Часто ли вы задумываетесь – почему что-то сделано так или иначе? Почему у вас микросервисы или монолит, двухзвенка или трехзвенка? Зачем вам многослойная архитектура и сколько у вас вообще слоев? Что такое бизнес-логика, логика приложения, презентационная логика и почему все так разделено? Посмотрите на свое приложение – как оно вообще спроектировано? Что в нем и где находится, почему это сделано именно так?
Потому что так написано в книжках или так говорят авторитетные личности? Какие ВАШИ проблемы решает тот или иной подход/паттерн?
Даже то, что на первый взгляд кажется очевидным, порой бывает очень сложно объяснить. А иногда, в попытке объяснения, приходит понимание того, что очевидные мысли были и вовсе ошибочны.
Давайте попробуем взять какой-нибудь пример и изучить на нем эти вопросы со всех сторон.
Игрушечный город
Виртуальный город
SOLID как много в этом слове …
Предметная область
Презентационная логика
Сохранение состояния
Многослойность
2-tier
N-tier
2 как 3
Сервисы
Инструменты
Теория и практика
Итог
Игрушечный город
Давайте представим небольшой игрушечный город. Он состоит из ряда строений, через него проходит несколько дорог. По дорогам перемещаются машины и ходят люди. Движение регулируют светофоры. Все происходящее в городе подчинено определенным правилам и всем этим многообразием можно управлять.
Людей и машины можно перемещать, светофоры переключать, менять время дня и ночи и т.п… С этим городом одновременно могут взаимодействовать несколько человек. Они могут или просто наблюдать, или что-то делать, заставляя город меняться. Все это прекрасно существует, но наступает момент, когда появляется необходимость перенести игрушечный город в виртуальный мир.
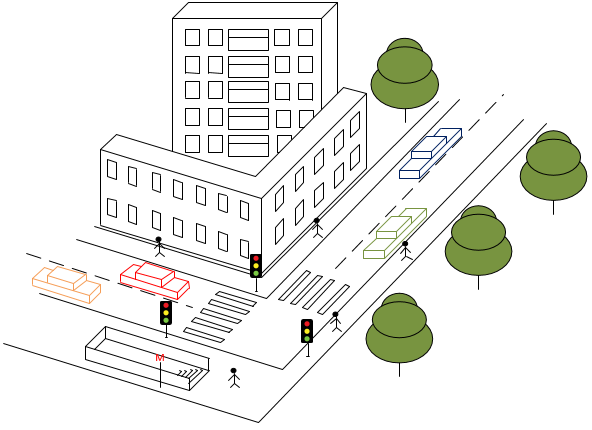
Те люди, которые взаимодействовали с городом напрямую, теперь поудобнее уселись в свои кресла и уставились в темные мониторы, сжав в одной руке мышку, а другую положив на клавиатуру, в ожидании того момента, когда все оживет и виртуальный город засияет своими красками перед их глазами. Но для того чтобы это произошло, предстоит пройти долгий путь.
Виртуальный город
Для начала нужно сделать самое главное – создать модель нашего виртуального города. Хоть это может и показаться чем-то простым, на самом деле, в этом кроется большинство проблем и сложностей. Но начинать все равно надо, так что приступим.
Наша цель – описать модель города в виртуальном виде. Для этого мы возьмем любой популярный объектно-ориентированный язык высокого уровня. Использование такого языка предполагает использование объектов в качестве основных кирпичиков для создания виртуальной модели города.
Конечно, можно просто описать всю модель в одном объекте, но это чревато только лишней сложностью и запутанностью. Когда все «свалено» в одно место и непонятно как перемешано, становится трудно понимать, что вообще происходит и тем более вносить какие-либо изменения. Поэтому, чтобы сделать проще и не запутаться в получившейся программе, мы разобьем описание нашего города на небольшие отдельные части.
В качестве таких частей мы возьмем то, что легко отделяется друг от друга при взгляде на наш реальный город — отдельные объекты этого города (дом культуры, красная БМВ на перекрестке, Петрович, бегущий по своим делам). Описание каждого объекта в виртуальном мире представляет собой описание его свойств (цвет, модель, название, расположение и т.п.). Чтобы не повторяться и не описывать одинаковые свойства для похожих объектов каждый раз, мы выделим группу таких свойств и назовем их типом объекта. Хорошими кандидатами являются такие общие типы, как машина, дом, человек и т.п. Они позволят сосредоточить в себе описание основных свойств. А различные виды машин, например, будут дополнять базовый тип «машина» своим уникальным набором свойств, создавая целый набор новых типов. Такие новые типы по отношению к исходным типам называются наследниками. А сам процесс создание нового типа, на основе существующего — наследованием.
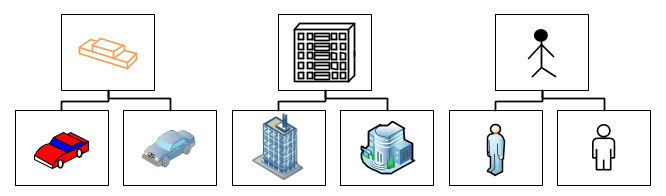
Все созданные нами типы объектов будут представлять модель нашего города.
После этого просто создадим экземпляры этих типов для каждого существующего в городе объекта и заполним их его уникальными значениями.
И вот вроде бы все расставлено по своим местам, группа машин стоит на перекрестке в ожидании зеленого сигнала светофора, девочка Юля — в ожидании своего лифта, и даже вода застыла в трубах огромного небоскреба. Мы наполнили нашу модель состоянием, повторив состояние нашего реального города за какой-то определенный момент времени.
Но, если мы внимательно посмотрим на наш реальный город, то мы увидим, что он постоянно меняется. Все изменения его состояния представляют собой изменения значения свойств различных объектов, появление новых объектов или исчезновение старых. Вот светофор переключился и поменял значение свойства «Текущий сигнал светофора» с красного на зеленый. Вот лифт поменял значение свойства «Этаж» со второго на первый и значение свойства «Открыты ли двери» с да на нет.
Значит для того чтобы наш город ожил, наша программа должна уметь менять состояние модели, а это значит — уметь менять свойства различных объектов, добавлять новые объекты или удалять старые, т.е. обладать поведением.
Для этого добавим в программу все возможные действия в нашем городе. Каждое такое действие можно описать в виде процедуры изменения свойств какого-либо объекта или группы объектов. После описания всех этих процедур становится видно, что их количество достаточно велико. Чтобы упростить поддержку и изменения всех доступных процедур их стоит разбить на группы. Недолго думая, можно сгруппировать такие процедуры по однотипности их действий, получив таким образом набор классов, каждый из которых будет отвечать за набор схожих действий.
Вроде бы, теперь все разделено и выглядит очень даже неплохо, но есть одно «но». Описание свойств наших объектов полностью отделено от процедур, которые эти свойства меняют и превращают нашу модель в анемичную модель. При таком разделении совершенно непонятно, как могут меняться свойства того или иного объекта. А если изменение одного свойства должно быть связано с изменением других свойств или зависит от значения других свойств, то это знание о внутреннем устройстве объекта придется продублировать во всех процедурах, меняющих это свойство. Чтобы избежать этих проблем мы не будем группировать процедуры по действиям, а разложим эти процедуры по тем типам, свойства которых они меняют.
Благодаря этому, для публичного доступа можно будет оставить только используемые другими свойства и методы, скрыв знания о внутреннем устройстве объекта. Такой процесс сокрытия внутренних принципов работы называется инкапсуляция. Например, мы хотим переместить лифт на несколько этажей. Для этого нужно проверить состояние дверей – открыты или закрыты, запустить и остановить двигатель и т.п. Вся эта логика будет просто скрыта за действием «переместиться на этаж». В итоге получается, что тип объекта представляет собой набор свойств и процедур, меняющих эти свойства.
Некоторые процедуры могут иметь одинаковый смысл, но быть связанными с различными объектами. Например, процедура «издать звуковой сигнал» есть и у красной BMW и у синих жигулей. И хоть внутри они могут быть выполнены совершенно по-разному, они несут в себе один и тот же смысл.
Так как у нас уже есть общий тип «машина», мы можем поместить процедуру «издать звуковой сигнал» туда. Если логика такого поведения у всех одна, то там же ее можно будет и определить. Это упростит производные типы и избавит от дублирования кода. Но если вдруг, в производных типах логика такого поведения будет отличаться, то ее можно легко поменять с помощью переопределения поведения. Такая возможность называется полиморфизмом.
Абстракция, наследование, инкапсуляция и полиморфизм – это те прелести ООП, следуя которым можно создавать более гибкий дизайн. В довесок к ним существует некоторый набор принципов, цель которых такая же – помочь создать более гибкий дизайн.
SOLID как много в этом слове …
SOLID – аббревиатура общеизвестных принципов объектно-ориентированного дизайна. В этой аббревиатуре их скрыто пять, по одному на каждую букву.
Single Responsibility Principle (принцип единственной ответственности) — у каждого объекта должна быть только одна причина для изменения.
Для того, чтобы в каждой комнате каждого дома можно было использовать и интернет, и электричество — была создана единая розетка с разъемами для интернет-провода и электрического провода.
public class Socket
{
private PowerWire _powerWire;
private EthernetWire _ethernetWire;
public Socket(PowerWire powerWire, EthernetWire ethernetWire)
{
_powerWire = powerWire;
_ethernetWire = ethernetWire;
}
...
}
Для работы такой розетки необходимо было подводить интернет-провод и электрический провод. И, казалось бы, нет ничего страшного в том, что не во всех розетках всегда используется и интернет, и электричество, зато компактно и удобно. Но все становится не таким удобным, когда наступает пора изменений.
Сначала появились квартиры и даже целые здания, в которых был не нужен интернет. Совсем. Но для того, чтобы наши розетки могли в них работать, пришлось протягивать интернет-провода и туда, что только увеличило стоимость работ, не принеся никакой пользы.
Потом появилось требование, что розетки должны быть оборудованы дополнительным проводом для заземления и из-за этого пришлось менять ВСЕ розетки, в том числе и те, которые использовались только для интернета. Был проделан большой объем работы, который мог бы быть меньше, если бы не затрагивались розетки, используемые только для интернета.
public class Socket
{
private PowerWire _powerWire;
private EthernetWire _ethernetWire;
private GroundWire _groundWire;
public Socket(PowerWire powerWire, EthernetWire ethernetWire, GroundWire groundWire)
{
_powerWire = powerWire;
_ethernetWire = ethernetWire;
_groundWire = groundWire;
}
...
}
Но последней каплей стало требование — поменять для всех интернет-розеток интернет-провод на новый стандарт. А так как вообще все розетки являются одновременно еще и интернет-розетками – то пришлось опять менять ВСЕ. Хотя объем работ мог бы быть гораздо меньше, так как количество розеток, используемых для интернета, в разы меньше количества всех розеток.
public class Socket
{
private PowerWire _powerWire;
private SuperEnthernetWire _superEnthernetWire;
private GroundWire _groundWire;
public Socket(PowerWire powerWire, SuperEthernetWire superEthernetWire, GroundWire groundWare)
{
_powerWire = powerWire;
_superEnthernetWire = superEnthernetWire;
_groundWare = groundWare;
}
...
}
Во всех случаях был проделан совершенно лишний объем работы из-за того, что в одном объекте было совмещено сразу несколько, совершенно не связанных обязанностей. И у каждой из этих обязанностей была своя, отдельная причина для изменения.
Чтобы избежать таких проблем — розетка должна была быть разделена на две, независимые друг от друга, части – электрическую розетку и интернет-розетку:
public PowerSocket
{
private PowerWire _powerWire;
private GroundWare _groundWare;
public PowerSocket(PowerWire powerWire, GroundWare groundWare)
{
_powerWire = powerWire;
_groundWare = groundWare;
}
...
}
public class EthernetSocket
{
private SuperEthernetWire _superEthernetWire;
public EthernetSocket (SuperEthernetWire _superEthernetWire)
{
_superEthernetWire = superEthernetWire;
}
...
}
А в тех случаях, когда действительно была бы нужна и электрическая и интернет-розетка можно было бы использовать агрегацию:
public PowerEthernetSocket
{
private PowerSocket _powerSocket;
private EthernetSocket _ethernetSocket;
public PowerEthernetSocket (PowerSocket powerSocket, EthernetSocket ethernetSocket)
{
_powerSocket = powerWire;
_ethernetSocket = ethernetSocket;
}
...
}
Open-closed principle (принцип открытости-закрытости) – объекты должны быть закрыты для модификаций, но открыты для расширений.
Для оповещения людей о важной информации в центре города, на самом оживленном перекресте был установлен большой экран. На нем отображался текст сообщений, приходящих из различных источников.
public class Message
{
public string Text { get; set; }
}
public class BigDisplay
{
public void DisplayMessage(Message message)
{
PrintText(message.Text);
}
public void PrintText(string text)
{
...
}
}
Спустя какое-то время появился новый вид сообщений — сообщения, содержащие дату. И для таких сообщений на экране было необходимо отображать и дату и текст. Доработку можно было выполнить различными способами.
1. Создать новый тип, производный от типа «сообщение», добавить ему атрибут «дата» и поменять процедуру отображения сообщений.
public class Message
{
public string Text { get; set; }
}
public class MessageWithDate : Message
{
public DateTime Date { get; set; }
}
...
public void DisplayMessage(Message message)
{
if (message is MessageWithDate)
PrintText(message.Date + Message.Text)
else
PrintText(message.Text);
}
Но такой способ плох тем, что придется менять поведение всех типов, которые каким-либо образом выводят сообщение. И если в дальнейшем появится еще какой-то новый, особый тип сообщений — все придется менять еще раз.
2.Добавить свойство «дата» в тип «сообщение» и поменять способ получения текста, чтобы получилось так:
public class Message
{
private string _text;
public string Text
{
get
{
if(Date.HasValue)
return Date.Value + _text;
else
return _text;
}
set { _text = value; }
}
public DateTime? Date { get; set; }
}
Но, во-первых, такой способ плох тем, что нам приходится менять основной тип и добавлять в него поведение, которое свойственно не всем сообщениям, из-за чего появляются лишние проверки. Во-вторых, при появлении нового типа сообщения нам придется создавать еще один атрибут, который будет не у всех сообщений, и добавлять лишние проверки в код. В-третьих, теперь отсутствует способ получения текста сообщения без даты для сообщений с датами. И в случае такой необходимости — текст сообщения придется выковыривать.
3. Сразу записывать дату в текст сообщения, чтобы вообще не создавать никакого нового типа и не менять способа отображения сообщения на экране. Но такой способ плох тем, что в тех местах, где от сообщения нужно будет получить только дату — сначала придется определять, содержит ли это сообщение дату вообще, а потом вычленять ее из текста сообщения.
Если следовать принципу открытости-закрытости, можно избежать всех этих проблем и пойти четвертым путем:
public class Message
{
public string Text { get; set; }
public virtual string GetDisplayText()
{
return Text;
}
}
public class MessageWithDate : Message
{
public DateTime Date { get; set; }
public override string GetDisplayText()
{
return Date + Text;
}
}
...
public void DisplayMessage(Message message)
{
PrintText(message.GetDisplayText());
}
При таком подходе нам не нужно менять базовый тип «сообщение» — он будет оставаться закрытым. В то же время он будет открытым для расширения его возможностей. Помимо этого, пропадут все проблемы, свойственные другим подходам.
Liskov substitution principle (принцип подстановки Барбары Лисков) — функции, которые используют базовый тип, должны иметь возможность использовать подтипы базового типа, не зная об этом.
После добавления в программу типа «велосипед» пришло время добавить еще один тип – «мопед». Мопед — он же как велосипед, только еще лучше. Значит велосипед отлично подойдет в качестве базового типа для мопеда. Сказано-сделано, и в программе появился еще один тип «мопед» — производный от типа «велосипед».
public class Bicycle
{
public int Location;
public void Move (int distance) { ... }
}
public class MotorBicycle : Bicycle
{
public int Fuel;
public override void Move(int distance)
{
if (fuel == 0)
return;
...
fuel = fuel – usedFuel;
}
}
Но по сравнению с велосипедом, у мопеда есть одна неприятная особенность – если бензин кончается, то мопед уже не может двигаться. И эту неприятную особенность пришлось учесть в коде. Учли, а значения придавать не стали – на то у нас и производный тип, чтобы учитывать всякие специфические особенности.
Так как мопед быстрее чем велосипед, то при возможности он стал использоваться в программе там, где раньше использовался велосипед. Но, в один прекрасный день программа зависла намертво. Поиск ошибки был долог и мучителен, т.к. проблема повторялась периодически и случайным образом. Опустим описание бессонных ночей и сразу перейдем к виновнику всех бед – методу, который перемещал велосипедиста между двумя, далеко расположенными друг от друга точками:
public void LongJourney (int to, Biker biker, Bicycle bicycle)
{
while(bicycle.location < to)
{
int distance = to - bicycle.location;
if (distance > 1000)
distance = 1000;
bicycle.move(distance);
biker.sleep();
}
}
Когда в метод вместо велосипеда передавался мопед с недостаточным количеством бензина, он зависал навсегда из-за того, что мопед не продвигался ни на сантиметр, даже если такое действие вызывали явно. Чтобы исправить эту проблему — можно было бы сделать так, конечно:
public void LongJourney (int to, Biker biker, Bicycle bicycle)
{
while(bicycle.location < to)
{
int distance = to - bicycle.location;
if (distance > 1000)
distance = 1000;
if (bicycle is MotorBicycle && bicycle.Fuel == 0)
FillFuel((MotorBicycle)bicycle);
bicycle.move(distance);
biker.sleep();
}
}
public void FillFuel(MotorBicycle motorBicycle)
{
...
