Один из этапов создания рекламной кампании — сбор семантического ядра. Оно включает в себя ключевые фразы пользователей, по которым будут показываться рекламные объявления. Релевантные ключевые слова и правильно написанный оффер — отличная возможность показать объявления целевой аудитории, привлечь клиентов и сэкономить бюджет. Как это сделать, читайте в инструкции по составлению семантического ядра от eLama.
Семантическое ядро для поисковых кампаний
1 этап. Сбор базовых ключевых слов
Прежде всего подумайте, какие слова характеризуют вашу нишу. Например, для интернет-магазина по продаже iPhone будут очевидны следующие слова: iPhone, айфон, купить, заказать и т. д. Для удобства записывайте слова в таблицу Excel.

Если у вас закончились идеи, то зайдите в yandex.wordstat.ru и посмотрите, что ищут при вводе, например, iPhone.

К собранному в Excel списку добавим слово «Цена».
Далее, найденные слова нужно скомпоновать. Это можно сделать через инструмент eLama «Комбинатор ключевых фраз»:

Полученные фразы мы будем использовать на следующем этапе.
Бесплатные кампании в Директе для старта
Для тех, кто раньше не запускал рекламу в Директе через eLama
Получить кампании
Этап 2. Подбор семантического ядра
Снова обратимся к сервису Wordstat и узнаем количество запросов пользователей по тому или иному слову. Это поможет в создании семантического ядра.
Установите расширение Yandex Wordstat Assistant для браузера, чтобы собрать запросы и их частотность быстрее:

Итак, получился список и одна свободная колонка, которая нужна для списка минус-слов.

Этап 3. Чистка семантического ядра
Теперь весь список ключевых слов нужно очистить от нерелевантных запросов, чтобы показывать рекламу только тем пользователям, которые ищут наши товары. Например, я не продаю iphone 7 в рассрочку в Минске, поэтому исключаю 7, минск, рассрочка. Содержащие эти слова и ключи стоит удалять сразу же, чтобы они случайно не попали в ключевые фразы.
Проще и удобнее это сделать в минусаторе eLama. Скопируйте собранную список семантики и вручную выделите все ненужные слова. В итоге у вас получится два списка: ключей и минус-слов. А еще в минусаторе можно применить готовый список минус-слов к списку ключевых фраз — инструмент найдет нерелевантные фразы и удалит их. Как работать с инструментом, читайте в другом нашем материале.
Можно продолжить работу в таблице, но так будет посложнее.

Если требуется удаление нескольких фраз, то сократите время поисков, используя фильтр Excel.

Для кампаний в Google Ads можно выбрать «Планировщик ключевых слов».

По сравнению с Wordstat он имеет больше функций, благодаря которым можно:
- узнать конкурентность ниши и процент показа объявлений;
- минимальные/максимальные ставки для показа объявлений внизу/вверху страницы.
В списке могут появиться фразы с минимальным различием, например, «iphone 8 в москве» и «iphone 8 купить спб». Для того, чтобы система показывала объявления, релевантные запросу, нужно провести кросс-минусацию, например, через eLama.
Для получения более точного результата попробуйте комбинировать все инструменты.
Этап 4. Заключительный
Теперь у вас есть отдельно список с ключевыми фразами и минус-словами. Вам нужно составить объявления таким образом, чтобы ключевая фраза была в первом или втором заголовке. Так вы сможете увеличить CTR объявления, а следовательно, уменьшить его стоимость.

Операторы и типы соответствия ключевых слов в Яндекс Директе и Google Ads
Операторы и типы соответствия необходимы для уточнения запросов пользователей. Например, вы создали акционное рекламное объявление, в котором говорите о продаже билетов из Москвы в Санкт-Петербург, то используйте оператор []. Таким образом, люди, которые хотят поехать из Санкт-Петербурга в Москву, не увидят ваше объявление.
Для экономии времени используйте «Комбинатор ключевых фраз», который автоматически добавит операторы +, ! в ваши списки. Под столбцами с собранным списком нажмите на «Дополнительно» и выберите оператор:

Если нужны типы соответствия/операторы, которых нет в «Комбинаторе ключевых фраз», то используйте Excel. Например, вы можете вставить оператор перед повторяющимся словом. Полный список операторов Яндекс.Директа есть на странице помощи, а для типов соответствия Google Ads — здесь.
Подбор ключевых слов для КМС и РСЯ
Ключевые фразы для РСЯ и КМС не нужно уточнять. Достаточно создать семантическое ядро с широкими ключевыми фразами, которые взаимосвязаны между собой. Если вы не уверены в собранных ключевых словах или боитесь мусорного трафика, то воспользуйтесь помощью Google Ads. Войдите в Аккаунт — Ключевые слова — Ключевые слова КМС или видео — введите свой сайт или услугу — система покажет релевантные ключи. Подобранные ключи можете использовать не только для КМС, но и для РСЯ.
Заключение
Сбор семантики — интересный, но в то же время сложный процесс. На каждом из этапов надо быть внимательным, чтобы не допустить нецелевых ключевых фраз. Однако следование подробной инструкции от eLama поможет сэкономить время на каждом этапе.
Вы запустили контекстную рекламу, но получаете по своим объявлениям мало показов и переходов. Не спешите увеличивать рекламный бюджет или делать выводы о неэффективности контекста. Возможно, причина в том, что вы не уделили достаточно времени сбору семантического ядра.
Для чего нужно собрать семантическое ядро перед запуском контекста и как это сделать, рассказали в статье.
Семантическое ядро: что это такое, из чего оно состоит
Семантическое ядро – набор запросов пользователей, в ответ на которые им показываются объявления на поиске и в сетях Яндекса и Google.
Пользователи могут искать один и тот же товар или услугу по-разному. Они могут вводить общие запросы, например «купить смартфон». Могут вводить геозависимые запросы, например «Samsung А70 Москва», или информационные запросы: «Samsung А70 отзывы», «Samsung А70 цена», «лучшие смартфоны Samsung» и т. д. Все это важно учитывать при сборе семантики для максимального охвата целевой аудитории.
Также запросы делятся по частоте на:
- высокочастотные (ВЧ). Для больших сайтов – от 10 000 запросов в месяц. Для региональных – от 1000. Представляют собой общие запросы, которые состоят из 1–2 слов. Например, «инверторный кондиционер», «установка окон». Обычно по таким запросам ищут товары и услуги пользователи, которые находятся на начальной стадии воронки продаж;
- среднечастотные (СЧ). От 100 запросов в месяц. Состоят из 2–3 слов и представляют собой уточненные высокочастотные фразы. Например, «инверторный кондиционер Samsung», «вызов сантехника Ростов». По таким запросам ищут информацию пользователи, которые уже знакомы с товарами и услугами;
- низкочастотные (НЧ). От 1 запроса в месяц. Состоят из 3–6 слов. Это наиболее подробные запросы, по которым ищет товары теплая аудитория. Например, «холодильник Electrolux erf4113aow Москва».
Также отдельно выделяются транзакционные запросы. Эти запросы выражают намерение пользователя купить товар или заказать какую-то услугу. Например, «заказать разработку брендбука», «купить Samsung A70». По таким ключевым фразам осуществляет поиск горячая аудитория, у которой уже сформирована потребность в товаре и есть запрос на его покупку.
При сборе семантического ядра для контекста важно учитывать специфику рекламируемых товаров и услуг, частотность запросов и интересы пользователей.
Как собрать семантику с помощью Яндекс.Wordstat
Яндекс.Wordstat позволяет определить частотность запросов и расширить семантическое ядро. Покажем, как это сделать, на примере интернет-магазина, который планирует запустить рекламу велосипедов.
Заходим в Яндекс.Wordstat. Вводим запрос «горный велосипед» в поисковую строку.
Ниже показывается, сколько раз за месяц пользователи вводили эту фразу в поисковую строку. Всего – 156 190 раз. По умолчанию результат показывается по всем регионам.
Интернет-магазин находится в Москве и планирует показывать рекламу в этом регионе. Поэтому кликаем на надпись «Все регионы» и выбираем «Москва и область».
После этого Вордстат нам будет показывать статистику по запросам в данном регионе:
В левой колонке указываются основные запросы, а справа – похожие запросы.
Для поиска идей и сбора семантического ядра просматриваем весь список приведенных фраз и выбираем те фразы, которые относятся к предлагаемым услугам. Выписываем их в отдельную таблицу и указываем частотность по ним:
Если надо расширить семантику по какому-то запросу, то достаточно кликнуть на этот запрос в Яндекс.Wordstat: система покажет основные и похожие фразы по данному запросу.
Например, нажимаем на фразу «Горный велосипед gt»:
Инструмент показывает нам похожие запросы и статистику по ним:
Расширяем предложенными фразами нашу таблицу и получаем развернутую семантику по товарам, которые планируем рекламировать.
Таким образом, мы подобрали семантическое ядро для рекламной кампании горных велосипедов с помощью Яндекс.Wordstat.
Для сбора семантики с помощью этого инструмента нужно заранее подготовить опорный список фраз. В этом списке должны находиться товары/услуги компании, которые она будет рекламировать. Далее с помощью Вордстата рекламодатель может уточнить частотность запросов по этим фразам и расширить семантику по ним.
Для этого можно использовать полностью автоматизированные инструменты, которые избавляют от ручного сбора слов и отдельного уточнения данных по каждому.
Парсинг внутренней семантики сайта
Регистрируемся в Click.ru или авторизируемся в аккаунте. В главном меню выбираем «Инструменты» – «Семантика» – «Подбор слов и медиапланирование»:
Указываем основные данные: URL, рекламные системы, геотаргетинг. Оставляем галочки на автоматической корректировке фраз минус-словами и фиксации стоп-слов.
Кликаем на кнопку «Начать новый подбор». Система на основании контента сайта подобрала 680 ключевых слов. Такой большой список ключевиков объясняется широким ассортиментом.
В таблице также показана:
- частотность запросов с учетом региона;
- прогноз средней цены клика;
- прогноз кликов;
- прогноз бюджета.
Эти данные позволяют отобрать слова нужной частотности и спрогнозировать бюджет на рекламу.
Нажимаем на кнопку «Показать все»:
Просматриваем все слова. В списке собранных фраз есть повторяющиеся. Не будем удалять их вручную: система автоматически удалит их на этапе добавления ключевых слов в медиаплан.
Добавляем слова в медиаплан:
После клика по кнопке «Добавить в медиаплан» система показывает сообщение об обнаруженных дублях ключевых слов. Нажимаем «Удалить», чтобы очистить семантику от повторяющихся фраз:
После удаления дублей в медиаплан добавлено 482 слова:
Click.ru предоставляет широкий набор инструментов для работы с семантикой, объявлениями и оптимизацией рекламных кампаний. Сервис позволяет вести кампании Яндекс.Директа и Google Ads в едином окне. К тому же, их очень просто перенести из рекламных кабинетов.
Парсинг ключей конкурента
Для расширения семантического ядра проанализируем, по каким словам показывают рекламу ближайшие конкуренты. Сделать это можно прямо в медиаплане.
Для этого в автоматическом подборе слов выбираем опцию «Слова конкурентов». Всего система предлагает 5 конкурентов, которые также продают аналогичную продукцию. При необходимости можно удалить неподходящий сайты и добавить конкурентов вручную:
Всего система отобрала 1500 слов конкурентов. Кликаем на кнопку «Показать слова конкурентов»:
Мы видим, что частотность некоторых запросов очень высока. Например, запрос «купить велосипед» пользователи вводили 633 041 раз за месяц. По таким запросам нет смысла показывать рекламу, так как клики будут обходиться очень дорого.
Поэтому оставим запросы с максимальной частотностью 1000 запросов в месяц. Для этого в столбце «Частотность» задаем фильтр – от 10 до 1000 запросов в месяц.
Всего система отобрала 78 слов нужной частотности из 1500 фраз. Добавим их в медиаплан. Для этого устанавливаем галочку вверху таблицы и кликаем на кнопку «Добавить медиаплан»:
Система автоматически предлагает удалить дубли слов. Нажимаем «Удалить»:
Система добавила в медиаплан 75 слов:
Таким образом, с помощью автоматического подбора слов мы отобрали 482 фразы со своего сайта и 75 – с сайтов конкурентов. Всего мы получили 557 фраз.
Ручной подбор слов
Ручной подборщик находится над таблицей с результатами автоподбора. Для добавления в ручной подборщик слов из автоподбора отметим галочками необходимые слова и кликнем на «Добавить в ручной подбор»:
Система автоматически перенесет выбранные слова в ручной подборщик. Нажимаем «Развернуть список вложенных слов». Система подбирает ключи из левой колонки Wordstat, в которых присутствуют заданные в ручном подборе слова. В результате каждому опорному ключу соответствует группа вложенных запросов:
Выбираем ключевые слова, которыми хотим расширить нашу семантику, и добавляем их в медиаплан.
Далее просматриваем вложенные фразы по каждому ключевому слову и выбираем те ключевые слова, которые хотим добавить в медиаплан.
Результат – мы добавили еще 29 ключевых слов в медиаплан, дополнив наше семантическое ядро.
Результат подбора слов
В общей сложности с автоматическим подборщиком мы собрали 586 фраз (557 + 29). Для нишевого интернет-магазина этого достаточно.
Для дальнейшей работы с семантикой выгружаем выбранные слова в XLS-файл. Для этого внизу таблицы кликаем на кнопку «Выгрузка в XLS»:
Группировка ключевых слов
В Click.ru есть кластеризатор запросов. Кластеризатор собирает запросы с одинаковым интентом в одну группу. В результате проще сформировать группы объявлений, не упустив нужных ключевых запросов.
В главном левом меню выбираем «Семантика» – «Кластеризация запросов»:
В настройках указываем адрес сайта и название проекта:
Загружаем список ключевых запросов. Для этого нажимаем кнопку «Загрузить XLSX-файл» и добавляем слова, которые мы собрали в результате автоматического и ручного подбора. Также можно внести список фраз для проверки вручную.
Для более точной группировки фраз выберем профессиональную настройку. Она позволяет задавать одно или несколько условий, при которых точность кластеризации будет увеличиваться.
Кликаем на кнопку «Запустить кластеризацию». Через несколько минут становится доступным отчет в формате XLSX.
Отчет состоит из нескольких листов с такой информацией:
- сгруппированными запросами по кластерам в Яндексе/ Google;
- лидерами тематик в Яндексе/Google;
- исходными настройками.
Содержание отчета и его размеры зависят от количества запросов и заданных настроек.
В результате мы не только сформировали семантическое ядро, но и получили сгруппированные по кластерам запросы на основе результатов поисковой выдачи.
Сформировали семантику – что дальше
После сбора семантики в Click.ru можно автоматически создать объявления. Для этого кликаем под медиапланом на кнопку «Создать объявление»:
Система автоматически генерирует объявления по предложенным ключевым словам: формирует заголовок и текст, указывает цену, подбирает картинки и ключевые слова.
Остается только отредактировать подходящие объявления и запустить рекламную кампанию.

