Время на прочтение
5 мин
Количество просмотров 1.1M
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев. Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM CustomersВыбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM CustomersWHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers
WHERE City = 'London'Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers
where City IN ('London', 'Berlin')select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers
GROUP BY CityГруппировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers
GROUP BY Country, CityГруппировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails
GROUP BY ProductIDГруппировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers
WHERE Country = 'Germany'
GROUP BY CityПереименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers
group by CityHAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers
group by City
HAVING count(CustomerID) >= 5 В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers
group by City
HAVING number_of_clients >= 5Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers
WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend')
group by City
HAVING number_of_clients >= 5ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers
ORDER BY CityОсуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers
ORDER BY Country, CityПо умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers
order by CustomerID DESCОбратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers
order by Country DESC, CityJOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders
JOIN Customers ON Orders.CustomerID = Customers.CustomerIDНередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders
join Customers on Orders.CustomerID = Customers.CustomerID
where Customers.CustomerID >10Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:

В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
В этой статье мы рассмотрим некоторые базовые запросы SQL, с изучения которых стоит начинать новичкам в этом языке. Вы научитесь создавать базу данных и таблицы, вносить в них данные и делать выборки нужных сведений.

Аббревиатура SQL расшифровывается как «Structured Query Language» — язык структурированных запросов. С помощью этого языка вы можете работать с записями в базах данных.
SQL состоит из команд и декларативных ключевых слов, которые являются как бы инструкциями для базы данных.
При помощи команд SQL можно создавать и удалять таблицы в базах данных, добавлять в них данные или вносить изменения, искать и быстро находить нужные сведения.
В этой статье мы рассмотрим основные ключевые слова и операторы SQL и разберем, как с их помощью запрашивать конкретную информацию из базы данных.
Структура базы данных
Прежде чем мы начнем разбирать запросы, нужно, чтобы вы поняли иерархию базы данных.
База данных SQL — это набор взаимосвязанных сведений, хранящихся в таблицах. В каждой таблице есть столбцы, описывающие хранящиеся в них данные, и строки, в которых эти данные хранятся. Поле — это отдельный кусочек данных в строке. Чтобы найти нужные данные, мы должны написать, что именно мы хотим получить.
Возьмем для примера некую компанию, штат которой разбросан по всему миру. Допустим, у этой компании есть много баз данных. Чтобы увидеть их полный список, нужно набрать SHOW DATABASES;
Результат может выглядеть как-то так:
+--------------------+ | Databases | +--------------------+ | mysql | | information_schema | | employees | | test | | sys | +--------------------+
В каждой отдельной базе данных может быть много таблиц. Чтобы увидеть, какие таблицы есть в базе данных employees из нашего примера, нужно набрать SHOW TABLES in employees;. В таблицах могут содержаться данные по разным командам, что отражается в названиях: engineering, product, marketing, sales.
+----------------------+ | Tables_in_employees | +----------------------+ | engineering | | product | | marketing | | sales | +----------------------+
Все таблицы состоят из различных столбцов, описывающих данные.
Чтобы просмотреть столбцы таблицы Engineering, используйте Describe Engineering;. Каждый столбец этой таблицы может описывать какой-то один атрибут сотрудника, например: employee_id, first_name, last_name, email, country и salary.
Вывод:
+-----------+-------------------+--------------+ | Name | Null | Type | +-----------+-------------------+--------------+ |EMPLOYEE_ID| NOT NULL | INT(6) | |FIRST_NAME | NOT NULL |VARCHAR2(20) | |LAST_NAME | NOT NULL |VARCHAR2(25) | |EMAIL | NOT NULL |VARCHAR2(255) | |COUNTRY | NOT NULL |VARCHAR2(30) | |SALARY | NOT NULL |DECIMAL(10,2) | +-----------+-------------------+--------------+
Таблицы также состоят из строк — отдельных записей. В нашем примере в строках будут указаны id, имена, фамилии, email, зарплата и страны проживания сотрудников. Каждая строка будет касаться одного сотрудника, допустим, из команды Engineering.
Базовые запросы SQL
Все операции, которые можно осуществлять с данными, входят в понятие «CRUD».
CRUD расшифровывается как Create, Read, Update и Delete (создать, прочесть, обновить, удалить). Это четыре основных операции, которые мы осуществляем, делая запросы к базе данных.
Мы создаем информацию в базе (CREATE), мы читаем, получаем информацию из базы (READ), мы обновляем данные или осуществляем какие-то манипуляции с ними (UPDATE) и, при желании, можем удалять данные (DELETE).
Для осуществления различных операций с данными в SQL есть специальные ключевые слова (операторы). Ниже мы рассмотрим некоторые простые запросы SQL и их синтаксис.
Ключевые слова в SQL
CREATE DATABASE
Для создания базы данных с именем engineering мы используем следующий код:
CREATE DATABASE engineering;
CREATE TABLE
Синтаксис:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype
);
Этот запрос создает новую таблицу в базе данных.
В нем задается имя таблицы, а также имена столбцов, которые нам нужны.
Что касается типов данных (datatype), они могут быть разными. Самые распространенные — INT, DECIMAL, DATETIME, VARCHAR, NVARCHAR, FLOAT и BIT.
В нашем примере запрос может быть таким:
CREATE TABLE engineering ( employee_id int(6) NOT NULL, first_name varchar(20) NOT NULL, last_name varchar(25) NOT NULL, email varchar(255) NOT NULL, country varchar(30), salary decimal(10,2) NOT NULL );
Таблица, созданная по этому запросу, будет выглядеть так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| |
ALTER TABLE
После создания таблицы мы можем изменять ее путем добавления столбцов.
Синтаксис:
ALTER TABLE table_name ADD column_name datatype;
Допустим, мы хотим добавить в только что созданную таблицу столбец с днями рождения сотрудников. Это можно сделать так:
ALTER TABLE engineering ADD birthday date;
Теперь таблица выглядит немного иначе:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | BIRTHDAY | |
| |
INSERT
Это ключевое слово служит для вставки данных в таблицы и создания новых строк. В аббревиатуре CRUD это соответствует букве C.
Синтаксис:
INSERT INTO table_name(column1, column2, column3,..) VALUES(value1, 'value2', value3,..);
Этот запрос создает новую запись в таблице, т. е. новую строку.
В части INSERT INTO мы указываем столбцы, которые хотим заполнить информацией. В VALUES указана информация, которую нужно сохранить.
При вставке строковых значений их нужно брать в одинарные кавычки.
Например:
INSERT INTO table_name(employee_id,first_name,last_name,email,country,salary) VALUES (1,'Timmy','Jones','timmy@gmail.com','USA',2500.00); (2,'Kelly','Smith','ksmith@gmail.com','UK',1300.00);
Теперь таблица будет выглядеть так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
SELECT
Это ключевое слово служит для выборки данных из базы. В CRUD эта операция соответствует букве R.
Синтаксис:
SELECT column1,column2 FROM table_name;
В нашем примере этот запрос будет выглядеть следующим образом:
SELECT first_name,last_name FROM engineering;
Результат:
+-----------+----------+ |FirstName | LastName | +-----------+----------+ | Timmy | Jones | | Kelly | Smith | +-----------+----------+
Ключевое слово SELECT указывает на конкретный столбец, из которого мы хотим выбрать данные.
В части FROM определяется сама таблица.
