Составление тезауруса считается одним из сложнейших
видов человеческой деятельности, которая требует участия различных
специалистов, в том числе лингвистов, специалистов по информационной
технологии, специалистов данной отрасли науки и технологии и т.д.
Термин «тезаурус»
употребляется по отношению к различным лингвистическим ресурсам и
словарям:
1). Во-первых, тезаурусом называется особый вид
словарей – идеографический,
лексика в которых организуется по тематическому принципу. Первым
такого рода словарем явился знаменитый Тезаурус Роже, созданный в 19
веке. Основное назначение таких словарей – помощь в подборе
синонимов и близких по смыслу слов при написании текста.
2). Второй тип тезаурусов –
информационно-поисковые тезаурусы,
описывающие отношения между терминами предметной области. Такие
словари создаются экспертами в некоторой предметной области и
предназначены для помощи при информационном поиске.
3). Тезаурусами также называют относительно
недавно появившиеся лингвистические
ресурсы типа
WordNet и
EuroWordNet, описывающие отношения
между лексическими значениями естественного языка как иерархическую
систему групп синонимов – синсетов.
4) Ассоциативные
тезаурусы, которые используют материалы
двух принципиально разных ресурсов.
С одной стороны, ассоциативным тезаурусом называется словарь,
описывающий психологические ассоциации между словами, возникающие у
людей. Таким словарем, например, является Русский ассоциативный
словарь.
Кроме того, термин «ассоциативный тезаурус»
употребляется для ссылки на ресурсы, создаваемые автоматически на
основе обработки текстовых коллекций и показывающие совместную
встречаемость пар слов в документах.
Между всеми этими употреблениями термина
«тезаурус» есть существенное сходство. Никитина С.Е.
определяет тезаурус
как словарь с концептуальным входом
и фиксированными семантическими связями
между его единицами. Она подчеркивает, что для определения тезауруса
существенны оба указанных независимых признака. В частности,
существуют словари, обеспечивающие концептуальный вход, например, по
набору синонимов, при этом отношения между словами описывают
традиционными толкованиями.
Далее рассматривается методика
построения информационно-поискового тезауруса, основные понятия и
назначение.
Под информационно-поисковым
тезаурусом (ИПТ) понимается словарь
лексических единиц информационно-поискового языка, в котором заданы
парадигматические (базисные) смысловые отношения между этими
единицами [3, с. 5-7].
Информационно-поисковый язык, ИПЯ:
Формализованный искусственный язык, предназначенный для
индексирования документов, информационных запросов и описания фактов
с целью последующего хранения и поиска [4].
Информационно-поисковые тезаурусы строятся для
описания лексики дескрипторных ИПЯ, лексическими единицами которых
являются дескрипторы.
Лексическая единица информационно-поискового
языка (ЛЕ). Обозначение отдельного
понятия, принятое в информационно-поисковом языке и неделимое в этой
функции.
Примечание –
лексические единицы могут представлять собой принятые в естественном
языке слова, устойчивые словосочетания, аббревиатуры, символы, даты,
общепринятые сокращения, лексически значимые компоненты сложных слов,
а также эквивалентные им кодовые или символические обозначения
искусственного языка, например коды классов классификационной системы
[4].
Дескриптор – это
ключевое слово, выбранное из группы условно эквивалентных ключевых
слов и представляющее данную группу при индексировании и поиске
информации. Дескриптор
также описывается как смысловая доминанта, или основное понятие с
относящимся к нему словом, подобно заголовочному слову в толковом
словаре. В роли дескрипторов выступают
термины, обозначающие отдельные понятия некоторой предметной области
и удовлетворяющие принципам общеупотребительности,
распространенности, краткости и терминологической точности.
Ключевое слово (КС)
– отдельное слово или словосочетание естественного языка,
выделяемое из текста информационного документа и отражающее его
основное содержание при индексировании.
Группа условно эквивалентных КС объединяет
не только те слова и словосочетания, которые признаются синонимами в
естественном языке, но и такие, которые можно считать условно
равнозначными с точки зрения информационного поиска, т. е. в рамках
данного ИПЯ.
Парадигматические
(базисные,
аналитические, ассоциативные) отношения
выражают
постоянные семантические (смысловые) связи
между ЛЕ
ИПЯ, не
зависящие от текста. Таковыми признаются отношения «род –
вид», «целое – часть» и т. п. Они являются
стабильными для каждой предметной области и могут быть зафиксированы
в словаре.
Например, судак,
лещ, сибас, форель
относятся к семантической категории «Рыбы»,
т.е. отношение «род-вид» между дескрипторами рыбы
– судак
являются контекстуально не зависимыми. Это парадигматическое
отношение.
В ИПТ обычно фиксируются следующие парадигматические отношения:
родо–видовые, отношения эквивалентности, ассоциативные
отношения.
Отношение «род
– вид» связывает два
дескриптора, если объем понятия, соответствующий одному из
дескрипторов, включает в себя объем понятия другого дескриптора,
например, рыба – форель,
рыболовные снасти – удочка, способы ловли рыбы –
спиннинг.
Отношение синонимии означает, что поиск по одному из условных или
истинных синонимов позволит найти в базе данных автоматизированной
информационной системы (АИС) те документы, которым приписаны в
качестве ключевых слов остальные.
Например, рыболовство
= рыбная ловля = рыбный промысел.
Ассоциативные отношения устанавливаются между КС,
принадлежащими к одной и той же или разным смысловым категориям и
произвольным уровням иерархии. Они аналогичны ассоциативным связям в
сознании человека, когда возникающее представление об одном объекте
вызывает представления о других.
Например, при поиске по дескриптору Рыболовство
пользователю АИС можно предложить провести дополнительные поиски по
дескрипторам: отрасль промышленности,
сырьевые ресурсы Мирового океана, водохранилища, виды рыб,
млекопитающие, моллюски, способы рыбной ловли, снасти и
т.д.
Ассоциативные связи, как правило, не различают в
ИПТ по их семантике. Однако имеет смысл упомянуть следующие виды
ассоциаций: «целое – часть»;
«причина – следствие», «близость
в пространстве или во времени», «антонимия»,
«предмет – обычая область его применения» и т.д.
[3, с. 5-7].
В соответствии с определениями стандартов,
информационно-поисковый тезаурус – это нормативный словарь,
точно указывающий отношения между терминами и предназначенный для
описания содержания документов и поисковых запросов.
Основными целями разработки информационно-поисковых тезаурусов
являются следующие:
-
Обеспечение перевода документов и запросов
пользователей на один и тот же словарь, используемый для
индексирования и поиска. Таким образом, различия в лексическом
составе документа и запроса пользователя сводятся к одним и тем же
единицам тезауруса. -
Обеспечение последовательного использования
единиц индексирования. -
Обеспечение отношений между терминами –
отношения между единицами тезауруса позволяют найти оптимальный
термин для описания документа или запроса. -
Использование как поискового средства при поиске документов.
Информационно-поисковые тезаурусы создавались как
инструмент для ручного описания документов
специалистами-индексаторами. Поисковый запрос также предполагалось
формулировать на основе единиц тезауруса.
Итак, при разработке информационно-поисковых тезаурусов первой
задачей является отбор терминов для включения в тезаурус. Существует
несколько возможных источников терминов для разработки
информационно-поисковых тезаурусов.
Прежде всего, должны быть изучены существующие
тезаурусы в близких предметных областях. Они могут содержать
значительное количество полезных терминов для нового тезауруса.
Термины – кандидаты на внесение в тезаурус – могут быть
предложены экспертами предметной области. Кроме того, термины
тезауруса могут быть получены из текстов предметной области
применением автоматизированных методов или ручной обработки
документов. При ручной обработке документов сначала некоторое время
индексаторы индексируют поступающие документы наиболее релевантными
ключевыми словами, которые затем сводятся в единый список, способный
служить основой для тезауруса [1, с. 24-32].
После того, как список терминов-кандидатов
получен, из него исключаются слишком частотные термины, поскольку
предполагается, что они являются малоинформативными для различения
отдельных документов. Относительно малочастотные термины могут быть
удалены из списка или представлены как аскрипторы
более общих или более
частотных понятий.
Герд
предлагает исключать некоторые конкретные термины, так как тезаурус,
в котором много уровней иерархии, труден в использовании: возрастает
субъективность индексирования, т. к. индексаторы могут использовать
для индексирования документов дескрипторы разного уровня [7].
Если в списке обнаруживается несколько близких по
смыслу терминов, то из них выделяется наиболее частотный термин,
остальные термины могут быть исключены и переведены в аскрипторы [1,
с. 24-32].
Разработчики тезауруса LIV Исследовательской службы Конгресса США
(LIV, 1994) описывают правила включения терминов в тезаурус следующим
образом:
-
Термины тезауруса должны представлять понятия, которые реально
упоминаются в литературе, и должны отбираться из соображений
эффективности их использования в поиске документов. -
Важным фактором включения термина является частотность его
упоминания в текстах, которую необходимо периодически проверять. -
Включение новых терминов в тезаурус должно
происходить с учетом уже включенных тезаурусных терминов.
Термины-кандидаты должны проверяться на предмет соответствия их
общности / специфичности к другим терминам тезауруса. Также должно
проверяться, представляет ли термин-кандидат отдельное понятие,
которому нет соответствий среди существующих терминов тезауруса.
