Алгоритм нахождения простых чисел
Время на прочтение
3 мин
Количество просмотров 432K
Оптимизация алгоритма нахождения простых чисел
2 3 5 7 11 13 17 19 23 29 31… $250.000…
Дело было давно, в университете, когда мы начали изучать язык программирования Pascal и домашним заданием стало создание алгоритма нахождения простых чисел.
Алгоритм был придуман и тутже реализован на изучаемом языке. Программа запрашивала у пользователя число N и искала все простые числа до N включительно. После первого успешного теста сразу же возникло непреодолимое желание ввести N = «много». Программа работала, но не так быстро как хотелось бы. Естественно, дело было в многочисленных проверках (порядка N*N/2), поэтому пришлось избавиться от лишних. В итоге получилось 5 похожих алгоритмов каждый из которых работал быстре предыдущего. Недавно захотелось их вспомнить и реализовать, но на этот раз на Python.
Итак, поехали. Первый алгоритм, ударивший в студенческую голову, продемонстрирован в Листинге 1.
# Листинг 1
# вводим N
n = input("n=")
# создаем пустой список для хранения простых чисел
lst = []
# в k будем хранить количество делителей
k = 0
# пробегаем все числа от 2 до N
for i in xrange(2, n+1):
# пробегаем все числа от 2 до текущего
for j in xrange(2, i):
# ищем количество делителей
if i % j == 0:
k = k + 1
# если делителей нет, добавляем число в список
if k == 0:
lst.append(i)
else:
k = 0
# выводим на экран список
print lst
Очень быстро понимаешь, что в подсчете делителей каждого числа нет никакой надобности и поэтому переменную k можно освободить от своих обязанностей. Действительно, если хотябы один делитель имеется, то число уже не простое. Смотрим Листинг 2.
# Листинг 2
n = input("n=")
lst = []
for i in xrange(2, n+1):
for j in xrange(2, i):
if i % j == 0:
# если делитель найден, число не простое.
break
else:
lst.append(i)
print lst
Конструкция break позволяет нам завершить выполнение внутреннего цикла и перейти к следующей итерации внешнего.
Далее возникает вопрос: «а зачем делить на 4, если на 2 число не делится?». Приходим к выводу, что искать делители нужно только среди простых чисел не превышающих делимое. Наш алгоритм превращается в… см. Листинг 3.
# Листинг 3
n = input("n=")
lst=[]
for i in xrange(2, n+1):
# пробегаем по списку (lst) простых чисел
for j in lst:
if i % j == 0:
break
else:
lst.append(i)
print lst
А потом вспоминаем теорию чисел и понимаем, что переберать надо только числа, не превосходящие корня из искомого. К примеру, если число M имеет делитель pi, то имеется делитель qi, такой, что pi * qi = M. То есть, чтобы найти пару, достаточно найти меньшее. Среди всех пар, предполагаемая пара с максимальным наименьшим — это пара с равными pi и qi, то есть pi * pi = M => pi = sqrt(M). Смотрим Листинг 4.
# Листинг 4
from math import sqrt
n = input("n=")
lst=[]
for i in xrange(2, n+1):
for j in lst:
if j > int((sqrt(i)) + 1):
lst.append(i)
break
if (i % j == 0):
break
else:
lst.append(i)
print lst
Код из Листинга 4 при N=10000 выполняется примерно в 1000 раз быстрее, чем самый первый вариант. Есть еще один «ускоритель», проверять только те числа, которые заканчиваются на 1, 3, 7 или 9 (так как остальные очевидно делятся на 2 или 5). Наблюдаем Листинг 5.
# Листинг 5
from math import sqrt
n = input("n=")
lst=[]
for i in xrange(2, n+1):
if (i > 10):
if (i%2==0) or (i%10==5):
continue
for j in lst:
if j > int((sqrt(i)) + 1):
lst.append(i)
break
if (i % j == 0):
break
else:
lst.append(i)
print lst
В следствии незначительного изменения Листинга 5 получаем небольшую прибавку в скорости:
# Листинг 6
from math import sqrt
n = input("n=")
lst=[2]
for i in xrange(3, n+1, 2):
if (i > 10) and (i%10==5):
continue
for j in lst:
if j > int((sqrt(i)) + 1):
lst.append(i)
break
if (i % j == 0):
break
else:
lst.append(i)
print lst
Итого: Программа из последнего листинга выполняется, примерно, в 1300 раз быстрее первоначального варианта.
Я не ставил перед собой задачи написать программу максимально быстро решающую данную задачу, это скорее демонстрация начинающим программистам того, что правильно составленный алгоритм играет далеко не последнюю роль в оптимизации Ваших программ.
P.S.
Благодаря замечаниям получаем Листинг 7:
# Листинг 7
n = input("n=")
lst=[2]
for i in xrange(3, n+1, 2):
if (i > 10) and (i%10==5):
continue
for j in lst:
if j*j-1 > i:
lst.append(i)
break
if (i % j == 0):
break
else:
lst.append(i)
print lst
при N=10000, поучаем время:
time 1 = 26.24
time 2 = 3.113
time 3 = 0.413
time 4 = 0.096
time 5 = 0.087
time 6 = 0.083
time 7 = 0.053
Решето Эратосфена:
# Листинг 8
n = input("n=")
a = range(n+1)
a[1] = 0
lst = []
i = 2
while i <= n:
if a[i] != 0:
lst.append(a[i])
for j in xrange(i, n+1, i):
a[j] = 0
i += 1
print lst
Результаты при n = 1 000 000:
time 7 = 7.088
time 8 = 1.143

