Основные структуры данных. Матчасть. Азы
Время на прочтение
5 мин
Количество просмотров 193K
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.

В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
- Массивы
- Стеки
- Очереди
- Связанные списки
- Графы
- Деревья
- Префиксные деревья
- Хэш таблицы
Массивы
Массив — это самая простая и широко используемая структура данных. Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
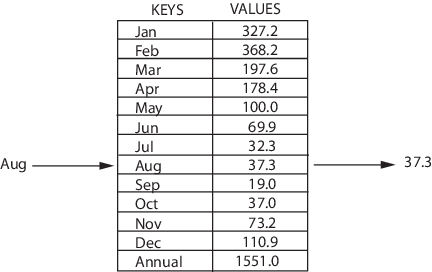
Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).

Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
- Insert-вставляет элемент по заданному индексу
- Get-возвращает элемент по заданному индексу
- Delete-удаление элемента по заданному индексу
- Size-получить общее количество элементов в массиве
Вопросы
- Найти второй минимальный элемент массива
- Первые неповторяющиеся целые числа в массиве
- Объединить два отсортированных массива
- Изменение порядка положительных и отрицательных значений в массиве
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ. last in — first out, «последним пришёл — первым вышел»).
Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.

Основные операции
- Push-вставляет элемент сверху
- Pop-возвращает верхний элемент после удаления из стека
- isEmpty-возвращает true, если стек пуст
- Top-возвращает верхний элемент без удаления из стека
Вопросы
- Реализовать очередь с помощью стека
- Сортировка значений в стеке
- Реализация двух стеков в массиве
- Реверс строки с помощью стека
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом. Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым

Основные операции
- Enqueue—) — вставляет элемент в конец очереди
- Dequeue () — удаляет элемент из начала очереди
- isEmpty () — возвращает значение true, если очередь пуста
- Top () — возвращает первый элемент очереди
Вопросы
- Реализовать cтек с помощью очереди
- Реверс первых N элементов очереди
- Генерация двоичных чисел от 1 до N с помощью очереди
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
1->2->3->4->NULL
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
NULL<-1<->2<->3->NULL
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
1->2->3->1
Самое частое, линейный однонаправленный список. Пример – файловая система.

Основные операции
- InsertAtEnd — Вставка заданного элемента в конец списка
- InsertAtHead — Вставка элемента в начало списка
- Delete — удаляет заданный элемент из списка
- DeleteAtHead — удаляет первый элемент списка
- Search — возвращает заданный элемент из списка
- isEmpty — возвращает True, если связанный список пуст
Вопросы
- Реверс связанного списка
- Определение цикла в связанном списке
- Возврат N элемента из конца в связанном списке
- Удаление дубликатов из связанного списка
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).
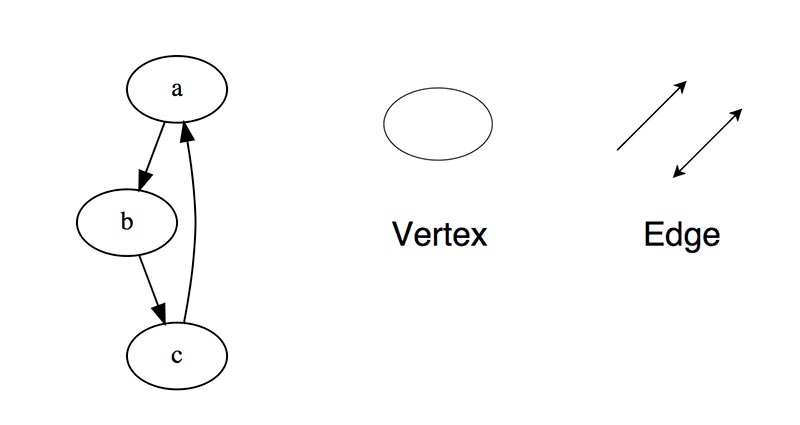
Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
- Матрица смежности
- Список смежности
Общие алгоритмы обхода графа
- Поиск в ширину – обход по уровням
- Поиск в глубину – обход по вершинам
Вопросы
- Реализовать поиск по ширине и глубине
- Проверить является ли граф деревом или нет
- Посчитать количество ребер в графе
- Найти кратчайший путь между двумя вершинами
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.
Простое дерево
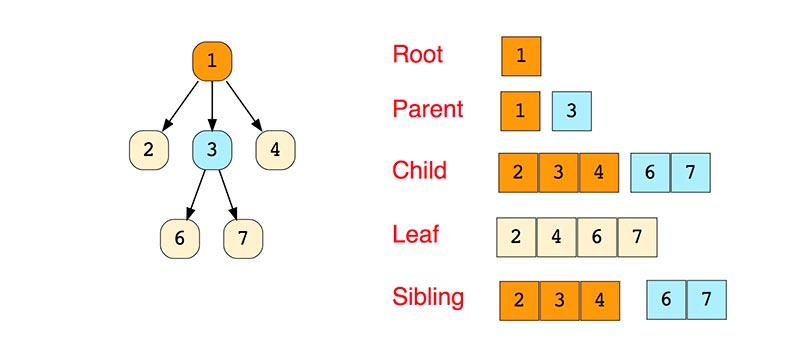
Типы деревьев
- N дерево
- Сбалансированное дерево
- Бинарное дерево
- Дерево Бинарного Поиска
- AVL дерево
- 2-3-4 деревья
Бинарное дерево самое распространенное.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
- В прямом порядке (сверху вниз) — префиксная форма.
- В симметричном порядке (слева направо) — инфиксная форма.
- В обратном порядке (снизу вверх) — постфиксная форма.
Вопросы
- Найти высоту бинарного дерева
- Найти N наименьший элемент в двоичном дереве поиска
- Найти узлы на расстоянии N от корня
- Найти предков N узла в двоичном дереве
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».

Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.
Вопросы
- Подсчитать общее количество слов
- Вывести все слова
- Сортировка элементов массива с префиксного дерева
- Создание словаря T9
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию.