Необходимо избегать включения терминов, чьи значения пересекаются со
значениями уже существующих тезаурусных терминов настолько, что
индексаторам и пользователям будет трудно различать их [6, с. 157].
Таким образом, для разработки актуального и хорошего
информационно-поискового тезауруса, необходимо соблюдать следующие
основыне критерии:
-
набор дескрипторов тезауруса должен быть достаточен для описания
произвольного документа предметной области, в частности,
«Рыболовство»; -
количество дескрипторов не должно быть слишком большим.
Литература:
-
Архангельская В.А., Базарнова С.В.
Информационно-поисковый тезаурус по экономике и демографии [Текст]
/В.А. Архангельская, С.В. Базарнова – 2001, с. 24-32. -
Лавренова О.А. Моделирование семантической
текстов научно-технического содержания в связи с автоматизацией
информационных процессов. Диссертация кандидата филологических наук:
10.02.21 -
Лавренова О.А Методика разработки информационно-поискового тезауруса
[Текст] / О.А. Лавренова – Москва, 2001-с.5-7. -
ГОСТ 7.74-96 СИБИД. Информационно-поисковые
языки. Термины и определения. -
СИБИД. Тезаурус информационно-поисковый
одноязычный: Правила разработки: структура, состав и форма
представления: Межгосударственный стандарт 7.25. – Минск:
Межгосударственный совет по стандартизации, метрологии и
сертификации, 2001. -
Соловьев В.Д., Добров Б.В., Иванов В.В.,
Лукашевич Н.В. Онтологии
и тезаурусы: Учебное пособие [Текст] / В.Д. Соловьев, Б.В. Добров,
Н.В. Лукашевич – Казань, Москва, 2006-с.157. -
ANSI/NISO Z39.19-2005, “Guidelines for the
Construction, Format, and Management of Monolingual Controlled
Vocabularies”,
http://www.niso.org/standards/resources/Z39-19-2005.pdf -
http://like-money.ru/stati/124-osnovnye-princzipy-razrabotki-tezaurusov-chast-1.
Основные термины (генерируются автоматически): предметная область, тезаурус, отношение, термин, LIV, информационно-поисковый язык, дескриптор, естественный язык, информационно-поисковый тезаурус, термин тезауруса.
Разработка
информационно-поискового тезауруса
включает несколько этапов:
-
построение
словаря (словника) ключевых слов; -
дескрипторизация
ключевых слов; -
установление
парадигматических отношений между
дескрипторами; -
оформление
тезауруса.
Разработка
тезауруса требует исследования системы
и логики знаний тех областей, которые
найдут отражение в нем. Терминология,
которая будет использована в тезаурусе,
должна быть полной, однородной и
охватывать все основные тематические
группы. В свою очередь, тематические
группы могут быть расширены в целях
охвата смежных проблем. При отборе
массива документов необходимо соблюдать:
-
точное
соответствие документов тематической
направленности работы; -
полный
охват каждой области знаний, а также
равномерное распределение их по
отдельным тематическим областям как
по характеру документов, так и по их
количеству; -
терминологическую
насыщенность информационных документов
и степень важности содержащейся в них
информации; -
освещение
тематики с учетом различных аспектов
(материалов исследований, сведений об
устройстве, применении и т. д.).
Критериями
количественных и качественных параметров
представительного массива документов
и словника являются:
-
скорость
роста массива документов и словника; -
дифференцированность
и устойчивость частотных характеристик
элементов; -
процентное
содержание в словнике специальных,
общих и смежных терминов; -
вероятность
использования элементов словника при
индексировании и поиске документов.
Процесс
создания тезауруса включает научную
разработку классификационных схем
понятий и выявление терминологического
фонда из представительного фонда
информационных документов. Кроме того,
предполагается дополнение его терминами,
которые позаимствованы из вспомогательных
источников:
-
тезаурусов
по родственной тематике; -
терминологических
и толковых словарей; -
энциклопедических
словарей; -
научно-технических
словарей и справочников; -
таблиц
универсальной десятичной (децимальной)
классификации (УДК); -
тематических
рубрикаторов; -
библиотечно-библиографической
классификации (ББК); -
государственных
стандартов и других источников
9.3.1 Составление словаря ключевых слов
Составление
словаря ключевых слов происходит путем
отбора из заглавий, аннотаций, рефератов
и текстов документов слов естественного
языка, которые могут использоваться в
поисковых образах документов (ПОД) и
поисковых предписаниях (ПП). Важнейшим
требованием к словарю ключевых слов
является полнота охвата терминологии,
так как в тезаурус включают терминологию,
фигурирующую в документах, вводимых в
ИПС. Таким образом, в тезаурусе могут
отсутствовать термины, требующиеся для
описания содержательных или формальных
аспектов вводимых в ИПС текстов. Такой
тезаурус может оказаться недостаточно
полным. Существует прямая зависимость
работоспособности тезауруса от методики
индексирования документов. Процесс
индексирования заключается в следующем:
-
составление
мысленной аннотации, в которой отражаются
основные и второстепенные темы документа,
представляющие интерес для пользователей
ИПС; -
выбор
из этой аннотации ключевых слов.
Составление
поисковых аннотаций считается творческим
процессом, поэтому результат этого
процесса в той или иной мере зависит от
субъективных качеств индексатора.
Результат обработки одного и того же
документа разными индексаторами может
быть различным. Для того чтобы предотвратить
расхождения в индексировании, необходимо
стандартизировать построение поисковых
образов. Для того чтобы отделить ключевые
слова от «неключевых» (не подлежащих
вводу в тезаурус), индексаторы используют
общие методические указания:
-
служебные
слова (предлоги, союзы, частицы и т. д.)
следует считать неключевыми; -
в
качестве ключевых слов могут выступать
существительные, прилагательные,
числительные, причастия и их сочетания,
наречия, деепричастия и местоимения в
состав ключевых слов не входят, глаголы
– очень редко; -
не
следует включать в словарь ключевых
слов термины, которые очень редко
встречаются в данном документном
массиве, их можно учесть в отдельном
списке в роли ключевых слов-кандидатов; -
часто
встречающиеся, но общие термины («метод»,
«система», «описание», «устройство» и
т. п.) надо либо исключить, либо использовать
в сочетании с другими словами, которые
сузили бы их значение; -
не
имеет смысла включать в словарь термины,
не относящиеся к данной терминологической
области; -
полисемичные
термины могут быть включены только в
тех значениях, в которых они употребляются
в данной тематической области, с
соответствующими пояснениями.
После
того как произведен отбор ключевых слов
из текстов, необходимо решить вопрос
об их формулировке.
Существует
два подхода к этой проблеме:
-
ориентироваться
на ключевые слова – развернутые
словосочетания. Например: «коммерческие
информационные службы»; -
ориентироваться
на ключевые слова – унитермы (отдельные
лексические единицы). Например:
«оформление», «механика», «логика».
В
зависимости от того, какой подход будет
использован при формулировке ключевых
слов, результат будет разным, т. е. будут
получены различные словари ключевых
слов, а значит и различные дескрипторные
языки. «Унитермная» ориентировка через
свободную манипуляцию элементами
поисковых образов обеспечит глубокое
и детальное индексирование и увеличит
количество точек доступа к разыскиваемым
документам. Но разделение устойчивых
словосочетаний, которые соответствуют
определенным научно- техническим
понятиям, грозит потерей информации
при поиске. Суть заключается в том, что
определенные понятия не всегда могут
быть выражены единичным термином. Иными
словами, ключевые слова, включаемые в
словарь, принимают с учетом точки зрения
интересов поиска информации для каждого
ключевого слова отдельно и с учетом их
лексикографической обработки.
Решение
о разделении или сохранении словосочетаний
или сложных слов принимают с учетом
лингвистических и прагматических
критериев. В лингвистике словосочетания
делятся на свободные
и устойчивые
(лексиколизованные) словосочетания.
Свободные словосочетания характерны
устной речи. Устойчивые словосочетания
являются цельными лексическими единицами
языка и по своим функциям эквивалентны
отдельным словам. Для координатного
индексирования рекомендуется вводить
в качестве ключевых слов устойчивые
словосочетания. При формировании
словника ключевых слов руководствуются
лингвистическими критериями. Словосочетание
является устойчивым, если:
-
при
его образовании одно из слов изменяет
свое значение – происходит переосмысление
одного из компонентов словосочетания.
Например: «легкая музыка», «легкая
промышленность» (переосмысливается
прилагательное «легкий»); -
употребляется
в единственном или во множественном
числе. Например: «немецкий язык»,
«европейские языки»; -
имеет
один или несколько синонимов. Например:
«перспективы» = «будущее» = «перспективы
развития» = «тенденции».
— при
замене составляющих его слов, изменении
порядка слов в нем или при преобразовании
прилагательного в существительное с
предлогом потеряется его смысл. Например:
«железная дорога».
К
устойчивым словосочетаниям относят
имена собственные или словосочетания,
включающие имена собственные. Например:
«Латинская Америка», «Таблица Менделеева».
Если
словосочетания соответствуют этим
критериям, они считаются устойчивыми.
На
решение о сохранении словосочетаний
влияют и прагматические соображения:
— рекомендуется
сохранять часто встречающиеся
словосочетания;
— рекомендуется
сохранять словосочетания, если их
компоненты не могут использоваться по
отдельности;
— рекомендуется
сохранять словосочетания как способ
устранения информационного шума.
