Всем привет! Сегодня я расскажу как реализовать, наверное, самую популярную структуру данных — односвязный список. Подразумевается, что вы уже знаете такие темы, как указатели, функции и конструкторы.
Односвязный список — это динамическая структура данных, состоящая из узлов. Каждый узел будет иметь какое-то значение (я буду использовать строку) и указатель на следующий узел.

Эта картинка демонстрирует, как будет выглядеть односвязный список.
Реализация узла
struct Node {
string val;
Node* next;
Node(string _val) : val(_val), next(nullptr){}
};В этом узле есть:
-
Значение, которое будет задавать пользователь
-
Указатель на следующий элемент (по умолчанию nullptr)
-
Конструктор
Реализация односвязного списка
В списке будет:
-
Указатель на первый узел
-
Указатель на последний узел
-
Конструктор
-
Функция проверки наличия узлов в списке
-
Функция добавления элемента в конец списка
-
Функция печати всего списка
-
Функция поиска узла в списке по заданному значению
-
Функция удаления первого узла
-
Функция удаления последнего узла
-
Функция удаления узла по заданному значению значению
-
Функция обращения к узлу по индексу (дополнительная функция)
Реализация 1-3 пункта
struct list {
Node* first;
Node* last;
list() : first(nullptr), last(nullptr) {}
};Функция проверки наличия узлов в списке
Это однострочная функция, в которой надо проверить является ли первый узел — пустым
bool is_empty() {
return first == nullptr;
}Функция добавления элемента в конец списка
Здесь надо рассмотреть два случая:
-
Список — пустой
-
Список не пустой
В обоих случаях надо создать сам узел со значением, которое мы передали в эту функцию.
void push_back(string _val) {
Node* p = new Node(_val);
}Первый случай:
Здесь нам как раз пригодиться функция проверки наличия узлов. Если список пустой, тогда мы присваиваем указателю на первый узел и последний узел указатель на новый узел и выходим из функции.
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
}Второй случай:
Нам уже не нужно проверка наличия узлов в списке, так как если первый случай не происходит, то в списке есть узлы. Раз мы добавляем в конец, надо указать, что новый узел стоит после последнего узла. Затем мы меняем значения указателя last.
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
last->next = p;
last = p;
}Теперь в список можно добавлять элементы.
Функция печати всего списка
Начинаем функцию с проверки is_empty(). Далее создаём указатель p на первый узел и выводим значение узла, пока p не пустой, при каждой итерации обновляем значение p на следующий узел.
void print() {
if (is_empty()) return;
while (p) { // p != nullptr
cout << p->val << " ";
p = p->next;
}
cout << endl;
}Тест уже написанных функций
Код который мы написали:
#include <iostream>
using namespace std;
struct Node {
string val;
Node* next;
Node(string _val) : val(_val), next(nullptr) {}
};
struct list {
Node* first;
Node* last;
list() : first(nullptr), last(nullptr) {}
bool is_empty() {
return first == nullptr;
}
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
last->next = p;
last = p;
}
void print() {
if (is_empty()) return;
Node* p = first;
while (p) {
cout << p->val << " ";
p = p->next;
}
cout << endl;
}
}
int main() {
list l;
cout << l.is_empty() << endl;
l.push_back("3");
l.push_back("123") l.push_back("8");
cout << l.is_empty() << endl;
l.print();
return 0;
}[Output]
1
3 123 8
0Функция поиска узла в списке по заданному значению
Также делаем проверку is_empty() и создаём указатель p на первый узел
if (is_empty()) return;
Node* p = first;Обходим список, пока указатель p не пустой и пока значение узла p не равно заданному значению. После цикла возвращаем наш узел
while (p && p->val != _val) p = p->next;
return p ? p : nullptr;Весь код функции:
Node* find(string _val) {
Node* p = first;
while (p && p->val != _val) p = p->next;
return (p && p->val == _val) ? p : nullptr;
}Функция удаления первого узла
Делаем проверку is_empty(). Далее создаём указатель p на первый узел списка. Меняем значение первого узла на следующий и удаляем узел p;
void remove_first() {
if (is_empty()) return;
Node* p = first;
first = p->next;
delete p;
}Функция удаления последнего узла
Это функция сложнее функции удаления первого узла. Сначала также делаем проверку is_empty(). А теперь надо надо рассмотреть два случая:
-
Конец списка одновременно и начало
-
Когда размер списка больше одного
Первый случай:
Сравниваем указатель на первый узел и указатель на последний узел, если они равны, то вызываем функцию удаления первого узла.
Второй случай:
Создаём указатель p на первый узел и обходим список, пока следующий узел не равен последнему. Убираем у указателя p следующий узел и удаляем p.
Код функции:
void remove_last() {
if (is_empty()) return;
if (first == last) {
remove_first();
return;
}
Node* p = first;
while (p->next != last) p = p->next;
p->next = nullptr;
delete last;
last = p;
}Функция удаления узла по заданному значению значению
Делаем проверку is_empty(). И рассматриваем уже три случая:
-
Узел, который нам нужен, равен первому
-
Узел, который нам нужен, равен последнему
-
Когда не первый и не второй случаи
Первый случай:
Сравниваем значение первого узла с заданным значением, если значения совпадают, тогда вызываем функцию удаления первого узла.
Второй случай:
Сравниваем значение последнего узла с заданным значением, если значения совпадают, тогда вызываем функцию удаления последнего узла.
Третий случай:
Создаём указатели slow, равный первому узлу, и fast, равный следующему узлу после первого. Затем пока fast не пустой и пока значения узла fast не равно заданному значению, при каждой итерации обновляем значения slow и fast на следующий после них узел. Далее делаем проверку, что указатель fast пустой, если это так, тогда мы выводим ошибку, иначе просто удаляем узел fast.
