Пусть
требуется изучить статистическую
совокупность относительно некоторого
количественного признака X.
Числовые значения признака будем
обозначать через хi.
Из
генеральной совокупности извлекается
выборка объёма п.
-
Количественный
признак Х
– дискретная
случайная величина.
Наблюдаемые
значения хi
называют вариантами,
а последовательность вариантов,
записанных в возрастающем
порядке, –
вариационным
рядом.
Пусть
x1
наблюдалось n1
раз,
x2
наблюдалось n2
раз,
xk
наблюдалось nk
раз,
причем
![]()
.
Числа ni
называют
частотами,
а их отношение к объёму выборки, т.е.
![]()
,
–
относительными
частотами (или
частостями), причем
![]()
.
Значение
вариант и соответствующие им частоты
или относительные
частоты можно записать в виде таблиц 1
и 2.
Таблица
1
|
Варианта |
x1 |
x2 |
… |
xk |
|
Частота |
n1 |
n2 |
… |
nk |
Таблицу
1 называют дискретным
статистическим
рядом распределения (ДСР) частот, или
таблицей частот.
Таблица
2
|
Варианта |
x1 |
x2 |
… |
xk |
|
Относительная |
w1 |
w2 |
… |
wk |
Таблица
2
ДСР
относительных частот, или
таблица относительных частот.
Определение.
Модой
называется наиболее часто встречающийся
вариант, т.е. вариант с наибольшей
частотой. Обозначается xмод.
Определение.
Медианой
называется
такое значение признака, которое делит
всю статистическую совокупность,
представленную в виде вариационного
ряда, на две равных по числу части.
Обозначается
![]()
.
Если
n
нечетно, т.е. n
= 2m
+ 1,
то
=
xm+1.
Если
n
четно, т.е. n
= 2m,
то
![]()
.
Пример
3.
По результатам наблюдений: 1, 7, 7, 2, 3, 2,
5, 5, 4, 6, 3, 4, 3, 5, 6, 6, 5, 5, 4, 4 построить ДСР
относительных частот. Найти моду и
медиану.
Решение.
Объем выборки n
= 20. Составим ранжированный ряд элементов
выборки: 1, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 5, 5, 6, 6, 6,
7, 7. Выделим варианты и подсчитаем их
частоты (в скобках): 1 (1), 2 (2), 3 (3),
4 (4),
5 (5), 6 (3), 7 (2). Строим таблицу:
|
xi |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
wi |
1/20 |
2/20 |
3/20 |
4/20 |
5/20 |
3/20 |
2/20 |
Наиболее
часто встречающийся вариант xi
=
5. Следовательно, xмод
=
5. Так
как объем выборки n
– четное число, то
![]()
Если
на плоскости нанести точки
![]()
и соединить их отрезками прямых, то
получим полигон
частот.
Если
на плоскости нанести точки
![]()
,
то получим полигон
относительных частот.
Пример 4.
Построить полигон частот и полигон
относительных частот по данному
распределению выборки:
|
xi |
4 |
7 |
8 |
12 |
17 |
|
ni |
2 |
4 |
5 |
6 |
3 |
|
wi |
2/20 |
4/20 |
5/20 |
6/20 |
3/20 |
Решение.
На рисунке 2 показан полигон частот и
на рисунке 3 – полигон относительных
частот.


Рис.
2 Рис.
3
Замечание.
Чем круче полигон, тем равномернее
процесс.
-
Пусть
количественный признак X
– непрерывная
случайная величина,
принимающая значения из интервала
(а,b).
Весь диапазон наблюдаемых данных делят
на частичные
интервалы
[хi;
xi+1),
которые берут обычно одинаковыми по
длине:

=
xi+1
–
xi
(i
= 0, 1, …, k).
Для определения величины интерваламожно использовать формулу
Стерджеса:
![]()
где
(xmax
–
xmin)
разность между наибольшим и наименьшим
значениями признака, k
= 1 + log2
n
число интервалов (log2
n
3,322
lg
n).
Если окажется, что h
дробное число, то за длину частичного
интервала следует брать либо ближайшее
целое число, либо ближайшую простую
дробь. За начало первого интервала
рекомендуется брать величину xнач
=
xmin
–
![]()
.
В каждом
из частичных интервалов подсчитывают
число наблюдаемых значений, т.е. частоту
ni.
По частотам находят относительные
частоты
![]()
.
Полученные интервалы и соответствующие
им частоты (или относительные частоты)
записывают в виде таблицы 3. При этом
правая граница последнего интервала
тоже включается.
Таблица
3
|
Частичный |
[x0, |
[x1, |
… |
[xk-1, |
|
Относительная |
w1 |
w2 |
… |
wk |
Таблица
3 называется интервальным
статистическим рядом распределения
(ИСР) относительных частот,
который задаёт распределение
выборки. Аналогично
составляется ИСР
частот.
Пример
5.
Измерили рост (с точностью до см) 30
наудачу отобранных студентов. Результаты
измерений таковы:
178,
160, 154, 183, 155, 153, 167, 186, 163, 155, 157, 175, 170, 166, 159,
173,
182, 167, 171, 169, 179, 165, 156, 179, 158, 171, 175, 173, 164, 172.
Построить
интервальный статистический ряд
относительных частот.
Решение.
Для
удобства проранжируем полученные
данные:
153,
154, 155, 155, 156, 157, 158, 159, 160, 163, 164, 165, 166, 167, 167,
169,
170, 171, 171, 172, 173, 173, 175, 175, 178, 179, 179, 182, 183, 186.
Отметим,
что Х
рост студента
непрерывная случайная величина. Как
видим, xmin
=
153, хmax
=
186; по формуле Стерджеса, при n
= 30, находим длину частичного интервала
![]()
Примем
![]()
= 6. Тогда хнач
= 153 –
![]()
=150.
Исходные данные разбиваем на шесть (k
=
1 + log230
= 5,907
6) интервалов:
[150,
156), [156, 162), [162, 168), [168, 174), [174, 180), [180, 186].
Подсчитав
число студентов ni,
попавших в каждый из полученных
промежутков, получим ИСР:
|
[xi,xi+1) |
[150, |
[156, |
[162, |
[168, |
[174,180) |
[180,186] |
|
ni |
4 |
5 |
6 |
7 |
5 |
3 |
|
wi |
4/30 |
5/30 |
6/30 |
7/30 |
5/30 |
3/30 |
Первая
и третья строчка таблицы образует ИСР
относительных частот.
Замечание.
При
решении учебных задач на построение
ИСР можно пользоваться следующими
правилами.
-
Назначаются нижняя
граница а
и верхняя граница b
для вариант так, чтобы отрезок [a;
b]
вместил всю выборку; часто полагают

,

,
но иногда a
и b
назначают из соображений удобства, но
не слишком далеко от

и

. -
Находится число
k
равных по длине частичных интервалов
варьирования, которое зависит от объема
выборки и обычно 6
k
20;
рассчитывается длина интервалов
группирования

.
Интервальный
статистический ряд распределения,
представленный графически, называется
гистограммой.
Гистограмма
относительных частот
строится следующим образом: по оси
абсцисс откладываются
интервалы (хi;
хi+1)
и на каждом из них строится прямоугольник
высотой
![]()
где
![]()
;
![]()
.
Площадь
i—го
прямоугольника
![]()
.
Площадь
всей гистограммы
![]()
.
З
амечание:
гистограмма на рисунке 4 – гистограмма
относительных частот.
x3
Рис.
4
Можно
построить гистограмму
частот,
высоты прямоугольников которых равны
![]()
.
Пример 6.
Построить гистограмму частот по данному
ИСР частот:
|
[xi; |
[100; |
[120; |
[140; |
[160; |
[180; |
|
ni |
20 |
50 |
80 |
40 |
10 |
Решение.
По ИСР частот находим длину частичных
интервалов
![]()
= 20 и высоты прямоугольников hi
=
![]()
.
Результаты занесем в таблицу:
|
[xi; |
[100; |
[120; |
[140; |
[160; |
[180; |
|
ni |
20 |
50 |
80 |
40 |
10 |
|
hi |
1 |
2,5 |
4 |
2 |
0,5 |
Искомая
гистограмма частот изображена на рис.
5.

