Как я написал свою поисковую систему для быстрого поиска личной информации
Время на прочтение
6 мин
Количество просмотров 6.2K

Предыстория
Все началось с того, что мне стало трудно находить нужную информацию, файлы. Чем больше файлов и папок у меня образовывалось, тем больше времени уходило на поиски нужного. Я понял, что каждый раз искать в бесконечных списках файлов и папок, особенно с условием вложенности это не вариант для больших объемов данных.
Что касается поиска по названию файла, то количество символов, указанных в названии ограниченно и слова при поиске должны быть в строго определенной последовательности. Тем более, если система индексирует другие, не нужные для поиска файла (системные файлы, файлы проектов), то поиск выдает много «мусора».
Поиск по содержанию файла даёт не самый релевантный результат. Может выдать бесполезные результаты с содержанием содержащие ключевые слова, но не относящиеся к тому, что действительно необходимо найти.
Более того по содержанию можно искать только текстовые файлы.
Структура содержания информации
Структура папок представляется собой в виде дерева. Мне это не нравится, потому что каждая папка может содержать только определенные файлы, если не учитывать копирование и ссылки.
Так же это можно представить с примером из реальной жизни, для того, чтобы найти зелёное свежее яблоко сорт «Девственный». Необходимо найти отдел с фруктами, затем отдел с яблоками, затем ищем зеленные, затем сорт, ну там ещё их на свежие, не свежие фасуют в этом воображаемом примере и наконец найти нужное apple.
Усложняется ещё все и тем, что я не помню есть ли там вообще яблоки, и если есть, то хранятся ли они в отделе фрукты.
А почему бы об этом просто не попросить прихвостня(они уже у всех есть, правда?) — «Принеси мне зелёное свежее яблоко».
Как сразу становится удобно!
В общем, всем этим я хочу сказать, что поиск нужной информации в папках хорош, если папок немного и если помнить какие папки существуют, а не перебирать все подряд.
А вот если мы не знаем существуют ли яблоки вообще, то спрашиваем прихвостня:
— Яблоки есть?
— Есть, господин! Сотни, игрушечные, красные, гнилые….
— Мне нужно свежее яблоко.
— Понял! Есть красное свежее яблоко «Сирота», красное свежее яблоко «Курага»,….
— А что насчёт зелёного свежего яблока.
— Есть! Зелёное свежее яблоко «Пух-тибидух» и Зелёное свежее яблоко «Девственный».
— В таком случае, принеси мне, пожалуй, Зелёное свежее яблоко «Девственный».
— Да, сэр.
Вот последняя фраза как раз таки и стала названием приложения. Как ответ на команду пользователя — «Yes Sir».
Возвращаясь к яблокам. Заметили, что в первом случае нужно искать яблоки не пойми где, а во втором мы задаём уточняющие условия к запросу?
 приходится обходить все узлы. А в случае графа(теги) можно получить результат, в лучше случае за проход по единственному узлу.")
Приведу пример более реалистичный. Есть папка с музыкой и подпапки для разделения на жанры. Но что если в какой-то момент мне захочется послушать французскую музыку не зависимо от жанра. Вот тут то и вся проблемность древовидной структуры папок вылазит. Можно конечно, как советовали на форумах, создавать отдельные папки под язык произведения и кидать ссылки, но опять папки…
А вот, что произойдет, если каждому файлу установить теги с жанром, языком, ну и конечно что это музыка, песня.
В этом случае возможно группировать, сортировать музыку гораздо гибче. Например, скомбинировав 3 тега: французская, русская, рок можно получить то, чего стандартными средствами Windows не возможно, ну или я чего-то не знаю.
Попытки найти готовое решение
Первой идеей было воспользоваться «тегированием» файлов, папок. Таким образом можно искать информацию комбинируя теги, не зависимо от порядка слов. И лучшими приложениями для этого, могу выделить XYplorer и Tagging for windows. Первая из себя представляет отдельный файловый менеджер с опцией тегирования. Второе приложение — дополнение к стандартному файловому менеджеру. Однако они позволяют искать файлы только на ПК и конечно нельзя написать как в Гугл поисковике запрос близкий к пользователю, а алгоритм уже бы сам выбрал из запроса теги и отсортировал информацию по приоритету. В последствии удалил обе, они подвисали и крашились частенько (возможно дело в моих надстройках Windows, не хочу делать анти пиар этих отличных программ).
Визуальный поиск
В попытках найти оптимальный способ поиска доходило до странного. Я больше визуал и поэтому загружал изображения более менее подходящее по теме информации в социальную сеть ВКонтакте, а саму информацию сохранял в комментариях под изображениями. Это дало некоторый прирост в скорости поиска и пользоваться можно с любого устройства. Но как вы, наверное, понимаете долго это продолжаться не могло. В конечном итоге я стал задумываться а к какой информации относится это изображение, на котором рельсы — означает адреса знакомых или желаемые места для путешествия… Ну а уж то, что под одним изображением образуется портянка из информации без возможности вложенности — это фиаско, бро.
Желаемый функционал
Я подумал, что было бы отлично разработать приложение, которое бы подходило по таким критериям:
-
Можно использовать с любого устройства без возможности подключения к интернету.
-
Поиск личной информации настолько быстро, насколько это возможно.
-
Поиск должен быть простым как Google Search.
-
Возможность сохранить всю текстовую информацию в текстовый файл.
Выбор технологий
1. По первому пункту из желаний было решено разработать веб приложение, так как с любого устройства, на котором есть браузер, можно получить к нему доступ. Данные хранятся в localstorage браузера, но при открытии сайта сразу выгружаются в переменную для обеспечения лучшей скорости.
Для синхронизации данных с другим устройством, браузером я взял базу данных mysql от 000webhost бесплатно, но потом перестал использовать из-за ограничений на объем. Сейчас единственный способ для обновления пользовательских данных — импорт и экспорт файла. Однако я делаю это очень редко, т.к. в основном пользуюсь только со смартфона. Что касается офлайн режима — я использовал serviceworking. Необходимо только один раз зайти на сайт, чтобы все ресурсы сайта загрузились и дальше использовать полностью офлайн из браузера.
2. Быстрый поиск.
Раз поиск должен осуществляться подобно Гугл поисковику, то нужно чтобы каждое слово из запроса проверять на существующий из уже созданного блока информации. Таким блоком у меня выступает объект с ключами: уникальное название блока, действие(показать информацию, открыть ссылку…), содержимое, теги.
Итак, по ключу «теги» у нас будет храниться массив из символов(слов) для конкретного блока информации.
Сразу возьмём пример блока.
Название: как создать сайт.
Действие: показать информацию.
Содержимое: берём html, добавляем js и украшаем css.
Теги: создание сайта, веб программирование, верстка.