Перед проведением рекламы в Яндекс.Директе необходимо сначала собрать ядро. Семантическое ядро в Директе – совокупность ключевых словы и фраз, которые позволяют увидеть рекламу потенциально заинтересованным пользователям. Поэтому в зависимости правильности подбора ядра в Яндекс.Директе зависит результативность рекламной кампании.
Мы рассмотрим основные способы сбора семантики в Яндекс.Директ и определим их достоинства и недостатки.
Типы ключевых фраз
Для эффективного сбора семантического ядра в Яндекс.Директе нужно понимать, какие есть виды ключевых фраз. Как правило, ключи подразделяются на такие типы, как:
- Брендовые – ключевые фразы, содержащие наименование продвигаемой компании, либо торгового знака.
- Общие ключевые фразы касаются каких-либо продуктов, а также услуг. Этот вид поискового запроса представляет собой отдельные выражения, в которых нельзя точно определить намерение пользователя или цель запроса. В качестве примера можно привести фразы: «автомобиль», «женская одежда».
- Транзакционные – ключевые фразы, в которых содержится желание пользователя совершить определенное действие, но необходимо подобрать подходящее предложение. К примеру: «купить детскую коляску».
- Информационными являются ключевые слова, которые используют с целью получить какую-то информацию или узнать о чем-то. В частности, к данным запросам относятся: «характеристики пылесоса», «как прибить полку».
- Геозависимые – это ключевые фразы, которые касаются определенного региона. Они помогают осуществлять сбор семантики для Директа, используя связь необходимого продукта с конкретной геолокацией. Например, «автосервис Москва», «торговые центры в Сочи».
- Околотематематическими являются ключевые фразы, относящиеся к сопутствующим продуктам. Они важны, потому что целевая аудитория теоретически может их искать. В качестве примера возьмем: «продажа телевизора» «ремонт телевизора».
Как собрать семантическое ядро для Яндекс.Директ
Разберем на примере, как собрать семантику для Директа. Есть необходимые пункты для сбора ядра для Директа, которые упрощают процесс.
- Подготовить ключевые фразы
Выше мы разобрали основные типа ключевых слов и фраз. Теперь определимся, каким образом их применять. Во-первых, нужно просмотреть свой сайт и выделить фразы, которые, на ваш взгляд, может искать целевая аудитория. Соберите сначала более широкие запросы, чтобы потом выводить из них более конкретные фразы. Например, “женские брюки”, “женские черные брюки”, “женские черные брюки 42 размера”, “женские черные брюки с высокой посадкой”.
Во-вторых, посмотрите, по каким запросам запускают рекламу конкуренты. Это поможет набраться идей и понять, какую тактику используют конкуренты. Можно смотреть варианты ключевых фраз не только у прямых, но и у косвенных конкурентов.
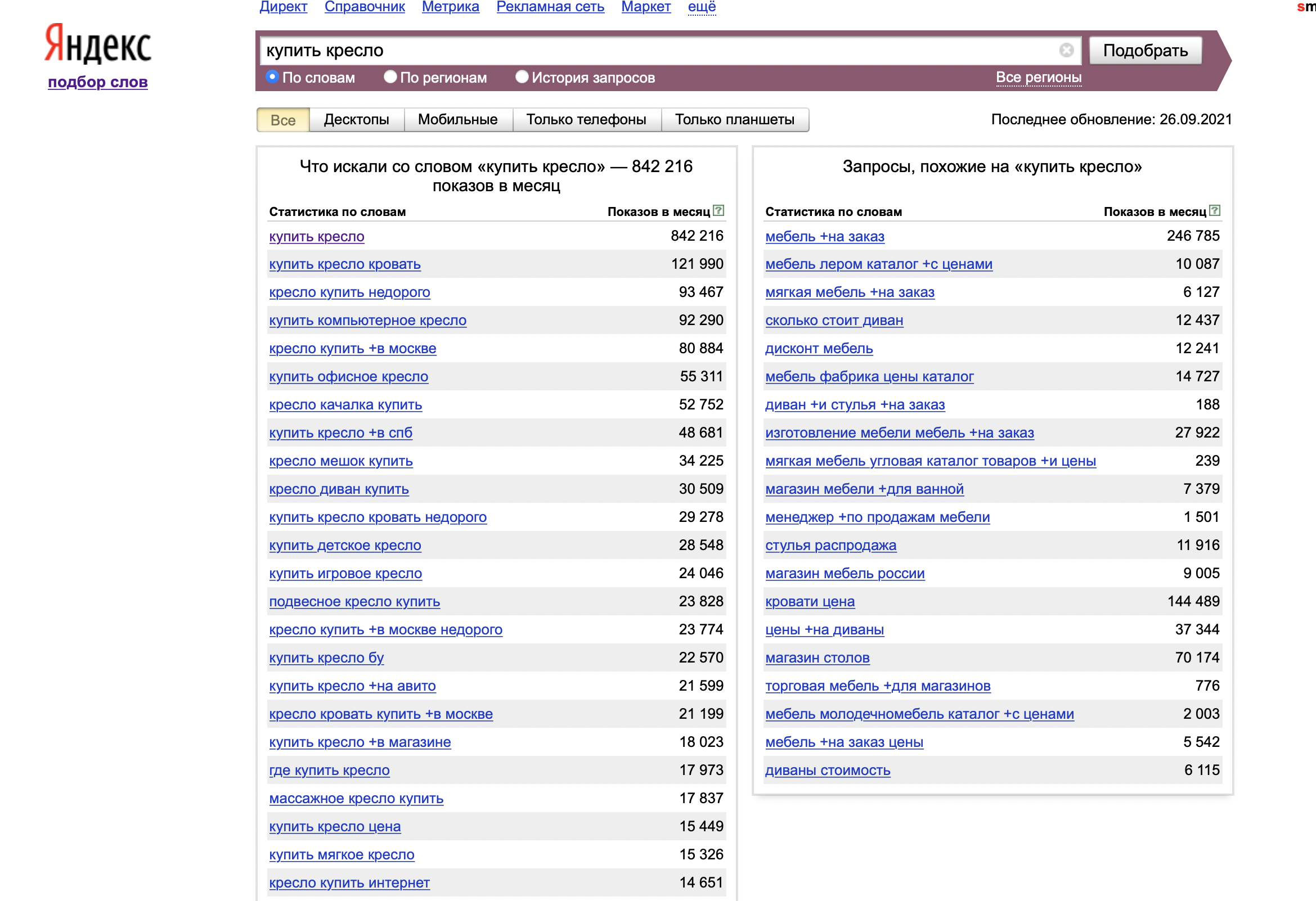
В-третьих, необходимо разделить ключевые фразы по частотности. Есть высокочастотные (более тысячи в месяц), среднечастотные (от трехсот до тысячи в месяц), а также низкочастотные (менее трехсот в месяц) запросы. Величина охвата напрямую оказывает влияние на показатель частотности. В этом случае у поискового запроса «приобрести кресло» частотность будет выше, но в то же время запрос «приобрести красное бархатное кресло» будет обладать более низкой частотностью.
В-четвертых, не забудьте добавить в список такие вещи, как:
1) однокоренные слова;
2) транлитерацию;
3) профессионализмы или сленг;
4) опечатки или ошибки, которые могут содержаться во фразах.
- Избавиться от ненужных фраз и оставить подходящие
Для этого пункта используют специальные инструменты, подбирающие ключи. Не нужно доверяться исключительно интуиции. Объективно собрать фактические запросы людей помогут определенные сервисы.
Wordstat от самого Яндекса является одним из самых востребованных и простых в использовании инструментов подбора ключевых фраз для сбора семантического ядра для Директа. В ходе подбора ключей через сервис ориентироваться лучше на частотность, чтобы выделить запросы, которые пользователи ищут чаще остальных.
Важно понимать, что такое кластеризация запросов семантического ядра. Кластеризация представляет собой объединение ключей по смыслу или деление фраз на кластеры. Кластеризацию семантического ядра в Яндекс.Директ можно сделать онлайн через определенные сервисы. Она может быть либо по фразам, либо в соответствии с топом.
Важно не выбирать ключевые слова, которые имеют низкую или нулевую частотность, так как они не принесут пользу рекламной кампании.
Есть различие при запуске рекламы на Поиске и в РСЯ. На Поиске рекомендуется брать запросы, которые обладают невысокой частотностью, но более конкретно описывают то, что вы предлагаете. Если хотите запустить рекламу занятий йогой в Москве, то широким запросом используйте «йога в Москве», но не просто «йога».
В РСЯ можно применять общие формулировки. Для эффективного поиска сайтов для показов рекламы используйте средне- и высокочастотные запросы. При выборе низкочастотных ключей в РСЯ можно потерять большое количество рекламных платформ.
В Wordstat есть также полезная функция, которая позволяет смотреть запросы, выбранные пользователями вместе с тем, который вы указали. Просмотр похожих вопросов отображается в колонке справа.
- Подобрать минус-слова
После подбора ключевых запросов исключите минус-слова. Минус-слова исключаются для того, чтобы не показываться той аудитории, которую интересуют другие цели. Это позволяет осуществлять контроль затрат, а также иметь высокий показатель кликабельности объявлений.
Например, при продаже бытовой техники в Спб минус-словами будут “Москва”, так как это не подходящая геолокация, “отзывы” и “характеристики”, так как они являются информационными запросами.
Однако при запуске рекламы в РСЯ нужно учитывать ее особенности при выборе минус-слов. В данной сети реклама не будет показывать на одной из ее площадок, даже если минус-слово присутствует в комментарии на форуме.
Для того чтобы узнать, как выгрузить семантику из Директа, перейдите в раздел Управление кампаниями, затем нажмите на ссылку XLS/XLSX. Там вы можете выгрузить рекламные кампании в одном из столбцов будут ключевые фразы.
Получайте бесплатные уроки и фишки по интернет-маркетингу
Как собирать семантику для Яндекс.Директа, вы узнаете в этой статье.
Парсинг
Итак, у нас готовы маски ключевых слов — теперь «копаем» в глубину. Задача — собрать семантическое ядро, которое обеспечит максимальный охват и целевой трафик.
Ручной способ
Вставляем словосочетание в Яндекс Wordstat:

Для фиксирования предлогов можно использовать оператор +.
Нам нужна вся выдача, на данный момент без фильтрации. Копируем её вместе со значениями частотности в таблицу Excel для удобства.
Чтобы получить как можно больше расширений, повторяем те же действия по каждой маске.
Рекомендации:
- Каждую смысловую группу лучше парсить отдельно, чтобы не запутаться;
- Копируйте все результаты от 1 показа и больше. Типичная ситуация — там, где Wordstat показывает 1, на самом деле 100-200 показов.
Далее — сбор подсказок Яндекса:
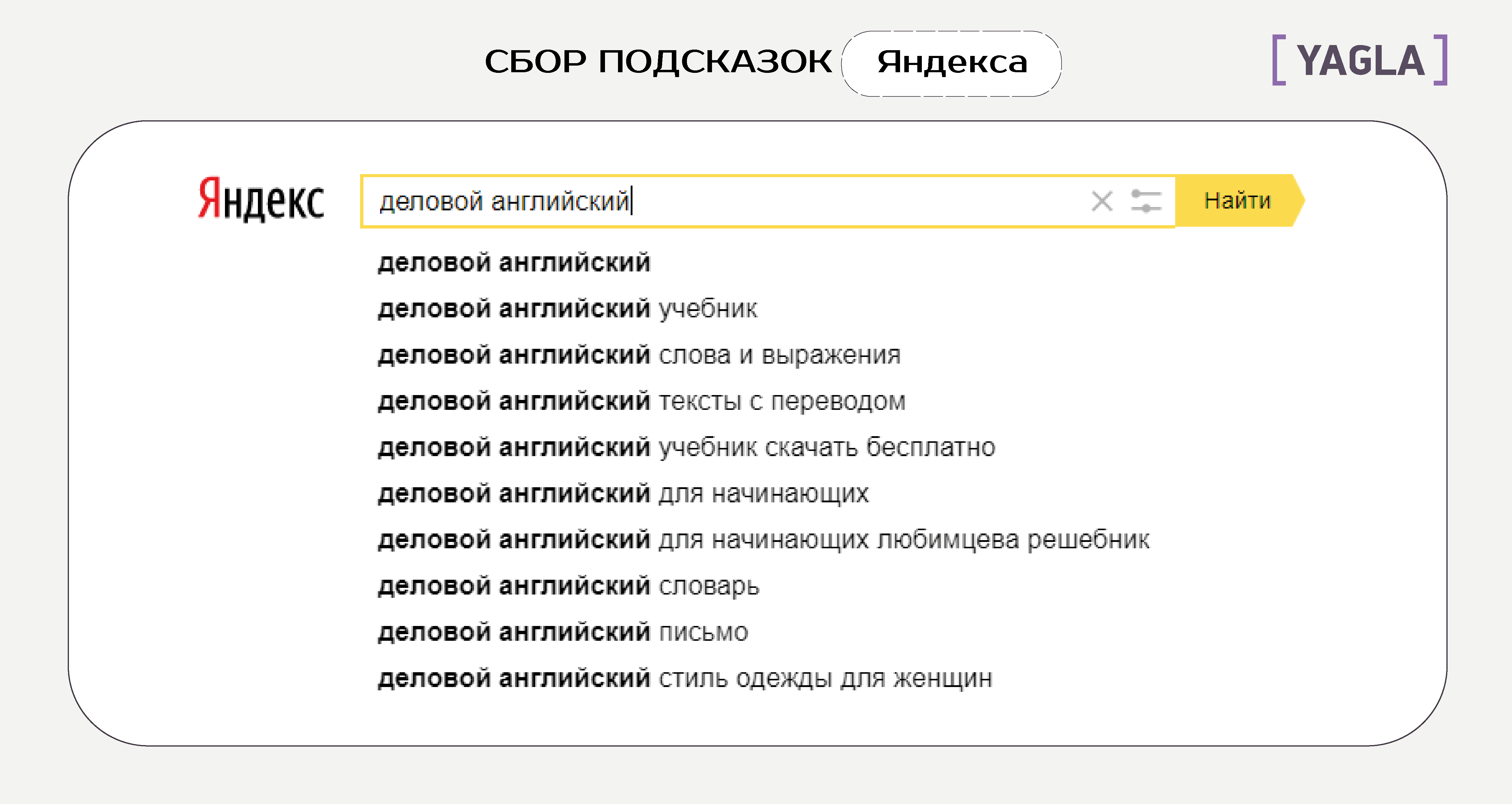
Каждый запрос дает отдельный набор подсказок. Весь список подсказок тоже добавляем в Excel.
Объединяем все расширения и подсказки по ним. Результат — статистически достоверная выборка со всеми уникальными низкочастотниками и минус-словами. Вероятность учесть все запросы и получить по ним чистый трафик высокая.
Автоматический способ
Избежать трудоемкой работы помогут инструменты для парсинга.
Самый популярный парсер ключевых слов Яндекса и других систем — Key Collector — дает такие возможности:
- Сбор информации напрямую с популярных источников
- Выбор региона и глубины поиска
Рекомендация: выбирайте глубину 2. Так вы сразу получаете не только результаты парсинга, но и дополнительную выдачу по каждому из них.
- Оценка фраз по стоимости продвижения, популярности, конкуренции, трафику и другим параметрам
- Экспресс-анализ содержимого сайта на соответствие СЯ + рекомендации по внутренней перелинковке
- Экспорт запросов из парсера в Excel и CSV
- Удобное табличное представление данных со всплывающими редакторами
Key Collector
Чтобы сделать парсинг в Key Collector, добавляем фразы:
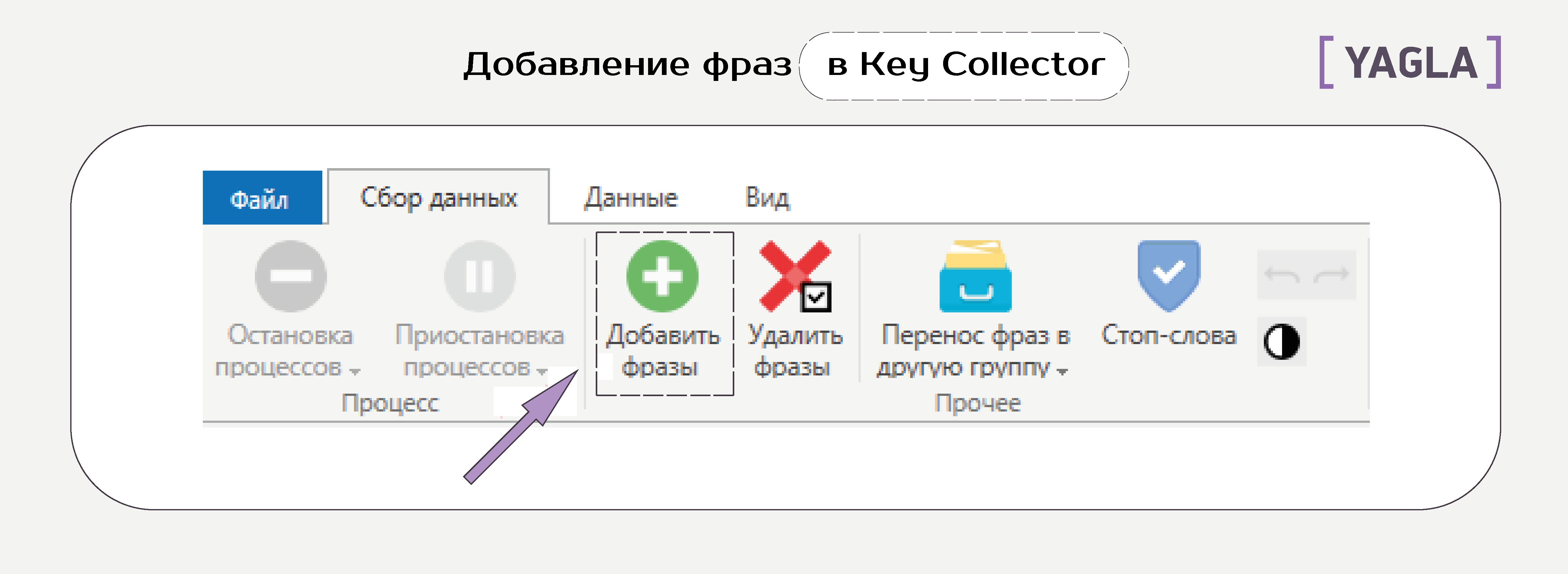
Запускаем парсер.
Вкладка Yandex.Wordstat
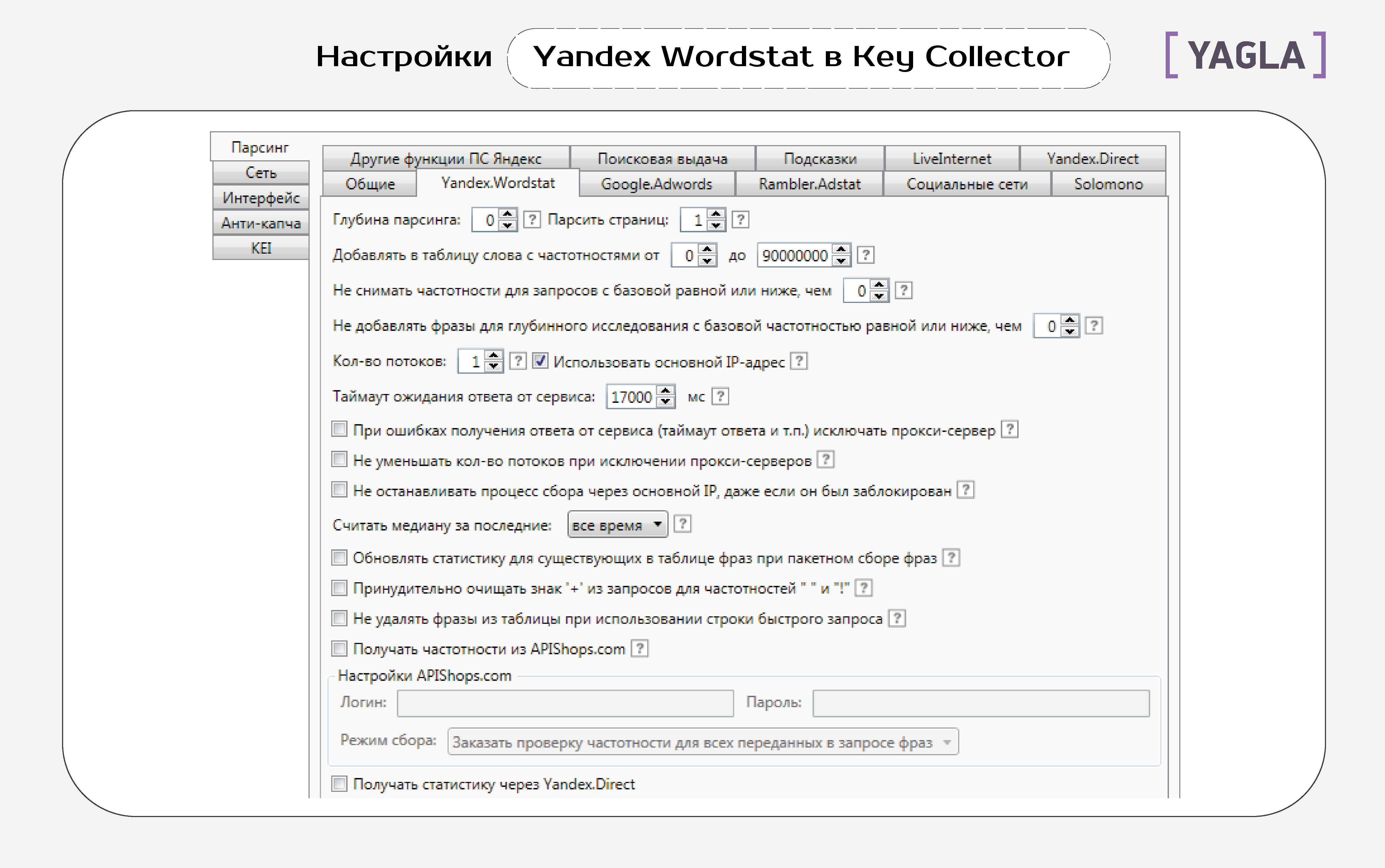
Вот что означают все эти опции.
Глубина парсинга. Количество обходов списка слов, которое делает программа для одного ключевика. С каждым разом растет количество слов и время на обработку.
