В этой главе будет показано, как писать XML схемы. Также вы узнаете, что схемы можно писать разными способами.
XML документ
Давайте посмотрим на следующий XML документ под названием «shiporder.xml»:
<?xml version="1.0" encoding="UTF-8"?>
<shiporder orderid="889923"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="shiporder.xsd">
<orderperson>John Smith</orderperson>
<shipto>
<name>Ola Nordmann</name>
<address>Langgt 23</address>
<city>4000 Stavanger</city>
<country>Norway</country>
</shipto>
<item>
<title>Empire Burlesque</title>
<note>Special Edition</note>
<quantity>1</quantity>
<price>10.90</price>
</item>
<item>
<title>Hide your heart</title>
<quantity>1</quantity>
<price>9.90</price>
</item>
</shiporder>
Приведенный выше XML документ состоит из корневого элемента shiporder с обязательным атрибутом orderid. Элемент shiporder содержит три дочерних элемента: orderperson, shipto и item. Элемент item используется дважды и содержит элемент title, необязательный элемент note, а также элементы quantity и price.
Строка xmlns:xsi=»http://www.w3.org/2001/XMLSchema-instance» говорит XML парсеру, что этот документ должен быть проверен на соответствие схеме. Строка xsi:noNamespaceSchemaLocation=»shiporder.xsd» указывает, где именно находится схема (в данном случае она находится в той же папке, что и файл «shiporder.xml»).
Создание XML схемы
Теперь для приведенного выше XML документа создадим XML схему.
Создадим новый файл, который назовем «shiporder.xsd». Для создания XML схемы будем просто следовать за структурой XML документа и определять каждый встреченный элемент. Начнем со стандартной XML декларации, за которой опишем элемент xs:schema, который и определяет саму схему:
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
...
</xs:schema>
Здесь мы используем стандартное пространство имен (xs) и URI, ассоциированный с этим пространством имен, который имеет стандартное значение http://www.w3.org/2001/XMLSchema.
Теперь мы должны определить элемент shiporder. У этого элемента есть атрибут, и он содержит другие элементы, поэтому мы рассматриваем его как элемент составного типа. Определения дочерних элементов элемента shiporder поместим в декларацию xs:sequence, что задает жесткую последовательность подэлементов:
<xs:element name="shiporder">
<xs:complexType>
<xs:sequence>
...
</xs:sequence>
</xs:complexType>
</xs:element>
Теперь определим элемент orderperson, который будет простого типа (так как он не содержит ни атрибуты, ни другие элементы). Его тип (xs:string) имеет префикс пространства имен, ассоциированного с XML схемой, что указывает на использование предопределенного типа данных:
<xs:element name="orderperson" type="xs:string"/>
Теперь нам нужно определить два элемента составного типа: shipto и item. Начнем с определения элемента shipto:
<xs:element name="shipto">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="address" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="country" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
При помощи схем мы можем определить число возможных вхождений любого элемента. В этом нам помогут атрибуты maxOccurs и minOccurs. Атрибут maxOccurs задает максимальное число вхождений элемента, а атрибут minOccurs задает минимальное число вхождений. По умолчанию значение обоих атрибутов равно 1.
Теперь определим элемент item. Этот элемент может использоваться неограниченное число раз внутри элемента shiporder. Определить такую особенность элемента item позволяет присваивание атрибуту maxOccurs значения «unbounded». Это означает, что элемент item может использоваться столько раз, сколько нужно автору документа. Обратите внимание, что элемент note опционален. Определим это установив атрибут minOccurs в нулевое значение:
<xs:element name="item" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="title" type="xs:string"/>
<xs:element name="note" type="xs:string" minOccurs="0"/>
<xs:element name="quantity" type="xs:positiveInteger"/>
<xs:element name="price" type="xs:decimal"/>
</xs:sequence>
</xs:complexType>
</xs:element>
Теперь мы можем декларировать атрибут элемента shiporder. Поскольку это обязательный атрибут, используем определение use=»required».
Примечание: Атрибуты должны всегда декларироваться последними:
<xs:attribute name="orderid" type="xs:string" use="required"/>
Вот полный код файла схемы «shiporder.xsd»:
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="shiporder">
<xs:complexType>
<xs:sequence>
<xs:element name="orderperson" type="xs:string"/>
<xs:element name="shipto">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string"/>
<xs:element name="address" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="country" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="item" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="title" type="xs:string"/>
<xs:element name="note" type="xs:string" minOccurs="0"/>
<xs:element name="quantity" type="xs:positiveInteger"/>
<xs:element name="price" type="xs:decimal"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="orderid" type="xs:string" use="required"/>
</xs:complexType>
</xs:element>
</xs:schema>
Разделение схемы
Предыдущий способ компоновки схемы весьма прост, однако, когда документ достаточно сложен, при подобном способе соответствующая схема может оказаться довольно громоздкой, что сильно скажется на удобстве ее чтения и поддержки.
Следующий способ компоновки схемы заключается в том, что сначала определяются все элементы и атрибуты, а затем на эти определения создаются ссылки при помощи атрибута ref.
Ниже приводится новая компоновка файла схемы («shiporder.xsd»):
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<!-- определение простых элементов -->
<xs:element name="orderperson" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="address" type="xs:string"/>
<xs:element name="city" type="xs:string"/>
<xs:element name="country" type="xs:string"/>
<xs:element name="title" type="xs:string"/>
<xs:element name="note" type="xs:string"/>
<xs:element name="quantity" type="xs:positiveInteger"/>
<xs:element name="price" type="xs:decimal"/>
<!-- определение атрибутов -->
<xs:attribute name="orderid" type="xs:string"/>
<!-- определение составных элементов -->
<xs:element name="shipto">
<xs:complexType>
<xs:sequence>
<xs:element ref="name"/>
<xs:element ref="address"/>
<xs:element ref="city"/>
<xs:element ref="country"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="item">
<xs:complexType>
<xs:sequence>
<xs:element ref="title"/>
<xs:element ref="note" minOccurs="0"/>
<xs:element ref="quantity"/>
<xs:element ref="price"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="shiporder">
<xs:complexType>
<xs:sequence>
<xs:element ref="orderperson"/>
<xs:element ref="shipto"/>
<xs:element ref="item" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute ref="orderid" use="required"/>
</xs:complexType>
</xs:element>
</xs:schema>
Использование поименованых типов
Третий способ компоновки схемы предполагает определение классов или типов, которые позволяют повторное использование определений элементов. Это становится возможным, если дать имена элементам simpleTypes и complexTypes, а затем указать на них при помощи атрибута type.
Третий способ компоновки файла схемы («shiporder.xsd»):
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:simpleType name="stringtype">
<xs:restriction base="xs:string"/>
</xs:simpleType>
<xs:simpleType name="inttype">
<xs:restriction base="xs:positiveInteger"/>
</xs:simpleType>
<xs:simpleType name="dectype">
<xs:restriction base="xs:decimal"/>
</xs:simpleType>
<xs:simpleType name="orderidtype">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]{6}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="shiptotype">
<xs:sequence>
<xs:element name="name" type="stringtype"/>
<xs:element name="address" type="stringtype"/>
<xs:element name="city" type="stringtype"/>
<xs:element name="country" type="stringtype"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="itemtype">
<xs:sequence>
<xs:element name="title" type="stringtype"/>
<xs:element name="note" type="stringtype" minOccurs="0"/>
<xs:element name="quantity" type="inttype"/>
<xs:element name="price" type="dectype"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="shipordertype">
<xs:sequence>
<xs:element name="orderperson" type="stringtype"/>
<xs:element name="shipto" type="shiptotype"/>
<xs:element name="item" maxOccurs="unbounded" type="itemtype"/>
</xs:sequence>
<xs:attribute name="orderid" type="orderidtype" use="required"/>
</xs:complexType>
<xs:element name="shiporder" type="shipordertype"/>
</xs:schema>
Элемент restriction указывает на то, что тип данных является производным от типов данных из пространства имен W3C XML Schema. Таким образом, следующий фрагмент кода означает, что значение элемента или атрибута должно быть строковым:
<xs:restriction base="xs:string">
Однако гораздо чаще элемент restriction используется для накладывания ограничений на элементы. Посмотрите на следующие строки из приведенной выше схемы:
<xs:simpleType name="orderidtype">
<xs:restriction base="xs:string">
<xs:pattern value="[0-9]{6}"/>
</xs:restriction>
</xs:simpleType>
Этот фрагмент кода указывает, что значение элемента или атрибута должно быть строковым, ровно шесть символов в длину, и этими символами должны быть цифры от 0 до 9.
Эта статья, являющаяся фрагментом руководства по языку XML, дает краткий
обзор основных понятий и механизмов работы с XML Schema и приводит аргументы в
пользу использования XML Schema, как более прогрессивного решения в области
описания документов и данных, чем, например, DTD. Приводится пример
XML-документа, разбирается его полная схема и предлагается создание
собственного варианта для данного документа. Кроме того, статья содержит ряд
полезных ссылок, с помощью которых читатель может более детально ознакомиться
со спецификациями DTD, проверить синтаксис самостоятельно созданной схемы
XML-документа, потренироваться на готовых образцах XML-документов с
приложенными к ним схемами, а также обратиться к полному руководству по XML
ресурса Msdn Online.
Что такое XML Schema?
XML Schema- это описание разметки XML-документа сделанное в соответствии с синтаксисом XML. XML Schema — это спецификация, поддержанная фирмой Microsoft и имеющая множество преимуществ перед Document Type Definition (DTD), являющимся первоначальной спецификацией описания XML-модели. Спецификации DTD имеют множество недостатков, включая использование специального, отличного отXML синтаксиса, невозможность типизации данных и нерасширяемость. Например, спецификации DTD не позволяют вам определять содержание элемента как что-либо отличное от другого такого же элемента или строки. Чтобы лучше разобраться в спецификациях DTD, вы можете обратиться к Рекомендациям W3C XML. XML Schema превосходит DTD по всем параметрам, включая поддержку пространств имен (namespaces). Например, XML Schema позволяет вам определять элемент как integer, float, boolean, URL и др.
XML-парсер в Internet Explorer 5 может проверять XML-документ на допустимость как согласно DTD, так и XML-Schema.
Как создать XML Schema?
Проведите мышкой по следующему XML-документу, чтобы увидеть описания схемы для каждого узла дерева.
<class xmlns="x-schema:classSchema.xml">
<student studentID="13429">
<name>James Smith</name>
<GPA>3.8</GPA>
</student>
</class>
Вы заметите в этом документе, что определено пространство имен по умолчанию "x-schema:classSchema.xml". Это помогает при проверке синтаксиса сравнить весь документ со схемой (x-schema) по следующему URL («classSchema.xml«).
Ниже приведена полная схема для данного документа. Она начинается с элемента Schema, содержащего описание пространства имен указанной схемы и, кроме того, в данном случае — еще и описание пространства имен типов данных. Первое, xmlns="urn:schemas-microsoft-com:xml-data", говорит о том, что данный XML-документ является схемой XML. Второе, xmlns:dt="urn:schemas-microsoft-com:datatypes", позволяет вам определять тип элемента и содержание атрибута с использованием префикса dt в атрибуте type в составе их определений ElementType и AttributeType.
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<AttributeType name='studentID' dt:type='string' required='yes'/>
<ElementType name='name' content='textOnly'/>
<ElementType name='GPA' content='textOnly' dt:type='float'/>
<ElementType name='student' content='mixed'>
<attribute type='studentID'/>
<element type='name'/>
<element type='GPA'/>
</ElementType>
<ElementType name='class' content='eltOnly'>
<element type='student'/>
</ElementType>
</Schema>
Элементы описания, используемые вами для определения элементов и атрибутов, выглядят следующим образом:
ElementType: Присваивает тип и ограничивает значения элемента, а также определяет, какие дочерние элементы он может содержать, если таковые имеются.AttributeType: Присваивает тип и ограничивает значения атрибута.attribute: Определяет что ранее описанный тип атрибута может появиться в составе данного элементаElementType.element: Определяет, что ранее описанный тип элемента может появиться в составе данного элементаElementType.
Содержание схемы начинается с объявления AttributeType и ElementType для элементов, имеющих наибольшую степень вложенности.
<AttributeType name='studentID' dt:type='string' required='yes'/>
<ElementType name='name' content='textOnly'>
<ElementType name='GPA' content='textOnly' dt:type='float'/>
Следующее объявление ElementType сопровождается его атрибутом и дочерними элементами. Когда элемент имеет атрибуты или дочерние элементы, все они должны быть включены в объявление ElementType. Кроме того, они должны быть заранее описаны в своих собственных объявлениях ElementType и AttributeType.
<ElementType name='student' content='mixed'>
<attribute type='studentID'/>
<element type='name'/>
<element type='GPA'/>
</ElementType>
Этот процесс выполняется для всей схемы, пока каждый элемент и атрибут не будут объявлены.
В противовес DTD, XML Schemas дают вам возможность иметь модель с открытым содержанием, позволяющую вам, например, задавать тип элементов или использовать значения по умолчанию без обязательных ограничений содержания.
В следующей схеме определен тип элемента GPA и ему присвоен атрибут со значением, заданным по умолчанию, но кроме этого никакие другие узлы элемента student не объявлены.
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<AttributeType name="scale" default="4.0"/>
<ElementType name="GPA" content="textOnly" dt:type="float">
<attribute type="scale"/>
</ElementType>
<AttributeType name="studentID"/>
<ElementType name="student" content="eltOnly" model="open" order="many">
<attribute type="studentID"/>
<element type="GPA"/>
</ElementType>
</Schema>
Вышеприведенная схема позволяет вам проверить только область, с которой вы работаете. Такой подход предоставляет вам больше возможностей для контроля над уровнем проверки вашего документа и позволяет вам использовать некоторые свойства, обеспечиваемые схемой, без обращения к строгой проверке.
Попробуйте!
Попробуйте создать схему следующего документа.
<order>
<customer>
<name>Fidelma McGinn</name>
<phone_number>425-655-3393</phone_number>
</customer>
<item>
<number>5523918</number>
<description>shovel</description>
<price>39.99<price>
</item>
<date_of_purchase>1998-10-23</date_of_purchase>
<date_of_delivery>1998-11-03</date_of_delivery>
</order>
Как только вы закончите эту схему, проверьте ее через
XML validator.
Download MSDN Online обеспечивает набор
примеров XML-файлов, включая документ XML с приложенной схемой. Загрузите эти примеры и попробуйте манипулировать документом и схемой. Для проверки правильности вашего XML относительно схемы, вы можете загрузить документ через XML Validator или просто просмотреть XML-файл в Mime Type Viewer.
Некоторые соображения:
- Объявления
ElementTypeиAttributeTypeдолжны предшествовать определениям содержанияattributeиelement, относящихся к этим типам. Например, вышеприведенная схема, определениеElementTypeдля элемента GPA должна предшествовать определениюElementTypeдля элементаstudent. - Значение по умолчанию атрибута
orderзависит от значение атрибутаcontent. Когда содержание установлено как «eltOnly,» порядок имеет значение по умолчаниюseq. Когда содержание определено как mixed, порядок имеет значение по умолчаниюmany. За дополнительной информацией по данным значениям, задаваемым по умолчанию, см. Руководство по XML Schema.
Автор:
Msdn Online
Схемы данных (Schemas) являются
альтернативным способом создания
правил построения XML-документов. По
сравнению с DTD, схемы обладают более
мощными средствами для определения
