АКТУАЛЬНОСТЬ ТЕМЫ
Общие положения
Про регрессионный анализ вообще, и его применение в DataScience написано очень много. Есть множество учебников, монографий, справочников и статей по прикладной статистике, огромное количество информации в интернете, примеров расчетов. Можно найти множество кейсов, реализованных с использованием средств Python. Казалось бы — что тут еще можно добавить?
Однако, как всегда, есть нюансы:
1. Регрессионный анализ — это прежде всего процесс, набор действий исследователя по определенному алгоритму: «подготовка исходных данных — построение модели — анализ модели — прогнозирование с помощью модели». Это ключевая особенность. Не представляет особой сложности сформировать DataFrame исходных данных и построить модель, запустить процедуру из библиотеки statsmodels. Однако подготовка исходных данных и последующий анализ модели требуют гораздо больших затрат человеко-часов специалиста и строк программного кода, чем, собственно, построение модели. На этих этапах часто приходится возвращаться назад, корректировать модель или исходные данные. Этому, к сожалению, во многих источниках, не удаляется достойного внимания, а иногда — и совсем не уделяется внимания, что приводит к превратному представлению о регрессионном анализе.
2. Далеко не во всех источниках уделяется должное внимание интерпретации промежуточных и финальных результатов. Специалист должен уметь интерпретировать каждую цифру, полученную в ходе работы над моделью.
3. Далеко не все процедуры на этапах подготовки исходных данных или анализа модели в источниках разобраны подробно. Например, про проверку значимости коэффициента детерминации найти информацию не представляет труда, а вот про проверку адекватности модели, построение доверительных интервалов регрессии или про специфические процедуры (например, тест Уайта на гетероскедастичность) информации гораздо меньше.
4. Своеобразная сложность может возникнуть с проверкой статистических гипотез: для отечественной литературы по прикладной статистике больше характерно проверять гипотезы путем сравнения расчетного значения критерия с табличным, а в иностранных источниках чаще определяется расчетный уровень значимости и сравнивается с заданным (чаще всего 0.05 = 1-0.95). В разных источниках информации реализованы разные подходы. Инструменты python (прежде всего библиотеки scipy и statsmodels) также в основном оперируют с расчетным уровнем значимости.
5. Ну и, наконец, нельзя не отметить, что техническая документация библиотеки statsmodels составлена, на мой взгляд, далеко не идеально: информация излагается путано, изобилует повторами и пропусками, описание классов, функций и свойств выполнено фрагментарно и количество примеров расчетов — явно недостаточно.
Поэтому я решил написать ряд обзоров по регрессионному анализу средствами Python, в которых акцент будет сделан на практических примерах, алгоритме действий исследователя, интерпретации всех полученных результатов, конкретных методических рекомендациях. Буду стараться по возможности избегать теории (хотя совсем без нее получится) — все-таки предполагается, что специалист DataScience должен знать теорию вероятностей и математическую статистику, хотя бы в рамках курса высшей математики для технического или экономического вуза.
В данном статье остановимся на самои простом, классическом, стереотипном случае — простой линейной регрессии (simple linear regression), или как ее еще принято называть — парной линейной регрессионной модели (ПЛРМ) — в ситуации, когда исследователя не подстерегают никакие подводные камни и каверзы — исходные данные подчиняются нормальному закону, в выборке отсутствуют аномальные значения, отсутствует ложная корреляция. Более сложные случаи рассмотрим в дальнейшем.
Для построение регрессионной модели будем пользоваться библиотекой statsmodels.
В данной статье мы рассмотрим по возможности полный набор статистических процедур. Некоторые из них (например, дескриптивная статистика или дисперсионный анализ регрессионной модели) могут показаться избыточными. Все так, но эти процедуры улучшают наше представление о процессе и об исходных данных, поэтому в разбор я их включил, а каждый исследователь сам вправе для себя определить, потребуются ему эти процедуры или нет.
Краткий обзор источников
Источников информации по корреляционному и регрессионному анализу огромное количество, в них можно просто утонуть. Поэтому позволю себе просто порекомендовать ряд источников, на мой взгляд, наиболее полезных:
-
Кобзарь А.И. Прикладная математическая статистика. Для инженеров и научных работников. — М.: ФИЗМАТЛИТ, 2006. — 816 с.
-
Львовский Е.Н. Статистические методы построения эмпирических формул. — М.: Высшая школа, 1988. — 239 с.
-
Фёрстер Э., Рёнц Б. Методы корреляционного и регрессионного анализа / пер с нем. — М.: Финансы и статистика, 1983. — 302 с.
-
Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ / пер с англ. — М.: Мир, 1982. — 488 с.
-
Дрейпер Н., Смит Г. Прикладной регрессионный анализ. Книга 1 / пер.с англ. — М.: Финансы и статистика, 1986. — 366 с.
-
Айвазян С.А. и др. Прикладная статистика: Исследование зависимостей. — М.: Финансы и статистика, 1985. — 487 с.
-
Прикладная статистика. Основы эконометрики: В 2 т. 2-е изд., испр. — Т.2: Айвазян С.А. Основы эконометрики. — М.: ЮНИТИ-ДАНА, 2001. — 432 с.
-
Магнус Я.Р. и др. Эконометрика. Начальный курс — М.: Дело, 2004. — 576 с.
-
Носко В.П. Эконометрика. Книга 1. — М.: Издательский дом «Дело» РАНХиГС, 2011. — 672 с.
-
Брюс П. Практическая статистика для специалистов Data Science / пер. с англ. — СПб.: БХВ-Петербург, 2018. — 304 с.
-
Уатт Дж. и др. Машинное обучение: основы, алгоритмы и практика применения / пер. с англ. — СПб.: БХВ-Петербург, 2022. — 640 с.
Прежде всего следует упомянуть справочник Кобзаря А.И. [1] — это безусловно выдающийся труд. Ничего подобного даже близко не издавалось. Всем рекомендую иметь под рукой.
Есть очень хорошее практическое пособие [2] — для начинающих и практиков.>
Добротная работа немецких авторов [3]. Все разобрано подробно, обстоятельно, с примерами — очень хорошая книга. Примеры приведены из области экономики.
Еще одна добротная работа — [4], с примерами медико-биологического характера.
Работа [5] считается одним из наиболее полных изложений прикладного регрессионного анализа.
Более сложные работы — [6] (классика жанра), [7], [8], [9] — выдержаны на достаточно высоком математическом уровне, примеры из экономической области.
Свежие работы [10] (с примерами на языке R) и [11] (с примерами на python).
Cтатьи
Статей про регрессионный анализ в DataScience очень много, обращаю внимание на некоторые весьма полезные из них.
Серия статей «Python, корреляция и регрессия», охватывающая весь процесс регрессионного анализа:
-
первичная обработка данных, визуализация и корреляционный анализ;
-
регрессия;
-
теория матриц в регрессионном анализе, проверка адекватности, мультиколлинеарность;
-
прогнозирование с помощью регрессионных моделей.
Очень хороший обзор «Интерпретация summary из statsmodels для линейной регрессии». В этой статье даны очень полезные ссылки:
-
Statistical Models
-
Interpreting Linear Regression Through statsmodels .summary()
Статья «Регрессионные модели в Python».
Основные предпосылки (гипотезы) регрессионного анализа
Очень кратко — об этом написано тысячи страниц в учебниках — но все же вспомним некоторые основы теории.
Проверка исходных предпосылок является очень важным моментом при статистическом анализе регрессионной модели. Если мы рассматриваем классическую линейную регрессионную модель вида:
![]()
то основными предпосылками при использовании обычного метода наименьших квадратов (МНК) для оценки ее параметров являются:
-
Среднее значение (математическое ожидание) случайной составляющей равно нулю:
![]()
-
Дисперсия случайной составляющей является постоянной:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением гетероскедастичности.
-
Значения случайной составляющей статистически независимы (некоррелированы) между собой:
![]()
В случае нарушения данного условия мы сталкиваемся с явлением автокорреляции.
-
Условие существования обратной матрицы
![]()
что эквивалентно одному из двух следующих условий:
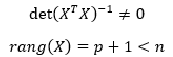
то есть число наблюдений должно превышать число параметров.
-
Значения случайной составляющей некоррелированы со значениями независимых переменных:
![]()
-
Случайная составляющая имеет нормальный закон распределения (с математическим ожиданием равным нулю — следует из условия 1):
![]()
Более подробно — см.: [3, с.90], [4, с.147], [5, с.122], [6, с.208], [7, с.49], [8, с.68], [9, с.88].
Кроме гетероскедастичности и автокорреляции возможно возникновение и других статистических аномалий — мультиколлинеарности, ложной корреляции и т.д.
Доказано, что оценки параметров, полученные с помощью МНК, обладают наилучшими свойствами (несмещенность, состоятельность, эффективность) при соблюдении ряда условий:
-
выполнение приведенных выше исходных предпосылок регрессионного анализа;
-
число наблюдений на одну независимую переменную должно быть не менее 5-6;
-
должны отсутствовать аномальные значения (выбросы).
Кроме обычного МНК существуют и другие его разновидности (взвешенный МНК, обобщенный МНК), которые применяются при наличии статистических аномалий. Кроме МНК применяются и другие методы оценки параметров моделей. В этом обзоре мы эти вопросы рассматривать не будем.
Алгоритм проведения регрессионного анализа
Алгоритм действий исследователя при построении регрессионной модели (полевые работы мы, по понятным причинам, не рассматриваем — считаем, что исходные данные уже получены):
-
Подготовительный этап — постановка целей и задач исследования.
-
Первичная обработка исходных данных — об этом много написано в учебниках и пособиях по DataScience, сюда могут относится:
-
выявление нерелевантных признаков (признаков, которые не несут полезной информации), нетипичных данных (выбросов), неинформативных признаков (имеющих большое количество одинаковых значений) и работа с ними (удаление/преобразование);
-
выделение категориальных признаков;
-
работа с пропущенными значениями;
-
преобразование признаков-дат в формат datetime и т.д.
-
Визуализация исходных данных — предварительный графический анализ.
-
Дескриптивная (описательная) статистика — расчет выборочных характеристик и предварительные выводы о свойствах исходных данных.
-
Исследование закона распределения исходных данных и, при необходимости, преобразование исходных данных к нормальному закону распределения.
-
Выявление статистически аномальных значений (выбросов), принятие решения об их исключении.
Этапы 4, 5 и 6 могут быть при необходимости объединены.
-
Корреляционный анализ — исследование корреляционных связей между исходными данными; это разведка перед проведением регрессионного анализа.
-
Построение регрессионной модели:
-
выбор моделей;
-
выбор методов;
-
оценка параметров модели.
-
Статистический анализ регрессионной модели:
-
оценка ошибок аппроксимации (error metrics);
-
анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков);
-
проверка адекватности модели;
-
проверка значимости коэффициента детерминации;
-
проверка значимости коэффициентов регрессии;
-
проверка мультиколлинеарности (для множественных регрессионных моделей; вообще мультиколлинеарные переменные выявляются еще на стадии корреляционного анализа);
-
проверка автокорреляции;
-
проверка гетероскедастичности.
Этапы 8 и 9 могут быть при необходимости повторяться несколько раз.
-
Сравнительный анализ нескольких регрессионных моделей, выбор наилучшей (при необходимости).
-
Прогнозирование с помощью регрессионной модели и оценка качества прогноза.
-
Выводы и рекомендации.
Само собой, этот алгоритм не есть истина в последней инстанции — в зависимости от особенностей исходных данных и вида модели могут возникать дополнительные задачи.
Применение пользовательских функций
Далее в обзоре мной будут использованы несколько пользовательских функций для решения разнообразных задач. Все эти функции созданы для облегчения работы и уменьшения размера программного кода. Данные функции загружается из пользовательского модуля my_module__stat.py, который доступен в моем репозитории на GitHub. Лично мне так удобнее работать, хотя каждый исследователь сам формирует себе инструменты по душе — особенно в части визуализации. Желающие могут пользоваться этими функциями, либо создать свои.
Итак, вот перечень данных функций:
-
graph_scatterplot_sns — функция позволяет построить точечную диаграмму средствами seaborn и сохранить график в виде png-файла;
-
graph_hist_boxplot_probplot_XY_sns — функция позволяет визуализировать исходные данные для простой линейной регрессии путем одновременного построения гистограммы, коробчатой диаграммы и вероятностного графика (для переменных X и Y) средствами seaborn и сохранить график в виде png-файла; имеется возможность выбирать, какие графики строить (h — hist, b — boxplot, p — probplot);
-
descriptive_characteristics — функция возвращает в виде DataFrame набор статистических характеристики выборки, их ошибок и доверительных интервалов;
-
detecting_outliers_mad_test — функция выполняет проверку наличия аномальных значений (выбросов) по критерию наибольшего абсолютного отклонения (более подробно — см.[1, с.547]);
-
norm_distr_check — проверка нормальности распределения исходных данных с использованием набора из нескольких статистических тестов;
-
corr_coef_check — функция выполняет расчет коэффициента линейной корреляции Пирсона, проверку его значимости и расчет доверительных интервалов; об этой функции я писал в своей статье.
-
graph_regression_plot_sns — — функция позволяет построить график регрессионной модели.
Ряд пользовательских функций мы создаем в процессе данного обзора (они тоже включены в пользовательский модуль my_module__stat.py):
-
regression_error_metrics — расчет ошибок аппроксимации регрессионной модели;
-
ANOVA_table_regression_model — вывод таблицы дисперсионного анализа регрессионной модели;
-
regression_model_adequacy_check — проверка адекватности регрессионной модели по критерию Фишера;
-
determination_coef_check — проверка значимости коэффициента детерминации по критерию Фишера;
-
regression_coef_check — проверка значимости коэффициентов регрессии по критеирю Стьюдента;
-
Goldfeld_Quandt_test, Breush_Pagan_test, White_test — проверка гетероскедастичности с использование тестов Голдфелда-Квандта, Бриша-Пэгана и Уайта соответственно;
-
regression_pair_predict — функция для прогнозирования с помощью парной регрессионной модели: рассчитывает прогнозируемое значение переменной Y по заданной модели, а также доверительные интервалы среднего и индивидуального значения для полученного прогнозируемого значения Y;
-
graph_regression_pair_predict_plot_sns — прогнозирование: построение графика регрессионной модели (с доверительными интервалами) и вывод расчетной таблицы с данными для заданной области значений X.
ПОСТАНОВКА ЗАДАЧИ
В качестве примера рассмотрим практическую задачу из области экспертизы промышленной безопасности — калибровку ультразвукового прибора для определения прочности бетона.
Итак, суть задачи: при обследовании несущих конструкций зданий и сооружений эксперт определяет прочность бетона с использованием ультразвукового прибора «ПУЛЬСАР-2.1», для которого необходимо предварительно построить градуировочную зависимость. Заключается это в следующем — производятся замеры с фиксацией следующих показателей:
-
X — показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с)
-
Y — результаты замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03.
Предполагается, что между показателями X и Y имеется линейная регрессионная зависимость, которая позволит прогнозировать прочность бетона на основании измерений, проведенных прибором «ПУЛЬСАР-2.1».
Были выполнены замеры фактической прочности бетона конструкций для бетонов одного вида с одним типом крупного заполнителя, с единой технологией производства. Для построения были выбраны 14 участков (не менее 12), включая участки, в которых значение косвенного показателя максимальное, минимальное и имеет промежуточные значения.
Настройка заголовков отчета:
# Общий заголовок проекта
Task_Project = 'Калибровка ультразвукового прибора "ПУЛЬСАР-2.1" nдля определения прочности бетона'
# Заголовок, фиксирующий момент времени
AsOfTheDate = ""
# Заголовок раздела проекта
Task_Theme = ""
# Общий заголовок проекта для графиков
Title_String = f"{Task_Project}n{AsOfTheDate}"
# Наименования переменных
Variable_Name_X = "Скорость УЗК (м/с)"
Variable_Name_Y = "Прочность бетона (МПа)"
# Константы
INCH = 25.4 # мм/дюйм
DecPlace = 5 # number of decimal places - число знаков после запятой
# Доверительная вероятность и уровень значимости:
p_level = 0.95
a_level = 1 - p_level Подключение модулей и библиотек:
# Стандартные модули и библиотеки
import os # загрузка модуля для работы с операционной системой
import sys
import platform
print('{:<35}{:^0}'.format("Текущая версия Python: ", platform.python_version()), 'n')
import math
from math import * # подключаем все содержимое модуля math, используем без псевдонимов
import numpy as np
#print ("Текущая версия модуля numpy: ", np.__version__)
print('{:<35}{:^0}'.format("Текущая версия модуля numpy: ", np.__version__))
from numpy import nan
import scipy as sci
print('{:<35}{:^0}'.format("Текущая версия модуля scipy: ", sci.__version__))
import scipy.stats as sps
import pandas as pd
print('{:<35}{:^0}'.format("Текущая версия модуля pandas: ", pd.__version__))
import matplotlib as mpl
print('{:<35}{:^0}'.format("Текущая версия модуля matplotlib: ", mpl.__version__))
import matplotlib.pyplot as plt
import seaborn as sns
print('{:<35}{:^0}'.format("Текущая версия модуля seaborn: ", sns.__version__))
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.graphics.api as smg
import statsmodels.stats.api as sms
from statsmodels.compat import lzip
print('{:<35}{:^0}'.format("Текущая версия модуля statsmodels: ", sm.__version__))
import statistics as stat # module 'statistics' has no attribute '__version__'
import sympy as sym
print('{:<35}{:^0}'.format("Текущая версия модуля sympy: ", sym.__version__))
# Настройки numpy
np.set_printoptions(precision = 4, floatmode='fixed')
# Настройки Pandas
pd.set_option('display.max_colwidth', None) # текст в ячейке отражался полностью вне зависимости от длины
pd.set_option('display.float_format', lambda x: '%.4f' % x)
# Настройки seaborn
sns.set_style("darkgrid")
sns.set_context(context='paper', font_scale=1, rc=None) # 'paper', 'notebook', 'talk', 'poster', None
# Настройки Mathplotlib
f_size = 8 # пользовательская переменная для задания базового размера шрифта
plt.rcParams['figure.titlesize'] = f_size + 12 # шрифт заголовка
plt.rcParams['axes.titlesize'] = f_size + 10 # шрифт заголовка
plt.rcParams['axes.labelsize'] = f_size + 6 # шрифт подписей осей
plt.rcParams['xtick.labelsize'] = f_size + 4 # шрифт подписей меток
plt.rcParams['ytick.labelsize'] = f_size + 4
plt.rcParams['legend.fontsize'] = f_size + 6 # шрифт легенды
# Пользовательские модули и библиотеки
Text1 = os.getcwd() # вывод пути к текущему каталогу
#print(f"Текущий каталог: {Text1}")
sys.path.insert(1, "D:REPOSITORYMyModulePython")
from my_module__stat import *ФОРМИРОВАНИЕ ИСХОДНЫХ ДАННЫХ
Показания ультразвукового прибора «ПУЛЬСАР-2.1» (м/с):
X = np.array([
4416, 4211, 4113, 4110, 4122,
4427, 4535, 4311, 4511, 4475,
3980, 4490, 4007, 4426
])Результаты замера прочности бетона (методом отрыва со скалыванием) прибором ИПС-МГ4.03:
Y = np.array([
34.2, 35.1, 31.5, 30.8, 30.0,
34.0, 35.4, 35.8, 38.0, 37.7,
30.0, 37.8, 31.0, 35.2
])Запишем данные в DataFrame:
calibrarion_df = pd.DataFrame({
'X': X,
'Y': Y})
display(calibrarion_df)
calibrarion_df.info()Сохраняем данные в csv-файл:
calibrarion_df.to_csv(
path_or_buf='data/calibrarion_df.csv',
mode='w+',
sep=';')Cоздаем копию исходной таблицы для работы:
dataset_df = calibrarion_df.copy()ВИЗУАЛИЗАЦИЯ ДАННЫХ
Границы значений переменных (при построении графиков):
(Xmin_graph, Xmax_graph) = (3800, 4800)
(Ymin_graph, Ymax_graph) = (25, 45)# Пользовательская функция
graph_scatterplot_sns(
X, Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
color='orange',
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
s=100,
file_name='graph/scatterplot_XY_sns.png')
Существует универсальный набор графиков — гистограмма, коробчатая диаграмма, вероятностный график — которые позволяют исследователю сделать предварительные выводы о свойствах исходных данных.
Так как объем выборки невелик (n=14), строить гистограммы распределения переменных X и Y не имеет смысла, поэтому ограничимся построением коробчатых диаграмм и вероятностных графиков:
# Пользовательская функция
graph_hist_boxplot_probplot_XY_sns(
data_X=X, data_Y=Y,
data_X_min=Xmin_graph, data_X_max=Xmax_graph,
data_Y_min=Ymin_graph, data_Y_max=Ymax_graph,
graph_inclusion='bp', # выбираем для построения виды графиков: b - boxplot, p - probplot)
data_X_label=Variable_Name_X,
data_Y_label=Variable_Name_Y,
title_figure=Task_Project,
file_name='graph/hist_boxplot_probplot_XY_sns.png') 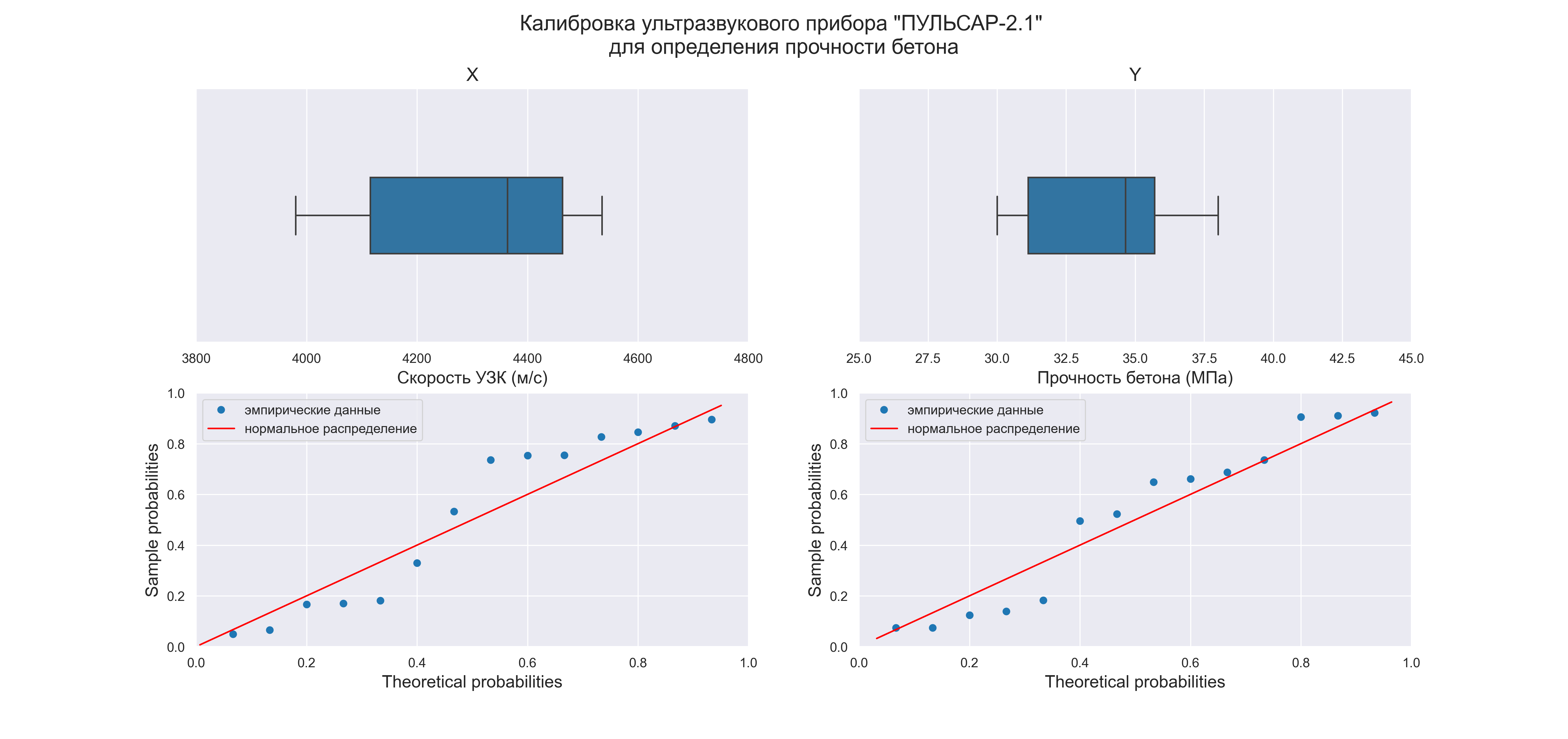
Для сравнения характера распределений переменных X и Y возможно также построить совмещенную коробчатую диаграмму по стандартизованным данным:
# стандартизуем исходные данные
standardize_df = lambda X: ((X - np.mean(X))/np.std(X))
dataset_df_standardize = dataset_df.copy()
dataset_df_standardize = dataset_df_standardize.apply(standardize_df)
display(dataset_df_standardize)
# построим график
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/2))
axes.set_title("Распределение стандартизованных переменных X и Y", fontsize = 16)
sns.boxplot(
data=dataset_df_standardize,
orient='h',
width=0.5,
ax=axes)
plt.show()
Графический анализ позволяет сделать следующие выводы:
-
Отсутствие выбросов на коробчатых диаграммах свидетельствует об однородности распределения переменных.
-
Смещение медианы вправо на коробчатых диаграммах свидетельствует о левосторонней асимметрии распределения.
ДЕСКРИПТИВНАЯ (ОПИСАТЕЛЬНАЯ СТАТИСТИКА)
Собственно говоря, данный этап требуется проводить далеко не всегда, однако с помощью статистических характеристик выборки мы тоже можем сделать полезные выводы.
Описательная статистика исходных данных средствами библиотеки Pandas — самый простой вариант:
dataset_df.describe()
Описательная статистика исходных данных средствами библиотеки statsmodels — более развернутый вариант, с большим количеством показателей:
from statsmodels.stats.descriptivestats import Description
result = Description(
dataset_df,
stats=["nobs", "missing", "mean", "std_err", "ci", "ci", "std", "iqr", "mad", "coef_var", "range", "max", "min", "skew", "kurtosis", "mode",
"median", "percentiles", "distinct", "top", "freq"],
alpha=a_level,
use_t=True)
display(result.summary())
Описательная статистика исходных данных с помощью пользовательской функции descriptive_characteristics:
# Пользовательская функция
descriptive_characteristics(X)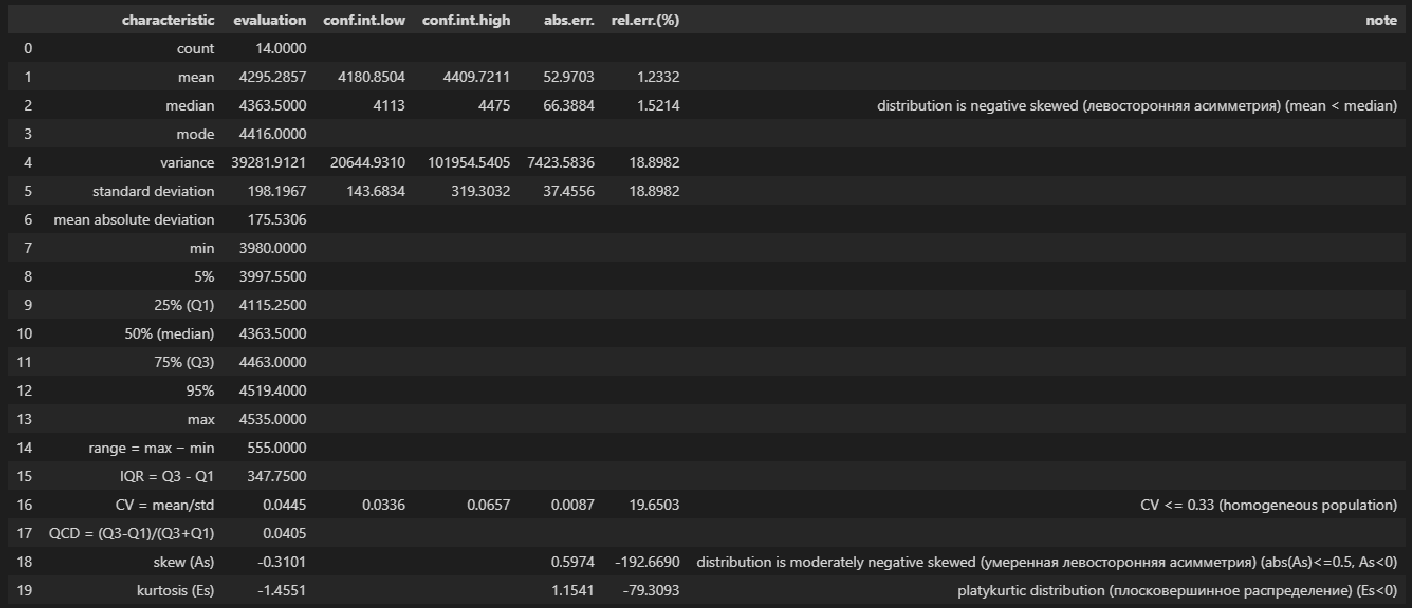
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0445 и доверительный интервал для него 0.0336 ≤ CV ≤ 0.0657 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.3101 свидетельствует об умеренной левосторонней асимметрии распределении (т.к. |As| ≤ 0.5, As < 0).
-
Значение показателя эксцесса kurtosis (Es) = -1.4551 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
# Пользовательская функция
descriptive_characteristics(Y)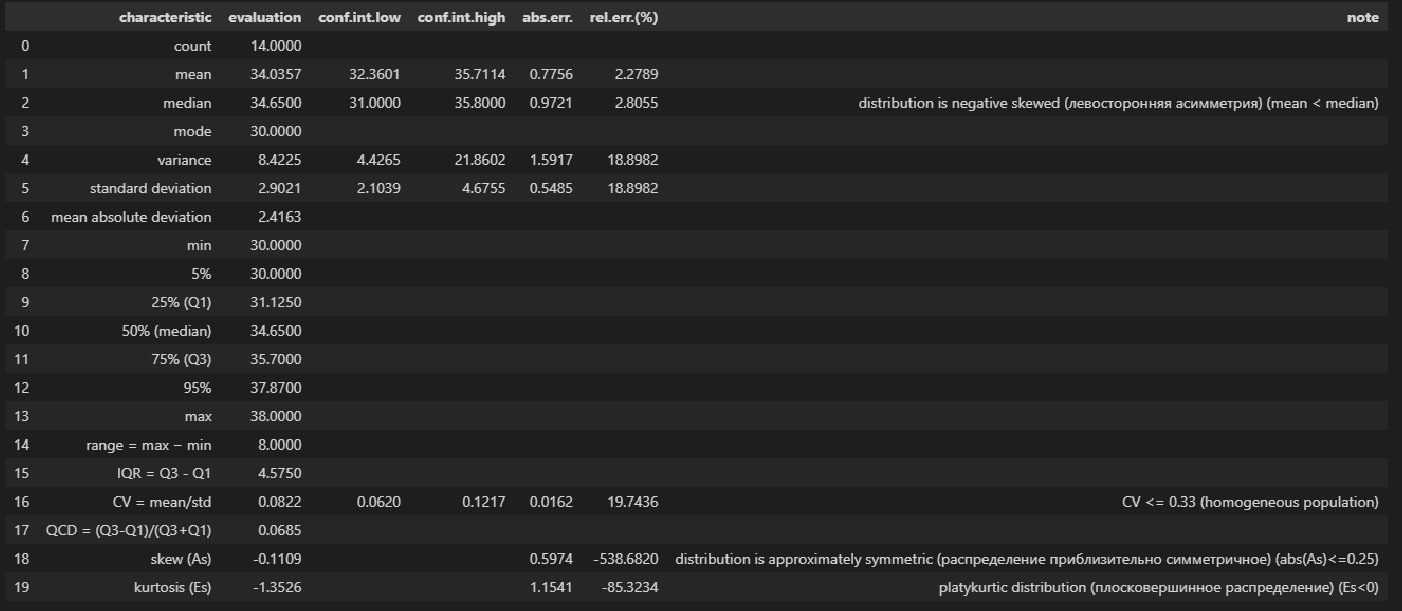
Выводы:
-
Сравнение показателей среднего арифметического (mean) и медианы (median) свидетельствует о левосторонней асимметрии (т.к.mean < median).
-
Значение коэффициента вариации CV = 0.0822 и доверительный интервал для него 0.06202 ≤ CV ≤ 0.1217 свидетельствует об однородности исходных данных (т.к. CV ≤ 0.33).
-
Значение показателя асимметрии skew (As) = -0.1109 свидетельствует о приблизительно симметричном распределении (т.к. |As| ≤ 0.25).
-
Значение показателя эксцесса kurtosis (Es) = -1.3526 свидетельствует о плосковершинном распределении (platykurtic distribution) (т.к. Es < 0).
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Для проверки нормальности распределения использована пользовательская функция norm_distr_check, которая объединяет в себе набор стандартных статистических тестов проверки нормальности. Все тесты относятся к стандартному инструментарию Pyton (библиотека scipy, модуль stats), за исключением теста Эппса-Палли (Epps-Pulley test); о том, как реализовать этот тест средствами Pyton я писал в своей статье https://habr.com/ru/post/685582/.
Примечание: для использования функции norm_distr_check в каталог с ipynb-файлом необходимо поместить папку table c файлом Tep_table.csv, который содержит табличные значения статистики критерия Эппса-Палли.
# пользовательская функция
norm_distr_check(X)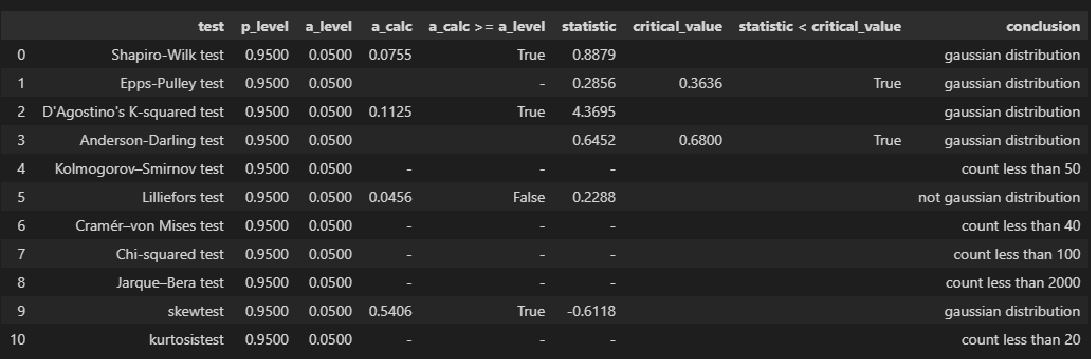
# Пользовательская функция
norm_distr_check (Y)
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения переменных X и Y.
ПРОВЕРКА АНОМАЛЬНЫХ ЗНАЧЕНИЙ (ВЫБРОСОВ)
Статистическую проверку аномальных значений (выбросов) не стоит путать с проверкой выбросов, которая проводится на этапе первичной обработки результатов наблюдений. Последняя проводится с целью отсеять явные ошибочные данные (например, в результате неправильно поставленной запятой величина показателя может увеличиться/уменьшиться на порядок); здесь же мы говорим о статистической проверке данных, которые уже прошли этап первичной обработки.
Имеется довольно много критериев для проверки аномальных значений (подробнее см.[1]); вообще данная процедура довольно неоднозначная:
-
критерии зависят от вида распределения;
-
мало данных о сравнительной мощности этих критериев;
-
даже в случае принятии гипотезы о нормальном распределении в выборке могут быть обнаружены аномальные значения и пр.
Кроме существует дилемма: если какие-то значения в выборке признаны выбросами — стоит или не стоит исследователю исключать их? Ведь каждое значение несет в себе информацию, причем иногда весьма ценную, а сильно отклоняющиеся от основного массива данные (которые не являются выбросами в смысле первичной обработки, но являются статистическим значимыми аномальными значениями) могут кардинально изменить статистический вывод.
В общем, о задаче выявления аномальных значений (выбросов) можно написать отдельно, а пока, в данном разборе, ограничимся проверкой аномальных значений по критерию наибольшего максимального отклонения (см.[1, с.547]) с помощью пользовательской функции detecting_outliers_mad_test. Данные функция возвращает DataFrame, которые включает список аномальных значений со следующими признаками:
-
value — проверяемое значение из выборки;
-
mad_calc и mad_table — расчетное и табличное значение статистики критерия;
-
outlier_conclusion — вывод (выброс или нет).
Обращаю внимание, что критерий наибольшего максимального отклонения можно использовать только для нормально распределенных данных.
# пользовательская функция
print("Проверка наличия выбросов переменной X:n")
result = detecting_outliers_mad_test(X)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])
# пользовательская функция
print("Проверка наличия выбросов переменной Y:n")
result = detecting_outliers_mad_test(Y)
mask = (result['outlier_conclusion'] == 'outlier')
display(result[mask])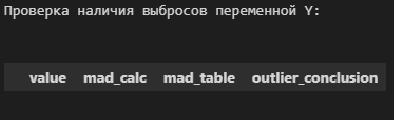
Вывод: в случае обеих переменных X и Y список пуст, следовательно, аномальных значений (выбросов) не выявлено.
КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
Корреляционный анализ — это разведка перед построением регрессионной модели.
Выполним расчет коэффициента линейной корреляции Пирсона, проверку его значимости и построение доверительных интервалов с помощью пользовательской функции corr_coef_check (про эту функцию более подробно написано в моей статье https://habr.com/ru/post/683442/):
# пользовательская функция
display(corr_coef_check(X, Y, scale='Evans'))
Выводы:
-
Значение коэффициента корреляции coef_value = 0.8900 свидетельствует о весьма сильной корреляционной связи (по шкале Эванса).
-
Коэффициент корреляции значим по критерию Стьюдента: t_calc ≥ t_table, a_calc ≤ a_level.
-
Доверительный интервал для коэффициента корреляции: 0.6621 ≤ coef_value ≤ 0.9625.
РЕГРЕССИОННЫЙ АНАЛИЗ
Предварительная визуализация
python позволяет выполнить предварительную визуализацию, например, с помощью функции jointplot библиотеки seaborn:
fig = plt.figure(figsize=(297/INCH, 210/INCH))
axes = sns.jointplot(
x=X, y=Y,
kind='reg',
ci=95)
plt.show()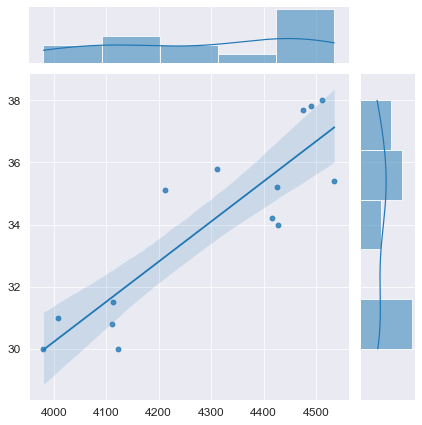
Построение модели
Выполним оценку параметров и анализ простой линейной регрессии (simple linear regression), используя библиотеку statsmodels (https://www.statsmodels.org/) и входящий в нее модуль линейной регрессии Linear Regression (https://www.statsmodels.org/stable/regression.html).
Данный модуль включает в себя классы, реализующие различные методы оценки параметров моделей линейной регрессии, в том числе:
-
класс OLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.OLS.html#statsmodels.regression.linear_model.OLS) — Ordinary Least Squares (обычный метод наименьших квадратов).
-
класс WLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.WLS.html#statsmodels.regression.linear_model.WLS) — Weighted Least Squares (метод взвешенных наименьших квадратов) (https://en.wikipedia.org/wiki/Weighted_least_squares), применяется, если имеет место гетероскедастичность данных (https://ru.wikipedia.org/wiki/Гетероскедастичность).
-
класс GLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLS.html#statsmodels.regression.linear_model.GLS) — Generalized Least Squares (обобщенный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Generalized_least_squares), применяется, если существует определенная степень корреляции между остатками в модели регрессии.
-
класс GLSAR (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.GLSAR.html#statsmodels.regression.linear_model.GLSAR) — Generalized Least Squares with AR covariance structure (обобщенный метод наименьших квадратов, ковариационная структура с автокорреляцией — экспериментальный метод)
-
класс RecurciveLS (https://www.statsmodels.org/stable/examples/notebooks/generated/recursive_ls.html) — Recursive least squares (рекурсивный метод наименьших квадратов) (https://en.wikipedia.org/wiki/Recursive_least_squares_filter)
-
классы RollingOLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingOLS.html#statsmodels.regression.rolling.RollingOLS) и RollingWLS (https://www.statsmodels.org/stable/generated/statsmodels.regression.rolling.RollingWLS.html#statsmodels.regression.rolling.RollingWLS) — скользящая регрессия (https://www.statsmodels.org/stable/examples/notebooks/generated/rolling_ls.html, https://help.fsight.ru/ru/mergedProjects/lib/01_regression_models/rolling_regression.htm)
и т.д.
Так как исходные данные подчиняются нормальному закону распределения и аномальные значения (выбросы) отсутствуют, воспользуемся для оценки параметров обычным методом наименьших квадратов (класс OLS):
model_linear_ols = smf.ols(formula='Y ~ X', data=dataset_df)
result_linear_ols = model_linear_ols.fit()
print(result_linear_ols.summary())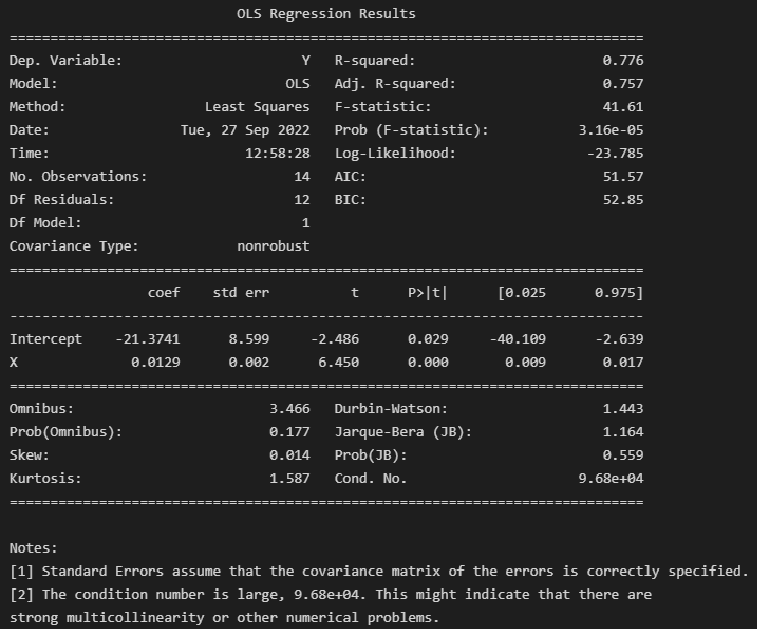
Альтернативная форма выдачи результатов:
print(result_linear_ols.summary2())
Результаты построения модели мы получаем как класс statsmodels.regression.linear_model.RegressionResults (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults).
Экспресс-выводы, которые мы можем сразу сделать из результатов построения модели:
-
Коэффициенты регрессии модели Y = b0 + b1∙X:
-
Intercept = b0 = -21.3741
-
b1 = 0.0129
-
-
Коэффициент детерминации R-squared = 0.776, его скорректированная оценка Adj. R-squared = 0.757 — это означает, что регрессионная модуль объясняет 75.75% вариации переменной Y.
-
Проверка значимости коэффициента детерминации:
-
расчетное значение статистики критерия Фишера: F-statistic = 41.61
-
расчетный уровень значимости Prob (F-statistic) = 3.16e-05
-
так как значение Prob (F-statistic) < 0.05, то нулевая гипотеза R-squared = 0 НЕ ПРИНИМАЕТСЯ, т.е. коэффициент детерминации ЗНАЧИМ
-
-
Проверка значимости коэффициентов регрессии:
-
расчетный уровень значимости P>|t| не превышает 0.05 — это означает, что оба коэффициента регрессии значимы
-
об этом же свидетельствует то, что доверительный интервал для обоих коэффициентов регрессии ([0.025; 0.975]) не включает в себя точку 0
Также в таблице результатов содержится прочая информация по коэффициентам регрессии: стандартная ошибка Std.Err. расчетное значение статистики критерия Стьюдента t для проверки гипотезы о значимости.
-
-
Анализ остатков модели:
-
Тест Omnibus — про этот тест подробно написано в https://en.wikipedia.org/wiki/Omnibus_test, https://medium.com/swlh/interpreting-linear-regression-through-statsmodels-summary-4796d359035a, http://work.thaslwanter.at/Stats/html/statsModels.html.
Расчетное значение статистики критерия Omnibus = 3.466 — по сути расчетное значение F-критерия (см. https://en.wikipedia.org/wiki/Omnibus_test).
Prob(Omnibus) = 0.177 — показывает вероятность нормального распределения остатков (значение 1 указывает на совершенно нормальное распределение).
Учитывая, что в дальнейшем мы проверим нормальность распределения остатков по совокупности различных тестов, в том числе с достаточно высокой мощностью, и все тесты позволят принять гипотезу о нормальном распределении — в данном случае к тесту Omnibus возникают вопросы. С этим тестом нужно разбираться отдельно.
-
Skew = 0.014 и Kurtosis = 1.587 — показатели асимметрии и эксцесса остатков свидетельствуют, что распределение остатков практически симметричное, островершинное.
-
проверка нормальности распределения остатков по критерию Харке-Бера: расчетное значение статистики критерия Jarque-Bera (JB) = 1.164 и расчетный уровень значимости Prob(JB) = 0.559. К данным результатам также возникают вопросы, особенно, если учесть, что критерий Харке-Бера является асимптотическим, расчетное значение имеет распределение хи-квадрат, поэтому данный критерий рекомендуют применять только для больших выборок (см. https://en.wikipedia.org/wiki/Jarque–Bera_test). Проверку нормальности распределения остатков модели лучше проводить с использованием набора стандартных статистических тестов python (см. далее).
-
-
Проверка автокорреляции по критерию Дарбина-Уотсона: Durbin-Watson = 1.443.
Мы не будем здесь разбирать данный критерий, так как явление автокорреляции больше характерно для данных, выражаемых в виде временных рядов. Однако, для грубой оценки считается, что при расчетном значении статистики криетрия Дарбина=Уотсона а интервале [1; 2] автокорреляция отсутствует (см.https://en.wikipedia.org/wiki/Durbin–Watson_statistic).
Более подробно про критерий Дарбина-Уотсона — см. [1, с.659].
Прочая информация, которую можно извлечь из результатов построения модели:
-
Covariance Type — тип ковариации, подробнее см. https://habr.com/ru/post/681218/, https://towardsdatascience.com/simple-explanation-of-statsmodel-linear-regression-model-summary-35961919868b#:~:text=Covariance type is typically nonrobust,with respect to each other.
-
Scale — масштабный коэффициент для ковариационной матрицы (https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.scale.html#statsmodels.regression.linear_model.RegressionResults.scale), равен величине Mean squared error (MSE) (cреднеквадратической ошибке), об подробнее см. далее, в разделе про ошибки аппроксимации моделей.
-
Показатели сравнения качества различных моделей:
-
Log-Likelihood — логарифмическая функция правдоподобия, подробнее см. https://en.wikipedia.org/wiki/Likelihood_function#Log-likelihood, https://habr.com/ru/post/433804/
-
AIC — информационный критерий Акаике (Akaike information criterion), подробнее см. https://en.wikipedia.org/wiki/Akaike_information_criterion
-
BIC — информационный критерий Байеса (Bayesian information criterion), подробнее см. https://en.wikipedia.org/wiki/Bayesian_information_criterion
В данной статье мы эти показатели рассматривать не будем, так как задача выбора одной модели из нескольких перед нами не стоит.
-
-
Число обусловленности Cond. No = 96792 используется для проверки мультиколлинеарности (считается, что мультиколлинеарность есть, если значение Cond. No > 30) (см. http://work.thaslwanter.at/Stats/html/statsModels.html). В нашем случае парной регрессионной модели о мультиколлинеарности речь не идет.
Далее будем извлекать данные из стандартного набора выдачи результатов и анализировать их более подробно. Последующие этапы вовсе не обязательно проводить в полном объеме при решении задач, но здесь мы рассмотрим их подробно.
Параметры и уравнение регрессионной модели
Извлечем параметры полученной модели — как свойство params модели:
print('Параметры модели: n', result_linear_ols.params, type(result_linear_ols.params))
Имея параметры модели, можем формализовать уравнение модели Y = b0 + b1*X:
b0 = result_linear_ols.params['Intercept']
b1 = result_linear_ols.params['X']
Y_calc = lambda x: b0 + b1*xГрафик регрессионной модели
Для построения графиков регрессионных моделей можно воспользоваться стандартными возможностями библиотек statsmodels, seaborn, либо создать пользовательскую функцию — на усмотрение исследователя:
1. Построение графиков регрессионных моделей с использованием библиотеки statsmodels
С помощью функции statsmodels.graphics.plot_fit (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_fit.html#statsmodels.graphics.regressionplots.plot_fit) — отображается график Y and Fitted vs.X (фактические и расчетные значения Y с доверительным интервалом для каждого значения Y):
fig, ax = plt.subplots(figsize=(297/INCH, 210/INCH))
fig = sm.graphics.plot_fit(
result_linear_ols, 'X',
vlines=True, # это параметр отвечает за отображение доверительных интервалов для Y
ax=ax)
ax.set_ylabel(Variable_Name_Y)
ax.set_xlabel(Variable_Name_X)
ax.set_title(Task_Project)
plt.show()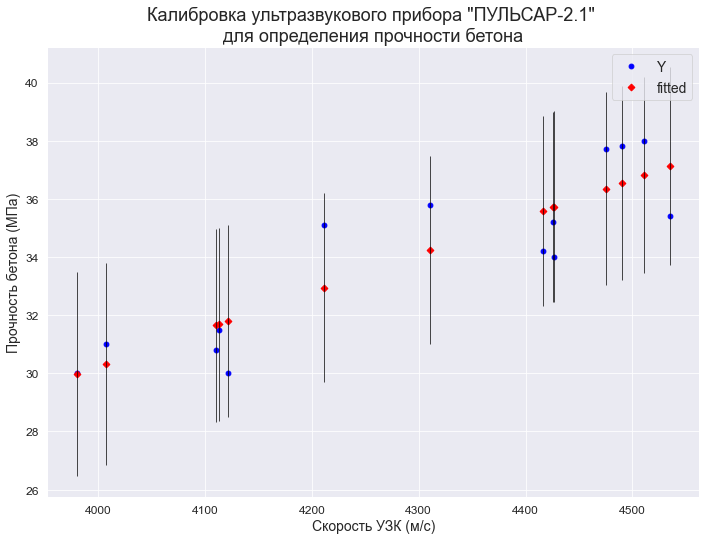
С помощью функции statsmodels.graphics.plot_regress_exog (https://www.statsmodels.org/stable/generated/statsmodels.graphics.regressionplots.plot_regress_exog.html#statsmodels.graphics.regressionplots.plot_regress_exog) — отображается область 2х2, которая содержит:
-
предыдущий график Y and Fitted vs.X;
-
график остатков Residuals versus X;
-
график Partial regression plot — график частичной регрессии, пытается показать эффект добавления другой переменной в модель, которая уже имеет одну или несколько независимых переменных (более подробно см. https://en.wikipedia.org/wiki/Partial_regression_plot);
-
график CCPR Plot (Component-Component plus Residual Plot) — еще один способ оценить влияние одной независимой переменной на переменную отклика, принимая во внимание влияние других независимых переменных (более подробно — см. https://towardsdatascience.com/calculating-price-elasticity-of-demand-statistical-modeling-with-python-6adb2fa7824d, https://www.kirenz.com/post/2021-11-14-linear-regression-diagnostics-in-python/linear-regression-diagnostics-in-python/).
fig = plt.figure(figsize=(297/INCH, 210/INCH))
sm.graphics.plot_regress_exog(result_linear_ols, 'X', fig=fig)
plt.show()
2. Построение графиков регрессионных моделей с использованием библиотеки seaborn
Воспользуемся модулем regplot библиотеки seaborn (https://seaborn.pydata.org/generated/seaborn.regplot.html). Данный модуль позволяет визуализировать различные виды регрессии:
-
линейную
-
полиномиальную
-
логистическую
-
взвешенную локальную регрессию (LOWESS — Locally Weighted Scatterplot Smoothing) (см. http://www.machinelearning.ru/wiki/index.php?title=Алгоритм_LOWESS, https://www.statsmodels.org/stable/generated/statsmodels.nonparametric.smoothers_lowess.lowess.html)
Более подробно про модуль regplot можно прочитать в статье: https://pyprog.pro/sns/sns_8_regression_models.html.
Есть более совершенный модуль lmplot (https://seaborn.pydata.org/generated/seaborn.lmplot.html), который объединяет в себе regplot и FacetGrid, но мы его здесь рассматривать не будем.
# создание рисунка (Figure) и области рисования (Axes)
fig = plt.figure(figsize=(297/INCH, 420/INCH/1.5))
ax1 = plt.subplot(2,1,1)
ax2 = plt.subplot(2,1,2)
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 18)
# заголовок области рисования (Axes)
title_axes_1 = 'Линейная регрессионная модель'
ax1.set_title(title_axes_1, fontsize = 16)
# график регрессионной модели
order_mod = 1 # порядок модели
#label_legend_regr_model = 'фактические данные'
sns.regplot(
#data=dataset_df,
x=X, y=Y,
#x_estimator=np.mean,
order=order_mod,
logistic=False,
lowess=False,
robust=False,
logx=False,
ci=95,
scatter_kws={'s': 30, 'color': 'red'},
line_kws={'color': 'blue'},
#label=label_legend_regr_model,
ax=ax1)
ax1.set_ylabel(Variable_Name_Y)
ax1.legend()
# график остатков
title_axes_2 = 'График остатков'
ax2.set_title(title_axes_2, fontsize = 16)
sns.residplot(
#data=dataset_df,
x=X, y=Y,
order=order_mod,
lowess=False,
robust=False,
scatter_kws={'s': 30, 'color': 'darkorange'},
ax=ax2)
ax2.set_xlabel(Variable_Name_X)
plt.show()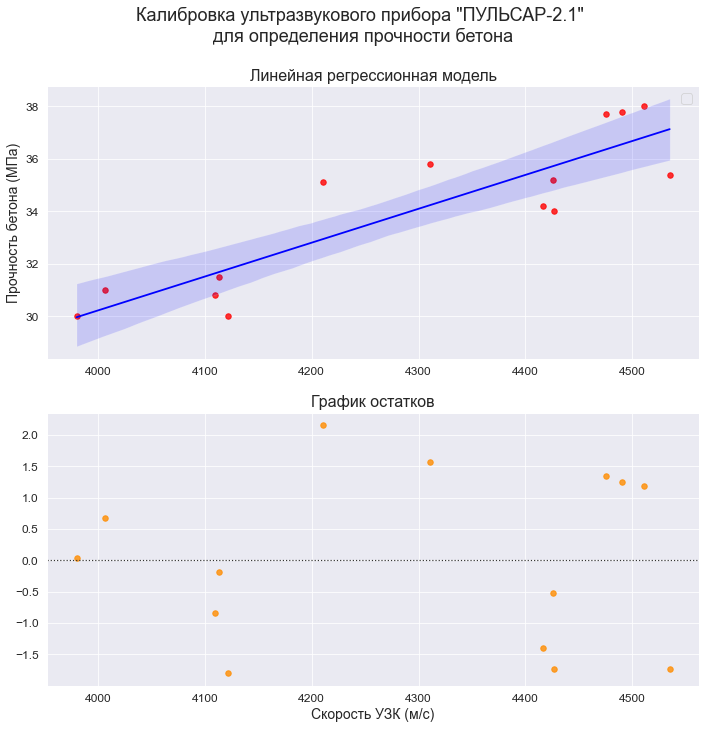
3. Построение графиков регрессионных моделей с помощью пользовательской функции
# Пользовательская функция
graph_regression_plot_sns(
X, Y,
regression_model=Y_calc,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=Ymin_graph, Ymax=Ymax_graph,
title_figure=Task_Project,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=80,
file_name='graph/regression_plot_lin.png')
Статистический анализ регрессионной модели
1. Расчет ошибки аппроксимации (Error Metrics)
Ошибки аппроксимации (Error Metrics) позволяют получить общее представление о качестве модели, а также позволяют сравнивать между собой различные модели.
Создадим пользовательскую функцию, которая рассчитывает основные ошибки аппроксимации для заданной модели:
-
Mean squared error (MSE) или Mean squared deviation (MSD) — среднеквадратическая ошибка (https://en.wikipedia.org/wiki/Mean_squared_error):
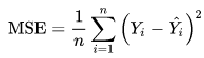
-
Root mean square error (RMSE) или Root mean square deviation (RMSD) — квадратный корень из MSE (https://en.wikipedia.org/wiki/Root-mean-square_deviation):
![]()
-
Mean absolute error (MAE) — средняя абсолютная ошибка (https://en.wikipedia.org/wiki/Mean_absolute_error):

