
В этой статье я хочу рассказать о том, как создать и вести свою коллекцию фильмов на компьютере. Все приложения бесплатные и помогают гибко вести каталог и импортировать список фильмов из файла.
Filmotech
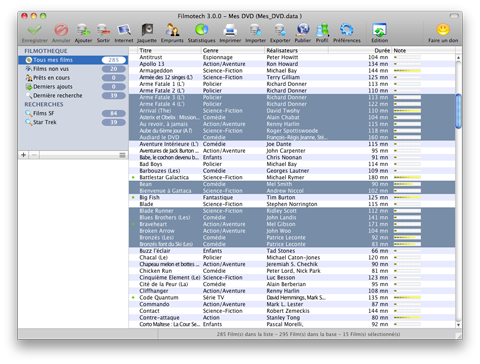
Одно из самых лучших приложений в данной категории. Есть версии для Windows, macOS и даже мобильников. К информации о фильме можно добавить название, жанр, год, синопсис, афишу, актёров, режиссёров и многое-многое другое.
Есть возможность импорта информации из популярных онлайн-сервисов и её автообновление. Можно импортировать и офлайн-базы в форматах XML, CSV и прочих. Аналогично данные Filmotech можно экспортировать в указанные форматы. Можно даже создать свой онлайн-каталог благодаря встроенной поддержке PHP и MySQL.
Скачать
Ant Movie Catalog
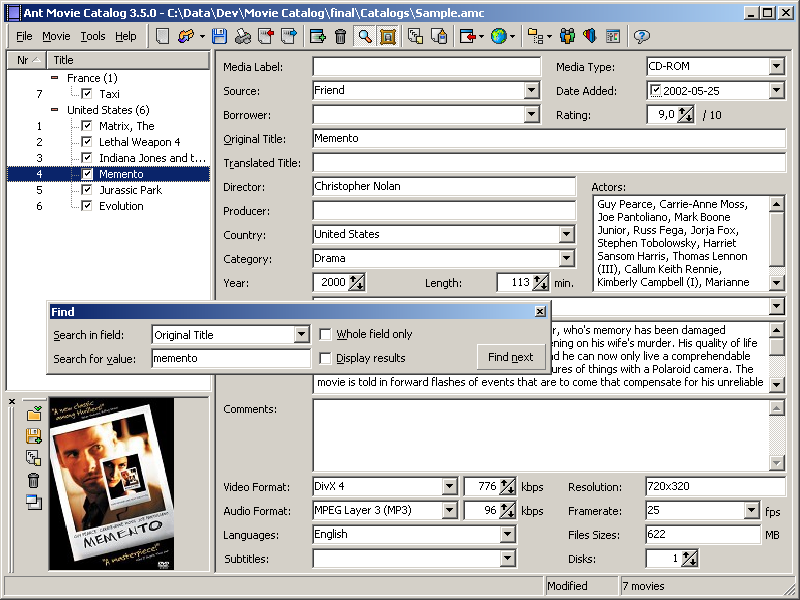
Это приложение даёт полный контроль над вашей базой фильмов. Можно добавлять название, локализованное название, режиссёра, продюсера, сценариста, актёров, страну, ссылку, описание, афишу, рейтинг и множество другой полезной информации.
Есть поддержка пользовательских полей и импорта из сторонних сервисов: MS Access Database, CSV/Excel, DVD Profiler (XML Report) и прочих. Есть экспорт базы в HTML, CSV, Excel, SQL, XML. А также синхронизация с онлайн-базами, вроде IMDb, Amazon, Youtube.
По каталогу также доступна статистика: сколько всего фильмов в базе, средняя длительность, общая длительность, распределение актёров, дата просмотра и прочее.
Скачать
Personal Video Database
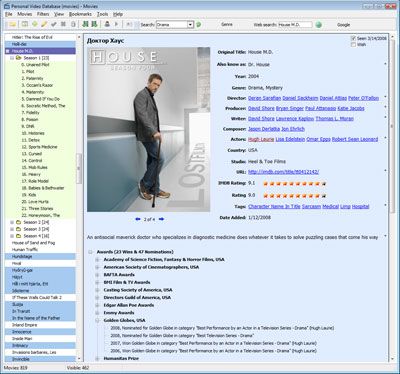
Как следует из названия, это приложение создано для ведения личной базы данных фильмов. Кроме стандартных полей, к фильму можно добавить слоган, комментарий, видеофайл и многое другое. Также есть поддержка сериалов и телевизионных шоу.
Фильмы можно добавлять в разделы Просмотрено и Хочу посмотреть. Также предоставляется различная статистика, вроде числа записей, графиков выхода в прокат и прочего.
Есть поиск по онлайн-каталогам для быстрого добавления информации в базу. Можно массово редактировать данные о фильмах. Базу можно экспортировать в CSV, HTML и др.
Скачать
MeD’s Movie Manager
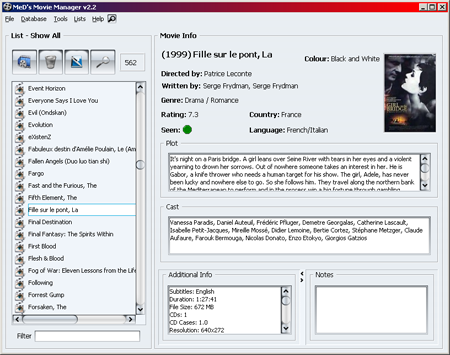
Приложение для любителей опенсорса. Описывать добавляемые поля к фильму я не буду, здесь есть вся необходимая информация. Есть импорт из текстовых файлов, таблиц, CSV и XML.
Есть встроенный генератор отчётов, который можно использовать для построения различной статистики по базе фильмов. Данные можно обновлять из IMDb или экспортировать в HTML, TXT, CSV, Excel, XML.
Скачать
GrieeX
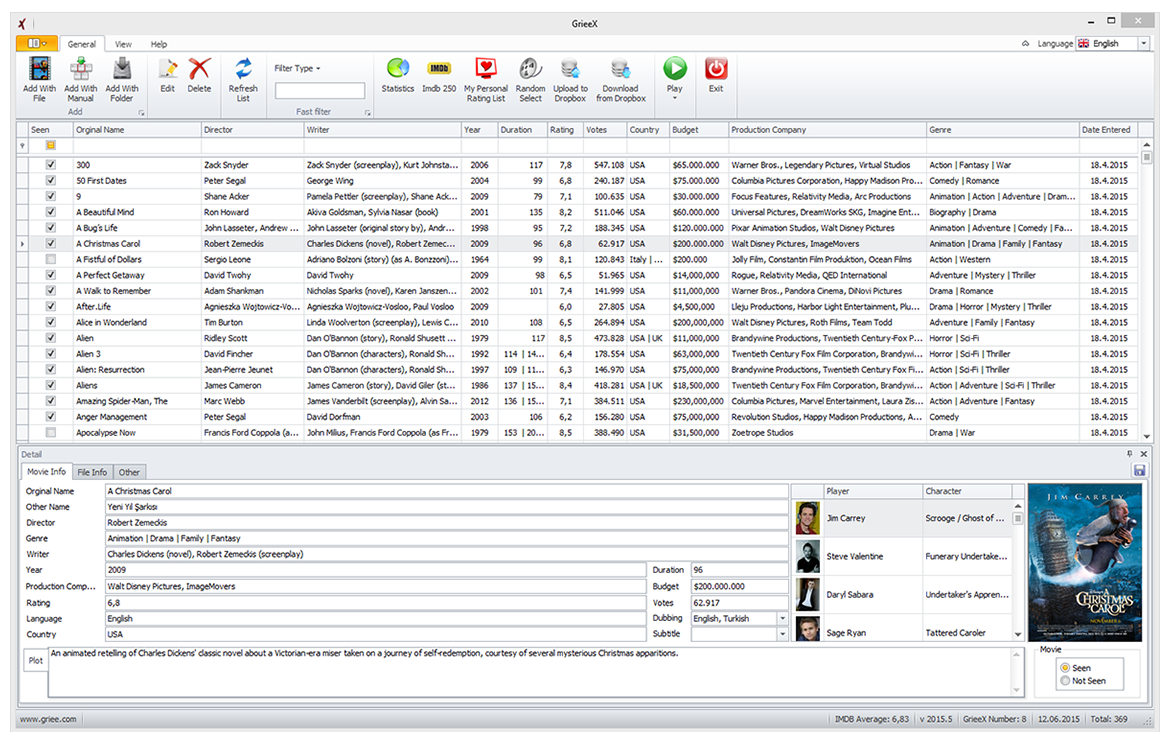
Удобное приложение для ведения баз фильмов, у которого есть Android-версия. Можно импортировать информацию из IMDb и TheMovieDb.
Из интересных фишек стоит выделить возможность отображения топа лучших фильмов по версии IMDb, поддержку персонального рейтинга, загрузку базы в Dropbox, разнообразную статистику и бекап. Можно импортировать и экспортировать Excel-файлы.
Скачать
EMDB
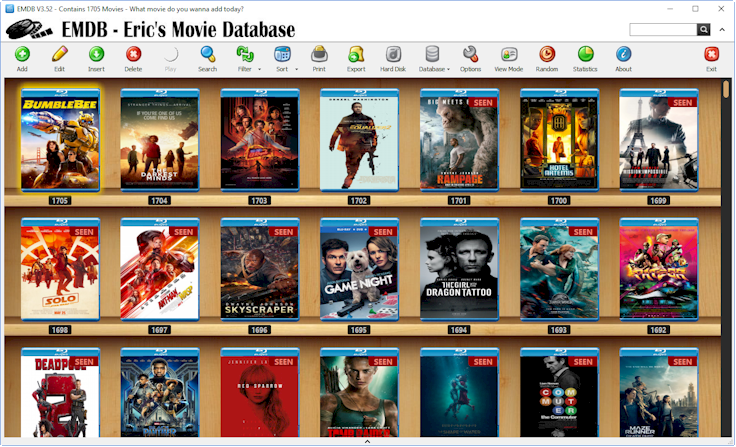
Если вы ищете максимально простой способ ведения базы фильмов, то стоит обратить внимание на это приложение. Есть ручной и автоматический способ добавления информации из IMDb и TheMovieDb.
Каталог можно фильтровать по различным параметрам: купленные фильмы, взятые на прокат, список желаемого, просмотренные фильмы и прочее. Есть экспорт в HTML, CSV, TXT.
Скачать
Letterboxd
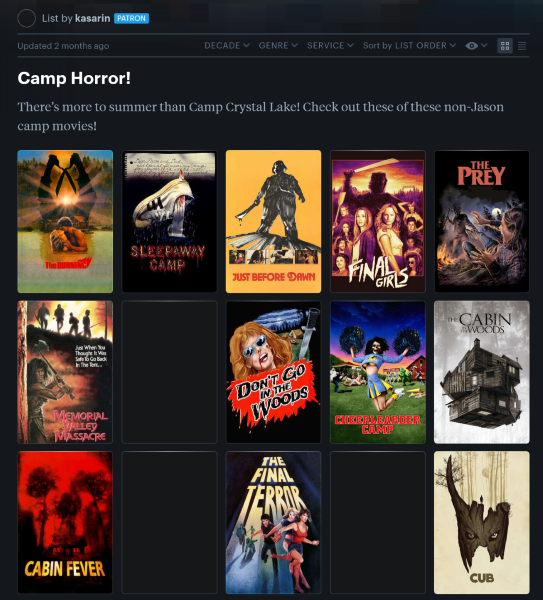
Это онлайн-сервис с социальной составляющей. Вы можете создать свою подборку фильмов или посмотреть подборки других пользователей Letterboxd. Фильм можно легко добавить с помощью поиска, который подскажет нужный тайтл и сам заполнит всю необходимую информацию.
Фильмы можно добавлять в список желаемого, добавлять отзывы и многое другое.
Скачать
Data Crow
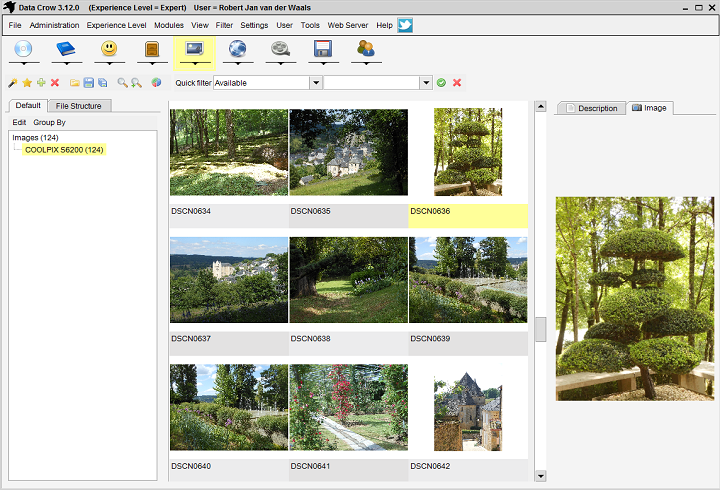
Простое и удобное приложение для создания и ведения собственного каталога фильмов. Есть возможность импорта информации из IMDB, Amazon FreedB и других популярных онлайн-ресурсов. Также можно добавлять видеофайлы различных форматов. Можно вести каталог одолженных фильмов.
Скачать
Теги:
Windows
macOS
web
Filmotech
Ant Movie Catalog
MeD’s Movie Manager
GrieeX
EMDB
Letterboxd
Data Crow
1. Что такое Podborki.com?
Это сайт-сообщество людей занимающихся созданием и улучшением тематических подборок.
2. Что такое подборка?
Это коллекция элементов, отобранных по одному признаку, например, «Научно-популярные фильмы про космос», «Топ сериалов про зомби», «Лучшие романтические книги всех времен».
3. Кто может создавать подборки?
Все пользователи с положительной кармой.
4. Как создать подборку?
Это просто, нажмите «Создать новую подборку» вверху страницы.
Дальше нужно назвать вашу подборку, выбрать что вы будете в нее добавлять и сообственно приступить к наполнению.
Пользуйтесь автодополнением, так как на сайте есть огромная база всего: от фильмов и сериалов до сайтов и программ. Вероятно, большинство того, что вы хотите добавить уже есть в нашем каталоге и вам не придется вводить все самому.
5. Можно ли, создавая подборку, взять за основу другую, уже существующую?
Да, нажав на кнопку «Создать свою версию» на странице выбранной подборки.
6. Могу ли я что-нибудь добавить в существующую подборку?
Просто создайте свою версию этой подборки и добавьте в нее все, что посчитаете нужным, а мы их автоматически объединим в одну суммирующую подборку.
7. Что такое суммирующая подборка?
Представим себе ситуацию, что 2 пользователя сделали подборку «Фильмы про зомби» и каждый добавил те фильмы, которые посчитал нужным.
Как это можно использовать? Как вариант, можно сделать еще одну подборку в которую добавить все фильмы из обоих подборок и отсортировать так, чтобы учесть сортировки обоих авторов.
Именно это мы и делаем! То есть суммирующая подборка — это подборка, которая создана автоматически из ее версий и учитывает все мнения.
8. Как сделать хорошую подборку?
Создать хорошую, интересную подборку не так уж и сложно, достаточно следовать нескольким советам.
Во-первых, объясните о чем ваша подборка. Несколько фильмов или книг выстроенных в ряд, без каких-либо пояснений, вряд ли можно назвать хорошей подборкой — люди хотят знать ваше мнение.
Если вы опишете вашу подборку и объясните ценность каждого пункта в подборке (это может быть что угодно, будьте креативны), то интерес среди других пользователей вырастет минимум на 100500%, можете нам поверить.
Во-вторых, подберите отличную картинку к вашей подборке. Значение хорошей картинки трудно переоценить, это то на что люди обращают внимание первым делом.
Также вы можете добавить большую иллюстрацию к каждому пункту подборки, это сделает ее еще более наглядной и интересной.
В-третьих, размер имеет значение. Постарайтесь раскрыть тему вашей подборки как можно глубже, не стесняйтесь добавить столько пунктов, сколько сможете вспомнить или найти — люди любят полные подборки.
9. Зачем мне создавать подборки?
Создание подборок — это очень увлекательное занятие и отличный способ привести в порядок все чем вы интересуетесь.
На случай если это вас не убедило, мы составили еще несколько причин начать создавать подборки.
Демонстрация эрудиции. У вас наверняка есть увлечения, почему бы не показать их другим людям?
Расширение кругозора. Другие пользователи могут создавать свои версии вашей подборки, тем самым расширяя ее.
Внесение ясности. Создав подборку вы сделаете свои знания более наглядными.
Участие. Создав версию подборки другого пользователя вы улучшаете ее. Делайте добро и получайте плюс в карму ;).
10. Как сортируются суммирующие подборки?
На сортировку суммирующих подборок влияют несколько факторов главным среди которых есть порядок элементов в ее версиях. Если вы не согласны с сортировкой подборки, лучший способ повлиять — создать свою версию и упорядочить по своему.
11. Чем отличается рецензия от комментария?
Рецензии созданы для выражения законченной мысли, они имеют ограничение снизу по длине и требуют чтобы вы поставили оценку.
Комментарии в свою очередь, не имеют никаких ограничений. В комментариях можно задавать вопросы, вести обсуждения с другими пользователями или просто сказать «Спасибо».

