Инфиксные, префиксные и постфиксные выражения¶
Когда вы записываете арифметическое выражение вроде B * C, то его форма
предоставляет вам достаточно информации для корректной интерпретации. В
данном случае мы знаем, что переменная B умножается на переменную C,
поскольку оператор умножения * находится в выражении между ними. Такой
тип записи называется инфиксной, поскольку оператор расположен между
(in between) двух операндов, с которыми он работает.
Рассмотрим другой инфиксный пример: A + B * C. Операторы + и * по-прежнему
располагаются между операндами, но тут уже есть проблема. С какими именно операндами
они будут работать? + работает с A и B или * принимает B и C? Выражение
выглядит неоднозначно.
Фактически, вы можете читать и писать выражения такого типа долгое время,
и они не будут вызывать у вас вопросов. Причина в том, что вы кое-что знаете
о + и *. Каждый оператор имеет свой приоритет. Операторы с высоким
приоритетом используются прежде операторов с низким. Единственной вещью,
которая может изменить порядок приоритетов, являются скобки. Для
арифметических операций умножение и деление стоят выше сложения и вычитания.
Если появляются два оператора одинакового приоритета, то используются порядок
слева направо, или их ассоциативность.
Давайте интерпретируем вызвавшее затруднение выражение A + B * C, используя
приоритет операторов. B и C перемножаются первыми, затем к результату
добавляется A. (A + B) * C заставит выполнить сложение A и B перед умножением.
В выражении A + B + C по очерёдности (через ассоциативность) первым будет
вычисляться самый левый +.
Хотя это очевидно для вас, помните: компьютер нуждается в
точном знании того, как и в какой последовательности вычисляются операторы.
Одним из способов записи выражения, гарантирующим, что не возникнет путаницы
по отношению к порядку операций, является создание того, что называется
выражением с полностью расставленными скобками. Такой тип выражения
использует пару скобок для каждого оператора. Скобки диктуют порядок операций,
так что здесь не возникает многозначности. Так же отпадает необходимость
помнить правила расстановки приоритетов.
Выражение A + B * C + D может быть переписано как ((A + (B * C)) + D) с целью
показать, что умножение происходит в первую очередь, а затем следует крайнее
левое сложение. A + B + C + D перепишется в (((A + B) + C) + D), поскольку
операции сложения ассоциируются слева направо.
Существует ещё два очень важных формата выражений, которые на первый взгляд
могут показаться вам неочевидными. Рассмотрим инфиксную запись A + B. Что
произойдёт, если мы поместим оператор перед двумя операндами? Результирующее
выражение будет + A B. Также мы можем переместить оператор в конец, получив
A B +. Всё это выглядит несколько странным.
Эти изменения позиции оператора по отношению к операндам создают два новых
формата — префиксный и постфиксный. Префиксная запись выражения требует,
чтобы все операторы предшествовали двум операндам, с которыми они работают.
Постфиксная, в свою очередь, требует, чтобы операторы шли после соответствующих
операндов. Несколько дополнительных примеров помогут прояснить этот момент
(см. таблицу 2).
A + B * C в префиксной нотации можно переписать как + A * B C. Оператор умножения
ставится непосредственно перед операндами B и C, указывая на приоритет * над +.
Затем следует оператор сложения перед A и результатом умножения.
В постфиксной записи выражение выглядит как A B C * +. Порядок операций вновь
сохраняется, поскольку * находится непосредственно после B и C, обозначая, что
он имеет приоритет выше следующего +. Хотя операторы перемещаются и теперь
находятся до или после соответствующих операндов, порядок последних по отношению
друг к другу остаётся в точности таким, как был.
| Инфиксная запись | Префиксная запись | Постфиксная запись |
|---|---|---|
| A + B | + A B | A B + |
| A + B * C | + A * B C | A B C * + |
А сейчас рассмотрим инфиксное выражение (A + B) * C. Напомним, что в
этом случае запись требует наличия скобок для указания выполнить сложение
перед умножением. Однако, когда A + B записывается в префиксной форме, то
оператор сложения просто помещается перед операндами: + A B. Результат
этой операции является первым операндом для умножения. Оператор умножения
перемещается в начало всего выражения, давая нам * + A B C. Аналогично, в
постфиксной записи A B + явно указывается, что первым происходит сложение.
Умножение может быть выполнено для получившегося результата и оставшегося
операнда C. Соответствующим постфиксным выражением будет A B + C *.
Рассмотрим эти три выражения ещё раз (см. таблицу 3).
Происходит что-то очень важное. Куда ушли скобки? Почему они не нужны нам в
префиксной и постфиксной записи? Ответ в том, что операторы больше не являются
неоднозначными по отношению к своим операндам. Только инфиксная запись требует
дополнительных символов. Порядок операций внутри префиксного и постфиксного
выражений полностью определён позицией операторов и ничем иным. Во многом именно
это делает инфиксную запись наименее желательной нотацией для использования.
| Инфиксное выражение | Префиксное выражение | Постфиксное выражение |
|---|---|---|
| (A + B) * C | * + A B C | A B + C * |
Таблица 4 демонстрирует некоторые дополнительные примеры
инфиксных выражений и эквивалентных им префиксных и постфиксных записей.
Убедитесь, что вы понимаете, почему они эквивалентны с точки зрения порядка
выполнения операций.
| Инфиксное выражение | Префиксное выражение | Постфиксное выражение |
|---|---|---|
| A + B * C + D | + + A * B C D | A B C * + D + |
| (A + B) * (C + D) | * + A B + C D | A B + C D + * |
| A * B + C * D | + * A B * C D | A B * C D * + |
| A + B + C + D | + + + A B C D | A B + C + D + |
Преобразование инфиксного выражения в префиксное и постфиксное¶
До сих пор мы использовали специальные методы для преобразования между
инфиксными выражениями и эквивалентными им префиксной и постфикской
записями. Как вы можете ожидать, существуют алгоритмические способы
выполнения таких преобразований, позволяющие корректно трансформировать
любое выражение любой сложности.
Первой из рассматриваемых нами техник будет использование идеи полной
расстановки скобок в выражении, рассмотренной нами ранее. Напомним, что
A + B * C можно записать как (A + (B * C)), чтобы явно показать приоритет
умножения перед сложением. Однако, при более близком рассмотрении вы увидите,
что каждая пара скобок также отмечает начало и конец пары операндов с
соответствующим оператором по середине.
Взгляните на правую скобку в подвыражении (B * C) выше. Если мы передвинем
символ умножения с его позиции и удалим соответствующую левую скобку, получив
B C *, то произойдёт конвертирование подвыражение в постфиксную нотацию.
Если оператор сложения тоже передвинуть к соответствующей правой скобке и удалить
связанную с ним левую скобку, то результатом станет полностью постфиксное выражение
(см. рисунок 6).
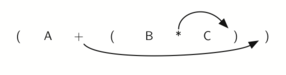
Рисунок 6: Перемещение операторов вправо для постфиксной записи
Если мы сделаем тоже самое, но вместо передвижения символа на позицию к правой
скобке, сдвинем его к левой, то получим префиксную нотацию
(см. рисунок 7). Позиция пары скобок на самом деле является
ключом к окончательной позиции заключённого между ними оператора.
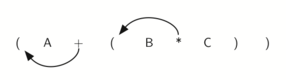
Рисунок 7: Перемещение операторов влево для префиксной записи.
