Как составить рейтинг кинофильмов
Собственный рейтинг фильмов можно использовать в самых разных целях: от рекомендаций друзьям до повторного просмотра. Но как его правильно составить, чтобы получился действительно хороший топ?

Вначале определитесь с критериями, которые вы будете оценивать. Во-первых, это должен быть жанр. Бесполезно сравнивать триллер и детский мультфильм, так как они находятся в совершенно разных категориях.
Во-вторых, вам нужно определить основные характеристики, которые вы будете учитывать: игра актеров, дубляж, спецэффекты и так далее. Может быть, вы будете задействовать только субъективную оценку, но это тоже необходимо учитывать.
В-третьих, вы можете составить рейтинг в компании. Так ваш топ получится гораздо правдивее, ведь он учитывает мнение множества людей. Причем, чем больше будет участников, тем достовернее будет рейтинг.
Оценка
Самый простой способ составления рейтинга – выставления оценок. Допустим, вы выбрали 100 фильмов одного жанра и решили расположить их в порядке качества съемки, сюжета и наличия спецэффектов. Сначала поставьте каждому показателю оценку самостоятельно, а затем попросите друзей, рассчитайте среднее значение и укажите результат.
Составляя рейтинг, учитывайте мнение экспертов. Не ленитесь просматривать специализированные журналы, в которых публикуются профессионалы. А также анализируйте чужие рейтинги. Это позволит сделать ваш топ объективнее.
Также неплохо писать комментарии. Это не обязательно должны быть полноценные рецензии, достаточно просто прокомментировать каждый из пунктов. Хорошо, если каждый из участников тоже отпишется. Однако, чем больше фильмов будет в рейтинге, тем меньше письменных отзывов вы получите.
Оформление
Тут тоже многое зависит от жанра. Допустим, если вы делаете обзор комедий, то можно использовать светлый фон и смешные скриншот. Составляя рейтинг ужасов, используйте темные цвета, кровь и страшные моменты из фильмов.
Подобные рейтинги лучше публиковать на блоговых ресурсах. Как правило, там находится целевая аудитория подобных проектов и вы сможете получить больше одобрений. Вам могут указать на недочеты и помочь с последующим составлением.
Вначале укажите название кинофильмов и его краткое содержание. Это необходимо, что ознакомить пользователей с картиной. Затем укажите несколько фрагментов и оценку. После этого поясните оценку и переходите к следующему пункту.
Лучше всего пользователи воспринимают рейтинги, изготовленные в виде длинных картинок, так как их удобно просматривать, однако html-версии тоже приветствуются. Оптимальный размер топа: 7-10 фильмов.
Видео по теме
И такая есть
Если вы вдруг не согласны с Академией кинематографических искусств и наук по поводу недавно врученных Оскаров, то это прекрасно! Вы ведь можете самостоятельно отсмотреть весь прошлогодний пул и составить свой рейтинг.
Но как добиться объективности и минимизировать влияние эмоций? Легко! (На самом деле сложно, но возможно)
Метод Кинопоиска в виде одинокой эмоциональной цифры сразу отметаем. Оценка такого комплексного произведения должна учитывать множество факторов. Короче говоря, нам нужна формула. И у меня такая есть! Со времен первой редакции она существенно изменилась и теперь выглядит так:
Красиво, но не понятно. Это ядерная физика?
Расшифровываю. На самом деле все достаточно просто:
- DIR ー режиссура, максимальный балл ー 8;
- OPE ー операторская работа, максимальный балл ー 8;
-
SCE ー сценарий, максимальный балл ー 8;
- ACT ー работа актерского состава, максимальный балл ー 8;
-
EDI ー монтаж, максимальный балл ー 8;
-
D&C ー декорации и костюмы максимальный балл ー 5;
-
M&S ー музыка и звук, максимальный балл ー 5;
-
IMP ー коэффициент впечатлений (те самые эмоции, влияние которых на итоговый балл мы и пытаемся уменьшить). Оцениваем в диапазоне от 1 (фильм совсем не впечатлил) до 1,4 (фильм очень впечатлил).