В чем суть: составить топ-список фильмов, сериалов. Поделиться с подписчиками, чем вас зацепила та или иная картина и посоветовать, что посмотреть.
Как сделать:
Для начала решите и выпишите, какие фильмы или сериалы вы бы хотели посоветовать подписчикам. Это могут быть как всем известные старые картины, так и новинки мира кино.
Составьте список. Вы можете ранжировать его по баллам, которыми вы оценили фильм или сериал, а можете не зацикливаться на рейтинге и просто пронумеровать картины.
Добавьте описание. Это может быть аннотация или кратко изложенный сюжет. Ваше описание должно заинтересовать подписчиков и заинтриговать так, чтобы они залайкали ваши посты и пошли смотреть кино.
Не забудьте поделиться вашим собственным мнением и впечатлением, которое произвел на вас фильм/сериал. Это будет полезнее, информативнее и интереснее, чем читать описание сюжета. Расскажите, какие вопросы у вас возникли при просмотре фильма или сериала, о чем картина заставила задуматься.
Однако, не раскрывайте все секреты сюжета. Не все любят спойлеры. Это наоборот может не понравиться подписчику. Оставьте для фоловеров вишенку на торте, пусть они сами погрузятся в атмосферу фильма или сериала.
Красивая фотография дополнит ваш пост и передаст эстетику кинокартины. Вы можете сделать скрин любимого момента или добавить отрезок видео. Если же в вашем контент-плане будет визуально выбиваться фото из фильма/сериала, выставите вашу фотографию или красивую раскладку, которая подойдет под общий вид аккаунта.
Создать креатив для этой идеи можно с помощью раздела «Холст» в SMMplanner. В нем есть инструменты для работы с фоном, слоями, элементами и текстом. Попробуйте – функция доступна бесплатно!
Чтобы поднять охваты и вовлеченность аккаунта, запустите игру в комментариях. Спросите у подписчиков, какой их любимый фильм или что они могут порекомендовать из новинок. Задача – ответить в комментариях и поделиться must visit кинокартинами. Не игнорируйте комментарии, ответьте каждому, что вы думаете о той или иной рекомендации. Держите обратную связь, так ваши подписчики смогут разглядеть в вас друга и прислушиваться к мнению. Придумайте приз для самого активного подписчика и разыграйте его в комментариях. Для подведения итогов вы можете использовать как специальную программу рандомного выбора, так и самостоятельно определить победителя.
Предостережения:
Советуйте те фильмы и сериалы, которые действительно вам понравились. Не гонитесь за популярными новинками и громкими названиями. Советуйте от души, так вы получите больше взаимности.
Не переживайте, если кто-то не согласен с вашим мнением. У каждого своя точка зрения: то, что нравится вам, могут оценить не все.
Остерегайтесь спойлеров. Ведь мало кто захочет включать фильм, когда знает, кто убийца или чем все закончится.
Примеры:
Алина Ланина, актриса театра и кино, известная большинству по роли Евы, жены Сельвестра в сериале «СашаТаня» на канале ТНТ. В своём Инстаграм* она не только рассказывает о нелегкой жизни актрисы, но и делится советами и подборками любимого кино.

