Проверка гипотезы использует выборочные данные, чтобы определить, верно ли какое-либо утверждение о параметре совокупности .
Всякий раз, когда мы выполняем проверку гипотезы, мы всегда пишем нулевую гипотезу и альтернативную гипотезу, которые принимают следующие формы:
H 0 (нулевая гипотеза): параметр совокупности =, ≤, ≥ некоторого значения
H A (Альтернативная гипотеза): параметр совокупности <, >, ≠ некоторое значение
Обратите внимание, что нулевая гипотеза всегда содержит знак равенства .
Мы интерпретируем гипотезы следующим образом:
Нулевая гипотеза: данные выборки не предоставляют никаких доказательств, подтверждающих какое-либо заявление, сделанное отдельным лицом.
Альтернативная гипотеза: данные выборки действительно предоставляют достаточные доказательства в поддержку заявления, сделанного отдельным лицом.
Например, предположим, что средняя высота определенного вида растений составляет 20 дюймов. Однако один ботаник утверждает, что истинная средняя высота превышает 20 дюймов.
Чтобы проверить это утверждение, она может пойти и собрать случайный образец растений. Затем она может использовать эти выборочные данные для проверки гипотезы, используя следующие две гипотезы:
H 0 : μ ≤ 20 (истинная средняя высота растений равна или даже меньше 20 дюймов)
H A : μ > 20 (истинная средняя высота растений больше 20 дюймов)
Если выборочные данные, собранные ботаником, показывают, что средняя высота этого вида растений значительно превышает 20 дюймов, он может отвергнуть нулевую гипотезу и сделать вывод, что средняя высота больше 20 дюймов.
Прочитайте следующие примеры, чтобы лучше понять, как написать нулевую гипотезу в различных ситуациях.
Пример 1: вес черепах
Биолог хочет проверить, действительно ли средний вес определенного вида черепах составляет 300 фунтов. Чтобы проверить это, он выходит и измеряет вес случайной выборки из 40 черепах.
Вот как написать нулевую и альтернативную гипотезы для этого сценария:
H 0 : μ = 300 (истинный средний вес равен 300 фунтам)
H A : μ ≠ 300 (истинный средний вес не равен 300 фунтам)
Пример 2: Рост мужчин
Предполагается, что средний рост мужчин в определенном городе составляет 68 дюймов. Однако независимый исследователь считает, что истинный средний рост превышает 68 дюймов. Чтобы проверить это, он выходит и собирает рост 50 мужчин в городе.
Вот как написать нулевую и альтернативную гипотезы для этого сценария:
H 0 : μ ≤ 68 (истинный средний рост равен или даже меньше 68 дюймов)
H A : μ > 68 (истинный средний рост больше 68 дюймов)
Пример 3: Коэффициенты выпуска
Университет заявляет, что 80% всех студентов заканчивают обучение вовремя. Однако независимый исследователь считает, что менее 80% всех студентов заканчивают обучение вовремя. Чтобы проверить это, она собирает данные о доле студентов, окончивших университет в срок в прошлом году.
Вот как написать нулевую и альтернативную гипотезы для этого сценария:
H 0 : p ≥ 0,80 (истинная доля студентов, закончивших обучение в срок, составляет 80% и выше)
H A : μ < 0,80 (истинная доля студентов, закончивших обучение вовремя, составляет менее 80%)
Пример 4: Вес бургеров
Исследователь продуктов питания хочет проверить, действительно ли средний вес гамбургера в определенном ресторане составляет 7 унций. Чтобы проверить это, он выходит и измеряет вес случайной выборки из 20 гамбургеров из этого ресторана.
Вот как написать нулевую и альтернативную гипотезы для этого сценария:
H 0 : μ = 7 (истинный средний вес равен 7 унциям)
H A : μ ≠ 7 (истинный средний вес не равен 7 унциям)
Пример 5: Поддержка граждан
Политик утверждает, что менее 30% жителей определенного города поддерживают тот или иной закон. Чтобы проверить это, он выходит и опрашивает 200 граждан на предмет того, поддерживают ли они закон.
Вот как написать нулевую и альтернативную гипотезы для этого сценария:
H 0 : p ≥ 0,30 (истинная доля граждан, поддерживающих закон, больше или равна 30%)
H A : μ < 0,30 (истинная доля граждан, поддерживающих закон, менее 30%)
Дополнительные ресурсы
Введение в проверку гипотез
Введение в доверительные интервалы
Объяснение P-значений и статистической значимости
![]()
Download Article
![]()
Download Article
Are you working on a research project and struggling with how to write a null hypothesis? Well, you’ve come to the right place! Start by recognizing that the basic definition of «null» is «none» or «zero»—that’s your biggest clue as to what a null hypothesis should say. Keep reading to learn everything you need to know about the null hypothesis, including how it relates to your research question and your alternative hypothesis as well as how to use it in different types of studies.