Вопросы
- Найти симметричные пары в массиве
- Найти, если массив является подмножеством другого массива
- Описать открытое хеширование
Список ресурсов
- medium.freecodecamp.org/the-top-data-structures-you-should-know-for-your-next-coding-interview-36af0831f5e3
- www.geeksforgeeks.org/commonly-asked-data-structure-interview-questions-set-1
- prog-cpp.ru/data-list
- habr.com/post/267855
- habr.com/post/273687
- habr.com/post/150732
- ruhighload.com/%D0%A7%D1%82%D0%BE+%D1%82%D0%B0%D0%BA%D0%BE%D0%B5+%D1%85%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D1%8B+%D0%B8+%D0%BA%D0%B0%D0%BA+%D0%BE%D0%BD%D0%B8+%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%B0%D1%8E%D1%82
- ru.wikipedia.org
Вместо заключения
Матчасть так же интересна, как и сами языки. Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
Бо Карнс – разработчик и преподаватель расскажет о наиболее часто используемых и общих структурах данных. Специально для вас мы перевели его статью.
«Плохие программисты беспокоятся о коде. Хорошие программисты беспокоятся о структурах данных и их отношениях ». — Линус Торвальдс, создатель Linux
Структуры данных являются важной частью разработки программного обеспечения и одной из наиболее распространенных тем для вопросов на собеседованиях с разработчиками.
Хорошая новость в том, что они в основном являются просто специализированными форматами для организации и хранения данных.
Из этой статьи вы узнаете о 10 наиболее распространенных структурах данных. Также сюда добавлены видеоролики (на английском языке) по каждой из структур, и код их реализации на JS. А чтобы вы немного попрактиковались, я добавил сюда задачи из бесплатной учебной программы freeCodeCamp.
Обратите внимание, что некоторые из этих структур данных включают временную сложность в нотации Big O. Это не относится ко всем из них, поскольку временная сложность иногда основана на реализации. Если вы хотите узнать больше о нотации Big O, посмотрите видео от Briana Marie .
Несмотря на то, что для каждой структуры я привожу код реализации на JavaScript, вам вероятно, никогда не придется делать этого самостоятельно, только если вы не будете использовать низкоуровневый язык вроде С. JavaScript (как и большинство языков высокого уровня) имеет встроенные реализации многих из этих структур данных.
Тем не менее, знание того, как реализовать эти структуры данных, даст вам огромное преимущество в поиске работы и может пригодиться, когда вы попытаетесь написать высокопроизводительный код.
Связные списки
Связный список является одной из самых основных структур данных. Его часто сравнивают с массивом, поскольку многие другие структуры данных могут быть реализованы либо с помощью массива, либо с помощью связного списка. У каждого из них есть свои преимущества и недостатки.
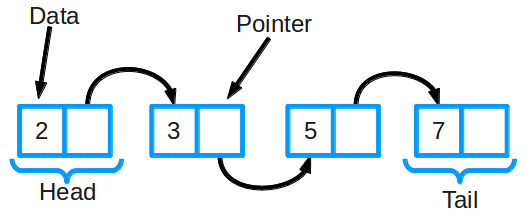
Связный список состоит из группы узлов, которые вместе представляют последовательность. Каждый узел содержит две вещи: фактические данные, которые хранятся (которые могут быть представлены любым типом данных), и указатель (или ссылка) на следующий узел в последовательности. Существуют также дважды связанные списки, в которых каждый узел имеет указатель и на следующий, и на предыдущий элемент в списке.
Самые основные операции в связанном списке включают добавление элемента в список, удаление элемента из списка и поиск в списке для элемента.
Реализация на JavaScript
Временная сложность связного списка ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
- Work with Nodes in a Linked List
- Create a Linked List Class
- Remove Elements from a Linked List
- Search within a Linked List
- Remove Elements from a Linked List by Index
- Add Elements at a Specific Index in a Linked List
- Create a Doubly Linked List
- Reverse a Doubly Linked List
Стеки
Стек — это базовая структура данных, в которой вы можете только вставлять или удалять элементы в начале стека. Он напоминает стопку книг. Если вы хотите взглянуть на книгу в середине стека, вы сначала должны взять книги, лежащие сверху.
Стек считается LIFO (Last In First Out) — это означает, что последний элемент, который добавлен в стек, — это первый элемент, который из него выходит.

Существует три основных операции, которые могут выполняться в стеках: вставка элемента в стек (называемый «push»), удаление элемента из стека (называемое «pop») и отображение содержимого стека (иногда называемого «pip»).
Реализация на JavaScript
Временная сложность стека ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
- Learn how a Stack Works
- Create a Stack Class Queues
Очереди
Вы можете думать об этой структуре, как об очереди людей в продуктовом магазине. Стоящий первым будет обслужен первым. Также как очередь.