Вот что получается. Если вы посмотрели идеальный фильм и выставили максимальные оценки, то получите итоговый балл 10 (но не думаю, что это достижимо):
((8 + 8 + 8 + 8 + 8 + 5 + 5) * 1,4) / 7 = 10
Уверен, что вы заметили отсутствие в списке критериев важной составляющей ー визуальных эффектов. В начальной редакции нашей чудо-формулы эти самые эффекты были, но их пришлось убрать. Дело в том, что почти половина хороших фильмов обходятся без CGI. Если кино построено на графике, то это просто скажется на других компонентах из нашего списка.
Теперь важный момент! Как сохранить объективность при оценке каждого компонента? Есть хороший совет. Вспомните фильм, который вы много раз смотрели и считаете его абсолютным середнячком. Дальше просто решаем, насколько оцениваемое кино лучше (или хуже) нашей образцовой посредственности. Работает надежно.
Да, это все равно очень субъективное оценивание. Но ведь мы работаем для себя и в свое удовольствие, а значит все хорошо.
Вот как это выглядит на практике. Пока я посмотрел только два фильма из оскаровского пула (непреодолимые обстоятельства в виде года боевых действий в стране). Это «Все везде и сразу» и «Банши Инишерина».
Все везде и сразу: ((6+7+5+7+7+3+3) × 1.2) / 7 = 6.51
(Кинопоиск: 7,3. IMDb: 7,9)
Банши Инишерина: ((7+7+7+7+6+3+3) × 1.3) / 7 = 7.42
(Кинопоиск: 7,5. IMDb: 7,7)
Отличная формула! Даже у Антона Долина такой нет!

IMDb расшифровывается как интернет-база кино (Internet movie data-base). Сайт агрегирует информацию о фильмах, режиссерах, актерах и фестивалях, создавая крупнейшую в интернете библиотеку. Ее ежемесячно посещают 500 миллионов пользователей, а сайт занимает 53-е место в мировом рейтинге (данные SimilarWeb).
Одной из ключевых причин такой популярности стали рейтинги IMDb, с которыми пользователи регулярно сверяются при выборе фильмов и сериалов.
Топ-5 рейтинга 250 фильмов IMDb
Как рассчитывается рейтинг IMDb
На сайте много рейтингов, но самыми популярными остаются списки 250 лучших фильмов и 250 лучших сериалов.
Любой проект оценивается пользователями по шкале от 1 до 10. На основе их голосов высчитывается средневзвешенное значение (не путать со средним арифметическим). Если коротко, то главное отличие между ними в весе голосов. При расчете среднего арифметического они имели бы одинаковый вес, поэтому в топ могла бы попасть малоизвестная картина, которой десять человек поставили бы десять баллов. Чтобы избежать таких ситуаций, ввели расчет средневзвешенного значения.
Средневзвешенный рейтинг = (v ÷ (v+m)) × R + (m ÷ (v+m)) × C
R = общий рейтинг сериала или фильма
v = число голосов за фильм
m = минимум голосов, требуемый для участия в списке 250 (сейчас – 25000)
C = среднее значение всего рейтинга
Достоверности рейтингам 250 IMDb добавляют дополнительные ограничения:
- Учитываются голоса только тех пользователей, которые голосуют регулярно (критерии, по которым пользователя считают регулярно голосующим, специально не раскрываются);
- Рейтинг обновляется несколько раз в день;
- Искусственные накрутки или занижения отслеживаются системой IMDb. Если их обнаружат, то сайт поменяет способ расчета рейтинга (его принципы не раскрываются).
- В случае с сериалами рейтинги выставляются как отдельным сериям, так и целому сезону. Особенно это удобно при просмотре антологий вроде «Черного зеркала».
Топ-5 серий «Черного зеркала» IMDb
Можно ли доверять рейтингу IMDb
Сайт предупреждает, что рейтинг «точен» только в том смысле, что рассчитывается по последовательной схеме. «Думайте о рейтингах больше как о руководстве, чем как о неопровержимом качественном вердикте».
IMDb не может установить, действительно ли человек смотрел фильм и действительно ли он ставит ту оценку, которую считает нужной. IMDb полагается на коллективное мнение сообщества и считает, что оно способно нивелировать намеренное занижение или завышение оценок.