-
Mean squared prediction error (MSPE) — среднеквадратическая ошибка прогноза (среднеквадратическая ошибка в процентах) (https://en.wikipedia.org/wiki/Mean_squared_prediction_error):
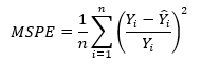
-
Mean absolute percentage error (MAPE) — средняя абсолютная ошибка в процентах (https://en.wikipedia.org/wiki/Mean_absolute_percentage_error):
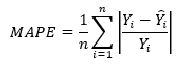
Про выбор метрики см. также https://machinelearningmastery.ru/how-to-select-the-right-evaluation-metric-for-machine-learning-models-part-2-regression-metrics-d4a1a9ba3d74/.
# Пользовательская функция
def regression_error_metrics(model, model_name=''):
model_fit = model.fit()
Ycalc = model_fit.predict()
n_fit = model_fit.nobs
Y = model.endog
MSE = (1/n_fit) * np.sum((Y-Ycalc)**2)
RMSE = sqrt(MSE)
MAE = (1/n_fit) * np.sum(abs(Y-Ycalc))
MSPE = (1/n_fit) * np.sum(((Y-Ycalc)/Y)**2)
MAPE = (1/n_fit) * np.sum(abs((Y-Ycalc)/Y))
model_error_metrics = {
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': MSPE,
'MAPE': MAPE}
result = pd.DataFrame({
'MSE': MSE,
'RMSE': RMSE,
'MAE': MAE,
'MSPE': "{:.3%}".format(MSPE),
'MAPE': "{:.3%}".format(MAPE)},
index=[model_name])
return model_error_metrics, result
(model_error_metrics, result) = regression_error_metrics(model_linear_ols, model_name='linear_ols')
display(result)
В литературе по прикладной статистике нет единого мнения о допустимом размере относительных ошибок аппроксимации: в одних источниках допустимой считается ошибка 5-7%, в других она может быть увеличена до 8-10%, и даже до 15%.
Вывод: модель хорошо аппроксимирует фактические данные (относительная ошибка аппроксимации MAPE = 3.405% < 10%).
2. Дисперсионный анализ регрессионной модели (ДАРМ)
ДАРМ не входит в стандартную форму выдачи результатов Regression Results, однако я решил написать здесь о нем по двум причинам:
-
Именно анализ дисперсии регрессионной модели, разложение этой дисперсии на составляющие дает фундаментальное представление о сути регрессии, а термины, используемые при ДАРМ, применяются на последующих этапах анализа.
-
С терминами ДАРМ в литературе по прикладной статистике имеется некоторая путаница, в разных источниках они могут именоваться по-разному (см., например, [8, с.52]), поэтому, чтобы двигаться дальше, необходимо определиться с понятиями.
При ДАРМ общую вариацию результативного признака (Y) принято разделять на две составляющие — вариация, обусловленная регрессией и вариация, обусловленная отклонениями от регрессии (остаток), при этом в разных источниках эти термины могут именоваться и обозначаться по-разному, например:
-
Вариация, обусловленная регрессией — может называться Explained sum of squares (ESS), Sum of Squared Regression (SSR) (https://en.wikipedia.org/wiki/Explained_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684), Sum of squared deviations (SSD).
-
Вариация, обусловленная отклонениями от регрессии (остаток) — может называться Residual sum of squares (RSS), Sum of squared residuals (SSR), Squared estimate of errors, Sum of Squared Error (SSE) (https://en.wikipedia.org/wiki/Residual_sum_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684); в отчественной практике также применяется термин остаточная дисперсия.
-
Общая (полная) вариация — может называться Total sum of squares (TSS), Sum of Squared Total (SST) (https://en.wikipedia.org/wiki/Partition_of_sums_of_squares, https://towardsdatascience.com/anova-for-regression-fdb49cf5d684).
Как видим, путаница знатная:
-
в разных источниках под SSR могут подразумеваться различные показатели;
-
легко перепутать показатели ESS и SSE;
-
в библиотеке statsmodel также есть смешение терминов: для показателя Explained sum of squares используется свойство ess, а для показателя Sum of squared (whitened) residuals — свойство ssr.
Мы будем пользоваться системой обозначений, принятой в большинстве источников — SSR (Sum of Squared Regression), SSE (Sum of Squared Error), SST (Sum of Squared Total). Стандартная таблица ДАРМ в этом случае имеет вид:

Примечания:
-
Здесь приведена таблица ДАРМ для множественной линейной регрессионной модели (МЛРМ), в нашем случае при ПЛРМ мы имеем частный случай p=1.
-
Показатели Fcalc-ad и Fcalc-det — расчетные значения статистики критерия Фишера при проверке адекватности модели и значимости коэффициента детерминации (об этом — см.далее).
Более подробно про дисперсионный анализ регрессионной модели — см.[4, глава 3].
Класс statsmodels.regression.linear_model.RegressionResults позволяет нам получить данные для ANOVA (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.html#statsmodels.regression.linear_model.RegressionResults) как свойства класса:
-
Сумма квадратов, обусловленная регрессией / SSR (Sum of Squared Regression) — свойство ess.
-
Сумма квадратов, обусловленная отклонением от регрессии / SSE (Sum of Squared Error) — свойство ssr.
-
Общая (полная) сумма квадратов / SST (Sum of Squared Total) — свойство centered_tss.
-
Кол-во наблюдений / Number of observations — свойство nobs.
-
Число степеней свободы модели / Model degrees of freedom — равно числу переменных модели (за исключением константы, если она присутствует — свойство df_model.
-
Среднеквадратичная ошибка модели / Mean squared error the model — сумма квадратов, объясненная регрессией, деленная на число степеней свободы регрессии — свойство mse_model.
-
Среднеквадратичная ошибка остатков / Mean squared error of the residuals — сумма квадратов остатков, деленная на остаточные степени свободы — свойство mse_resid.
-
Общая среднеквадратичная ошибка / Total mean squared error — общая сумма квадратов, деленная на количество наблюдений — свойство mse_total.
Также имеется модуль statsmodels.stats.anova.anova_lm, который позволяет получить результаты ДАРМ (нескольких типов — 1, 2, 3):
# тип 1
print('The type of Anova test: 1')
display(sm.stats.anova_lm(result_linear_ols, typ=1))
# тип 2
print('The type of Anova test: 2')
display(sm.stats.anova_lm(result_linear_ols, typ=2))
# тип 3
print('The type of Anova test: 3')
display(sm.stats.anova_lm(result_linear_ols, typ=3))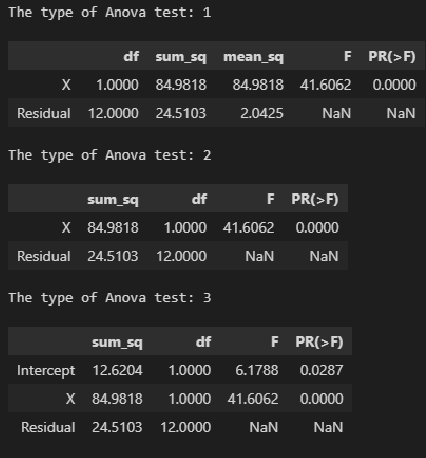
На мой взгляд, форма таблица результатов statsmodels.stats.anova.anova_lm не вполне удобна, поэтому сформируем ее самостоятельно, для чего создадим пользовательскую функцию ANOVA_table_regression_model:
# Пользовательская функция
def ANOVA_table_regression_model(model_fit):
n = int(model_fit.nobs)
p = int(model_fit.df_model)
SSR = model_fit.ess
SSE = model_fit.ssr
SST = model_fit.centered_tss
result = pd.DataFrame({
'sources_of_variation': ('regression (SSR)', 'deviation from regression (SSE)', 'total (SST)'),
'sum_of_squares': (SSR, SSE, SST),
'degrees_of_freedom': (p, n-p-1, n-1)})
result['squared_error'] = result['sum_of_squares'] / result['degrees_of_freedom']
R2 = 1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']
F_calc_adequacy = result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']
F_calc_determ_check = result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']
result['F-ratio'] = (F_calc_determ_check, F_calc_adequacy, '')
return result
result = ANOVA_table_regression_model(result_linear_ols)
display(result)
print(f"R2 = 1 - SSE/SST = {1 - result.loc[1, 'sum_of_squares'] / result.loc[2, 'sum_of_squares']}")
print(f"F_calc_adequacy = MST / MSE = {result.loc[2, 'squared_error'] / result.loc[1, 'squared_error']}")
print(f"F_calc_determ_check = MSR / MSE = {result.loc[0, 'squared_error'] / result.loc[1, 'squared_error']}")
ДАРМ позволяет визуализировать вариацию:
fig, axes = plt.subplots(figsize=(210/INCH, 297/INCH/1.5))
axes.pie(
(result.loc[0, 'sum_of_squares'], result.loc[1, 'sum_of_squares']),
labels=(result.loc[0, 'sources_of_variation'], result.loc[1, 'sources_of_variation']),
autopct='%.1f%%',
startangle=60)
plt.show()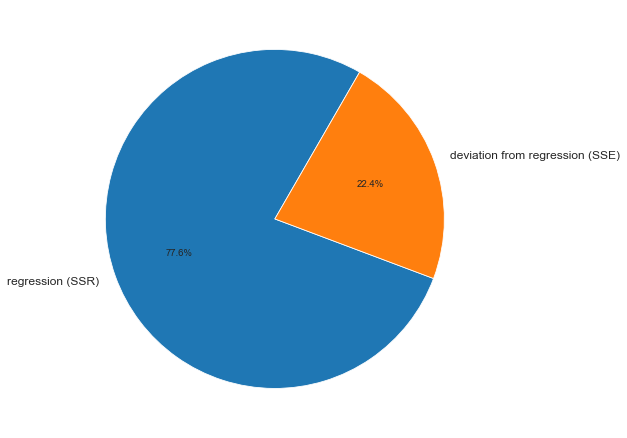
На основании данных ДАРМ мы рассчитали ряд показателей (R2, Fcalc-ad и Fcalc-det), которые будут использоваться в дальнейшем.
3. Анализ остатков (проверка нормальности распределения остатков и гипотезы о равенстве нулю среднего значения остатков)
Проверка нормальности распределения остатков — один их важнейших этапов анализа регрессионной модели. Требование нормальности распределения остатков не требуется для отыскания параметров модели, но необходимо в дальнейшем для проверки статистических гипотез с использованием критериев Фишера и Стьюдента (проверка адекватности модели, значимости коэффициента детерминации, значимости коэффициентов регрессии) и построения доверительных интервалов [5, с.122].
Остатки регрессионной модели:
print('Остатки регрессионной модели:n', result_linear_ols.resid, type(result_linear_ols.resid))
res_Y = np.array(result_linear_ols.resid)statsmodels может выдавать различные преобразованные виды остатков (см. https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.resid_pearson.html, https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.wresid.html).
График остатков:
# Пользовательская функция
graph_scatterplot_sns(
X, res_Y,
Xmin=Xmin_graph, Xmax=Xmax_graph,
Ymin=-3.0, Ymax=3.0,
color='red',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=18,
x_label=Variable_Name_X,
y_label='ΔY = Y - Ycalc',
s=75,
file_name='graph/residuals_plot_sns.png')
Проверка нормальности распределения остатков:
# Пользовательская функция
graph_hist_boxplot_probplot_sns(
data=res_Y,
data_min=-2.5, data_max=2.5,
graph_inclusion='bp',
data_label='ΔY = Y - Ycalc',
#title_figure=Task_Project,
title_axes='Остатки линейной регрессионной модели', title_axes_fontsize=16,
file_name='graph/residuals_hist_boxplot_probplot_sns.png') 
norm_distr_check(res_Y)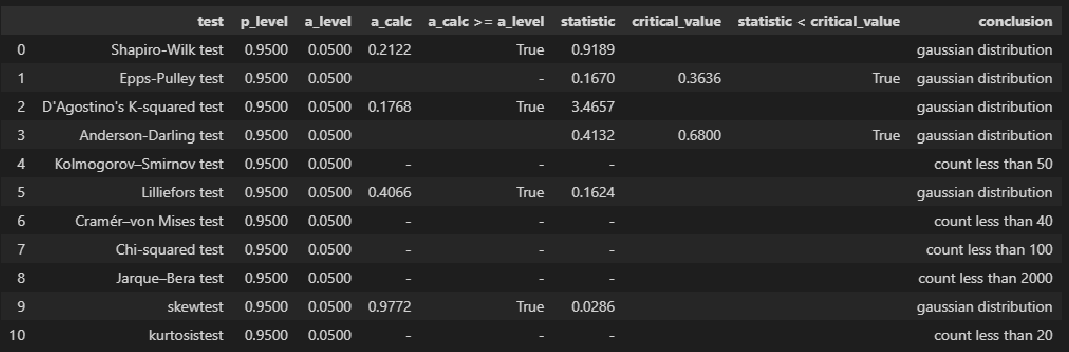
Вывод: большинство статистических тестов позволяют принять гипотезу о нормальности распределения остатков.
Проверка гипотезы о равенстве нулю среднего значения остатков — так как остатки имеют нормальное распределение, воспользуемся критерием Стьюдента (функция scipy.stats.ttest_1samp, https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ttest_ind.html):
sps.ttest_1samp(res_Y, popmean=0)![]()
Вывод: так как расчетный уровень значимости превышает заданный (0.05), то нулевая гипотеза о равенстве нулю остатков ПРИНИМАЕТСЯ.
4. Проверка адекватности модели
Суть проверки адекватности регрессионной модели заключается в сравнении полной дисперсии MST и остаточной дисперсии MSE — проверяется гипотеза о равенстве этих дисперсий по критерию Фишера. Если дисперсии различаются значимо, то модель считается адекватной. Более подробно про проверку адекватности регрессионной — см.[1, с.658], [2, с.49], [4, с.154].
Для проверки адекватности регрессионной модели создадим пользовательскую функцию regression_model_adequacy_check:
def regression_model_adequacy_check(
model_fit,
p_level: float=0.95,
model_name=''):
n = int(model_fit.nobs)
p = int(model_fit.df_model) # Число степеней свободы регрессии, равно числу переменных модели (за исключением константы, если она присутствует)
SST = model_fit.centered_tss # SST (Sum of Squared Total)
dfT = n-1
MST = SST / dfT
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE
F_calc = MST / MSE
F_table = sci.stats.f.ppf(p_level, dfT, dfE, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, dfT, dfE, loc=0, scale=1)
conclusion_model_adequacy_check = 'adequacy' if F_calc >= F_table else 'adequacy'
# формируем результат
result = pd.DataFrame({
'SST': (SST),
'SSE': (SSE),
'dfT': (dfT),
'dfE': (dfE),
'MST': (MST),
'MSE': (MSE),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'adequacy_check': (conclusion_model_adequacy_check),
},
index=[model_name]
)
return result
regression_model_adequacy_check(result_linear_ols, p_level=0.95, model_name='linear_ols')
Вывод: модель является АДЕКВАТНОЙ.
5. Коэффициент детерминации и проверка его значимости
Различают несколько видов коэффициента детерминации:
-
Собственно обычный коэффициент детерминации:

Его значение может быть получено как свойство rsquared модели.
-
Скорректированный (adjusted) коэффициент детерминации — используется для того, чтобы была возможность сравнивать модели с разным числом признаков так, чтобы число регрессоров (признаков) не влияло на статистику R2, при его расчете используются несмещённые оценки дисперсий:

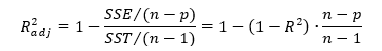
Его значение может быть получено как свойство rsquared_adj модели.
-
Обобщённый (extended) коэффициент детерминации — используется для сравнения моделей регрессии со свободным членом и без него, а также для сравнения между собой регрессий, построенных с помощью различных методов: МНК, обобщённого метода наименьших квадратов (ОМНК), условного метода наименьших квадратов (УМНК), обобщённо-условного метода наименьших квадратов (ОУМНК). В данном разборе ПЛРМ рассматривать этот коэффициент мы не будем.
Более подробно с теорией вопроса можно ознакомиться, например: http://www.machinelearning.ru/wiki/index.php?title=Коэффициент_детерминации), а также в [7].
Значения коэффициента детерминации и скорректированного коэффициента детерминации, извлеченные с помощью свойств rsquared и rsquared_adj модели.
print('R2 =', result_linear_ols.rsquared)
print('R2_adj =', result_linear_ols.rsquared_adj)
Значимость коэффициента детерминации можно проверить по критерию Фишера [3, с.201-203; 8, с.83].
Расчетное значение статистики критерия Фишера может быть получено с помощью свойства fvalue модели:
print(f"result_linear_ols.fvalue = {result_linear_ols.fvalue}")![]()
Расчетный уровень значимости при проверке гипотезы по критерию Фишера может быть получено с помощью свойства f_pvalue модели:
print(f"result_linear_ols.f_pvalue = {result_linear_ols.f_pvalue}")![]()
Можно рассчитать уровень значимости самостоятельно (так сказать, для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Фишера scipy.stats.f, свойством cdf (функция распределения):
df1 = int(result_linear_ols.df_model)
df2 = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
F_calc = result_linear_ols.fvalue
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
print(a_calc)![]()
Как видим, результаты совпадают.
Табличное значение статистики критерия Фишера получить с помощью Regression Results нельзя. Рассчитаем его самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.f, свойством ppf (процентные точки):
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
print(F_table)![]()
Для удобства создадим пользовательскую функцию determination_coef_check для проверки значимости коэффициента детерминации, которая объединяет все вышеперечисленные расчеты:
# Пользовательская функция
def determination_coef_check(
model_fit,
p_level: float=0.95):
a_level = 1 - p_level
R2 = model_fit.rsquared
R2_adj = model_fit.rsquared_adj
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
F_calc = R2 / (1 - R2) * (n-p-1)/p
df1 = int(p)
df2 = int(n-p-1)
F_table = sci.stats.f.ppf(p_level, df1, df2, loc=0, scale=1)
a_calc = 1 - sci.stats.f.cdf(F_calc, df1, df2, loc=0, scale=1)
conclusion_determ_coef_sign = 'significance' if F_calc >= F_table else 'not significance'
# формируем результат
result = pd.DataFrame({
'notation': ('R2'),
'coef_value (R)': (sqrt(R2)),
'coef_value_squared (R2)': (R2),
'p_level': (p_level),
'a_level': (a_level),
'F_calc': (F_calc),
'df1': (df1),
'df2': (df2),
'F_table': (F_table),
'F_calc >= F_table': (F_calc >= F_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_determ_coef_sign),
'conf_int_low': (''),
'conf_int_high': ('')
},
index=['Coef. of determination'])
return result
determination_coef_check(
result_linear_ols,
p_level=0.95)
Вывод: коэффициент детерминации ЗНАЧИМ.
6. Коэффициенты регрессии и проверка их значимости
Ранее мы уже извлекли коэффициенты регрессии как параметры модели b0 и b1 (как свойство params модели). Также можно получить их значения, как свойство bse модели:
print(b0, b1)
print(result_linear_ols.bse, type(result_linear_ols.bse))
Значимость коэффициентов регрессии можно проверить по критерию Стьюдента [3, с.203-212; 8, с.78].
Расчетные значения статистики критерия Стьюдента могут быть получены с помощью свойства tvalues модели:
print(f"result_linear_ols.tvalues = n{result_linear_ols.tvalues}")
Расчетные значения уровня значимости при проверке гипотезы по критерию Стьюдента могут быть получены с помощью свойства pvalues модели:
print(f"result_linear_ols.pvalues = n{result_linear_ols.pvalues}")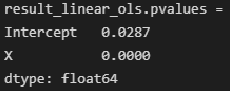
Доверительные интервалы для коэффициентов регрессии могут быть получены с помощью свойства conf_int модели:
print(result_linear_ols.conf_int(), 'n')
Можно рассчитать уровень значимости самостоятельно (как ранее для критерия Фишера — для лучшего понимания и общей демонстрации возможностей) — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством cdf (функция распределения):
t_calc = result_linear_ols.tvalues
df = int(result_linear_ols.nobs - result_linear_ols.df_model - 1)
a_calc = 2*(1-sci.stats.t.cdf(abs(t_calc), df, loc=0, scale=1))
print(a_calc)![]()
Как видим, результаты совпадают.
Табличные значения статистики критерия Стьюдента получить с помощью Regression Results нельзя. Рассчитаем их самостоятельно — для этого воспользуемся библиотекой scipy, модулем распределения Стьюдента scipy.stats.t, свойством ppf (процентные точки):
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
print(t_table)![]()
Для удобства создадим пользовательскую функцию regression_coef_check для проверки значимости коэффициентов регрессии, которая объединяет все вышеперечисленные расчеты:
def regression_coef_check(
model_fit,
notation_coef: list='',
p_level: float=0.95):
a_level = 1 - p_level
# параметры модели (коэффициенты регрессии)
model_params = model_fit.params
# стандартные ошибки коэффициентов регрессии
model_bse = model_fit.bse
# проверка гипотезы о значимости регрессии
t_calc = abs(model_params) / model_bse
n = model_fit.nobs # объем выборки
p = model_fit.df_model # Model degrees of freedom. The number of regressors p. Does not include the constant if one is present.
df = int(n - p - 1)
t_table = sci.stats.t.ppf((1 + p_level)/2 , df)
a_calc = 2*(1-sci.stats.t.cdf(t_calc, df, loc=0, scale=1))
conclusion_ = ['significance' if elem else 'not significance' for elem in (t_calc >= t_table).values]
# доверительный интервал коэффициента регрессии
conf_int_low = model_params - t_table*model_bse
conf_int_high = model_params + t_table*model_bse
# формируем результат
result = pd.DataFrame({
'notation': (notation_coef),
'coef_value': (model_params),
'std_err': (model_bse),
'p_level': (p_level),
'a_level': (a_level),
't_calc': (t_calc),
'df': (df),
't_table': (t_table),
't_calc >= t_table': (t_calc >= t_table),
'a_calc': (a_calc),
'a_calc <= a_level': (a_calc <= a_level),
'significance_check': (conclusion_),
'conf_int_low': (conf_int_low),
'conf_int_high': (conf_int_high),
})
return result
regression_coef_check(
result_linear_ols,
notation_coef=['b0', 'b1'],
p_level=0.95)
Вывод: коэффициенты регрессии b0 и b1 ЗНАЧИМЫ.
7. Проверка гетероскедастичности
Для проверка гетероскедастичности statsmodels предлагает нам следующие инструменты:
-
тест Голдфелда-Квандта (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_goldfeldquandt.html#statsmodels.stats.diagnostic.het_goldfeldquandt) — теорию см. [8, с.178], также https://ru.wikipedia.org/wiki/Тест_Голдфелда_—_Куандта.
-
тест Бриша-Пэгана (Breush-Pagan test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_breuschpagan.html#statsmodels.stats.diagnostic.het_breuschpagan) — теорию см.[8, с.179], также https://en.wikipedia.org/wiki/Breusch–Pagan_test.
-
тест Уайта (White test) (https://www.statsmodels.org/stable/generated/statsmodels.stats.diagnostic.het_white.html#statsmodels.stats.diagnostic.het_white) — теорию см.[8, с.177], а также https://ru.wikipedia.org/wiki/Тест_Уайта.
Тест Голдфелда-Квандта (Goldfeld–Quandt test)
# тест Голдфелда-Квандта (Goldfeld–Quandt test)
test = sms.het_goldfeldquandt(result_linear_ols.resid, result_linear_ols.model.exog)
test_result = lzip(['F_calc', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_calc = F_calc_tuple[1]
print(f"Расчетное значение статистики F-критерия: F_calc = {round(F_calc, DecPlace)}")
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
print(f"Расчетное значение доверительной вероятности: p_calc = {round(p_calc, DecPlace)}")
#a_calc = 1 - p_value
#print(f"Расчетное значение уровня значимости: a_calc = 1 - p_value = {round(a_calc, DecPlace)}")
# вывод
if p_calc < a_level:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} < a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются значимо, т.е. гипотеза о наличии гетероскедастичности ПРИНИМАЕТСЯ"
else:
conclusion_GQ_test = f"Так как p_calc = {round(p_calc, DecPlace)} >= a_level = {round(a_level, DecPlace)}" +
", то дисперсии в подвыборках отличаются незначимо, т.е. гипотеза о наличии гетероскедастичности ОТВЕРГАЕТСЯ"
print(conclusion_GQ_test)
Для удобства создадим пользовательскую функцию Goldfeld_Quandt_test:
def Goldfeld_Quandt_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_goldfeldquandt(model_fit.resid, model_fit.model.exog)
test_result = lzip(['F_statistic', 'p_calc'], test) # распаковка результатов теста
# расчетное значение статистики F-критерия
F_calc_tuple = test_result[0]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости
p_calc_tuple = test_result[1]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Goldfeld–Quandt test'),
'p_level': (p_level),
'a_level': (a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Бриша-Пэгана (Breush-Pagan test)
# тест Бриша-Пэгана (Breush-Pagan test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_breuschpagan(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)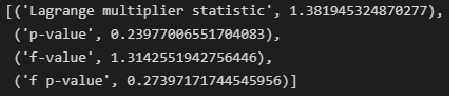
Для удобства создадим пользовательскую функцию Breush_Pagan_test:
def Breush_Pagan_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_breuschpagan(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('Breush-Pagan test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Тест Уайта (White test)
# тест Уайта (White test)
name = ["Lagrange multiplier statistic", "p-value", "f-value", "f p-value"]
test = sms.het_white(result_linear_ols.resid, result_linear_ols.model.exog)
lzip(name, test)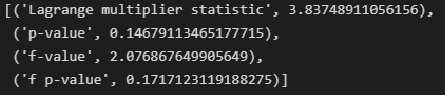
Для удобства создадим пользовательскую функцию White_test:
def White_test(
model_fit,
p_level: float=0.95,
model_name=''):
a_level = 1 - p_level
# реализация теста
test = sms.het_white(model_fit.resid, model_fit.model.exog)
name = ['Lagrange_multiplier_statistic', 'p_calc_LM', 'F_statistic', 'p_calc']
test_result = lzip(name, test) # распаковка результатов теста
# расчетное значение статистики теста множителей Лагранжа
LM_calc_tuple = test_result[0]
Lagrange_multiplier_statistic = LM_calc_tuple[1]
# расчетный уровень значимости статистики теста множителей Лагранжа
p_calc_LM_tuple = test_result[1]
p_calc_LM = p_calc_LM_tuple[1]
# расчетное значение F-статистики гипотезы о том, что дисперсия ошибки не зависит от x
F_calc_tuple = test_result[2]
F_statistic = F_calc_tuple[1]
# расчетный уровень значимости F-статистики
p_calc_tuple = test_result[3]
p_calc = p_calc_tuple[1]
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
# вывод
conclusion_test = 'heteroscedasticity' if p_calc < a_level else 'not heteroscedasticity'
result = pd.DataFrame({
'test': ('White test'),
'p_level': (p_level),
'a_level': (a_level),
'Lagrange_multiplier_statistic': (Lagrange_multiplier_statistic),
'p_calc_LM': (p_calc_LM),
'p_calc_LM < a_level': (p_calc_LM < a_level),
'F_statistic': (F_statistic),
'p_calc': (p_calc),
'p_calc < a_level': (p_calc < a_level),
'heteroscedasticity_check': (conclusion_test)
},
index=[model_name])
return result
White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Объединим результаты всех тестов гетероскедастичность в один DataFrame:
Goldfeld_Quandt_test_df = Goldfeld_Quandt_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
Breush_Pagan_test_df = Breush_Pagan_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
White_test_df = White_test(result_linear_ols, p_level=0.95, model_name='linear_ols')
heteroscedasticity_tests_df = pd.concat([Breush_Pagan_test_df, White_test_df, Goldfeld_Quandt_test_df])
display(heteroscedasticity_tests_df)
Выводы
Итак, мы провели статистический анализ регрессионной модели и установили:
-
исходные данные имеют нормальное распределение;
-
между переменными имеется весьма сильная корреляционная связь;
-
регрессионная модель хорошо аппроксимирует фактические данные;
-
остатки модели имеют нормальное распределение;
-
регрессионная модель адекватна по критерию Фишера;
-
коэффициент детерминации значим по критеию Фишера;
-
коэффициенты регрессии значимы по критерию Стьюдента;
-
гетероскедастичность отсутствует.
Применительно к рассматриваемой задаче выполнять проверку автокорреляции не имеет особого смысла из-за особенностей исходных данных (результаты замеров прочности бетона на разных участках здания).
Про статистический анализ регрессионных моделей с помощью statsmodels— см. еще https://www.statsmodels.org/stable/examples/notebooks/generated/regression_diagnostics.html.
Доверительные интервалы регрессионной модели
Для регрессионных моделей определяют доверительные интервалы двух видов [3, с.184-192; 4, с.172; 8, с.205-209]:
-
Доверительный интервал средних значений переменной Y.
-
Доверительный интервал индивидуальных значений переменной Y.
При этом размер доверительного интервала для индивидуальных значений больше, чем для средних значений.
Доверительные интервалы регрессионных моделей (ДИРМ) могут быть найдены разными способами:
-
непосредственно путем расчетов по формулам (см., например, https://habr.com/ru/post/558158/);
-
с использованием инструментария библиотеки statsmodels (см., например, https://www.stackfinder.ru/questions/17559408/confidence-and-prediction-intervals-with-statsmodels).
Разбререм более подробно способ с использованием библиотеки statsmodels. Прежде всего, с помощью свойства summary_table класса statsmodels.stats.outliers_influence.OLSInfluence (https://www.statsmodels.org/stable/generated/statsmodels.stats.outliers_influence.OLSInfluence.html?highlight=olsinfluence) мы можем получить таблицу данных, содержащую необходимую нам информацию:
-
Dep Var Population — фактические значения переменной Y;
-
Predicted Value — предсказанные значения переменной Y по по регрессионной модели;
-
Std Error Mean Predict — среднеквадратическая ошибка предсказанного среднего;
-
Mean ci 95% low и Mean ci 95% upp — границы доверительного интервала средних значений переменной Y;
-
Predict ci 95% low и Predict ci 95% upp — границы доверительного интервала индивидуальных значений переменной Y;
-
Residual — остатки регрессионной модели;
-
Std Error Residual — среднеквадратическая ошибка остатков;
-
Student Residual — стьюдентизированные остатки (подробнее см. http://statistica.ru/glossary/general/studentizirovannie-ostatki/);
-
Cook’s D — Расстояние Кука (Cook’s distance) — оценивает эффект от удаления одного (рассматриваемого) наблюдения; наблюдение считается выбросом, если Di > 4/n (более подробно — см.https://translated.turbopages.org/proxy_u/en-ru.ru.f584ceb5-63296427-aded8f31-74722d776562/https/en.wikipedia.org/wiki/Cook’s_distance, http://www.machinelearning.ru/wiki/index.php?title=Расстояние_Кука).
from statsmodels.stats.outliers_influence import summary_table
st, data, ss2 = summary_table(result_linear_ols, alpha=0.05)
print(st, 'n', type(st))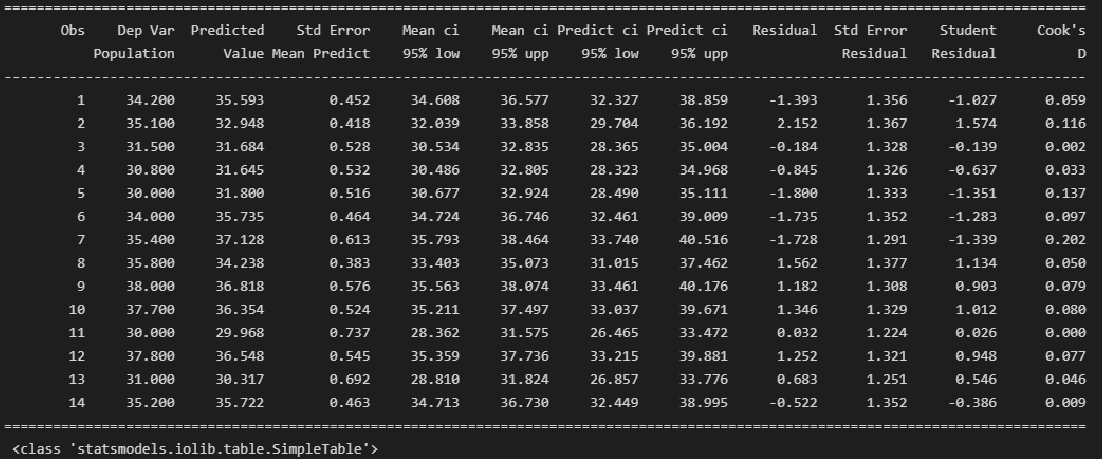
В нашем случае критическое значение расстояния Кука равно:
print(f'D_crit = 4/n = {4/result_linear_ols.nobs}')![]()
то есть выбросов, смещающих оценки коэффициентов регрессии, не наблюдается.
Мы получили данные как класс statsmodels.iolib.table.SimpleTable. Свойство data преобразует данные в список. Далее для удобства работы преобразуем данные в DataFrame:
st_data_df = pd.DataFrame(st.data)Будем использовать данный DataFrame в дальнейшем, несколько преобразуем его:
-
изменим наименование столбцов (с цифр на названия показателей из таблицы summary_table)
-
удалим строки с текстовыми значениями
-
изменим индекс
-
добавим новый столбец — значения переменной X
-
отсортируем по возрастанию значений переменной X (это необходимо, чтобы графики границ доверительных интервалов выглядели как линии)
st_df = st_data_df.copy()
# изменим наименования столбцов
str = st_df.iloc[0,0:] + ' ' + st_df.iloc[1,0:]
st_df = st_df.rename(str, axis='columns')
# удалим строки 0, 1
st_df = st_df.drop([0,1])
# изменим индекс
st_df = st_df.set_index(np.arange(0, result_linear_ols.nobs))
# добавим новый столбец - значения переменной X
st_df.insert(1, 'X', X)
# отсортируем по возрастанию значений переменной X
st_df = st_df.sort_values(by='X')
display(st_df)
С помощью полученных данных мы можем построить график регрессионной модели с доверительными интервалами:
# создание рисунка (Figure) и области рисования (Axes)
fig, axes = plt.subplots(figsize=(297/INCH, 210/INCH))
# заголовок рисунка (Figure)
title_figure = Task_Project
fig.suptitle(title_figure, fontsize = 16)
# заголовок области рисования (Axes)
title_axes = 'Линейная регрессионная модель'
axes.set_title(title_axes, fontsize = 14)
# фактические данные
sns.scatterplot(
x=st_df['X'], y=st_df['Dep Var Population'],
label='фактические данные',
s=50,
color='red',
ax=axes)
# график регрессионной модели
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X'
sns.lineplot(
x=st_df['X'], y=st_df['Predicted Value'],
label=label_legend_regr_model,
color='blue',
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = st_df['Mean ci 95% low']
plt.plot(
st_df['X'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = st_df['Mean ci 95% upp']
plt.plot(
st_df['X'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = st_df['Predict ci 95% low']
plt.plot(
st_df['X'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = st_df['Predict ci 95% upp']
plt.plot(
st_df['X'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlabel(Variable_Name_X)
axes.set_ylabel(Variable_Name_Y)
axes.legend(prop={'size': 12})
plt.show()
Однако, мы получили данные о границах доверительных интервалов регрессионной модели только в пределах области фактических значений переменной X. Как быть, если мы хотим распространить прогноз за пределы этой области?
Прогнозирование
Под прогнозированием мы в данном случае будем понимать определение значений переменной Y и доверительных интервалов для ее средних и индивидуальных значений при заданном X. По сути, нам предстоит построить аналог рассмотренной выше таблицы summary_table, только с другими значениями X, причем эти значения могут выходить за пределы тех значений, которые использовались нами для построения регрессии.
Методика расчета доверительных интервалов регрессионных моделей разобрана в статье «Python, корреляция и регрессия: часть 4» (https://habr.com/ru/post/558158/), всем рекомендую ознакомиться.
Найти прогнозные значения Y не представляет труда, так как ранее мы уже формализовали модель в виде лямбда-функции, а вот для построения доверительных интервалов придется выполнить расчеты по формулам. Для этого создадим пользовательскую функцию regression_pair_predict, которая в случае парной регрессии (pair regression) для заданного значения X возвращает:
-
прогнозируемое по регрессионной модели значение y_calc
-
доверительный интервал [y_calc_mean_ci_low, y_calc_mean_ci_upp] средних значений переменной Y
-
доверительный интервал [y_calc_predict_ci_low, y_calc_predict_ci_upp] индивидуальных значений переменной Y
Алгоритм расчета доверительных интервалов для множественной регрессии (multiple regression) отличается и в данном обзоре не рассматривается (рассмотрим в дальнейшем).
Про прогнозирование с помощью регрессионных моделей — см.также:
-
https://www.statsmodels.org/stable/generated/statsmodels.regression.linear_model.RegressionResults.predict.html?highlight=predict#statsmodels.regression.linear_model.RegressionResults.predict
-
How to Make Predictions Using Regression Model in Statsmodels
-
https://www.statsmodels.org/stable/examples/notebooks/generated/predict.html
def regression_pair_predict(
x_in,
model_fit,
regression_model,
p_level: float=0.95):
a_level = 1 - p_level
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
# вспомогательные величины
n = int(result_linear_ols.nobs)
SSE = model_fit.ssr # SSE (Sum of Squared Error)
dfE = n - p - 1
MSE = SSE / dfE # остаточная дисперсия
Xmean = np.mean(X)
SST_X = np.sum([(X[i] - Xmean)**2 for i in range(0, n)])
t_table = sci.stats.t.ppf((1 + p_level)/2 , dfE)
S2_y_calc_mean = MSE * (1/n + (x_in - Xmean)**2 / SST_X)
S2_y_calc_predict = MSE * (1 + 1/n + (x_in - Xmean)**2 / SST_X)
# прогнозируемое значение переменной Y
y_calc=regression_model(x_in)
# доверительный интервал средних значений переменной Y
y_calc_mean_ci_low = y_calc - t_table*sqrt(S2_y_calc_mean)
y_calc_mean_ci_upp = y_calc + t_table*sqrt(S2_y_calc_mean)
# доверительный интервал индивидуальных значений переменной Y
y_calc_predict_ci_low = y_calc - t_table*sqrt(S2_y_calc_predict)
y_calc_predict_ci_upp = y_calc + t_table*sqrt(S2_y_calc_predict)
result = y_calc, y_calc_mean_ci_low, y_calc_mean_ci_upp, y_calc_predict_ci_low, y_calc_predict_ci_upp
return resultСравним результаты расчета доверительных интервалов разными способами — с использованием функции regression_pair_predict и средствами statsmodels, для этого сформируем DaraFrame с новыми данными:
regression_pair_predict_df = pd.DataFrame(
[regression_pair_predict(elem, result_linear_ols, regression_model=Y_calc) for elem in st_df['X'].values],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
regression_pair_predict_df.insert(0, 'X', st_df['X'].values)
display(regression_pair_predict_df)
Видим, что результаты расчетов идентичны, следовательно мы можем использовать функцию regression_pair_predict для прогнозирования.
def graph_regression_pair_predict_plot_sns(
model_fit,
regression_model_in,
Xmin=None, Xmax=None, Nx=10,
Ymin_graph=None, Ymax_graph=None,
title_figure=None, title_figure_fontsize=18,
title_axes=None, title_axes_fontsize=16,
x_label=None,
y_label=None,
label_fontsize=14, tick_fontsize=12,
label_legend_regr_model='', label_legend_fontsize=12,
s=50, linewidth_regr_model=2,
graph_size=(297/INCH, 210/INCH),
result_output=True,
file_name=None):
# фактические данные
X = pd.DataFrame(model_fit.model.exog)[1].values # найти лучшее решение
Y = model_fit.model.endog
X = np.array(X)
Y = np.array(Y)
# границы
if not(Xmin) and not(Xmax):
Xmin=min(X)
Xmax=max(X)
Xmin_graph=min(X)*0.99
Xmax_graph=max(X)*1.01
else:
Xmin_graph=Xmin
Xmax_graph=Xmax
if not(Ymin_graph) and not(Ymax_graph):
Ymin_graph=min(Y)*0.99
Ymax_graph=max(Y)*1.01
# формируем DataFrame данных
Xcalc = np.linspace(Xmin, Xmax, num=Nx)
Ycalc = regression_model_in(Xcalc)
result_df = pd.DataFrame(
[regression_pair_predict(elem, model_fit, regression_model=regression_model_in) for elem in Xcalc],
columns=['y_calc', 'y_calc_mean_ci_low', 'y_calc_mean_ci_upp', 'y_calc_predict_ci_low', 'y_calc_predict_ci_upp'])
result_df.insert(0, 'x_calc', Xcalc)
# заголовки графика
fig, axes = plt.subplots(figsize=graph_size)
fig.suptitle(title_figure, fontsize = title_figure_fontsize)
axes.set_title(title_axes, fontsize = title_axes_fontsize)
# фактические данные
sns.scatterplot(
x=X, y=Y,
label='фактические данные',
s=s,
color='red',
ax=axes)
# график регрессионной модели
sns.lineplot(
x=Xcalc, y=Ycalc,
color='blue',
linewidth=linewidth_regr_model,
legend=True,
label=label_legend_regr_model,
ax=axes)
# доверительный интервал средних значений переменной Y
Mean_ci_low = result_df['y_calc_mean_ci_low']
plt.plot(
result_df['x_calc'], Mean_ci_low,
color='magenta', linestyle='--', linewidth=1,
label='доверительный интервал средних значений Y')
Mean_ci_upp = result_df['y_calc_mean_ci_upp']
plt.plot(
result_df['x_calc'], Mean_ci_upp,
color='magenta', linestyle='--', linewidth=1)
# доверительный интервал индивидуальных значений переменной Y
Predict_ci_low = result_df['y_calc_predict_ci_low']
plt.plot(
result_df['x_calc'], Predict_ci_low,
color='orange', linestyle='-.', linewidth=2,
label='доверительный интервал индивидуальных значений Y')
Predict_ci_upp = result_df['y_calc_predict_ci_upp']
plt.plot(
result_df['x_calc'], Predict_ci_upp,
color='orange', linestyle='-.', linewidth=2)
axes.set_xlim(Xmin_graph, Xmax_graph)
axes.set_ylim(Ymin_graph, Ymax_graph)
axes.set_xlabel(x_label, fontsize = label_fontsize)
axes.set_ylabel(y_label, fontsize = label_fontsize)
axes.tick_params(labelsize = tick_fontsize)
#axes.tick_params(labelsize = tick_fontsize)
axes.legend(prop={'size': label_legend_fontsize})
plt.show()
if file_name:
fig.savefig(file_name, orientation = "portrait", dpi = 300)
if result_output:
return result_df
else:
return
graph_regression_pair_predict_plot_sns(
model_fit=result_linear_ols,
regression_model_in=Y_calc,
Xmin=Xmin_graph-300, Xmax=Xmax_graph+200, Nx=25,
Ymin_graph=Ymin_graph-5, Ymax_graph=Ymax_graph+5,
title_figure=Task_Project, title_figure_fontsize=16,
title_axes='Линейная регрессионная модель', title_axes_fontsize=14,
x_label=Variable_Name_X,
y_label=Variable_Name_Y,
label_legend_regr_model=f'линейная регрессия Y = {b0:.3f} + {b1:.4f}*X',
s=50,
result_output=True,
file_name='graph/regression_plot_lin.png')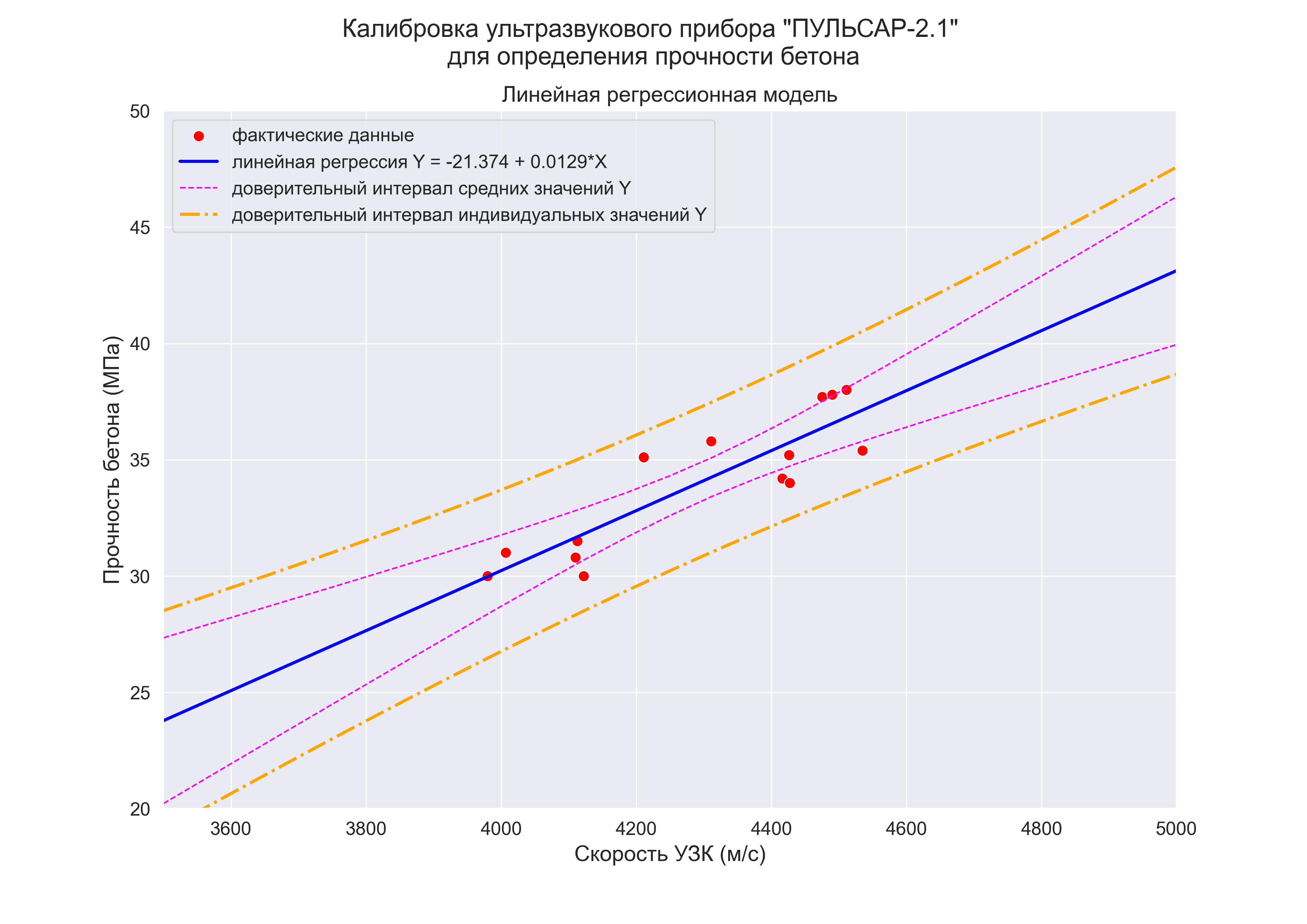
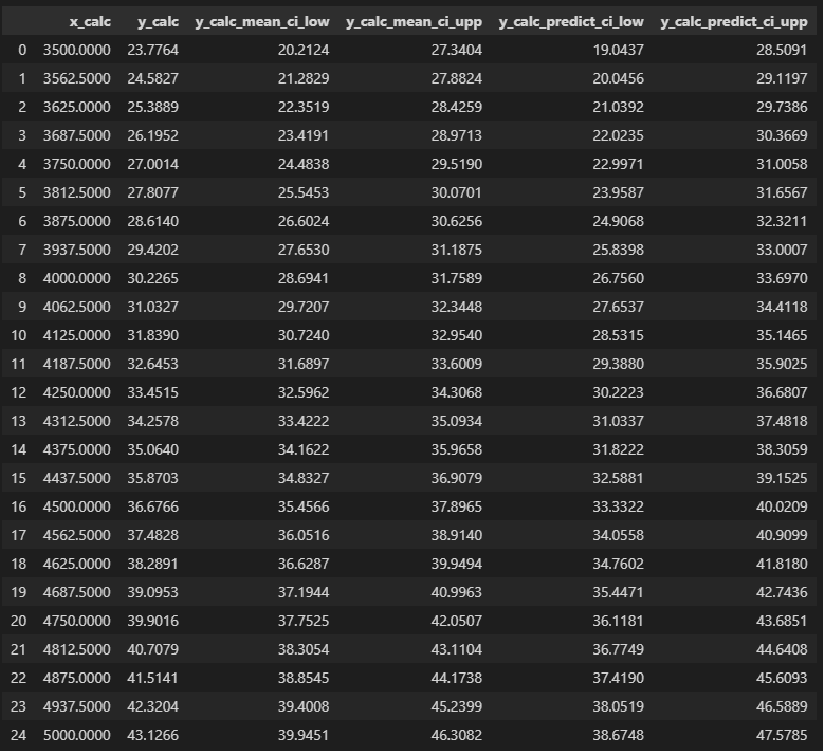
Выводы и рекомендации
Исследована зависимость показаний ультразвукового прибора «ПУЛЬСАР-2.1» (X) и результатов замера прочности бетона (методом отрыва со скалыванием) склерометром ИПС-МГ4.03 (Y).
Между переменными имеется весьма сильная линейная корреляционная связь. Получена регрессионная модель:
Y = b0 + b1∙X = -21.3741 + 0.0129∙X
Модель хорошо аппроксимирует фактические данные, является адекватной, значимой и может использоваться для предсказания прочности бетона.
Также построен график прогноза с доверительными интервалами.
ИТОГИ
Итак, мы рассмотрели все этапы регрессионного анализа в случае простой линейной регрессии (simple linear regression) с использованием библиотеки statsmodels на конкретном практическом примере; подробно остановились на статистическом анализа модели с проверкой гипотез; также предложен ряд пользовательских функций, облегчающих работу исследователя и уменьшающих размер программного кода.
Конечно, мы разобрали далеко не все вопросы анализа регрессионных моделей и возможности библиотеки statsmodels применительно к simple linear regression, в частности статистики влияния (Influence Statistics), инструмент Leverage, анализ стьюдентизированных остатков и пр. — это темы для отдельных обзоров.
Исходный код находится в моем репозитории на GitHub.
Надеюсь, данный обзор поможет специалистам DataScience в работе.
Полное руководство: как сообщать о результатах регрессии
17 авг. 2022 г.
читать 2 мин
В статистике модели линейной регрессии используются для количественной оценки взаимосвязи между одной или несколькими переменными-предикторами и переменной отклика .
Мы можем использовать следующий общий формат для отчета о результатах простой модели линейной регрессии :
Простая линейная регрессия использовалась для проверки того, достоверно ли предсказала [переменная-предиктор] [переменная-ответ].
Подобранная регрессионная модель была: [подобранное уравнение регрессии]
Общая регрессия была статистически значимой (R 2 = [значение R 2 ], F (регрессия df, остаток df) = [значение F], p = [значение p]).
Было обнаружено, что [переменная-предиктор] достоверно предсказала [переменную ответа] (β = [β-значение], p = [p-значение]).
И мы можем использовать следующий формат для отчета о результатах модели множественной линейной регрессии :
Множественная линейная регрессия использовалась для проверки того, действительно ли [переменная-предиктор 1], [переменная-предиктор 2]… значительно предсказала [переменную ответа].
Подобранная регрессионная модель была: [подобранное уравнение регрессии]
Общая регрессия была статистически значимой (R 2 = [значение R 2 ], F (регрессия df, остаток df) = [значение F], p = [значение p]).
Было обнаружено, что [предикторная переменная 1] значительно предсказала [переменную ответа] (β = [β-значение], p = [p-значение]).
Было обнаружено, что [предикторная переменная 2] значимо не предсказывала [переменная ответа] (β = [β-значение], p = [p-значение]).
В следующих примерах показано, как сообщать результаты регрессии как для простой модели линейной регрессии, так и для модели множественной линейной регрессии.
Пример: отчет о результатах простой линейной регрессии
Предположим, профессор хотел бы использовать количество часов обучения, чтобы предсказать экзаменационный балл, который студенты получат на определенном экзамене. Он собирает данные для 20 студентов и использует простую модель линейной регрессии.
На следующем снимке экрана показаны выходные данные регрессионной модели:
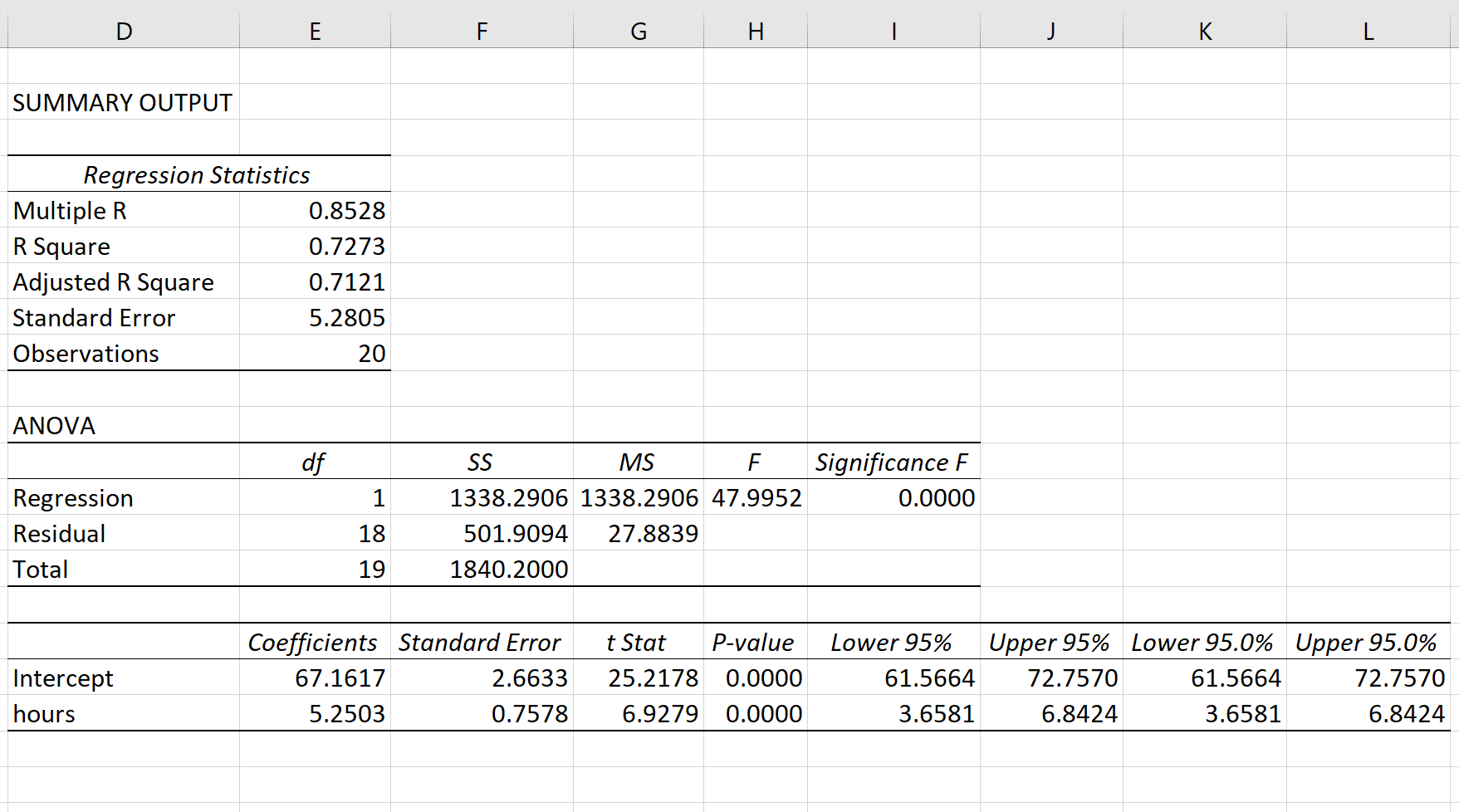
Вот как сообщить о результатах модели:
Простая линейная регрессия использовалась для проверки того, насколько количество часов обучения значительно предсказывало результат на экзамене.
Подобранная регрессионная модель была следующей: Экзаменационный балл = 67,1617 + 5,2503*(изучаемые часы).
Общая регрессия была статистически значимой (R 2 = 0,73, F (1, 18) = 47,99, p < 0,000).
Было обнаружено, что количество часов обучения значительно предсказывает оценку экзамена (β = 5,2503, p < 0,000).
Пример: отчет о результатах множественной линейной регрессии
Предположим, профессор хотел бы использовать количество часов обучения и количество сданных подготовительных экзаменов, чтобы предсказать экзаменационный балл, который студенты получат на определенном экзамене. Он собирает данные по 20 учащимся и использует модель множественной линейной регрессии.
На следующем снимке экрана показаны выходные данные регрессионной модели:
Вот как сообщить о результатах модели:
Множественная линейная регрессия использовалась для проверки того, насколько количество часов обучения и сданные подготовительные экзамены предсказывают результаты экзамена.
Подобранная регрессионная модель была следующей: Экзаменационный балл = 67,67 + 5,56*(часы обучения) – 0,60*(пройденные подготовительные экзамены)
Общая регрессия была статистически значимой (R 2 = 0,73, F(2, 17) = 23,46, p = <0,000).
Было обнаружено, что количество часов обучения значительно предсказывало результат экзамена (β = 5,56, p = <0,000).
Было обнаружено, что сданные подготовительные экзамены не в значительной степени предсказывали экзаменационную оценку (β = -0,60, p = 0,52).
Дополнительные ресурсы
Как читать и интерпретировать таблицу регрессии
Понимание нулевой гипотезы для линейной регрессии
Понимание F-теста общей значимости в регрессии
Написано
![]()
Замечательно! Вы успешно подписались.
Добро пожаловать обратно! Вы успешно вошли
Вы успешно подписались на кодкамп.
Срок действия вашей ссылки истек.
Ура! Проверьте свою электронную почту на наличие волшебной ссылки для входа.
Успех! Ваша платежная информация обновлена.
Ваша платежная информация не была обновлена.
Содержание:
Регрессионный анализ:
Регрессионным анализом называется раздел математической статистики, объединяющий практические методы исследования корреляционной зависимости между случайными величинами по результатам наблюдений над ними. Сюда включаются методы выбора модели изучаемой зависимости и оценки ее параметров, методы проверки статистических гипотез о зависимости.
Пусть между случайными величинами X и Y существует линейная корреляционная зависимость. Это означает, что математическое ожидание Y линейно зависит от значений случайной величины X. График этой зависимости (линия регрессии Y на X) имеет уравнение 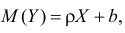
Линейная модель пригодна в качестве первого приближения и в случае нелинейной корреляции, если рассматривать небольшие интервалы возможных значений случайных величин.
Пусть параметры линии регрессии 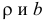 неизвестны, неизвестна и величина коэффициента корреляции
неизвестны, неизвестна и величина коэффициента корреляции 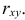 Над случайными величинами X и Y проделано n независимых наблюдений, в результате которых получены n пар значений:
Над случайными величинами X и Y проделано n независимых наблюдений, в результате которых получены n пар значений: 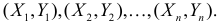 Эти результаты могут служить источником информации о неизвестных значениях
Эти результаты могут служить источником информации о неизвестных значениях 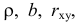 надо только уметь эту информацию извлечь оттуда.
надо только уметь эту информацию извлечь оттуда.
Неизвестная нам линия регрессии 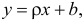 как и всякая линия регрессии, имеет то отличительное свойство, что средний квадрат отклонений значений Y от нее минимален. Поэтому в качестве оценок для можно принять те их значения, при которых имеет минимум функция
как и всякая линия регрессии, имеет то отличительное свойство, что средний квадрат отклонений значений Y от нее минимален. Поэтому в качестве оценок для можно принять те их значения, при которых имеет минимум функция 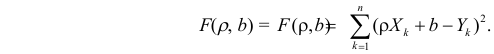
Такие значения , согласно необходимым условиям экстремума, находятся из системы уравнений:
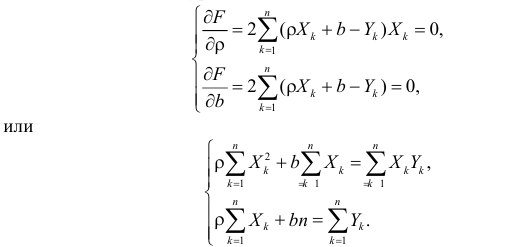
Решения этой системы уравнений дают оценки называемые оценками по методу наименьших квадратов.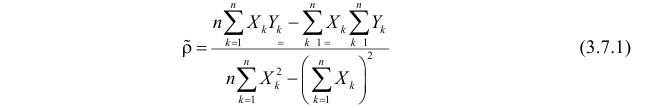
и
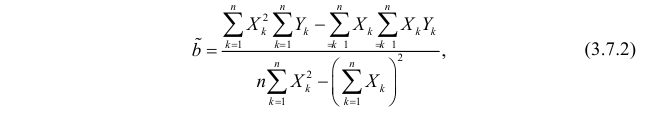
Известно, что оценки по методу наименьших квадратов являются несмещенными и, более того, среди всех несмещенных оценок обладают наименьшей дисперсией. Для оценки коэффициента корреляции можно воспользоваться тем, что 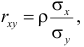 где
где 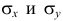 средние квадратические отклонения случайных величин X и Y соответственно. Обозначим через
средние квадратические отклонения случайных величин X и Y соответственно. Обозначим через 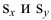 оценки этих средних квадратических отклонений на основе опытных данных. Оценки можно найти, например, по формуле (3.1.3). Тогда для коэффициента корреляции имеем оценку
оценки этих средних квадратических отклонений на основе опытных данных. Оценки можно найти, например, по формуле (3.1.3). Тогда для коэффициента корреляции имеем оценку 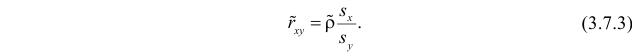
По методу наименьших квадратов можно находить оценки параметров линии регрессии и при нелинейной корреляции. Например, для линии регрессии вида 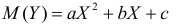 оценки параметров
оценки параметров  находятся из условия минимума функции
находятся из условия минимума функции
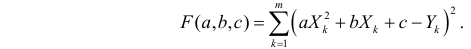
Пример:
По данным наблюдений двух случайных величин найти коэффициент корреляции и уравнение линии регрессии Y на X 
Решение. Вычислим величины, необходимые для использования формул (3.7.1)–(3.7.3):
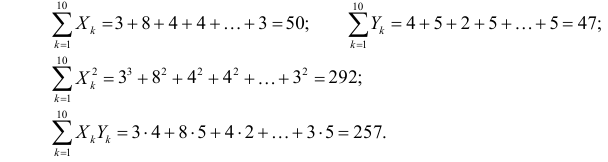
По формулам (3.7.1) и (3.7.2) получим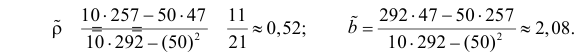
Итак, оценка линии регрессии имеет вид 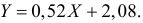 Так как
Так как 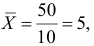 то по формуле (3.1.3)
то по формуле (3.1.3)
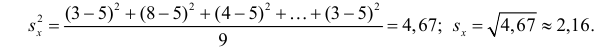
Аналогично, 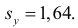 Поэтому в качестве оценки коэффициента корреляции имеем по формуле (3.7.3) величину
Поэтому в качестве оценки коэффициента корреляции имеем по формуле (3.7.3) величину 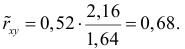
Ответ. 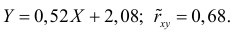
Пример:
Получена выборка значений величин X и Y
Для представления зависимости между величинами предполагается использовать модель 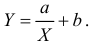 Найти оценки параметров
Найти оценки параметров 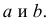
Решение. Рассмотрим сначала задачу оценки параметров этой модели в общем виде. Линия 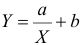 играет роль линии регрессии и поэтому параметры ее можно найти из условия минимума функции (сумма квадратов отклонений значений Y от линии должна быть минимальной по свойству линии регрессии)
играет роль линии регрессии и поэтому параметры ее можно найти из условия минимума функции (сумма квадратов отклонений значений Y от линии должна быть минимальной по свойству линии регрессии)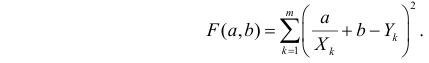
Необходимые условия экстремума приводят к системе из двух уравнений: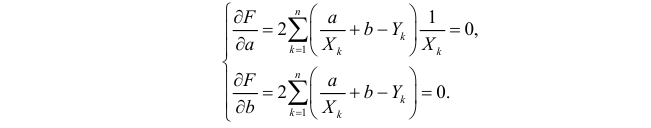
Откуда
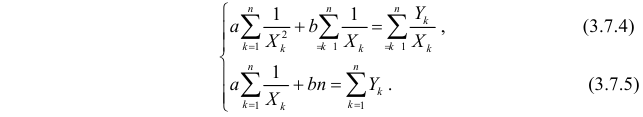
Решения системы уравнений (3.7.4) и (3.7.5) и будут оценками по методу наименьших квадратов для параметров 
На основе опытных данных вычисляем: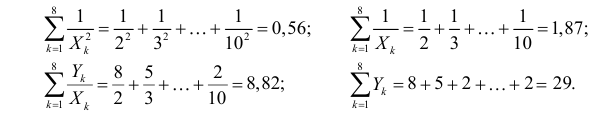
В итоге получаем систему уравнений (?????) и (?????) в виде 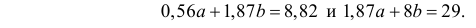
Эта система имеет решения 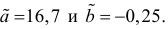
Ответ. 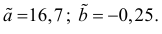
Если наблюдений много, то результаты их обычно группируют и представляют в виде корреляционной таблицы.
В этой таблице 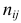 равно числу наблюдений, для которых X находится в интервале
равно числу наблюдений, для которых X находится в интервале 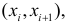 а Y – в интервале
а Y – в интервале 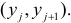 Через
Через 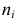 обозначено число наблюдений, при которых
обозначено число наблюдений, при которых 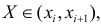 а Y произвольно. Число наблюдений, при которых
а Y произвольно. Число наблюдений, при которых 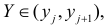 а X произвольно, обозначено через
а X произвольно, обозначено через 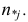
Если величины дискретны, то вместо интервалов указывают отдельные значения этих величин. Для непрерывных случайных величин представителем каждого интервала считают его середину и полагают, что 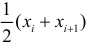 и
и 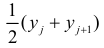 наблюдались
наблюдались 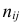 раз.
раз.
При больших значениях X и Y можно для упрощения вычислений перенести начало координат и изменить масштаб по каждой из осей, а после завершения вычислений вернуться к старому масштабу.
Пример:
Проделано 80 наблюдений случайных величин X и Y. Результаты наблюдений представлены в виде таблицы. Найти линию регрессии Y на X. Оценить коэффициент корреляции.