Сайт переезжает. Большинство статей уже перенесено на новую версию.
Скоро добавим автоматические переходы, но пока обновленную версию этой статьи можно найти там.
Теория чисел
- Простые числа
- Разложение на простые множители
- Решето Эратосфена
- Линейное решето Эратосфена*
- НОД и НОК
- Алгоритм Евклида
- Расширенный алгоритм Евклида*
- Операции по модулю
- Быстрое возведение в степень
- Деление по простому модулю*
Простые числа
Простым называется натуральное число, которое делится только на единицу и на себя. Единица при этом простым числом не считается. Составным числом называют непростое число, которое еще и не единица.
Примеры простых чисел: (2), (3), (5), (179), (10^9+7), (10^9+9).
Примеры составных чисел: (4), (15), (2^{30}).
Еще одно определение простого числа: (N) — простое, если у (N) ровно два делителя. Эти делители при этом равны (1) и (N).
Проверка на простоту за линию
С точки зрения программирования интересно научиться проверять, является ли число (N) простым. Это очень легко сделать за (O(N)) — нужно просто проверить, делится ли оно хотя бы на одно из чисел (2, 3, 4, ldots, N-1) . (N > 1) является простым только в случае, если оно не делится на на одно из этих чисел.
def is_prime(n):
if n == 1:
return False
for i in range(2, n): # начинаем с 2, так как на 1 все делится; n не включается
if n % i == 0:
return False
return True
for i in range(1, 10):
print(i, is_prime(i))(1, False)
(2, True)
(3, True)
(4, False)
(5, True)
(6, False)
(7, True)
(8, False)
(9, False)Проверка на простоту за корень
Алгоритм можно ускорить с (O(N)) до (O(sqrt{N})).
Пусть (N = a times b), причем (a leq b). Тогда заметим, что (a leq sqrt N leq b).
Почему? Потому что если (a leq b < sqrt{N}), то (ab leq b^2 < N), но (ab = N). А если (sqrt{N} < a leq b), то (N < a^2 leq ab), но (ab = N).
Иными словами, если число (N) равно произведению двух других, то одно из них не больше корня из (N), а другое не меньше корня из (N).
Из этого следует, что если число (N) не делится ни на одно из чисел (2, 3, 4, ldots, lfloorsqrt{N}rfloor), то оно не делится и ни на одно из чисел (lceilsqrt{N}rceil + 1, ldots, N-2, N-1), так как если есть делитель больше корня (не равный (N)), то есть делитель и меньше корня (не равный 1). Поэтому в цикле for достаточно проверять числа не до (N), а до корня.
def is_prime(n):
if n == 1:
return False
# Удобно вместо for i in range(2, n ** 0.5) писать так:
i = 2
while i * i <= n:
if n % i == 0:
return False
i += 1
return True
for i in [1, 2, 3, 10, 11, 12, 10**9+6, 10**9+7]:
print(i, is_prime(i))(1, False)
(2, True)
(3, True)
(10, False)
(11, True)
(12, False)
(1000000006, False)
(1000000007, True)Разложение на простые множители
Любое натуральное число можно разложить на произведение простых, и с такой записью очень легко работать при решении задач. Разложение на простые множители еще называют факторизацией.
[11 = 11 = 11^1] [100 = 2 times 2 times 5 times 5 = 2^2 times 5^2] [126 = 2 times 3 times 3 times 7 = 2^1 times 3^2 times 7^1]
Рассмотрим, например, такую задачу:
Условие: Нужно разбить (N) людей на группы равного размера. Нам интересно, какие размеры это могут быть.
Решение: По сути нас просят найти число делителей (N). Нужно посмотреть на разложение числа (N) на простые множители, в общем виде оно выглядит так:
[N= p_1^{a_1} times p_2^{a_2} times ldots times p_k^{a_k}]
Теперь подумаем над этим выражением с точки зрения комбинаторики. Чтобы «сгенерировать» какой-нибудь делитель, нужно подставить в степень (i)-го простого число от 0 до (a_i) (то есть (a_i+1) различное значение), и так для каждого. То есть делитель (N) выглядит ровно так: [M= p_1^{b_1} times p_2^{b_2} times ldots times p_k^{b_k}, 0 leq b_i leq a_i] Значит, ответом будет произведение ((a_1+1) times (a_2+1) times ldots times (a_k + 1)).
Алгоритм разложения на простые множители
Применяя алгоритм проверки числа на простоту, мы умеем легко находить минимальный простой делитель числа N. Ясно, что как только мы нашли простой делитель числа (N), мы можем число (N) на него поделить и продолжить искать новый минимальный простой делитель.
Будем перебирать простой делитель от (2) до корня из (N) (как и раньше), но в случае, если (N) делится на этот делитель, будем просто на него делить. Причем, возможно, нам понадобится делить несколько раз ((N) может делиться на большую степень этого простого делителя). Так мы будем набирать простые делители и остановимся в тот момент, когда (N) стало либо (1), либо простым (и мы остановились, так как дошли до корня из него). Во втором случае надо еще само (N) добавить в ответ.
Напишем алгоритм факторизации:
def factorize(n):
factors = []
i = 2
while i * i <= n: # перебираем простой делитель
while n % i == 0: # пока N на него делится
n //= i # делим N на этот делитель
factors.append(i)
i += 1
# возможно, в конце N стало большим простым числом,
# у которого мы дошли до корня и поняли, что оно простое
# его тоже нужно добавить в разложение
if n > 1:
factors.append(n)
return factors
for i in [1, 2, 3, 10, 11, 12, 10**9+6, 10**9+7]:
print(i, '=', ' x '.join(str(x) for x in factorize(i)))1 =
2 = 2
3 = 3
10 = 2 x 5
11 = 11
12 = 2 x 2 x 3
1000000006 = 2 x 500000003
1000000007 = 1000000007Задание
За сколько работает этот алгоритм?
.
.
.
.
Решение
За те же самые (O(sqrt{N})). Итераций цикла while с перебором делителя будет не больше, чем (sqrt{N}). Причем ровно (sqrt{N}) операций будет только в том случае, если (N) — простое.
А итераций деления (N) на делители будет столько, сколько всего простых чисел в факторизации числа (N). Понятно, что это не больше, чем (O(log{N})).
Задание
Докажите, что число (N) имеет не больше, чем (O(log{N})) простых множителей в факторизации.
Разные свойства простых чисел*
Вообще, про простые числа известно много свойств, но почти все из них очень трудно доказать. Вот еще некоторые из них:
- Простых чисел, меньших (N), примерно (frac{N}{ln N}).
- N-ое простое число равно примерно (Nln N).
- Простые числа распределены более-менее равномерно. Например, если вам нужно найти какое-то простое число в промежутке, то можно их просто перебрать и проверить — через несколько сотен какое-нибудь найдется.
- Для любого (N ge 2) на интервале ((N, 2N)) всегда найдется простое число (Постулат Бертрана)
- Впрочем, существуют сколь угодно длинные отрезки, на которых простых чисел нет. Самый простой способ такой построить — это начать с (N! + 2).
- Есть алгоритмы, проверяющие число на простоту намного быстрее, чем за корень.
- Максимальное число делителей равно примерно (O(sqrt[3]{n})). Это не математический результат, а чисто эмпирический — не пишите его в асимптотиках.
- Максимальное число делителей у числа на отрезке ([1, 10^5]) — 128
- Максимальное число делителей у числа на отрекзке ([1, 10^9]) — 1344
- Максимальное число делителей у числа на отрезке ([1, 10^{18}]) — 103680
- Наука умеет факторизовать числа за (O(sqrt[4]{n})), но об этом как-нибудь в другой раз.
- Любое число больше трёх можно представить в виде суммы двух простых (гипотеза Гольдбаха), но это не доказано.
Решето Эратосфена
Часто нужно не проверять на простоту одно число, а найти все простые числа до (N). В этом случае наивный алгоритм будет работать за (O(Nsqrt N)), так как нужно проверить на простоту каждое число от 1 до (N).
Но древний грек Эратосфен предложил делать так:
Запишем ряд чисел от 1 до (N) и будем вычеркивать числа: * делящиеся на 2, кроме самого числа 2 * затем деляющиеся на 3, кроме самого числа 3 * затем на 5, затем на 7, и так далее и все остальные простые до n. Таким образом, все незачеркнутые числа будут простыми — «решето» оставит только их.
Красивая визуализация
Задание
Найдите этим способом на бумажке все простые числа до 50, потом проверьте с программой:
N = 50
prime = [1] * (N + 1)
prime[0], prime[1] = 0, 0
for i in range(2, N + 1): # можно и до sqrt(N)
if prime[i]:
for j in range(2 * i, N + 1, i): # идем с шагом i, можно начиная с i * i
prime[j] = 0
for i in range(1, N + 1):
if prime[i]:
print(i)2
3
5
7
11
13
17
19
23
29
31
37
41
43
47У этого алгоритма можно сразу заметить несколько ускорений.
Во-первых, число (i) имеет смысл перебирать только до корня из (N), потому что при зачеркивании составных чисел, делящихся на простое (i > sqrt N), мы ничего не зачеркнем. Почему? Пусть существует составное (M leq N), которое делится на %i%, и мы его не зачеркнули. Но тогда (i > sqrt N geq sqrt M), а значит по ранее нами доказанному утверждению (M) должно делиться и на простое число, которое меньше корня. Но это значит, что мы его уже вычеркнули.
Во-вторых, по этой же самое причине (j) имеет смысл перебирать только начиная с (i^2). Зачем вычеркивать (2i), (3i), (4i), …, ((i-1)i), если они все уже вычеркнуты, так как мы уже вычеркивали всё, что делится на (2), (3), (4), …, ((i-1)).
Асимптотика
Такой код будет работать за (O(N log log N)) по причинам, которые мы пока не хотим объяснять формально.
Гармонический ряд
Научимся оценивать асимптотику величины (1 + frac{1}{2} + ldots + frac{1}{N}), которая нередко встречается в задачах, где фигурирует делимость.
Возьмем (N) равное (2^i — 1) и запишем нашу сумму следующим образом: [left(frac{1}{1}right) + left(frac{1}{2} + frac{1}{3}right) + left(frac{1}{4} + ldots + frac{1}{7}right) + ldots + left(frac{1}{2^{i — 1}} + ldots + frac{1}{2^i — 1}right)]
Каждое из этих слагаемых имеет вид [frac{1}{2^j} + ldots + frac{1}{2^{j + 1} — 1} le frac{1}{2^j} + ldots + frac{1}{2^j} = 2^j frac{1}{2^j} = 1]
Таким образом, наша сумма не превосходит (1 + 1 + ldots + 1 = i le 2log_2(2^i — 1)). Тем самым, взяв любое (N) и дополнив до степени двойки, мы получили асимптотику (O(log N)).
Оценку снизу можно получить аналогичным образом, оценив каждое такое слагаемое снизу значением (frac{1}{2}).
Попытка объяснения асимптотики** (для старших классов)
Мы знаем, что гармонический ряд (1 + frac{1}{2} + frac{1}{3} + ldots + frac{1}{N}) это примерно (log N), а значит [N + frac{N}{2} + frac{N}{3} + ldots + frac{N}{N} sim N log N]
А что такое асимптотика решета Эратосфена? Мы как раз ровно (frac{N}{p}) раз зачеркиваем числа делящиеся на простое число (p). Если бы все числа были простыми, то мы бы как раз получили (N log N) из формули выше. Но у нас будут не все слагаемые оттуда, только с простым (p), поэтому посмотрим чуть более точно.
Известно, что простых чисел до (N) примерно (frac{N}{log N}), а значит допустим, что k-ое простое число примерно равно (k ln k). Тогда
[sum_{substack{2 leq p leq N \ text{p is prime}}} frac{N}{p} sim frac{1}{2} + sum_{k = 2}^{frac{N}{ln N}} frac{N}{k ln k} sim int_{2}^{frac{N}{ln N}} frac{N}{k ln k} dk =N(lnlnfrac{N}{ln N} — lnln 2) sim N(lnln N — lnlnln N) sim N lnln N]
Но вообще-то решето можно сделать и линейным.
Задание
Решите 5 первых задач из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34271