Массив из тегов формируется из текстов полученных с полей ввода для тегов и названия. Каждое слово это тег, разделять можно запятой и пробелом. Была идея конечно сделать как на Ютубе, теги как словосочетания, но я решил остановиться на более широкой выдаче по ключевым словам. Из примера блока выше массив тегов будет таким: [«как», «создать», «сайт», «создание», «сайта», «веб», «программирование», «верстка»].
Теперь самое важное — определиться как будет происходить поиск. Первое, что пришло в голову это брать каждое слово из поискового запроса и сравнивать с каждым словом из тега каждого блока. В голову как пришло, так и ушло, это отвратительная идея. Следующей идеей было создание объекта, в котором каждый тег это отдельный ключ, а значение это массив из индексов блоков.
3. Итак, при вводе запроса проверяется есть ли слово в хранилище тегов, если да, то блок добавляется в массив на отображение.Теперь нужно отсортировать по приоритету. Чем выше результат в выдаче, тем более он подходит запросу. Это я реализовал с помощью количества ключевых слов в запросе, чем больше слов из запроса содержится в массиве тегов блока, тем более блок приоритетнее.
4. И насчёт сохранение в файл совсем кратко. Можно сохранять и импортировать файл в виде json.Так же мой опыт с использованием ВКонтакте как поисковик по изображениям дал мне идею для возможности добавлять изображение к каждому блоку при желании.
Итоги
В результате я сделал то, чем пользуюсь уже больше года. Как веб, так и ПК версия оказались очень полезными. Использую для работы и личной жизни. Скорость поиска, которую я в итоге получил меня многократно выручала, когда нужно было найти что-то очень быстро.
Ответвление в другие проекты
Веб приложение мне настолько понравилось, что я захотел написать программу для исполнения программ по команде от запроса пользователя на ПК. Вдохновлённый голосовыми помощниками, я создал программу, которая ищет и исполняет файлы. А поиск соответственно так же подобен веб поисковику. Особенность в том, что можно перетащить файл/файлы напрямую в программу и алгоритм автоматически установит теги исходя из названия файла и папок, в которых он содержится. Но это тема другого поста, если этот окажется интересным.
Послесловие
Буду рад любым комментариям. Узнать ваше мнение по поводу идеи. Полная ли это ерунда. Или, в чем я почти не сомневаюсь, есть уже приложения с подобной реализацией.
Спасибо!
Ссылка на проект: https://eugeniouglov.000webhostapp.com/yessir/#main
Custom Search Engine (CSE) — мощный инструмент профессионального сорсера. С его помощью можно создать поисковый движок, который будет находить нужных вам кандидатов именно в тех источниках, которые вы укажете.
Основатель кадрового агентства Tech-recruiter и Академии IT-рекрутинга Язиля Насибуллина объяснила, как создать и настроить CSE. А для тех, кто не хочет возиться с настройками, Язиля рассказала про готовые движки для поиска на GitHub, LinkedIn, Behance, Хабр Карьере и в других источниках.
Язиля Насибуллина
основатель агентства Tech-recruiter, автор канала IT-рекрутинг
Зачем сорсеру CSE
CSE — это инструмент от компании Гугл, который позволяет настроить поиск под свои задачи:
- выбрать ресурсы или даже разделы сайтов, которые нужно сканировать;
- искать в определенных регионах;
- задать синонимы, которые будут автоматически подставляться в запрос;
- нацелить поиск на конкретные типы файлов;
- и многое другое, о чем я еще расскажу.
Владельцы сайтов пользуются CSE, чтобы организовать внутренний поиск по своим ресурсам. А сорсеры применяют этот инструмент, чтобы экономить время и получать максимально качественные выдачи.
Когда полезен Custom Search Engine:
- Не хватает возможностей X-ray и внутреннего поиска по сайту. Например, можно создать поисковый движок для GitHub и LinkedIn, используя операторы, которые работают только внутри CSE. Кроме того, поисковый запрос в Гугле ограничен 32 словами — Custom Search Engine позволяет обойти этот лимит.
- Нужно ограничить поиск на определенных сайтах, добавить или исключить конкретные регионы. В стандартном поиске Гугла это сделать сложнее — часто в выдачу попадают нерелевантные результаты, несмотря на оператор «-».
- Надо настроить поиск для начинающих ресечеров и рекрутеров. Например, опытный сорсер создает набор движков, которыми будут пользоваться его коллеги — просто вбивать название должности и получать резюме. Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
- Необходимо найти редкого эксперта с уникальным стеком — можно создать под него отдельный движок. И наоборот: чем стандартнее запрос и больше кандидатов на рынке, тем меньше нужны все эти «сорсинговые штучки».
Как создать поисковый движок
Создание движка в стандартном интерфейсе
Здесь нужно указать:
- сайты для поиска;
- язык;
- название системы — желательно осмысленное, чтобы быстро находить нужный вариант, когда у вас будет набор движков на все случаи жизни.
Например, создаю систему для поиска по профилям пользователей на LinkedIn:
Здесь я указываю адрес linkedin. com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
Как только докажу, что я не робот, и нажму на кнопку «Создать», меня перебросит на следующую страницу со ссылкой на поисковую систему — движок уже будет работать.
Создание движка в новом интерфейсе
Сначала нужно выбрать название системы и указать сайты, по которым надо искать. Потом этот список сайтов можно будет изменить в настройках. Например, создам движок для Хабр Карьеры:
Кстати, можно не ограничиваться конкретными сайтами, а задать целые доменные зоны, например так: *. ru или *. com. Когда я нажму кнопку «Создать», мне предложат настроить систему:
- Выбрать регион поиска — разрешается указать только один. По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
- Добавить в поиск новые сайты.
- Исключить из поиска какие-то адреса. Можно убрать из области поиска не только сайт целиком, но и отдельные веб-страницы или разделы (www. example. com/jobs/*), а также весь домен (*. example. com).
Я настраиваю поиск кандидатов по Хабр Карьере, так что исключу разделы с вакансиями, курсами и информацией о компаниях:
Продвинутая настройка CSE
Предупрежу сразу: все настройки я буду проводить в стандартном интерфейсе — так привычнее. Кроме того, на момент выхода этой статьи новая версия панели управления считается предварительной — многое еще может поменяться. В целом, различия между версиями косметические. Если научиться работать в старом интерфейсе, то будет легко найти аналогичные разделы в новой панели.
Самые полезные настройки находятся в подразделе «Функции в результатах поиска» раздела «Изменение поисковой системы»:
Добавление запроса
Можно прописать дополнительные запросы, которые будут включаться в поиск автоматически. Для этого:
- В разделе «Функции в результатах поиска» нужно перейти во вкладку «Дополнительно».
- Открыть там раздел «Настройки веб-поиска».
- В поле «Добавление запроса» вписать фразу, которая будет подставляться автоматически — писать ее при каждом запросе не придется.
