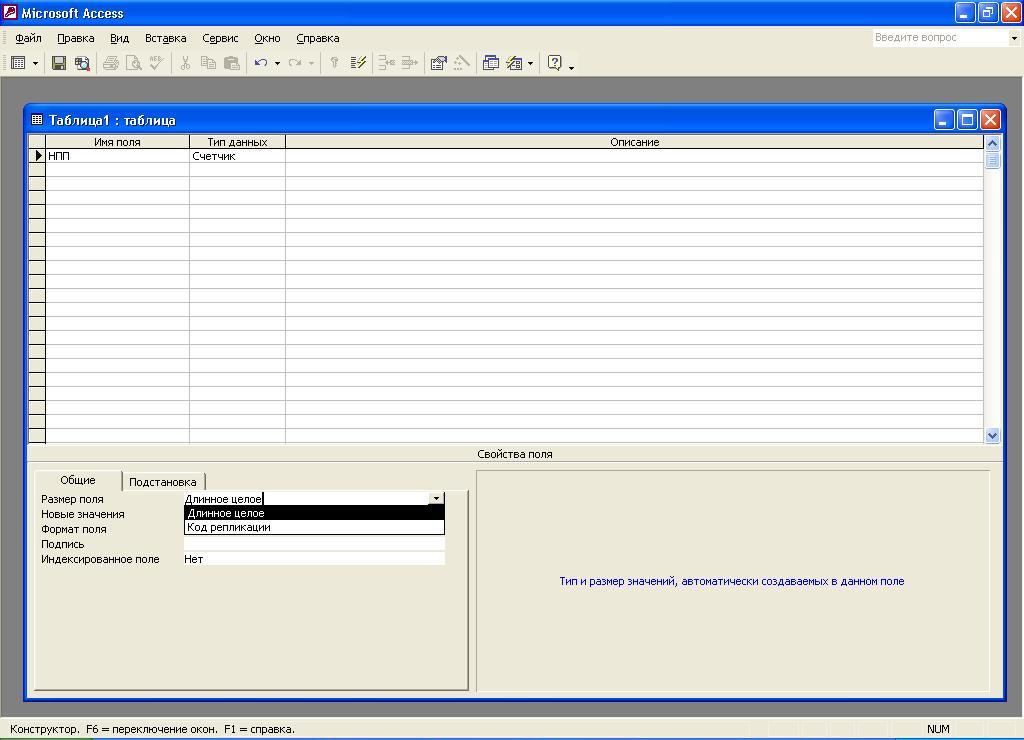
Рис. 5.6б. Окно
Конструктора таблицы со спискам свойств
паля типа счетчик
* Теперь дадим
описание свойств поля НПП типа счетчик:
Размер паля.
Данные шля типа счетчик выполняют;
определенную функцию — автоматическую
идентификацию записей таблицы. Поэтому,
во-первых, счетчик — всегда целое число;
во-вторых, оно может быть как угодно
велико. Эти особенности должны быть
учтены при описании свойства Размер
поля.
Для занесения
размера поля
необходимо:
-
щелкнув по строке
Размер шля, вызвать значок (символ)
списка -
щелкнув по значку
список, вызвать список типов числовых
полей; -
выбрать тип поля
— Длинное
целое.
Новые значения.
Наращивание значения поля происходит
автоматически. Есть два варианта
изменения счетчика: последовательный
и случайный. Нас устраивает первый. Он
устанавливается по умолчанию. При втором
варианте сдерет вызвать список новых
значений и выбрать нужный.
Подпись поля
— заносится: № записи.
Индексированное
поле —
поскольку оно не ключевое, автоматически
После
занесения свойств
поля НПП
окно Конструктора таблицы будем иметь
вид, представленный на рис. 5.6 в.
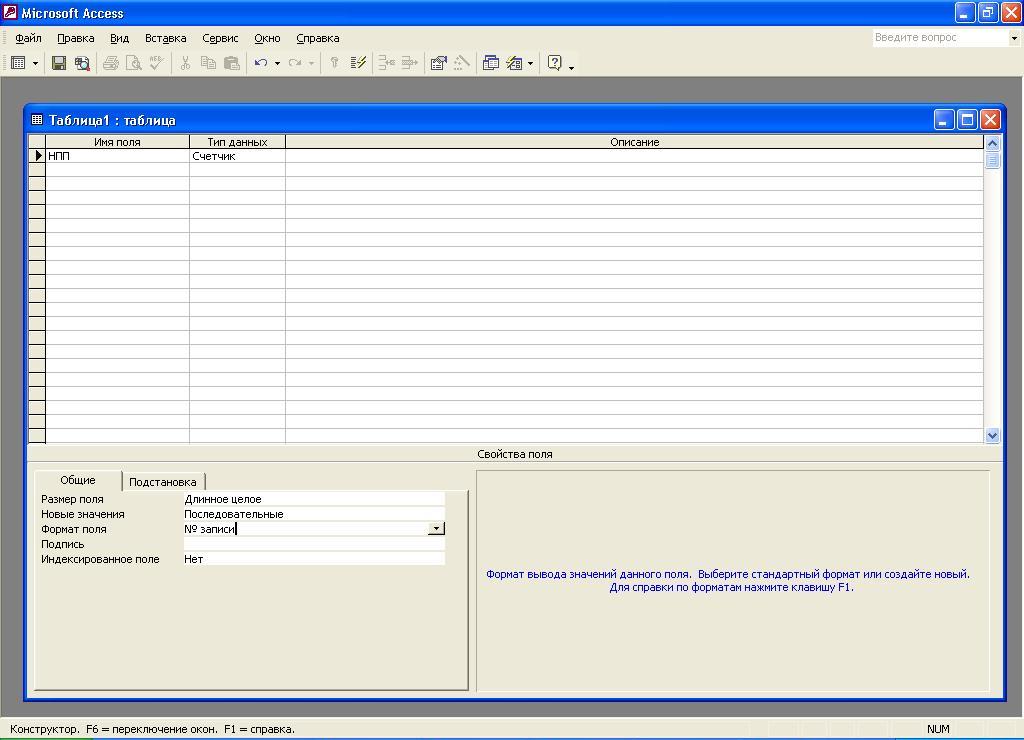
Рис.
5.6 в. Окно
Конструктора
таблицы со
свойствами поля НПП
Поле КС
Описание
поля в окне Конструктора таблицы (Таблица
1: таблица)
занимает вторую строку верхней части
бланка.
Занесение
имени
поля —
КС
и
выбор типа
данных —
текстовый
выполняются
аналогично описанию работы с полем НПП.
Одновременно
с занесением типа поля на вкладке Общие
(раздел «Свойства
поля») автоматически
появляется список свойств полей типа
текстовый
(рис.
5.7а).
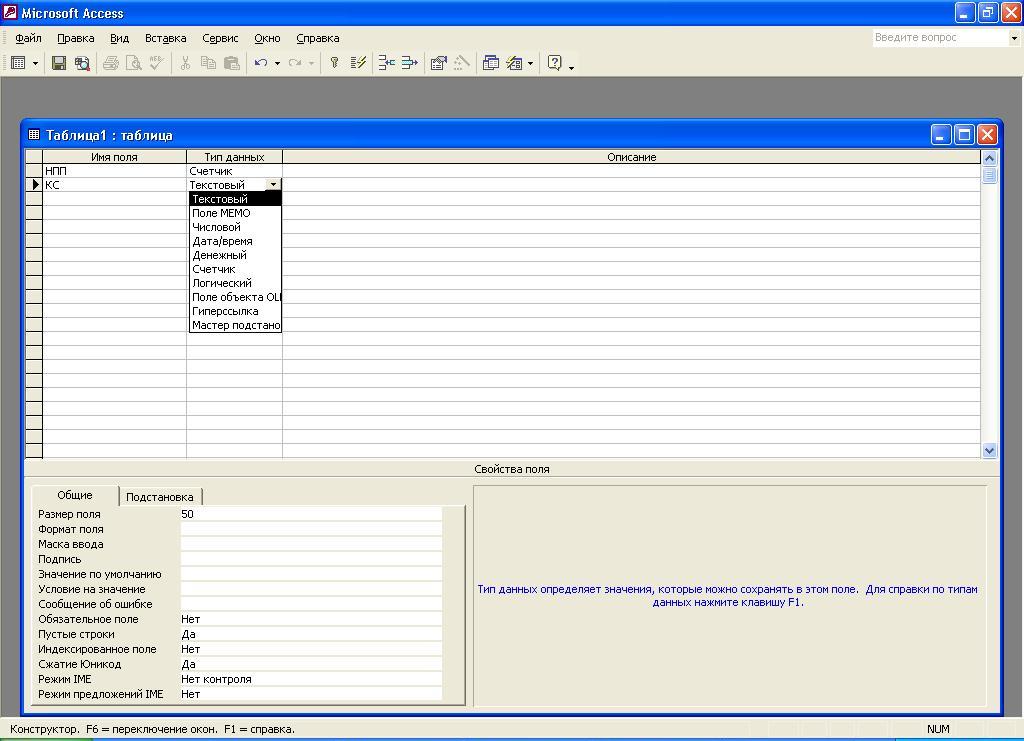
Рис. 5.7а. Окно
Конструктора таблицы со
списком свойств поля типа текстовый
Описание свойств
поля КС:
Размер поля.
Автоматически устанавливается равным
50. Снимем эту размерность и установим
нужную — 2.
Подпись поля —
склад.
Обязательное поле
— нет (устанавливается по умолчанию).
Индексированное
поле- нет (устанавливается по умолчанию).
После занесения
свойств поля КС окно Конструктора
таблицы будет иметь вид, представленный
на рис. 5.76.
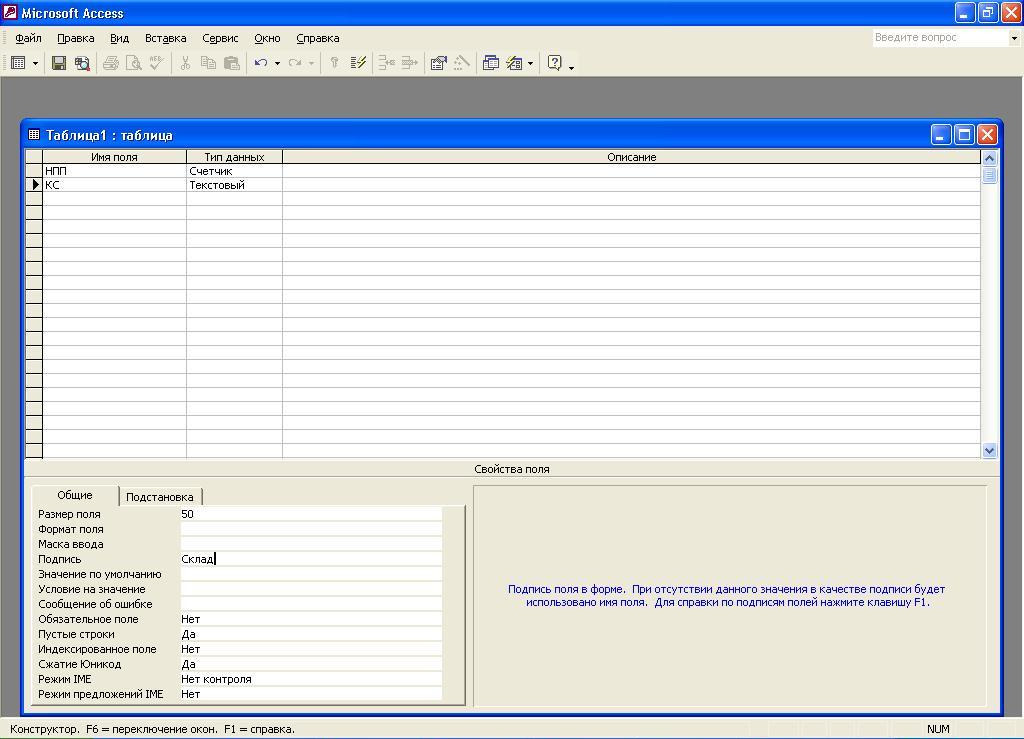
Рис.
5.76. Окно Конструктора таблицы со
свойствами поля КС
Поле
КМ.
Описание
поля в окне Конструктора таблицы занимает
третью строку
верхней части бланка.
Имя
поля —
КМ,
тип данных —
текстовый,
размер поля —
6,
подпись
поля —
код
материала заносятся
так же, как для поля КС.
Поле КМ -ключевое.
Для
задания ключевого поля следует в бланке
установить курсор на
строку поля КМ и на панели инструментов
щелкнуть кнопку
![]()
Ключевое
поле или,
щелкнув правой кнопкой мыши, вызвать
контекстное
меню и в нем выбрать команду Ключевое
поле. Признаком
установки ключа будет его изображение
слева от имени поля.
Обязательное
поле — Да. Для
ключевого поля другого ответа быть
не может: иначе не установить логические
связи. Ответ Да
выбирается
из списка значений этого свойства.
Индексированное
поле — Да (совпадения не допускаются).
Для
ключевого
поля другого ответа не может быть по
определению. Ответ выбирается
из списка значений этого свойства.
После
занесения свойств
поля КМ окно
Конструктора таблицы будет
«меть вид, представленный на рис. 5.8.
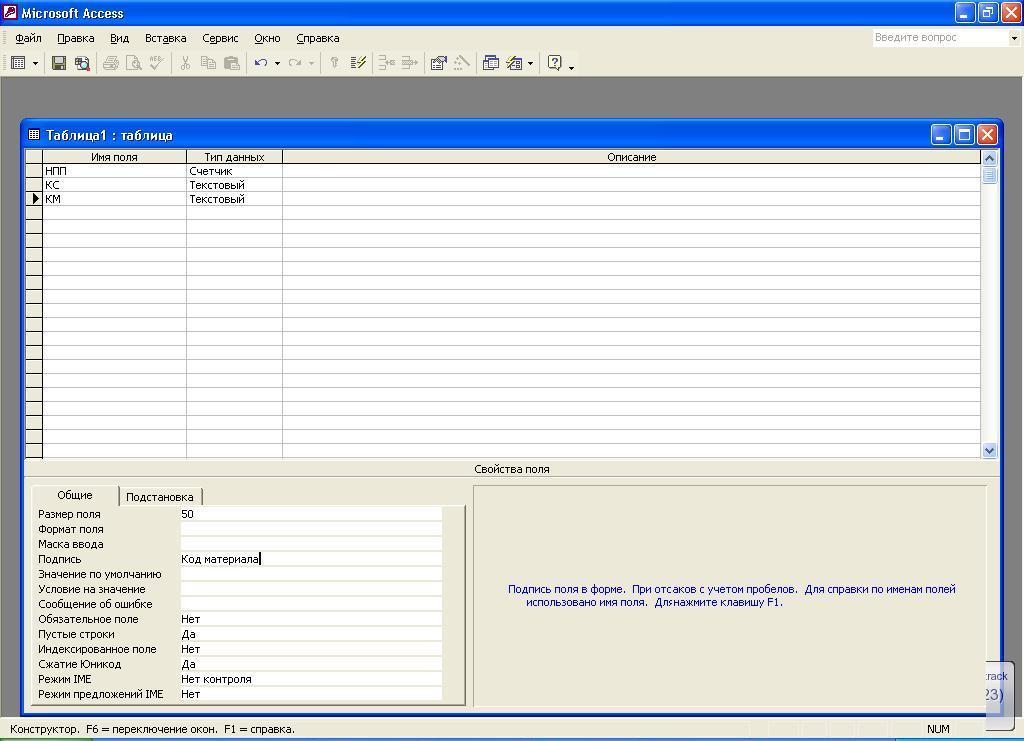
Рис.
5.8. Окно Конструктора таблицы со
свойствами поля КМ
Поля
НМ и ЕИ. Порядок
описания этих полей аналогичен описанию
КС.
Поля