Линейное решето Эратосфена*
Наша цель — для каждого числа до (N) посчитать его минимальный простой делитель. Будем хранить его в массиве min_d. Параллельно будем хранить и список всех найденных простых чисел primes — это ровно те числа (x), у которых (min_d[x] = x).
Основное утверждение такое:
Пусть у числа (M) минимальный делитель равен (a). Тогда, если (M) составное, мы хотим вычеркнуть его ровно один раз при обработке числа (frac{M}{a}).
Мы также перебираем число (i) от (2) до (N). Если (min_d[i]) равно 0 (то есть мы не нашли ни один делитель у этого числа еще), значит оно простое — добавим в primes и сделаем (min_d[i] = i).
Далее мы хотим вычеркнуть все числа (i times k) такие, что (k) — это минимальный простой делитель этого числа. Из этого следует, что необходимо и достаточно перебрать (k) в массиве primes, и только до тех пор, пока (k < min_d[i]). Ну и перестать перебирать, если (i times k > N).
Алгоритм пометит все числа по одному разу, поэтому он корректен и работает за (O(N)).
N = 30
primes = []
min_d = [0] * (N + 1)
for i in range(2, N + 1):
if min_d[i] == 0:
min_d[i] = i
primes.append(i)
for p in primes:
if p > min_d[i] or i * p > N:
break
min_d[i * p] = p
print(i, min_d)
print(min_d)
print(primes)2 [0, 0, 2, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
3 [0, 0, 2, 3, 2, 0, 2, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
4 [0, 0, 2, 3, 2, 0, 2, 0, 2, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
5 [0, 0, 2, 3, 2, 5, 2, 0, 2, 3, 2, 0, 0, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0]
6 [0, 0, 2, 3, 2, 5, 2, 0, 2, 3, 2, 0, 2, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 0, 0]
7 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 0, 0, 0, 0, 0, 3, 0, 0, 0, 5, 0, 0, 0, 0, 0]
8 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 0, 0, 0, 3, 0, 0, 0, 5, 0, 0, 0, 0, 0]
9 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 0, 0, 3, 0, 0, 0, 5, 0, 3, 0, 0, 0]
10 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 0, 2, 3, 0, 0, 0, 5, 0, 3, 0, 0, 0]
11 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 0, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 0, 5, 0, 3, 0, 0, 0]
12 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 0, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 0, 3, 0, 0, 0]
13 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 0, 0, 0]
14 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 0]
15 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
16 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 0, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
17 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
18 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 0, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
19 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
20 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
21 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
22 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 0, 2, 5, 2, 3, 2, 0, 2]
23 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
24 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
25 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
26 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
27 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
28 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 0, 2]
29 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 29, 2]
30 [0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 29, 2]
[0, 0, 2, 3, 2, 5, 2, 7, 2, 3, 2, 11, 2, 13, 2, 3, 2, 17, 2, 19, 2, 3, 2, 23, 2, 5, 2, 3, 2, 29, 2]
[2, 3, 5, 7, 11, 13, 17, 19, 23, 29]Этот алгоритм работает асимптотически быстрее, чем обычное решето. Но на практике, если писать обычное решето Эратсфена с оптимизациями, то оно оказывается быстрее линейнего. Также линейное решето занимает гораздо больше памяти — ведь в обычном решете можно хранить просто (N) бит, а здесь нам нужно (N) чисел и еще массив primes.
Зато один из «побочных эффектов» алгоритма — он неявно вычисляет факторизацию всех чисел от (1) до (N). Ведь зная минимальный простой делитель любого числа от (1) до (N) можно легко поделить на это число, посмотреть на новый минимальный простой делитель и так далее.
НОД и НОК
Введем два определения.
Наибольший общий делитель (НОД) чисел (a_1, a_2, ldots, a_n) — это максимальное такое число (x), что все (a_i) делятся на (x).
Наименьшее общее кратное (НОК) чисел (a_1, a_2, ldots, a_n) — это минимальное такое число (x), что (x) делится на все (a_i).
Например, * НОД(18, 30) = 6 * НОД(60, 180, 315) = 15 * НОД(1, N) = 1 * НОК(12, 30) = 6 * НОК(1, 2, 3, 4) = 12 * НОК(1, (N)) = (N)
Зачем они нужны? Например, они часто возникают в задачах.
Условие: Есть (N) шестеренок, каждая (i)-ая зацеплена с ((i-1))-ой. (i)-ая шестеренка имеет (a_i) зубчиков. Сколько раз нужно повернуть полносьтю первую шестеренку, чтобы все остальные шестеренки тоже вернулись на изначальное место?
Решение: Когда одна шестеренка крутится на 1 зубчик, все остальные тоже крутятся на один зубчик. Нужно найти минимальное такое число зубчиков (x), что при повороте на него все шестеренки вернутся в изначальное положение, то есть (x) делится на все (a_i), то есть это НОК((a_1, a_2, ldots, a_N)). Ответом будет (frac{x}{a_1}).
Еще пример задачи на применение НОД и НОК:
Условие: Город — это прямоугольник (n) на (m), разделенный на квадраты единичного размера. Вертолет летит из нижнего левого угла в верхний правый по прямой. Вертолет будит людей в квартале, когда он пролетает строго над его внутренностью (границы не считаются). Сколько кварталов разбудит вертолёт?
Решение: Вертолет пересечет по вертикали ((m-1)) границу. С этим ничего не поделать — каждое считается как новое посещение какого-то квартала. По горизонтали то же самое — ((n-1)) переход в новую ячейку будет сделан.
Однако еще есть случай, когда он пересекает одновременно обе границы (то есть пролетает над каким-нибудь углом) — ровно тот случай, когда нового посещения квартала не происходит. Сколько таких будет? Ровно столько, сколько есть целых решений уравнения (frac{n}{m} = frac{x}{y}). Мы как бы составили уравнение движения вертолёта и ищем, в скольки целых точках оно выполняется.
Пусть (t = НОД(n, m)), тогда (n = at, m = bt).
Тогда (frac{n}{m} = frac{a}{b} = frac{x}{y}). Любая дробь с натуральными числителем и знаменателем имеет ровно одно представление в виде несократимой дроби, так что (x) должно делиться на (a), а (y) должно делиться на (b). А значит, как ответ подходят ((a, b), (2a, 2b), (3a, 3b), cdots, ((t-1)a, (t-1)b)). Таких ответов ровно (t = НОД(n, m))
Значит, итоговый ответ: ((n-1) + (m-1) — (t-1)).
Кстати, когда (НОД(a, b) = 1), говорят, что (a) и (b) взаимно просты.
Алгоритм Евклида
Осталось придумать, как искать НОД и НОК. Понятно, что их можно искать перебором, но мы хотим хороший быстрый способ.
Давайте для начала научимся искать (НОД(a, b)).
Мы можем воспользоваться следующим равенством: [НОД(a, b) = НОД(a, b — a), b > a]
Оно доказывается очень просто: надо заметить, что множества общих делителей у пар ((a, b)) и ((a, b — a)) совпадают. Почему? Потому что если (a) и (b) делятся на (x), то и (b-a) делится на (x). И наоборот, если (a) и (b-a) делятся на (x), то и (b) делится на (x). Раз множства общих делитей совпадают, то и максимальный делитель совпадает.
Из этого равенства сразу следует следующее равенство: [НОД(a, b) = НОД(a, b operatorname{%} a), b > a]
(так как (НОД(a, b) = НОД(a, b — a) = НОД(a, b — 2a) = НОД(a, b — 3a) = ldots = НОД(a, b operatorname{%} a)))
Это равенство дает идею следующего рекурсивного алгоритма:
[НОД(a, b) = НОД(b operatorname{%} a, a) = НОД(a operatorname{%} , (b operatorname{%} a), b operatorname{%} a) = ldots]
Например: [НОД(93, 36) = ] [= НОД(36, 93spaceoperatorname{%}36) = НОД(36, 21) = ] [= НОД(21, 15) = ] [= НОД(15, 6) = ] [= НОД(6, 3) = ] [= НОД(3, 0) = 3]
Задание:
Примените алгоритм Евклида и найдите НОД чисел: * 1 и 500000 * 10, 20 * 18, 60 * 55, 34 * 100, 250
По-английски наибольший общий делитель — greatest common divisor. Поэтому вместо НОД будем в коде писать gcd.
def gcd(a, b):
if b == 0:
return a
return gcd(b, a % b)
print(gcd(1, 500000))
print(gcd(10, 20))
print(gcd(18, 60))
print(gcd(55, 34))
print(gcd(100, 250))
print(gcd(2465473782, 12542367456))1
10
6
1
50
6Вообще, в C++ такая функция уже есть в компиляторе g++ — называется __gcd. Если у вас не Visual Studio, то, скорее всего, у вас g++. Вообще, там много всего интересного.
А за сколько оно вообще работает?
Задание
Докажите, что алгоритм Евклида для чисел (N), (M) работает за (O(log(N+M))).
Кстати, интересный факт: самыми плохими входными данными для алгоритма Евклида являются числа Фибоначчи. Именно там и достигается логарифм.
Как выразить НОК через НОД
(НОК(a, b) = frac{ab}{НОД(a, b)})
По этой формуле можно легко найти НОК двух чисел через их произведение и НОД. Почему она верна?
Посмотрим на разложения на простые множители чисел a, b, НОК(a, b), НОД(a, b).
[ a = p_1^{a_1}times p_2^{a_2}timesldotstimes p_n^{a_n} ] [ b = p_1^{b_1}times p_2^{b_2}timesldotstimes p_n^{b_n} ] [ ab = p_1^{a_1+b_1}times p_2^{a_2+b_2}timesldotstimes p_n^{a_n+b_n} ]
Из определений НОД и НОК следует, что их факторизации выглядят так: [ НОД(a, b) = p_1^{min(a_1, b_1)}times p_2^{min(a_2, b_2)}timesldotstimes p_n^{min(a_n, b_n)} ] [ НОК(a, b) = p_1^{max(a_1, b_1)}times p_2^{max(a_2, b_2)}timesldotstimes p_n^{max(a_n, b_n)} ]
Тогда посчитаем (НОД(a, b) times НОК(a, b)): [ НОД(a, b)НОК(a, b) = p_1^{min(a_1, b_1)+max(a_1, b_1)}times p_2^{min(a_2, b_2)+max(a_2, b_2)}timesldotstimes p_n^{min(a_n, b_n)+max(a_n, b_n)} =] [ = p_1^{a_1+b_1}times p_2^{a_2+b_2}timesldotstimes p_n^{a_n+b_n} = ab]
Формула доказана.
Как посчитать НОД/НОК от более чем 2 чисел
Для того, чтобы искать НОД или НОК у более чем двух чисел, достаточно считать их по цепочке:
(НОД(a, b, c, d, ldots) = НОД(НОД(a, b), c, d, ldots))
(НОК(a, b, c, d, ldots) = НОК(НОК(a, b), c, d, ldots))
Почему это верно?
Ну просто множество общих делителей (a) и (b) совпадает с множеством делителей (НОД(a, b)). Из этого следует, что и множество общих делителей (a), (b) и еще каких-то чисел совпадает с множеством общих делителей (НОД(a, b)) и этих же чисел. И раз совпадают множества общих делителей, то и наибольший из них совпадает.
С НОК то же самое, только фразу “множество общих делителей” надо заменить на “множество общих кратных”.
Задание
Решите задачи F, G, H, I из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34271
Расширенный алгоритм Евклида*
Очень важным для математики свойством наибольшего общего делителя является следующий факт:
Для любых целых (a, b) найдутся такие целые (x, y), что (ax + by = d), где (d = gcd(a, b)).