Решение. Представителем каждого интервала будем считать его середину. Перенесем начало координат и изменим масштаб по каждой оси так, чтобы значения X и Y были удобны для вычислений. Для этого перейдем к новым переменным  Значения этих новых переменных указаны соответственно в самой верхней строке и самом левом столбце таблицы.
Значения этих новых переменных указаны соответственно в самой верхней строке и самом левом столбце таблицы.
Чтобы иметь представление о виде линии регрессии, вычислим средние значения  при фиксированных значениях
при фиксированных значениях  :
:
Нанесем эти значения на координатную плоскость, соединив для наглядности их отрезками прямой (рис. 3.7.1).
По виду полученной ломанной линии можно предположить, что линия регрессии Y на X является прямой. Оценим ее параметры. Для этого сначала вычислим с учетом группировки данных в таблице все величины, необходимые для использования формул (3.31–3.33): 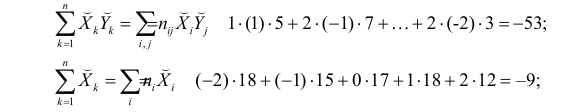
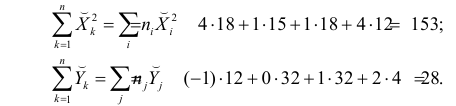
Тогда
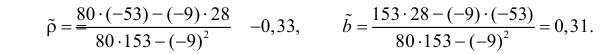
В новом масштабе оценка линии регрессии имеет вид 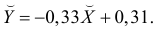 График этой прямой линии изображен на рис. 3.7.1.
График этой прямой линии изображен на рис. 3.7.1.
Для оценки 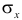 по корреляционной таблице можно воспользоваться формулой (3.1.3):
по корреляционной таблице можно воспользоваться формулой (3.1.3):
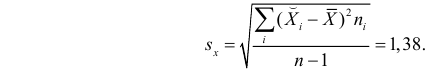
Подобным же образом можно оценить 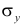 величиной
величиной 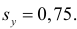 Тогда оценкой коэффициента корреляции может служить величина
Тогда оценкой коэффициента корреляции может служить величина 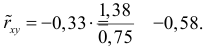
Вернемся к старому масштабу:
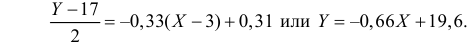
Коэффициент корреляции пересчитывать не нужно, так как это величина безразмерная и от масштаба не зависит.
Ответ. 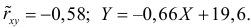
Пусть некоторые физические величины X и Y связаны неизвестной нам функциональной зависимостью  Для изучения этой зависимости производят измерения Y при разных значениях X. Измерениям сопутствуют ошибки и поэтому результат каждого измерения случаен. Если систематической ошибки при измерениях нет, то
Для изучения этой зависимости производят измерения Y при разных значениях X. Измерениям сопутствуют ошибки и поэтому результат каждого измерения случаен. Если систематической ошибки при измерениях нет, то 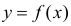 играет роль линии регрессии и все свойства линии регрессии приложимы к
играет роль линии регрессии и все свойства линии регрессии приложимы к 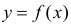 . В частности,
. В частности, 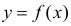 обычно находят по методу наименьших квадратов.
обычно находят по методу наименьших квадратов.
Регрессионный анализ
Основные положения регрессионного анализа:
Основная задача регрессионного анализа — изучение зависимости между результативным признаком Y и наблюдавшимся признаком X, оценка функции регрессий.
Предпосылки регрессионного анализа:
- Y — независимые случайные величины, имеющие постоянную дисперсию;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание
 можно представить в виде
можно представить в виде
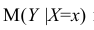 можно представить в виде
можно представить в виде 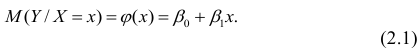
Выражение (2.1), как уже упоминалось в п. 1.2, называется функцией регрессии (или модельным уравнением регрессии) Y на X. Оценке в этом выражении подлежат параметры  называемые коэффициентами регрессии, а также
называемые коэффициентами регрессии, а также 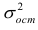 — остаточная дисперсия.
— остаточная дисперсия.
Остаточной дисперсией называется та часть рассеивания результативного признака, которую нельзя объяснить действием наблюдаемого признака; Остаточная дисперсия может служить для оценки точности подбора вида функции регрессии (модельного уравнения регрессии), полноты набора признаков, включенных в анализ. Оценки параметров функции регрессии находят, используя метод наименьших квадратов.
В данном вопросе рассмотрен линейный регрессионный анализ. Линейным он называется потому, что изучаем лишь те виды зависимостей которые линейны по оцениваемым параметрам, хотя могут быть нелинейны по переменным X. Например, зависимости
которые линейны по оцениваемым параметрам, хотя могут быть нелинейны по переменным X. Например, зависимости 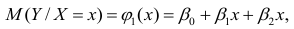
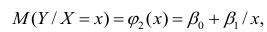
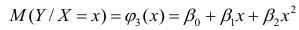 линейны относительно параметров
линейны относительно параметров 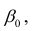
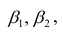 хотя вторая и третья зависимости нелинейны относительно переменных х. Вид зависимости
хотя вторая и третья зависимости нелинейны относительно переменных х. Вид зависимости 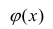 выбирают, исходя из визуальной оценки характера расположения точек на поле корреляции; опыта предыдущих исследований; соображений профессионального характера, основанных и знании физической сущности процесса.
выбирают, исходя из визуальной оценки характера расположения точек на поле корреляции; опыта предыдущих исследований; соображений профессионального характера, основанных и знании физической сущности процесса.
Важное место в линейном регрессионном анализе занимает так называемая «нормальная регрессия». Она имеет место, если сделать предположения относительно закона распределения случайной величины Y. Предпосылки «нормальной регрессии»:
- Y — независимые случайные величины, имеющие постоянную дисперсию и распределенные по нормальному закону;
- X— величины наблюдаемого признака (величины не случайные);
- условное математическое ожидание можно представить в виде (2.1).
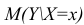 можно представить в виде (2.1).
можно представить в виде (2.1).В этом случае оценки коэффициентов регрессии — несмещённые с минимальной дисперсией и нормальным законом распределения. Из этого положения следует что при «нормальной регрессии» имеется возможность оценить значимость оценок коэффициентов регрессии, а также построить доверительный интервал для коэффициентов регрессии и условного математического ожидания M(YX=x).
Линейная регрессия
Рассмотрим простейший случай регрессионного анализа — модель вида (2.1), когда зависимость 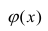 линейна и по оцениваемым параметрам, и
линейна и по оцениваемым параметрам, и
по переменным. Оценки параметров модели (2.1) 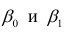 обозначил
обозначил 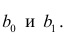 Оценку остаточной дисперсии
Оценку остаточной дисперсии 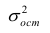 обозначим
обозначим 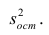 Подставив в формулу (2.1) вместо параметров их оценки, получим уравнение регрессии
Подставив в формулу (2.1) вместо параметров их оценки, получим уравнение регрессии 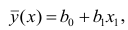 коэффициенты которого
коэффициенты которого 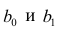 находят из условия минимума суммы квадратов отклонений измеренных значений результативного признака
находят из условия минимума суммы квадратов отклонений измеренных значений результативного признака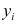 от вычисленных по уравнению регрессии
от вычисленных по уравнению регрессии 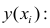
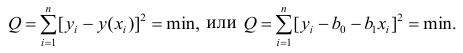
Составим систему нормальных уравнений: первое уравнение
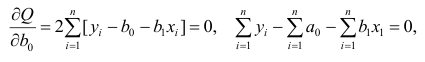
откуда 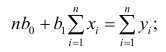
второе уравнение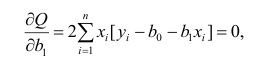
откуда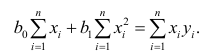
Итак,
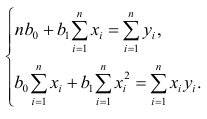
Оценки, полученные по способу наименьших квадратов, обладают минимальной дисперсией в классе линейных оценок. Решая систему (2.2) относительно найдём оценки параметров
найдём оценки параметров 
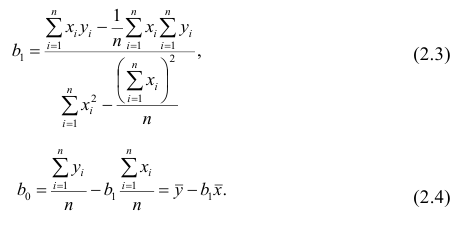
Остаётся получить оценку параметра 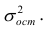 . Имеем
. Имеем
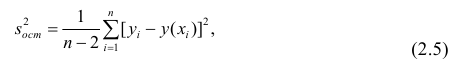
где т — количество наблюдений.
Еслит велико, то для упрощения расчётов наблюдавшиеся данные принята группировать, т.е. строить корреляционную таблицу. Пример построения такой таблицы приведен в п. 1.5. Формулы для нахождения коэффициентов регрессии по сгруппированным данным те же, что и для расчёта по несгруппированным данным, но суммы заменяют на
заменяют на
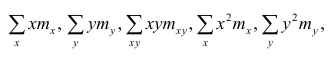
где  — частоты повторений соответствующих значений переменных. В дальнейшем часто используется этот наглядный приём вычислений.
— частоты повторений соответствующих значений переменных. В дальнейшем часто используется этот наглядный приём вычислений.
Нелинейная регрессия
Рассмотрим случай, когда зависимость нелинейна по переменным х, например модель вида
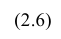
На рис. 2.1 изображено поле корреляции. Очевидно, что зависимость между Y и X нелинейная и её графическим изображением является не прямая, а кривая. Оценкой выражения (2.6) является уравнение регрессии
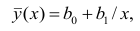
где 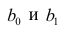 —оценки коэффициентов регрессии
—оценки коэффициентов регрессии 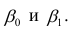
Принцип нахождения коэффициентов тот же — метод наименьших квадратов, т.е.
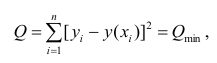
или
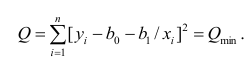
Дифференцируя последнее равенство по 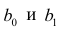 и приравнивая правые части нулю, получаем так называемую систему нормальных уравнений:
и приравнивая правые части нулю, получаем так называемую систему нормальных уравнений:
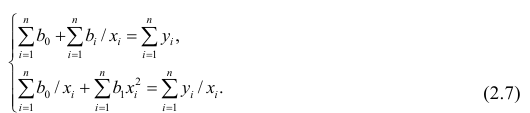
В общем случае нелинейной зависимости между переменными Y и X связь может выражаться многочленом k-й степени от x:
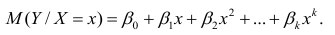
Коэффициенты регрессии определяют по принципу наименьших квадратов. Система нормальных уравнений имеет вид
Вычислив коэффициенты системы, её можно решить любым известным способом.
Оценка значимости коэффициентов регрессии. Интервальная оценка коэффициентов регрессии
Проверить значимость оценок коэффициентов регрессии — значит установить, достаточна ли величина оценки для статистически обоснованного вывода о том, что коэффициент регрессии отличен от нуля. Для этого проверяют гипотезу о равенстве нулю коэффициента регрессии, соблюдая предпосылки «нормальной регрессии». В этом случае вычисляемая для проверки нулевой гипотезы  статистика
статистика