Вот еще один пример запроса SELECT:
SELECT * FROM table_name;
Астериск (звездочка) означает, что нам нужна вся информация из указанной таблицы (а не отдельный столбец).
WHERE
WHERE позволяет составлять более специфичные (конкретные) запросы.
Например, мы можем использовать WHERE, чтобы выбрать из нашей таблицы Engineering сотрудников с определенным уровнем зарплаты.
SELECT employee_id,first_name,last_name,email,country FROM engineering WHERE salary > 1500
Таблица из предыдущего примера:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
Теперь вывод будет такой:
+-----------+----------+----------+----------------+------------+ |employee_id|first_name|last_name |email |country | +-----------+----------+----------+----------------+------------+ | 1| Timmy |Jones |timmy@gmail.com | USA | +-----------+----------+----------+----------------+------------+
Данные отфильтрованы, и нам показывается только то, что отвечает условию. То есть в выводе мы получаем только строки, где зарплата больше 1500.
Операторы AND, OR, BETWEEN в SQL
Эти операторы позволяют еще больше уточнить запрос. С их помощью можно добавить больше критериев в блоке WHERE.
Оператор AND принимает два условия, причем, чтобы строка попала в результат, оба условия должны быть истинными.
SELECT column_name
FROM table_name
WHERE column1 =value1
AND column2 = value2;
OR тоже принимает два условия, но чтобы строка попала в результат, достаточно истинности хотя бы одного.
SELECT column_name
FROM table_name
WHERE column_name = value1
OR column_name = value2;
Оператор BETWEEN отфильтровывает результаты в определенном диапазоне чисел или текста.
SELECT column1,column2 FROM table_name WHERE column_name BETWEEN value1 AND value2;
Все эти операторы можно комбинировать друг с другом.
Допустим, наша таблица выглядит так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Если мы напишем такой запрос:
SELECT * FROM engineering
WHERE employee_id BETWEEN 3 AND 7
AND
country = 'Germany';
Мы получим следующий результат:
+------------+-----------+-----------+----------------+--------+--------+ |employee_id | first_name| last_name | email |country |salary | +------------+-----------+-----------+----------------+--------+--------+ |5 |Emilia |Fischer |emfis@gmail.com | Germany| 2365.90| |7 |Louis |Meyer |lmey@gmail.com | Germany| 2145.70| +------------+-----------+-----------+----------------+--------+--------+
Были выбраны все столбцы, где employee_id от 3 до 7, а страна проживания — Германия.
ORDER BY
Ключевое слово ORDER BY позволяет отсортировать выдачу по столбцам, указанным в SELECT.
Отсортированные результаты выводятся в порядке возрастания или убывания.
По умолчанию сортировка идет по возрастанию. Но мы можем указать желаемый порядок явно — при помощи команды ORDER BY column_name DESC | ASC .
SELECT employee_id, first_name, last_name,salary FROM engineering ORDER BY salary DESC;
В этом примере мы отсортировали зарплату сотрудников в команде engineering и представили вывод в порядке убывания числовых значений (DESC — от англ. descending — «нисходящий»).
GROUP BY
Ключевое слово GROUP BY в SQL позволяет комбинировать строки с идентичными и похожими данными.
Это полезно для приведения в порядок дублирующихся данных и записей, которые повторяются в таблице многократно.
SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;
Здесь COUNT(*) подсчитывает все строки и возвращает число строк в указанной таблице, группируя строки-дубликаты.
От редакции Techrocks: о COUNT и других агрегатных функциях можно почитать в статье «Агрегатные функции в SQL: объяснение с примерами запросов».
LIMIT
При помощи LIMIT можно указать максимальное число строк, которые должны попасть в результат.
Это бывает полезно при работе с большими наборами данных. Если данных много, запрос может обрабатываться слишком долго. Но когда будет достигнут лимит результатов, обработка прекратится.
Синтаксис:
SELECT column1,column2 FROM table_name LIMIT number;
UPDATE
Ключевое слово UPDATE позволяет обновлять записи в таблице. В CRUD этой операции соответствует буква U.
Синтаксис:
UPDATE table_name
SET column1 = value1,
column2 = value2
WHERE condition;
В условии WHERE указывается запись, которую нужно отредактировать.
UPDATE engineering SET country = 'Spain' WHERE employee_id = 1
Прежде наша таблица выглядела так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | USA | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Теперь, после выполнения запроса, она выглядит так:
| EMPLOYEE_ID | FIRST_NAME | LAST_NAME | COUNTRY | SALARY | |
| 1 | Timmy | Jones | timmy@gmail.com | Spain | 2500.00 |
| 2 | Kelly | Smith | ksmith@gmail.com | UK | 1300.00 |
| 3 | Jim | White | jwhite@gmail.com | UK | 1200.76 |
| 4 | José Luis | Martìnez | jmart@gmail.com | Mexico | 1275.87 |
| 5 | Emilia | Fischer | emfis@gmail.com | Germany | 2365.90 |
| 6 | Delphine | Lavigne | lavigned@gmail.com | France | 2108.00 |
| 7 | Louis | Meyer | lmey@gmail.com | Germany | 2145.70 |
Обновилась страна проживания сотрудника с id 1.
Обновить информацию можно и с помощью значений из другой таблицы. Для этого применяется ключевое слово JOIN.
UPDATE table_name
SET table_name1.column_name1 = table_name2.column_name1
table_name1.column_name2 = table_name2.column2
FROM table_name1
JOIN table_name2
ON table_name1.column_name = table_2.column_name;
DELETE
Ключевое слово DELETE служит для удаления записей из таблицы. В CRUD операция удаления представлена буквой D.
Синтаксис:
DELETE FROM table_name WHERE condition;
Пример с нашей таблицей:
DELETE FROM engineering WHERE employee_id = 2;
При выполнении запроса будет удалена запись о сотруднике с id 2 из команды engineering.
DROP COLUMN
Чтобы удалить из таблицы столбец, можно воспользоваться следующим кодом:
ALTER TABLE table_name DROP COLUMN column_name;
DROP TABLE
Для удаления всей таблицы выполните следующий запрос:
DROP TABLE table_name;
Итоги
В этой статье мы пробежались по самым базовым запросам, с которых начинают все новички в SQL.
Мы научились создавать таблицы и строки, группировать и обновлять данные и, наконец, удалять их. Попутно мы также разобрали SQL-запросы в привязке к операциям CRUD.
Перевод статьи «Learn SQL Queries – Database Query Tutorial for Beginners».
От редакции Techrocks. Вам также могут быть интересны другие статьи по теме SQL:
- Топ-30 вопросов по SQL на технических собеседованиях
- ТОП-10 сайтов, на которых можно потренировать SQL-запросы
- Порядок выполнения SQL-операций
- Выражение CASE в SQL: объяснение на примерах
SQL — язык структурированных запросов. Его создали в 1974 году, чтобы хранить и обрабатывать данные. Все реляционные СУБД — системы управления базами данных — используют его в качестве препроцессора для обработки команд. Сами же базы данных представляют наборы таблиц, где запись — это строка.
SQL в работе используют разработчики и тестировщики, чтобы улучшать сайт или приложение через грамотную работу с базами данных. Тестировщики таким образом помогают бизнесу принимать эффективные решения на основе данных. Маркетологи — глубже анализировать поведение пользователей.

Инженер-тестировщик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT
Узнать больше
Виды SQL-запросов
Ключевые слова этого языка делят на четыре логические группы.