сложных структур данных,
обеспечивают более понятный способ
описания грамматики языка,
способны легко модернизироваться и
расширяться. Безусловным
достоинством схем является также
то, что они позволяют описывать
правила для XML- документа
средствами самого же XML.
Однако это не означает, что схемы
могут полностью заменить DTD-
описания — этот способ определения
грамматики языка используется
сейчас практическими всеми
верифицирующими анализаторами XML и,
более того, сами схемы, как обычные
XML- элементы, тоже описываются DTD. Но
серьезные возможности нового языка
и его относительная простота,
безусловно, дают основания
утверждать, что будущий стандарт
найдет широкое применение в
качестве удобного и эффективного
средства проверки корректности
составления документов.
В настоящее время в W3 консорциуме
идет работа над первой
спецификацией схем данных. В этом
разделе мы рассмотрим основные
возможности схем данных,
попытаемся использовать их для
проверки корректности ранее
описываемых XML- документов.
Как это выглядит
Внешне документы схем очень
похожи на те документы XML, с
которыми мы уже встречались в
предыдущих разделах. Мы размечаем
документ при помощи специальных
элементов, выполняющих в схемах
роль инструкций. Эти инструкции
составляют набор правил, используя
которые, программа-клиент будет
делать вывод о том, корректен
документ или нет. Схема данных,
например, может выглядеть
следующем образом:
<schema id="OurSchema"> <elementType id="#title"> <string/> </elementType> <elementType id="photo"> <element type="#title"> <attribute name="src"/> </elementType> <elementType id="gallery"> <element type="#photo"> </elementType> </schema>
Если мы включим приведенные
правила внутрь XML- документа,
программа-клиент сможет
использовать их для проверки. Т.е.
она теперь сможет определить, что
правильным будет являться
следующий фрагмент:
<gallery> <photo id="1"><title>My computer</title></photo> <photo id="2"><title>My family</title></photo> <photo id="3"><title>My dog</title></photo> </gallery>
, а некорректным этот:
<gallery> <photo id="1"/> <photo index="2"><title>My family</title></photo> <photo index="3"><title> My dog </title><dogname>Sharik</dogname></photo> </gallery>
Все конструкции языка схем
описываются правилами «XML DTD for
XML-Data-Schema». Этот документ вы
можете найти среди другой
официальной документации,
доступной на сервере W3 —
консорциума. В этой статье мы
коснемся лишь основных приемов для
работы со схемами данных. Ссылки на
более подробные источники
приведены в конце.
Область схемы данных
Создавая схемы данных, мы
определяем в документе специальный
элемент, <schema>;, внутри
которого содержатся описания
правил:
<schema id="OurSchema"> <!-- последовательность инструкций --> </schema>
Если использовать отдельное
пространство имен, то полный
XML-документ, содержащий в себе схему
данных, будет выглядеть следующим
образом:
<?XML version='1.0' ?> <?xml:namespace href="http://www.mrcpk.nstu.ru/schemas/" as="s"/?> <s:schema id="OurSchema"> <!-- последовательность инструкций --> </s:schema>
Описание элементов
Для определения класса элемента,
к которому в дальнейшем будут
применяться инструкции,
описывающие его содержимое и
структуру, предназначен
специальный элемент схемы elementType,
<elementType id="issue"> <descript>Элемент содержит информацию об очередном выпуске журнала</descript> </elementType>
Название элемента задается
атрибутом id . Все дальнейшие
инструкции, которые относятся к
описываемому классу, определяют
его внутреннюю структуру и набор
допустимых данных, содержатся
внутри блока, заданного тэгами
<elementType> и </elementType>. Мы
рассмотрим эти инструкции чуть
позже.
Как видно из примера, при
определении класса элемента, можно
также использовать комментарии к
нему, которые заключаются в тэги <descript></descript>
Атрибуты элемента
Для того, чтобы в описании
элемента определить его атрибуты и
описать свойства этих атрибутов мы
должны использовать элемент attribute:
<elementType id="photo"> <attribute name="src"/> <empty/> </elementType>
В данном примере элементу <photo>
определяется атрибут src,
значением которого может быть
любая последовательность
разрешенных символов:
<photo src="0"/> <photo src="some text">
Подобно DTD, схемы данных позволяют
устанавливать ограничения на
значения и способ использования
атрибутов. Для этого в дескрипторе
<attribute> необходимо использовать
параметр atttype.
Например, если мы хотим указать,
что значение атрибута должно
использоваться
программой-анализатором как
уникальный идентификатор, то нам
необходимо создать следующее
правило:
<elementType id="bouquet"> <attribute name="id" atttype="ID"> </elementType>
Если же требуется задать список
возможных значений атрибута, то
пример будет выглядеть следующим
образом:
<attribute name="flower" atttype="ENUMERATION" values="red green blue" default="red">
Для приведенных примеров
корректным будет являться
следующий фрагмент XML-документа:
<bouquet id="0"> <flower color="red">rose</flower> <flower color="green">leaf</flower> <flower color="blue">bluet</flower> </bouquet>
Модель содержимого элемента
Под моделью содержимого в схеме
данных понимают описание всех
допустимых объектов XML- документа,
использование которых внутри
данного элемента является
корректным. Модель содержимого
определяется инструкциями,
расположенными внутри блока
<elementType>.
<elementType id="article"> <attribute name="id" atttype="ID"> <element type="#title"> <string/> </elementType>
Для этого правила корректным
будет являться следующий фрагмент
документа:
<article id="0"> <title>Психи и маньяки в Интернет</title> </article>
Вложенные элементы описываются
при помощи инструкции element, в
которой параметром type указывается
класс объекта — ссылка на его
определение:
<elementType id="article"> <element type="#title"/> <element type="#author"/> </elementType>
Если требуется указать режим
использования вложенного элемента,
то надо определить параметр occurs:
<elementType id="article"> <element type="#title" occurs="REQUIRED"/> <element type="#author" occurs="OPTIONAL"/> <element type="#subject" occurs="ONEORMORE"/> </elementType>
Возможные значения этого
параметра таковы:
- REQUIRED — элемент должен быть
обязательно определен - OPTIONAL — использование элемента
не является обязательным - ZEROORMORE — вложенный элемент может
встречаться несколько раз или
ни разу - ONEORMORE — элемент должен
встречаться хотя бы один раз
Примеры правильных XML-документа,
использующих приведенную выше
схему:
<article> <title>Зачем он нужен, XML?</title> <author>Иван Петров</author> <subject>Что такое XML</subject> <subject>нужен ли он нам</subject> </article>
или
<article> <title>Зачем он нужен, XML?</title> <subject>Что такое XML</subject> </article>
Кроме элементов, содержимым
XML-документа могут также является
обычный текст и области CDATA. Для
обозначения типов содержимого
текущего элемента в схемах
используются следующие инструкции:
- <string/> — указывает на то,
что содержимым элемента
является только свободная
текстовая информация(секция
PCDATA) :<elementType id="flower"> <string/> </elementType>
- <any/> — указывает на то,
что содержимым элемента должны
являться только элементы, без
текста, незаключенного ни в
один элемент:<elementType id="issue"> <any/> </elementType>
- <mixed> — любое сочетание
элементов и текста<elementType id="contacts"> <mixed/> </elementType>
- <empty> — пустой элемент
Пример:
<elementType id="title"> <string/> </elementType> <elementType id="chapter"> <string/> </elementType> <elementType id="chapters-list"> <any/> </elementType> <elementType id="content"> <element type="#chapters-list" occurs="OPTIONAL"> </elementType> <elementType id="article"> <mixed><element type="#title"></mixed> <element type="#content" occurs="OPTIONAL"> </elementType>
О типах данных, которые можно
определять с помощью схем, мы
поговорим чуть позже
Группировка элементов
Элемент group используется для
того, чтобы задать некоторую
последовательность вложенных
объектов:
<elementType id="contacts"> <element type="#tel" occurs="ONEORMORE"> <group occurs="OPTIONAL"> <element type="#email"> <element type="#url"> </group> </elementType>
Группировка объектов позволяет
определять сразу группу объектов
различных типов, которые могут
находится внутри данного объекта. В
приведенном примере мы указали, что
внутри объекта типа contacts могут быть
включены элементы tel, email, и url,
причем атрибутом occurs мы указали,
что элементы в группе являются
необязательными. Корректным для
таких схем будут являться
следующие фрагменты документов:
<contacts> <tel>12-12-12</tel> <email>info@j.com</email> <url>http://www.j.com</url> </contacts> ... <contacts> <tel>12-12-12</tel> </contacts> ... <contacts> <tel>12-12-12</tel> <email>info@j.com</email> </contacts>
При помощи атрибута groupOrder можно
также задавать режим использования
группированных элементов При
установленном значении OR возможно
использование не всех элементов
группы, а лишь некоторых из них.
Если задано значение AND, то оба
элемента должны быть включены в
обязательном порядке. Например, для
следующей группы правил:
<elementType id="contacts"> <element type="#tel" occurs="ONEORMORE"> <group groupOrder="AND" occurs="OPTIONAL"> <element type="#email"> <element type="#url"> </group> </elementType>
будут считаться правильными
только следующие варианты:
<contacts> <tel>12-12-12</tel> <email>info@j.com</email> <url>http://www.j.com</url> </contacts>
или
<contacts> <tel>12-12-12</tel> </contacts>
Закрытая и открытая модели
описания содержимого элемента
Когда мы определяем модель
содержимого текущего элемента,
список дополнительных допустимых
элементов правилами не
ограничивается — он может свободно
расширяться. Например, для
приведенного выше правила, кроме
обозначенных элементов
<tel>,<url> и <email> вполне могут
использоваться дополнительные
элементы, неописанные правилами,
например, <fax>:
<contacts> <tel>12-12-12</tel> <fax>21-21-21</fax> <email>info@j.com</email> <url>http://www.j.com</url> </contacts>
Однако в том случае, если мы хотим
ограничить создаваемые нами
правила от включения
дополнительных элементов, мы
должны использовать атрибут content и
установить для него специальное
значение CLOSED:
<elementType id="contacts" content="CLOSED"> <element type="#tel"> <element type="#email"> <element type="#url"> </elementType>
Теперь приведенный фрагмент
XML-документа будет считаться
некорректным, т.к. параметром content
запрещено использование внутри
элемента contacts других объектов,
кроме указанных в правиле.
Иерархия классов
Для того, чтобы при описании
класса ограничить список объектов,
которые могут являться
родительскими для данного
элемента, необходимо использовать
элемент схемы domain.
Инструкция <domain> указывает, что
текущий объект должен определяться
строго внутри элемента, заданного
этим тэгом. Например, в следующем
фрагменте указывается, что элемент
<author> может быть определен
строго внутри тэга <article>:
<elementType id="author"> <element type="#lastname"> <element type="#firstname"> <domain type="#article"/> </elementType>
Ограничения на значения
Значения элементов могут быть
ограничены при помощи тэгов <min>
и <max>;:
<elementType id="room"> <element type="#floor"><min>0</min><max>100</max> </elementType>
Внутри этих элементов могут
указываться и символьные
ограничения:
<elementType id="line"> <element type="#character"><min>A</min><max>Z</max> </elementType>
Использование правил из внешних
схем
Схема может использовать
элементы и атрибуты из других схем.
Для этого надо использовать
атрибут href, в котором указывается
название внешней схемы. Например:
<?XML version='1.0' ?> <?xml:namespace name="urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/" as="s"/?> <s:schema> <elementType id="author"> <string/> </elementType> <elementType id="title"> <string/> </elementType> <elementType id="Book"> <element type="#title" occurs="OPTIONAL"/> <element type="#author" occurs="ONEORMORE"/> <element href="http://mrcpk.org/" /> </elementType></s:schema> </elementType> </s:schema>
Компоненты схем
Компоненты, или макроопределении,
используются в схемах точно также,
как и в DTD. Для их определения
предназначены тэги <intEntityDcl/> и
<extEntityDcl/>;:
<intEntityDcl name="MRCPK"> Новосибирский Межотраслевой Региональный Центр Переподготовки Кадров </intEntityDcl> <extEntityDcl name="logo" notation="#gif" systemId="http://www.mrcpk.nstu.ru/logo.gif"/>
Типы данных
В разделе, посвященном DTD, мы уже
выяснили, для чего
программе-клиенту необходима
информация о формате данных
содержимого элемента. В схемах
существует возможность задавать
тот или иной тип данных, используя
при определении элемента директиву
<datatype> с указанием
конкретного типа:
<elementType id="counter"> <datatype dt="int"> </elementType>
В DTD мы должны были создать
атрибут с конкретным названием,
определяющим операцию назначения
формата данных, и значением,
определенным как fixed .Использование
элемента <datatype> позволяет
указывать это автоматически, но для
обеспечения программной
независимости необходимо сначала
договориться об обозначениях типов
данных(значения, которые должны
передаваться параметру dt элемента
dataype), для чего могут
использоваться, например,
универсальные идентификаторы
ресурсов URI. В любом случае, как и
прежде, все необходимые действия,
связанные с конкретной
интерпретацией данных,
содержащихся в документе,
осуществляются
программой-клиентом и определяются
логикой его работы. В разделе,
посвященном DTD, мы уже
рассматривали пример XML- документа,
реализующего описанные нами
возможности. Вот как выглядел бы
этот пример при использовании схем
данных:
<schema id="someschema"> <elementType id="#rooms_num"> <string/> <datatype dt="int"> </schema> <elementType id="#floor"> <string/> <datatype dt="int"> </schema> <elementType id="#living_space"> <string/> <datatype dt="float"> </schema> <elementType id="#is_tel"> <string/> <datatype dt="boolean"> </schema> <elementType id="#counter"> <string/> <datatype dt="float"> </schema> <elementType id="#price"> <string/> <datatype dt="float"> </schema> <elementType id="#comments"> <string/> <datatype dt="string"> </schema> <elementType id="#house"> <element type="#rooms_num" occurs="ONEORMORE"/> <element type="#floor" occurs="ONEORMORE"/> <element type="#living_space" occurs="ONEORMORE"/> <element type="#is_tel" occurs="OPTIONAL"/> <element type="#counter" occurs="ONEORMORE"/> <element type="#price" occurs="ONEORMORE"/> <element type="#comments" occurs="OPTIONAL"/> </elementType> </schema> ... <house id="0"> <rooms_num>5</rooms_num> <floor>2</floor> <living_space>32.5</living_space> <is_tel>true</is_tel> <counter>18346</counter> <price>34.28</price> <comments>С видом на cеверный полюс</comments> </house> ...
Подводя итог всему сказанному,
необходимо отметить, что процесс
развития современных
информационных систем настолько
динамичен, что временной
промежуток между появлением новой
технологии и ее практическим
использованием в реально
действующих приложениях сегодня
слишком мал. На смену устаревающему
стандарту HTML в самое ближайшее
время должен будет прийти новый,
более гибкий и универсальный язык
описания данных. И тот факт, что XML
как язык еще не стандартизирован и
некоторые его составляющие до сих
пор находятся в стадии разработки,
видимо, не является причиной
невозможности его использования
уже сегодня, для решения конкретных
задач в реальных системах. Примером
этому может служить возникновение
огромного количества языков
описания документов, некоторые из
которых приведены в Приложении
В этой статье были рассмотрены
лишь самые основные аспекты,
касающиеся новой XML- технологии. В
будущем, мы, возможно, остановимся
несколько подробнее на производных
от XML языках описания данных — SMIL, RDF,
MathML, механизмах описания
пространства имен и рассмотрим
некоторые вопросы, касающиеся
создания программ-анализаторов для
этих языков.
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про XML.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Так что увидеть его можно не только в API, но и в коде.
Этот формат рекомендован Консорциумом Всемирной паутины (W3C), поэтому он часто используется для передачи данных по API. В SOAP API это вообще единственно возможный формат входных и выходных данных!
См также:
Что такое API — общее знакомство с API
Что такое JSON — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST.
Так что давайте разберемся, как он выглядит, как его читать, и как ломать! Да-да, а куда же без этого? Надо ведь выяснить, как отреагирует система на кривой формат присланных данных.