Таким образом, при преобразовании выражения (неважно, насколько сложного) в
префиксную или постфиксную запись для установления порядка выполнения операций
используется полная расстановка скобок. Затем находящийся внутри
них оператор передвигается на крайнюю левую или крайнюю правую позицию — в зависимости от
того, префиксную или постфиксную запись вы хотите получить.
Вот более сложное выражение: (A + B) * C — (D — E) * (F + G).
Рисунок 8 демонстрирует его преобразование в постфиксный
и префиксный виды.
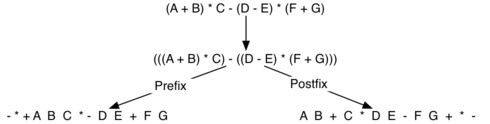
Рисунок 8: Преобразование сложного выражения к префиксной и постфиксной записи.
Обобщённое преобразование из инфиксного в постфиксный вид¶
Нам необходимо разработать алгоритм преобразования любого инфиксного выражения
в постфиксное. Для этого посмотрим ближе на сам процесс конвертирования.
Рассмотрим ещё раз выражение A + B * C. Как было показано выше, его постфиксным
эквивалентом является A B C * +. Мы уже отмечали, что операнды A, B и C остаются
на своих местах, а местоположение меняют только операторы. Ещё раз взглянем на
операторы в инфиксном выражении. Первым при проходе слева направо нам попадётся +.
Однако, в постфиксном выражении + находится в конце, так как следующий оператор,
*, имеет приоритет над сложением. Порядок операторов в первоначальном выражении
обратен результирующему постфиксному выражению.
В процессе обработки выражения операторы должны где-то храниться, пока не найден
их соответствующий правый операнд. Также порядок этих сохраняемых операторов может
быть обратным (из-за их приоритета), как в данном примере со сложением и умножением.
Поскольку оператор сложения, появляющийся перед оператором умножения, имеет
более низкий приоритет, то он должен появиться после использования последнего.
Из-за такого обратного порядка имеет смысл рассмотреть использование стека для хранения
операторов до тех пор, пока они не понадобятся.
Что насчёт (A + B) * C? Напомним его постфиксный эквивалент: A B + C *.
Повторимся, что обрабатывая это инфиксное выражение слева направо, первым мы
встретим +. В этом случае, когда мы увидим *, + уже будет помещён в результирующее
выражение, поскольку имеет преимущество над * в силу использования скобок. Теперь
можно приступить к рассмотрению работы алгоритма преобразования. Когда мы
видим левую скобку, то сохраняем её как знак, что должен будет появиться другой
оператор с высоким приоритетом. Он будет ожидать, пока не появится соответствующая
правая скобка, чтобы отметить его местоположение (вспомните технику полной расстановки
скобок). После появления правой скобки оператор выталкивается из стека.
Поскольку мы сканируем инфиксное выражение слева направо, то для хранения операторов будем использовать
стек. Это предоставит нам обратный порядок, который был
отмечен в первом примере. На вершине стека всегда будет последний сохранённый
оператор. Когда бы мы не прочитали новый оператор, мы должны сравнить его по
приоритету с операторами в стеке (если таковые имеются).
Предположим, что инфиксное выражение есть строка токенов, разделённых пробелами.
Токенами операторов являются *, /, + и — вместе с правой и левой скобками, ( и ).
Токены операндов — это однобуквенные идентификаторы A, B, C и так далее.
Следующая последовательность шагов даст строку токенов в постфиксном порядке.
- Создать пустой стек с названием opstack для хранения операторов.
Создать пустой список для вывода. - Преобразовать инфиксную строку в список, используя строковый метод
split. - Сканировать список токенов слева направо.
- Если токен является операндом, то добавить его в конец выходного
списка. - Если токен является левой скобкой, положить его в opstack.
- Если токен является правой скобкой, то выталкивать элементы из
opstack пока не будет найдена соответствующая левая скобка.
Каждый оператор добавлять в конец выходного списка. - Если токен является оператором *, /, + или -, поместить его в
opstack. Однако, перед этим вытолкнуть любой из операторов, уже
находящихся в opstack, если он имеет больший или равный
приоритет, и добавить его в результирующий список.
- Если токен является операндом, то добавить его в конец выходного
#. Когда входное выражение будет полностью обработано, проверить opstack.
Любые операторы, всё ещё находящиеся в нём, следует вытолкнуть и добавить в конец
итогового списка.
Рисунок 9 демонстрирует алгоритм преобразования, работающий
над выражением A * B + C * D. Заметьте, что первый оператор * удаляется до того,
как мы встречаем оператор +. Также + остаётся в стеке, когда появляется второй *,
поскольку умножение имеет приоритет перед сложением. В конце инфиксного выражения
из стека дважды происходит выталкивание, удаляя оба оператора и помещая + как
последний элемент в результирующее постфиксное выражение.
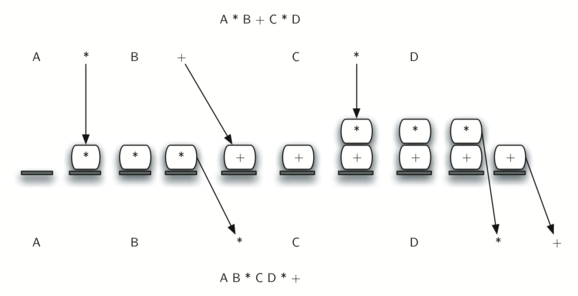
Рисунок 9: Преобразование A * B + C * D в постфиксную запись
Чтобы закодировать алгоритм на Python, мы будем использовать словарь под
именем prec для хранения значений приоритета операторов. Он связывает каждый
оператор с целым числом, которые можно сравнивать с числами других операторов, как уровень
приоритетности (для этого мы произвольно выбрали целые числа 3, 2 и 1). Левая скобка
получит самое низкое значение. Таким образом, любой сравниваемый с ней оператор будет
иметь приоритет выше и располагаться над ней. Строка 15 определяет, что операнды могут
быть любыми символами в верхнем регистре или цифрами. Полная функция преобразования
показана в ActiveCode 8.
Преобразование инфиксного выражения в постфиксное (intopost)
Ниже показаны ещё несколько примеров выполнения этой функции.
>>> infixtopostfix("( A + B ) * ( C + D )") 'A B + C D + *' >>> infixtopostfix("( A + B ) * C") 'A B + C *' >>> infixtopostfix("A + B * C") 'A B C * +' >>>
Постфиксные вычисления¶
В последнем примере использования стека мы рассмотрим вычисление выражения,
которое уже находится в постфиксной форме. В этом случае структурой для решения задачи вновь выбран
стек. Однако, поскольку вы сканируете
постфиксное выражение, ждать своей очереди должны уже операнды, а не операторы,
в противоположность алгоритму выше. Ещё один способ думать об этом решении:
когда на входе обнаружится оператор, для вычисления будут использованы два
самых последних операнда.
Чтобы разобраться в этом более детально, рассмотрим постфиксное выражение 4 5 6 * +.
Сканируя его слева направо, вы прежде всего натолкнётесь на операнды 4 и 5.
Что с ними делать неизвестно, пока не известен следующий символ. Помещение
каждого из них в стек гарантирует их доступность на случай, если следующим
появится оператор.
В нашем случае следующий символ — ещё один операнд. Так что мы, как и раньше,
помещаем его в стек и проверяем следующий символ. Видим оператор *,
что означает перемножение двух самых последних операндов. Сделав
выталкивание из стека дважды, получим необходимые множители, а затем выполним умножение
(в данном случае результатом будет 30).