Разница между рейтингами IMDb и «Кинопоиска»
Механика расчета в общем одинаковая: оба сайта рассчитывают рейтинг по средневзвешенному значению, в обоих случаях голоса принимаются только от постоянных пользователей, на обоих сайтах действует система защиты от накруток. Разница в том, что на «Кинопоиске» до рейтинга допускают фильмы минимум с 500 голосов (против 25000 у IMDb), а оценки учитывают только за последний год.
Хотя некоторые позиции в рейтингах похожи (в топ-10 половина фильмов одинаковые), есть и различия. Например, на «Кинопоиске» больше советских фильмов. Это объясняется разницей аудиторий.
IMDb работает на глобальном уровне, в то время как «Кинопоиск» агрегирует русскоязычных пользователей. Это подтверждает и статистика: 145 миллионов пользователей в месяц у «Кинопоиска» против 500 миллионов у IMDb, 266-е место в мировом рейтинге против 53-го.
Получается, что рейтинг «Кинопоиска» больше отражает локальные предпочтения аудитории, в то время как рейтинг IMDb – глобальные (как минимум, предпочтения западной аудитории).
Кто и как вершит судьбу фильмов: всё, что нужно знать о кинорейтингах
Каждый из нас слышал про различные кинорейтинги – главным образом, конечно, IMDb, но и другие списки «лучших из лучших» по версии тех или иных авторитетных журналов и ассоциаций. Зачастую как раз они становятся лучшим источником идей, когда встает вопрос, что бы такого посмотреть сегодня вечером, ну а гениальность кинолент, занимающих первые строчки, вроде того же «Побега из Шоушенка» или «Списка Шиндлера», пожалуй, ни у кого не вызывает сомнения. Но как составляются эти рейтинги, кто вершит судьбы фильмов, почему интересные, талантливые и оригинальные, казалось бы, картины не попадают в эти списки и правда ли, что только у творений голливудских режиссеров есть шанс попасть туда? Итак, обо всем по порядку.
Аббревиатура IMDb расшифровывается как Internet Movie Database – «интернет-база кинофильмов». Это не какое-то умудренное опытом сообщество кинокритиков, а просто крупнейший в мире портал о кинематографе. В его базе более 2,5 млн фильмов разных лет и стран, а также информация о сериалах, актерах, режиссерах. Вот этот сайт: imdb.com. Голосуют здесь не профессиональные кинокритики, а мы с вами – обыкновенные зрители, которым есть что сказать о том или ином фильме. Правда, для этого необходимо залогиниться через одну из международных социальных сетей – например, через Facebook, Google или же Amazon, которому в настоящее время и принадлежит ресурс.
Голосовать за один фильм можно только единожды – это чтобы друзья малоизвестного кинорежиссера не накручивали рейтинг. По мере увеличения количества оценок и вычисляется средний рейтинг фильма – причем делается это по сложной формуле, где учитывается и средняя оценка для фильма, и количество проголосовавших, и минимальное количество голосов, необходимых для выставления балла. При этом, опять же, чтобы отсечь рьяных друзей малоизвестного режиссера, создатели портала учитывают только голоса тех, кто регулярно оценивает киноленты.
Вопреки распространенному мнению далеко не все фильмы в рейтинге – американского производства, и если вы изучите список из 250 лучших картин, вы убедитесь в этом. Здесь много европейского кино, значительное количество японских, австралийских картин, даже пара советских. Да-да, настоящее искусство времени неподвластно, а потому в рейтинге соседствуют культовые фильмы 30-х – 40-х годов и современные блокбастеры, сравнительно недавно вышедшие в прокат. Последних, впрочем, действительно меньше, потому что хорошее кино – это ведь как хорошее вино: со временем становится только лучше, и должно, что называется, «выстояться». Пожалуй, в этом списке есть фильмы из каждого десятилетия.
По части разнообразных кинорейтингов впереди планеты всей Америка. Оно и понятно: все-таки в этой стране самая мощная индустрия кино, в которую вкладываются невероятные деньги. Есть, впрочем, и некоммерческие организации – например, Американский институт киноискусства. (www.afi.com) Он существует еще с 1967 года. Периодически институт публикует свои рейтинги. Как правило, это к чему-то приурочено – например, к 100-летию американского кино. Среди списков, опубликованных этой организацией – 100 лучших фильмов, 100 звезд, 100 комедий, 100 остросюжетных фильмов, 100 страстей, 100 героев и злодеев, 100 киноцитат, 25 саундтреков, 25 мюзиклов, 100 вдохновляющих фильмов, 10 фильмов из 10 жанров. Ознакомиться с этими рейтингами можно на сайте Института. Эта версия несколько отличается от подборки IMDb.