Если рассматривать очередь с точки доступа к данным, то она является FIFO (First In First Out). Это означает, что после добавления нового элемента все элементы, которые были добавлены до этого, должны быть удалены до того, как новый элемент будет удален.
В очереди есть только две основные операции: enqueue и dequeue. Enqueue означает вставить элемент в конец очереди, а dequeue означает удаление переднего элемента.
Реализация на JavaScript
Временная сложность очереди ╔═══════════╦═════════╦══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(1) ║ ║ Delete ║ O(1) ║ O(1) ║ ╚═══════════╩═════════╩══════════════╝
Задания с freeCodeCamp:
- Create a Queue Class
- Create a Priority Queue Class
- Create a Circular Queue
Множества
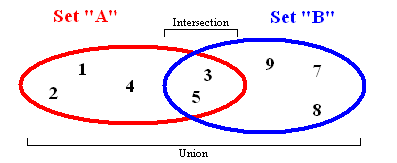
Множества хранят данные без определенного порядка и без повторяющихся значений. Помимо возможности добавления и удаления элементов, есть несколько других важных функций, которые работают с двумя наборами одновременно.
- Union (Объединение). Объединяет все элементы из двух разных множеств и возвращает результат, как новый набор (без дубликатов).
- Intersection (Пересечение). Если заданы два множества, эта функция вернет другое множество, содержащее элементы, которые имеются и в первом и во втором множестве.
- Difference (Разница). Вернет список элементов, которые находятся в одном множестве, но НЕ повторяются в другом.
- Subset(Подмножество) — возвращает булево значение, показывающее, содержит ли одно множество все элементы другого множества.
Реализация на JavaScript
Задания с freeCodeCamp:
- Create a Set Class
- Remove from a Set
- Size of the Set
- Perform a Union on Two Sets
- Perform an Intersection on Two Sets of Data
- Perform a Difference on Two Sets of Data
- Perform a Subset Check on Two Sets of Data
- Create and Add to Sets in ES6
- Remove items from a set in ES6
- Use .has and .size on an ES6 Set
- Use Spread and Notes for ES5 Set()
Map
Map — это структура данных, которая хранит данные в парах ключ / значение, где каждый ключ уникален. Map иногда называется ассоциативным массивом или словарем. Она часто используется для быстрого поиска данных. Map’ы позволяют сделать следующее:
- Добавление пары в коллекцию
- Удаление пары из коллекции
- Изменение существующей пары
- Поиск значения, связанного с определенным ключом
Реализация на JavaScript
Задания с freeCodeCamp:
- Create a Map Data Structure
- Create an ES6 JavaScript Map
Хэш-таблицы
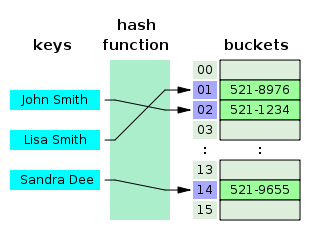
Хэш-таблица — это структура данных, реализующая интерфейс map, который позволяет хранить пары ключ / значение. Она использует хеш-функцию для вычисления индекса в массиве, по которым можно найти желаемое значение.
Хеш-функция обычно принимает строку и возвращает числовое значение. Хеш-функция всегда должна возвращать одинаковое число для одного и того же ввода. Когда два ввода хешируются с одним и тем же цифровым выходом, это коллизия. Суть в том, чтобы их было как можно меньше.
Поэтому, когда вы вводите пару ключ / значение в хеш-таблице, ключ проходит через хеш-функцию и превращается в число. Это числовое значение затем используется в качестве фактического ключа, в котором значение хранится. Когда вы снова попытаетесь получить доступ к тому же ключу, хеширующая функция обработает ключ и вернет тот же числовой результат. Затем число будет использовано для поиска связанного значения. Это обеспечивает очень эффективное время поиска O (1) в среднем.
Реализация на JavaScript
Временная сложность хэш-таблицы ╔═══════════╦═════════╦═══════════════╗ ║ Алгоритм ║В среднем║Худший случай ║ ╠═══════════╬═════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(1) ║ O(n) ║ ║ Insert ║ O(1) ║ O(n) ║ ║ Delete ║ O(1) ║ O(n) ║ ╚═══════════╩═════════╩═══════════════╝
Задания с freeCodeCamp:
- Create a Hash Table
Двоичное дерево поиска
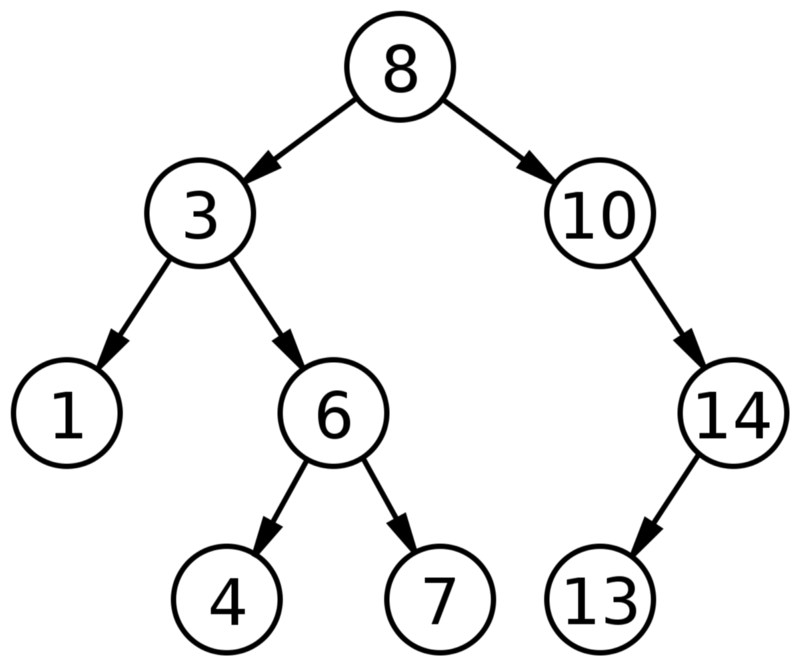
Дерево — это структура данных, состоящая из узлов. Она имеет следующие характеристики:
- Каждое дерево имеет корневой узел (вверху).
- Корневой узел имеет ноль или более дочерних узлов.
- Каждый дочерний узел имеет ноль или более дочерних узлов и т. д.
Двоичное дерево поиска имеет + две характеристики:
- Каждый узел имеет до двух детей(потомков).
- Для каждого узла его левые потомки меньше текущего узла, что меньше, чем у правых потомков.
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Способ их настройки означает, что в среднем каждое сравнение позволяет операциям пропускать половину дерева, так что каждый поиск, вставка или удаление занимает время, пропорциональное логарифму количества элементов, хранящихся в дереве.
Реализация на JavaScript
Временная сложность двоичного поиска ╔═══════════╦══════════╦══════════════╗ ║ Алгоритм ║В среднем ║Худший случай ║ ╠═══════════╬══════════╬══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(log n) ║ O(n) ║ ║ Insert ║ O(log n) ║ O(n) ║ ║ Delete ║ O(log n) ║ O(n) ║ ╚═══════════╩══════════╩══════════════╝
Задания с freeCodeCamp:
- Find the Minimum and Maximum Value in a Binary Search Tree
- Add a New Element to a Binary Search Tree