1️⃣ DDL
Data Definition Language — язык определения данных. В него входят ключевые слова CREATE, DROP, RENAME и другие, которые относят к определению и манипулированию структурой базы данных. Их используют, чтобы создавать базы данных и описывать структуру, устанавливать, как размещать данные.
2️⃣ DML
Data Manipulation Language — язык манипулирования данными. В этой группе — запросы SELECT, INSERT, UPDATE, DELETE и другие. Их используют, чтобы изменять, получать, обновлять и удалять данные из базы.
3️⃣ DCL
Data Control Language — язык управления данными. К этой группе относят запросы разрешений, прав и различных ограничивающих доступ настроек. Например, GRANT или DENY.
4️⃣ TCL
Transaction Control Language — язык управления транзакциями. В эту группу входят все запросы, которые относят к управлению транзакциями и их жизненными циклами. Например, BEGIN TRANSACTION, ROLLBACK TRANSACTION, COMMIT TRANSACTION.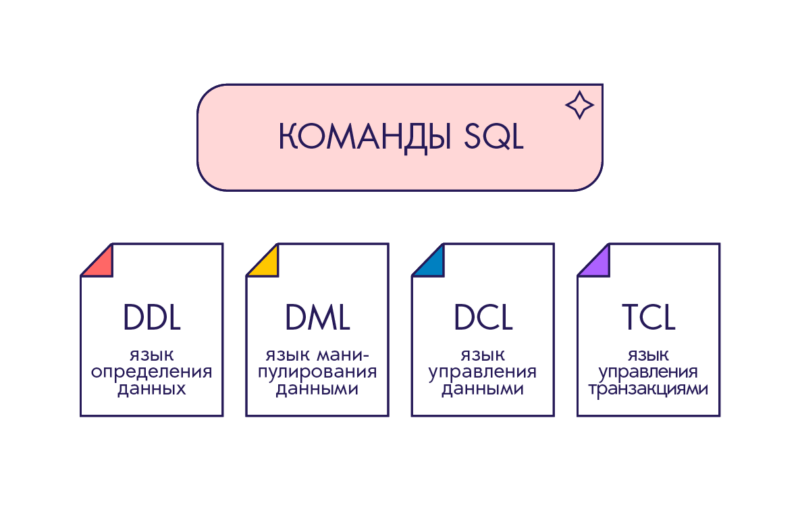
Структура SQL-запросов
Запросы на языке SQL последовательны: логика их составления почти не отличается от обычного предложения. Например, вы хотите отфильтровать записи, чтобы получить только те, где в первом столбце значение равно единице. А после получить значения второго и третьего столбцов в выборке. Предложение на такую команду будет следующее:
Выбрать Столбец2, Столбец3 из Таблица1, где Столбец1 равен одному
На SQL это выглядит похоже:
SELECT (Column2, Column3) FROM Table1 WHERE Column1 = 1
Простые запросы SQL
Ключевые слова
Их используют, чтобы составить запросы:
✔️ WHERE
Это ключевое слово отфильтровывает записи. Мы использовали его в абстрактном примере:
SELECT (Column2, Column3) FROM Table1 WHERE Column1 = 1
✔️ GROUP BY
Группирует записи выборки по значениям указанных столбцов. Это ключевое слово должно следовать после WHERE.
✔️ AND, OR и BETWEEN
AND или OR расширяют выборку, создаваемую с помощью WHERE. Либо сужают ее, если указать дополнительные значения. Ключевое слово BETWEEN позволяет указать диапазон значений, чтобы создать выборку.
✔️ LIMIT
Лимитирует количество значений выборки. Например, по указанным фильтрам получено 100 значений, а нужны только первые 10. Тогда применяют синтаксис LIMIT 10.
Команды
С них начинаются запросы.
Предположим, нам необходимо создать базу данных, чтобы хранить информацию о прочитанных книгах, извлекать и изменять данные. В примерах мы будем использовать самую простую СУБД — sqlite3 в среде Linux. Создайте базу данных командой sqlite3 demo.db — и сразу попадете в командную строку программы:
sqlite3 demo.db SQLite version 3.27.2 2019-02-25 16:06:06 Enter ".help" for usage hints. sqlite>
🚀 CREATE TABLE
Чтобы создать таблицу, используют команду CREATE TABLE. Если создаете таблицу с прочитанными книгами, вероятно, понадобятся три столбца: id, название и автор.
sqlite> CREATE TABLE Books (id INTEGER PRIMARY KEY, title CHAR(255), author CHAR(255)); sqlite> .tables Books
Команда .tables отображает список таблиц.
🚀 INSERT
Команда создает новые записи. Добавим три книги в нашу таблицу:
sqlite> INSERT INTO Books(title, author) VALUES
...> ("Язык SQL", "Неизвестный автор"),
...> ("SQL. Сборник рецептов", "Энтони Молинаро"),
...> ("Книга №3", "Без автора");
Указываем, в какие столбцы нужно вставить данные, игнорируя столбец id: он помечен как первичный ключ. Будет автоматически инкрементироваться, генерируя уникальные значения. В примере вставляем несколько записей за один запрос.
🚀 SELECT
Извлекает записи из таблицы:
sqlite> SELECT * FROM Books; 1|Язык SQL|Неизвестный автор 2|SQL. Сборник рецептов|Энтони Молинаро 3|Книга №3|Без автора
Каждая запись будет на новой строке, а значения столбцов — разделены вертикальной линией. Если, например, нужны не все, а определенные столбцы, то звездочку замените на названия столбцов через запятую:
sqlite> SELECT title, author FROM Books; Язык SQL|Неизвестный автор SQL. Сборник рецептов|Энтони Молинаро Книга №3|Без автора
🚀 UPDATE
Изменяет существующие записи. Чтобы использовать эту команду, укажите уникальный идентификатор изменяемой записи. Либо характеристику, по которой можно получить одну запись или группу из нескольких записей. Обновим авторов у первой и последней записи:
sqlite> UPDATE Books ...> SET author = "Unknown" ...> WHERE id = 1 OR id = 3; sqlite> sqlite> SELECT title, author FROM Books; Язык SQL|Unknown SQL. Сборник рецептов|Энтони Молинаро Книга №3|Unknown
🚀 DELETE
Удаляет записи из таблицы по поисковому запросу. Удалим книгу с id, равным двум:
sqlite> DELETE FROM Books WHERE id = 2; sqlite> sqlite> SELECT * FROM Books; 1|Язык SQL|Unknown 3|Книга №3|Unknown
🚀 DROP TABLE
Удаляет таблицы из базы данных. Создадим и удалим демонстрационную таблицу:
sqlite> CREATE TABLE Demo (id INTEGER PRIMARY KEY, text TEXT); sqlite> sqlite> .tables Books Demo sqlite> sqlite> DROP TABLE Demo; sqlite> sqlite> .tables Books
🚀 ALTER TABLE
Команда в сочетании с другими ключевыми словами изменяет названия таблиц или добавляет новые столбцы. Изменим название нашей таблицы Books:
sqlite> ALTER TABLE Books RENAME TO MyBooks; sqlite> sqlite> .tables MyBooks
Добавим в нее новый столбец is_finished с булевым значением:
sqlite> ALTER TABLE MyBooks ADD COLUMN is_finished BOOLEAN; sqlite> UPDATE MyBooks ...> SET is_finished = True; sqlite> sqlite> SELECT * FROM MyBooks; 1|Язык SQL|Unknown|1 3|Книга №3|Unknown|1
Агрегатные функции
Их используют, чтобы проводить дополнительные вычисления внутри полученной выборки:
✔️ COUNT(название_столбца) — возвращает количество строк выборки, где значение столбца не NULL.