hi
xi
xi
Рис.
5
В
теории вероятностей гистограмме
относительных частот соответствует
график плотности распределения
вероятностей. Распределение выборки,
задаваемое интервальным статистическим
рядом (табл. 3) или таблицей относительных
частот (табл. 2), называется эмпирическим
распределением случайной величины.
По
теореме Бернулли относительная частота
wi,
появление события в п
независимых
испытаниях
сходится
по вероятности к вероятности рi
этого события
![]()
.
Значит во второй строке таблицы 3 и
таблицы 2 стоят
приближённые значения вероятностей рi
следующих событий
![]()
и
![]()
,
поэтому
распределение выборки называют
эмпирическим распределением случайной
величины X.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Поможем решить контрольную, написать реферат, курсовую и диплом от 800р
Узнать стоимость
Статистическое распределение выборки
Содержание:
- Примеры использования формул и таблиц для решения практических задач
- Статистический интервальный ряд распределения
Предположим случай, когда из генеральной совокупности извлекается некоторая выборка, при этом каждому значению соответствует некоторый параметр, означающий количество раз, когда появлялось данное значение. Здесь $x_1$ было зафиксировано $n_1$ раз, $x_2$ было обнаружено $n_2$$x_k$ выявлено $n_k$. При этом
$sum_{i=1}^{k}n_i=n$
Где n — объём рассматриваемой выборки.
Определение 1
Используется следующая терминология: $x_k$ носят наименование вариантов, а последовательность таких вариантов, зафиксированный по возрастанию именуется вариационным рядом. Количество наблюдений каждого из вариантов носят название частот. При этом частное частот и выборки называют относительными частотами.
Определение 2
Статистическое распределение —это название всего набора вариантов и частот, которые с ними соотносятся. Чаще всего задаётся с помощью специальной таблицы, где представлены частоты, а также интервалы им соответствующие.
| $x_1$ | $x_2$ | … | $x_k$ |
| $n_1$ | $n_2$ | … | $n_k$ |
| $frac{n_1}{n}$ | $frac{n_2}{n}$ | $frac{n_k}{n}$ |
Здесь в первой строке представлены варианты, во второй частоты, в третьеq взяты относительные частоты.
Для определения размера интервала используется следующее выражение:
$d=frac{x_{max}- x_{min}}{1+3,332cdot lg n}$
Здесь $x_{max}$, $x_{min}$ наибольшее и наименьшее значения ряда вариантов, а n характеризуем объём выборки.
Примеры использования формул и таблиц для решения практических задач
Пример 1
В ходе проведения измерений в однородных группах, были определены следующие значения выборки: 71, 72, 74, 70, 70, 72, 71, 74, 71, 72, 71, 73, 72, 72, 72, 74, 72, 73, 72, 74. Необходимо использовать данные значения, что определить ряд распределения частот и ряд распределения относительных частот.
Решение.
1) Составим статистический ряд распределения частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| ni | 2 | 4 | 8 | 2 | 4 |
2) Рассчитаем суммарный размер выборки: n=2+4+8+2+4=20. Определим относительные частоты, для этого используем формулы: ni/n=wi: wi=2/20=0.1; w2=4/20=0.2; w3=0.4; w4=4/20=0.1; w5=2/20=0.2. Теперь зафиксируем в таблице распределение относительных частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| wi | 0.1 | 0.2 | 0.4 | 0.1 | 0.2 |
Контрольная сумма должна равняться единице: 0,1+0,2+0,4+0,1+0,2=1.
Полигон частот
Название «полигоном частот» применяют для обозначения ломаной линии, каждый отрезок, которой соединяют точки $(х_1,n_1),(х_2,n_2),…,(х_k,n_k)$. Для построения на графике полигона частот по оси абсцисс отмечают варианты $х_2$, при этом на оси ординат отсчитывают– соответствующие частоты $n_i$. Когда полученные точки $(х_i,n_i)$ соединяются с помощью отрезков, то автоматически получают полигон частот.
Статистический интервальный ряд распределения.
Статистическим дискретным рядом (или эмпирической функцией распределения) обычно пользуются, если число различающихся вариант в полученной выборке не слишком большое. Также применение возможно, когда дискретность имеет важное значение для экспериментатора. В тех случаях, когда важный для задачи признак генеральной совокупности Х распределяется непрерывным образом, либо его дискретность нет возможности учесть, то варианты предпочтительнее всего группировать, чтобы получить интервалы.
Статистическое распределение допустимо задавать в том числе в качестве последовательности интервалов и частот, соответствующих этим интервалам. При это за частоту какого-либо интервала принимается сумма всех частот, вошедших в данный интервал.
Особенно следует отметить ,что $h_i-h_{i-1}=h$ при всех i, т.е. группировка проводится с равным шагом h. Также в вопросе группировки можно ориентироваться на ряд полученных опытным путём рекомендацийу, касающихся таких параметров, как а, k и $h_i$:
1. $Rраз_{мах}=X_{max}-X_{min}$
2. $h=R/k$; k-число групп
3.$ kgeq 1+3.321lgn$ (формула Стерджеса)
4. $a=x_{min}, b=x_{max}$
5.$ h=a+h_i, i=0,1…k$
Определённую в ходе решения задачи группировку удобнее всего скомпоновать и перевести в вид специальной таблицы, которая также может именоваться — «статистический интервальный ряд распределения»:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Частоты | n1 | n2 | … | nk-1 | nk |
Таблицу подобного вида можно сделать, поменяв частоты $n_i$ на относительные частоты:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Отн. частоты | w1 | w2 | … | wk-1 | wk |