Код функции:
void remove(string _val) {
if (is_empty()) return;
if (first->val == _val) {
remove_first();
return;
}
else if (last->val == _val) {
remove_last();
return;
}
Node* slow = first;
Node* fast = first->next;
while (fast && fast->val != _val) {
fast = fast->next;
slow = slow->next;
}
if (!fast) {
cout << "This element does not exist" << endl;
return;
}
slow->next = fast->next;
delete fast;
}Функция обращения к узлу по индексу
Для этой функции надо перегрузить оператор []
Node* operator[] (const int index)Дальше делаем проверку is_empty(). Создадим указатель p на первый узел списка. С помощью цикла for будем обновлять значение указателя p на следующий указатель, также делаем проверку на пустоту указателя p. В конце возвращаем узел p.
Node* operator[] (const int index) {
if (is_empty()) return nullptr;
Node* p = first;
for (int i = 0; i < index; i++) {
p = p->next;
if (!p) return nullptr;
}
return p;
}Тест программы
Весь код:
#include <iostream>
using namespace std;
struct Node {
string val;
Node* next;
Node(string _val) : val(_val), next(nullptr) {}
};
struct list {
Node* first;
Node* last;
list() : first(nullptr), last(nullptr) {}
bool is_empty() {
return first == nullptr;
}
void push_back(string _val) {
Node* p = new Node(_val);
if (is_empty()) {
first = p;
last = p;
return;
}
last->next = p;
last = p;
}
void print() {
if (is_empty()) return;
Node* p = first;
while (p) {
cout << p->val << " ";
p = p->next;
}
cout << endl;
}
Node* find(string _val) {
Node* p = first;
while (p && p->val != _val) p = p->next;
return (p && p->val == _val) ? p : nullptr;
}
void remove_first() {
if (is_empty()) return;
Node* p = first;
first = p->next;
delete p;
}
void remove_last() {
if (is_empty()) return;
if (first == last) {
remove_first();
return;
}
Node* p = first;
while (p->next != last) p = p->next;
p->next = nullptr;
delete last;
last = p;
}
void remove(string _val) {
if (is_empty()) return;
if (first->val == _val) {
remove_first();
return;
}
else if (last->val == _val) {
remove_last();
return;
}
Node* slow = first;
Node* fast = first->next;
while (fast && fast->val != _val) {
fast = fast->next;
slow = slow->next;
}
if (!fast) {
cout << "This element does not exist" << endl;
return;
}
slow->next = fast->next;
delete fast;
}
Node* operator[] (const int index) {
if (is_empty()) return nullptr;
Node* p = first;
for (int i = 0; i < index; i++) {
p = p->next;
if (!p) return nullptr;
}
return p;
}
};
int main()
{
list l;
cout << l.is_empty() << endl;
l.push_back("3");
l.push_back("123");
l.push_back("8");
l.print();
cout << l.is_empty() << endl;
l.remove("123");
l.print();
l.push_back("1234");
l.remove_first();
l.print();
l.remove_last();
l.print();
cout << l[0]->val << endl;
return 0;
}
[Output]
1
3 123 8
0
3 8
8 1234
8
8Заключение
Вот Вы и научились реализовывать односвязный список, и, надеюсь, стали лучше его понимать.
Курс по структурам данных: https://stepik.org/a/134212
Мы продолжаем знакомиться с односвязными
списками. На прошлом занятии мы в целом увидели структуру и основные операции с
такими списками. На этом закрепим материал и реализуем односвязные списки на
языке С++.
В стандартной
библиотеке С++ уже есть готовая реализация односвязных списков:
std::forward_list
а также стеки и
очереди, которые основаны на таких списках, но это уже несколько другие
структуры данных и о них мы еще будем говорить. Однако, на этом занятии мы с
нуля создадим односвязный список на С++.
Почему я выбрал
именно этот язык? На мой взгляд, он очень хорошо подходит, для демонстрации всех
нюансов создания и работы с объектами в памяти компьютера. А потому, мы сможем
буквально заглянуть «под капот» односвязного списка, сделанного на С++.
Вначале я
напомню его общую структуру. У нас имеется набор объектов, в которых хранятся
некоторые данные (data) и ссылка next на следующий
объект. Если next равен NULL, то следующего
объекта нет и это конец списка.
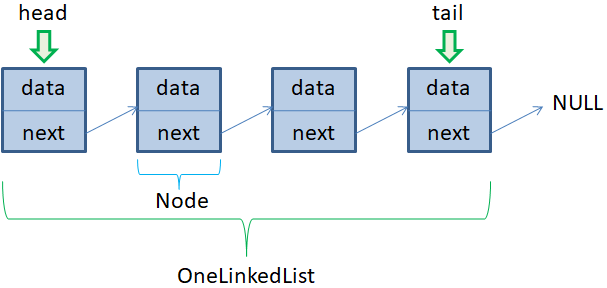
Отдельный объект
этого списка мы определим через класс Node, а работу со
списком в целом – через класс OneLinkedList.
Вначале объявим
класс Node следующим
образом:
class Node { public: double data; Node* next; public: Node(double data) { this->data = data; this->next = NULL; } };
Каждый объект
этого класса будет иметь две публичные переменные: data – хранимое
вещественное значение; next – указатель на следующий объект класса Node. Также имеется
конструктор Node с одним
параметром data и в момент
создания объекта сохраняется переданное значение data, а указатель next принимает
значение NULL.
Далее объявим
класс OneLinkedList, который будет управлять работой односвязного списка:
class OneLinkedList { public: Node* head, * tail; public: OneLinkedList() { this->head = this->tail = NULL; } ~OneLinkedList() { while (head != NULL) pop_front(); } };
В нем определены
указатели head и tail на первый и
последний объекты списка, а также конструктор с деструктором. В конструкторе мы
инициализируем указатели head и tail значением NULL, т.к.