}
Но тогда внесение таких изменений потребовало бы изменения большого числа процедур, что, во-первых, долго, во-вторых, чревато тем, что это можно забыть и такая забывчивость приведет к очередным неуловимым проблемам. Помимо этого, добавление таких условий являлось бы утечкой абстракции. А в случае появления еще какого-либо фактора, влияющего на поведение, все эти сложности только удвоились бы.
На самом деле, изначальная проблема кроется в том, что мопед не является разновидностью велосипеда, не смотря на всю свою внешнюю схожесть. Поэтому попытки привести их к общему знаменателю не привели ни к чему хорошему. Для мопеда пришлось сделать отдельный, независимый от велосипеда тип, и учесть это во всех нужных процедурах.
Interface segregation principle (принцип разделения интерфейсов) — клиенты не должны зависеть от методов, которые они не используют.
Для придания большей реалистичности было добавлено одно интересное поведение. Если в неположенном месте, на дороге, появлялся человек, то транспортное средство, которому он помешал — должно было остановиться и посигналить. Для этого был реализован метод:
public void CheckIntersect(Car car, People[] people)
{
...
if (Intersect(car, people))
{
car.Stop();
car.Beep();
}
}
public bool Intersect(Car car, People[] people)
{
...
}
Поведение было проверено и все было хорошо до тех пор, пока в системе не появился велосипед и не сбил человека, выбежавшего на шоссе. И это не удивительно, ведь проверку столкновения и автоматическую остановку сделали только для автомобилей.
Первой же безумной идеей могло быть стать желание сделать велосипед производным типом от типа «машина», чтобы его можно было легко подставлять в такие методы, без их изменения. Ведь если приглядеться повнимательнее, в процедуре используются только такие действия машины, которые есть и у велосипеда, и ничего страшного не произойдет. Но это только в этом методе. Если такой странный производный тип передать в какую-нибудь другую процедуру, использующую что-нибудь машинно-специфичное, то такая процедура обязательно сломается.
Второй безумной идеей могло бы стать желание создать отдельную процедуру для проверки столкновения велосипеда с человеком. Но тогда получится, что вся логика будет продублирована. И более того, придется создавать для каждого нового транспортного средства отельную процедуру. Это получится совсем не гибко.
Но, если в процедуре проверки столкновения используются только такие два действия, которые есть у любого транспортного средства, зачем передавать в метод какой-то конкретный тип?
Мы можем определить контракт, который должен соблюдать тип, который можно использовать в этом методе и реализовать его во всех транспортных средствах.
public interface IVehicle
{
...
void Stop();
void Beep();
}
public class Car : IVehicle { ... }
public class Bycycle : IVehicle { ... }
public void CheckIntersect(IVehicle vehicle, People[] peoples)
{
...
if (Intersect(vehicle, peoples))
{
vehicle.Stop();
vehicle.Beep();
}
}
public bool Intersect(IVehicle vehicle, People[] people)
{
...
}
Тогда, в такой метод можно будет передать любой существующий вид транспортного средства и любой вид, который появится в дальнейшем, при соблюдении им условий контракта.
Dependency Inversion Principle (принцип инверсии зависимостей) — абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
В нашем городе существует система оповещения новостей. Система получает важные новости и транслирует их через систему динамиков города.
public class NotifySystem
{
private SpeakerSystem _speakerSystem = new SpeakerSystem();
public void NotifyOnWarning(string message)
{
_speakerSystem.Play(message);
}
}
Все работает прекрасно, но требованиям свойственно меняться. Теперь мы должны иногда передавать сообщения не через систему динамиков, а через мобильные телефоны, отправляя их в виде смс. Конечно, мы можем сделать еще один объект для отправки уведомлений о сообщениях через смс, но для этого придется дублировать большую часть логики. Чтобы этого избежать — мы пойдем другим путем. Системе оповещения, в принципе, все равно как ее сообщения будут отображаться. Самое главное – это их отправка. Поэтому, мы можем сделать так:
public class NotifySystem
{
private IMessageDelivery _messageDelivery;
public public NotifySystem(IMessageDelivery messageDelivery)
{
_messageDelivery = messageDelivery;
}
public void NotifyOnWarning(string message)
{
_messageDelivery.SendMessage(message);
}
}
Мы просто объявим интерфейс системы доставки сообщений, которую мы будем использовать, внутри системы оповещения. А реализация этого интерфейса ляжет на плечи тех, кто захочет пользоваться системой оповещения. По сути, мы создаем некий шаблон поведения, который позволяем расширить так, как удобно потребителю.
— А можно было бы просто не заморачиваться всеми этими принципами и писать код как получится?
— Конечно!
— И все равно все бы так же работало?
— Естественно!
— Для чего же тогда нужно использовать все эти сложности в виде ООП, ООД? Если я не буду думать обо всех этих сложностях — я гораздо быстрее напишу программу! А чем быстрее напишу, тем лучше!
— Если программа достаточно проста, а ее дальнейшее развитие, доработка или исправление ошибок не предвидится, то все это, в принципе, и не нужно. Но! Если программа сложная, планируется ее доработка и поддержка, то применение всех этих «лишних сложностей» будет напрямую влиять на самое главное – на количество потраченных ресурсов, требуемых для доработок и поддержки, а это значит – на стоимость.
Все эти правила, шаблоны, парадигмы объединяет одна основная мысль – сделать код модульным, гибким, легко расширяемым и устойчивым к изменениям. Изменение поведения таких маленьких, слабосвязанных модулей, как правило, стоит дешевле, чем изменения поведения большого модуля, в котором все смешано в кучу.
Предметная область
— Запомни, если плохой алгоритм будет стоить тебе тысячу, то плохая архитектура будет стоить тебе миллион.
Тем не менее, все, что было описано выше – это, в основном, решение проблем технических. О том, что такое ООП, ООД, какие плюсы у них есть и как их использовать расписано уже десятки лет назад. Достаточно вбить пару ключевых слов, например, SOLID и получить кучу пояснительной информации.
Если проблема достаточно общая и требует для своего решения какой-нибудь алгоритм, то, скорее всего, он тоже уже есть — достаточно только протянуть руку. Пару запросов в поисковике, например, «посчитать вагоны, сцепленные по кругу, решение» и сотни результатов перед вами.
Но вот для того, чтобы правильно разделять логику на модули и сервисы — одних технических знаний недостаточно, и поисковик тут уже никак не поможет. Нужно хорошее понимание предметной области, а с этим уже проблемы, так как надо прикладывать много сил для изучения чего-то, совершенно с программированием не связанного. Поэтому разработчики больше любят решать технические проблемы, отдавая решение бизнес-проблем на откуп аналитиков. Но аналитикам неизвестно внутреннее устройство программы, которое отражает не структуру бизнеса, а представления разработчика об этой структуре. И чем дальше это представление от реальности, тем сложнее эту структуру будет менять для соответствия изменениям, произошедшим в бизнесе.
Это связано в том числе и с двойной интерпретацией задачи. Сначала аналитик пытается понять то, что нужно добавить или изменить в приложении, общаясь с бизнес-пользователями. Затем эти знания он пытается своими словами передать разработчику. В результате, истина может искажаться и все эти искажения могут вылиться в не самую подходящую структуру программы.
Пользователь высказал пожелание о том, что в комнаты домов днем должен попадать дневной свет так, чтобы все было видно. Разработчик, недолго думая, выдолбил в стене круглую дыру и проверил — оказалось, что света все еще недостаточно. Тогда разработчик выдолбил еще две дыры рядом и опять проверил. Убедившись, что света достаточно, разработчик решил, что задача выполнена. По этому принципу дыры были выдолблены во всех домах. Требования были соблюдены.
Но лето кончилось и наступила зима, а вместе с ней и холода. Злой пользователь прибежал и стал ругаться на то, что в комнатах стало ужасно холодно. При выяснении причин стало ясно, что из-за дыр, выдолбленных под солнечный свет, в комнату попадает много холодного воздуха с улицы и она промерзает. После выяснений обстоятельств оказалось, что пользователь хотел обычное окно, но какие-то требования забыл упомянуть он, а что-то по-своему передал аналитик, и получилось то, что получилось. Так как все промерзло – решать проблему пришлось на ходу, времени на разработку хороших окон и переделку дыр под окна в зимний период уже не было. Поэтому было принято решение обойтись «костылем» и заделать дыры полиэтиленом. Такой способ помог избавиться от сильного промерзания и позволил оставить солнечный свет днем. Но кто знает, сколько новых проблем неполное понимание изначальных требований еще принесет…
Для того, чтобы решить эту проблему между всеми участниками разработки должно выработаться общее, одинаковое представление о том, что происходит и что для чего нужно. Для этого существует целый подход – Domain Driven Design, целью которого как раз и является выработка общего понимания и общей терминологии (общего языка) среди всех участников разработки.
Плохое понимание модели приводит к тому, что разработчик старается заниматься тем, что ему ближе и понятнее – решением технических проблем. В том числе и решением бизнес-проблем чисто техническим способом. А в случае отсутствия технических проблем — их изобретением и их же героическим решением. Все это будет приводить только к появлению странных, малопонятных конструкций в программе. С другой стороны, это может быть осознанным выбором, если разработчик следует Ipoteka Driven Development.
Но пришла пора заканчивать небольшое путешествие по принципам ООД и другим отвлеченным темам и возвращаться к программе. После добавления бизнес-логики к нашей модели, у нас получился уже не просто снимок застывшего города, а его полноценная модель. Модель, состояние которой можно легко менять так же, как и состояние реальной модели.
Презентационная логика
Несмотря на все наши успехи, пользователи продолжают нетерпеливо ждать перед погасшим монитором. Мы создали модель нашего города, вдохнули в него жизнь, описав логику его изменения, проделав тем самым очень важный объем работы. Теперь нам осталось дать возможность пользователям «увидеть» то, что мы сделали. Для этого нам нужно научить наше приложение взаимодействовать с пользователями. Во-первых, пользователь хочет смотреть, что происходит с его городом, как двигаются машинки, как загораются ночные окна, как куда-то спешат люди. А во-вторых, он хочет влиять на город — переключать светофор, менять день на ночь, создавать новые дома и т.п.
Но охватить всю картинку целиком возможно только в простых случаях. Если наша модель сложная, то отобразить ее целиком на экране, а уж тем более понять, становится не просто сложно, а практически невозможно. Самый лучший способ борьбы со сложностью – это разделение на более простые части, как мы и поступим. Мы будем отображать состояние нашей модели по частям. Самое главное – это правильно определить эти части. Каждая такая часть должна быть по возможности самодостаточной. Самодостаточной для понимания какой-то полезной информации или для принятия какого-либо нужного решения об изменении. Итак, мы поделим наше состояние на части в соответствии с пользовательскими задачами и попробуем отобразить их пользователю.
Например, мы хотим регулировать светофор на перекресте. Для этого нам не нужно знать какие дома стоят вокруг, где работают или живут люди, которые ждут зеленый сигнал светофора или то, что происходит на другом конце города. Все, что нам нужно для принятия решения — это информация о перекресте и о том, что на нем находится. Сколько машин и на каких полосах стоит, сколько людей стоит в ожидании на пешеходном переходе и какой сигнал у светофора. Перекресток в разрезе этой задачи — это корневой объект, с которым связаны другие объекты (машины, светофор, люди). В случае другой задачи, например, управления всего транспортного потока города, наш перекресток будет всего лишь частью другого корневого объекта – транспортной инфраструктуры всего города.
Отображая состояние перекрестка на экране пользователя, по сути, мы показываем его «фотографию» на момент обращения к программе, давая пользователю возможность изучить ее и принять решение. Пользователь может изучить эту «фотографию» со всех ракурсов и узнать для себя что-нибудь полезное. Опираясь на эти знания, он может принять решение об изменении состояния модели. Для этого он может, например, переключить сигнал светофора. Конечно, наша фотография может быть не застывшей, а анимированной. Периодически меняться и отображать произошедшие изменения. Но все равно не будет никаких гарантий, что отображается самое последнее состояние.
В процессе переноса реальной модели в виртуальную – она превратилась в обезличенный набор параметров и их значений. И этот набор данных можно крутить и трансформировать, как только душе угодно. Поэтому наш перекресток, как и любую другую часть нашей модели, можно отобразить огромным числом различных способов. И далеко не все из них будут удобны пользователю. Это удобство будет выражаться в скорости и качестве принятия решения пользователем.
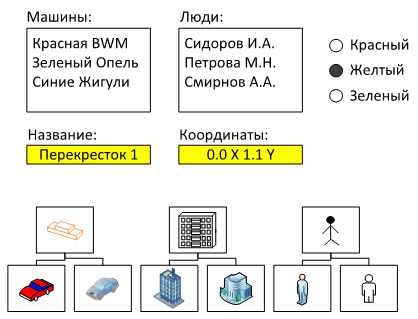
Например, состояние нашего перекрестка мы можем отобразить на экране в виде нескольких списков. В одном мы перечислим все машины, которые на нем сейчас находятся, в другом — людей, которые стоят на переходах. Помимо списков на экране будет изображен набор переключателей, отображающих сигнал светофора и несколько текстовых полей с названием и координатами перекрестка.
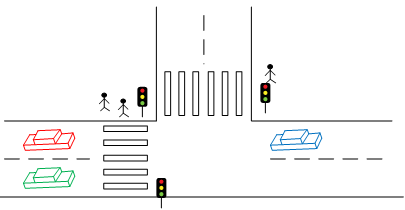
Или же, мы может отобразить перекресток в более удобном для человека виде – нарисовать его так же, как он выглядит в реальной модели, расставить на нем машинки и человечков, нарисовать светофор. Где-нибудь в углу отобразить мини-карту города, значком обозначив расположение перекрестка. Очевидно, что во втором случае восприятие состояния будет гораздо более удобным и быстрым. Хотя в обоих случаях на экране отображены одни и те же данные.
Так же и с остальной частью программы – очень важно не просто отобразить данные пользователю на экране, а сделать это максимально удобным и понятным для него способом.
А если взять что-нибудь, типа Microsoft HoloLens, то вообще можно отображать наш виртуальный город так же, как он выглядел в реальности или даже еще удобнее.
Сохранение состояния
После нескольких часов непрерывной работы пользователь, с радостью от проделанной работы, откидывается на спинку стула.
— Уффф – произносит усталый пользователь.
— Чпок – отвечают ему пробки и свет в мониторе гаснет.
В глазах разработчика появляется вселенская грусть. Ничего не подозревающий пользователь включает свет обратно и запускает компьютер. Запустив свой виртуальный город — пользователь видит, что все что он успел сделать – пропало. Город выглядит точно так же, как и в момент первого запуска …
Конечно же, наш мир далек от совершенства и компьютеры не могут работать непрерывно. Помимо этого, оперативной памяти компьютера тоже может быть недостаточно для того, чтобы удержать в памяти все состояние модели. Поэтому сохранение состояния способом, который умеет переживать выключения компьютера, является важной составляющей большинства программ. А так как все объекты нашей модели не меняются одновременно, мы вообще можем держать ее всегда в сохраненном состоянии и восстанавливать из сохраненного состояния небольшими частями, для просмотра или внесения нужных изменений. После чего можем спокойно сохранять новое состояние обратно.
Существуют различные способы сохранения состояния: можно хранить его в файле, придумав какой-нибудь формат, можно записывать на диск или флешку, можно использовать специальные системы хранения данных. Наиболее распространенным способом на текущий момент является использование для этого баз данных. Самыми популярными из них на сегодняшний день являются реляционные базы данных.
Не будем изобретать велосипед и решим проблему сохранения состояния модели при помощи РСУБД. Помимо удобства сохранения и извлечения данных, она предоставляет дополнительные полезные возможности, такие как, контроль целостности данных, который реализуется с помощью различных ограничений. Так же, база данных защищает от различных сбоев в момент сохранения, не давая возможности записать изменившееся состояние лишь частично, тем самым приводя его в поломанное состояние.
В базе данных вся информация хранятся в таблицах. Как правило, для каждого типа объекта существует своя таблица. А для каждого свойства объекта в этой таблице существует колонка. Значит, для того, чтобы сохранить экземпляр какого-либо типа — нам нужно создать для него соответствующую таблицу, с соответствующим набором колонок.
Описав всю необходимую структуру таблиц, мы, наконец-то, можем сохранить наше состояние в базе данных, чтобы не переживать о его сохранности. Но для этого нам нужно научить наше приложение использовать эти таблицы для сохранения и загрузки состояния. Для этого мы возьмем готовый инструмент в виде ORM и опишем сопоставление между типами и таблицами в базе данных. Хотя в случае, когда типов не так уж и много или использовать сторонний инструмент не хочется или не представляется возможным, существуют и другие способы.
Еще одним интересным способом сохранения является хранение не самого состояния модели, а описания действий, которые это состояние поменяли. Это напоминает redo-лог в базах данных или запись шахматной партии, в виде последовательности ходов. Такой подход называется event sourcing.
— Слушай. Получается, что создавая структуры для хранения данных, добавляя к ним ограничения, триггера, связи между таблицами и т.п. мы дублируем бизнес-ограничения, которые уже есть в модели, на сервере приложения?
— Получается, что так.
— Выходит, что мы все время учимся тому, что дублировать – это плохо, а тут рррраз и надублировали. Хммм….
Многослойность
Так как мы аккуратно создавали нашу программу и старались не смешивать различные действия, то, в итоге, у нас выделилось несколько разных слоев логики.
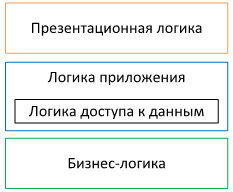
Бизнес-логика
Это та часть логики программы, которая отвечает за изменение состояния нашей модели. Она описывает условия, которые должны соблюдаться для совершения изменения и сами изменения. Ей известна и доступна только модель.
Презентационная логика
Это та логика программы, которая отвечает за отображение состояния модели и доступных действий пользователю. Ей известна модель, которую нужно отобразить и бизнес-логика, которую можно вызвать.