Marina Prikhodko — блогер в индустрии моды. Однако ее Инстаграм* — это находка для сериаломанов. Девушка рассказывает о новинках и делится своим мнением, объективно сопоставляя плюсы и минусы.

ВКонтакте существует огромное количество пабликов, где публикуют примеры постов не только с рекомендациями фильмов и сериалов, но и с советами подписчиков о новых картинах. Здесь вы сможете “подглядеть” пару советов о том, как интересно рассказать о кино.

Одной из самых быстроразвивающихся групп ВКонтакте является Badcomedian. Этот популярный блогер пишет обзоры на фильмы и рассказывает о новинках кино. На его страничке фоловерам никогда не бывает скучно. Есть чему поучиться! Бери на заметку идеи и реализуй их в собственном стиле.

Телеграмм не уступает ВКонтакте по постам с примерами публикаций кино и сериалов. Здесь существуют как просто каналы с фильмами, так и специальные боты, которые помогают быстрее найти нужную картину. Если ты компьютерный гений, воспользуйся возможностью и попробуй посоревноваться между ботами, создав своего личного. Это взорвет твои охваты и вовлеченность.

Старый добрый, всеми любимый Фейсбук* также предлагает множество постов с фильмами и сериалами. Здесь примеры обзоров, трейлеров и даже спойлеров. Загляни и найди идею по душе для своего аккаунта!

Ещё несколько идей в арсенал:
- Подарок
- История из жизни
- Цитата из книги
*Соцсеть признана экстремистской и запрещена в России.

Время на прочтение
13 мин
Количество просмотров 9.4K

«Без опыта я никому не нужен! Где взять опыт?» — часто думают люди, осваивающие новую для себя сферу или изучающие новый язык программирования. Решение есть — делать пет-проекты. Представленный под катом проект системы рекомендации фильмов не претендует на сложность и точность аналогичных систем от энтерпрайз-контор, но может стать практическим стартом для новичка, которому интересны системы рекомендации в целом. Этот пост также подойдет для демонстрации как использовать Python-библиотеку EasyGUI на практике.
Важное предупреждение: если вы крепкий миддл либо сеньор, то проект может показаться вам простым. Однако не стоит спешить опускать палец вниз и забывать про тех, кто не так опытен, и кому пост может быть полезен, ведь все мы когда-то были джунами.
Начало работы
В этой статье я расскажу, как создать базовую систему рекомендаций фильмов со встроенным графическим пользовательским интерфейсом. Прежде всего нам нужны данные. Чтобы получить хорошее представление о том, насколько хорошо система рекомендаций работает на самом деле, нам понадобится довольно большой набор данных. Используем MovieLens на 25M, который вы можете скачать здесь. Набор данных состоит из шести файлов .csv и файла readme, объясняющих набор данных. Не стесняйтесь взглянуть на него, если хотите. Мы будем использовать только эти три файла:
movies.csv; ratings.csv; tags.csv
Также потребуется несколько библиотек Python:
- NumPy
- Pandas
- Progress (pip install progress)
- Fuzzywuzzy (pip install fuzzywuzzy & pip install python-Levenshtein)
- EasyGUI
Вероятно, все они могут быть установлены через pip. Точные команды будут зависеть от ОС. Кроме того, должна работать любая IDE Python (см. материал по ним вот тут). Я пользуюсь Geany, легкой IDE для Raspbian. Посмотрим на набор данных:
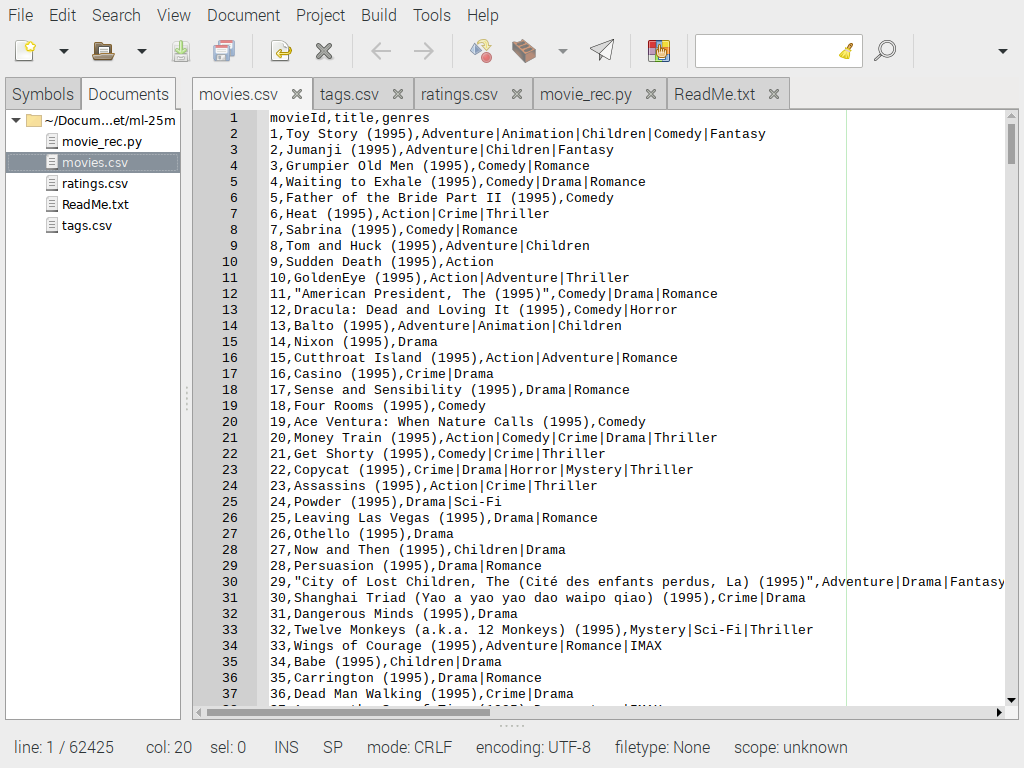
movies.csv
Выше показан файл movies.csv с тремя столбцами данных, а именно: movieId, title и genres — идентификатор фильма, название и жанр. Все очень удобно и просто. Будем работать со всеми тремя.
Ниже мы видим tags.csv. Здесь используются только столбцы movieId и tag, связывающие тег со столбцом movieId, которые также есть в файлах movies.csv и rating.csv.
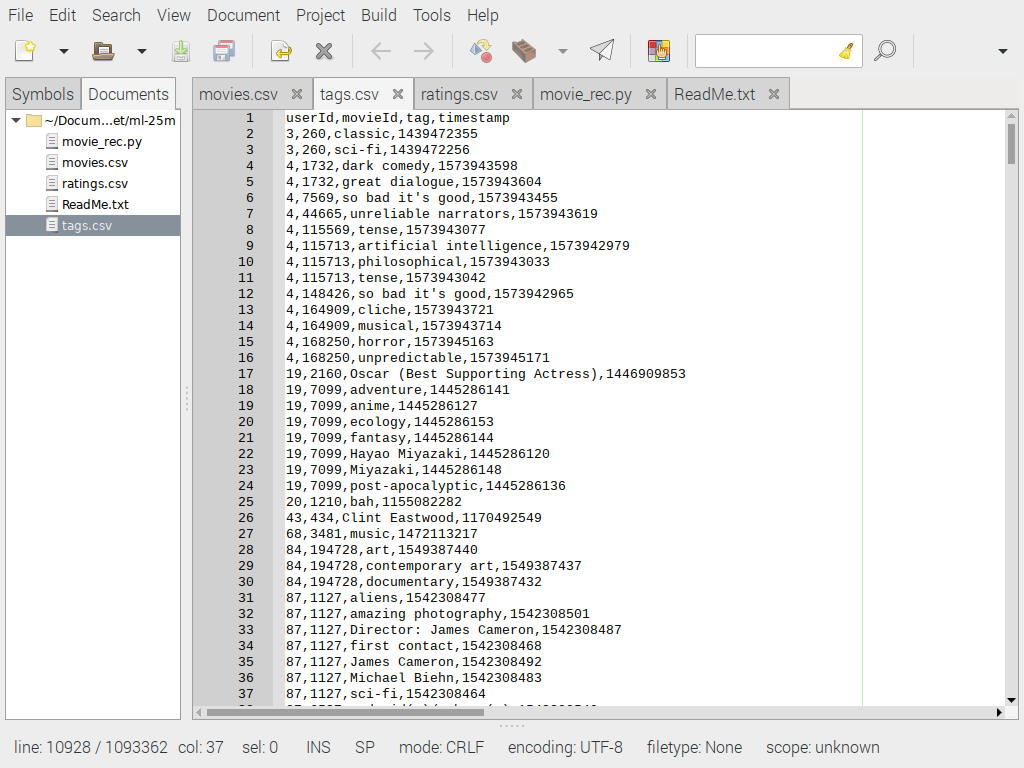
tags.csv
И последний, но не менее важный файл: rating.csv. От этого парня мы возьмем столбцы movieId и rating.