Таким
образом, разработчикам тезауруса следует
ориентироваться на единичные ключевые
слова, сохраняя устойчивые словосочетания,
удовлетворяющие выше приведенным
лингвистическим и прагматическим
критериям.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Каков наилучший способ создать тезаурус, так как письмо всегда является самой сложной частью получения высоких баллов во многих языковых тестах?
Таким образом, многие учащиеся стараются как можно больше практиковаться в письме. Одним из многих советов по улучшению качества письма является использование тезауруса. Но что вы знаете о тезаурусе и о том, как эффективно создавать тезаурус?
В этой статье вы узнаете новое понимание тезауруса и полезные советы по созданию тезауруса, чтобы играть со словами как в формальном, так и в неформальном языковом употреблении.
Дополнительные советы с AhaSlides
- Живой генератор облака слов
- Генератор прилагательных
- Случайные английские слова

Содержание
- Что такое тезаурус?
- Список способов создания тезауруса
- №1. AhaSlides — инструмент создания тезауруса
- № 2. Thesaurus.com – инструмент для создания тезауруса
- №3. Monkeylearn — инструмент для создания тезауруса
- № 4. Synonyms.com – инструмент создания тезауруса
- № 5. Word Hippos — инструмент для создания тезауруса
- № 6. Визуальный тезаурус — инструмент создания тезауруса
- № 7. WordArt.com — инструмент создания тезауруса
- 4 альтернативы облаку слов AhaSlides
- №1. Только одно слово
- № 2. Синоним скремблировать
- №3. Генератор прилагательных
- № 4. Генератор синонимов имени
- Преимущества «Создать тезаурус»
- Заключение
Что такое тезаурус?
Если вы давно пользуетесь словарем, возможно, вы уже слышали о слове «тезаурус». Понятие тезауруса происходит от особого способа использования более функционального словаря, в котором люди могут искать ряд слов. синонимов и соответствующие концепции, а иногда антонимы слов в группе слов.
Слово тезаурус происходит от греческого слова «сокровище»; упрощенно, это также означает книгу. В 1852 году слово «тезаурус» стало популярным благодаря вкладу Питера Марка Роже, который использовал его в своем «Тезаурусе Роже». В современной жизни тезаурус является официальным словом в свете словаря синонимов. Кроме того, интересен тот факт, что Соединенные Штаты являются первой страной, отметившей «День национального тезауруса», который ежегодно отмечается 18 января.
Список способов создания тезауруса
Есть много способов создать тезаурус с помощью генератора слов тезауруса. В эпоху цифровых технологий люди слишком привыкли использовать онлайн-словарь вместо печатного словаря, поскольку это более удобно и экономит время, некоторые из них бесплатны и переносимы на ваш мобильный телефон. Здесь мы даем вам 7 лучших онлайн-сайтов, создающих тезаурусы, чтобы найти похожие слова, на которые вы должны обратить внимание:

№1. AhaSlides — инструмент создания тезауруса
Почему AhaSlides? Учебное программное обеспечение AhaSlides подходит для создания тезаурусов классами с помощью функции Word Cloud и может использоваться в любой точке взаимодействия в системах Android и iOS. Использование AhaSlides — это идеальный способ вовлечь учащихся в занятия в классе. Вы можете настроить различные игры и викторины на тематическом фоне, чтобы сделать генератор тезауруса более привлекательным и интересным.
№ 2. Thesaurus.com – инструмент для создания тезауруса
Лучшим генератором синонимов, который можно упомянуть, является Thesaurus.com. Это полезная платформа для поиска синонимов со многими удобными функциями. Вы можете искать синоним к слову или фразе. Его впечатляющие функции, генератор слов дня, публикация одного синонима и кроссворд ежедневно — вот что этот веб-сайт показывает вам вместе с грамматикой и советами по написанию стратегии обучения навыкам написания. Он также предлагает различные игры, такие как Scrabble Word Finder, Outspell, Word Wipe Game и другие, которые помогут вам более эффективно создавать список тезауруса.
№3. Monkeylearn — инструмент для создания тезауруса
Вдохновленное технологией искусственного интеллекта MonkeyLearn, сложное программное обеспечение для электронного обучения, его функция облака слов может использоваться в качестве генератора случайных слов-синонимов. Его чистый UX и пользовательский интерфейс позволяют пользователям удобно работать со своими приложениями, не отвлекаясь на рекламу.
Введя релевантные и целенаправленные ключевые слова в поле, автоматическое обнаружение сгенерирует необходимые синонимы и связанные термины. Кроме того, есть функция, которая поможет вам настроить цвет и шрифт в соответствии с вашими предпочтениями, а также настроить количество слов, чтобы упростить получение результатов.
№ 4. Synonyms.com – инструмент создания тезауруса
Еще один онлайн-словарь для создания тезауруса — Synonyms.com, который работает очень похоже на Thesaurus.com, например, ежедневное скремблирование слов и считывание словарных карточек. После проведения исследования слова веб-сайт представит вам группу похожих слов, ряд определений, его историю и некоторые антонимы, а также гиперссылки с другими соответствующими понятиями.
№ 5. Word Hippos — инструмент для создания тезауруса
Если вы хотите найти синоним напрямую, вы можете найти Word Hipps для вас. Простой в использовании пользовательский интерфейс поможет вам самым разумным образом. Помимо представления вам синонимов, он выделяет различные контексты использования рассматриваемого слова и синонимов более подходящим образом. Вы можете попробовать игру под названием «Слова из 5 букв, начинающиеся с буквы А», которую предлагает Word Hipps в качестве ледокола.
№ 6. Визуальный тезаурус — инструмент создания тезауруса
Знаете ли вы, что изучение слова с помощью визуальных эффектов более эффективно? Инновационный генератор синонимов, такой как визуальный тезаурус, предназначен для максимального получения информации и поощряет исследование и обучение. Вы можете найти любой из необходимых вам тезаурусов, даже самый редкий, поскольку он предлагает 145,000 115,000 английских слов и XNUMX XNUMX значений. Например, генератор существительных слов, генератор старых английских слов и генератор причудливых слов с картами слов, разветвленными друг на друга.
№ 7. WordArt.com — инструмент создания тезауруса
Иногда сочетание генератора облака слов для тезауруса с формальным словарем синонимов является эффективным способом обучения новому языку в классе. WordArt.com может стать для вас хорошим учебным пособием. WordArt, ранее известный как Tagul, считается самым многофункциональным генератором облаков слов с потрясающими изображениями слов.
Альтернативы облаку слов AhaSlides
Кажется, пришло время создать собственный генератор тезауруса с Облако слов AhaSlides. Итак, как создать генератор облака слов синонимов с АгаСлайды, вот несколько важных советов:
- Представляем облако слов на AhaSlides, а затем пересылаем ссылку в верхней части облака вашей аудитории.
- Получив ответы, отправленные аудиторией, вы можете транслировать вызов облака слов в прямом эфире на своем экране вместе с другими.
- Настройте вопросы и типы вопросов в соответствии с общим дизайном вашей игры.

Начните за секунды.
Узнайте, как использовать AhaSlides Live Word Cloud Generator для большего удовольствия на работе, в классе или просто для использования в сообществе!
🚀 Что такое облако слов?
Игры со словами — это интригующие занятия, которые повышают умственные способности, а также проверяют способность использовать словарный запас и другие языковые навыки. Поэтому мы даем вам несколько лучших идей для игр с генератором тезаурусов для повышения продуктивности вашего обучения в классе.
№1. Всего одно слово — сгенерируйте идею игры тезауруса
Это самое легкое и простое правило игры, которое вы когда-либо могли себе представить. Однако стать победителем в этой игре совсем не просто. Люди могут играть в группе или индивидуально с таким количеством раундов, сколько необходимо. Ключ к успеху — произнести слово как можно быстрее и сосредоточиться, избегая повторения рассматриваемого слова, если вы не хотите, чтобы вас уволили. Однако нет никакой гарантии, что у вас будет достаточно слов для победы. Вот почему мы должны учить новые слова из этой удивительной игры.
№ 2. Synonym scramble — Генерация идеи игры тезауруса
Вы легко можете встретить такой сложный тест во многих учебниках по языковой практике. Перепутать все буквы — лучший способ потренировать мозг в запоминании новой работы за ограниченное время. С помощью Word Cloud вы можете скремблировать один и тот же набор списков слов или антонимов, чтобы учащиеся могли быстро расширять свой словарный запас.
№3. Генератор прилагательных — сгенерируйте идею игры тезауруса
Вы когда-нибудь играли в MadLibs, одну из самых захватывающих онлайн-игр в слова? Существует задача повествования, когда вам нужно придумать кучу случайных прилагательных, чтобы они соответствовали сюжетной линии, которую вы создаете. Вы можете играть в подобные игры в своем классе с помощью Word Cloud. Например, вы можете создать историю, а учащиеся должны придумать персонажей с одной и той же сюжетной линией. Каждая команда должна использовать ряд синонимов, чтобы их история звучала разумно, но не может повторять чужие прилагательные.
№ 4. Генератор синонимов имен — сгенерируйте идею игры тезауруса
Когда вы хотите назвать своих новорожденных, вы хотите выбрать самое красивое, оно должно нести в себе особый смысл. Для того же значения существует множество имен, которые могут вас запутать. Прежде чем перейти к последнему, вам может понадобиться Word Cloud, чтобы помочь вам создать как можно больше имен синонимов. Вы можете быть удивлены тем, что есть еще имена, о которых вы никогда раньше не думали, но они звучат точно так же, как то, что предназначено вашему ребенку.