Теперь можно обработать полученное значение, поместив его обратно в стек,
чтобы оно могло использоваться в качестве операнда для последующих операторов в
выражении. Когда будет обработан последний оператор, в стеке останется только одно
значение. Выталкиваем его и возвращаем как результат выражения.
Рисунок 10 демонстрирует содержание стека на протяжении всего
процесса вычисления выражения из примера.
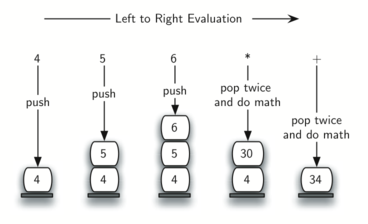
Рисунок 10: Содержание стека в процессе вычисления
На рисунке 11 показан несколько более сложный
пример: 7 8 + 3 2 + /. Здесь есть два момента, которые стоит отметить.
Первый: размер стека возрастает, уменьшается и вновь растёт в процессе вычисления
подвыражений. Второй: обрабатывать оператор деления нужно очень внимательно.
Напомним, что операнды в постфиксном выражении идут в их изначальном порядке,
поскольку постфикс меняет только положение оператора. Когда операнды деления
выталкиваются из стека, они находятся в обратной последовательности. Поскольку
деление не коммутативный оператор (другими словами, (15/5) не то же
самое, что (5/15)), мы должны быть уверены, что порядок операндов не изменился.
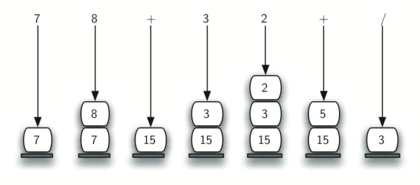
Рисунок 11: Более сложный пример вычисления
Предположим, что постфиксное выражение — это строка токенов, разделённых пробелами.
Операторами являются *, /, + и -, а под операндами понимаются одноразрядные целые
значения. На выходе будет целочисленный результат.
- Создаём пустой стек под названием operandStack.
- Преобразовываем строку в список, используя строковый метод split.
- Сканируем список токенов слева направо.
- Если токен является операндом, то преобразовываем его из строки в целое
число и помещаем значение в operandStack. - Если токен является оператором *, /, + или -, то он нуждается в двух
операндах. Производим выталкивание из operandStack дважды. Сначала
вытолкнется второй операнд, а затем — первый. Выполняем арифметическую
операцию и помещаем результат обратно в operandStack.
- Если токен является операндом, то преобразовываем его из строки в целое
- Когда входное выражение полностью обработано, его результат находится в стеке.
Выталкиваем его из operandStack и возвращаем в качестве ответа.
Полностью функция для вычисления постфиксных выражений показана в
ActiveCode 9. Для помощи с арифметикой определена
вспомогательная функция doMath. Она принимает два операнда и оператор,
после чего совершает надлежащую арифметическую операцию.
Постфиксное вычисление (postfixeval)
Важно отметить, что для обеих программ — постфиксного преобразования и
постфиксного вычисления — мы предполагаем отсутствие ошибок во входном выражении.
Используя эти программы, как точку отсчёта, вы можете легко увидеть,
как в них могут быть включены определение ошибок и сообщение об этом.
Мы оставляем это как упражнение в конце главы.
Самопроверка
Q-45: Без использования функции activecode infixToPostfix преобразуйте следующее выражение в постфиксную форму
10 + 3 * 5 / (16 — 4)
Q-47: Модифицируйте функцию infixToPostfix таким образом, чтобы она могла конвертировать следующее выражение:
5 * 3 ^ (4 — 2)
Вставьте ответ сюда:
Польская нотация или как легко распарсить алгебраическое выражение
Время на прочтение
6 мин
Количество просмотров 42K
Введение
Целью данной статьи является продемонстрировать способ вычисления алгебраического выражения, представленного в виде строки, посредством преобразования из инфиксной формы в постфиксную и парсинга (англ. parse — разбор) преобразованной строки.
Перед прочтением рекомендуется прочитать следующее:
-
Стек;
-
«Унарный», «бинарный», «операнд»;
-
C# 10 и .NET 6.
Префиксная, инфиксная и постфиксная формы
Инфиксная форма — самая распространнёная форма, так как человека она проще для представления. Она представляет из себя выражение, в котором операторы располагаются между операндами. Отсюда исходит название данной формы.
Пример инфиксной формы:
![]()
Префиксная же форма представляет из себя выражение, в котором операторы находятся перед операндами:
![]()
Соответственно, постфиксная форма представляет из себя выражение, в котором оператор находится после операндов:
![]()
Для вычисления выражения, записанного в инфиксной формы, необходимо его предварительно проанализировать с учётом старшинства операторов и скобок. В свою очередь, префиксная и постфиксная формы такого не требуют, так как операторы записываются в порядке их вычисления и без скобок.
Выражения, записанные в префиксном или постфиксном виде, также называют бесскобочной или польской записью. Их называют польскими в честь автора — польского математика Ян Лукасевича.
Более подробно об представленных формах записи алгебраических выражений можно прочитать в Википедии.

Алгоритм Дейкстра
Для преобразования в постфиксную форму будем использовать улучшенный Эдсгером Вибе Дейкстрой алгоритм.
Принцип работы алгоритма Дейкстра:
-
Проходим исходную строку;
-
При нахождении числа, заносим его в выходную строку;
-
При нахождении оператора, заносим его в стек;
-
Выталкиваем в выходную строку из стека все операторы, имеющие приоритет выше рассматриваемого;
-
При нахождении открывающейся скобки, заносим её в стек;
-
При нахождении закрывающей скобки, выталкиваем из стека все операторы до открывающейся скобки, а открывающуюся скобку удаляем из стека.
Реализация алгоритма Дейкстры
Реализуем класс Mather, в котором определим приватные поля infixExpr для хранения инфиксного выражения, postfixExprдля постфиксного выражения и operationPriority, в котором определим список всех операторов и их приоритет:
public class Mather
{
// Хранит инфиксное выражение
public string infixExpr {get; private set; }
// Хранит постфиксное выражение
public string postfixExpr { get; private set; }
// Список и приоритет операторов
private Dictionary<char, int> operationPriority = new() {
{'(', 0},
{'+', 1},
{'-', 1},
{'*', 2},
{'/', 2},
{'^', 3},
{'~', 4} // Унарный минус
};
// Конструктор класса
public Mather(string expression)
{
// Инициализируем поля
infixExpr = expression;
postfixExpr = ToPostfix(infixExpr + "r");
}
}В поле operationPriority скобка (‘(‘) определена лишь для того, чтобы затем не выдавало ошибки при парсинге, а тильда (‘~’) добавлена для упрощения последующего разбора и представляет собой унарный минус.