ЦОтп, НЗ, Ост Порядок
описания этих полей аналогичен описанию
предыдущих с той лишь разницей, что из
списка типа данных для
них выбирается — числовой,
а
для свойства Размер
поля из
списка типов
числовых полей выбираются соответственно:
Длинное
целое; Целое;
Целое.
После
описания всех полей таблицы и их свойств
окно Конструктора
таблицы будет иметь вид, представленный
на рис. 5.9.
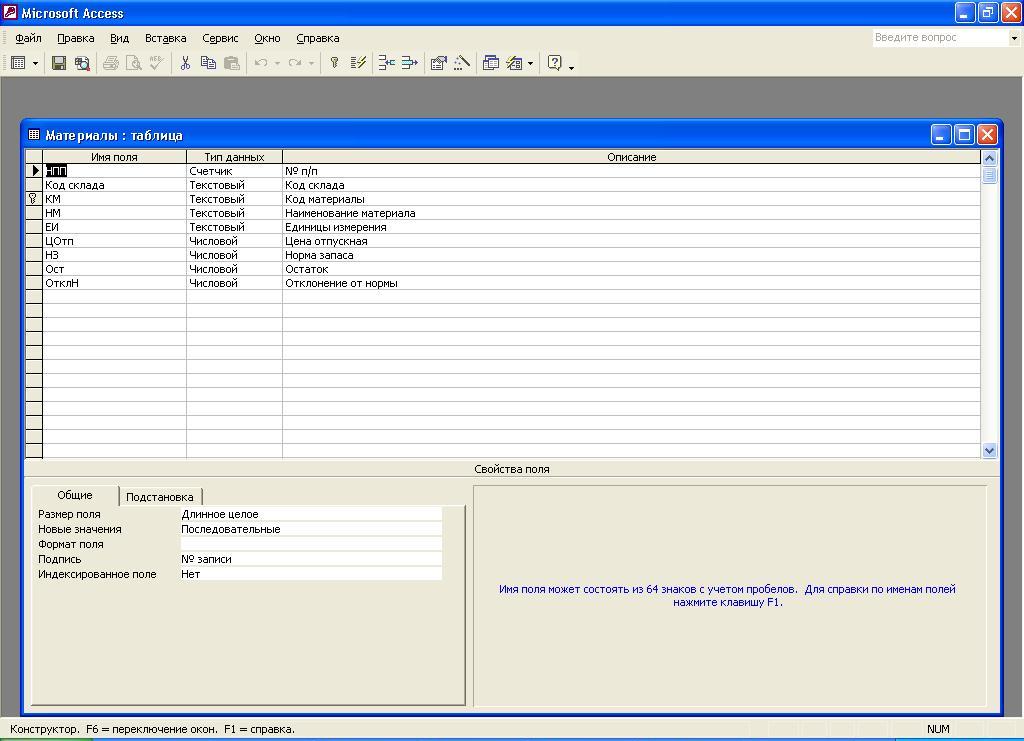
Рис.
5.9. Окно Конструктора таблицы с
описанием структуры таблицы Материалы
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Логическое проектирование базы данных
Создание и проверка локальной логической модели данных для отдельных пользовательских представлений
На этом этапе каждая локальная концептуальная модель данных, созданная на этапе 1, преобразуется в локальную логическую модель данных, состоящую из ER-диаграммы реляционной схемы и сопроводительной документации.
По завершении этого этапа должна быть получена правильная, полная и непротиворечивая модель представления. Если в приложении применяется только одно представление, то на этом стадия логического проектирования базы данных, предусмотренная в методологии, заканчивается. А если имеется несколько представлений, должен быть выполнен еще один этап, на котором отдельные локальные логические модели данных объединяются в глобальную логическую модель данных организации.
Исключение особенностей, несовместимых с реляционной моделью (необязательный этап)
- Удаление двухсторонних связей «многие ко многим» (*:*)
- Если в концептуальной модели данных присутствует связь «многие ко многим» (*:*), может быть выполнена декомпозиция этой связи для выявления промежуточной сущности. Связь *:* заменяется двумя связями «один ко многим» (1:*), в которых участвует вновь выявленная сущность.
- Удаление рекурсивных связей «многие ко многим» (*:*)
- Рекурсивная связь представляет собой особый тип связи, в которой определенный тип сущности соединен связью сам с собой. Ниже перечислены три типа рекурсивных связей:
- Рекурсивная связь «один к одному» (1:1);
- Рекурсивная связь «один ко многим» (1:*);
- Рекурсивная связь «многие ко многим» (*:*).
- Первые две связи могут быть преобразованы в одно отношение реляционной модели без какой-либо структуризации, но если рекурсивная связь 1:* допускает необязательное участие со стороны связи «многие», то для уменьшения количества пустых значений, хранимых в базе данных, целесообразнее создать второе отношение. Способы преобразования рекурсивных связей 1:1 и 1:* рассматриваются на этапе 2.2. А если в концептуальной модели данных присутствует рекурсивная связь *:*, то следует выполнить декомпозицию этой связи для выявления промежуточной сущности.
- Удаление сложных связей
- Сложной называется связь, в которой участвуют три или более типов сущностей. Если в концептуальной модели данных присутствует сложная связь, можно выполнить ее декомпозицию для выявления промежуточной сущности. А сложная связь заменяется необходимым количеством (двухсторонних) связей 1:* со вновь выявленной сущностью. Например, трехсторонняя связь Registers в представлении Branch соответствует той ситуации, когда сотрудник компании регистрирует нового клиента в отделении (рис. а). Эту связь можно упростить, введя новую сущность и определив (двухсторонние) связи между каждой из первоначальных сущностей и новой сущностью.