Things You Should Know
- Write a research null hypothesis as a statement that the studied variables have no relationship to each other, or that there’s no difference between 2 groups.
- Write a statistical null hypothesis as a mathematical equation, such as
 if you’re comparing group means.
if you’re comparing group means. - Adjust the format of your null hypothesis to match the statistical method you used to test it, such as using «mean» if you’re comparing the mean between 2 groups.

-
A null hypothesis states that there’s no relationship between 2 variables. When you’re doing research, you start by asking a question about the relationship between those 2 variables. Your hypothesis (also called an alternative hypothesis) is your prediction about the relationship between the 2 variables you’re studying. In contrast, the null hypothesis predicts there’s no relationship at all. If you’re studying statistics, you’ll use a mathematical format that reflects the method of data analysis you’re using.[1]
- Research hypothesis: States in plain language that there’s no relationship between the 2 variables or there’s no difference between the 2 groups being studied.
- Statistical hypothesis: States the predicted outcome of statistical analysis through a mathematical equation related to the statistical method you’re using.

Advertisement
-
1
Research question: How effective is high school sex education at reducing the rate of teen pregnancy?[2]
-
2
Research question: Does daily use of social media affect the attention span of children under 16?[3]
-
3
Research question: Are women more likely than men to go vegan?[4]
-
4
Research question: Do people have difficulty reading highway signs at a distance as they get older?[5]




Advertisement
-
1
Null hypotheses and alternative hypotheses are mutually exclusive. This means that if one of your hypotheses is true, the other must be false. Be careful here, though, because this isn’t the same as saying they’re opposites. It’s possible that they could both be false.[6]
- For example, your alternative hypothesis could state a positive correlation between 2 variables while your null hypothesis states there’s no relationship. If there’s a negative correlation, then both hypotheses are false.
-
2
Proving the null hypothesis false is a precursor to proving the alternative. If your null hypothesis states that the 2 variables have no relationship, and you prove it false, you can say this demonstrates that the 2 variables do have some relationship. But at the same time, this doesn’t necessarily mean that the relationship between the 2 variables is the one you proposed in your alternative hypothesis.[7]
- You need additional data or evidence to show that your alternative hypothesis is correct—proving the null hypothesis false is just the first step.
- In smaller studies, sometimes it’s enough to show that there’s some relationship and your hypothesis could be correct—you can leave the additional proof as an open question for other researchers to tackle.


Advertisement
-
Use statistical methods on collected data to test the null hypothesis. Collect and organize your data, then choose a good statistical method to test it. There are many different methods used to analyze data—these are some of the simplest and most common:[8]
-
Group means: Compare the mean of the variable in your sample with the mean of the variable in the general population.[9]
-
Group proportions: Compare the proportion of the variable in your sample with the proportion of the variable in the general population.[10]
-
Correlation: Correlation analysis looks at the relationship between 2 variables—specifically, whether they tend to happen together.[11]
-
Regression: Regression analysis reveals the correlation between 2 variables while also controlling for the effect of other, interrelated variables.[12]
-
Group means: Compare the mean of the variable in your sample with the mean of the variable in the general population.[9]

-
1
Group means You’re testing whether the mean of a specific, dependent variable differs between 2 groups, or between a group and the population as a whole. The 2 groups are distinguished using a separate, independent variable.[13]
-
2
Group proportions You’re testing the proportion of a specific, dependent variable in a specific population or sample as compared to a larger population. The 2 groups are distinguished using a separate, independent variable.[14]
- Research null hypothesis: The proportion of [dependent variable] in [group 1] and [group 2] is the same.
-
Statistical null hypothesis:
-
3
Correlation You’re testing if there is a correlation between 2 variables in a specific, defined population. This is a controlled study in which there are no other variables that could possibly affect the outcome.[15]
- Research null hypothesis: There is no correlation between [independent variable] and [dependent variable] in the population.
-
Statistical null hypothesis:
-
4
Regression You’re testing if there is a correlation between 2 variables in a specific, defined population. However, there are other intertwined variables that could possibly affect the outcome.[16]
- Research null hypothesis: There is no relationship between [independent variable] and [dependent variable] in the population.
-
Statistical null hypothesis:







Advertisement
Ask a Question
200 characters left
Include your email address to get a message when this question is answered.
Submit
Advertisement
Thanks for submitting a tip for review!
References
About This Article
Thanks to all authors for creating a page that has been read 10,149 times.
Did this article help you?
Get all the best how-tos!
Sign up for wikiHow’s weekly email newsletter
Subscribe
You’re all set!
В научном эксперименте нулевая гипотеза – это утверждение об отсутствии эффекта или связи между явлениями или популяциями. Если нулевая гипотеза верна, любое наблюдаемое различие в явлениях или популяциях будет связано с ошибкой выборки (случайной случайностью) или ошибкой эксперимента. Нулевая гипотеза полезна, потому что она может быть проверена и признана ложной, что затем подразумевает, что существует связь между наблюдаемыми данными. Возможно, будет проще думать об этом как о гипотезе, не подлежащей проверке , или как о гипотезе, которую исследователь пытается опровергнуть. Нулевая гипотеза также известна как H 0, или гипотеза отсутствия различий.
Альтернативная гипотеза H A или H 1 предполагает, что на наблюдения влияет неслучайный фактор. В эксперименте альтернативная гипотеза предполагает, что экспериментальная или независимая переменная влияет на зависимую переменную.
Содержание
- Как сформулировать нулевую гипотезу
- Примеры нулевых гипотез
- Зачем проверять нулевую гипотезу?
Как сформулировать нулевую гипотезу
Есть два способа сформулировать нулевую гипотезу. Один состоит в том, чтобы сформулировать его как декларативное предложение, а другой – в виде математического утверждения.
Например, предположим, что исследователь подозревает, что упражнения – это коррелирует с потерей веса при условии, что диета не изменится. Средняя продолжительность похудения составляет шесть недель, если человек тренируется пять раз в неделю. Исследователь хочет проверить, занимает ли потеря веса больше времени, если количество тренировок сокращается до трех раз в неделю.
Первый шаг к написанию нуля гипотеза состоит в том, чтобы найти (альтернативную) гипотезу. В подобной словесной задаче вы ищете то, что вы ожидаете от эксперимента. В этом случае гипотеза: «Я ожидаю, что потеря веса займет больше шести недель».
Математически это можно записать как: H 1 : μ> 6
В этом примере μ – это среднее значение.
Нулевая гипотеза – это то, что вы ожидаете, если эта гипотеза не . В этом случае, если потеря веса не достигается более чем за шесть недель, то она должна происходить в срок, равный или менее шести недель. Математически это можно записать как:
H 0 : μ ≤ 6
Другой способ сформулировать нулевую гипотезу – не делать никаких предположений о результате эксперимента. В этом случае нулевая гипотеза просто состоит в том, что лечение или изменение не повлияют на результат эксперимента. В этом примере сокращение количества тренировок не повлияет на время, необходимое для похудания:
H 0 : μ = 6
Примеры нулевых гипотез
«Гиперактивность не связана с употреблением сахара» – это пример нулевая гипотеза. Если гипотеза проверяется и оказывается ложной с помощью статистики, то может быть указана связь между гиперактивностью и потреблением сахара. Тест значимости – это наиболее распространенный статистический тест, используемый для подтверждения достоверности нулевой гипотезы.
Другой пример нулевой гипотезы: «Скорость роста растений не зависит от наличие кадмия в почве ». Исследователь мог проверить гипотезу, измерив скорость роста растений, выращенных в среде без кадмия, по сравнению со скоростью роста растений, выращенных в средах, содержащих различное количество кадмия. Опровержение нулевой гипотезы создаст основу для дальнейших исследований эффектов различных концентраций элемента в почве.
Зачем проверять нулевую гипотезу?
Вам может быть интересно, зачем вам проверять гипотезу только для того, чтобы найти ее ложной. Почему бы просто не проверить альтернативную гипотезу и не признать ее верной? Короткий ответ: это часть научного метода. В науке утверждения явно не «доказываются». Скорее, наука использует математику для определения вероятности того, что утверждение истинно или ложно. Оказывается, гипотезу опровергнуть гораздо проще, чем ее доказать. Кроме того, хотя нулевая гипотеза может быть просто сформулирована, есть большая вероятность, что альтернативная гипотеза неверна.
Например, если ваша нулевая гипотеза заключается в том, что рост растений не зависит от продолжительности солнечного света, вы можете сформулировать альтернативную гипотезу несколькими способами. Некоторые из этих утверждений могут быть неверными. Вы могли бы сказать, что растениям наносят вред более 12 часов солнечного света или что растениям требуется не менее трех часов солнечного света и т. Д. Существуют явные исключения из этих альтернативных гипотез, поэтому, если вы протестируете неправильные растения, вы можете прийти к неверному выводу. Нулевая гипотеза – это общее утверждение, которое можно использовать для разработки альтернативной гипотезы, которая может быть верной, а может и нет.
Расчет нулевой гипотезы, на примере анализа зарплат украинских программистов
Время на прочтение
5 мин
Количество просмотров 19K
Решил поделиться, да бы и самому не забывать, как можно использовать простые статистические инструменты для анализа данных. В качестве примера использовался анонимный опрос относительно зарплат, стажа и позиций украинских программистов за 2014 и 2019 год. (1)
Этапы анализа
- Препроцессинг данных и предварительный анализ (кому интересно код тут)
- Графическое представление данных. Функция плотности распределения.
- Формулируем нулевую гипотезу (H0) (2)
- Выбираем метрику для анализа
- Используем метод bootstraping для формирования нового массива данных
- Рассчитываем p-value (3) для подтверждения или опровержения гипотезы
Препроцессинг данных
После некоторых манипуляций (код тут), приводим данные в следующий вид:
# Строка здесь это отдельный результат опроса, колонки переменные.
display(data_14_1.head(), data_19_1.head())
print('Всего опрошенных программистов: n
{} чел. в 14 году и {} в 19 году'.format(len(data_14_1), len(data_19_1)))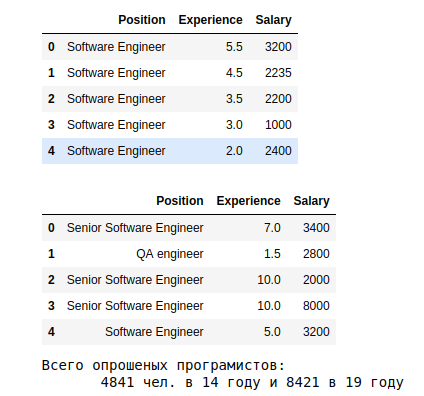
Немного больше группировок для одного года (пусть 19-й):
# Группируем, считаем 19 год
display(pd.DataFrame(df.groupby(['Experience'])['Salary'].mean().sort_values(ascending=False)),
pd.DataFrame(df.groupby(['Position'])['Salary'].mean().sort_values(ascending=False)),
df.Position.value_counts())
Первые оценки такие.
а. По результатам видно, что в среднем в 19 году, те кто работает более 10 лет получает более 3.5к. Прослеживается зависимость стаж -> з.п.
в. Средние з.п. в 19 году, в зависимости от специализации показывают разброс в 10 раз — от 5к для System Architect, до 575 для Junior QA.
с. В последней табличке распределение по специальностям. Больше всего данных о Software Engineer, без указания уровня квалификации.
Обращаем внимание на особенности 19 года: Что-то не так с 9 годом стажа и отсутствует классификация по уровням junior, middle, senior. Можно глубже разобраться причинами outlier 9-го года. Но для данного анализа примем это как есть.
А вот с категориями — стоит разобраться. в 19 году Software Engineer 2739 человек (35% от всех) без указания уровня квалификации. Давайте посчитаем среднее и отклонения по тем, кто указал.
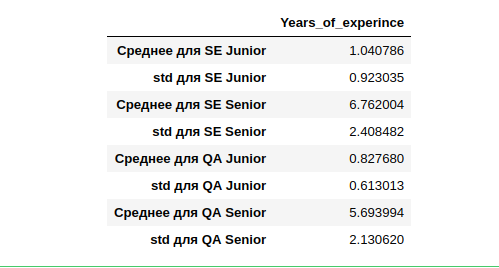
Получается, что средний опыт работы (кто его указал) для SE Junior год, с достаточно широким отклонением в один год. Больше всего опыта у SE Senior c так же большим отклонением в 2,4 года.
Если попытаться рассчитать Middle и использовать средний стаж у тех кто его указал, то для категоризации того кто его не указал, мы можем не верно кластеризировать всю выборку. Особенно сильно будем ошибаться на других специальностях (не SE and QA) т.е. данных слишком мало. Тем более их мало для сравнения с 14 годом.
Что можно использовать еще?
Давайте берем только уровень зарплаты как достоверный показатель уровня квалификации! (думаю будут несогласные).Сначала строим как выглядит распределение по зарплатам для 19-го года.