✔️ SUM(название_столбца) — вычисляет и возвращает сумму значений в указанном столбце.
✔️ AVG(название_столбца) — вычисляет и возвращает среднее значение по столбцу.
✔️ MIN(название_столбца) — возвращает наименьшее значение для указанного столбца.
✔️ MAX(название_столбца) — возвращает наибольшее значение указанного столбца.
Вложенные подзапросы
Это SQL-запрос внутри другого SQL-запроса. Подзапросы помогают, если выборку фильтруют по значениям, которые тоже можно отфильтровать. Например, получим названия футбольных команд — участников соревнований с 2010 по 2020 годы:
SELECT DISTINCT club_name FROM clubs WHERE game_year = 2010 AND club_id IN (SELECT club_id FROM clubs WHERE game_year = 2020 );
Ключевое слово DISTINCT убирает из выборки дублирующиеся результаты.
Главное
- SQL используют в реляционных СУБД, где хранят данные в виде таблиц.
- Основные команды SQL делят на четыре логические группы: DDL, DML, DCL, TCL.
- С SQL можно создавать, читать, изменять и удалять данные. Например, чтобы создать таблицу, используют команду CREATE TABLE, извлечь записи — SELECT, удалить таблицу баз данных — DROP TABLE.
- Для дополнительных вычислений нужны агрегатные функции: вычислять и возвращать сумму, наименьшее и наибольшее значение для указанного столбца.
Узнайте, как решать бизнес-задачи с помощью SQL, на курсе Skypro «Аналитик данных». За 5-9 месяцев научитесь фильтровать, группировать и объединять данные из разных таблиц, проводить аналитические исследования, вычислять показатели из большого объема информации. Студенты участвуют в вебинарах и выполняют задания, разбирают реальные задачи на командных мастер-классах под руководством эксперта.
Руководство о всех SQL-запросах и примерах их использования.
Этот пост постоянно обновляется и дополняется, сохраняйте пост себе и делитесь ссыслкой с друзьями.
@sqlhub – задачи, курсы , разбор вопросов с собеседований SQL
1. Запросы для поиска данных
SELECT: используется для выбора данных из базы данных
SELECT*FROMtable_name;
DISTINCT: отфильтровывает повторяющиеся значения и возвращает строки указанного столбца
SELECT DISTINCTcolumn_name;
WHERE: используется для фильтрации записей/строк
SELECTcolumn1, column2FROMtable_nameWHEREcondition;SELECT*FROMtable_nameWHEREcondition1ANDcondition2;SELECT*FROMtable_nameWHEREcondition1ORcondition2;SELECT*FROMtable_nameWHERE NOTcondition;SELECT*FROMtable_nameWHEREcondition1AND(condition2ORcondition3);SELECT*FROMtable_nameWHERE EXISTS(SELECTcolumn_nameFROMtable_nameWHEREcondition);
ORDER BY: используется для сортировки набора результатов в порядке возрастания или убывания
SELECT*FROMtable_nameORDER BYcolumn;SELECT*FROMtable_nameORDER BYcolumnDESC;SELECT*FROMtable_nameORDER BYcolumn1ASC, column2DESC;
SELECT TOP: используется для указания количества записей, возвращаемых из верхней части таблицы
SELECT TOPnumber columns_namesFROMtable_nameWHEREcondition;SELECT TOPpercent columns_namesFROMtable_nameWHEREcondition;- Not all database systems support
SELECT TOP. The MySQL equivalent is theLIMITclause SELECTcolumn_namesFROMtable_nameLIMIToffset, count;
LIKE: оператор, используемый в предложении WHERE для поиска определенного шаблона в столбце
WHERE CustomerName LIKE ‘a%’ Находит любые значения, которые начинаются с “a”
WHERE CustomerName LIKE ‘%a’ Находит любые значения, которые заканчиваются на “a”
WHERE CustomerName LIKE ‘%or%’ Находит любые значения, которые имеют “or” в любой позиции
WHERE CustomerName LIKE ‘_r%’ Находит любые значения, имеющие букву “r” во второй позиции
WHERE CustomerName LIKE ‘a__%’ Находит любые значения, начинающиеся с буквы “a” и имеющие длину не менее 3 символов
WHERE ContactName LIKE ‘a%o’ Находит любые значения, которые начинаются с “a” и заканчиваются “о”
IN: оператор, который позволяет указать несколько значений в предложении WHERE
- по сути, оператор IN является сокращением для нескольких условий OR
SELECTcolumn_namesFROMtable_nameWHEREcolumn_nameIN(value1, value2, …);SELECTcolumn_namesFROMtable_nameWHEREcolumn_nameIN(SELECT STATEMENT);
BETWEEN: оператор выбирает значения в заданном диапазоне включительно
SELECTcolumn_namesFROMtable_nameWHEREcolumn_nameBETWEENvalue1ANDvalue2;SELECT*FROMProductsWHERE(column_nameBETWEENvalue1ANDvalue2)AND NOTcolumn_name2IN(value3, value4);SELECT*FROMProductsWHEREcolumn_nameBETWEEN#01/07/1999# AND #03/12/1999#;
NULL
SELECT*FROMtable_nameWHEREcolumn_nameIS NULL;SELECT*FROMtable_nameWHEREcolumn_nameIS NOT NULL;
AS: используются для присвоения временного имени таблице или столбцу
SELECTcolumn_nameASalias_nameFROMtable_name;SELECTcolumn_nameFROMtable_nameASalias_name;SELECTcolumn_nameASalias_name1, column_name2ASalias_name2;SELECTcolumn_name1, column_name2 + ‘, ‘ + column_name3ASalias_name;
UNION: используется в SQL для объединения набора результатов двух или более операторов SELECT
- Каждый оператор SELECT в UNION должен иметь одинаковое количество столбцов.
- Столбцы должны иметь похожие типы данных
- Столбцы в каждом операторе SELECT также должны быть в том же порядке.
SELECTcolumns_namesFROMtable1UNION SELECTcolumn_nameFROMtable2;- Оператор UNION выбирает только отдельные значения, UNION ALL разрешает дубликаты
INTERSECT: используется для возврата записей, общих для двух операторов SELECT.
- Обычно используется так же, как UNION
SELECTcolumns_namesFROMtable1INTERSECT SELECTcolumn_nameFROMtable2;
EXCEPT: оператор, используемый для возврата всех записей в первом операторе SELECT, которые не найдены во втором операторе SELECT.
- Обычно используется так же, как UNION выше.
SELECTcolumns_namesFROMtable1EXCEPT SELECTcolumn_nameFROMtable2;
ANY|ALL: оператор, используемый для проверки условий подзапроса, используемых в предложениях WHERE или HAVING.
- Оператор ANY возвращает значение true, если какие-либо значения подзапроса соответствуют условию.
- Оператор ALL возвращает значение true, если все значения подзапроса соответствуют условию
SELECTcolumns_namesFROMtable1WHEREcolumn_name operator (ANY|ALL) (SELECTcolumn_nameFROMtable_nameWHEREcondition);
GROUP BY: оператор, часто используемый с агрегатными функциями (COUNT, MAX, MIN, SUM, AVG) для группировки набора результатов по одному или нескольким столбцам.
SELECTcolumn_name1, COUNT(column_name2)FROMtable_nameWHEREconditionGROUP BYcolumn_name1ORDER BYCOUNT(column_name2) DESC;
HAVING: Оператор SQL HAVING является указателем на результат выполнения агрегатных функций. Агрегатной функцией в языке SQL называется функция, возвращающая какое-либо одно значение по набору значений столбца. Такими функциями являются: SQL COUNT(), SQL MIN(), SQL MAX(), SQL AVG(), SQL SUM().
SELECTCOUNT(column_name1), column_name2FROMtableGROUP BYcolumn_name2HAVINGCOUNT(column_name1)> 5;
WITH: запрос, который часто используется для извлечения иерархических данных
WITH RECURSIVEcteAS(
SELECTc0.*FROMcategoriesASc0WHEREid = 1# Starting point
UNION ALL
SELECTc1.*FROMcategoriesASc1JOINcteONc1.parent_category_id = cte.id
)SELECT*FROMcte
2. Запросы для модификации данных
INSERT INTO: используется для вставки новых записей/строк в таблицу
INSERT INTOtable_name (column1, column2)VALUES(value1, value2);INSERT INTOtable_nameVALUES(value1, value2 …);
UPDATE: используется для изменения существующих записей в таблице
UPDATEtable_nameSETcolumn1 = value1, column2 = value2WHEREcondition;UPDATEtable_nameSETcolumn_name = value;
DELETE: используется для удаления существующих записей/строк в таблице
DELETE FROMtable_nameWHEREcondition;DELETE*FROMtable_name;
3. Считаем количество записей
COUNT: возвращает количество вхождений
SELECT COUNT (DISTINCTcolumn_name);
MIN() and MAX(): MIN() и MAX(): возвращает наименьшее/наибольшее значение выбранного столбца.
SELECT MIN (column_names) FROMtable_nameWHEREcondition;SELECT MAX (column_names) FROMtable_nameWHEREcondition;
AVG(): возвращает среднее значение числового столбца
SELECT AVG (column_name) FROMtable_nameWHEREcondition;
SUM(): возвращает общую сумму числового столбца
SELECT SUM (column_name) FROMtable_nameWHEREcondition;
4. Join запросы SQL
INNER JOIN: возвращает записи, имеющие совпадающее значение в обеих таблицах
SELECTcolumn_namesFROMtable1INNER JOINtable2ONtable1.column_name=table2.column_name;SELECTtable1.column_name1, table2.column_name2, table3.column_name3FROM((table1INNER JOINtable2ONrelationship)INNER JOINtable3ONrelationship);
LEFT (OUTER) JOIN: возвращает все записи из левой таблицы (таблица1) и соответствующие записи из правой таблицы (таблица2)
SELECTcolumn_namesFROMtable1LEFT JOINtable2ONtable1.column_name=table2.column_name;
RIGHT (OUTER) JOIN: возвращает все записи из правой таблицы (таблица2) и соответствующие записи из левой таблицы (таблица1)
SELECTcolumn_namesFROMtable1RIGHT JOINtable2ONtable1.column_name=table2.column_name;
FULL (OUTER) JOIN
SELECTcolumn_namesFROMtable1FULL OUTER JOINtable2ONtable1.column_name=table2.column_name;
Self JOIN: обычные джоины
SELECTcolumn_namesFROMtable1 T1, table1 T2WHEREcondition;
5. Запросы на просмотр
CREATE: create a view
CREATE VIEWview_nameAS SELECTcolumn1, column2FROMtable_nameWHEREcondition;
SELECT: retrieve a view
SELECT*FROMview_name;
DROP: drop a view
DROP VIEWview_name;
6. Altering запросы
ADD: add a column
ALTER TABLEtable_nameADDcolumn_name column_definition;
MODIFY: change data type of column
ALTER TABLEtable_nameMODIFYcolumn_name column_type;
DROP: delete a column
ALTER TABLEtable_nameDROP COLUMNcolumn_name;
CREATE: create a table
CREATE TABLEtable_name(column1datatype,column2datatype,column3datatype,column4datatype,);
SQL. Обобщенное табличное выражение
WITH CTE_Name (column1, column2)
AS
-- Define the CTE query.
(
SELECT column1, column2
FROM Table1
WHERE column1 IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT *
FROM CTE_Name
GROUP BY column1, column2
ORDER BY column1, column2;
GO
star_border
Поиск текста в SP
SET QUOTED_IDENTIFIER ON
SET ANSI_NULLS ON
GO
CREATE PROCEDURE [dbo].[Find_Text_In_SP]
@StringToSearch VARCHAR(100),
@StringToSearch2 VARCHAR(100) = '',
@StringToSearch3 VARCHAR(100) = '',
@Name VARCHAR(100) = ''
AS
SET @StringToSearch = '%' +@StringToSearch + '%'
SET @StringToSearch2 = '%' +@StringToSearch2 + '%'
SET @StringToSearch3 = '%' +@StringToSearch3 + '%'
SET @Name = '%' +@Name + '%'
SELECT ROUTINE_NAME, LEN(OBJECT_DEFINITION(OBJECT_ID(ROUTINE_NAME))) AS SP_Length
FROM INFORMATION_SCHEMA.ROUTINES
WHERE OBJECT_DEFINITION(OBJECT_ID(ROUTINE_NAME)) LIKE @stringtosearch
AND OBJECT_DEFINITION(OBJECT_ID(ROUTINE_NAME)) LIKE @StringToSearch2
AND OBJECT_DEFINITION(OBJECT_ID(ROUTINE_NAME)) LIKE @StringToSearch3
AND (ROUTINE_TYPE='PROCEDURE' OR ROUTINE_TYPE='FUNCTION')
AND ROUTINE_NAME LIKE @Name
ORDER BY routine_name
GOOFFSET FETCH
Пропустить первые 10 строк из отсортированного набора результатов и вернуть остальные строки. SELECT column1, column2 FROM table_name ORDER BY column1 OFFSET 10 ROWS;
- Пропустить первые 10 строк из отсортированного набора результатов и вернуть следующие 5 строк. SELECT column1, column2 FROM table_name ORDER BY column1 OFFSET 10 ROWS FETCH NEXT 5 ROWS ONLY;
Переименование a Table
exec sp_rename '[schema.old_table_name]', 'new_table_name'
Переименование a Column
exec sp_rename 'table_name.[oldColumName]' , 'newColumName', 'COLUMN'
SCOPE_IDENTITY
-- returns the last IDENTITY value inserted into an IDENTITY column in the same scope -- returns the last identity value generated for any table in the current session and the current scope -- A scope is a module; a Stored Procedure, trigger, function, or batch SELECT SCOPE_IDENTITY()
НАЙТИ, КАКОЙ ТАБЛИЦЕ ПРИНАДЛЕЖИТ ОГРАНИЧЕНИЕ
SELECT OBJECT_NAME(o.parent_object_id) FROM sys.objects o WHERE o.name = 'MyConstraintName' AND o.parent_object_id <> 0
TRY-CATCH
BEGIN TRY
BEGIN TRANSACTION
-- Do something here
COMMIT TRANSACTION
END TRY
BEGIN CATCH
DECLARE
@ErrorMessage NVARCHAR(4000),
@ErrorSeverity INT,
@ErrorState INT;
SELECT
@ErrorMessage = ERROR_MESSAGE(),
@ErrorSeverity = ERROR_SEVERITY(),
@ErrorState = ERROR_STATE();
RAISERROR (
@ErrorMessage,
@ErrorSeverity,
@ErrorState
);
ROLLBACK TRANSACTION
END CATCH
Условия с переменными WHERE CLAUSE
-- using '=' operator WHERE Column = IIF(@Variable IS NULL ,@Variable, Column) -- using 'LIKE, IN, etc.' WHERE (@Variable IS NULL OR Column LIKE '%' + @Variable + '%' )
ВСТАВИТЬ РАЗДЕЛЕННУЮ ЗАПЯТОЙ СТРОКУ В ТАБЛИЦУ
DECLARE @String = '1, 4, 3'
DECLARE @Tbl TABLE(ID INT);
INSERT INTO @Tbl
(
ID
)
(SELECT value
FROM STRING_SPLIT(@String, ',')
WHERE RTRIM(value) <> '');
UPDATE WITH JOIN
UPDATE Table1
SET Table1.Column = B.Column
FROM Table1 A
INNER JOIN Table2 B
ON A.ID = B.ID
DELETE WITH JOIN
DELETE A FROM Table1 A INNER JOIN Table2 B ON B.Id = A.Id WHERE A.Column = 1 AND B.Column = 2
UPDATE/INSERT IDENTITY COLUMN
SET IDENTITY_INSERT YourTable ON -- UPDATE/INSERT STATEMENT HERE SET IDENTITY_INSERT YourTable OFF
Находим Foreign Key ограничения ссылок таблицы
SELECT
OBJECT_NAME(f.parent_object_id) TableName,
COL_NAME(fc.parent_object_id,fc.parent_column_id) ColName
FROM
sys.foreign_keys AS f
INNER JOIN
sys.foreign_key_columns AS fc
ON f.OBJECT_ID = fc.constraint_object_id
INNER JOIN
sys.tables t
ON t.OBJECT_ID = fc.referenced_object_id
WHERE
OBJECT_NAME (f.referenced_object_id) = 'Table_Name'
Парсим JSON файл в таблицу
-- JSON Data sample:
-- {
-- "label": "test ",
-- "value": 1
-- },
-- {
-- "label": "test2 ",
-- "value": 2
-- }
DECLARE @tbl TABLE (id INT, label VARCHAR(500));
DECLARE @json VARCHAR(max);
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:jsonFile.json', SINGLE_CLOB) as j
INSERT INTO @tbl (id, label)
SELECT [value], label
FROM OPENJSON(@json)
WITH ([value] int,
label nvarchar(max))
SELECT * FROM @tbl
Добавляем FK в существующую колонку
ALTER TABLE [Table1]
ADD CONSTRAINT FK_Table2_Id FOREIGN KEY (Table1_Id)
REFERENCES Table2(Table2_Id);
Список всех пользовательских функций по типу
SELECT [Name], [Definition], [Type_desc]
FROM sys.sql_modules m
INNER JOIN sys.objects o
ON m.object_id=o.object_id
WHERE [Type_desc] like '%function%'
Обновляем и изменяем часть строки
UPDATE dbo.[Table] SET Value = REPLACE(Value, '123', '') WHERE ID <=4
Генерируем случайные INT SQL
---- Create the variables for the random number generation DECLARE @Random INT; DECLARE @Upper INT; DECLARE @Lower INT ---- This will create a random number between 1 and 999 SET @Lower = 1 ---- The lowest random number SET @Upper = 999 ---- The highest random number SELECT @Random = ROUND(((@Upper - @Lower -1) * RAND() + @Lower), 0) SELECT @Random
Создаем случайные ДАТЫ между двумя диапазонами
DECLARE @FromDate DATE = '2019-09-01'; DECLARE @ToDate DATE = '2019-12-31'; SELECT DATEADD(DAY, RAND(CHECKSUM(NEWID()))*(1+DATEDIFF(DAY, @FromDate, @ToDate)), @FromDate)
Получаем Список таблиц
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_TYPE='BASE TABLE'
Проверить, существует ли таблица в базе данных
IF EXISTS(SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'dbo' AND TABLE_NAME = 'Table') BEGIN -- exists END
Сгенерировать 6-значный уникальный номер
SELECT LEFT(CAST(RAND()*1000000000+999999 AS INT),6) AS OTP
Ищем table name
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE '%%'
Поиск между двумя датами
--convert to date to ignore time SELECT * FROM Table T WHERE CONVERT(DATE,T.DateColumn) BETWEEN COALESCE(CONVERT(DATE,@DateFrom), CONVERT(DATE,T.DateColumn)) AND COALESCE(CONVERT(DATE,@DateTo), CONVERT(DATE,T.DateColumn))
Формат дат
--Output: 21/03/2022 SELECT FORMAT (getdate(), 'dd/MM/yyyy ') as date --Output: 21/03/2022, 11:36:14 SELECT FORMAT (getdate(), 'dd/MM/yyyy, hh:mm:ss ') as date --Output: Wednesday, March, 2022 SELECT FORMAT (getdate(), 'dddd, MMMM, yyyy') as date --Output: Mar 21 2022 SELECT FORMAT (getdate(), 'MMM dd yyyy') as date --Output: 03.21.22 SELECT FORMAT (getdate(), 'MM.dd.yy') as date --Output: 03-21-22 SELECT FORMAT (getdate(), 'MM-dd-yy') as date --Output: 11:36:14 AM SELECT FORMAT (getdate(), 'hh:mm:ss tt') as date --Output: 03/21/2022 SELECT FORMAT (getdate(), 'd','us') as date
Триггеры
create trigger t1 on table1
after insert
as
begin
insert into Audit
(Column)
select 'Insert New Row with Key' + cast(t.Id as nvarchar(10)) + 'in table1'
from table1 t where Id IN (select Id from inserted)
end
go
Найти все таблицы, содержащие столбец с указанным именем
SELECT c.name AS 'ColumnName'
,t.name AS 'TableName'
FROM sys.columns c
JOIN sys.tables t ON c.object_id = t.object_id
WHERE c.name LIKE '%COLUMN_NAME%'
ORDER BY TableName
,ColumnName;
Скрипт для создания отбрасываемых всех таблиц с префиксом
SELECT 'DROP TABLE ' + TABLE_NAME + '' FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME LIKE 'PREFIX_%'
Скрипт для изменения таблиц, чтобы удалить все ограничения
DECLARE @SQL varchar(4000)='' SELECT @SQL = @SQL + 'ALTER TABLE ' + s.name+'.'+t.name + ' DROP CONSTRAINT [' + RTRIM(f.name) +'];' + CHAR(13) FROM sys.Tables t INNER JOIN sys.foreign_keys f ON f.parent_object_id = t.object_id INNER JOIN sys.schemas s ON s.schema_id = f.schema_id WHERE t.name LIKE 'PREFIX_%' --EXEC (@SQL) PRINT @SQL
Cursor
Перебрать набор данных
-- two variables to hold product name and list price (gonna be used on the loop)
DECLARE
@product_name VARCHAR(MAX),
@list_price DECIMAL;
--defines the result set for the cursor
DECLARE cursor_product CURSOR
FOR SELECT
product_name,
list_price
FROM
dbo.products;
-- open cursor
OPEN cursor_product;
--fetch a row from the cursor into one or more variables
FETCH NEXT FROM cursor_product INTO
@product_name,
@list_price;
-- loop through the cursor
WHILE @@FETCH_STATUS = 0
BEGIN
-- use current product_name and list_price from current index of the cursor in the loop
PRINT @product_name + CAST(@list_price AS varchar);
-- fetch next row from the cursor
FETCH NEXT FROM cursor_product INTO
@product_name,
@list_price;
END;
-- close cursor
CLOSE cursor_product;
-- deallocate the cursor to release it
DEALLOCATE cursor_product;
Join Multiple Tables
SELECT
comments.body,
posts.title,
users.first_name,
users.last_name
FROM comments
INNER JOIN posts on posts.id = comments.post_id
INNER JOIN users on users.id = comments.user_id
ORDER BY posts.title;
Aggregate Functions
SELECT COUNT(id) FROM users;
SELECT MAX(age) FROM users;
SELECT MIN(age) FROM users;
SELECT SUM(age) FROM users;
SELECT UCASE(first_name), LCASE(last_name) FROM users;
Group By
SELECT age, COUNT(age) FROM users GROUP BY age;
SELECT age, COUNT(age) FROM users WHERE age > 20 GROUP BY age;
SELECT age, COUNT(age) FROM users GROUP BY age HAVING count(age) >=2;
Просмотры: 5 864
 Обновлено: 21.01.2022
Обновлено: 21.01.2022
Опубликовано: 14.06.2017
Тематические термины: MariaDB, MySQL, SQL
В инструкции мы рассмотрим пример запросов MySQL/MariaDB, которые будут интересны новичкам или опытным пользователям в качестве шпаргалки.
Все запросы, за исключением выборки, несут потенциальную опасность для данных, которые хранятся в базе. Перед началом работы с рабочей базой, сделайте резервную копию.
Простые запросы
Обычная выборка
Объединение (JOIN)
Даты (DATE)
Максимум, минимум и средний
Длина строки
Лимиты (LIMIT)
Более сложные запросы
Объединение и группировка (GROUP_CONCAT)
Группировка данных по нескольким полям
Объединение таблиц (UNION)
Средние значения, сгруппированные за каждый час
Операторы IF и CASE
Вставка (INSERT)
Обновление (UPDATE)
Удаление (DELETE)
Создание таблицы
Использование в PHP
Экранирование
Переменные
Простые примеры использования SELECT
Синтаксис:
> SELECT <fields1> FROM <table> [JOIN <table2>] [ WHERE <conditions> ORDER BY <fields2> LIMIT <count> ]
* где fields1 — поля для выборки через запятую, также можно указать все поля знаком *; table — имя таблицы, из которой вытаскиваем данные; conditions — условия выборки; fields2 — поле или поля через запятую, по которым выполнить сортировку; count — количество строк для выгрузки.
* запрос в квадратных скобках не является обязательным для выборки данных.
1. Обычная выборка данных
> SELECT * FROM users
* в данном примере мы получаем список всех записей из таблицы users.
2. Выборка данных с объединением двух таблиц (JOIN)
SELECT u.name, r.* FROM users u JOIN users_rights r ON r.user_id=u.id
* в данном примере идет выборка данных с объединением таблиц users и users_rights. Объединяются они по полям user_id (в таблице users_rights) и id (users). Извлекается поле name из первой таблицы и все поля из второй.
3. Выборка с интервалом по времени и/или дате
Варианты запросов и примеров могут быть самые разные. Мы рассмотрим те, с которыми чаще всего приходилось иметь дело автору.
а) известна точка начала и определенный временной интервал:
> SELECT * FROM users WHERE date >= DATE_SUB(NOW(), INTERVAL 1 HOUR)
* будут выбраны данные за последний час (поле date).
б) известны дата начала и дата окончания:
> SELECT * FROM users WHERE date >= ‘2017-10-25’ AND date <= ‘2017-11-25’
* выбираем данные в промежутке между 25.10.2017 и 25.11.2017.
в) известны даты начала и окончания + время:
> SELECT * FROM users WHERE DATE(date) BETWEEN ‘2018-03-25 00:15:00’ AND ‘2018-04-25 15:33:09’;
* выбираем данные в промежутке между 25.03.2018 0 часов 15 минут и 25.04.2018 15 часов 33 минуты и 9 секунд.
г) вытаскиваем данные за определенные месяц и год:
> SELECT * FROM study WHERE MONTH(date) = 4 AND YEAR(date) = 2018
* извлечем данные, где в поле date присутствуют значения для апреля 2018 года.
д) текущая дата минут год:
> SELECT * FROM study WHERE date < (CURDATE() — INTERVAL 1 YEAR)
* мы получим данные, которые имеют в колонке date дату, старше одного года.
4. Выборка максимального, минимального и среднего значения
> SELECT max(area), min(area), avg(area) FROM country
* max — максимальное значение; min — минимальное; avg — среднее.
5. Использование длины строки
> SELECT * FROM users WHERE CHAR_LENGTH(name) = 5;
* данный запрос должен показать всех пользователей, имя которых состоит из 5 символов.
6. Использование лимитов (LIMIT)
Применяется для ограничения количества выводимых результатов. Синтаксис:
<основной запрос> LIMIT [<число2>,] <число1>
* где число1 — сколько результатов вернуть; число2 — сколько результатов пропустить, необязательный параметр — если его не писать, то отсчет начнется с первой строки.
а) извлечь максимум 15 строк:
> SELECT * FROM users LIMIT 15;
б) выбрать строки с 16 по 25 (запрос со смещением):
> SELECT * FROM users LIMIT 15, 10;
* 15 строк пропускаем, 10 извлекаем.
Примеры более сложных запросов или используемых редко
1. Объединение с группировкой выбранных данных в одну строку (GROUP_CONCAT)
> SELECT GROUP_CONCAT(DISTINCT CONVERT(id USING ‘utf8’) SEPARATOR ‘, ‘) as ids FROM users
* из таблицы users извлекаются данные по полю id, все они помещаются в одну строку, значения разделяются запятыми.
2. Группировка данных по двум и более полям
> SELECT * FROM users GROUP BY CONCAT(title, ‘::’, birth)
* итого, в данном примере мы сделаем выгрузку данных из таблицы users и сгруппируем их по полям title и birth. Перед группировкой мы делаем объединение полей в одну строку с разделителем ::.
3. Объединение результатов из двух и более таблиц (UNION)
а) простой вариант использования UNION:
> (SELECT id, fio, address, ‘Пользователи’ as type FROM users)
UNION
(SELECT id, fio, address, ‘Покупатели’ as type FROM customers)
* в данном примере идет выборка данных из таблиц users и customers.
б) если нам нужно использовать WHERE после UNION, запрос будет сложнее:
> SELECT * FROM (
(SELECT id, fio, address, ‘Пользователи’ as type FROM users)
UNION
(SELECT id, fio, address, ‘Покупатели’ as type FROM customers)
) as U
WHERE U.address LIKE «Садовая%»
4. Выборка средних значений, сгруппированных за каждый час
SELECT avg(temperature), DATE_FORMAT(datetimeupdate, ‘%Y-%m-%d %H’) as hour_datetime FROM archive GROUP BY DATE_FORMAT(datetimeupdate, ‘%Y-%m-%d %H’)
* здесь мы извлекаем среднее значение поля temperature из таблицы archive и группируем по полю datetimeupdate (с разделением времени за каждый час).
5. Использование операторов IF и CASE
Данные операторы позволяют определять исход запроса исходя из условия.
а) выбрать пол мужской или женский:
SELECT IF(sex = ‘m’, ‘мужчина’, ‘женщина’) as sex FROM people
* в данном примере мы возвращаем слово «мужчина», если поле sex равно ‘m‘, иначе — «женщина».
б) заменяем идентификатор времени года более понятным человеку значением:
SELECT CASE season_id WHEN 1 THEN ‘зима’ WHEN 2 THEN ‘весна’ WHEN 3 THEN ‘лето’ WHEN 4 THEN ‘осень’ ELSE ‘неправильный идентификатор времени года’ END as season FROM ` seasons
* в данном примере мы используем оператор CASE. Если 1, то вернем слово «зима», если 2 — «весна» и так далее.
Вставка (INSERT)
Синтаксис 1:
> INSERT INTO <table> (<fields>) VALUES (<values>)
Синтаксис 2:
> INSERT INTO <table> VALUES (<values>)
* где table — имя таблицы, в которую заносим данные; fields — перечисление полей через запятую; values — перечисление значений через запятую.
* первый вариант позволит сделать вставку только по перечисленным полям — остальные получат значения по умолчанию. Второй вариант потребует вставки для всех полей.
1. Вставка нескольких строк одним запросом:
> INSERT INTO cities (`name`, `country`) VALUES (‘Москва’, ‘Россия’), (‘Париж’, ‘Франция’), (‘Фунафути’ ,’Тувалу’);
* в данном примере мы одним SQL-запросом добавим 3 записи.
2. Вставка из другой таблицы (копирование строк, INSERT + SELECT):
Синтаксис при копировании строк из одной таблицы в другую выглядит так:
> INSERT INTO <table1> SELECT * FROM <table2> WHERE <условие для select>;
* где table1 — куда копируем; table2 — откуда копируем.
а) скопировать все без разбора:
> INSERT INTO cities-new SELECT * FROM cities;
* в данном примере мы скопируем все строки из таблицы cities в таблицу cities-new.
б) скопировать определенные столбцы строк с условием:
> INSERT INTO cities-new (`name`, `country`) SELECT `name`, `country` FROM cities WHERE name LIKE ‘М%’;
* извлекаем все записи из таблицы cities, названия которых начинаются на «М» и заносим в таблицу cities-new.
в) копирование с обновлением повторяющихся ключей.
Если копировать таблицы несколько раз, то может возникнуть проблема повторения первичного ключа. В базах данных значения таких ключей должны быть уникальными и при попытке вставить повтор мы получим ошибку «Duplicate entry ‘xxx’ for key ‘PRIMARY’». Чтобы новые строки вставить, а повторяющиеся обновить (если есть изменения), используем «ON DUPLICATE KEY UPDATE»:
> INSERT INTO cities-new SELECT * FROM cities ON DUPLICATE KEY UPDATE `name`=VALUES(`name`), `country`=VALUES(`country`);
* в данном примере, как и в предыдущих, мы копируем данные из таблицы cities в таблицу cities-new. Но при совпадении значений первичного ключа мы будем обновлять поля name и country.
Обновление (UPDATE)
Синтаксис:
> UPDATE <table> SET <field>='<value>’ WHERE <conditions>
* где table — имя таблицы; field — поле, для которого будем менять значение; value — новое значение; conditions — условие (без него делать update опасно — можно заменить все данные во всей таблице).
Обновление с использованием замены (REPLACE):
UPDATE <table> SET <field> = REPLACE(<field>, ‘<что меняем>’, ‘<на что>’);
Примеры:
UPDATE cities SET name = REPLACE(name, ‘Масква’, ‘Москва’);
UPDATE cities SET name = REPLACE(name, ‘Масква’, ‘Москва’) WHERE country = ‘Россия’;
UPDATE cities SET name = REPLACE(name, ‘Ма’, ‘Мо’) WHERE name = ‘Масква’;
Если мы хотим перестраховаться, результат замены можно сначала проверить с помощью SELECT:
SELECT REPLACE(name, ‘Ма’, ‘Мо’) FROM cities WHERE name = ‘Масква’;
Удаление (DELETE)
Синтаксис:
> DELETE FROM <table> WHERE <conditions>
* где table — имя таблицы; conditions — условие (как и в случае с UPDATE, использовать DELETE без условия опасно — СУБД не запросит подтверждения, а просто удалит все данные).
Более сложный вариант — удаление данных с объединением таблиц. Запрос будет такого вида:
> DELETE u FROM users u JOIN users_rights r ON r.user_id=u.id WHERE r.admin=’1′
* в данном примере мы удалим записи только из таблицы users (u), которые при объединении с таблицей users_rights будут соответствовать условию r.admin=’1′.
Создание таблицы
Синтаксис:
> CREATE TABLE <table> (<field1> <options1>, <field2> <options2>) <table options>
Пример:
> CREATE TABLE IF NOT EXISTS `users_rights` (
`id` int(10) unsigned NOT NULL,
`user_id` int(10) unsigned NOT NULL,
`rights` int(10) unsigned NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
* где table — имя таблицы (в примере users_rights); field1, field2 — имя полей (в примере создается 3 поля — id, user_id, rights); options1, options2 — параметры поля (в примере int(10) unsigned NOT NULL); table options — общие параметры таблицы (в примере ENGINE=InnoDB DEFAULT CHARSET=utf8).
Использование запросов в PHP
Подключаемся к базе данных:
mysql_connect (‘localhost’, ‘login’, ‘password’) or die («MySQL connect error»);
mysql_select_db (‘db_name’);
mysql_query(«SET NAMES ‘utf8′»);
* где подключение выполняется к базе на локальном сервере (localhost); учетные данные для подключения — login и password (соответственно, логин и пароль); в качестве базы используется db_name; используемая кодировка UTF-8.
Также можно создать постоянное подключение:
mysql_pconnect (‘localhost’, ‘login’, ‘password’) or die («MySQL connect error»);
* однако есть вероятность достигнуть максимально разрешенного лимита хостинга. Данным способом стоит пользоваться на собственных серверах, где мы сами можем контролировать ситуацию.
Завершить подключение:
mysql_close();
* в PHP выполняется автоматически, кроме постоянных подключений (mysql_pconnect).
Запрос к MySQL (Mariadb) в PHP делается функцией mysql_query(), а извлечение данных из запроса — mysql_fetch_array():
$result = mysql_query(«SELECT * FROM users»);
while ($mass = mysql_fetch_array($result)) {
echo $mass[name] . ‘<br>’;
}
* в данном примере выполнен запрос к таблице users. Результат запроса помещен в переменную $result. Далее используется цикл while, каждая итерация которого извлекает массив данных и помещает его в переменную $mass — в каждой итерации мы работаем с одной строкой базы данных.
Используемая функция mysql_fetch_array() возвращает ассоциативный массив, с которым удобно работать, но есть еще альтернатива — mysql_fetch_row(), которая возвращает обычный нумерованный массив.
Экранирование
При необходимости включения в строку запроса спецсимвола, например, %, необходимо использовать экранирование с помощью символа обратного слэша —
Например:
> SELECT * FROM producrions WHERE kpd = ‘100%’
* если выполнить такой запрос без экранирования, знак %, будет восприниматься как любое количество символов после 100.
Использование переменных
Пременные задаются с помощью знака собаки, например:
> SET @number = 101;
* мы создали переменную number со значением 101.
Теперь можно применить переменную в запросе, например:
> INSERT INTO users (`user_number`, `user_name`) VALUES (@number, CONCAT(‘Пользователь ‘, @number));