Парсить страниц. Количество страниц в выдаче, которое просматривает программа. Максимум в Wordstat — 40, на каждой — до 50 фраз, то есть 2 тысячи результатов по одной фразе. Сервис предлагает такое количество лишь для высокочастотных запросов.
Добавлять в таблицу фразы с частотностями от … до … Мы задаем диапазон частотностей. Чтобы избежать потери важных ключевиков, используйте фильтрацию в таблицах данных.
Не снимать частотности для фраз с базовой равной или ниже, чем … Это экономит время, трафик, а также позволяет снизить вероятность получения капчи, так как исключает из проверки заведомо неподходящие фразы.
Не добавлять фразы для глубинного исследования с базовой частотностью равной или ниже, чем … Это сокращает время на сбор информации за счет игнорирования фраз, у которых низкая базовая частотность.
Количество потоков. Во сколько потоков собирается статистика Yandex.Direct. Рекомендуем не создавать больше одного потока на IP-адрес и аккаунт.
Таймаут ожидания ответа от сервиса. Как долго программа ждет ответа на запрос, прежде чем сообщить об ошибке, и не переходит к следующей фразе или не совершает повторный запрос.
При ошибках получения ответа от сервиса (таймаут ответа и т.п.) исключать прокси-сервер. При запуске процесса программа берет список прокси-серверов из настроек и работает с каждым. Можно увеличить скорость сбора информации, если удалять из очереди те, которые не отвечают на запросы или которым не отвечает сервис.
Не уменьшать количество потоков при исключении прокси-серверов. В нормальном режиме сервис сокращает количество потоков, чтобы не допустить перегрузку на еще не исключенных прокси-серверах. Можно это отключить.
Не останавливать процесс сбора через основной IP, даже если он заблокирован. В результате этого получение статистики какое-то время будет отвергаться, и возобновится, когда провайдер назначит новый IP.
Считать медиану за последние … месяцев. Программа вычисляет значение по этому периоду при сборе данных о сезонности.
Обновлять статистику для существующих в таблице фраз при пакетном сборе фраз. Опция позволяет обновлять базовую частотность Yandex.Wordstat фраз в таблице, когда вы одновременно запускаете сбор данных из различных источников.