Логика доступа к данным
Это та логика программы, которая знает, как сохранять и загружать состояние модели. Ей известна модель и то, как ее можно заполнить данными из базы данных.
Логика приложения
Это та логика, которая связывает все воедино, как клей. Ей известно и о бизнес-логике, и о логике доступа к данным, и о презентационной логике. Она объединяет их, помогает им и налаживает друг с другом взаимодействие.
Соблюдение такого разделения упрощает изменения приложения. Чем меньше слоям известно друг о друге и чем больше их логики скрыто друг от друга, тем проще их менять. Ведь, по сути, какая разница презентационной логике, где и как хранится состояние модели? И наоборот, какая разница логике хранения данных, где и как отображаются эти данные на интерфейсе? Ведь способов их отображения может быть несколько и они могут очень сильно отличаться друг от друга. В то же время модели все равно, как приложение сохраняет ее состояние или как это состояние отображается на экране. Только изменение модели или бизнес-логики может затронуть другие слои, так как они являются центральной частью программы.
2-tier
— Эй! – крикнул один пользователь другому. – Ты же должен был добавить новое здание в этом месте!
— Так я его и добавил, вот, посмотри. – ответил второй первому.
— Действительно… – почесал в затылке первый. — Странно, что я его не вижу у себя.
— Ничего странного, – ответил им разработчик. – ведь у каждого из вас своя база данных, т.е., по сути, у каждого свой собственный город.
— А зачем нам каждому свой город? – спросили раздраженные пользователи. – ведь он у нас был один, общий и мы хотим один, общий.
В глазах разработчика снова появилась вселенская грусть.
Для того, чтобы видеть изменения друг друга — пользователи должны работать с одним и тем же состоянием модели. Так как состояние нашей модели хранится в базе данных, это означает то, что пользователи должны использовать общую базу данных. Как правило, она располагается на отдельном компьютере, к которому программы всех пользователей имеют доступ.
Теперь одновременно несколько пользователей могут смотреть и менять одно и то же состояние модели. Но, появилась другая проблема – проблема конкурентного доступа. Ее можно решить различными способами. Наиболее распространенный способ – блокировка ресурсов для единоличного доступа перед внесением в них изменений, чем мы и воспользуемся. Для этого придется внимательно изучить всю программу и понять, в каких местах нам нужно добавить блокировки.
Хорошо, если задача требует блокировки малого числа ресурсов на короткий промежуток времени. Плохо, когда приходится блокировать большое число ресурсов и делать это продолжительное время. В таких случаях можно попробовать применить другой подход.
После физического разделения программы на два компьютера — у нас получилась клиент-серверная (двухзвенная) архитектура.
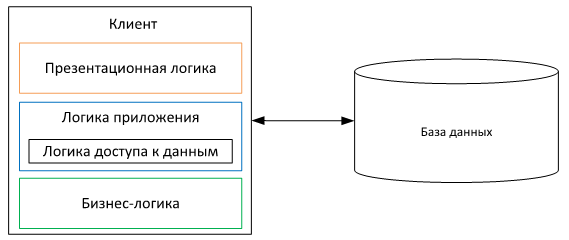
Это физическое разделение прибавляет дополнительные технические проблемы. Во-первых, сетевые соединения могут обрываться, и это будет являться дополнительной точкой отказа. Это надо будет учитывать при разработке приложения, чтобы правильно обрабатывать ошибки обрыва сети или недоступности сервера.
Во-вторых, передача данных по сети требует больше времени и это тоже надо учитывать. С одной стороны, для ускорения получения данных, данные могут кэшироваться на клиенте. С другой стороны, изменения могут отправляться не постоянно, а накапливаться в рамках задачи и отправляться один запросом.
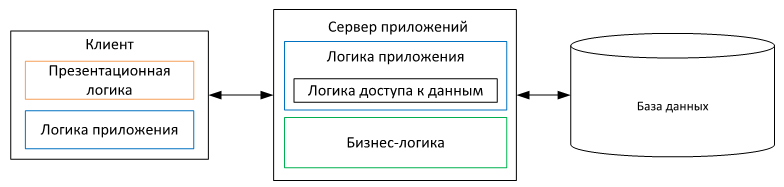
N-tier
— А мне бы еще нормально с планшета управлять городом, а то там такие сложные вычисления, что я засыпаю раньше, чем он что-то посчитает, пока я на работу еду из дома. – попросил один из пользователей.
— А мне нужно, чтобы некоторые новые пользователи имели доступ не ко всем действиям. – сказал другой пользователь.
В глазах разработчика появился уже знакомый взгляд…
Для решения новых проблем придется перенести бизнес-логику программы с пользовательского компьютера на отдельный, специально выделенный для этого компьютер, который обычно называют сервером приложений.
Наше аккуратное разделение логики на слои сыграло нам на руку. Презентационная логика и бизнес-логика и так были уже достаточно разделены, так что тут осталось только физически разделить их и создать дополнительную логику приложения для их взаимодействия. Наш толстый клиент, который содержал в себе бизнес-логику, значительно «похудел» и стал тонким клиентом.
К минусам, как и в случае клиент-серверного подхода, добавятся возможные сетевые проблемы и замедление скорости работы приложения за счет физического разделения бизнес-логики и презентационной логики. Помимо этого, к минусам можно отнести то, что внесение изменений станет более сложным, т.к. будет затрагивать больше кода, в том числе и того, который нужен для передачи данных между сервером приложений и клиентом.
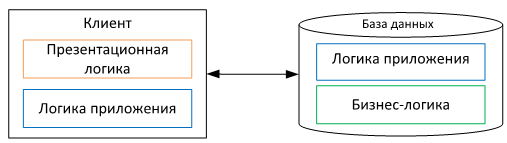
2 как 3
На самом деле, для решения проблем, перечисленных выше, не обязательно иметь трехзвенную архитектуру. Решить эти проблемы можно и в двухзвенной архитектуре, переместив бизнес-логику в базу данных, тем самым оставив клиент тонким. У такого подхода есть как свои плюсы, так и свои минусы.
Из плюсов хочется отметить — отсутствие физического разделения бизнес-логики и состояния модели, что может положительно сказаться как на скорости работы, так и на отказоустойчивости. Из минусов хочется отметить то, что самое главное в базе данных – это умение сохранять и извлекать данные, а не поддерживать бизнес-логику. Поэтому возможности языков, используемых в базах данных, уступают по возможностям современным высокоуровневым языкам. Помимо этого, отсутствует нормальная возможность использования большого разнообразия различных фреймворков. Все это сказывается на возможности и стоимости написания гибкого кода.
Другим минусом является возможность масштабирования. Масштабировать сервера приложений под высоконагруженные операции проще, нежели чем базы данных. Учитывая эти аспекты, получается то, что использование для бизнес-логики отдельного звена в качестве сервера приложений зачастую будет дешевле, чем содержание ее в базе данных.
Сервисы
— У нас тут вчера сломалось управление транспортом в городе и из-за этого не работала вся программа. – начал один из пользователей, – Но, с управлением транспорта никак не связано управление электроэнергией или водопроводной системой – продолжил он. – Можно как-нибудь сделать так, чтобы возможность их использования не зависела от проблем в несвязанных с ними областях? – спросил пользователь в итоге.
— У меня тоже есть просьба – продолжил другой пользователь – Можно сделать так, чтобы для обновления различных возможностей программы не нужно было бы ждать довольно долго обновления всей программы? – спросил он.
Потратив достаточно времени в самом начале и хорошо поняв предметную область, мы смогли выделить группу сервисов. Например, сервис управления светофорами, сервис управления электроэнергией или даже сервис управления зданиями. Все эти сервисы являются частью нашего виртуального города, но между собой они связаны достаточно мало, а зачастую, не связаны вовсе. Поэтому код программы был написан так же, с разбивкой на сервисы. Чтобы этого достичь — мы выделили необходимый для каждого сервиса публичный набор методов, спрятав все остальное. Таким образом, мы превратили наш сервис в «черный ящик». Этого легко удалось достичь, используя различные средства языка, такие как: модификаторы доступа методов, интерфейсы, абстрактные классы и т.п.
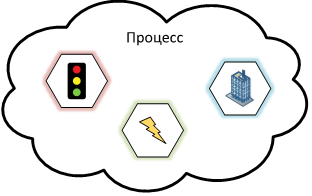
Благодаря слабой связанности — в большинстве случаев все эти сервисы можно менять независимо друг от друга. Но, т.к. физически все эти сервисы являются одной программой, такие изменения нельзя независимо установить клиенту. Если сервис меняется достаточно часто, и такие изменения нужно как можно раньше устанавливать клиенту, это становится не очень удобно. Появляется вынужденная зависимость от других сервисов, которую хотелось бы избежать.
Чтобы справится с этой проблемой, мы физически разделили программу на несколько частей. Таким физическим разделением может являться выделение сервисов в различные файлы (библиотеки). Это позволило разбить программу на несколько файлов – основной запускаемый файл и набор библиотек.
С помощью такого физического разделения появляется возможность независимого обновления сервисов, представляющее простую замену библиотеки сервиса. Несмотря на то, что сервисы стали физически разделены, они продолжают использовать общую логику приложения, что достаточно удобно, и живут в одном процессе — что позволяет использовать все возможности единого приложения. Помимо этого, такое явное разделение позволяет некоторым разработчикам работать только над определенным сервисами.
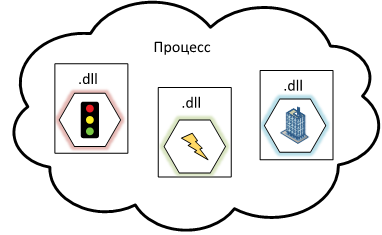
Для того, чтобы избежать «падения» всей программы, добавим в программу механизм обработки различных ошибок, возникающих при работе сервисов, который позволит программе оставаться работоспособной даже если какой-то сервис сбоит.
Но, если такой устойчивости будет недостаточно, можно разделить сервисы на разные процессы. Для этого придется доработать логику приложения для поддержки межпроцессного взаимодействия каким-либо удобным способом.
К плюсам такого подхода можно так же отнести — возможность использования для каждого отдельного сервиса своего набора технологий. Что, безусловно, является отличной приманкой для разработчиков. Но, в таком случае пропадет взаимозаменяемость разработчиков, что может стать недостатком.
К минусам такого подхода, как и в похожих случаях, можно отнести проблемы, связанные с уменьшением скорости взаимодействия, а так же, возможные перебои в передаче данных между процессами. Так же, еще можно добавить и то, что при разделении бизнес-логики появляются дополнительные проблемы в виде необходимости поддержки целостности данных в задачах, затрагивающих сразу несколько сервисов, например, с помощью распределенных транзакций.
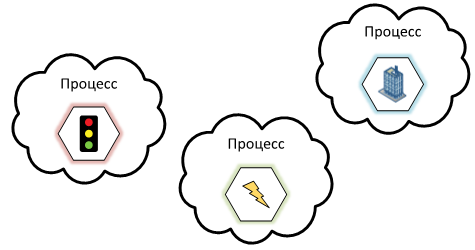
— Слушай, а что всё так носятся с этими микросервисами?
— Разработчики думают, что физически разделив бизнес-логику, смогут писать слабосвязанные, легкозаменяемые устойчивые модули.
— Как будто им раньше что-то мешало…
Любое физическое разделение решает одни технические проблемы, но взамен привносит проблемы другие. Решать изначальные технические проблем, безусловно, надо, но всегда стоит подумать, превысит ли выгода от их решения недостаток от появления новых проблем.
Каждый раз, когда происходит физическое разделение частей программы, необходимо реализовывать инфраструктурную прослойку, которая будет скрывать это разделение. Да, с технической точки зрения создание такой инфраструктуры — это, безусловно, интересная чисто техническая задача, поэтому программисты с радостью берутся за нее. Но если это толком не решает никаких проблем, то это лишь увеличивает стоимость и сложность программы, не принося никакой выгоды.
Инструменты
-А зачем, вместо того, чтобы сделать нормальный запрос к БД, он вытягивает обе таблицы на сервер приложения, затем героически объединяет их и фильтрует результат для получения необходимых данных?
— Когда у тебя в руках только молоток, все задачи кажутся гвоздями.
Языки, библиотеки, фреймворки, утилиты – это все то, чем пользуется разработчик в процессе работы. Все это нужно для максимального снижения стоимости решения технических проблем, оставляя больше времени для решения уникальных для проекта проблем бизнеса. Поэтому правильный выбор инструментов важен, так как напрямую влияет на производительность труда. Грубо говоря, можно что-то полдня выпиливать пилой, а можно взять электролобзик — вжик и готово!
Так как инструменты бывают разные и предназначены для разных целей – их правильное применение не менее важно. Забивать гвозди ломом, конечно, можно (и это будет удобнее, чем кулаками), но все-таки, не так легко и удобно, как молотком.
Но, среди разработчиков существует один очень плохой синдром под названием – «Not invented here». Его смысл в том, что вместо того, чтобы взять какой-либо готовый инструмент для решения определенного круга задач, разработчики начинают изобретать свой. Наиболее сильно это может проявляться в желании создания своей платформы.
Так как создание таких инструментов — задача чисто техническая и какого-либо понимания предметной области бизнеса для этого не нужно, разработчики с удовольствием любят этим заниматься. Но, когда разработчик нацелен на решение бизнес-проблем — он наоборот, с радостью упрощает себе жизнь сторонними инструментами.
Теория и практика
В теории, теория и практика одно и тоже. На практике — нет.
В теории, конечно, все красиво, но на практике все совсем не так. Недостаток технических знаний, знаний предметной области, времени или людей – все это ведет к появлению нежелательных проблем в коде и влияет на качество программы.
В реальности разработчики часто стоят перед компромиссом между качеством и скоростью. Попытка угодить заказчику и уложиться в срок заставляет делать все наспех. Это, в итоге, дает обратный эффект. Спешное решение проблем заставляет создавать плохие решения, которые, в итоге, накапливаются как большой снежный ком, пытаясь похоронить под собой весь проект. Из-за них поддержка и исправление начинают стоить еще дороже, что только усугубляет проблему, особенно в объяснениях заказчику, почему стоимость однотипных изменений стала стоить дороже.
Такие плохие решения практически неизбежны в любом проекте, поэтому очень важно находить время на рефакторинг.

Итог
В конечном итоге, все упирается в деньги. Чем дешевле стоимость разработки и поддержки, тем выгоднее создавать программу. Поэтому все подходы/инструменты/шаблоны/парадигмы и т.п. нацелены на одно – удешевления процесса разработки и поддержки.
Но разработка — это в том числе и творческий процесс. К решению одной и той же задачи можно прийти невероятно большим количеством путей, у каждого из которых будут свои плюсы и минусы.
И только от разработчика зависит насколько хорошим будет этот путь. Поэтому в разработке программ люди — это главный и самый важный ресурс.
Перевод статьи
«How to Improve Your Logic Building Skills in Programming».

Построение логики это фундаментальная
часть программирования. Если вы знаете
много языков программирования, но у вас
нет навыков построения логики, больших
высот вы не достигнете. Чтобы иметь
возможность придумывать различные
решения для каждой отдельной проблемы,
нужно изучать алгоритмы и практиковаться
в написании кода. Сегодня я поделюсь с
вами несколькими советами относительно
того, как улучшить свои навыки построения
логики и логического мышления.
1. Просматривайте код других
программистов

Просто подписаться на лучших программистов на разных сайтах будет недостаточно. Чтобы понять, как они мыслят, нужно читать их код. Каждая задача имеет разные решения, и эти решения можно найти в интернете. Попробуйте проанализировать найденные решения и понять, как применяется разная логика для решения одной задачи. Когда разберетесь, найдите способы улучшить логику или реализацию решения различных задач.
2. Разбивайте сложные задачи
до базовых

То, что задача сложная, не означает,
что ее можно решить только при помощи
тысячи строк кода. Способность с умом
подходить к решению сложных задач –
вот, что отличает опытного программиста
от новичка.
Когда вам попадается сложная задача,
сначала попробуйте визуализировать ее
сложность. Затем разбейте ее на несколько
задач или модулей. А после этого начинайте
реализовывать логику и решать каждую
часть задачи. Это поможет улучшить ваши
навыки построения логики.
3. Решайте реальные задачи

Записывать шаги алгоритмов и делать
сухие запуски кода это очень полезно
на начальных стадиях, но ваше умение
строить логику улучшится, только когда
вы начнете писать код систематически.
Выберите свой любимый язык программирования
и начинайте решать задачи. Сначала
простые и средней сложности, затем
переходите к более сложным.
Только не надо, увидев задачу, сразу
бросаться писать код. Сначала постарайтесь
понять ее, подумайте обо всех возможных
вариантах решения, выделите основные
элементы задачи, а затем приступайте к
реализации. Со временем ваши навыки
построения логики улучшатся.
4. Думайте условиями

Программирование это условия и циклы.
Вам нужно тоже начать думать условиями
в стиле «если условие А истинно, сделай
В, а иначе – С».
Здесь есть существенный «плюс»: условия
повторяются и могут встречаться снова
и снова. Старайтесь больше практиковаться
в if-else, switch и других простых условиях,
чем изучать гипотезы и теории об условном
и логическом мышлении.
5. Изучайте парадигмы
программирования

Изучение парадигм программирования
может очень сильно помочь улучшить ваши
навыки построения логики. Это своего
рода план создания наших проектов. Есть
три основные и часто встречающиеся
парадигмы программирования: императивная,
функциональная и объектно-ориентированная.
Императивное программирование
предполагает наличие последовательности
операторов, которые изменяют состояние
программы. Парадигма функционального
программирования в основном используется
для выполнения математических функций
без изменения состояния. Наконец, в
основе самой популярной –
объектно-ориентированной – лежит идея,
что все может быть представлено как
объект. Возьмите, к примеру, стул, и
посмотрите на него как на объект. Все
стулья имеют почти одинаковые свойства,
но их значения не всегда одинаковы.
Заключение
Это простые советы, следуя которым, вы сможете улучшить свои навыки построения логики. Если бы мне нужно было выбрать самый дельный совет, я бы выбрал как можно более частое написание кода. Углублять знания и изучать разные языки это здорово, но это вам поможет, только если у вас есть хорошие навыки построения логики.

Опубликовано 19.10.2020 10:21

Что общего между программистом и художником, кроме творческого беспорядка на столе? Они оба создают интересные вещи, используя креативность и выходя за рамки привычного мышления. Главное отличие в том, что программист следует законам логики и разрабатывает точные алгоритмы создания произведения. Об этом мы сегодня и поговорим.
Где логика?
Логика – это наука о правильном мышлении. Или в нашем случае – о правильной постановке команд, которые приведут к нужному результату.
Последовательность таких команд в виде инструкций, описывающих порядок действий, называется Алгоритмом. Набор инструкций, которые идут друг за другом по определённому алгоритму, называется Программой.
Наименьшая автономная часть программы – это инструкция (команда или набор команд). По-другому инструкции называют «оператор» или «statements». Один оператор выполняет конкретный программный код. Это главная часть любой программы.
Пишите максимально подробные и логичные инструкции для компьютера, чтобы он понял команду именно так, как вам требуется. Если этого не сделать – нужного результата не выйдет.
По сути, инструкции и алгоритмы – это то, чему подчиняются все процессы в реальном мире. Чтобы наглядно показать, как всё это работает, приведем пример из жизни.
Разбираем «на пальцах»
Вот Алексей. Он обычный парень, который любит играть в футбол. Нам необходимо прописать программу, симулирующую игру Лёши. Для этого мы прописываем конкретную инструкцию, которая состоит из таких команд:
-
Надеть спортивную одежду.
-
Взять мяч.
-
Выйти на улицу.
-
Поставить мяч на землю.
-
Ударить по мячу.
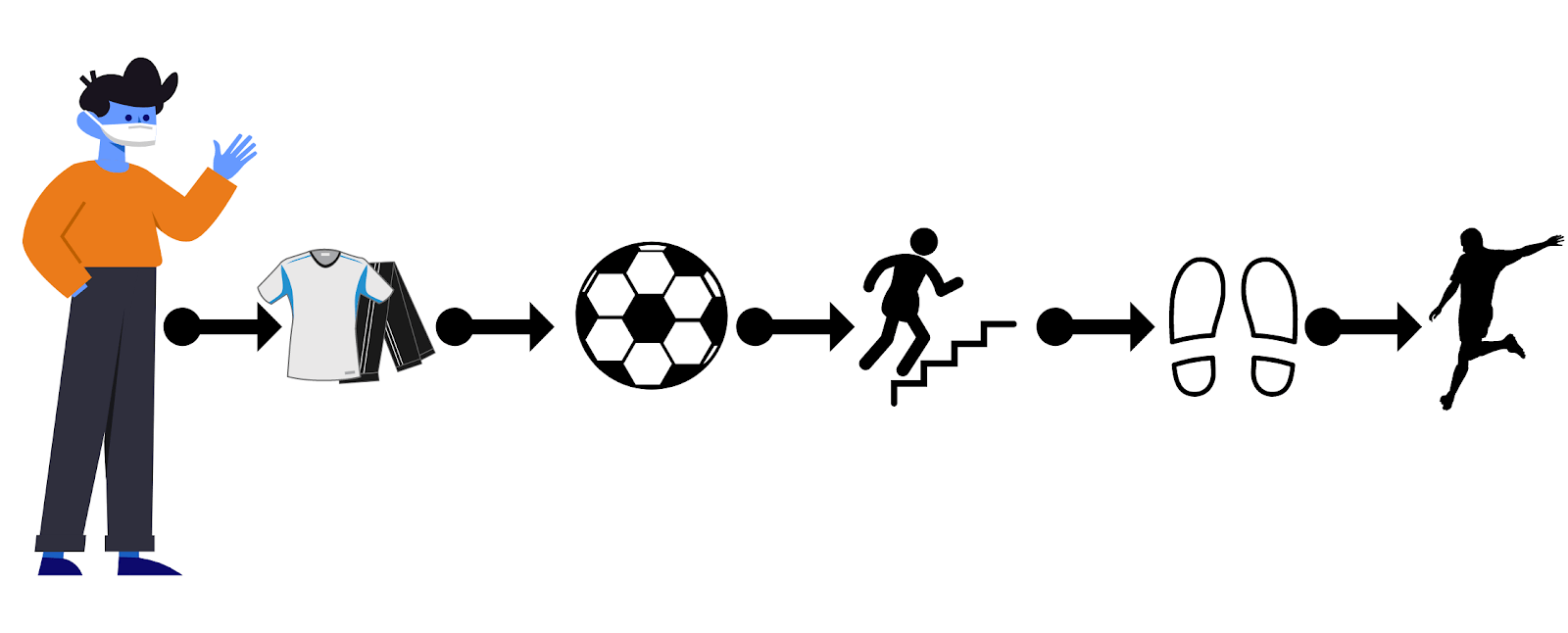
Запускаем игру и понимаем, что что-то идёт не так. Причина в том, что Алексей вышел играть в туфлях, а не в спортивной обуви, так как мы не учли в инструкции этот нюанс.

Возвращаемся назад и дополняем:
-
Надеть спортивную одежду.
-
Надеть спортивную обувь.
-
Взять мяч.
-
Выйти на улицу.
-
Поставить мяч на землю.
-
Ударить по мячу.
Теперь игра идёт так, как мы задумали.
Этот вариант примитивный. В настоящей программе инструкций будет гораздо больше. Каждое действие Алексея придётся прописывать подробно. Например, выход из дома:
-
Открыть дверь.
-
Выйти.
-
Закрыть дверь.
-
Подойти к лифту.
-
Нажать на кнопку.
-
Зайти в лифт.
-
Нажать кнопку первого этажа.
-
Выйти из лифта и т. д.
Чем подробнее прописаны стейтменты, тем более качественно работает программа.
Представьте количество команд, инструкций и сложность алгоритма в искусственном интеллекте или роботе. Сколько подробных инструкций предусматривает и прописывает программист, чтобы искусственный интеллект самостоятельно принимал решения, а робот ходил, разговаривал, отвечал и реагировал на действия.
Программа – живой организм, который постоянно развивается и изменяется. Актуализировать её придётся бесконечно: дописывать инструкции, расширять функционал, упрощать. При этом программа всё ещё не будет идеальной. Всегда есть что добавить или изменить.
В случае с Алексеем, дополнительно понадобилось бы прописать и то, что он идёт на выбранную спортивную площадку или стадион, зовёт с собой друзей и т. д.
Учитывайте тот факт, что ваша программа обязательно будет изменяться и дополняться. Тот, кто после вас займётся её поддержкой и развитием, должен понять вашу логику. Не слишком стремитесь к упрощению и минималистичности.
Виды алгоритмов
Последовательность команд и инструкций может быть разной. Но в основе лежат три вида алгоритмов:
Линейный
Каждое действие выполняется последовательно друг за другом в строгом порядке. Когда выполнено одно, начинается другое. И так до последнего.

Циклический
По достижении определенного действия алгоритм возвращается на любое из предыдущих сколько угодно раз. Это делается с помощью циклов, которые мы обсудим на следующих уроках. В примере с футболистом цикличным алгоритм считался бы в том случае, если бы Алексей бесконечно бил по мячу.

Ветвление
В одной из команд (или нескольких) прописывается разветвление. Доходя до него, необходимо выбрать на какую из ветвей пойти дальше. Представьте, что идёте по дороге и встречаете развилку. Вам необходимо выбрать путь налево или направо. Это и есть алгоритм ветвления.
В чистом виде эти алгоритмы встречаются лишь в простейших программах. Чаще всего они комбинируются между собой. Именно комбинируемый алгоритм – самый распространённый вид алгоритма.
Каждая программа состоит из сложного набора инструкций, где есть и циклы, и ветвления, и прямые линии. Со стороны это похоже на большое дерево с множеством веток, которые растут в разные стороны.
Все алгоритмы выполняют конкретные логические задачи: сортировка, поиск, сравнение и т. д. В каждой из задач эффективными будут разные алгоритмические последовательности. Для сортировки одни, для поиска другие.
Для разработки подходящего алгоритма и потребуется креативность. Вы сами выбираете путь и способы достижения результата, вдохновляясь природными процессами, опираясь на собственные ощущения, и описываете их в программе. Вспомните об этом, когда кто-нибудь снова скажет, что программирование – это только математика 
Домашнее задание
Напишите линейный, циклический или разветвленный алгоритм. Это должен быть порядок действий, список команд, конкретная инструкция. Программа должна упростить вашу жизнь, делать то, что сами вы делать не хотите.
|
670 / 216 / 88 Регистрация: 21.07.2016 Сообщений: 1,036 Записей в блоге: 2 |
|
|
1 |
|
Проектирование (разработка логики приложения): как это делать правильно?28.09.2016, 16:33. Показов 4752. Ответов 10
Добрейшего времени суток. Зачастую при решении разных задач возникают проблемы с архитектурой приложений. А именно при получении задачи я сразу же берусь за написание кода, от этого и много проблем и ошибок разного рода, и как следствие приходится многое переписывать/передумывать. Недостатки этого недоподхода очевидны, да и к тому же затратны по времени. Собственно вопрос — как бороться с этим недугом? Где можно что почитать? До «Совершенный код» Макконнелла руки пока не доходят, постоянно откладываю на потом, да и думаю пока еще рано за эту книгу браться.
0 |

|
3222 / 1749 / 435 Регистрация: 03.05.2010 Сообщений: 3,867 |
|
|
29.09.2016, 11:23 |
2 |
|
Решение
Собственно вопрос — как бороться с этим недугом? Где можно что почитать? До «Совершенный код» Макконнелла руки пока не доходят, постоянно откладываю на потом, да и думаю пока еще рано за эту книгу браться. Ну почему же, Макконнелл как раз своевременно и в тему. Конечно, он отпугивает своей толщиной, и воды в нем многовато, но его нужно читать выборочно.
при получении задачи я сразу же берусь за написание кода, от этого и много проблем и ошибок разного рода, и как следствие приходится многое переписывать/передумывать. Ну, вы наверно сразу с реализации начинаете, т.е. снизу вверх, а надо с проектирования начинать, т.е. сверху вниз.
1 |
 Сообщение было отмечено dailydose как решение
Сообщение было отмечено dailydose как решение

|
8724 / 4304 / 958 Регистрация: 15.11.2014 Сообщений: 9,751 |
|
|
29.09.2016, 15:38 |
3 |
|
как бороться с этим недугом?
До «Совершенный код» Макконнелла руки пока не доходят тогда — страдать.
1 |
|
dailydose 670 / 216 / 88 Регистрация: 21.07.2016 Сообщений: 1,036 Записей в блоге: 2 |
||||
|
29.09.2016, 15:52 [ТС] |
4 |
|||
|
Роберт Мартин приводит очень простой и эффективный способ: я сам как-то пришёл к похожему способу, например.
т.е. так же разбиваю на функции, и обычным cout вывожу на экран сообщение, дабы удостовериться что попал в нужную функцию. Mr.X, мой архивчик
Дональд Кнут — искусство программирования шаблоны проектирования алан шаллоуей Джеймс р Тротт Гради Буч: Объектно-ориентированный анализ и проектирование Интерфейс: новые направления в проектировании компьютерных систем
0 |
|
3222 / 1749 / 435 Регистрация: 03.05.2010 Сообщений: 3,867 |
|
|
29.09.2016, 17:45 |
5 |
|
а вообще с какой книге посоветуете сейчас начать? Ну, из этих книг мне «Чистый код» больше всего нравится. Умно и толково пишет о самых важных вещах и особо не растекается мыслью по древу.
1 |
|
Ушел с форума
16458 / 7422 / 1186 Регистрация: 02.05.2013 Сообщений: 11,617 Записей в блоге: 1 |
|
|
29.09.2016, 18:42 |
6 |
|
Решение
Собственно вопрос — как бороться с этим недугом? Бери листик, ручку (условно) и описывай для себя, как будет работать
1 |
|
dailydose 670 / 216 / 88 Регистрация: 21.07.2016 Сообщений: 1,036 Записей в блоге: 2 |
||||||||||||||||||||||||
|
29.09.2016, 21:20 [ТС] |
7 |
|||||||||||||||||||||||
|
Бери листик, ручку (условно) и описывай для себя, как будет работать Как-то раз пришла идея сделать тупенький аймбот. Для начала задача была простая, с возможностью дальнейшего оброста функционала. Пример испытвал на CS:GO, причём удачно. Суть проста:
и вот во что это превратилось main.cpp
Mouse.h
Mouse.cpp
Color.h
Color.cpp
0 |
")
|
Любитель чаепитий 3737 / 1796 / 563 Регистрация: 24.08.2014 Сообщений: 6,014 Записей в блоге: 1 |
|
|
29.09.2016, 21:27 |
8 |
|
Не по теме:
Пример испытвал на CS:GO, причём удачно. Надеюсь, что вы на Non-steam тестили, а то Vac-ban к Вам уже бежит. А вообще:
5.7. Запрещено создание и распространение вредоносного ПО, вирусов, кряков и взлома лицензионного софта, а также публикация ссылок для их скачивания. Так что тему закроют, либо Ваше сообщение удалят.
1 |
|
670 / 216 / 88 Регистрация: 21.07.2016 Сообщений: 1,036 Записей в блоге: 2 |
|
|
29.09.2016, 21:59 [ТС] |
9 |
|
Надеюсь, что вы на Non-steam тестили, а то Vac-ban к Вам уже бежит. Вак не страшен — все равно игры редко играю
Так что тему закроют, либо Ваше сообщение удалят. я не думаю что это уж прям таки злостный чит — это же всеголишь stupid aimbot
0 |
|
Модератор
5148 / 2327 / 339 Регистрация: 20.02.2013 Сообщений: 5,718 Записей в блоге: 20 |
|
|
30.09.2016, 08:11 |
10 |
|
думаю пока еще рано за эту книгу браться Не рано. Самое то.
1 |
|
670 / 216 / 88 Регистрация: 21.07.2016 Сообщений: 1,036 Записей в блоге: 2 |
|
|
30.09.2016, 10:45 [ТС] |
11 |
|
Пожалуй начну с Роберта Мартина «Чистый код». Дальше видно будет. Вопрос закрыт, всем спасибо
0 |
Проектирование Сервисного Слоя и Логики Приложения¶
Эта статья посвящена вопросам управления Логикой Приложения и проектированию Сервисного Слоя (Service Layer), Use Case, CQRS, Event Sourcing, MVC и др.
Содержание
- Проектирование Сервисного Слоя и Логики Приложения
- Виды логики
- Layered Architecture
- Что такое Бизнес-Логика (Business Logic)?
- Подвиды Бизнес-Правил (Business Rules)
- Почему важно отделять Business Logic от Application Logic?
- Способы организации Логики Приложения (Application Logic)
- Что такое Сервис?
- Классификация Сервисов по уровням логики
- Сервисы уровня Доменной Логики (Domain Logic)
- Сервисы уровня Логики Приложения (Application Logic)
- Сервисы уровня Инфраструктурного Слоя (Infrastructure Layer)
- Классификация Сервисов по способу взаимодействия
- Оркестровые Сервисы
- Хореографические Сервисы
- Частые ошибки проектирования Хореографических Сервисов
- Классификация Сервисов по способу обмена данными
- Классификация Сервисов по состоянию
- Stateless Service
- Statefull Service
- Назначение Сервисного Слоя
- Когда Сервисный Слой не нужен?
- Сервис — не обертка для DataMapper
- Реализация Сервисного Слоя
- Инверсия Управления
- Распространенная проблема Django-приложений
- Проблема Django-аннотаций
- Особенности сервисного слоя на стороне клиента
- Проблема параллельного обновления
- CQRS
- Event Sourcing
- Что почитать
Виды логики¶
Прежде чем копнуть вглубь, было бы неплохо разобраться с тем, что такое Логика Приложения (Application Logic) и чем она отличается от Бизнес-Логики (Business Logic).
Layered Architecture¶
Одно из наиболее часто-цитируемых определений основных концептуальных слоев дает Eric Evans:
- User Interface (or Presentation Layer)
- Responsible for showing information to the user and interpreting the user’s
commands. The external actor might sometimes be another computer
system rather than a human user.- Application Layer
- Defines the jobs the software is supposed to do and directs the expressive
domain objects to work out problems. The tasks this layer is responsible
for are meaningful to the business or necessary for interaction with the
application layers of other systems.
This layer is kept thin. It does not contain business rules or knowledge, but
only coordinates tasks and delegates work to collaborations of domain
objects in the next layer down. It does not have state reflecting the
business situation, but it can have state that reflects the progress of a task
for the user or the program.- Domain Layer (or Model Layer)
- Responsible for representing concepts of the business, information about
the business situation, and business rules. State that reflects the business
situation is controlled and used here, even though the technical details of
storing it are delegated to the infrastructure. This layer is the heart of
business software.- Infrastructure Layer
- Provides generic technical capabilities that support the higher layers:
message sending for the application, persistence for the domain, drawing
widgets for the UI, and so on. The infrastructure layer may also support
the pattern of interactions between the four layers through an
architectural framework.— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4] by Eric Evans
Ward Cunningham дает следующие определения:
Factor your application classes into four layers in the following way (see Figure 1: FourLayerArchitecture):
The View layer. This is the layer where the physical window and widget objects live. It may also contain Controller classes as in classical MVC. Any new user interface widgets developed for this application are put in this layer. In most cases today this layer is completely generated by a window-builder tool.