изначально список пустой, а в деструкторе выполняем удаление всех элементов
списка (освобождаем память, которую они занимают).
Давайте сразу
пропишем метод pop_front(), который удаляет первый элемент
односвязного списка. Как мы с вами говорили, сначала нужно переместить
указатель head на следующий
элемент, а затем, освободить память первого элемента:
void pop_front() { if (head == NULL) return; if (head == tail) { delete tail; head = tail = NULL; return; } Node* node = head; head = node->next; delete node; }
Вначале мы
проверяем, есть ли вообще элементы в связном списке, и если их нет, то
выполняется команда return, которая завершает метод. Далее, идет
проверка, что в списке всего один элемент. Тогда указатели head и tail приравниваются
значению NULL и освобождается
память из под первого элемента. Если же в списке более одного элемента, то
выполняем перемещение указателя head на следующий элемент и освобождаем
память первого элемента.
Следующий метод push_back() служит для
добавления элемента в конец односвязного списка. Делается это достаточно
просто:
void push_back(double data) { Node* node = new Node(data); if (head == NULL) head = node; if (tail != NULL) tail->next = node; tail = node; }
Параметр data содержит число,
которое сохраняется в добавляемом элементе. Затем, создается сам элемент в
памяти компьютера и на него ведет указатель node. После этого
делаем проверку, если добавляется первый элемент, то указатель head должен ссылаться
на этот объект. Следующая проверка, если tail ссылается на
существующий объект, то указатель next этого объекта
должен вести на добавляемый. В конце мы перемещаем указатель tail в конец списка,
т.е. присваиваем ему значение node.
Похожим образом
работает метод добавления элемента в начало списка:
void push_front(double data) { Node* node = new Node(data); node->next = head; head = node; if (tail == NULL) tail = node; }
Здесь data – по-прежнему
параметр, содержащий вещественное число для сохранения его в добавляемом
элементе. Затем, создается новый объект списка. Указатель next этого объекта
должен вести на объект head. После этого указатель head перемещаем на
начало списка и еще проверяем, если добавляется первый элемент в список (tail равен NULL), то tail должен быть
равен node.
Следующий метод pop_back() выполняет
удаление последнего элемента односвязного списка:
void pop_back() { if (tail == NULL) return; if (head == tail) { delete tail; head = tail = NULL; return; } Node* node = head; for (; node->next != tail; node = node->next); node->next = NULL; delete tail; tail = node; }
Вначале делаем
проверку на наличие последнего элемента. Если его нет, то метод завершается.
Далее, если в списке всего один элемент, то освобождаем из под него память и
указатели head и tail приравниваем NULL. Если же в
списке более одного элемента, то с помощью цикла for переходим к
предпоследнему, устанавливаем у него указатель next на значение NULL, освобождаем
память из под последнего элемента и указатель tail присваиваем
значение node – адрес
последнего элемента.
Следующий метод getAt()
возвращает указатель на элемент с индексом k:
Node* getAt(int k) { if (k < 0) return NULL; Node* node = head; int n = 0; while (node && n != k && node->next) { node = node->next; n++; } return (n == k) ? node : NULL; }
Если значение k меньше нуля, то
возвращается NULL, т.к. такого
индекса не существует. Далее, создаем временный указатель node, который
изначально равен указателю head. Также создается счетчик n для индексов.
Запускается цикл, в котором проверяем, существует ли объект node и если да, то
дополнительно проверяем, чтобы n было не равно k и указатель next текущего объекта
был не равен NULL. То есть, если
будет найден элемент с индексом k, то цикл завершится. Также цикл
завершится если будет достигнут конец списка. В конце возвращаем либо адрес
найденного элемента, если n равно k, либо значение NULL, если объект с
указанным индексом отсутствует в списке.
Следующий метод insert()
выполняет вставку элемента в односвязный список:
void insert(int k, double data) { Node* left = getAt(k); if (left == NULL) return; Node* right = left->next; Node* node = new Node(data); left->next = node; node->next = right; if (right == NULL) tail = node; }
При его вызове
мы указываем индекс элемента, после которого предполагается вставить новый
элемент, и значение data, которое сохраняется в новом элементе.
Вначале получаем
адрес элемента с индексом k с помощью метода getAt(). Если такого
объекта нет, то метод insert() завершает свою работу. Иначе
через указатель right сохраняем адрес следующего после left объекта, создаем
новый объект Node с данными data. Указатель next объекта left приравниваем node, а у node next приравниваем right. В итоге
настраиваем все необходимые связи односвязного списка. В конце делаем проверку,
если right равен NULL, то вставляется
последний элемент (в конец списка), значит, нужно переместить указатель tail в конец, т.е.
присвоить ему значение node.
Последний метод erase() удаляет
элемент с индексом k из односвязного списка:
void erase(int k) { if (k < 0) return; if (k == 0) { pop_front(); return; } Node* left = getAt(k - 1); Node* node = left->next; if (node == NULL) return; Node* right = node->next; left->next = right; if (node == tail) tail = left; delete node; }
Вначале
проверяем корректность индекса, если он отрицателен, то метод завершает свою
работу. Если k равен нулю, то
удаляется первый элемент, а для этого уже есть метод pop_front(). Его мы и
вызываем. В противном случае, получаем указатель на k-1 элемент.
Затем, указатель node указывает на k-й удаляемый
элемент. Если он не существует, то метод erase() завершает
свою работу. Иначе формируем еще один указатель right на объект после
удаляемого. Далее, указатель next должен ссылаться
на right и в конце
проверка, если удаляется последний элемент, то tail нужно перевести
на предпоследний. В конце освобождаем память из под удаляемого элемента.