А вот Американская киноассоциация (mpaa.org) имеет, скорее, социальную направленность и рейтинги свои публикует исходя из ограничений для аудитории – чаще всего возрастных. В настоящее время любому из выходящих в прокат американских фильмов присваивается определенная категория. Например, G – General audiences – означает, что фильм демонстрируется для зрителей всех возрастов и не содержит ничего неприемлемого, а NC-17 предупреждает, что детей до 18 лет лучше не допускать к просмотру. Для составления этого рейтинга создана особая комиссия, каждый из членов которой голосует. Режиссер, если не согласен с вердиктом, подает апелляцию, и тогда созывают повторную комиссию с большим количеством участников. Все обсуждается повторно, но решение этой комиссии уже не подлежит обсуждению – разве что режиссер может перемонтировать или вырезать «проблемные» сцены.
На отечественном ресурсе Кинопоиск (kinopoisk.ru) – система практически та же, что и на IMDb, только ориентирован сайт в большей степени на отечественное кино. Рейтинг формируется исходя из оценки большинства голосующих, но чем больше человек обозначил свое мнение насчет фильма, тем объективнее эта отметка. Обыкновенно у лент, которые хорошо раскручивались, но на деле не являются настолько уж выдающимися, в первые дни после проката рейтинг завышен, а потом всегда опускается. Бывает и наоборот: рейтинг объективно вырастает после того, как зрители «распробуют» кино. Впрочем, предсказать динамику практически невозможно. «Всплески» голосований могут быть связаны с какими-то датами, событиями в жизни главных актеров, трансляциями фильма по ТВ – да мало ли чем можно подогреть интерес к уже довольно старым кинолентам!
Конечно, любой кинорейтинг достаточно субъективен, но ведь никаких откровенно третьесортных лент, снискавших, тем не менее, популярность, в подобных списках обычно нет. Чаще всего получается подборка – иногда интерактивная – по-настоящему качественного кино. Все-таки большая часть голосующих – не вредные невежды, а люди, которые знают толк в хороших фильмах и любят их. Пожалуй, такой компании можно доверять свой досуг на вечер.
Как мы учились рекомендовать фильмы и почему не стоит полагаться только на оценки
Время на прочтение
8 мин
Количество просмотров 16K

Представьте, что вы хотите провести вечер за просмотром фильма, но не знаете, какой выбрать. Пользователи Яндекса часто оказываются в такой же ситуации, поэтому наша команда разрабатывает рекомендации, которые можно встретить в Поиске и Эфире. Казалось бы, что тут сложного: берём оценки пользователей, с их помощью обучаем машину находить фильмы, которым с высокой вероятностью поставят 5 баллов, получаем готовый список фильмов. Но этот подход не работает. Почему? Вот об этом я сегодня и расскажу вам.
Немного истории. В далёком 2006 году Netflix запустила конкурс по машинному обучению Netflix Prize. Если вы вдруг забыли, тогда компания ещё не занималась стримингом в интернете, а сдавала в прокат фильмы на DVD. Но уже тогда ей было важно предугадывать оценку пользователя, чтобы что-то рекомендовать ему. Итак, суть конкурса: предсказать оценки зрителей на 10% лучше (по метрике RMSE), чем Cinematch, рекомендательная система Netflix. Это было одно из первых массовых соревнований такого рода. Интерес подогревал огромный датасет (больше 100 миллионов оценок), а также приз в 1 млн долларов.
Конкурс закончился в 2009 году. Команды BellKor’s Pragmatic Chaos и The Ensemble пришли к финишу с одинаковым результатом (RMSE = 0,8567), но The Ensemble заняла второе место, потому что отправила решение на 20 минут позже конкурентов. Результаты и работы можно найти тут. Но самое интересное в другом. Если верить неоднократным рассказам на профильных конференциях, алгоритмы-победители так и не оказались в продакшене в запущенном вскоре сервисе видеостриминга. Я не могу говорить о причинах чужих решений, но расскажу, почему мы поступили аналогичным образом.