- Пример преобразования связи: а) сложная связь Registers; б) декомпозиция сложной связи на три двухсторонние связи (‘Registers, Processes и Agrees) и новую (слабую) сущность Registration.
- В этом примере в результате декомпозиции связи Registers выявлена новая (слабая) сущность Registration (Регистрация). Новая сущность связывается с первоначальными сущностями с помощью трех новых двухсторонних связей: Branch Registers Registration (В отделении проводится регистрация), Staff Processes Registration (Сотрудник компании проводит регистрацию) и Client Agrees Registration (Клиент соглашается на регистрацию), как показано на рис. б.
- Удаление многозначных атрибутов
- Многозначный атрибут хранит несколько значений, соответствующих одной сущности. Если в концептуальной модели данных присутствует многозначный атрибут, может быть выполнена декомпозиция этого атрибута для выявления некоторой сущности.
Определение набора отношений исходя из структуры локальной логической модели данных
Связь между двумя сущностями отображается с использованием механизма «первичный ключ/внешний ключ». При определении того, в каком отношении должен находиться атрибут (атрибуты) внешнего ключа, необходимо вначале выяснить, какая из сущностей, участвующих в связи, является родительской, а какая дочерней. Родительской называется сущность, которая передает копию своего первичного ключа в отношение, представляющее дочернюю сущность, для использования в качестве внешнего ключа.
Ниже описаны способы создания отношений на основе структур, представленных в модели данных.
- Сильные типы сущностей
- Для каждой сильной сущности в модели данных создается отношение, включающее все простые атрибуты этой сущности. В случае составных атрибутов в отношение включаются только составляющие их простые атрибуты.
- Слабые типы сущностей
- Для каждой слабой сущности, присутствующей в модели данных, создается отношение, включающее все простые атрибуты этой сущности. Первичный ключ слабой сущности частично или полностью зависит от ключа сущности-владельца и поэтому выявление первичного ключа слабой сущности невозможно выполнить до тех пор, пока не завершено преобразование в отношения всех связей сущностей-владельцев.
- Двухсторонние связи типа «один ко многим» (1:*)
- Для каждой двухсторонней связи 1:* сущность, находящаяся на стороне связи «один», определяется как родительская, а сущность на стороне связи «многие» — как дочерняя. Для обозначения этой связи копия атрибута (атрибутов) первичного ключа родительской сущности передается в отношение, соответствующее дочерней сущности, для использования в качестве внешнего ключа. В том случае, если связь 1:* охватывает один или несколько атрибутов, такие атрибуты должны следовать за вставкой первичного ключа в дочернее отношение.
- Двухсторонние связи типа «один к одному» (1:1)
- Обязательное участие обеих сторон в связи типа 1:1
- В этом случае необходимо объединить в одно отношение сущности, участвующие в связи, и выбрать один из первичных ключей первоначальных сущностей для использования в качестве первичного ключа нового отношения, а другой первичный ключ (если он существует) — для использования в качестве альтернативного ключа. В том случае, если связь 1:1 с обязательным участием обеих сторон имеет один или несколько атрибутов, эти атрибуты должны быть также включены в создаваемое отношение. Следует отметить, что две сущности могут быть объединены в одно отношение только в том случае, если между ними нет других прямых связей, исключающих возможность выполнения такой операции объединения (например, связи 1:*).
- Задача определения родительской и дочерней сущностей для связи 1:1 с использованием ограничения степени участия решается просто. Сущность, которая характеризуется необязательным участием в связи, обозначается как родительская, а сущность, которая должна обязательно участвовать в связи, определяется как дочерняя.
- К концу данного этапа должны быть выявлены все новые первичные или потенциальные ключи, сформированные в этом процессе, а также соответствующим образом обновлен словарь данных.
- Необязательное участие обеих сторон в связи типа 1:1
- В таком случае одну из сущностей можно обозначить как родительскую, а другую — как дочернюю произвольным образом, если отсутствует какая-либо дополнительная информация о рассматриваемой связи, которая могла бы помочь принять решение в пользу одной из сторон.
- Рекурсивные связи «один к одному» (1:1)
- На рекурсивные связи 1:1 также распространяются правила учета степени участия, описанные выше применительно к связи 1:1. Но в этом особом случае связи типа 1:1 на обеих сторонах связи находится одна и та же сущность. Рекурсивная связь 1:1 с обязательным участием обеих сторон должна быть представлена как одно отношение с двумя копиями первичного ключа. Как и в обычной связи 1:1, одна из копий первичного ключа соответствует внешнему ключу и должна быть переименована для указания на то, что отношение отображает соответствующую связь.
- Что касается рекурсивной связи 1:1 с обязательным участием только одной стороны, то в этом случае имеется возможность либо создать одно отношение с двумя копиями первичного ключа, как описано выше, либо создать новое отношение, отображающее эту связь. Новое отношение должно иметь только два атрибута, которые являются копиями первичного ключа. Как и в предыдущем случае, эти копии первичного ключа применяются в качестве внешних ключей и должны быть переименованы для указания на то, в чем состоит их назначение в каждом из отношений. А что касается рекурсивной связи 1:1 с необязательным участием обеих сторон, то и в этом случае должно быть создано новое отношение, как описано выше.
- Связи типа суперкласс/подкласс
- Для каждой связи типа суперкласс/подкласс в концептуальной модели данных сущность, соответствующая суперклассу, определяется как родительская, а сущность, соответствующая подклассу, — как дочерняя. Имеется также возможность преобразовать подобную связь в одно или несколько отношений. Выбор наиболее подходящего способа преобразования зависит от многих факторов, таких как ограничения непересочения и степени участия, которые распространяются на связь типа суперкласс/подкласс, от того, участвуют ли подклассы в разных связях, а также от количества сущностей, участвующих в связи суперкласс/подкласс. К этому моменту процесс преобразования должен быть завершен, при условии, что выполнен этап 2.1. Но если этот этап был пропущен, может потребоваться провести следующие три дополнительных преобразования.
- Двухсторонние связи «многие ко многим» (*:*)
- Для каждой двухсторонней связи *:* необходимо создать отношение, представляющее эту связь, и включить в него все атрибуты, которые входят в состав этой связи. Копии атрибутов первичного ключа сущностей, участвующих в связи, передаются в новое отношение для использования в качестве внешних ключей. Эти внешние ключи образуют также первичный ключ нового отношения, возможно, в сочетании с некоторыми другими атрибутами связи. Если уникальность могут обеспечить один или несколько атрибутов, образующих связь, то в концептуальной модели данных не учтена какая-то сущность. Но этот недостаток может быть устранен в описанном процессе преобразования.
- Сложные типы связей
- Для каждой сложной связи создается отношение, отображающее эту связь, и в него включаются все атрибуты, входящие в состав рассматриваемой связи. В новое отношение передаются для использования в качестве внешних ключей копии атрибутов первичного ключа сущностей, участвующих в сложной связи.
- Все внешние ключи, соответствующие стороне связи «многие» (например, 1..*, 0..*), как правило, образуют также первичный ключ этого нового отношения, возможно, в сочетании с некоторыми другими атрибутами связи.
- Многозначные атрибуты
- Для каждого многозначного атрибута в сущности создается новое отношение, соответствующее многозначному атрибуту, и в это новое отношение передается первичный ключ сущности для использования в качестве внешнего ключа. Если сам многозначный атрибут не является альтернативным ключом сущности, то первичный ключ нового отношения представляет собой сочетание многозначного атрибута и первичного ключа сущности.
- По завершении этапа 2.2 необходимо формально описать на языке DBDL состав отношений, полученных на основе логической модели данных.
- Теперь для каждого отношения определен полный набор атрибутов, поэтому разработчик получает возможность определить все новые первичные и/или альтернативные ключи. Эту операцию особенно важно выполнить для слабых сущностей, собственный первичный ключ которых формируется путем передачи первичного ключа из родительской сущности (или сущностей).
Проверка отношений с помощью правил нормализации
Задача состоит в проверке корректности состава каждого из созданных отношений путем применения к ним процедуры нормализации. Процесс нормализации включает следующие основные этапы:
- приведение к первой нормальной форме (1НФ), позволяющее удалить из отношений повторяющиеся группы атрибутов;
- приведение ко второй нормальной форме (2НФ), позволяющее устранить частичную зависимость атрибутов от первичного ключа;
- приведение к третьей нормальной форме (ЗНФ), позволяющее устранить транзитивную зависимость атрибутов от первичного ключа;
- приведение к нормальной форме Бойса-Кодда (НФБК), позволяющее удалить из функциональных зависимостей оставшиеся аномалии.
Целью выполнения этих этапов является получение гарантий того, что каждое из отношений, созданных на основании логической модели данных, отвечает, по крайней мере, требованиям НФБК. Если будут найдены отношения, не отвечающие требованиям НФБК, это может указывать на то, что часть логической модели данных неверна либо что при преобразовании логической модели в набор отношений допущена ошибка. При необходимости потребуется перестроить модель данных и убедиться, что она верно отображает моделируемую часть информационной структуры организации.
Проверка соответствия отношений требованиям пользовательских транзакций
Необходимо проверить, что указанные транзакции поддерживаются также отношениями, созданными на предыдущем этапе. Для этого все необходимые операции доступа к данным должны быть выполнены вручную с помощью отношений, линий связи первичного ключа/внешнего ключа, соединяющих отношения, ER-диаграммы и словаря данных. Если нам удастся подобным образом выполнить все требуемые транзакции, то на этом проверка логической модели данных будет завершена. Однако если какую-либо из транзакций выполнить вручную не удастся, значит, составленная модель данных является неадекватной и содержит ошибки, которые потребуется устранить. Необходимо вернуться к предыдущим этапам, проверить те области модели данных, которые затрагиваются рассматриваемой транзакцией, найти и устранить ошибку.
Определение требований поддержки целостности данных
Ограничения целостности данных вводятся с целью предотвратить появление в базе противоречивых данных. Ниже рассматриваются пять типов ограничений целостности данных.
Обязательные данные
Некоторые атрибуты всегда должны содержать одно из допустимых значений. Другими словами, эти атрибуты не могут иметь пустого значения. Эти ограничения должны фиксироваться при занесении сведений об атрибуте в словарь данных.
Ограничения для доменов атрибутов
Каждый атрибут имеет домен, представляющий собой набор его допустимых значений.
Целостность сущностей
Первичный ключ любой сущности не может содержать пустого значения.
Ссылочная целостность
Внешний ключ связывает каждую строку дочернего отношения с той строкой родительского отношения, которая содержит это же значение соответствующего потенциального ключа. Понятие ссылочной целостности означает, что если внешний ключ содержит некоторое значение, то оно обязательно должно присутствовать в одной из строк родительского отношения.
Необходимо решить несколько важных вопросов, связанных с использованием внешних ключей. Прежде всего, следует проанализировать, допустимо ли использование во внешних ключах пустых значений. В общем случае, если участие дочернего отношения в связи является обязательным, то пустые значения не допускаются. С другой стороны, если участие дочернего отношения в связи является необязательным, то могут быть разрешены пустые значения. Следующая проблема связана с организацией поддержки ссылочной целостности. Реализация этой поддержки осуществляется путем задания ограничений существования, определяющих условия, при которых может вставляться, обновляться или удаляться каждое значение потенциального или внешнего ключа.
Рассмотрим следующие случаи, которые могут возникнуть при обработке данных, моделируемых связью типа 1:*:
- Вставка новой строки в дочернее отношение
Для обеспечения ссылочной целостности необходимо убедиться, что значение атрибута внешнего ключа новой строки отношения равно пустому значению либо некоторому конкретному значению, присутствующему в одной из строк отношения.
- Удаление строки из дочернего отношения
При удалении строки из дочернего отношения никаких нарушений ссылочной целостности не происходит.
- Обновление внешнего ключа в строке дочернего отношения
Этот случай подобен случаю 1. Для сохранения ссылочной целостности необходимо убедиться, что атрибут в обновленной строке отношения содержит либо пустое значение, либо некоторое конкретное значение, присутствующее в одной из строк отношения.
- Вставка строки в родительское отношение
Вставка строки в родительское отношение не может вызвать нарушения ссылочной целостности. Добавленная строка просто становится родительским объектом, не имеющим дочерних объектов.
- Удаление строки из родительского отношения
При удалении строки из родительского отношения ссылочная целостность будет нарушена в том случае, если в дочернем отношении будут существовать строки, ссылающиеся на удаленную строку родительского отношения. В этом случае может быть использована одна из следующих стратегий:
- NO ACTION. Удаление строки из родительского отношения запрещается, если в дочернем отношении существует хотя бы одна ссылающаяся на нее строка.
- CASCADE.Удаление строки родительского отношения автоматически распространяется на все дочерние отношения.
- SET NULL.При удалении строки из родительского отношения во всех ссылающихся на нее строках дочернего отношения в атрибут внешнего ключа автоматически записывается пустое значение.
- SET DEFAULT. При удалении строки из родительского отношения в атрибут внешнего ключа всех ссылающихся на нее строк дочернего отношения автоматически помещается значение, указанное для этого атрибута как значение по умолчанию.
- NO CHECK. При удалении строки из родительского отношения никаких действий по поддержанию ссылочной целостности данных не предпринимается.
Обновление первичного ключа в строке родительского отношения
Если значение первичного ключа некоторой строки родительского отношения будет обновлено, нарушение ссылочной целостности будет иметь место в том случае, когда в дочернем отношении существуют строки, ссылающиеся на исходное значение первичного ключа. Для обеспечения ссылочной целостности может использоваться любая из описанных выше стратегий.
Ограничения предметной области
В заключение требуется проанализировать ограничения, называемые ограничениями предметной области. Например, обновление сущностей может регламентироваться принятыми в организации правилами, описывающими методы выполнения реальных транзакций, связанных с подобными обновлениями. Поместите сведения обо всех установленных ограничениях целостности данных в словарь данных. Они потребуются на этапе физической реализации базы данных.
Обсуждение разработанных локальных логических моделей данных с конечными пользователями
К этому моменту локальная логическая модель данных, соответствующая конкретному пользовательскому представлению, должна быть закончена и полностью описана в документации. Однако прежде чем данный этап разработки можно будет считать полностью завершенным, необходимо обсудить с пользователями созданные логические модели данных и всю сопроводительную документацию.
Если в приложении базы данных предусмотрено только одно представление, то можно непосредственно перейти к этапу физического проектирования базы данных, который описан в следующей главе. А если имеется несколько представлений и применяется подход, предусматривающий интеграцию представлений, необходимо перейти к третьему этапу методологии, описанному ниже.
Создание и проверка глобальной логической модели данных
На данном этапе методологии логического проектирования баз данных путем слияния отдельных локальных логических моделей данных, соответствующих конкретным пользовательским представлениям, создается глобальная логическая модель данных. По завершении объединения локальных моделей может потребоваться проверить правильность полученной глобальной модели как в отношении правил нормализации, так и в отношении возможности выполнения транзакций, предусмотренных спецификациями всех представлений. Проверка происходит с использованием тех же методов, которые применялись при выполнении этапов 2.3 и 2.4. Однако проведение нормализации потребуется только в том случае, если в процессе слияния были внесены изменения в состав отдельных отношений. Аналогичным образом, проверка возможности выполнения транзакций требуется только для тех транзакций, связанных с областями модели, которые были подвергнуты изменениям в ходе слияния. В больших системах подобный подход позволяет существенно сократить объем требуемых повторных проверок.
При слиянии локальных логических моделей данных в единую глобальную модель придется прилагать усилия для устранения конфликтов между отдельными представлениями, а также устранять их возможное перекрытие.
Слияние локальных логических моделей данных в единую глобальную модель данных
К данному моменту для каждой локальной логической модели данных должны быть подготовлены ER-диаграмма, реляционная схема, словарь данных и сопроводительная документация с описанием ограничений, которые распространяются на эту модель. На текущем этапе все перечисленные компоненты используются для выявления аналогий и различий между локальными логическими моделями данных, что способствует объединению этих моделей.
Ниже описан подход, который можно использовать для выполнения слияния локальных моделей и устранения любых возникающих при этом несовместимостей.
- Анализ имен и содержимого сущностей/отношений и их потенциальных ключей
- Может оказаться целесообразным предварительно проанализировать имена сущностей, присутствующих в локальных моделях данных; эти сведения можно найти в словаре данных. Проблемы имеют место в следующих случаях:
- если две или несколько сущностей/отношений имеют одно и то же имя, но на самом деле отличаются друг от друга (проблема омонимов);
- если две или несколько сущностей/отношений являются одинаковыми, но имеют разные имена (проблема синонимов).
- Для решения этих проблем может потребоваться сравнить содержимое данных каждой сущности/отношения. В частности, обнаружить эквивалентные сущности/отношения с разными именами, которые применяются в тех или иных представлениях, поможет сравнение их потенциальных ключей.
- Анализ имен и содержимого связей/внешних ключей
- Эти действия аналогичны выполняемым для сущностей/отношений. Даже при первом взгляде на имена связей/внешние ключи в каждом представлении можно понять, в какой степени эти представления перекрываются.
- Необходимо убедиться в том, что сущности или связи, которые имеют одинаковые имена, соответствуют одной и той же концепции в «реальном мире» и что разные имена в каждом представлении отражают разные концепции. Для решения этой задачи необходимо сравнить атрибуты, которые относятся к каждой сущности, а также относящиеся к ним связи с другими сущностями. Следует также учитывать, что сущности или связи в одном представлении могут быть выражены в виде атрибутов в другом представлении.
- Слияние сущностей/отношений, соответствующих локальным моделям данных
- Проверка имени и содержимого каждой сущности/отношения в моделях, предназначенных для объединения, для определения того, соответствуют ли сущности/отношения одним и тем же «реальным объектам» и могут ли быть объединены. Как правило, на этом этапе выполняются следующие задачи:
- Объединение сущностей/отношений с одинаковыми именами и первичными ключам
- Как правило, сущности/отношения с одинаковыми первичными ключами соответствуют одному и тому же объекту «реального мира» и должны быть объединены. Объединенная сущность/отношение включает все атрибуты из первоначальных сущностей/отношений с удаленными дубликатами.
- Объединение сущностей/отношений с одинаковыми именами, но разными первичными ключами
- В некоторых ситуациях могут обнаружиться две сущности/отношения с одинаковыми именами и аналогичными потенциальными ключами, но с разными первичными ключами. В таких случаях сущности/отношения также должны быть объединены, как описано выше. Но необходимо также выбрать для использования в качестве первичного ключа только один ключ, а другой первичный ключ преобразовать в альтернативный. Например, на рисунке перечислены атрибуты, принадлежащие двум отношениям BusinessOwner, которые определены в двух представлениях. Первичным ключом отношения BusinessOwner в представлении Branch является bName, а первичным ключом в отношении BusinessOwner представления Staff — ownerNo.