Принудительно очищать знак + из запросов для частотностей « » и «!». При снятии частотностей вида « » и «!», запрос заключается в кавычки. При этом знак +, если это оператор, теряет смысл — его нужно отфильтровать, что и позволяет эта опция. Если это часть запроса, фильтрация не нужна.
Не удалять запросы из таблицы при использовании строки быстрого поиска. По умолчанию после этого таблица очищается. Эта опция позволяет добивать недостающие фразы через строку быстрого поиска и не терять данные.
Получать частотности из APIShop.com. Вы можете зарегистрироваться в сервисе, пополнить баланс и получать данные о частотностях без капчи и задержек без обращений к Yandex.Wordstat.
Получать статистику через Yandex.Direct. Опция позволяет снимать статистику Yandex.Wordstat кроме данных сезонности через интерфейс Yandex.Direct. Это резервный режим на случай блокирования доступа к Yandex.Wordstat. Для его запуска нужно прописать доступ к аккаунтам Яндекс.Директа во вкладке «Yandex.Direct»..
Вкладка Yandex.Direct
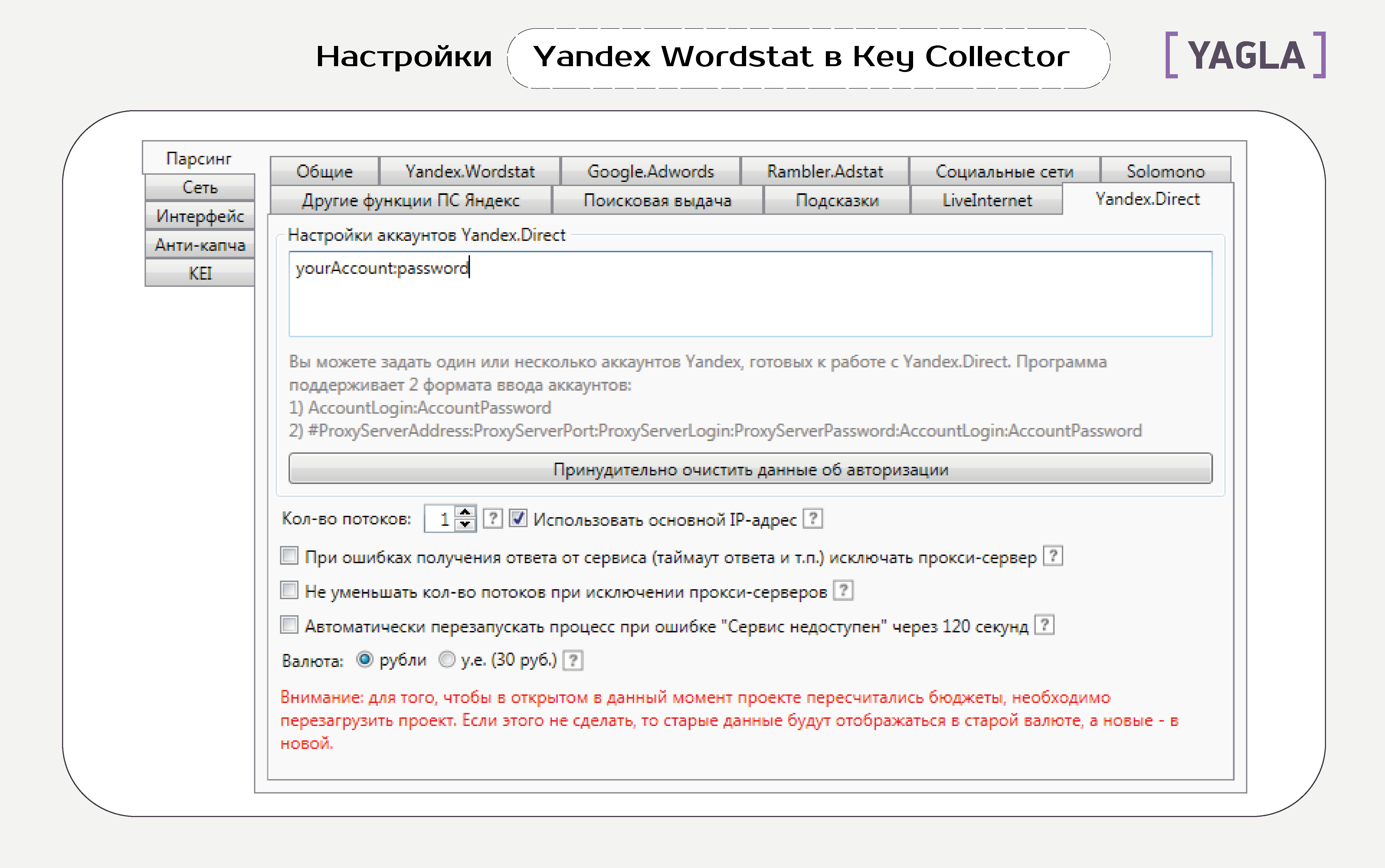
Минус: иногда этот способ выдает гораздо меньше информации в левой и правой колонке.
Внимание: доступ к Директу также могут заблокировать из-за автоматических запросов. Нужно использовать только специальные аккаунты Директа для сбора данных.
Автоматически перезапускать процесс при ошибке «Сервис недоступен» через 120 секунд. Иногда Yandex.Direct становится недоступным. Эта галочка включает повторную попытку собрать статистику.
Валюта. По умолчанию цены, бюджеты, стоимость клика в рублях. После изменения типа необходимо переоткрыть проект.
Вкладка «Подсказки»
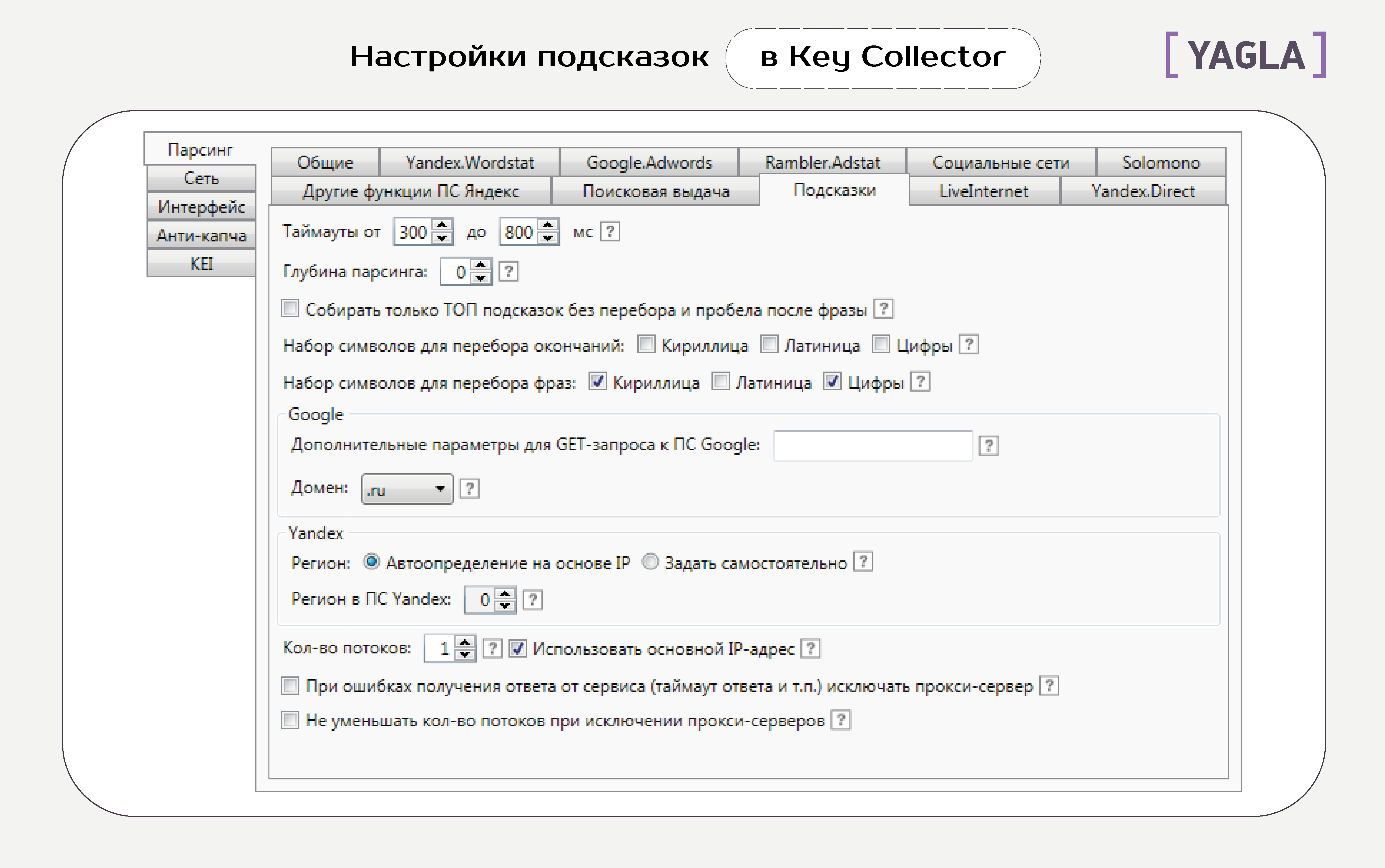
Вкладка «Общие настройки»
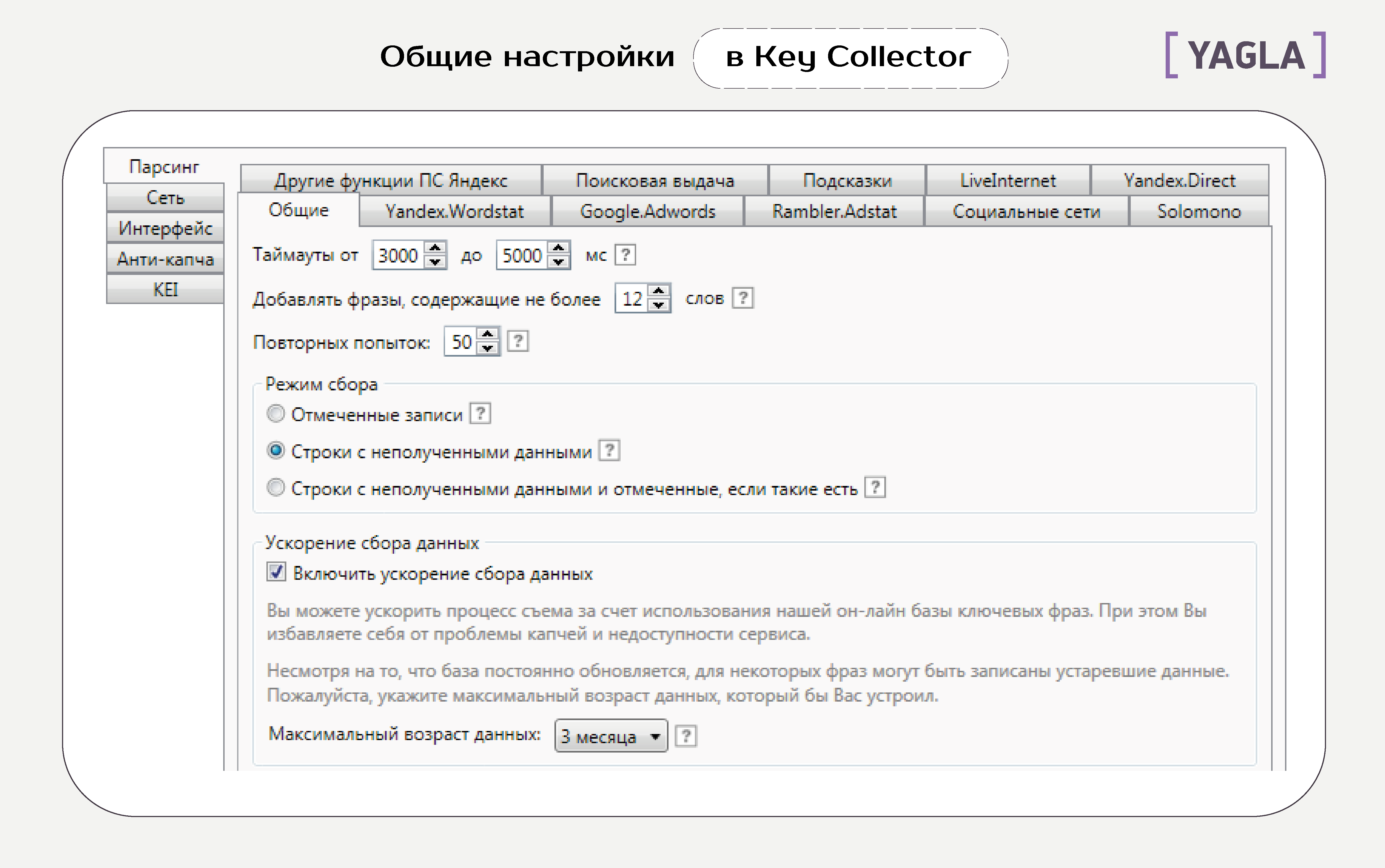
СловоЕБ
Есть также бесплатная программа — СловоЕБ. Основное отличие от Key Collector — ограничение в источниках. Парсер работает только с левой и правой колонкой в Wordstat, Rambler.Adstat и поисковыми подсказками Яндекс и Google.