Из этого следует, что существует решение в целых числах, например, у таких уравнений: * (8x + 6y = 2) * (4x — 5y = 1) * (116x + 44y = 4) * (3x + 11y = -1)
Мы сейчас не только докажем, что решения у таких уравнений существуют, но и приведем быстрый алгоритм нахождения этих решений. Здесь нам вновь пригодится алгоритм Евклида.
Рассмотрим один шаг алгоритма Евклида, преобразующий пару ((a, b)) в пару ((b, a operatorname{%} b)). Обозначим (r = a operatorname{%} b), то есть запишем деление с остатком в виде (a = bq + r).
Предположим, что у нас есть решение данного уравнения для чисел (b) и (r) (их наибольший общий делитель, как известно, тоже равен (d)): [bx_0 + ry_0 = d]
Теперь сделаем в этом выражении замену (r = a — bq):
[bx_0 + ry_0 = bx_0 + (a — bq)y_0 = ay_0 + b(x_0 — qy_0)]
Tаким образом, можно взять (x = y_0), а (y = (x_0 — qy_0) = (x_0 — (a operatorname{/} b)y_0)) (здесь (/) обозначает целочисленное деление).
В конце алгоритма Евклида мы всегда получаем пару ((d, 0)). Для нее решение требуемого уравнения легко подбирается — (d * 1 + 0 * 0 = d). Теперь, используя вышесказанное, мы можем идти обратно, при вычислении заменяя пару ((x, y)) (решение для чисел (b) и (a operatorname{%} b)) на пару ((y, x — (a / b)y)) (решение для чисел (a) и (b)).
Это удобно реализовывать рекурсивно:
def extended_gcd(a, b):
if b == 0:
return a, 1, 0
d, x, y = extended_gcd(b, a % b)
return d, y, x - (a // b) * y
a, b = 3, 5
res = extended_gcd(a, b)
print("{3} * {1} + {4} * {2} = {0}".format(res[0], res[1], res[2], a, b))3 * 2 + 5 * -1 = 1Но также полезно и посмотреть, как будет работать расширенный алгоритм Евклида и на каком-нибудь конкретном примере. Пусть мы, например, хотим найти целочисленное решение такого уравнения: [116x + 44y = 4] [(2times44+28)x + 44y = 4] [44(2x+y) + 28x = 4] [44x_0 + 28y_0 = 4] Следовательно, [x = y_0, y = x_0 — 2y_0] Будем повторять такой шаг несколько раз, получим такие уравнения: [116x + 44y = 4] [44x_0 + 28y_0 = 4, x = y_0, y = x_0 — 2y_0] [28x_1 + 16y_1 = 4, x_0 = y_1, y_0 = x_1 — y_1] [16x_2 + 12y_2 = 4, x_1 = y_2, y_1 = x_2 — y_2] [12x_3 + 4y_3 = 4, x_2 = y_3, y_2 = x_3 — y_3] [4x_4 + 0y_4 = 4, x_3 = y_4, y_3 = x_4 — 3 y_4] А теперь свернем обратно: [x_4 = 1, y_4 = 0] [x_3 = 0, y_3 =1] [x_2 = 1, y_2 =-1] [x_1 = -1, y_1 =2] [x_0 = 2, y_0 =-3] [x = -3, y =8]
Действительно, (116times(-3) + 44times8 = 4)
Задание
Решите задачу J из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34273
Операции по модулю
Выражение (a equiv b pmod m) означает, что остатки от деления (a) на (m) и (b) на (m) равны. Это выражение читается как «(a) сравнимо (b) по модулю (m)».
Еще это можно опрделить так: (a) сравнимо c (b) по модулю (m), если ((a — b)) делится на (m).
Все целые числа можно разделить на классы эквивалентности — два числа лежат в одном классе, если они сравнимы по модулю (m). Говорят, что мы работаем в «кольце остатков по модулю (m)», и в нем ровно (m) элементов: (0, 1, 2, cdots, m-1).
Сложение, вычитение и умножение по модулю определяются довольно интуитивно — нужно выполнить соответствующую операцию и взять остаток от деления.
С делением намного сложнее — поделить и взять по модулю не работает. Об этом подробнее поговорим чуть дальше.
a = 30
b = 50
mod = 71
print('{} + {} = {} (mod {})'.format(a, b, (a + b) % mod, mod))
print('{} - {} = {} (mod {})'.format(a, b, (a - b) % mod, mod)) # на C++ это может не работать, так как модуль от отрицательного числа берется странно
print('{} - {} = {} (mod {})'.format(a, b, (a - b + mod) % mod, mod)) # на C++ надо писать так, чтобы брать модулю от гарантированно неотрицательного числа
print('{} * {} = {} (mod {})'.format(a, b, (a * b) % mod, mod))
# print((a / b) % mod) # а как писать это, пока неясно30 + 50 = 9 (mod 71)
30 - 50 = 51 (mod 71)
30 - 50 = 51 (mod 71)
30 * 50 = 9 (mod 71)Задание
Посчитайте: * (2 + 3 pmod 5) * (2 * 3 pmod 5) * (2 ^ 3 pmod 5) * (2 — 4 pmod 5) * (5 + 5 pmod 6) * (2 * 3 pmod 6) * (3 * 3 pmod 6)
Для умножения (в C++) нужно ещё учитывать следующий факт: при переполнении типа всё ломается (разве что если вы используете в качестве модуля степень двойки).
intвмещает до (2^{31} — 1 approx 2 cdot 10^9).long longвмещает до (2^{63} — 1 approx 8 cdot 10^{18}).long long longв плюсах нет, при попытке заиспользовать выдает ошибкуlong long long is too long.- Под некоторыми компиляторами и архитектурами доступен
int128, но не везде и не все функции его поддерживают (например, его нельзя вывести обычными методами).
Зачем нужно считать ответ по модулю
Очень часто в задаче нужно научиться считать число, которое в худшем случае гораздо больше, чем (10^{18}). Тогда, чтобы не заставлять вас писать длинную арифметику, автор задачи часто просит найти ответ по модулю большого числа, обычно (10^9 + 7)
Кстати, вместо того, чтобы писать (1000000007) удобно просто написать (1e9 + 7). (1e9) означает (1 times 10^9)
int mod = 1e9 + 7; # В C++
cout << mod;1000000007N = 1e9 + 7 # В питоне такое число становится float
print(N)
print(int(N))1000000007.0
1000000007Быстрое возведение в степень
Задача: > Даны натуральные числа (a, b, c < 10^9). Найдите (a^b) (mod (c)).
Мы хотим научиться возводить число в большую степень быстро, не просто умножая (a) на себя (b) раз. Требование на модуль здесь дано только для того, чтобы иметь возможность проверить правильность алгоритма для чисел, которые не влезают в int и long long.
Сам алгоритм довольно простой и рекурсивный, постарайтесь его придумать, решая вот такие примеры (прямо решать необязательно, но можно придумать, как посчитать значение этих чисел очень быстро):
- (3^2)
- (3^4)
- (3^8)
- (3^{16})
- (3^{32})
- (3^{33})
- (3^{66})
- (3^{132})
- (3^{133})
- (3^{266})
- (3^{532})
- (3^{533})
- (3^{1066})
Да, здесь специально приведена такая последовательность, в которой каждое следующее число легко считается через предыдущее: его либо нужно умножить на (a=3), либо возвести в квадрат. Так и получается рекурсивный алгоритм:
- (a^0 = 1)
- (a^{2k}=(a^{k})^2)
- (a^{2k+1}=a^{2k}times a)
Нужно только после каждой операции делать mod: * (a^0 pmod c = 1) * (a^{2k} pmod c = (a^{k} pmod c)^2 pmod c) * (a^{2k+1} pmod c = ((a^{2k}pmod c) times a) pmod c)
Этот алгоритм называется быстрое возведение в степень. Он имеет много применений: * в криптографии очень часто надо возводить число в большую степень по модулю * используется для деления по простому модулю (см. далее) * можно быстро перемножать не только числа, но еще и матрицы (используется для динамики, например)
Асимптотика этого алгоритма, очевидно, (O(log c)) — за каждые две итерации число уменьшается хотя бы в 2 раза.
Задание
Решите задачу K из этого контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34271
Задание
Решите как можно больше задач из практического контеста:
https://informatics.msk.ru/mod/statements/view.php?id=34273
Деление по модулю*
Давайте все-таки научимся не только умножать, но и делить по простому модулю. Вот только что это значит?
(a / b) = (a times b^{-1}), где (b^{-1}) — это обратный элемент к (b).
Определение: (b^{-1}) — это такое число, что (bb^{-1} = 1)
Утверждение: в кольце остатков по простому модулю (p) у каждого остатка (кроме 0) существует ровно один обратный элемент.
Например, обратный к (2) по модулю (5) это (3) ((2 times 3 = 1 pmod 5)))
Задание
Найдите обратный элемент к: * числу (3) по модулю (5) * числу (3) по модулю (7) * числу (1) по модулю (7) * числу (2) по модулю (3) * числу (9) по модулю (31)
Давайте докажем это утверждение: надо заметить, что если каждый ненулевой остаток (1, 2, ldots, (p-1)) умножить на ненулевой остаток (a), то получатся числа (a, 2a, ldots, (p-1)a) — и они все разные! Они разные, потому что если (xa = ya), то ((x-y)a = 0), а значит ((x — y) a) делится на (p), (a) — ненулевой остаток, а значит (x = y), и это не разные числа. И из того, что все числа получились разными, это все ненулевые, и их столько же, следует, что это ровно тот же набор чисел, просто в другом порядке!
Из этого следует, что среди этих чисел есть (1), причем ровно один раз. А значит существует ровно один обратный элемент (a^{-1}). Доказательство закончено.
Это здорово, но этот обратный элемент еще хочется быстро находить. Быстрее, чем за (O(p)).
Есть несколько способов это сделать.
Через малую теорему Ферма
Малая теорема Ферма: > (a^{p-1} = 1 pmod p), если (p) — простое, (a neq 0 pmod p)).
Доказательство: В предыдущем пункте мы выяснили, что множества чисел (1, 2, ldots, (p-1)) и (a, 2a, ldots, (p-1)a) совпадают. Из этого следует, что их произведения тоже совпадают по модулю: ((p-1)! = a^{p-1} (p-1)! pmod p).
((p-1)!neq 0 pmod p) а значит на него можно поделить (это мы кстати только в предыдущем пункте доказали, поделить на число — значит умножить на обратный к нему, который существует).
А значит, (a^{p — 1} = 1 pmod p).
Как это применить Осталось заметить, что из малой теоремы Ферма сразу следует, что (a^{p-2}) — это обратный элемент к (a), а значит мы свели задачу к возведению (a) в степень (p-2), что благодаря быстрому возведению в степень мы умеем делать за (O(log p)).
Обобщение У малой теоремы Ферма есть обобщение для составных (p):
Теорема Эйлера: > (a^{varphi(p)} = 1 pmod p), (a) — взаимно просто с (p), а (varphi(p)) — это функция Эйлера (количество чисел, меньших (p) и взаимно простых с (p)).
Доказывается теорема очень похоже, только вместо ненулевых остатков (1, 2, ldots, p-1) нужно брать остатки, взаимно простые с (p). Их как раз не (p-1), а (varphi(p)).
Для нахождения обратного по этой теореме достаточно посчитать функцию Эйлера (varphi(p)) и найти (a^{-1} = a^{varphi(p) — 1}).
Но с этим возникают большие проблемы: посчитать функцию Эйлера сложно. Более того, на предполагаемой невозможности быстро ее посчитать построены некоторые криптографические алгоритм типа RSA. Поэтому быстро делить по составному модулю этим способом не получится.
Через расширенный алгоритм Евклида
Этим способом легко получится делить по любому модулю! Рекомендую.
Пусть мы хотим найти (a^{-1} pmod p), (a) и (p) взаимно простые (а иначе обратного и не будет существовать).
Давайте найдем корни уравнения
[ax + py = 1]
Они есть и находятся расширенным алгоритмом Евклида за (O(log p)), так как (НОД(a, p) = 1), ведь они взаимно простые.
Тогда если взять остаток по модулю (p):
[ax = 1 pmod p]
А значит, найденный (x) и будет обратным элементом к (a).
То есть надо просто найти (x) из решения того уравнения по модулю (p). Можно брать по модулю прямо походу решения уравнения, чтобы случайно не переполниться.
In number theory, a formula for primes is a formula generating the prime numbers, exactly and without exception. No such formula which is efficiently computable is known.[clarification needed] A number of constraints are known, showing what such a «formula» can and cannot be.
Formulas based on Wilson’s theorem[edit]
A simple formula is