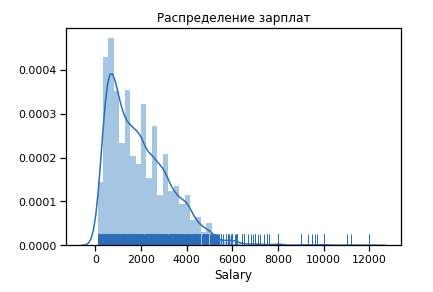
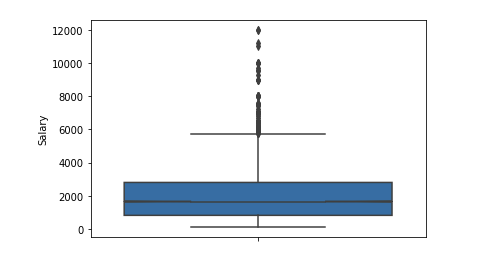
Outliers значительное число после 6$k. Оставим диапазон ограничений [400 — 4000]. Любой программист должен получать больше 400 
df_new = data_19_1[(data_19_1['Salary'] > 400) & (data_19_1['Salary'] < 4000)]
sns.distplot(df_new['Salary'], rug=True, norm_hist=True)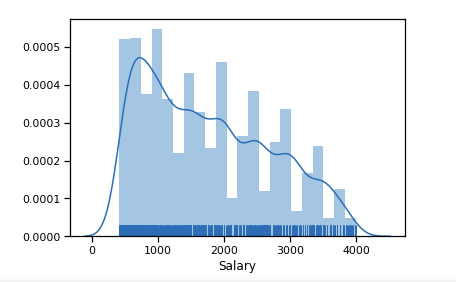
Уже чуть ближе к нормальному распределению.
Составляем для 19 года, уровни квалификации в зависимости от зп. Range в 3600$ дает нам хороший делитель на 3 категории — 1200 $
df_new.reset_index()
df_new.loc['level'] = 0
df_new.loc[df_new.Salary <= 1200, 'level'] = 'Junior'
df_new.loc[(df_new.Salary > 1200) & (df_new.Salary <= 2400), 'level'] = 'Middle'
df_new.loc[df_new.Salary > 2401, 'level'] = 'Senior'Рисуем — плотность распределения по категориям для 19 года.
sns.set(style="whitegrid")
fig, ax = plt.subplots()
fig.set_size_inches(11.7, 8.27)
plt.title('Распределение зарплат по уровню квалификации в 19 году')
sns.barplot(x='level', y='Salary', hue='Experience', hue_order=[1,3,5,7,10], palette='Blues',
data=df_new, ci='sd')
Добавив указанное количество опыта (левый угол), можно увидеть разные нюансы. Например, что в среднем Junior получает до 1к и его опыт работы — 5 лет. Самые большие разбросы по зп у Senior (черная короткая линия на верху каждого столбца) и многое другие интересные детали.
На этом первые два этапа закончены, переходим собственно к проверки гипотез при помощи бутстрапинга.
Формулируем нулевую гипотезу (H0)
На первых этапах мы выяснили, что указанный опыт работы, не очень точно означает уровень квалификации. Тогда формируем нулевую гипотезу (ту самую которую нужно опровергнуть)
Тут много вариантов (например):
- Зависимость зарплаты от стажа в 14 году такие же как в 19-м.
- Зарплаты junior не изменились с 14 года.
Однако раз указанный стаж плохой индикатор, а расчет по отдельным категориям может запутать, то берем простой и более предметный вариант: Средний уровень зп в 14 году, такой же как в 19 году это наша нулевая гипотеза H0 (2).
То есть предполагаем, что зарплаты за 5 лет не изменились.
НЕ верность гипотезы, несмотря на всю ее очевидность, мы сможем точно проверить рассчитав P-value для нулевой гипотезы.
# Считаем среднии зп по всей выборке (14 и 19 года), рассчитываем доверительный интервал 95 %
mean_salary_14 = np.mean(data_14_1['Salary'])
conf_salary_14 = np.percentile(data_14_1['Salary'], [2.5, 97.5])
mean_salary_19 = np.mean(data_19_1['Salary'])
conf_salary_19 = np.percentile(data_19_1['Salary'], [2.5, 97.5])
diff_mean_salary = mean_salary_19 - mean_salary_14
Средняя зп в 14 году 1797$, где доверительный интервал 95% [300.0 4000.0]
Средняя зп в 19 году 1949$, где доверительный интервал 95% [300.0 5000.0]
Разница в средних зарплатах в 14 и 19 году: 152$
Метрика для анализа
Логично выбрать именно средние значения в качестве нашей метрики. Возможны и другие варианты, например медиана, что часто делают в случае значительного количества outliers. Однако средняя как оценка проста в понимании и тоже неплохо даст необходимое представление.