Все, мы с вами
описали все основные методы для работы с односвязным списком. Давайте теперь
протестируем его работу. Для этого в функции main() создадим
объект класса OneLinkedList и запишем в него несколько элементов с помощью
методов push_front() и push_back():
int main() { OneLinkedList lst; lst.push_front(1); lst.push_back(2); Node* n = lst.getAt(0); double d = (n != NULL) ? n->data : 0; std::cout << d << std::endl; lst.erase(1); lst.insert(0, 5); lst.insert(0, 2); lst.pop_back(); for (Node* node = lst.head; node != NULL; node = node->next) { std::cout << node->data << " "; } std::cout << std::endl; return 0; }
Далее, возьмем
объект по индексу 0 и выведем значение data на экран
монитора. Причем, сделаем проверку, если объект не существует, то data будет равна 0.
После этого
удалим элемент с индексом 1, вставим элемент с индексом 0 и еще раз повторим
эту же операцию. Удалим последний элемент. И, наконец, с помощью цикла for выведем значения
всех элементов в консоль.
Если все было
сделано верно, то мы должны увидеть на экране соответствующие значения
элементов односвязного списка lst.
Вот пример того,
как можно реализовать на С++ односвязный список. Надеюсь, из этого занятия вы
лучше поняли его структуру и принцип работы основных команд.
Курс по структурам данных: https://stepik.org/a/134212
Видео по теме

Стандартная библиотека C++ включает достаточно много структур данных. Среди них есть списки, очереди, стеки, множества и т. д. Но если вы хотите эффективно их использовать, необходимо понимать особенности их работы. В этой статье поговорим о базовой структуре в С++ — односвязном списке.
Односвязный список: теория
Если хотите понять, как построен односвязный список, представьте цепь. У неё есть и начало, и конец, плюс звенья последовательно соединены друг с другом. Можно легко пройти от начала до конца цепи, перебирая звенья.
Схожим образом работают односвязные списки. В них начало списка — это головной элемент, звенья — это узлы, а конец списка определяется посредством NULL — специального узла. Причём, чтобы структура списка была полезной, на каждый узел «вешают» определённое значение.
У односвязного списка есть преимущество — вставка и удаление узлов осуществляется довольно легко в любом месте списка. Однако список нельзя индексировать в качестве массива, а структура списка ограничивает доступ к узлам по индексу. Если нужно попасть на какой-нибудь узел односвязного списка, нужно пройти весь путь последовательно, начиная от головного элемента, заканчивая нужным узлом.
Интерфейс класса односвязного списка
Однонаправленный список используют при хранении упорядоченного набора однотипных элементов. Дабы не определять для каждого типа данных свой список, лучше определить шаблонный класс:
template< typename T > class List { private: // Объявляем структуру узла для использования в классе Iterator struct Node; public: // Класс итератора односвязного списка class Iterator { // Пока что опускаем ... }; public: List(); ~List(); // Добавляем узел в список void append( const T& t ); // Удаляем последний добавленный узел из списка void remove(); // Получаем головной элемент списка T head() const; // Получаем итератор на начало списка Iterator begin() const; // Получаем итератор на конец списка Iterator end() const; // Получаем размер списка size_t size() const; private: // Структура узла односвязного списка struct Node { Node() : m_next( NULL ) { } Node( const T& t ) : m_t( t ), m_next( NULL ) { } // Значение узла T m_t; // Указатель на следующий узел Node* m_next; }; // Голова односвязного списка Node* m_head; };Класс односвязного списка поддерживает добавление узла в начало, получение значения головного элемента и удаление последнего добавленного узла. Также реализован обход списка посредством итераторов, плюс добавлена функция для расчета длины списка.
Определение узла осуществляется посредством структуры Node, содержащей два поля:
— значение, привязанное к узлу, — m_t;
— указатель на следующий узел — m_next.Изначально список является пустым, а значит, головной элемент указывает на NULL:
template< typename T > List< T >::List() : m_head( NULL ) { }Добавляем элемент в односвязный список
Добавление узла в список производится в самое начало. То есть узел, который добавлен, сам превратится в новый головной элемент нашего списка:
template< typename T > void List< T >::append( const T &t ) { // Создаём новый узел для значения // Если произойдёт исключение, контейнер не пострадает Node* node = new Node( t ); // Новый узел привязывается к старому головному элементу node->m_next = m_head; // Новый узел сам становится головным элементом m_head = node; }Удаляем элемент из односвязного списка
В процессе удаления узла из списка усекается головной элемент. Таким образом, если в списке остаются узлы, новым головным элементом становится тот узел, который следует за головным элементом, в обратном случае — NULL:
template< typename T > void List< T >::remove() { if( m_head ) { // Если список не пуст: // Сохраняем указатель на второй узел, который станет новым головным элементом Node* newHead = m_head->m_next; // Освобождаем память, выделенную для удаляемого головного элемента delete m_head; // Назначаем новый головной элемент m_head = newHead; } // Иначе мы могли бы возбудить исключение }Идём дальше. Список — динамическая структура. Когда добавляются новые узлы, из кучи выделяется память — её нужно освободить, дабы не создавались утечки памяти. А имея в наличии функцию удаления элементов, мы без проблем реализуем деструктор односвязного списка:
template< typename T > List< T >::~List() { while( m_head ) { remove(); } }Односвязный список: итератор
Функциональность для удаления и добавления узлов в список не стоит смешивать с задачей его обхода. Для этих целей есть итераторы. Давайте создадим итератор списка в стиле C++. Для начала вернёмся к его определению, которое раньше пропустили:
class Iterator { public: Iterator( Node* node ) : m_node( node ) { } // Проверка на равенство bool operator==( const Iterator& other ) const { if( this == &other ) { return true; } return m_node == other.m_node; } // Проверка на неравенство bool operator!=( const Iterator& other ) const { return !operator==( other ); } // Получение значения текущего узла T operator*() const { if( m_node ) { return m_node->m_t; } // Иначе достигнут конец списка. Здесь уместно возбудить исключение return T(); } // Переход к следующему узлу void operator++() { if( m_node ) { m_node = m_node->m_next; } // Иначе достигнут конец списка. Здесь уместно возбудить исключение } private: Node* m_node; };В качестве итераторов для конца и начала нашего списка вернём следующее:
template< typename T > typename List< T >::Iterator List< T >::begin() const { // Итератор пойдет от головного элемента... return Iterator( m_head ); } template< typename T > typename List< T >::Iterator List< T >::end() const { // ... и до упора, т.е. NULL return Iterator( NULL ); }Что же, теперь мы можем легко обойти список с начала до конца. Но не стоит забывать про функцию вычисления длины. Для упрощения задачи будем использовать механизм итераторов:
«`cplus
template< typename T >
size_t List< T >::size() const {
size_t s = 0;
for( Iterator it = begin(); it != end(); ++it ) {
++s;
}/* Но можно и без итераторов for( Node* n = m_head; n != NULL; n = n->m_next ) { ++s; } */ return s;}
Вместо заключения
Рассмотренный выше пример — лишь краткая демонстрация, из которой можно понять принципы работы с односвязным списком в C++. Однако практика показывает, что в реальных приложениях почти всегда лучше будет использовать стандартную библиотечную реализацию как списка, так и любой другой структуры данных. В этом случае работы от вас потребуется меньше. Кроме того, вы сразу получите в своё распоряжение оптимизированную и хорошо отлаженную версию, которой можно будет смело пользоваться.