Персональный рейтинг
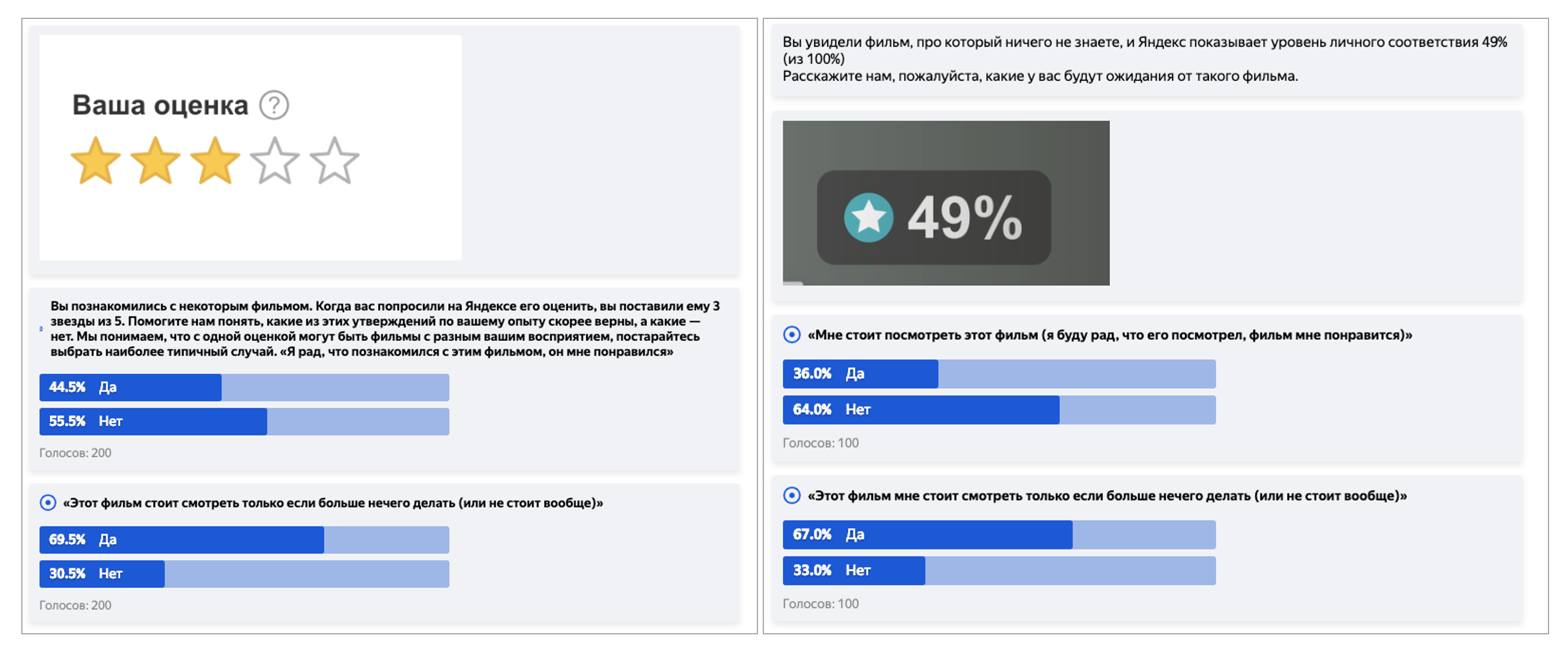
Уже достаточно давно пользователи Яндекса могут оценивать просмотренные фильмы. Причём не только на КиноПоиске, но и в результатах поиска. Со временем у нас накопились сотни миллионов оценок десятков миллионов людей. В какой-то момент мы решили воспользоваться этими данными, чтобы помочь пользователям понять, насколько тот или иной фильм им понравится. По сути, мы решали ту же задачу, что и на конкурсе Netflix Prize, то есть предсказывали, какую оценку пользователь поставит фильму. На тот момент уже существовали рейтинги КиноПоиска и IMDB, которые строились на основе оценок людей. Мы же строили персональный рейтинг, поэтому решили использовать отдельную шкалу в процентах, чтобы избежать визуального сходства и путаницы.