for positive integer  , where
, where  is the floor function, which rounds down to the nearest integer.
is the floor function, which rounds down to the nearest integer.
By Wilson’s theorem,  is prime if and only if
is prime if and only if  . Thus, when is prime, the first factor in the product becomes one, and the formula produces the prime number . But when is not prime, the first factor becomes zero and the formula produces the prime number 2.[1]
. Thus, when is prime, the first factor in the product becomes one, and the formula produces the prime number . But when is not prime, the first factor becomes zero and the formula produces the prime number 2.[1]
This formula is not an efficient way to generate prime numbers because evaluating  requires about
requires about  multiplications and reductions modulo .
multiplications and reductions modulo .
In 1964, Willans gave the formula

for the th prime number  .[2]
.[2]
This formula reduces to[3][4] ![{displaystyle p_{n}=1+sum _{i=1}^{2^{n}}[pi (i)<n]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2f088c57fed2d59382f5604c02828d5604903517) ; that is, it tautologically defines as the smallest integer m for which the prime-counting function
; that is, it tautologically defines as the smallest integer m for which the prime-counting function  is at least n. This formula is also not efficient. In addition to the appearance of
is at least n. This formula is also not efficient. In addition to the appearance of  , it computes by adding up copies of
, it computes by adding up copies of  ; for example,
; for example,  .
.
The articles What is an Answer? by Herbert Wilf (1982)[5] and Formulas for Primes by Underwood Dudley (1983)[6] have further discussion about the worthlessness of such formulas.
Formula based on a system of Diophantine equations[edit]
Because the set of primes is a computably enumerable set, by Matiyasevich’s theorem, it can be obtained from a system of Diophantine equations. Jones et al. (1976) found an explicit set of 14 Diophantine equations in 26 variables, such that a given number k + 2 is prime if and only if that system has a solution in nonnegative integers:[7]