- Но альтернативным ключом отношения BusinessOwner в представлении Staff служит bName. Итак, в этих двух отношениях применяются разные первичные ключи, а первичный ключ отношения BusinessOwner в представлении Branch является альтернативным ключом отношения BusinessOwner в представлении Staff. Поэтому можно объединить эти два отношения, как показано на рисунке, и включить в полученное отношение атрибут bName в качестве альтернативного ключа.
- Объединение сущностей/отношений с разными именами с использованием одинаковых или разных первичных ключей
- В некоторых случаях могут обнаружиться сущности/отношения, имеющие разные имена, но, по-видимому, выполняющие аналогичную роль. Подобные сущности/отношения могут быть выявлены следующим образом:
- по их именам, которые указывают на аналогичное назначение;
- по их содержанию и особенно по их первичному ключу;
- на основании того, что они принимают участие в определенных связях.
- Включение (без слияния) сущностей/отношений, характерных только для отдельных локальных моделей данных
- На предыдущем этапе должны быть выделены все сущности, описывающие аналогичные объекты. Все остальные сущности просто включаются в глобальную модель без внесения каких-либо изменений.
- Слияние связей/внешних ключей из отдельных локальных моделей данных
- На этом этапе рассматриваются имя и назначение каждой связи/внешнего ключа в моделях данных. Перед объединением связей/внешних ключей необходимо устранить все противоречия между связями, в частности несоответствие ограничений кратности. На этом этапе выполняются следующие действия:
- объединение связей/внешних ключей с одинаковыми именами и назначениями;
- объединение связей/внешних ключей с разными именами, но с одинаковыми назначениями.
- Включение (без слияния) связей/внешних ключей, характерных только для отдельных локальных моделей данных
- Итак, в результате выполнения предыдущей задачи должны быть выявлены одинаковые связи/внешние ключи. Все остальные связи/внешние ключи переносятся в глобальную модель без изменения.
- Проверка того, нет ли пропущенных сущностей/отношений и связей/внешних ключей
- Если в организации имеется корпоративная модель данных, то сущности и связи, которые не вошли ни в одну локальную модель данных, могут быть обнаружены с ее помощью. Еще один вариант состоит в изучении атрибутов каждой сущности/отношения и проверки ссылок на сущности/отношения в других локальных моделях данных.
- Проверка внешних ключей
- На этом этапе могут быть объединены сущности/отношения и связи/внешние ключи, изменены первичные ключи и выявлены новые связи. Следует проверить, что внешние ключи в дочерних отношениях все еще остаются правильными, и внести все необходимые изменения.
- Проверка ограничений целостности
- Если в процессе объединения были выявлены какие-либо новые связи и созданы новые внешние ключи, то необходимо проверить, что для них заданы соответствующие ограничения ссылочной целостности. Любые обнаруженные противоречия необходимо устранять по согласованию с пользователями.
- Формирование глобальной ER-диаграммы/схемы отношений
- Теперь можно приступить к формированию окончательной диаграммы, на которой отображены все объединенные локальные логические модели данных.
- Обновление документации
- На этом этапе необходимо пересмотреть всю документацию с учетом изменений, внесенных в процессе разработки глобальной модели данных. Очень важно следить за тем, чтобы документация всегда была актуальной и соответствовала текущей модели данных.
Проверка глобальной логической модели данных
Этот этап аналогичен этапам 2.3 и 2.4, на которых выполнялась проверка каждой локальной логической модели данных. Но в данном случае необходимо проверить только те области модели, которые были созданы в результате любых изменений, внесенных в процессе объединения моделей.
Проверка возможностей расширения модели в будущем
В процессе проектирования очень важно добиться того, чтобы в глобальную логическую модель данных можно было легко вносить изменения. Важно добиться того, чтобы разработанная модель была расширяемой и обладала способностью к развитию с учетом новых требований, оказывая при этом минимальное влияние на работу существующих пользователей.
Обсуждение глобальной логической модели данных с пользователями
К этому моменту глобальная логическая модель данных для организации должна быть полной и точной. Теперь саму модель и документацию с описанием модели необходимо обсудить с пользователями, чтобы убедиться в том, что она полностью соответствует структуре данных в организации.
Разработка концептуальной и логической схемы при создании базы данных
NovaInfo 75, с.1-8, скачать PDF
Опубликовано 1 декабря 2017
Раздел: Физико-математические науки
Просмотров за месяц: 89
Аннотация
На примере разработки информационной системы для сервис-центра были рассмотрены инфологический и логический этапы проектирования.
Ключевые слова
ИНФОЛОГИЧЕСКАЯ МОДЕЛЬ, ЛОГИЧЕСКАЯ СХЕМА, БАЗЫ ДАННЫХ, ИНФОРМАЦИОННАЯ СИСТЕМА
Текст научной работы
В ходе выполнения данной работы была разработана информационная система для сервис-центра.
Инфологической моделью можно назвать описание базы данных, которое состоит из таких элементов как формулы, графики, таблиц и диаграмм, а также других средств. Смысл такой модели состоит в реальном описании процессов, информационных потоков, функций системы с помощью общедоступного всем языка, понятного всем [1-3].
Результаты инфологического проектирования могут быть выражены в виде инфологической или концептуальной модели, которая представляет структуру данных. Для построения концептуальной модели используется метод моделирования «Сущность — связь» или ER-диаграмма.
После того, как было проведено исследование предметной области сервис-центра и проведен анализ структуры системы были выделены сущности, атрибуты и первичный ключ.
|
№ |
Название и обозначение сущности |
Ключ сущности и его обозначение |
Атрибуты сущности и их обозначение |
|
1 |
Запчасти |
код_запчасти |
категория наименование серийный номер марка количество цена в наличии |
|
2 |
Типы |
код_типа |
категория описание |
|
3 |
Сотрудники |
код_сотрудника |
ФИО_сотрудника дата_рождения паспорт должность телефон пол образование |
|
4 |
Ремонт |
код_ремонта |
дата_ремонта название имя_клиента имя_сотрудника запчасти стоимость_ремонта статус |
|
5 |
Клиенты |
код_клиента |
ФИО телефон адрес е-mail |
|
№ |
Связь |
|
1 |
Запчасти СОСТОЯТ из Типов |
|
2 |
Запчасти ИСПОЛЬЗУЮТСЯ при Ремонте |
|
3 |
Сотрудники ВЫПОЛНЯЮТ Ремонт |
|
4 |
Клиенты ЗАКАЗЫВАЮТ Ремонт |
На основе сущностей и связи между ними получаем ER-диаграмму предметной области (рис.1):