Каждый узел однонаправленного (односвязного) линейного списка (ОЛС) содержит одно поле указателя на следующий узел. Поле указателя последнего узла содержит нулевое значение (указывает на NULL).

Узел ОЛС можно представить в виде структуры
struct list
{
int field; // поле данных
struct list *ptr; // указатель на следующий элемент
};
Основные действия, производимые над элементами ОЛС:
- Инициализация списка
- Добавление узла в список
- Удаление узла из списка
- Удаление корня списка
- Вывод элементов списка
- Взаимообмен двух узлов списка
Инициализация ОЛС
Инициализация списка предназначена для создания корневого узла списка, у которого поле указателя на следующий элемент содержит нулевое значение.

1
2
3
4
5
6
7
8
9
struct list * init(int a) // а- значение первого узла
{
struct list *lst;
// выделение памяти под корень списка
lst = (struct list*)malloc(sizeof(struct list));
lst->field = a;
lst->ptr = NULL; // это последний узел списка
return(lst);
}
Добавление узла в ОЛС
Функция добавления узла в список принимает два аргумента:
- Указатель на узел, после которого происходит добавление
- Данные для добавляемого узла.
Процедуру добавления узла можно отобразить следующей схемой:

Добавление узла в ОЛС включает в себя следующие этапы:
- создание добавляемого узла и заполнение его поля данных;
- переустановка указателя узла, предшествующего добавляемому, на добавляемый узел;
- установка указателя добавляемого узла на следующий узел (тот, на который указывал предшествующий узел).
Таким образом, функция добавления узла в ОЛС имеет вид:
1
2
3
4
5
6
7
8
9
10
struct list * addelem(list *lst, int number)
{
struct list *temp, *p;
temp = (struct list*)malloc(sizeof(list));
p = lst->ptr; // сохранение указателя на следующий узел
lst->ptr = temp; // предыдущий узел указывает на создаваемый
temp->field = number; // сохранение поля данных добавляемого узла
temp->ptr = p; // созданный узел указывает на следующий элемент
return(temp);
}
Возвращаемым значением функции является адрес добавленного узла.
Удаление узла ОЛС
В качестве аргументов функции удаления элемента ОЛС передаются указатель на удаляемый узел, а также указатель на корень списка.
Функция возвращает указатель на узел, следующий за удаляемым.
Удаление узла может быть представлено следующей схемой:

Удаление узла ОЛС включает в себя следующие этапы:
- установка указателя предыдущего узла на узел, следующий за удаляемым;
- освобождение памяти удаляемого узла.
1
2
3
4
5
6
7
8
9
10
11
12
struct list * deletelem(list *lst, list *root)
{
struct list *temp;
temp = root;
while (temp->ptr != lst) // просматриваем список начиная с корня
{ // пока не найдем узел, предшествующий lst
temp = temp->ptr;
}
temp->ptr = lst->ptr; // переставляем указатель
free(lst); // освобождаем память удаляемого узла
return(temp);
}
Удаление корня списка
Функция удаления корня списка в качестве аргумента получает указатель на текущий корень списка. Возвращаемым значением будет новый корень списка — тот узел, на который указывает удаляемый корень.
1
2
3
4
5
6
7
struct list * deletehead(list *root)
{
struct list *temp;
temp = root->ptr;
free(root); // освобождение памяти текущего корня
return(temp); // новый корень списка
}
Вывод элементов списка
В качестве аргумента в функцию вывода элементов передается указатель на корень списка.
Функция осуществляет последовательный обход всех узлов с выводом их значений.
1
2
3
4
5
6
7
8
9
void listprint(list *lst)
{
struct list *p;
p = lst;
do {
printf(«%d «, p->field); // вывод значения элемента p
p = p->ptr; // переход к следующему узлу
} while (p != NULL);
}
Взаимообмен узлов ОЛС
В качестве аргументов функция взаимообмена ОЛС принимает два указателя на обмениваемые узлы, а также указатель на корень списка. Функция возвращает адрес корневого элемента списка.
Взаимообмен узлов списка осуществляется путем переустановки указателей. Для этого необходимо определить предшествующий и последующий узлы для каждого заменяемого. При этом возможны две ситуации:
- заменяемые узлы являются соседями;
- заменяемые узлы не являются соседями, то есть между ними имеется хотя бы один элемент.