Содержание
- Как устроен XML
- Теги
- Корневой элемент
- Значение элемента
- Атрибуты элемента
- XML пролог
- XSD-схема
- Практика: составляем свой запрос
- Well Formed XML
- 1. Есть корневой элемент
- 2. У каждого элемента есть закрывающийся тег
- 3. Теги регистрозависимы
- 4. Правильная вложенность элементов
- 5. Атрибуты оформлены в кавычках
- Итого
Как устроен XML
Возьмем пример из документации подсказок Дадаты по ФИО:
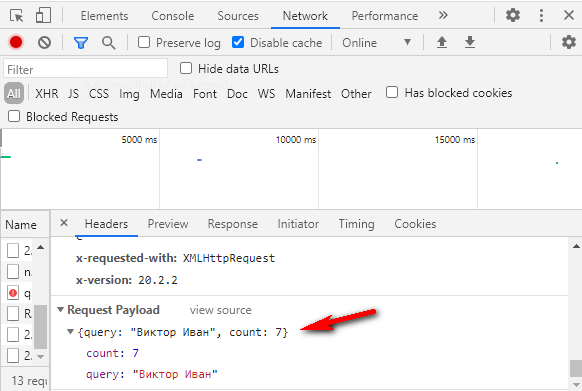
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>И разберемся, что означает эта запись.