The ApplicationModel layer. This layer mediates between the various user interface components on a GUI screen and translates the messages that they understand into messages understood by the objects in the domain model. It is responsible for the flow of the application and controls navigation from window to window. This layer is often partially generated by a window-builder and partially coded by the developer.
The DomainModel layer. This is the layer where most objects found in an OO analysis and design will reside. Examples of the types of objects found in this layer may be Orders, Employees, Sensors, or whatever is appropriate to the problem domain.
The Infrastructure layer. This is where the objects that represent connections to entities outside the application (specifically those outside the object world) reside. Examples of objects in this layer would include SQLTables, 3270Terminals, SerialPorts, SQLBrokers and the like.
— Four Layer Architecture, Ward Cunningham
Но что означает сам термин Бизнес (Business)?
Непонимание этого термина часто приводит к серьезным проблемам проектирования.
В это трудно поверить, но большинство разработчиков, даже с многолетним стажем, этого не понимают, и полагают что это что-то связанное с финансами.
Что такое Бизнес-Логика (Business Logic)?¶
Самое авторитетное пояснение термина Business можно найти, как обычно, на сайте Ward Cunningham:
Software intersects with the Real World. Imagine that.
Там же можно найти и определение термина Business Rule:
A Business Rule (in a programming context) is knowledge that gets applied to a set of data to create new value. Or it may be a rule about how to create, modify, or remove data. Or perhaps it is a rule that specifies when certain processes occur.
For example, we have a rule about email addresses – when the Driver Name field on our object identifier changes, we erase the email address. When we receive a new email address, we make sure that it contains an “@” sign and a valid domain not on our blacklist.
Business Logic Definition:
Business logic is that portion of an enterprise system which determines how data is:
- Transformed and/or calculated. For example, business logic determines how a tax total is calculated from invoice line items.
- Routed to people or software systems, aka workflow.
Следует отличать термин Business (по сути — синоним слова Domain) от термина Business Domain:
A category about the business domain, such as accounting, finance, inventory, marketing, tracking, billing, reporting, charting, taxes, etc.
Также следует отличать Business и от Business Process:
A Business Process is some reproduceable process within an organization. Often it is a something that you want to setup once and reuse over and over again.
Companies spend a lot of time and money identifying Business Processes, designing the software that captures a Business Process and then testing and documenting these processes.
One example of a Business Process is “Take an order on my web site”. It might involve a customer, items from a catalog and a credit card. Each of these things is represented by business objects and together they represent a Business Process.
Википедия дает следующее определение термину Business Logic:
In computer software, business logic or domain logic is the part of the program that encodes the real-world Business Rules that determine how data can be created, stored, and changed. It is contrasted with the remainder of the software that might be concerned with lower-level details of managing a database or displaying the user interface, system infrastructure, or generally connecting various parts of the program.
И поясняет, чем отличается Business Logic от Business Rules:
Business logic should be distinguished from business rules.[“Definition of business logic“] Business logic is the portion of an enterprise system which determines how data is transformed or calculated, and how it is routed to people or software (workflow). Business rules are formal expressions of business policy. Anything that is a process or procedure is business logic, and anything that is neither a process nor a procedure is a business rule. Welcoming a new visitor is a process (workflow) consisting of steps to be taken, whereas saying every new visitor must be welcomed is a business rule. Further, business logic is procedural whereas business rules are declarative.[William Ulrich. “OMG Business Rules Symposium” (архив оригинала от 2013-12-24)]
Craig Larman считает термин Business синонимом к термину Domain, и в книге “Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and Iterative Development” он многократно приводит их рядом, дополняя один термин другим, взятым в скобки.
Термину Business Rules он дает следующее определение:
Business Rules — Business rules (also called Domain Rules) typically describe requirements or policies that transcend one software project — they are required in the domain or business, and many applications may need to conform to them. An excellent example is government tax laws. Domain rule details may be recorded in the Supplementary Specification, but because they are usually more enduring and applicable than for one software project, placing them in a central Business Rules artifact (shared by all analysts of the company) makes for better reuse of the analysis effort.
<…>
The Business Rules (or Domain Rules) capture long-living and spanning rules or policies, such as tax laws, that transcend one particular application.
<…>
Domain rules [Ross97, GK00] dictate how a domain or business may operate. They are not requirements of any one application, although an application’s requirements are often influenced by domain rules. Company policies, physical laws (such as how oil flows underground), and government laws are common domain rules.
They are commonly called business rules, which is the most common type, but that term is poor, as many software applications are for non-business problems, such as weather simulation or military logistics. A weather simulation has “domain rules,” related to physical laws and relationships, that influence the application requirements.
It’s useful to identify and record domain rules in a separate application-independent artifact — what the UP calls the Business Rules artifact — so that this analysis can be shared and reused across the organization and across projects, rather than buried within a project-specific document.
—“Applying UML and Patterns: An Introduction to Object-Oriented Analysis and Design and Iterative Development” by Craig Larman
Резюмируя, я обобщу все своими словами:
- Бизнес-Логика (деловые регламенты, доменные модели) —
- это моделирование объектов и процессов предметной области (т.е. реального мира).
Это то, что программа должна делать (от слова “дело” — именно так переводится слово “business”), и ради чего она создается. - Логика приложения —
- это то, что обеспечивает и координирует работу Бизнес-Логики.
Подвиды Бизнес-Правил (Business Rules)¶
Robert Martin в “Clean Architecture” подразделяет Бизнес-Правила на два вида:
-
Application-specific Business Rules
-
Application-independent Business Rules
То есть систему можно разделить на горизонтальные уровни: пользовательский интерфейс, Бизнес-Правила, характерные для приложения, Бизнес-Правила, не зависящие от приложения, и база данных — кроме всего прочего.
Thus we find the system divided into decoupled horizontal layers—the UI, application-specific Business Rules, application-independent Business Rules, and the database, just to mention a few.
— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin
Главы 16, 20 и 22 of Clean Architecture разъясняют в подробностях типы Бизнес-Правил.
При этом, Robert Martin выводит свои 4 слоя: Entities, Use Cases, Interface Adapters, Frameworks and Drivers.
Нужно отметить, что Robert Martin под “Business Rules” понимает не только правила, но и процедуры, смывая грань между “Business Rules” и “Business Logic”:
Строго говоря, бизнес-правила — это правила или процедуры, делающие или экономящие деньги.
Strictly speaking, business rules are rules or procedures that make or save the business money.
— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin, Chapter 20 “Business Rules”
При этом, у него можно наблюдать небольшое противоречие.
С одной стороны, вся суть “Business Rules” у него сводится к тому, что они относятся исключительно к реальному миру:
Строго говоря, бизнес-правила — это правила или процедуры, делающие или экономящие деньги.
Еще строже говоря, бизнес-правила — это правила, делающие или экономящие деньги независимо от наличия или отсутствия их реализации на компьютере.
Они делают или экономят деньги, даже когда выполняются вручную.Банк взимает N% за кредит — это бизнес-правило, которое приносит банку деньги.
И неважно, имеется ли компьютерная программа, вычисляющая процент, или служащий вычисляет его на счетах.Strictly speaking, business rules are rules or procedures that make or save the business money.
Very strictly speaking, these rules would make or save the business money, irrespective of whether they were implemented on a computer.
They would make or save money even if they were executed manually.The fact that a bank charges N% interest for a loan is a business rule that makes the bank money.
It doesn’t matter if a computer program calculates the interest, or if a clerk with an abacus calculates the interest.— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin, Chapter 20 “Business Rules”
Далее Robert Martin говорит важную информацию — “Business Rules” являются причиной существования Приложения.
Из этого следует, что Приложение уже не может являться причиной существования “Business Rules”:
Бизнес-правила являются причиной существования программной системы.
Они составляют основу функционирования.
Они порождают код, который делает или экономит деньги.
Они — наши семейные реликвии.Бизнес-правила должны оставаться в неприкосновенности, незапятнанными низкоуровневыми аспектами, такими как пользовательский интерфейс или база данных.
В идеале код, представляющий бизнес-правила, должен быть сердцем системы, а другие задачи — просто подключаться к ним.
Реализация бизнес-правил должна быть самым независимым кодом в системе, готовым к многократному использованию.Business rules are the reason a software system exists.
They are the core functionality.
They carry the code that makes, or saves, money.
They are the family jewels.The business rules should remain pristine, unsullied by baser concerns such as the user interface or database used.
Ideally, the code that represents the business rules should be the heart of the system, with lesser concerns being plugged in to them.
The business rules should be the most independent and reusable code in the system.— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin, Chapter 20 “Business Rules”
Однако, с другой стороны, он допускает существование “Business Rules” в контексте функционирования приложения:
Не все бизнес-правила так же чисты, как сущности.
Некоторые бизнес-правила делают или экономят деньги, определяя и ограничивая деятельность автоматизированной системы.
Эти правила не могут выполняться вручную, потому что имеют смысл только как часть автоматизированной системы.Not all business rules are as pure as Entities.
Some business rules make or save money for the business by defining and constraining the way that an automated system operates.
These rules would not be used in a manual environment, because they make sense only as part of an automated system.— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin, Chapter 20 “Business Rules”
Не совсем понятно — “Business Rules” являются причиной существования Приложения, или имеют имеют смысл только как часть Приложения?
“Business rules are the reason a software system exists” или “they make sense only as part of an automated system”?
Тут просматривается небольшое взаимоисключение, и это именно та причина, по которой я придерживаюсь формулировки Eric Evans — “Application Layer does not contain business rules”.
Тут нужно добавить, что в силу “DDD Trilemma”, доменная логика все-таки может просачиваться на уровень логики приложения, см. вариант “Domain model purity + Performance” (“Split the decision-making process between the domain layer and controllers ”).
Понятно, что здесь не хватает термина для выражения различных явлений, и Robert Martin решает дифференцировать уже существующий термин “Business Rules”, разделив его на два уровня — “Critical Business Rules” и “Application-specific Business Rules”:
Вариант использования описывает способ использования автоматизированной системы.
Он определяет, что должен ввести пользователь, что должно быть выведено в ответ и какие действия должны быть выполнены для получения выводимой информации.
В отличие от критических бизнес-правил внутри сущностей, вариант использования описывает бизнес-правила, характерные для конкретного приложения.A use case is a description of the way that an automated system is used.
It specifies the input to be provided by the user, the output to be returned to the user, and the processing steps involved in producing that output.
A use case describes application-specific business rules as opposed to the Critical Business Rules within the Entities.— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin, Chapter 20 “Business Rules”
Но далее он сводит обязанности Use Case к обязанностям Application Logic, и подчеркивает, что Use Case координирует “Critical Business Rules”, реализованных в виде Entities:
Варианты использования определяют, как и когда вызываются критические бизнес-правила в сущности.
Варианты использования управляют действиями сущности.<…>
Почему сущности относятся к высокому уровню, а варианты использования к низкому?
Потому что варианты использования характерны для единственного приложения и, соответственно, ближе к вводу и выводу системы.
Сущности — это обобщения, которые можно использовать в множестве разных приложений, соответственно, они дальше от ввода и вывода системы.
Варианты использования зависят от сущностей; сущности не зависят от вариантов использования.Use cases contain the rules that specify how and when the Critical Business Rules within the Entities are invoked.
Use cases control the dance of the Entities.<…>
Why are Entities high level and use cases lower level?
Because use cases are specific to a single application and, therefore, are closer to the inputs and outputs of that system.
Entities are generalizations that can be used in many different applications, so they are farther from the inputs and outputs of the system.
Use cases depend on Entities; Entities do not depend on use cases.— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin, Chapter 20 “Business Rules”
Хотя, Robert Martin выделяет отдельную категорию классов UseCase (Interactor) для Application-specific Business Rules, на практике этот уровень часто “округляется” до уровня Application Logic.
Так, например, Martin Fowler и Randy Stafford разделяют “Business Logic” на два вида — Логика Домена (Domain Logic) и Логика Приложения (Application Logic):
Подобно сценарию транзакции (Transaction Script, 133) и модели предметной области
(Domain Model, 140), слой служб представляет собой типовое решение по организации
бизнес-логики. Многие проектировщики, и я в том числе, любят разносить бизнес-логику
по двум категориям: логика домена (domain logic) имеет дело только с предметной
областью как таковой (примером могут служить стратегии вычисления зачтенного дохода
по контракту), а логика приложения (application logic) описывает сферу ответственности
приложения [11] (скажем, уведомляет пользователей и сторонние приложения о протекании
процесса вычисления доходов). Логику приложения часто называют также
“логикой рабочего процесса”, несмотря на то что под “рабочим процессом” часто понимаются
совершенно разные вещи.Like Transaction Script (110) and Domain Model (116), Service Layer is a pattern for organizing business logic.
Many designers, including me, like to divide “business logic” into two kinds: “domain logic,” having to
do purely with the problem domain (such as strategies for calculating revenue recognition on a contract), and
“application logic,” having to do with application responsibilities [Cockburn UC] (such as notifying contract
administrators, and integrated applications, of revenue recognition calculations). Application logic is
sometimes referred to as “workflow logic,” although different people have different interpretations of
“workflow.”— “Patterns of Enterprise Application Architecture” [3] by Martin Fowler, Randy Stafford
Местами он склонен относить “Business Rules” к Доменой Логике (Domain Logic):
Проблемы возникли с усложнением доменой логики — бизнес-правил, алгоритмов вычислений, условий проверок и т.д.
The problem came with domain logic: business rules, validations, calculations, and the like.
— “Patterns of Enterprise Application Architecture” [3] by Martin Fowler
И даже признает наличие определенной расплывчатости:
Не стоит забывать и о том, что принято обозначать расплывчатым термином бизнес-логика.
Я нахожу его забавным, поскольку могу припомнить только несколько вещей, менее логичных, нежели так называемая бизнес-логика.Then there’s the matter of what comes under the term “business logic.”
I find this a curious term because there are few things that are less logical than business logic.— “Patterns of Enterprise Application Architecture” [3] by Martin Fowler
Почему важно отделять Business Logic от Application Logic?¶
Поскольку целью создания приложения является реализация именно Business Logic — критически важно обеспечить их переносимость, и отделить их от Application Logic.
Эти два вида логики будут изменяться в разное время, с разной частотой и по разным причинам, поэтому их следует разделить
так, чтобы их можно было изменять независимо [2] .
В свое время Гради Буч сказал, что “Архитектура отражает важные проектные решения по формированию системы, где важность определяется стоимостью изменений” [2] .
Способы организации Логики Приложения (Application Logic)¶
Широко распространены четыре способа организации Логики Приложения (Application Logic):
- Оркестровый Сервис (“request/response”, т.е. сервис осведомлен об интерфейсе других сервисов), он же — Сервисный Слой (Service Layer).
- Хореографический Сервис (Event-Driven, т.е. loosely coupled), который является разновидностью паттерна Command, и используется, как правило, в Event-Driven Architecture (в частности, в CQRS и Event Sourcing приложениях, наглядный пример — reducer в Redux), и в DDD-приложениях (обработчик Domain/Integration Event).
- Front Controller и Application Controller (которые тоже, по сути, является разновидностью паттерна Command).
“A Front Controller handles all calls for a Web site, and is usually structured in two parts: a Web handler and a command hierarchy.”
— “Patterns of Enterprise Application Architecture” [3] by Martin Fowler and others.
“For both the domain commands and the view, the application controller needs a way to store something it can invoke.
A Command [Gang of Four] is a good choice, since it allows it to easily get hold of and run a block of code.”— “Patterns of Enterprise Application Architecture” [3] by Martin Fowler and others.
4. Use Case (см. также), который также, является разновидностью паттерна Command.
На 15:50 Robert C. Martin проводит параллель между Use Case и паттерном Command.
Собственно говоря, производной паттерна Command является даже Method Object.
Use Case обязан своим существованием именно наличию application-specific Business Rules, которые не имеют смысла существования вне контекста приложения.
Он обеспечивает их независимость от приложения путем инверсии контроля (IoC).
Если бы Use Case не содержал Бизнес-Логики, то не было бы и смысла отделять его от Page Controller, иначе приложение пыталось бы абстрагироваться от самого себя же.
Мы видим, что в организации Логики Приложения широко применяются разновидности паттерна Команда (Command).
Рассмотренные способы организовывают, в первую очередь, Логику Приложения, и лишь во вторую очередь, Бизнес-Логику, которая не обязательно должна присутствовать, кроме случая использования Use Case, т.к. иначе он утратил бы причины для существования.
При правильной организации Бизнес-Логики, и высоком качестве ORM (в случае его использования, конечно же), зависимость Бизнес-Логики от приложения будет минимальна.
Основная сложность любого ORM заключается в том, чтобы организовать доступ к связанным объектам не подмешивая Логику Приложения (и логику доступа к данным) в Domain Models, — эту тему мы подробно рассмотрим в одном из следующих постов.
Понимание общих признаков в способах управления Логикой Приложения позволяет проектировать более гибкие приложения, и, как результат, более безболезненно заменять архитектурный шаблон, например, из Layered в Event-Driven.
Частично эта тема затрагивается в Chapter 16 “Independence” of “Clean Architecture” by Robert C. Martin и в разделе “Premature Decomposition” of Chapter 3 “How to Model Services” of “Building Microservices” by Sam Newman.
Что такое Сервис?¶
SERVICE — An operation offered as an interface that stands alone in the model, with no encapsulated state.
— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4]
In some cases, the clearest and most pragmatic design includes operations that do not
conceptually belong to any object. Rather than force the issue, we can follow the natural contours
of the problem space and include SERVICES explicitly in the model.There are important domain operations that can’t find a natural home in an ENTITY or VALUE
OBJECT . Some of these are intrinsically activities or actions, not things, but since our modeling
paradigm is objects, we try to fit them into objects anyway…A SERVICE is an operation offered as an interface that stands alone in the model, without
encapsulating state, as ENTITIES and VALUE OBJECTS do. S ERVICES are a common pattern in technical
frameworks, but they can also apply in the domain layer.The name service emphasizes the relationship with other objects. Unlike ENTITIES and VALUE
OBJECTS , it is defined purely in terms of what it can do for a client. A SERVICE tends to be named for
an activity, rather than an entity—a verb rather than a noun. A SERVICE can still have an abstract,
intentional definition; it just has a different flavor than the definition of an object. A SERVICE should
still have a defined responsibility, and that responsibility and the interface fulfilling it should be
defined as part of the domain model. Operation names should come from the UBIQUITOUS
LANGUAGE or be introduced into it. Parameters and results should be domain objects.SERVICES should be used judiciously and not allowed to strip the ENTITIES and VALUE OBJECTS of all
their behavior. But when an operation is actually an important domain concept, a SERVICE forms a
natural part of a MODEL-DRIVEN DESIGN . Declared in the model as a SERVICE, rather than as a
phony object that doesn’t actually represent anything, the standalone operation will not mislead
anyone.A good SERVICE has three characteristics.
1. The operation relates to a domain concept that is not a natural part of an ENTITY or VALUE
OBJECT .
2. The interface is defined in terms of other elements of the domain model.
3. The operation is stateless.Statelessness here means that any client can use any instance of a particular SERVICE without
regard to the instance’s individual history. The execution of a SERVICE will use information that is
accessible globally, and may even change that global information (that is, it may have side
effects). But the SERVICE does not hold state of its own that affects its own behavior, as most
domain objects do.When a significant process or transformation in the domain is not a natural
responsibility of an ENTITY or VALUE OBJECT, add an operation to the model as a
standalone interface declared as a SERVICE. Define the interface in terms of the
language of the model and make sure the operation name is part of the UBIQUITOUS
LANGUAGE. Make the SERVICE stateless.— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4]
Классификация Сервисов по уровням логики¶
Eric Evans разделяет Сервисы на три уровня логики:
Partitioning Services into Layers
- Application
Funds Transfer App Service
- Digests input (such as an XML request).
- Sends message to domain service for fulfillment.
- Listens for confirmation.
- Decides to send notification using infrastructure service.
- Domain
Funds Transfer Domain Service
- Interacts with necessary Account and Ledger objects, making appropriate debits and credits.
- Supplies confirmation of result (transfer allowed or not, and so on).
- Infrastructure Send Notification Service
- Sends e-mails, letters, and other communications as directed by the application.
— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4]
Most SERVICES discussed in the literature are purely technical and belong in the infrastructure layer.
Domain and application SERVICES collaborate with these infrastructure SERVICES.
For example, a bank might have an application that sends an e-mail to a customer when an account balance falls below a specific threshold.
The interface that encapsulates the e-mail system, and perhaps alternate means of notification, is a SERVICE in the infrastructure layer.It can be harder to distinguish application SERVICES from domain SERVICES.
The application layer is responsible for ordering the notification.
The domain layer is responsible for determining if a threshold was met—though this task probably does not call for a SERVICE, because it would fit the responsibility of an “account” object.
That banking application could be responsible for funds transfers.
If a SERVICE were devised to make appropriate debits and credits for a funds transfer,that capability would belong in the domain layer.
Funds transfer has a meaning in the banking domain language, and it involves fundamental business logic.
Technical SERVICES should lack any business meaning at all.Many domain or application SERVICES are built on top of the populations of ENTITIES and VALUES, behaving like scripts that organize the potential of the domain to actually get something done.
ENTITIES and VALUE OBJECTS are often too fine-grained to provide a convenient access to the capabilities of the domain layer.
Here we encounter a very fine line between the domain layer and the application layer.
For example, if the banking application can convert and export our transactions into a spreadsheet file for us to analyze, that export is an application SERVICE.
There is no meaning of “file formats” in the domain of banking, and there are no business rules involved.On the other hand, a feature that can transfer funds from one account to another is a domain SERVICE because it embeds significant business rules (crediting and debiting the appropriate accounts, for example) and because a “funds transfer” is a meaningful banking term.
In this case, the SERVICE does not do much on its own; it would ask the two Account objects to do most of the work.
But to put the “transfer” operation on the Account object would be awkward, because the operation involves two accounts and some global rules.— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4]
Модель предметной области более предпочтительна в сравнении со сценарием транзакции,
поскольку исключает возможность дублирования бизнес-логики и позволяет
бороться со сложностью с помощью классических проектных решений.
Но размещение логики приложения в “чистых” классах домена чревато нежелательными последствиями.
Во-первых, классы домена допускают меньшую вероятность повторного использования,
если они реализуют специфическую логику приложения и зависят от тех или иных прикладных
инструментальных пакетов.
Во-вторых, смешивание логики обеих категорий в контексте одних и тех же классов затрудняет возможность новой реализации логики
приложения с помощью специфических инструментальных средств, если необходимость
такого шага становится очевидной.
По этим причинам слой служб предусматривает распределение “разной” логики по отдельным слоям, что обеспечивает традиционные
преимущества расслоения, а также большую степень свободы применения классов домена
в разных приложениях.Domain Models (116) are preferable to Transaction Scripts (110) for avoiding domain logic duplication and
for managing complexity using classical design patterns.
But putting application logic into pure domain object classes has a couple of undesirable consequences.
First, domain object classes are less reusable across applications if they implement application-specific logic and depend on application-specific packages.
Second, commingling both kinds of logic in the same classes makes it harder to reimplement the application
logic in, say, a workflow tool if that should ever become desirable.
For these reasons Service Layer factors each kind of business logic into a separate layer, yielding the usual benefits of layering and rendering the pure domain object classes more reusable from application to application.— “Patterns of Enterprise Application Architecture” [3]
Сервисы уровня Доменной Логики (Domain Logic)¶
Политика самого высокого уровня принадлежит Доменной Логике (Domain Logic), поэтому, с нее и начнем.
К счастью, это самый немногочисленный представитель Сервисов.
Подробно тему Сервисов Логики Предметной Области и причины их существования раскрывает Vaughn Vernon:
Further, don’t confuse a Domain Service with an Application Service.
We don’t want to house business logic in an Application Service, but we do want business logic housed in a Domain Service.
If you are confused about the difference, compare with Application.
Briefly, to differentiate the two, an Application Service, being the natural client of the domain model, would normally be the client of a Domain Service.
You’ll see that demonstrated later in the chapter.
Just because a Domain Service has the word service in its name does not mean that it is required to be a coarse-grained, remote-capable, heavyweight transactional operation.…
You can use a Domain Service to
- Perform a significant business process
- Transform a domain object from one composition to another
- Calculate a Value requiring input from more than one domain object
— “Implementing Domain-Driven Design” by Vaughn Vernon
Сервисы уровня Логики Приложения (Application Logic)¶
Это самый многочисленный представитель Сервисов.
Именно его часто называют Сервисный Слой (Service Layer).
Сервисы уровня Инфраструктурного Слоя (Infrastructure Layer)¶
Отдельно следует выделять Сервисы уровня Инфраструктурного Слоя (Infrastructure Layer).
The infrastructure layer usually does not initiate action in the domain layer. Being “below” the
domain layer, it should have no specific knowledge of the domain it is serving. Indeed, such
technical capabilities are most often offered as SERVICES . For example, if an application needs to
send an e-mail, some message-sending interface can be located in the infrastructure layer and the
application layer elements can request the transmission of the message. This decoupling gives
some extra versatility. The message-sending interface might be connected to an e-mail sender, a
fax sender, or whatever else is available. But the main benefit is simplifying the application layer,
keeping it narrowly focused on its job: knowing when to send a message, but not burdened with
how.The application and domain layers call on the SERVICES provided by the infrastructure layer. When
the scope of a SERVICE has been well chosen and its interface well designed, the caller can remain
loosely coupled and uncomplicated by the elaborate behavior the SERVICE interface encapsulates.But not all infrastructure comes in the form of SERVICES callable from the higher layers. Some
technical components are designed to directly support the basic functions of other layers (such as
providing an abstract base class for all domain objects) and provide the mechanisms for them to
relate (such as implementations of MVC and the like). Such an “architectural framework” has
much more impact on the design of the other parts of the program.— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4]
Infrastructure Layer — Provides generic technical capabilities that support the higher layers:
message sending for the application, persistence for the domain, drawing
widgets for the UI, and so on. The infrastructure layer may also support
the pattern of interactions between the four layers through an
architectural framework.— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4]
Классификация Сервисов по способу взаимодействия¶
По способу взаимодействия Сервисы разделяются на Оркестровые (“request/response”, т.е. сервис осведомлен об интерфейсе других сервисов) и Хореографические (Event-Driven, т.е. loosely coupled) [8].
Их еще называют идиоматическими стилями взаимодействия.
Главный недостаток первого — это высокая осведомленность об интерфейсе других Сервисов, т.е. Высокое Сопряжение (High Coupling), что снижает их реиспользование.
Последний же является разновидностью паттерна Command, и используется, как правило, в Event-Driven Architecture (в частности, в CQRS и Event Sourcing приложениях, наглядный пример — reducer в Redux), и в DDD-приложениях (обработчик Domain/Integration Event).
With orchestration, we rely on a central brain to guide and drive the process, much like the conductor in an orchestra. With choreography, we inform each part of the system of its job, and let it work out the details, like dancers all finding their way and reacting to others around them in a ballet.
<…>
The downside to this orchestration approach is that the customer service can become too much of a central governing authority. It can become the hub in the middle of a web, and a central point where logic starts to live.
I have seen this approach result in a small number of smart “god” services telling anemic CRUD-based services what to do.With a choreographed approach, we could instead just have the customer service emit an event in an asynchronous manner, saying Customer created.
The email service, postal service, and loyalty points bank then just subscribe to these events and react accordingly, as in Figure 4-4.
This approach is significantly more decoupled.
If some other service needed to reach to the creation of a customer, it just needs to subscribe to the events and do its job when needed.
The downside is that the explicit view of the business process we see in Figure 4-2 is now only implicitly reflected in our system.— “Building Microservices. Designing Fine-Grained Systems” [8] by Sam Newman
Оркестровые Сервисы¶
Оркестровые Сервисы являются представителями классического Сервисного Слоя, и подробнее рассматриваются ниже по тексту.
Хореографические Сервисы¶
Существует интересная статья “Clarified CQRS” by Udi Dahan, на которую ссылается Martin Fowler в своей статье “CQRS”.
И в этой статье есть интересный момент.
The reason you don’t see this layer explicitly represented in CQRS is that it isn’t really there…
— “Clarified CQRS” by Udi Dahan
На самом деле, обработчик команды — это и есть Сервис, только событийно-ориентированный, который следует заданному интерфейсу.
Он должен содержать логику уровня приложения (а не бизнес-логику).
Our command processing objects in the various autonomous components actually make up our service layer.
— “Clarified CQRS” by Udi Dahan
Хореографические Сервисы бывают только уровня Логики Приложения, даже если они подписаны на Доменные События (Domain Event).
Частые ошибки проектирования Хореографических Сервисов¶
Иногда, особенно у frontend-разработчиков, можно наблюдать как они проксируют Оркестровыми Сервисами обращения к Хореографическим Сервисам.
Часто это происходит при использовании Redux/NgRx в Angular-приложении, в котором широко используются Сервисы.
Имея слабо-сопряженные (Low Coupling) событийно-ориентированные Сервисы в виде обработчиков команды, было бы проектной ошибкой пытаться связать их в сильно-зацепленные (High Coupling) классические Сервисы Оркестрового типа (с единственной целью — помочь Логике Приложения скрыть их от самой же себя).
Each command is independent of the other, so why should we allow the objects which handle them to depend on each other?
— “Clarified CQRS” by Udi Dahan
Тут, правда, возникает вопрос осведомленности обработчиков команды и самого приложения об интерфейсе конкретной реализации CQRS.
Для выравнивания интерфейсов служит паттерн Adapter, которому, при необходимости, можно предусмотреть место.
Другой распространенной ошибкой является размещение Бизнес-Логики в Хореографических Сервисах и искусственное вырождение поведения Доменных Моделей с выносом всей бизнес-логики в обработчики команд, т.е. в Сервисы.
Это приводит к появлению проблемы, о которой говорил Eric Evans:
“Если требования архитектурной среды к распределению обязанностей таковы, что элементы, реализующие концептуальные объекты, оказываются физически разделенными, то код больше не выражает модель.
Нельзя разделять до бесконечности, у человеческого ума есть свои пределы, до которых он еще способен соединять разделенное;
если среда выходит за эти пределы, разработчики предметной области теряют способность расчленять модель на осмысленные фрагменты.”“If the framework’s partitioning conventions pull apart the elements implementing the
conceptual objects, the code no longer reveals the model.There is only so much partitioning a mind can stitch back together, and if the framework uses
it all up, the domain developers lose their ability to chunk the model into meaningful pieces.”— “Domain-Driven Design: Tackling Complexity in the Heart of Software” by Eric Evans
В приложениях с обширной бизнес-логикой это может сильно ухудшить качество бизнес-моделирования, и препятствовать процессу дистилляции моделей по мере переработки бизнес-знаний [4].
Также такой код обретает признаки “Divergent Change” [7] и “Shotgun Surgery” [7], что сильно затрудняет исправление ошибок бизнес-моделирования и Итерационное Проектирование (Evolutionary Design).
В конечном итоге это приводит к стремительному росту стоимости изменения программы.
Должен заметить, что Udi Dahan в своей статье допускает и использование Transaction Script для организации бизнес-логики.
В таком случае, выбор между Transaction Script и Domain Model подробно рассмотрен в “Patterns of Enterprise Application Architecture” by M. Fowler and others.
Transaction Script может быть уместным при сочетании Redux и GraphQL для минимизации сетевого трафика.
При использовании же REST-API, и наличии обширной бизнес-логики, более уместным будет использование Domain Model и DDD.
Классификация Сервисов по способу обмена данными¶
По способу обмена данными Сервисы разделяются на Синхронные и Асинхронные.
Классификация Сервисов по состоянию¶
Stateless Service¶
Как правило, большинство сервисов являются stateless, т.е. не имеют состояния.
Они хорошо изучены, и добавить по ним нечего.
Statefull Service¶
Классы UseCases/Interactors [2] являются разновидностью паттерна Команда (Command), и, в определенной мере, могут рассматриваться как Statefull Сервис.
Похожую идею выражает и Eric Evans:
We might like to create a Funds Transfer object to represent the two entries plus the rules and history around the transfer. But we are still left with calls to SERVICES in the interbank networks.
What’s more, in most development systems, it is awkward to make a direct interface between a domain object and external resources. We can dress up such external SERVICES with a FACADE that takes inputs in terms of the model, perhaps returning a Funds Transfer object as its result.
But whatever intermediaries we might have, and even though they don’t belong to us, those SERVICES are carrying out the domain responsibility of funds transfer.— “Domain-Driven Design: Tackling Complexity in the Heart of Software” [4]
И Randy Stafford с Martin Fowler:
Двумя базовыми вариантами реализации слоя служб являются создание интерфейса
доступа к домену (domain facade) и конструирование сценария операции (operation script).
При использовании подхода, связанного с интерфейсом доступа к домену, слой служб
реализуется как набор “тонких” интерфейсов, размещенных “поверх” модели предметной
области. В классах, реализующих интерфейсы, никакая бизнес-логика отражения не
находит — она сосредоточена исключительно в контексте модели предметной области.
Тонкие интерфейсы устанавливают границы и определяют множество операций, посредством
которых клиентские слои взаимодействуют с приложением, обнаруживая тем самым
характерные свойства слоя служб.Создавая сценарий операции, вы реализуете слой служб как множество более “толстых”
классов, которые непосредственно воплощают в себе логику приложения, но за бизнес-логикой
обращаются к классам домена. Операции, предоставляемые клиентам слоя
служб, реализуются в виде сценариев, создаваемых группами в контексте классов, каждый
из которых определяет некоторый фрагмент соответствующей логики. Подобные
классы, расширяющие супертип слоя (Layer Supertype, 491) и уточняющие объявленные
в нем абстрактные характеристики поведения и сферы ответственности, формируют “службы”
приложения (в названиях служебных типов принято употреблять суффикс “Service”).
Слой служб и заключает в себе эти прикладные классы.The two basic implementation variations are the domain facade approach and the operation script approach. In
the domain facade approach a Service Layer is implemented as a set of thin facades over a Domain Model
(116). The classes implementing the facades don’t implement any business logic. Rather, the Domain Model
(116) implements all of the business logic. The thin facades establish a boundary and set of operations through
which client layers interact with the application, exhibiting the defining characteristics of Service Layer.In the operation script approach a Service Layer is implemented as a set of thicker classes that directly
implement application logic but delegate to encapsulated domain object classes for domain logic. The
operations available to clients of a Service Layer are implemented as scripts, organized several to a class
defining a subject area of related logic. Each such class forms an application “service,” and it’s common for
service type names to end with “Service.” A Service Layer is comprised of these application service classes,
which should extend a Layer Supertype (475), abstracting their responsibilities and common behaviors.— “Patterns of Enterprise Application Architecture” [3] by Martin Fowler, Randy Stafford
Обратите внимание на использование термина “Domain Model”.
Эти ребята — последние из числа тех, кто может спутать “Domain Model” и “DataMapper”, особенно, при таком количестве редакторов и рецензентов.
Т.е. клиент ожидает от доменной модели интерфейс, который она, по какой-то причине (обычно это Single Responsibility Principle), не реализует и не должна реализовать.
С другой стороны, клиент не может реализовать это поведение сам, так как это привело бы к появлению “G14: Feature Envy” [1].