Кстати, необходимость соотнести балльную шкалу и процентную — это отдельная неочевидная головная боль, поэтому коротко расскажу и о ней. Казалось бы, для 10-балльной шкалы возьмите по 10% на каждый балл — и дело в шляпе. Но нет. Причина в психологии и привычках. Например, с точки зрения пользователей, оценка 8/10 — это сильно лучше, чем 80%. Как такое соотнести? С помощью краудсорсинга! Так мы и поступили: запустили задание в Толоке, в котором толокеры описывали ожидания от фильмов с определённым баллом или процентом персонального рейтинга. На основе такой разметки мы подобрали функцию, которая переводит предсказание оценки из балльной в процентную так, чтобы при этом сохранялись ожидания пользователей.
Пример заданий в Толоке
Предсказывать ожидания от фильма полезно, но хорошо бы ещё и рекомендации строить. То есть сразу показывать человеку список хороших фильмов. В этот момент многие из вас могли подумать: «А давайте просто отсортируем по персональному рейтингу те фильмы, которые пользователь ещё не смотрел». Мы тоже так подумали сначала. Но затем пришлось решать две проблемы.
Проблема инструмента
Когда пользователь ищет определённый фильм (или хочет взять конкретный DVD напрокат), то сервис должен предсказать оценку именно этого фильма. Ровно эта задача и решалась на конкурсе Netflix Prize, где использовалась метрика RMSE. Но в рекомендациях решается другая задача: нужно не угадать оценку, а найти фильм, который и будет в итоге просмотрен. И метрика RMSE плохо справляется с этой задачей. Например, штраф за предсказание оценки 2 вместо 1 точно такой же, как за 5 вместо 4. Но наша система вообще никогда не должна рекомендовать фильмы, которым пользователь поставит 2! Для решения этой задачи гораздо лучше подходят метрики на основе списка, например Precision@K, Recall@K, MRR или NDCG. Не могу не рассказать о них чуть подробнее (но если метрики вам неинтересны, то просто пропустите следующий абзац).
Начнём с метрики MRR (mean reciprocal rank). Будем смотреть, на какой позиции в ранжировании окажется фильм, с которым пользователь взаимодействовал (например, посмотрел или высоко оценил) в тестовом периоде. Метрика MRR — это усреднённая по пользователям обратная позиция такого фильма. То есть
 . Такая метрика, в отличие от RMSE, оценивает список целиком, но, к сожалению, смотрит только на первый угаданный элемент. Впрочем, легко модифицировать метрику, чтобы избавиться от этого недостатка. Мы можем посчитать сумму обратных позиций всех фильмов, с которыми взаимодействовал пользователь. Такая метрика называется Average Reciprocal Hit Rank. Такая метрика учитывает все угаданные фильмы в выдаче. Заметим, что позиция k в выдаче получает вес 1/k за угаданный фильм и вес 0 за другой фильм. Часто вместо 1/k используют 1/log(k): это лучше соответствует вероятности, что пользователь доскроллит выдачу до k позиции. Получится метрика DCG (discounted cumulative gain)
. Такая метрика, в отличие от RMSE, оценивает список целиком, но, к сожалению, смотрит только на первый угаданный элемент. Впрочем, легко модифицировать метрику, чтобы избавиться от этого недостатка. Мы можем посчитать сумму обратных позиций всех фильмов, с которыми взаимодействовал пользователь. Такая метрика называется Average Reciprocal Hit Rank. Такая метрика учитывает все угаданные фильмы в выдаче. Заметим, что позиция k в выдаче получает вес 1/k за угаданный фильм и вес 0 за другой фильм. Часто вместо 1/k используют 1/log(k): это лучше соответствует вероятности, что пользователь доскроллит выдачу до k позиции. Получится метрика DCG (discounted cumulative gain)
 . Но вклад разных пользователей в метрику разный: для кого-то мы угадали все фильмы, для кого-то не угадали ничего. Поэтому, как правило, эту метрику нормируют. Поделим DCG каждого пользователя на DCG наилучшего ранжирования для этого пользователя. Полученная метрика называется NDCG (normalized discounted cumulative gain). Она широко используется для оценки качества ранжирования.
. Но вклад разных пользователей в метрику разный: для кого-то мы угадали все фильмы, для кого-то не угадали ничего. Поэтому, как правило, эту метрику нормируют. Поделим DCG каждого пользователя на DCG наилучшего ранжирования для этого пользователя. Полученная метрика называется NDCG (normalized discounted cumulative gain). Она широко используется для оценки качества ранжирования.
