Нормальное распределение
Время на прочтение
7 мин
Количество просмотров 36K
Автор статьи: Виктория Ляликова
Нормальный закон распределения или закон Гаусса играет важную роль в статистике и занимает особое положение среди других законов. Вспомним как выглядит нормальное распределение

где a -математическое ожидание, ![]() — среднее квадратическое отклонение.
— среднее квадратическое отклонение.
Тестирование данных на нормальность является достаточно частым этапом первичного анализа данных, так как большое количество статистических методов использует тот факт, что данные распределены нормально. Если выборка не подчиняется нормальному закону, тогда предположении о параметрических статистических тестах нарушаются, и должны использоваться непараметрические методы статистики
Нормальное распределение естественным образом возникает практически везде, где речь идет об измерении с ошибками. Например, координаты точки попадания снаряда, рост, вес человека имеют нормальный закон распределения. Более того, центральная предельная теорема вообще утверждает, что сумма большого числа слагаемых сходится к нормальной случайной величине, не зависимо от того, какое было исходное распределение у выборки. Таким образом, данная теорема устанавливает условия, при которых возникает нормальное распределение и нарушение которых ведет к распределению, отличному от нормального.
Можно выделить следующие этапы проверки выборочных значений на нормальность
-
Подсчет основных характеристик выборки. Выборочное среднее, медиана, коэффициенты асимметрии и эксцесса.
-
Графический. К этому методу относится построение гистограммы и график квантиль-квантиль или кратко QQ
-
Статистические методы. Данные методы вычисляют статистику по данным и определяют, какая вероятность того, что данные получены из нормального распределения
При нормальном распределении, которое симметрично, значения медианы и выборочного среднего будут одинаковы, значения эксцесса равно 3, а асимметрии равно нулю. Однако ситуация, когда все указанные выборочные характеристики равны именно таким значениям, практически не встречается. Поэтому после этапа подсчета выборочных характеристик можно переходить к графическому представлению выборочных данных.
Гистограмма позволяет представить выборочные данные в графическом виде – в виде столбчатой диаграммы, где данные делятся на заранее определенное количество групп. Вид гистограммы дает наглядное представление функции плотности вероятности некоторой случайной величины, построенной по выборке.
График QQ (квантиль-квантиль) является графиком вероятностей, который представляет собой графический метод сравнения двух распределений путем построения их квантилей. QQ график сравнивает наборы данных теоретических и выборочных (эмпирических) распределений. Если два сравниваемых распределения подобны, тогда точки на графике QQ будут приблизительно лежать на линии y=x. Основным шагом в построении графика QQ является расчет или оценка квантилей.
Существует множество статистических тестов, которые можно использовать для проверки выборочных значений на нормальность. Каждый тест использует разные предположения и рассматривает разные аспекты данных.
Чтобы применять статистические критерии сформулируем задачу. Выдвигаются две гипотезы H0 и H1, которые утверждают
H0 — Выборка подчиняется нормальному закону распределения
H1 — Выборка не подчиняется нормальному распределению
Установи уровень значимости alpha=0,05.
Теперь задача состоит в том, чтобы на основании какого-то критерия отвергнуть или принять основную нулевую гипотезу при уровне значимости
Критерий Шапиро-Уилка
Критерий Шапиро-Уилка основан на отношении оптимальной линейной несмещенной оценки дисперсии к ее обычной оценке методом максимального правдоподобия. Статистика критерия имеет вид

Числитель является квадратом оценки среднеквадратического отклонения Ллойда. Коэффициенты ![]() и критические
и критические ![]() значения статистики являются табулированными значениями. Если
значения статистики являются табулированными значениями. Если ![]() , то нулевая гипотеза нормальности распределения отклоняется на уровне значимости
, то нулевая гипотеза нормальности распределения отклоняется на уровне значимости ![]() .
.
В Python функция ![]() содержится в библиотеке scipy.stats и возвращает как статистику, рассчитанную тестом, так и значение p. В Python можно использовать выборку до 5000 элементов. Интерпретация вывода осуществляется следующим образом
содержится в библиотеке scipy.stats и возвращает как статистику, рассчитанную тестом, так и значение p. В Python можно использовать выборку до 5000 элементов. Интерпретация вывода осуществляется следующим образом
Если значение ![]() , тогда принимается гипотеза H0, в противном случае, т.е. если,
, тогда принимается гипотеза H0, в противном случае, т.е. если, ![]() , тогда принимается гипотеза H1, т.е. что выборка не подчиняется нормальному закону.
, тогда принимается гипотеза H1, т.е. что выборка не подчиняется нормальному закону.
Критерий Д’Агостино
В данном критерии в качестве статистики для проверки нормальности распределения используется отношение оценки Даутона для стандартного отклонения к выборочному стандартному отклонению, оцененному методом максимального правдоподобия

В качестве статистики критерия Д’Агостино используется величина
![]()
значение которой рассчитывается на основе центральной предельной теоремы, которая утверждает, что при ![]()
![limlimits_{x to infty}Pbigg(frac{D-M[D]}{sqrt{D[D]}}{<x}bigg)=Phi(x)](https://habrastorage.org/getpro/habr/upload_files/942/0a9/b3a/9420a9b3a29c728265cf3734143c97bd.svg)
где![]() стандартная нормальная случайная величина.
стандартная нормальная случайная величина.

Критические значения являются табулированными значениями. Гипотеза нормальности принимается, если значение статистики лежит в интервале критических значений. Данный критерий показывает хорошую мощность против большого спектра альтернатив, по мощности немного уступая критерию Шапиро-Уилка.
В Python функция normaltest() также содержится в библиотеке scipy.stats и возвращает статистику теста и значение p. Интерпретация результата аналогична результатам в критерии Шапиро-Уилка.
Критерий согласия![]() — Пирсона
— Пирсона
Данный критерий является одним из наиболее распространенных критериев проверки гипотез о виде закона распределения и позволяет проверить значимость расхождения эмпирических (наблюдаемых) и теоретических (ожидаемых) частот. Таким образом, данный критерий позволяет проверить гипотезу о принадлежности наблюдаемой выборки некоторому теоретическому закону. Можно сказать, что критерий является универсальным, так как позволяет проверить принадлежность выборочных значений практическому любому закону распределения.
Для решения задачи используется статистика ![]() — Пирсона
— Пирсона

где![]() — эмпирические частоты (подсчитывается число элементов выборки, попавших в интервал),
— эмпирические частоты (подсчитывается число элементов выборки, попавших в интервал), ![]() — теоретические частоты. Подсчитывается критическое значение
— теоретические частоты. Подсчитывается критическое значение ![]() . Если
. Если ![]() , отклоняется гипотеза о принадлежности выборки нормальному распределению и принимается, если
, отклоняется гипотеза о принадлежности выборки нормальному распределению и принимается, если ![]() .
.
Теперь перейдем к практической части. Для демонстрации функций будем использовать Dataset, взятый с сайта kaggle.com по прогнозированию инсульта по 11 клиническим характеристикам.
Загружаем необходимые библиотеки
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as npЗагружаем датасет
data_healthcares = pd.read_csv('E:/vika/healthcare-dataset-stroke-data.csv')
Набор состоит из 5110 строк и 12 столбцов.
Посмотрим на основные характеристики, каждого признака.data_healthcares.describe()

Из данных характеристик можно увидеть, что есть пропущенные значения в показателях индекс массы тела. Посчитаем количество пропущенных значений.

Если бы нам необходимо было делать модель для прогноза, то пропущенные значения bmi являются достаточно большой проблемой, в которой возникает вопрос как их восстановить. Поэтому будем предполагать, что значения столбца bmi (индекс массы тела) подчиняются нормальному закону распределения (предварительно был построен график распределения, поэтому сделано такое предположение). Но так как, на данный момент, у нас нет необходимости в построении модели для прогноза, то удалим все пропущенные значения
new_data=data_healthcares.dropna()
Теперь можем приступать к проверке выборочных значений показателя bmi на нормальность. Вычислим основные выборочные характеристики
|
Выборочная характеристика |
Код в python |
Значение характеристики |
|
Выборочное среднее |
new_data.bmi.mean() |
28,89 |
|
Выборочная медиана |
new_data.bmi.median() |
28,1 |
|
Выборочная мода |
new_data.bmi.mode() |
28,7 |
|
Выборочное среднеквадратическое отклонение |
new_data.bmi.std() |
7.854066729680458 |
|
Выборочный коэффициент асиметрии |
new_data.bmi.skew() |
1.0553402052962928 |
|
Выборочный эксцесс |
new_data.bmi.kurtosis() |
3.362659165623678 |
После вычислений основных характеристик мы видим, что выборочное среднее и медиана можно сказать принимают одинаковые значения и коэффициент эксцесса равен 3. Но, к сожалению коэффициент асимметрии равен 1, что вводить нас в некоторое замешательство, т.е. мы уже можем предположить, что значения bmi не подчиняются нормальному закону. Продолжим исследования, перейдем к построению графиков.
Строим гистограмму
fig = plt.figure
fig,ax= plt.subplots(figsize=(7,7))
sns.distplot(new_data.bmi,color='red',label='bmi',ax=ax)
plt.show()
Гистограмма достаточно хорошо напоминает нормальное распределение, кроме конечно, небольшого выброса справа, но смотрим дальше. Тут скорее, можно предположить, что значения bmi подчиняются распределению ![]() .
.
Строим QQ график. В python есть отличная функция qqplot(), содержащаяся в библиотеке statsmodel, которая позволяет строить как раз такие графики.
from statsmodels.graphics.gofplots import qqplot
from matplotlib import pyplot
qqplot(new_data.bmi, line=’s’)
Pyplot.show
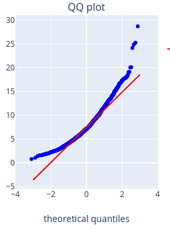
Что имеем из графика QQ? Наши выборочные значений имеют хвосты слева и справа, и также в правом верхнем углу значения становятся разреженными.
На основе данных графика можно сделать вывод, что значения bmi не подчиняются нормальному закону распределения. Рядом приведен пример QQ графика распределения хи-квадрат с 8 степенями свободы из выборки в 1000 значений.
Для примера построим график QQ для выборки из нормального распределения с такими же показателями стандартного отклонения и среднего, как у bmi.
std=new_data.bmi.std() # вычисляем отклонение
mean=new_data.bmi.mean() #вычисляем среднее
Z=np.random.randn(4909)*std+mean # моделируем нормальное распределение
qqplot(Z,line='s') # строим график
pyplot.show()
Продолжим исследования. Перейдем к статистическим критериям. Будем использовать критерий Шапиро-Уилка и Д’Агостино, чтобы окончательно принять или опровергнуть предположение о нормальном распределении. Для использования критериев подключим библиотеки
from scipy.stats import shapiro
from scipy.stats import normaltest
shapiro(new_data.bmi)
ShapiroResult(statistic=0.9535483717918396, pvalue=6.623218133972133e-37)
Normaltest(new_data.bmi)
NormaltestResult(statistic=1021.1795052962864, pvalue=1.793444363882936e-222)После применения двух тестов мы имеем, что значение p-value намного меньше заданного критического значения alpha , значит выборочные значения не принадлежат нормальному закону.
Конечно, мы рассмотрели не все тесты на нормальности, которые существуют. Какие можно дать рекомендации по проверке выборочных значений на нормальность. Лучше использовать все возможные варианты, если они уместны.
На этом все. Еще хочу порекомендовать бесплатный вебинар, который 15 июня пройдет на платформе OTUS в рамках запуска курса Математика для Data Science. На вебинаре расскажут про несколько часто используемых подходов в анализе данных, а также разберут, какие математические идеи работают у них под капотом и почему эти подходы вообще работают так, как нам нужно. Регистрация на вебинар доступна по этой ссылке.
В статье подробно показано, что такое нормальный закон распределения случайной величины и как им пользоваться при решении практически задач.
Нормальное распределение в статистике
История закона насчитывает 300 лет. Первым открывателем стал Абрахам де Муавр, который придумал аппроксимацию биномиального распределения еще 1733 году. Через много лет Карл Фридрих Гаусс (1809 г.) и Пьер-Симон Лаплас (1812 г.) вывели математические функции.
Лаплас также обнаружил замечательную закономерность и сформулировал центральную предельную теорему (ЦПТ), согласно которой сумма большого количества малых и независимых величин имеет нормальное распределение.
Нормальный закон не является фиксированным уравнением зависимости одной переменной от другой. Фиксируется только характер этой зависимости. Конкретная форма распределения задается специальными параметрами. Например, у = аx + b – это уравнение прямой. Однако где конкретно она проходит и под каким наклоном, определяется параметрами а и b. Также и с нормальным распределением. Ясно, что это функция, которая описывает тенденцию высокой концентрации значений около центра, но ее точная форма задается специальными параметрами.
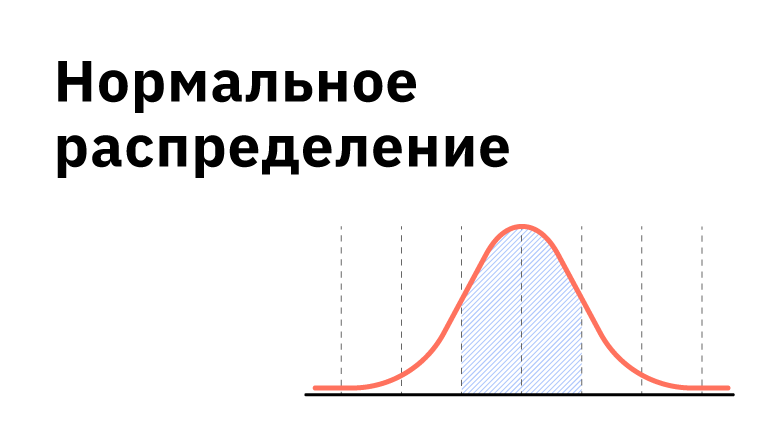
Кривая нормального распределения Гаусса имеет следующий вид.