The 14 equations α0, …, α13 can be used to produce a prime-generating polynomial inequality in 26 variables:

That is,
![{displaystyle {begin{aligned}&(k+2)(1-{}\[6pt]&[wz+h+j-q]^{2}-{}\[6pt]&[(gk+2g+k+1)(h+j)+h-z]^{2}-{}\[6pt]&[16(k+1)^{3}(k+2)(n+1)^{2}+1-f^{2}]^{2}-{}\[6pt]&[2n+p+q+z-e]^{2}-{}\[6pt]&[e^{3}(e+2)(a+1)^{2}+1-o^{2}]^{2}-{}\[6pt]&[(a^{2}-1)y^{2}+1-x^{2}]^{2}-{}\[6pt]&[16r^{2}y^{4}(a^{2}-1)+1-u^{2}]^{2}-{}\[6pt]&[n+ell +v-y]^{2}-{}\[6pt]&[(a^{2}-1)ell ^{2}+1-m^{2}]^{2}-{}\[6pt]&[ai+k+1-ell -i]^{2}-{}\[6pt]&[((a+u^{2}(u^{2}-a))^{2}-1)(n+4dy)^{2}+1-(x+cu)^{2}]^{2}-{}\[6pt]&[p+ell (a-n-1)+b(2an+2a-n^{2}-2n-2)-m]^{2}-{}\[6pt]&[q+y(a-p-1)+s(2ap+2a-p^{2}-2p-2)-x]^{2}-{}\[6pt]&[z+pell (a-p)+t(2ap-p^{2}-1)-pm]^{2})\[6pt]&>0end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3484e9eb9010c1c6264c9001fadcfa14fccf3239)
is a polynomial inequality in 26 variables, and the set of prime numbers is identical to the set of positive values taken on by the left-hand side as the variables a, b, …, z range over the nonnegative integers.
A general theorem of Matiyasevich says that if a set is defined by a system of Diophantine equations, it can also be defined by a system of Diophantine equations in only 9 variables.[8] Hence, there is a prime-generating polynomial as above with only 10 variables. However, its degree is large (in the order of 1045). On the other hand, there also exists such a set of equations of degree only 4, but in 58 variables.[9]
Mills’ formula[edit]
The first such formula known was established by W. H. Mills (1947), who proved that there exists a real number A such that, if

then

is a prime number for all positive integers n.[10] If the Riemann hypothesis is true, then the smallest such A has a value of around 1.3063778838630806904686144926… (sequence A051021 in the OEIS) and is known as Mills’ constant.[11] This value gives rise to the primes  ,
,  ,
,  , … (sequence A051254 in the OEIS). Very little is known about the constant A (not even whether it is rational). This formula has no practical value, because there is no known way of calculating the constant without finding primes in the first place.
, … (sequence A051254 in the OEIS). Very little is known about the constant A (not even whether it is rational). This formula has no practical value, because there is no known way of calculating the constant without finding primes in the first place.
Note that there is nothing special about the floor function in the formula. Tóth proved that there also exists a constant  such that
such that

is also prime-representing for  .[12]
.[12]
In the case  , the value of the constant begins with 1.24055470525201424067… The first few primes generated are:
, the value of the constant begins with 1.24055470525201424067… The first few primes generated are:


Without assuming the Riemann hypothesis, Elsholtz developed several prime-representing functions similar to those of Mills. For example, if  , then
, then  is prime for all positive integers . Similarly, if
is prime for all positive integers . Similarly, if  , then
, then  is prime for all positive integers .[13]
is prime for all positive integers .[13]
Wright’s formula[edit]
Another prime-generating formula similar to Mills’ comes from a theorem of E. M. Wright. He proved that there exists a real number α such that, if
- and
- for ,



then

is prime for all  .[14]
.[14]
Wright gives the first seven decimal places of such a constant:  . This value gives rise to the primes
. This value gives rise to the primes  ,
,  , and
, and  .
.  is even, and so is not prime. However, with
is even, and so is not prime. However, with  ,
,  ,
,  , and
, and  are unchanged, while is a prime with 4932 digits.[15] This sequence of primes cannot be extended beyond without knowing more digits of
are unchanged, while is a prime with 4932 digits.[15] This sequence of primes cannot be extended beyond without knowing more digits of  . Like Mills’ formula, and for the same reasons, Wright’s formula cannot be used to find primes.
. Like Mills’ formula, and for the same reasons, Wright’s formula cannot be used to find primes.
A function that represents all primes[edit]
Given the constant  (sequence A249270 in the OEIS), for
(sequence A249270 in the OEIS), for  , define the sequence
, define the sequence
-
(1)

where  is the floor function.
is the floor function.
Then for ,  equals the th prime:
equals the th prime:
 ,
,
 ,
,
 , etc.
, etc.
[16]
The initial constant  given in the article is precise enough for equation (1) to generate the primes through 37, the
given in the article is precise enough for equation (1) to generate the primes through 37, the  th prime.
th prime.
The exact value of  that generates all primes is given by the rapidly-converging series
that generates all primes is given by the rapidly-converging series

where is the th prime, and  is the product of all primes less than . The more digits of that we know, the more primes equation (1) will generate. For example, we can use 25 terms in the series, using the 25 primes less than 100, to calculate the following more precise approximation:
is the product of all primes less than . The more digits of that we know, the more primes equation (1) will generate. For example, we can use 25 terms in the series, using the 25 primes less than 100, to calculate the following more precise approximation:

This has enough digits for equation (1) to yield again the 25 primes less than 100.
As with Mills’ formula and Wright’s formula above, in order to generate a longer list of primes, we need to start by knowing more digits of the initial constant, , which in this case requires a longer list of primes in its calculation.
Plouffe’s formulas[edit]
In 2018 Simon Plouffe conjectured a set of formulas for primes. Similarly to the formula of Mills, they are of the form

where  is the function rounding to the nearest integer. For example, with
is the function rounding to the nearest integer. For example, with  and
and  , this gives 113, 367, 1607, 10177, 102217… Using
, this gives 113, 367, 1607, 10177, 102217… Using  and
and  with
with  a certain number between 0 and one half, Plouffe found that he could generate a sequence of 50 probable primes (with high probability of being prime). Presumably there exists an ε such that this formula will give an infinite sequence of actual prime numbers. The number of digits starts at 501 and increases by about 1% each time.[17][18]
a certain number between 0 and one half, Plouffe found that he could generate a sequence of 50 probable primes (with high probability of being prime). Presumably there exists an ε such that this formula will give an infinite sequence of actual prime numbers. The number of digits starts at 501 and increases by about 1% each time.[17][18]
Prime formulas and polynomial functions[edit]
It is known that no non-constant polynomial function P(n) with integer coefficients exists that evaluates to a prime number for all integers n. The proof is as follows: suppose that such a polynomial existed. Then P(1) would evaluate to a prime p, so  . But for any integer k,
. But for any integer k,  also, so
also, so  cannot also be prime (as it would be divisible by p) unless it were p itself. But the only way
cannot also be prime (as it would be divisible by p) unless it were p itself. But the only way  for all k is if the polynomial function is constant.
for all k is if the polynomial function is constant.
The same reasoning shows an even stronger result: no non-constant polynomial function P(n) exists that evaluates to a prime number for almost all integers n.
Euler first noticed (in 1772) that the quadratic polynomial

is prime for the 40 integers n = 0, 1, 2, …, 39, with corresponding primes 41, 43, 47, 53, 61, 71, …, 1601. The differences between the terms are 2, 4, 6, 8, 10… For n = 40, it produces a square number, 1681, which is equal to 41 × 41, the smallest composite number for this formula for n ≥ 0. If 41 divides n, it divides P(n) too. Furthermore, since P(n) can be written as n(n + 1) + 41, if 41 divides n + 1 instead, it also divides P(n). The phenomenon is related to the Ulam spiral, which is also implicitly quadratic, and the class number; this polynomial is related to the Heegner number  . There are analogous polynomials for
. There are analogous polynomials for  (the lucky numbers of Euler), corresponding to other Heegner numbers.
(the lucky numbers of Euler), corresponding to other Heegner numbers.
Given a positive integer S, there may be infinitely many c such that the expression n2 + n + c is always coprime to S. The integer c may be negative, in which case there is a delay before primes are produced.
It is known, based on Dirichlet’s theorem on arithmetic progressions, that linear polynomial functions  produce infinitely many primes as long as a and b are relatively prime (though no such function will assume prime values for all values of n). Moreover, the Green–Tao theorem says that for any k there exists a pair of a and b, with the property that is prime for any n from 0 through k − 1. However, as of 2020, the best known result of such type is for k = 27:
produce infinitely many primes as long as a and b are relatively prime (though no such function will assume prime values for all values of n). Moreover, the Green–Tao theorem says that for any k there exists a pair of a and b, with the property that is prime for any n from 0 through k − 1. However, as of 2020, the best known result of such type is for k = 27:

is prime for all n from 0 through 26.[19] It is not even known whether there exists a univariate polynomial of degree at least 2, that assumes an infinite number of values that are prime; see Bunyakovsky conjecture.
Possible formula using a recurrence relation[edit]
Another prime generator is defined by the recurrence relation

where gcd(x, y) denotes the greatest common divisor of x and y. The sequence of differences an+1 − an starts with 1, 1, 1, 5, 3, 1, 1, 1, 1, 11, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 23, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 47, 3, 1, 5, 3, … (sequence A132199 in the OEIS). Rowland (2008) proved that this sequence contains only ones and prime numbers. However, it does not contain all the prime numbers, since the terms gcd(n + 1, an) are always odd and so never equal to 2. 587 is the smallest prime (other than 2) not appearing in the first 10,000 outcomes that are different from 1. Nevertheless, in the same paper it was conjectured to contain all odd primes, even though it is rather inefficient.[20]
Note that there is a trivial program that enumerates all and only the prime numbers, as well as more efficient ones, so such recurrence relations are more a matter of curiosity than of any practical use.
See also[edit]
- Prime number theorem
References[edit]
- ^ Mackinnon, Nick (June 1987), «Prime number formulae», The Mathematical Gazette, 71 (456): 113–114, doi:10.2307/3616496, JSTOR 3616496, S2CID 171537609.
- ^ Willans, C. P. (December 1964), «On formulae for the th prime number», The Mathematical Gazette, 48 (366): 413–415, doi:10.2307/3611701, JSTOR 3611701, S2CID 126149459.
- ^ Neill, T. B. M.; Singer, M. (October 1965), «To the Editor, The Mathematical Gazette«, The Mathematical Gazette, 49 (369): 303–303, doi:10.2307/3612863, JSTOR 3612863
- ^ Goodstein, R. L.; Wormell, C. P. (February 1967), «Formulae For Primes», The Mathematical Gazette, 51 (375): 35–38, doi:10.2307/3613607, JSTOR 3613607
- ^ Wilf, Herbert S. (1982), «What is an answer?», The American Mathematical Monthly, 89 (5): 289–292, doi:10.2307/2321713, JSTOR 2321713, MR 0653502
- ^ Dudley, Underwood (1983), «Formulas for primes», Mathematics Magazine, 56 (1): 17–22, doi:10.2307/2690261, JSTOR 2690261, MR 0692169
- ^ Jones, James P.; Sato, Daihachiro; Wada, Hideo; Wiens, Douglas (1976), «Diophantine representation of the set of prime numbers», American Mathematical Monthly, Mathematical Association of America, 83 (6): 449–464, doi:10.2307/2318339, JSTOR 2318339, archived from the original on 2012-02-24.
- ^ Matiyasevich, Yuri V. (1999), «Formulas for Prime Numbers», in Tabachnikov, Serge (ed.), Kvant Selecta: Algebra and Analysis, vol. II, American Mathematical Society, pp. 13–24, ISBN 978-0-8218-1915-9.
- ^ Jones, James P. (1982), «Universal diophantine equation», Journal of Symbolic Logic, 47 (3): 549–571, doi:10.2307/2273588, JSTOR 2273588, S2CID 11148823.
- ^ Mills, W. H. (1947), «A prime-representing function» (PDF), Bulletin of the American Mathematical Society, 53 (6): 604, doi:10.1090/S0002-9904-1947-08849-2.
- ^ Caldwell, Chris K.; Cheng, Yuanyou (2005), «Determining Mills’ Constant and a Note on Honaker’s Problem», Journal of Integer Sequences, 8, Article 05.4.1.
- ^ Tóth, László (2017), «A Variation on Mills-Like Prime-Representing Functions» (PDF), Journal of Integer Sequences, 20 (17.9.8), arXiv:1801.08014.
- ^ Elsholtz, Christian (2020), «Unconditional Prime-Representing Functions, Following Mills», American Mathematical Monthly, Washington, DC: Mathematical Association of America, 127 (7): 639–642, arXiv:2004.01285, doi:10.1080/00029890.2020.1751560, S2CID 214795216
- ^ E. M. Wright (1951), «A prime-representing function», American Mathematical Monthly, 58 (9): 616–618, doi:10.2307/2306356, JSTOR 2306356
- ^ Baillie, Robert (5 June 2017), «Wright’s Fourth Prime», arXiv:1705.09741v3 [math.NT]
- ^ Fridman, Dylan; Garbulsky, Juli; Glecer, Bruno; Grime, James; Tron Florentin, Massi (2019), «A Prime-Representing Constant», American Mathematical Monthly, Washington, DC: Mathematical Association of America, 126 (1): 70–73, arXiv:2010.15882, doi:10.1080/00029890.2019.1530554, S2CID 127727922
- ^ Steckles, Katie (January 26, 2019), «Mathematician’s record-beating formula can generate 50 prime numbers», New Scientist
- ^ Simon Plouffe (2019), «A set of formulas for primes», arXiv:1901.01849 [math.NT] As of January 2019, the number he gives in the appendix for the 50th number generated is actually the 48th.
- ^ PrimeGrid’s AP27 Search, Official announcement, from PrimeGrid. The AP27 is listed in «Jens Kruse Andersen’s Primes in Arithmetic Progression Records page».
- ^ Rowland, Eric S. (2008), «A Natural Prime-Generating Recurrence», Journal of Integer Sequences, 11 (2): 08.2.8, arXiv:0710.3217, Bibcode:2008JIntS..11…28R.
Further reading[edit]
- Regimbal, Stephen (1975), «An explicit Formula for the k-th prime number», Mathematics Magazine, Mathematical Association of America, 48 (4): 230–232, doi:10.2307/2690354, JSTOR 2690354.
- A Venugopalan. Formula for primes, twinprimes, number of primes and number of twinprimes. Proceedings of the Indian Academy of Sciences—Mathematical Sciences, Vol. 92, No 1, September 1983, pp. 49–52 errata
External links[edit]
- Eric W. Weisstein, Prime Formulas (Prime-Generating Polynomial) at MathWorld.

- 1-е простое число: p(1)=2
- 2-е простое число: p(2)=3
- 3-е простое число: p(3)=5
- 4-е простое число: p(4)=7
- 5-е простое число: p(5)=11
- …
- n-е простое число: p(n)=? — Какая общая формула n-го члена последовательности простых чисел?

Универсальной формулы, которая давала бы а) все простые числа, и б) только простые числа, не существует. Ну то есть даже если такая и может существовать, то по сей день её не найдено.
Есть несколько формул, которые дают какой-то ограниченный набор простых чисел. Есть формулы, которые дают неограниченный набор простых чисел, но среди значений, которые вычисляются по этим формулам, попадаются и составные числа, то есть требуется дополнительная проверка получаемых результатов.
Подробный разбор различных формул, связанных с порождением простых чисел, можно найти в журнале «Квант», №5 за 1975 год. По счастью, он доступен по Сети. В частности, там упоминаются полиномиальные многочлены и формула Джулии Робинсон, которая на данный момент удовлетворяет задачи порождения простых чисел наилучшим образом.
автор вопроса выбрал этот ответ лучшим

ОлегТ
[32.4K]
8 месяцев назад
Вроде длинный ответ надо давать. А как его тут дашь, если ответ простой и тут не разгуляешься.
Давайте поймем, что же это за простые числа. Это Натуральные числа больше 1, такие что имеют только 2 делителя: единицу и само число. А числа, которые имеют более 2 делителей — будут составными. Составные числа можно разложить на простые множители.
Теперь попробуем решить несколько иную задачу: Пусть есть некое число N. Как понять простое оно или составное?
Надо просто проверить делится ли оно на что то еще кроме «1 и N». Понятно, что если делиться, то делитель будет больше 1 и меньше N.
Немножко поразмыслив, можно понять, что делимость можно проверять только на простые числа из этого диапазона. А еще подумав, можно понять, что можно проверять не все числа, а до некого p(n), такого что p(n)² ≤ N, а p(n+1)² > N. И даже если после проверки окажется, что все p(n) — не являются делителями N, то есть N — будет простым. Все равно неизвестен его номер. Оно может идти по счету «k»-тым после «n». N = p(n+k). И сколько этих «k» может быть неизвестно.
Вообщем на сегодняшний день нет общей формулы по нахождению простых чисел по его порядковому номеру.
А числа находят путем проверки делимости. Занимаются этим конечно компьютеры.

simpl
[131K]
8 месяцев назад
Нет никакой формулы нахождения простых чисел, есть большие доводы, что их распределение имеет случайный характер..
И не нужно придумывать ерунду и отсебятину..
Но есть алгоритмы нахождения ряда простых чисел, самый известный и древний — это т.н. «Решето Эратосфена»..
Для нахождения всех простых чисел вплоть до заданного, согласно Решету Эратосфена нужно:
- Выписать целые числа от двух до заданного числа, ограничивающего ряд
2.Вычеркнуть из списка числа кратные 2 до заданного числа
3.Первое не зачёркнутое число, большее чем 2, является простым
4.Вычеркнуть из ряда все числа, кратные найденному числу — это 3
Нужно начинать вычёркивание с заранее известного числа, например 2, потом все числа, кратные 2 и так до конца ряда, найти первое попавшееся не зачёркнутое число и вычеркнуть все последующие кратные ему..
Вычёркиваем все кратные числа первому не зачеркнутому..
В итоге — все не вычеркнутые числа в списке — простые числа.