Итак, каждой задаче — своя метрика. А вот следующая проблема уже не такая очевидная.
Проблема выбора
Её достаточно трудно описать, но я попробую. Оказывается, люди ставят высокие оценки не тем фильмам, которые обычно смотрят. Высшие оценки получают редкие киношедевры, классика, артхаус, но это не мешает людям вечером после работы с удовольствием посмотреть неплохую комедию, новый боевичок или эффектную космооперу. Добавьте к этому, что пользователи оценили в Яндексе далеко не все фильмы, которые когда-то и где-то уже посмотрели. И если ориентироваться только на высшие оценки, то мы рискуем получить ленту рекомендованных фильмов, которая будет выглядеть логично, пользователи могут даже признать её качество, но смотреть в итоге ничего не станут.
Например, вот так могла бы выглядеть моя лента фильмов, если бы мы отранжировали её по персональному рейтингу и ничего не знали о моих просмотрах в прошлом. Отличные фильмы. Но пересматривать сегодня я их не хочу.

Получается, что в условиях разрозненности оценок и дефицита фильмов с высоким рейтингом стоит смотреть не только на рейтинг. Хорошо, тогда обучим машину предсказывать просмотр рекомендованного фильма, а не оценку. Казалось бы, логично, ведь пользователь этого и хочет. Что же может пойти не так? Проблема в том, что лента заполнится фильмами, каждый из которых вполне подойдёт для лёгкого времяпровождения вечером, но их персональный рейтинг будет невысок. Пользователи, конечно же, обратят внимание на то, что в ленте нет «шедевров», а значит, доверие к рекомендациям будет подорвано, они не станут смотреть то, что в иных условиях посмотрели бы.
В итоге мы пришли к пониманию, что необходим баланс между двумя крайностями. Нужно обучать машину так, чтобы учитывался и потенциал для просмотра, и восприятие рекомендации человеком.
Как работают наши рекомендации
Наша система — часть Поиска, так что нам нужно строить рекомендации очень быстро: время ответа сервиса должно быть меньше 100 миллисекунд. Поэтому мы стараемся как можно больше тяжёлых операций выполнять в офлайне, на этапе подготовки данных. Все фильмы и пользователи в рекомендательной системе представлены профилями (важно не путать с аккаунтом), которые включают в себя ключи объекта, счётчики и эмбеддинги (проще говоря, векторы в некотором пространстве). Профили фильмов каждый день готовятся на YT (читается как «Ыть») и загружаются в оперативную память машин, которые отвечают на запросы. А вот с пользователями всё немного сложнее.
Каждый день мы также строим основной профиль пользователя на YT и отправляем в хранилище Яндекса, из которого можно получать профиль за пару десятков миллисекунд. Но данные быстро устаревают, если человек активно смотрит и оценивает видео. Нехорошо, если рекомендации начнут отставать. Поэтому мы читаем поток событий пользователя и формируем динамическую часть профиля. Когда человек вводит запрос, мы объединяем профиль из хранилища с динамическим профилем и получаем единый профиль, который всего на несколько секунд может отставать от реальности.
Это происходит в офлайне (то есть заранее), а теперь переходим непосредственно к рантайму. Здесь рекомендательная система состоит из двух шагов. Ранжировать всю базу фильмов слишком долго, поэтому на первом шаге мы просто отбираем несколько сотен кандидатов, то есть находим фильмы, которые могут быть интересны зрителю. Сюда попадают как популярные картины, так и близкие к пользователю по некоторым эмбеддингам. Существует несколько алгоритмов для быстрого нахождения ближайших соседей, мы используем HNSW (Hierarchical Navigable Small World). С его помощью мы находим ближайшие к пользователю фильмы всего за несколько миллисекунд.
На втором шаге мы извлекаем фичи (иногда их ещё называют факторами) по фильмам, пользователю и паре пользователь/фильм и ранжируем кандидатов с помощью CatBoost. Напомню: мы уже поняли, что нужно ориентироваться не только на просмотры, но и на другие характеристики качества рекомендаций, поэтому для ранжирования мы пришли к комбинации нескольких моделей CatBoost, обученных на различные таргеты.
