

КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Любому бизнесу интересно заглянуть в будущее и правильно ответить на вопрос: «А сколько денег мы заработаем за следующий период?» Ответить на такого рода вопросы позволяют различные методики прогнозирования. В данной статье мы с вами рассмотрим несколько таких методик и произведем все необходимые расчеты в Excel. Еще больше про анализ данных в Excel мы рассказываем на нашем открытом курсе «Аналитика в Excel».
Постановка задачи
Исходные данные
Для начала, давайте определимся, какие у нас есть исходные данные и что нам нужно получить на выходе. Фактически, все что у нас есть, это некоторые исторические данные. Если мы говорим о прогнозировании продаж, то историческими данными будут продажи за предыдущие периоды.
Примечание. Собранные в разные моменты времени значения одной и той же величины образуют временной ряд. Каждое значение такого временного ряда называется измерением. Например: данные о продажах за последние 5 лет по месяцам — временной ряд; продажи за январь прошлого года — измерение.
Составляющие прогноза
Следующий шаг: давайте определимся, что нам нужно учесть при построении прогноза. Когда мы исследуем наши данные, нам необходимо учесть следующие факторы:
- Изменение нашей пронозируемой величины (например, продаж) подчиняется некоторому закону. Другими словами, в временном ряде можно проследить некую тенденцию. В математике такая тенденция называется трендом.
- Изменение значений в временном ряде может зависить от промежутка времени. Другими словами, при построении модели необходимо будет учесть коэффициент сезонности. Например, продажи арбузов в январе и августе не могут быть одинаковыми, т.к. это сезонный продукт и летом продажи значительно выше.
- Изменение значений в временном ряде периодически повторяется, т.е. наблюдается некоторая цикличность.
Эти три пункта в совокупность образуют регулярную составляющую временного ряда.
Примечание. Не обязательно все три элемента регулярной составляющей должны присутствовать в временном ряде.
Однако, помимо регулярной составляющей, в временном ряде присутствует еще некоторое случайное отклонение. Интуитивно это понятно – продажи могут зависеть от многих факторов, некоторые из которых могут быть случайными.
Вывод. Чтобы комплексно описать временной ряд, необходимо учесть 2 главных компонента: регулярную составляющую (тренд + сезонность + цикличность) и случайную составляющую.
Виды моделей
Следующий вопрос, на который нужно ответить при построении прогноза: “А какие модели временного ряда бывают?”
Обычно выделяют два основных вида:
- Аддитивная модель: Уровень временного ряда = Тренд + Сезонность + Случайные отклонения
- Мультипликативная модель: Уровень временного ряда = Тренд X Сезонность X Случайные отклонения
Иногда также выделают смешанную модель в отдельную группу:
- Смешанная модель: Уровень временного ряда = Тренд X Сезонность + Случайные отклонения
С моделями мы определились, но теперь возникает еще один вопрос: «А когда какую модель лучше использовать?»
Классический вариант такой:
— Аддитивная модель используется, если амплитуда колебаний более-менее постоянная;
— Мультипликативная – если амплитуда колебаний зависит от значения сезонной компоненты.
Пример:
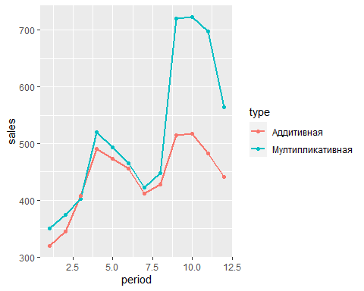
Решение задачи с помощью Excel
Итак, необходимые теоретические знания мы с вами получили, пришло время применить их на практике. Мы будем с вами использовать классическую аддитивную модель для построения прогноза. Однако, мы построим с вами два прогноза:
- с использованием линейного тренда
- с использованием полиномиального тренда
Во всех руководствах, как правило, разбирается только линейный тренд, поэтому полиномиальная модель будет крайне полезна для вас и вашей работы!
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Модель с линейным трендом
Пусть у нас есть исходная информация по продажам за 2 года:
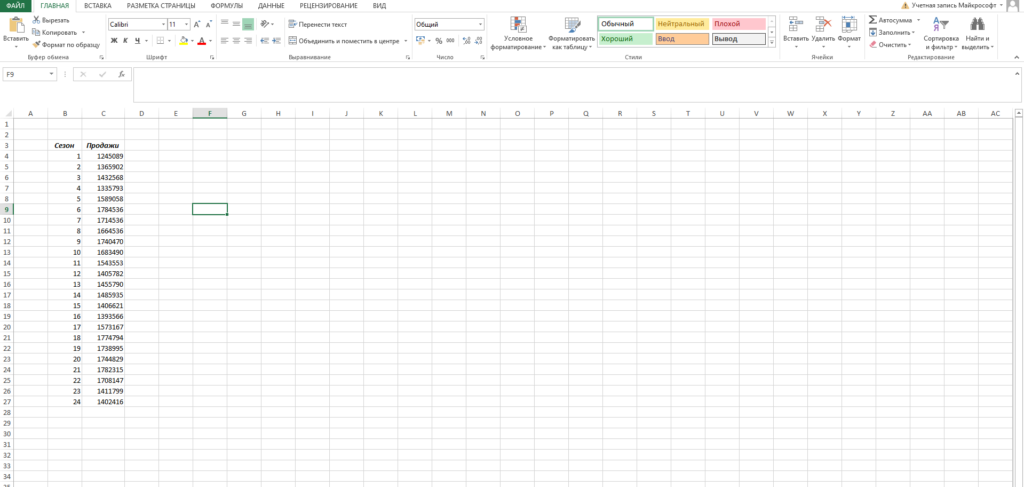
Учитывая, что мы используем линейный тренд, то нам необходимо найти коэффициенты уравнения
y = ax + b
где:
- y – значения продаж
- x – номер периода
- a – коэффициент наклона прямой тренда
- b – свободный член тренда
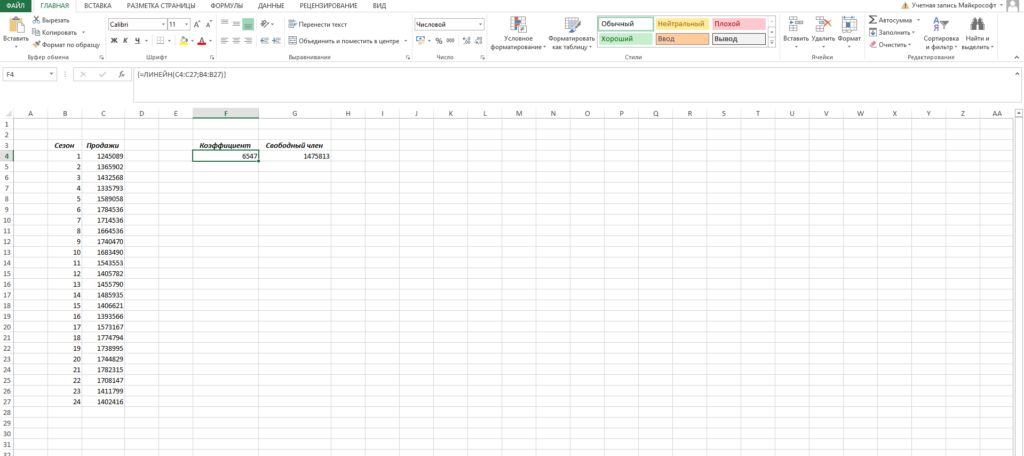
Рассчитать коэффициенты данного уравнения можно с помощью формулы массива и функции ЛИНЕЙН. Нам необходимо будет сделать следующую последовательность действий:
- Выделяем две ячейки рядом
- Ставим курсор в поле формул и вводим формулу =ЛИНЕЙН(C4:C27;B4:B27)
- Нажимаем Ctrl+Shift+Enter, чтобы активировать формулу массива
На выходе мы получили 2 числа: первое — коэффициент a, второе – свободный член b.
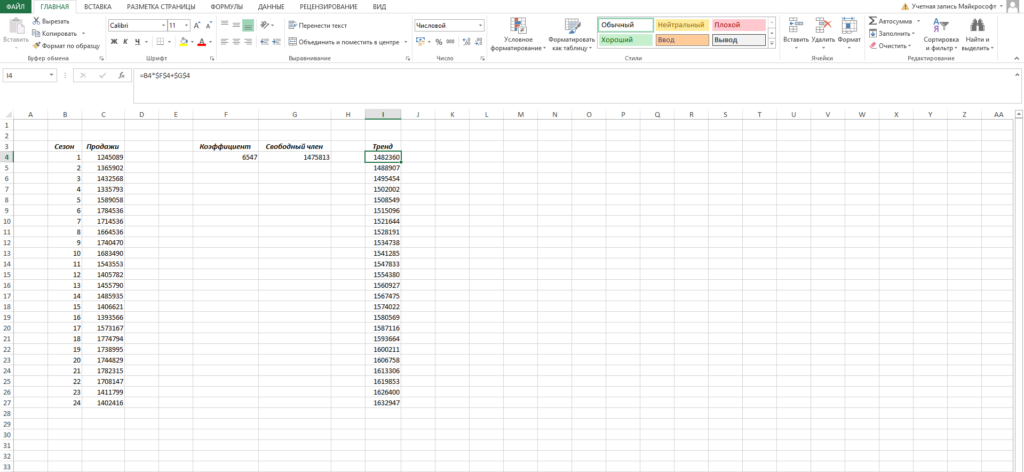
Теперь нам нужно рассчитать для каждого периода значение линейного тренда. Сделать это крайне просто — достаточно в полученное уравнение подставить известные номера периодов. Например, в нашем случае, мы прописываем формулу =B4*$F$4+$G$4 в ячейке I4 и протягиваем ее вниз по всем периодам.
Нам осталось рассчитать коэффициент сезонности для каждого периода. Учитывая, что у нас есть исторические данные за два года, разумно будет учесть это при расчете. Можем сделать следующим образом: в ячейке J4 прописываем формулу =(C4+C16)/СРЗНАЧ($C$4:$C$27)/2 и протягиваем вниз на 12 месяцев (т.е. до J15).
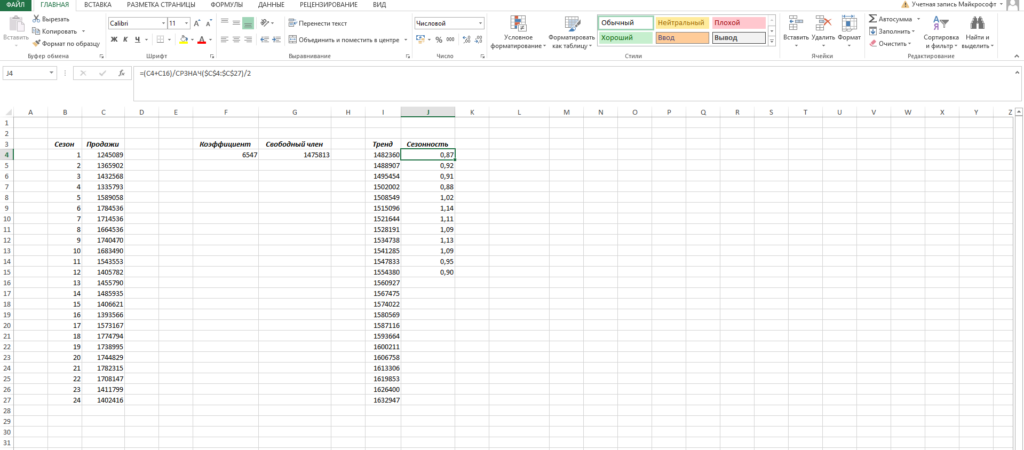
Что нам это дало? Мы посчитали, сколько суммарно продавалось каждый январь/каждый февраль и так далее, а потом разделили это на среднее значение продаж за все два периода.
То есть мы выяснили, как продажи двух январей отклонялись от средних продаж за два года, как продажи двух февралей отклонялись и так далее. Это и дает нам коэффициент сезонности. В конце формулы делим на 2, т.к. в расчете фигурировало 2 периода.
Примечание. Рассчитали только 12 коэффициентов, т.к. один коэффициент учитывает продажи сразу за 2 аналогичных периода.
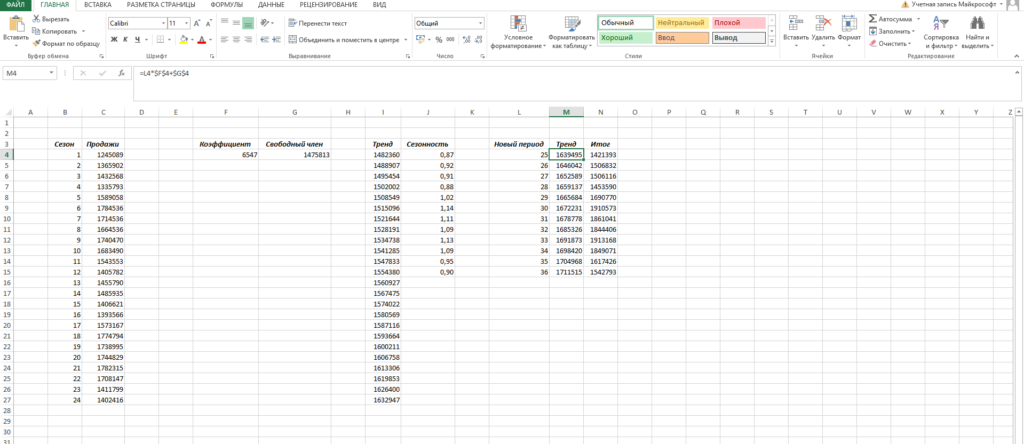
Итак, теперь мы на финишной прямой. Нам осталось рассчитать тренд для будущих периодов и учесть коэффициент сезонности для них. Давайте амбициозно построим прогноз на год вперед.
Сначала создаем столбец, в котором прописываем номера будущих периодов. В нашем случае нумерация начинается с 25 периода.
