Время на прочтение
16 мин
Количество просмотров 123K
В наше время редко возникает необходимость писать на чистом ассемблере, но я определённо рекомендую это всем, кто интересуется программированием. Вы увидите вещи под иным углом, а навыки пригодятся при отладке кода на других языках.
В этой статье мы напишем с нуля калькулятор обратной польской записи (RPN) на чистом ассемблере x86. Когда закончим, то сможем использовать его так:
$ ./calc "32+6*" # "(3+2)*6" в инфиксной нотации
30Весь код для статьи здесь. Он обильно закомментирован и может служить учебным материалом для тех, кто уже знает ассемблер.
Начнём с написания базовой программы Hello world! для проверки настроек среды. Затем перейдём к системным вызовам, стеку вызовов, стековым кадрам и соглашению о вызовах x86. Потом для практики напишем некоторые базовые функции на ассемблере x86 — и начнём писать калькулятор RPN.
Предполагается, что у читателя есть некоторый опыт программирования на C и базовые знания компьютерной архитектуры (например, что такое регистр процессора). Поскольку мы будем использовать Linux, вы также должны уметь использовать командную строку Linux.
Настройка среды
Как уже сказано, мы используем Linux (64- или 32-битный). Приведённый код не работает в Windows или Mac OS X.
Для установки нужен только компоновщик GNU ld из binutils, который предварительно установлен в большинстве дистрибутивов, и ассемблер NASM. На Ubuntu и Debian можете установить и то, и другое одной командой:
$ sudo apt-get install binutils nasmЯ бы также рекомендовал держать под рукой таблицу ASCII.
Hello, world!
Для проверки среды сохраните следующий код в файле calc.asm:
; Компоновщик находит символ _start и начинает выполнение программы
; отсюда.
global _start
; В разделе .rodata хранятся константы (только для чтения)
; Порядок секций не имеет значения, но я люблю ставить её вперёд
section .rodata
; Объявляем пару байтов как hello_world. Псевдоинструкция базы NASM
; допускает однобайтовое значение, строковую константу или их сочетание,
; как здесь. 0xA = новая строка, 0x0 = нуль окончания строки
hello_world: db "Hello world!", 0xA, 0x0
; Начало секции .text, где находится код программы
section .text
_start:
mov eax, 0x04 ; записать число 4 в регистр eax (0x04 = write())
mov ebx, 0x1 ; дескриптор файла (1 = стандартный вывод, 2 = стандартная ошибка)
mov ecx, hello_world ; указатель на выводимую строку
mov edx, 14 ; длина строки
int 0x80 ; отправляем сигнал прерывания 0x80, который ОС
; интерпретирует как системный вызов
mov eax, 0x01 ; 0x01 = exit()
mov ebx, 0 ; 0 = нет ошибок
int 0x80Комментарии объясняют общую структуру. Список регистров и общих инструкций можете изучить в «Руководстве по ассемблеру x86 университета Вирджинии». При дальнейшем обсуждении системных вызовов это тем более понадобится.
Следующие команды собирают файл ассемблера в объектный файл, а затем компонует исполняемый файл:
$ nasm -f elf_i386 calc.asm -o calc
$ ld -m elf_i386 calc.o -o calcПосле запуска вы должны увидеть:
$ ./calc
Hello world!Makefile
Это необязательная часть, но для упрощения сборки и компоновки в будущем можно сделать Makefile. Сохраните его в том же каталоге, что и calc.asm:
CFLAGS= -f elf32
LFLAGS= -m elf_i386
all: calc
calc: calc.o
ld $(LFLAGS) calc.o -o calc
calc.o: calc.asm
nasm $(CFLAGS) calc.asm -o calc.o
clean:
rm -f calc.o calc
.INTERMEDIATE: calc.oЗатем вместо вышеприведённых инструкций просто запускаем make.
Системные вызовы
Системные вызовы Linux указывают ОС выполнить для нас какие-то действия. В этой статье мы используем только два системных вызова: write() для записи строки в файл или поток (в нашем случае это стандартное устройство вывода и стандартная ошибка) и exit() для выхода из программы:
syscall 0x01: exit(int error_code)
error_code - используем 0 для выхода без ошибок и любые другие значения (такие как 1) для ошибок
syscall 0x04: write(int fd, char *string, int length)
fd — используем 1 для стандартного вывода, 2 для стандартного потока вывода ошибок
string — указатель на первый символ строки
length — длина строки в байтах
Системные вызовы настраиваются путём сохранения номера системного вызова в регистре eax, а затем его аргументов в ebx, ecx, edx в таком порядке. Можете заметить, что у exit() только один аргумент — в этом случае ecx и edx не имеют значения.
| eax | ebx | ecx | edx |
|---|---|---|---|
| Номер системного вызова | arg1 | arg2 | arg3 |
Стек вызовов

Стек вызовов — структура данных, в которой хранится информация о каждом обращении к функции. У каждого вызова собственный раздел в стеке — «фрейм». Он хранит некоторую информацию о текущем вызове: локальные переменные этой функции и адрес возврата (куда программа должна перейти после выполнения функции).
Сразу отмечу одну неочевидную вещь: стек увеличивается вниз по памяти. Когда вы добавляете что-то на верх стека, оно вставляется по адресу памяти ниже, чем предыдущий элемент. Другими словами, по мере роста стека адрес памяти в верхней части стека уменьшается. Чтобы избежать путаницы, я буду всё время напоминать об этом факте.
Инструкция push заносит что-нибудь на верх стека, а pop уносит данные оттуда. Например, push еах выделяет место наверху стека и помещает туда значение из регистра eax, а pop еах переносит любые данные из верхней части стека в eax и освобождает эту область памяти.
Цель регистра esp — указать на вершину стека. Любые данные выше esp считаются не попавшими в стек, это мусорные данные. Выполнение инструкции push (или pop) перемещает esp. Вы можете манипулировать esp и напрямую, если отдаёте отчёт своим действиям.
Регистр ebp похож на esp, только он всегда указывает примерно на середину текущего кадра стека, непосредственно перед локальными переменными текущей функции (поговорим об этом позже). Однако вызов другой функции не перемещает ebp автоматически, это нужно каждый раз делать вручную.
Соглашение о вызовах для архитектуры x86
В х86 нет встроенного понятия функции как в высокоуровневых языках. Инструкция call — это по сути просто jmp (goto) в другой адрес памяти. Чтобы использовать подпрограммы как функции в других языках (которые могут принимать аргументы и возвращать данные обратно), нужно следовать соглашению о вызовах (существует много конвенций, но мы используем CDECL, самое популярное соглашение для x86 среди компиляторов С и программистов на ассемблере). Это также гарантирует, что регистры подпрограммы не перепутаются при вызове другой функции.
Правила вызывающей стороны
Перед вызовом функции вызывающая сторона должна:
- Сохранить в стек регистры, которые обязан сохранять вызывающий. Вызываемая функция может изменить некоторые регистры: чтобы не потерять данные, вызывающая сторона должна сохранить их в памяти до помещения в стек. Речь идёт о регистрах
eax,ecxиedx. Если вы не используете какие-то из них, то их можно не сохранять. - Записать аргументы функции на стек в обратном порядке (сначала последний аргумент, в конце первый аргумент). Такой порядок гарантирует, что вызываемая функция получит из стека свои аргументы в правильном порядке.
- Вызвать подпрограмму.
По возможности функция сохранит результат в eax. Сразу после call вызывающая сторона должна:
- Удалить из стека аргументы функции. Обычно это делается путём простого добавления числа байтов в
esp. Не забывайте, что стек растёт вниз, поэтому для удаления из стека необходимо добавить байты. - Восстановить сохранённые регистры, забрав их из стека в обратном порядке инструкцией
pop. Вызываемая функция не изменит никакие другие регистры.
Следующий пример демонстрирует, как применяются эти правила. Предположим, что функция _subtract принимает два целочисленных (4-байтовых) аргумента и возвращает первый аргумент за вычетом второго. В подпрограмме _mysubroutine вызываем _subtract с аргументами 10 и 2:
_mysubroutine:
; ...
; здесь какой-то код
; ...
push ecx ; сохраняем регистры (я решил не сохранять eax)
push edx
push 2 ; второе правило, пушим аргументы в обратном порядке
push 10
call _subtract ; eax теперь равен 10-2=8
add esp, 8 ; удаляем 8 байт со стека (два аргумента по 4 байта)
pop edx ; восстанавливаем сохранённые регистры
pop ecx
; ...
; ещё какой-то код, где я использую удивительно полезное значение из eax
; ...Правила вызываемой подпрограммы
Перед вызовом подпрограмма должна:
- Сохранить указатель базового регистра
ebpпредыдущего фрейма, записав его на стек. - Отрегулировать
ebpс предыдущего фрейма на текущий (текущее значениеesp). - Выделить больше места в стеке для локальных переменных, при необходимости переместить указатель
esp. Поскольку стек растёт вниз, нужно вычесть недостающую память изesp. - Сохранить в стек регистры вызываемой подпрограммы. Это
ebx,ediиesi. Необязательно сохранять регистры, которые не планируется изменять.
Стек вызовов после шага 1:

Стек вызовов после шага 2:

Стек вызовов после шага 4:

На этих диаграммах в каждом стековом фрейме указан адрес возврата. Его автоматически вставляет в стек инструкция call. Инструкция ret извлекает адрес с верхней части стека и переходит на него. Эта инструкция нам не нужна, я просто показал, почему локальные переменные функции находятся на 4 байта выше ebp, но аргументы функции — на 8 байт ниже ebp.
На последней диаграмме также можно заметить, что локальные переменные функции всегда начинается на 4 байта выше ebp с адреса ebp-4 (здесь вычитание, потому что мы двигаемся вверх по стеку), а аргументы функции всегда начинается на 8 байт ниже ebp с адреса ebp+8 (сложение, потому что мы двигаемся вниз по стеку). Если следовать правилам из этой конвенции, так будет c переменными и аргументами любой функции.
Когда функция выполнена и вы хотите вернуться, нужно сначала установить eax на возвращаемое значение функции, если это необходимо. Кроме того, нужно:
- Восстановить сохранённые регистры, вынеся их из стека в обратном порядке.
- Освободить место в стеке, выделенное локальным переменным на шаге 3, если необходимо: делается простой установкой
espв ebp - Восстановить указатель базы
ebpпредыдущего фрейма, вынеся его из стека. - Вернуться с помощью
ret
Теперь реализуем функцию _subtract из нашего примера:
_subtract:
push ebp ; сохранение указателя базы предыдущего фрейма
mov ebp, esp ; настройка ebp
; Здесь я бы выделил место на стеке для локальных переменных, но они мне не нужны
; Здесь я бы сохранил регистры вызываемой подпрограммы, но я ничего не
; собираюсь изменять
; Тут начинается функция
mov eax, [ebp+8] ; копирование первого аргумента функции в eax. Скобки
; означают доступ к памяти по адресу ebp+8
sub eax, [ebp+12] ; вычитание второго аргумента по адресу ebp+12 из первого
; аргумента
; Тут функция заканчивается, eax равен её возвращаемому значению
; Здесь я бы восстановил регистры, но они не сохранялись
; Здесь я бы освободил стек от переменных, но память для них не выделялась
pop ebp ; восстановление указателя базы предыдущего фрейма
retВход и выход
В приведённом примере вы можете заметить, что функция всегда запускается одинаково: push ebp, mov ebp, esp и выделение памяти для локальных переменных. В наборе x86 есть удобная инструкция, которая всё это выполняет: enter a b, где a — количество байт, которые вы хотите выделить для локальных переменных, b — «уровень вложенности», который мы всегда будем выставлять на 0. Кроме того, функция всегда заканчивается инструкциями pop ebp и mov esp, ebp (хотя они необходимы только при выделении памяти для локальных переменных, но в любом случае не причиняют вреда). Это тоже можно заменить одной инструкцией: leave. Вносим изменения:
_subtract:
enter 0, 0 ; сохранение указателя базы предыдущего фрейма и настройка ebp
; Здесь я бы сохранил регистры вызываемой подпрограммы, но я ничего не
; собираюсь изменять
; Тут начинается функция
mov eax, [ebp+8] ; копирование первого аргумента функции в eax. Скобки
; означают доступ к памяти по адресу ebp+8
sub eax, [ebp+12] ; вычитание второго аргумента по адресу ebp+12 из
; первого аргумента
; Тут функция заканчивается, eax равен её возвращаемому значению
; Здесь я бы восстановил регистры, но они не сохранялись
leave ; восстановление указателя базы предыдущего фрейма
retНаписание некоторых основных функций
Усвоив соглашение о вызовах, можно приступить к написанию некоторых подпрограмм. Почему бы не обобщить код, который выводит «Hello world!», для вывода любых строк: функция _print_msg.
Здесь понадобится ещё одна функция _strlen для подсчёта длины строки. На C она может выглядеть так:
size_t strlen(char *s) {
size_t length = 0;
while (*s != 0)
{ // начало цикла
length++;
s++;
} // конец цикла
return length;
}
Другими словами, с самого начала строки мы добавляем 1 к возвращаемым значением для каждого символа, кроме нуля. Как только замечен нулевой символ, возвращаем накопленное в цикле значение. В ассемблере это тоже довольно просто: можно использовать как базу ранее написанную функцию _subtract:
_strlen:
enter 0, 0 ; сохраняем указатель базы предыдущего фрейма и настраиваем ebp
; Здесь я бы сохранил регистры вызываемой подпрограммы, но я ничего не
; собираюсь изменять
; Здесь начинается функция
mov eax, 0 ; length = 0
mov ecx, [ebp+8] ; первый аргумент функции (указатель на первый
; символ строки) копируется в ecx (его сохраняет вызывающая
; сторона, так что нам нет нужды сохранять)
_strlen_loop_start: ; это метка, куда можно перейти
cmp byte [ecx], 0 ; разыменование указателя и сравнение его с нулём. По
; умолчанию память считывается по 32 бита (4 байта).
; Иное нужно указать явно. Здесь мы указываем
; чтение только одного байта (один символ)
je _strlen_loop_end ; выход из цикла при появлении нуля
inc eax ; теперь мы внутри цикла, добавляем 1 к возвращаемому значению
add ecx, 1 ; переход к следующему символу в строке
jmp _strlen_loop_start ; переход обратно к началу цикла
_strlen_loop_end:
; Здесь функция заканчивается, eax равно возвращаемому значению
; Здесь я бы восстановил регистры, но они не сохранялись
leave ; восстановление указателя базы предыдущего фрейма
ret
Уже неплохо, верно? Сначала написать код на C может помочь, потому что большая его часть непосредственно преобразуется в ассемблер. Теперь можно использовать эту функцию в _print_msg, где мы применим все полученные знания:
_print_msg:
enter 0, 0
; Здесь начинается функция
mov eax, 0x04 ; 0x04 = системный вызов write()
mov ebx, 0x1 ; 0x1 = стандартный вывод
mov ecx, [ebp+8] ; мы хотим вывести первый аргумент этой функции,
; сначала установим edx на длину строки. Пришло время вызвать _strlen
push eax ; сохраняем регистры вызываемой функции (я решил не сохранять edx)
push ecx
push dword [ebp+8] ; пушим аргумент _strlen в _print_msg. Здесь NASM
; ругается, если не указать размер, не знаю, почему.
; В любом случае указателем будет dword (4 байта, 32 бита)
call _strlen ; eax теперь равен длине строки
mov edx, eax ; перемещаем размер строки в edx, где он нам нужен
add esp, 4 ; удаляем 4 байта со стека (один 4-байтовый аргумент char*)
pop ecx ; восстанавливаем регистры вызывающей стороны
pop eax
; мы закончили работу с функцией _strlen, можно инициировать системный вызов
int 0x80
leave
retИ посмотрим плоды нашей тяжёлой работы, используя эту функцию в полной программе “Hello, world!”.
_start:
enter 0, 0
; сохраняем регистры вызывающей стороны (я решил никакие не сохранять)
push hello_world ; добавляем аргумент для _print_msg
call _print_msg
mov eax, 0x01 ; 0x01 = exit()
mov ebx, 0 ; 0 = без ошибок
int 0x80Хотите верьте, хотите нет, но мы рассмотрели все основные темы, которые нужны для написания базовых программ на ассемблере x86! Теперь у нас есть весь вводный материал и теория, так что полностью сосредоточимся на коде и применим полученные знания для написания нашего калькулятора RPN. Функции будут намного длиннее и даже станут использовать некоторые локальные переменные. Если хотите сразу увидеть готовую программу, вот она.
Для тех из вас, кто не знаком с обратной польской записью (иногда называемой обратной польской нотацией или постфиксной нотацией), то здесь выражения вычисляются с помощью стека. Поэтому нужно создать стек, а также функции _pop и _push для манипуляций с этим стеком. Понадобится ещё функция _print_answer, которая выведет в конце вычислений строковое представление числового результата.
Создание стека
Сначала определим для нашего стека пространство в памяти, а также глобальную переменную stack_size. Желательно изменить эти переменные так, чтобы они попали не в раздел .rodata, а в .data.
section .data
stack_size: dd 0 ; создаём переменную dword (4 байта) со значением 0
stack: times 256 dd 0 ; заполняем стек нулями
Теперь можно реализовать функции _push и _pop:
_push:
enter 0, 0
; Сохраняем регистры вызываемой функции, которые будем использовать
push eax
push edx
mov eax, [stack_size]
mov edx, [ebp+8]
mov [stack + 4*eax], edx ; Заносим аргумент на стек. Масштабируем по
; четыре байта в соответствии с размером dword
inc dword [stack_size] ; Добавляем 1 к stack_size
; Восстанавливаем регистры вызываемой функции
pop edx
pop eax
leave
ret
_pop:
enter 0, 0
; Сохраняем регистры вызываемой функции
dec dword [stack_size] ; Сначала вычитаем 1 из stack_size
mov eax, [stack_size]
mov eax, [stack + 4*eax] ; Заносим число на верх стека в eax
; Здесь я бы восстановил регистры, но они не сохранялись
leave
retВывод чисел
_print_answer намного сложнее: придётся конвертировать числа в строки и использовать несколько других функций. Понадобится функция _putc, которая выводит один символ, функция mod для вычисления остатка от деления (модуля) двух аргументов и _pow_10 для возведения в степень 10. Позже вы поймёте, зачем они нужны. Это довольно просто, вот код:
_pow_10:
enter 0, 0
mov ecx, [ebp+8] ; задаёт ecx (сохранённый вызывающей стороной) аргументом
; функции
mov eax, 1 ; первая степень 10 (10**0 = 1)
_pow_10_loop_start: ; умножает eax на 10, если ecx не равно 0
cmp ecx, 0
je _pow_10_loop_end
imul eax, 10
sub ecx, 1
jmp _pow_10_loop_start
_pow_10_loop_end:
leave
ret
_mod:
enter 0, 0
push ebx
mov edx, 0 ; объясняется ниже
mov eax, [ebp+8]
mov ebx, [ebp+12]
idiv ebx ; делит 64-битное целое [edx:eax] на ebx. Мы хотим поделить
; только 32-битное целое eax, так что устанавливаем edx равным
; нулю.
; частное сохраняем в eax, остаток в edx. Как обычно, получить
; информацию по конкретной инструкции можно из справочников,
; перечисленных в конце статьи.
mov eax, edx ; возвращает остаток от деления (модуль)
pop ebx
leave
ret
_putc:
enter 0, 0
mov eax, 0x04 ; write()
mov ebx, 1 ; стандартный вывод
lea ecx, [ebp+8] ; входной символ
mov edx, 1 ; вывести только 1 символ
int 0x80
leave
ret
Итак, как мы выводим отдельные цифры в числе? Во-первых, обратите внимание, что последняя цифра числа равна остатку от деления на 10 (например, 123 % 10 = 3), а следующая цифра — это остаток от деления на 100, поделенный на 10 (например, (123 % 100)/10 = 2). В общем, можно найти конкретную цифру числа (справа налево), найдя (число % 10**n) / 10**(n-1), где число единиц будет равно n = 1, число десятков n = 2 и так далее.
Используя это знание, можно найти все цифры числа с n = 1 до n = 10 (это максимальное количество разрядов в знаковом 4-байтовом целом). Но намного проще идти слева направо — так мы сможем печатать каждый символ, как только находим его, и избавиться от нулей в левой части. Поэтому перебираем числа от n = 10 до n = 1.
На C программа будет выглядеть примерно так:
#define MAX_DIGITS 10
void print_answer(int a) {
if (a < 0) { // если число отрицательное
putc('-'); // вывести знак «минус»
a = -a; // преобразовать в положительное число
}
int started = 0;
for (int i = MAX_DIGITS; i > 0; i--) {
int digit = (a % pow_10(i)) / pow_10(i-1);
if (digit == 0 && started == 0) continue; // не выводить лишние нули
started = 1;
putc(digit + '0');
}
}Теперь вы понимаете, зачем нам эти три функции. Давайте реализуем это на ассемблере:
%define MAX_DIGITS 10
_print_answer:
enter 1, 0 ; используем 1 байт для переменной "started" в коде C
push ebx
push edi
push esi
mov eax, [ebp+8] ; наш аргумент "a"
cmp eax, 0 ; если число не отрицательное, пропускаем этот условный
; оператор
jge _print_answer_negate_end
; call putc for '-'
push eax
push 0x2d ; символ '-'
call _putc
add esp, 4
pop eax
neg eax ; преобразуем в положительное число
_print_answer_negate_end:
mov byte [ebp-4], 0 ; started = 0
mov ecx, MAX_DIGITS ; переменная i
_print_answer_loop_start:
cmp ecx, 0
je _print_answer_loop_end
; вызов pow_10 для ecx. Попытаемся сделать ebx как переменную "digit" в коде C.
; Пока что назначим edx = pow_10(i-1), а ebx = pow_10(i)
push eax
push ecx
dec ecx ; i-1
push ecx ; первый аргумент для _pow_10
call _pow_10
mov edx, eax ; edx = pow_10(i-1)
add esp, 4
pop ecx ; восстанавливаем значение i для ecx
pop eax
; end pow_10 call
mov ebx, edx ; digit = ebx = pow_10(i-1)
imul ebx, 10 ; digit = ebx = pow_10(i)
; вызываем _mod для (a % pow_10(i)), то есть (eax mod ebx)
push eax
push ecx
push edx
push ebx ; arg2, ebx = digit = pow_10(i)
push eax ; arg1, eax = a
call _mod
mov ebx, eax ; digit = ebx = a % pow_10(i+1), almost there
add esp, 8
pop edx
pop ecx
pop eax
; завершение вызова mod
; делим ebx (переменная "digit" ) на pow_10(i) (edx). Придётся сохранить пару
; регистров, потому что idiv использует для деления и edx, eax. Поскольку
; edx является нашим делителем, переместим его в какой-нибудь
; другой регистр
push esi
mov esi, edx
push eax
mov eax, ebx
mov edx, 0
idiv esi ; eax хранит результат (цифру)
mov ebx, eax ; ebx = (a % pow_10(i)) / pow_10(i-1), переменная "digit" в коде C
pop eax
pop esi
; end division
cmp ebx, 0 ; если digit == 0
jne _print_answer_trailing_zeroes_check_end
cmp byte [ebp-4], 0 ; если started == 0
jne _print_answer_trailing_zeroes_check_end
jmp _print_answer_loop_continue ; continue
_print_answer_trailing_zeroes_check_end:
mov byte [ebp-4], 1 ; started = 1
add ebx, 0x30 ; digit + '0'
; вызов putc
push eax
push ecx
push edx
push ebx
call _putc
add esp, 4
pop edx
pop ecx
pop eax
; окончание вызова putc
_print_answer_loop_continue:
sub ecx, 1
jmp _print_answer_loop_start
_print_answer_loop_end:
pop esi
pop edi
pop ebx
leave
ret
Это было тяжкое испытание! Надеюсь, комментарии помогают разобраться. Если вы сейчас думаете: «Почему нельзя просто написать printf("%d")?», то вам понравится окончание статьи, где мы заменим функцию именно этим!
Теперь у нас есть все необходимые функции, осталось реализовать основную логику в _start — и на этом всё!
Вычисление обратной польской записи
Как мы уже говорили, обратная польская запись вычисляется с помощью стека. При чтении число заносится на стек, а при чтении оператор применяется к двум объектам наверху стека.
Например, если мы хотим вычислить 84/3+6* (это выражение также можно записать в виде 6384/+*), процесс выглядит следующим образом:
| Шаг | Символ | Стек перед | Стек после |
|---|---|---|---|
| 1 | 8 |
[] |
[8] |
| 2 | 4 |
[8] |
[8, 4] |
| 3 | / |
[8, 4] |
[2] |
| 4 | 3 |
[2] |
[2, 3] |
| 5 | + |
[2, 3] |
[5] |
| 6 | 6 |
[5] |
[5, 6] |
| 7 | * |
[5, 6] |
[30] |
Если на входе допустимое постфиксное выражение, то в конце вычислений на стеке остаётся лишь один элемент — это и есть ответ, результат вычислений. В нашем случае число равно 30.
В ассемблере нужно реализовать нечто вроде такого кода на C:
int stack[256]; // наверное, 256 слишком много для нашего стека
int stack_size = 0;
int main(int argc, char *argv[]) {
char *input = argv[0];
size_t input_length = strlen(input);
for (int i = 0; i < input_length; i++) {
char c = input[i];
if (c >= '0' && c <= '9') { // если символ — это цифра
push(c - '0'); // преобразовать символ в целое число и поместить в стек
} else {
int b = pop();
int a = pop();
if (c == '+') {
push(a+b);
} else if (c == '-') {
push(a-b);
} else if (c == '*') {
push(a*b);
} else if (c == '/') {
push(a/b);
} else {
error("Invalid inputn");
exit(1);
}
}
}
if (stack_size != 1) {
error("Invalid inputn");
exit(1);
}
print_answer(stack[0]);
exit(0);
}Теперь у нас имеются все функции, необходимые для реализации этого, давайте начнём.
_start:
; аргументы _start получаются не так, как в других функциях.
; вместо этого esp указывает непосредственно на argc (число аргументов), а
; esp+4 указывает на argv. Следовательно, esp+4 указывает на название
; программы, esp+8 - на первый аргумент и так далее
mov esi, [esp+8] ; esi = "input" = argv[0]
; вызываем _strlen для определения размера входных данных
push esi
call _strlen
mov ebx, eax ; ebx = input_length
add esp, 4
; end _strlen call
mov ecx, 0 ; ecx = "i"
_main_loop_start:
cmp ecx, ebx ; если (i >= input_length)
jge _main_loop_end
mov edx, 0
mov dl, [esi + ecx] ; то загрузить один байт из памяти в нижний байт
; edx. Остальную часть edx обнуляем.
; edx = переменная c = input[i]
cmp edx, '0'
jl _check_operator
cmp edx, '9'
jg _print_error
sub edx, '0'
mov eax, edx ; eax = переменная c - '0' (цифра, не символ)
jmp _push_eax_and_continue
_check_operator:
; дважды вызываем _pop для выноса переменной b в edi, a переменной b - в eax
push ecx
push ebx
call _pop
mov edi, eax ; edi = b
call _pop ; eax = a
pop ebx
pop ecx
; end call _pop
cmp edx, '+'
jne _subtract
add eax, edi ; eax = a+b
jmp _push_eax_and_continue
_subtract:
cmp edx, '-'
jne _multiply
sub eax, edi ; eax = a-b
jmp _push_eax_and_continue
_multiply:
cmp edx, '*'
jne _divide
imul eax, edi ; eax = a*b
jmp _push_eax_and_continue
_divide:
cmp edx, '/'
jne _print_error
push edx ; сохраняем edx, потому что регистр обнулится для idiv
mov edx, 0
idiv edi ; eax = a/b
pop edx
; теперь заносим eax на стек и продолжаем
_push_eax_and_continue:
; вызываем _push
push eax
push ecx
push edx
push eax ; первый аргумент
call _push
add esp, 4
pop edx
pop ecx
pop eax
; завершение call _push
inc ecx
jmp _main_loop_start
_main_loop_end:
cmp byte [stack_size], 1 ; если (stack_size != 1), печать ошибки
jne _print_error
mov eax, [stack]
push eax
call _print_answer
; print a final newline
push 0xA
call _putc
; exit successfully
mov eax, 0x01 ; 0x01 = exit()
mov ebx, 0 ; 0 = без ошибок
int 0x80 ; здесь выполнение завершается
_print_error:
push error_msg
call _print_msg
mov eax, 0x01
mov ebx, 1
int 0x80
Понадобится ещё добавить строку error_msg в раздел .rodata:
section .rodata
; Назначаем на некоторые байты error_msg. Псевдоинструкция db в NASM
; позволяет использовать однобайтовое значение, строковую константу или их
; сочетание. 0xA = новая строка, 0x0 = нуль окончания строки
error_msg: db "Invalid input", 0xA, 0x0И мы закончили! Удивите всех своих друзей, если они у вас есть. Надеюсь, теперь вы с большей теплотой отнесётесь к языкам высокого уровня, особенно если вспомнить, что многие старые программы писали полностью или почти полностью на ассемблере, например, оригинальный RollerCoaster Tycoon!
Весь код здесь. Спасибо за чтение! Могу продолжить, если вам интересно.
Дальнейшие действия
Можете попрактиковаться, реализовав несколько дополнительных функций:
- Выдать вместо segfault сообщение об ошибке, если программа не получает аргумент.
- Добавить поддержку дополнительных пробелов между операндами и операторами во входных данных.
- Добавить поддержку многоразрядных операндов.
- Разрешить ввод отрицательных чисел.
- Заменить
_strlenна функцию из стандартной библиотеки C, а_print_answerзаменить вызовомprintf.
Дополнительные материалы
- «Руководство по ассемблеру x86 университета Вирджинии» — более подробное изложение многих тем, рассмотренных нами, в том числе дополнительная информация по всем популярным инструкциям x86.
- «Искусство выбора регистров Intel». Хотя большинство регистров x86 — регистры общего назначения, но у многих есть историческое значение. Следование этим соглашениям может улучшить читаемость кода и, как интересный побочный эффект, даже немного оптимизировать размер двоичных файлов.
- NASM: Intel x86 Instruction Reference — полное руководство по всем малоизвестным инструкциям x86.
Ты решил освоить ассемблер, но не знаешь, с чего начать и какие инструменты для этого нужны? Сейчас расскажу и покажу — на примере программы «Hello, world!». А попутно объясню, что процессор твоего компьютера делает после того, как ты запускаешь программу.
Содержание
- Основы ассемблера
- Если наборы инструкций у процессоров разные, то на каком учить ассемблер лучше всего?
- Что и как процессор делает после запуска программы
- Регистры процессора: зачем они нужны, как ими пользоваться
- Подготовка рабочего места
- Написание, компиляция и запуск программы «Hello, world!»
- Инструкции, директивы
- Метки, условные и безусловные переходы
- Комментарии, алгоритм, выбор регистров
- Взаимодействие с пользователем: получение данных с клавиатуры
- Полезные мелочи: просмотр машинного кода, автоматизация компиляции
- Выводы
Основы ассемблера
Я буду исходить из того, что ты уже знаком с программированием — знаешь какой-нибудь из языков высокого уровня (С, PHP, Java, JavaScript и тому подобные), тебе доводилось в них работать с шестнадцатеричными числами, плюс ты умеешь пользоваться командной строкой под Windows, Linux или macOS.
Если наборы инструкций у процессоров разные, то на каком учить ассемблер лучше всего?
Знаешь, что такое 8088? Это дедушка всех компьютерных процессоров! Причем живой дедушка. Я бы даже сказал — бессмертный и бессменный. Если с твоего процессора, будь то Ryzen, Core i9 или еще какой-то, отколупать все примочки, налепленные туда под влиянием технологического прогресса, то останется старый добрый 8088.
SGX-анклавы, MMX, 512-битные SIMD-регистры и другие новшества приходят и уходят. Но дедушка 8088 остается неизменным. Подружись сначала с ним. После этого ты легко разберешься с любой примочкой своего процессора.
РЕКОМЕНДУЕМ:
Лучшие игры для программистов и технарей
Больше того, когда ты начинаешь с начала — то есть сперва выучиваешь классический набор инструкций 8088 и только потом постепенно знакомишься с современными фичами, — ты в какой-то миг начинаешь видеть нестандартные способы применения этих самых фич.
Что и как процессор делает после запуска программы
После того как ты запустил софтину и ОС загрузила ее в оперативную память, процессор нацеливается на первый байт твоей программы. Вычленяет оттуда инструкцию и выполняет ее, а выполнив, переходит к следующей. И так до конца программы.
Некоторые инструкции занимают один байт памяти, другие два, три или больше. Они выглядят как-то так:
|
90 B0 77 B8 AA 77 C7 06 66 55 AA 77 |
Вернее, даже так:
|
90 B0 77 B8 AA 77 C7 06 66 55 AA 77 |
Хотя погоди! Только машина может понять такое. Поэтому много лет назад программисты придумали более гуманный способ общения с компьютером: создали ассемблер.
Благодаря ассемблеру ты теперь вместо того, чтобы танцевать с бубном вокруг шестнадцатеричных чисел, можешь те же самые инструкции писать в мнемонике:
|
nop mov al, 0x77 mov ax, 0x77AA mov word [0x5566], 0x77AA |
Согласись, такое читать куда легче. Хотя, с другой стороны, если ты видишь ассемблерный код впервые, такая мнемоника для тебя, скорее всего, тоже непонятна. Но мы сейчас это исправим.
Регистры процессора: зачем они нужны, как ими пользоваться
Что делает инструкция
mov? Присваивает число, которое указано справа, переменной, которая указана слева.
Переменная — это либо один из регистров процессора, либо ячейка в оперативной памяти. С регистрами процессор работает быстрее, чем с памятью, потому что регистры расположены у него внутри. Но регистров у процессора мало, так что в любом случае что-то приходится хранить в памяти.
Когда программируешь на ассемблере, ты сам решаешь, какие переменные хранить в памяти, а какие в регистрах. В языках высокого уровня эту задачу выполняет компилятор.
У процессора 8088 регистры 16-битные, их восемь штук (в скобках указаны типичные способы применения регистра):
- AX — общего назначения (аккумулятор);
- BX — общего назначения (адрес);
- CX — общего назначения (счетчик);
-
DX — общего назначения (расширяет
AX до 32 бит); - SI — общего назначения (адрес источника);
- DI — общего назначения (адрес приемника);
- BP — указатель базы (обычно адресует переменные, хранимые на стеке);
- SP — указатель стека.
Несмотря на то что у каждого регистра есть типичный способ применения, ты можешь использовать их как заблагорассудится. Четыре первых регистра —
AX,
BX,
CX и
DX — при желании можно использовать не полностью, а половинками по 8 бит (старшая
H и младшая
L):
AH,
BH,
CH,
DH и
AL,
BL,
CL,
DL. Например, если запишешь в
AX число
0x77AA (
mov ax, 0x77AA), то в
AH попадет
0x77, в
AL —
0xAA.
С теорией пока закончили. Давай теперь подготовим рабочее место и напишем программу «Hello, world!», чтобы понять, как эта теория работает вживую.
Подготовка рабочего места
- Скачай компилятор NASM с www.nasm.us. Обрати внимание, он работает на всех современных ОС: Windows 10, Linux, macOS. Распакуй NASM в какую-нибудь папку. Чем ближе папка к корню, тем удобней. У меня это
c:nasm (я работаю в Windows). Если у тебя Linux или macOS, можешь создать папку
nasm в своей домашней директории. - Тебе надо как-то редактировать исходный код. Ты можешь пользоваться любым текстовым редактором, который тебе по душе: Emacs, Vim, Notepad, Notepad++ — сойдет любой. Лично мне нравится редактор, встроенный в Far Manager, с плагином Colorer.
- Чтобы в современных ОС запускать программы, написанные для 8088, и проверять, как они работают, тебе понадобится DOSBox или VirtualBox.
Написание, компиляция и запуск программы «Hello, world!»
Сейчас ты напишешь свою первую программу на ассемблере. Назови ее как хочешь (например,
first.asm) и скопируй в папку, где установлен
nasm.

Если тебе непонятно, что тут написано, — не переживай. Пока просто постарайся привыкнуть к ассемблерному коду, пощупать его пальцами. Чуть ниже я все объясню. Плюс студенческая мудрость гласит: «Тебе что-то непонятно? Перечитай и перепиши несколько раз. Сначала непонятное станет привычным, а затем привычное — понятным».
Теперь запусти командную строку, в Windows это cmd.exe. Потом зайди в папку
nasm и скомпилируй программу, используя вот такую команду:
|
nasm —f bin first.asm —o first.com |
Если ты все сделал правильно, программа должна скомпилироваться без ошибок и в командной строке не появится никаких сообщений.
NASM просто создаст файл
first.com и завершится.
Чтобы запустить этот файл в современной ОС, открой DOSBox и введи туда вот такие три команды:
Само собой, вместо
c:nasm тебе надо написать ту папку, куда ты скопировал компилятор. Если ты все сделал правильно, в консоли появится сообщение «Hello, world!».

Инструкции, директивы
В нашей с тобой программе есть только три вещи: инструкции, директивы и метки.
Инструкции. С инструкциями ты уже знаком (мы их разбирали чуть выше) и знаешь, что они представляют собой мнемонику, которую компилятор переводит в машинный код.
Директивы (в нашей программе их две:
org и
db) — это распоряжения, которые ты даешь компилятору. Каждая отдельно взятая директива говорит компилятору, что на этапе ассемблирования нужно сделать такое-то действие. В машинный код директива не переводится, но она влияет на то, каким образом будет сгенерирован машинный код.
Директива
org говорит компилятору, что все инструкции, которые последуют дальше, надо размещать не в начале сегмента кода, а отступить от начала столько-то байтов (в нашем случае 0x0100).
Директива
db сообщает компилятору, что в коде нужно разместить цепочку байтов. Здесь мы перечисляем через запятую, что туда вставить. Это может быть либо строка (в кавычках), либо символ (в апострофах), либо просто число.
В нашем случае:
db «Hello, world», ‘!’, 0.
Обрати внимание, символ восклицательного знака я отрезал от остальной строки только для того, чтобы показать, что в директиве
db можно оперировать отдельными символами. А вообще писать лучше так:
Метки, условные и безусловные переходы
Метки используются для двух целей: задавать имена переменных, которые хранятся в памяти (такая метка в нашей программе только одна:
string), и помечать участки в коде, куда можно прыгать из других мест программы (таких меток в нашей программе три штуки — те, которые начинаются с двух символов собаки).
Что значит «прыгать из других мест программы»? В норме процессор выполняет инструкции последовательно, одну за другой. Но если тебе надо организовать ветвление (условие или цикл), ты можешь задействовать инструкцию перехода. Прыгать можно как вперед от текущей инструкции, так и назад.
РЕКОМЕНДУЕМ:
Язык программирования Ада
У тебя в распоряжении есть одна инструкция безусловного перехода (
jmp) и штук двадцать инструкций условного перехода.
В нашей программе задействованы две инструкции перехода:
je и
jmp. Первая выполняет условный переход (Jump if Equal — прыгнуть, если равно), вторая (Jump) — безусловный. С их помощью мы организовали цикл.
Обрати внимание: метки начинаются либо с буквы, либо со знака подчеркивания, либо со знака собаки. Цифры вставлять тоже можно, но только не в начало. В конце метки обязательно ставится двоеточие.
Комментарии, алгоритм, выбор регистров
Итак, в нашей программе есть только три вещи: инструкции, директивы и метки. Но там могла бы быть и еще одна важная вещь: комментарии. С ними читать исходный код намного проще.
Как добавлять комментарии? Просто поставь точку с запятой, и все, что напишешь после нее (до конца строки), будет комментарием. Давай добавим комментарии в нашу программу.
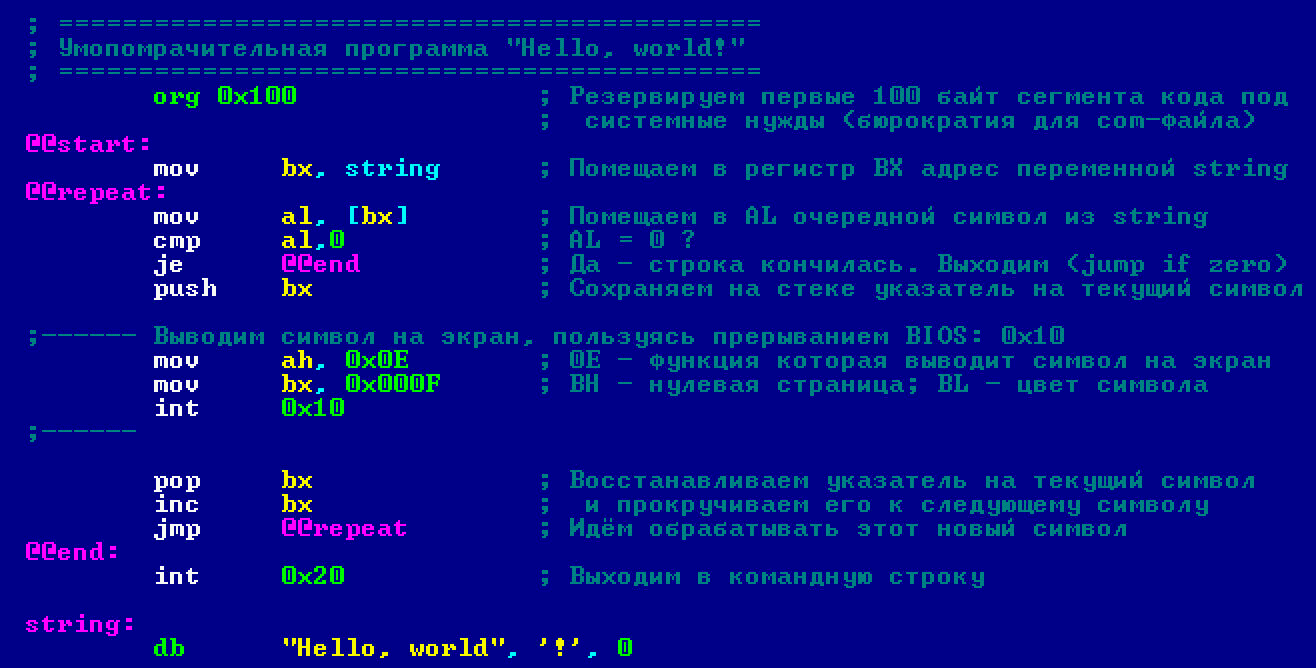
Теперь, когда ты разобрался во всех частях программы по отдельности, попробуй вникнуть, как все части служат алгоритму, по которому работает наша программа.
- Поместить в
BX адрес строки. - Поместить в
AL очередную букву из строки. - Если вместо буквы там 0, выходим из программы — переходим на 6-й шаг.
- Выводим букву на экран.
- Повторяем со второго шага.
- Конец.
Обрати внимание, мы не можем использовать
AX для хранения адреса, потому что нет таких инструкций, которые бы считывали память, используя
AX в качестве регистра-источника.
Взаимодействие с пользователем: получение данных с клавиатуры
От программ, которые не могут взаимодействовать с пользователем, толку мало. Так что смотри, как можно считывать данные с клавиатуры. Сохрани вот этот код как
second.asm.

Потом иди в командную строку и скомпилируй его в NASM:
|
nasm —f bin second.asm —o second.com |
Затем запусти скомпилированную программу в DOSBox:
Как работает программа? Две строки после метки
@@start вызывают функцию BIOS, которая считывает символы с клавиатуры. Она ждет, когда пользователь нажмет какую-нибудь клавишу, и затем кладет ASCII-код полученного значения в регистр
AL. Например, если нажмешь заглавную
A, в
AL попадет
0x41, а если строчную
A —
0x61.
Дальше смотрим: если нажата клавиша с кодом 0x1B (клавиша ESC), то выходим из программы. Если же нажата не ESC, вызываем ту же функцию, что и в предыдущей программе, чтобы показать символ на экране. После того как покажем — прыгаем в начало (
jmp):
start.
Обрати внимание, инструкция
cmp (от слова compare — сравнить) выполняет сравнение, инструкция
je (Jump if Equal) — прыжок в конец программы.
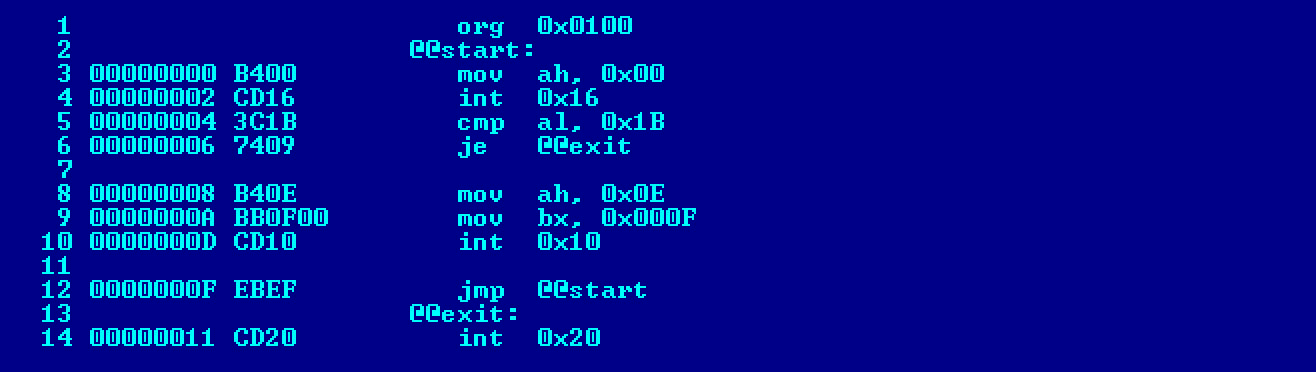
Полезные мелочи: просмотр машинного кода, автоматизация компиляции
Если тебе интересно, в какой машинный код преобразуются инструкции программы, скомпилируй исходник вот таким вот образом (добавь опцию
—l):
|
nasm —f bin second.asm —l second.lst —o second.com |
Тогда NASM создаст не только исполняемый файл, но еще и листинг:
second.lst. Листинг будет выглядеть как-то так.
Еще тебе наверняка уже надоело при каждом компилировании вколачивать в командную строку длинную последовательность одних и тех же букв. Если ты используешь Windows, можешь создать батник (например,
m.bat) и вставить в него вот такой текст.

Теперь ты можешь компилировать свою программу вот так:
Само собой, вместо
first ты можешь подставить любое имя файла.
Выводы
Итак, ты теперь знаешь, как написать простейшую программу на ассемблере, как ее скомпилировать, какие инструменты для этого нужны. Конечно, прочитав одну статью, ты не станешь опытным программистом на ассемблере. Чтобы придумать и написать на нем что-то стоящее — вроде Floppy Bird и «МикроБ», которые написал я, — тебе предстоит еще много пройти. Но первый шаг в эту сторону ты уже сделал.
 (2 оценок, среднее: 5,00 из 5)
(2 оценок, среднее: 5,00 из 5)
![]() Загрузка…
Загрузка…
Многие считают, что Assembler – уже устаревший и нигде не используемый язык, однако в основном это молодые люди, которые не занимаются профессионально системным программированием. Разработка ПО, конечно, хорошо, но в отличие от высокоуровневых языков программирования, Ассемблер научит глубоко понимать работу компьютера, оптимизировать работку с аппаратными ресурсами, а также программировать любую технику, тем самым развиваясь в направлении машинного обучения. Для понимания этого древнего ЯП, для начала стоит попрактиковаться с простыми программами, которые лучше всего объясняют функционал Ассемблера.
IDE для Assembler
Первый вопрос: в какой среде разработки программировать на Ассемблере? Ответ однозначный – MASM32. Это стандартная программа, которую используют для данного ЯП. Скачать её можно на официальном сайте masm32.com в виде архива, который нужно будет распаковать и после запустить инсталлятор install.exe. Как альтернативу можно использовать FASM, однако для него код будет значительно отличаться.
Перед работой главное не забыть дописать в системную переменную PATH строчку:
С:masm32bin
Программа «Hello world» на ассемблере
Считается, что это базовая программа в программировании, которую начинающие при знакомстве с языком пишут в первую очередь. Возможно, такой подход не совсем верен, но так или иначе позволяет сразу же увидеть наглядный результат:
.386 .model flat, stdcall option casemap: none include /masm32/include/windows.inc include /masm32/include/user32.inc include /masm32/include/kernel32.inc includelib /masm32/lib/user32.lib includelib /masm32/lib/kernel32.lib .data msg_title db "Title", 0 msg_message db "Hello world", 0 .code start: invoke MessageBox, 0, addr msg_message, addr msg_title, MB_OK invoke ExitProcess, 0 end start
Для начала запускаем редактор qeditor.exe в папке с установленной MASM32, и в нём пишем код программы. После сохраняем его в виде файла с расширением «.asm», и билдим программу с помощью пункта меню «Project» → «Build all». Если в коде нет ошибок, программа успешно скомпилируется, и на выходе мы получим готовый exe-файл, который покажет окно Windows с надписью «Hello world».

Сложение двух чисел на assembler
В этом случае мы смотрим, равна ли сумма чисел нулю, или же нет. Если да, то на экране появляется соответствующее сообщение об этом, и, если же нет – появляется иное уведомление.
.486
.model flat, stdcall
option casemap: none
include /masm32/include/windows.inc
include /masm32/include/user32.inc
include /masm32/include/kernel32.inc
includelib /masm32/lib/user32.lib
includelib /masm32/lib/kernel32.lib
include /masm32/macros/macros.asm
uselib masm32, comctl32, ws2_32
.data
.code
start:
mov eax, 123
mov ebx, -90
add eax, ebx
test eax, eax
jz zero
invoke MessageBox, 0, chr$("В eax не 0!"), chr$("Info"), 0
jmp lexit
zero:
invoke MessageBox, 0, chr$("В eax 0!"), chr$("Info"), 0
lexit:
invoke ExitProcess, 0
end start
Здесь мы используем так называемые метки и специальные команды с их использованием (jz, jmp, test). Разберём подробнее:
- test – используется для логического сравнения переменных (операндов) в виде байтов, слов, или двойных слов. Для сравнения команда использует логическое умножение, и смотрит на биты: если они равны 1, то и бит результата будет равен 1, в противном случае – 0. Если мы получили 0, ставятся флаги совместно с ZF (zero flag), которые будут равны 1. Далее результаты анализируются на основе ZF.
- jnz – в случае, если флаг ZF нигде не был поставлен, производится переход по данной метке. Зачастую эта команда применяется, если в программе есть операции сравнения, которые как-либо влияют на результат ZF. К таким как раз и относятся test и cmp.
- jz – если флаг ZF всё же был установлен, выполняется переход по метке.
- jmp – независимо от того, есть ZF, или же нет, производится переход по метке.
Программа суммы чисел на ассемблере
Примитивная программа, которая показывает процесс суммирования двух переменных:
.486 .model flat, stdcall option casemap: none include /masm32/include/windows.inc include /masm32/include/user32.inc include /masm32/include/kernel32.inc includelib /masm32/lib/user32.lib includelib /masm32/lib/kernel32.lib include /masm32/macros/macros.asm uselib masm32, comctl32, ws2_32 .data msg_title db "Title", 0 A DB 1h B DB 2h buffer db 128 dup(?) format db "%d",0 .code start: MOV AL, A ADD AL, B invoke wsprintf, addr buffer, addr format, eax invoke MessageBox, 0, addr buffer, addr msg_title, MB_OK invoke ExitProcess, 0 end start
В Ассемблере для того, чтобы вычислить сумму, потребуется провести немало действий, потому как язык программирования работает напрямую с системной памятью. Здесь мы по большей частью манипулируем ресурсами, и самостоятельно указываем, сколько выделить под переменную, в каком виде воспринимать числа, и куда их девать.
Получение значения из командной строки на ассемблере
Одно из важных основных действий в программировании – это получить данные из консоли для их дальнейшей обработки. В данном случае мы их получаем из командной строки и выводим в окне Windows:
.486
.model flat, stdcall
option casemap: none
include /masm32/include/windows.inc
include /masm32/include/user32.inc
include /masm32/include/kernel32.inc
includelib /masm32/lib/user32.lib
includelib /masm32/lib/kernel32.lib
include /masm32/macros/macros.asm
uselib masm32, comctl32, ws2_32
.data
.code
start:
call GetCommandLine ; результат будет помещен в eax
push 0
push chr$("Command Line")
push eax ; текст для вывода берем из eax
push 0
call MessageBox
push 0
call ExitProcess
end start
Также можно воспользоваться альтернативным методом:
.486
.model flat, stdcall
option casemap: none
include /masm32/include/windows.inc
include /masm32/include/user32.inc
include /masm32/include/kernel32.inc
includelib /masm32/lib/user32.lib
includelib /masm32/lib/kernel32.lib
include /masm32/macros/macros.asm
uselib masm32, comctl32, ws2_32
.data
.code
start:
call GetCommandLine ; результат будет помещен в eax
invoke GetCommandLine
invoke MessageBox, 0, eax, chr$("Command Line"), 0
invoke ExitProcess, 0
push 0
call ExitProcess
end start
Здесь используется invoke – специальный макрос, с помощью которого упрощается код программы. Во время компиляции макрос-команды преобразовываются в команды Ассемблера. Так или иначе, мы пользуемся стеком – примитивным способом хранения данных, но в тоже время очень удобным. По соглашению stdcall, во всех WinAPI-функциях переменные передаются через стек, только в обратном порядке, и помещаются в соответствующий регистр eax.
Циклы в ассемблере
Вариант использования:
.data msg_title db "Title", 0 A DB 1h buffer db 128 dup(?) format db "%d",0 .code start: mov AL, A .REPEAT inc AL .UNTIL AL==7 invoke wsprintf, addr buffer, addr format, AL invoke MessageBox, 0, addr buffer, addr msg_title, MB_OK invoke ExitProcess, 0 end start
.data msg_title db "Title", 0 buffer db 128 dup(?) format db "%d",0 .code start: mov eax, 1 mov edx, 1 .WHILE edx==1 inc eax .IF eax==7 .BREAK .ENDIF .ENDW invoke wsprintf, addr buffer, addr format, eax invoke MessageBox, 0, addr buffer, addr msg_title, MB_OK invoke ExitProcess, 0
Для создания цикла используется команда repeat. Далее с помощью inc увеличивается значение переменной на 1, независимо от того, находится она в оперативной памяти, или же в самом процессоре. Для того, чтобы прервать работу цикла, используется директива «.BREAK». Она может как останавливать цикл, так и продолжать его действие после «паузы». Также можно прервать выполнение кода программы и проверить условие repeat и while с помощью директивы «.CONTINUE».
Сумма элементов массива на assembler
Здесь мы суммируем значения переменных в массиве, используя цикл «for»:
.486 .model flat, stdcall option casemap: none include /masm32/include/windows.inc include /masm32/include/user32.inc include /masm32/include/kernel32.inc includelib /masm32/lib/user32.lib includelib /masm32/lib/kernel32.lib include /masm32/macros/macros.asm uselib masm32, comctl32, ws2_32 .data msg_title db "Title", 0 A DB 1h x dd 0,1,2,3,4,5,6,7,8,9,10,11 n dd 12 buffer db 128 dup(?) format db "%d",0 .code start: mov eax, 0 mov ecx, n mov ebx, 0 L: add eax, x[ebx] add ebx, type x dec ecx cmp ecx, 0 jne L invoke wsprintf, addr buffer, addr format, eax invoke MessageBox, 0, addr buffer, addr msg_title, MB_OK invoke ExitProcess, 0 end start
Команда dec, как и inc, меняет значение операнда на единицу, только в противоположную сторону, на -1. А вот cmp сравнивает переменные методом вычитания: отнимает одно значение из второго, и, в зависимости от результата ставит соответствующие флаги.
С помощью команды jne выполняется переход по метке, основываясь на результате сравнения переменных. Если он отрицательный – происходит переход, а если операнды не равняются друг другу, переход не осуществляется.
Ассемблер интересен своим представлением переменных, что позволяет делать с ними что угодно. Специалист, который разобрался во всех тонкостях данного языка программирования, владеет действительно ценными знаниями, которые имеют множество путей использования. Одна задачка может решаться самыми разными способами, поэтому путь будет тернист, но не менее увлекательным.
Post Views:
58 159
Генерация кода
Вступление
Генерация кода — это процесс перевода промежуточного представления, в частности абстрактного синтаксического дерева, в выходной код на некотором языке, в том числе и на языке ассемблера.
Мы не будем рассматривать генерацию машинных кодов, потому что они имеют очень много тонкостей, которые выходят за рамки этой главы. Мы остановимся на генерации в ассемблерный код. В качестве ассемблера выберем MASM (Macro Assembler).
Задача генерации кода, в нашем случае, будет состоять в переводе AST в ассемблерный код!
В первую очередь мы поговорим о самом ассемблере, о том, как он работает, как на нем писать простейшие конструкции, а также как его компилировать в исполняемый файл. Я буду показывать только самые необходимые вещи, так что некоторые, неважные в рамках этой статьи, могут остаться вне поля зрения.
Ассемблер (MASM)
Ассемблер — это низкоуровневый язык программирования. Все команды в нем, являются более удобными заменами двоичного представления команд процессора.
Сам ассемблер не является сложным языком в плане синтаксиса, у него простая структура и небольшой набор доступных команд. Однако ассемблер сложен тем, что такие вещи как циклы, условия не существуют, как готовые языковые конструкции, они описываются вручную с помощью определенного набора доступных команд. Это довольно непривычно, но мы разберем все основные конструкции на примерах.
Установка компилятора для MASM
Для того, чтобы исходный код на ассемблере преобразовывать в готовые для запуска, исполняемые файлы, нам понадобится компилятор ассемблера. Для masm существует набор инструментов под общим названием masm32, который включает в себя компилятор.
Инструкция по установке:
- Переходим по ссылке на официальный сайт и выбираем любой из вариантов для скачивания;
- Открываем архив и запускаем файл
install.exe; - Далее нажимаем кнопку
installи следуем дальнейшим инструкциям. Процесс установки довольно долгий, так что придется подождать. После установки откроется редактор, его можно спокойно закрывать; - Теперь необходимо добавить путь к папке с установленным
masm32в переменную окруженияPath. Откройте проводник и вставьте в адресную строкуControl PanelSystem and SecuritySystemи нажмитеEnter; - Дальше в меню слева выберите пункт
Расширенные настройки системы; - В появившемся окне кликнете на кнопку
Переменные среды; - В верхней таблице найдите запись у которой первый столбец имеет значение
Pathи кликнете по ней два раза; - В проводнике, найдите папку, в которую вы установили MASM (обычно это папка
masm32на диске, который вы выбрали в начале установки); - Скопируйте путь до папки
binв папке, где установлен MASM.; - В появившемся ранее окне нажмите на пустое место, и в появившееся поле вставьте скопированный путь. Это необходимо, чтобы получить быстрый доступ к таким программам, как
ml.exeиlink.exe, которые понадобятся для компиляции; - Нажмите ОК и еще раз ОК;
- Откройте PowerShell (воспользуйтесь поиском Window, для быстрого поиска) и введите команду
ml, если ошибки нет, значит компилятор для MASM установлен верно.
Первая программа на ассемблере
Теперь, когда компилятор установлен, давайте скомпилируем небольшую тестовую программу, которая будет выводить "Hello World!" в консоль.
В папке, где вы пишите код компилятора, создайте папку с любым названием, например, test_asm.
Для дальнейших действий вы можете использовать любую консоль, будь то PowerShell или стандартную консоль Windows. Я буду показывать все в PowerShell, хотя все действия полностью идентичны.
Откроем PowerShell. Скопируем полный путь до папки test_asm и пропишем следующую команду в консоли:
где [path_to_test_asm] заменим на путь к папке.
Выполните команду нажатием клавиши Enter. Эта команда сменит текущий каталог, на каталог который был прописан на месте [path_to_test_asm], тем самым мы перейдем в каталог в котором будет файл, где мы будем писать ассемблерный код. Это удобно, так как, не надо прописывать длинный путь к файлу с ассемблерным кодом, а достаточно указать его название: test.asm.
Важно!
Весь код, который рассматривается в этой главе должен быть сохранен в кодировке ASCII или другой кодировке на основе ASCII (например, windows-1251).
Время добавить этот файл с ассемблерным кодом. Создайте файл test.asm со следующим содержанием:
Далее, последовательно введите в PowerShell две команды:
Если все верно, то вы должны получить файл test.exe. Если вы его запустите, то увидите надпись Hello World!.
Если вы получаете ошибку на подобии этой:
то это означает, что есть проблемы с установкой masm32. Возможно вы не прописали путь в переменной окружения Path, которая описана в 7 пункте инструкции по установке. Если проблема все еще существует, попробуйте перезапустить PowerShell с правами администратора.
Теперь давайте разберем, что это за команды:
Первая команда отвечает за компиляцию программы в объектный файл. Это файл еще не является исполняемым, поэтому, чтобы сделать из него исполняемый, мы используем линкер с помощью второй командой:
В результате мы получим готовый исполняемый файл, который можем запустить.
Итак, теперь мы умеем компилировать ассемблерный код.
Давайте выделим основное:
Чтобы скомпилировать ассемблерный код, нужно в первую очередь перейти в каталог с исходным кодом, чтобы не прописывать длинные пути, с помощью команды
cd [путь_до_папки], а затем выполнить следующие две команды:Первая из которых скомпилирует ассемблерный код в объектный файл, а вторая создаст на его основе исполняемый файл.
Лайфхак
Прописывать эти команды каждый раз, долго. Однако есть способ избежать этого. Для этого создадим в папке файл run.bat со следующим содержанием:
Это те же команды, что мы прописывали в консоли, однако добавилась еще одна команда, которая будет запускать полученный исполняемый файл. Это избавит нас от лишнего действия.
И теперь, чтобы перекомпилировать ассемблерный код, достаточно запустить файл run.bat двойным кликом.
Если вы хотите компилировать файл с названием отличным от
test.asm, просто поменяйте название во всех командах на необходимое.
Основы ассемблера
Основа программ на ассемблере — это команды. Команды выполняются одна за другой до тех пор, пока не будет встречен конец программы. Благодаря некоторым конструкциям языка, мы можем переходить к любому месту в программе при необходимости, это позволяет создавать все возможные конструкции циклов или условий.
Пустая программа
Давайте рассмотрим «костяк» любой программы на ассемблере. Это код можно просто копировать из программы в программу, он везде будет одинаков.
Рассмотрим код по-блочно:
Первый блок — это блок определений для ассемблера.
В первой строке обозначается набор используемых инструкций, в данном случае мы используем i586 набор, который является достаточно универсальным для процессоров Intel и AMD.
Во второй строке задается модель памяти программы, а также модель вызова процедур. Так как мы программируем под WIndows, то модель памяти должна быть flat, а модель вызова процедур — stdcall.
В данный момент примем это, как данность и будем просто копировать из программы в программу.
Следующий блок, это сегмент данных:
Сегмент данных используется для задания всех необходимых в программе переменных. Объявлять переменные вне этого сегмента нельзя.
Следующий блок, это сегмент команд:
Сегмент команд может называться любым именем, но стандартно его называют text. Сегмент команд — это то место в коде, где пишутся все исполняемые команды программы. Писать команды вне сегмента команд нельзя.
В сегменте команд обязательна начальная метка (о том, что это такое мы поговорим дальше) :
Эта метка должны быть закрыта, сразу же после завершения сегмента команд:
Данная метка, как функция main в С/С++, с нее начинается выполнение команд, то есть программа начнет свое исполнение с первой команды после метки __main:.
В нашем случае это команда ret. Сейчас не будем вдаваться в подробности, эта команда завершает выполнение программы.
Однако команды можно писать и до метки __main:, но тогда они не будут исполнены, в нормальном течении программы. Так как команды выполняются друг за другом, пока не будет встречен конец.
До метки __main обычно пишут функции, которые вызываются командами после метки __main:. Об этом мы поговорим в разделе про функции.
Это все блоки, которые понадобятся нам в написании нашего ассемблерного кода.
Отмечу еще один факт, большая часть ассемблера не учитывает регистр, поэтому записи:
равноценны. Однако некоторые части являются регистрозависимыми, в этом случае, это будет указано явно.
Подведем итоги:
Переменные определяются между
data segmentиdata ends! Этот блок называется сегментом данных!Весь код программы пишется между
text segmentиtext ends(этот блок называется сегментом команд) после метки__main:! Однако если задается функция, то она обычно пишется до метки:Весь остальной код, можно просто копировать из программы в программу, он не изменяется!
Комментарии начинаются с символа точка с запятой
;Большая часть ассемблера не учитывает регистр, поэтому записи:
равноценны. Однако некоторые части являются регистрозависимыми, в этом случае, это будет указано явно!
Регистры
Следующее, что мы рассмотрим — это регистры.
Регистры — это специальные ячейки памяти расположенные прямо в процессоре. Работа с ними происходит намного быстрее, чем с оперативной памятью, поэтому они предпочтительнее для большинства операций, чем переменные.
Регистры по сути такие же переменные, в которые можно записывать и считывать данные.
Регистров не так много, ниже приведена сводная таблица:
| Название | Разрядность | Основное назначение |
|---|---|---|
EAX |
32 | Аккумулятор |
EBX |
32 | База |
ECX |
32 | Счётчик |
EDX |
32 | Регистр данных |
EBP |
32 | Указатель базы |
ESP |
32 | Указатель стека |
ESI |
32 | Индекс источника |
EDI |
32 | Индекс приёмника |
EFLAGS |
32 | Регистр флагов |
EIP |
32 | Указатель инструкции (команды) |
CS |
16 | Сегментный регистр |
DS |
16 | Сегментный регистр |
ES |
16 | Сегментный регистр |
FS |
16 | Сегментный регистр |
GS |
16 | Сегментный регистр |
SS |
16 | Сегментный регистр |
Регистры EAX, EBX, ECX, EDX — это регистры общего назначения. Они имеют определённое историческое назначение, однако в них можно хранить любую информацию. Они имеют размер 32 бита или 4 байта, что очень похоже на переменные типа int, которые также занимают 4 байта.
Регистры EBP, ESP, ESI, EDI— это также регистры общего назначения. Однако они имеют уже более конкретное назначение, поэтому использовать их нужно аккуратно. Они имеют размер также 32 бита или 4 байта.
Регистр флагов и сегментные регистры мы оставим на потом, так как их описание довольно большое и сложное.
Регистры можно рассматривать, как обычные переменные с предопределенными именами и имеющие размер 4 байта.
Регистры общего назначения также можно использовать не полностью, можно использовать их первые 16 бит или использовать первые 8 бит и вторые 8 бит, это сделано для совместимости со старыми процессорами, однако использовать это мы не будет.
Давайте выделим основное:
Регистр — это ячейка в памяти процессора, которую можно рассматривать, как переменную с предопределенным именем. Есть 4 регистра (
EAX,EBX,ECX,EDX), которые можно свободно использовать для своих целей, каждый из которых имеет размер 32 бита или 4 байта.
Переменные
Переменные в ассемблере не отличаются от переменных в привычных нам языках. Помните в каком сегменте они задаются? Правильно в сегменте данных:
Числовые
Числовые переменные могут быть следующих типов:
| Директива | Название | Размер |
|---|---|---|
DB |
Byte |
1 байт |
DW |
Word |
2 байта |
DD |
DoubleWord |
4 байта |
DQ |
QuadWord |
8 байт |
DT |
TWord |
10 байт |
Переменные объявляются следующим образом:
Если начального значения нет, то необходимо поставить на его место знак вопроса (?)
Давайте посмотрим на объявление нескольких переменных:
Массивы
В ассемблере массивы можно задавать несколькими способами, мы рассмотрим два варианта, как набор значений через запятую, и как массив n-размера заполненный каким-то значением.
Первый вариант имеет следующий синтаксис:
Давайте посмотрим на объявление некоторых массивов:
Второй вариант имеет следующий синтаксис:
Ключевое слово dup задает массив определенного размера заполненный некоторым значением.
Давайте посмотрим на объявление некоторых массивов:
А что, если попробовать объявить массив однобайтных символов? Например такой:
И так и правда можно, таким образом мы задали строку World! Обратите внимание на ноль, он будет говорить программе, что эта строка завершена. Вспомните, в Си все строки заканчиваются нулем терминатором по-умолчанию. Ассемблер же сам не вставляет в конец нуль-терминатор, поэтому его нужно объявлять явно, с помощью еще одного элемента массива в виде нуля.
Однако так задавать строки очень неудобно, поэтому в ассемблере есть более удобный синтаксис для задания строк.
Строки
Синтаксис задания строки следующий:
Здесь тип DB обязателен, так как мы задаем строку с однобайтными символами. Не стоит забывать, что строки, как и в Си хранятся в виде массива, на что явно указывал способ объявления выше. Ноль после строки выполняет ту же роль, что была обозначена выше.
Давайте объявим несколько строк:
А помните, пример вывода Hello World! в самом начале, когда мы только изучали компиляцию? Там как раз таки в сегменте данных были объявлены две строки:
Выделим самое основное:
- Числовые переменные могут быть следующих типов:
Директива Название Размер DBByte1 байт DWWord2 байта DDDoubleWord4 байта DQQuadWord8 байт DTTWord10 байт
Синтаксис объявления численной переменной:
Массивы можно задавать двумя способами:
Строки задаются следующим образом:
После строки обязательно надо поставить ноль, чтобы явно обозначить завершение строки!
Метки
Очень важной частью программирования на ассемблере являются метки и переходы к ним.
Метка — это конструкция языка, которая имеет уникальное имя, после которого идет двоеточие (:) и перенос строки, позволяющая переходить между исполняемыми командами:
Метки ставятся в любом месте сегмента команд. Метка — это место в коде, в которое можно перейти и начать исполнение команд непосредственно с этой метки, то есть вне зависимости от места где сейчас исполняется код, можно перейти к метке и продолжить выполнять команды расположенные после этой метки.
Помните начальную метку __main:, с которой начинается выполнение команд? Эта также метка, только переход к ней происходит в автоматическом режиме при запуске программы.
Рассмотрим пример использования метки:
Команды
Дальше мы переходим к основной части ассемблера, а именно к командам. Однако изучать сухую теорию не очень весело, поэтому сейчас мы создадим тестовый стенд, где сможем выводить значение регистра eax, после использования каких-то команд. Тем самым мы сразу будем видеть результат выполнения команды.
Для начала, изменим содержание нашего файл test.asm на следующее:
В дальнейшем, я буду описывать только код между enter 0, 0 и push eax. Пока что не заморачивайтесь, что здесь написано, главное, что эта программа будет выводить значение регистра eax (помните, что регистры — это переменные? Так что мы выводим просто значение переменной, ничего сложного).
Теперь попробуем скомпилировать программу. Для этого используем наш файл run.bat, запустим его двойным щелчком. Если все хорошо, то в консоли будет выведено случайное число. (Посмотрите, что будет, если несколько раз подряд запустить программу?).
Теперь переходим к командам.
[] в описании команды, означает, что на этом месте будет что-либо. Конкретное описание того, что там может быть будет в описании команды.
MOV [приемник], [источник]
Первая команда, это команда mov, расшифровывается, как move, что переводится как «перемещать».
Эта команда перемещает значение из источника в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Итак, давайте поиграем с этой командой. Помните, что мы изменяем только код между enter 0, 0 и push eax? Если да, то начинаем.
Давайте напишем следующий код:
Сохраним и запустим компиляцию файлом run.bat. В выводе должно появится число 100. (Помните, что мы выводим значение eax?) Таким образом, мы поместили значение 100 в регистр eax. Здорово, не правда ли? А теперь давайте поместим значение в другой регистр, и значение этого регистра поместим в eax:
После компиляции в выводе должно быть число 200. То есть, здесь, мы сначала поместили в регистр ebx значение 200, а затем значение ebx (которое равно 200) мы поместили в регистр eax. Держите в голове тот факт, что регистр можно рассматривать, как переменную.
Следующие команды описывают команды для арифметических действий с числами. Пришло время посчитать.
ADD [приемник], [источник]
Команда add расшифровывается, как addition, что переводится как «сложение».
Эта команда складывает значения из приемника со значением источника и кладет его в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Давайте напишем следующий код:
Здесь мы сначала поместили значение 100 в регистр eax, а затем прибавили к значению eax число 5. Тем самым на выводе мы должны получить число 105. Так и есть.
Все просто, а что если сначала поместить значение в ebx, затем в eax, а затем сложить eax и ebx? Это ваше задание, напишите такую программу, значения могут быть любыми.
Если вы не знаете, как это написать, попробуйте написать по подобию примеров, это не так сложно, однако именно практика дает 50% запоминания и понимания материала, так что обязательно делайте эти небольшие задания.
SUB [приемник], [источник]
Команда sub расшифровывается, как subtraction, что переводится как «вычитание».
Эта команда вычитает значение источника из значения приемника и кладет его в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Мы уже умеем складывать, теперь пробуем вычитать:
У нас есть такой код, скажите, как вы думаете, что должно быть выведено? Правильно, 95. Ничего сложного, все как и со сложением.
А если написать такой код, то что выведется?
Да, выведется 0, так как мы из eax вычитаем eax.
Теперь, когда мы знаем две операции, напишите программу, которая посчитает значение выражения:
На выходе вы должны получить 12.
IMUL [приемник], [источник]
Команда imul расшифровывается, как integer multiplication, что переводится как «умножение целых чисел».
Эта команда перемножает значение источника со значением приемника и кладет результат в приемник.
- Приемником может быть регистр или переменная;
- Источником может быть регистр, переменная или константа.
Наконец то мы добрались до умножения. Здесь все также очень похоже на две команды выше.
Что должно быть выведено в итоге? Правильно, 400.
Теперь, когда вы знаете 3 арифметические операции, ваша задача написать код, который будет рассчитывать дискриминант.
Формула дискриминанта:
Значения, a, b, c можно взять любыми. Главное, чтобы результат был выведен на экран. (Не забывайте, мы выводим регистр eax, поэтому результат должен быть именно в нем).
DIV [источник]
Команду для деления мы пока что разбирать не будем, так как она слишком сложная, на этом этапе изучения ассемблере. Вернемся к ней позже.
Следующие команды, это команды для сравнения и условных переходов.
Условные переходы — это переходы в какую-то метку программы, в зависимости от того, какой результат был получен в результате последней команды cmp.
CMP [значение_1], [значение_2]
Команда cmp расшифровывается, как compare, что переводится как «сравнить».
Эта команда сравнивает значение 1 со значением 2, а результат записывает в регистр флагов. О регистре флагов мы поговорим дальше, сейчас просто поймите это, как то, что результат записывается в регистре флагов и мы можем его использовать с помощью следующих команд.
- Значение 1 может быть регистром, переменной или константой;
- Значение 2 может быть регистром, переменной или константой.
Например:
Следующие команды описывают условные переходы. То есть эти команды переходят к меткам в зависимости от результата предыдущей команды, например, команды cmp.
JNE [имя_метки]
Команда jne расшифровывается, как jump if not equal, что переводится как «прыгнуть если НЕравно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был НЕравен второму
Давайте попробуем использовать эту и предыдущую команды и попробуем создать цикл:
Данный код описывает простой цикл, в нем значение ebx увеличивается на 1, а затем проверяется на равенство ecx. Таким образом, переход к метке loop_start будет происходить до тех пор, пока значения ebx и ecx не станут равными, тогда код продолжит выполнять код за пределами данного отрывка (помним, что мы описываем не весь код, а его часть, дальше идет вывод значения eax).
Если вы запустите код, вы должны получить 512. Таким образом мы написали расчет степени двойки, чтобы поменять расчетную степень, надо изменить первоначальное значение ecx.
Ваша задача написать на основе этого кода программу, которая будет рассчитывать степень числа 5. Ответ в приложении.
JE [имя_метки]
Команда je расшифровывается, как jump if equal, что переводится как «прыгнуть если равно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был равен второму
Сейчас мы рассмотрим простейшую реализацию конструкции if else. Предположим, что нам нужно сравнить значение ebx и ecx и в случае равенства вывести 1, а в обратном случае — 0.
Казалось бы, вроде все верно, если равно, то переходим к одной метке, если нет — к другой. Но здесь проявляется особенность ассемблера, он выполняет команды одну за другой, несмотря ни на что. Поэтому в данном случае, если числа будут равны, eax станет равным 1, но после этого же, ему будет присвоен 0 и в результате работы будет выведен 0.
Чтобы избежать такого, создают специальную метку, в случае, если числа равны, эта метка будет переходить к коду после команд, которые должны были быть выполнены в случае неравенства.
Для этого используется команды jmp, давайте отвлечемся на ее описание, а после вернемся к примеру.
JMP [имя_метки]
Команда jmp расшифровывается, как jump, что переводится как «прыгнуть».
Эта команда переходит к метке, вне зависимости от чего-либо. Это безусловный переход.
Теперь вернемся к нашему примеру и добавим эту метку и переход к ней:
Теперь, если числа равны, то программа перейдет к метке if_equal, а потом «перепрыгнет» команды, так как встретит безусловный перед к метке if_end, таким образом команды которые должны были выполнится в случае неравенства будут пропущены.
В случае же неравенства, программа перейдет к метке if_not_equal и продолжит выполнять программу до конца, метка if_end в данном случае будет просто пропущена.
JG [имя_метки]
Команда jg расшифровывается, как jump if greater, что переводится как «прыгнуть если больше».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был строго больше второму.
JL [имя_метки]
Команда jl расшифровывается, как jump if less, что переводится как «прыгнуть если меньше».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был строго меньше второму.
JGE [имя_метки]
Команда jge расшифровывается, как jump if greater or equal, что переводится как «прыгнуть если больше или равно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был больше или равен второму.
JLE [имя_метки]
Команда jle расшифровывается, как jump if less or equal, что переводится как «прыгнуть если меньше или равно».
Эта команда переходит к метке, если в результате последнего вызова команды cmp первый операнд был меньше или равен второму.
Все эти команды работают также как и предыдущие 3, поэтому не будем на них обращать пристальное внимание.
Однако, у вас есть задача. Предыдущий цикл будет корректно работать только в том случае, если в результате прибавления, ebx когда то станет равным ecx, но если мы поменяем приращение на 2, то мы получим бесконечный цикл, так как значения никогда не будут равны и программа будет постоянно переходить к метке.
Вам нужно исправить этот код, используя команды выше, чтобы он не уходил в бесконечный цикл.
Ответ в приложении.
На этом основные команды закончены.
Стек
Мы переходим к одной из самых сложных частей ассемблера — стеку. В первую очередь, давайте рассмотрим, что вообще такое стек, как структура данных.
Стек — это структура данных, при использовании которой возможны только две операции:
- Поместить на вершину стека значение;
- Извлечь значение из вершины стека.
Таким образом, если мы поместили в стек 3 значения, то получить доступ мы можем только к последнему добавленному элементу, а чтобы получить доступ к элементу посередине, нужно сначала извлечь все элементы до него.
Стек можно сравнить со стопкой тарелок. Если вы хотите достать тарелку из середины, то вам нужно сначала убрать все тарелки над ней. Также, когда вы добавляете новую тарелку, вы кладете ее на вершину стопки.
Если говорить о том, что такое стек в программе, то — это область программы для временного хранения произвольных данных.
Конечно, можно хранить все данные в сегменте памяти, в виде переменных, но это увеличивает размер программы и количество используемых имен.
Память в стеке используется многократно, что удобно, так как занимает меньше памяти.
Для работы со стеком есть две основных команды:
PUSH [значение]
Команда push переводится как «протолкнуть».
Эта команда добавляет значение в стек.
Значение может быть регистром, переменной или константой;
POP [приемник]
Команда pop переводится как «вытолкнуть».
Эта команда извлекает значение вершины стека и помещает его в приемник.
Приемник может быть регистром или переменной;
Давайте попробуем написать что-нибудь с использованием стека:
Предположим у нас есть 5 чисел:
10, 5, 6, 3, 2
Наша задача сложить их. Но мы не сможем их задать одновременно, так как регистров у нас только 4, а чисел 5. Конечно, здесь можно использовать и переменные, но давайте реализуем это с помощью стека:
В первую очередь помещаем все наши значения в стек:
После того, как значения в стеке, нам надо 5 раз достать значение из стека и прибавить его к eax:
Таким непритязательным кодом, мы реализовали нашу задачу. Однако у вас будет задача чуть сложнее, она будет охватывать и все предыдущие команды.
Ваша задача написать программу, которая в самом начале поместит в стек числа от 100 до 1, а потом извлечет их и сложит. Нужно использовать циклы из прошлых команд, а также стек. Ответ, как всегда, в приложении.
Регистрыesp и ebp
Помните в самом начале мы рассматривали вторую четверку общих регистров? И было сказано, что у них есть конкретные назначения. Так вот два из них используются в стеке. Это регистры esp и ebp. Это регистры-указатели, то есть их значения трактуются, как адреса. Ассемблер работает с ними, предполагая, что в них хранится адрес, вне зависимости от тог, что там находится в реальности. Это означает, что если вы поместите в них число 4, то при разыменовании будет обращение к памяти по адресу 4, а если эта память недоступна, то вы получите ошибку.
Давайте посмотрим, на что они указывают, когда программа только запущена:
![]()
Оба указателя находятся под стеком, то есть указывают на элемент под стеком.
Когда мы помещаем значение в стек, регистр esp начинает указывать на верхний, то есть на последний добавленный элемент в стеке:

Если мы добавим еще один элемент, то esp вновь будет указывать на вершину стека:

Таким образом, с помощью регистра esp мы можем получить доступ к последнему добавленному элементу стека, а также к произвольному значению в стеке. Для того, чтобы получить значение по некоторому адресу используется синтаксис разыменования.
Разыменование указателей
Для того, чтобы разыменовать указатель нужно заключить регистр в квадратные скобки:
mov eax, [esp]
Таким образом в eax будет помещено значение по адресу esp. Если написать просто:
mov eax, esp
То тогда в регистре eax будет адрес, который хранится в esp, но однако никто не запрещает разыменовать и его:
mov eax, [eax]
Давайте попробуем поместить в стек пару значений и получить значение элемента после самого последнего:
В последней строке мы используем разыменование, но однако до этого мы сдвигаем указатель на 4 байта, такой синтаксис корректен, он означает, что начала из адреса вычитается 4, а потом происходит разыменование. В итоге, мы получим в выводе 20, так как адрес esp + 4 указывает на следующий, после вершины стека, элемент.
Однако, вас может смутить, почему для того, чтобы получить элемент под верхним, нужно прибавлять 4, а не отнимать. Дело в том, что адреса в стеке уменьшаются снизу вверх:

Поэтому для получения элементов ниже последнего нужно прибавлять, а выше — вычитать.
Но почему именно 4? Дело в том, что мы помещаем в стек 4 байтные значения по-умолчанию, и чтобы обратится именно к следующему элементу нужно прибавить 4. Если вы попробуете прибавить, например, 2, то вы получите число, которое описывается 4 байтами, начиная с текущего, то есть программа просто возьмет 32 бита из стека и поместит их в eax абсолютно не думая о том, что это могут быть не те данные, обычно это приведет к ошибкам.
Функции
Следующая очень важная тема, это функции. Функции в ассемблере задаются с помощью ключевого слова PROC (регистр не важен, см. введение).
Так, например, объявление функции выглядит следующим образом:
Каждая функция должна заканчиваться командой ret для явного выхода из функции.
Вызвать функцию можно с помощью команд условного и безусловного перехода, но для этого есть более специализированные команды.
Для вызова функции используется команда call.
CALL [имя_функции]
Команда call переводится как «вызвать».
Эта команда помещает в стек адрес возврата (адрес следующей, после этой, команды) и переходит к началу функции. Адрес возврата нужен, чтобы после завершения выполнения перейти к команде, которые должны быть выполнены после вызова функции.
Пролог функции (Начало функции)
Каждая функция начинается с так называемого пролога процедуры.
Пролог процедуры — это фрагмент кода, нужный для того, чтобы сохранить текущее состояние стека, то есть сохранить адрес последнего элемента стека в момент вызова функции.
Код пролога следующий:
В первой строке мы помещаем в стек ebp, чтобы потом, после того, как функция завершит свою работу восстановить изначальное значение. Это нужно, так как в следующей строке мы кладем значение esp в ebp. Но что это означает на деле.
Предположим, у нас в стеке лежит два значения. Мы вызываем функцию с помощью команды call. В стек кладется адрес возврата (см. описание функции call):

После того, как мы выполним первую команду пролога, стек будет следующим:

То есть мы помещаем ebp в стек, при этом esp указывает на последний элемент, то есть на значение ebp, которое было только что добавлено. Сам регистр ebp все еще указывает на дно стека.
После того, как мы выполним вторую команду пролога, стек будет следующим:

Все что изменилось, это то, что ebp стало равным esp.
Таким образом, после пролога, в ebp будет хранится адрес вершины стека (или верхнего элемента стека) в момент вызова функции. Это нужно, чтобы, когда мы в функции будем добавлять элементы в стек, то в ebp адрес все еще будет указывать на начальный для esp в начале функции:

Это нужно, чтобы можно было обращаться к элементам стека, которые были до вызова функции по фиксированным сдвигам. Так, например, если мы хотим получить значение 20 то достаточно прибавить 8 к ebp, а вот для esp необходимо сначала вычесть количество добавленных в функции новых значений и только потом вычесть 8, что намного сложнее. Поэтому мы будем использовать ebp для доступа к элементам стека, которые были добавлены до вызова функции, это понадобится нам в дальнейшем для передачи аргументов.
Эпилог функции (Конец функции)
После того, как функция завершена, выполняется так называемый эпилог процедуры. Эпилог процедуры восстанавливает значение ebp, которое мы сохранили в стек в прологе.
Код эпилога следующий:
Стек после эпилога будет следующий:

То есть теперь ebp будет вновь указывать на дно стека (будет иметь первоначальное значение, которые мы сохранили в прологе), а значение из стека будет изъято. Теперь на вершине стека лежит адрес возврата. Встречая команду ret, из стека извлекается значение и трактуется, как адрес возврата, то есть в виде адреса команды, с которой нужно продолжить выполнение программы после того, как функция закончена.
Например, у вас есть следующий код:
Когда функция someFunction вызывается, то в стек помещается адрес следующей команды, то есть в нашем случае адрес команды mov.
После того, как функция закончила работу, из стека извлекается этот адрес и выполнение продолжается, начиная с команды по этому адресу, то есть с команды mov.
Проблема при работе со стеком в функции
Однако здесь таится большая возможная проблема, а что если мы в функции поместили в стек какое-то значение?
И после добавления у нас идет эпилог функции. Тогда в ebp будет помещено значение из вершины стека, где у нас лежит значение 5.

Теперь ebp указывает на неизвестно что, а на вершине стека лежит адрес ebp, который мы поместили еще в прологе. Теперь, так как после пролога идет команда ret, будет извлечено значение из стека и оно будет рассматриваться, как адрес возврата, но это не адрес возврата, а адрес ebp. Поэтому мы получим ошибку, так как пытаемся получить доступ к памяти, которая нам недоступна.
Чтобы этого избежать, нужно тщательно следить за стеком!
Если вы в функции добавляете какие-то значения в стек, то их обязательно нужно извлечь оттуда до пролога!