№ 5. Создатель необычных заголовков — сгенерируйте идею игры тезауруса
Генератор синонимов имени немного отличается от генератора причудливых заголовков. Вы хотите назвать свой новый бренд уникальным, но уже существуют тысячи причудливых названий? Трудно найти тот, который имеет соответствующее значение для вашего фаворита. Так что использование тезауруса может вам как-то помочь. Вы можете создать игру, чтобы побудить участников придумать причудливые названия для названия вашего бренда или книги или чего-то еще, не теряя ее духа.
Преимущества создания тезауруса
«Создать тезаурус» — это распространенный способ показать свою языковую компетентность по четырем навыкам в разных контекстах. Понимание сути намеренного создания тезауруса полезно для вашего прогресса в обучении и других связанных с языком действий. Цель «создать тезаурус» состоит в том, чтобы помочь вам избежать пустых слов и повысить эффективность и точность вашего выражения.
Кроме того, частое повторение одних и тех же фраз или слов является табу, что может сделать письмо скучным, особенно в творческом письме. Вместо того, чтобы говорить «Я очень устал», вы можете сказать, например, «Я устал».
Кроме того, вы можете создать генератор тезаурусных фраз с такой фразой, как «ваша одежда выглядит очень красиво», эксперт с динамическим списком синонимов может сделать ее более увлекательной во многих отношениях, например: «ваш костюм такой потрясающий» или « твой наряд необыкновенный»…
В некоторых конкретных контекстах, таких как тесты на знание языка, копирайтинг, классные занятия и т. д., шаг «создать тезаурус» может быть огромным подспорьем, как показано ниже:
Практика тестирования на знание языка: возьмем, к примеру, IELTS. Существует тест высокого стандарта для изучающих иностранный язык, который они должны пройти, если хотят поехать за границу для учебы, работы или иммиграции. Подготовка к IELTS — долгий путь, так как чем выше целевая группа, тем сложнее.
Изучение синонимов и антонимов — лучший способ увеличить словарный запас. Для многих людей «создание тезауруса» является обязательным действием для создания конечного списка словарного запаса для использования в письменной и устной речи, чтобы учащиеся могли более активно и эффективно играть со словами в течение ограниченного времени для любого вопроса.
Преимущества создания тезауруса в копирайтинге
В последние годы быть фрилансером в области копирайтинга — многообещающая карьера, поскольку это гибридная работа, в которой вы можете оставаться дома и писать текст в любое время, не беспокоясь о скучных 9-5 рабочих часах. Быть хорошим писателем требовало отличных навыков письменного общения и убедительного, повествовательного, пояснительного или описательного стиля письма.
Улучшение вашего стиля общения и письма путем создания собственного генератора слов важно, поскольку вы используете слова более гибко, а не застреваете, пытаясь найти идеальный способ выразить свою инициативу. Воспользовавшись преимуществами живого тезауруса в ваших предложениях, ваше письмо может быть намного более очаровательным.
Преимущества создания тезауруса в занятиях класса
Умение свободно пользоваться языком является обязательным для всех стран как на их национальном, так и на втором языке. Кроме того, есть много компаний, которые также пытаются внедрить курсы английского языка для своих сотрудников в качестве основного развивающего обучения.
Преподавание и изучение языка, особенно новой лексики, может быть более продуктивным процессом, в то же время получая огромное удовольствие от генераторов слов для игр. Некоторые словесные игры, такие как «Кроссворды» и «Эрудит», являются одними из любимых ледоколов класса, которые будут стимулировать участие учащихся в учебе.
Выводы
Если вы любите играть со словами или просто хотите улучшить свои навыки письма, не забывайте часто обновлять свой тезаурус и писать по одной статье каждый день.
Теперь, когда вы узнали о тезаурусе и о некоторых идеях по использованию Word Cloud для создания тезауруса, давайте приступим к созданию собственного тезауруса и игр Word Cloud с помощью Облако слов AhaSlides правильный путь.
Что такое тезаурус и как определить семантическое сходство слов
Время на прочтение
7 мин
Количество просмотров 6.3K
При разработке чат-ботов и голосовых ассистентов часто возникает задача нахождения семантического сходства слов. Причина тому – наличие в языке большого количества схожих по смыслу слов и выражений. Так, пользователь может задать один и тот же вопрос как минимум двумя способами:
-
Почему электрические батареи быстрее разряжаются на холоде?
-
Из-за чего батарейки быстрее садятся на морозе?
Для человека не составит труда понять, что предложения имеют схожий смысл, несмотря на различие в лексике. Мы знаем, что слова электрические батареи и батарейки, разряжаются и садятся, холод и мороз – синонимы, они имеют практически одинаковое значение и могут быть взаимозаменяемы.

Но как компьютеру понять, что под разными словами подразумевается одно и то же? Решение этой задачи состоит в вычислении меры семантического сходства слов: для синонимов она близка к единице, для совершенно непохожих слов – к нулю.
Дистрибутивные модели
Сейчас подавляющее большинство решений основано на моделях дистрибутивной семантики. Идея в следующем: если слова встречаются в похожих контекстах, то они имеют похожие значения. Для этого метода не требуются предварительно подготовленные данные, вся семантическая информация извлекается из неструктурированных текстов на основе совместной встречаемости слов.
Однако вот в чем проблема: подобный подход не учитывает, что отношения между словами из одной семантической области могут иметь различный характер. В качестве «синонимов», то есть близких по смыслу слов, будут определены как синонимы в традиционном понимании, так и противоположные по смыслу слова, хоть и относящиеся к той же семантической области, которые со школы мы привыкли называть антонимами: например, жара для слова холод и заряжаться для слова разряжаться.


Словари с иерархической структурой
Решением проблемы мог бы стать лингвистический ресурс, содержащий: а) большое количество слов и словосочетаний, б) семантические отношения между ними.
Нам повезло, и такие ресурсы придуманы уже давно – они имеют названия тезаурусов. Первый тезаурус (конечно, в бумажном виде) был создан в 1805 году. Наиболее современная и полная лексическая база знаний разработана Принстонским университетом под названием WordNet. Эти тезаурусы включают слова и словосочетания английского языка. Существует также тезаурус для русского языка – RuWordNet.
В тезаурусе между словами установлена иерархическая структура: выделены наиболее общие понятия (гиперонимы) и наиболее частные (гипонимы), а также похожие по смыслу слова (синонимы). Например, для слова собака гиперонимами являются слова млекопитающее и домашнее животное, гипонимами – конкретные породы собак, как бульдог, пудель, лабрадор и другие.

Иерархическая структура тезауруса позволяет рассчитывать семантическое сходство между словами. Для этого существуют различные метрики, некоторые из них имеют программную реализацию на основе тезауруса WordNet для английского языка. На примере данного ресурса мы рассмотрим методы нахождения семантического сходства слов по тезаурусу и приведем примеры подсчета метрик с помощью пакета WordNet библиотеки NLTK.
Тезаурус WordNet для английского языка
Доступ к тезаурусу WordNet возможен из библиотеки NLTK на Python, для этого необходимо импортировать соответствующий пакет:
from nltk.corpus import wordnet as wnВ тезаурусе слова представлены в виде так называемых синсетов: это объединение слов с похожими понятиями, их лексические значения вместе формируют лексическое значение самого слова. К примеру, синсет слова hand tool ‘ручной инструмент’ состоит из одного понятия.
wn.synsets('hand_tool')[Synset('hand_tool.n.01')]
Синсет слова hammer ‘молоток’ включает нескольких синонимичных понятий, где malleus переводится как ‘молоточек’, слуховая косточка среднего уха, mallet обозначает ‘молоток для игры в крокет’, а forge имеет значение ‘кузница’.