Для сравнения: Key Collector поддерживает всё вышеперечисленное, плюс Google Ads, подсказки Mail, Wordstat полностью и системы аналитики Google Analytics, Яндекс.Метрика, LiveInternet.
Другие ограничения программы СловоЕБ:
- Проверяет частоту запросов только по Wordstat, а КК также по Yandex.Direct, Google.Ads, LiveInternet, Rambler.Adstat, APIShop.com;
- Оценивает конкурентность запросов для Яндекс и Google, в то время как в КК 4 формулы оценки KEI, которые можно менять вручную;
- Нет поиска конкурентов;
- Не сохраняет проекты в аккаунте;
- Экспортирует результаты только в csv.
Однако этого функционала вполне хватает для небольших проектов.
MOAB Tools
Еще альтернативный сервис — MOAB Tools. Этот парсер предлагает разные тарифы в зависимости от количества запросов.
Парсер слов анализирует подсказки Яндекса по каждому запросу из Вордстата, автоматически удаляет дубли и проверяет частотность по суммарному отчету. Интеграция с Key Collector позволяет делать это в одно нажатие кнопки и получать результат в КК с частотностью по каждой фразе.
В расширенных настройках можно выбрать способ сбора подсказок по устройству, глубине парсинга и способу сбора:
- Фразы
- Фразы и пробелы
- Фразы и цифры
и т.д.
Очистка СЯ от «мусора»
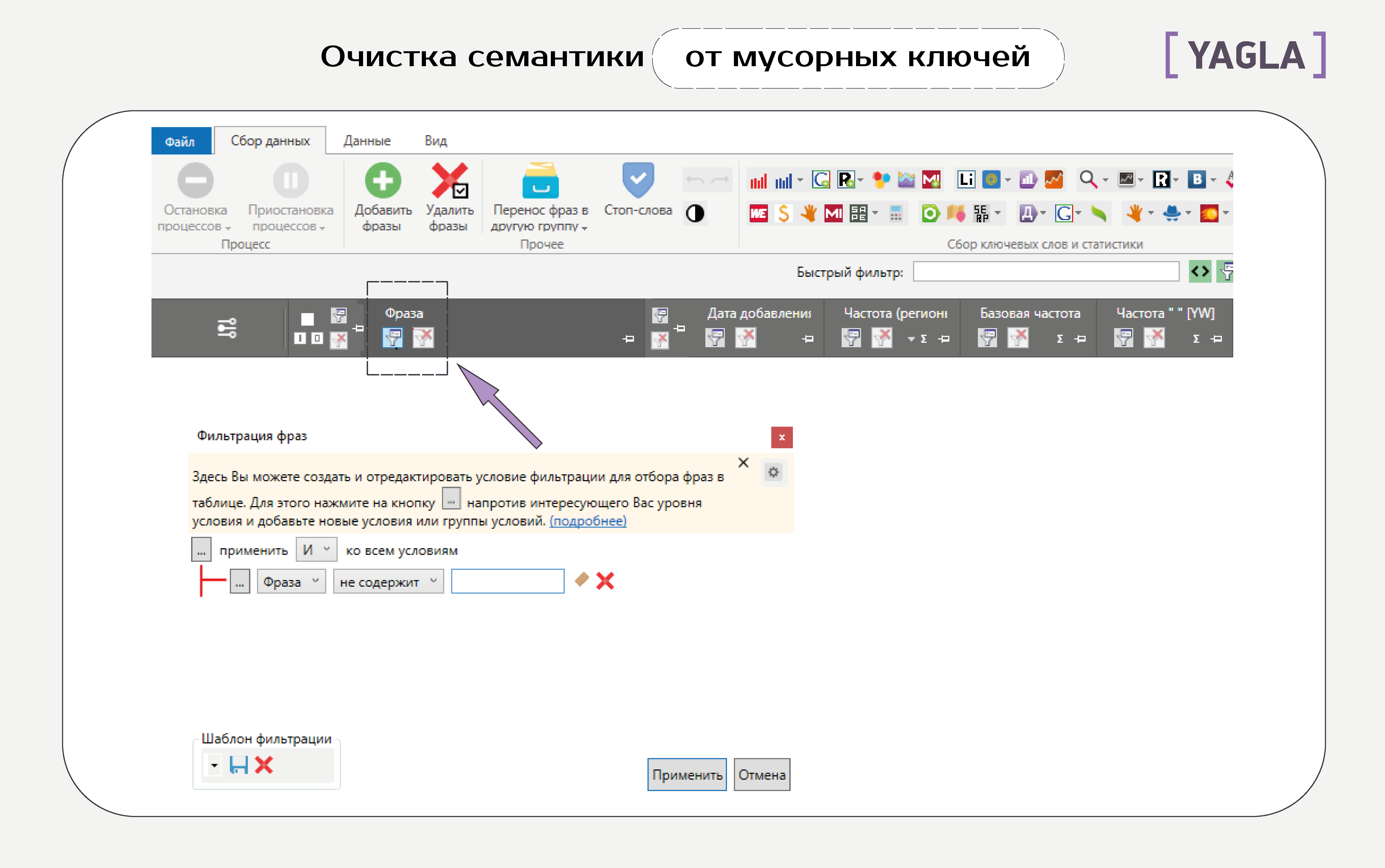
Покажем, как очистить семантику в парсере Key Collector.
- Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации, задаем условие, как на скриншоте ниже, и пишем слова:
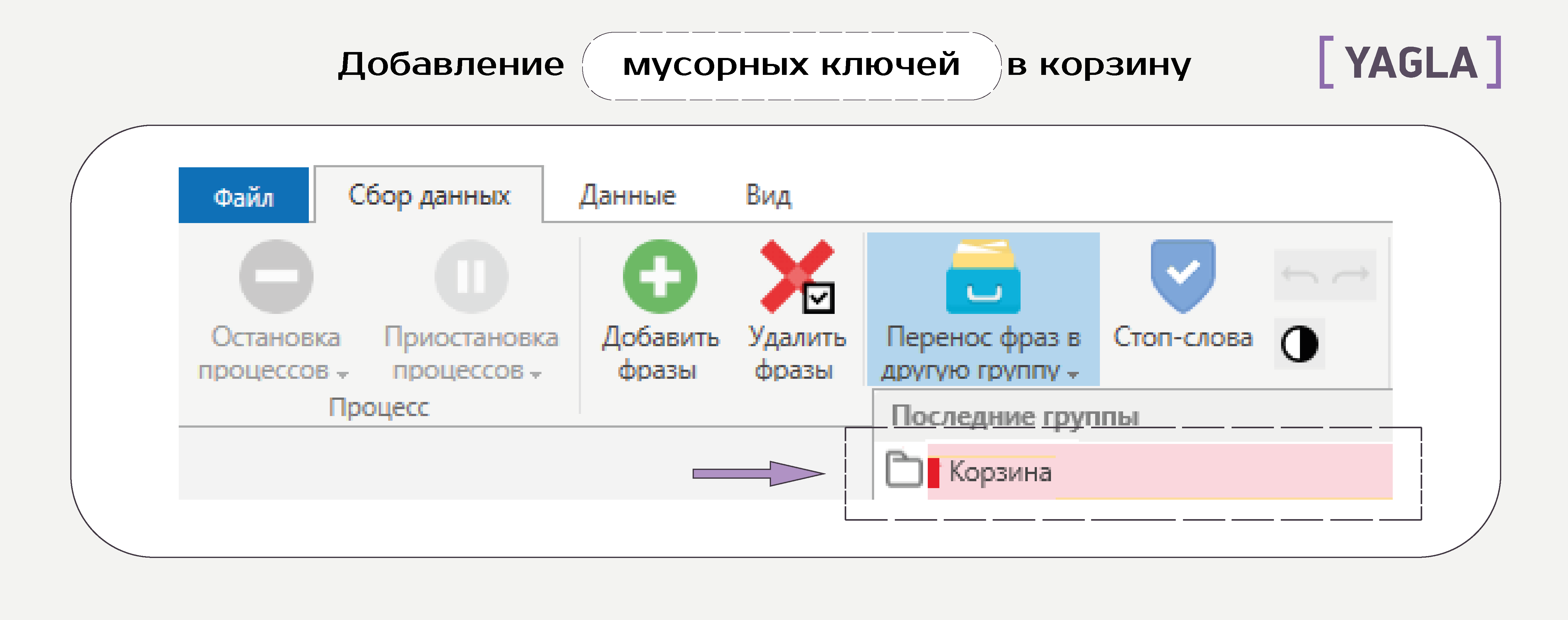
Отмечаем фразы и добавляем в корзину:
- Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
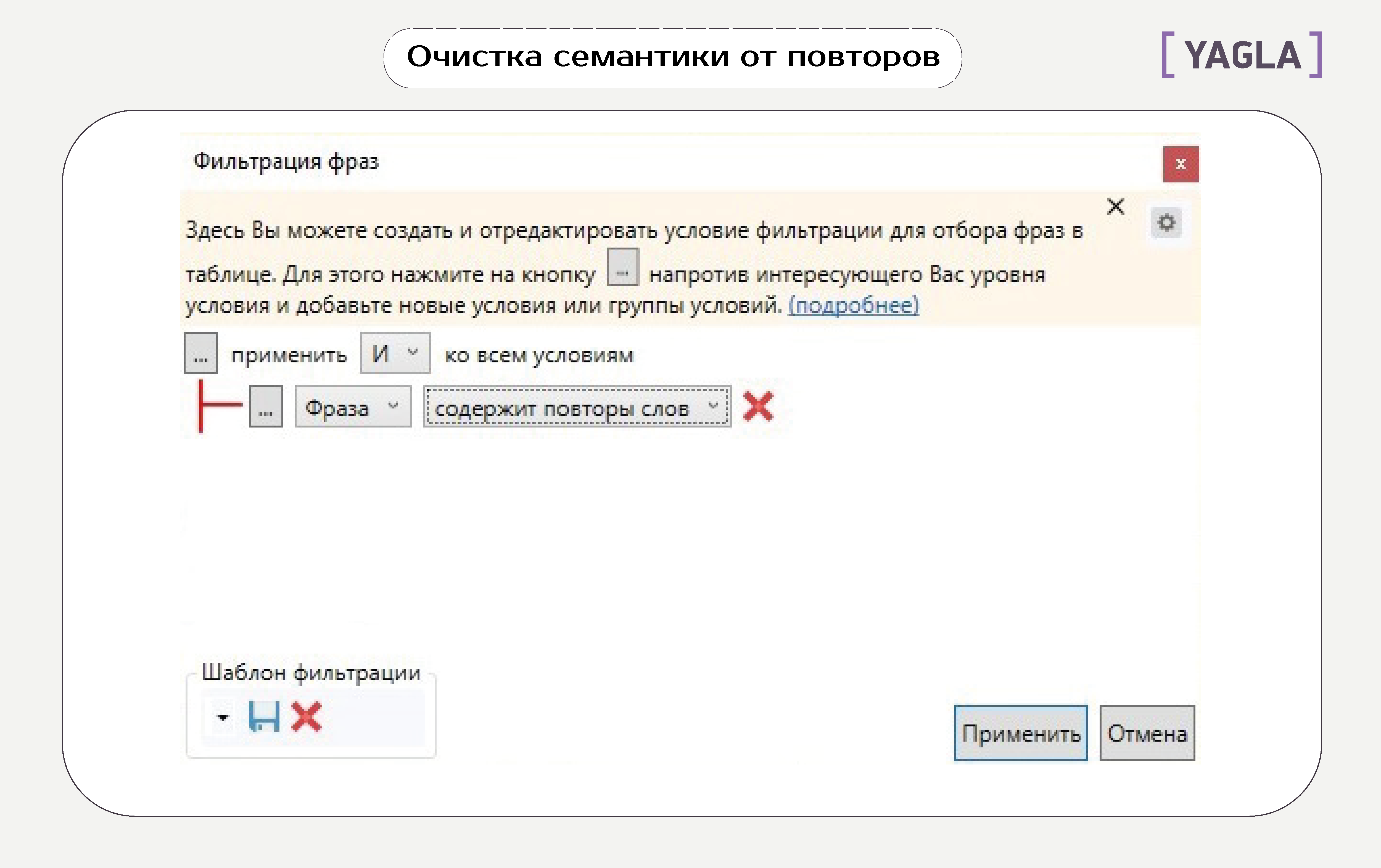
- Стоп-слова
К ним относятся информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.
В окне настроек добавляем фразы и разбиваем по группам:
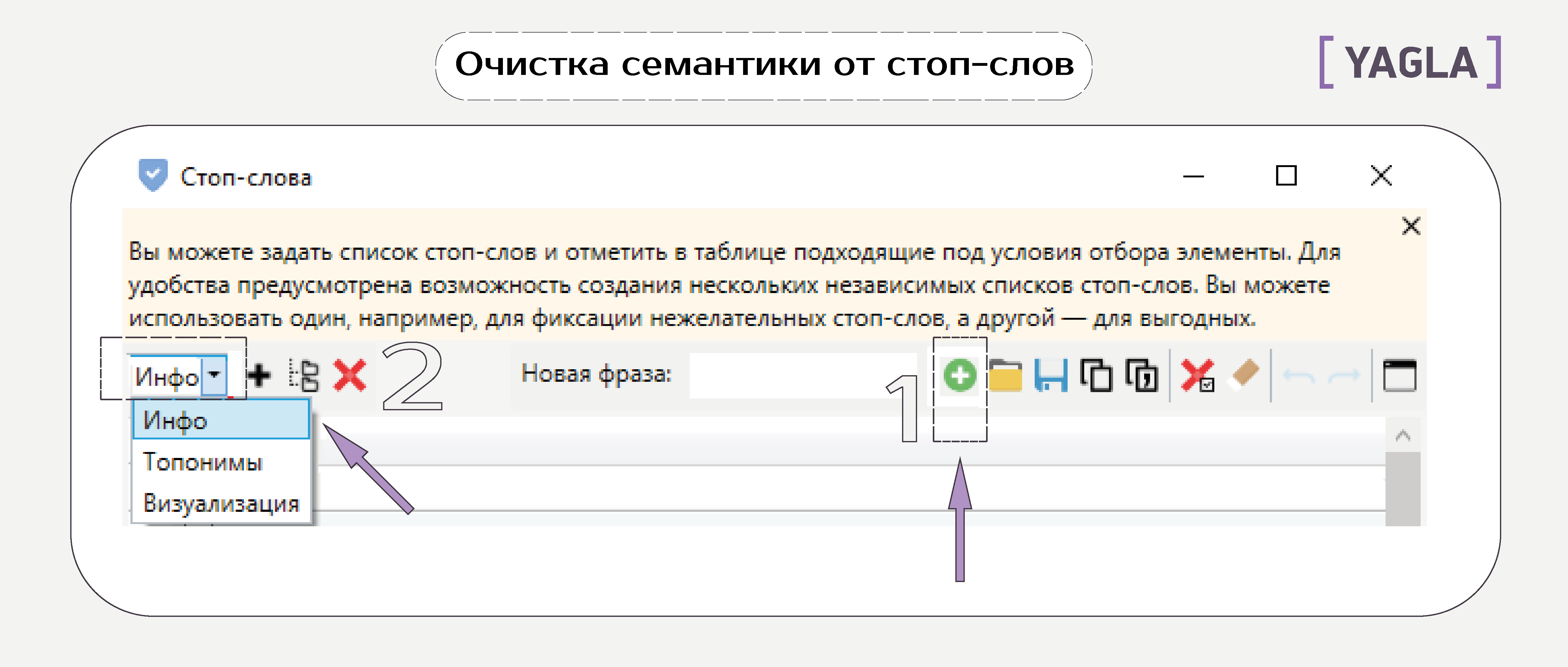
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
-
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:
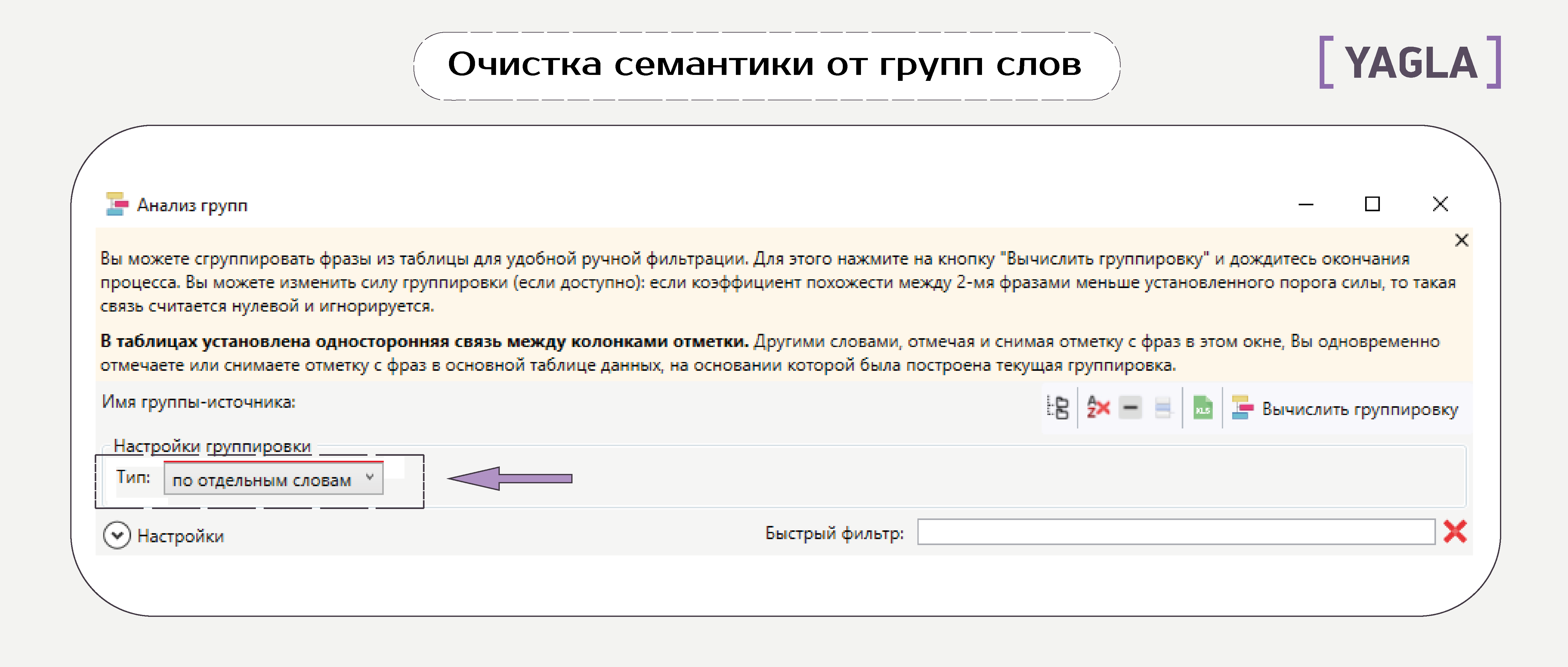
Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
-
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:

Далее — требования по частоте:
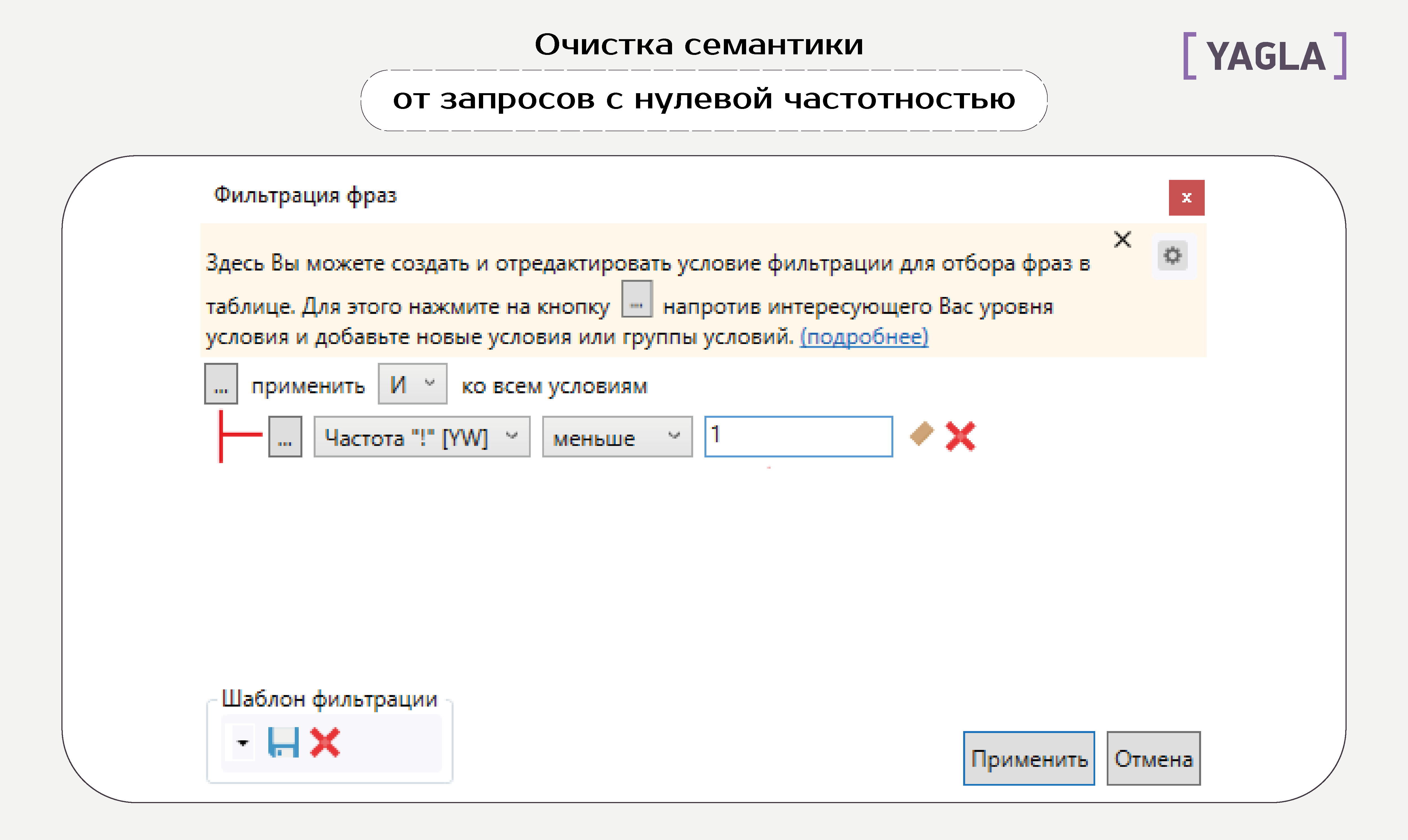
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись.
Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей, подсказок поисковиков и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе.
Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу.
Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха или осушка воздуха. Больше расширений можно насобирать по слову «осушка».
Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную.
Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
Метод перемножения
Шаг 1: расширения масок
Добавляем к базовым маскам расширения из одного слова, чтобы уточнить запрос по разным характеристикам в зависимости от специфики продукта:
- Тип транзакции — заказать, купить, сделать
- Кто оказывает услугу — подрядчик, фирма
- Качество — долговечный, красивый
- Цена — стоимость, расценки, прайс
- Гео
- Сервис — гарантия, срок, быстро, предоплата
- Цель — родителям, детям, для себя
Какие категории использовать — решаете сами. Варианты можно брать с сайтов конкурентов, из подсказок Яндекса и Гугла, словарей синонимов, тематических форумов и блогов — всё, где можно найти идеи о том, что именно в продукте интересует целевую аудиторию. Это могут быть синонимы, жаргоны, специфическая лексика и т.д.
Всё заносим для удобства в Excel. Получаем по каждому базису примерно такую таблицу:
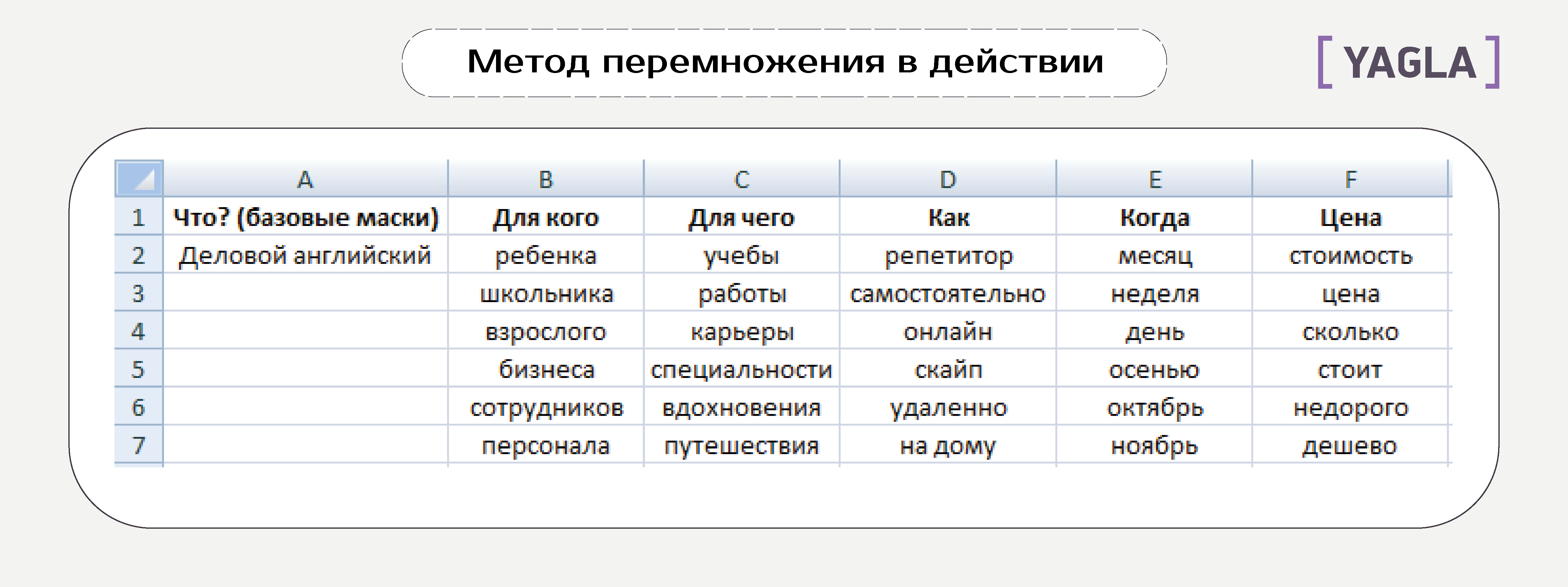
Принцип: 1 ячейка = 1 слово.
Шаг 2: перемножение
Перемножаем первый столбец с остальными по очереди в любом сервисе генерирования ключевых слов:
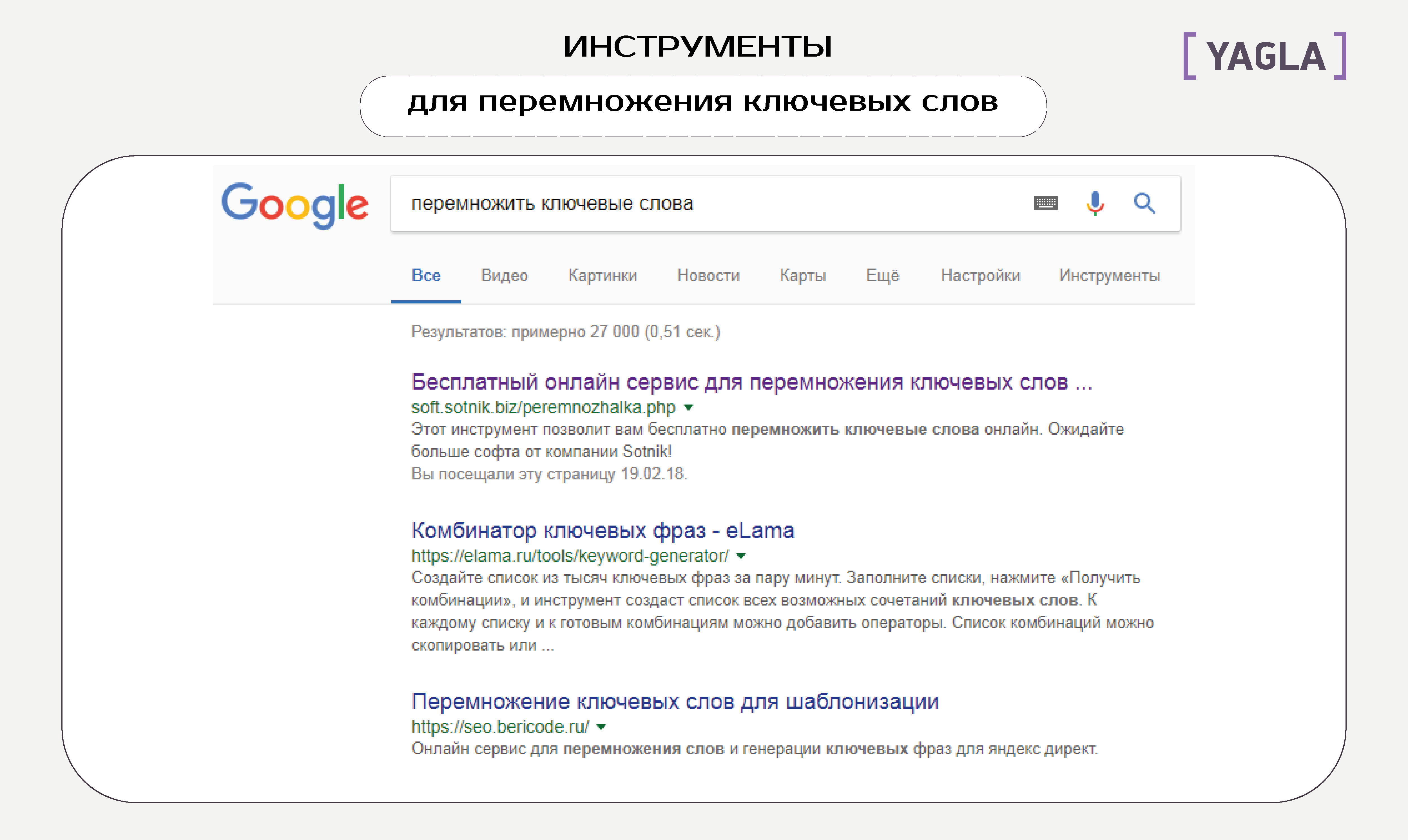
Результаты переносим на отдельный лист, удаляем нецелевые и ультранизкочастотные запросы.
Чек-лист по оптимизации семантического ядра в Яндекс.Директ
После того, как вы собрали первичный массив ключевых фраз, нужно удалить из них:
- Запросы, которые не соответствуют продукту. Например, если вы продаете промышленные светильники, удаляете всё, что связано со светильниками для дома
- Точные дубли
- Стоп-слова
- Фразы с нулевой частотностью
- «Холодные» запросы
- Неочевидные минус-слова
Ключевики для рекламных кампаний готовы. Следующий этап — группировка ключевых слов и создание групп объявлений. Об этом — в следующей статье.
Хотите тоже написать статью для читателей Yagla? Если вам есть что рассказать про маркетинг, аналитику, бизнес, управление, карьеру для новичков, маркетологов и предпринимателей. Тогда заведите себе блог на Yagla прямо сейчас и пишите статьи. Это бесплатно и просто
Статья про сбор и разгребание ключей для Директа, как подготовиться и как потом заминусовать мусор и получить чистую целевую семантику, на которую потом не грех настроить Директ.
Мифы про семантику
Перед тем, как составлять семантическое ядро для Директа, стоит сказать про цель того, ради чего мы тут все собрались.
Во главе стола — эффективно вложить средства в Яндекс Директ, чтобы они вернулись к нам в виде прибыли от продажи нашего продукта. Но специалисты-на-все-руки воплями сотрясают воздух, что везде и в любой тематике надо собирать десятки и сотни тысяч ключей, чтобы показываться вообще везде.
Я за сбор только целевой коммерческой семантики, ибо даже при настройке исключительно по ней, процентов 80 коммерческих фраз никогда не принесут вам клиентов, что уж говорить про информационные и косвенные запросы.
Банально, «купить фотоаппарат кэнон 6д» сконвертится лучше и быстрее, чем «кэнод 6д или 5д что выбрать» — во втором случае человек еще не определился с выбором, и предлагать ему конкретику на данном этапе глупо — продажи не будет.
Как доказательство обратного, мне приводят аргументы — так косвенные запросы стоят дешевле — значит и заявки будут дешевле. Нихрена подобного. Косвенные запросы конвертятся в лида в десятки раз хуже еще на уровне сайта (100 кликов по 10 рублей и 1 заявка за 1000 рублей с косвенных, против 10 кликов по 50 рублей и 1 заявкой за 500 рублей с целевых запросов — тут с целевых ДОРОГИХ запросов можно получить в 2 раза больше заявок), так и потом по телефону понятно, что человек еще не готов к покупке, он че-почем спросить зашел и купит этот фотоаппарат явно не сегодня.
К тому же, обслуживать 10 000 ключей потом нереально, половина запросов через неделю-две уйдет в «мало показов».
Для каждой ниши в разных регионах — свое количество целевых ключевых фраз, где-то 200, где то 2000, а где-то вообще 20.
Как составить семантическое ядро для Яндекс Директ
Описание задачи «как составить семантическое ядро для Яндекс Директ» очень простое — собрать ключевые фразы, которые точно означают желание пользователя купить ваш товар или воспользоваться вашей услугой и настроить на них объявления. А остальные ключевые фразы вынести в отдельный список и занести нецелевые мусорные слова в список минус слов.
Целевые фразы (в будущем, семантика для Директа) в данном случае будут построены по схеме «название товара/услуги в разных вариациях + слово, означающее коммерческую заинтересованность»
Пример: «фотоаппарат кэнон 6д купить» и «фотоаппарат кэнон 6д отзывы реальных пользователей». Первая фраза — коммерческая, вторая — информационная. Другими словами, в первом случае посетитель уже знает про этот фотоаппарат все, и уже ищет магазин, где может его без проблем купить. Во втором случае, пользователь еще не определился с выбором, купит он его явно не сегодня, и помогать ему выбрать фотоаппарат за свои деньги мы конечно же не будем.
Возникает вопрос: а где же взять эти целевые фразы? Неопытные юнцы пойдут сочинять запросы и думать, что так же, как и они, мыслит нужный им регион. Просто возьмут наименование марки, умножат ее на кучу транзакционных слов (купить, заказать, цена, стоимость, прайс и т.д) и настроят на них объявлений. Практика, в принципе, имеет место быть, если бы не минус-слова.
Придумали вы к примеру, «фотоаппарат кэнон 6д купить». А в реальности показываетесь по запросам «фотоаппарат кэнон 6д купить запчасти» или «фотоаппарат кэнон 6д купить авито» и реальность такова что продаж с таких запросов вы не получите, потому что нерелевантны таким запросам.
Как собрать семантику для Директа
Надо представлять всю картину по тому, какие же запросы реально вводят пользователи в определенном регионе по заданной тематике. Чтобы получить такие запросы, их надо спарсить из Вордстата.
Вордстат это сервис Яндекса, который дает информацию, какие запросы вводили пользователи в поисковик и примерное количество таких пользователи. Иначе говоря, мы можем посмотреть, сколько людей в Зажопинске искали, где купить этот чертов Кэнон 6д, и искали ли вообще.
Кстати, такая подготовка дает понять, стоит ли начинать продавать эти девайсы в Зажопинске. А то вы за сайт 200к занесете, фотоаппаратами на лям рублей склад забьете, а потом на этапе сбора фраз (после предоплаты Директологу от 10к) выяснится, что зажопинцы вообще не покупают фотоаппараты.
Сбор направлений
Чтобы что-то парсить, нам надо собрать направления для парсинга. Направления — это те фразы, которые имеют в себе полный охват пользователей, в которых точно есть клиенты. В данном случае — не закажешь ты кэнон 6д, не вбив в поисковик «транзакцинное слово + кэнон 6д».
«Купить фотоаппарат кэнон» — плохое решение, ибо там ищут фотики от конкретного дешмана до 1кк рублей — и мы своим 6д как седло корове нахуй не нужны.
Чтобы знать, как собрать семантическое ядро для Директа и не потерять охват, составляем для себя таблицу:
|
|
Буквы «д» и «d» допом специально ставим без шестерки, ибо есть риск не собрать фразы вроде «кэнон 6 д», где марку целевого фотоаппарата просто написали с пробелами.
Далее, через сервисы мультипликации ключевых фраз перемножаем эти фразы, и у нас получаются целевые направления:
Кэнон 6d
Кэнон 6д
Кэнон д
Кэнон d
кенон 6d
кенон 6д
кенон д
кенон d
canon 6d
canon 6д
canon д
canon d
… которые мы потом закидываем в парсинг через Кей Коллектор.
Понятно, что у нас получаются иногда бредовые вещи, вроде переключения языка посреди фразы, но это позволяет собрать РЕАЛЬНО полный охват, и мы не потерям потенциальных клиентов. Парсить нулевики, естественно, не надо.