Пишем bootstrapping функцию.
# Функция для bootstraping
def bootstrap(data, func):
boots = np.random.choice(data, len(data))
return func(boots)
def bootstrapping(data, func=np.mean, size=1):
reps = np.empty(size)
for i in range(size):
reps[i] = bootstrap(data, func)
return repsРассчитываем нашу статистику.
# Объединяем 14 и 19 года вместе - что бы создать перемешанный массив данных
data = np.concatenate((data_14_1['Salary'].values, data_19_1['Salary'].values))
# Считаем среднее значение за 2 года
data_mean = np.mean(data)
# Создаем измененные массивы данных за 14 и 19 года, от значения зп отнимаем среднее и добавляем среднее обьеденненого массива
data_14_shifted = data_14_1['Salary'].values - np.mean(data_14_1['Salary'].values) + data_mean
data_19_shifted = data_19_1['Salary'].values - np.mean(data_19_1['Salary'].values) + data_mean
# Генерируем 10000 копий массивов используя нашу функцию, выбранную метрику
data_14_bootsted = bootstrapping(data_14_shifted, np.mean, size=10000)
data_19_bootsted = bootstrapping(data_19_shifted, np.mean, size=10000)
# Считаем разницу в средних в сгенерированных массивах. Что бы знать с чем сравнивать.
mean_diff = data_19_bootsted - data_14_bootsted
# Рассчитываем P value как доля суммы средних нашей сгенерированной через бутстрапинг выборки со средними к размеры самой выборки.
p_value = sum(mean_diff >= diff_mean_salary) / len(mean_diff)
print('p-value = {}'.format(p_value))p-value = 0.0
Значения p-value до 0,05 считаются незначительными, а в нашем случае оно равно = 0. Что означает, нулевая гипотеза опровергнута — средние значения зарплат в 14 году и 19 году разные и это не случайный результат или значительное количество outliers.
Сгенерированные нами 10 тыс подобных массивов, в среднем не смогли получить в сумме большей таких ототожнений, чем непосредственно сами данные.
Хотя мы потратили много внимания на первые два этапа, мы сформулировали правильную гипотезу и выбрали верную метрику. В более сложных задачах, с большим количеством переменных, без таких предварительных этапов, аналитика может привести к неверной интерпретации. Не стоит их пропускать.
В результате нашего исследования уровня зарплат за 14 и 19 года, мы пришли к следующим выводам:
- Исходя из данных опроса, указанный стаж не совсем подходящий критерий для определения уровня зарплат и квалификации.
- Разделение на уровень квалификации точнее всего будет проводиться на основании уровня зарплат.
- Зарплаты программистов с 14 года по 19 выросли (в среднем на 8.5%) и это не случайный результат.
Спасибо за Ваше внимание. Буду рад комментариям и критике.
Источники
- https://jobs.dou.ua/salaries/ (результаты опросов)
- https://en.wikipedia.org/wiki/Null_hypothesis
- https://en.wikipedia.org/wiki/P-value
Статистика — сложная наука об измерении и анализе различных данных. Как и во многих других дисциплинах, в этой отрасли существует понятие гипотезы. Так, гипотеза в статистике — это какое-либо положение, которое нужно принять или отвергнуть. Причём в данной отрасли есть несколько видов таких допущений, схожих между собой по определению, но отличающихся на практике. Нулевая гипотеза — сегодняшний предмет изучения.
От общего к частному: гипотезы в статистике
От основного определения предположений отходит ещё одно, не менее важное, — статистическая гипотеза есть изучение генеральной совокупности важных для науки объектов, относительно коих учёными делаются выводы. Ее можно проверить с помощью выборки (части генеральной совокупности). Приведём несколько примеров статистических гипотез:
 1. Успеваемость всего класса, возможно, зависит от уровня образования каждого учащегося.
1. Успеваемость всего класса, возможно, зависит от уровня образования каждого учащегося.
2. Начальный курс математики в равной степени усваивается как детьми, пришедшими в школу в 6 лет, так и детьми, пришедшими в 7.
Простой гипотезой в статистике называют такое предположение, которое однозначно характеризует определённый параметр величины, взятой учёным.
Сложная состоит из нескольких или бесконечного множества простых. Указывается некоторая область или нет точного ответа.
Полезно понимать несколько определений гипотез в статистике, чтобы не путать их на практике.
Концепция нулевой гипотезы
Нулевая гипотеза — это теория о том, что есть некие две совокупности, которые не различаются между собой. Однако на научном уровне нет понятия «не различаются», но есть «их сходство равно нулю». От этого определения и было образовано понятие. В статистике нулевая гипотеза обозначается как Н0. Причём крайним значением невозможного (маловероятного) считается от 0.01 до 0.05 или менее.
Лучше разобрать, что такое нулевая гипотеза, пример из жизни поможет. Педагог в университете предположил, что различный уровень подготовки учащихся двух групп к зачётной работе вызван незначительными параметрами, случайными причинами, не влияющими на общий уровень образования (разница в подготовке двух групп студентов равна нулю).
Однако встречно стоит привести пример альтернативной гипотезы — допущения, опровергающего утверждение нулевой теории (Н1). Например: директор университета предположил, что различный уровень в подготовке к зачётной работе у учащихся двух групп вызван применением педагогами разных методик обучения (разница в подготовке двух групп существенна и на то есть объяснение).
 Теперь сразу видна разница между понятиями «нулевая гипотеза» и «альтернативная гипотеза». Примеры иллюстрируют эти понятия.
Теперь сразу видна разница между понятиями «нулевая гипотеза» и «альтернативная гипотеза». Примеры иллюстрируют эти понятия.
Проверка нулевой гипотезы
Создать предположение — это ещё полбеды. Настоящей проблемой для новичков считается проверка нулевой гипотезы. Именно тут многих и ожидают трудности.
Используя метод альтернативной гипотезы, утверждающей нечто обратное нулевой теории, можно сравнить оба варианта и выбрать верный. Так действует статистика.
Пусть нулевая гипотеза Н0, а альтернативная Н1, тогда:
Н0: c = c0;
Н1: c ≠ c0.
Здесь c — это некое среднее значение генеральной совокупности, которое предстоит найти, а c0 — данное изначально значение, по отношению к которому проверяется гипотеза. Также есть некоторое число Х — среднее значение выборки, по которому определяется c0.
Итак, проверка заключается в сравнении Х и c0, если Х=c0 ,то принимается нулевая гипотеза. Если же Х≠c0, то по условию верной считается альтернативная.
«Доверительный» способ проверки
Существует наиболее действенный способ, с помощью которого нулевая статистическая гипотеза легко проверяется на практике. Он заключается в построении диапазона значений до 95% точности.
Для начала понадобится знать формулу расчёта доверительного интервала:
X — t*Sx ≤ c ≤ X + t*Sx,
где Х — данное изначально число на основе альтернативной гипотезы;
t — табличные величины (коэффициент Стьюдента);
Sx — стандартная средняя ошибка, которая рассчитывается как Sx = σ/√n, где в числителе стандартное отклонение, а в знаменателе — объём выборки.
Итак, предположим ситуацию. До ремонта конвейер в день выпускал 32.1 кг конечной продукции, а после ремонта, как утверждает предприниматель, коэффициент полезного действия вырос, и конвейер, по недельной проверке, начал выпускать 39.6 кг в среднем.
 Нулевая гипотеза будет утверждать, что ремонт никак не повлиял на КПД конвейера. Альтернативная гипотеза скажет, что ремонт коренным образом изменил КПД конвейера, поэтому производительность его повысилась.
Нулевая гипотеза будет утверждать, что ремонт никак не повлиял на КПД конвейера. Альтернативная гипотеза скажет, что ремонт коренным образом изменил КПД конвейера, поэтому производительность его повысилась.
По таблице находим n=7, t = 2,447, откуда формула примет следующий вид:
39,6 – 2,447*4,2 ≤ с ≤ 39,6 + 2,447*4,2;
29,3 ≤ с ≤ 49,9.
Получается, что значение 32.1 входит в диапазон, а следовательно, значение, предложенное альтернативой — 39.6 — не принимается автоматически. Помните, что сначала проверяется на правильность нулевая гипотеза, а потом — противоположная.
Разновидности отрицания
До этого рассматривался такой вариант построения гипотезы, где Н0 утверждает что-либо, а Н1 это опровергает. Откуда можно было составить подобную систему:
Н0: с = с0;
Н1: с ≠ с0.
Но существует ещё два родственных способа опровержения. К примеру, нулевая гипотеза утверждает, что средняя оценка успеваемости класса больше 4.54, а альтернативная тогда скажет, что средняя успеваемость того же класса менее 4.54. И выглядеть в виде системы это будет так:
Н0: с ⩾ 4.54;
Н1: с < 4.54.