wn.synsets('hammer')[Synset('hammer.n.01'), Synset('hammer.n.02'), Synset('malleus.n.01'), Synset('mallet.n.02'), Synset('hammer.n.05'), Synset('hammer.n.06'), Synset('hammer.n.07'), Synset('hammer.n.08'), Synset('hammer.v.01'), Synset('forge.v.01')]
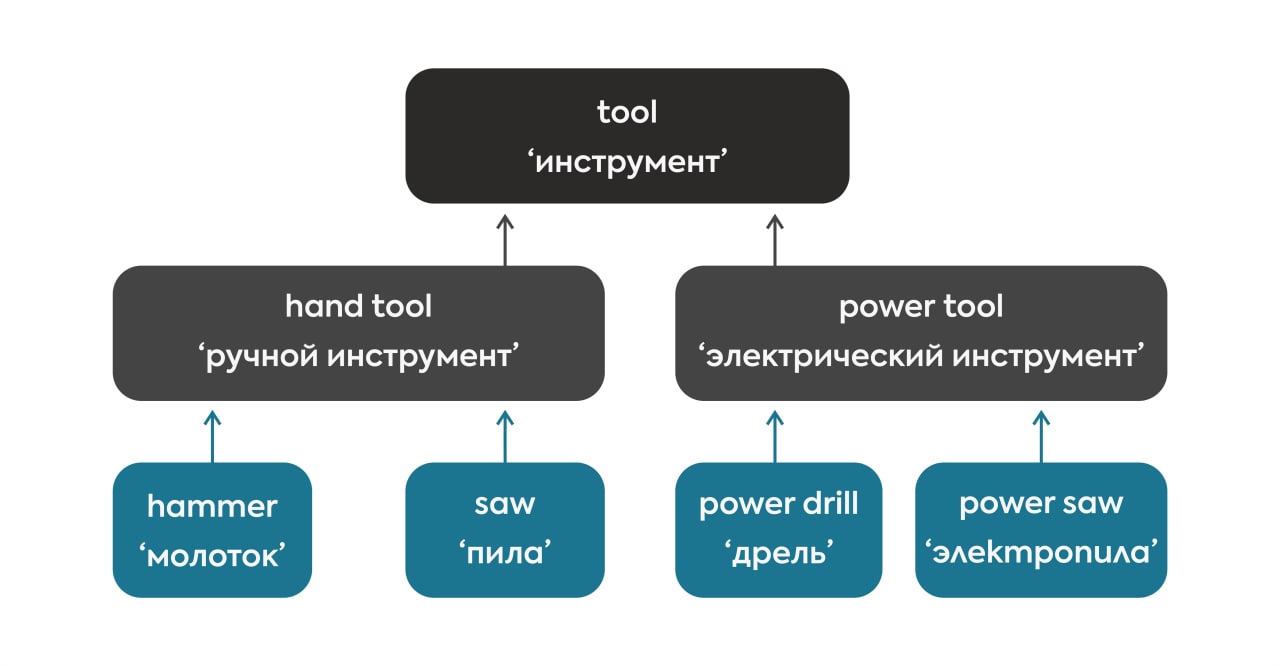
Как мы упоминали ранее, тезаурус имеет иерархическую структуру. Следовательно, для каждого слова можно узнать как более общие понятия – гиперонимы, так и более конкретные понятия – гипонимы. Так, слово hand tool ‘ручной инструмент’ имеет только один гипероним – tool ‘инструмент’ и много гипонимов, среди которых уже знакомый hammer ‘молоток’ с индексом «02», а также awl ‘шило’, saw ‘пила’, wrench ‘гаечный ключ’ и другие названия ручных инструментов:
hand_tool = wn.synset('hand_tool.n.01')
print(hand_tool.hypernyms())
print(hand_tool.hyponyms())[Synset('tool.n.01')]
[Synset('awl.n.01'), Synset('bevel.n.02'), Synset('bodkin.n.03'), Synset('bodkin.n.04'), Synset('crank.n.04'), Synset('dibble.n.01'), Synset('file.n.04'), Synset('float.n.05'), Synset('graver.n.01'), Synset('gutter.n.04'), Synset('hammer.n.02'), Synset('hand_shovel.n.01'), Synset('marlinespike.n.01'), Synset('miter_box.n.01'), Synset('opener.n.03'), Synset('pallet.n.03'), Synset('pestle.n.03'), Synset('pick.n.06'), Synset('pincer.n.01'), Synset('pipe_cutter.n.01'), Synset('pitchfork.n.01'), Synset('plane.n.05'), Synset('pliers.n.01'), Synset('plumber's_snake.n.01'), Synset('plunger.n.03'), Synset('ravehook.n.01'), Synset('sandblaster.n.01'), Synset('saw.n.02'), Synset('scraper.n.01'), Synset('screwdriver.n.01'), Synset('shovel.n.01'), Synset('soldering_iron.n.01'), Synset('spatula.n.02'), Synset('spreader.n.01'), Synset('square.n.08'), Synset('straightedge.n.01'), Synset('tire_iron.n.01'), Synset('trowel.n.01'), Synset('weeder.n.02'), Synset('wire_stripper.n.01'), Synset('wrench.n.03')]
Несложно догадаться, что гиперонимом для слова hammer ‘молоток’ с индексом «02» будет понятие hand tool ‘ручной инструмент’, а гипонимами – различные виды молотков, как ball-peen hammer ‘шариковый молоток’, maul ‘кувалда’ и другие:
hammer = wn.synset('hammer.n.02')
print(hammer.hypernyms())
print(hammer.hyponyms())[Synset('hand_tool.n.01')]
[Synset('ball-peen_hammer.n.01'), Synset('bricklayer's_hammer.n.01'), Synset('carpenter's_hammer.n.01'), Synset('mallet.n.03'), Synset('maul.n.01'), Synset('plexor.n.01'), Synset('tack_hammer.n.01')]
Интересно, что понятие power tool ‘электрический инструмент’ имеет два гиперонима: это не только слово tool ‘инструмент’, но и слово machine ‘механизм’. Гипонимами этого понятия также являются названия конкретных инструментов: buffer ‘амортизатор’, power drill ‘дрель’, power saw ‘электропила’, а также снова hammer, только уже в значении ‘электромолоток’, о чем говорит изменившийся индекс «07»:
power_tool = wn.synset('power_tool.n.01')
print(power_tool.hypernyms())
print(power_tool.hyponyms())[Synset('machine.n.01'), Synset('tool.n.01')]
[Synset('buffer.n.05'), Synset('burr.n.04'), Synset('drum_sander.n.01'), Synset('hammer.n.07'), Synset('plane.n.04'), Synset('power_drill.n.01'), Synset('power_saw.n.01'), Synset('router.n.03'), Synset('stamping_machine.n.01')]
Иерархическая структура тезауруса позволяет довольно точно рассчитывать семантическое сходство между понятиями с помощью специальных мер, которые мы рассмотрим в следующем разделе.
Меры семантического сходства по тезаурусу
Попробуем рассчитать семантическое сходство между парами слов, обозначающими различные строительные инструменты: hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’, hammer ‘молоток’ и saw ‘пила’. Для наглядности представим их иерархическое расположение в тезаурусе в виде графической схемы:
Можно выделить два метода подсчета семантической схожести.
Первая мера сходства основана на длине пути между парой понятий. Интуитивно кажется правильным подсчитывать расстояние между узлами в иерархии для вычисления меры семантической схожести. Данная мера имеет название PATH (с английского ‘путь’) и учитывает длину кратчайшего пути между двумя понятиями А и В (shortest path (А,В)). Отметим, что при подсчете учитываются именно узлы, а не переходы между узлами:
![]()
Рассчитаем меру сходства PATH между парами слов hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’, hammer ‘молоток’ и saw ‘пила’. Кратчайший путь между понятиями для обоих пар равен 3. Автоматический подсчет меры PATH показывает, что семантическое сходство между словами является одинаковым:
hand_tool.path_similarity(power_tool)0.3333333333333333
hammer.path_similarity(saw)0.3333333333333333
При подсчете этой меры предполагается, что все расстояния между узлами имеют одинаковый вес. Однако это не совсем так — понятия, лежащие ниже в иерархии, являются более специфичными, и семантическое расстояние между такими понятиями кажется меньшим, нежели расстояние между более общими понятиями. Поэтому эффективно использовать не только расстояние между узлами, но и глубину узлов в иерархи: PATH + DEPTH (с английского ‘глубина’). Под глубиной подразумевается длина кратчайшего пути между целевым понятием А и корневым понятием.
![]()
Данная мера имеет название WUP по фамилиям исследователей Z. Wu и M. Palmer, предложивших использовать ее в статье 1994 года. Она учитывает глубину наименее общего родового понятия, то есть ближайшего понятия, которое является общим для обоих целевых слов (Least Common Subsumer, сокращенно LCS):

Подсчитаем семантическое сходство по мере WUP между уже известными парами слов. Результат показывает, что для слов hammer ‘молоток’ и saw ‘пила’ значение меры сходства оказывается выше, чем для пары hand tool ‘ручной инструмент’ и power tool ‘электрический инструмент’:
hand_tool.wup_similarity(power_tool)0.8888888888888888
hammer.wup_similarity(saw)0.9
Это соответствует нашим интуитивным ожиданиям: конкретные понятия, как названия типов ручных инструментов, кажутся семантически более близкими, чем общие понятия, как названия групп инструментов. Таким образом, мера семантического сходства, учитывающая не только расстояние между узлами, но и глубину вложения, является более показательной и надежной.
Некоторые итоги
В статье мы рассмотрели меры нахождения семантического сходства по тезаурусу. Дистрибутивные методы, так распространенные сейчас, показывают высокое качество в задачах понимания текста, но обладают важным недостатком: они не учитывают семантические отношения между словами, такие как синонимия, антонимия, отношения гипоним-гипероним. Эту проблему решают словари с иерархической структурой – тезаурусы. Мы познакомились с устройством тезауруса WordNet для английского языка и рассчитали семантическое сходство между понятиями с помощью библиотеки NLTK. Оказалось, что более достоверные результаты показывают меры, которые учитывают не только на расстояние между узлами (PATH), но и глубину узлов в иерархии (DEPTH).
В заключение добавим, что семантическое сходство слов по тезаурусу может использоваться во многих задачах понимания текста, среди которых построение вопросно-ответных систем, разрешение неоднозначности слов, нахождении сходства между предложениями, расширение поискового запроса и нахождение связей между частями текста.
Гендина Н.И.,
доктор пед. наук, профессор
кафедры ТАОИ КемГУКИ
Информационно-поисковые тезаурусы:
структура, назначение и порядок разработки
План
1. Тезаурус как способ систематизированного представления знаний и
разновидность идеографического словаря.