Для выравнивания интерфейсов служит паттерн Adapter (aka Wrapper), см. “Design Patterns Elements of Reusable Object-Oriented Software” [6].
Отличается Statefull Services от обычного Adapter только тем, что он содержит логику более низкого уровня, т.е. Логику Приложения (Application Logic), нежели Доменная Модель.
Этот подход сильно напоминает мне “Cross-Cutting Concerns” [1] с тем только отличием, что “Cross-Cutting Concerns” реализует интерфейс оригинального объекта, в то время как domain facade дополняет его.
Когда объект-обертка реализует интерфейс оригинального объекта, то его обычно называют Aspect или Decorator.
Часто в таких случаях можно услышать термин Proxy, но, на самом деле паттерн Proxy имеет немного другое назначение.
Такой подход часто используется для того, чтобы наделить Доменную Модель логикой доступа к связанным объектам, при этом сохраняя Доменную Модель совершенно “чистой”, т.е. отделенной от поведения логики более низкого уровня.
При работе с унаследованным кодом мне доводилось встречать разбухшие Доменные Модели с огромным числом методов (я встречал до нескольких сотен методов).
При анализе таких моделей часто обнаруживаются посторонние обязанности в классе, а размер класса, как известно, измеряется количеством его обязанностей.
Statefull Сервисы и паттерн Adapter — хорошая альтернатива для того, чтобы вынести из модели несвойственные ей обязанности, и заставить похудеть разбухшие модели.
Назначение Сервисного Слоя¶
Слой служб устанавливает множество доступных действий и координирует отклик приложения на каждое действие.
A Service Layer defines an application’s boundary with a layer of services that establishes a set of available
operations and coordinates the application’s response in each operation.— “Patterns of Enterprise Application Architecture” [3]
Корпоративные приложения обычно подразумевают применение разного рода интерфейсов к хранимым данным и реализуемой логике — загрузчиков данных, интерфейсов пользователя, шлюзов интеграции и т.д.
Несмотря на различия в назначении, подобные интерфейсы часто нуждаются в одних и тех же функциях взаимодействия с приложением для манипулирования данными и выполнения бизнес-логики.
Функции могут быть весьма сложными и способны включать транзакции, охватывающие многочисленные ресурсы, а также операции по координации реакций на действия.
Описание логики взаимодействия в каждом отдельно взятом интерфейсе сопряжено с многократным повторением одних и тех же фрагментов кода.Слой служб определяет границы приложения и множество операций, предоставляемых им для интерфейсных клиентских слоев кода.
Он инкапсулирует бизнес-логику приложения, управляет транзакциями и координирует реакции на действия.Enterprise applications typically require different kinds of interfaces to the data they store and the logic they implement: data loaders, user interfaces, integration gateways, and others.
Despite their different purposes, these interfaces often need common interactions with the application to access and manipulate its data and invoke its business logic.
The interactions may be complex, involving transactions across multiple resources and the coordination of several responses to an action.
Encoding the logic of the interactions separately in each interface causes a lot of duplication.A Service Layer defines an application’s boundary and its set of available operations from the perspective of interfacing client layers.
It encapsulates the application’s business logic, controlling transactions and coordinating responses in the implementation of its operations.— “Patterns of Enterprise Application Architecture” [3]
Преимуществом использования слоя служб является возможность определения набора
общих операций, доступных для применения многими категориями клиентов, и координация
откликов приложения на выполнение каждой операции. В сложных случаях
отклики могут включать в себя логику приложения, передаваемую в рамках атомарных
транзакций с использованием нескольких ресурсов. Таким образом, если у бизнес-логики
приложения есть более одной категории клиентов, а отклики на варианты
использования передаются через несколько ресурсов транзакций, использование слоя
служб с транзакциями, управляемыми на уровне контейнера, становится просто необходимым,
даже если архитектура приложения не является распределенной.The benefit of Service Layer is that it defines a common set of application operations available to many kinds
of clients and it coordinates an application’s response in each operation. The response may involve application
logic that needs to be transacted atomically across multiple transactional resources. Thus, in an application
with more than one kind of client of its business logic, and complex responses in its use cases involving
multiple transactional resources, it makes a lot of sense to include a Service Layer with container-managed
transactions, even in an undistributed architecture.— “Patterns of Enterprise Application Architecture” [3]
Один из общих подходов к реализации бизнес-логики состоит в расщеплении слоя
предметной области на два самостоятельных слоя: “поверх” модели предметной области
или модуля таблицы располагается слой служб (Service Layer, 156). Обычно это целесообразно
только при использовании модели предметной области или модуля таблицы, поскольку
слой домена, включающий лишь сценарий транзакции, не настолько сложен,
чтобы заслужить право на создание дополнительного слоя. Логика слоя представления
взаимодействует с бизнес-логикой исключительно при посредничестве слоя служб, который
действует как API приложения.Поддерживая внятный интерфейс приложения (API), слой служб подходит также для
размещения логики управления транзакциями и обеспечения безопасности. Это дает
возможность снабдить подобными характеристиками каждый метод слоя служб. Для таких
целей обычно применяются файлы свойств, но атрибуты .NET предоставляют удобный
способ описания параметров непосредственно в коде.A common approach in handling domain logic is to split the domain layer in two. A Service Layer (133) is
placed over an underlying Domain Model (116) or Table Module (125). Usually you only get this with a
Domain Model (116) or Table Module (125) since a domain layer that uses only Transaction Script (110) isn’t
complex enough to warrant a separate layer. The presentation logic interacts with the domain purely through
the Service Layer (133), which acts as an API for the application.As well as providing a clear API, the Service Layer (133) is also a good spot to place such things as
transaction control and security. This gives you a simple model of taking each method in the Service Layer
(133) and describing its transactional and security characteristics. A separate properties file is a common
choice for this, but .NET’s attributes provide a nice way of doing it directly in the code.— “Patterns of Enterprise Application Architecture” [3]
Традиционно Сервисный Слой относится к логике уровня Приложения.
Т.е. Сервисный Слой имеет более низкий уровень, чем слой предметной области (domain logic), именуемый так же деловыми регламентами (business rules).
Из этого также следует и то, что объекты предметной области не должны быть осведомлены о наличии Сервисного Слоя.
Кроме перечисленного выше, сервисный слой может выполнять следующие обязанности:
- Компоновки атомарных операций (например, требуется одновременно сохранить данные в БД, редисе, и на файловой системе, в рамках одной бизнес-транзакции, или откатить все назад).
- Сокрытия источника данных (здесь он дублирует функции паттерна Repository) и может быть опущен, если нет других причин.
- Компоновки реиспользуемых операций уровня приложения (например, некая часть логики уровня приложения используется в нескольких различных контроллерах).
- Как основа для реализации Интерфейса удаленного доступа.
- Когда контроллер имеет какой-то большой метод, он нуждается в декомпозиции, и к нему применяется Extract Method для вычленения обязанностей в отдельные методы. При этом растет количество методов класса, что влечет за собой падение его сфокусированности или Связанности (т.е. коэффициент совместного использования свойств класса его методами). Чтобы восстановить связанность, эти методы выделяются в отдельный класс, образуя Method Object. И вот этот метод-объект и может быть преобразован в сервисный слой.
- Сервисный слой можно использовать в качестве концентратора запросов, если он стоит поверх паттерна Repository и использует паттерн Query object. Дело в том, что паттерн Repository ограничивает свой интерфейс посредством интерфейса Query Object. А так как класс не должен делать предположений о своих клиентах, то накапливать предустановленные запросы в классе Repository нельзя, ибо он не может владеть потребностями всех клиентов. Клиенты должны сами заботиться о себе. А сервисный слой как раз и создан для обслуживания клиентов.
В остальных случаях логику сервисного слоя можно размещать прямо на уровне приложения (обычно — контроллер).
Когда Сервисный Слой не нужен?¶
Гораздо легче ответить на вопрос, когда слой служб не нужно использовать. Скорее
всего, вам не понадобится слой служб, если у логики приложения есть только одна категория
клиентов, например пользовательский интерфейс, отклики которого на варианты
использования не охватывают несколько ресурсов транзакций. В этом случае управление
транзакциями и выбор откликов можно возложить на контроллеры страниц (Page
Controller, 350), которые будут обращаться непосредственно к слою источника данных.
Тем не менее, как только у вас появится вторая категория клиентов или начнет
использоваться второй ресурс транзакции, вам неизбежно придется ввести слой служб, что
потребует полной переработки приложения.The easier question to answer is probably when not to use it. You probably don’t need a Service Layer if your
application’s business logic will only have one kind of client say, a user interface and its use case responses
don’t involve multiple transactional resources. In this case your Page Controllers can manually control
transactions and coordinate whatever response is required, perhaps delegating directly to the Data Source
layer.
But as soon as you envision a second kind of client, or a second transactional resource in use case responses, it
pays to design in a Service Layer from the beginning.— “Patterns of Enterprise Application Architecture” [3]
Тем не менее, широко распространена точка зрения, что доступ к модели должен всегда производиться через сервисный слой:
Таким образом, на вашем месте я предпочел бы самый тонкий слой служб, какой
только возможен (если он вообще нужен). Обычно же я добавляю его только тогда, когда
он действительно необходим. Впрочем, мне знакомы хорошие специалисты, которые
всегда применяют слой служб, содержащий взвешенную долю бизнес-логики, так что
этим моим советом вы можете благополучно пренебречь.My preference is thus to have the thinnest Service Layer (133) you can, if you even need one. My usual
approach is to assume that I don’t need one and only add it if it seems that the application needs it. However, I
know many good designers who always use a Service Layer (133) with a fair bit of logic, so feel free to ignore
me on this one.— “Patterns of Enterprise Application Architecture” [3]
Идея вычленения слоя служб из слоя предметной области основана на подходе, предполагающем возможность отмежевания логики процесса от “чистой” бизнес-логики.
Уровень служб обычно охватывает логику, которая относится к конкретному варианту
использования системы или обеспечивает взаимодействие с другими инфраструктурами
(например, с помощью механизма сообщений).
Стоит ли иметь отдельные слои служб и предметной области — вопрос, достойный обсуждения.
Я склоняюсь к мысли о том, что подобное решение может оказаться полезным, хотя и не всегда, но некоторые уважаемые мною коллеги эту точку зрения не разделяют.The idea of splitting a services layer from a domain layer is based on a separation of workflow logic from
pure domain logic. The services layer typically includes logic that’s particular to a single use case and also
some communication with other infrastructures, such as messaging. Whether to have separate services and
domain layers is a matter some debate. I tend to look as it as occasionally useful rather than mandatory, but
designers I respect disagree with me on this.— “Patterns of Enterprise Application Architecture” [3]
Сервис — не обертка для DataMapper¶
Часто Service Layer ошибочно делают как враппер над DataMapper.
Это не совсем верно.
Data Mapper обслуживает одну Domain Model (модель предметной области), Repository обслуживает один Aggregate [9], а Cервис обслуживает клиента (или группу клиентов).
Сервисный слой может манипулировать в рамках бизнес-транзакции или в интересах клиента несколькими мапперами и другими сервисами.
Поэтому методы сервиса обычно содержат имя возвращаемой Модели Домена в качестве суффикса (например, getUser()), в то время как методы Маппера и Хранилища в этом суффиксе не нуждается (так как имя МОдели Домена уже и так присутствует в имени класса Маппера, и Маппер обслуживает только одну Модель Домена).
Установить, какие операции должны быть размещены в слое служб, отнюдь не сложно.
Это определяется нуждами клиентов слоя служб, первой (и наиболее важной) из
которых обычно является пользовательский интерфейс.Identifying the operations needed on a Service Layer boundary is pretty straightforward. They’re determined
by the needs of Service Layer clients, the most significant (and first) of which is typically a user interface.
(“Patterns of Enterprise Application Architecture” [3])
Инверсия Управления¶
Используйте инверсию управления, желательно в виде “Пассивного внедрения зависимостей” [1], Dependency Injection (DI).
Истинное внедрение зависимостей идет еще на один шаг вперед. Класс не
предпринимает непосредственных действий по разрешению своих зависимостей;
он остается абсолютно пассивным. Вместо этого он предоставляет set-методы
и/или аргументы конструктора, используемые для внедрения зависимостей.
В процессе конструирования контейнер DI создает экземпляры необходимых
объектов (обычно по требованию) и использует аргументы конструктора или
set-методы для скрепления зависимостей. Фактически используемые
зависимые объекты задаются в конфигурационном файле или на программном уровне
в специализированном конструирующем модуле.True Dependency Injection goes one step further. The class takes no direct steps to
resolve its dependencies; it is completely passive. Instead, it provides setter methods or
constructor arguments (or both) that are used to inject the dependencies. During the con-
struction process, the DI container instantiates the required objects (usually on demand)
and uses the constructor arguments or setter methods provided to wire together the depen-
dencies. Which dependent objects are actually used is specified through a configuration
file or programmatically in a special-purpose construction module.
“Clean Code: A Handbook of Agile Software Craftsmanship” [1]
Одна из основных обязанностей Сервисного Слоя — это сокрытие источника данных.
Для тестирования можно использовать фиктивный Сервис (Service Stub).
Этот же прием можно использовать для параллельной разработки, когда реализация сервисного слоя еще не готова.
Иногда бывает полезно подменить Сервис генератором фэйковых данных.
В общем, пользы от сервисного слоя будет мало, если нет возможности его подменить (или подменить используемые им зависимости).
Распространенная проблема Django-приложений¶
Широко распространенная ошибка — использование класса django.db.models.Manager (а то и django.db.models.Model) в качестве сервисного слоя.
Нередко можно встретить, как какой-то метод класса django.db.models.Model принимает в качестве аргумента объект HTTP-запроса django.http.request.HttpRequest, например, для проверки прав.
Объект HTTP-запроса — это логика уровня приложения (application), в то время как класс модели — это логика уровня предметной области (domain), т.е. объекты реального мира, которую также называют правилами делового регламента (business rules).
Проверка прав — это тоже логика уровня приложения.
Нижележащий слой не должен ничего знать о вышестоящем слое.
Логика уровня домена не должна быть осведомлена о логике уровня приложения.
Классу django.db.models.Manager более всего соответствует класс Finder описанный в “Patterns of Enterprise Application Architecture” [3].
При реализации шлюза записи данных возникает вопрос: куда “пристроить” методы
поиска, генерирующие экземпляр данного типового решения? Разумеется, можно
воспользоваться статическими методами поиска, однако они исключают возможность
полиморфизма (что могло бы пригодиться, если понадобится определить разные методы
поиска для различных источников данных). В подобной ситуации часто имеет смысл
создать отдельные объекты поиска, чтобы у каждой таблицы реляционной базы данных
был один класс для проведения поиска и один класс шлюза для сохранения результатов
этого поиска.Иногда шлюз записи данных трудно отличить от активной записи (Active Record, 182).
В этом случае следует обратить внимание на наличие какой-либо логики домена; если
она есть, значит, это активная запись. Реализация шлюза записи данных должна включать
в себя только логику доступа к базе данных и никакой логики домена.With a Row Data Gateway you’re faced with the questions of where to put the find operations that generate this
pattern. You can use static find methods, but they preclude polymorphism should you want to substitute
different finder methods for different data sources. In this case it often makes sense to have separate finder
objects so that each table in a relational database will have one finder class and one gateway class for the results.It’s often hard to tell the difference between a Row Data Gateway and an Active Record (160). The crux of the
matter is whether there’s any domain logic present; if there is, you have an Active Record (160). A Row Data
Gateway should contain only database access logic and no domain logic.
(Chapter 10. “Data Source Architectural Patterns : Row Data Gateway”, “Patterns of Enterprise Application Architecture” [3])
Хотя Django не использует паттерн Repository, она использует абстракцию критериев выборки, своего рода разновидность паттерна Query Object.
Подобно паттерну Repository, класс модели (ActiveRecord) ограничивает свой интерфейс посредством интерфейса Query Object.
Клиенты должны пользоваться предоставленным интерфейсом, а не возлагать на модель и ее менеджер свои обязанности по знанию своих запросов.
А так как никакой класс не должен делать предположений о своих клиентах, то накапливать предустановленные запросы в классе модели нельзя, ибо он не может владеть потребностями всех клиентов.
Клиенты должны сами заботиться о себе.
А сервисный слой как раз и создан для обслуживания клиентов.
Попытки исключить Сервинсый Слой из Django-приложений приводит к появлению менеджеров с огромным количеством методов.
Хорошей практикой было бы сокрытие посредством сервисного слоя способа реализации Django Models в виде ActiveRecord.
Это позволит безболезненно подменить ORM в случае необходимости.
Можно было бы поспорить и о размещении логики приложения. Думаю, некоторые
предпочли бы реализовать ее в методах объектов домена, таких, как
Contract. calculateRevenueRecognitions (), ИЛИ вообще В слое источника данных, ЧТО
позволило бы обойтись без отдельного слоя служб. Тем не менее подобное размещение
логики приложения кажется мне весьма нежелательным, и вот почему. Во-первых, классы
объектов домена, которые реализуют логику, специфичную для приложения (и зависят
от шлюзов и других объектов, специфичных для приложения), менее подходят для
повторного использования другими приложениями. Это должны быть модели частей
предметной области, представляющих интерес для данного приложения, поэтому подобные
объекты вовсе не обязаны описывать возможные отклики на все варианты использования
приложения. Во-вторых, инкапсуляция логики приложения на более высоком
уровне (каковым не является слой источника данных) облегчает изменение реализации
этого слоя, возможно, посредством некоторых специальных инструментальных средств.Some might also argue that the application logic responsibilities could be implemented in domain object
methods, such as Contract.calculateRevenueRecognitions(), or even in the data source layer,
thereby eliminating the need for a separate Service Layer. However, I find those allocations of responsibility
undesirable for a number of reasons. First, domain object classes are less reusable across applications if they
implement application-specific logic (and depend on application-specific Gateways (466), and the like). They
should model the parts of the problem domain that are of interest to the application, which doesn’t mean all of
application’s use case responsibilities. Second, encapsulating application logic in a “higher” layer
dedicated to that purpose (which the data source layer isn’t) facilitates changing the implementation of that
layer perhaps to use a workflow engine.