Следующим этапом проектирования является логическая схема — это модель данных конкретной области вопросов, выраженная в терминах технологии управления данными. При проектировании логической структуры реляционной базы данных определяется оптимальный состав таблиц для хранения исходной информации. Для каждой таблицы указывается ее название, перечень полей и первичный ключ. Идентифицируются связи между таблицами. После использования правила отображения ER-диаграммы на логическую схему, получаем примерно такие таблицы:
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_запчасти |
Счетчик |
|
Наименование |
Текстовый |
|
|
Серийный номер |
Числовой |
|
|
Марка |
Текстовый |
|
|
Количество |
Числовой |
|
|
Цена |
Числовой |
|
|
В наличии |
Текстовый |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_типа |
Счетчик |
|
Категория |
Текстовый |
|
|
Описание |
Поле МЕМО |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_сотрудника |
Счетчик |
|
ФИО_сотрудника |
Текстовый |
|
|
дата_рождения |
Дата/время |
|
|
Паспорт |
Текстовый |
|
|
Должность |
Текстовый |
|
|
Телефон |
Текстовый |
|
|
Пол |
Текстовый |
|
|
Образование |
Текстовый |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_ремонта |
Счетчик |
|
Дата_заказа |
Текстовый |
|
|
ФИО_сотрудника |
Текстовый |
|
|
ФИО_клиента |
Текстовый |
|
|
Запчасти |
Текстовый |
|
|
Стоимость_ремонта |
Денежный |
|
Ключевое поле |
Название поля |
Тип поля |
|
Ключ |
код_клиента |
Счетчик |
|
ФИО_клиента |
Текстовый |
|
|
Телефон |
Текстовый |
|
|
Адрес |
Текстовый |
|
|
|
Текстовый |
Для физической реализации разработки базы данных была выбрана программа Microsoft Access, так как она позволяет быстро создавать таблицы и заполнять их без использования специальных конструкций [4].
На рисунке 2 представлена схема разработанной базы данных, в которой показаны таблицы и связи таблиц между собой.