236
проверенных автора готовы помочь в написании работы любой сложности
Мы помогли уже 4 430 ученикам и студентам сдать работы от решения задач до дипломных на отлично! Узнай стоимость своей работы за 15 минут!
Пример 2
На склад пришла крупная партия деталей. Из них методом случайного отбора взято 50 экземпляров. Рассматривая изделия по одному, особенно интересующему признаку — размеру, определённому с точностью до 1 см, получим следующий вариационный ряд: 22, 47, 26, 26, 30, 28, 28, 31, 31, 31, 32, 32, 33, 33, 33, 33, 34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 40, 40, 40, 40, 40, 41, 41, 43, 44, 44, 45, 45, 47, 50. Требуется произвести расчёт и определить статистический интервальный ряд распределения.
Решение
Найдём параметры выборки используя сведения из условия задачи.
$k geq1+3,321cdot lg50=1+3.32lg(5cdot10)=1+3.32(lg5+lg10)=6.6$
Получили a=22, k=7, h=(50-22)/7=4, hi=22+4i, i=0,1,…,7.
| Интервалы группировки | 22-26 | 26-30 | 30-34 | 34-38 | 38-42 | 42-46 | 46-50 |
| Частоты | 1 | 4 | 10 | 18 | 9 | 5 | 3 |
| Отн. частоты | 0.02 | 0.08 | 0.2 | 0.36 | 0.18 | 0.1 | 0.06 |
Десятичные логарифмы от 1 до 10
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| lnn≈ | 0 | 0.3 | 0.48 | 0.6 | 0.7 | 0.78 | 0.85 | 0.9 | 0.95 | 1 |
Не получается написать работу самому?
Доверь это кандидату наук!
При систематизации данных выборочных обследований используются статистические дискретные и интервальные ряды распределения.
1. Статистическое дискретное распределение. Полигон.
Пусть из генеральной совокупности извлечена выборка, причем х1 наблюдалось n1 раз, х2 – n2 раз, хk – nk раз и ∑ni=n — объем выборки. Наблюдаемые значения х1 называют вариантами, а последовательность вариант, записанных в возрастающем порядке – вариационным рядом. Число наблюдений варианты называют частотой, а ее отношение к объему выборки — относительной частотой ni/n=wi
ОПРЕДЕЛЕНИЕ. Статистическим (эмпирическим) законом распределения выборки, или просто статистическим распределением выборки называют последовательность вариант хi и соответствующих им частот ni или относительных частот wi.
Статистическое распределение выборки удобно представлять в форме таблицы распределения частот, называемой статистическим дискретным рядом распределения:
| x1 | x2 | … | xm |
| n1 | n2 | … | nm |
(сумма всех частот равна объему выборки ∑ni=n)
или в виде таблицы распределения относительных частот:
| x1 | x2 | … | xm |
| w1 | w2 | … | wm |
(сумма всех относительных частот равна единице ∑wi=1)
Пример 1. При измерениях в однородных группах обследуемых получены следующие выборки: 71, 72, 74, 70, 70, 72, 71, 74, 71, 72, 71, 73, 72, 72, 72, 74, 72, 73, 72, 74 (частота пульса). Составить по этим результатам статистический ряд распределения частот и относительных частот.
Решение. 1) Статистический ряд распределения частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| ni | 2 | 4 | 8 | 2 | 4 |
2) Объем выборки: n=2+4+8+2+4=20. Найдем относительные частоты, для чего разделим частоты на объем выборки ni/n=wi: wi=2/20=0.1; w2=4/20=0.2; w3=0.4; w4=4/20=0.1; w5=2/20=0.2. Напишем распределение относительных частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| wi | 0.1 | 0.2 | 0.4 | 0.1 | 0.2 |
Контроль: 0,1+0,2+0,4+0,1+0,2=1.
Полигоном частот называют ломаную, отрезки, которой соединяют точки (х1,n1),(х2,n2),…,(хk,nk). Для построения полигона частот на оси абсцисс откладывают варианты х2, а на оси ординат – соответствующие им частоты ni. Точки (хi,ni) соединяют отрезками и получают полигон частот.
Полигоном относительных частот называют ломаную, отрезки, которой соединяют точки (х1,w1),(х2,w2),…,(хk,wk). Для построения полигона относительных частот на оси абсцисс откладывают варианты хi, а на оси ординат соответствующие им частоты wi. Точки (хi,wi) соединяют отрезками и получают полигон относительных частот.
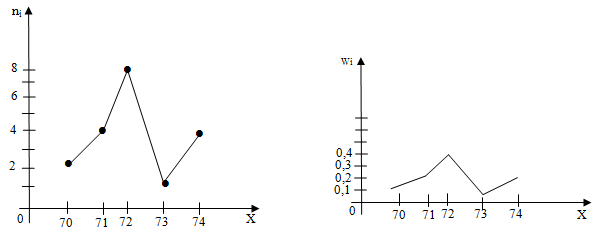
Пример 2. Постройте полигон частот и относительных частот по данным примера 1.
Решение: Используя дискретный статистический ряд распределения, составленный в примере 1 построим полигон частот и полигон относительных частот:
2. Статистический интервальный ряд распределения. Гистограмма. Статистическим дискретным рядом (или эмпирической функцией распределения) обычно пользуются в том случае, когда отличных друг от друга вариант в выборке не слишком много, или тогда, когда дискретность по тем или иным причинам существенна для исследователя. Если же интересующий нас признак генеральной совокупности Х распределен непрерывно или его дискретность нецелесообразно ( или невозможно) учитывать, то варианты группируются в интервалы.
Статистическое распределение можно задать также в виде последовательности интервалов и соответствующих им частот (в качестве частоты, соответствующей интервалу, принимают сумму частот, попавших в этот интервал).
Замечание. Часто hi-hi-1=h при всех i, т.е. группировку осуществляют с равным шагом h. В этой ситуации можно руководствоваться следующими эмперическими рекомендациями по выборке а, k и hi:
1. Rразмах=Xmax-Xmin
2. h=R/k; k-число групп
3. k≥1+3.321lgn (формула Стерджеса)
4. a=xmin, b=xmax
5. h=a+ih, i=0,1…k
Полученную группировку удобно представить в форме частотной таблицы, которая носит название статистический интервальный ряд распределения:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Частоты | n1 | n2 | … | nk-1 | nk |
Аналогическую таблицу можно образовать, заменяя частоты ni относительными частотами:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Отн. частоты | w1 | w2 | … | wk-1 | wk |
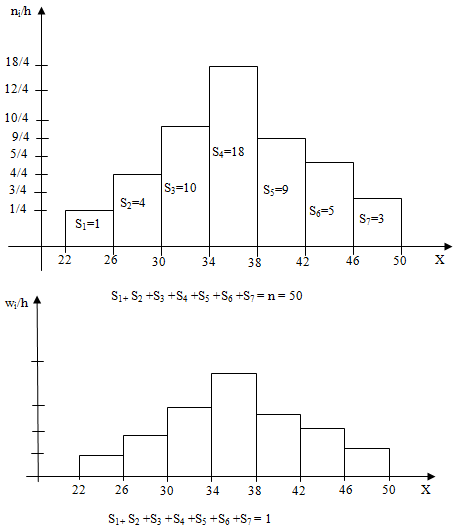
Пример 3. Из очень большой партии деталей извлечена случайная выборка объема 50 интересующий нас признак Х-размеры деталей, измеренные с точностью до 1см, представлен следующим вариоционным рядом: 22, 47, 26, 26, 30, 28, 28, 31, 31, 31, 32, 32, 33, 33, 33, 33, 34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 40, 40, 40, 40, 40, 41, 41, 43, 44, 44, 45, 45, 47, 50. Найти статистический интервальный ряд распределения.
Решение. Определим характеристики группировки с помощью замечания.
k≥1+3.321lg50=1+3.32lg(5•10)=1+3.32(lg5+lg10)=6.6
Имеем, a=22, k=7, h=(50-22)/7=4, hi=22+4i, i=0,1,…,7.
| Интервалы группировки | 22-26 | 26-30 | 30-34 | 34-38 | 38-42 | 42-46 | 46-50 |
| Частоты ni | 1 | 4 | 10 | 18 | 9 | 5 | 3 |
| Отн.частоты wi | 0.02 | 0.08 | 0.2 | 0.36 | 0.18 | 0.1 | 0.06 |
Десятичные логарифмы от 1 до 10