2. Информационно-поисковые тезаурусы: сущность и назначение
3. Структура ИПТ
4. Порядок разработки, экспертизы, регистрации и ведения ИПТ.
Список литературы
1. ГОСТ 7.74 – 96. Информационно-поисковые языки. Термины и определения [Текст]. – Введ. 1997-07-01. – Минск: Межгосударственный совет по стандартизации, метрологии и сертификации, 1997. – 34 с. (Система стандартов по информации библиотечному и издательскому делу) ТК 191.
2. ГОСТ 7.25-2001. Тезаурус информационно-поисковый одноязычный. Правила разработки, структура, состав и форма представления [Текст]. – Взамен ГОСТ 7.25-80; Введ. 2002-07-01. – М.: ИПК Изд-во стандартов, 2001. – 16 с. МТК 191.
3. ГОСТ 7.24-2007 Тезаурус информационно-поисковый многоязычный. Состав, структура и основные требования к построению. – Взамен ГОСТ 7.24-90; введ. 2008-07-01. / Межгосударственный совет по стандартизации, метрологии и сертификации. – М.: Стандартинформ, 2008. – 7 с. (Система стандартов по информации, библиотечному и издательскому делу)
4. Баранов, О. С. Идеографический словарь русского языка [Текст] / О. С. Баранов. – М.:Издательство ЭТС, 1995. – 820 c
5. Жмайло, С. В. К вопросу об определении тезауруса [Текст] / С. В. Жмайло // НТИ. Сер. 1 Организация и методика информационной работы. – 2003. – №12. – С.20 – 25.
6. Жмайло, С. В. К разработке современных информационно-поисковых тезаурусов [Текст] / С. В. Жмайло // НТИ. Сер. 1 Организация и методика информационной работы. –2004. – №1. – С.23 – 31.
7. Пробст, М. А. Тезаурус и информационный поиск [Текст] / М. А. Пробст // НТИ. Сер. 2. Информационные процессы и системы – 1979. – №9. – С. 14 – 20.
1. Тезаурус как способ систематизированного представления знаний и разновидность идеографического словаря
Тезаурус (от греч. Thesauros – клад, сокровище, сокровищница) – многозначное слово, имеющее, как минимум, два значения:
1) тезаурус как идеальный объект – это «совокупность знаний, накопленных человеком или некоторым коллективом. Это упорядоченный и отраженный в сознании человека «лексикон», «мир» отдельной личности. В русском языке наиболее адекватный перевод слова «тезаурус» – это «мир знаний и интересов». Например, «мир знаний и интересов ребенка – тезаурус ребенка» и «мир знаний и интересов взрослого – тезаурус взрослого»; «мир знаний и интересов художника – тезаурус художника», «мир знаний и интересов бизнесмена – тезаурус бизнесмена» и т.п. В теории информации тезаурусом называют запас знаний (понятий, суждений), размещенных в памяти воспринимающего информацию субъекта. Это структурированное знание в виде понятий и смысловых отношений между ними,
2) тезаурус как материально существующий объект – словарь. Тезаурус – это словарь особого типа или идеографический словарь, в котором слова располагаются не по алфавиту, а по степени смысловой близости. Лексика языка представлена в них в виде систематизированных групп слов, в той или иной степени близких в смысловом отношении (синонимы, гиперонимы, гипонимы, антонимы, паронимы и др.). Тезаурус представляет собой упорядоченную совокупность лексических единиц, в которой в явном виде с помощью специальных помет отражены смысловые отношения (синонимические, родовидовые и ассоциативные) между лексическими единицами. Иными словами, упорядочение лексики в тезаурусе осуществляется не по алфавитному или другому формальному признаку, а по смысловому (семантическому).
В основе построения идеографических словарей лежит логическая классификация всего понятийного содержания лексики. Систематизация слов в таких словарях основана на психологических ассоциациях предметов и понятий, называемых какой-либо лексической единицей. Лексические единицы группируются в поля, в центре каждого из которых стоит слово, объединяющее другие слова, в той или иной степени близкие ему по значению или ассоциирующиеся с ним по смыслу (например: насекомое – муха, пчела, муравей, бабочка; ползать, летать, прыгать…). Как правило, слова и словосочетания внутри поля кратко толкуются таким образом, чтобы было видно, чем каждое из них отличается от всех других членов поля. Слова или словосочетания группируются на основании общности обозначаемых ими явлений действительности по определённым темам, например, «Животные», «Насекомые», «Дом», «Театр», «Улица», «Транспорт» и т. д.
Так, в идеографическом словаре русского языка О. С. Баранова (4) выделены 12 высших разделов идеографического словаря, среди которых: «порядок, природа, человек, деятельность, общество, культура» и др., каждый из которых делится на группы, подгруппы, отделы, разделы. Все слова в этом словаре собраны в гнезда по смыслу и группируются вокруг некоторого понятия, с которым они связаны чаще всего видовыми отношениями. Гнезда в свою очередь группируются в подразделы и т.д. На данный момент в словаре 5923 гнезд, 7 уровней деления (по данным www.rifmovnik.ru/thesaurus.htm на 16.02.2010 г.). Приведем пример словарной статьи из этого словаря:
178.4.7 аромат
▲ запах
↑ ароматный
аромат - приятный запах (например, запах цветов, травы, сена. нежный #. пьянящий #).
ароматизация
благоухание. благоухать.
благовоние.
амбре. фимиам.
Код слова «аромат» отражает принятую в данном словаре идеографическую классификацию, в частности, соотнесенность данного слова с категорией «178- Ощущения».
Таким образом, термины «тезаурус», «идеографический словарь», «словарь типа тезаурус», в первую очередь означают, что совокупность слов языка в них представлена таким образом, что в одну группу слов входят слова, близкие по смыслу. Основное назначение идеографических словарей — описать совокупности лексических единиц, объединённых общим понятием; это облегчает читателю выбор наиболее подходящих средств для адекватного выражения мысли и способствует активному владению языком.
Из истории тезаурусов
История появления и развития тезаурусов рассматривается в работах (5,7). В них отмечается, что история возникновения тезаурусов восходит к великим мыслителям древности и, прежде всего, к Аристотелю. Ему принадлежат слова, возраст которых 2,5 тыс. лет: «Из слов, высказываемых без какой-либо связи, каждое означает или сущность, или качество, или количество, или отношение, или обладание, или действие, или страдание» (Аристотель, Аналитики. – М.:Госполитиздат, 1952. – 438 с.).
Одной из наиболее древних попыток идеографических классификаций является труд Аристофана Византийского (директор Александрийской библиотеки, умер в 180 г. до н.э.). Во 11 в. н.э. появляется работа Юлия Поллукса «Ономастикон», составленная на материале греческого языка. Это словарь, состоящий из 10 книг. Каждая книга содержала слова, относящиеся к определенной теме. Например, в первой – слова, относящиеся к богам и царям; в седьмой – к теме «торговля», в десятой – к теме «утварь». Слова в этом словаре сопровождались краткими толкованиями.
Между II и III в н.э. появляется санскритский словарь «Амарокоша», который содержал около 10 тыс. слов и состоял из трех книг, каждая из которых делилась на главы, главы – на секции. Так, первая книга была посвящена небу, богам и всему тому, что с ними связано. В ней имелись секции «времена года», «небесный свод» и т.п. Вторая книга содержала слова, относящиеся к земле, растительному и животному миру и человеку. Для лучшего запоминания толкования давались в стихотворной форме.
Сам термин «тезаурус» был применен впервые в ХIII в. флорентийским ученым Брунето Латини, который использовал его в заголовке своего труда – систематизированной энциклопедии, назвав ее «Книга о сокровище». Это вполне соответствовало семантике употребленного слова «Thesauros», т.е. «сокровище», «богатство», «запас».
Современный этап истории идеографических словарей открывается работой П.М.Роже «Тезаурус английских слов и выражений» (1852 г.) Его тезаурус – это глубоко структурированная система, восходящая к самым общим категориям: абстрактные отношения, пространство, материя, дух. Всю понятийную область английского языка Роже разбивает на 4 класса: абстрактные отношения, пространство, материя и дух (разум, воля, чувства). Далее эти категории делятся на 24 класса, классы – на подклассы и т.д. Классы распадаются на категории, категории – на секции, секции – на группы. Всего у Роже 1000 понятийных групп, в каждую из которых он собирает слова, близкие по смыслу. Так, есть понятийные группы «рождение», «житель», «помещение», «удовлетворение».
Почти в то же время (1862 г.) появился «Аналогический словарь французского языка» Буасьера. Отобрав две тысячи слов французского языка, которые составляют активный словарь (слова повседневного употребления), и, взяв каждое такое слово за основу, Буасьер собирает все слова, семантически с ним связанные.
Следует подчеркнуть, что первые тезаурусы составлялись без всякой связи с особенностями информационной деятельности, они были органически связаны с фундаментальными проблемами познания, отображая представление о мире в целом и закономерностях его постижения средствами естественного языка. В дальнейшем, при проникновении идей тезауруса в автоматизированные ИПС, тезаурус стал рассматриваться как словарь для построения поисковых образов документов и запросов, качество которых существенно влияло на качество поиска информации.
2. Информационно-поисковые тезаурусы: сущность и назначение
Среди тезаурусов, понимаемых как идеографические словари, в особую группу выделяются информационно-поисковые тезаурусы (ИПТ), появление и развитие которых связано с автоматизацией информационного поиска в середине ХХ в.