Таблицы создавались с учетом оптимального использования памяти и простоты представляемых данных согласно ER-модели. Была проведена нормализация ER-модели для последующей оптимальной работы с базой данной.
В ходе разработки структуры базы были созданы следующие таблицы:
1. Ремонт — таблица предназначена для хранения информации об ремонте. На рисунке 3 показана заполненная таблица Ремонт, где ключевым полем объявлено поле «КодРемонта», имеющее тип счетчика, а остальные поля используются для задания значения фамилии и данных клиентов.

2. Клиенты — таблица предназначена для хранения информации о клиентах, такой как ФИО клиента, телефон, адрес и электронная почта.
Для таблицы Клиенты задано ключевое поле, которое отвечает за уникальный номер группы для сохранения однозначности в связях с другими таблицами. На рисунке 4 показана заполненная таблица «Клиенты».

3. Типы — таблица предназначена для хранения информации о типах запчастей.
На рисунке 5 показана таблица «Типы».

4. Запчасти — таблица предназначена для хранения информации о запчастях, которые могут пригодиться при ремонте. На рисунке 6 представлена таблица «Запчасти».

5. Сотрудники — таблица предназначена для хранения информации о сотрудниках, которые работают в данном сервисном центре. На рисунке 7 представлена таблица «Сотрудники».