Например, сделаю движок для поиска файлов в формате pdf и docx — предполагается, что это будут резюме. Использую оператор «filetype»:
Уточнения
Усовершенствую движок для LinkedIn — настрою поиск так, чтобы отдельно показывались профили кандидатов с контактными данными. Это можно сделать с помощью уточнений.
В разделе «Функции в результатах поиска» нужно перейти во вкладку «Уточнения», нажать на кнопку «Добавить» и создать дополнительные условия поиска. Результаты по каждому условию будут выводиться на отдельную вкладку.
Например, добавлю поиск по всем профилям, в которых есть почта на gmail. com и ссылка на телеграм:
Синонимы
Вручную прописывать десятки синонимов через OR при каждом запросе утомительно. В CSE для каждого ключевого слова можно задать набор синонимов, которые будут добавляться автоматически.
Для этого надо:
- Перейти в раздел «Функции в результатах поиска», а оттуда — во вкладку «Синонимы».
- Нажать на кнопку «Добавить».
- На верхней строчке написать ключевое слово, а на нижней — набор синонимов к нему.
Как искать с помощью CSE
Если перейдете по ссылке вашего поискового движка, то вы увидите обычную поисковую строку и больше ничего. Не нужно писать «site:» и название сайта для поиска — этот запрос скрыт «под капотом» системы, как и остальные настройки. А в остальном здесь работают все стандартные операторы, в том числе: OR, —, “” .
Например, так будет выглядеть запрос в движке для LinkedIn на поиск PHP-разработчиков из Москвы:
Сейчас движок сканирует всю страницу пользователя целиком. Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
- «more:p:person-jobtitle:» — поиск по позиции;
- «more:p:person-org:» — поиск по компании или учебному заведению;
- «more:p:person-role:» — поиск в заголовке страницы.
А у GitHub есть свой оператор, который обращается к строке «о себе» — «more:p:metatags-og_description:».
Готовые поисковые движки
Вам не обязательно создавать движок самостоятельно — можно воспользоваться готовыми вариантами, если они подходят под ваши задачи. Например, поисковики от Ирины Шамаевой и Балажа Парочай:
- XING,
- HackerRank,
- MeetUp,
- ResearchGate.
Мои поисковые системы:
- GitHub.
- Behance — поиск резюме. Настройки самые простые: в сайтах для поиска я указала «behance. net/*/resume» — раздел, где хранятся резюме пользователей.
- Хабр Карьера. Здесь к каждому допросу автоматически добавляется фраза «последний визит», чтобы искать только по личным страницам пользователей.
- Европейский LinkedIn. Я занимаюсь международным рекрутингом и ищу кандидатов по всей Европе. Для этого сделала движок поиска по доменным областям LinkedIn тех стран, которые мне интересны.
Наш блог читают более 12 000 рекрутеров и профессионалов HR-индустрии. Подкасты, интервью, тематические статьи и экспертные мнения. Переходите по ссылке:
Каждый пользователь в интернете может назвать несколько популярных поисковых систем. Но при этом некоторые из них не оставляют идею создать собственную такую систему, поэтому вопрос: «Как создать свой поисковик?» остается на слуху.
Свой поисковик может быть двух типов:
большая поисковая система, которая будет работать по всему интернету и составлять конкуренцию Google, Яндекс, Bing и др.;
небольшой поисковик, организованный на своем сайте с различными свойства поиска.
Как создать свой поисковик и создать конкуренцию известным «поисковым гигантам»
Создать свой поисковик наподобие Гугла и Яндекса, на самом деле, не так сложно. Любой более-менее уверенный в себе разработчик сможет это сделать. Любой поисковик состоит из 3-х основных элементов:
Пользовательский интерфейс.
Базы данных с сайтами для их индекса.
Поисковый робот, который будет обходить сайты и обновлять/добавлять информацию о них в базу данных.
Техническая реализация поисковой системы не так сложна, как кажется. Плюс в сети есть уже много готовых скриптов как платных, так и бесплатных, с помощью которых вы сможете реализовать свою идею. Создать свой поисковик можно самостоятельно или в небольшой команде. В принципе, если найти соратников в команду, которые готовы поработать на голом энтузиазме, создать свой поисковик можно практически бесплатно.
Но проблема в другом. Сможете ли вы создать действительно конкурирующий программный продукт? Ведь для того, чтобы конкурировать с известными поисковиками, вам нужно будет:
нанять высококвалифицированных специалистов и организовать им рабочее пространство;
оборудовать собственный дата-центр или арендовать мощности у надежной компании;
быть готовым в течение нескольких лет терпеть убытки.
И при этом никто не даст гарантий, что ваш поисковик станет популярным и вы сможете его монетизировать. Потому что пока вы будете развивать свой продукт, Гугл с Яндексом также будут развиваться. А чтобы их «переплюнуть», вам нужно будет внедрить в свой продукт какую-нибудь «фишку» или ноу-хау, чтобы переманить к себе пользователей — это что касается функционала. А с технической стороны ваш поиск должен быть точнее, быстрее и эффективнее, чем у ваших конкурентов, чтобы пользователи это «почувствовали» и перешли на вашу сторону.
Почему люди в основном пользуются Гуглом или Яндексом (или другими)? Потому что им там комфортно и им там нравится. Поэтому, чтобы пользователи перешли именно к вашему поисковику, вы должны стать лучше.
Вот и получается, что создать свой поисковик нетрудно, но вот развивать его и сделать конкурентоспособным — на это потребуется немало усилий и финансовых вложений. Но с другой стороны, Гугл тоже когда-то был в позиции «новичка», а в кого он превратился спустя годы упорного труда — мы все прекрасно видим.
Другое дело с локальными поисковиками, которые вы можете организовать на собственном сайте.
Как создать небольшой локальный поисковик на своем сайте
Небольшой локальный поисковик — это более «приземленная» идея поисковой системы. И в некоторых ситуациях подобный поисковик будет работать эффективнее, чем глобальный Гугл с Яндексом. Например, когда вам нужно ограничить объем поиска. Допустим, у вас есть некий веб—ресурс, который ведет взаимоотношения с 500 поставщиками и 400 различными партнерами, плюс в качестве дополнительной информации вы используете еще 900 разных источников. Вы можете организовать собственную поисковую систему на 1000+ источников, чтобы вашим клиентам было проще искать нужную информацию, касающуюся ваших услуг или товаров. Если они будут это делать через глобальную поисковую систему, то в выдаче у них будет очень много «мусора», который, по сути, им никогда не пригодится. А ваша ПС даст именно те результаты, которые нужны вашим клиентам.
В качестве дополнения собственная тематическая ПС — это:
удобство поиска для ваших клиентов;
дополнительный способ монетизации вашего проекта;
много плюсов к вашему престижу, брендингу и узнаваемости.
Что самое интересное — подобные локальные системы организовать довольно просто. В сети есть масса готовых решений по этому поводу. Самое узнаваемое решение — это создать свой поисковик, используя поисковый потенциал Google. Для этого пройдите по ссылке.
Заключение
Теперь вы знаете, как можно создать свой поисковик. Если это будет глобальная поисковая система, то к этому нужно подготовиться финансово и морально. Если локальный поисковик на собственном сайте, то самый простой способ — это использовать готовое решение. При этом если вы с программированием на «ты», то для вас не составит труда создать свой собственный поисковик с нуля.
Как создать поисковую систему в интернете
 Опубликовано в Бизнес в интернете, Обо всем
Опубликовано в Бизнес в интернете, Обо всем  Теги: Бизнес в интернете, Стартап
Теги: Бизнес в интернете, Стартап
Создаем свой поисковик
Как создать свой поисковик? — спрашивает Коля К. из Киева.
Создать поисковик несложно — отвечаю я
Идея создания своей поисковой системы может кому-то показаться бредовой, хотя на самом деле это очень удобно.
Критиканы сразу же начинают возражать вот есть ведь яндекс, рамблер, тот же google. Зачем еще один?
Ответ лежит на поверхности.
— Во первых свою поисковую систему имеет смысл строить на ограниченом объеме выдачи. Допустим у вас есть 400 компаний поставщиков и 300 компаний партнеров. + на вашем рынке фигурирует еще 1000 тематических сайтов содержащих полезную информацию. Использование обычных ПС даст горы мусора в выдаче. Обработка в ручную для таких объемов в принципе невозможна. Вывод?
Нужна поисковая система проводящая поиск по ограниченному набору строго определенных сайтов
— Во вторых такой самостоятельно созданый поисковик является хорошей рекламной площадкой, которая может монетизироваться.
— В третьих вы определенно можете предоставить своим клиентам удобный и очень полезный сервис тематического поиска.
Ну и наконец в четвертых это вопрос брендинга. Компания способная создать поисковик всегда круче компании на это неспособной. А при учете того что большинство людей считает создание своей поисковой системы сложной, если не сказать неподъемной задачей, то ваш престиж растет до небес.
-Нужно сказать что благодаря современным технологиям достаточно нетривиальная задача разработки системы поиска вылилась в простое и лаконичное решение от команды Ашманова.
Система Flexum — cервис для создания поиска по группе сайтов.
Все гениальное просто. Пользуйтесь!
Как не надо делать сервисы и организовывать стартапы
Что русскому хорошо, то немцу похмелье. Новая биржа Индек убейся ап стену.
Тема продолжения сегодняшнего поста — что такое хороший сервис.
1. Простая регистрация. Не беспокойте меня активацией, не просите ввести 10 капч, не нужно генерить 20 полей данных, мне все равно на вашу безопасность, я хочу получить решение проблемы и если вы сделаете все красиво и быстро Вы останетесь с баблом, а я довольный
2. Чем проще — тем лучше. Хороший сервис позволяет делать 1-2 действия, но при этом офигенно. Я давно не пользуюсь ACDSee потому что она дрочь. Она умеет жарить яишницу и запускать ракеты, а я мечтаю о удобном просмотре картинок, тоже самое касается Nero. Из всего пакета 90% пользователей использует 2 программы, повторяю 2. остальное нафиг не надо.
3. Простота изменений интерфейса, самого интерфейса и интеграции системы с другими вот залог успеха. Я не хочу изучать ваш апи я хочу поставить на сайт одну строчку и получить полный автомат.
4. Не задавайте глупых вопросов. В ходе работы по косвенным данным о пользователе можно собрать достаточно информации чтобы снять тонну ненужных вопросов. Дайте человеку работать а не настраивать вашу офигенную систему.
Как и зачем я создал свой поисковик Pick: история создания и примеры кода
Поскольку Яндекс не захотел парсить мои сайты сославшись на то, что они не умеют обрабатывать контент в формате deflate мне захотелось разобраться в чем дело и попробовать написать свой поисковый сервис. Вообще служба техподдержки Яндекс оказалась для меня бесполезной, поскольку два дня Платоны доказывали мне, что сайты на Revolver CMF отдают битую кодировку. В то же время это был просто сжатый в deflate HTML. В итоге я решил написать свой индексатор, который умеет индексировать сжатый HTML и не только.
Создавать было решено антибюрократический Open Source поисковик, ранжирующий результаты в выдаче на основе голосов зарегистрированных пользователей без участия модерации.
Название мы с друзьями выбрали созвучно всем известной Picus Networks из мира компьютерной игры DeusEx. Осталось создать два алгоритма Pick для выполнения запросов и Picker для индексации контента.
Как создавался Pick
Можно было реализовать поисковую систему отдельно, но я использовал framework RevolveR, который предоставляет доступ к API работы с базой данных и ее кэширование, обработку POST и GET запросов с защитой, а также fetch API для динамических запросов.
А после интеграции Pick стал частью ядра. Скачать RevolveR CMF можно со страницы проекта GitHub.
Создаем индекс в базе данных
Очевидно, что нам нужен свой поисковый индекс, который будет храниться в базе данных. Для этого сформируем структуру на SBQ (structure based queries), которая хранится в файле /Kernel/Structures/DataBase.php:
Мы создали структуру будущей таблицы revolver_index, которую будут использовать модели для записи и хранения данных. Полям content , description и title назначаем полнотекстовый индекс для ускорения запросов SELECT, а для поля host укажем тип индекса simple (это поможет сделать быстрый поиск по всем индексированным ссылкам определённого ресурса).
Также у нас есть поля date и hash . Дата хранит последний момент индексации ресурса, а hash указывает на актуальность данных (если хэш заново полученной страницы не отличается от хранимого в БД значения, то обновление не выполняется).
Поле uri будет содержать полную ссылку страницы.
Теперь нам понадобится таблица в БД которая будет хранить рейтинги материалов в формате 5 звезд на основе голосов зарегистрированных пользователей (API для рейтингов есть и о том как оно работает чуть ниже).
Создадим еще одну структуру:
Таблица очень простая. Она хранит ID ресурса, ID пользователя и оценку.
Давайте зарегистрируем структуры в схеме базы данных:
Таблицы сформированы и описаны и нам осталось выполнить SBQ через API RevolveR CMF для создания этих таблиц в базе данных:
После выполнения этого кода в базе данных появится таблицы revolver__index и revolver__index_ratings, а мы сможем использовать API моделей для работы с ними.
Регистрируем сервис индексации и страницу поиска
В RevolveR CMF есть такое понятие как сервисы. Они используются для выполнения каких-то задач при обращении к ним с аргументами, но не имеют кэширования и не обрабатываются шаблоном.

Чтобы зарегистрировать сервис индексации просто пропишем параметры в файл /private/config.php:
Здесь все предельно просто. Type service указывает на то, что URL /picker/ будет служить обработчиком запросов, которые избегают систему кэширования фреймворка и игнорируют формирование шаблона.
Теперь сразу же зарегистрируем путь, который будет отображать страницу выполнения поисковых запросов к базе данных. Для этого в этом же файле добавим строки:
Параметр menu указывает на то, что мы отображаем пункт в главном меню, а type равное node указывает на то, что регистрируемый путь является узлом, который подвергается кэшированию по умолчанию и может быть подключен к шаблону.
Мы зарегистрировали 2 URI и теперь нужно подключить обработчики сервиса и узла. Поскольку было решено сделать Pick компонентом ядра, мы модернизируем файл /Kernel/Modules/Switch.php:
Этими строками мы создали подключение NodePick и RoutePicker, которые будут содержать основные исходные коды алгоритмов поискового движка. Нам достаточно всего 2 файла.
Индексатор URL Picker
Чтобы проиндексировать какой либо сайт мы должны иметь доступ по сети и уметь парсить сайты. Для этого была использована стандартная библиотека cURL для PHP.
Вот исходный код функции, которая открывает URL и достает содержимое страницы:
Работает алгоритм очень просто. При передаче URL происходит открытие web-страницы и обработчик проверяет корректность SSL соединения. Далее мы смотрим что тип документа характеризует ценные для нас данные HTML или Application xHTML, а также проверяем код ответа сервера. Все, что препятствует получению данных приводит к возврату значения null .
Дополнительно проверяем, что отдаваемый сервером контент может быть сжатым в gzip, deflate или compress.
Теперь нам нужна функция для работы с самим полученным документом. Мы должны извлечь текстовое содержимое без тегов и получит все ссылки на странице:
Здесь вы могли заметить еще две вспомогательные функции. Одна из них, getMetaTags() , извлекает из HTML содержимого все мета теги, а другая, getHost() , распаковывает URL и возвращает host .
Исходный код функций получения meta тегов и хоста:
При этом алгоритм рассчитан таким образом, что превращает все относительные ссылки документа в абсолютные и фильтрует бесполезные ссылки содержащие хэш фрагменты.
Мы собираем только ссылки на этот же ресурс для того, чтобы crawler не убежал слишком далеко, а корректно закончил индексацию всего ресурса.
Поддержка Robots.txt
Не все ссылки бывают полезны и не все страницы несут какую либо смысловую нагрузку. Чтобы профильтровать информацию добавим поддержку подгрузки файла robots.txt:
Загружаем мы robots.txt только единожды за проход и сохраняем полученный массив правил в переменную:
Далее нам понадобится обработчик правил robots.txt. Для этого используем функцию:
При передаче аргумента $xurl происходит сверка с правилами robots.txt и функция возвращает либо true либо null , что символизирует разрешение на добавление в базу данных.
Обработка индекса
Чтобы базу индекса могли индексировать только администраторы и писатели ресурса мы обернем код в проверку роли и добавим фильтр запроса. Черпать аргумент будем из контроллера переменных SV[‘g’] .
Таким образом мы получаем значение host из GET запроса и можем приступить к созданию поискового индекса.
Обработчик индекса поисковой базы
Изначально мы делаем запрос с проверкой наличия искомого URL в базе данных. Если индекс уже существует — просто выясняем свежий ли он, а если его нет, то запишем результат в базу данных. Попутно мы делаем запрос к robots.txt, распаковываем ссылки и метаданные из документов.
Отвечает за это следующая функция:
После записи основной страницы, с которой начинается индексация, происходит обработка всех URL, которые она содержит. Здесь работают две модели:
Модель GET проверяет наличие адреса в индексе.
Модель SET использует автоматическое чтение схемы БД из SBQ и выполняет запрос записи или обновления автоматически.
Алгоритм использует timeout .5 секунды между запросами по ссылкам и не нагружает ресурсы, когда происходит сканирование.
Стоит обратить внимание на hash . В данном случае мы сначала распаковываем тело документа, а затем избавляемся от всех тегов. MD5 полученного текста мы будем использовать для проверки актуальности данных.
Если страницы изменялись, то алгоритм подметит это при проверке:
Для того, чтобы не загружать заново обработанные в процессе прохода ссылки мы передаем аргумент &$indexed по ссылке и на каждую итерацию заполняет глобальный массив ссылками при этом проверяя, что url нет в списке.
Выполняем поисковые запросы
Обладая собственным индексом мы можем приступить к созданию самого сервиса поиска. Для этого мы применим экспертную модель работающую на основе SBQ:
Здесь мы не используем классический LIKE MySQL запрос, а применяем RegExp поиска по базе данных.
Также не забудем, что нам нужно реализовать сортировку по рейтингу, а для этого мы получаем все рейтинги связанного url.
Сам аргумент qs мы будем брать из контроллера переменных SV[‘p’] (стек POST запросов):
Также в этом коде происходит сверка значения captcha, которая усиливает надёжность и предотвращает спам запросы с удаленных серверов.
Сама форма строится с использованием Form API и ее структура (FS) выглядит следующим образом:
К форме подключен автоматический перевод заголовков полей и меток, а сама структура формы должна быть передана в CLASS:
Теперь наша форма работает и умеет передавать пост параметр динамически используя fetch запрос, а каптча предотвращает перегрузку и генерацию запросов ботами.
Алгоритм ранжирования
Сначала мы отсортируем результаты по рейтингу, а дальше перетасуем их в пределах своей цифры рейтинга:
Пишем обработку сниппета
Нам осталось передать поля выбранные предварительным регулярным выражением из базы данных и генерировать сниппет поисковой выдачи.
Мы будем выбирать фрагмент из текста и помечать совпадение запросу:
Здесь пришлось повозиться. Простой подход совсем не подразумевал, что PHP начнет обрабатывать UTF-8 корректно, но я смог добиться работы с русским и английским языками.
Это обычный список возможностью выбора одного из 5ти вариантов голосования по шкале звезд. Голосовать мы предоставим возможность только зарегистрированным пользователям не более одно раза за ссыку, что исключит факт накрутки.

Сам JavaScript для обработки голоса находится в файле /Interface/interface.js и он также подключен к другим материалам подвергаемым голосованию(новости, страницы блога, страницы форума, комментарии и так далее).
Отдельно обратим внимание на обработку голосования. В Revolver CMF уже есть функциональность для голосования и она располагается в сервисе в файле /Kernel/Routes/RouteRating.php.
Нам нужно просто добавить HTML разметку хэндлера для, которая будет инициализировать по клику функцию голосования:
Это обычный список возможностью выбора одного из 5ти вариантов голосования по шкале звезд. Голосовать мы предоставим возможность только зарегистрированным пользователям не более одно раза за ссыку, что исключит факт накрутки.
Сам JavaScript для обработки голоса находится в файле /Interface/interface.js и он также подключен к другим материалам подвергаемым голосованию (новости, страницы блога, страницы форума, комментарии и так далее).
Отдельно обратим внимание на обработку голосования. В Revolver CMF уже есть функциональность для голосования и она располагается в сервисе в файле /Kernel/Routes/RouteRating.php.
Handler голосования автоматически подключается к fetch , а нам осталось только добавить параметр $tpe и прописать таблицу для которой устанавливаются голоса:
Будущее Pick
В будущем, в Revolver CMF будет интегрирована опция связывания индексов и поисковая база расшириться результатами других инсталляций.
Это мне кажется идеально. Во первых, пользователи сами решают какие сайты индексировать, а во вторых положение в поисковой выдаче — это продукт оценки живых людей, которые выполняют поисковые запросы.
Выдачи с разных сайтов могут отличаться и выдача будет формироваться на основе рейтингов разных включенных в индекс ресурсов.
Здесь найдется и место для нейронной сети, чтобы было интереснее и круче.
Запросы будут монетизироваться. Стоимость использования внешнего индекса будет определяться мощностью поисковой базы (размером тематического индекса) и частотой запросов. Также есть мысли о создании собственной валюты (не крипто), которую можно будет приобретать и выводить через основной сайт проекта Pick.
Скачать дистрибутив RevolveR CMF с поисковой системой Pick можно со страницы проекта GitHub.
Сейчас индекс поиска официального сайта почти пустой, но протестировать поисковую систему можно здесь.
Поисковые технологии или в чем загвоздка написать свой поисковик
Когда-то давно взбрела мне в голову идея: написать свой собственный поисковик. Было это очень давно, тогда я еще учился в ВУЗе, мало чего знал про технологии разработки больших проектов, зато отлично владел парой десятков языков программирования и протоколов, да и сайтов своих к тому времени было понаделано много.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Здесь я в первый раз, публично, опишу то, что было сделано лично мной. Думаю, многим будет интересно как же работают Яндекс, Google и почти все мне известные поисковики изнутри.
Есть много задач при построении таких систем, которые почти нереально решить в общем случае, однако с помощью некоторых ухищрений, придумок и хорошего понимания как работает железячная часть Вашего компьютера можно серьезно упростить. Как пример – пересчет PR, который в случае нескольких десятков миллионов страниц уже невозможно поместить в самой большой оперативной памяти, особенно если Вы, как и я, жадны до информации, и хотите кроме 1 цифры хранить еще много полезностей. Другая задача – хранение и обновление индекса, как минимум двумерной базы данных, в которой конкретному слову сопоставляется список документов, на которых оно встречается.
Просто вдумайтесь, Google хранит, по одной из оценок, более 500 миллиардов страниц в индексе. Если бы каждое слово встречалось на 1 странице только 1 раз, и на хранение этого надо было 1 байт – что невозможно, т.к. надо хранить хотя бы id страницы – уже от 4 байт, так вот тогда объем индекса бы был 500гб. В реальности одно слово встречается на странице в среднем до 10 раз, объем информации на вхождение редко когда меньше 30-50 байт, весь индекс увеличивается в тысячи раз… Ну и как прикажите это хранить? А обновлять?
Ну вот, как это все устроено и работает, я буду рассказывать планомерно, так же как и про то как считать PR быстро и инкрементально, про то как хранить миллионы и миллиарды текстов страниц, их адреса и быстро искать по адресам, как организованы разные части моей базы данных, как инкрементально обновлять индекс на много сотен гигов, ну и наверное расскажу как сделать обучающийся алгоритм ранжирования.
На сегодня объем только индекса, по которому происходит поиск — 57Gb, увеличивается каждый день примерно на 1Gb. Объем сжатых текстов – 25Gb, ну и я храню кучу другой полезной инфы, объем которой очень трудно посчитать из-за ее обилия.
Custom Search Engine (CSE) — мощный инструмент профессионального сорсера. С его помощью можно создать поисковый движок, который будет находить нужных вам кандидатов именно в тех источниках, которые вы укажете.
Основатель кадрового агентства Tech-recruiter и Академии IT-рекрутинга Язиля Насибуллина объяснила, как создать и настроить CSE. А для тех, кто не хочет возиться с настройками, Язиля рассказала про готовые движки для поиска на GitHub, LinkedIn, Behance, Хабр Карьере и в других источниках.
О чем вы узнаете
⭐ Что такое CSE и зачем он нужен
⭐ Как создать поисковый движок в стандартном интерфейсе
⭐ Как создать поисковый движок в новом интерфейсе
⭐ Настройка: как добавить запрос
⭐ Настройка: как добавить уточнения
⭐ Настройка: как добавить синонимы
⭐ Как искать с помощью CSE
⭐ Где взять готовые поисковые движки

Язиля Насибуллина, основатель агентства Tech-recruiter, автор канала IT-рекрутинг
CSE — это инструмент от компании Гугл, который позволяет настроить поиск под свои задачи:
- выбрать ресурсы или даже разделы сайтов, которые нужно сканировать;
- искать в определенных регионах;
- задать синонимы, которые будут автоматически подставляться в запрос;
- нацелить поиск на конкретные типы файлов;
- и многое другое, о чем я еще расскажу.
Владельцы сайтов пользуются CSE, чтобы организовать внутренний поиск по своим ресурсам. А сорсеры применяют этот инструмент, чтобы экономить время и получать максимально качественные выдачи.
Когда полезен Custom Search Engine:
- Не хватает возможностей X-ray и внутреннего поиска по сайту. Например, можно создать поисковый движок для GitHub и LinkedIn, используя операторы, которые работают только внутри CSE. Кроме того, поисковый запрос в Гугле ограничен 32 словами — Custom Search Engine позволяет обойти этот лимит.
- Нужно ограничить поиск на определенных сайтах, добавить или исключить конкретные регионы. В стандартном поиске Гугла это сделать сложнее — часто в выдачу попадают нерелевантные результаты, несмотря на оператор «-».
- Надо настроить поиск для начинающих ресечеров и рекрутеров. Например, опытный сорсер создает набор движков, которыми будут пользоваться его коллеги — просто вбивать название должности и получать резюме. Но нужно учитывать, что один и тот же запрос может давать разные результаты в зависимости от настроек и страны нахождения пользователя.
- Необходимо найти редкого эксперта с уникальным стеком — можно создать под него отдельный движок. И наоборот: чем стандартнее запрос и больше кандидатов на рынке, тем меньше нужны все эти «сорсинговые штучки».
Как создать поисковый движок
Зайдите в сервис «Программируемая поисковая система» и выберите, в каком интерфейсе будете работать — в стандартном или новом.
Создание движка в стандартном интерфейсе
Здесь нужно указать:
- сайты для поиска;
- язык;
- название системы — желательно осмысленное, чтобы быстро находить нужный вариант, когда у вас будет набор движков на все случаи жизни.
Например, создаю систему для поиска по профилям пользователей на LinkedIn:

Здесь я указываю адрес linkedin.com/in, где хранятся личные страницы пользователей, и использую символ *, чтобы искать по всем доменам соцсети. В поле «Язык» можно выбрать язык выдаваемого профиля, но я не советую этого делать. Даже если вы ищете русскоязычных разработчиков, то стоит помнить — это международный сайт, поэтому многие пользователи заполняют профиль на английском.
Как только докажу, что я не робот, и нажму на кнопку «Создать», меня перебросит на следующую страницу со ссылкой на поисковую систему — движок уже будет работать.
Создание движка в новом интерфейсе
Сначала нужно выбрать название системы и указать сайты, по которым надо искать. Потом этот список сайтов можно будет изменить в настройках. Например, создам движок для Хабр Карьеры:
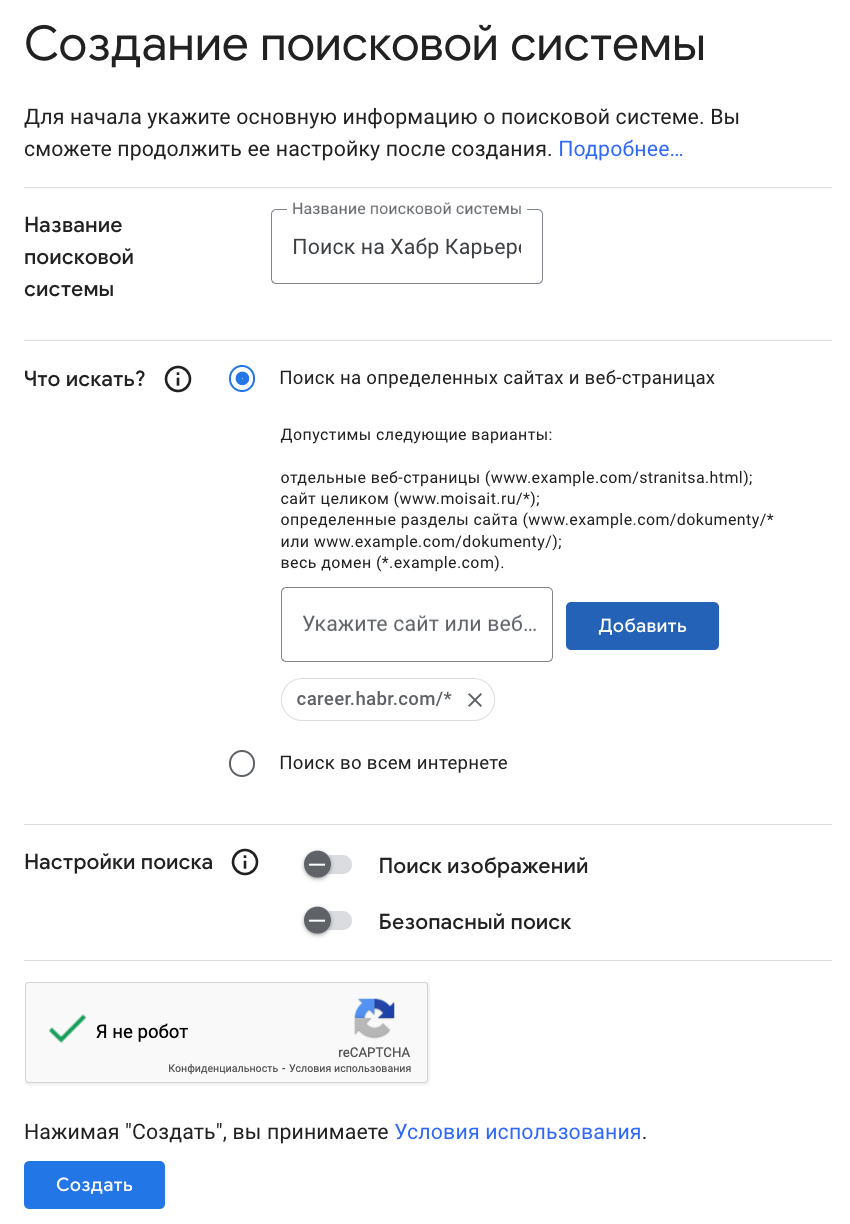
Кстати, можно не ограничиваться конкретными сайтами, а задать целые доменные зоны, например так: *.ru или *.com. Когда я нажму кнопку «Создать», мне предложат настроить систему:
- Выбрать регион поиска — разрешается указать только один. По моему опыту, лучше оставить «Все регионы», а зоны поиска корректировать с помощью доменов и ключевых слов.
- Добавить в поиск новые сайты.
- Исключить из поиска какие-то адреса. Можно убрать из области поиска не только сайт целиком, но и отдельные веб-страницы или разделы (www.example.com/jobs/*), а также весь домен (*.example.com).
Я настраиваю поиск кандидатов по Хабр Карьере, так что исключу разделы с вакансиями, курсами и информацией о компаниях:

Продвинутая настройка CSE
Предупрежу сразу: все настройки я буду проводить в стандартном интерфейсе — так привычнее. Кроме того, на момент выхода этой статьи новая версия панели управления считается предварительной — многое еще может поменяться. В целом, различия между версиями косметические. Если научиться работать в старом интерфейсе, то будет легко найти аналогичные разделы в новой панели.
Самые полезные настройки находятся в подразделе «Функции в результатах поиска» раздела «Изменение поисковой системы»:
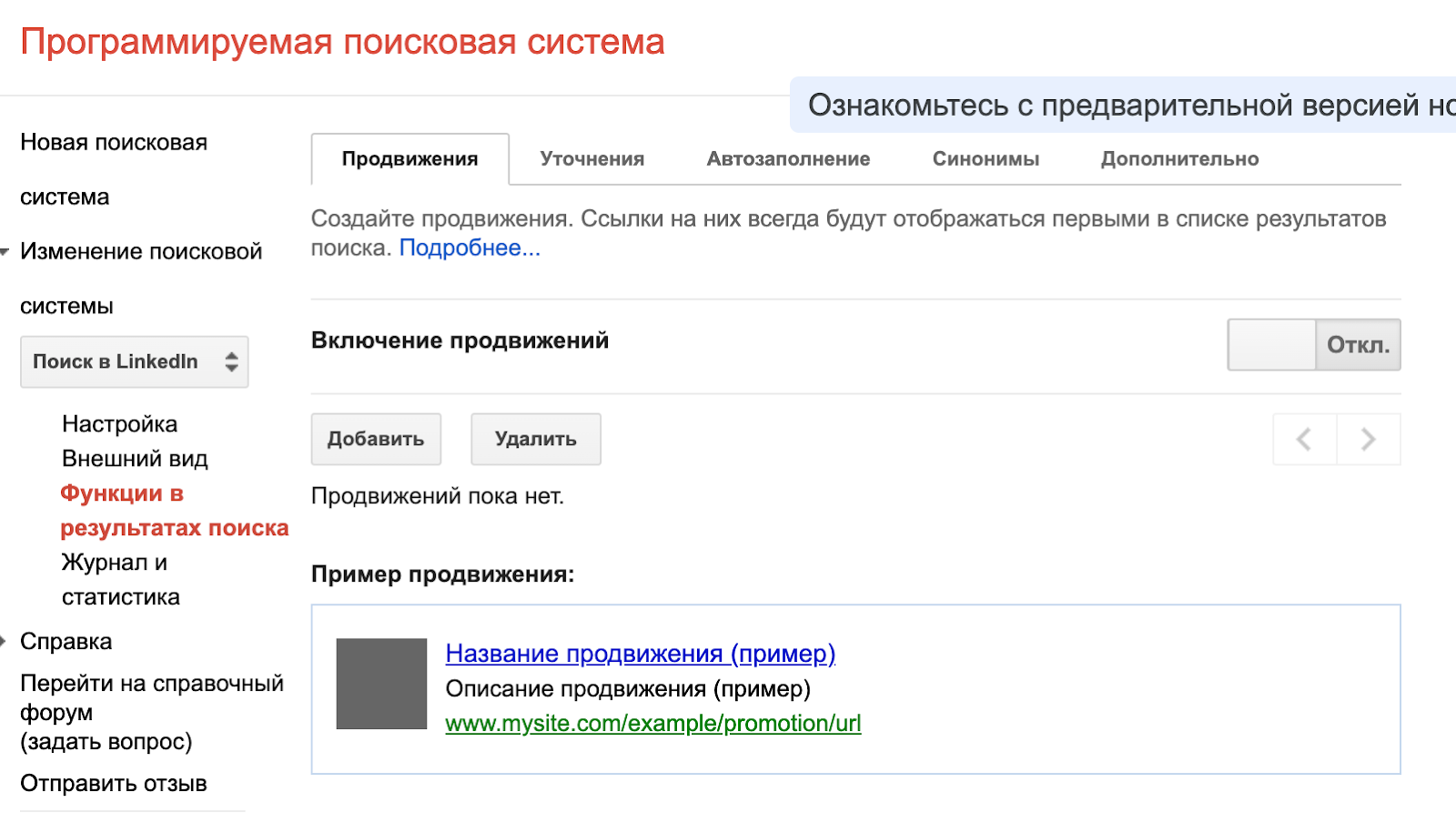
Добавление запроса
Можно прописать дополнительные запросы, которые будут включаться в поиск автоматически. Для этого:
- В разделе «Функции в результатах поиска» нужно перейти во вкладку «Дополнительно».
- Открыть там раздел «Настройки веб-поиска».
- В поле «Добавление запроса» вписать фразу, которая будет подставляться автоматически — писать ее при каждом запросе не придется.
Например, сделаю движок для поиска файлов в формате pdf и docx — предполагается, что это будут резюме. Использую оператор «filetype»:

Уточнения
Усовершенствую движок для LinkedIn — настрою поиск так, чтобы отдельно показывались профили кандидатов с контактными данными. Это можно сделать с помощью уточнений.
В разделе «Функции в результатах поиска» нужно перейти во вкладку «Уточнения», нажать на кнопку «Добавить» и создать дополнительные условия поиска. Результаты по каждому условию будут выводиться на отдельную вкладку.
Например, добавлю поиск по всем профилям, в которых есть почта на gmail.com и ссылка на телеграм:

Синонимы
Вручную прописывать десятки синонимов через OR при каждом запросе утомительно. В CSE для каждого ключевого слова можно задать набор синонимов, которые будут добавляться автоматически.
Для этого надо:
- Перейти в раздел «Функции в результатах поиска», а оттуда — во вкладку «Синонимы».
- Нажать на кнопку «Добавить».
- На верхней строчке написать ключевое слово, а на нижней — набор синонимов к нему.

Как искать с помощью CSE
Если перейдете по ссылке вашего поискового движка, то вы увидите обычную поисковую строку и больше ничего. Не нужно писать «site:» и название сайта для поиска — этот запрос скрыт «под капотом» системы, как и остальные настройки. А в остальном здесь работают все стандартные операторы, в том числе: OR, — , “ ”.
Например, так будет выглядеть запрос в движке для LinkedIn на поиск PHP-разработчиков из Москвы:

Сейчас движок сканирует всю страницу пользователя целиком. Но существуют операторы, которые позволяют ориентировать его поиск по конкретным блокам и элементам профиля. Например, в LinkedIn, Xing, ResearchGate, Google Scholar и Speakerhub работают такие операторы:
- «more:p:person-jobtitle:» — поиск по позиции;
- «more:p:person-org:» — поиск по компании или учебному заведению;
- «more:p:person-role:» — поиск в заголовке страницы.
А у GitHub есть свой оператор, который обращается к строке «о себе» — «more:p:metatags-og_description:».
Готовые поисковые движки
Вам не обязательно создавать движок самостоятельно — можно воспользоваться готовыми вариантами, если они подходят под ваши задачи. Например, поисковики от Ирины Шамаевой и Балажа Парочай:
- XING,
- HackerRank,
- MeetUp,
- ResearchGate.
Мои поисковые системы:
- GitHub.
- Behance — поиск резюме. Настройки самые простые: в сайтах для поиска я указала «behance.net/*/resume» — раздел, где хранятся резюме пользователей.
- Хабр Карьера. Здесь к каждому допросу автоматически добавляется фраза «последний визит», чтобы искать только по личным страницам пользователей.
- Европейский LinkedIn. Я занимаюсь международным рекрутингом и ищу кандидатов по всей Европе. Для этого сделала движок поиска по доменным областям LinkedIn тех стран, которые мне интересны.
Главное про CSE
- Custom Search Engine — инструмент для создания собственных поисковых систем. С его помощью сорсер экономит время и получает более релевантные результаты.
- Принцип простой: вы один раз проводите настройку, убирая повторяющиеся части запросов и синонимы «под капот», а потом используете систему, чтобы находить подходящих кандидатов.
- Чтобы часть запроса подставлялась автоматически:
- перейдите во вкладку «Дополнительно» в разделе «Функции в результатах поиска»;
- откройте раздел «Настройки веб-поиска»;
- в поле «Добавление запроса» впишите нужную фразу.
- Можно добавлять или исключать из поиска целые доменные зоны, сайты целиком, отдельные страницы и разделы.
- Настройка «синонимы» позволяет задать набор синонимов, которые будут автоматически добавляться к запросу для каждого ключевого слова.
- С помощью уточнений вы можете создать вкладки с результатами ответов на дополнительные запросы. Например, это удобно, когда нужно посмотреть, у кого из найденных кандидатов есть контактные данные в профиле.