При замене соседних узлов переустановка указателей выглядит следующим образом:

При замене узлов, не являющихся соседними переустановка указателей выглядит следующим образом:

При переустановке указателей необходима также проверка, является ли какой-либо из заменяемых узлов корнем списка, поскольку в этом случае не существует узла, предшествующего корневому.
Функция взаимообмена узлов списка выглядит следующим образом:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
struct list * swap(struct list *lst1, struct list *lst2, struct list *head)
{
// Возвращает новый корень списка
struct list *prev1, *prev2, *next1, *next2;
prev1 = head;
prev2 = head;
if (prev1 == lst1)
prev1 = NULL;
else
while (prev1->ptr != lst1) // поиск узла предшествующего lst1
prev1 = prev1->ptr;
if (prev2 == lst2)
prev2 = NULL;
else
while (prev2->ptr != lst2) // поиск узла предшествующего lst2
prev2 = prev2->ptr;
next1 = lst1->ptr; // узел следующий за lst1
next2 = lst2->ptr; // узел следующий за lst2
if (lst2 == next1)
{ // обмениваются соседние узлы
lst2->ptr = lst1;
lst1->ptr = next2;
if (lst1 != head)
prev1->ptr = lst2;
}
else
if (lst1 == next2)
{
// обмениваются соседние узлы
lst1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst2;
}
else
{
// обмениваются отстоящие узлы
if (lst1 != head)
prev1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst1;
lst1->ptr = next2;
}
if (lst1 == head)
return(lst2);
if (lst2 == head)
return(lst1);
return(head);
}
Назад: Структуры данных
Введение. Основные операции
Односвязный список – структура данных, в которой каждый элемент (узел) хранит информацию, а также ссылку на следующий элемент. Последний элемент списка ссылается на NULL.
Для нас односвязный список полезен тем, что
- 1) Он очень просто устроен и все алгоритмы интуитивно понятны
- 2) Односвязный список – хорошее упражнение для работы с указателями
- 3) Его очень просто визаулизировать, это позволяет «в картинках» объяснить алгоритм
- 4) Несмотря на свою простоту, односвязные списки часто используются в программировании, так что это не пустое упражнение.
- 5) Эта структуру данных можно определить рекурсивно, и она часто используется в рекурсивных алгоритмах.
Для простоты рассмотрим односвязный список, который хранит целочисленное значение.
Односвязный список состоит из узлов. Каждый узел содержит значение и указатель на следующий узел, поэтому представим его в качестве структуры
typedef struct Node {
int value;
struct Node *next;
} Node;
Чтобы не писать каждый раз struct мы определили новый тип.
Теперь наша задача написать функцию, которая бы собирала список из значений, которые мы ей передаём. Стандартное имя функции – push, она должна получать в качестве аргумента значение, которое вставит в список. Новое значение будет вставляться в начало списка.
Каждый новый элемент списка мы должны создавать на куче. Следовательно, нам будет удобно иметь один указатель на первый элемент списка.
Node *head = NULL;
Вначале списка нет и указатель ссылается на NULL.
Для добавления нового узла необходимо
- 1) Выделить под него память.
- 2) Задать ему значение
- 3) Сделать так, чтобы он ссылался на предыдущий элемент (или на NULL, если его не было)
- 4) Перекинуть указатель head на новый узел.
1) Создаём новый узел
Создали новый узел, на который ссылается локальная переменная tmp
2) Присваиваем ему значение
3) Присваиваем указателю tmp адрес предыдущего узла
Перекинули указатель tmp на предыдущий узел
4) Присваиваем указателю head адрес нового узла
Перекинули указатель head на вновь созданный узел tmp
5) После выхода из функции переменная tmp будет уничтожена. Получим список, в который будет вставлен новый элемент.
void push(Node **head, int data) {
Node *tmp = (Node*) malloc(sizeof(Node));
tmp->value = data;
tmp->next = (*head);
(*head) = tmp;
}
Так как указатель head изменяется, то необходимо передавать указатель на указатель.
Теперь напишем функцию pop: она удаляет элемент, на который указывает head и возвращает его значение.
Если мы перекинем указатель head на следующий элемент, то мы потеряем адрес первого и не сможем его удалить и тем более вернуть его значения. Для этого необходимо сначала создать локальную переменную, которая будет хранить адрес первого элемента
Локальная переменная хранит адрес первого узла
Уже после этого можно удалить первый элемент и вернуть его значение
Перекинули указатель head на следующий элемент и удалили узел
int pop(Node **head) {
Node* prev = NULL;
int val;
if (head == NULL) {
exit(-1);
}
prev = (*head);
val = prev->value;
(*head) = (*head)->next;
free(prev);
return val;
}
Не забываем, что необходимо проверить на NULL голову.
Таким образом, мы реализовали две операции push и pop, которые позволяют теперь использовать односвязный список как стек. Теперь
добавим ещё две операции — pushBack (её ещё принято называть shift или enqueue), которая добавляет новый элемент в конец списка, и
функцию popBack (unshift, или dequeue), которая удаляет последний элемент списка и возвращает его значение.
Для дальнейшего разговора необходимо реализовать функции getLast, которая возвращает указатель на последний элемент списка, и nth, которая возвращает указатель на n-й элемент списка.
Так как мы знаем адрес только первого элемента, то единственным способом добраться до n-го будет последовательный перебор всех элементов списка. Для того, чтобы получить следующий элемент, нужно перейти к нему через указатель next текущего узла
Node* getNth(Node* head, int n) {
int counter = 0;
while (counter < n && head) {
head = head->next;
counter++;
}
return head;
}
Переходя на следующий элемент не забываем проверять, существует ли он. Вполне возможно, что был указан номер, который больше размера списка. Функция вернёт в таком случае NULL. Сложность операции O(n), и это одна из проблем односвязного списка.
Для нахождение последнего элемента будем передирать друг за другом элементы до тех пор, пока указатель next одного из элементов не станет равным NULL
Node* getLast(Node *head) {
if (head == NULL) {
return NULL;
}
while (head->next) {
head = head->next;
}
return head;
}
Теперь добавим ещё две операции — pushBack (её ещё принято называть shift или enqueue), которая добавляет новый элемент в конец списка, и функцию popBack (unshift, или dequeue), которая удаляет последний элемент списка и возвращает его значение.
Для вставки нового элемента в конец сначала получаем указатель на последний элемент, затем создаём новый элемент, присваиваем ему значение и перекидываем указатель next старого элемента на новый
void pushBack(Node *head, int value) {
Node *last = getLast(head);
Node *tmp = (Node*) malloc(sizeof(Node));
tmp->value = value;
tmp->next = NULL;
last->next = tmp;
}
Односвязный список хранит адрес только следующего элемента. Если мы хотим удалить последний элемент, то необходимо изменить указатель next предпоследнего элемента. Для этого нам понадобится функция getLastButOne, возвращающая указатель на предпоследний элемент.
Node* getLastButOne(Node* head) {
if (head == NULL) {
exit(-2);
}
if (head->next == NULL) {
return NULL;
}
while (head->next->next) {
head = head->next;
}
return head;
}
Функция должна работать и тогда, когда список состоит всего из одного элемента. Вот теперь есть возможность удалить последний элемент.
void popBack(Node **head) {
Node *lastbn = NULL;
//Получили NULL
if (!head) {
exit(-1);
}
//Список пуст
if (!(*head)) {
exit(-1);
}
lastbn = getLastButOne(*head);
//Если в списке один элемент
if (lastbn == NULL) {
free(*head);
*head = NULL;
} else {
free(lastbn->next);
lastbn->next = NULL;
}
}
Удаление последнего элемента и вставка в конец имеют сложность O(n).
Можно написать алгоритм проще. Будем использовать два указателя. Один – текущий узел, второй – предыдущий. Тогда можно обойтись без вызова функции getLastButOne:
int popBack(Node **head) {
Node *pFwd = NULL; //текущий узел
Node *pBwd = NULL; //предыдущий узел
//Получили NULL
if (!head) {
exit(-1);
}
//Список пуст
if (!(*head)) {
exit(-1);
}
pFwd = *head;
while (pFwd->next) {
pBwd = pFwd;
pFwd = pFwd->next;
}
if (pBwd == NULL) {
free(*head);
*head = NULL;
} else {
free(pFwd->next);
pBwd->next = NULL;
}
}
Теперь напишем функцию insert, которая вставляет на n-е место новое значение. Для вставки, сначала нужно будет пройти до нужного узла, потом создать новый элемент и поменять указатели. Если мы вставляем в конец, то указатель next нового узла будет указывать на NULL, иначе на следующий элемент
void insert(Node *head, unsigned n, int val) {
unsigned i = 0;
Node *tmp = NULL;
//Находим нужный элемент. Если вышли за пределы списка, то выходим из цикла,
//ошибка выбрасываться не будет, произойдёт вставка в конец
while (i < n && head->next) {
head = head->next;
i++;
}
tmp = (Node*) malloc(sizeof(Node));
tmp->value = val;
//Если это не последний элемент, то next перекидываем на следующий узел
if (head->next) {
tmp->next = head->next;
//иначе на NULL
} else {
tmp->next = NULL;
}
head->next = tmp;
}
Покажем на рисунке последовательность действий
Создали новый узел и присвоили ему значение
После этого делаем так, чтобы новый элемент ссылался на следующий после n-го
Теперь значение next нового узла хранит адрес того же узла, что и элемент, на который ссылается head
Перекидываем указатель next n-го элемента на вновь созданный узел
Теперь узел, адрес которого хранит head, указывает на новый узел tmp
Функция удаления элемента списка похожа на вставку. Сначала получаем указатель на элемент, стоящий до удаляемого, потом перекидываем ссылку на следующий элемент за удаляемым, потом удаляем элемент.
int deleteNth(Node **head, int n) {
if (n == 0) {
return pop(head);
} else {
Node *prev = getNth(*head, n-1);
Node *elm = prev->next;
int val = elm->value;
prev->next = elm->next;
free(elm);
return val;
}
}
Рассмотрим то же самое в картинках. Сначала находим адреса удаляемого элемента и того, который стоит перед ним
Для удаления узла, на который ссылается elm необходим предыдущий узел, адрес которого хранит prev
После чего прокидываем указатель next дальше, а сам элемент удаляем.
Прекидываем указатель на следующий за удалённым узел и освобождаем память
Кроме создания списка необходимо его удаление. Так как самая быстрая функция у нас этот pop, то для удаления будем последовательно выталкивать элементы из списка.
void deleteList(Node **head) {
while ((*head)->next) {
pop(head);
*head = (*head)->next;
}
free(*head);
}
Вызов pop можно заменить на тело функции и убрать ненужные проверки и возврат значения
void deleteList(Node **head) {
Node* prev = NULL;
while ((*head)->next) {
prev = (*head);
(*head) = (*head)->next;
free(prev);
}
free(*head);
}
Осталось написать несколько вспомогательных функций, которые упростят и ускорят работу. Первая — создать список из массива. Так как операция push имеет минимальную сложность, то вставлять будем именно с её помощью. Так как вставка произойдёт задом наперёд, то массив будем обходить с конца к началу:
void fromArray(Node **head, int *arr, size_t size) {
size_t i = size - 1;
if (arr == NULL || size == 0) {
return;
}
do {
push(head, arr[i]);
} while(i--!=0);
}
И обратная функция, которая возвратит массив элементов, хранящихся в списке. Так как мы будем создавать массив динамически, то сначала определим его размер, а только потом запихнём туда значения.