ratings.csv
Отлично, теперь давайте запустим IDE и начнем. Импортируем библиотеки, как показано ниже. Pandas и NumPy хорошо известны в области Data Science. Fuzzywuzzy, EasyGUI и библиотека Progress менее известны^ судя по тому, что мне удалось собрать, однако вы, возможно, знакомы с ними. Я добавлю в код много комментариев, чтобы все было понятно. Посмотрите:
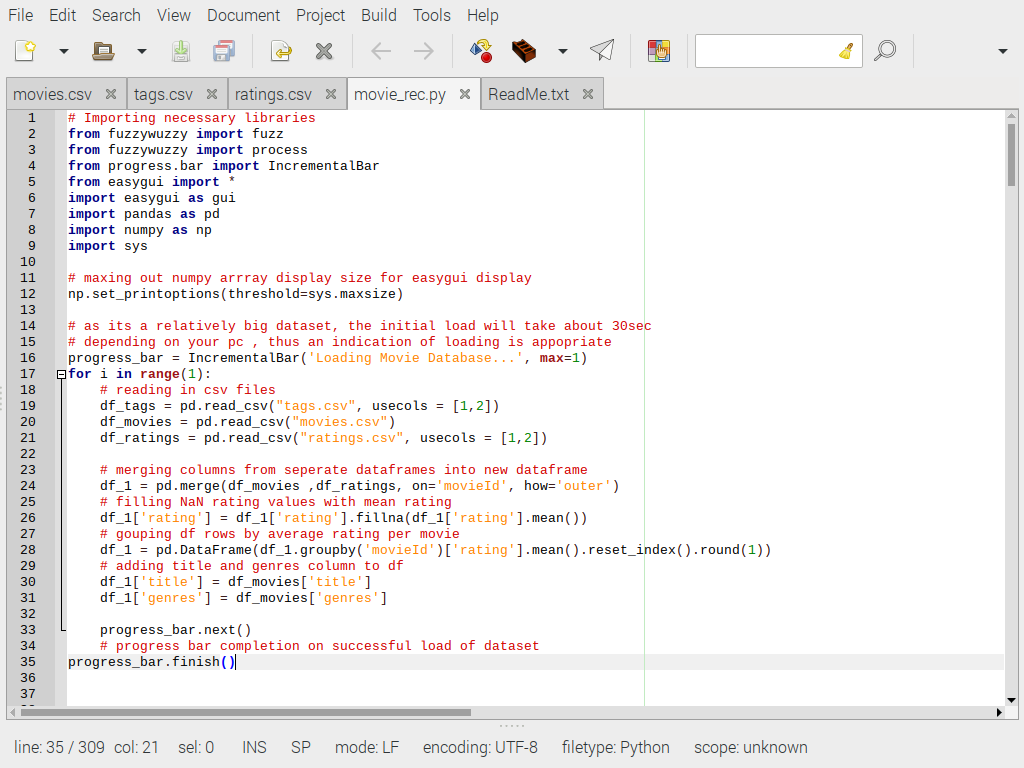
Программа в основном состоит из набора функций, кроме начальной загрузки набора данных и настройки дисплея для gui, в который будет подаваться массив NumPy. Без настройки отображения в строке 12, когда список рекомендуемых фильмов из системы слишком длинный, мы получим урезанное и бесполезное изображение.
Есть разные способы сортировки значений на дисплее, например, цикл по массиву и добавление каждой строки к переменной, инициализированной в пустой список, однако этот метод мы будем использовать именно в строке 12.
Строки 16, 17, 33 и 35 — это, в основном, индикатор прогресса из библиотеки Progress. Цикл выполняется только один раз. Загрузка набора данных в мою систему занимает около 30 секунд, поэтому мы используем индикатор прогресса, чтобы показать, что набор данных загружается после запуска программы, как показано ниже. После этого нам не придется загружать его снова во время навигации по графическому интерфейсу.
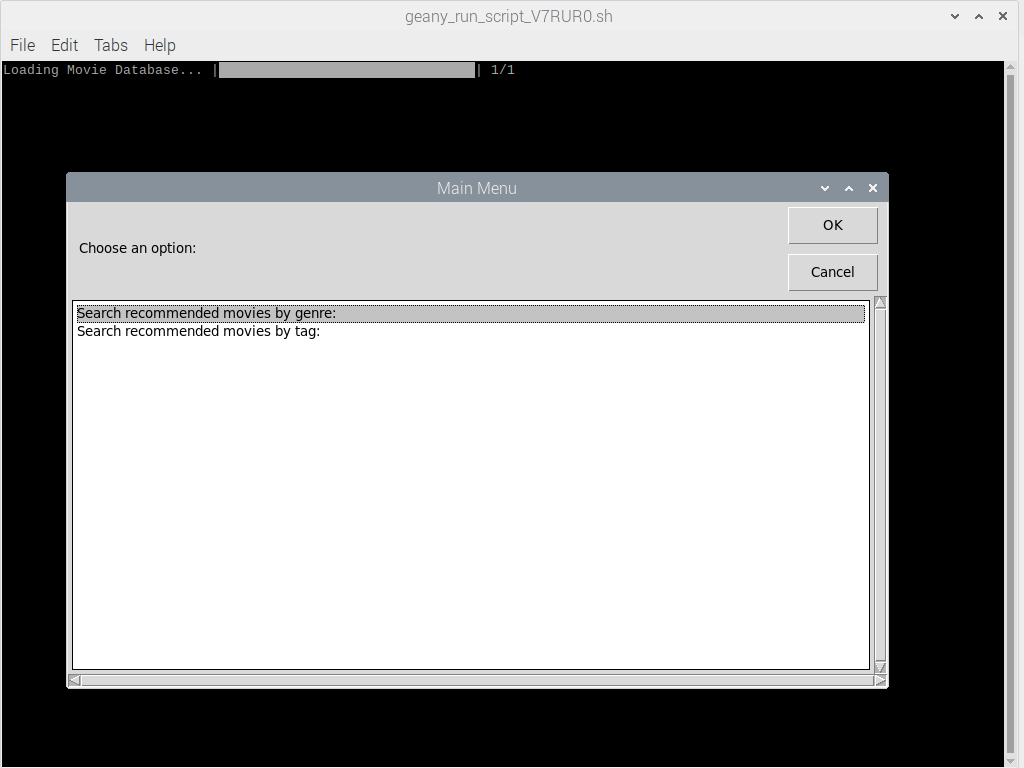
Загрузка набора данных и главное меню графического интерфейса пользователя.
Внутри цикла, набор данных загружается во фреймы Pandas и данные немного изменяются для удобства. Начнем со слияния фильма и рейтингового фрейма в один фрейм. В столбце рейтинга есть несколько значений NaN, и мы будем иметь дело с этим, заполняя его средним рейтингом, вычисленным во всей колонке рейтингов. Поскольку некоторые фильмы имеют оценки с сотен площадок, мы хотим получить средний рейтинг каждого фильма и сгруппировать фильмы по movieId, который связан с названием фильма. Теперь, когда с данными проще работать, пришло время создавать функции.
Первая функция называется which_way(). Эта функция вызывает главное меню графического интерфейса пользователя и предлагает сделать выбор. Ищите фильмы по жанру или по тегу. Пользователь, конечно, тоже может нажать кнопку отмены и вообще не искать фильмы, это полностью его дело.