имеет распределение Стьюдента с к= n-2 степенями свободы (b — оценка коэффициента регрессии,  — оценка среднеквадратического отклонения
— оценка среднеквадратического отклонения
коэффициента регрессии, иначе стандартная ошибка оценки). По уровню значимости а и числу степеней свободы к находят по таблицам распределения Стьюдента (см. табл. 1 приложений) критическое значение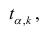 удовлетворяющее условию
удовлетворяющее условию 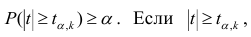 то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, коэффициент считают значимым. При
то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают, коэффициент считают значимым. При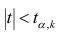 нет оснований отвергать нулевую гипотезу.
нет оснований отвергать нулевую гипотезу.
Оценки среднеквадратического отклонения коэффициентов регрессии вычисляют по следующим формулам:
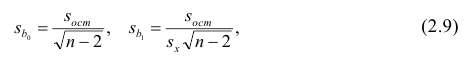
где 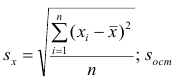 — оценка остаточной дисперсии, вычисляемая по
— оценка остаточной дисперсии, вычисляемая по
формуле (2.5).
Доверительный интервал для значимых параметров строят по обычной схеме. Из условия
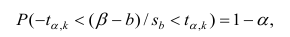
где а — уровень значимости, находим

Интервальная оценка для условного математического ожидания
Линия регрессии характеризует изменение условного математического ожидания результативного признака от вариации остальных признаков.
Точечной оценкой условного математического ожидания  является условное среднее
является условное среднее  Кроме точечной оценки для
Кроме точечной оценки для 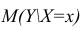 можно
можно
построить доверительный интервал в точке 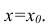
Известно, что 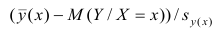 имеет распределение
имеет распределение
Стьюдента с k=n—2 степенями свободы. Найдя оценку среднеквадратического отклонения для условного среднего, можно построить доверительный интервал для условного математического ожидания 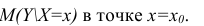
Оценку дисперсии условного среднего вычисляют по формуле
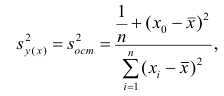
или для интервального ряда
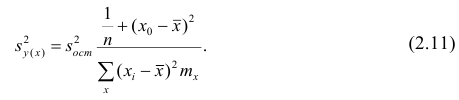
Доверительный интервал находят из условия
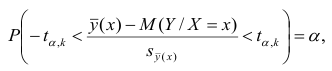
где а — уровень значимости. Отсюда
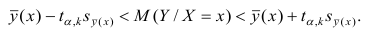
Доверительный интервал для условного математического ожидания можно изобразить графически (рис, 2.2).
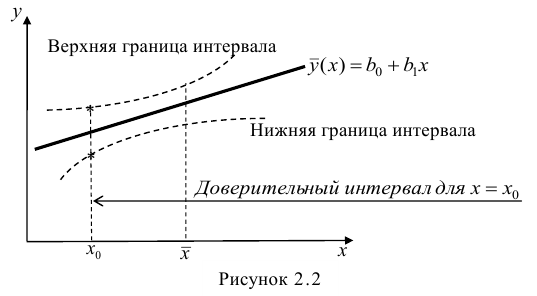
Из рис. 2.2 видно, что в точке 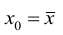 границы интервала наиболее близки друг другу. Расположение границ доверительного интервала показывает, что прогнозы по уравнению регрессии, хороши только в случае, если значение х не выходит за пределы выборки, по которой вычислено уравнение регрессии; иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
границы интервала наиболее близки друг другу. Расположение границ доверительного интервала показывает, что прогнозы по уравнению регрессии, хороши только в случае, если значение х не выходит за пределы выборки, по которой вычислено уравнение регрессии; иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
Проверка значимости уравнения регрессии
Оценить значимость уравнения регрессии — значит установить, соответствует ли математическая, модель, выражающая зависимость между Y и X, экспериментальным данным. Для оценки значимости в предпосылках «нормальной регрессии» проверяют гипотезу 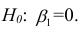 Если она отвергается, то считают, что между Y и X нет связи (или связь нелинейная). Для проверки нулевой гипотезы используют основное положение дисперсионного анализа о разбиении суммы квадратов на слагаемые. Воспользуемся разложением
Если она отвергается, то считают, что между Y и X нет связи (или связь нелинейная). Для проверки нулевой гипотезы используют основное положение дисперсионного анализа о разбиении суммы квадратов на слагаемые. Воспользуемся разложением 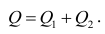 — Общая сумма квадратов отклонений результативного признака
— Общая сумма квадратов отклонений результативного признака
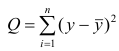 разлагается на
разлагается на 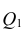 (сумму, характеризующую влияние признака
(сумму, характеризующую влияние признака
X) и 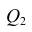 (остаточную сумму квадратов, характеризующую влияние неучтённых факторов). Очевидно, чем меньше влияние неучтённых факторов, тем лучше математическая модель соответствует экспериментальным данным, так как вариация У в основном объясняется влиянием признака X.
(остаточную сумму квадратов, характеризующую влияние неучтённых факторов). Очевидно, чем меньше влияние неучтённых факторов, тем лучше математическая модель соответствует экспериментальным данным, так как вариация У в основном объясняется влиянием признака X.
Для проверки нулевой гипотезы вычисляют статистику 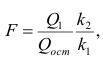 которая имеет распределение Фишера-Снедекора с А
которая имеет распределение Фишера-Снедекора с А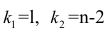 степенями свободы (в п — число наблюдений). По уровню значимости а и числу степеней свободы
степенями свободы (в п — число наблюдений). По уровню значимости а и числу степеней свободы  находят по таблицам F-распределение для уровня значимости а=0,05 (см. табл. 3 приложений) критическое значение
находят по таблицам F-распределение для уровня значимости а=0,05 (см. табл. 3 приложений) критическое значение удовлетворяющее условию
удовлетворяющее условию 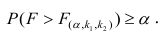 . Если
. Если 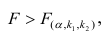 нулевую гипотезу отвергают, уравнение считают значимым. Если
нулевую гипотезу отвергают, уравнение считают значимым. Если 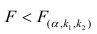 то нет оснований отвергать нулевую гипотезу.
то нет оснований отвергать нулевую гипотезу.
Многомерный регрессионный анализ
В случае, если изменения результативного признака определяются действием совокупности других признаков, имеет место многомерный регрессионный анализ. Пусть результативный признак У, а независимые признаки  Для многомерного случая предпосылки регрессионного анализа можно сформулировать следующим образом: У -независимые случайные величины со средним
Для многомерного случая предпосылки регрессионного анализа можно сформулировать следующим образом: У -независимые случайные величины со средним 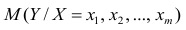 и постоянной дисперсией
и постоянной дисперсией 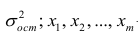 — линейно независимые векторы
— линейно независимые векторы 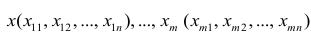 . Все положения, изложенные в п.2.1, справедливы для многомерного случая. Рассмотрим модель вида
. Все положения, изложенные в п.2.1, справедливы для многомерного случая. Рассмотрим модель вида
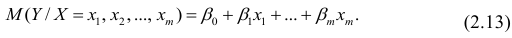
Оценке подлежат параметры 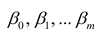 и остаточная дисперсия.
и остаточная дисперсия.
Заменив параметры их оценками, запишем уравнение регрессии
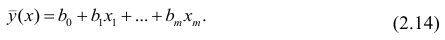
Коэффициенты в этом выражении находят методом наименьших квадратов.
Исходными данными для вычисления коэффициентов 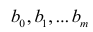 является выборка из многомерной совокупности, представляемая обычно в виде матрицы X и вектора Y:
является выборка из многомерной совокупности, представляемая обычно в виде матрицы X и вектора Y:

Как и в двумерном случае, составляют систему нормальных уравнений
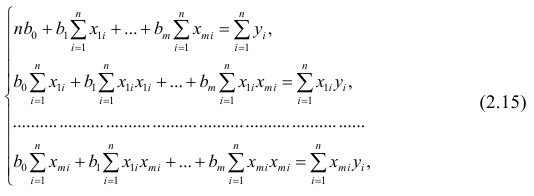
которую можно решить любым способом, известным из линейной алгебры. Рассмотрим один из них — способ обратной матрицы. Предварительно преобразуем систему уравнений. Выразим из первого уравнения значение 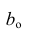 через остальные параметры:
через остальные параметры:
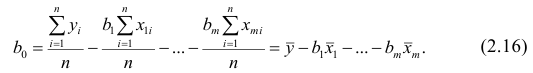
Подставим в остальные уравнения системы вместо 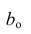 полученное выражение:
полученное выражение:
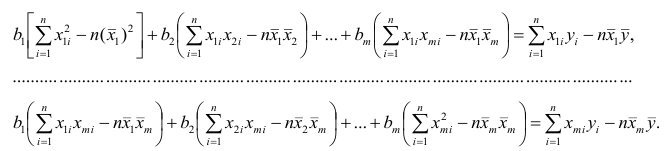
Пусть С — матрица коэффициентов при неизвестных параметрах 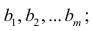
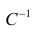 — матрица, обратная матрице С;
— матрица, обратная матрице С; 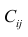 — элемент, стоящий на пересечении i-Й строки и i-го столбца матрицы
— элемент, стоящий на пересечении i-Й строки и i-го столбца матрицы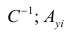 — выражение
— выражение
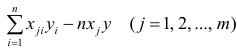 . Тогда, используя формулы линейной алгебры,
. Тогда, используя формулы линейной алгебры,
запишем окончательные выражения для параметров:
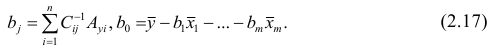
Оценкой остаточной дисперсии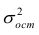 является
является
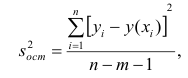
где 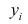 — измеренное значение результативного признака;
— измеренное значение результативного признака;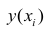 значение результативного признака, вычисленное по уравнению регрессий.
значение результативного признака, вычисленное по уравнению регрессий.
Если выборка получена из нормально распределенной генеральной совокупности, то, аналогично изложенному в п. 2.4, можно проверить значимость оценок коэффициентов регрессии, только в данном случае статистику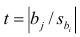 вычисляют для каждого j-го коэффициента регрессии
вычисляют для каждого j-го коэффициента регрессии
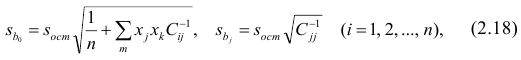
где 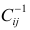 —элемент обратной матрицы, стоящий на пересечении i-й строки и j-
—элемент обратной матрицы, стоящий на пересечении i-й строки и j-
го столбца;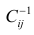 —диагональный элемент обратной матрицы.
—диагональный элемент обратной матрицы.
При заданном уровне значимости а и числе степеней свободы к=n— m—1 по табл. 1 приложений находят критическое значение 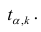 Если
Если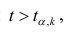 то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают. Оценку коэффициента считают значимой. Такую проверку производят последовательно для каждого коэффициента регрессии. Если
то нулевую гипотезу о равенстве нулю коэффициента регрессии отвергают. Оценку коэффициента считают значимой. Такую проверку производят последовательно для каждого коэффициента регрессии. Если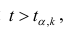 то нет оснований отвергать нулевую гипотезу, оценку коэффициента регрессии считают незначимой.
то нет оснований отвергать нулевую гипотезу, оценку коэффициента регрессии считают незначимой.
Для значимых коэффициентов регрессии целесообразно построить доверительные интервалы по формуле (2.10). Для оценки значимости уравнения регрессии следует проверить нулевую гипотезу о том, что все коэффициенты регрессии (кроме свободного члена) равны нулю: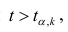
 — вектор коэффициентов регрессии). Нулевую гипотезу проверяют, так же как и в п. 2.6, с помощью статистики
— вектор коэффициентов регрессии). Нулевую гипотезу проверяют, так же как и в п. 2.6, с помощью статистики 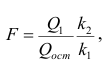 , где
, где 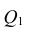 — сумма квадратов, характеризующая влияние признаков X;
— сумма квадратов, характеризующая влияние признаков X; 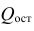 — остаточная сумма квадратов, характеризующая влияние неучтённых факторов;
— остаточная сумма квадратов, характеризующая влияние неучтённых факторов; 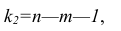
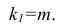 Для уровня значимости а и числа степеней свободы
Для уровня значимости а и числа степеней свободы  по табл. 3 приложений находят критическое значение
по табл. 3 приложений находят критическое значение 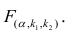 Если
Если 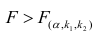 то нулевую гипотезу об одновременном равенстве нулю коэффициентов регрессии отвергают. Уравнение регрессии считают значимым. При
то нулевую гипотезу об одновременном равенстве нулю коэффициентов регрессии отвергают. Уравнение регрессии считают значимым. При 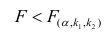 нет оснований отвергать нулевую гипотезу, уравнение регрессии считают незначимым.
нет оснований отвергать нулевую гипотезу, уравнение регрессии считают незначимым.
Факторный анализ
Основные положения. В последнее время всё более широкое распространение находит один из новых разделов многомерного статистического анализа — факторный анализ. Первоначально этот метод
разрабатывался для объяснения многообразия корреляций между исходными параметрами. Действительно, результатом корреляционного анализа является матрица коэффициентов корреляций. При малом числе параметров можно произвести визуальный анализ этой матрицы. С ростом числа параметра (10 и более) визуальный анализ не даёт положительных результатов. Оказалось, что всё многообразие корреляционных связей можно объяснить действием нескольких обобщённых факторов, являющихся функциями исследуемых параметров, причём сами обобщённые факторы при этом могут быть и неизвестны, однако их можно выразить через исследуемые параметры.
Один из основоположников факторного анализа Л. Терстоун приводит такой пример: несколько сотен мальчиков выполняют 20 разнообразных гимнастических упражнений. Каждое упражнение оценивают баллами. Можно рассчитать матрицу корреляций между 20 упражнениями. Это большая матрица размером 20><20. Изучая такую матрицу, трудно уловить закономерность связей между упражнениями. Нельзя ли объяснить скрытую в таблице закономерность действием каких-либо обобщённых факторов, которые в результате эксперимента непосредственно, не оценивались? Оказалось, что обо всех коэффициентах корреляции можно судить по трём обобщённым факторам, которые и определяют успех выполнения всех 20 гимнастических упражнений: чувство равновесия, усилие правого плеча, быстрота движения тела.
Дальнейшие разработки факторного анализа доказали, что этот метод может быть с успехом применён в задачах группировки и классификации объектов. Факторный анализ позволяет группировать объекты со сходными сочетаниями признаков и группировать признаки с общим характером изменения от объекта к объекту. Действительно, выделенные обобщённые факторы можно использовать как критерии при классификации мальчиков по способностям к отдельным группам гимнастических упражнений.
Методы факторного анализа находят применение в психологии и экономике, социологии и экономической географии. Факторы, выраженные через исходные параметры, как правило, легко интерпретировать как некоторые существенные внутренние характеристики объектов.
Факторный анализ может быть использован и как самостоятельный метод исследования, и вместе с другими методами многомерного анализа, например в сочетании с регрессионным анализом. В этом случае для набора зависимых переменных наводят обобщённые факторы, которые потом входят в регрессионный анализ в качестве переменных. Такой подход позволяет сократить число переменных в регрессионном анализе, устранить коррелированность переменных, уменьшить влияние ошибок и в случае ортогональности выделенных факторов значительно упростить оценку значимости переменных.
Представление, информации в факторном анализе
Для проведения факторного анализа информация должна быть представлена в виде двумерной таблицы чисел размерностью 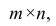 аналогичной приведенной в п. 2.7 (матрица исходных данных). Строки этой матрицы должны соответствовать объектам наблюдений
аналогичной приведенной в п. 2.7 (матрица исходных данных). Строки этой матрицы должны соответствовать объектам наблюдений 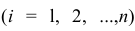 столбцы — признакам
столбцы — признакам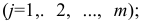 таким образом, каждый признак является как бы статистическим рядом, в котором наблюдения варьируют от объекта к объекту. Признаки, характеризующие объект наблюдения, как правило, имеют различную размерность. Чтобы устранить влияние размерности и обеспечить сопоставимость признаков, матрицу исходных данных обычно нормируют, вводя единый масштаб. Самым распространенным видом нормировки является стандартизация. От переменных
таким образом, каждый признак является как бы статистическим рядом, в котором наблюдения варьируют от объекта к объекту. Признаки, характеризующие объект наблюдения, как правило, имеют различную размерность. Чтобы устранить влияние размерности и обеспечить сопоставимость признаков, матрицу исходных данных обычно нормируют, вводя единый масштаб. Самым распространенным видом нормировки является стандартизация. От переменных 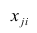 переходят к переменным
переходят к переменным 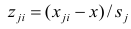 В дальнейшем, говоря о матрице исходных переменных, всегда будем иметь в виду стандартизованную матрицу.
В дальнейшем, говоря о матрице исходных переменных, всегда будем иметь в виду стандартизованную матрицу.
Основная модель факторного анализа. Основная модель факторного анализа имеет вид
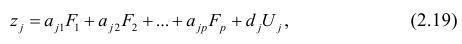
где 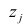 -j-й признак (величина случайная);
-j-й признак (величина случайная); 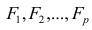 — общие факторы (величины случайные, имеющие нормальный закон распределения);
— общие факторы (величины случайные, имеющие нормальный закон распределения); 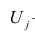 — характерный фактор;
— характерный фактор; 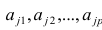 — факторные нагрузки, характеризующие существенность влияния каждого фактора (параметры модели, подлежащие определению);
— факторные нагрузки, характеризующие существенность влияния каждого фактора (параметры модели, подлежащие определению);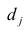 — нагрузка характерного фактора.
— нагрузка характерного фактора.
Модель предполагает, что каждый из j признаков, входящих в исследуемый набор и заданных в стандартной форме, может быть представлен в виде линейной комбинации небольшого числа общих факторов 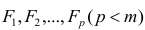 и характерного фактора
и характерного фактора 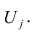
Термин «общий фактор» подчёркивает, что каждый такой фактор имеет существенное значение для анализа всех признаков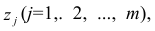 , т.е.
, т.е.
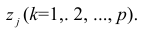
Термин «характерный фактор» показывает, что он относится только к данному j-му признаку. Это специфика признака, которая не может быть, выражена через факторы 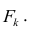
Факторные нагрузки 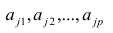 . характеризуют величину влияния того или иного общего фактора в вариации данного признака. Основная задача факторного анализа — определение факторных нагрузок. Факторная модель относится к классу аппроксимационных. Параметры модели должны быть выбраны так, чтобы наилучшим образом аппроксимировать корреляции между наблюдаемыми признаками.
. характеризуют величину влияния того или иного общего фактора в вариации данного признака. Основная задача факторного анализа — определение факторных нагрузок. Факторная модель относится к классу аппроксимационных. Параметры модели должны быть выбраны так, чтобы наилучшим образом аппроксимировать корреляции между наблюдаемыми признаками.
Для j-го признака и i-го объекта модель (2.19) можно записать в. виде
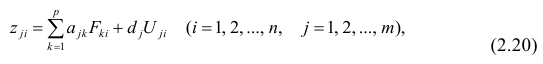
где 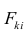 значение k-го фактора для i-го объекта.
значение k-го фактора для i-го объекта.
Дисперсию признака 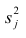 можно разложить на составляющие: часть, обусловленную действием общих факторов, — общность
можно разложить на составляющие: часть, обусловленную действием общих факторов, — общность  и часть, обусловленную действием j-го характера фактора, характерность
и часть, обусловленную действием j-го характера фактора, характерность 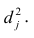 Все переменные представлены в стандартизированном виде, поэтому дисперсий у-го признака
Все переменные представлены в стандартизированном виде, поэтому дисперсий у-го признака 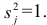 Дисперсия признака может быть выражена через факторы и в конечном счёте через факторные нагрузки.
Дисперсия признака может быть выражена через факторы и в конечном счёте через факторные нагрузки.
Если общие и характерные факторы не коррелируют между собой, то дисперсию j-го признака можно представить в виде
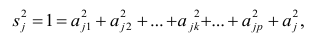
где 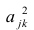 —доля дисперсии признака
—доля дисперсии признака 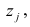 приходящаяся на k-й фактор.
приходящаяся на k-й фактор.
Полный вклад k-го фактора в суммарную дисперсию признаков
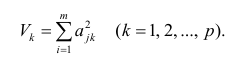
Вклад общих факторов в суммарную дисперсию 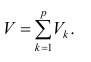
Факторное отображение
Используя модель (2.19), запишем выражения для каждого из параметров:
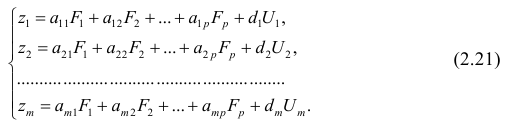
Коэффициенты системы (2,21) — факторные нагрузки — можно представить в виде матрицы, каждая строка которой соответствует параметру, а столбец — фактору.
Факторный анализ позволяет получить не только матрицу отображений, но и коэффициенты корреляции между параметрами и
факторами, что является важной характеристикой качества факторной модели. Таблица таких коэффициентов корреляции называется факторной структурой или просто структурой.
Коэффициенты отображения можно выразить через выборочные парные коэффициенты корреляции. На этом основаны методы вычисления факторного отображения.
Рассмотрим связь между элементами структуры и коэффициентами отображения. Для этого, учитывая выражение (2.19) и определение выборочного коэффициента корреляции, умножим уравнения системы (2.21) на соответствующие факторы, произведём суммирование по всем n наблюдениям и, разделив на n, получим следующую систему уравнений:
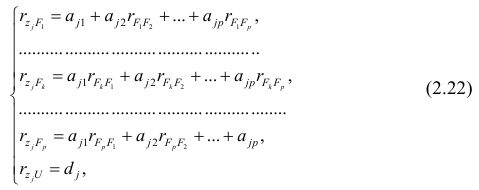
где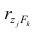 — выборочный коэффициент корреляции между j-м параметром и к-
— выборочный коэффициент корреляции между j-м параметром и к-
м фактором;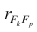 — коэффициент корреляции между к-м и р-м факторами.
— коэффициент корреляции между к-м и р-м факторами.
Если предположить, что общие факторы между собой, не коррелированы, то уравнения (2.22) можно записать в виде
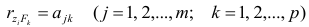 , т.е. коэффициенты отображения равны
, т.е. коэффициенты отображения равны
элементам структуры.
Введём понятие, остаточного коэффициента корреляции и остаточной корреляционной матрицы. Исходной информацией для построения факторной модели (2.19) служит матрица выборочных парных коэффициентов корреляции. Используя построенную факторную модель, можно снова вычислить коэффициенты корреляции между признаками и сравнись их с исходными Коэффициентами корреляции. Разница между ними и есть остаточный коэффициент корреляции.
В случае независимости факторов имеют место совсем простые выражения для вычисляемых коэффициентов корреляции между параметрами: для их вычисления достаточно взять сумму произведений коэффициентов отображения, соответствующих наблюдавшимся признакам: 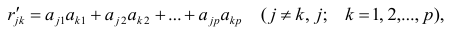
где 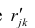 —вычисленный по отображению коэффициент корреляции между j-м
—вычисленный по отображению коэффициент корреляции между j-м
и к-м признаком. Остаточный коэффициент корреляции
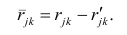
Матрица остаточных коэффициентов корреляции называется остаточной матрицей или матрицей остатков
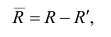
где 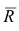 — матрица остатков; R — матрица выборочных парных коэффициентов корреляции, или полная матрица; R’— матрица вычисленных по отображению коэффициентов корреляции.
— матрица остатков; R — матрица выборочных парных коэффициентов корреляции, или полная матрица; R’— матрица вычисленных по отображению коэффициентов корреляции.
Результаты факторного анализа удобно представить в виде табл. 2.10.