В ходе выполнения данной работы была разработана информационная система для сервис-центра и были решены следующие задачи:
- Проведен тщательный анализ предметной области сервисного центра;
- Обработана и систематизирована полученная информация;
- Построена ER-диаграмму и получена логическая схема базы данных в Microsoft Office Access;
- Создано приложение для работы базой данных в Embarcadero Rad Studio;
- Разработан удобный интерфейс для пользователей приложения и предоставлена возможность обработки информации: создание, удаление, изменение записей.
Спроектированная информационная система дает возможность удобного ввода, редактирования, удаления и хранения данных. Для реализации данного программного обеспечения были использованы Microsoft Access и Embarcadero Rad Studio и изученERWin.
Читайте также
-
Применение Borland Delphi для разработки интерфейса
- Хусаинова Г.Я.
-
Разработка информационной системы средствами MS Access
- Хусаинова Г.Я.
-
Математическое моделирование барабанного нефтесборщика с рифленой поверхностью
- Хусаинова Г.Я.
-
Исследование полей температуры вязкопластичных жидкостей при плоскорадиальном фильтрационном течении
- Хусаинова Г.Я.
-
Автоматизированное рабочее место администратора фитнес-клуба
- Хусаинова Г.Я.
Список литературы
- Айнуров К.И. Использование информационных технологий в обучении. – Магнитогорск.: МГПУ, 2014. – 85 с.
- Викторов С.У. Развитие информационных технологий.– Пермь: ЛНА, 2011. – 74 с.
- Хусаинов И.Г., Рахимова Р.А. Роль интерактивных технологий на уроках информатики в развитии этического воспитания учащихся // Современные проблемы науки и образования. – 2015. – № 3. – С. 488.
- Хусаинова Г.Я. Исследование температурных полей при стационарном течении аномальных жидкостей // Автоматизация. Современные технологии. 2016. № 7. С. 13-16.
Цитировать
Хусаинова, Г.Я. Разработка концептуальной и логической схемы при создании базы данных / Г.Я. Хусаинова. — Текст : электронный // NovaInfo, 2017. — № 75. — С. 1-8. — URL: https://novainfo.ru/article/14280 (дата обращения: 28.05.2023).
Поделиться
Проектирование баз данных является и искусством, и наукой. Научная часть состоит в необходимости придерживаться определенных правил и условий, наподобие нормализации. А искусством проектирование баз данных является потому, что моделировать отношения требуется на основании своего собственного понимания реальных функций организации.
Логическим проектированием баз данных формально можно считать процесс создания модели мира самой базы данных, без той системы, которая будет позволять ей работать, и прочих физических деталей. Точность и полнота играют в этом процессе ключевую роль. Одним из главных преимуществ этого этапа является то, что всегда можно взять черновой проект, отложить его в сторону и начать все заново или просто внести желаемые поправки. Гораздо легче менять те или иные детали на этапе проектирования, чем иметь дело с проблемами уже реализованной производственной базы данных, которая плохо спроектирована.
Этап логического проектирования иногда делят на концептуальную и логическую часть, но это отличие чисто номинально. Концептуальное проектирование базы данных (conceptual database design) обычно предшествует этапу логического проектирования и подразумевает моделирование информации без использования какой-либо базовой модели данных. Что касается этапа логического проектирования, то он уже предполагает явное применение конкретной модели данных, например, реляционной, и фокусирование внимания на логических отношениях, которые были определены на этапе концептуального проектирования. В частности, логическое проектирование заключается в концептуальном моделировании базы данных и гарантии того, что данные в таблицах проходят проверку на целостность и не являются избыточными. Для удовлетворения этих требований реализуются принципы нормализации данных, о которых будет более подробно рассказываться чуть позже.
Методика, которую чаще всего применяют для логического представления и анализа компонентов бизнес-системы и моделирования подходящего решения после завершения анализа требований, называется ER-моделированием (Entity Relationship Modeling — создание моделей типа “сущность-отношение”). ER-модели легко конструировать, а, благодаря акценту на графическом представлении, еще и очень легко понимать. Тем не менее, создавать настоящую РСУБД на основании одной только ER-модели предприятия нельзя. Польза ER-моделирования заключается в проектировании, а не в реализации баз данных. Образовывать основу для высокоуровневого языка манипулирования данными вроде SQL ER-моделирование не позволяет, поэтому та модель, которую проектировщики создают с помощью ER-моделирования, для реализации преобразуется в реляционную модель. То есть за счет преобразования абстрактной структуры с сущностями и отношениями в схему реляционной базы данных реляционная модель помогает преобразовывать ER-модель в реляционную СУБД.
ER-моделирование в логическом моделировании базы
Прежде чем переходить непосредственно к созданию баз данных, нужно нарисовать концептуальную модель информационной системы организации, чтобы легко видеть, какие отношения существуют в ней между различным компонентами. Модели данных являются просто представлениями сложных реальных структур данных и помогают изображать не только сами структуры данных, но и отношения между их компонентами и любые ограничения, которые существуют. Создание концептуальной модели предприятия приводит к получению четкой картины касательно того, какие таблицы доведется создавать позже и какие отношения должны существовать между этими таблицами. ER-моделирование подразумевает создание допустимых моделей производственных процессов с использованием стандартных ER-диаграмм. Обратите внимание на то, что при создании концептуальной модели программные и аппаратные детали в расчет никогда не берутся.
ER-моделирование впервые было предложено Питером Ченом (Peter Chen) в 1976 г. и теперь является очень часто применяемой методикой для проектирования баз данных. (Загрузить копию исходного документа Чена в виде PDF-файла можно по адресу http://citeseer.ist.psu.edu/519283.html.) Несмотря на это, помимо ER-моделирования для использования доступно еще несколько методик проектирования. В частности, в течение вот уже нескольких лет исследователи пытаются моделировать настоящий мир более реалистично с применением так называемых семантических моделей данных (semantic data models), которые, по идее, должны позволять даже выходить за рамки возможностей традиционного ER-моделирования.
Важно! Члены консорциума W3C (World Wide Web Consortium) сейчас занимаются разработкой совместного проекта под названием Semantic Web, который представляет собой общий каркас для совместного и повторного использования данных за пределами приложений и общественных границ. В его основе лежит каркас RDF (Resource Description Framework — каркас описания ресурсов), который позволяет использовать общие форматы для интеграции данных, извлекаемых из разных источников. Кроме того, Semantic Web представляет собой унифицированный язык, помогающий фиксировать то, каким образом данные соотносятся с реальными объектами. В общем, идея состоит в том, чтобы попробовать привнести хоть какое-то значение в огромное количество доступных данных и информации. Информация, выкладываемая в Интернете, рассчитана на людей и потому представляется в соответствующем формате, но в Semantic Web данные будут форматироваться таким образом, чтобы их могли понимать не только люди, но и компьютеры. В Semantic Web для выполнения поиска данных и информации нужно будет пользоваться программными агентами. Узнать больше о проекте Semantic Web можно по адресу http://www.w3.org/2001/sw/. Еще есть одна замечательная посвященная этому проекту статья Тима Бернерса-Ли (Tim Berners-Lee), Джеймса Хендлера (James Hendler) и Ора Лассила (Ora Lassila), которая называется “The Semantic Web” и доступна по адресу http://www.scientificamerican.com/article.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21&catID=2.
Созданная концептуальная модель организации может выступать в роли средства передачи информации и, как таковая, применяться для облегчения взаимодействия между проектировщиками баз данных, программистами приложений и конечными пользователями. Хорошие концептуальные модели способны помогать разрешать различающие концепции данных между этими группами. Вдобавок, концептуальные модели помогают определять ограничения, которые организация накладывает на данные, и разъяснять потребности в плане обработки данных, тем самым способствуя в создании надежных баз данных.
В ER-моделировании все объекты деловой сферы рассматриваются как сущности (entities), обладающие определенными атрибутами. Сущностью считается любой объект, который представляет интерес для системы и существует в деловом мире. Сущность может быть как реальной (например, студент), так и концептуальной (скажем, прием студента на курс, который фактически не происходит до тех пор, пока данные студента и курса не будут объединены после подачи студентом заявки на поступление на определенный курс). Концептуальные сущности обычно обнаруживать очень трудно, но ER-моделирование, как можно будет увидеть позже, помогает и в этом.
Атрибутами сущностей называются свойства сущностей, которые представляют интерес. Например, у сущности, представляющей студента, атрибутами могут быть идентификационный номер студента (Student ID), его адрес (Address), номер телефона (Phone Number) и т.п.
Далее в ER-моделировании описываются отношения (relationships) между всеми бизнес-сущностями. Эти отношения отображают то, каким образом различные сущности связаны (или соотносятся) между собой. Например, сотрудник может представлять собой сущность, обладающую атрибутами вроде имени (Name) и адреса (Address), и быть связанным в модели с другой сущностью под названием “Отдел” (Department) на основании того факта, что он работает в этом отделе. В данном случае глагол “работает” как раз и описывает отношение между сотрудником и отделом.
Типы отношений
В каждом отношении может присутствовать две и более сущностей, и в зависимости от количества сущностей отношения между ними могут описываться как бинарные (binary), тернарные (ternary), кватернарные (quaternary) и т.д. В реальной жизни чаще всего встречаются отношения бинарного типа, поэтому давайте остановимся на них более подробно.
Мощность (cardinality), или количество элементов, отношения показывает, сколько экземпляров одной сущности может соотноситься с экземпляром другой сущности. Тот факт, что бинарное отношение отражает взаимоотношения между двумя сущностями, вовсе не означает, что между ними всегда существует отношение типа “один к одному”.
Отношения между сущностями могут представлять собой и отношения типа “один к од- ному”, и “один ко многим”, и “многие ко многим” или отношения еще какого-то другого типа. Чаще всего встречаются отношения следующих типов (при условии наличия двух сущностей, A и B).
- Один ко многим. В таких отношениях каждый экземпляр сущности A может иметь отношение с несколькими членами другой сущности B. Например, сущность под названием Клиент может брать много книг из библиотеки, но каждая книга за раз может выдаваться только одному единственному Клиенту. Соответственно получается, что между сущностями Клиент и Книга должно существовать отношение типа “один ко многим”. Разумеется, такое отношение может и не существовать при наличии Клиента, который еще не брал никакой Книги. То есть фактически отношение должно гласить следующее: “один Клиент может брать ноль, одну или более Книг”.
- Один к одному. В таких отношениях только один экземпляр любой из сущностей может иметь отношение с экземпляром другой сущности. Например, у каждого человека может быть только один действительный номер карточки социального страхования (Social Security Number — SSN), а каждый номер карточки социального страхования может ссылаться только на одного человека.
- Многие ко многим. В таких отношениях каждый экземпляр сущности A может иметь отношение с одним и более экземплярами сущности B, а каждый экземпляр сущности B — с одним и более экземплярами сущности A. В качестве примера возьмем сущность под названием Кинозвезда и сущность под названием Кинофильм. Каждая кинозвезда может сниматься в нескольких Кинофильмах, и в каждом Кинофильме может принимать участие несколько Кинозвезд. В реальной жизни отношения типа “многие ко многим” обычно разбиваются на более простые отношения типа “один ко многим”, которые, как сложилось, являются наиболее распространенной формой отношений между сущностями.
Правильное определение мощностей отношений играет ключевую роль для создания хорошо спроектированной реляционной базы данных. Некорректное моделирование отношений чревато появлением проблем вроде избыточности, дублирования и аномалий данных.
Потенциальные ключи и уникальные идентификаторы
Потенциальными ключами (candidate keys) являются атрибуты, которые способны уникальным образом идентифицировать строку в таблице, и в каждой таблице таких ключей может быть несколько. Например, достаточно часто в таблице сотрудников присутствует как генерируемый уникальный порядковый номер, так и еще какой-то идентификатор, вроде номера сотрудника (или номера его карточки социального страхования). (Разумеется, любая целая строка сама тоже может служить потенциальным ключом, поскольку в реляционной модели по определению не может существовать никаких дублированных кортежей. Однако целая строка редко применяется в качестве ключа, потому что сам смысл ключа состоит в обеспечении легкого доступа к строке.)
Потенциальный ключ, который в конечном итоге выбирается для уникальной идентификации каждой строки в таблице, называется первичным ключом (primary key). Для простоты и эффективности всегда лучше выбирать стараться такой ключ, который основан на одном, а не на нескольких атрибутах.
Ключи начинают играть очень важную роль, когда дело доходит до физического построения ER-моделей. Первичный ключ, состоящий из элементов данных или атрибутов сущностей, называется естественным (natural). Практически во всех современных реляционных базах данных, в том числе и базах данных Oracle, в качестве альтернативы естественному первичному ключу также предлагаются простые системные или порядковые номера, генерируемые и обслуживаемые РСУБД (наподобие порядкового номера для идентификации заказов). Такие ключи часто называются суррогатными (surrogate) или искусственными (artificial) первичными ключами.
При выборе первичного ключа — как естественного, так суррогатного — нужно обязательно помнить о перечисленных ниже моментах.
- Значение первичного ключа должно быть уникальным.
- Первичный ключ не может быть нулевым (пустым).
- Первичный ключ не может изменяться (он должен оставаться стабильным на протяжении всей жизни сущности).
- Первичный ключ должен быть настолько коротким, насколько это возможно.
Вас заинтересует / Intresting for you:
Руководство по разработке структуры и проектированию базы данных
Следуя принципам, описанным в этой статье, можно создать базу данных, которая работает надлежащим образом и в будущем может быть адаптирована под новые требования. Мы рассмотрим основные принципы проектирования базы данных, а также способы ее оптимизации.
- Этапы создания базы данных
- Анализ требований: определение цели базы данных
- Структура базы данных: построение блоков
- Создание связей между сущностями
- Связь «один-к одному»
- Связь «один-ко-многим»
- Связь «многие-ко-многим»
- Обязательно или нет?
- Рекурсивные связи
- Лишние связи
- Нормализация базы данных
- Первая форма нормализации
- Вторая форма нормализации
- Третья форма нормализации
- Многомерные данные
- Правила целостности данных
- Добавление индексов и представлений
- Расширенные свойства
- SQL и UML
- Системы управления базами данных
Надлежащим образом структурированная база данных:
- Помогает сэкономить дисковое пространство за счет исключения лишних данных;
- Поддерживает точность и целостность данных;
- Обеспечивает удобный доступ к данным.
Основные этапы разработки базы данных:
- Анализ требований или определение цели базы данных;
- Организация данных в таблицах;
- Указание первичных ключей и анализ связей;
- Нормализация таблиц.
Рассмотрим каждый этап проектирования баз данных подробнее. Обратите внимание, что в этом руководстве рассматривается реляционная модель базы данных Эдгара Кодда, написанная на языке SQL (а не иерархическая, сетевая или объектная модели).
Например, если вы создаете базу данных для публичной библиотеки, нужно продумать, каким образом и читатели, и библиотекари должны получать доступ к БД.
Вот несколько способов сбора информации перед созданием базы данных:
- Опрос людей, которые будут ее использовать;
- Анализ бизнес-форм, таких как счета-фактуры, расписания, опросы;
- Рассмотрение всех существующих систем данных (включая физические и цифровые файлы).
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Клиенты
- Имя;
- Адрес;
- Город, штат, почтовый индекс;
- Адрес электронной почты.
Товары
- Название;
- Цена;
- Количество в наличии;
- Количество под заказ.
Заказы
- Номер заказа;
- Торговый представитель;
- Дата;
- Товар;
- Количество;
- Цена;
- Стоимость.
При проектировании реляционной базы данных эта информация позже станет частью словаря данных, в котором описаны таблицы и поля БД. Разбейте информацию на минимально возможные части. Например, подумайте о том, чтобы разделить поле почтового адреса и штата, чтобы можно было фильтровать людей по штату, в котором они проживают.
После того, как вы определились с тем, какие данные будут включены в базу, откуда эти данные будут поступать, и как они будут использоваться, можно приступить к планированию фактической БД.
Следующим шагом будет визуальное представление базы данных. Для этого нужно точно знать, как структурируются реляционные БД. Внутри базы связанные данные группируются в таблицы, каждая из которых состоит из строк и столбцов.
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.