which_way()
Внутри функции мы определяем параметры для EasyGUI chiocebox, который отображается пользователю. Строка параметра, которую вводит пользователь, возвращается и сохраняется в переменной fieldValues. После условный оператор направляет пользователя к следующей функции или окну на основе выбора.
Если пользователь нажимает отмену, программа завершается. Но если пользователь нажимает поиск фильмов по жанру или поиск фильмов по тегу, то будут вызваны функции genre_entry() или tag_entry() и появится что-то, известное как EasyGUI multenterbox.
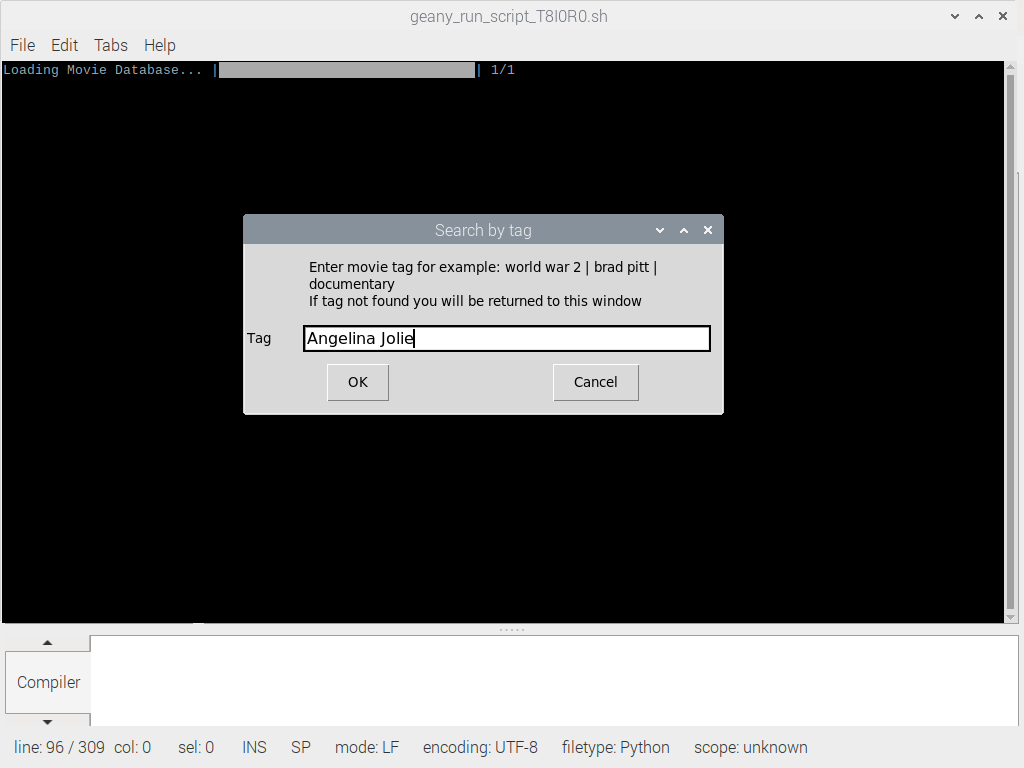
Из названия понятно, что это поле ввода может принимать несколько входных значений, когда необходимо. Обе функции genre_entry() и tag_entry() очень похожи, поэтому я объясню только одну из них, но в исходный код включу обе. Давай посмотрим на tag_entry().
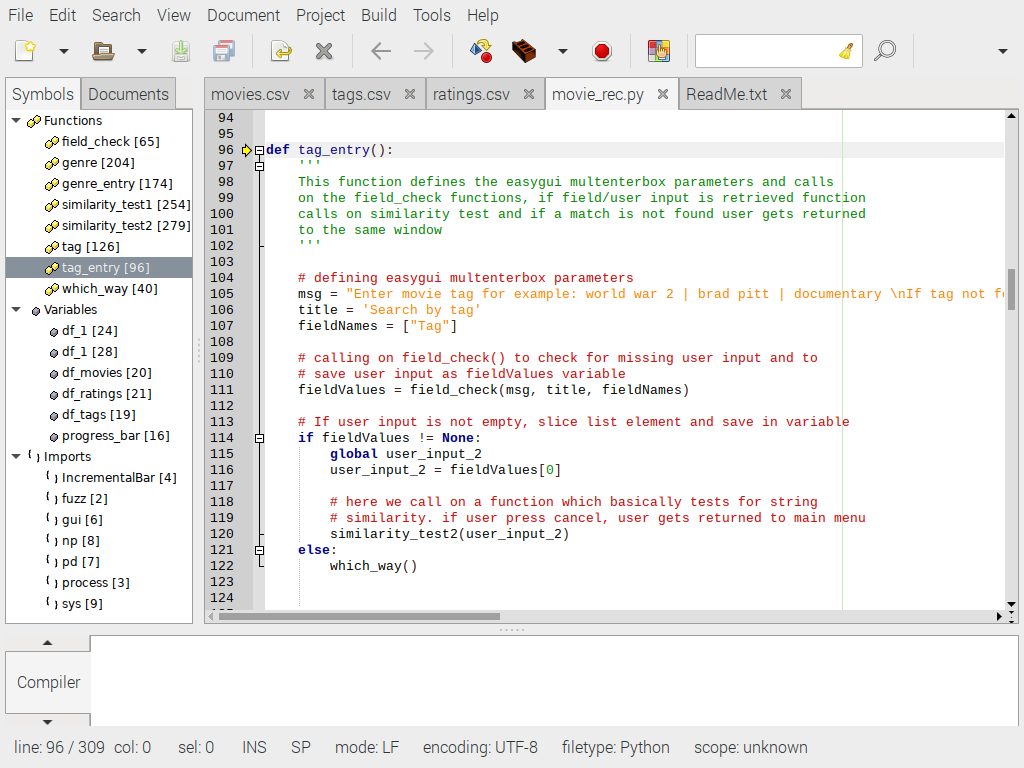
После передачи параметров отображения multenterbox вызывается другая функция, которая проверяет ввод данных пользователем. Пользовательский ввод возвращается функцией field_check. Давайте взглянем на нее:
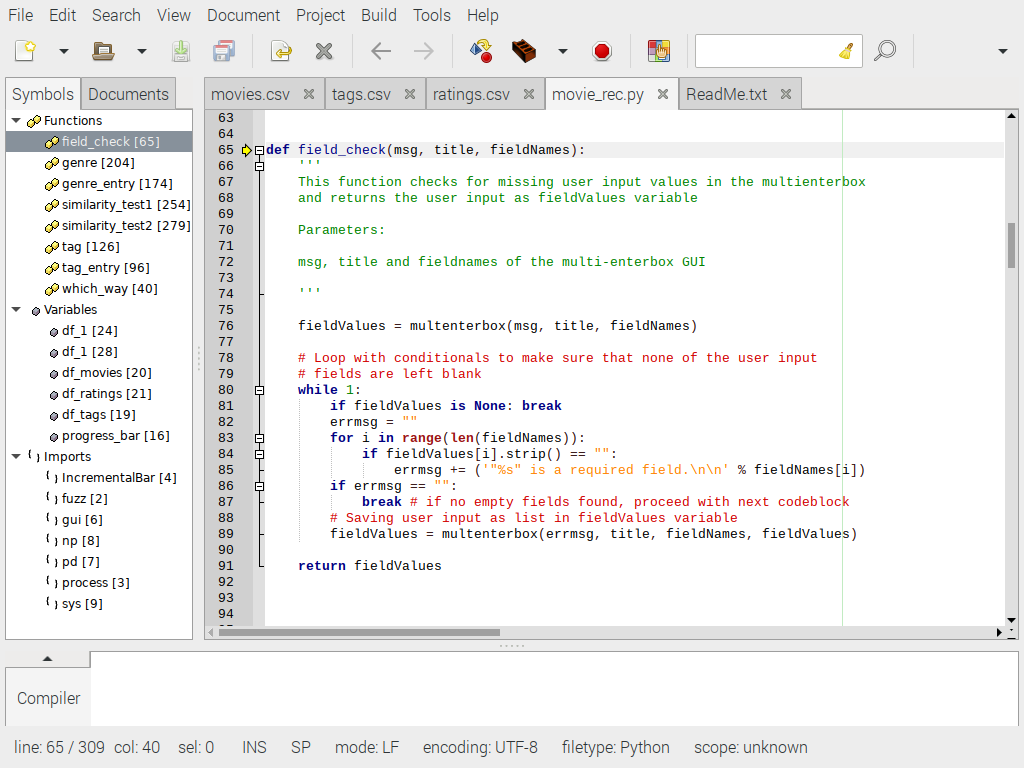
Иногда пользователи оставляют значение в поле пустым, возможно, по ошибке. Чтобы контролировать такое поведение, а также сделать графический интерфейс более надежным, нам нужны такие функции. Я нашел эту конкретную функцию на странице документации EasyGUI. По сути, пока вы вводите пустое поле, вам сообщат, что это поле является обязательным, и вы застрянете в цикле.
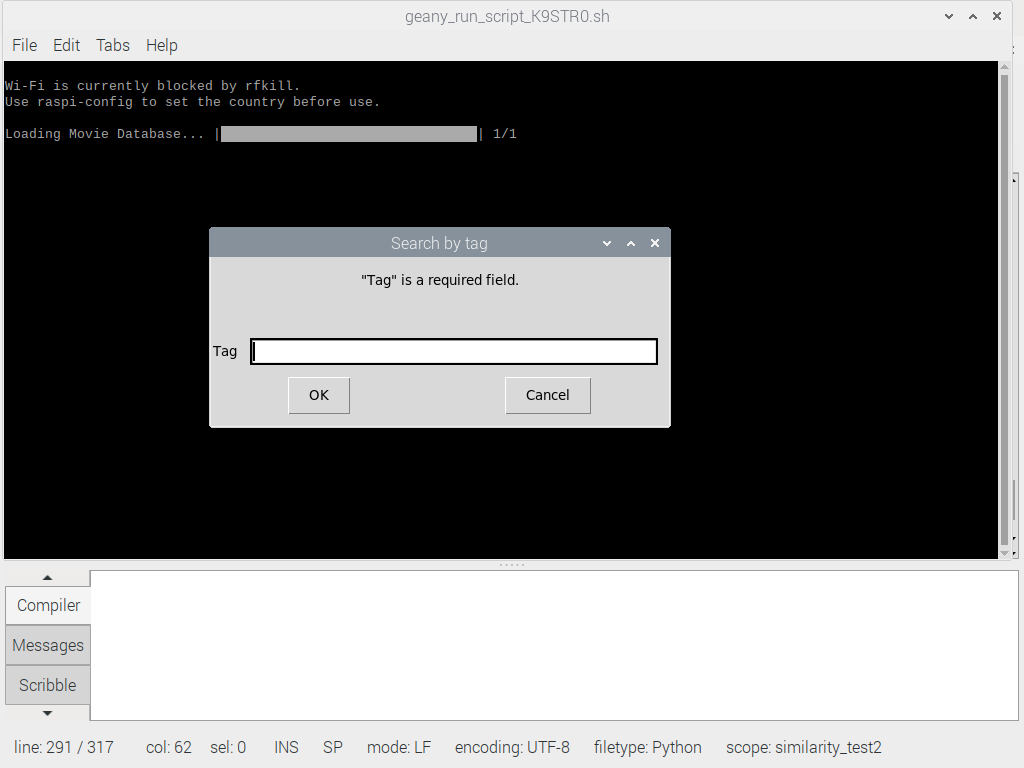
Как только пользователь что-то вводит, текст (строка) сохраняется в переменной fieldValues, а код работает со строки 114 в функции tag_entry. Пользовательский ввод из поля EasyGUI multenter возвращается в виде списка. При нажатии кнопки отмены возвращается «Нет». Чтобы использовать этот ввод и в других функциях, нам нужно объявить переменную как глобальную.
Теперь мы нарезаем список пользовательского ввода из multenterbox, и сохраняем как переменную user_input_2. Нас интересует только возвращаемый текст, если пользователь не нажимает кнопку отмены, отсюда и условный оператор:
if fieldValues != None:Если пользователь был достаточно любезен, чтобы ввести какой-то текст, мы переходим к функции Similarity_test2(), которая в основном содержит базовые аспекты этой системы рекомендаций, в качестве альтернативы пользователь возвращается в главное меню. Similarity_test1() и Similarity_test2() очень похожи, так же как genre_entry и tag_entry. Я буду рассматривать здесь только Similarity_test2(). Давайте посмотрим на это:

Как мы видим, она принимает один параметр, переменнаую user_input_2 из функции tag_entry(). Помните тот фрейм данных, который мы создали в строке 19 из файла tags.csv? Сначала мы хотим собрать все уникальные теги из столбца тегов и сохранить их в переменной.
Существует множество способов применения библиотеки Fuzzywuzzy в зависимости от ваших задач. Мы будем работать так: output = process.extract(query, choices)
Можно передать дополнительный параметр — тип счетчика. Мы просто будем использовать синтаксис по умолчанию. По сути Fuzzywuzzy работает с расстоянием Левенштейна для вычисления различий между последовательностями и возвращает оценку в пределах 100%.
Функция process.extract(query, choices) возвращает список оценок, где каждая строка и ее оценка заключена в скобки, например (строка 95) в качестве элементов списка.
После перебора всего списка тегов и поиска совпадений с переменной user_input_2, мы перебираем список оценок и вырезаем только совпадения выше 90% и сохраняем их в переменной final_2. Мы объявляем его глобальным, чтобы использовать в следующей функции. Если fuzzywuzzy не нашел для нас соответствия, вернется []. Если совпадение по условию не найдено, просим пользователя повторить попытку, вернувшись к функции tag_entry(). В качестве альтернативы, когда у нас есть совпадения более чем на 90%, мы можем использовать их в функции tag(), как показано ниже:
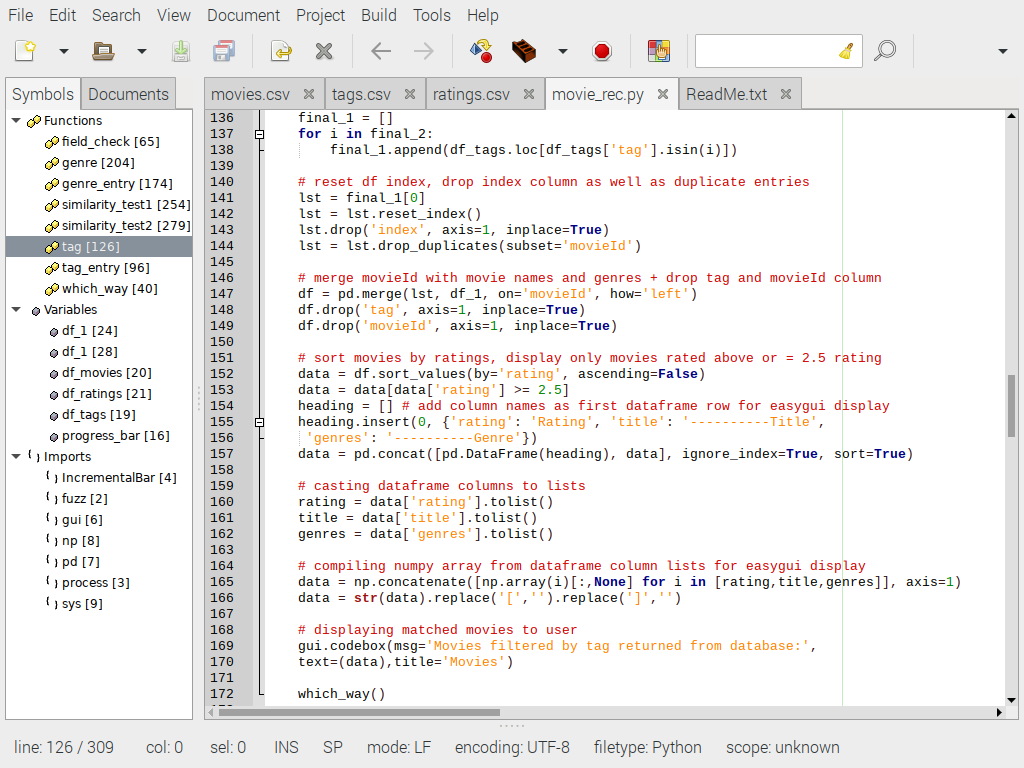
tag()
Теперь, когда у нас есть совпадения более 90%, перебираем их в цикле и просматриваем каждую строку столбца tag фрейма данных df_tags, чтобы увидеть, какие теги соответствуют строкам из Fuzzywuzzy. Теперь сохраняем все совпадения тегов вместе с идентификатором movieId в переменной final_1. Чтобы очистить добавленные данные, мы отрезаем первый элемент и сбрасываем индекс фрейма данных. Теперь можно удалить столбец с именем index и все дубликаты из столбца movieId. Чтобы фильмы с наивысшим рейтингом отображались первыми в порядке убывания, отсортируем фрейм данных и удалим фильмы с рейтингом меньше 2,5/5,0.
Теперь мы можем вставить новую строку во фрейм данных прямо вверху и дублировать имена столбцов над ними. Это делается только для отображения EasyGUI. Элементу codebox не очень нравится фрейм данных pandas, поэтому нужно изменить формат фрейма.
Преобразуем каждый столбец фрейма в список, а затем повторно соберем его с помощью numpy. Да, мы просто убираем скобки и переходим к окну codebox для отображения списка. Это всё! Давайте найдем фильм по тегу: «hacker» и посмотрим, что покажут рекомендации.
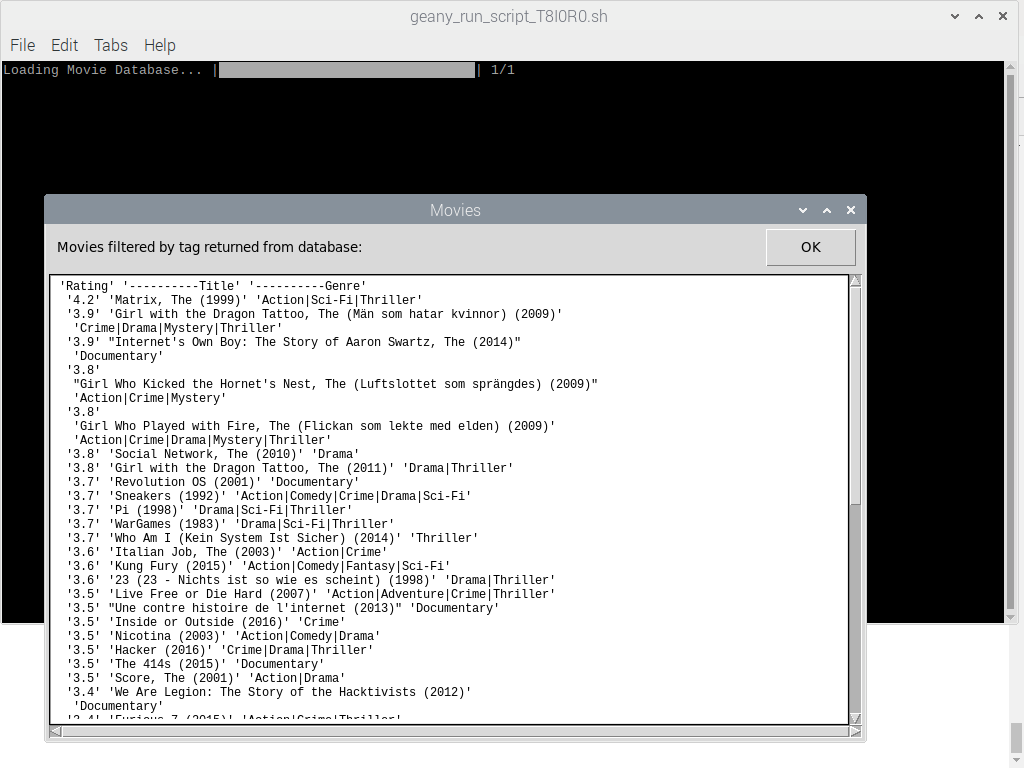
Программа работает. Не стесняйтесь экспериментировать с ней и, пожалуйста, дайте мне знать, если я где-то ошибся!
Исходный код проекта (осторожно, под спойлером целая простыня)
# импорт библиотек
from fuzzywuzzy import fuzz
from fuzzywuzzy import process
from progress.bar import IncrementalBar
from easygui import *
import easygui as gui
import pandas as pd
import numpy as np
import sys
# максимальное увеличение размера массива отображения numpy для отображения easygui
np.set_printoptions(threshold=sys.maxsize)
# фрейм данных относительно большой, начальная загрузка займет около 30 секунд
# в зависимости от вашего компьютера, поэтому здесь уместна индикация загрузки
progress_bar = IncrementalBar('Loading Movie Database...', max=1)
for i in range(1):
# чтение файлов csv
df_tags = pd.read_csv("tags.csv", usecols = [1,2])
df_movies = pd.read_csv("movies.csv")
df_ratings = pd.read_csv("ratings.csv", usecols = [1,2])
# объединение столбцов из отдельных фреймов данных в новый фрейм
df_1 = pd.merge(df_movies ,df_ratings, on='movieId', how='outer')
# заполнение значений NaN средним рейтингом
df_1['rating'] = df_1['rating'].fillna(df_1['rating'].mean())
# группирование строк df по среднему рейтингу фильма
df_1 = pd.DataFrame(df_1.groupby('movieId')['rating'].mean().reset_index().round(1))
# добавление столбцов title и genres в df
df_1['title'] = df_movies['title']
df_1['genres'] = df_movies['genres']
progress_bar.next()
# заполнение индикатора загрузки при успешной загрузке
progress_bar.finish()
def which_way():
'''
Эта функция, которая выполняется при запуске программы.
Работает как перекресток, вы выбираете поиск фильмов по
тегу или по жанру. По выбору пользователь переходит к следующему окну.
'''
# определение параметров easygui choicebox
msg = "Choose an option:"
title = "Main Menu"
choices = ["Search recommended movies by genre:","Search recommended movies by tag:"]
fieldValues = choicebox(msg,title, choices)
# переменная fieldValues - это пользовательский ввод, который возвращается из графического интерфейса
# условный оператор, направляющий пользователя к следующему интерфейсу на основе ввода
if fieldValues == "Search recommended movies by genre:":
genre_entry()
elif fieldValues == "Search recommended movies by tag:":
tag_entry()
def field_check(msg, title, fieldNames):
'''
Эта функция проверяет отсутствие вводимых пользователем значений в multenterbox
и возвращает пользовательский ввод как переменную fieldValues.
Параметры:
msg, title и fieldnames графического интерфейса multienterbox
'''
fieldValues = multenterbox(msg, title, fieldNames)
# Цикл с условием, чтобы проверить,
# что поля ввода не пусты
while 1:
if fieldValues is None: break
errmsg = ""
for i in range(len(fieldNames)):
if fieldValues[i].strip() == "":
errmsg += ('"%s" is a required field.nn' % fieldNames[i])
if errmsg == "":
break # если пустых полей не найдено, перейти к следующему блоку кода
# cохранить пользовательский ввода в виде списка в переменной fieldValues
fieldValues = multenterbox(errmsg, title, fieldNames, fieldValues)
return fieldValues
def tag_entry():
'''
Эта функция определяет параметры easygui multenterbox и вызывает
field_check, если пользователь вводил значнеие,
вызывает тест на подобие; если совпадение не найдено, пользователь возвращается
в окно ввода
'''
# определение параметров easygui multenterbox
msg = "Enter movie tag for example: world war 2 | brad pitt | documentary nIf tag not found you will be returned to this window"
title = 'Search by tag'
fieldNames = ["Tag"]
# вызов field_check() для проверки отсутствия пользовательского ввода и
# сохранения вода как переменной fieldValues
fieldValues = field_check(msg, title, fieldNames)
# Если пользователь ввел значение, сохраняем его в fieldValues[0]
if fieldValues != None:
global user_input_2
user_input_2 = fieldValues[0]
# здесь мы вызываем функцию, которая в основном проверяет строку
# на схожесть с другими строками. Когда пользователь нажимает кнопку отмены, он возвращается в главное меню
similarity_test2(user_input_2)
else:
which_way()
def tag():
'''
Эта функция добавляет все совпадающие по тегам фильмы во фрейм данных pandas,
изменяет фрейм данных для правильного отображения easygui, отбросив некоторые
столбцы, сбрасывая индекс df, объединяя фреймы и сортируя элементы так,
чтобы показывались фильмы с рейтингом >= 2.5. Она также преобразует столбцы df в списки
и приводит их в порядок в массиве numpy для отображения easygui.
'''
# добавление тегов найденных фильмов как объекта фрейма
final_1 = []
for i in final_2:
final_1.append(df_tags.loc[df_tags['tag'].isin(i)])
# сброс индекса df, удаление столбца индекса, а также повторяющихся записей
lst = final_1[0]
lst = lst.reset_index()
lst.drop('index', axis=1, inplace=True)
lst = lst.drop_duplicates(subset='movieId')
# слияние movieId с названиями и жанрами + удаление тега и идентификатора фильма
df = pd.merge(lst, df_1, on='movieId', how='left')
df.drop('tag', axis=1, inplace=True)
df.drop('movieId', axis=1, inplace=True)
# сортировка фильмов по рейтингам, отображение только фильмов с рейтингом выше или равным 2,5
data = df.sort_values(by='rating', ascending=False)
data = data[data['rating'] >= 2.5]
heading = [] # добавление названий столбцов как первой строки фрейма данных для отображения easygui
heading.insert(0, {'rating': 'Rating', 'title': '----------Title',
'genres': '----------Genre'})
data = pd.concat([pd.DataFrame(heading), data], ignore_index=True, sort=True)
# преобразование столбцов фрейма данных в списки
rating = data['rating'].tolist()
title = data['title'].tolist()
genres = data['genres'].tolist()
# составление массива numpy из списков столбцов dataframe для отображения easygui
data = np.concatenate([np.array(i)[:,None] for i in [rating,title,genres]], axis=1)
data = str(data).replace('[','').replace(']','')
# отображение фильмов пользователю
gui.codebox(msg='Movies filtered by tag returned from database:',
text=(data),title='Movies')
which_way()
def genre_entry():
'''
Эта функция определяет параметры easygui multenterbox
и вызывает field_check, если пользователь что-то вводил,
вызывается тест на подобие. Если совпадение не найдено, пользователь возвращается
в то же окно
'''
# определение параметров easygui multenterbox
msg = "Enter movie genre for example: mystery | action comedy | war nIf genre not found you will be returned to this window"
title = "Search by genre"
fieldNames = ["Genre"]
# вызов field_check() для проверки отсутствия пользовательского ввода и
# сохранения ввода в fieldValues.
fieldValues = field_check(msg, title, fieldNames)
# Если пользовательский ввод не пуст, сохраняет его в переменной user_input
if fieldValues != None:
global user_input
user_input = fieldValues[0]
# здесь мы вызываем функцию, которая в основном проверяет строку
# на подобие с другими строками. Если пользователь нажмет кнопку отмена, то он вернется в главное меню
similarity_test1(user_input)
else:
which_way()
def genre():
'''
Эта функция добавляет все соответствующие жанру фильмы во фрейм pandas,
изменяет фрейм для правильного отображения easygui, отбросив некоторые
столбцы, сбрасывает индекс df, объединеняет фреймы и сортирует фильмы для отображения
только фильмов с рейтингом >= 2.5. Она также преобразует столбцы конечного df в списки
и приводит их в порядок в массиве numpy для отображения easygui.
'''
# добавление соответствующих жанру фильмов во фрейм.
final_1 = []
for i in final:
final_1.append(df_movies.loc[df_movies['genres'].isin(i)])
# сброс индекса df, удаление индекса столбцов и дубликатов записей
lst = final_1[0]
lst = lst.reset_index()
lst.drop('index', axis=1, inplace=True)
lst.drop('title', axis=1, inplace=True)
lst.drop('genres', axis=1, inplace=True)
lst = lst.drop_duplicates(subset='movieId')
# объединение идентификатора фильма с названием, рейтингом и жанром + удаление индекса, названия и жанра
df = pd.merge(lst, df_1, on='movieId', how='left')
# сортировка по рейтингу, отображение только фильмов с рейтингом выше или равным 2,5
data = df.sort_values(by='rating', ascending=False)
data.drop('movieId', axis=1, inplace=True)
data = data[data['rating'] >= 2.5]
heading = [] # add column names as first dataframe row for easygui display
heading.insert(0, {'rating': 'Rating', 'title': '----------Title',
'genres': '----------Genre'})
data = pd.concat([pd.DataFrame(heading), data], ignore_index=True, sort=True)
# преобразование столбцов фрейма данных в списки
rating = data['rating'].tolist()
title = data['title'].tolist()
genres = data['genres'].tolist()
# составление массива numpy из списков столбцов фрейма для отображения easygui
data = np.concatenate([np.array(i)[:,None] for i in [rating,title,genres]], axis=1)
data = str(data).replace('[','').replace(']','')
# отображение фильмов пользователю
gui.codebox(msg='Movies filtered by genre returned from database:',
text=(data),title='Movies')
which_way()
def similarity_test1(user_input):
'''
Эта функция проверяет схожесть строк путем сопоставления пользовательского ввода
для жанров фильмов, совпадения > 90% сохраняется в переменной, которая
затем передается функции жанра для сопоставления с базой данных и
возврата в окно ввода, если совпадение не найдено
'''
# сохранение жанров фильмов в качестве тестовой базы и пользовательского ввода для тестирования
genre_list = df_movies['genres'].unique()
query = user_input
choices = genre_list
# here fuzzywuzzy does its magic to test for similarity
output = process.extract(query, choices)
# сохранение совпадений в переменной и их передача следующей функции
global final
final = [i for i in output if i[1] > 90]
# если совпадений > 90% не найдено, вернуть пользователя в окно жанра
if final == []:
genre_entry()
else:
genre()
def similarity_test2(user_input_2):
'''
Эта функция проверяет схожесть строк путем сопоставления пользовательского ввода
в теги фильмов, совпадение > 90% сохраняется в переменной, которая
затем передается в функцию тега для сопоставления базы данных и
возврата в окно ввода, если совпадение не найдено
'''
# сохранение тега фильма в качестве тестовой базы и пользовательского ввода для тестирования
tag_list = df_tags['tag'].unique()
query = user_input_2
choices = tag_list
# here fuzzywuzzy does its magic to test for similarity
output = process.extract(query, choices)
# сохранение возвращенных совпадений в переменной и их передача следующей функции
global final_2
final_2 = [i for i in output if i[1] > 90]
#если совпадение> 90% не найдено, возврат в окно ввода
if final_2 == []:
tag_entry()
else:
tag()
if __name__ == '__main__':
which_way()