Чтобы находить кандидатов, мы используем эмбеддинги из нескольких матричных разложений: от классического варианта ALS, который предсказывает оценку, до более сложных вариаций на базе SVD++. В качестве фич для ранжирования используются как простые счётчики событий пользователя и фильмы, CTR’ы по разным событиям, так и более сложные предобученные модели. Например, предсказание ALS тоже выступает в роли фичи. Одна из наиболее полезных моделей — нейросеть Recommender DSSM, о которой я, пожалуй, расскажу чуть подробнее.
Recommender DSSM
DSSM — это нейросеть из двух башен. Каждая башня строит свой эмбеддинг, затем между эмбеддингами считается косинусное расстояние, это число — выход сети. То есть сеть учится оценивать близость объектов в левой и правой башне. Подобные нейросети используются, например, в веб-поиске, чтобы находить релевантные запросу документы. Для задачи поиска в одну из башен подаётся запрос, в другую — документ. Для нашей сети роль запроса играет пользователь, а в качестве документов выступают фильмы.
Башня фильма строит эмбеддинг на основе данных о фильме: это заголовок, описание, жанр, страна, актёры и т. д. Эта часть сети достаточно сильно похожа на поисковую. Однако для зрителя мы хотим использовать его историю. Чтобы это сделать, мы агрегируем эмбеддинги фильмов из истории с затуханием по времени с момента события. Затем поверх суммарного эмбеддинга применяем несколько слоёв сети и в итоге получаем эмбеддинг размера 400.
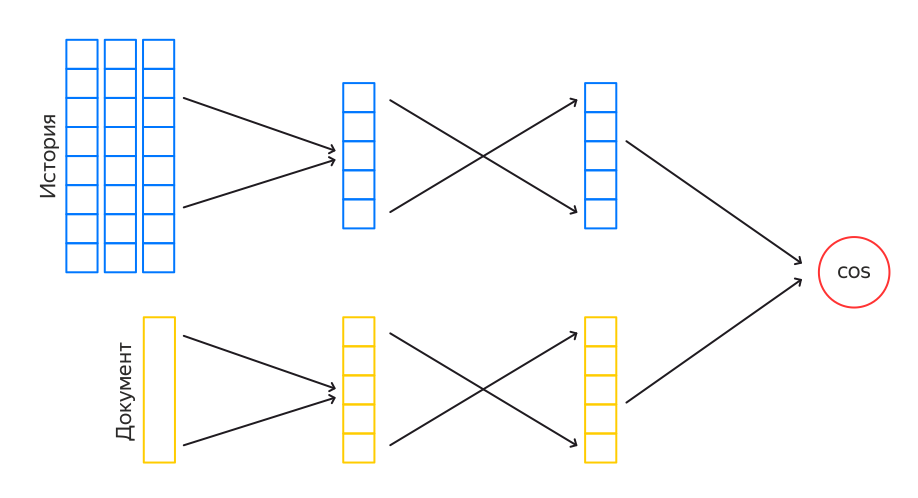
Если учитывать сразу всю историю пользователя в эмбеддинге, то это сильно замедлит обучение. Поэтому идём на хитрость и учим сеть в два этапа. Сначала учится более простой InnerDSSM. На вход он получает только последние 50 событий из истории пользователя без разделения на типы событий (просмотры, оценки…). Затем мы переобучаем полученный InnerDSSM на всей истории пользователя, но уже с разбиением на типы событий. Так получаем OuterDSSM, который и используется в рантайме.
Применение сети в рантайме в лоб требует довольно много вычислительных ресурсов. Поэтому мы сохраняем эмбеддинги из башни фильмов в базе, а эмбеддинги по истории пользователя обновляем near real-time. Таким образом, во время обработки запроса нужно применить только небольшую часть OuterDSSM и посчитать косинусы, это не занимает много времени.
Заключение
Сейчас наши рекомендации уже доступны в нашем поиске (например, по запросу [что посмотреть]), в сервисе Яндекс.Эфир, а ещё адаптированная версия этой технологии применяется в Яндекс.Станции. Но это не значит, что нам можно расслабиться. Мы постоянно обучаем новые модели, применяем всё больше данных, пробуем новые подходы к обучению и новые метрики качества. На мой взгляд, чем старше область, тем сложнее её развивать. Но в этом и заключается главный интерес для специалистов.