int* toArray(const Node *head) {
int leng = length(head);
int *values = (int*) malloc(leng*sizeof(int));
while (head) {
values[--leng] = head->value;
head = head->next;
}
return values;
}
И ещё одна функция, которая будет печатать содержимое списка
void printLinkedList(const Node *head) {
while (head) {
printf("%d ", head->value);
head = head->next;
}
printf("n");
}
Теперь можно провести проверку и посмотреть, как работает односвязный список
void main() {
Node* head = NULL;
int arr[] = {1,2,3,4,5,6,7,8,9,10};
//Создаём список из массива
fromArray(&head, arr, 10);
printLinkedList(head);
//Вставляем узел со значением 333 после 4-го элемента (станет пятым)
insert(head, 4, 333);
printLinkedList(head);
pushBack(head, 11);
pushBack(head, 12);
pushBack(head, 13);
pushBack(head, 14);
printLinkedList(head);
printf("%dn", pop(&head));
printf("%dn", popBack(&head));
printLinkedList(head);
//Удаляем пятый элемент (индексация с нуля)
deleteNth(&head, 4);
printLinkedList(head);
deleteList(&head);
getch();
}
Сортировка односвязного списка
Сортировать список будем слиянием. Этот метод очень похож на сортировку слиянием для массива. Для его реализации нам
понадобятся две функции: одна буде делить список пополам, а другая будет объединять два упорядоченных односвязных списка, не создавая при этом новых узлов.
Наша реализация не будет оптимальной, однако, некоторые решения, которые мы применим, могут быть использованы и в других алгоритмах.
Вспомогательная функция – слияние двух отсортированных списков. Функция не должна создавать новых узлов, так что будем использовать только имеющиеся. Для начала проверим, если хоть один из списков пуст, то вернём другой.
Node tmp;
*c = NULL;
if (a == NULL) {
*c = b;
return;
}
if (b == NULL) {
*c = a;
return;
}
После этого нужно, чтобы наша локальная переменная стала хранить адрес большего из узлов двух списков, от него и будем танцевать дальше
if (a->value < b->value) {
*c = a;
a = a->next;
} else {
*c = b;
b = b->next;
}
Теперь сохраним указатель c, так как в дальнейшем он будет использоваться для прохода по списку
tmp.next = *c;
После этого проходим по спискам, сравниваем значения и перекидываем их
while (a && b) {
if (a->value < b->value) {
(*c)->next = a;
a = a->next;
} else {
(*c)->next = b;
b = b->next;
}
(*c) = (*c)->next;
}
В конце, может остаться один список, который пройден не до конца. Добавим его узлы
if (a) {
while (a) {
(*c)->next = a;
(*c) = (*c)->next;
a = a->next;
}
}
if (b) {
while (b) {
(*c)->next = b;
(*c) = (*c)->next;
b = b->next;
}
}
Теперь указатель c хранит адрес последнего узла, а нам нужна ссылка на голову. Она как раз хранится во второй переменной tmp
*c = tmp.next;
Весь алгоритм
void merge(Node *a, Node *b, Node **c) {
Node tmp;
*c = NULL;
if (a == NULL) {
*c = b;
return;
}
if (b == NULL) {
*c = a;
return;
}
if (a->value < b->value) {
*c = a;
a = a->next;
} else {
*c = b;
b = b->next;
}
tmp.next = *c;
while (a && b) {
if (a->value < b->value) {
(*c)->next = a;
a = a->next;
} else {
(*c)->next = b;
b = b->next;
}
(*c) = (*c)->next;
}
if (a) {
while (a) {
(*c)->next = a;
(*c) = (*c)->next;
a = a->next;
}
}
if (b) {
while (b) {
(*c)->next = b;
(*c) = (*c)->next;
b = b->next;
}
}
*c = tmp.next;
}
Ещё одна важная функция – нахождение середины списка. Для этих целей будем использовать два указателя. Один из них — fast – за одну итерацию будет два раза изменять значение и продвигаться по списку вперёд. Второй – slow, всего один раз. Таким образом, если список чётный, то slow окажется ровно посредине списка, а если список нечётный, то второй подсписок будет на один элемент длиннее.
void split(Node *src, Node **low, Node **high) {
Node *fast = NULL;
Node *slow = NULL;
if (src == NULL || src->next == NULL) {
(*low) = src;
(*high) = NULL;
return;
}
slow = src;
fast = src->next;
while (fast != NULL) {
fast = fast->next;
if (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
}
(*low) = src;
(*high) = slow->next;
slow->next = NULL;
}
Очевидно, что можно было один раз узнать длину списка, а потом передавать размер в каждую функцию. Это было бы проще и быстрее. Но мы не ищем лёгких путей)))
Теперь у нас есть функция, которая позволяет разделить список на две части и функция слияния отсортированных списков. С их помощью реализуем функцию сортировки слиянием.
Сортировка слиянием для односвязного списка
Функция рекурсивно вызывает сама себя, передавая части списка. Если в функцию пришёл список длинной менее двух элементов, то рекурсия прекращается. Идёт обратная сборка списка. Сначала из двух списков, каждый из которых хранит один элемент, создаётся отсортированный список, далее из таких списков собирается новый отсортированный список, пока все элементы не будут включены.
void mergeSort(Node **head) {
Node *low = NULL;
Node *high = NULL;
if ((*head == NULL) || ((*head)->next == NULL)) {
return;
}
split(*head, &low, &high);
mergeSort(&low);
mergeSort(&high);
merge(low, high, head);
}
Если Вы желаете изучать этот материал с преподавателем, советую обратиться к
репетитору по информатике
Q&A
Всё ещё не понятно? – пиши вопросы на ящик 
Различные реализации стека