В этом примере я специально выбрал город до 300к населения, чтобы мне НЕ спарсилось несколько тысяч ключей, для простоты объяснения.
Очень простой вывод — этот фотоаппарат в данном регионе никто не ищет, а эти мифические 48 человек из самого частого запроса — процентов на 90 состоят из информационки. Коммерческой направленность там даже не пахнет, но мы таки пропарсим в глубину и посмотрим.
Парсим направления в глубину
Спарсив эти направления в глубину, у нас появилось 164 фразы, из которых только 2-3 являются коммерческими, остальные — или 100% информационка, или непонятны намерения пользователя, исходя из запроса — хз, хочет он купить или так, посмотреть зашел. Проверять за свои деньги мы естественно не будем.
Собирается семантика для Директа в КейКоллекторе, из которой потом надо будет заминусовать нецелевое, оставив только целевые для нас фразы.

Чистим семантику
Потом мы выделяем галочками те фразы (или идем в анализ групп и настраиваем по фен-шую), которые НЕ целевые, разбиваем их по словам, и нецелевые слова улетают в список минус-слов, которые блокируют показы и клики по объявлениям по этим фразам — ПРОФИТ!
Составление семантики для Яндекс Директ — только половина качественной настройки.
Кстати, могу помочь с этим — обращайтесь за настройкой Яндекс Директ.