График нормального распределения напоминает колокол, поэтому можно встретить название колоколообразная кривая. У графика имеется «горб» в середине и резкое снижение плотности по краям. В этом заключается суть нормального распределения. Вероятность того, что случайная величина окажется около центра гораздо выше, чем то, что она сильно отклонится от середины.

На рисунке выше изображены два участка под кривой Гаусса: синий и зеленый. Основания, т.е. интервалы, у обоих участков равны. Но заметно отличаются высоты. Синий участок удален от центра, и имеет существенно меньшую высоту, чем зеленый, который находится в самом центре распределения. Следовательно, отличаются и площади, то бишь вероятности попадания в обозначенные интервалы.
Формула нормального распределения (плотности) следующая.
![]()
Формула состоит из двух математических констант:
π – число пи 3,142;
е – основание натурального логарифма 2,718;
двух изменяемых параметров, которые задают форму конкретной кривой:
m – математическое ожидание (в различных источниках могут использоваться другие обозначения, например, µ или a);
σ2 – дисперсия;
ну и сама переменная x, для которой высчитывается плотность вероятности.
Конкретная форма нормального распределения зависит от 2-х параметров: математического ожидания (m) и дисперсии (σ2). Кратко обозначается N(m, σ2) или N(m, σ). Параметр m (матожидание) определяет центр распределения, которому соответствует максимальная высота графика. Дисперсия σ2 характеризует размах вариации, то есть «размазанность» данных.
Параметр математического ожидания смещает центр распределения вправо или влево, не влияя на саму форму кривой плотности.

А вот дисперсия определяет остроконечность кривой. Когда данные имеют малый разброс, то вся их масса концентрируется у центра. Если же у данных большой разброс, то они «размазываются» по широкому диапазону.

Плотность распределения не имеет прямого практического применения. Для расчета вероятностей нужно проинтегрировать функцию плотности.
Вероятность того, что случайная величина окажется меньше некоторого значения x, определяется функцией нормального распределения:
![]()
Используя математические свойства любого непрерывного распределения, несложно рассчитать и любые другие вероятности, так как
P(a ≤ X < b) = Ф(b) – Ф(a)
Стандартное нормальное распределение
Нормальное распределение зависит от параметров средней и дисперсии, из-за чего плохо видны его свойства. Хорошо бы иметь некоторый эталон распределения, не зависящий от масштаба данных. И он существует. Называется стандартным нормальным распределением. На самом деле это обычное нормальное нормальное распределение, только с параметрами математического ожидания 0, а дисперсией – 1, кратко записывается N(0, 1).
Любое нормальное распределение легко превращается в стандартное путем нормирования:
![]()
где z – новая переменная, которая используется вместо x;
m – математическое ожидание;
σ – стандартное отклонение.
Для выборочных данных берутся оценки:
![]()
Среднее арифметическое и дисперсия новой переменной z теперь также равны 0 и 1 соответственно. В этом легко убедиться с помощью элементарных алгебраических преобразований.
В литературе встречается название z-оценка. Это оно самое – нормированные данные. Z-оценку можно напрямую сравнивать с теоретическими вероятностями, т.к. ее масштаб совпадает с эталоном.
Посмотрим теперь, как выглядит плотность стандартного нормального распределения (для z-оценок). Напомню, что функция Гаусса имеет вид:
![]()
Подставим вместо (x-m)/σ букву z, а вместо σ – единицу, получим функцию плотности стандартного нормального распределения:
![]()
График плотности:

Центр, как и ожидалось, находится в точке 0. В этой же точке функция Гаусса достигает своего максимума, что соответствует принятию случайной величиной своего среднего значения (т.е. x-m=0). Плотность в этой точке равна 0,3989, что можно посчитать даже в уме, т.к. e0=1 и остается рассчитать только соотношение 1 на корень из 2 пи.
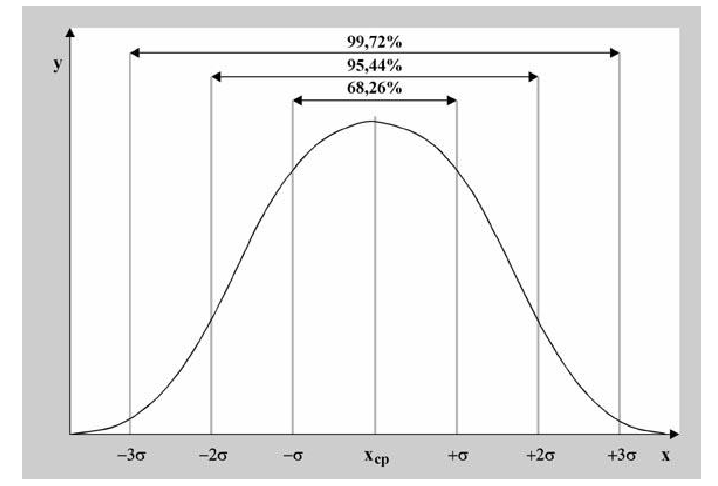
Таким образом, по графику хорошо видно, что значения, имеющие маленькие отклонения от средней, выпадают чаще других, а те, которые сильно отдалены от центра, встречаются значительно реже. Шкала оси абсцисс измеряется в стандартных отклонениях, что позволяет отвязаться от единиц измерения и получить универсальную структуру нормального распределения. Кривая Гаусса для нормированных данных отлично демонстрирует и другие свойства нормального распределения. Например, что оно является симметричным относительно оси ординат. В пределах ±1σ от средней арифметической сконцентрирована большая часть всех значений (прикидываем пока на глазок). В пределах ±2σ находятся большинство данных. В пределах ±3σ находятся почти все данные. Последнее свойство широко известно под названием правило трех сигм для нормального распределения.
Функция стандартного нормального распределения позволяет рассчитывать вероятности.
![]()
Понятное дело, вручную никто не считает. Все подсчитано и размещено в специальных таблицах, которые есть в конце любого учебника по статистике.
Таблица нормального распределения
Таблицы нормального распределения встречаются двух типов:
— таблица плотности;
— таблица функции (интеграла от плотности).
Таблица плотности используется редко. Тем не менее, посмотрим, как она выглядит. Допустим, нужно получить плотность для z = 1, т.е. плотность значения, отстоящего от матожидания на 1 сигму. Ниже показан кусок таблицы.

В зависимости от организации данных ищем нужное значение по названию столбца и строки. В нашем примере берем строку 1,0 и столбец 0, т.к. сотых долей нет. Искомое значение равно 0,2420 (0 перед 2420 опущен).
Функция Гаусса симметрична относительно оси ординат. Поэтому φ(z)= φ(-z), т.е. плотность для 1 тождественна плотности для -1, что отчетливо видно на рисунке.

Чтобы не тратить зря бумагу, таблицы печатают только для положительных значений.
На практике чаще используют значения функции стандартного нормального распределения, то есть вероятности для различных z.
В таких таблицах также содержатся только положительные значения. Поэтому для понимания и нахождения любых нужных вероятностей следует знать свойства стандартного нормального распределения.
Функция Ф(z) симметрична относительно своего значения 0,5 (а не оси ординат, как плотность). Отсюда справедливо равенство:
![]()
Это факт показан на картинке:

Значения функции Ф(-z) и Ф(z) делят график на 3 части. Причем верхняя и нижняя части равны (обозначены галочками). Для того, чтобы дополнить вероятность Ф(z) до 1, достаточно добавить недостающую величину Ф(-z). Получится равенство, указанное чуть выше.
Если нужно отыскать вероятность попадания в интервал (0; z), то есть вероятность отклонения от нуля в положительную сторону до некоторого количества стандартных отклонений, достаточно от значения функции стандартного нормального распределения отнять 0,5:
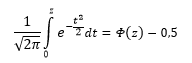
Для наглядности можно взглянуть на рисунок.

На кривой Гаусса, эта же ситуация выглядит как площадь от центра вправо до z.

Довольно часто аналитика интересует вероятность отклонения в обе стороны от нуля. А так как функция симметрична относительно центра, предыдущую формулу нужно умножить на 2:

Рисунок ниже.

Под кривой Гаусса это центральная часть, ограниченная выбранным значением –z слева и z справа.

Указанные свойства следует принять во внимание, т.к. табличные значения редко соответствуют интересующему интервалу.
Для облегчения задачи в учебниках обычно публикуют таблицы для функции вида:

Если нужна вероятность отклонения в обе стороны от нуля, то, как мы только что убедились, табличное значение для данной функции просто умножается на 2.
Теперь посмотрим на конкретные примеры. Ниже показана таблица стандартного нормального распределения. Найдем табличные значения для трех z: 1,64, 1,96 и 3.

Как понять смысл этих чисел? Начнем с z=1,64, для которого табличное значение составляет 0,4495. Проще всего пояснить смысл на рисунке.

То есть вероятность того, что стандартизованная нормально распределенная случайная величина попадет в интервал от 0 до 1,64, равна 0,4495. При решении задач обычно нужно рассчитать вероятность отклонения в обе стороны, поэтому умножим величину 0,4495 на 2 и получим примерно 0,9. Занимаемая площадь под кривой Гаусса показана ниже.

Таким образом, 90% всех нормально распределенных значений попадает в интервал ±1,64σ от средней арифметической. Я не случайно выбрал значение z=1,64, т.к. окрестность вокруг средней арифметической, занимающая 90% всей площади, иногда используется для проверки статистических гипотез и расчета доверительных интервалов. Если проверяемое значение не попадает в обозначенную область, то его наступление маловероятно (всего 10%).
Для проверки гипотез, однако, чаще используется интервал, накрывающий 95% всех значений. Половина вероятности от 0,95 – это 0,4750 (см. второе выделенное в таблице значение).

Для этой вероятности z=1,96. Т.е. в пределах почти ±2σ от средней находится 95% значений. Только 5% выпадают за эти пределы.

Еще одно интересное и часто используемое табличное значение соответствует z=3, оно равно по нашей таблице 0,4986. Умножим на 2 и получим 0,997. Значит, в рамках ±3σ от средней арифметической заключены почти все значения.

Так выглядит правило 3 сигм для нормального распределения на диаграмме.
С помощью статистических таблиц можно получить любую вероятность. Однако этот метод очень медленный, неудобный и сильно устарел. Сегодня все делается на компьютере. Далее переходим к практике расчетов в Excel.
В Excel есть несколько функций для подсчета вероятностей или обратных значений нормального распределения.

Функция НОРМ.СТ.РАСП
Функция НОРМ.СТ.РАСП предназначена для расчета плотности ϕ(z) или вероятности Φ(z) по нормированным данным (z).
=НОРМ.СТ.РАСП(z;интегральная)
z – значение стандартизованной переменной
интегральная – если 0, то рассчитывается плотность ϕ(z), если 1 – значение функции Ф(z), т.е. вероятность P(Z<z).
Рассчитаем плотность и значение функции для различных z: -3, -2, -1, 0, 1, 2, 3 (их укажем в ячейке А2).
Для расчета плотности потребуется формула =НОРМ.СТ.РАСП(A2;0). На диаграмме ниже – это красная точка.
Для расчета значения функции =НОРМ.СТ.РАСП(A2;1). На диаграмме – закрашенная площадь под нормальной кривой.

В реальности чаще приходится рассчитывать вероятность того, что случайная величина не выйдет за некоторые пределы от средней (в среднеквадратичных отклонениях, соответствующих переменной z), т.е. P(|Z|<z).

Определим, чему равна вероятность попадания случайной величины в пределы ±1z, ±2z и ±3z от нуля. Потребуется формула 2Ф(z)-1, в Excel =2*НОРМ.СТ.РАСП(A2;1)-1.

На диаграмме отлично видны основные основные свойства нормального распределения, включая правило трех сигм. Функция НОРМ.СТ.РАСП – это автоматическая таблица значений функции нормального распределения в Excel.
Может стоять и обратная задача: по имеющейся вероятности P(Z<z) найти стандартизованную величину z ,то есть квантиль стандартного нормального распределения.
Функция НОРМ.СТ.ОБР
НОРМ.СТ.ОБР рассчитывает обратное значение функции стандартного нормального распределения. Синтаксис состоит из одного параметра:
=НОРМ.СТ.ОБР(вероятность)
вероятность – это вероятность.
Данная формула используется так же часто, как и предыдущая, ведь по тем же таблицам искать приходится не только вероятности, но и квантили.

Например, при расчете доверительных интервалов задается доверительная вероятность, по которой нужно рассчитать величину z.

Учитывая то, что доверительный интервал состоит из верхней и нижней границы и то, что нормальное распределение симметрично относительно нуля, достаточно получить верхнюю границу (положительное отклонение). Нижняя граница берется с отрицательным знаком. Обозначим доверительную вероятность как γ (гамма), тогда верхняя граница доверительного интервала рассчитывается по следующей формуле.
![]()
Рассчитаем в Excel значения z (что соответствует отклонению от средней в сигмах) для нескольких вероятностей, включая те, которые наизусть знает любой статистик: 90%, 95% и 99%. В ячейке B2 укажем формулу: =НОРМ.СТ.ОБР((1+A2)/2). Меняя значение переменной (вероятности в ячейке А2) получим различные границы интервалов.

Доверительный интервал для 95% равен 1,96, то есть почти 2 среднеквадратичных отклонения. Отсюда легко даже в уме оценить возможный разброс нормальной случайной величины. В общем, доверительным вероятностям 90%, 95% и 99% соответствуют доверительные интервалы ±1,64, ±1,96 и ±2,58 σ.
В целом функции НОРМ.СТ.РАСП и НОРМ.СТ.ОБР позволяют произвести любой расчет, связанный с нормальным распределением. Но, чтобы облегчить и уменьшить количество действий, в Excel есть несколько других функций. Например, для расчета доверительных интервалов средней можно использовать ДОВЕРИТ.НОРМ. Для проверки статистической гипотезы о средней арифметической есть формула Z.ТЕСТ.
Рассмотрим еще пару полезных формул с примерами.
Функция НОРМ.РАСП
Функция НОРМ.РАСП отличается от НОРМ.СТ.РАСП лишь тем, что ее используют для обработки данных любого масштаба, а не только нормированных. Параметры нормального распределения указываются в синтаксисе.
=НОРМ.РАСП(x;среднее;стандартное_откл;интегральная)
x – значение (или ссылка на ячейку), для которого рассчитывается плотность или значение функции нормального распределения
среднее – математическое ожидание, используемое в качестве первого параметра модели нормального распределения
стандартное_откл – среднеквадратичное отклонение – второй параметр модели
интегральная – если 0, то рассчитывается плотность, если 1 – то значение функции, т.е. P(X<x).
Например, плотность для значения 15, которое извлекли из нормальной выборки с матожиданием 10, стандартным отклонением 3, рассчитывается так:

Если последний параметр поставить 1, то получим вероятность того, что нормальная случайная величина окажется меньше 15 при заданных параметрах распределения. Таким образом, вероятности можно рассчитывать напрямую по исходным данным.
Функция НОРМ.ОБР
Это квантиль нормального распределения, т.е. значение обратной функции. Синтаксис следующий.
=НОРМ.ОБР(вероятность;среднее;стандартное_откл)
вероятность – вероятность
среднее – матожидание
стандартное_откл – среднеквадратичное отклонение
Назначение то же, что и у НОРМ.СТ.ОБР, только функция работает с данными любого масштаба.
Пример показан в ролике в конце статьи.
Моделирование нормального распределения
Для некоторых задач требуется генерация нормальных случайных чисел. Готовой функции для этого нет. Однако В Excel есть две функции, которые возвращают случайные числа: СЛУЧМЕЖДУ и СЛЧИС. Первая выдает случайные равномерно распределенные целые числа в указанных пределах. Вторая функция генерирует равномерно распределенные случайные числа между 0 и 1. Чтобы сделать искусственную выборку с любым заданным распределением, нужна функция СЛЧИС.
Допустим, для проведения эксперимента необходимо получить выборку из нормально распределенной генеральной совокупности с матожиданием 10 и стандартным отклонением 3. Для одного случайного значения напишем формулу в Excel.
=НОРМ.ОБР(СЛЧИС();10;3)
Протянем ее на необходимое количество ячеек и нормальная выборка готова.
Для моделирования стандартизованных данных следует воспользоваться НОРМ.СТ.ОБР.
Процесс преобразования равномерных чисел в нормальные можно показать на следующей диаграмме. От равномерных вероятностей, которые генерируются формулой СЛЧИС, проведены горизонтальные линии до графика функции нормального распределения. Затем от точек пересечения вероятностей с графиком опущены проекции на горизонтальную ось.

На выходе получаются значения с характерной концентрацией около центра. Вот так обратный прогон через функцию нормального распределения превращает равномерные числа в нормальные. Excel позволяет за несколько секунд воспроизвести любое количество выборок любого размера.
Как обычно, прилагаю ролик, где все вышеописанное показывается в действии.
Скачать файл с примером.
Поделиться в социальных сетях:
Содержание:
- Примеры с решением
- Нормальное распределение и его числовые характеристики
- Логарифмически-нормальное распределение
Нормальное распределение является наиболее распространенным типом распределения, предполагаемым в техническом анализе фондового рынка и в других видах статистического анализа. Стандартное нормальное распределение имеет два параметра: среднее значение и стандартное отклонение . Для нормального распределения 68% наблюдений находятся в пределах +/- одно стандартное отклонение от среднего значения, 95% находятся в пределах +/- два стандартных отклонения, а 99,7% находятся в пределах + — три стандартных отклонения.

Определение:
Общим нормальным распределением вероя тностей непрерывной случайной величины  называется распределение с плотностью
называется распределение с плотностью 
Нормальное распределение задается двумя параметрами:  и
и  .
.

По определениям математического ожидания и дисперсии после выполнения соответствующих интегрирований можно вывести, что для нормального распределения справедливы формулы: 
По этой ссылке вы найдёте полный курс лекций по высшей математике:
Определение:
Нормальное распределение с параметрами  и
и  называется нормированным; его плотность
называется нормированным; его плотность 
Поскольку функция является четной, неопределенный интеграл от нее — нечетная функция, и потому вместо функции распределения используется функция Лапласа  Функции табулированы Графики плотности нормального распределения для разных значений
Функции табулированы Графики плотности нормального распределения для разных значений  показаны на рис. 2.6.
показаны на рис. 2.6. 
Пусть случайная величина X задана плотностью нормального распределения ; тогда вероятность того, что  примет значение на интервале
примет значение на интервале  согласно формулам равна:
согласно формулам равна:  Преобразование этой формулы путем введения новой переменной интегрирования
Преобразование этой формулы путем введения новой переменной интегрирования  приводит к удобной вычислительной формуле
приводит к удобной вычислительной формуле  где
где  — функция Лапласа, определенная по формуле.
— функция Лапласа, определенная по формуле.
Возможно вам будут полезны данные страницы:
Модель нормального распределения мотивирована центральной предельной теоремой.
Теория утверждает, что средние значения, рассчитанные из независимых идентично распределенных случайных величин, имеют приблизительно нормальные распределения, независимо от типа распределения, из которого выбираются переменные (при условии, что они имеют конечную дисперсию). Нормальное распределение иногда путают с симметричным распределением. Симметричное распределение — это то, где разделительная линия создает два зеркальных изображения, но фактические данные могут быть двумя горбами или серией холмов в дополнение к кривой колокола, которая указывает на нормальное распределение.

Примеры с решением
Пример 1.
Случайная величина распределена по нормальному закону с математическим ожиданием и средним квадратическим отклонением, соответственно равными 10 и 5. Найти вероятность того, что  примет значение на интервале (20, 30).
примет значение на интервале (20, 30).
Решение:
Воспользуемся формулой . По условию 
 Следовательно,
Следовательно,  По табл. 2 приложения находим соответствующие значения функции Лапласа и окончательно получаем:
По табл. 2 приложения находим соответствующие значения функции Лапласа и окончательно получаем: 
Пример 2.
Магазин продает мужские костюмы. По данным статистики, распределение по размерам является нормальным с математическим ожиданием и средним квадратическим отклонением, соответственно равным 48 и 2. Определить процент спроса на костюмы 50-го размера при условии разброса значений этого размера в интервале (49, 51).
Решение:
По условию задачи  Используя формулу (2.66), получаем, что вероятность спроса на костюмы 50-го размера в заданном интервале равна:
Используя формулу (2.66), получаем, что вероятность спроса на костюмы 50-го размера в заданном интервале равна: 
Следовательно, спрос на костюмы 50-го размера составит около 24%, и магазину нужно предусмотреть это в общем объеме закупки.
Нормальное распределение и его числовые характеристики
ДСВ — дискретная случайная величина
НСВ — непрерывная случайная величина.
В этом подразделе мы создадим функцию распределения для каждого типа НСВ и создадим график, выясним числовые свойства этого типа НСВ и узнаем тип НСВ в реальных ситуациях из содержания задачи. вы будете учиться. Наиболее распространенным в природе, экономике, социологии и других науках является нормальное распределение непрерывных случайных величин.
Используя нормальное распределение, вы можете описать плотность вероятности НСВ, когда появляются отклонения от среднего случайного значения из-за различных явлений, действующих независимо друг от друга, но в одинаковой степени.
Чем больше случайных случайных величин добавлено, тем точнее результат. Все эти явления не зависят друг от друга, но, воздействуя на процесс изготовления примерно с одинаковой силой, обусловливают то, что закон, по которому изменяется НСВ (например, размер конкретной детали), описывается нормальным распределением.
Самое точное изготовление детали с заданными размерами — «эталон» — будет соответствовать математическому ожиданию т, разброс фактических значений случайной величины размера детали — понятию дисперсии (точнее — среднеквадратическому отклонению  ). Случайная величина с нормальным распределением существует в интервале
). Случайная величина с нормальным распределением существует в интервале  и описывается законами: плотности вероятности
и описывается законами: плотности вероятности  называемой «кривой Гаусса» (рис. 2.9, а)
называемой «кривой Гаусса» (рис. 2.9, а)  где
где  и
и  — параметры нормального распределения, причем
— параметры нормального распределения, причем  функции распределения
функции распределения  (рис. 2.9, б):
(рис. 2.9, б):

Рис. 2.9

Подстановкой  интеграл приводится к виду
интеграл приводится к виду 
Поэтому для удобства вводится нечетная функция 
 называемая функцией Лапласа. Функцию Лапласа называют также «интегралом вероятности», или «функцией ошибок». Очевидно, что
называемая функцией Лапласа. Функцию Лапласа называют также «интегралом вероятности», или «функцией ошибок». Очевидно, что 
Математическое ожидание  случайной величины
случайной величины  распределенной нормааьно, равно
распределенной нормааьно, равно  дисперсия равна
дисперсия равна  поэтому параметр
поэтому параметр  — среднеквадратическое отклонение.
— среднеквадратическое отклонение.
Случайную величину распределенную нормально с параметрами
распределенную нормально с параметрами  и
и  обозначают
обозначают  На практике для вычисления значений функции Лапласа используются таблицы, которые приводятся в справочной литературе (табл. П. 3). Вероятность попадания в интервал
На практике для вычисления значений функции Лапласа используются таблицы, которые приводятся в справочной литературе (табл. П. 3). Вероятность попадания в интервал  НСВ, распределенной по нормальному закону, можно найти с помощью функции Лапласа
НСВ, распределенной по нормальному закону, можно найти с помощью функции Лапласа  по формуле
по формуле 
Величины параметров нормального распределения СВ  непосредственно влияют на форму кривой
непосредственно влияют на форму кривой  при
при  она принимает максимальное значение, равное
она принимает максимальное значение, равное  Поэтому с увесил личением (уменьшением)
Поэтому с увесил личением (уменьшением)  максимальная ордината убывает (возрастает) и кривая становится более пологой, приближаясь к оси
максимальная ордината убывает (возрастает) и кривая становится более пологой, приближаясь к оси 
Величина математического ожидания  влияет на расположение кривой
влияет на расположение кривой относительно оси ординат: при возрастании (убывании)
относительно оси ординат: при возрастании (убывании)  кривая смещается вправо (влево). Поэтому с помощью подстановки
кривая смещается вправо (влево). Поэтому с помощью подстановки  можно получить функцию
можно получить функцию  плотности вероятности, график которой симметричен относительно оси
плотности вероятности, график которой симметричен относительно оси  Такая кривая соответствует нормированному закону нормального распределения с параметрами
Такая кривая соответствует нормированному закону нормального распределения с параметрами  и
и  Величину
Величину  называют стандартно нормальной. Ее функция распределения имеет вид
называют стандартно нормальной. Ее функция распределения имеет вид 
Логарифмически-нормальное распределение
Определение. Непрерывная случайная величина  имеет логарифмически-нормальное (сокращенно логнормальное распределение), если ее логарифм подчинен нормальному закону. Так как при
имеет логарифмически-нормальное (сокращенно логнормальное распределение), если ее логарифм подчинен нормальному закону. Так как при  неравенства
неравенства  равносильны, то функция распределения логнормального распределения совпадает с функцией нормального распределения для случайной величины
равносильны, то функция распределения логнормального распределения совпадает с функцией нормального распределения для случайной величины  т.е. в соответствии с
т.е. в соответствии с 
Дифференцируя по  получим выражение плотности вероятности для логнормального распределения
получим выражение плотности вероятности для логнормального распределения 

(рис. 4.14).
Можно доказать, что числовые характеристики случайной величины  распределенной по логнормальному закону, имеют вид: математическое ожидание
распределенной по логнормальному закону, имеют вид: математическое ожидание  дисперсия
дисперсия  мода
мода  медиана
медиана  Очевидно, чем меньше
Очевидно, чем меньше  тем ближе друг к другу значения моды, медианы и математического ожидания, а кривая распределения — ближе к симметрии.
тем ближе друг к другу значения моды, медианы и математического ожидания, а кривая распределения — ближе к симметрии.
Если в нормальном законе параметр а выступает в качестве среднего значения случайной величины, то в логнормальном — в качестве медианы. Логнормальное распределение используется для описания распределения доходов, банковских вкладов, цен активов, месячной заработной платы, посевных площадей под разные культуры, долговечности изделий в режиме износа и старения и др.
Нормальное распределение, также известное как распределение Гаусса, является распределением вероятностей , симметричным относительно среднего значения, показывающим, что данные около среднего значения встречаются чаще, чем данные, далекие от среднего значения.
Пример 3.
Проведенное исследование показало, что вклады населения в данном банке могут быть описаны случайной величиной  распределенной по логнормальному закону с параметрами
распределенной по логнормальному закону с параметрами  Найти: а) средний размер вклада; б) долю вкладчиков, размер вклада которых составляет не менее 1000 ден. ед.; в) моду и медиану случайной величины
Найти: а) средний размер вклада; б) долю вкладчиков, размер вклада которых составляет не менее 1000 ден. ед.; в) моду и медиану случайной величины  и пояснить их смысл.
и пояснить их смысл.
Решение:
а) Найдем средний размер вклада, т.е. 
б) Доля вкладчиков, размер вклада которых составляет не менее 1000 ден. ед., есть 
При определении  воспользуемся тем, что функция логнормального распределения случайной величины
воспользуемся тем, что функция логнормального распределения случайной величины  совпадает с функцией нормального распределения случайной величины
совпадает с функцией нормального распределения случайной величины  т.е. с учетом имеем:
т.е. с учетом имеем:

Теперь 
(рис. 4.15). 
в) Вычислим моду случайной величины 
 т.е. наиболее часто встречающийся банковский вклад равен 280 ден. ед. (точнее, наиболее часто встречающийся элементарный интервал с центром 280 ден. ед., т.е. интервал (
т.е. наиболее часто встречающийся банковский вклад равен 280 ден. ед. (точнее, наиболее часто встречающийся элементарный интервал с центром 280 ден. ед., т.е. интервал ( Если исходить из вероятностного смысла параметра
Если исходить из вероятностного смысла параметра  логнормального распределения, то медиана
логнормального распределения, то медиана  т.е. половина вкладчиков имеют вклады до 530 ден. ед., а другая половина — сверх 530 ден. ед.
т.е. половина вкладчиков имеют вклады до 530 ден. ед., а другая половина — сверх 530 ден. ед.


Лекции:
- Площадь поверхности цилиндра
- Найти определитель матрицы
- Как привести к общему знаменателю
- Геометрическое распределение
- Замечательные пределы примеры решения
- Формула Муавра
- Интерполяция кусочно-полиномиальными функциями
- Дисперсия случайной величины
- Уравнение прямой
- Найдите координаты точки пересечения прямых
Содержание:
Нормальный закон распределения:
Нормальный закон распределения имеет плотность вероятности
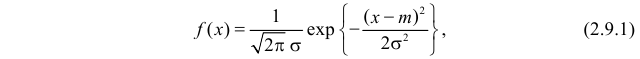
где 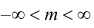
График функции плотности вероятности (2.9.1) имеет максимум в точке 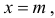 а точки перегиба отстоят от точки
а точки перегиба отстоят от точки 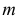 на расстояние
на расстояние 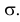 При
При 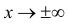 функция (2.9.1) асимптотически приближается к нулю (ее график изображен на рис. 2.9.1).
функция (2.9.1) асимптотически приближается к нулю (ее график изображен на рис. 2.9.1).
Помимо геометрического смысла, параметры нормального закона распределения имеют и вероятностный смысл. Параметр равен математическому ожиданию нормально распределенной случайной величины, а дисперсия  Если
Если 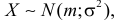 т.е. X имеет нормальный закон распределения с параметрами и
т.е. X имеет нормальный закон распределения с параметрами и 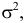 то
то 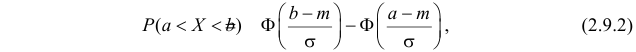
где 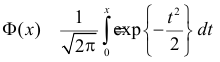 – функция Лапласа
– функция Лапласа
Значения функции 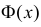 можно найти по таблице (см. прил., табл. П2). Функция Лапласа нечетна, т.е.
можно найти по таблице (см. прил., табл. П2). Функция Лапласа нечетна, т.е. 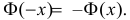 Поэтому ее таблица дана только для неотрицательных
Поэтому ее таблица дана только для неотрицательных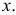 График функции Лапласа изображен на рис. 2.9.2. При значениях
График функции Лапласа изображен на рис. 2.9.2. При значениях 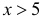 она практически остается постоянной. Поэтому в таблице даны значения функции только для
она практически остается постоянной. Поэтому в таблице даны значения функции только для 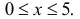 При значениях можно считать, что
При значениях можно считать, что 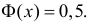
Если  то
то
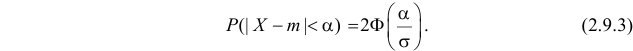
Пример:
Случайная величина X имеет нормальный закон распределения 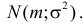 Известно, что
Известно, что 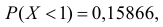 а
а 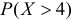
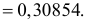 Найти значения параметров
Найти значения параметров 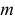 и
и 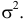
Решение. Воспользуемся формулой (2.9.2): 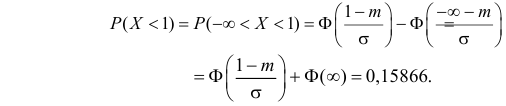
Так как 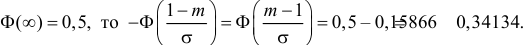 По таблице функции Лапласа (см. прил., табл. П2) находим, что
По таблице функции Лапласа (см. прил., табл. П2) находим, что 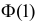
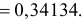 Поэтому
Поэтому 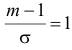 или
или 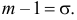
Аналогично 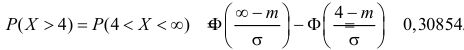 Так как
Так как 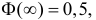 то
то 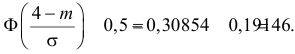 По таблице функции Лапласа (см. прил., табл. П2) находим, что
По таблице функции Лапласа (см. прил., табл. П2) находим, что 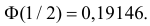 Поэтому
Поэтому 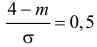 или
или 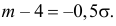 Из системы двух уравнений
Из системы двух уравнений 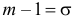 и
и 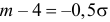 находим, что
находим, что 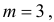 а
а 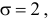 т.е.
т.е. 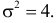 Итак, случайная величина X имеет нормальный закон распределения N(3;4).
Итак, случайная величина X имеет нормальный закон распределения N(3;4).
График функции плотности вероятности этого закона распределения изображен на рис. 2.9.3.
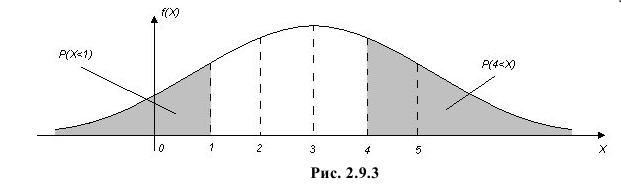
Ответ. 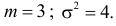
Пример:
Ошибка измерения X имеет нормальный закон распределения, причем систематическая ошибка равна 1 мк, а дисперсия ошибки равна 4 мк2. Какова вероятность того, что в трех независимых измерениях ошибка ни разу не превзойдет по модулю 2 мк?
Решение. По условиям задачи 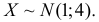 Вычислим сначала вероятность того, что в одном измерении ошибка не превзойдет 2 мк. По формуле (2.9.2)
Вычислим сначала вероятность того, что в одном измерении ошибка не превзойдет 2 мк. По формуле (2.9.2)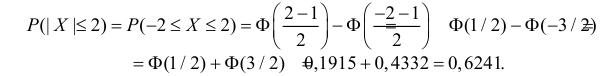
Вычисленная вероятность численно равна заштрихованной площади на рис. 2.9.4.
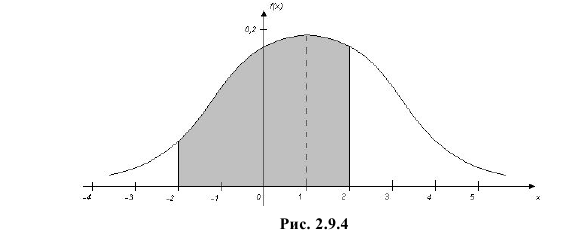
Каждое измерение можно рассматривать как независимый опыт. Поэтому по формуле Бернулли (2.6.1) вероятность того, что в трех независимых измерениях ошибка ни разу не превзойдет 2 мк, равна 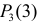
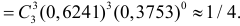
Ответ. 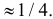
Пример:
Функция плотности вероятности случайной величины X имеет вид 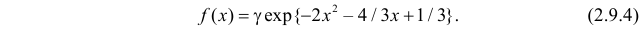
Требуется определить коэффициент 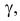 найти
найти 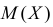 и
и 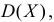 определить тип закона распределения, нарисовать график функции
определить тип закона распределения, нарисовать график функции 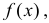 вычислить вероятность
вычислить вероятность 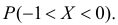
Замечание. Если каждый закон распределения из некоторого семейства законов распределения имеет функцию распределения , 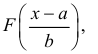 где
где 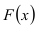 – фиксированная функция распределения, a
– фиксированная функция распределения, a 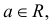
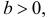 то говорят, что эти законы распределения принадлежат к одному виду или типу распределений. Параметр
то говорят, что эти законы распределения принадлежат к одному виду или типу распределений. Параметр 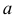 называют параметром сдвига,
называют параметром сдвига, 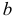 – параметром масштаба.
– параметром масштаба.
Решение. Так как (2.9.4) функция плотности вероятности, то интеграл от нее по всей числовой оси должен быть равен единице: 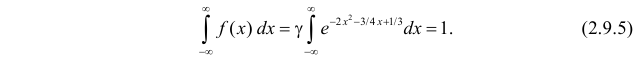
Преобразуем выражение в показателе степени, выделяя полный квадрат: 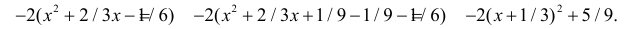
Тогда (2.9.5) можно записать в виде 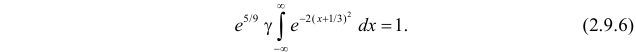
Сделаем замену переменных так, чтобы 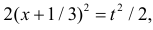 т.е.
т.е. 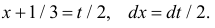 Пределы интегрирования при этом останутся прежними. Тогда (2.9.6) преобразуется к виду
Пределы интегрирования при этом останутся прежними. Тогда (2.9.6) преобразуется к виду

Умножим и разделим левую часть равенства на  Получим равенство
Получим равенство 
Так как  как интеграл по всей числовой оси от функции плотности вероятности стандартного нормального закона распределения N(0,1), то приходим к выводу, что
как интеграл по всей числовой оси от функции плотности вероятности стандартного нормального закона распределения N(0,1), то приходим к выводу, что

Поэтому
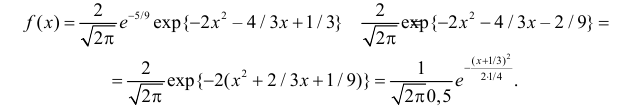
Последняя запись означает, что случайная величина имеет нормальный закон распределения с параметрами 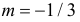 и
и 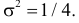 График функции плотности вероятности этого закона изображен на рис. 2.9.5. Распределение случайной величины X принадлежит к семейству нормальных законов распределения. По формуле (2.9.2)
График функции плотности вероятности этого закона изображен на рис. 2.9.5. Распределение случайной величины X принадлежит к семейству нормальных законов распределения. По формуле (2.9.2)
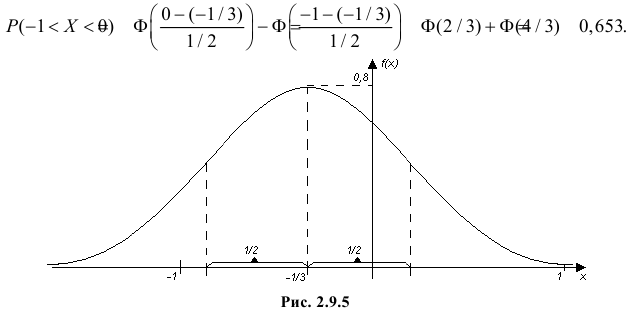
Ответ. 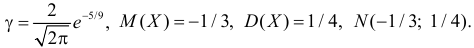
Пример:
Цех на заводе выпускает транзисторы с емкостью коллекторного перехода 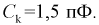 Сколько транзисторов попадет в группу
Сколько транзисторов попадет в группу 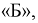 если в нее попадают транзисторы с емкостью коллекторного перехода от 1,80 до 2,00 пФ. Цех выпустил партию в 1000 штук.
если в нее попадают транзисторы с емкостью коллекторного перехода от 1,80 до 2,00 пФ. Цех выпустил партию в 1000 штук.
Решение.
Статистическими исследованиями в цеху установлено, что 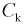 можно трактовать как случайную величину, подчиняющуюся нормальному закону.
можно трактовать как случайную величину, подчиняющуюся нормальному закону.
Чтобы вычислить количество транзисторов, попадающих в группу необходимо учитывать, что вся партия транзисторов имеет разброс параметров, накрывающий всю (условно говоря) числовую ось. То есть кривая Гаусса охватывает всю числовую ось, центр ее совпадает с 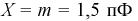 (т. к. все установки в цеху настроены на выпуск транзисторов именно с этой емкостью). Вероятность попадания отклонений параметров всех транзисторов на всю числовую ось равна 1. Поэтому нам необходимо фактически определить вероятность попадания случайной величины
(т. к. все установки в цеху настроены на выпуск транзисторов именно с этой емкостью). Вероятность попадания отклонений параметров всех транзисторов на всю числовую ось равна 1. Поэтому нам необходимо фактически определить вероятность попадания случайной величины 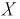 в интервал
в интервал 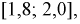 а затем пересчитать количество пропорциональной вероятности.
а затем пересчитать количество пропорциональной вероятности.
Для расчета этой вероятности надо построить математическую модель. Экспериментальные данные говорят о том, что нормальное распределение можно принять в качестве математической модели. Эмпирическая оценка (установлена статистическими исследованиями в цеху) среднего значения 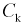
дает 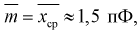 оценка среднего квадратического отклонения
оценка среднего квадратического отклонения 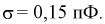
Обозначая 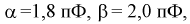 подставим приведенные значения в (6.3):
подставим приведенные значения в (6.3):
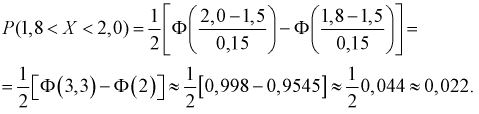
Тогда количество транзисторов 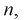 попавших в интервал [1,8; 2,0] пФ, можно найти так:
попавших в интервал [1,8; 2,0] пФ, можно найти так:  Таким образом можно планировать и рассчитывать количество транзисторов, попадающих в ту или иную группу.
Таким образом можно планировать и рассчитывать количество транзисторов, попадающих в ту или иную группу.
Нормальное распределение и его свойства
Если выйти на улицу любого города и случайным образом выбранных прохожих спросить о том, какой у них рост, вес, возраст, доход, и т.п., а потом построить график любой из этих величин, например, роста… Но не будем спешить, сначала посмотрим, как можно построить такой график.
Сначала, мы просто запишем результаты своего исследования. Потом, мы отсортируем всех людей по группам, так чтобы каждый попал в свой диапазон роста, например, «от 180 до 181 включительно».
После этого мы должны посчитать количество людей в каждой подгруппе-диапазоне, это будет частота попадания роста жителей города в данный диапазон. Обычно эту часть удобно оформить в виде таблички. Если затем эти частоты построить по оси у, а диапазоны отложить по оси х, можно получить так называемую гистограмму, упорядоченный набор столбиков, ширина которых равна, в данном случае, одному сантиметру, а длина будет равна той частоте, которая соответствует каждому диапазону роста. Если
Вам попалось достаточно много жителей, то Ваша схема будет выглядеть примерно так:
Дальше можно уточнить задачу. Каждый диапазон разбить на десять, жителей рассортировать по росту с точностью до миллиметра. Диаграмма станет глаже, но уменьшится по высоте, «оплывет» вниз, т.к. в каждом маленьком диапазоне количество жителей уменьшается. Чтобы избежать этого, просто увеличим масштаб по вертикальной оси в 10 раз. Если гипотетически повторить эту процедуру несколько раз, будет вырисовываться та знаменитая колоколообразная фигура, которая характерна для нормального (или Гауссова) распределения. В результате, относительная частота встречаемости каждого конкретного диапазона роста может быть посчитана как отношение площади «ломтика» кривой, приходящегося на этот диапазон к площади подо всей кривой. Стандартизированные кривые нормального распределения, значения функций которых приводятся в таблицах книг по статистике, всегда имеют суммарную площадь под кривой равную единице. Это связано с тем, что, как Вы помните из курса теории вероятности, вероятность достоверного события всегда равна 100% (или единице), а для любого человека иметь хоть какое-то значение роста — достоверное событие. А вот вероятность того, что рост произвольного человека попадет в определенный выбранный нами диапазон, будет зависеть от трех факторов.
Во-первых, от величины такого диапазона — чем точнее наши требования, тем меньше вероятности, что нам повезет.
Во-вторых, от того, насколько «популярен» выбранный нами рост. Напомним, что мода — самое часто встречающееся значение роста. Кстати для нормального распределения мода, медиана и среднее значение совпадают. Кривая нормального распределения симметрична относительно среднего значения.
И, в-третьих, вероятность попадания роста в определенный диапазон зависит от характеристики рассеивания случайной величины. Отчасти это связано с единицами измерения (представьте, что мы бы измеряли людей в дюймах, а не в миллиметрах, но сами люди и их рост были бы теми же). Но дело не только в этом. Просто некоторые процессы кучнее группируются возле среднего значения, в то время как другие более разбросаны.
Например, рост собак и рост домашних кошек имеют разный разброс значений, их кривые нормального распределения будут выглядеть по-разному (напомним еще раз, что площадь под обеими кривыми будет единичной).
Так, кривая для роста кошек будет более узкой и высокой, а для роста собак кривая будет ниже и шире. Для характеристики разброса конечного ряда данных в прошлом разделе мы использовали величину среднего квадратического отклонения. Аналогичная величина используется для характеристики кривой нормального распределения. Она обозначается буквой s и называется в этом случае стандартным отклонением. Это очень важная величина для кривой нормального распределения. Кривая нормального распределения полностью задана, если известно среднее значение 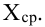 и отклонение s. Кроме того, любой житель города с вероятностью 68% попадет в диапазон роста
и отклонение s. Кроме того, любой житель города с вероятностью 68% попадет в диапазон роста 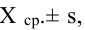 с вероятностью 95% — в диапазон
с вероятностью 95% — в диапазон 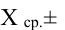
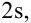 и с вероятностью 99,7% — в диапазон
и с вероятностью 99,7% — в диапазон 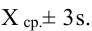
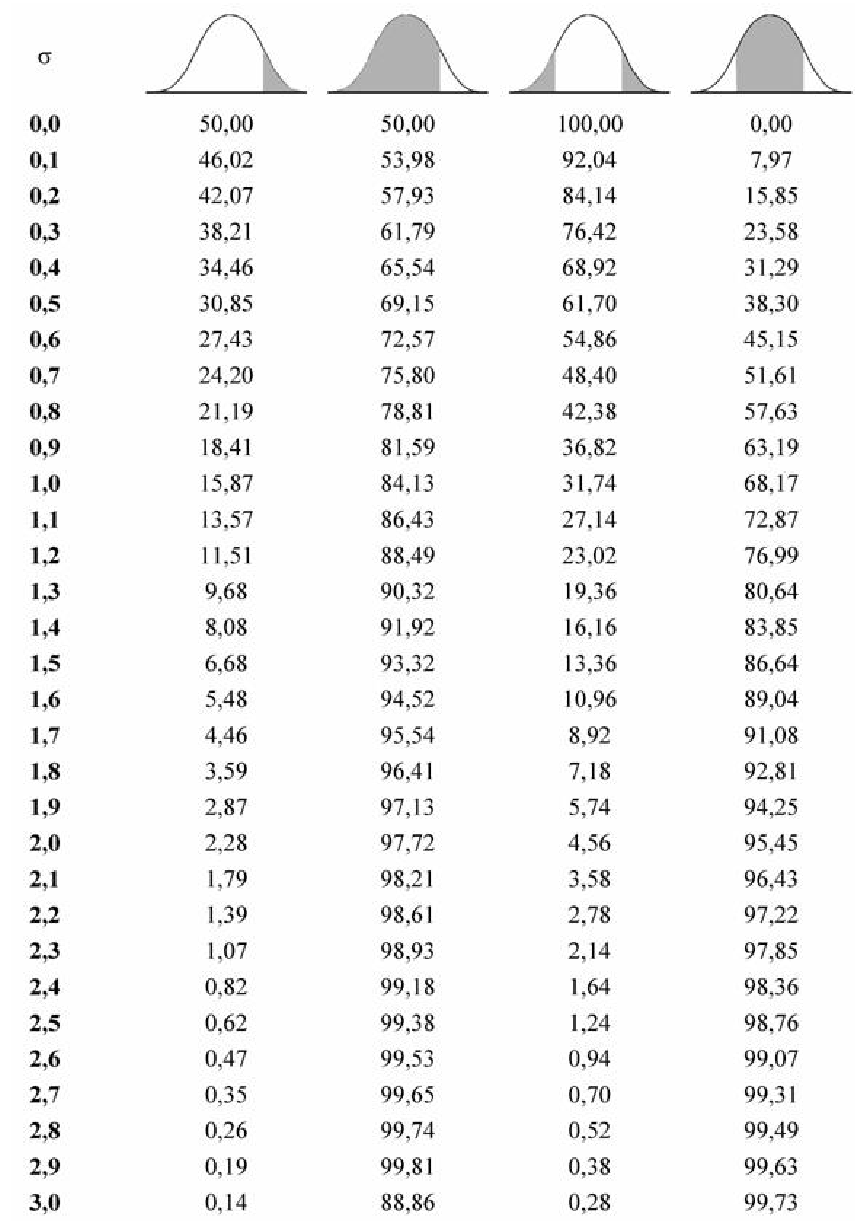
Для вычисления других значений вероятности, которые могут Вам понадобиться, можно воспользоваться приведенной таблицей:
Таблица вероятности попадания случайной величины в отмеченный (заштрихованный) диапазон
Нормальный закон распределения
Нормальный закон распределения случайных величин, который иногда называют законом Гаусса или законом ошибок, занимает особое положение в теории вероятностей, так как 95 % изученных случайных величин подчиняются этому закону. Природа этих случайных величин такова, что их значение в проводимом эксперименте связано с проявлением огромного числа взаимно независимых случайных факторов, действие каждого из которых составляет малую долю их совокупного действия. Например, длина детали, изготавливаемой на станке с программным управлением, зависит от случайных колебаний резца в момент отрезания, от веса и толщины детали, ее формы и температуры, а также от других случайных факторов. По нормальному закону распределения изменяются рост и вес мужчин и женщин, дальность выстрела из орудия, ошибки различных измерений и другие случайные величины.
Определение: Случайная величина X называется нормальной, если она подчиняется нормальному закону распределения, т.е. ее плотность распределения задается формулой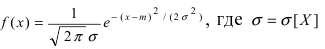 — средне-квадратичное отклонение, a m = М[Х] — математическое ожидание.
— средне-квадратичное отклонение, a m = М[Х] — математическое ожидание.
Приведенная дифференциальная функция распределения удовлетворяет всем свойствам плотности вероятности, проверим, например, свойство 4.:
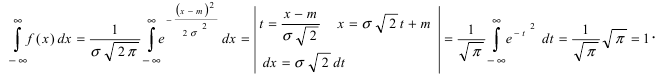
Выясним геометрический смысл параметров  Зафиксируем параметр
Зафиксируем параметр 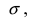 и будем изменять параметр m. Построим графики соответствующих кривых (Рис. 8).
и будем изменять параметр m. Построим графики соответствующих кривых (Рис. 8). 
Рис. 8. Изменение графика плотности вероятности в зависимости от изменения математического ожидания при фиксированном значении средне-квадратичного отклонения. Из рисунка видно, кривая 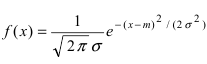 получается путем смещения кривой
получается путем смещения кривой 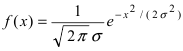 вдоль оси абсцисс на величину m, поэтому параметр m определяет центр тяжести данного распределения. Кроме того, из рисунка видно, что функция
вдоль оси абсцисс на величину m, поэтому параметр m определяет центр тяжести данного распределения. Кроме того, из рисунка видно, что функция 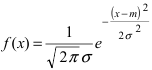 достигает своего максимального значения в точке
достигает своего максимального значения в точке 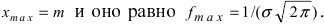 Из этой формулы видно, что при уменьшении параметра
Из этой формулы видно, что при уменьшении параметра 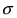 значение максимума возрастает. Так как площадь под кривой плотности распределения всегда равна 1, то с уменьшением параметра
значение максимума возрастает. Так как площадь под кривой плотности распределения всегда равна 1, то с уменьшением параметра 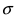 кривая вытягивается вдоль оси ординат, а с увеличением параметра
кривая вытягивается вдоль оси ординат, а с увеличением параметра  кривая прижимается к оси абсцисс. Построим график нормальной плотности распределения при m = 0 и разных значениях параметра
кривая прижимается к оси абсцисс. Построим график нормальной плотности распределения при m = 0 и разных значениях параметра  (Рис. 9):
(Рис. 9): 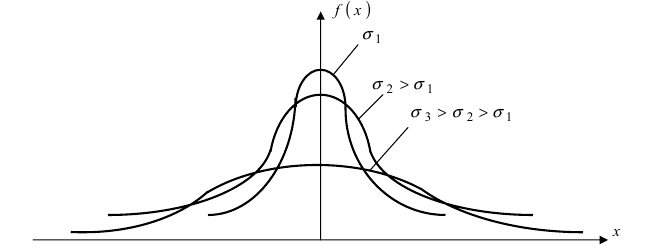
Рис. 9. Изменение графика плотности вероятности в зависимости от изменения средне-квадратичного отклонения при фиксированном значении математического ожидания.
Интегральная функция нормального распределения имеет вид: 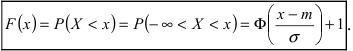
График функции распределения имеет вид (Рис. 10): 
Рис. 10. Графика интегральной функции распределения нормальной случайной величины.
Вероятность попадания нормальной случайной величины в заданный интервал
Пусть требуется определить вероятность того, что нормальная случайная величина попадает в интервал 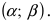 Согласно определению
Согласно определению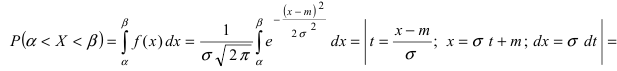 пересчитаем пределы интегрирования
пересчитаем пределы интегрирования 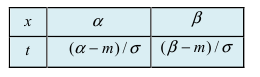
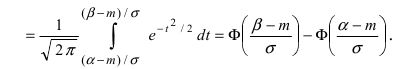 Следовательно,
Следовательно,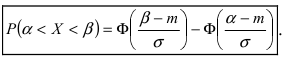
Рассмотрим основные свойства функции Лапласа Ф(х):
- Ф(0) = 0 — график функции Лапласа проходит через начало координат.
- Ф (-х) = — Ф(х) — функция Лапласа является нечетной функцией, поэтому
- таблицы для функции Лапласа приведены только для неотрицательных значений аргумента.
 — график функции Лапласа имеет горизонтальные асимптоты
— график функции Лапласа имеет горизонтальные асимптоты
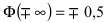 — график функции Лапласа имеет горизонтальные асимптоты
— график функции Лапласа имеет горизонтальные асимптоты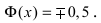
Следовательно, график функции Лапласа имеет вид (Рис. 11): 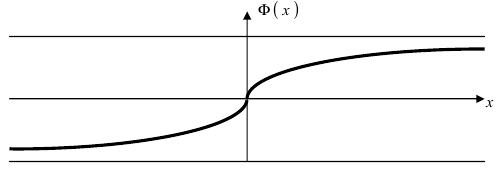
Рис. 11. График функции Лапласа.
Пример №1
Закон распределения нормальной случайной величины X имеет вид: 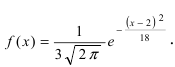 Определить вероятность попадания случайной величины X в интервал (-1;8).
Определить вероятность попадания случайной величины X в интервал (-1;8).
Решение:
Согласно условиям задачи 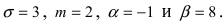 Поэтому искомая вероятность равна:
Поэтому искомая вероятность равна: 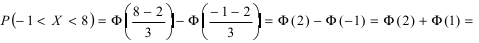 0,4772 + 0,3413 = 0,8185.
0,4772 + 0,3413 = 0,8185.
Вычисление вероятности заданного отклонения
Вычисление вероятности заданного отклонения. Правило 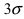 .
.
Если интервал, в который попадает нормальная случайная величина X, симметричен относительно математического ожидания 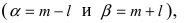 то, используя свойство нечетности функции Лапласа, получим
то, используя свойство нечетности функции Лапласа, получим
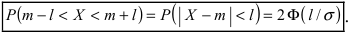
Данная формула показывает, что отклонение случайной величины Х от ее математического ожидания на заданную величину l равна удвоенному значению функции Лапласа от отношения / к среднему квадратичному отклонению. Если положить 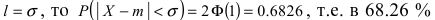 случаях нормальная случайная величина X отличается от своего математического ожидания на величину равную среднему квадратичному отклонению. Если
случаях нормальная случайная величина X отличается от своего математического ожидания на величину равную среднему квадратичному отклонению. Если 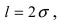 то вероятность отклонения равна
то вероятность отклонения равна 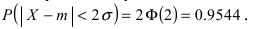 Наконец, в случае
Наконец, в случае 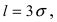 то вероятность отклонения равна
то вероятность отклонения равна 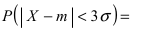
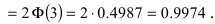 Из последнего равенства видно, что только приблизительно в 0.3 % случаях отклонение нормальной случайной величины X от своего математического ожидания превышает
Из последнего равенства видно, что только приблизительно в 0.3 % случаях отклонение нормальной случайной величины X от своего математического ожидания превышает 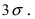 Это свойство нормальной случайной величины X называется правилом “трех сигм”. На практике это правило применяется следующим образом: если отклонение случайной величины X от своего математического ожидания не превышает
Это свойство нормальной случайной величины X называется правилом “трех сигм”. На практике это правило применяется следующим образом: если отклонение случайной величины X от своего математического ожидания не превышает 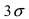 то эта случайная величина распределена по нормальному закону.
то эта случайная величина распределена по нормальному закону.
Показательный закон распределения
Определение: Закон распределения, определяемый фу нкцией распределения:
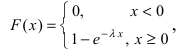 называется экспоненциальным или показательным.
называется экспоненциальным или показательным.
График экспоненциального закона распределения имеет вид (Рис. 12): 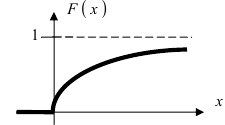
Рис. 12. График функции распределения для случая экспоненциального закона.
Дифференциальная функция распределения (плотность вероятности) имеет вид: 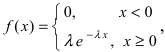 а ее график показан на (Рис. 13):
а ее график показан на (Рис. 13): 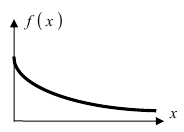
Рис. 13. График плотности вероятности для случая экспоненциального закона.
Пример №2
Случайная величина X подчиняется дифференциальной функции распределения 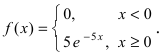 Найти вероятность того, что случайная величина X попадет в интервал (2; 4), математическое ожидание M[Х], дисперсию D[X] и среднее квадратичное отклонение
Найти вероятность того, что случайная величина X попадет в интервал (2; 4), математическое ожидание M[Х], дисперсию D[X] и среднее квадратичное отклонение 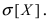 Проверить выполнение правила “трех сигм” для показательного распределения.
Проверить выполнение правила “трех сигм” для показательного распределения.
Решение:
Интегральная функция распределения 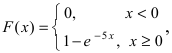 следовательно, вероятность того, что случайная величина X попадет в интервал (2; 4), равна:
следовательно, вероятность того, что случайная величина X попадет в интервал (2; 4), равна: 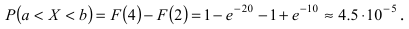 Математическое ожидание
Математическое ожидание 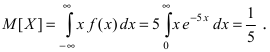 Вычислим значение величины М
Вычислим значение величины М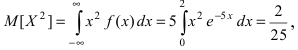 тогда дисперсия случайной величины X равна
тогда дисперсия случайной величины X равна 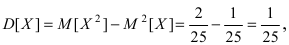 а средне-квадратичное
а средне-квадратичное
отклонение 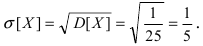 Для проверки правила “трех сигм” вычислим вероятность заданного отклонения:
Для проверки правила “трех сигм” вычислим вероятность заданного отклонения:
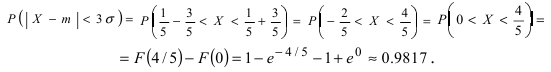
- Основные законы распределения вероятностей
- Асимптотика схемы независимых испытаний
- Функции случайных величин
- Центральная предельная теорема
- Повторные независимые испытания
- Простейший (пуассоновский) поток событий
- Случайные величины
- Числовые характеристики случайных величин
Нормальный закон распределения и его параметры:
Нормальный закон распределения (часто называемый законом Гаусса) играет исключительно важную роль в теории вероятностей и занимает среди других законов распределения особое положение. Это — наиболее часто встречающийся на практике закон распределения. Главная особенность, выделяющая нормальный закон среди других законов, состоит в том, что он является предельным законом, к которому приближаются другие законы распределения при весьма часто встречающихся типичных условиях.
Можно доказать, что сумма достаточно большого числа независимых (или слабо зависимых) случайных величин, подчиненных каким угодно законам распределения (при соблюдении некоторых весьма нежестких ограничений), приближенно подчиняется нормальному закону, и это выполняется тем точнее, чем большее количество случайных величин суммируется. Большинство встречающихся на практике случайных величин, таких, например, как ошибки измерений, ошибки стрельбы и т. д., могут быть представлены как суммы весьма большого числа сравнительно малых слагаемых — элементарных ошибок, каждая из которых вызвана действием отдельной причины, не зависящей от остальных. Каким бы законам распределения ни были подчинены отдельные элементарные ошибки, особенности этих распределений в сумме большого числа слагаемых нивелируются, и сумма оказывается подчиненной закону, близкому к нормальному. Основное ограничение, налагаемое на суммируемые ошибки, состоит в том, чтобы они все равномерно играли в общей сумме относительно малую роль. Если это условие не выполняется и, например, одна из случайных ошибок окажется по своему влиянию на сумму резко превалирующей над всеми другими, то закон распределения этой превалирующей ошибки наложит свое влияние на сумму и определит в основных чертах ее закон распределения.
Теоремы, устанавливающие нормальный закон как предельный для суммы независимых равномерно малых случайных слагаемых, будут подробнее рассмотрены в главе 13.
Нормальный закон распределения характеризуется плотностью вероятности вида:
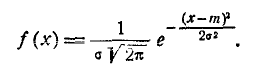 (6.1.1)
(6.1.1)
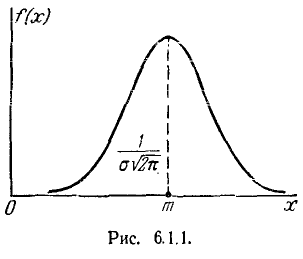
Кривая распределения по нормальному закону имеет симметричный холмообразный вид (рис. 6.1.1). Максимальная ордината кривой, равная 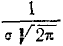 , соответствует точке х = m по мере удаления от точки m плотность распределения падает, и при
, соответствует точке х = m по мере удаления от точки m плотность распределения падает, и при  кривая асимптотически приближается к оси абсцисс.
кривая асимптотически приближается к оси абсцисс.
Выясним смысл численных параметров т и о, входящих в выражение нормального закона (5.1.1); докажем, что величина m есть не что иное, как математическое ожидание, а величина 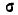 — среднее квадратическое отклонение величины X. Для этого вычислим основные числовые характеристики величины X — математическое ожидание и дисперсию.
— среднее квадратическое отклонение величины X. Для этого вычислим основные числовые характеристики величины X — математическое ожидание и дисперсию.
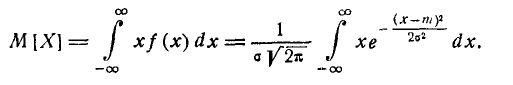
Применяя замену переменной
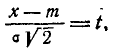
имеем:
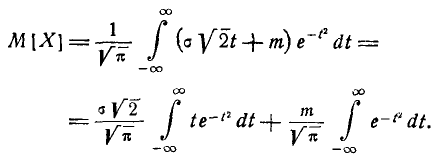 (6.1.2)
(6.1.2)
Нетрудно убедиться, что первый из двух интервалов в формуле (5.1.2) равен нулю; второй представляет собой известный интеграл Эйлера — Пуассона:
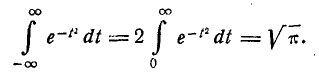 (6.1.3)
(6.1.3)
Следовательно, М[Х] = m
т. е. параметр m представляет собой математическое ожидание вели- величины X. Этот параметр, особенно в задачах стрельбы, часто называют центром рассеивания (сокращенно — ц. р.). Вычислим дисперсию величины X:
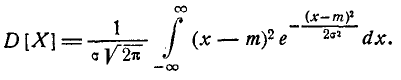
Применив снова замену переменной
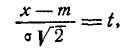
имеем:
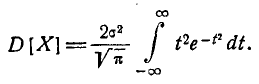
Интегрируя по частям, получим:
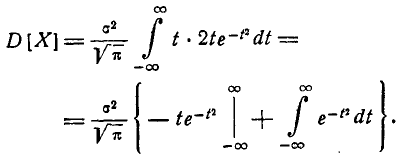
Первое слагаемое в фигурных скобках равно нулю (так как 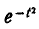 При
При 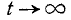 убывает быстрее, чем возрастает любая степень f), второе слагаемое по формуле 5.1.3) равно
убывает быстрее, чем возрастает любая степень f), второе слагаемое по формуле 5.1.3) равно 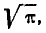 откуда
откуда 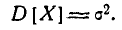
Следовательно, параметр о в формуле 5.1.1) есть не что иное, как среднее квадратическое отклонение величины X.
Выясним смысл параметров m и 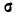 нормального распределения. Непосредственно из формулы 5.1.1) видно, что центром симметрии распределения является центр рассеивания m. Это ясно из того, что при изменении знака разности (х — m) на обратный выражение 5.1.1) не меняется. Если изменять центр рассеивания т. кривая распределения будет смещаться вдоль оси абсцисс, не изменяя своей формы (рис. 6.1.2). Центр рассеивания характеризует положение распределения на оси абсцисс.
нормального распределения. Непосредственно из формулы 5.1.1) видно, что центром симметрии распределения является центр рассеивания m. Это ясно из того, что при изменении знака разности (х — m) на обратный выражение 5.1.1) не меняется. Если изменять центр рассеивания т. кривая распределения будет смещаться вдоль оси абсцисс, не изменяя своей формы (рис. 6.1.2). Центр рассеивания характеризует положение распределения на оси абсцисс.
Размерность центра рассеивания—та же, что размерность случайной величины X.
Параметр о характеризует не положение, а самую форму кривой распределения. Это есть характеристика рассеивания. Наибольшая ордината кривой распределения обратно пропорциональна ; при увеличении максимальная ордината уменьшается. Так как площадь
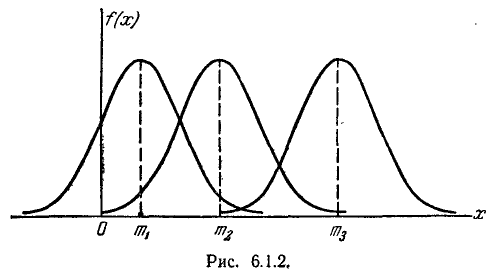
кривой распределения всегда должна оставаться равной единице, то при увеличении о кривая распределения становится более плоской, растягиваясь вдоль оси абсцисс; напротив, при уменьшении кривая распределения вытягивается вверх, одновременно сжимаясь с боков, и становится более иглообразной. На рис. 6.1.3 показаны три нормальные кривые (/, //, ///) при m=0; из них кривая l соответствует 
самому большому, а кривая /// — самому малому значению . Изменение параметра равносильно изменению масштаба кривой распределения— увеличению масштаба по одной оси и такому же уменьшению по другой.
Размерность параметра , естественно, совпадает с раpмерноcтью случайной величины X.
В некоторых курсах теории вероятностей в качестве характеристики рассеивания для нормального закона вместо среднего квадратического отклонения применяется так называемая мера точности. Мерой точности называется величина, обратно пропорциональная среднему квадратическому отклонению : 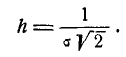
Размерность меры точности обратна размерности случайной величины.
Термин «мера точности» заимствован из теории ошибок измерений: чем точнее измерение, тем больше мера точности. Пользуясь мерой точности h, можно записать нормальный закон в виде: 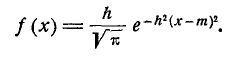
Моменты нормального распределения
Выше мы доказали, что математическое ожидание случайной вели- величины, подчиненной нормальному закону 6.1.1), равно m, а среднее квадратическое отклонение равно .
Выведем общие формулы для центральных моментов любого порядка.
По определению:
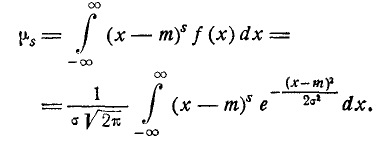
Делая замену переменной
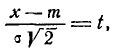
получим:
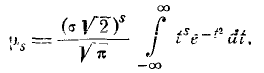 (6.2.1)
(6.2.1)
Применим к выражению (6.2.1) формулу интегрирования по частям: 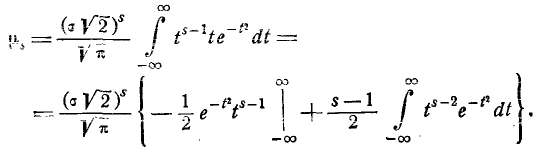
Имея в виду, что первый член внутри скобок равен нулю, получим: 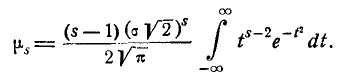 (6.2.2)
(6.2.2)
Из формулы (6.2.1) имеем следующее выражение для 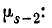
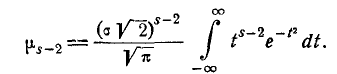 (6.2.3)
(6.2.3)
Сравнивая правые части формул (6.2.2) и (6.2.3), видим, что они отличаются между собой только множителем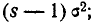 следовательно,
следовательно,
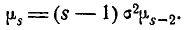 (6.2.4)
(6.2.4)
Формула (6.2.4) представляет собой простое рекуррентное соотношение, позволяющее выражать моменты высших порядков через моменты низших порядков. Пользуясь этой формулой и имея в виду, что 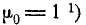 и
и  можно вычислить центральные моменты всех порядков. Так как то из формулы (6.2.4) следует, что все нечетные моменты нормального распределения равны нулю. Это, впрочем, непосредственно следует из симметричности нормального закона.
можно вычислить центральные моменты всех порядков. Так как то из формулы (6.2.4) следует, что все нечетные моменты нормального распределения равны нулю. Это, впрочем, непосредственно следует из симметричности нормального закона.
Для четных s из формулы (6.2.4) вытекают следующие выражения для последовательных моментов:
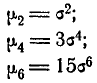
и т. д. Общая формула для момента s-гo порядка при любом четном s имеет вид:
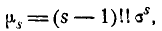
где под символам (s—1)!! понимается произведение всех нечетных чисел от 1 до s— 1. Так как для нормального закона  то асимметрия его также равна нулю:
то асимметрия его также равна нулю:
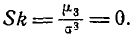
Из выражения четвертого момента
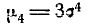
имеем:
‘) Нулевой момент любой случайной величины равен единице как математическое ожидание нулевой степени этой величины.
т. е. эксцесс нормального распределения равен нулю. Это и естественно, так как назначение эксцесса — характеризовать сравнительную крутость данного закона по сравнению с нормальным.
Вероятность попадания случайной величины, подчиненной нормальному закону, на заданный участок. Нормальная функция распределения
Во многих задачах, связанных с нормально распределенными случайными величинами, приходится определять вероятность попадания случайной величины X, подчиненной нормальному закону с параметрами m, , на участок от а до  Для вычисления этой вероятности воспользуемся общей формулой
Для вычисления этой вероятности воспользуемся общей формулой
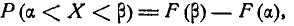 (6.3.1)
(6.3.1)
где F (х)— функция распределения величины X.
Найдем функцию распределения F(x) случайной величины X, распределенной по нормальному закону с параметрами m, . Плот- Плотность распределения величины X равна:
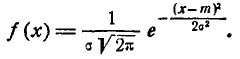 (6.3.2)
(6.3.2)
Отсюда находим функцию распределения
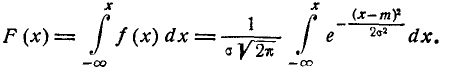 (6.3.3)
(6.3.3)
Сделаем в интеграле (6.3.3) замену переменной
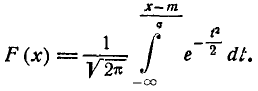 (6.3.4)
(6.3.4)
и приведем его к виду:
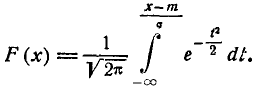 (6.3.4)
(6.3.4)
Интеграл (6.3.4) не выражается через элементарные функции, но его можно вычислить через специальную функцию, выражающую определенный интеграл от выражения 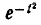 или
или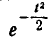 (так называемый интеграл вероятностей), для которого составлены таблицы. Существует много разновидностей таких функций, например:
(так называемый интеграл вероятностей), для которого составлены таблицы. Существует много разновидностей таких функций, например:
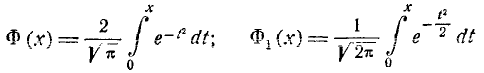
и т. д. Какой из этих функций пользоваться — вопрос вкуса. Мы выберем в качестве такой функции
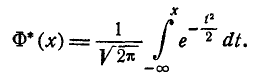 (6.3.5)
(6.3.5)
Нетрудно видеть, что эта функция представляет собой не что иное, как функцию распределения для нормально распределенной случайной величины с параметрами от m = 0, =1.
Условимся называть функцию Ф*(х) нормальной функцией распределения. В приложении (табл. 1) приведены таблицы значений функции Ф*(х)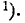
Выразим функцию распределения (6.3.3) величины X с пара- параметрами m и через нормальную функцию распределения Ф*(х). Очевидно,
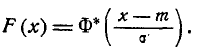 (6.3.6)
(6.3.6)
Теперь найдем вероятность попадания случайной величины X на участок от а до Согласно формуле (6.3.1)
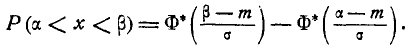 (6.3.7)
(6.3.7)
Таким образом, мы выразили вероятность попадания на участок случайной величины X, распределенной по нормальному закону с любыми параметрами, через стандартную функцию распределения Ф* (х), соответствующую простейшему нормальному . закону с параметрами 0,1. Заметим, что аргументы функции Ф* в фор- формуле (6.3.7) имеют очень простой смысл: 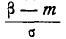 есть расстояние от правого конца участка
есть расстояние от правого конца участка  до центра рассеивания, выраженное в средних квадратических отклонениях;
до центра рассеивания, выраженное в средних квадратических отклонениях; 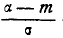 — такое же расстояние для левого конца участка, причем это расстояние считается положительным, если конец расположен справа от центра рассеивания , и отрицательным, если слева.
— такое же расстояние для левого конца участка, причем это расстояние считается положительным, если конец расположен справа от центра рассеивания , и отрицательным, если слева.
Как и всякая функция распределения,, функция Ф*(х) обладает свойствами:
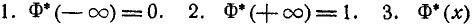 -неубывающая функция
-неубывающая функция
Кроме того, из симметричности нормального распределения с параметрами m = 0, =1 относительно начала координат следует, что
ф* (— х)=1— Ф* (х). (6.3.8)
Для облегчения интерполяции в таблицах рядом со значениями функции приведены ее приращения за один шаг таблиц 
Пользуясь этим свойством, собственно говоря, можно было бы ограничить таблицы функции Ф(х) только положительными значениями аргумента, но, чтобы избежать лишней операции (вычитание из единицы), в таблице 1 приложения приводятся значения Ф(х) как для положительных, так и для отрицательных аргументов.
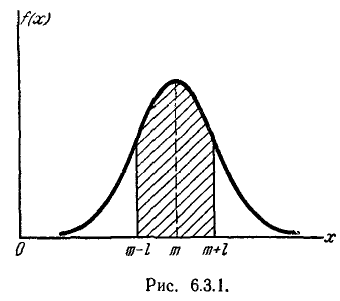
На практике часто встречается задача вычисления вероятности попадания нормально распределенной случайной величины на участок, симметричный относительно центра рассеивания m. Рассмотрим такой участок длины 2l (рис. 6.3.1). Вычислим вероятность попадания на этот участок по формуле (6.3.7): 
Учитывая свойство (6.3.8) функции Ф*(х) и придавая левой части формулы (6.3.9) более компактный вид, получим формулу для вероятности попадания случайной величины, распределенной по нормальному закону, на участок, симметричный относительно центра рассеивания:
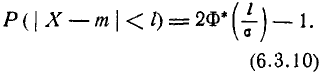
Решим следующую задачу. Отложим от центра рассеивания m последовательные отрезки длиной (рис. 6.3.2) и вычислим вероятность попадания случайной величины X в каждый из них. Так как кривая нормального закона симметрична, достаточно отложить такие отрезки только в одну сторону.
По формуле (6.3.7) находим:
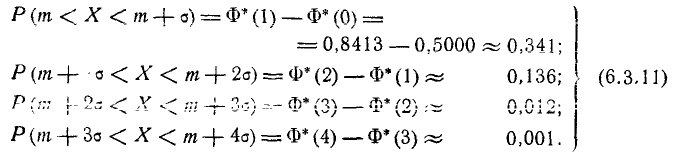
Как видно из этих данных, вероятности попадания на каждый из следующих отрезков (пятый, шестой и т. д.) с точностью до 0,001 равны нулю.
Округляя вероятности попадания в отрезки до 0,01 (до 1%). получим три числа, которые легко запомнить: 0,34; 0,14; 0,02.
Сумма этих трех значений равна 0,5. Это значит, что для нормально распределенной случайной величины все рассеивание (с точностью до долей процента) укладывается на участке m± З.
Это позволяет, зная среднее квадратическое отклонение и математическое ожидание случайной величины, ориентировочно указать интервал ее практически возможных значений. Такой способ оценки диапазона возможных значений случайной величины известен в математической статистике под названием «правило трех сигма«. Из правила трех сигма вытекает также ориентировочный способ определения среднего квадратического отклонения случайной величины: берут максимальное практически возможное отклонение от среднего и делят его на три. Разумеется, этот грубый прием может быть рекомендован, только если нет других, более точных способов определения .
Пример:
Случайная величина X, распределенная по нормальному закону, представляет собой ошибку измерения некоторого расстояния. При измерении допускается систематическая ошибка в сторону завышения на 1,2 (м) среднее квадратическое отклонение ошибки измерения равно 0,8 (м). Найти вероятность того, что отклонение измеренного значения от истинного не превзойдет по абсолютной величине 1,6 (м).
Решение:
Ошибка измерения есть случайная величина X, подчинен- подчиненная нормальному закону с параметрами m= 1,2 и = 0,8. Нужно найти вероятность попадания этой величины на участок от а =—1,6 до 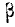 = + 1,6. По формуле (6.3.7) имеем:
= + 1,6. По формуле (6.3.7) имеем:
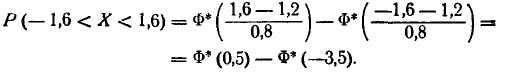
Пользуясь таблицами функции Ф* (х) (приложение, табл. 1), найдем:
Ф* (0,5) = 0,6915; Ф* (—3,5) = 0,0002,
откуда Р (—1,6 < X < 1,6) = 0,6915 — 0,0002 = 0,6913 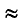 0,691.
0,691.
Пример:
Найти ту же вероятность, что в предыдущем примере, но при условии, что систематической ошибки нет.
Решение:
По формуле (6.3.10), полагая l=1.6, найдем:
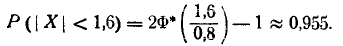
Пример:
По цели, имеющей вид полосы (автострада), ширина которой равна 20 м, ведется стрельба в направлении, перпендикулярном автостраде, прицеливание ведется по средней линии автострады. Среднее квадратическое отклонение в направлении стрельбы равно = 8 м. Имеется систематическая ошибка в направлении стрельбы: недолет 3 м. Найти вероятность попадания в автостраду при одном выстреле.
Решение:
Выберем начало координат в любой точке на средней линии автострады (рис. 6.3.3) и направим ось абсцисс перпендикулярно автостраде. Попадание или непопадание снаряда в автостраду определяется значением только одной координаты точки падения X (другая координата Y нам безразлична). Случайная величина X распределена по нормальному закону
с параметрами m = —3, = 8. Попадание снаряда в автостраду соответствует попаданию величины X на участок от а = — 10 до 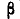 = 4-10. Применяя формулу (6.3.7), имеем:
= 4-10. Применяя формулу (6.3.7), имеем:
Пример:
Имеется случайная величина Х, нормально распределенная, с центром рассеивания m (рис. 6.3.4) и некоторый участок  оси абсцисс. Каково должно быть среднее квадратическое отклонение о случайной величины X для того, чтобы вероятность попадания р на участок достигала максимума?
оси абсцисс. Каково должно быть среднее квадратическое отклонение о случайной величины X для того, чтобы вероятность попадания р на участок достигала максимума?
Решение:
Имеем:
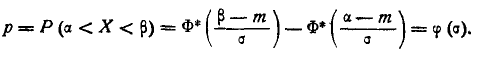
Продифференцируем эту функцию величины :
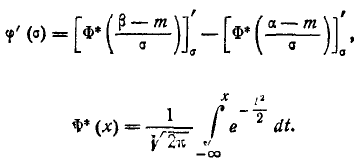
Применяя правило дифференцирования интеграла по переменной, входящей в его предел, получим:
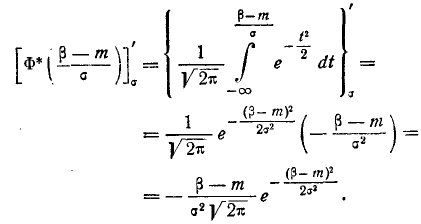
Аналогично
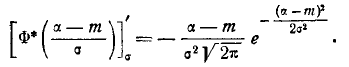
Для нахождения экстремума положим:
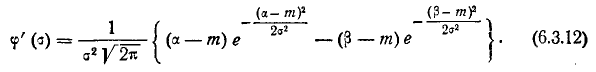
При  это выражение обращается в нуль и вероятность р достигает минимума. Максимум р получим из условия
это выражение обращается в нуль и вероятность р достигает минимума. Максимум р получим из условия 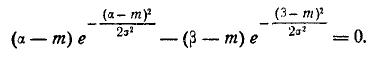 (6.3.13)
(6.3.13)
Уравнение (6.3.13) можно решить численно или графически.
6.4. Вероятное (срединное) отклонение
В ряде областей практических применений теории вероятностей (в частности, в теории стрельбы) часто, наряду со средним квадратическим отклонением, пользуются еще одной характеристикой рассеивания, так называемым вероятным, или срединным, отклонением. Вероятное отклонение обычно обозначается буквой Е (иногда В).
Вероятным (срединным) отклонением случайной величины X, распределенной по нормальному закону, называется половина длины участка, симметричного относительно центра рассеивания, вероятность попадания в который равна половине.
Геометрическая интерпретация вероятного отклонения показана на рис. 6.4.1. Вероятное отклонение Е — это половина длины участка оси абсцисс, симметричного относительно точки m, на кото- который опирается половина площади кривой распределения.
Поясним смысл термина «срединное отклонение» или «срединная ошибка», которым часто пользуются в артиллерийской практике вместо «вероятного отклонения».
Рассмотрим случайную величину X, распределенную по нормальному закону. Вероятность того, что она отклонится от центра рассеивания m меньше чем на Е, по определению вероятного отклонения Е, равна 
 (6.4.1)
(6.4.1)
Вероятность того, что она отклонится от m больше чем на Е, тоже равна
Таким образом, при большом числе опытов в среднем половина значений случайной величины X отклонится от m больше чем на Е, а половина — меньше. Отсюда и термины «срединная ошибка», «срединное отклонение».
Очевидно, вероятное отклонение, как характеристика рассеивания, должно находиться в прямой зависимости от среднего rвадратического отклонения . Установим эту зависимость. Вычислим вероятность события | X — m | < Е в уравнении (6.4.1) по формуле (6.3.10). Имеем:
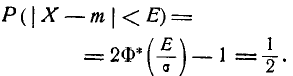
Отсюда
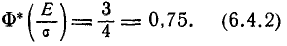
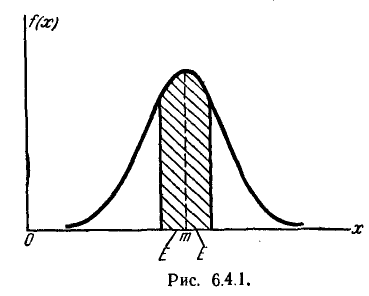
По таблицам функции Ф* (х) можно найти такое значение аргумента х, при котором она равна 0,75. Это значение аргумента приближенно равно 0,674; отсюда
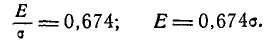 (6.4.3)
(6.4.3)
Таким образом, зная значение , можно сразу найти пропорциональное ему значение Е. Часто пользуются еще такой формой записи этой зависимости:
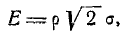 (6.4.4)
(6.4.4)
где р — такое значение аргумента, при котором одна из форм интеграла вероятностей — так называемая функция Лапласа 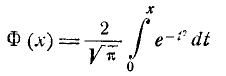
— равна половине. Численное значение величины р приближенно равно 0,477.
В настоящее время вероятное отклонение, как характеристика рассеивания, все больше вытесняется более универсальной характеристикой . В ряде областей приложений теории вероятностей она сохраняется лишь по традиции.
Если в качестве характеристики рассеивания принято вероятное отклонение Е, то плотность нормального распределения записывается в виде:
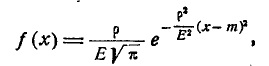 (6.4.5)
(6.4.5)
а вероятность попадания на участок от а до чаще всего записывается в виде:
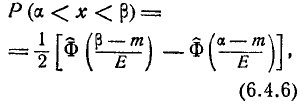
где
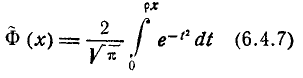 — так называемая приведенная функция Лапласа.
— так называемая приведенная функция Лапласа. 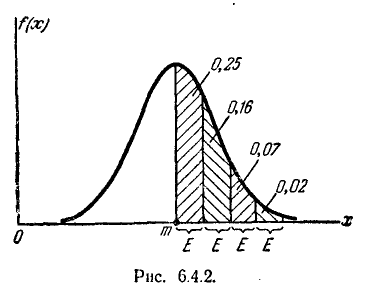
Сделаем подсчет, аналогичный выполненному в предыдущем п° для среднего квадратического отклонения : отложим от центра рассеивания т. последовательные отрезки длиной в одно вероятное отклонение Е (рис. 6.4.2) и подсчитаем вероятности попа- попадания в эти отрезки с точностью до 0,01. Получим: 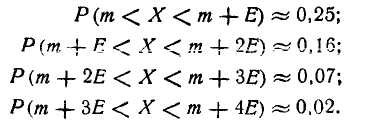
Отсюда видно, что с точностью до 0,01 все значения нормально распределенной случайной величины укладываются на участке 
Пример:
Самолет-штурмовик производит обстрел колонны войск противника, ширина которой’ равна 8 м. Полет — вдоль колонны, прицеливание— по средней линии колонны; вследствие скольжения имеется систематическая ошибка: 2 м вправо но направлению полета. Главные вероятные отклонения: по направлению полета  = 15 м, в боковом направлении
= 15 м, в боковом направлении  = 5 М. Не имея в своем распоряжении никаких таблиц интеграла вероятностей, а зная только числа:
= 5 М. Не имея в своем распоряжении никаких таблиц интеграла вероятностей, а зная только числа:
25%, 16%, 7%, 2%,
оценить грубо-приближенно вероятность попадания в колонну при одном выстреле и вероятность хотя бы одного попадания при трех независимых выстрелах.
Решение:
Для решения задачи достаточно рассмотреть одну координату точки попадания — абсциссу X в направлении, перпендикулярном колонне. Эта абсцисса распределена по нормальному закону с центром рассеивания m = 2 и вероятным отклонением 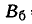 =Е = 5 (м). Отложим мысленно от центра рассеивания в ту и другую сторону отрезки длиной в 5 м. Вправо от центра рассеивания цель занимает участок 2 м, который составляет 0,4 вероятного отклонения. Вероятность попадания на этот участок приближенно равна:
=Е = 5 (м). Отложим мысленно от центра рассеивания в ту и другую сторону отрезки длиной в 5 м. Вправо от центра рассеивания цель занимает участок 2 м, который составляет 0,4 вероятного отклонения. Вероятность попадания на этот участок приближенно равна:
0,4-25% =0,1.
Влево от центра рассеивания цель занимает участок б м. Это — целое вероятное отклонение E м), вероятность попадания в которое равна 25% плюс часть длиной 1 м следующего (второго от центра) вероятного отклонения, вероятность попадания в которое равна 16%. Вероятность попадания в часть длиной 1 м приближенно равна: 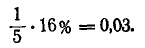
Таким образом, вероятность попадания в колонну приближенно равна:
0,1+0,25 + 0,03 = 0,38.
Вероятность хотя бы одного попадания при трех выстрелах равна: 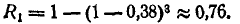
Закон нормального распределения случайных величин

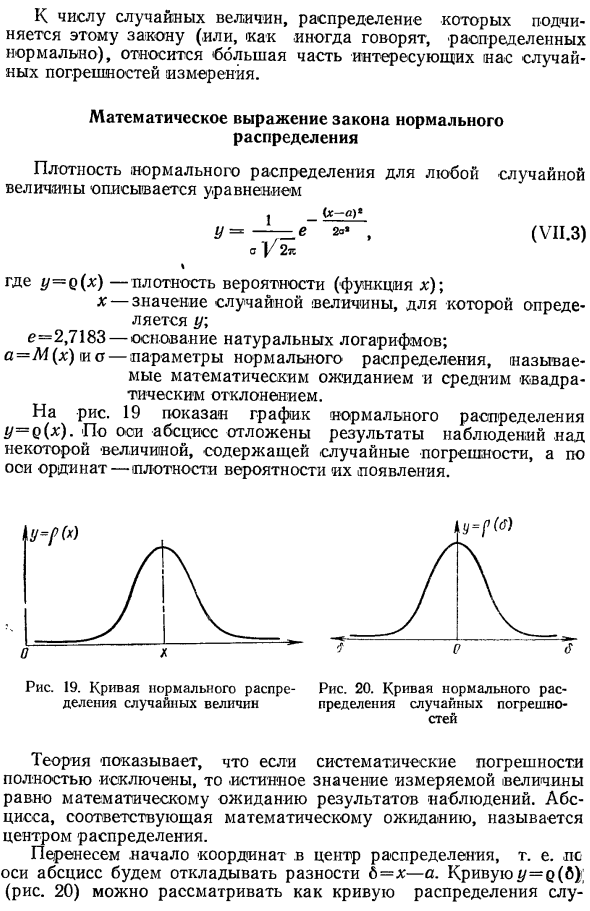


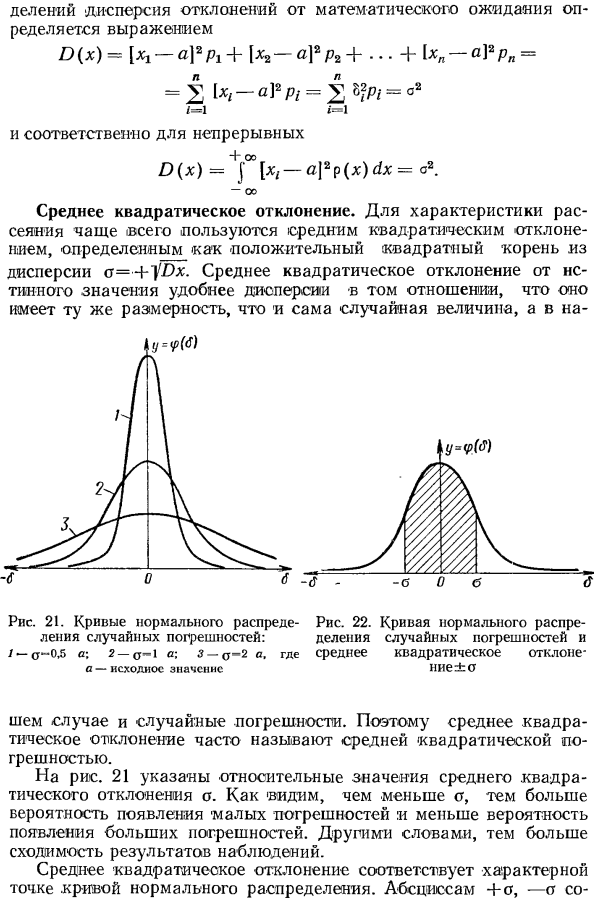

Смотрите также:
Решение заданий и задач по предметам:
- Теория вероятностей
- Математическая статистика
Дополнительные лекции по теории вероятностей:
- Случайные события и их вероятности
- Случайные величины
- Функции случайных величин
- Числовые характеристики случайных величин
- Законы больших чисел
- Статистические оценки
- Статистическая проверка гипотез
- Статистическое исследование зависимостей
- Теории игр
- Вероятность события
- Теорема умножения вероятностей
- Формула полной вероятности
- Теорема о повторении опытов
- Определение законов распределения случайных величин на основе опытных данных
- Системы случайных величин
- Нормальный закон распределения для системы случайных величин
- Вероятностное пространство
- Классическое определение вероятности
- Геометрическая вероятность
- Условная вероятность
- Схема Бернулли
- Многомерные случайные величины
- Предельные теоремы теории вероятностей
- Оценки неизвестных параметров
- Генеральная совокупность