Далее, для расчета значения тренда просто прописываем уже известную нам формулу =L4*$F$4+$G$4 и протягиваем вниз на все 12 прогнозируемых периодов.
И последний штрих — умножаем полученное значение на коэффициент сезонности. Вуаля, это и есть итоговый ответ в данной модели!
Модель с полиномиальным трендом
Конструкция, которую мы только что с вами построили, достаточно проста. Но у нее есть один большой минус — далеко не всегда она дает достоверные результаты.
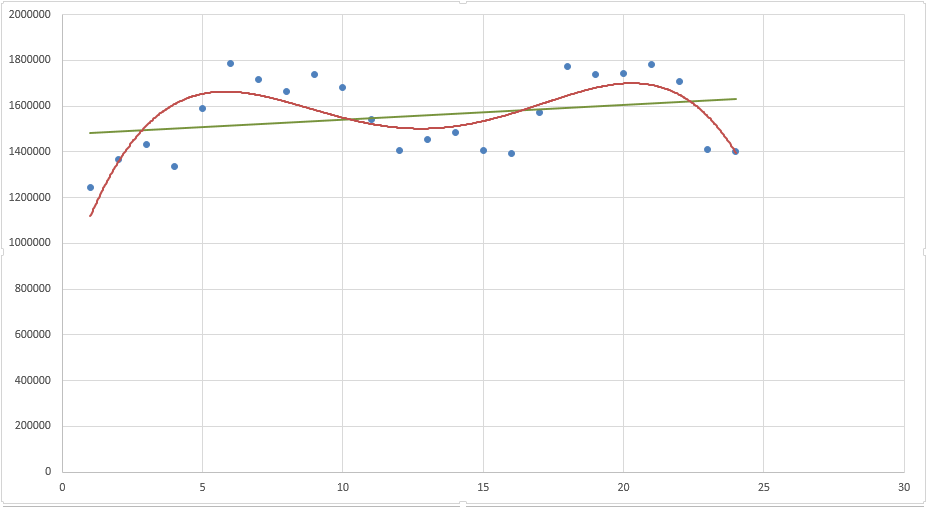
Посмотрите сами, какая модель более точно аппроксимирует наши точки — линейный тренд (прямая зеленая линия) или полиномиальный тренд (красная кривая)? Ответ очевиден. Поэтому сейчас мы с вами и разберем, как построить полиномиальную модель в Excel.
Пусть все исходные данные у нас будут такими же. Для простоты модели будем учитывать только тренд, без сезонной составляющей.
Для начала давайте определимся, чем полиномиальный тренд отличается от обычного линейного. Правильно — формой уравнения. У линейного тренда мы разбирали обычный график прямой:
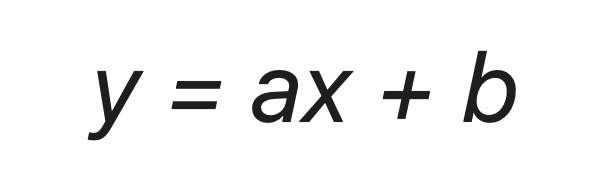
У полиномиального тренда же уравнение выглядит иначе:
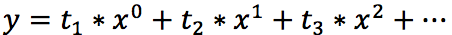
где конечная степень определяется степенью полинома.
Т.е. для полинома 4 степени необходимо найти коэффициенты уравнения:
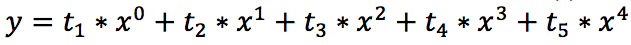
Согласитесь, выглядит немного страшно. Однако, ничего страшного нет, и мы с легкостью можем решить эту задачку с помощью уже известных нам методов.
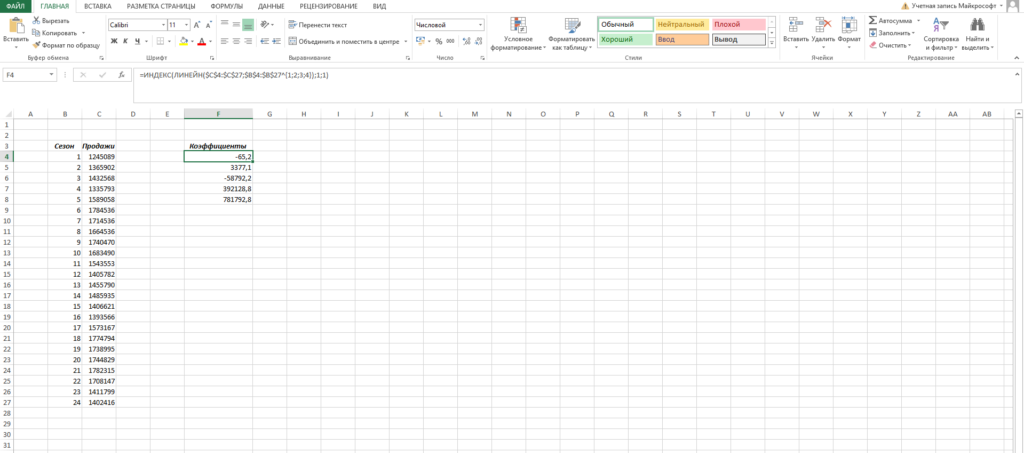
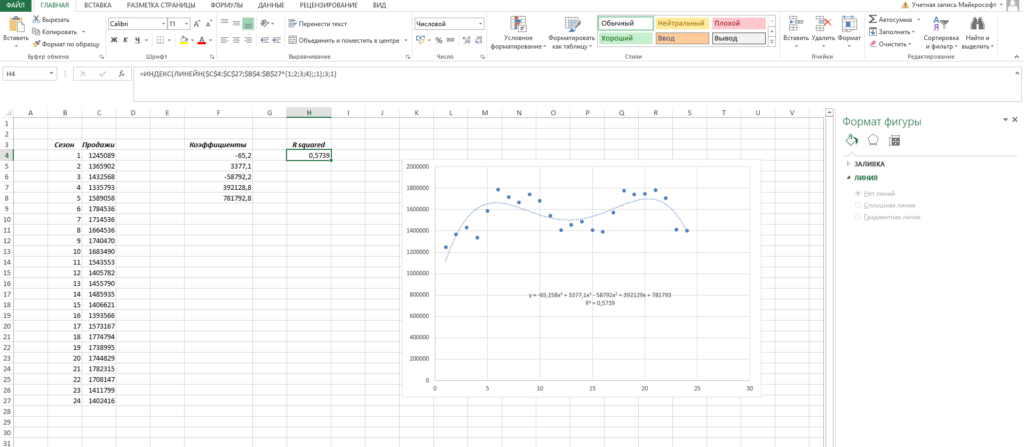
- Ставим в ячейку F4 курсор и вводим формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;1). Функция ЛИНЕЙН позволяет произвести расчет коэффициентов, а с помощью функции ИНДЕКС мы вытаскиваем нужный нам коэффициент. В данном случае за выбор коэффициента отвечает самый последний аргумент. У нас стоит 1 — это коэффициент при самой высокой степени (т.е. при 4 степени, коэффициент). Кстати, узнать о самых полезных математических формулах Excel можно в нашем бесплатном гайде «Математические функции Excel».
- Аналогично прописываем формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4});1;2) в ячейке ниже.
- Делаем такие же действия, пока не найдем все коэффициенты.
Кстати говоря, мы можем легко сами себя проверить. Давайте построим график наших продаж и добавим к нему полиномиальный тренд.
- Выделяем столбец с продажами
- Выбираем «Вставка» → «График» → «Точечный» → «Точечная диаграмма»
- Нажимаем на любую точку графика правой кнопкой мыши и выбираем «Добавить линию тренда»
- В открывшемся справа меню выбираем «Полиномиальная модель», меняем степень на 4 и ставим галочку на «Показывать уравнение на диаграмме»
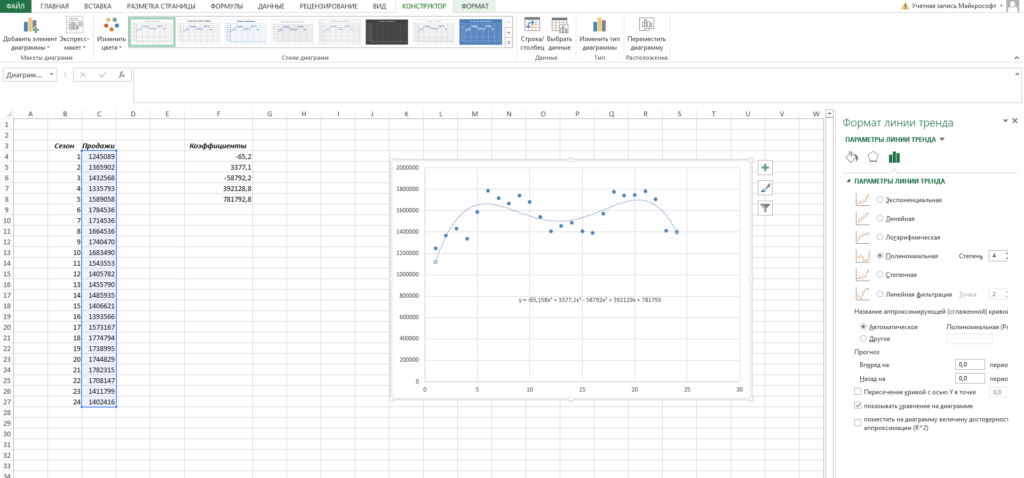
Теперь вы наглядно можете видеть, как рассчитанный тренд аппроксимирует исходные данные и как выглядит само уравнение. Можно сравнить уравнение на графике с вашими коэффициентами. Сходится? Значит сделали все верно!
Помимо всего прочего, вы можете сразу оценить точность аппроксимации (не полностью, но хотя бы первично). Это делается с помощью коэффициента R^2. Тут у вас снова есть два пути:
- Вы можете вывести коэффициент на график, поставив галочку «Поместить на диаграмму величину достоверности аппроксимации»
- Вы можете рассчитать коэффициент R^2 самостоятельно по формуле =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^{1;2;3;4};;1);3;1)
Заключение
Мы с вами подробно разобрали вопрос прогнозирования — изучили необходимые термины и виды моделей, построили аддитивную модель в Excel с использованием линейного и полиномиального тренда, а также научились отображать результаты своих вычислений на графиках. Все это позволит вам эффективно внедрять полученные знания на работе, усложнять существующие модели и уточнять прогнозы. Чем большим количеством методов и инструментов вы будете владеть, тем выше будет ваш профессиональный уровень и статус на рынке труда.
Если вас интересуют еще какие-то модели прогнозирования — напишите нам об этом, и мы постараемся осветить эти темы в дальнейших своих статьях! Или запишитесь на курс «Excel Academy» от SF Education, где мы рассказываем про возможности Excel, необходимые для анализа.
Автор: Алексанян Андрон, эксперт SF Education
КУРС
EXCEL ACADEMY
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Блог SF Education
Data Science
5 примеров экономии времени в Excel
Что для работодателя главное в сотруднике? Добросовестность, ответственность, профессионализм и, конечно же, умение пользоваться отведенным временем! Предлагаем познакомиться с очень нужными, на наш взгляд,…
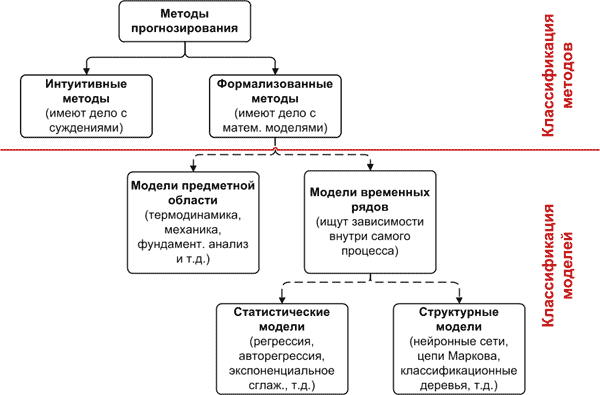
Классификация методов и моделей прогнозирования
Время на прочтение
5 мин
Количество просмотров 157K
Я занимаюсь прогнозированием временных рядов уже более 5 лет. В прошлом году мною была защищена диссертация по теме «Модель прогнозирования временных рядов по выборке максимального подобия», однако вопросов после защиты осталось порядочно. Вот один из них — общая классификация методов и моделей прогнозирования.
Обычно в работах как отечественных, так и англоязычных авторы не задаются вопросом классификации методов и моделей прогнозирования, а просто их перечисляют. Но мне кажется, что на сегодняшний день данная область так разрослась и расширилась, что пусть самая общая, но классификация необходима. Ниже представлен мой собственный вариант общей классификации.
В чем разница между методом и моделью прогнозирования?
Метод прогнозирования представляет собой последовательность действий, которые нужно совершить для получения модели прогнозирования. По аналогии с кулинарией метод есть последовательность действий, согласно которой готовится блюдо — то есть сделается прогноз.
Модель прогнозирования есть функциональное представление, адекватно описывающее исследуемый процесс и являющееся основой для получения его будущих значений. В той же кулинарной аналогии модель есть список ингредиентов и их соотношение, необходимый для нашего блюда — прогноза.
Совокупность метода и модели образуют полный рецепт!