- Check if an Element is Present in a Binary Search Tree
- Find the Minimum and Maximum Height of a Binary Search Tree
- Use Depth First Search in a Binary Search Tree
- Use Breadth First Search in a Binary Search Tree
- Delete a Leaf Node in a Binary Search Tree
- Delete a Node with One Child in a Binary Search Tree
- Delete a Node with Two Children in a Binary Search Tree
- Invert a Binary Tree
Префиксное дерево
Бор, луч или дерево префикса — это своего рода дерево поиска. Оно хранит данные в шагах, каждый из которых является его узлом. Префиксное дерево из-за быстрого поиска и функции автоматического дописания часто используют для хранения слов.
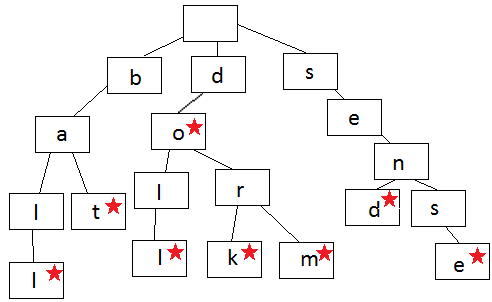
Каждый узел в префиксном дереве содержит одну букву слова. Вы следуете ветвям дерева, чтобы записать слово, по одной букве за раз. Шаги начинают расходиться, когда порядок букв отличается от других слов в дереве или, когда заканчивается слово. Каждый узел содержит букву (данные) и логическое значение, указывающее, является ли узел последним узлом в слове.
Посмотрите на изображение, и вы можете создавать слова. Всегда начинайте с корневого узла вверху и двигайтесь вниз. Показанное здесь дерево содержит слово ball, bat, doll, do, dork, dorm, send, sense.
Реализация на JavaScript
Задания с freeCodeCamp:
- Create a Trie Search Tree
Двоичная куча
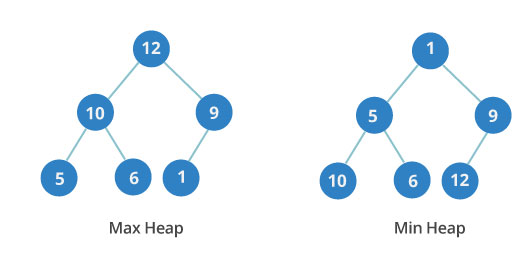
Двоичная куча — это очередное дерево, в каждом узле которого не более двух детей. Кроме того, это полное дерево. Это означает, что все уровни полностью заполнены до последнего уровня, а последний уровень заполняется слева направо.
Двоичная куча может быть либо минимальной, либо максимальной. В максимальной -ключи родительских узлов всегда больше или равны тем, что у детей. В минимальной -ключи родительских узлов меньше или равны ключам дочерних элементов.
Важен порядок между уровнями, но не узлами на одном уровне. На изображении вы можете видеть, что третий уровень минимальной кучи имеет значения 10, 6 и 12. Они расположены не по порядку.
Реализация на JavaScript
Временная сложность двоичной кучи ╔═══════════╦══════════╦═══════════════╗ ║ Алгоритм ║В среднем ║ Худший случай ║ ╠═══════════╬══════════╬═══════════════╣ ║ Space ║ O(n) ║ O(n) ║ ║ Search ║ O(n) ║ O(n) ║ ║ Insert ║ O(1) ║ O(log n) ║ ║ Delete ║ O(log n) ║ O(log n) ║ ║ Peek ║ O(1) ║ O(1) ║ ╚═══════════╩══════════╩═══════════════╝
Задания с freeCodeCamp:
- Insert an Element into a Max Heap
- Remove an Element from a Max Heap
- Implement Heap Sort with a Min Heap
Графы
Графы представляют собой совокупности узлов (также называемых вершинами) и связей (называемых ребрами) между ними. Графы также известны как сети.
Одним из примеров графов является социальная сеть. Узлы — это люди, а ребра — дружба.
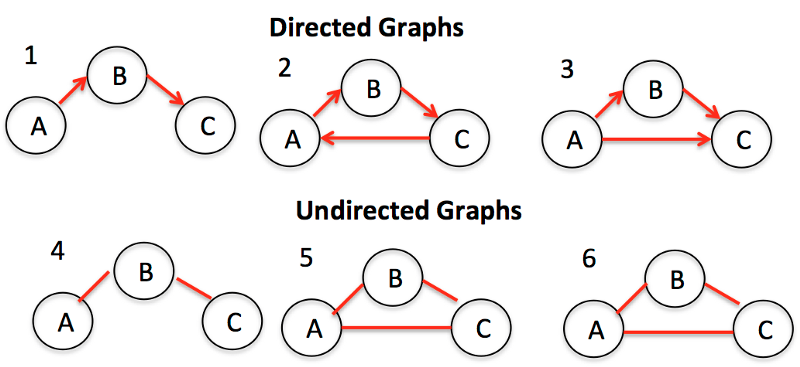
Существует два основных типа графов: ориентированные и неориентированные. Второй тип — это графы без какого-либо направления на ребрах между узлами. Ориентированные графы, напротив, представляют собой графы с направлением на них.
Два частых способа представления графа — это список смежности и матрица смежности.
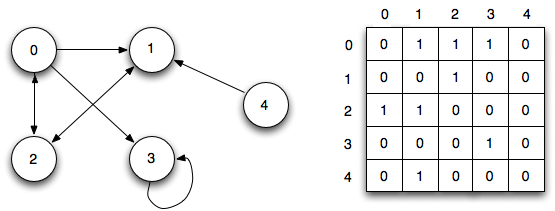
Список смежности может быть представлен как список, где левая сторона является узлом, а правая — списком всех других узлов, с которыми он соединен.
Матрица смежности представляет собой таблицу чисел, где каждая строка или столбец представляет собой другой узел на графе. На пересечении строки и столбца есть число, которое указывает на отношение. Нули означают, что нет ребер или отношений. Единицы означают, что есть отношения. Числа выше единицы могут использоваться для отображения разных весов.
Алгоритмы обхода — это алгоритмы для перемещения или посещения узлов в графе. Основными типами алгоритмов обхода являются поиск в ширину и поиск в глубину. Одно из применений заключается в определении того, насколько близко узлы расположены по отношению к корневому узлу. Посмотрите, как реализовать поиск по ширине в JavaScript в приведенном ниже видео.
Реализация на JavaScript
Временная сложность списка смежности (граф) ╔═══════════════╦════════════╗ ║ Алгоритм ║ Время ║ ╠═══════════════╬════════════╣ ║ Storage ║ O(|V|+|E|) ║ ║ Add Vertex ║ O(1) ║ ║ Add Edge ║ O(1) ║ ║ Remove Vertex ║ O(|V|+|E|) ║ ║ Remove Edge ║ O(|E|) ║ ║ Query ║ O(|V|) ║ ╚═══════════════╩════════════╝
Задания с freeCodeCamp:
- Introduction to Graphs
- Adjacency List
- Adjacency Matrix
- Incidence Matrix
- Breadth-First Search
- Depth-First Search
Если хотите узнать больше:
Книга Grokking Algorithms — лучшая книга на эту тему, если вы новичок в структурах данных / алгоритмах и не обладаете базой компьютерных наук. Автор использует простые объяснения и юмор, рисованные иллюстрации (он является ведущим разработчиком в Etsy), чтобы объяснить некоторые структуры данных, представленные в этой статье.
Структуры данных
- Связный список
- Стек
- Очередь
- Множество
- Map
- Хэш-таблица
- Двоичное дерево поиска
- Префиксное дерево
- Двоичная куча
- Граф
- Полезные ссылки
Связный список

Связный список — одна из базовых структур данных. Ее часто сравнивают с массивом, так как многие другие структуры можно реализовать с помощью либо массива, либо связного списка. У этих двух типов есть преимущества и недостатки.
Связный список состоит из группы узлов, которые вместе образуют последовательность. Каждый узел содержит две вещи: фактические данные, которые в нем хранятся (это могут быть данные любого типа) и указатель (или ссылку) на следующий узел в последовательности. Также существуют двусвязные списки: в них у каждого узла есть указатель и на следующий, и на предыдущий элемент в списке.
Основные операции:
- Добавление элемента
- Удаление элемента
- Поиск элемента
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
| Поиск | O(n) | O(n) |
| Вставка | O(1) | O(1) |
| Удаление | O(1) | O(1) |
Реализация на Python
Реализация на JavaScript
Стек

Стек — базовая структура данных, которая позволяет добавлять или удалять элементы только в ее начале. Она похожа на стопку книг: если вы хотите взглянуть на книгу в середине стека, сперва придется убрать лежащие сверху.
Стек организован по принципу LIFO (Last In First Out, «последним пришел — первым вышел») . Это значит, что последний элемент, который вы добавили в стек, первым выйдет из него.
Основные операции:
- Добавление элемента (
push) - Удаление элемента (
pop) - Отображение содержимого стека (
pip)
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
| Поиск | O(n) | O(n) |
| Вставка | O(1) | O(1) |
| Удаление | O(1) | O(1) |
Реализация на Python
Реализация на JavaScript
Очередь

Эту структуру можно представить как очередь в продуктовом магазине. Первым обслуживают того, кто пришел в самом начале — все как в жизни.
Очередь устроена по принципу FIFO (First In First Out, «первый пришел — первый вышел»). Это значит, что удалить элемент можно только после того, как были убраны все ранее добавленные элементы.
Основные операции:
- Добавление элемента в конец (
enqueue) - Удаление первого элемента (
dequeue)
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
| Поиск | O(n) | O(n) |
| Вставка | O(1) | O(1) |
| Удаление | O(1) | O(1) |
Реализация на Python
Реализация на JavaScript
Множество

Множество хранит значения данных без определенного порядка, не повторяя их. Оно позволяет не только добавлять и удалять элементы: есть еще несколько важных функций, которые можно применять к двум множествам сразу.
- Объединение комбинирует все элементы из двух разных множеств, превращая их в одно (без дубликатов)
- Пересечение анализирует два множества и создает еще одно из тех элементов, которые присутствуют в обоих изначальных множествах
- Разность выводит список элементов, которые есть в одном множестве, но отсутствуют в другом
- Подмножество выдает булево значение, которое показывает, включает ли одно множество все элементы другого множества
Реализация на Python
Реализация на JavaScript
Map

Map — структура, которая хранит данные в парах ключ/значение, где каждый ключ уникален. Иногда ее также называют ассоциативным массивом или словарем. Map часто используют для быстрого поиска данных. Она позволяет делать следующие вещи:
- Добавлять пары в коллекцию
- Удалять пары из коллекции
- Изменять существующей пары
- Искать значение, связанное с определенным ключом
Реализация на JavaScript
Хэш-таблица

Хэш-таблица — похожая на Map структура, которая содержит пары ключ/значение. Она использует хэш-функцию для вычисления индекса в массиве из блоков данных, чтобы найти желаемое значение.
Обычно хэш-функция принимает строку символов в качестве вводных данных и выводит числовое значение. Для одного и того же ввода хэш-функция должна возвращать одинаковое число. Если два разных ввода хэшируются с одним и тем же итогом, возникает коллизия. Цель в том, чтобы таких случаев было как можно меньше.
Таким образом, когда вы вводите пару ключ/значение в хэш-таблицу, ключ проходит через хэш-функцию и превращается в число. В дальнейшем это число используется как фактический ключ, который соответствует определенному значению. Когда вы снова введете тот же ключ, хэш-функция обработает его и вернет такой же числовой результат. Затем этот результат будет использован для поиска связанного значения. Такой подход заметно сокращает среднее время поиска.
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
| Поиск | O(1) | O(n) |
| Вставка | O(1) | O(n) |
| Удаление | O(1) | O(n) |
Реализация на Python
Реализация на JavaScript
Двоичное дерево поиска

Дерево — структура данных, состоящая из узлов. Ей присущи следующие свойства:
- Каждое дерево имеет корневой узел (вверху)
- Корневой узел имеет 0 или более дочерних узлов
- Каждый дочерний узел имеет 0 или более дочерних узлов, и т.д.
У двоичного дерева поиска есть 2 дополнительных свойства:
- Каждый узел имеет до 2 дочерних узлов (потомков)
- Каждый узел меньше своих потомков справа, а его потомки слева меньше его самого
Двоичные деревья поиска позволяют быстро находить, добавлять и удалять элементы. Они устроены так, что время каждой операции пропорционально логарифму общего числа элементов в дереве.
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
| Поиск | O(log n) | O(n) |
| Вставка | O(log n) | O(n) |
| Удаление | O(log n) | O(n) |
Реализация на Python
Реализация на JavaScript
Префиксное дерево

Префиксное (нагруженное) дерево — разновидность дерева поиска. Оно хранит данные в метках, каждая из которых представляет собой узел на дереве. Такие структуры часто используют, чтобы хранить слова и выполнять быстрый поиск по ним — например, для функции автозаполнения.
Каждый узел в языковом префиксном дереве содержит одну букву слова. Чтобы составить слово, нужно следовать по ветвям дерева, проходя по одной букве за раз. Дерево начинает ветвиться, когда порядок букв отличается от других имеющихся в нем слов или когда слово заканчивается. Каждый узел содержит букву (данные) и булево значение, которое указывает, является ли он последним в слове.
Реализация на Python
Реализация на JavaScript
Двоичная куча

Двоичная куча — еще одна древовидная структура данных. В ней у каждого узла не более двух потомков. Также она является совершенным деревом: это значит, что в ней полностью заняты данными все уровни, а последний заполнен слева направо.
Двоичная куча может быть минимальной или максимальной. В максимальной куче ключ любого узла всегда больше ключей его потомков или равен им. В минимальной куче все устроено наоборот: ключ любого узла меньше ключей его потомков или равен им.
Порядок уровней в двоичной куче важен, в отличие от порядка узлов на одном и том же уровне.
Алгоритмическая сложность:
| Алгоритм | Среднее значение | Худший случай |
|---|---|---|
| Поиск | O(n) | O(n) |
| Вставка | O(1) | O(log n) |
| Удаление | O(log n) | O(log n) |
Реализация на Python
Реализация на JavaScript
Граф

Графы — совокупности узлов (вершин) и связей между ними (ребер). Также их называют сетями. По такому принципу устроены социальные сети: узлы — это люди, а ребра — их отношения.
Графы делятся на два основных типа: ориентированные и неориентированные. У неориентированных графов ребра между узлами не имеют какого-либо направления, тогда как у ребер в ориентированных графах оно есть.
Чаще всего граф изображают в каком-либо из двух видов: это может быть список смежности или матрица смежности.

Список смежности можно представить как перечень элементов, где слева находится один узел, а справа — все остальные узлы, с которыми он соединяется.
Матрица смежности — это сетка с числами, где каждый ряд или колонка соответствуют отдельному узлу в графе. На пересечении ряда и колонки находится число, которое указывает на наличие связи. Нули означают, что она отсутствует; единицы — что связь есть. Чтобы обозначить вес каждой связи, используют числа больше единицы.
Существуют специальные алгоритмы для просмотра ребер и вершин в графах — так называемые алгоритмы обхода. К их основным типам относят поиск в ширину (breadth-first search) и поиск в глубину (depth-first search). Как вариант, с их помощью можно определить, насколько близко к корневому узлу находятся те или иные вершины графа.
Реализация матрицы смежности на Python
Реализация на JavaScript
Полезные ссылки
- Оригинал статьи
- Примеры реализации на Python
Основные структуры данных
1 Линейные структуры данных.
2 Табличные структуры данных.
3 Иерархические структуры данных.
4 Достоинства и недостатки различных
структур данных.
Работа с большими наборами данных
автоматизируются проще, когда днныые
упорядочены. т.е. образуют заданную
структуру. Существует три основных
типа структур данных: линейная,
иерархическая и табличная.
Например, в любой книге
страницы упорядочены в соответствии
с простой линейной структурой, разделы,
главы и параграфы книги имеют
иерархическую структуру, а содержание
книги строится на основе табличной
структуры.
1 Линейные структуры данных
Примером линейной структуры данных
является список студентов, обучающихся
в группе
(журнал).
№ п/п Ф И О.
1. Беляков И.П
2. Иванов Л.В
3. Смирнова Г.В.
21. Яковлев С.П.
Линейные структуры данных
( или
списки) – это упорядоченные структуры,
в которых адрес элемента однозначно
определяется его номером.
Элементы данных любого
списка можно разбить по строкам (как
это сделано выше) или
разместить линейно в одной строке с
использованием специальных разделителей.
Например,
Беляков И.П. * Иванов Л. В. * Смирнова
Г.В. * … * Яковлев С.П.
Если все элементы списка имеют равную
длину, то такие упрощенные списки
называют векторами данных. Работать
с ними более удобно.
2 Табличные структуры данных
Табличные структуры отличаются от
списочных тем,
что элементы данных определяются не
номером, аадресом ячейки, который
состоит не из одного параметра, как в
списках, а из нескольких (например,
номер строки и столбца).
Пример:
|
товар |
цена |
количество |
сумма |
|
телевизор |
8000 |
2 |
16000 |
|
холодильник |
14000 |
1 |
14000 |
|
электропечь |
6000 |
4 |
24000 |
Элементы данных, принадлежащих табличной
структуре, также можно разместить
линейно с
использованием специальных разделителей
различных типов. Например:
товар * цена* количество* сумма #
телевизор * 8000 *2 * 16000 #холодильник
*14000 *14000 #электропечъ * 6000 *4* 24000
Если все элементы таблицы имеют равную
длину, то такие таблицы называются
матрицами.
Итак, табличные структуры данных —
это упорядоченные структуры, в
которых адрес элемента определяется
номером строки и номером столбца,
на пересечении которых находится
ячейка, содержащая искомый элемент
.Таблицы, в которых адрес элемента
определяется не двумя, а большим
количеством параметров, называются
многомерными.
В качестве примера 4-х мерной таблицы
можно привести структуру данных,
определяемую следующими четырьмя
параметрами:
Номер курса: 1
Номер специальности: 061000
Номер группы: М-72
Номер студента в группе: 10
3.Иерархические структуры данных
Нерегулярные данные,
которые трудно представить в виде
списка или таблицы, часто представляют
в виде иерархических структур. Например,
иерархическую структуру имеетсистема почтовых адресов.
В иерархической
структуре, адрес
каждого элемента определяется путем
доступа(маршрутом),
ведущим от вершины
структуры к данному элементу.
Например, маршрут для
установки ориентации печатного листа
в текстовом редакторе WORD
выглядит следующим образом Файл
—> параметры
страницы —>
Размер бумаги —>Ориентация.
4. Достоинства и недостатки различных
структур данных
Списочные и табличные структуры являются
простыми, поэтому они легко упорядочиваются.
Основным методом упорядочивания
является сортировка по какому-либо
признаку.
Несмотря на многочисленные удобства,
основной недостаток простых структур
данных состоит в том, что их трудно
обновлять. При добавлении произвольного
элемента в упорядоченную структуру
списка может происходить изменение
адресных данных у других элементов.
Например, при добавлении нового студента
в конец списка группы нарушается
упорядочивание по алфавиту. Если его
вписать в соответствии с алфавитом, то
изменятся порядковые номера всех
студентов, которые следуют за ним.
Иерархические структуры данных по фирме
сложнее, чем линейные и табличные, но
они не создают проблем с обновлением
данных. Недостатком иерархических
структур является относительная
трудоемкость записи адреса элемента
данных и сложность упорядочивания.
Методы упорядочивания в таких структурах
основываются на предварительной
индексации, которая заключается в
том , что каждому элементу данных
присваивается свой уникальный индекс
(номер),который можно использовать при
поиске, сортировке и т.п. После такой
индексации данные легко разыскиваются
по двоичному коду, связанного с ними
индекса. Одним из примеров индексации
является алфавитный указатель в конце
книги. Если данные хранятся в организованной
структуре, то каждый элемент данных
приобретает свой параметр, который
называется егоадресом. Работать с
упорядоченными данными удобнее, но за
это надо платить их размножением,
поскольку адреса элементов — это тоже
данные, которые также надо хранить и
обрабатывать. Главное, чтобы размер
адресных данных не становился больше,
чем размер самих данных, на которые
указывает адрес. Чтобы избежать такой
ситуации, используются специальные
методы организации хранения данных.
8
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Необходимым условием хранения информации в памяти компьютера является возможность преобразования этой самой информации в подходящую для компьютера форму. В том случае, если это условие выполняется, следует определить структуру, пригодную именно для наличествующей информации, ту, которая предоставит требующийся набор возможностей работы с ней.
Здесь под структурой понимается способ представления информации, посредством которого совокупность отдельно взятых элементов образует нечто единое, обусловленное их взаимосвязью друг с другом. Скомпонованные по каким-либо правилам и логически связанные межу собой, данные могут весьма эффективно обрабатываться, так как общая для них структура предоставляет набор возможностей управления ими – одно из того за счет чего достигаются высокие результаты в решениях тех или иных задач.
Но не каждый объект представляем в произвольной форме, а возможно и вовсе для него имеется лишь один единственный метод интерпретации, следовательно, несомненным плюсом для программиста будет знание всех существующих структур данных. Таким образом, часто приходиться делать выбор между различными методами хранения информации, и от такого выбора зависит работоспособность продукта.
Говоря о не вычислительной технике, можно показать ни один случай, где у информации видна явная структура. Наглядным примером служат книги самого разного содержания. Они разбиты на страницы, параграфы и главы, имеют, как правило, оглавление, то есть интерфейс пользования ими. В широком смысле, структурой обладает всякое живое существо, без нее органика навряд-ли смогла бы существовать.
Вполне вероятно, читателю приходилось сталкиваться со структурами данных непосредственно в информатике, например, с теми, что встроены в язык программирования. Часто они именуются типами данных. К таковым относятся: массивы, числа, строки, файлы и т. д.
Методы хранения информации, называемые «простыми», т. е. неделимыми на составные части, предпочтительнее изучать вместе с конкретным языком программирования, либо же глубоко углубляться в суть их работы. Поэтому здесь будут рассмотрены лишь «интегрированные» структуры, те которые состоят из простых, а именно: массивы, списки, деревья и графы.
Массивы.
Массив – это структура данных с фиксированным и упорядоченным набором однотипных элементов (компонентов). Доступ к какому-либо из элементов массива осуществляется по имени и номеру (индексу) этого элемента. Количество индексов определяет размерность массива. Так, например, чаще всего встречаются одномерные (вектора) и двумерные (матрицы) массивы. Первые имеют один индекс, вторые – два.
Пусть одномерный массив называется A, тогда для получения доступа к его i-ому элементу потребуется указать название массива и номер требуемого элемента: A[i]. Когда A – матрица, то она представляема в виде таблицы, доступ к элементам которой осуществляется по имени массива, а также номерам строки и столбца, на пересечении которых расположен элемент: A[i, j], где i – номер строки, j – номер столбца.
В разных языках программирования работа с массивами может в чем-то различаться, но основные принципы, как правило, везде одни. В языке Pascal, обращение к одномерному и двумерному массиву происходит точно так, как это показано выше, а, например, в C++ двумерный массив следует указывать так: A[i][j]. Элементы массива нумеруются поочередно. На то, с какого значения начинается нумерация, влияет язык программирования. Чаще всего этим значением является 0 или 1.
Массивы, описанного типа называются статическими, но существуют также массивы по определенным признакам отличные от них: динамические и гетерогенные. Динамичность первых характеризуется непостоянностью размера, т. е. по мере выполнения программы размер динамического массива может изменяться. Такая функция делает работу с данными более гибкой, но при этом приходится жертвовать быстродействием, да и сам процесс усложняется.
Обязательный критерий статического массива, как было сказано, это однородность данных, единовременно хранящихся в нем. Когда же данное условие не выполняется, то массив является гетерогенным. Его использование обусловлено недостатками, которые имеются в предыдущем виде, но оно оправданно во многих случаях.
Таким образом, даже если Вы определились со структурой, и в качестве нее выбрали массив, то этого все же недостаточно. Ведь массив это только общее обозначение, род для некоторого числа возможных реализаций. Поэтому необходимо определиться с конкретным способом представления, с наиболее подходящим массивом.
Списки.
Список – абстрактный тип данных, реализующий упорядоченный набор значений. Списки отличаются от массивов тем, что доступ к их элементам осуществляется последовательно, в то время как массивы – структура данных произвольного доступа. Данный абстрактный тип имеет несколько реализаций в виде структур данных. Некоторые из них будут рассмотрены здесь.
Список (связный список) – это структура данных, представляющая собой конечное множество упорядоченных элементов, связанных друг с другом посредствам указателей. Каждый элемент структуры содержит поле с какой-либо информацией, а также указатель на следующий элемент. В отличие от массива, к элементам списка нет произвольного доступа.

Односвязный список
В односвязном списке, приведенным выше, начальным элементом является Head list (голова списка [произвольное наименование]), а все остальное называется хвостом. Хвост списка составляют элементы, разделенные на две части: информационную (поле info) и указательную (поле next). В последнем элементе вместо указателя, содержится признак конца списка – nil.
Односвязный список не слишком удобен, т. к. из одной точки есть возможность попасть лишь в следующую точку, двигаясь тем самым в конец. Когда кроме указателя на следующий элемент есть указатель и на предыдущий, то такой список называется двусвязным.

Двусвязный список
Возможность двигаться как вперед, так и назад полезна для выполнения некоторых операций, но дополнительные указатели требуют задействования большего количества памяти, чем таковой необходимо в эквивалентном односвязном списке.
Для двух видов списков описанных выше существует подвид, называемый кольцевым списком. Сделать из односвязного списка кольцевой можно добавив всего лишь один указатель в последний элемент, так чтобы он ссылался на первый. А для двусвязного потребуется два указателя: на первый и последний элементы.

Кольцевой список
Помимо рассмотренных видов списочных структур есть и другие способы организации данных по типу «список», но они, как правило, во многом схожи с разобранными, поэтому здесь они будут опущены.
Кроме различия по связям, списки делятся по методам работы с данными. О некоторых таких методах сказано далее.

Стек
Стек.
Стек характерен тем, что получить доступ к его элементом можно лишь с одного конца, называемого вершиной стека, иначе говоря: стек – структура данных, функционирующая по принципу LIFO (last in — first out, «последним пришёл — первым вышел»).
Изобразить эту структуру данных лучше в виде вертикального списка, например, стопки каких-либо вещей, где чтобы воспользоваться одной из них нужно поднять все те вещи, что лежат выше нее, а положить предмет можно лишь на вверх стопки.
В показанном односвязном списке операции над элементами происходят строго с одного конца: для включения нужного элемента в пятую по счету ячейку необходимо исключить тот элемент, который занимает эту позицию.
Если бы было, например 6 элементов, а вставить конкретный элемент требовалось также в пятую ячейку, то исключить бы пришлось уже два элемента.
Очередь.
Структура данных «Очередь» использует принцип организации FIFO (First In, First Out — «первым пришёл — первым вышел»). В некотором смысле такой метод более справедлив, чем тот, по которому функционирует стек, ведь простое правило, лежащее в основе привычных очередей в различные магазины, больницы считается вполне справедливым, а именно оно является базисом этой структуры.
Пусть данное наблюдение будет примером. Строго говоря, очередь – это список, добавление элементов в который допустимо, лишь в его конец, а их извлечение производиться с другой стороны, называемой началом списка.

Очередь
Дек.
Дек (deque — double ended queue, «двухсторонняя очередь») – стек с двумя концами. Действительно, несмотря конкретный перевод, дек можно определять не только как двухстороннюю очередь, но и как стек, имеющий два конца. Это означает, что данный вид списка позволяет добавлять элементы в начало и в конец, и то же самое справедливо для операции извлечения.

Дек
Эта структура одновременно работает по двум способам организации данных: FIFO и LIFO. Поэтому ее допустимо отнести к отдельной программной единице, полученной в результате суммирования двух предыдущих видов списка.
Графы.
Раздел дискретной математики, занимающийся изучением графов, называется теорией графов. В теории графов подробно рассматриваются известные понятия, свойства, способы представления и области применения этих математических объектов. Нас же интересует, лишь те ее аспекты, которые важны в программировании.
Граф – совокупность точек, соединенных линиями. Точки называются вершинами (узлами), а линии – ребрами (дугами).
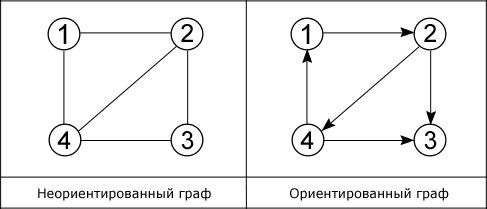
Как показано на рисунке различают два основных вида графов: ориентированные и неориентированные. В первых ребра являются направленными, т. е. существует только одно доступное направление между двумя связными вершинами, например из вершины 1 можно пройти в вершину 2, но не наоборот. В неориентированном связном графе из каждой вершины можно пройти в каждую и обратно. Частный случай двух этих видов – смешанный граф. Он характерен наличием как ориентированных, так и неориентированных ребер.
Степень входа вершины – количество входящих в нее ребер, степень выхода – количество исходящих ребер.
Ребра графа необязательно должны быть прямыми, а вершины обозначаться именно цифрами, так как показано на рисунке. К тому же встречаются такие графы, ребрам которых поставлено в соответствие конкретное значение, они именуются взвешенными графами, а это значение – весом ребра. Когда у ребра оба конца совпадают, т. е. ребро выходит из вершины F и входит в нее, то такое ребро называется петлей.
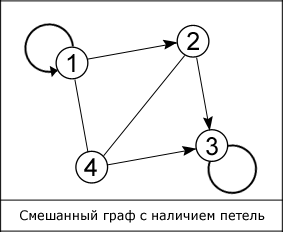
Графы широко используются в структурах, созданных человеком, например в компьютерных и транспортных сетях, web-технологиях. Специальные способы представления позволяют использовать граф в информатике (в вычислительных машинах). Самые известные из них: «Матрица смежности», «Матрица инцидентности», «Список смежности», «Список рёбер». Два первых, как понятно из названия, для репрезентации графа используют матрицу, а два последних – список.
Деревья.

Неупорядоченное дерево
Дерево как математический объект это абстракция из соименных единиц, встречающихся в природе. Схожесть структуры естественных деревьев с графами определенного вида говорит о допущении установления аналогии между ними. А именно со связанными и вместе с этим ациклическими (не имеющими циклов) графами. Последние по своему строению действительно напоминают деревья, но в чем то и имеются различия, например, принято изображать математические деревья с корнем расположенным вверху, т. е. все ветви «растут» сверху вниз. Известно же, что в природе это совсем не так.
Поскольку дерево это по своей сути граф, у него с последним многие определения совпадают, либо интуитивно схожи. Так корневой узел (вершина 6) в структуре дерева – это единственная вершина (узел), характерная отсутствием предков, т. е. такая, что на нее не ссылается ни какая другая вершина, а из самого корневого узла можно дойти до любой из имеющихся вершин дерева, что следует из свойства связности данной структуры.
Узлы, не ссылающиеся ни на какие другие узлы, иначе говоря, ни имеющие потомков называются листьями (2, 3, 9), либо терминальными узлами. Элементы, расположенные между корневым узлом и листьями – промежуточные узлы (1, 1, 7, 8). Каждый узел дерева имеет только одного предка, или если он корневой, то не имеет ни одного.
Поддерево – часть дерева, включающая некоторый корневой узел и все его узлы-потомки. Так, например, на рисунке одно из поддеревьев включает корень 8 и элементы 2, 1, 9.
С деревом можно выполнять многие операции, например, находить элементы, удалять элементы и поддеревья, вставлять поддеревья, находить корневые узлы для некоторых вершин и др. Одной из важнейших операций является обход дерева. Выделяются несколько методов обхода. Наиболее популярные из них: симметричный, прямой и обратный обход. При прямом обходе узлы-предки посещаются прежде своих потомков, а в обратном обходе, соответственно, обратная ситуация. В симметричном обходе поочередно просматриваются поддеревья главного дерева.
Представление данных в рассмотренной структуре выгодно в случае наличия у информации явной иерархии. Например, работа с данными о биологических родах и видах, служебных должностях, географических объектах и т. п. требует иерархически выраженной структуры, такой как математические деревья.