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| lnn≈ | 0 | 0.3 | 0.48 | 0.6 | 0.7 | 0.78 | 0.85 | 0.9 | 0.95 | 1 |
Наиболее информативной графической формой частот является специальный график, называемы гистограммой частот.
Гистограммой частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиною h, а высоты равны отношению ni/h (плотность частоты).
Для построения гистограммы частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии ni/h. Площадь i-го частичного прямоугольника равна h•ni/h=ni — сумме частот вариант i-го интервала; следовательно, площадь гистограммы частот равна сумме всех частот, т.е. объему выборки.
Гистограммой относительных частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиною h, а высоты равны отношению wi/h (плотность относительной частоты).
Для построения гистограммы относительных частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии wi/h. Площадь i-го частичного прямоугольника равна h•wi/h=wi — относительной частоте вариант, попавших в i-й интервал. Следовательно, площадь гистограммы относительных частот равна сумме всех относительных частот, т.е. единице.
Пример 4. Постройте гистограмму частот и относительных частот по данным примера 3.
Выборочная медиана – это середина вариационного ряда, значение, расположенное на одинаковом расстоянии от левой и правой границы выборки.
Выборочная мода – это наиболее вероятное, т.е. чаще всего встречающееся, значение в выборке.
Добавлять комментарии могут только зарегистрированные пользователи.
Регистрация Вход
17 авг. 2022 г.
читать 3 мин
Выборочное распределение — это вероятностное распределение определенной статистики , основанное на множестве случайных выборок из одной совокупности .
В этом руководстве объясняется, как выполнить следующие действия с выборочными распределениями в Excel:
- Сгенерируйте выборочное распределение.
- Визуализируйте распределение выборки.
- Рассчитайте среднее значение и стандартное отклонение выборочного распределения.
- Рассчитайте вероятности относительно выборочного распределения.
Создание выборочного распределения в Excel
Предположим, мы хотим сгенерировать выборочное распределение, состоящее из 1000 выборок, в каждой из которых размер выборки равен 20 и происходит от нормального распределения со средним значением 5,3 и стандартным отклонением 9 .
Мы можем легко сделать это, введя следующую формулу в ячейку A2 нашего рабочего листа:
= NORM.INV ( RAND (), 5.3, 9)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и перетащить формулу на 20 ячеек вправо и на 1000 ячеек вниз:
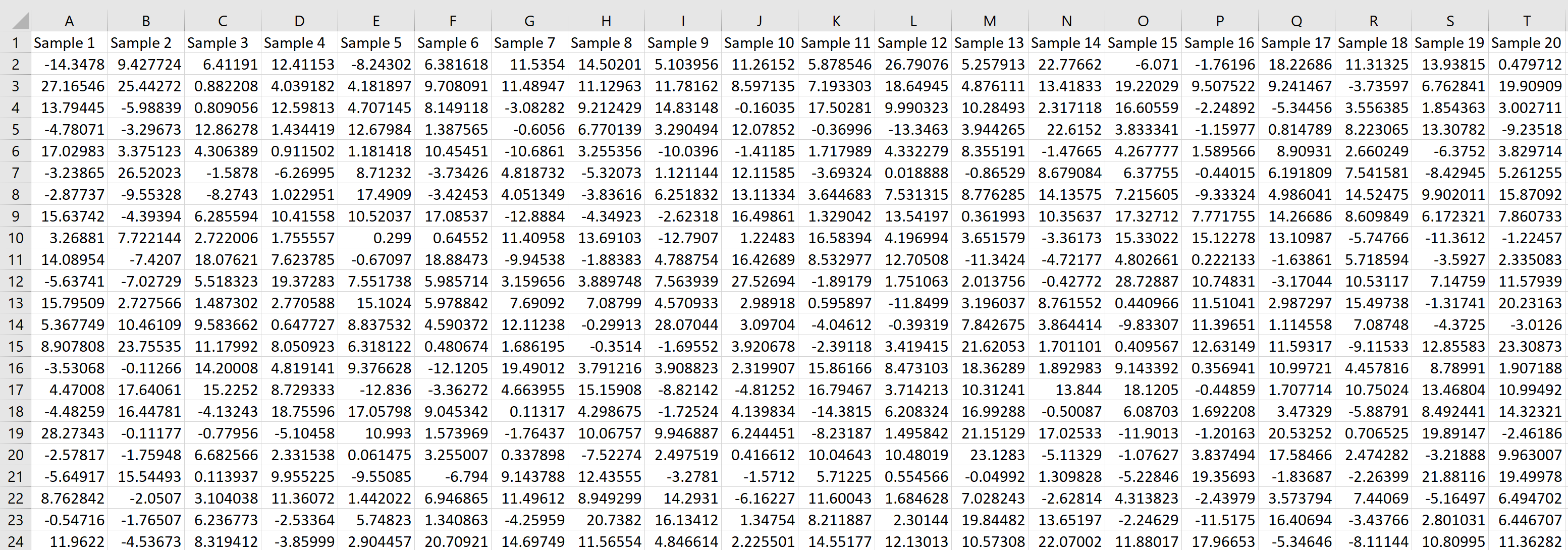
Каждая строка представляет выборку размера 20, в которой каждое значение получено из нормального распределения со средним значением 5,3 и стандартным отклонением 9.
Найдите среднее значение и стандартное отклонение
Чтобы найти среднее значение и стандартное отклонение этого выборочного распределения средних значений выборки, мы можем сначала найти среднее значение каждой выборки, введя следующую формулу в ячейку U2 нашего рабочего листа:
= AVERAGE (A2:T2)
Затем мы можем навести указатель мыши на правый нижний угол ячейки, пока не появится крошечный + , и дважды щелкнуть, чтобы скопировать эту формулу в каждую другую ячейку в столбце U:

Мы видим, что первая выборка имела среднее значение 7,563684, вторая выборка имела среднее значение 10,97299 и так далее.
Затем мы можем использовать следующие формулы для расчета среднего значения и стандартного отклонения среднего значения выборки:

Теоретически среднее значение выборочного распределения должно быть 5,3. Мы видим, что фактическое среднее значение выборки в этом примере равно 5,367869 , что близко к 5,3.
И теоретически стандартное отклонение выборочного распределения должно быть равно s/√n, что будет равно 9/√20 = 2,012. Мы видим, что фактическое стандартное отклонение выборочного распределения составляет 2,075396 , что близко к 2,012.
Визуализируйте распределение выборки
Мы также можем создать простую гистограмму для визуализации выборочного распределения выборочных средних.
Для этого просто выделите все средние значения выборки в столбце U, щелкните вкладку « Вставка », затем выберите параметр « Гистограмма » в разделе « Диаграммы ».
В результате получается следующая гистограмма:
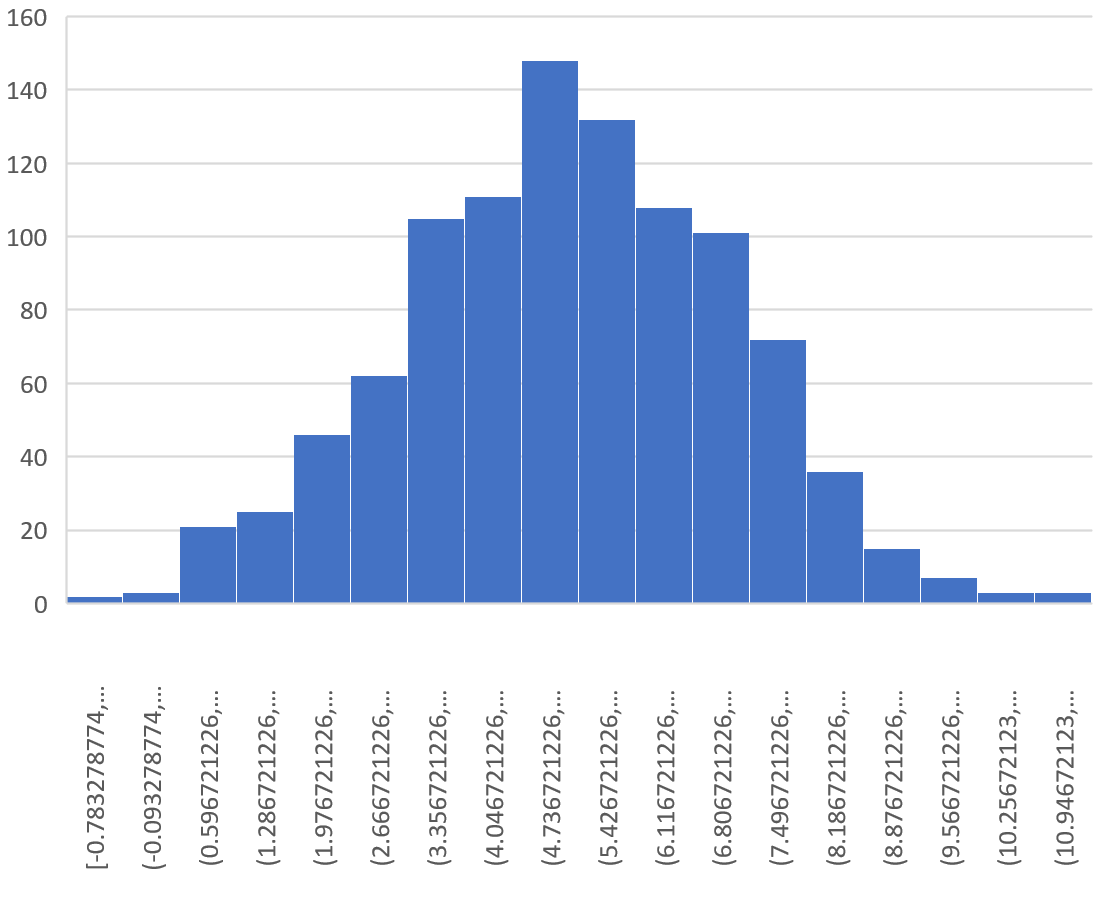
Мы видим, что распределение выборки имеет форму колокола с пиком около значения 5.
Однако из хвостов распределения мы можем видеть, что некоторые выборки имели средние значения больше 10, а некоторые — меньше 0.
Рассчитать вероятности