Обратите внимание, что нулевая гипотеза утверждает, что значение больше или равно, а статистическая — что строго меньше. Строгость знака неравенства имеет большое значение!
Статистическая проверка
Статистическая проверка нулевых гипотез заключается в использовании статистического критерия. Такие критерии подчиняются различным законам распределения.
 К примеру, существует F-критерий, который рассчитывается по распределению Фишера. Есть T-критерий, чаще всего используемый на практике, зависящий от распределения Стьюдента. Квадратный критерий согласия Пирсона и т. д.
К примеру, существует F-критерий, который рассчитывается по распределению Фишера. Есть T-критерий, чаще всего используемый на практике, зависящий от распределения Стьюдента. Квадратный критерий согласия Пирсона и т. д.
Область принятия нулевой гипотезы
В алгебре есть понятие «область допустимых значений». Это такой отрезок или точка на оси Х, на котором находится множество значений статистики, при которых нулевая гипотеза верна. Крайние точки отрезка — критические значения. Лучи по правую и левую сторону отрезка — критические области. Если найденное значение входит в них, то нулевая теория опровергается и принимается альтернативная.
Опровержение нулевой гипотезы
Нулевая гипотеза в статистике временами очень изворотливое понятие. Во время проверки её можно допустить ошибки двух типов:
 1. Отвержение верной нулевой гипотезы. Обозначим первый тип как а=1.
1. Отвержение верной нулевой гипотезы. Обозначим первый тип как а=1.
2. Принятие ложной нулевой гипотезы. Второй тип обозначим как а=2.
Стоит понимать, что это не одинаковые параметры, исходы ошибок могут существенно различаться между собой и иметь разные выборки.
Пример ошибок двух типов
Со сложными понятиями легче разобраться на примере.
Во время производства некоего лекарства от учёных требуется чрезвычайная осторожность, так как превышение дозы одного из компонентов провоцирует высокий уровень токсичности готового препарата, от которого пациенты, принимающие его, могут умереть. Однако на химическом уровне выявить передозировку невозможно.
Из-за этого перед тем как выпустить лекарство в продажу, небольшую его дозу проверяют на крысах или кроликах, вводя им препарат. Если большая часть испытуемых умирает, то лекарство в продажу не допускается, если подопытные живы, то лекарство разрешают продавать в аптеках.
 Первый случай: на самом деле лекарство было не токсично, но во время эксперимента была допущена оплошность и препарат классифицировали как токсичный и не допустили в продажу. А=1.
Первый случай: на самом деле лекарство было не токсично, но во время эксперимента была допущена оплошность и препарат классифицировали как токсичный и не допустили в продажу. А=1.
Второй случай: в ходе другого эксперимента при проверке другой партии лекарства решено, что препарат не токсичен, и в продажу его допустили, хотя на самом деле препарат был ядовит. А=2.
Первый вариант повлечёт за собой крупные финансовые затраты поставщика-предпринимателя, так как придётся уничтожить всю партию лекарства и начинать с нуля.
Вторая ситуация спровоцирует смерть пациентов, купивших и употреблявших это лекарство.
Теория вероятности
Не только нулевые, но все гипотезы в статистике и экономике разделяют по уровню значимости.
Уровень значимости — процент появления ошибок первого рода (отклонение верной нулевой гипотезы).
• первый уровень — 5% или 0.05, т. е. вероятность ошибиться 5 к 100 или 1 к 20.
• второй уровень — 1% или 0.01, т. е. вероятность 1 к 100.
• третий уровень — 0.1% или 0.001, вероятность 1 к 1000.
Критерии проверки гипотезы
Если учёным уже был сделан вывод о правильности нулевой гипотезы, то её необходимо подвергнуть проверке. Это необходимо, чтобы исключить ошибку. Существует основной критерий проверки нулевой гипотезы, состоящий из нескольких этапов:
1. Берётся допустимая ошибочная вероятность P=0.05.
2. Подбирается статистика для критерия 1.
3. По известному методу находится область допустимых значений.
4. Теперь вычисляется значение статистики Т.
5. Если Т (статистика) принадлежит области принятия нулевой гипотезы (как в «доверительном» методе), то предположения считаются верными, а значит, и сама нулевая гипотеза остаётся верной.
Именно так действует статистика. Нулевая гипотеза при грамотной проверке будет принята или отвергнута.
Стоит заметить, что для обычных предпринимателей и пользователей первые три этапа бывает очень сложно выполнить безошибочно, поэтому их доверяют профессиональным математикам. Зато 4 и 5 этапы может выполнить любой человек, в достаточной мере знающий статистические методы проверки.