ГОСТ 7.74-96 «Информационно-поисковые языки. Термины и определения» определяет ИПТ следующим образом: «Информационно-поисковый тезаурус (ИПТ) – нормативный словарь дескрипторного ИПЯ с зафиксированными в нем парадигматическими отношениями».
ИПТ не следует путать с дескрипторным словарем. ГОСТ 7.74-96 «Информационно-поисковые языки. Термины и определения» дает следующее разграничение этих понятий: «Дескрипторный словарь – словарь дескрипторного ИПЯ, в котором приведены в общем алфавитном ряду дескрипторы и их синонимы без указания других отношений лексических единиц. Дескрипторный словарь является упрощенным вариантом ИПТ, в котором зафиксированы преимущественно или только синонимические связи».
Таким образом, термин «информационно-поисковый тезаурус» используется для обозначения словаря-справочника, в котором перечислены все лексические единицы дескрипторного ИПЯ с указанием их синонимов, а также явно выражены важнейшие смысловые отношения между дескрипторами».
Следует подчеркнуть, что на практике, в инструктивно-методической литературе существует большая путаница в понятийном аппарате. Тезаурусом подчас называют любую классификацию, любой рубрикатор или даже список. Тем не менее, следует отличать ИПТ от словарей синонимов, антонимов и ассоциативных; от компьютерных словарных списков взаиморасположения терминов в документах, которые часто в литературе называют автоматизированными тезаурусами; от списков предметных заголовков и ключевых слов, если в них не выражены семантические отношения между терминами.
ИПТ – это структурированный словарь для контроля лексики, в котором явно и системно определяются основные семантические отношения (эквивалентности, иерархические и ассоциативные) между терминами естественного языка. В соответствии с ГОСТ 7.25-2001 ИПТ ориентированы, прежде всего, на использование в рамках автоматизированных информационных систем и сетей научно-технической информации.
Назначение ИПТ
Появление ИПТ неразрывно связано с развитием автоматизированных информационных систем (АИС). Первоначально целью создания ИПТ являлось повышение показателей качества поиска информации в АИС. В соответствии с этой целью назначение ИПТ заключалось в следующем:
1. Обеспечивать индексирование документов и запросов средствами дескрипторного языка путем замены ключевых слов соответствующими дескрипторами, а также осуществлять избыточное индексирование документов и/или информационных запросов за счет использования вышестоящих, нижестоящих и ассоциативных понятий;
2. Отражать парадигматические отношения, существующие между лексическими единицами какой-либо отрасли науки или техники.
3. Служить средством контроля и нормализации лексики конкретной отрасли знания, обеспечивать единое и формализованное представление информации в ИПС.
Кроме того, ИПТ использовались и используются при традиционном (ручном) информационном поиске как средство терминологического контроля, позволяющее на основе эксплицитного представления парадигматических отношений между дескрипторами сужать или расширять область поиска, уточнять информационные запросы пользователей, осуществлять корректировку поисковых предписаний.
3. Структура ИПТ
В соответствии с ГОСТ 7.25-2001 «Тезаурус информационно-поисковый одноязычный. Правила разработки, структура, состав и форма представления» в состав ИПТ входят следующие элементы:
1) вводная часть;
2) основная часть (лексико-семантический указатель);
3)дополнительные части (систематический, пермутационный, иерархический и другие указатели и списки специальных категорий лексических единиц).
Обязательными составными частями являются вводная часть и лексико-семантический указатель.
Допускается в состав ИПТ вводить приложения, содержащие дополнительные сведения о разработке и использовании ИПТ.
Вводная часть включает титульный лист и введение.
На титульном листе должны быть приведены:
— наименование ИПТ, включающее термин «информационно-поисковый тезаурус» и указывающее область его применения;
— наименование организации-разработчика и дополнительные сведения об авторстве ИПТ;
— сведения о переиздании;
— место и год создания или издания ИПТ.
Введение должно содержать:
— цель создания и область применения тезауруса, описанные кодами
и наименованиями рубрик Межгосударственного рубрикатора НТИ;
— ссылки на источники, использованные для сбора лексики ИПТ;
— ссылки на нормативные и методические документы, использованные при составлении ИПТ;
— описание порядка составления тезауруса, включая обоснование
представительности использованных источников лексики;
— описание состава и структуры;
— перечень отношений между лексическими единицами и методические основания для их установления;
— перечень всех символов и специальных сокращений, допущенных
для представления;
— порядок алфавитного расположения (расположение букв разных
алфавитов, небуквенных символов и др.);
— количественные характеристики тезауруса (общее число статей, число дескрипторов, аскрипторов и др.);
— описание состава и формы представления дополнительных данных в словарных статьях;
— абзац следующего содержания: «Тезаурус подготовлен в соответствии с ГОСТ 7.25».
Введение к последующим изданиям (версиям) ИПТ дополнительно должно содержать:
— обоснование необходимости составления новой версии тезауруса;
— указание на характер внесенных изменений.
Лексико-семантический указатель – это упорядоченная последовательностью словарных статей ИПТ, сформированная я путем расположения их в алфавитном порядке заглавных лексических единиц. Представляет собой алфавитный перечень всех дескрипторов и аскрипторов с их словарными статьями.
Приведем фрагмент лексико-семантического указателя из ИПТ по швейной промышленности:
|
КУРТКИ 2302 в Изделия костюмные Изделия пальтовые Изделия швейные н Куртка двубортная Куртка комбинированная Куртка спортивная КУСОК ТКАНИ 2203 с Отрез в Меры упаковочные а Выпада межлекальные Лоскут Метраж ткани Остатки материала Отходы материала «Полотна красные» Рулон |
ЛАВСАН 2304 в Волокно полиэфирное Волокна синтетические ЛАСТИК ЖАККАРДОВЫЙ 2304 в Ткани подкладочные Ткани ЛЕКАЛА 2305 с Выкройки Чертежи кроя н — Лекала рабочие — Лекала-эталоны а Развертка поверхности Трафареты Шаблоны Лекала вспомогательные см Лекала производные |
Дескрипторная статья состоит из заглавного дескриптора, списка дескрипторов и аскрипторов, семантически связанных с ним, с обозначением видов связи. В рамках дескрипторной статьи термины располагают в следующем порядке:
— заглавный дескриптор;
— дополнительные данные;
— лексическое примечание;
— аскрипторы или дескрипторы-синонимы;
— вышестоящие дескрипторы;
— нижестоящие дескрипторы;
— ассоциативные дескрипторы;
— дескрипторы, связанные другими видами отношений.
Внутри каждой группы ЛЕ, связанных с заглавным дескриптором одним видом парадигматических отношений, должен быть алфавитный порядок расположения. Например:
АЛГОРИТМИЧЕСКИЕ ЯЗЫКИ
с языки алгоритмические
машиноориентированные языки
проблемноориентированные языки
в ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
ФОРМАЛЬНЫЕ ЯЗЫКИ
н АВТОКОДЫ
АЛГОЛ
ИПЛ
КОБОЛ
КОМИТ
ПЛ/1
ФОРТРАН
а АЛГОРИТМЫ
ПРОГРАММИРОВАНИЕ ср искусственные языки
Аскрипторная статья состоит из аскриптора и заменяющих его при обработке и поиске информации дескрипторов или комбинации дескрипторов. Приведем примеры аскрипторных статей:
Алфавитно-цифровые знаки
исп к БУКВЫ
ЦИФРЫ
Языки
исп а ФОРМАЛЬНЫЕ ЯЗЫКИ
ЕСТЕСТВЕННЫЕ ЯЗЫКИ
Языки программирования
см АЛГОРИТМИЧЕСКИЕ ЯЗЫКИ
Словарная статья может также включать:
— частоту использования дескриптора;
— кодовый номер дескриптора;
— код дескриптора по систематическому указателю;
— классификационные индексы;
— дополнительные семантические и лексикографические пометы;
— иноязычные эквиваленты.
Качество лексико-семантического указателя определяется полнотой включенных в него лексических единиц. Полнота понимается как вероятность вхождения в тезаурус любого информативно-значащего слова для данной тематической области. Полнота лексико-семантического указателя, а, следовательно, и всего тезауруса оказывает существенное воздействие на результаты индексирования документов и запросов.
Дополнительные части могут включать в свой состав систематический, пермутационный, иерархический и другие указатели и списки специальных категорий лексических единиц.
Систематический указатель – это указатель, в котором дескрипторы сгруппированы согласно принятой в ИПТ рубрикации. Систематический указатель определяет тематическое направление тезауруса, раскрывает его содержание и отражает те отрасли науки и техники, по которым можно с той или иной глубиной детализации проводить поиск. Необходимость его как составной части ИПТ обусловлена тем, что он дает наглядное представление об общем состоянии терминологии в той или иной области знаний, позволяет построить стройную терминологическую модель и учесть по возможности все термины и понятия, которые должны найти место в тезаурусе. Он предназначен для облегчения поиска терминов при составлении поисковых образов документов и запросов путем упорядочения множества дескрипторов и аскрипторов по предметному признаку.
Например, в ИПТ технологии машиностроения, в лексико-семантическом указателе имеется дескрипторная статья:
ГИСТЕРЕЗИС 1913
н Гистерезис диэлектрический
Гистерезис магнитный
Код заглавного дескриптора 1913 показывает связь лексико-семантического указателя с систематическим указателем ИПТ. Первые две цифры отражают первый уровень иерархии – дескрипторную область «19 Физика», к которой относится данный термин. Вторые две цифры отражают второй уровень иерархии в этой области – дескрипторную группу «1913 Электричество и магнетизм».