Добавим приватный метод GetStringNumber, предназначенный для парсинга целочисленных значений:
/// <summary>
/// Парсинг целочисленных значений
/// </summary>
/// <param name="expr">Строка для парсинга</param>
/// <param name="pos">Позиция</param>
/// <returns>Число в виде строки</returns>
private string GetStringNumber(string expr, ref int pos)
{
// Хранит число
string strNumber = "";
// Перебираем строку
for (; pos < expr.Length; pos++)
{
// Разбираемый символ строки
char num = expr[pos];
// Проверяем, является символ числом
if (Char.IsDigit(num))
// Если да - прибавляем к строке
strNumber += num;
else
{
// Если нет, то перемещаем счётчик к предыдущему символу
pos--;
// И выходим из цикла
break;
}
}
// Возвращаем число
return strNumber;
}Далее создадим метод ToPostfix , который будет конвентировать в обратную польскую (постфиксную) запись:
private string ToPostfix(string infixExpr)
{
// Выходная строка, содержащая постфиксную запись
string postfixExpr = "";
// Инициализация стека, содержащий операторы в виде символов
Stack<char> stack = new();
// Перебираем строку
for (int i = 0; i < infixExpr.Length; i++)
{
// Текущий символ
char c = infixExpr[i];
// Если симовол - цифра
if (Char.IsDigit(c))
{
// Парсии его, передав строку и текущую позицию, и заносим в выходную строку
postfixExpr += GetStringNumber(infixExpr, ref i) + " ";
}
// Если открывающаяся скобка
else if (c == '(')
{
// Заносим её в стек
stack.Push(c);
}
// Если закрывающая скобка
else if (c == ')')
{
// Заносим в выходную строку из стека всё вплоть до открывающей скобки
while (stack.Count > 0 && stack.Peek() != '(')
postfixExpr += stack.Pop();
// Удаляем открывающуюся скобку из стека
stack.Pop();
}
// Проверяем, содержится ли символ в списке операторов
else if (operationPriority.ContainsKey(c))
{
// Если да, то сначала проверяем
char op = c;
// Является ли оператор унарным символом
if (op == '-' && (i == 0 || (i > 1 && operationPriority.ContainsKey( infixExpr[i-1] ))))
// Если да - преобразуем его в тильду
op = '~';
// Заносим в выходную строку все операторы из стека, имеющие более высокий приоритет
while (stack.Count > 0 && ( operationPriority[stack.Peek()] >= operationPriority[op]))
postfixExpr += stack.Pop();
// Заносим в стек оператор
stack.Push(op);
}
}
// Заносим все оставшиеся операторы из стека в выходную строку
foreach (char op in stack)
postfixExpr += op;
// Возвращаем выражение в постфиксной записи
return postfixExpr;
}Алгоритм вычисления постфиксной записи
После получения постфиксной записи, необходимо вычислить её значение. Для этого воспользуемся алгоримом очень похожим на прошлый алгоритмом, только этот будет использовать всего один стек.
Разберём принцип работы данного алгоритма:
-
Проходим постфиксную запись;
-
При нахождении числа, парсим его и заносим в стек;
-
При нахождении бинарного оператора, берём два последних значения из стека в обратном порядке;
-
При нахождении унарного оператора, в данном случае — унарного минуса, берём последнее значение из стека и вычитаем его из нуля, так как унарный минус является правосторонним оператором;
-
Последнее значение, после отработки алгоритма, является решением выражения.
Реализация алгоритма вычисления постфиксной записи
Создадим приватный метод Execute, который будет выполнять операции, соответствующие оператору и возвращать результат:
/// <summary>
/// Вычисляет значения, согласно оператору
/// </summary>
/// <param name="op">Оператор</param>
/// <param name="first">Первый операнд (перед оператором)</param>
/// <param name="second">Второй операнд (после оператора)</param>
private double Execute(char op, double first, double second) => op switch {
'+' => first + second, // Сложение
'-' => first - second, // Вычитание
'*' => first * second, // Умножение
'/' => first / second, // Деление
'^' => Math.Pow(first, second), // Степень
_ => 0 // Возвращает, если не был найден подходящий оператор
};Теперь реализуем сам алгоритм, создав метод Calc, в котором определим следующее:
public double Calc()
{
// Стек для хранения чисел
Stack<double> locals = new();
// Счётчик действий
int counter = 0;
// Проходим по строке
for (int i = 0; i < postfixExpr.Length; i++)
{
// Текущий символ
char c = postfixExpr[i];
// Если символ число
if (Char.IsDigit(c))
{
// Парсим
string number = GetStringNumber(postfixExpr, ref i);
// Заносим в стек, преобразовав из String в Double-тип
locals.Push(Convert.ToDouble(number));
}
// Если символ есть в списке операторов
else if (operationPriority.ContainsKey(c))
{
// Прибавляем значение счётчику
counter += 1;
// Проверяем, является ли данный оператор унарным
if (c == '~')
{
// Проверяем, пуст ли стек: если да - задаём нулевое значение,
// еси нет - выталкиваем из стека значение
double last = locals.Count > 0 ? locals.Pop() : 0;
// Получаем результат операции и заносим в стек
locals.Push(Execute('-', 0, last));
// Отчитываемся пользователю о проделанной работе
Console.WriteLine($"{counter}) {c}{last} = {locals.Peek()}");
// Указываем, что нужно перейти к следующей итерации цикла
// для того, чтобы пропустить остальной код
continue;
}
// Получаем значения из стека в обратном порядке
double second = locals.Count > 0 ? locals.Pop() : 0,
first = locals.Count > 0 ? locals.Pop() : 0;
// Получаем результат операции и заносим в стек
locals.Push(Execute(c, first, second));
// Отчитываемся пользователю о проделанной работе
Console.WriteLine($"{counter}) {first} {c} {second} = {locals.Peek()}");
}
}
// По завершению цикла возвращаем результат из стека
return locals.Pop();
}Испытание алгоритмов
Попробуем пропустить выражение 15/(7-(1+1))*3-(2+(1+1))*15/(7-(200+1))3-(2+(1+1))(15/(7-(1+1))*3-(2+(1+1))+15/(7-(1+1))*3-(2+(1+1))) через составленный алгоритм и посмотрим, верно ли он работает. Для ориентирования ниже представлен вариант решения от Яндекса.

Код программы:
using MatherExecuter;
public class Program
{
static public void Main()
{
string expression = "15/(7-(1+1))*3-(2+(1+1))*15/(7-(200+1))*3-(2+(1+1))*(15/(7-(1+1))*3-(2+(1+1))+15/(7-(1+1))*3-(2+(1+1)))";
Mather mather = new(expression);
Console.WriteLine("Ввод: " + mather.infixExpr);
Console.WriteLine("Постфиксная форма: " + mather.postfixExpr);
Console.WriteLine("Итого: " + mather.Calc());
}
}Запустив данный код, мы получим следующее:

Итоги
Хоть реализованные здесь алгоритмы и работают, однако тут не учтены пробелы между символами, дробные значения, проверка на нуль в операции деления, не реализованы функции и тому подобное, поэтому данный код предствален лишь как пример.
Рекомендуется прочитать эту статью. В данной статье автор рассказывает, как реализовать полноценный интерпретатор математических выражений с поддержкой переменных, констант и функций. Однако в этой статье автор строит интерпретатор с использованием анализатора и парсера.
-
Главная
-
Блог
-
Инфраструктура
-
Порядок выполнения операций в программировании

На уроках математики нас учили правильно вычислять значения выражений. Один из пунктов получения правильного ответа — корректно определить порядок выполнения операций. Ещё со школы мы знаем, что выражение в скобках выполняют в первую очередь, а деление и умножение приоритетнее сложения и вычитания.
Человек мыслит в этой математической парадигме. А вот компьютер не “мыслит” как человек. В этой статье мы взглянем под капот и узнаем, как в программировании работают с математическими операциями.
Инфиксная, префиксная и постфиксная формы
Инфиксная форма
Форма записи или нотация — это правила составления выражений и их декомпозиции. Возьмем простое выражение:
10 + 15*4 + 6/2Вот классический алгоритм вычисления значения этого выражения:
- Вычисляем 15*4 = 60;
- Вычисляем 6/2 = 3;
- Складываем все слагаемые: 10 + 60 + 3 = 73.