Alex-soldier
[138]
более месяца назад
В англоязычном пространстве можно найти подборки подобных формул, опирающихся на ту или иную теорему или свойство чисел (формулы страшные, здесь их так просто не воспроизвести, поэтому см. ссылки ниже).
Но по факту это синтетически скомпонованные и крайне замороченные выражения, которые сколько-нибудь пригодны для практического использования только для небольших интервалов n (обычно из-за того, что с ростом n происходит колоссальный рост вычислительной сложности выражения, и, в определенный момент, становится проще найти очередное по счету Простое число банальным Решетом).
Кстати о Решетах. Наиболее популярны три: Решето Эратосфена, Решето Аткина, Решето Сундарама. Аткин и Сундарам работают быстрее Эратосфена, но в них необходимо хранить большие массивы данных, поэтому их применение оправдано лишь на небольших начальных интервалах [2;N]. А вот Эратосфен при реализации оказывается более экономичным, поэтому обычно именно его используют для глубокого просеивания в программах поиска больших Простых чисел.
См. https://en.wikipedia.org/wiki/Formula_for_primes
См. https://mathworld.wolfram.com/PrimeFormulas.html
См. https://ru.wikipedia.org/wiki/Решето_Аткина
См. https://ru.wikipedia.org/wiki/Решето_Сундарама
Знаете ответ?
Простые числа — это чудеса деления
Здравствуйте, уважаемые читатели блога KtoNaNovenkogo.ru. Сегодня мы поговорим о таком математическом понятии, как ПРОСТЫЕ ЧИСЛА.
В школе это проходят в 5 или 6 классе, в зависимости от программы обучения.
И интересно, что если спросить школьников, что такое простые числа, то они, скорее всего, ответят правильно.

А вот взрослые задумаются и не факт, что вспомнят точное определение. Так что это статья скорее для них.
Простые числа — это…
Итак, вот как выглядит официальное определение:
Простые числа – это такие числа, которые имеют только два делителя. Один из них – единица, а другое – само число.
Чтобы было более понятно, приведем простой пример. Для чисел 5 и 7 надо найти все возможные делители, чтобы в результате образовалось целое число.
Если вы попробуете решить эту задачку, то получите, что 5 и 7 делятся только на 1 и 5, и 1 и 7 соответственно. Во всех других случаях вы получите дробное число. И это как раз означает, что числа 5 и 7 относятся к простым.
А вот попробуем по той же схеме разобрать числа 6 и 9. В первом случае мы получим, что 6 можно поделить на 1, 2, 3 и 6, а число 9 – на 1, 3 и 9. И это уже противоречит определению простых чисел, значит, 6 и 9 таковыми не являются.
Они называются в математике – СОСТАВНЫМИ ЧИСЛАМИ.
Список и таблица простых чисел
Некоторые ошибочно полагают, что наименьшее простое число – это единица.
С одной стороны, в этом есть логика, так как 1 делится только на 1. Но это получается одно и то же число (единица), что противоречит определению простых чисел, в котором четко прописано – «делителей должно быть два».
Значит, минимальное простое число – это 2. А первоначальный ряд выглядит следующим образом:
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97, 101, 103, 107, 109, 113, 127, 131, 137, 139, 149, 151, 157, 163, 167, 173, 179, 181, 191, 193, 197, 199…
При желании можете проверить эти числа на предмет деления. Мы же скажем, что этот ряд на самом деле не окончательный.
Количество простых чисел не ограничено. Или говоря математическим языком, оно стремится к бесконечности.
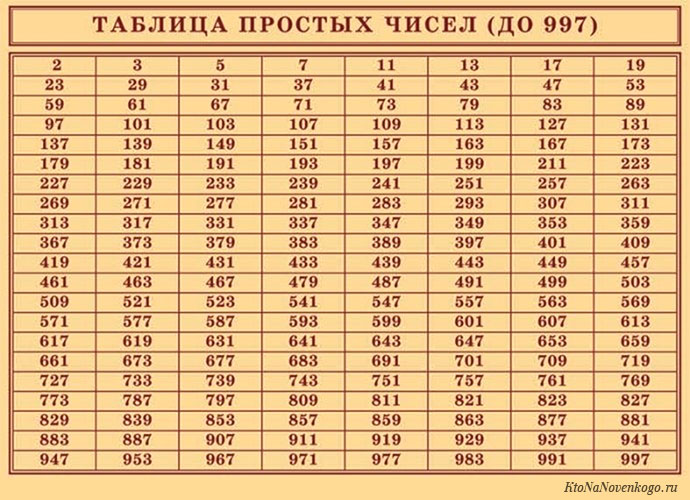
История простых чисел
Первые упоминания о простых числах относятся к Древнему Египту. В Британском музее хранится папирус, который датируется 2000 годом до нашей эры. И на нем, согласно расшифровке, содержится учебное пособие по арифметике.
В том числе и про деление чисел. Называется этот артефакт – папирус Райнда, по имени его первого владельца.

В этом документе есть таблица, в которой указаны числа, делящиеся на различные знаменатели. Причем они разделены таким образом, что становится понятно – древние египтяне может и не пользовались понятиям «простое число», но хотя бы имели о нем представление.
Ну а первые исследования простых чисел датируются 300 годом до нашей эры. И связаны они с именем знаменитого древнегреческого математика Евклида.
Как и многое другое, он описал простые и составные числа в своем известном произведении «Начала».
В частности, Евклид описал такие вещи, как:
- Основная теорема арифметики;
- Бесконечность прямых чисел;
- Лемма Евклида.
Сейчас расскажем об этих понятиях подробнее.

Основная теорема арифметики
Основная теорема арифметики, которую придумал еще Евклид, гласит:
Любое натуральное число (это что?), которое больше единицы, может быть представлено в виде произведения простых чисел. Причем их количество не ограничено, а порядок следования неважен.
Если обозначить исходное число буквой N, а простые числа буквами Р1, Р2, Р3 и так далее, то можно записать эту теорему следующим образом:
N = Р1 * Р2 * Р3 * … * РК
Например, возьмем число 100. Его можно разложить на следующие простые числа:
100 = 5 * 5 * 2 * 2
Или более сложный пример – число 23244:
23244 = 149 * 13 * 3 * 2 * 2
Раскладывать на простые числа легко. Можно сперва делить на 2 и 3, а уже в конце автоматически получить более сложные делители.
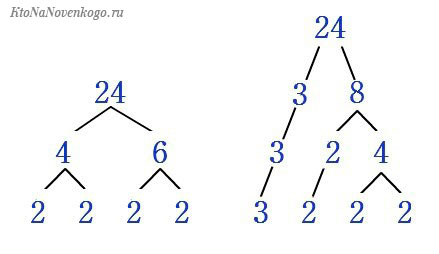
Ради интереса придумайте любое число и сами найдите его составляющие.
Лемма Евклида
Еще одна теорема, которая имеет прямое отношение к простым числам. Она гласит;
Если некое простое число Р делит произведение чисел X и Y без остатка, то оно может точно так же поделить или X, или Y.
Звучит несколько сложновато, хотя на деле все это просто. Так, возьмем для примера P = 2, X = 6, Y = 9. И тогда получается, что
X * Y = 6 * 9 = 54
В нашем примере P делит это произведение без остатка:
(X * Y) / P = 54/2 = 27
А значит наша P может поделить без остатка или X, или Y. Очевидно, что это X:
X/P = 6/2 = 3
Y/P = 9/2 = 4,5 (не подходит)
Как быстро и легко определить простые числа
И еще одно понятие, которое связано с простыми числами. Оно названо в честь другого древнегреческого математика Эратосфена Киренского.
Этот человек придумал, как быстро и легко определить простые числа. В частности, он сделал таблицу, в которой были указаны значения до 1000.

Свою таблицу он нарисовал на глиняной дощечке. А после прокалывал те клеточки, на которых были написаны составные числа. В результате получилось нечто вроде решета, отсюда собственно и название метода.
Кстати, пользоваться решетом Эратосфена весьма просто. Например, сделаем таблицу до 50.
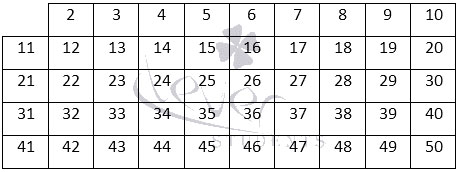
После этого из нее надо поочередно вычеркивать числа, которые кратны 2, 3, 5, 7 и 11. В результате получится вот это:
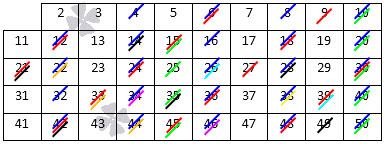
Те числа, которые остались, и есть простые. Можете сравнить этот ряд с тем, который мы давали в начале статьи. Точно таким же способом можно составить абсолютно любой ряд простых чисел = хоть до тысячи, хоть до миллиона и больше.
Вот и все, что мы хотели рассказать о ПРОСТЫХ ЧИСЛАХ в математике.