Пользуясь систематическим указателем, можно определить, термины каких областей знания используются в данном ИПТ. Так, ИПТ по технологии машиностроения включает термины из таких предметных областей, как «Строительство», «Физика», «Химия», «Электротехника и радиоэлектроника» и др.
Систематический указатель, по существу, представляет собой классификационную схему наполнения тезауруса терминологией, так как он строится путем упорядочения множества дескрипторов по предметно-тематическим областям.
Систематические указатели ИПТ подразделяют на три типа:
— тематические,
— категориальные,
— смешанные.
Такое деление отражает принцип построения классификационной схемы систематического указателя.
Основные функции, выполняемые систематическим указателем ИПТ:
— использование в качестве вспомогательного средства при индексировании, обеспечивающее, прежде всего, возможность поиска дескрипторов для индексирования понятий, не представленных в тезаурусе в явном виде (поисковая функция);
— использование в процессе ведения тезауруса (функция ведения ИПТ);
— использование в качестве структурной основы ИПТ, как средство управления его разработкой (конструктивная функция).
В соответствии с ГОСТ 7.25-2001 (2) при построении систематического указателя тематического и смешанного типов в его тематической части следует использовать рубрики Межгосударственного рубрикатора НТИ или рубрикатора конкретной АСНТИ, совместимого с Межгосударственным рубрикатором НТИ. При построении систематического указателя категориального и смешанного типов в его категориальной части следует использовать следующие общие категории:
— названия дисциплин и отраслей деятельности;
— предметы, материалы;
— методы, процессы, операции, явления;
— свойства, величины, параметры, характеристики;
— отношения, структуры, модели, законы, правила, абстрактные понятия.
Иерархический указатель. Иерархический указатель – указатель, в котором дан перечень списков дескрипторов, причем каждый список начинается с дескриптора, не имеющего вышестоящих. Он отражает полную структуру иерархических отношений в ИПТ. После каждого дескриптора приведены непосредственно дескрипторы с указанием их уровня в иерархии путем применения нумерации либо графического обозначения уровня:
|
Консервирование •Консервирование антисептиками • Консервирование инертными газами • Консервирование продовольствия •• Вяление ••Квашение ••Копчение •• Маринование •• Посол (соление) |
Консервирование 1 Консервирование антисептиками 1 Консервирование инертными газами 1 Консервирование продовольствия 2 Вяление 2 Квашение 2 Копчение 2 Маринование 2 Посол (соление) |
Необходимость разработки иерархического указателя ИПТ бывает вызвана тем, что в словарных статьях ИПТ не закрепляется вся система подчиненности понятий, т.к. это повлекло бы за собой значительное увеличение лексико-семантического указателя. Отсюда возникает необходимость разработки самостоятельного раздела ИПТ – иерархического указателя, который бы отражал всю иерархическую цепочку подчиненности дескрипторов сверху донизу.
Пермутационный указатель – указатель, в котором в алфавитном порядке перечислены все отдельные слова, входящие в компоненты словосочетаний, обозначающих дескрипторы и для каждого из них указаны все дескрипторы, в состав которых входят эти слова. Следовательно, каждый термин встречается в пермутационном указателе столько раз, сколько значащих слов он содержит. Назначение пермутационного указателя – обеспечивать поиск дескрипторов-словосочетаний по любому слову, входящему в их состав, в том числе и по тем, которые не стоят в начале лексической единицы. Он позволяет группировать в одном месте однокоренные слова.
Как правило, пермутационный указатель составляется автоматизированным способом и имеет обычно вид указателя типа KWIC (Key Word – In Context – «Ключевые слова в контексте»), в котором все значащие слова – элементы терминов – располагаются в алфавитном порядке. Вход в пермутационный указатель находится в центре колонки, которую образуют микроконтексты элементов терминов, а неуместившаяся часть терминов переносится в левую часть той же строки:
|
оптические квантовые возбуждения электрические с зависимым возбуждением |
ГЕНЕРАТОРЫ помех ГЕНЕРАТОРЫ последовательного ГЕНЕРАТОРЫ постоянного тока ГЕНЕРАТОРЫ постоянного тока |
Включение в ИПТ пермутационного указателя позволяет устранить повторы, выявить и ликвидировать омонимию, получить высокий уровень накопления терминов, связанных родовидовыми и ассоциативными отношениями, выявить не представленные полностью группы однородных понятий и дополнить их, ввести пропущенные понятия.
Создание пермутационного указателя позволяет решить проблему инверсии прилагательного и существительного. Независимо от того, какое слово использовано для входа в указатель, термин будет найден с принятым для него порядком слов. Кроме того,
весьма важен тот факт, что в пермутационном указателе все термины, содержащие одинаковые слова, собраны вместе, что дает при поиске нить к тем терминам, которые потенциально могут оказаться необходимыми.
4.Порядок разработки, экспертизы, регистрации и ведения ИПТ
В настоящее время порядок разработки, экспертизы и регистрации ИПТ определяется двумя стандартами: ГОСТ 7.25-2001 «Тезаурус информационно-поисковый одноязычный. Правила разработки, структура, состав и форма представления» и ГОСТ 7.24-2007 «Тезаурус информационно-поисковый многоязычный. Состав, структура и основные требования к построению». В соответствии с этими стандартами функции экспертизы и регистрации ИПТ выполняют национальный и международный депозитарные фонды.
Национальный депозитарный фонд ИПТ на русском языке (включая ИПТ, содержащие эквиваленты дескрипторов на русском языке) находится в Москве, в ВИНИТИ.
Существует также два международных депозитарных фонда ИПТ:
1) международный депозитарный фонд ИПТ на английском языке, включая ИПТ, содержащие эквиваленты дескрипторов на английском языке. Он находится в Канаде, в г. Торонто, в библиотеке факультета информационных наук Университета в Торонто (Thesaurus Clearinghouse – «расчетная палата», The Library, Faculty of Information Studies, University of Toronto, TORONTO, Canada);
2) международный депозитарный фонд ИПТ на всех других языках, кроме английского. Он находится в Польше, в Варшаве, в институте научной и технико-экономической информации (Instytut Informacji Naukowej, Technicznej i Ekonomicznej, Clearinghouse, WARSZAW A, Poland.).
Полные адреса этих организаций приводятся в ГОСТ 7.25-2001.
ГОСТ 7.25-2001 и ГОСТ 7.24-2007 определяют последовательность действий разработчиков ИПТ следующим образом:
1. До начала работ по созданию ИПТ разработчик должен обратиться в соответствующий национальный или международный депозитарный фонд с целью определения наличия зарегистрированных тезаурусов по заданной тематике. При наличии таких тезаурусов проводят оценку возможности внедрения их в данной системе. Если такие тезаурусы не обнаружены, разработчик может приступать к созданию ИПТ. При этом вся технология работы по созданию ИПТ должна строго соответствовать ГОСТ 7.25-2001 и ГОСТ 7.24-2007
2. Готовые (разработанные) ИПТ должны пройти экспертизу на соответствие ГОСТ 7.25-2001. Если они соответствуют стандарту, то Национальный депозитарий выдает разработчику сертификат соответствия. После этого ИПТ депонируется (сдается на хранение) в соответствующем национальном или в одном из международных депозитарных фондах (в Торонто или Варшаве).
Национальные депозитарии распространяют информацию о составе фонда депонированных ИПТ и предоставляют их разработчикам новых ИПТ с целью заимствования элементов и обеспечения совместимости лингвистического обеспечения различных информационных систем. Таким образом, они выполняют функции экспертизы, регистрации, хранения ИПТ и информирования об имеющихся ИПТ.
Ведение ИПТ. Следует помнить, что тезаурус никогда не может считаться вполне законченным, так как его содержание, объем и форма постоянно изменяются в связи с развитием науки, техники и производства. Среди причин, требующих периодически корректировать ИПТ, можно назвать:
— количественные и качественные изменения документального потока, поступающего в систему (например, появление нового тематического направления или поступление новых типов документов или, наоборот, прекращение их поступлений);
— изменение режимов поиска в системе; изменение средств реализации АИС (например, внедрение более мощных компьютеров нового поколения, позволяющих автоматизировать многие операции по ведению ИПТ);
— переход АИС от независимого функционирования к работе в режиме сети (при использовании ИПТ в рамках единой информационной сети принципы их ведения должны быть согласованы).
Процедура поддержания ИПТ в рабочем состоянии называется ведением или корректировкой тезауруса. Обычно она включает следующие операции:
— изменение лексического состава ИПТ: внесение новых лексических единиц, их удаление, изменение статуса лексических единиц (перевод ключевого слова в дескрипторы и наоборот);
— изменение парадигматических отношений в ИПТ (усиление, дифференциация, ослабление);
— переиздание ИПТ, которое рекомендуется производить следующим образом: второе и третье издание – через год, а последующие – через два-три года.
Процедура ведения ИПТ предполагает обязательное использование средств автоматизации, позволяющих оперативно производить такие трудоемкие операции, как алфавитная сортировка словника, частотный анализ лексики, проверка взаимности и непротиворечивости ссылок, с помощью которых в ИПТ фиксируются парадигматические отношения и др.