В настоящее время принято использовать английские аббревиатуры названий как моделей, так и методов. Например, существует знаменитая модель прогнозирования авторегрессия проинтегрированного скользящего среднего с учетом внешнего фактора (auto regression integrated moving average extended, ARIMAX). Эту модель и соответствующий ей метод обычно называют ARIMAX, а иногда моделью (методом) Бокса-Дженкинса по имени авторов.
Сначала классифицируем методы
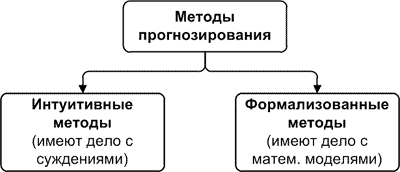
Если посмотреть внимательно, то быстро выясняется, что понятие «метод прогнозирования» гораздо шире понятия «модель прогнозирования». В связи с этим на первом этапе классификации обычно делят методы на две группы: интуитивные и формализованные [1].
Если мы вспомним нашу кулинарную аналогию, то и там можно разделить все рецепты на формализованные, то есть записанные по количеству ингредиентов и способу приготовления, и интуитивные, то есть нигде не записанные и получаемые из опыта кулинара. Когда мы не пользуемся рецептом? Когда блюдо очень просто: пожарить картошку или сварить пельмени — тут рецепт не нужен. Когда еще мы не пользуемся рецептом? Когда желаем изобрести что-то новенькое!
Интуитивные методы прогнозирования имеют дело с суждениями и оценками экспертов. На сегодняшний день они часто применяются в маркетинге, экономике, политике, так как система, поведение которой необходимо спрогнозировать, или очень сложна и не поддается математическому описанию, или очень проста и в таком описании не нуждается. Подробности о такого рода методах можно глянуть в [2].
Формализованные методы — описанные в литературе методы прогнозирования, в результате которых строят модели прогнозирования, то есть определяют такую математическую зависимость, которая позволяет вычислить будущее значение процесса, то есть сделать прогноз.
На этом общая классификация методов прогнозирования на мой взгляд может быть закончена.
Далее сделаем общую классификация моделей
Здесь необходимо переходить к классификации моделей прогнозирования. На первом этапе модели следует разделить на две группы: модели предметной области и модели временных рядов.
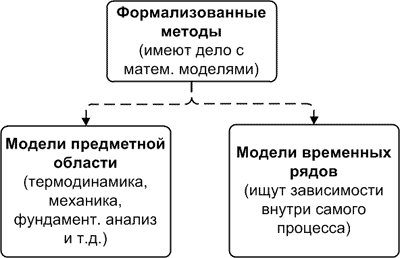
Модели предметной области — такие математические модели прогнозирования, для построения которых используют законы предметной области. Например, модель, на которой делают прогноз погоды, содержит уравнения динамики жидкостей и термодинамики. Прогноз развития популяции делается на модели, построенной на дифференциальном уравнении. Прогноз уровня сахара крови человека, больного диабетом, делается на основании системы дифференциальных уравнений. Словом, в таких моделях используются зависимости, свойственные конкретной предметной области. Такого рода моделям свойственен индивидуальный подход в разработке.
Модели временных рядов — математические модели прогнозирования, которые стремятся найти зависимость будущего значения от прошлого внутри самого процесса и на этой зависимости вычислить прогноз. Эти модели универсальны для различных предметных областей, то есть их общий вид не меняется в зависимости от природы временного ряда. Мы можем использовать нейронные сети для прогнозирования температуры воздуха, а после аналогичную модель на нейронных сетях применить для прогноза биржевых индексов. Это обобщенные модели, как кипяток, в которые если бросить продукт, то он сварится вне зависимости от его природы.
Классифицируем модели временных рядов
Мне кажется, что составить общую классификацию моделей предметной области не представляется возможным: сколько областей, столько и моделей! Однако модели временных рядов легко поддаются простому делению [3]. Модели временных рядов можно разделить на две группы: статистические и структурные.
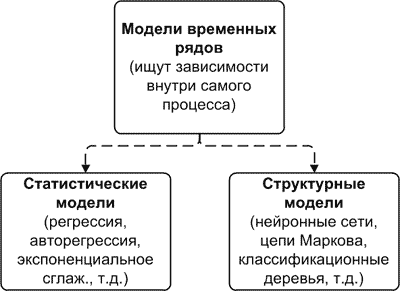
В статистических моделях зависимость будущего значения от прошлого задается в виде некоторого уравнения. К ним относятся:
- регрессионные модели (линейная регрессия, нелинейная регрессия);
- авторегрессионные модели (ARIMAX, GARCH, ARDLM);
- модель экспоненциального сглаживания;
- модель по выборке максимального подобия;
- и т.д.
В структурных моделях зависимость будущего значения от прошлого задается в виде некоторой структуры и правил перехода по ней. К ним относятся:
- нейросетевые модели;
- модели на базе цепей Маркова;
- модели на базе классификационно-регрессионных деревьев;
- и т.д.
Для обоих групп я указала основные, то есть наиболее распространенные и подробно описанные модели прогнозирования. Однако на сегодняшний день моделей прогнозирования временных рядов имеется уже громадное количество и для построения прогнозов, например, стали использовать SVM (support vector machine) модели, GA (genetic algorithm) модели и многие другие.
Общая классификация
Таким образом мы получили следующую классификацию моделей и методов прогнозирования.
Ссылки.
- Тихонов Э.Е. Прогнозирование в условиях рынка. Невинномысск, 2006. 221 с.
- Armstrong J.S. Forecasting for Marketing // Quantitative Methods in Marketing. London: International Thompson Business Press, 1999. P. 92 – 119.
- Jingfei Yang M. Sc. Power System Short-term Load Forecasting: Thesis for Ph.d degree. Germany, Darmstadt, Elektrotechnik und Informationstechnik der Technischen Universitat, 2006. 139 p.
UPD. 15.11.2016.
Господа, дошло до маразма! Недавно мне прислали на рецензию статью для ВАКовского издания со ссылкой на эту запись. Обращаю внимание, что ни в дипломах, ни в статьях, ни тем более в диссертациях ссылаться на блог нельзя! Если хотите ссылку, то используйте эту: Чучуева И.А. МОДЕЛЬ ПРОГНОЗИРОВАНИЯ ВРЕМЕННЫХ РЯДОВ ПО ВЫБОРКЕ МАКСИМАЛЬНОГО ПОДОБИЯ, диссертация… канд. тех. наук / Московский государственный технический университет им. Н.Э. Баумана. Москва, 2012.
This blog gives you a detailed overview of predictive modeling techniques in data science. It covers everything from the introduction to various predictive modeling techniques to their real-world applications.
How do e-commerce platforms offer us the best possible offers and discounts to purchase a product? How do banks alert us when there is suspicious activity in our accounts? It all begins with the magic of predictive modelling techniques!