(“Patterns of Enterprise Application Architecture” [3])
Проблема Django-аннотаций¶
Я часто наблюдал такую проблему, когда в Django Model добавлялось какое-то новое поле, и начинали сыпаться проблемы, так как это имя уже было использовано либо с помощью аннотаций, либо с помощью Raw-SQL.
Также реализация аннотаций в Django ORM делает невозможным использование паттерна Identity Map.
Storm ORM/SQLAlchemy реализуют аннотации более удачно.
Если Вам все-таки пришлось работать с Django Model, воздержитесь от использования механизма Django аннотаций в пользу голого паттерна DataMapper.
Особенности сервисного слоя на стороне клиента¶
Использование концепции агрегата и библиотек реактивного программирования, таких как RxJS, позволяет реализовывать Сервисный Слой с помощью простейшего паттерна Gateway, смотрите, например, учебный пример из документации Angular.
В таком случае, Query Object обычно реализуется в виде простого словаря, который преобразуется в список GET-параметров URL.
Общается такой Сервис с сервером обычно либо посредством JSON-RPC, либо посредством REST-API Actions.
Все работает хорошо до тех пор, пока не возникает необходимость выражать приоритезированные запросы, например, использующие логический оператор OR, который использует меньший приоритет чем логический оператор AND.
Это порождает вопрос, кто должен отвечать за построение запроса, Сервисный Слой клиента или Сервисный Слой сервера?
С одной стороны, сервер не должен делать предположений о своих клиентах, и должен ограничивать свой интерфейс посредством интерфейса Query Object.
Но это резко увеличивает уровень сложности клиента, в частности, при реализации Service Stub.
Для облегчения реализации можно использовать библиотеку rql, упомянутую в статье “Реализация паттерна Repository в браузерном JavaScript”.
С другой стороны, Сервисный Слой, пусть и удаленного вызова, предназначен для обслуживания клиентов, а значит, может концентрировать в себе логику построения запросов.
Если клиент не содержит сложной логики, позволяющей интерпретировать приоритезированные запросы для Service Stub, то нет необходимости его усложнять этим.
В таком случае проще добавить новый метод в сервисе удаленного вызова, и избавиться от необходимости в приоритезированных запросах.
Проблема параллельного обновления¶
Появление интернета открыло доступ к огромному количеству данных, которое несопоставимо велико с возможностями одного сервера.
Возникла необходимость в масштабировании и в распределенном хранении и обработке данных.
Одна из самых острых проблем — это проблема параллельного обновления данных.
Все состояния гонки (race condition), взаимоблокировки (deadlocks) и проблемы параллельного обновления обусловлены изменяемостью переменных.
Если в программе нет изменяемых переменных, она никогда не окажется в состоянии гонки и никогда не столкнется с проблемами одновременного изменения.
В отсутствие изменяемых блокировок программа не может попасть в состояние взаимоблокировки.All race conditions, deadlock conditions, and concurrent update problems are due to mutable variables.
You cannot have a race condition or a concurrent update problem if no variable is ever updated.
You cannot have deadlocks without mutable locks.— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin
Любой порядок выражается в правильном наложении ограничений.
CQRS¶
Проблему параллельного обновления в значительной мере можно уменьшить наложением ограничения на двунаправленные изменения состояния путем введения однонаправленных изменений, т.е. путем отделения чтения от записи.
Именно такой подход используется в Redux.
“it allows us to host the two services differently eg: we can host the read service on 25 servers and the write service on two.
The processing of commands and queries is fundamentally asymmetrical, and scaling the services symmetrically does not make a lot of sense.”— “CQRS, Task Based UIs, Event Sourcing agh!” by Greg Young
Управление Логикой Приложения и Бизнес-Логикой хорошо раскрывается в статье “Clarified CQRS” by Udi Dahan.
Использование CQRS способствует использованию парадигмы Функционального Программирования.
— В последнее время наметилась тенденция в популяризации функциональных языков и функциональной парадигмы программирования. Что вы скажите, является ли объектная технология конкурентом функциональному программированию?
— Нет, эти две парадигмы не являются конкурентами, они успешно могут дополнять друг друга. Тем не менее, тенденция к функциональному программированию является важной и интересной.
На мой взгляд, когда речь идет о высокоуровневой структуре приложения (особенно больших программ), то в мире нет ничего лучше объектного подхода. Я просто не вижу, как можно писать действительно большую программу исключительно на функциональном языке.
С другой стороны, если общая структура приложения построена на основе объектов, то очень даже полезно, если некоторые ее части будут написаны на функциональном языке, для обеспечения простоты и возможности доказательства корректности, о которых я говорил ранее.
Несколько лет назад я опубликовал статью на эту тему, где сравнивал ОО и ФП подходы. В ней я постарался показать, что ОО метод включает функциональное программирование, а не наоборот.
— Да, я кажется читал эту статью, которая затем вошла в качестве одной из глав в книгу “Beautiful Architecture”.
— Вы знаете об этом? Я очень впечатлен.
— (Смеюсь…) Да, и насколько я помню, это был ваш ответ на статью Саймона Пейтона Джонса, в которой автор старался показать, что ФП подход является более предпочтительным.
— Да, совершенно верно.
ПРИМЕЧАНИЕ: Речь идет о статье Бертрана “Software Architecture: Functional vs. Object-Oriented Design in Beautiful Architecture”, опубликованной в книге “Идеальная архитектура. Ведущие специалисты о красоте программных архитектур.”. Эта статья Мейера была ответом на статью Саймона “Composing contracts: an adventure in financial engineering.”
— Давайте все же немного вернемся к вопросу OOP vs FP. Какие именно преимущества у функционального подхода на “низком уровне”?
— В Eiffel существует очень важный принцип, под названием Command-Query Separation Principle, который можно рассматривать, в некотором роде, как сближение ОО и ФП миров. Я не считаю, что наличие состояния – это однозначно плохо. Но очень важно, чтобы мы могли ясно различать операции, которые это состояние изменяют (т.е. командами), и операции, которые лишь возвращают информацию о состоянии, его не изменяя (т.е. запросами). В других языках эта разница отсутствует. Так, например, в С/С++ часто пишут функции, которые возвращают результат и изменяют состояние. Следование этому принципу позволяет безопасно использовать выражения с запросами зная, что они не изменяют состояние. В некоторых случаях можно пойти еще дальше и работать в чисто функциональном мире с полным отсутствием побочных эффектов.
— Bertrand Meyer в интервью Сергея Теплякова “Интервью с Бертраном Мейером“
For both theoretical and practical reasons detailed elsewhere [10], the command-query separation principle is a methodological rule, not a language feature, but all serious software developed in Eiffel observes it scrupulously, to great referential transparency advantage.
Although other schools of object-oriented programming regrettable do not apply it (continuing instead the C style of calling functions rather than procedures to achieve changes), but in my view it is a key element of the object-oriented approach.
It seems like a viable way to obtain the referential transparency goal of functional programming — since expressions, which only involve queries, will not change the state, and hence can be understood as in traditional mathematics or a functional language — while acknowledging, through the notion of command, the fundamental role of the concept of state in modeling systems and computations.— “Software architecture: object-oriented vs functional” by Bertrand Meyer
Функциональное Программирование по своей сути не может порождать побочных эффектов (т.к. Функциональное Программирование накладывает ограничение на присваивание (изменяемость)), и именно этим обусловлен рост его популярности в эпоху распределенных вычислений.
Нет изменяемого состояния — нет проблем параллельного обновления.
Следует отличать парадигму Функционального Программирования от языков, поддерживающих эту парадигму, поскольку нередко языки, поддерживающие эту парадигму, позволяют не следовать ей.
Однако, несмотря на открывшиеся возможности использовать Функциональное Программирование в коде, само хранилище данных (IO-устройство) все еще подвержено проблемам параллельного обновления, поскольку имеет изменяемые записи, а значит, имеет побочный эффект.
Решением этой проблемы обычно является замена CRUD (Create, Read, Update, Delete) на CR, т.е. наложение ограничения на изменение (Update) и удаление (Delete) записей в хранилище, что получило распространение под термином Event Sourcing.
Существуют специализированные хранилища, реализующие его, но он реализуется не обязательно специализированными инструментами.
Event Sourcing¶
Если CQRS позволяет работать с хранилищами данных в Императивном стиле, и отделяет действия (побочный эффект) от запроса (чтения) данных, то Event Sourcing идет еще дальше, и накладывает ограничение на изменение и удаление данных, превращая CRUD в CR.
Такой шаблон позволяет работать с хранилищами данных в Функциональном стиле, и предоставляет такие же выгоды: нет изменяемого состояния — нет проблемы параллельного обновления.
И такие же недостатки — потребность в большом количестве памяти и процессорной мощности.
Именно поэтому, данный шаблон широко используется в распределенных системах, где остро проявляется потребность в его достоинствах, и, вместе с тем, не проявляются его недостатки (ведь распределенные системы не лимитированы ни в памяти, ни в процессорной мощности).
Наглядным примером Event Sourcing может быть принцип организации банковского счета в базе данных, когда счет не является источником истины, а просто отражает совокупное значение всех транзакций (т.е. событий).
Наиболее ясно эта тема раскрывается в Chapter 6 “Functional Programming” of “Clean Architecture” by Robert C. Martin.
Что особенно важно, никакая информация не удаляется из такого хранилища и не изменяется.
Как следствие, от набора CRUD-операций в приложениях остаются только CR.
Также отсутствие операций изменения и/или удаления с хранилищем устраняет любые проблемы конкурирующих
обновлений.Обладая хранилищем достаточного объема и достаточной вычислительной мощностью, мы можем сделать свои приложения полностью неизменяемыми — и, как следствие, полностью функциональными.
Если это все еще кажется вам абсурдным, вспомните, как работают системы управления версиями исходного кода.
More importantly, nothing ever gets deleted or updated from such a data store.
As a consequence, our applications are not CRUD; they are just CR. Also, because neither updates nor deletions occur in the data store, there cannot be any concurrent update issues.If we have enough storage and enough processor power, we can make our applications entirely immutable—and, therefore, entirely functional.
If this still sounds absurd, it might help if you remembered that this is precisely the way your source code control system works.
— “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin
Event Sourcing is naturally functional.
It’s an append only log of facts that have happened in the past.
You can say that any projection any state is a left fold over your previous history.— Greg Young, “A Decade of DDD, CQRS, Event Sourcing” at 16:44
I have always said that Event Sourcing is “Functional Data Storage”.
In this talk we will try migrating to a idiomatic functional way of looking at Event Sourcing.
Come and watch all the code disappear!
By the time you leave you will never want an “Event Sourcing Framework (TM)” ever again!— Greg Young, “Functional Data”, NDC Conferences
Что почитать¶
-
- “Clean Code: A Handbook of Agile Software Craftsmanship” by Robert C. Martin [1], chapters:
-
- Dependency Injection … 157
- Cross-Cutting Concerns … 160
- Java Proxies … 161
- Pure Java AOP Frameworks … 163
-
- “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” [2] by Robert C. Martin
-
- Chapter 6 Functional Programming : Event Sourcing
- Chapter 16 Independence
- Chapter 18 Boundary Anatomy : Services
- Chapter 20 Business Rules
- Chapter 22 The Clean Architecture
- Chapter 34 The Missing Chapter
-
- “Patterns of Enterprise Application Architecture” by Martin Fowler [3], chapters:
-
- Part 1. The Narratives : Chapter 2. Organizing Domain Logic : Service Layer
- Part 1. The Narratives : Chapter 8. Putting It All Together
- Part 2. The Patterns : Chapter 9. Domain Logic Patterns : Service Layer
-
- “Domain-Driven Design: Tackling Complexity in the Heart of Software” by Eric Evans [4], chapters:
-
- Part II: The Building Blocks of a Model-Driven Design : Chapter Four. Isolating the Domain : Layered Architecture
- Part II: The Building Blocks of a Model-Driven Design : Chapter Five. A Model Expressed in Software : Services
-
- “Implementing Domain-Driven Design” [5] by Vaughn Vernon
-
- Chapter 4 Architecture : Command-Query Responsibility Segregation, or CQRS
- Chapter 4 Architecture : Event-Driven Architecture : Long-Running Processes, aka Sagas
- Chapter 4 Architecture : Event-Driven Architecture : Event Sourcing
- Chapter 7 Services
- Chapter 14 Application : Application Services
- Appendix A Aggregates and Event Sourcing: A+ES : Inside an Application Service
-
- “Microsoft Application Architecture Guide” 2nd Edition (Patterns & Practices) by Microsoft Corporation (J.D. Meier, David Hill, Alex Homer, Jason Taylor, Prashant Bansode, Lonnie Wall, Rob Boucher Jr., Akshay Bogawat), chapters:
-
- Chapter 5: Layered Application Guidelines … 55
- Chapter 5: Layered Application Guidelines : Services and Layers … 58
- Chapter 9: Service Layer Guidelines … 115
- Chapter 17: Crosscutting Concerns … 205
- Chapter 21: Designing Web Applications : Service Layer … 288
- Chapter 25: Designing Service Applications : Service Layer … 371
-
- “Microsoft .NET: Architecting Applications for the Enterprise” 2nd Edition by Dino Esposito, Andrea Saltarello, chapters:
-
- Chapter 5 Discovering the domain architecture : The layered architecture … 129
- Chapter 10 Introducing CQRS … 255
- Chapter 11 Implementing CQRS … 291
- Chapter 12 Introducing event sourcing … 311
- Chapter 13 Implementing event sourcing … 325
-
- “Design Patterns Elements of Reusable Object-Oriented Software” by Erich Gamma [6], chapters:
-
- Design Pattern Catalog : 4 Structural Patterns : Adapter … 139
- Design Pattern Catalog : 4 Structural Patterns : Decorator … 175
-
- “Building Microservices. Designing Fine-Grained Systems” by Sam Newman, chapters:
-
- Chapter 3 How to Model Services : Premature Decomposition … 33
-
- “Monolith to Microservices Evolutionary Patterns to Transform Your Monolith” by Sam Newman
-
- Chapter 4. Decomposing the Database : Sagas
-
- “Cloud Design Patterns. Prescriptive architecture guidance for cloud applications” by Alex Homer, John Sharp, Larry Brader, Masashi Narumoto, Trent Swanson, chapters:
-
- Command and Query Responsibility Segregation (CQRS) pattern
- Event Sourcing pattern
- Compensating Transaction pattern
-
- “.NET Microservices: Architecture for Containerized .NET Applications” edition v2.2.1 (mirror) by Cesar de la Torre, Bill Wagner, Mike Rousos, chapters:
-
- Tackle Business Complexity in a Microservice with DDD and CQRS Patterns
- Apply simplified CQRS and DDD patterns in a microservice
- Apply CQRS and CQS approaches in a DDD microservice in eShopOnContainers
- Implement reads/queries in a CQRS microservice
-
- “CQRS Journey” by Dominic Betts, Julián Domínguez, Grigori Melnik, Fernando Simonazzi, Mani Subramanian, chapters:
-
- Reference 1: CQRS in Context
- Reference 2: Introducing the Command Query Responsibility Segregation Pattern
- Reference 3: Introducing Event Sourcing
- Reference 4: A CQRS and ES Deep Dive
- Reference 6: A Saga on Sagas
-
- “Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions” by Gregor Hohpe, Bobby Woolf, chapters:
-
-
- Message routing : Process manager … 278
-
-
- “Microservices Patterns: With examples in Java” 1st Edition by Chris Richardson
-
- Pattern: Command Query Responsibility Segregation (CQRS)
- Pattern: Event sourcing
- Pattern: Saga
-
“CQRS“
-
“Command Query Separation
-
“Event Sourcing“
-
“What do you mean by “Event-Driven”?“
-
“Patterns for Accounting“
-
“Accounting Patterns“
-
“CQRS, Task Based UIs, Event Sourcing agh!” by Greg Young
-
“Clarified CQRS” by Udi Dahan
-
“CQRS Documents” by Greg Young
-
“Sagas” by Hector Garcia-Molina and Kenneth Salem
-
“Domain services vs Application services” by Vladimir Khorikov
-
“Sagas” by Clemens Vasters (“Sample Code”)
This article in English “Design of Service Layer and Application Logic”.
Footnotes
| [1] | (1, 2, 3, 4, 5) “Clean Code: A Handbook of Agile Software Craftsmanship” by Robert C. Martin |
| [2] | (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13) “Clean Architecture: A Craftsman’s Guide to Software Structure and Design” by Robert C. Martin |
| [3] | (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19) “Patterns of Enterprise Application Architecture” by Martin Fowler, David Rice, Matthew Foemmel, Edward Hieatt, Robert Mee, Randy Stafford |
| [4] | (1, 2, 3, 4, 5, 6, 7, 8, 9, 10) “Domain-Driven Design: Tackling Complexity in the Heart of Software” by Eric Evans |
| [5] | “Implementing Domain-Driven Design” by Vaughn Vernon |
| [6] | (1, 2) “Design Patterns Elements of Reusable Object-Oriented Software” by Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides, 1994 |
| [7] | (1, 2) “Refactoring: Improving the Design of Existing Code” by Martin Fowler, Kent Beck, John Brant, William Opdyke, Don Roberts |
| [8] | (1, 2) “Building Microservices. Designing Fine-Grained Systems” by Sam Newman |
| [9] | “.NET Microservices: Architecture for Containerized .NET Applications” edition v2.2.1 (mirror) by Cesar de la Torre, Bill Wagner, Mike Rousos |
Updated on Oct 12, 2019