Теги
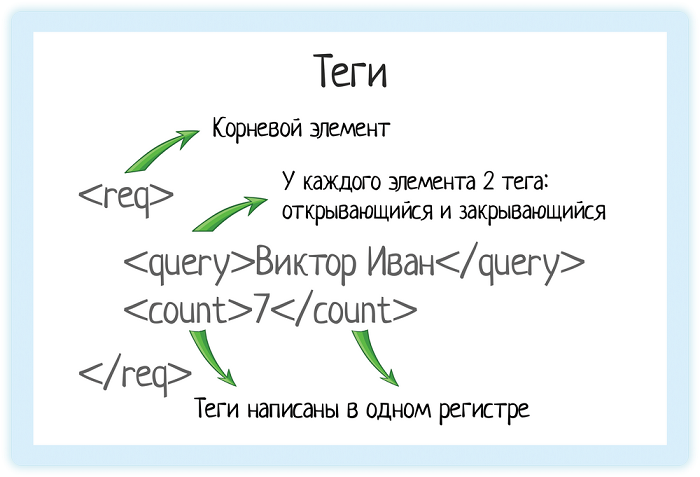
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Текст внутри угловых скобок — название тега.
Тега всегда два:
- Открывающий — текст внутри угловых скобок
<tag> - Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
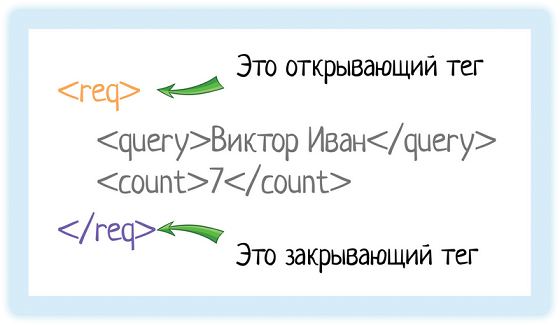
Ой, ну ладно, подловили! Не всегда. Бывают еще пустые элементы, у них один тег и открывающий, и закрывающий одновременно. Но об этом чуть позже!
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается». Это как дорожные знаки:
— На въезде в город написано его название: Москва
— На выезде написано то же самое название, но перечеркнутое:
Москва
*
* Пример с дорожными знаками я когда-то давно прочитала в статье Яндекса, только ссылку уже не помню. А пример отличный!

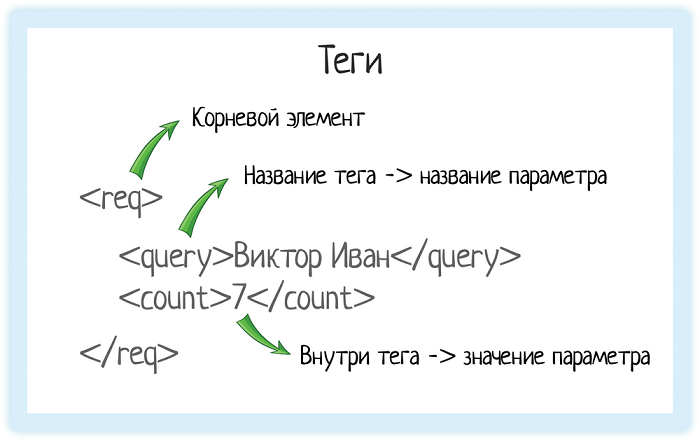
Корневой элемент
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. В случае REST API документ — это запрос, который отправляет система. Или ответ, который она получает.
Чтобы обозначить этот запрос, нам нужен корневой элемент. В подсказках корневой элемент — «req».

Он мог бы называться по другому:
<main><sugg>Да как угодно. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа — сам запрос. Те параметры, которые мы передаем внешней системе. Разумеется, они тоже будут в тегах, но уже в обычных, а не корневых.
Значение элемента
Значение элемента хранится между открывающим и закрывающим тегами. Это может быть число, строка, или даже вложенные теги!
Вот у нас есть тег «query». Он обозначает запрос, который мы отправляем в подсказки.

Внутри — значение запроса.
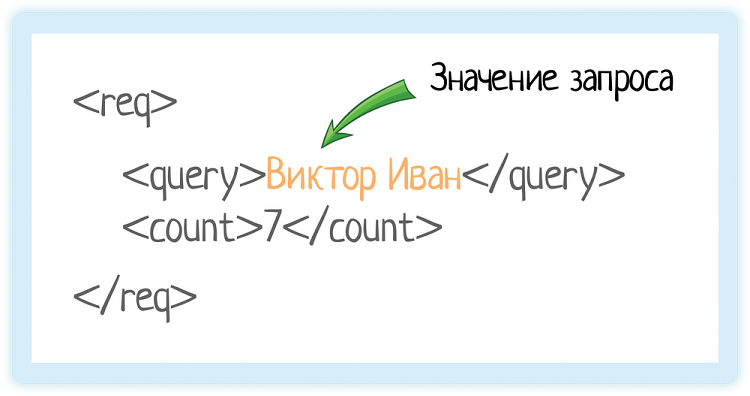
Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
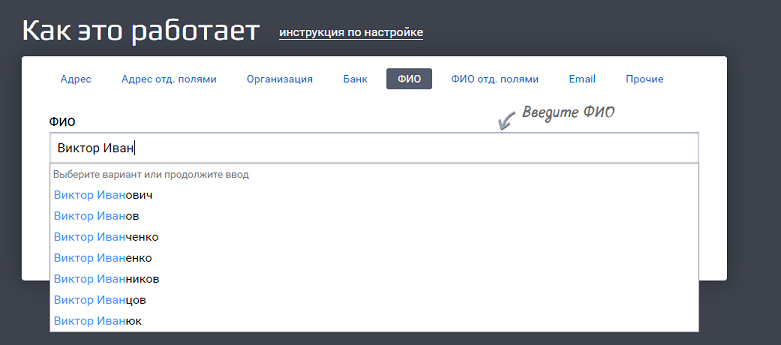
Пользователю лишняя обвязка не нужна, ему нужна красивая формочка. А вот системе надо как-то передать, что «пользователь ввел именно это». Как показать ей, где начинается и заканчивается переданное значение? Для этого и используются теги.
Система видит тег «query» и понимает, что внутри него «строка, по которой нужно вернуть подсказки».
Параметр count = 7 обозначает, сколько подсказок вернуть в ответе. Если тыкать подсказки на демо-форме Дадаты, нам вернется 7 подсказок. Это потому, что туда вшито как раз значение count = 7. А вот если обратиться к документации метода, count можно выбрать от 1 до 20.
Откройте консоль разработчика через f12, вкладку Network, и посмотрите, какой запрос отправляется на сервер. Там будет значение count = 7.
См также:
Что тестировщику надо знать про панель разработчика — подробнее о том, как использовать консоль.
Обратите внимание:
- Виктор Иван — строка
- 7 — число
Но оба значения идут
без
кавычек. В XML нам нет нужды брать строковое значение в кавычки (а вот в JSON это сделать придется).
Атрибуты элемента
У элемента могут быть атрибуты — один или несколько. Их мы указываем внутри отрывающегося тега после названия тега через пробел в виде
название_атрибута = «значение атрибута»Например:
<query attr1=“value 1”>Виктор Иван</query>
<query attr1=“value 1” attr2=“value 2”>Виктор Иван</query>
Зачем это нужно? Из атрибутов принимающая API-запрос система понимает, что такое ей вообще пришло.
Например, мы делаем поиск по системе, ищем клиентов с именем Олег. Отправляем простой запрос:
<query>Олег</query>А в ответ получаем целую пачку Олегов! С разными датами рождения, номерами телефонов и другими данными. Допустим, что один из результатов поиска выглядит так:
<party type="PHYSICAL" sourceSystem="AL" rawId="2">
<field name=“name">Олег </field>
<field name="birthdate">02.01.1980</field>
<attribute type="PHONE" rawId="AL.2.PH.1">
<field name="type">MOBILE</field>
<field name="number">+7 916 1234567</field>
</attribute>
</party>Давайте разберем эту запись. У нас есть основной элемент party.

У него есть 3 атрибута:
- type = «PHYSICAL» — тип возвращаемых данных. Нужен, если система умеет работать с разными типами: ФЛ, ЮЛ, ИП. Тогда благодаря этому атрибуту мы понимаем, с чем именно имеем дело и какие поля у нас будут внутри. А они будут отличаться! У физика это может быть ФИО, дата рождения ИНН, а у юр лица — название компании, ОГРН и КПП
- sourceSystem = «AL» — исходная система. Возможно, нас интересуют только физ лица из одной системы, будем делать отсев по этому атрибуту.
- rawId = «2» — идентификатор в исходной системе. Он нужен, если мы шлем запрос на обновление клиента, а не на поиск. Как понять, кого обновлять? По связке sourceSystem + rawId!

Внутри party есть элементы field.

У элементов field есть атрибут name. Значение атрибута — название поля: имя, дата рождения, тип или номер телефона. Так мы понимаем, что скрывается под конкретным field.

Это удобно с точки зрения поддержки, когда у вас коробочный продукт и 10+ заказчиков. У каждого заказчика будет свой набор полей: у кого-то в системе есть ИНН, у кого-то нету, одному важна дата рождения, другому нет, и т.д.
Но, несмотря на разницу моделей, у всех заказчиков будет одна XSD-схема (которая описывает запрос и ответ):
— есть элемент party;
— у него есть элементы field;
— у каждого элемента field есть атрибут name, в котором хранится название поля.
А вот конкретные названия полей уже можно не описывать в XSD. Их уже «смотрите в ТЗ». Конечно, когда заказчик один или вы делаете ПО для себя или «вообще для всех», удобнее использовать именованные поля — то есть «говорящие» теги. Какие плюшки у этого подхода:
— При чтении XSD сразу видны реальные поля. ТЗ может устареть, а код будет актуален.
— Запрос легко дернуть вручную в SOAP Ui — он сразу создаст все нужные поля, нужно только значениями заполнить. Это удобно тестировщику + заказчик иногда так тестирует, ему тоже хорошо.
В общем, любой подход имеет право на существование. Надо смотреть по проекту, что будет удобнее именно вам. У меня в примере неговорящие названия элементов — все как один будут field. А вот по атрибутам уже можно понять, что это такое.
Помимо элементов field в party есть элемент attribute. Не путайте xml-нотацию и бизнес-прочтение:
- с точки зрения бизнеса это атрибут физ лица, отсюда и название элемента — attribute.
- с точки зрения xml — это элемент (не атрибут!), просто его назвали attribute. XML все равно (почти), как вы будете называть элементы, так что это допустимо.

У элемента attribute есть атрибуты:
- type = «PHONE» — тип атрибута. Они ведь разные могут быть: телефон, адрес, емейл…
- rawId = «AL.2.PH.1» — идентификатор в исходной системе. Он нужен для обновления. Ведь у одного клиента может быть несколько телефонов, как без ID понять, какой именно обновляется?

Такая вот XML-ка получилась. Причем упрощенная. В реальных системах, где хранятся физ лица, данных сильно больше: штук 20 полей самого физ лица, несколько адресов, телефонов, емейл-адресов…
Но прочитать даже огромную XML не составит труда, если вы знаете, что где. И если она отформатирована — вложенные элементы сдвинуты вправо, остальные на одном уровне. Без форматирования будет тяжеловато…
А так всё просто — у нас есть элементы, заключенные в теги. Внутри тегов — название элемента. Если после названия идет что-то через пробел: это атрибуты элемента.
XML пролог
Иногда вверху XML документа можно увидеть что-то похожее:
<?xml version="1.0" encoding="UTF-8"?>Эта строка называется XML прологом. Она показывает версию XML, который используется в документе, а также кодировку. Пролог необязателен, если его нет — это ок. Но если он есть, то это должна быть первая строка XML документа.
UTF-8 — кодировка XML документов по умолчанию.
XSD-схема
XSD (XML Schema Definition) — это описание вашего XML. Как он должен выглядеть, что в нем должно быть? Это ТЗ, написанное на языке машины — ведь схему мы пишем… Тоже в формате XML! Получается XML, который описывает другой XML.
Фишка в том, что проверку по схеме можно делегировать машине. И разработчику даже не надо расписывать каждую проверку. Достаточно сказать «вот схема, проверяй по ней».
Если мы создаем SOAP-метод, то указываем в схеме:
- какие поля будут в запросе;
- какие поля будут в ответе;
- какие типы данных у каждого поля;
- какие поля обязательны для заполнения, а какие нет;
- есть ли у поля значение по умолчанию, и какое оно;
- есть ли у поля ограничение по длине;
- есть ли у поля другие параметры;
- какая у запроса структура по вложенности элементов;
- …
Теперь, когда к нам приходит какой-то запрос, он сперва проверяется на корректность по схеме. Если запрос правильный, запускаем метод, отрабатываем бизнес-логику. А она может быть сложной и ресурсоемкой! Например, сделать выборку из многомиллионной базы. Или провести с десяток проверок по разным таблицам базы данных…
Поэтому зачем запускать сложную процедуру, если запрос заведом «плохой»? И выдавать ошибку через 5 минут, а не сразу? Валидация по схеме помогает быстро отсеять явно невалидные запросы, не нагружая систему.

Более того, похожую защиту ставят и некоторые программы-клиенты для отправки запросов. Например, SOAP Ui умеет проверять ваш запрос на well formed xml, и он просто не отправит его на сервер, если вы облажались. Экономит время на передачу данных, молодец!

А простому пользователю вашего SOAP API схема помогает понять, как составить запрос. Кто такой «простой пользователь»?
- Разработчик системы, использующей ваше API — ему надо прописать в коде, что именно отправлять из его системы в вашу.
- Тестировщик, которому надо это самое API проверить — ему надо понимать, как формируется запрос.
Да-да, в идеале у нас есть подробное ТЗ, где всё хорошо описано. Но увы и ах, такое есть не всегда. Иногда ТЗ просто нет, а иногда оно устарело. А вот схема не устареет, потому что обновляется при обновлении кода. И она как раз помогает понять, как запрос должен выглядеть.

Итого, как используется схема при разработке SOAP API:
- Наш разработчик пишет XSD-схему для API запроса: нужно передать элемент такой-то, у которого будут такие-то дочерние, с такими-то типами данных. Эти обязательные, те нет.
- Разработчик системы-заказчика, которая интегрируется с нашей, читает эту схему и строит свои запросы по ней.
- Система-заказчик отправляет запросы нам.
- Наша система проверяет запросы по XSD — если что-то не так, сразу отлуп.
- Если по XSD запрос проверку прошел — включаем бизнес-логику!
А теперь давайте посмотрим, как схема может выглядеть! Возьмем для примера метод doRegister в Users. Чтобы отправить запрос, мы должны передать email, name и password. Есть куча способов написать запрос правильно и неправильно:
Попробуем написать для него схему. В запросе должны быть 3 элемента (email, name, password) с типом «string» (строка). Пишем:
<xs:element name="doRegister ">
<xs:complexType>
<xs:sequence>
<xs:element name="email" type="xs:string"/>
<xs:element name="name" type="xs:string"/>
<xs:element name="password" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>А в WSDl сервиса она записана еще проще:
<message name="doRegisterRequest">
<part name="email" type="xsd:string"/>
<part name="name" type="xsd:string"/>
<part name="password" type="xsd:string"/>
</message>Конечно, в схеме могут быть не только строковые элементы. Это могут быть числа, даты, boolean-значения и даже какие-то свои типы:
<xsd:complexType name="Test">
<xsd:sequence>
<xsd:element name="value" type="xsd:string"/>
<xsd:element name="include" type="xsd:boolean" minOccurs="0" default="true"/>
<xsd:element name="count" type="xsd:int" minOccurs="0" length="20"/>
<xsd:element name="user" type="USER" minOccurs="0"/>
</xsd:sequence>
</xsd:complexType>А еще в схеме можно ссылаться на другую схему, что упрощает написание кода — можно переиспользовать схемы для разных задач.
См также:
XSD — умный XML — полезная статья с хабра
Язык определения схем XSD — тут удобные таблички со значениями, которые можно использовать
Язык описания схем XSD (XML-Schema)
Пример XML схемы в учебнике
Официальный сайт w3.org
Практика: составляем свой запрос
Ок, теперь мы знаем, как «прочитать» запрос для API-метода в формате XML. Но как его составить по ТЗ? Давайте попробуем. Смотрим в документацию. И вот почему я даю пример из Дадаты — там классная документация!

Что, если я хочу, чтобы мне вернулись только женские ФИО, начинающиеся на «Ан»? Берем наш исходный пример:
<req>
<query>Виктор Иван</query>
<count>7</count>
</req>В первую очередь меняем сам запрос. Теперь это уже не «Виктор Иван», а «Ан»:
<req>
<query>Ан</query>
<count>7</count>
</req>Далее смотрим в ТЗ. Как вернуть только женские подсказки? Есть специальный параметр — gender. Название параметра — это название тегов. А внутри уже ставим пол. «Женский» по английски будет FEMALE, в документации также. Итого получили:
<req>
<query>Ан</query>
<count>7</count>
<gender>FEMALE</gender>
</req>Ненужное можно удалить. Если нас не волнует количество подсказок, параметр count выкидываем. Ведь, согласно документации, он необязательный. Получили запрос:
<req>
<query>Ан</query>
<gender>FEMALE</gender>
</req>Вот и все! Взяли за основу пример, поменяли одно значение, один параметр добавили, один удалили. Не так уж и сложно. Особенно, когда есть подробное ТЗ и пример )))
Попробуй сам!
Напишите запрос для метода MagicSearch в Users. Мы хотим найти всех Ивановых по полному совпадению, на которых висят актуальные задачи.
Well Formed XML
Разработчик сам решает, какой XML будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. XML должен быть well formed, то есть синтаксически корректный.
Чтобы проверить XML на синтаксис, можно использовать любой XML Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
В готовый валидатор вы просто вставляете свой XML (например, запрос для сервера) и смотрите, всё ли с ним хорошо. Но можете проверить его и сами. Пройдитесь по правилам синтаксиса и посмотрите, следует ли им ваш запрос.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.
Давайте пройдемся по каждому правилу и обсудим, как нам применять их в тестировании. То есть как правильно «ломать» запрос, проверяя его на well-formed xml. Зачем это нужно? Посмотреть на фидбек от системы. Сможете ли вы по тексту ошибки понять, где именно облажались?
См также:
Сообщения об ошибках — тоже документация, тестируйте их! — зачем тестировать сообщения об ошибках
1. Есть корневой элемент
Нельзя просто положить рядышком 2 XML и полагать, что «система сама разберется, что это два запроса, а не один». Не разберется. Потому что не должна.
И если у вас будет лежать несколько тегов подряд без общего родителя — это плохой xml, не well formed. Всегда должен быть корневой элемент:
Что мы делаем для тестирования этого условия? Правильно, удаляем из нашего запроса корневые теги!
2. У каждого элемента есть закрывающийся тег
Тут все просто — если тег где-то открылся, он должен где-то закрыться. Хотите сломать? Удалите закрывающийся тег любого элемента.
Но тут стоит заметить, что тег может быть один. Если элемент пустой, мы можем обойтись одним тегом, закрыв его в конце:
<name/>Это тоже самое, что передать в нем пустое значение
<name></name>Аналогично сервер может вернуть нам пустое значение тега. Можно попробовать послать пустые поля в Users в методе FullUpdateUser. И в запросе это допустимо (я отправила пустым поле name1), и в ответе SOAP Ui нам именно так и отрисовывает пустые поля.

Итого — если есть открывающийся тег, должен быть закрывающийся. Либо это будет один тег со слешом в конце.
Для тестирования удаляем в запросе любой закрывающийся тег.
3. Теги регистрозависимы
Как написали открывающий — также пишем и закрывающий. ТОЧНО ТАК ЖЕ! А не так, как захотелось.
А вот для тестирования меняем регистр одной из частей. Такой XML будет невалидным
4. Правильная вложенность элементов
Элементы могут идти друг за другом
Один элемент может быть вложен в другой

Но накладываться друг на друга элементы НЕ могут!
5. Атрибуты оформлены в кавычках
Даже если вы считаете атрибут числом, он будет в кавычках:
<query attr1=“123”>Виктор Иван</query>
<query attr1=“атрибутик” attr2=“123” >Виктор Иван</query>Для тестирования пробуем передать его без кавычек:
<query attr1=123>Виктор Иван</query>Итого
XML (eXtensible Markup Language) используется для хранения и передачи данных.
Передача данных — это запросы и ответы в API-методах. Если вы отправляете SOAP-запрос, вы априори работаете именно с этим форматом. Потому что SOAP передает данные только в XML. Если вы используете REST, то там возможны варианты — или XML, или JSON.
Хранение данных — это когда XML встречается внутри кода. Его легко понимает как машина, так и человек. В формате XML можно описывать какие-то правила, которые будут применяться к данным, или что-то еще.
Вот пример использования XML в коде open-source проекта folks. Я не знаю, что именно делает JacksonJsonProvider, но могу «прочитать» этот код — есть функционал, который мы будем использовать (featuresToEnable), и есть тот, что нам не нужен(featuresToDisable).
Формат XML подчиняется стандартам. Синтаксически некорректный запрос даже на сервер не уйдет, его еще клиент порежет. Сначала проверка на well formed, потом уже бизнес-логика.
Правила well formed XML:
- Есть корневой элемент.
- У каждого элемента есть закрывающийся тег.
- Теги регистрозависимы!
- Соблюдается правильная вложенность элементов.
- Атрибуты оформлены в кавычках.

Если вы тестировщик, то при тестировании запросов в формате XML обязательно попробуйте нарушить каждое правило! Да, система должна уметь обрабатывать такие ошибки и возвращать адекватное сообщение об ошибке. Но далеко не всегда она это делает.
А если система публичная и возвращает пустой ответ на некорректный запрос — это плохо. Потому что разработчик другой системы налажает в запросе, а по пустому ответу даже не поймет, где именно. И будет приставать к поддержке: «Что же у меня не так?», кидая информацию по кусочкам и в виде скринов исходного кода. Оно вам надо? Нет? Тогда убедитесь, что система выдает понятное сообщение об ошибке!
См также:
Что такое XML
Учебник по XML
Изучаем XML. Эрик Рэй (книга по XML)
Заметки о XML и XLST
Что такое JSON — второй популярный формат
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
XML Schema
Так же как DTD схема XML Schema определяет допустимые строительные блоки XML документа.
XML Schema:
- элементы, входящие в документ
- атрибуты, допустимые в документе
- дочерние элементы
- порядок дочерних элементов
- количество дочерних элементов
- может ли элемент быть пустым или может содержать текст
- типы элементов и атрибутов
- фиксированные и значения по умолчанию элементов и атрибутов
Предполагается, что в перспективе DTD схемы будут замещены XML Schema в большинстве веб-приложений поскольку XML Schema:
- Расширяема для будущих добавлений.
- Более богатые и мощные выразительные возможности.
- Является реализацией XML.
- Поддерживает типы данных.
- Поддерживают пространства имен.
XML Schema стала W3C рекомендацией в 2001 году.
Рассмотрим в качестве примера XML документ:
<?xml version="1.0" encoding="Windows-1251"?> <mail> <to>user1@domain.ru</to> <from>user2@domain.ru </from> <subject>Встреча</subject> <body>Позвони мне завтра утром</body> </mail>
Структура данного документа может быть рассмотрена с помощью следующей XML Schema:
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.myhp.edu"
xmlns=" http://www.myhp.edu"
elementFormDefault="qualified">
<xs:element name="mail">
<xs:complexType>
<xs:sequence>
<xs:element name="to" type="xs:string"/>
<xs:element name="from" type="xs:string"/>
<xs:element name="subject" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
В данном примере элемент mail имеет тип complexType, поскольку содержит другие элементы. Другие элементы документа имеют простой тип, поскольку не включают других элементов.
Ссылка на схему в XML документе выглядит следующим образом:
<?xml version="1.0"?> <mail xmlns="http:// www.myhp.edu " xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.myhp.edu mail.xsd"> <to>user1@domain.ru</to> <from>user2@domain.ru </from> <subject>Встреча</subject> <body>Позвони мне завтра утром</body> </mail>
Элемент <schema> является корневым элементом любой схемы XML Schema.
Данный элемент может содержать несколько атрибутов, например:
<?xml version="1.0"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.myhp.edu" xmlns="http://www.myhp.edu" elementFormDefault="qualified"> ... ... </xs:schema>
Следующий фрагмент:
xmlns:xs="http://www.w3.org/2001/XMLSchema"
указывает на то, что элементы и типы данных, используемые в схеме входят в пространство http://www.w3.org/2001/XMLSchema. Причем, все элементы и типы данных из этого пространства имен должны иметь префикс xs.
Фрагмент:
targetNamespace="http://www.myhp.edu"
указывает на то, что элементы, определяемые в схеме входят в пространство «http://www.myhp.edu».
Во фрагменте:
xmlns="http://www.myhp.edu"
указывается, что пространством имен по умолчанию является «http://www.myhp.edu»
Следующий фрагмент:
elementFormDefault="qualified"
указывает на то, что любые элементы, объявленные в схеме, должны принадлежать пространству имен.
Ссылка на внешнюю схему может выглядеть следующим образом:
<?xml version="1.0"?> <mail xmlns=" http://www.myhp.edu " xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation=" http://www.myhp.edu mail.xsd"> <to>user1@domain.ru</to> <from>user2@domain.ru </from> <subject>Встреча</subject> <body>Позвони мне завтра утром</body> </mail>
Здесь строка
xsi:schemaLocation=" http://www.myhp.edu mail.xsd">
указывает на местоположение файла схемы.
Определение простых элементов
Синтаксис для определения простого элемента:
<xs:element name="xxx" type="yyy"/>
где xxx – имя элемента и yyy тип данных элемента.
Встроенными типами данных элементов являются следующие:
- xs:string
- xs:decimal
- xs:integer
- xs:boolean
- xs:date
- xs:time
Например, фрагмент XML документа:
<lastname>Refsnes</lastname> <age>36</age> <dateborn>1970-03-27</dateborn>
описывается в схеме следующим образом:
<xs:element name="lastname" type="xs:string"/> <xs:element name="age" type="xs:integer"/> <xs:element name="dateborn" type="xs:date"/>
Следующие фрагменты:
<xs:element name="color" type="xs:string" default="red"/>
и
<xs:element name="color" type="xs:string" fixed="red"/>
описывают значение элемента по умолчанию и фиксированное значения соответственно.
Все атрибуты описываются простыми типами данных.
Простые элементы не могут иметь атрибутов. Если элемент имеет атрибуты, он рассматривается как имеющий сложный тип. Сам атрибут рассматривается всегда как имеющий простой тип.
Описание атрибута обычно дается следующим образом:
<xs:attribute name="xxx" type="yyy"/>
где xxx – имя атрибута, а yyy — определяет тип данных атрибута.
Встроенными типами данных для атрибутов являются соледующие:
- xs:string
- xs:decimal
- xs:integer
- xs:boolean
- xs:date
- xs:time
Например, XML элемент с атрибутом:
<lastname lang="EN">Smith</lastname>
описывается соответствующей схемой:
<xs:attribute name="lang" type="xs:string"/>
Значение по умолчанию и фиксированное значение атрибута описываются следующим образом:
<xs:attribute name="lang" type="xs:string" default="EN"/>
и
<xs:attribute name="lang" type="xs:string" fixed="EN"/>
соответственно.
Для описания обязательных атрибутов (по умолчанию все атрибуты являются необязательными) используется следующая нотация:
<xs:attribute name="lang" type="xs:string" use="required"/>