Здесь используется инфиксная форма записи — операции (сложение, вычитание, умножение и деление) записываются между аргументами (числами, переменными, функциями и другими математическими объектами). Инфиксная форма естественна для человека и используется людьми в повседневной жизни.
Но компьютеру сложнее разобрать такую форму записи. Поэтому обычно в компьютерах используется префиксная или постфиксная формы.
Префиксная форма
Префиксная нотация — это форма записи, в которой операторы располагают слева от аргументов.
Возьмем пример 5 + 10. Это запись в инфиксной форме. В префиксной форме она будет иметь такой вид:
+5 10Для лучшего понимания стоит переводить этот пример в человеческий язык “Прибавить к 5 10”. Аналогично с – 5 10 — “Отнять от 5 10”. Возьмем пример посложнее:
64 – 15*4 + 20/4Переведем это выражение в префиксную форму:
- Расставим в выражении скобки, руководствуясь приоритетностью операций (для читабельности используем разные скобки):
{ [64 – ( 15*4 ) ] + [ 20/4 ] } - Вынесем за пределы скобок операции, а в скобках оставим аргументы:
+ { – [64 * ( 15 4) ] / [20 4] }- Уберем скобки и получим префиксную форму записи:
+ – 64 * 15 4 / 20 4+ – 64 * 15 4 / 20 4 — это префиксная форма записи выражения 64 – 15*4 + 20/4. Прочитать её можно как “ПРИБАВИМ к результату ВЫЧИТАНИЯ из 64 ПРОИЗВЕДЕНИЯ 15 и 4 результат ДЕЛЕНИЯ 20 на 4.
Как перевести запись обратно? Есть рекурсивный способ сделать это. Возьмем выражение + x y (в инфиксной x+y) и переведем в инфиксную форму:
- Берем первый оператор:
+- Ставим слева от него первый аргумент:
x+- Справа ставим второй аргумент:
x+yВ качестве x и y могут выступать выражения в префиксной записи, к которым рекурсивно можно применять этот алгоритм. Возьмем наше выражение:
+ – 64 * 15 4 / 20 4- Первый оператор — это
+. Начинаем с него. - Первый аргумент — это
– 64 * 15 4. Запишем его в скобках справа от оператора:
(– 64 * 15 4) +- Второй аргумент — это
/ 20 4. Записываем его справа от оператора:
(– 64 * 15 4) + (/ 20 4)Теперь рекурсивно применяем алгоритм к каждому слагаемому. Сначала для – 64 * 15 4:
- Первый оператор — это
–. Начинаем с него. - Первый аргумент — это
64. Запишем его справа от оператора:
64 –- Второй аргумент — это
* 15 4. Записываем его справа от оператора:
64 – (* 15 4)Для * 15 4:
- Оператор
*; - Первый аргумент –
15; - Второй –
4;
Получаем 15 * 4 и вставляем его в 64 – (* 15 4). Вот первый аргумент “основного” примера:
64 – 15 * 4Для / 20 4:
- Оператор
/; - Первый аргумент –
20; - Второй –
4;
Получаем 20 / 4. Вставляем его и первый аргумент в “основной” пример:
64 – 15 * 4 + 20 / 4Постфиксная форма записи выражений
Постфиксная нотация — это форма записи, в которой операторы располагаются справа от аргументов. Выражение 5 + 10 в постфиксной форме будет иметь вид 5 10 +. Возьмем предыдущий пример и переведем его постфиксную форму аналогичным способом:
64 – 15*4 + 20/4Перевод инфиксной в постфиксную нотацию:
- Расставляем скобки по приоритетности операций. Также для читабельности используем разные скобки:
{ [64 – ( 15*4 ) ] + [ 20/4 ] } - Выносим за скобки операции и ставим их справа от аргументов:
{ [64 ( 15 4 ) * ] – [ 20 4 ] / } +- Убираем все скобки и получаем постфиксную форму:
64 15 4 * – 20 4 / +Для перевода из постфиксной в инфиксную будем идти не от большего к малому, как с префи, а наоборот. Рассмотрим рекурсивный алгоритм действий для x y +:
- Берем первый аргумент
x; - Берем второй аргумент
y; - Между ними помещаем оператор
+:x + y
Применим его для 64 15 4 * – 20 4 / +:
- Берем первый аргумент
64; - Берем следующий аргумент
15; - Дальше идет тоже аргумент, а значит есть более “вложенная” операция.
Разбираемся с аргументом 15:
- Берем следующий аргумент
4; - Берем операцию
*; - Совмещаем и получаем
15 * 4;
Возвращаемся к 64 со вторым аргументом 15 * 4:
- Берем операцию
–и помещаем между аргументами:
64 – 15 * 4Переходим к 20:
- Видим, что после
20идет не операция, и разбираемся с20 4 /. Получаем20 / 4.
Возвращаемся к 64 – 15 * 4. Это первый аргумент, 20 / 4 — второй. Смотрим операцию и вставляем её между аргументами:
64 – 15 * 4 + 20 / 4Зачем нужна префиксная и постфиксная форма?
Когда человек смотрит на пример в инфиксной форме, он видит картину целиком и может расставить порядок операций, отталкиваясь от их приоритета.
В компьютер математический пример поступает последовательно: сначала аргумент, потом операция и не ясно, будет ли дальше более приоритетная операция. В постфиксной и префиксной форме порядок операций определяется самой записью и компьютер может вычислять пример последовательно.
Алгоритм сортировочной станции
Алгоритм сортировочной станции или сортировочная станция Дейкстры — это алгоритм для преобразования инфиксной формы в постфиксную нотацию или дерево, придуманный и разработанный Эдсгером Дейкстрой.
В алгоритме используется два объекта для хранения — стек и очередь. Разберемся, что это такое.
Стек (Stack) — это список для хранения данных, организованный по принципу LIFO (Last In First Out). Этот принцип означает, что новый элемент в стеке становится первым в списке. Стек похож на стакан, в который что-то насыпают, например горохом: внизу будет горох, который первый оказался в стакане, а сверху самый последний.
Очередь (Queue) — это список, организованный по принципу FIFO (First In First Out). Он как очередь в магазине — кто первый пришел, того раньше и обслужат.
Вот сам алгоритм:
- На вход поступает выражение в инфиксной форме. Проходим по нему слева направо;
- Если встречаем аргумент, то помещаем его в очередь;
- Если встречаем операцию, то есть три варианта:
- Если стек пустой, то помещаем операцию в стек;
- Если входящая операция имеет более высокий приоритет, чем операция в начале стека, то входящая операция помещается в стек;
- Если входящая операция имеет такой же приоритет, то операция в начале стека помещается в очередь и удаляется из стека; входящая операция помещается в стек;
- Если входящая операция имеет более низкий приоритет, то операция в начале стека помещается в очередь и входящая операция опять сравнивается с началом стека;
- Если конец выражения, то перемещаем оставшиеся операции из стека в очередь.
Прогоним алгоритм по выражению из предыдущих примеров — 64 – 15*4 + 20/4. Будем отслеживать текущее состояние с помощью operand stack (стек операций) и Queue (очередь)
1. Встретили аргумент 64. Помещаем в очередь. Текущее состояние:
Stack = []; Queue = [“64”]; Выражение = – 15*4 + 20/42. Встретили оператор –. Стек пустой, значит помещаем его туда. Текущее состояние:
Stack = [“ – “]; Queue = [“64”]; Выражение = 15*4 + 20/43. Встретили аргумент 15. Помещаем в очередь. Текущее состояние:
Stack = [“ – “]; Queue = [“64”, “15”]; Выражение = *4 + 20/44. Встретили оператор *. Оператор имеет больший приоритет, чем вершина стека, значит помещаем его туда. Текущее состояние:
Stack = [“*”, “ – “]; Queue = [“64”, “15”]; Выражение = 4 + 20/45. Встретили аргумент 15. Помещаем в очередь. Текущее состояние:
Stack = [“*”, “ – “]; Queue = [“64”, “15”, “4” ]; Выражение = + 20/46. Встретили оператор +. Оператор имеет меньший, чем вершина стека, значит помещаем вершину стека в очередь. Следующий оператор имеет такой же приоритет — его тоже переносим. Входящий помещаем в стек. Текущее состояние:
Stack = [“ + ”]; Queue = [“64”, “15”, “4” ,“*”, “ – “]; Выражение = 20/47. Встретили аргумент 20. Помещаем в очередь. Текущее состояние:
Stack = [“ + ”]; Queue = [“64”, “15”, “4” ,“*”, “ – “, “20” ]; Выражение = /48. Встретили оператор / . Оператор имеет больший приоритет, чем вершина стека, значит помещаем его туда. Текущее состояние:
Stack = [“/”,“ + ”]; Queue = [“64”, “15”, “4” ,“*”, “ – “, “20” ]; Выражение = 49. Встретили аргумент 4. Помещаем в очередь.Текущее состояние:
Stack = [“/”,“ + ”]; Queue = [“64”, “15”, “4” ,“*”, “ – “, “20”, “4”]; Выражение = []10. Конец выражения. Помещаем стек в очередь. Конечное состояние:
Stack = []; Queue = [“64”, “15”, “4” ,“*”, “ – “, “20”, “4”,“/”,“ + ”]; Выражение = []В конце мы получили 64 15 4 * – 20 4 / +, что соответствует предыдущим примерам.
Заключение
Мы разобрались, как в программировании работают с базовыми математическими операциями. Если вы планируете начать учиться программированию, на cloud.timeweb.com можно заказать недорогой облачный сервер для учебы и тестов.
А в своем официальном канале Timeweb Cloud собрали комьюнити из специалистов, которые говорят про IT-тренды, делятся полезными инструкциями и даже приглашают к себе работать.
Слайд 1
Префиксная и постфиксная формы записи выражений
Слайд 2
Структура, в которой одни элементы, «подчиняются» другим, называется иерархией . В информатике иерархическую структуру называют деревом . корень лист лист лист лист лист
Слайд 3
Дерево состоит из узлов и связей между ними (они называются дугами) дуга корень листья промежуточные узлы
Слайд 4
A D B E F G C «Сыновья» А : B, C . «Родитель» B : A . «Потомки» А : B, C , D, E, F, G . «Предки» F : A, C . Корень – узел, не имеющий предков (A) . Лист – узел, не имеющий потомков (D, E, F, G) . Высота – наибольшее расстояние от корня до листа.
Слайд 5
Деревья – классификации Псовые Енотовые Медвежьи Кошачьи Гиеновые Мангустовые Псообразные Кошкообразные Хищные Глава 1. Псообразные 1.1. Псовые 1.2. Енотовые 1.3. Медвежьи … Глава 2. Кошкоообразные 2.1 . Кошачьи 2.2 . Гиеновые 2.3. Мангустовые … многоуровневый список
Слайд 6
Иерархия – файловая система Документы Фотографии Доходы .doc Расходы . odt Отдых.txt Папа.jpg Мама.gif Тексты Документы Тексты Фотографии Доходы.doc Расходы.odt Отдых.txt Папа. jpg Мама. gif Документы Доходы.doc Расходы.odt Отдых.txt Тексты Фотографии Папа. jpg Мама. gif
Слайд 7
Деревья и арифметические выражения a 3 — + * 5 2 b * (a+3)*5-2*b (-(*(+(a,3),5) ,*(2,b) )) ( корень ( левое , правое )) — * + a 3 5 * 2 b Префиксная форма – операция перед данными. Двоичное дерево! ! левый сын правый сын
Слайд 8
Префиксная форма – вычисление с конца — * + a 3 5 * 2 b — * + a 3 5 ( 2 * b ) — * ( a+3) 5 ( 2 * b ) — ( a+3)*5 ( 2 * b ) ( a+3)*5 – (2 * b ) Скобки не нужны, вычисляется однозначно! ! Идём с конца, встретили знак операции – выполнили её.
Слайд 9
Префиксная форма – вычисление с конца (идём с конца, встретили знак операции – выполнили её). Операция записывается перед данными! Пример: ( a+3)* 5–( 2 * b ) -*+a35 * 2 b 1) — * + a 3 5 ( 2 * b ) 2) — * ( a+3) 5 ( 2 * b ) 3) — ( a+3)*5 ( 2 * b ) (корень (левое, правое))
Слайд 10
Постфиксная форма ( левое-правое-корень ) a 3 — + * 5 2 b * (a+3)*5-2*b a 3 + 5 * 2 b * — Вычисляется с начала! ! (a+3) 5 * 2 b * — (a+3)*5 2 b * — (a+3)*5 ( 2 * b ) — (a+3)*5 — ( 2 * b )
Слайд 11
Постфиксная форма . Вычисляется с начала! (a+3)*5-2*b Пример: a3+5 *2b *- 1) (a+3 ) 5 * 2 b * — 2) (a+3 )*5 2 b * — 3) (a+3 )*5 ( 2 * b ) — левое, правое, корень Операция записывается после данных!
Слайд 12
Постфиксная форма для компьютера предпочтительней Когда программа на языке программирования высокого уровня переводится в машинные коды, математические выражения записываются в бесскобочной постфиксной форме, так и вычисляются. Когда программа доходит до знака операции, все данные для этой операции уже готовы. a 3 + 5 * 2 b * —
Слайд 13
Определите выражени е , соответствующее данному дереву, в «нормальном» виде со скобками (эту форму называют инфиксной – операция записывается между данными). Постройте постфиксную форму. Решение: a-( b+c )*d Постфиксная форма: abc+d *- b c — + a d *
Слайд 14
Записать выражение в префиксной форме: (2* a-3*d)*c+2*b + * — * 2 a * 3 d c * 2 b префиксная форма Идём с конца, встретили знак операции – выполнили её.
Слайд 15
Записать выражение в постфиксной форме: (2* a-3*d)*c+2*b 2 a * 3 d * — c * 2 b * + постфиксная форма Вычисляется с начала!
Слайд 16
(2* a-3*d)*c+2*b 2 * 3 d — c а * b + * 2 *
Слайд 17
Выполнить самостоятельно в тетради: задания 1б, 2а, 3а ( у чебник, стр. 49-50) Ответы: 1б — a-(b-(c-d)) a b c d — — — 2a * + a b + c * 2 d a b + c 2 d * + * 3a 66 (12+6)*(7-3-1)+12 + * + 12 6 — — 7 3 1 12
Слайд 18
Домашнее задание: Учебник стр. 38-40 читать Задания 1в, 2в, 3б,в письменно в тетради
Write a program to convert an Infix expression to Postfix form.
Infix expression: The expression of the form “a operator b” (a + b) i.e., when an operator is in-between every pair of operands.
Postfix expression: The expression of the form “a b operator” (ab+) i.e., When every pair of operands is followed by an operator.
Examples:
Input: A + B * C + D
Output: ABC*+D+Input: ((A + B) – C * (D / E)) + F
Output: AB+CDE/*-F+
Why postfix representation of the expression?
The compiler scans the expression either from left to right or from right to left.
Consider the expression: a + b * c + d
- The compiler first scans the expression to evaluate the expression b * c, then again scans the expression to add a to it.
- The result is then added to d after another scan.
The repeated scanning makes it very inefficient. Infix expressions are easily readable and solvable by humans whereas the computer cannot differentiate the operators and parenthesis easily so, it is better to convert the expression to postfix(or prefix) form before evaluation.
The corresponding expression in postfix form is abc*+d+. The postfix expressions can be evaluated easily using a stack.
How to convert an Infix expression to a Postfix expression?
To convert infix expression to postfix expression, use the stack data structure. Scan the infix expression from left to right. Whenever we get an operand, add it to the postfix expression and if we get an operator or parenthesis add it to the stack by maintaining their precedence.
Below are the steps to implement the above idea:
- Scan the infix expression from left to right.
- If the scanned character is an operand, put it in the postfix expression.
- Otherwise, do the following
- If the precedence and associativity of the scanned operator are greater than the precedence and associativity of the operator in the stack [or the stack is empty or the stack contains a ‘(‘ ], then push it in the stack. [‘^‘ operator is right associative and other operators like ‘+‘,’–‘,’*‘ and ‘/‘ are left-associative].
- Check especially for a condition when the operator at the top of the stack and the scanned operator both are ‘^‘. In this condition, the precedence of the scanned operator is higher due to its right associativity. So it will be pushed into the operator stack.
- In all the other cases when the top of the operator stack is the same as the scanned operator, then pop the operator from the stack because of left associativity due to which the scanned operator has less precedence.
- Else, Pop all the operators from the stack which are greater than or equal to in precedence than that of the scanned operator.
- After doing that Push the scanned operator to the stack. (If you encounter parenthesis while popping then stop there and push the scanned operator in the stack.)
- If the precedence and associativity of the scanned operator are greater than the precedence and associativity of the operator in the stack [or the stack is empty or the stack contains a ‘(‘ ], then push it in the stack. [‘^‘ operator is right associative and other operators like ‘+‘,’–‘,’*‘ and ‘/‘ are left-associative].
- If the scanned character is a ‘(‘, push it to the stack.
- If the scanned character is a ‘)’, pop the stack and output it until a ‘(‘ is encountered, and discard both the parenthesis.
- Repeat steps 2-5 until the infix expression is scanned.
- Once the scanning is over, Pop the stack and add the operators in the postfix expression until it is not empty.
- Finally, print the postfix expression.
Illustration:
Follow the below illustration for a better understanding
Consider the infix expression exp = “a+b*c+d”
and the infix expression is scanned using the iterator i, which is initialized as i = 0.1st Step: Here i = 0 and exp[i] = ‘a’ i.e., an operand. So add this in the postfix expression. Therefore, postfix = “a”.
Add ‘a’ in the postfix
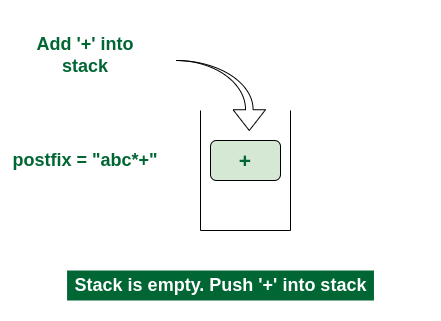
2nd Step: Here i = 1 and exp[i] = ‘+’ i.e., an operator. Push this into the stack. postfix = “a” and stack = {+}.
Push ‘+’ in the stack
3rd Step: Now i = 2 and exp[i] = ‘b’ i.e., an operand. So add this in the postfix expression. postfix = “ab” and stack = {+}.
Add ‘b’ in the postfix
4th Step: Now i = 3 and exp[i] = ‘*’ i.e., an operator. Push this into the stack. postfix = “ab” and stack = {+, *}.
Push ‘*’ in the stack
5th Step: Now i = 4 and exp[i] = ‘c’ i.e., an operand. Add this in the postfix expression. postfix = “abc” and stack = {+, *}.
Add ‘c’ in the postfix
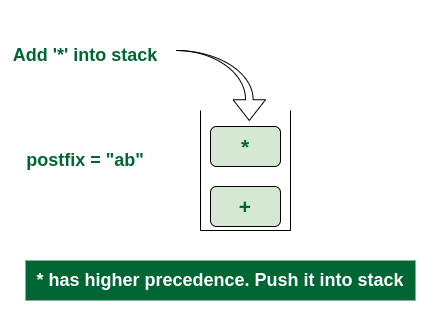
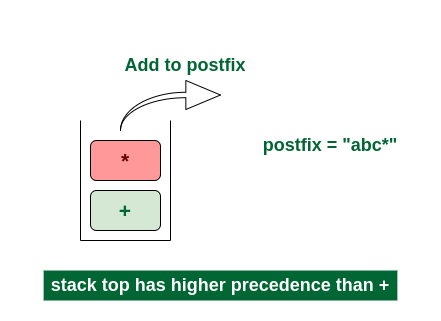
6th Step: Now i = 5 and exp[i] = ‘+’ i.e., an operator. The topmost element of the stack has higher precedence. So pop until the stack becomes empty or the top element has less precedence. ‘*’ is popped and added in postfix. So postfix = “abc*” and stack = {+}.
Pop ‘*’ and add in postfix
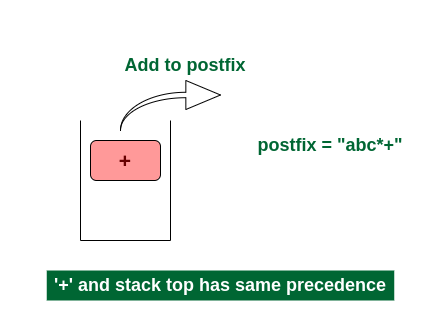
Now top element is ‘+‘ that also doesn’t have less precedence. Pop it. postfix = “abc*+”.
Pop ‘+’ and add it in postfix
Now stack is empty. So push ‘+’ in the stack. stack = {+}.
Push ‘+’ in the stack
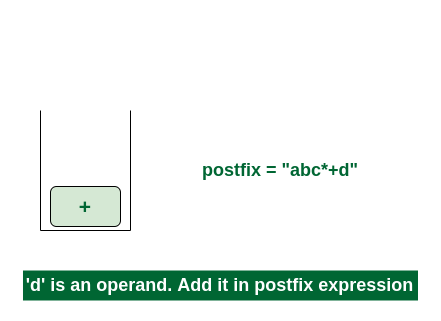
7th Step: Now i = 6 and exp[i] = ‘d’ i.e., an operand. Add this in the postfix expression. postfix = “abc*+d”.
Add ‘d’ in the postfix
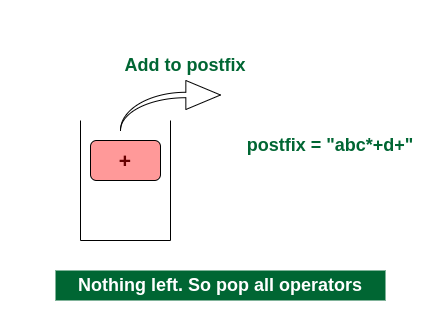
Final Step: Now no element is left. So empty the stack and add it in the postfix expression. postfix = “abc*+d+”.
Pop ‘+’ and add it in postfix


Below is the implementation of the above algorithm:
C
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define MAX_EXPR_SIZE 100
int precedence(char operator)
{
switch (operator) {
case '+':
case '-':
return 1;
case '*':
case '/':
return 2;
case '^':
return 3;
default:
return -1;
}
}
int isOperator(char ch)
{
return (ch == '+' || ch == '-' || ch == '*' || ch == '/'
|| ch == '^');
}
char* infixToPostfix(char* infix)
{
int i, j;
int len = strlen(infix);
char* postfix = (char*)malloc(sizeof(char) * (len + 2));
char stack[MAX_EXPR_SIZE];
int top = -1;
for (i = 0, j = 0; i < len; i++) {
if (infix[i] == ' ' || infix[i] == 't')
continue;
if (isalnum(infix[i])) {
postfix[j++] = infix[i];
}
else if (infix[i] == '(') {
stack[++top] = infix[i];
}
else if (infix[i] == ')') {
while (top > -1 && stack[top] != '(')
postfix[j++] = stack[top--];
if (top > -1 && stack[top] != '(')
return "Invalid Expression";
else
top--;
}
else if (isOperator(infix[i])) {
while (top > -1
&& precedence(stack[top])
>= precedence(infix[i]))
postfix[j++] = stack[top--];
stack[++top] = infix[i];
}
}
while (top > -1) {
if (stack[top] == '(') {
return "Invalid Expression";
}
postfix[j++] = stack[top--];
}
postfix[j] = '';
return postfix;
}
int main()
{
char infix[MAX_EXPR_SIZE] = "a+b*(c^d-e)^(f+g*h)-i";
char* postfix = infixToPostfix(infix);
printf("%sn", postfix);
free(postfix);
return 0;
}
C++14
#include <bits/stdc++.h>
using namespace std;
int prec(char c)
{
if (c == '^')
return 3;
else if (c == '/' || c == '*')
return 2;
else if (c == '+' || c == '-')
return 1;
else
return -1;
}
void infixToPostfix(string s)
{
stack<char> st;
string result;
for (int i = 0; i < s.length(); i++) {
char c = s[i];
if ((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z')
|| (c >= '0' && c <= '9'))
result += c;
else if (c == '(')
st.push('(');
else if (c == ')') {
while (st.top() != '(') {
result += st.top();
st.pop();
}
st.pop();
}
else {
while (!st.empty()
&& prec(s[i]) <= prec(st.top())) {
result += st.top();
st.pop();
}
st.push(c);
}
}
while (!st.empty()) {
result += st.top();
st.pop();
}
cout << result << endl;
}
int main()
{
string exp = "a+b*(c^d-e)^(f+g*h)-i";
infixToPostfix(exp);
return 0;
}
Java
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.Stack;
class Test {
static int Prec(char ch)
{
switch (ch) {
case '+':
case '-':
return 1;
case '*':
case '/':
return 2;
case '^':
return 3;
}
return -1;
}
static String infixToPostfix(String exp)
{
String result = new String("");
Deque<Character> stack
= new ArrayDeque<Character>();
for (int i = 0; i < exp.length(); ++i) {
char c = exp.charAt(i);
if (Character.isLetterOrDigit(c))
result += c;
else if (c == '(')
stack.push(c);
else if (c == ')') {
while (!stack.isEmpty()
&& stack.peek() != '(') {
result += stack.peek();
stack.pop();
}
stack.pop();
}
else
{
while (!stack.isEmpty()
&& Prec(c) <= Prec(stack.peek())) {
result += stack.peek();
stack.pop();
}
stack.push(c);
}
}
while (!stack.isEmpty()) {
if (stack.peek() == '(')
return "Invalid Expression";
result += stack.peek();
stack.pop();
}
return result;
}
public static void main(String[] args)
{
String exp = "a+b*(c^d-e)^(f+g*h)-i";
System.out.println(infixToPostfix(exp));
}
}
Python3
class Conversion:
def __init__(self, capacity):
self.top = -1
self.capacity = capacity
self.array = []
self.output = []
self.precedence = {'+': 1, '-': 1, '*': 2, '/': 2, '^': 3}
def isEmpty(self):
return True if self.top == -1 else False
def peek(self):
return self.array[-1]
def pop(self):
if not self.isEmpty():
self.top -= 1
return self.array.pop()
else:
return "$"
def push(self, op):
self.top += 1
self.array.append(op)
def isOperand(self, ch):
return ch.isalpha()
def notGreater(self, i):
try:
a = self.precedence[i]
b = self.precedence[self.peek()]
return True if a <= b else False
except KeyError:
return False
def infixToPostfix(self, exp):
for i in exp:
if self.isOperand(i):
self.output.append(i)
elif i == '(':
self.push(i)
elif i == ')':
while((not self.isEmpty()) and
self.peek() != '('):
a = self.pop()
self.output.append(a)
if (not self.isEmpty() and self.peek() != '('):
return -1
else:
self.pop()
else:
while(not self.isEmpty() and self.notGreater(i)):
self.output.append(self.pop())
self.push(i)
while not self.isEmpty():
self.output.append(self.pop())
for ch in self.output:
print(ch, end="")
if __name__ == '__main__':
exp = "a+b*(c^d-e)^(f+g*h)-i"
obj = Conversion(len(exp))
obj.infixToPostfix(exp)
C#
using System;
using System.Collections.Generic;
public class Test {
internal static int Prec(char ch)
{
switch (ch) {
case '+':
case '-':
return 1;
case '*':
case '/':
return 2;
case '^':
return 3;
}
return -1;
}
public static string infixToPostfix(string exp)
{
string result = "";
Stack<char> stack = new Stack<char>();
for (int i = 0; i < exp.Length; ++i) {
char c = exp[i];
if (char.IsLetterOrDigit(c)) {
result += c;
}
else if (c == '(') {
stack.Push(c);
}
else if (c == ')') {
while (stack.Count > 0
&& stack.Peek() != '(') {
result += stack.Pop();
}
if (stack.Count > 0
&& stack.Peek() != '(') {
return "Invalid Expression";
}
else {
stack.Pop();
}
}
else
{
while (stack.Count > 0
&& Prec(c) <= Prec(stack.Peek())) {
result += stack.Pop();
}
stack.Push(c);
}
}
while (stack.Count > 0) {
result += stack.Pop();
}
return result;
}
public static void Main(string[] args)
{
string exp = "a+b*(c^d-e)^(f+g*h)-i";
Console.WriteLine(infixToPostfix(exp));
}
}
Javascript
function prec(c) {
if(c == '^')
return 3;
else if(c == '/' || c=='*')
return 2;
else if(c == '+' || c == '-')
return 1;
else
return -1;
}
function infixToPostfix(s) {
let st = [];
let result = "";
for(let i = 0; i < s.length; i++) {
let c = s[i];
if((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z') || (c >= '0' && c <= '9'))
result += c;
else if(c == '(')
st.push('(');
else if(c == ')') {
while(st[st.length - 1] != '(')
{
result += st[st.length - 1];
st.pop();
}
st.pop();
}
else {
while(st.length != 0 && prec(s[i]) <= prec(st[st.length - 1])) {
result += st[st.length - 1];
st.pop();
}
st.push(c);
}
}
while(st.length != 0) {
result += st[st.length - 1];
st.pop();
}
document.write(result + "</br>");
}
let exp = "a+b*(c^d-e)^(f+g*h)-i";
infixToPostfix(exp);
Time Complexity: O(N), where N is the size of the infix expression
Auxiliary Space: O(N), where N is the size of the infix expression
Please write comments if you find anything incorrect, or you want to share more information about the topic discussed above.
Last Updated :
27 Mar, 2023
Like Article
Save Article