Получить востребованную профессию с нуля или Level Up по навыкам и зарплате, можно, пройдя наши онлайн-курсы.
- Курс «Python для веб-разработки»
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
- Профессия Java-разработчик с нуля
- Курс по JavaScript
Читать еще
- Как сделать интерактивную карту с помощью Python и open source библиотек
- Данные внутри нас: Чем занимаются биоинформатики?
- Machine Learning и Computer Vision в добывающей промышленности
Сколько фильмов вы смотрели за всю свою жизнь? Сколько еще вы планируете смотреть в то время, которое еще впереди? Если вы увлекаетесь кино, у вас будет список фильмов, которые вы хотите посмотреть где-нибудь. Скорее всего, это будет в вашем мозгу или нацарапано на бумаге.
Настоящий синий фанат уклонится от обоих и вместо этого выберет множество онлайн-приложений для каталогизации фильмов. , которые вошли в картину (каламбур). Но каталогизация фильмов — это смешной взгляд на это. Создание пользовательских списков фильмов (например, список фильмов, которые я не видел) — это упражнение для веселья и открытий. Самое приятное в том, что он помогает вам выкапывать фильмы, о которых вы даже не слышали.
Итак, вот пять приложений, которые помогут вам создать свой личный список фильмов и найти новые в процессе.
IMDb — Мои фильмы

Что может быть лучше для создания личного списка фильмов, чем на одном из самых популярных сайтов фильмов в Интернете. Зарегистрируйтесь или войдите под своей учетной записью Facebook. Как ни странно, это не позволило мне зарегистрироваться с моей учетной записью Gmail. Это также немного сбивает с толку, потому что бесплатная пробная версия IMDb Pro пытается отвлечь вас от своего платного предложения.
Но как только вы войдете, вы можете использовать огромную базу данных сайта, чтобы создать свой личный список фильмов, отсортировать их по категориям, пометить их своими заметками, а также использовать функцию расширенного поиска для просмотра своих обширных списков. Вы можете искать на сайте, как обычно. На странице каждого фильма вы увидите значок с надписью « Добавить в MyMovies» . Если вы щелкнете по нему, фильм будет помещен в корзину « Ожидание ». Это самый простой способ начать с вашего списка. Новая функция позволяет вам поделиться списком публично.
Flickchart

Если создание собственного списка фильмов звучит как дурацкий материал, Flickchart возвращает веселье обратно. Mahendra сделала полный обзор когда это пошло бета. Flickchart помогает вам составить список, показывая вам постеры двух фильмов одновременно. Вы можете нажать на один или оба, если вы их не видели. Вы можете настроить отображение фильмов по жанрам, по дате, по названию, по актерам и по студии. Ваш профиль пользователя перечисляет и оценивает фильмы, которые вы еще не видели. Вы также можете быстро создать другие пользовательские списки, используя выпадающие фильтры.
iCheckMovies

Этот веб-сайт пока не позволяет создавать собственные списки фильмов, но на нем размещено множество собственных списков. Вы можете просматривать эти списки и выбирать фильмы для просмотра. Различные топ-листы — IMDb, Критики (например, «Лучшие 1000 фильмов за всю историю»), Призы (например, «Лучший фильм BAFTA»), Веб-сайты (Например: 250 Quintessential Noir Films), Институт (Например: 100 лучших британцев) Фильмы) и Разные списки.
Сайт использует ваши любимые, чтобы дать вам рекомендации фильмов, которые вы должны увидеть. Вы можете добавлять фильмы в свой список просмотра или даже не любить фильм. Когда вы просматриваете фильмы и заканчиваете их смотреть, вы можете отметить их в списках.
Flixster

Flixster — это социальная сеть для любителей кино. Как участник сообщества, вы можете делиться своими вкусами в фильмах с другими и открывать для себя новые фильмы, обмениваясь заметками с теми, которые вы видели. Несмотря на свою долю критики , сайт находится в чартах популярности сайтов о кино.
На странице профиля пользователя есть инструмент « Мои фильмы» , в котором можно создавать собственные списки и добавлять фильмы с помощью поиска (по фильмам или актерам). Вы можете создать столько личных списков фильмов, сколько захотите, и поделиться ими или заблокировать их как личные. Связанные списки — это быстрый доступ к списку любимых фильмов и фильмов, которые вы, возможно, пропустили.
MListr

Может быть, есть какие-нибудь фильмы, которые вы планируете посмотреть во время предстоящих каникул? Или есть список, который вы хотите создать для своего ребенка? MListr не только стремится быть базой данных для вашего личного выбора фильмов, но также хочет использовать ваши вкусы и рекомендовать вам несколько вариантов, используя механизм рекомендаций. MListr также проводит несколько конкурсов, где участники награждаются за свои списки. Вы можете найти фильм и быстро добавить его в любой из списков по умолчанию или в пользовательский. У некоторых из названий и их пользовательских отзывов, которые появляются в поиске, могут быть спойлеры. Сайт может быть лучше с лучшим дизайном и большим участием пользователей, но он позволяет быстро создавать списки фильмов и сохранять работу.
Мои собственные списки фильмов послужили одной важной цели. Много раз эти списки спасли меня от покупки фильма, который я уже посмотрел. Благодаря рекомендациям они также спасли меня от просмотра плохого.
Посмотрите 8 онлайн путеводителей по лучшим и худшим фильмам всех времен от Махендры и дайте нам знать, что ваши личные списки фильмов сделали с вашим опытом просмотра фильмов.