Мы также можем рассчитать вероятность получения определенного значения среднего значения выборки на основе среднего значения совокупности, стандартного отклонения совокупности и размера выборки.
Например, мы можем использовать следующую формулу, чтобы найти вероятность того, что среднее значение выборки меньше или равно 6, учитывая, что среднее значение генеральной совокупности равно 5,3, стандартное отклонение генеральной совокупности равно 9 и размер выборки равен:
= COUNTIF (U2:U1001, " <=6 ")/ COUNT (U2:U1001)
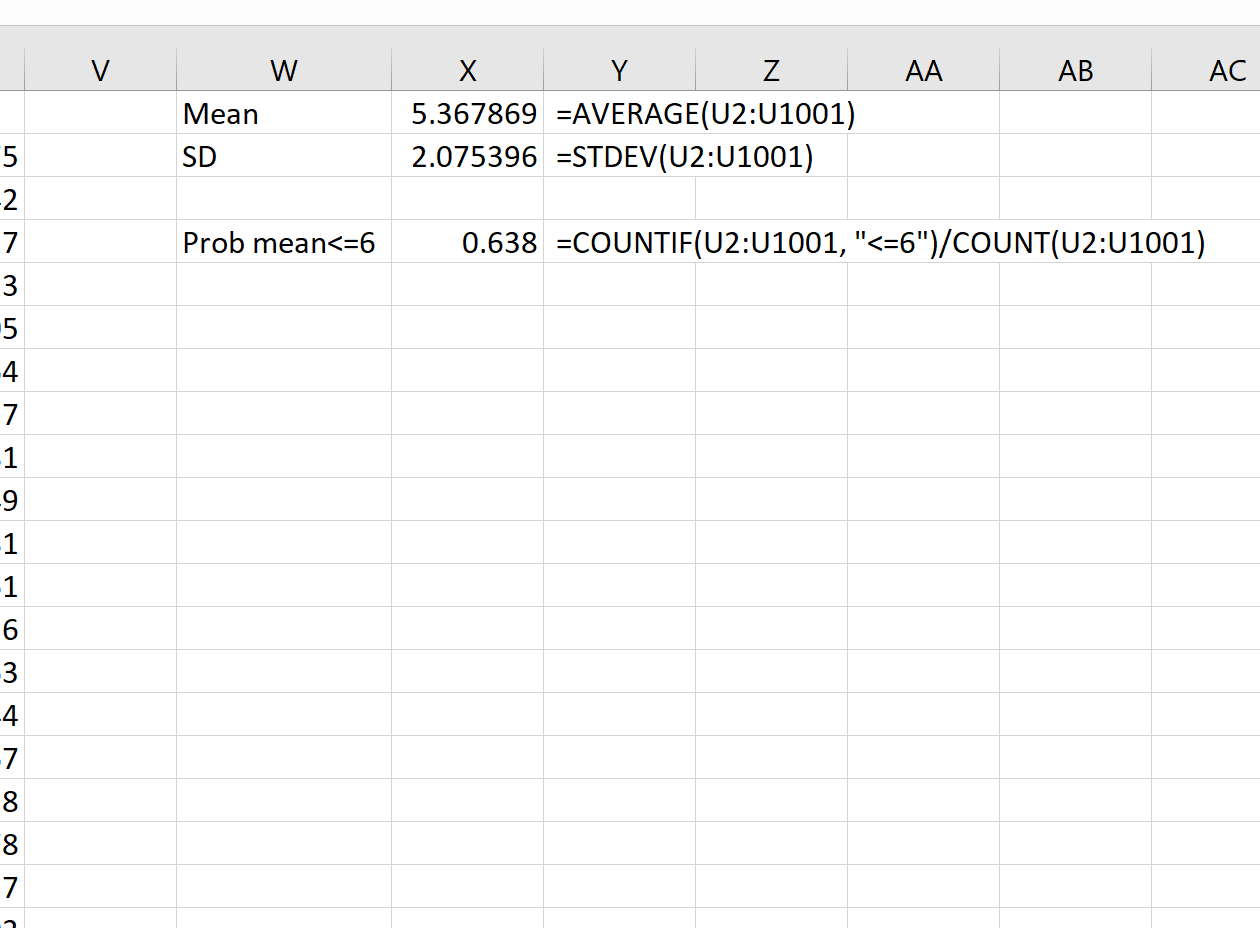
Мы видим, что вероятность того, что среднее значение выборки меньше или равно 6, составляет 0,638.
Это очень близко к вероятности, рассчитанной Калькулятором распределения выборки :

Дополнительные ресурсы
Введение в выборочные распределения
Калькулятор распределения выборки
Введение в центральную предельную теорему
План урока:
Понятие выборки и генеральной совокупности
Среднее арифметическое выборки
Упорядоченный ряд и таблица частот
Размах выборки
Мода выборки
Медиана выборки
Ошибки в статистике
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.

Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:

Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:


Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):
(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.