Здесь суммы квадратов нагрузок по строкам — общности параметров, а суммы квадратов нагрузок по столбцам — вклады факторов в суммарную дисперсию параметров. Имеет место соотношение
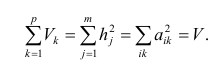
Определение факторных нагрузок
Матрицу факторных нагрузок можно получить различными способами. В настоящее время наибольшее распространение получил метод главных факторов. Этот метод основан на принципе последовательных приближений и позволяет достичь любой точности. Метод главных факторов предполагает использование ЭВМ. Существуют хорошие алгоритмы и программы, реализующие все вычислительные процедуры.
Введём понятие редуцированной корреляционной матрицы или просто редуцированной матрицы. Редуцированной называется матрица выборочных коэффициентов корреляции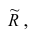 у которой на главной диагонали стоят значения общностей
у которой на главной диагонали стоят значения общностей 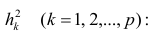 :
: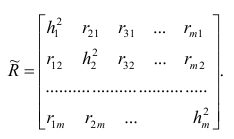
Редуцированная и полная матрицы связаны соотношением

где D — матрица характерностей.
Общности, как правило, неизвестны, и нахождение их в факторном анализе представляет серьезную проблему. Вначале определяют (хотя бы приближённо) число общих факторов, совокупность, которых может с достаточной точностью аппроксимировать все взаимосвязи выборочной корреляционной матрицы. Доказано, что число общих факторов (общностей) равно рангу редуцированной матрицы, а при известном ранге можно по выборочной корреляционной матрице найти оценки общностей. Числа общих факторов можно определить априори, исходя из физической природы эксперимента. Затем рассчитывают матрицу факторных нагрузок. Такая матрица, рассчитанная методом главных факторов, обладает одним интересным свойством: сумма произведений каждой пары её столбцов равна нулю, т.е. факторы попарно ортогональны.
Сама процедура нахождения факторных нагрузок, т.е. матрицы А, состоит из нескольких шагов и заключается в следующем: на первом шаге ищут коэффициенты факторных нагрузок при первом факторе так, чтобы сумма вкладов данного фактора в суммарную общность была максимальной:
Максимум  должен быть найден при условии
должен быть найден при условии
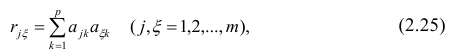
где 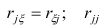 —общность
—общность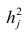 параметра
параметра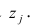
Затем рассчитывают матрицу коэффициентов корреляции с учётом только первого фактора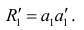 Имея эту матрицу, получают первую матрицу остатков:
Имея эту матрицу, получают первую матрицу остатков: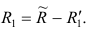
На втором шаге определяют коэффициенты нагрузок при втором факторе так, чтобы сумма вкладов второго фактора в остаточную общность (т.е. полную общность без учёта той части, которая приходится на долю первого фактора) была максимальной. Сумма квадратов нагрузок при втором факторе
Максимум 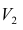 находят из условия
находят из условия
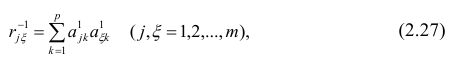
где 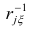 — коэффициент корреляции из первой матрицы остатков;
— коэффициент корреляции из первой матрицы остатков; 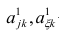 — факторные нагрузки с учётом второго фактора. Затем рассчитыва коэффициентов корреляций с учётом второго фактора и вычисляют вторую матрицу остатков:
— факторные нагрузки с учётом второго фактора. Затем рассчитыва коэффициентов корреляций с учётом второго фактора и вычисляют вторую матрицу остатков: 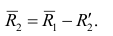
Факторный анализ учитывает суммарную общность. Исходная суммарная общность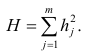 Итерационный процесс выделения факторов заканчивают, когда учтённая выделенными факторами суммарная общность отличается от исходной суммарной общности меньше чем на
Итерационный процесс выделения факторов заканчивают, когда учтённая выделенными факторами суммарная общность отличается от исходной суммарной общности меньше чем на 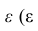 — наперёд заданное малое число).
— наперёд заданное малое число).
Адекватность факторной модели оценивается по матрице остатков (если величины её коэффициентов малы, то модель считают адекватной).
Такова последовательность шагов для нахождения факторных нагрузок. Для нахождения максимума функции (2.24) при условии (2.25) используют метод множителей Лагранжа, который приводит к системе т уравнений относительно m неизвестных 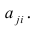
Метод главных компонент
Разновидностью метода главных факторов является метод главных компонент или компонентный анализ, который реализует модель вида
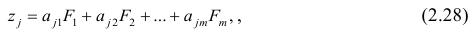
где m — количество параметров (признаков).
Каждый из наблюдаемых, параметров линейно зависит от m не коррелированных между собой новых компонент (факторов) 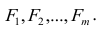 По сравнению с моделью факторного анализа (2.19) в модели (2.28) отсутствует характерный фактор, т.е. считается, что вся вариация параметра может быть объяснена только действием общих или главных факторов. В случае компонентного анализа исходной является матрица коэффициентов корреляции, где на главной диагонали стоят единицы. Результатом компонентного анализа, так же как и факторного, является матрица факторных нагрузок. Поиск факторного решения — это ортогональное преобразование матрицы исходных переменных, в результате которого каждый параметр может быть представлен линейной комбинацией найденных m факторов, которые называют главными компонентами. Главные компоненты легко выражаются через наблюдённые параметры.
По сравнению с моделью факторного анализа (2.19) в модели (2.28) отсутствует характерный фактор, т.е. считается, что вся вариация параметра может быть объяснена только действием общих или главных факторов. В случае компонентного анализа исходной является матрица коэффициентов корреляции, где на главной диагонали стоят единицы. Результатом компонентного анализа, так же как и факторного, является матрица факторных нагрузок. Поиск факторного решения — это ортогональное преобразование матрицы исходных переменных, в результате которого каждый параметр может быть представлен линейной комбинацией найденных m факторов, которые называют главными компонентами. Главные компоненты легко выражаются через наблюдённые параметры.
Если для дальнейшего анализа оставить все найденные т компонент, то тем самым будет использована вся информация, заложенная в корреляционной матрице. Однако это неудобно и нецелесообразно. На практике обычно оставляют небольшое число компонент, причём количество их определяется долей суммарной дисперсии, учитываемой этими компонентами. Существуют различные критерии для оценки числа оставляемых компонент; чаще всего используют следующий простой критерий: оставляют столько компонент, чтобы суммарная дисперсия, учитываемая ими, составляла заранее установленное число процентов. Первая из компонент должна учитывать максимум суммарной дисперсии параметров; вторая — не коррелировать с первой и учитывать максимум оставшейся дисперсии и так до тех пор, пока вся дисперсия не будет учтена. Сумма учтённых всеми компонентами дисперсий равна сумме дисперсий исходных параметров. Математический аппарат компонентного анализа полностью совпадает с аппаратом метода главных факторов. Отличие только в исходной матрице корреляций.
Компонента (или фактор) через исходные переменные выражается следующим образом:
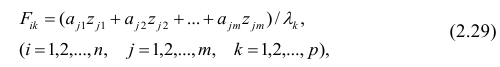
где 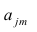 — элементы факторного решения:
— элементы факторного решения: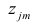 — исходные переменные;
— исходные переменные; 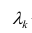 .— k-е собственное значение; р — количество оставленных главных
.— k-е собственное значение; р — количество оставленных главных
компонент.
Для иллюстрации возможностей факторного анализа покажем, как, используя метод главных компонент, можно сократить размерность пространства независимых переменных, перейдя от взаимно коррелированных параметров к независимым факторам, число которых р
Следует особо остановиться на интерпретации результатов, т.е. на смысловой стороне факторного анализа. Собственно факторный анализ состоит из двух важных этапов; аппроксимации корреляционной матрицы и интерпретации результатов. Аппроксимировать корреляционную матрицу, т.е. объяснить корреляцию между параметрами действием каких-либо общих для них факторов, и выделить сильно коррелирующие группы параметров достаточно просто: из корреляционной матрицы одним из методов
факторного анализа непосредственно получают матрицу нагрузок — факторное решение, которое называют прямым факторным решением. Однако часто это решение не удовлетворяет исследователей. Они хотят интерпретировать фактор как скрытый, но существенный параметр, поведение которого определяет поведение некоторой своей группы наблюдаемых параметров, в то время как, поведение других параметров определяется поведением других факторов. Для этого у каждого параметра должна быть наибольшая по модулю факторная нагрузка с одним общим фактором. Прямое решение следует преобразовать, что равносильно повороту осей общих факторов. Такие преобразования называют вращениями, в итоге получают косвенное факторное решение, которое и является результатом факторного анализа.
Приложения
Значение t — распределения Стьюдента 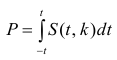
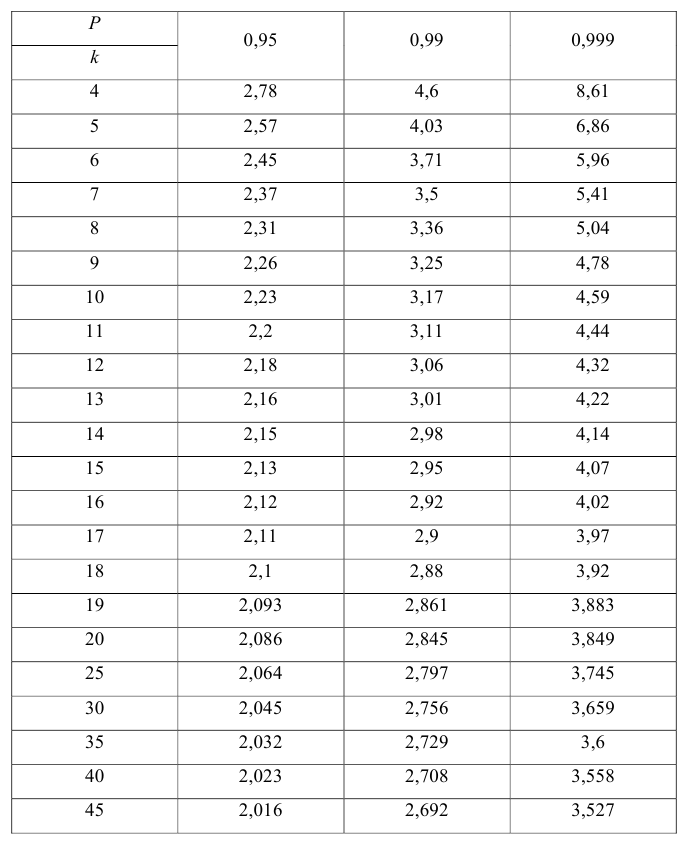
Понятие о регрессионном анализе. Линейная выборочная регрессия. Метод наименьших квадратов (МНК)
Основные задачи регрессионного анализа:
- Вычисление выборочных коэффициентов регрессии
- Проверка значимости коэффициентов регрессии
- Проверка адекватности модели
- Выбор лучшей регрессии
- Вычисление стандартных ошибок, анализ остатков
Построение простой регрессии по экспериментальным данным.
Предположим, что случайные величины 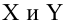 связаны линейной корреляционной зависимостью
связаны линейной корреляционной зависимостью 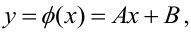 для отыскания которой проведено
для отыскания которой проведено 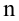 независимых измерений
независимых измерений 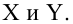
Диаграмма рассеяния (разброса, рассеивания)
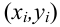 — координаты экспериментальных точек.
— координаты экспериментальных точек.
Выборочное уравнение прямой линии регрессии  имеет вид
имеет вид
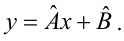
Задача: подобрать  таким образом, чтобы экспериментальные точки как можно ближе лежали к прямой
таким образом, чтобы экспериментальные точки как можно ближе лежали к прямой 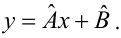
Для того, что бы провести прямую 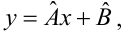 воспользуемся МНК. Потребуем,
воспользуемся МНК. Потребуем,
чтобы 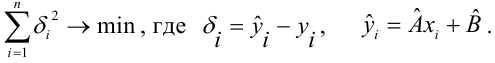
Постулаты регрессионного анализа, которые должны выполняться при использовании МНК.
- подчинены нормальному закону распределения.
- Дисперсия постоянна и не зависит от номера измерения.
- Результаты наблюдений в разных точках независимы.
- Входные переменные независимы, неслучайны и измеряются без ошибок.
 подчинены нормальному закону распределения.
подчинены нормальному закону распределения. постоянна и не зависит от номера измерения.
постоянна и не зависит от номера измерения. в разных точках независимы.
в разных точках независимы.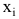 независимы, неслучайны и измеряются без ошибок.
независимы, неслучайны и измеряются без ошибок.Введем функцию ошибок 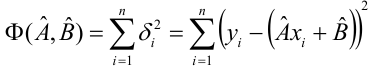 и найдём её минимальное значение
и найдём её минимальное значение
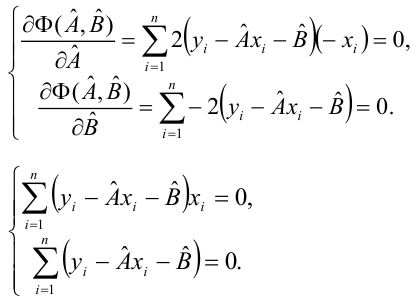
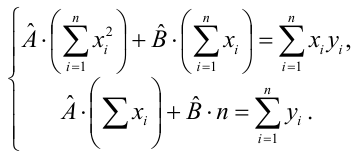
Решив систему, получим искомые значения 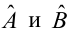
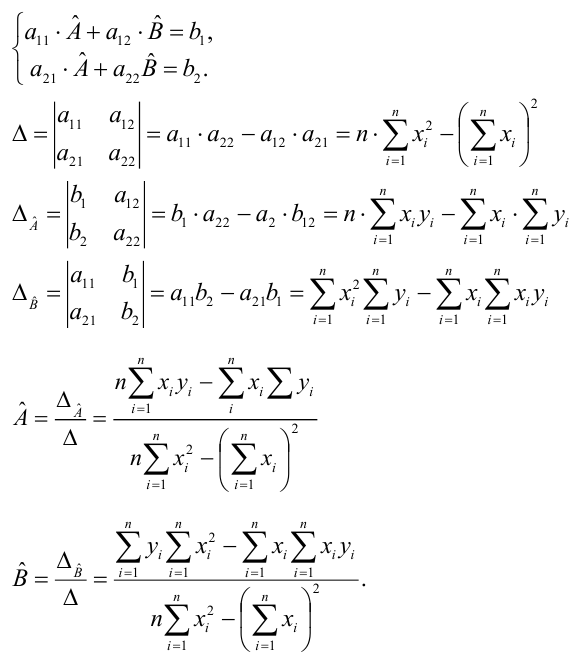
 является несмещенными оценками истинных значений коэффициентов
является несмещенными оценками истинных значений коэффициентов 
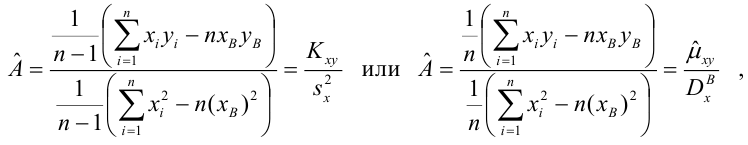 где
где
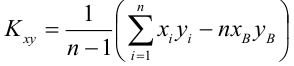 несмещенная оценка корреляционного момента (ковариации),
несмещенная оценка корреляционного момента (ковариации),
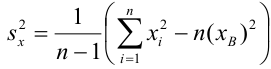 несмещенная оценка дисперсии
несмещенная оценка дисперсии 
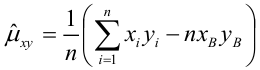 выборочная ковариация,
выборочная ковариация,
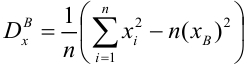 выборочная дисперсия
выборочная дисперсия 
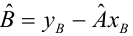
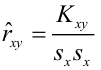 — выборочный коэффициент корреляции
— выборочный коэффициент корреляции
Коэффициент детерминации
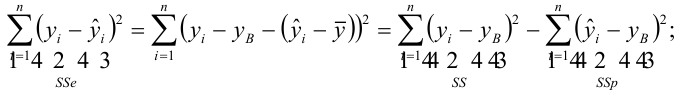
 — наблюдаемое экспериментальное значение
— наблюдаемое экспериментальное значение  при
при 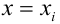
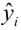 — предсказанное значение
— предсказанное значение  удовлетворяющее уравнению регрессии
удовлетворяющее уравнению регрессии
 — средневыборочное значение
— средневыборочное значение 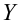
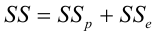
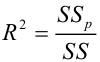 — коэффициент детерминации, доля изменчивости
— коэффициент детерминации, доля изменчивости 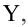 объясняемая рассматриваемой регрессионной моделью. Для парной линейной регрессии
объясняемая рассматриваемой регрессионной моделью. Для парной линейной регрессии 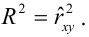
Коэффициент детерминации принимает значения от 0 до 1. Чем ближе значение коэффициента к 1, тем сильнее зависимость. При оценке регрессионных моделей это используется для доказательства адекватности модели (качества регрессии). Для приемлемых моделей предполагается, что коэффициент детерминации должен быть хотя бы не меньше 0,5 (в этом случае коэффициент множественной корреляции превышает по модулю 0,7). Модели с коэффициентом детерминации выше 0,8 можно признать достаточно хорошими (коэффициент корреляции превышает 0,9). Подтверждение адекватности модели проводится на основе дисперсионного анализа путем проверки гипотезы о значимости коэффициента детерминации.
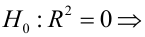 регрессия незначима
регрессия незначима
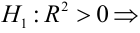 регрессия значима
регрессия значима
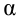 — уровень значимости
— уровень значимости
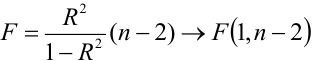 — статистический критерий
— статистический критерий
Критическая область — правосторонняя; 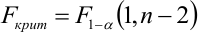
Если  то нулевая гипотеза отвергается на заданном уровне значимости, следовательно, коэффициент детерминации значим, следовательно, регрессия адекватна.
то нулевая гипотеза отвергается на заданном уровне значимости, следовательно, коэффициент детерминации значим, следовательно, регрессия адекватна.
Мощность статистического критерия. Функция мощности
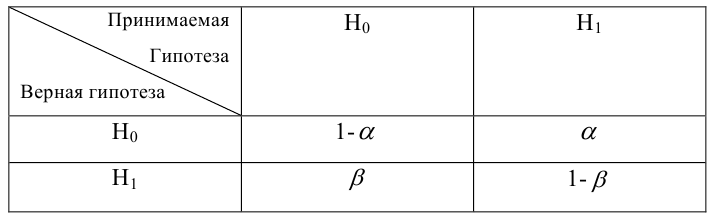
Определение. Мощностью критерия 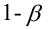 называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза.
называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза.
Задача: построить критическую область таким образом, чтобы мощность критерия была максимальной.
Определение. Наилучшей критической областью (НКО) называют критическую область, которая обеспечивает минимальную ошибку второго рода 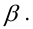
Пример:
По паспортным данным автомобиля расход топлива на 100 километров составляет 10 литров. В результате измерения конструкции двигателя ожидается, что расход топлива уменьшится. Для проверки были проведены испытания 25 автомобилей с модернизированным двигателем; выборочная средняя расхода топлива по результатам испытаний составила 9,3 литра. Предполагая, что выборка получена из нормально распределенной генеральной совокупности с математическим ожиданием  и дисперсией
и дисперсией 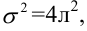 проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
проверить гипотезу, утверждающую, что изменение конструкции двигателя не повлияло на расход топлива.
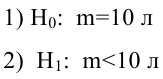
3) Уровень значимости 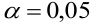
4) Статистический критерий
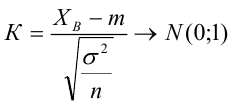
5) Критическая область — левосторонняя
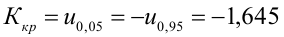
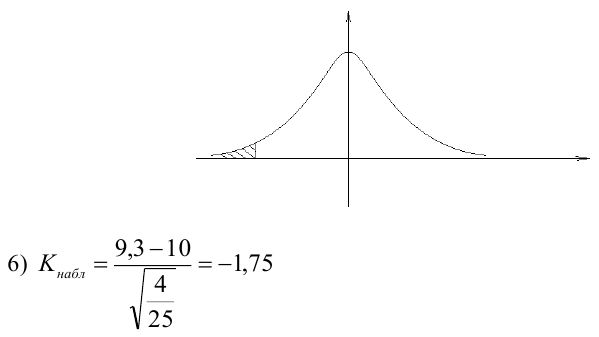
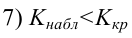 следовательно
следовательно  отвергается на уровне значимости
отвергается на уровне значимости 
Пример:
В условиях примера 1 предположим, что наряду с 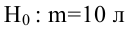 рассматривается конкурирующая гипотеза
рассматривается конкурирующая гипотеза 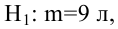 а критическая область задана неравенством
а критическая область задана неравенством 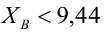 Найти вероятность ошибок I рода и II рода.
Найти вероятность ошибок I рода и II рода.
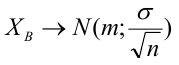
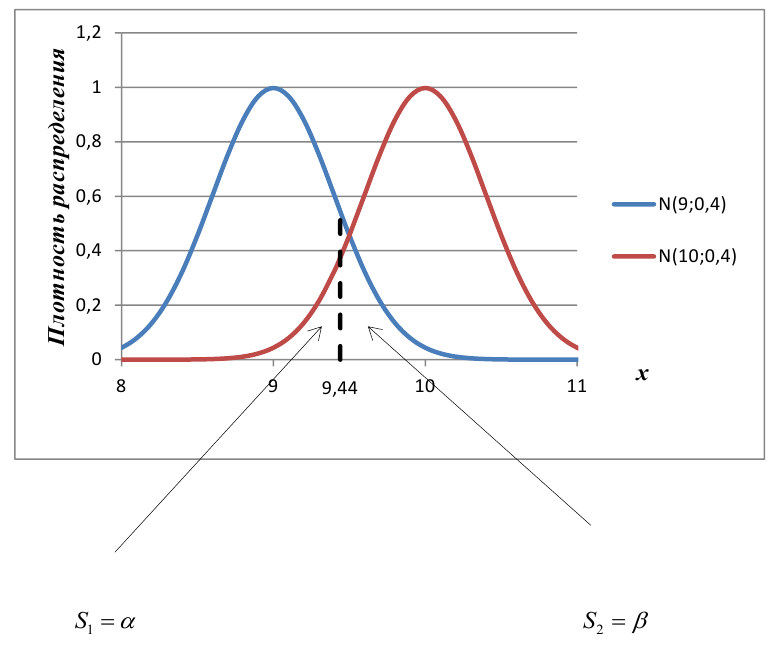
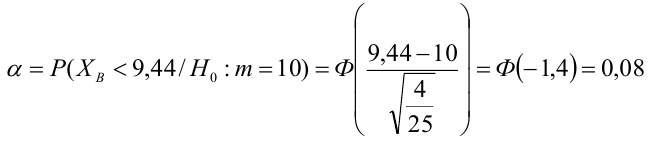
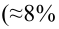 автомобилей имеют меньший расход топлива)
автомобилей имеют меньший расход топлива)
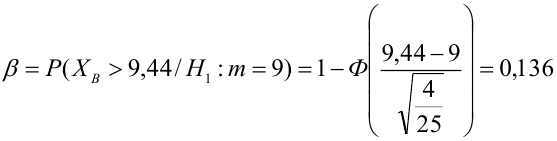
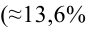 автомобилей, имеющих расход топлива 9л на 100 км, классифицируются как автомобили, имеющие расход 10 литров).
автомобилей, имеющих расход топлива 9л на 100 км, классифицируются как автомобили, имеющие расход 10 литров).
Определение. Пусть проверяется 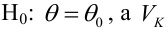 — критическая область критерия с заданным уровнем значимости
— критическая область критерия с заданным уровнем значимости 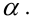 Функцией мощности критерия
Функцией мощности критерия 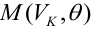 называется вероятность отклонения
называется вероятность отклонения 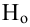 как функция параметра
как функция параметра 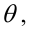 т.е.
т.е.
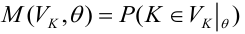
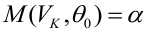 — ошибка 1-ого рода
— ошибка 1-ого рода
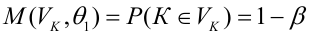 — мощность критерия
— мощность критерия
Пример:
Построить график функции мощности из примера 2 для 
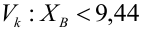 попадает в критическую область.
попадает в критическую область.
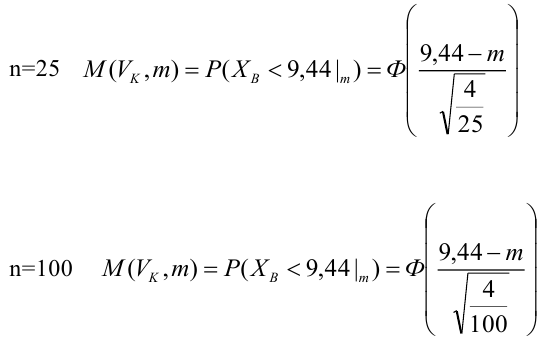
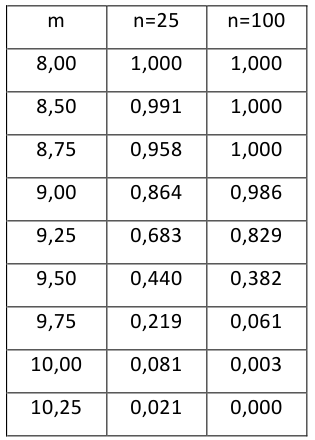
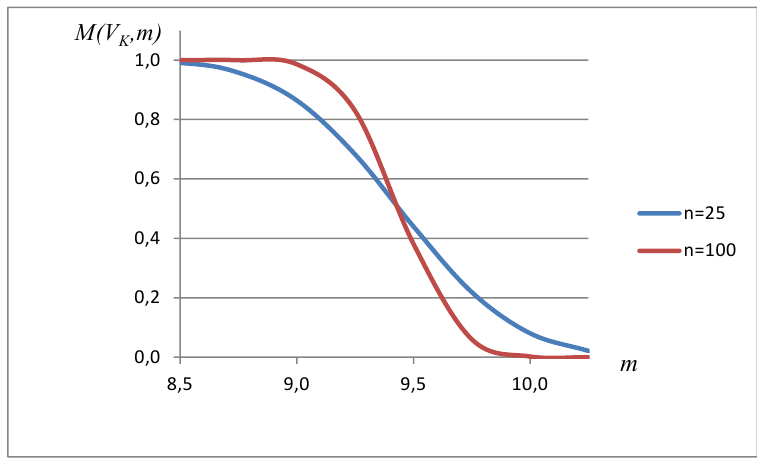
Пример:
Какой минимальный объем выборки следует взять в условии примера 2 для того, чтобы обеспечить 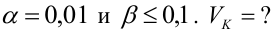
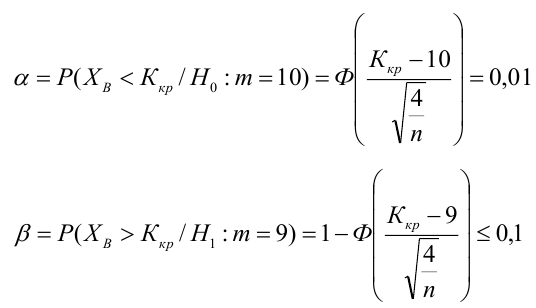
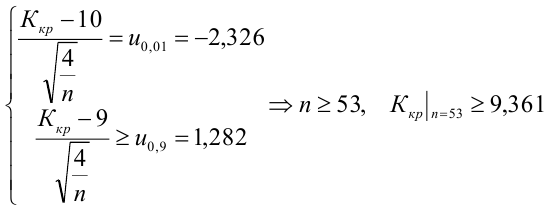
Лемма Неймана-Пирсона.
При проверке простой гипотезы 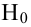 против простой альтернативной гипотезы
против простой альтернативной гипотезы 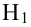 наилучшая критическая область (НКО) критерия заданного уровня значимости
наилучшая критическая область (НКО) критерия заданного уровня значимости 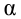 состоит из точек выборочного пространства (выборок объема
состоит из точек выборочного пространства (выборок объема 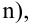 для которых справедливо неравенство:
для которых справедливо неравенство:
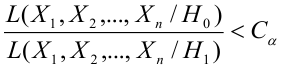
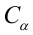 — константа, зависящая от
— константа, зависящая от 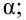
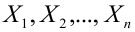 — элементы выборки;
— элементы выборки;
 — функция правдоподобия при условии, что соответствующая гипотеза верна.
— функция правдоподобия при условии, что соответствующая гипотеза верна.
Пример:
Случайная величина  имеет нормальное распределение с параметрами
имеет нормальное распределение с параметрами 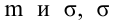 известно. Найти НКО для проверки
известно. Найти НКО для проверки 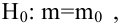 против
против  причем
причем 
Решение:
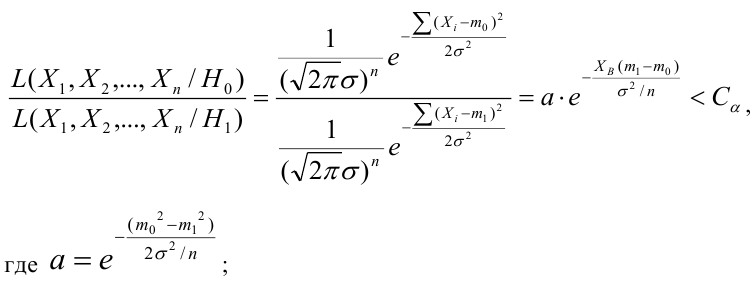
Ошибка первого рода: 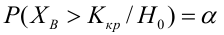
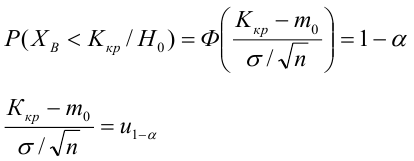
НКО: 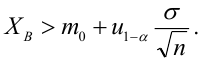
Пример:
Для зависимости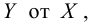 заданной корреляционной табл. 13, найти оценки параметров
заданной корреляционной табл. 13, найти оценки параметров 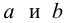 уравнения линейной регрессии
уравнения линейной регрессии 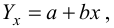 остаточную дисперсию; выяснить значимость уравнения регрессии при
остаточную дисперсию; выяснить значимость уравнения регрессии при 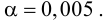
Решение. Воспользуемся предыдущими результатами
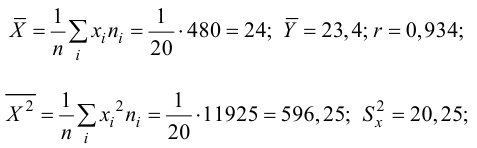
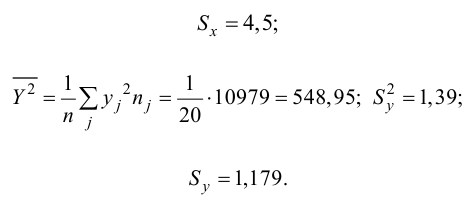
Согласно формуле (24), уравнение регрессии будет иметь вид 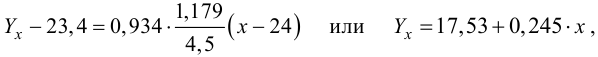 тогда
тогда 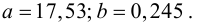
Для выяснения значимости уравнения регрессии вычислим суммы  Составим расчетную таблицу:
Составим расчетную таблицу:
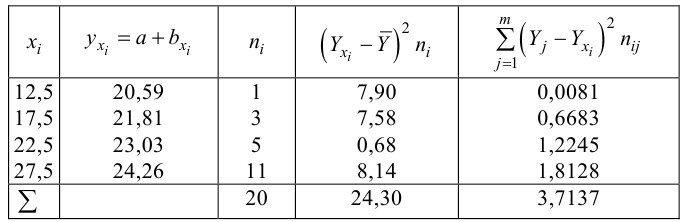
Из (27) и (28) по данным таблицы получим 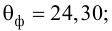
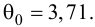
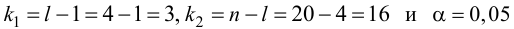 по табл. П7 находим
по табл. П7 находим 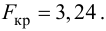
Вычислим статистику
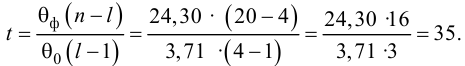
Так как 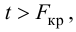 то уравнение регрессии значимо. Остаточная дисперсия равна
то уравнение регрессии значимо. Остаточная дисперсия равна 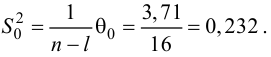
- Корреляционный анализ
- Статистические решающие функции
- Случайные процессы
- Выборочный метод
- Проверка гипотезы о равенстве вероятностей
- Доверительный интервал для математического ожидания
- Доверительный интервал для дисперсии
- Проверка статистических гипотез
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Регрессионный анализ в Excel
Показывает влияние одних значений (самостоятельных, независимых) на зависимую переменную. К примеру, как зависит количество экономически активного населения от числа предприятий, величины заработной платы и др. параметров. Или: как влияют иностранные инвестиции, цены на энергоресурсы и др. на уровень ВВП.
Результат анализа позволяет выделять приоритеты. И основываясь на главных факторах, прогнозировать, планировать развитие приоритетных направлений, принимать управленческие решения.
Регрессия бывает:
- линейной (у = а + bx);
- параболической (y = a + bx + cx2);
- экспоненциальной (y = a * exp(bx));
- степенной (y = a*x^b);
- гиперболической (y = b/x + a);
- логарифмической (y = b * 1n(x) + a);
- показательной (y = a * b^x).
Рассмотрим на примере построение регрессионной модели в Excel и интерпретацию результатов. Возьмем линейный тип регрессии.
Задача. На 6 предприятиях была проанализирована среднемесячная заработная плата и количество уволившихся сотрудников. Необходимо определить зависимость числа уволившихся сотрудников от средней зарплаты.