Ecommerce product reviews — Pairwise ranking and sentiment analysis
Downloadable solution code | Explanatory videos | Tech Support
Start Project
Predictive modelling is the machine learning technique that would work best for any company that wants to predict the future outcomes for its business growth. After spending many years exploring the applications of this data science technique, businesses are now finally leveraging it to its maximum potential. Enterprises are using unique predictive models and algorithms that support predictive analytics tools. Getting the best out of predictive analytics tools and harnessing data to make informed decisions requires determining which predictive data modeling techniques are ideal for a business. But before we dive into the pool of predictive models and methods, let us get a clear picture of what predictive modeling techniques are all about!
Table of Contents
- Predictive Modeling Techniques — A Gentle Introduction
- What is Predictive Modelling?
- How do Predictive Modelling Techniques Benefit Businesses?
- Predictive Modelling Examples
- How to Build a Predictive Model? | Predictive Modelling Process
- Types of Predictive Models
- 1. Classification Model
- 2. Clustering Model
- 3. Outliers Model
- 4. Forecast Model
- 5. Time Series Model
- Predictive Modeling Techniques in Machine Learning
- 1. Linear Regression
- 2. Logistic Regression
- 3. Decision Trees
- 4. Gradient Boosted Model
- 5. Neural Networks
- 6. Random Forest
- Predictive Modeling Techniques in Data Mining
- 1. ARIMA
- 2. Support Vector Machines (SVM)
- Let the Magic of Predictive Modeling Techniques Begin!
- FAQs on Predictive Modelling Techniques
- 1. How to Build a Predictive Model?
- 2. What are the Steps in Predictive Modelling?
- 3. What are Predictive Modeling Techniques?
- 4. What are the two techniques associated with Predictive Modeling?
- 5. How to Select the Correct Predictive Modeling Technique?

Predictive Modeling Techniques — A Gentle Introduction
Predictive modeling techniques use existing data to build (or train) a model that can predict outcomes for new data. Implementing such techniques enables businesses to optimize decision-making and generate new insights that lead to more effective and profitable actions.
For instance-
-
healthcare organizations apply predictive modeling techniques to optimize diagnostic procedures,
-
banking institutions use these techniques to detect and avoid fraudulent activities,
-
retail stores implement such techniques to optimize their inventory stock and boost customer satisfaction, etc.
Now we know what are predictive modeling techniques, but how do these techniques actually work? Let us find out!
What is Predictive Modelling?
Predictive modeling is a statistical approach that analyzes data patterns to determine future events or outcomes. It’s an essential aspect of predictive analytics, a type of data analytics that involves machine learning and data mining approaches to predict activity, behavior, and trends using current and past data.

Banking institutions, for example, may leverage predictive modeling to collect a customer’s credit record and other historical data. They might then use this information to calculate a person’s credit score and the odds of them making timely credit payments.
How do Predictive Modelling Techniques Benefit Businesses?

Organizations implement predictive analytics using predictive models, which assists them in making better business decisions. Predictive models let companies understand their customer base better, predict future sales prospects, etc. Following are some of the ways in which predictive models benefit various businesses-
-
Implement techniques to acquire a competitive advantage,
-
Gain a better understanding of the consumer base and their demands,
-
Assess and mitigate financial risks,
-
Enhance existing products to boost revenue,
-
Minimize time and expenses in predicting outcomes,
-
Predict external elements that may have an impact on productivity, etc.
Predictive Modelling Examples

Below you will find a few examples and real-world use cases of how various industries are leveraging predictive models to accelerate workflows and boost revenue-
-
Retail— Predictive analytics helps retailers in multiple regions with inventory planning and dynamic pricing, evaluating the performance of promotional campaigns, and deciding which personalized retail offers are best for customers.
By researching consumer behavior and acquiring a better understanding of its customers with the help of predictive models, Staples has achieved a 137 percent return on investment.
-
Healthcare— The healthcare industry employs predictive analytics and modeling to analyze and forecast future population healthcare needs by leveraging healthcare data. Predictive models in the healthcare industry help identify activities that increase patient satisfaction, resource usage, and budget control. Predictive modeling also enables the healthcare industry to improve financial management to optimize patient outcomes.
The Centre for Addiction and Mental Health (CAMH), Canada’s leading mental health teaching center, uses predictive modeling to streamline treatment for ALC patients and maximize bed space. -
Banking— The banking industry benefits from predictive analytics by creating a credit risk-aware mindset, managing capital and liquidity, and satisfying regulatory obligations. Predictive analytics models provide more significant detection and protection and better control and compliance. Predictive models allow banks and other financial organizations to tailor each client interaction, reduce customer churn, earn customer trust, and generate remarkable customer experiences.
OTP Bank Romania, part of the OTP Bank Group, implements predictive analytics to govern the quality of loan issuances, yield more precise business and risk forecasts, and meet profit goals for the bank’s credit portfolios. -
Manufacturing- Manufacturing companies use predictive modeling to forecast maintenance risks and reduce costs on sudden breakdowns. Predictive analytics models help businesses improve their performance and overall equipment efficiency, and also allow companies to enhance product quality and boost consumer experience.
SPG Dry Cooling, a prominent manufacturer of air-cooled condensers, uses predictive modeling to acquire better insights into performance and optimize maintenance, resulting in higher dependability and cost reductions.
How to Build a Predictive Model? | Predictive Modelling Process

Once a set of current and historical data is ready for predictive analysis, the predictive modeling process can begin. To develop the predictive model, data science experts or analysts generate standard predictive algorithms and statistical models, train them using subsets of the data, and execute them against the entire data set. Let us understand how to build a predictive model using simple and easy-to-understand steps —
-
Data Collection- The process of data collection is acquiring the information needed for analysis, and it entails obtaining historical data from a reliable source to implement predictive analysis.
-
Data Mining- You cleanse your data sets through data mining or data cleaning. You delete incorrect data during the data cleansing process, and the data mining process entails removing identical and redundant data from your data collections.
-
Exploratory Data Analysis (EDA)- Data exploration is essential for the predictive modeling process. You gather critical data and summarize it by recognizing patterns or trends. EDA is the final step in your data preparation phase.
-
Predictive Model Development- You will utilize various techniques to create predictive analytics models based on the patterns you’ve discovered. Use Python, R, MATLAB, other programming languages, and standard statistical models to test your hypothesis.
-
Model Evaluation- Validation is a crucial phase in predictive analytics. You run a series of tests to see how effectively your model can predict outcomes. Given the sample data or input sets to evaluate the model’s validity, you must assess the model’s accuracy.
-
Predictive Model Deployment- Deployment allows you to test your model in a real-world scenario, which helps in practical decision making and makes it ready for implementation.
-
Model Tracking- Check the performance of your models constantly to ensure that you are receiving the best future outcomes possible. It involves comparing model predictions to actual data sets.
Wondering if Spark is suitable for Big Data? Find out by working on Apache Spark Projects that will help you understand the fundamentals of Spark.
Types of Predictive Models

Let us now explore the various predictive models that help make forecasts using machine learning and data mining approaches.
1. Classification Model
The classification model is one of the most popular predictive analytics models. These models perform categorical analysis on historical data. Various industries adopt classification models because they can retrain these models with current data and as a result, they obtain useful and detailed insights that help them build appropriate solutions. Classification models are customizable and are helpful across industries, including banking and retail.
2. Clustering Model
The clustering model gathers data and divides it into groups based on common characteristics. Hard clustering facilitates data classification, determining if each data point belongs to a cluster, and soft clustering allocates a probability to each data point.
In some applications, such as marketing, the ability to partition data into distinct datasets depending on specific features is highly beneficial. A clustering model can help businesses plan marketing campaigns for certain groups of customers.
3. Outliers Model
Unlike the classification and forecast models, the outlier model deals with anomalous data items within a dataset. It works by detecting anomalous data, either on its own or with other categories and numbers. Outlier models are essential in industries like retail and finance, where detecting abnormalities can save businesses millions of dollars. Outlier models can quickly identify anomalies, so predictive analytics models are efficient in fraud detection.
4. Forecast Model
One of the most prominent predictive analytics models is the forecast model. It manages metric value predictions by calculating new data values based on historical data insights. Forecast models also generate numerical values in historical data if none are present. One of the most powerful features of forecast models is that they can manage multiple parameters at a time. As a result, they’re one of the most popular predictive models in the market.
Various industries can use a forecast model for different business purposes. For example, a call center can use forecast analytics to predict how many support calls they will receive in a day, or a retail store can forecast inventory for the upcoming holiday sales periods, etc.
5. Time Series Model
Time series predictive models analyze datasets where the input parameter is time sequences. The time series model develops a numerical value that predicts trends within a specific period by combining multiple data points (from the previous year’s data). A Time Series model outperforms traditional ways of calculating a variable’s progress because it may forecast for numerous regions or projects at once or focus on a single area or task, depending on the organization’s needs.
Time Series predictive models are helpful if organizations need to know how a specific variable changes over time. For example, if a small business owner wishes to track sales over the last four quarters, they will need to use a Time Series model. It can also look at external factors like seasons or periodical variations that could influence future trends.
Predictive Modeling Techniques in Machine Learning

Predictive modeling is an effective data analytics technique that supports artificial intelligence (AI). With the help of various machine learning tools and techniques, predictive modeling helps predict future events and determines how future decisions affect existing situations. Here is a brief overview of the machine learning techniques that are useful in predictive modeling-
1. Linear Regression
One of the simplest machine learning techniques is linear regression. A generalized linear model simulates the relationship between one or more independent factors and the target response (dependent variable). Linear regression is a statistical approach that helps organizations get insights into customer behavior, business operations, and profitability. Regular linear regression can assess trends and generate estimations or forecasts in business.
For example, suppose a company’s sales have increased gradually every month for the past several years. In that case, the company might estimate sales in the coming months by linearly analyzing the sales data with monthly sales.
Learn how linear regression helps in predictive modeling by working on these predictive modelling projects-
-
Avocado Price Prediction Machine Learning Project
-
Rossmann Store Sales Machine Learning Project
2. Logistic Regression
Logistic regression is a statistical technique for describing and explaining relationships between binary dependent variables and one or more nominal, interval, or ratio-level independent variables. Logistic regression allows you to predict the unknown values of a discrete target variable based on the known values of other variables.
In marketing, the logistic regression algorithm deals with creating probability models that forecast a customer’s likelihood of making a purchase using customer data. Giving marketers a more detailed perspective of customers’ choices offers them the knowledge they need to generate more effective and relevant outreach.
Learn how logistic regression helps in predictive modeling by working on these predictive analytics projects-
-
Credit Card Fraud Detection Data Science Project
-
Predicting survival on the Titanic Data Science Project
3. Decision Trees
A decision tree is an algorithm that displays the likely outcomes of various actions by graphing structured or unstructured data into a tree-like structure. Decision trees divide different decisions into branches and then list alternative outcomes beneath each one. It examines the training data and chooses the independent variable that separates it into the most diverse logical categories. The popularity of decision trees stems from the fact that they are simple to understand and interpret.
Decision trees also work well with incomplete datasets and are helpful in selecting relevant input variables. Businesses generally leverage decision trees to detect the essential target variable in a dataset. They may also employ them because the model may generate potential outcomes from incomplete datasets.
Learn how decision trees help in predictive modeling by working on these analytics projects-
-
TalkingData AdTracking Fraud Detection
-
Customer Churn Prediction Analysis using Ensemble Techniques
4. Gradient Boosted Model
A gradient boosted model employs a series of related decision trees to create rankings. It builds one tree at a time, correcting defects in the first to produce a better second tree. The gradient boosted model resamples the data set multiple times to get results that create a weighted average of the resampled data set. These models allow certain businesses to predict possible search engine results. The gradient boosted approach expresses data sets better than other techniques; hence, it is the best technique for overall data accuracy.
Learn how the gradient boosted model helps in predictive modeling by working on these projects-
-
BigMart Sales Prediction Data Science Project
-
Loan Eligibility Prediction using Gradient Boosting Classifier
5. Neural Networks
Neural networks are complex algorithms that can recognize patterns in a given dataset. A neural network is helpful for clustering data and defining categories for various datasets. There are three layers in a neural network- the input layer transfers data to the hidden layer. As the name suggests, the hidden layer hides the functions that build predictors. The output layer gathers data from such predictors and generates a final, accurate outcome. You can use neural networks with other predictive models like time series or clustering.
Learn how neural networks help in predictive modeling by working on these neural network projects-
-
Time Series Forecasting with LSTM Neural Network
-
Human Activity Recognition Using Multiclass Classification
6. Random Forest
A random forest is a vast collection of decision trees, each making its prediction. Random forests can perform both classification and regression. The values of a random vector sampled randomly with the same distribution for all trees in the random forest determine the shape of each tree. The power of this model comes from the ability to create several trees with various sub-features from the features. Random forest uses the bagging approach, i.e., it generates data subsets from training samples that you can randomly choose with replacement.
Learn how random forest algorithm helps in predictive modeling by working on these projects-
-
Inventory Demand Forecasting using Machine Learning
-
Ecommerce product reviews — Pairwise ranking and sentiment analysis
Predictive Modeling Techniques in Data Mining

As data science reaches its peak, predictive modeling appears to be a useful data mining technique, allowing businesses and enterprises to generate predictive results based on data already available. Predictive modeling is a significant part of data mining as it helps better understand future outcomes and shapes the decision-making processes to be more precise.
Here are a few examples of predictive modeling techniques in data mining-
1. ARIMA
ARIMA stands for ‘AutoRegressive Integrated Moving Average,’ and it’s a predictive model based on the assumption that existing values of a time series can alone predict future values. ARIMA models only need previous data from a time series to generalize the forecast. These models manage to boost prediction accuracy while keeping the model simplistic. ARIMA models use differencing to change a non-stationary time series into a stationary one, then use historical data to forecast potential values. These models use auto-correlations and moving averages over residual data errors to generate predictions.
ARIMA models have a wide range of applications in various industries. It is helpful in demand forecasting, such as predicting future demand in the food industry. This is mainly because the model offers managers reliable standards for making supply chain decisions.
Learn how the ARIMA model helps in predictive modeling by working on the following project-
-
Time Series Forecasting Project-Building ARIMA Model in Python
2. Support Vector Machines (SVM)
Support Vector Machines (SVMs) are top-rated in machine learning and data mining. The support vector machine is a data classification technique for predictive analysis that allocates incoming data items to one of several specified groups. In most circumstances, SVM acts as a binary classifier, which means it considers the data has two possible target values. Compared with other classifiers, support vector machines offer reliable, accurate predictions and are less prone to overfitting.
SVM transforms your data using a technique known as the kernel trick and then determines an ideal boundary between the potential outputs based on these alterations. Simply told, it performs some extremely complex data transformations before deciding how to separate your data using the labels or results you choose.
Learn how the SVM model helps in predictive modeling by working on the following project-
-
Retail Price Recommendation Project
-
Wine Quality Prediction Project
Let the Magic of Predictive Modeling Techniques Begin!
Predictive modeling can do wonders for businesses if only they apply it in the best possible ways. Any organization or individual can minimize the technical and organizational barriers with the help of various predictive modelling techniques and models. So, if you want to let your company reach new heights of success, dive into the field of predictive modeling today!
Get your hand-dirty with some of the most valuable and exciting industry-relevant predictive analytics projects. Wondering how? Explore the ProjectPro repository that offers more than 200 end-to-end solved projects on Data Science and Big Data.
FAQs on Predictive Modelling Techniques
1. How to Build a Predictive Model?
Here are the steps to build a predictive model-
-
Define the business requirements.
-
Identify and explore data relevant to your analysis.
-
Clean the data and remove any unwanted or redundant data.
-
Perform EDA on clean data and build a suitable predictive model using statistical data modeling techniques.
-
Validate your model’s accuracy and deploy it once the validation is successful.
-
Monitor your model regularly to optimize its performance, etc.
2. What are the Steps in Predictive Modelling?
The steps in predictive modeling are as follows-
-
Understanding the scope and requirements of the business problem.
-
Data Collection and Preprocessing.
-
Data cleaning and EDA.
-
Predictive Model Building.
-
Validating the Model.
-
Model Deployment.
-
Monitoring and Tracking the Model.
3. What are Predictive Modeling Techniques?
Predictive modeling techniques are the various statistical approaches that help us build predictive models using existing data to generate potential future outcomes.
E.g., Logistic regression, linear regression, random forest, decision trees, K-means, etc.
4. What are the two techniques associated with Predictive Modeling?
Neural networks and regression are two techniques associated with predictive modeling.
5. How to Select the Correct Predictive Modeling Technique?
You can select the correct predictive modeling technique by assessing the available data types and determining the desired forecast’s nature. You should begin by defining what prediction questions you want to answer and, more importantly, what you want to do with the results. Identify the strengths of each model and how each may be enhanced using different predictive analytics algorithms before deciding how to apply them to your business effectively.

На чтение 9 мин. Просмотров 1.1k.
Прогнозная или предиктивная аналитика в последние годы привлекает большое внимание бизнеса благодаря достижениям в области вспомогательных технологий, особенно в области больших данных, машинного обучения и искусственного интеллекта.
Способность предсказывать будущие события и тенденции имеет решающее значение во всех отраслях. Предиктивная аналитика появляется чаще, чем вы думаете, — от вашего еженедельного прогноза погоды до медицинских достижений с помощью алгоритмов. Ниже теоретические основы предиктивной аналитики, который поможет вам начать работу по формулированию стратегии и принятию решений на основе правильной интерпретации и анализа данных.
Предиктивная и прогнозная аналитика — это тождественные понятия, поэтому в рамках этой статьи мы будем употреблять как одно, так и другое словосочетание, не теряя общий смысл.
Содержание
- Что такое предиктивная аналитика?
- Как работает прогнозная аналитика?
- Шаг 1 Импорт данных
- Шаг 2 Очистка и агрегирование данных
- Шаг 3 Разработка прогнозной модели
- Шаг 4 Интеграция модели в систему прогнозирования
- 4 примера предиктивной аналитики в действии
- Финансы: прогнозирование будущих денежных потоков
- Развлечения и гостиничный бизнес: определение потребности в персонале
- Маркетинг: поведенческий таргетинг
- Производство: предотвращение неисправности
- 5 важных вопросов о предиктивной аналитике
Что такое предиктивная аналитика?
Предиктивная аналитика [англ. predictive analytics] — это использование исторических данных, статистических алгоритмов и разнообразных методов машинного обучения для определения вероятности будущих событий и результатов. Целью такого использования данных является выход за рамки знания того, что произошло, и оценка вероятности того, что произойдет в будущем.

Если простыми словами, то предиктивная аналитика — это использование данных для прогнозирования будущих тенденций и событий.
Прогнозный анализ может проводиться вручную или с использованием алгоритмов машинного обучения. В любом случае, исторические данные используются для того, чтобы делать предположения о будущем. При этом прогнозы могут относиться как к ближайшему будущему, так и в отделенной перспективе. Например:
- предсказание поломки машины после выявления неисправности какого-либо агрегата
- прогнозирование денежных потоков вашей компании на ближайшие пять лет
Краткое объяснение, что такое предиктивная аналитика на примере рекламного видео ролика программного решения (о эффективности самого решения пояснять не станем, а вот объяснение определения и работы прогнозной аналитики в данном видео, довольно подробное).
Как работает прогнозная аналитика?
Учитывая тот факт, что прогнозная аналитика — это некий процесс использования фактических данных для создания прогнозов с помощью методов машинного обучения, то и подходить к изучению и внедрению необходимо как к процессу.
Прогнозная аналитика начинается с бизнес-цели: использовать данные для сокращения потерь, экономии времени или сокращения затрат. Далее в этом процессе необходимо объединить разнородные, часто массивные наборы данных в модели, которые могут генерировать четкие и действенные результаты для поддержки достижения этой цели. А у же на нормальных данных выстраиваются прогнозные решения, позволяющие перестраивать бизнес под конкретные задачи и цели.
В качестве примера работы предиктивной аналитики, рассмотрим пошаговый алгоритм рабочего процесса.
Шаг 1 Импорт данных
Импорт данных может осуществляться из различных источников, таких как веб-архивы, базы данных и электронные таблицы. При этом выгрузка должна быть не только фактических данных, но и сопутствующих (например, состояние рынка, прогноз погоды, численность населения), которые могут помочь вам в составлении прогнозной идеи.
И вот тут хотелось бы заметить, что данных много не бывает и чем их будет больше и чем разностороннее они будут, тем интереснее будут вывод и точнее прогноз. Но это должны быть не хаотичные, а четко структурированные данные, обогащенные справочной информацией.
Шаг 2 Очистка и агрегирование данных
На практике, большинство реальных данных включают отсутствующие или ошибочные значения, и прежде чем их можно будет исследовать, данные необходимо идентифицировать и устранить. На этом же шаге нам необходимо выявить являются ли эти всплески аномальными и их необходимо игнорировать или они указывают на явления, которые необходимо учитывать в модели.
После удаления аномальных точек из данных нам необходимо принять решение, что делать с отсутствующими точками данных, появившимися в результате их удаления. Тут 2 варианта:
- отсутствующие точки данных можно просто игнорировать, так у нас будет меньше данных
- заменить отсутствующие значения аппроксимациями путем интерполяции
И тот и другой способ имеет место быть.
Шаг 3 Разработка прогнозной модели
Разработайте прогностическую модель на основе агрегированных данных, используя статистику, инструменты подбора кривых или машинное обучение. Сам процесс прогнозирования — это сложный процесс со многими переменными, поэтому придется использовать методы машинного обучения, такие как деревья решений или нейронные сети для построения и обучения модели прогнозирования. К сожалению, стажером с одним Excel тут не отделаться и нужен специализированный софт и прокачанные скилы специалистов.
Существует огромное множество методов моделирования данных, какой применять вам зависит от имеющихся возможностей в компании. Когда обучение завершено, вы можете протестировать модель на новых данных, чтобы увидеть, насколько хорошо она работает.
Шаг 4 Интеграция модели в систему прогнозирования
Как только будет найдена модель, которая сможет довольно точно прогнозировать показатели, вы можете перенести ее в свою производственную систему, сделав аналитику доступной для программ или устройств, включая веб-приложения, серверы или мобильные устройства.
Прогнозирование может помочь вам принимать более обоснованные решения и разрабатывать стратегии, основанные на данных. Вот несколько примеров прогнозной аналитики в действии, которые вдохновят вас на ее использование в вашей организации.
4 примера предиктивной аналитики в действии
Финансы: прогнозирование будущих денежных потоков
Каждому предприятию необходимо периодически вести финансовые отчеты, и предиктивная аналитика может сыграть большую роль в прогнозировании будущего состояния организации. Используя исторические данные из предыдущих финансовых отчетов, а также данные из более широкой отрасли, вы можете прогнозировать продажи, доходы и расходы, чтобы составить картину будущего и принять решения.
«Менеджеры должны смотреть вперед, чтобы планировать будущее здоровье своего бизнеса. Независимо от того, в какой области вы работаете, в этом процессе всегда присутствует большая доля неопределенности», — говорил Нараянан (прим. 10 президент Индии).
Подробный и наглядный пример внедрения предиктивной аналитики в финансовой сфере в подробном кейсе регионального банка на видео
Развлечения и гостиничный бизнес: определение потребности в персонале
В сфере развлечений и гостеприимства приток и отток клиентов зависят от различных факторов, каждый из которых влияет на то, сколько сотрудников требуется заведению или отелю в данный момент времени. Раздутие штата стоит денег, а не доукомплектование может привести к ухудшению качества обслуживания клиентов, переутомлению сотрудников и дорогостоящим ошибкам.
Чтобы предсказать количество заселений в отель в определенный день, разрабатывается модель множественной регрессии, учитывающую несколько факторов. Такая модель позволила Caesars (прим. мировая сеть отелей) укомплектовать свои отели и казино персоналом и максимально избежать перерасхода персонала.
Маркетинг: поведенческий таргетинг
В маркетинге данных о потребителях предостаточно, и они используются для создания контента, рекламы и стратегий, позволяющих лучше охватить потенциальных клиентов там, где они есть. Изучая исторические поведенческие данные и используя их для прогнозирования того, что произойдет в будущем, вы занимаетесь прогнозной аналитикой.
Предиктивная аналитика может применяться в маркетинге для прогнозирования тенденций продаж в разное время года и соответствующего планирования кампаний.
Кроме того, исторические поведенческие данные могут помочь вам спрогнозировать вероятность того, что лид переместится по воронке вниз от осведомленности к покупке. Например, вы можете использовать единую модель линейной регрессии, чтобы определить, что количество предложений контента, с которыми взаимодействует лид, предсказывает — со статистически значимым уровнем достоверности — вероятность их конверсии в клиента в будущем. Обладая этими знаниями, вы можете планировать таргетированную рекламу на различных этапах жизненного цикла клиента.
Производство: предотвращение неисправности
Хотя в приведенных выше примерах прогнозная аналитика используется для принятия мер на основе вероятных сценариев, вы также можете использовать прогнозную аналитику для предотвращения возникновения нежелательных или опасных ситуаций. Например, в производственной сфере алгоритмы можно обучать, используя исторические данные, чтобы точно предсказывать, когда часть оборудования может выйти из строя.
Когда критерии предстоящей неисправности соблюдены, алгоритм срабатывает, чтобы предупредить сотрудника, который может остановить машину и потенциально сэкономить компании тысячи, если не миллионы долларов на поврежденном продукте и затратах на ремонт. Этот анализ прогнозирует сценарии сбоев в данный момент, а не на месяцы или годы вперед.
5 важных вопросов о предиктивной аналитике
В каких сферах можно применять предиктивную аналитику?
Любая отрасль может использовать прогнозную аналитику для снижения рисков, оптимизации операций и увеличения доходов.
Что необходимо, чтобы начать использовать предиктивную аналитику?
Для внедрения предиктивной аналитики потребуется:
- Внедрить два предыдущих типа аналитики — подробная статья про описательную аналитику; все нюансы диагностической аналитики.
- Четко ответить на вопросы: Что вы хотите понять и предсказать? Какие решения и действия будут предприняты на основе полученных идей?
- Найти данные (собрать из всевозможных источников)
- Научиться агрегировать данные (Query, SQL, Python в помощь)
- Найти команду специалистов или прокачать скилы своих сотрудников
- Построить прогнозную модель
Почему важна предиктивная аналитика?
Сейчас потребность в прогнозной аналитике, возможно, более критична, чем когда-либо. Прогнозная аналитика помогает компаниям найти значимые закономерности в совокупности данных, а затем построить модели, которые предсказывают, что, вероятно, произойдет в будущем.
Какое программное обеспечение использовать?
Существует огромное множество программных решений для прогнозной аналитики. Какое выбрать именно для вашей компании решать вам, в зависимости от компетенций и бюджета. Ниже лишь несколько примеров:
- прогнозная аналитика SAP
- расширенная аналитика SAS
- QlikSense
- Студия IBM Watson
- Sisense Forecast
- Microsoft Azure
- аналитика MATLAB
Какие методы прогнозной аналитики применять?
В предиктивной аналитике используются следующие методы:
Дерево решений — это методология аналитики, основанная на машинном обучении, которая использует алгоритмы интеллектуального анализа данных для прогнозирования потенциальных рисков и преимуществ при выборе определенных вариантов. Это наглядная диаграмма, напоминающая перевернутое дерево, на котором изображен предполагаемый результат решения. При использовании для аналитики он может решать все виды задач классификации и отвечать на сложные вопросы.
Нейронные сети — это биологически вдохновленные системы обработки данных, которые используют исторические и текущие данные для прогнозирования будущих значений. Их архитектура позволяет им идентифицировать сложные связи, скрытые в данных, таким образом, что они воспроизводят системы обнаружения закономерностей человеческого мозга.
Текстовая аналитика используется, когда компания хочет предвидеть числовое значение. Он построен на подходах из статистики, машинного обучения и лингвистики. Он помогает прогнозировать темы документа и анализирует слова, используемые в предоставленной форме.
Метод регрессии имеет решающее значение для организации, когда речь идет об оценке числового значения, например, сколько времени потребуется целевой аудитории, чтобы вернуться к бронированию авиабилетов перед покупкой, или сколько денег кто-то потратит на оплату транспортных средств в течение определенного периода времени.
ARIMA — модель авторегрессии скользящего среднего, которая применяется для построения краткосрочных прогнозов величины на основании её предыдущих значений. Разбираем построение модели в Loginom для прогноза объема продаж сезонных товаров зимнего спорта по месяцам.
- Исходные данные
- Построение модели
- Результаты прогнозирования
- Построение графика
- Анализ полученных результатов
- Увеличение точности прогноза
- Автоматизация прогнозирования в Loginom
Для большинства бизнесов процесс принятия решений напрямую связан с результатами прогнозирования, которые используются при планировании производства, оптимизации запасов и прочее.
Для этого часто применяются методы анализа временных рядов — математических моделей, в которых определяется зависимость будущего значения от прошлых внутри самого процесса. На основе выявленных зависимостей построится прогноз.
Анализ временных рядов лучше использовать для краткосрочного прогнозирования, т.к. при увеличении горизонта прогноза модель начинает рассчитывать новые значения на основании своих же предсказаний. Это допустимо на определенном временном интервале, но по мере увеличения горизонта прогнозы становятся гораздо менее точными из-за накапливающейся погрешности.
Важно учитывать и ограничения — такой метод подходит только для планирования стохастических (стационарных) процессов, в которых не изменяется распределение вероятности при смещении времени. Например, для расчета объема продаж.
Существует класс моделей, в которых реализуется этот метод:
- ARIMA. Авторегрессионная модель скользящего среднего с интеграцией.
- ARIMAX. Отличается от ARIMA тем, что дополнительно учитывается воздействие внешних (eXtended) факторов, влияющих на изменение исходного показателя.
Данные аббревиатуры можно расшифровать следующим образом:
- AR – модель авторегрессии. Вычисление значения прогнозируемой величины в заданный момент времени на основе её предыдущих значений.
- I – интеграция. Изучение не самих значений процесса, а изменений его показателей друг относительно друга.
- MA – модель скользящего среднего. Фильтр, сглаживающий выбросы временного ряда посредством замены исходного значения средним арифметическим значением нескольких ближайших к нему членов.
- X – расширения. Добавление в модель внешних факторов, влияние которых будет учитываться в прогнозе.
Учет внешнего фактора важен для построения прогнозов высокой точности, но сбор и обработка таких данных как правило занимают время, а в некоторых случаях вообще сложно предсказать их поведение.
Например, при анализе объема продаж товаров для зимнего спорта важным параметром становится температура воздуха, но каждый знает, что метеорологи регулярно ошибаются с прогнозами на день вперед. Поэтому при планировании на несколько месяцев, точность данных о погоде будет настолько низкой, то нет смысла её учитывать.
В данной статье рассмотрим пример прогнозирования значений величины на основе модели ARIMA. В этом случае никаких дополнительных данных, кроме самого прогнозируемого показателя для построения прогноза не требуется.
Оставим за скобками процессы предобработки и дальнейшего использования данных и разберемся, как работает обработчик ARIMAX.
Исходные данные
Для получения корректного прогноза необходимо достаточное количество данных о предыдущих значениях продаж. Важно учитывать, что совсем старые данные не могут быть использованы, иначе прогноз будет недостоверным.
Кроме того, чем больший интервал прогноза будет рассматриваться, тем больше данных потребуется. В нашем случае для прогнозирования потребления на 5 месяцев вперед потребуется информация как минимум о нескольких годовых периодах в прошлом.
Ниже представлена таблица 1, которая состоит из следующих столбцов:
- Дата. Первое число каждого месяца, т.к. временной интервал взят помесячно.
- Продажи (руб.). Суммарные объемы продаж товаров для зимнего спорта за месяц.
Таблица 1. Исходные данные:
| Дата | Продажи (руб.) |
|---|---|
| 01.05.2015 | 250 127.68 |
| 01.06.2015 | 225 127.56 |
| 01.07.2015 | 184 265.77 |
| 01.08.2015 | 200 792.53 |
| 01.09.2015 | 265 275.44 |
| 01.10.2015 | 339 285.82 |
| 01.11.2015 | 390 677.54 |
| 01.12.2015 | 417 945.20 |
| … | … |
Построение модели
В Loginom есть специальный обработчик ARIMAX, который включает в себя математическую модель ARIMA с расширениями, влияние которых будет учитываться при построении прогноза. Если внешних данных не поступает на вход, то он превращается в ARIMA.
Перенесем этот элемент на область построения сценария, подав на вход узла исходные данные.
Настроим обработчик ARIMAX для получения прогнозных данных. Первое окно — «Настройка входных столбцов», здесь каждому столбцу исходных данных нужно задать одно из трех возможных значений:
- Не задано. Автоматически устанавливается для всех полей.
- Входное. Нужно задать для полей, которые соответствуют внешнему фактору, в нашем примере их нет.
- Прогнозируемое. Может быть установлено только для одного поля, в нашем случае «Продажи (руб.)».

Настройка входных столбцов обработчика ARIMAX
После настройки входных столбцов доступна нормализация входных и выходных полей. В подавляющем большинстве случаев её не нужно применять ни к данным временного поля, ни к внешним параметрам.
Основные настройки задаются в окне «Настройки ARIMAX», причем при отсутствии конкретных критериев прогноза можно установить отметку в поле «Определить структуру автоматически», и обработчик рассчитает необходимые параметры для ваших данных.
По умолчанию значение горизонта прогноза устанавливается равным 1, это значит, что мы получим прогноз на один период вперед. Чтобы нагляднее увидеть работу узла, изменим это значение на 5.

Автоматическая настройка обработчика ARIMAX
Сразу после сохранения настроек элемента запускать на исполнение его нельзя. Сначала нужно обучить данный узел.
Для этого в контекстном меню выберем «Переобучить узел».

Переобучение узла
Результаты прогнозирования
В узле ARIMAX три выходных порта:
- Выход модели
- Коэффициенты модели
- Сводка
После запуска обработчика ARIMAX можно открыть «Быстрый просмотр» на первом выходном порту и увидеть, что исходные данные дополнились следующими выходными столбцами:
- Продажи (руб.)ǀПрогноз. Прогноз объема продаж на основе предыдущих периодов.
- Продажи (руб.)ǀНижняя граница. Нижняя граница прогноза объема продаж на основе предыдущих периодов.
- Продажи (руб.)ǀВерхняя граница. Верхняя граница прогноза объема продаж на основе предыдущих периодов.
- Продажи (руб.)ǀОшибка аппроксимации. Среднее отклонение расчетных значений от фактических, будет отображаться, если установлена отметка в «Рассчитать ошибку аппроксимации».

Выход модели ARIMAX
Причем прогнозные данные будут рассчитаны и для тех месяцев, по которым уже известен объем продаж, и для новых периодов. Стоит отметить, что в самом начале таблицы новые столбцы с прогнозами будут пустыми, их количество зависит от установленного значения в поле «Порядок AR части».
Если мы обратимся ко второму выходному порту, то увидим таблицу с коэффициентами модели, а к третьему — сводку значений переменных, показывающих количество примеров, ошибки на обучающем множестве, информационные критерии, коэффициенты детерминации, числа степеней свободы.
Данные выходных портов дают исчерпывающую информацию о выполненном прогнозе, но табличное представление сложно воспринимать, поэтому в большинстве случаев потребуются визуализаторы.
Прежде, чем переходить к построению графиков, необходимо заполнить значения временного ряда для появившихся строк, иначе график прогноза будет отображаться только на исходном временном периоде, а значения на горизонте прогноза не будут отражены. Для этого добавим узел «Калькулятор».
В настройках узла создадим переменную AllDates, которая будет содержать все значения временного ряда. Расчет будет строиться с помощью функции условия If. Если поле даты пустое, то функция AddMonth добавляет необходимое количество месяцев к последнему известному значению, в противном случае вносит ту дату, которая указана в поле.
Для того, чтобы вычислить количество месяцев, необходимо сначала найти разность между номером текущей строки (функция RowNum()) и количеством уникальных значений поля Date (функция Stat(«Date», «UniqueCount»)), а затем добавить к полученному результату 2. Важно учитывать, что нумерация строк начинается с 0, а в количестве уникальных значений присутствуют не только исходные даты, но и пустое значение в появившихся после прогноза строках, именно поэтому вводится цифра 2.

Калькулятор Loginom
После выполнения узла «Калькулятор» в таблице на его выходном порту появится столбец «Все даты».
Построение графика
Для того, чтобы визуально оценить прогнозные значения и их корреляцию с фактическими показателями, построим графики исходных значений объема продаж и прогноза этой величины, полученного в результате использования модели ARIMA.
В результате получим график, на котором отображаются кривые прогноза и исходных значений объема продаж в рублях.

График прогноза продаж
Анализ полученных результатов
На графике отчетливо выделяются 3 временных периода:
- Обучение модели. На этом временном отрезке возможно построение только кривой фактических данных.
- Построение прогноза при наличии фактических значений величины. На графике присутствуют сразу две кривые, что позволяет визуально оценить, насколько близки полученные в результате работы модуля ARIMA прогнозные значения к фактическим.
- Горизонт прогноза — отображается кривая прогноза.
В качестве этапа обучения модели обработчик ARIMAX задал временной промежуток 29 месяцев (около 2 лет). На втором интервале видно, что графики объема продаж и его прогноза имеют одинаковую форму, но при этом значения величин в некоторых точках значительно отличаются. Линия прогноза на 3 временном промежутке визуально повторяет форму кривой исходных значений продаж.
Увеличение точности прогноза
В случае, когда точность прогноза с автоматически заданными параметрами оказалась недостаточной, можно задать эти значения вручную.
Важно понимать, что нет универсальных правил, которые могут быть применимы ко всем задачам прогнозирования, поэтому для каждого набора данных они будут свои. В документации можно подробно ознакомиться с описанием структуры ARIMAX и определениями каждого из настраиваемых параметров.
Изменим показатели в окне настройки ARIMAX, как это показано на рисунке ниже.

Настройка обработчика ARIMAX
Далее необходимо будет произвести переобучение данного узла.
Значения прогноза будут пересчитаны, и в визуализаторе мы сможем увидеть, что графики кривых на 2 временном периоде приняли почти одинаковый вид. Это говорит о том, что точность прогноза увеличилась.
График прогноза продаж
Чтобы убедиться в том, что прогноз стал точнее, откроем вкладку «Сводка» на третьем выходном порте модели. Значение средней относительной ошибки на обучающем множестве сократились в несколько раз по сравнению с предыдущими.
Ошибки сводки ARIMAX
Автоматизация прогнозирования в Loginom
В данном примере мы построили прогноз объема продаж сезонных товаров для зимнего спорта с помощью модели ARIMA.
При автоматически заданных параметрах обработчика ARIMAX был получен корректный прогноз с минимальным количеством входных данных. Кроме того, удалось добиться увеличения точности прогноза с помощью ручного подбора параметров модели ARIMAX.
Сам обработчик ARIMAX характеризуется простотой использования и быстрой работой, достаточно подать на вход данные и ввести показатели прогнозирования (а можно и не вводить вовсе), и уже через несколько секунд получить корректный прогноз. Кроме того, в Loginom можно построить графики с кривыми фактических и прогнозных значений, что в полной мере позволяет визуально оценить полученный результат.
Другие материалы по теме:
Автоматизация прогнозирования розничных продаж. Кейс Estee Lauder Companies Inc.
Прогнозирование аварий и обнаружение потерь на объектах газоснабжения
Прогнозирование в разрезе SKU. Новые возможности повышения адекватности прогнозов