Чтобы при проектировании модели базы данных обеспечить согласованность разных записей, назначьте соответствующий тип данных для каждого столбца. К общим типам данных относятся:
- CHAR — конкретная длина текста;
- VARCHAR — текст различной длины;
- TEXT — большой объем текста;
- INT — положительное или отрицательное целое число;
- FLOAT, DOUBLE — числа с плавающей запятой;
- BLOB — двоичные данные.
Некоторые СУБД также предлагают тип данных Autonumber, который автоматически генерирует уникальный номер в каждой строке.
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:

При проектировании информационной базы данных необходимо решить, какие атрибуты будут служить в качестве первичного ключа для каждой таблицы, если таковые будут. Первичный ключ (PK) — это уникальный идентификатор для данного объекта. С его помощью вы можете выбрать данные конкретного клиента, даже если знаете только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL (они не могут быть пустыми). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно (это называется составным ключом).
Когда придет время создавать фактическую БД, вы реализуете как логическую, так и физическую структуру через язык определения данных, поддерживаемый вашей СУБД.
Также необходимо оценить размер БД, чтобы убедиться, что можно получить требуемый уровень производительности и у вас достаточно места для хранения данных.
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь «один-к одному» (часто обозначается 1:1). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:

Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Но при определенных обстоятельствах целесообразнее создавать таблицы со связями 1:1. Если есть поле с необязательными данными, например «описание», которое не заполнено для многих записей, можно переместить все описания в отдельную таблицу, исключая пустые поля и улучшая производительность базы данных.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи «один- ко-многим» (1:M) обозначаются так называемой «меткой ноги вороны», как в этом примере:

Чтобы реализовать связь 1:M, добавьте первичный ключ из «одной» таблицы в качестве атрибута в другую таблицу. Если первичный ключ таким образом указан в другой таблице, он называется внешним ключом. Таблица со стороны связи «1» представляет собой родительскую таблицу для дочерней таблицы на другой стороне.
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь «многие-ко-многим» (M:N). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:

При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи «один-ко-многим».
Для этого нужно создать между этими двумя таблицами новую сущность. Если между продажами и продуктами существует связь M:N, можно назвать этот новый объект «sold_products», так как он будет содержать данные для каждой продажи. И таблица продаж, и таблица товаров будут иметь связь 1:M с sold_products. Этот вид промежуточного объекта в различных моделях называется таблицей ссылок, ассоциативным объектом или таблицей связей.
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:

Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:

Два объекта могут быть взаимозависимыми (один не может существовать без другого).
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи — это те, которые выражены более одного раза. Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект «ученики» имеет прямую связь с другим объектом, называемым «учителя», но также имеет косвенные отношения с учителями через «предметы», нужно удалить связь между «учениками» и «учителями». Так как единственный способ, которым ученикам назначают учителей — это предметы.
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени (OLTP), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой (OLAP), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации (сокращенно 1NF) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF:

Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF:

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу «Реквизиты продаж», которая будет соответствовать конкретным продуктам с продажами. «Продажи» будут иметь связь 1:M с «Реквизитами продаж».
Вторая форма нормализации (2NF) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут «возраст» зависит от «дня рождения», который, в свою очередь, зависит от «ID студента», имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут «название товара» зависит от идентификатора продукта, но не от номера заказа:
- Номер заказа (первичный ключ);
- ID товара (первичный ключ);
- Название товара.
Третья форма нормализации (3NF): каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.
В соответствии с 3NF, нельзя хранить в таблице любые производные данные, такие как столбец «Налог», который в приведенном ниже примере, напрямую зависит от общей стоимости заказа:

В свое время были предложены дополнительные формы нормализации. В том числе форма нормализации Бойса-Кодда, четвертая-шестая формы и нормализации доменного ключа, но первые три являются наиболее распространенными.
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

Также с помощью средств проектирования баз данных необходимо настроить БД с учетом возможности проверки данных на соответствие определенным правилам. Многие СУБД, такие как Microsoft Access, автоматически применяют некоторые из этих правил.
Правило целостности гласит, что первичный ключ никогда не может быть равен NULL. Если ключ состоит из нескольких столбцов, ни один из них не может быть равен NULL. В противном случае он может неоднозначно идентифицировать запись.
Правило целостности ссылок требует, чтобы каждый внешний ключ, указанный в одной таблице, сопоставлялся с одним первичным ключом в таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо реализовать во всех объектах, на которые ссылается этот ключ в базе данных.
Правила целостности бизнес-логики обеспечивают соответствие данных определенным логическим параметрам. Например, время встречи должно быть в пределах стандартных рабочих часов.
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
После того как схема базы данных будет готова можно уточнить БД с помощью расширенных свойств, таких как справочный текст, маски ввода и правила форматирования, которые применяются к конкретной схеме, представлению или столбцу. Преимущество этого метода заключается в том, что, поскольку эти правила хранятся в самой базе, представление данных будет согласовано между несколькими программами, которые обращаются к данным.
Унифицированный язык моделирования (UML) — это еще один визуальный способ выражения сложных систем, созданных на объектно-ориентированном языке. Некоторые из концепций, упомянутых в этом руководстве, известны в UML под разными названиями. Например, объект в UML известен, как класс.
Сейчас UML используется не так часто. В наши дни он применяется академически и в общении между разработчиками программного обеспечения и их клиентами.
Проектируемая структура базы данных зависит от того, какую СУБД вы используете. Некоторые из наиболее распространенных:
- Oracle DB;
- MySQL;
- Microsoft SQL Server;
- PostgreSQL;
- IBM DB2.
Подходящую систему управления базами данных можно выбирать исходя из стоимости, установленной операционной системы, наличия различных функций и т. д.