Модель линейной регрессии имеет следующий вид:
У = а0 + а1х1 +…+акхк.
Где а – коэффициенты регрессии, х – влияющие переменные, к – число факторов.
В нашем примере в качестве У выступает показатель уволившихся работников. Влияющий фактор – заработная плата (х).
В Excel существуют встроенные функции, с помощью которых можно рассчитать параметры модели линейной регрессии. Но быстрее это сделает надстройка «Пакет анализа».
Активируем мощный аналитический инструмент:
- Нажимаем кнопку «Офис» и переходим на вкладку «Параметры Excel». «Надстройки».
- Внизу, под выпадающим списком, в поле «Управление» будет надпись «Надстройки Excel» (если ее нет, нажмите на флажок справа и выберите). И кнопка «Перейти». Жмем.
- Открывается список доступных надстроек. Выбираем «Пакет анализа» и нажимаем ОК.



После активации надстройка будет доступна на вкладке «Данные».

Теперь займемся непосредственно регрессионным анализом.
- Открываем меню инструмента «Анализ данных». Выбираем «Регрессия».
- Откроется меню для выбора входных значений и параметров вывода (где отобразить результат). В полях для исходных данных указываем диапазон описываемого параметра (У) и влияющего на него фактора (Х). Остальное можно и не заполнять.
- После нажатия ОК, программа отобразит расчеты на новом листе (можно выбрать интервал для отображения на текущем листе или назначить вывод в новую книгу).



В первую очередь обращаем внимание на R-квадрат и коэффициенты.
R-квадрат – коэффициент детерминации. В нашем примере – 0,755, или 75,5%. Это означает, что расчетные параметры модели на 75,5% объясняют зависимость между изучаемыми параметрами. Чем выше коэффициент детерминации, тем качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5 (такой анализ вряд ли можно считать резонным). В нашем примере – «неплохо».
Коэффициент 64,1428 показывает, каким будет Y, если все переменные в рассматриваемой модели будут равны 0. То есть на значение анализируемого параметра влияют и другие факторы, не описанные в модели.
Коэффициент -0,16285 показывает весомость переменной Х на Y. То есть среднемесячная заработная плата в пределах данной модели влияет на количество уволившихся с весом -0,16285 (это небольшая степень влияния). Знак «-» указывает на отрицательное влияние: чем больше зарплата, тем меньше уволившихся. Что справедливо.
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.

Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.

Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:

Корреляционно-регрессионный анализ
На практике эти две методики часто применяются вместе.
Пример:

- Строим корреляционное поле: «Вставка» — «Диаграмма» — «Точечная диаграмма» (дает сравнивать пары). Диапазон значений – все числовые данные таблицы.
- Щелкаем левой кнопкой мыши по любой точке на диаграмме. Потом правой. В открывшемся меню выбираем «Добавить линию тренда».
- Назначаем параметры для линии. Тип – «Линейная». Внизу – «Показать уравнение на диаграмме».
- Жмем «Закрыть».




Теперь стали видны и данные регрессионного анализа.
Будем использовать
алгоритм пошагового
регрессионного анализа с последовательным
исключением незначимых регрессоров,
пока все входящие в регрессионную
модель факторы не будут иметь значимые
коэффициенты.
Построение и
оценка регрессионной модели осуществляется
в Excel
с помощью модуля регрессии пакета
анализа данных. (Если по каким-то
причинам недоступен пакет анализа
данных, все основные параметры
регрессионной модели можно получить
с помощью встроенной статистической
функции Excel
ЛИНЕЙН и
остальные расчёты произвести по
формулам, рассматриваемым далее).
Выбираем в меню
(Office
2003)
 СЕРВИС
СЕРВИС
 Анализ
Анализ
данных (Data
Analysis)
Регрессия
(Regression)
или в меню
Office
2007
 ДАННЫЕ
ДАННЫЕ
 Анализ
Анализ
данных (Data
Analysis)
Регрессия
(Regression)
Элементы
диалогового окна «Регрессия»
1. Входной интервал y (Input y Range)
Введите ссылку
на диапазон анализируемых зависимых
данных. Диапазон должен состоять из
одного столбца — зависимой переменной
Y.
2. Входной
интервал X (Input
X
Range)
Введите ссылку
на диапазон независимых данных,
подлежащих анализу. Microsoft Excel располагает
независимые переменные этого диапазона
слева направо в порядке возрастания.
Максимальное число входных диапазонов
равно 16.
Введем массив
объясняющих переменных (X1,
X2,
X3
, X4).
3. Метки (Labels)
Установите
флажок, если первая строка или первый
столбец входного интервала содержит
заголовки. Снимите флажок, если заголовки
отсутствуют; в этом случае подходящие
названия для данных выходного диапазона
будут созданы автоматически.
4. Уровень
надежности
(Confidence Level)
Установите
флажок, чтобы включить в выходной
диапазон дополнительный уровень. В
соответствующее поле введите уровень
надежности, который будет использован
дополнительно к уровню 95%, применяемому
по умолчанию.
Можно указать
здесь ещё какой-нибудь уровень надёжности
– например, 98%, тогда для коэффициентов
регрессии будет построено два интервала
– для γ=0,95
и γ=0,98).
5.
Константа
– ноль
(Constant is Zero)
Установите
флажок, чтобы линия регрессии прошла
через начало координат.
У нас нет такой цели, поэтому этот флажок
нас нет такой цели, поэтому этот флажок
не устанавливаем.
Важное замечание.
Это необходимо
будет сделать тем, у кого на
последнем этапе,
когда в регрессионной модели все
коэффициенты регрессии при всех
факторных признаках Xi
будут
значимы, и
окажется только коэффициент b0
(const)
– незначим. Вот тогда регрессионный
анализ проводят ещё раз, убирая из
анализа эту незначимую константу,
установив соответствующий флажок.
6. Выходной диапазон
Введите ссылку
на левую верхнюю ячейку выходного
диапазона. Отведите, по крайней мере,
семь столбцов для итогового диапазона,
который будет включать в себя: результаты
дисперсионного анализа, коэффициенты
регрессии, стандартную погрешность
вычисления Y, среднеквадратичные
отклонения, число наблюдений, стандартные
погрешности для коэффициентов.
7. Новый лист
Установите
переключатель, чтобы открыть новый
лист в книге и вставить результаты
анализа, начиная с ячейки A1. Если в этом
есть необходимость, введите имя нового
листа в поле, расположенном напротив
соответствующего положения переключателя.
8. Новая книга
Установите
переключатель, чтобы открыть новую
книгу и вставить результаты анализа в
ячейку A1 на первом листе в этой книге.
Пп. 6-8. Лучше всего
выводить результаты регрессионного
анализа на отдельный лист (выбрать
п.7).
9. Остатки
(Residuals)
Установите
флажок, чтобы включить остатки в выходной
диапазон.
10. Стандартизированные
остатки
(Standardized Residuals)
Установите
флажок, чтобы включить стандартизированные
остатки в выходной диапазон.
Пп. 9-10. Флажки в
Остатки
и Стандартизованные
остатки
имеет смысл установить на самом
последнем этапе пошагового регрессионного
анализа, когда все коэффициенты
регрессионной модели значимы.
11. График
остатков
Установите
флажок, чтобы построить диаграмму
остатков для каждой независимой
переменной.
12. График
подбора
Установите
флажок, чтобы построить диаграммы
наблюдаемых и предсказанных значений
для каждой независимой переменной.
13. График
нормальной вероятности
Установите
флажок, чтобы построить диаграмму
нормальной вероятности.
Эти графики
(пп.11,12,13) в рамках данного исследования
строить не нужно.
Итак, приступаем
к анализу.
I
ЭТАП РЕГРЕССИОННОГО АНАЛИЗА.
В модель включены
все факторные признаки (X1,
X2,
X3
, X4).
Результаты
регрессионного анализа выдаются в
следующем виде (в скобках указаны
принятые у нас обозначения):
|
ВЫВОД |
||||||||
|
Регрессионная |
||||||||
|
Множественный |
0,75322 |
|||||||
|
R-квадрат |
0,56735 |
|||||||
|
Нормированный |
0,49812 |
|||||||
|
Стандартная |
4,09622 |
|||||||
|
Наблюдения |
30 |
|||||||
|
Дисперсионный |
||||||||
|
df
(число |
SS
(сумма |
MS
(средний |
F
(Fнабл= |
Значимость |
||||
|
Регрессия |
4 |
550,065 |
137,5163 |
8,195725 |
0,000229 |
|||
|
Остаток |
25 |
419,476 |
16,77902 |
|||||
|
Итого |
29 |
969,541 |
||||||
|
Коэффи-циенты (bi) |
Стандартная (Ŝbi) |
t-ста-тистика (tнабл) |
P-Значение |
Нижние |
Верхние |
Нижние |
Верхние |
|
|
Y-пересечение |
17,28356 |
6,62546 |
2,6087 |
0,0151 |
3,6382 |
30,9290 |
0,8186 |
33,7485 |
|
Переменная |
-0,50132 |
0,14108 |
-3,5534 |
0,0015 |
-0,7919 |
-0,2108 |
-0,8519 |
-0,1507 |
|
Переменная |
6,22430 |
2,20638 |
2,8210 |
0,0092 |
1,6802 |
10,7684 |
0,7412 |
11,7074 |
|
Переменная |
-0,21218 |
0,47694 |
-0,4449 |
0,6602 |
-1,1945 |
0,7701 |
-1,3974 |
0,9731 |
|
Переменная |
-0,05118 |
0,02013 |
-2,5423 |
0,0176 |
-0,0926 |
-0,0097 |
-0,1012 |
-0,0012 |
В регрессионной
статистике
указываются множественный коэффициент
корреляции (Множественный
R)
и
детерминации (R-квадрат)
между Y
и массивом факторных признаков (что
совпадает с полученными ранее значениями
в корреляционном анализе).
Средняя часть
таблицы (Дисперсионный
анализ)
необходима
для проверки значимости уравнения
регрессии.
Нижняя часть
таблицы – точечные оценки bi
генеральных
коэффициентов регрессии βi,
проверка
их значимости и интервальная оценка.
Оценка вектора
коэффициентов b
(столбец
Коэффициенты):

Тогда оценка
уравнения регрессии имеет вид:
![]()
Необходимо
проверить значимость уравнения регрессии
и полученных коэффициентов регрессии.
Проверим на уровне
α=0,05
значимость уравнения регрессии, т.е.
гипотезу H0:
β1=β2=β3=…=βk=0.
Для этого рассчитывается наблюдаемое
значение F-статистики:

Excel
выдаёт это в результатах дисперсионного
анализа:

В столбце F
указывается значение Fнабл.
По таблицам
F-распределения
(см. Приложение, таб. П.2.3) или с помощью
встроенной статистической функции
FРАСПОБР
для уровня значимости α=0,05
и числа степеней свободы числителя
ν1=k=4
и знаменателя ν2=n—k—1=25
находим критическое значение
F-статистики,
равное
Fкр
=
2,75871
Так как наблюдаемое
значение F-статистики
превосходит ее критическое значение
8,1957 > 2,7587, то гипотеза о равенстве
вектора коэффициентов отвергается с
вероятностью ошибки, равной 0,05.
Следовательно, хотя бы один элемент
вектора β=(β1,β2,β3,β4)T
значимо отличается от нуля.
Проверим значимость
отдельных коэффициентов уравнения
регрессии, т.е. гипотезу
![]() .
.
Проверку значимости
регрессионных коэффициентов проводят
на основе t-статистики
![]() для уровня значимости
для уровня значимости![]() .
.
Наблюдаемые
значения t-статистик
указаны в таблице результатов в столбце
t-статистика.
-
Коэффициенты
(bi)
t-статистика
(tнабл)
Y-пересечение
b0
=
17,283562,6087
Переменная
X1b1
=
-0,50132-3,5534
Переменная
X2b2
=
6,224302,8210
Переменная
X3b3
=
-0,21218-0,4449
Переменная
X4b4
=
-0,05118-2,5423
При отсутствии
пакета анализа данных, t-статистики
можно получить, исходя из результатов
оценки коэффициентов модели и их
стандартных ошибок:
![]()
![]()
![]()
![]()
![]()
Их необходимо
сравнить с критическим значением tкр,
найденным для уровня значимости α=0,05
и числа степеней свободы ν=n
– k
— 1.
Для этого используем
встроенную статистическую функцию
Excel СТЬЮДРАСПОБР,
введя в
предложенное меню вероятность α=0,05 и
число степеней свободы ν=
n–k-1=30-4-1=25.
(Можно найти значения tкр
по таблицам математической статистики
(см. Приложение, таб. П.2.2)).
Получаем
tкр=2,05953854.
Для
![]()
![]() наблюдаемое значениеt-статистики
наблюдаемое значениеt-статистики
больше критического по модулю
![]()
![]()
Следовательно,
гипотеза о равенстве нулю этих
коэффициентов отвергается с вероятностью
ошибки, равной 0,05, т.е. соответствующие
коэффициенты значимы.
Для
![]() наблюдаемое значениеt-статистики
наблюдаемое значениеt-статистики
меньше критического значения по модулю
![]() ,
,
следовательно, гипотезаH0
не отвергается, т.е.
![]() — незначим.
— незначим.
Значимость
регрессионных коэффициентов проверяют
и следующие столбцы результирующей
таблицы:
Столбец p-значение
показывает значимость параметров
модели граничным 5%-ым уровнем, т.е. если
p≤0,05,
то соответствующий коэффициент считается
значимым, если p>0,05,
то незначимым.
И последние столбцы
– нижние
95% и
верхние 95%
и нижние
98% и
верхние 98% — это
интервальные оценки регрессионных
коэффициентов с заданными уровнями
надёжности для γ=0,95
(выдаётся всегда) и
γ=0,98 (выдаётся
при установке соответствующей
дополнительной надёжности).
Если нижние и
верхние границы имеют одинаковый знак
(ноль не входит в доверительный интервал),
то соответствующий коэффициент регрессии
считается значимым, в противном случае
– незначимым..
Как видно из
таблицы, для коэффициента β3
p—значение
p=0,6602
>0,05 и
доверительные интервалы включают ноль,
т.е. по всем проверочным критериям этот
коэффициент является незначимым.
Согласно алгоритму
пошагового регрессионного анализа с
исключением незначимых регрессоров,
на следующем этапе необходимо исключить
из рассмотрения переменную X3
(фондовооруженность труда), имеющую
незначимый коэффициент регрессии
![]() .
.
В случае, когда
при оценке регрессии выявлено несколько
незначимых коэффициентов, первым из
уравнения регрессии исключается
регрессор, для которого t-статистика
(![]() )
)
минимальна по модулю.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #