Время на прочтение
4 мин
Количество просмотров 498K
Xpath — это язык запросов к элементам xml или xhtml документа. Также как SQL, xpath является декларативным языком запросов. Чтобы получить интересующие данные, необходимо всего лишь создать запрос, описывающий эти данные. Всю «черную» работу за вас выполнит интерпретатор языка xpath.
Очень удобно, не правда ли? Давайте посмотри какие возможности предлагает xpath для доступа к узлам веб-страниц.
Создание запроса к узлам веб-страниц
Предлагаю вашему вниманию небольшую лабораторную работу, в ходе которой я продемонстрирую создание xpath запросов к веб-странице. Вы сможете повторить приведенные мной запросы и, самое главное, попробуете выполнить свои. Я надеюсь, что благодаря этому статья будет одинаково интересна новичкам и программистам знакомым с xpath по xml.
Для лабораторной нам понадобятся:
— веб-страница xhtml;
— браузер Mozilla Firefox с дополнениями;
— firebug;
— firePath;
(вы можете использовать любой другой браузер с визуальной поддержкой xpath)
— немного времени.
В качестве веб-страницы для проведения эксперимента предлагаю главную страницу сайта консорциума всемирной паутины (‘http://w3.org’). Именно эта организация разрабатывает языки xquery(xpath), спецификацию xhtml и многие другие стандарты интернета.
Задача
Получить из xhtml-кода главной страницы w3.org информацию о конференциях консорциума при помощи запросов xpath.
Приступим к написанию xpath запросов.
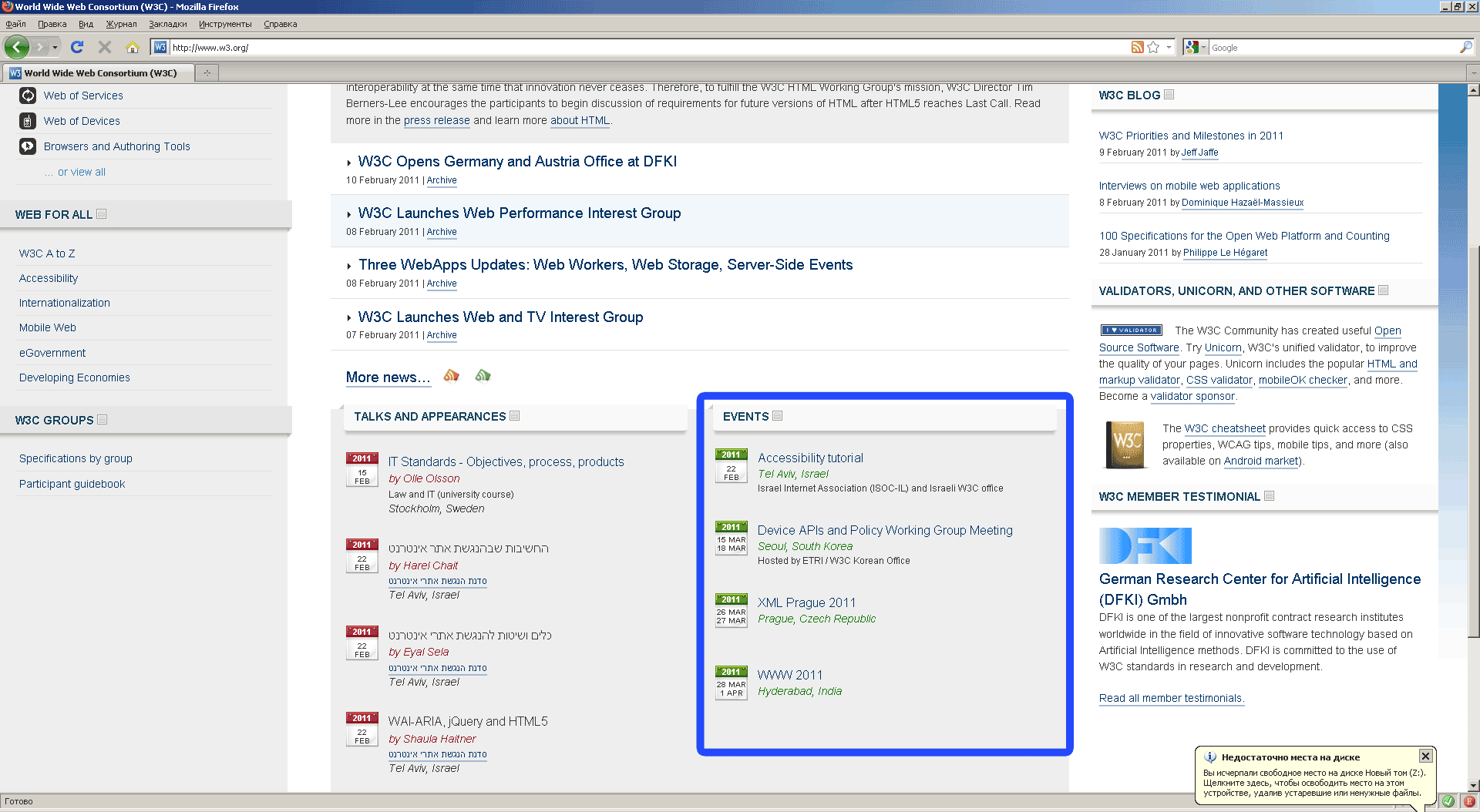
Первый Xpath запрос
Открываем закладку Firepath в FireBug, выделяем с селектором элемент для анализа, нажимаем: Firepath создал xpath запрос к выбранному элементу.
Если вы выделили заголовок первого события, то запрос будет таким:
.//*[@id='w3c_home_upcoming_events']/ul/li[1]/div[2]/p[1]/a
После удаления лишних индексов запрос станет соответствовать всем элементам типа «заголовок».
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p/a
Firepath подсвечивает элементы, которые соответствуют запросу. Вы можете в реальном времени увидеть, какие узлы документа соответствуют запросу.
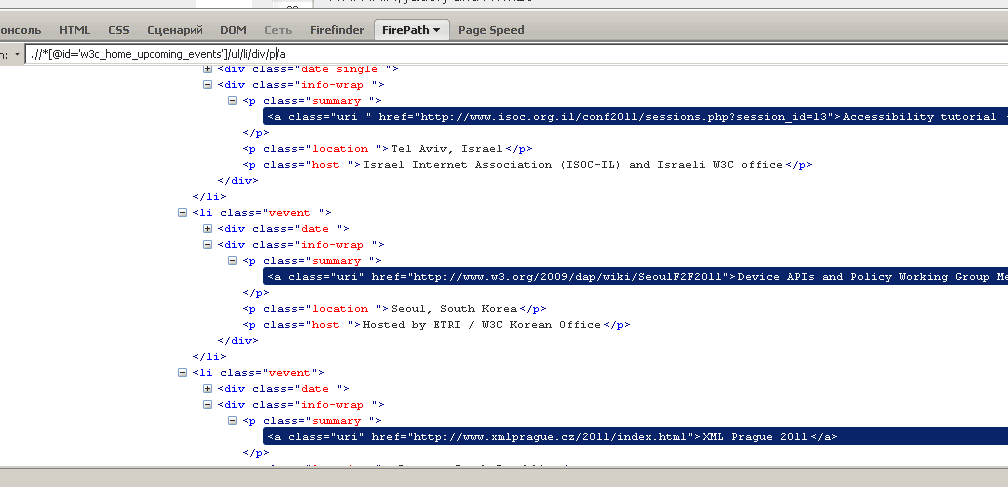
Идем дальше. Создаем запросы для поиска мест проведения конференций и их спонсоров либо с помощью селектора, либо модифицировав первый запрос.
Запрос для получения информации о местах проведения конференций:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]
Так мы получим список спонсоров:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]
Синтаксис xpath
Давайте вернемся к созданным запросам и разберемся в том, как они устроены.
Рассмотрим подробно первый запрос

В этом запросе я выделил три части для демонстрации возможностей xpath. (Деление на части уловное)
Первая часть
.// — рекурсивный спуск на ноль или более уровней иерархии от текущего контекста. В нашем случае текущий контекст это корень документа
Вторая часть
* — любой элемент,
[@id=’w3c_home_upcoming_events’] – предикат, на основе которого осуществляем поиск узла, имеющего атрибут id равным ‘w3c_home_upcoming_events’. Идентификаторы элементов XHTML должны быть уникальны. Поэтому запрос «любой элемент с конкретным ID» должен вернуть единственный искомый нами узел.
Мы можем заменить * на точное имя узла div в этом запросе
div[@id='w3c_home_upcoming_events']
Таким образом, мы спускаемся по дереву документа до нужного нам узла div[@id=’w3c_home_upcoming_events’]. Нас абсолютно не волнует, из каких узлов состоит DOM-дерево и сколько уровней иерархии осталось выше.
Третья часть
/ul/li/div/p/a –xpath-путь до конкретного элемента. Путь состоит из шагов адресации и условия проверки узлов (ul, li и т.д.). Шаги разделяются символом » /»(косая черта).
Коллекции xpath
Не всегда удается получить доступ к интересующему узлу с помощью предиката или шагов адресации. Очень часто на одном уровне иерархии находится насколько узлов одинакового типа и необходимо выбрать «только первые» или «только вторые» узлы. Для таких случаев предусмотрены коллекции.
Коллекции xpath позволяют получить доступ к элементу по его индексу. Индексы соответствуют тому порядку, в котором элементы были представлены в исходном документе. Порядковый номер в коллекциях отсчитывается от единицы.
Исходя из того, что «место проведения» всегда второй параграф после «названия конференции», получаем следующий запрос:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[2]
Где p[2] – второй элемент в наборе для каждого узла списка /ul/li/div.
Аналогично список спонсоров мы можем получить запросом:
.//*[@id='w3c_home_upcoming_events']/ul/li/div/p[3]
Некоторые функции хpath
В хpath существует множество функций для работы с элементами внутри коллекции. Я приведу только некоторые из них.
last():
Возвращает последний элемент коллекции.
Запрос ul/li/div/p[last()] — возвратит последние параграфы для каждого узла списка «ul».
Функция first() не предусмотрена. Для доступа к первому элементу используйте индекс «1».
text():
Возвращает тестовое содержание элемента.
.//a[text() = 'Archive'] – получаем все ссылки с текстом «Archive».
position() и mod:
position() — возвращает позицию элемента в множестве.
mod — остаток от деления.
Комбинацией данных функций можем получить:
— не четные элементы ul/li[position() mod 2 = 1]
— четные элементы: ul/li[position() mod 2 = 0]
Операции сравнения
- < — логическое «меньше»
- > — логическое «больше»
- <= — логическое «меньше либо равно»
- >= — логическое «больше либо равно»
ul/li[position() > 2] , ul/li[position() <= 2] — элементы списка начиная с 3го номера и наоборот.
Полный список функций
Самостоятельно
Попробуйте получить:
— четные URL ссылки из левого меню «Standards»;
— заголовки всех новостей, кроме первой с главной страницы w3c.org.
Xpath в PHP5
$dom = new DomDocument();
$dom->loadHTML( $HTMLCode );
$xpath = new DomXPath( $dom );
$_res = $xpath->query(".//*[@id='w3c_home_upcoming_events']/ul/li/div/p/a");
foreach( $_res => $obj ) {
echo 'URL: '.$obj->getAttribute('href');
echo $obj->nodeValue;
}
В заключение
На простом примере мы увидели возможности xpath для доступа к узлам веб-страниц.
Xpath является отраслевым стандартом для доступа к элементам xml и xhtml, xslt преобразований.
Вы можете применять его для парсинга любой html-страницы. В случае если исходный html-код содержит значительные ошибки в разметке пропустите его через tidy. Ошибки будут исправлены.
Старайтесь отказаться от регулярных выражений при парсинге веб-страниц в пользу xpath.
Это сделает ваш код проще, понятнее. Вы допустите меньше ошибок. Сократиться время отладки.
Ресурсы
Firepath дополнение Mozzilla Firefox
Краткая аннотация языка в википедии
Xороший справочник по xpath. Не обращайте внимание на то, что он для NET Framework. Xpath во всех средах работает одинаково, за исключением пары специфичных функций
Cпецификация xpath 1.0
Cпецификация xpath 1.0 на русском
XQuery 1.0 and XPath 2.0
Tidy
PHP5 tidy::repairFile
Язык разметки XML с самого первого стандарта окружает пользователей компьютеров. Таблицы в Excel, выгрузки из интернет-магазинов, RSS-ленты с новостями — все это основано на XML. Хоть визуальное отображение отличается на устройствах и в программах, но в основе всегда лежит единый формат.
Внутри XML-файла может находиться огромное количество информации, поэтому и встает вопрос о перемещении и выборке внутри документа. Как это сделать быстро? Какие средства применять, чтобы в интернет-магазине найти нужный товар из десятков тысяч других? Для навигации и поиска внутри XML используется язык запросов XPath.
В этой статье разберем:
- для кого может быть полезен XPath
- базовые конструкции языка для поиска информации в XML
- чем XPath отличается от CSS-селекторов при поиске в HTML
- Синтаксис XPath
- Отличия от CSS-селекторов
- Кому нужен Xpath
- Заключение
Синтаксис XPath
Для начала создадим базовый пример XML, с которым и будем работать весь урок. Например, список курсов по верстке на Хекслете в XML будет выглядеть так:
<?xml version="1.0" encoding="UTF-8"?>
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
<course>
<name>Основы современной верстки</name>
<tags>HTML5, CSS, DevTools, верстка</tags>
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
</course>
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
</courses>
Это учебный пример, но для отработки навыков XPath подойдет и любой другой XML. Принципы XPath сохранятся при любой структуре файла, потому что по стандарту XML можно использовать элементы с произвольными тегами.
Для тестирования результата подойдут такие онлайн-сервисы, как:
- Code Beautify
- XPather
Абсолютные пути
Самый простой запрос состоит из обращения к корневому элементу. Для этого достаточно выполнить запрос /courses. Нам вернется XML в почти таком же виде, что и в примере выше. Обратите внимание на строку <?xml version="1.0" encoding="UTF-8"?>. Она отличается, потому что элемент не внутри <courses>:
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
<course>
<name>Основы современной верстки</name>
<tags>HTML5, CSS, DevTools, верстка</tags>
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
</course>
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
</courses>
В качестве результата XPath возвращает узлы XML-документа.
Продолжим цепочку и обратимся к описанию из элемента <description>. Для этого добавим в запрос путь к description: /courses/description. Результатом выполнения станет:
<description>На курсах по верстке вы познакомитесь с основами HTML и CSS, научитесь верстать адаптивные страницы, работать с препроцессорами. Освоите современные технологии и инструменты, включая Flex, Sass, Bootstrap.</description>
Путь, который строится от корневого элемента, называется абсолютным. Используем схему из прошлого запроса и обратимся к любому элементу внутри XML.
Попробуем обратиться к имени курса. В этом случае вернется поле <name> из всех курсов. Запрос /courses/course/name вернет:
<name>Основы современной верстки</name>
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Вот список некоторых базовых запросов и их результат:
| Запрос | Результат |
|---|---|
/courses/course |
Все данные из всех элементов <course></course> |
/courses/course/name |
<name>Основы современной верстки</name><name>Основы верстки контента</name><name>Bootstrap 5: Основы верстки</name> |
/courses/course/duration |
<duration value="9">9 часов</duration><duration value="18">18 часов</duration><duration value="10">10 часов</duration> |
Относительные пути
Прошлые запросы строились с помощью абсолютных путей — то есть мы указывали полный путь до информации. Бывают ситуации, когда полный путь не подходит: например, мы хотим обраться к какому-то уникальному полю или не знаем полный путь. В этом случае можно использовать относительный путь — он произведет поиск по всему XML и вернет узлы, подходящие под запрос.
Чтобы записать относительный путь, нужно использовать конструкцию //. После нее можно написать любое поле и получить результат. Например, //name вернет поля <name> из всего XML:
<name>Основы современной верстки</name>
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Проблема такого подхода — уникальность полей. В документах одни и те же имена полей могут обозначать разные данные в зависимости от расположения. Поэтому используйте относительные пути только там, где уверены в возвращаемых данных. Например, в нашем примере название курса может быть заключено в <title>:
<courses>
<title>Курсы HTML и CSS (верстка)</title>
<!-- ... -->
<course>
<title>Основы современной верстки</title>
<!-- ... -->
</course>
<course>
<title>Основы верстки контента</title>
<!-- ... -->
</course>
<course>
<title>Bootstrap 5: Основы верстки</title>
<!-- ... -->
</course>
</courses>
Запрос //title вернет не только имена курсов, но и узел, который находится в <courses>:
<title>Курсы HTML и CSS (верстка)</title>
<title>Основы современной верстки</title>
<title>Основы верстки контента</title>
<title>Bootstrap 5: Основы верстки</title>
Чтобы сэкономить пару секунд, разработчики опускают корневой элемент и пользуются относительными путями. Например, вместо /courses/course/name они пишут //course/name. Для практики попробуйте прошлые примеры перевести на относительные пути с помощью такого механизма.
Несколько примеров запросов с идентичными ответами, как и в прошлой таблице:
| Запрос | Результат |
|---|---|
//course |
Все данные из всех элементов <course></course> |
//name |
<name>Основы современной верстки</name><name>Основы верстки контента</name><name>Bootstrap 5: Основы верстки</name> |
//course/duration |
<duration value="9">9 часов</duration><duration value="18">18 часов</duration><duration value="10">10 часов</duration> |
Предикаты
В примерах запросов к именам возвращались имена всех найденных курсов. В некоторых ситуациях это может быть избыточно. Что делать, если хочется получить данные только по первому курсу в <courses>? На помощь приходят предикаты — конструкции, с помощью которых можно отфильтровать элементы по заданным условиям.
Выберем ключевые слова первого курса по верстке. Для этого достаточно использовать запрос //course[1]/tags:
<tags>HTML5, CSS, DevTools, верстка</tags>
Обратите внимание на[1]. Это предикат с таким условием: «Взять элемент по индексу 1». Попробуйте сделать запрос ко второму или третьему элементу. Достаточно поменять всего одну цифру!
В XPath индексы элементов начинаются с единицы, а не с нуля, как в принятых стандартах программирования. Если вы уже программируете, это может немного запутать.
Предикаты помогают делать точные выборки. Например, получить ссылки на русскоязычные страницы курсов. Для этого нужно получить элементы <url>, у которых атрибут lang равен ru. Делается это указанием атрибута и значения. Чтобы XPath отличил атрибут от элемента перед атрибутом указывается символ @.
Теперь запрос будет выглядеть так: //course/url[@lang="ru"]
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
Иногда полезно выбрать элементы, которые имеют хоть какой-то атрибут. Для этого можно использовать конструкцию //*[@*]:
<duration value="9">9 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/layout-designer-basics</url>
<url lang="en">https://hexlet.io/courses/layout-designer-basics</url>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
По примеру выше видно, знак * обозначает «все/любой».
Когда выбраны элементы по атрибутам, можно произвести дополнительную фильтрацию по этим значениям. Например, найдем элементы <duration> со значением атрибута value больше 9. Внутри предикатов используются операторы сравнения, знакомые по языкам программирования:
>— больше<— меньше>=— больше или равно<=— меньше или равно=— равно!=— не равно
Запрос будет выглядеть так: //course/duration[@value > 9]:
<duration value="18">18 часов</duration>
<duration value="10">10 часов</duration>
Мы разобрались, как выбирать одно поле — это интересная, но редкая задача. Чаще разработчики обрабатывают данные по всему файлу или нескольким полям. Попробуем одновременно использовать предикат и обратиться к другим полям. Обратите внимание на два момента:
- Предикат необязательно должен идти в конце запроса
- Внутри предиката могут находиться новые пути, которые нужно проверить
Мы уже знаем, как с помощью предиката отфильтровать данные по полю <duration>. Эту задачу мы выполняли с помощью конструкции duration[@value > 9]. А теперь попробуем сделать эту конструкцию предикатом для <course>. Так мы получим данные о курсах с длительностью больше 9 часов: //course[duration[@value > 9]]:
<course>
<title>Основы верстки контента</title>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css-content</url>
<url lang="en">https://hexlet.io/courses/css-content</url>
</course>
<course>
<title>Bootstrap 5: Основы верстки</title>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
Можно продолжить этот запрос и получить только имена курсов. Тогда предикат будет в середине запроса, а не в его конце: `//course[duration[@value > 9]]/name
<name>Основы верстки контента</name>
<name>Bootstrap 5: Основы верстки</name>
Функции
В прошлых примерах запросы затрагивали теги и атрибуты. Сами данные мы не затрагивали, хотя это огромный пласт информации, по которой можно делать выборки. Для решения этой задачи используются встроенные в XPath функции. Они являются частью предикатов — например, @. Попробуем найти курс с названием «Основы верстки контента».
Для поиска по тексту внутри элемента используется функция text(). Ее задача — получить текстовое значение элемента и сравнить его с условием по необходимости. Вот как будет выглядеть запрос для поиска курса с нужным именем: //course[name[text()="Основы верстки контента"]]
<course>
<name>Основы верстки контента</name>
<tags>CSS3, HTML5, Селекторы, Доступность, CSS Columns, CSS Units, Верстка</tags>
<duration value="18">18 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/css:content</url>
<url lang="en">https://hexlet.io/courses/css:content</url>
</course>
Но что, если нам известно только часть названия? Для этого существует функция contains(), которая принимает два аргумента:
- Строка, где будет производиться поиск
- Подстрока, которая будет искаться
Для примера найдем курс, у которого в ключевых словах есть слово «Bootstrap». Функция примет текстовое значение элемента tags и найдет там слово «Bootstrap»: //course[tags[contains(text(), "Bootstrap")]]
<course>
<name>Bootstrap 5: Основы верстки</name>
<tags>Bootstrap 5, Адаптивность, HTML, CSS3</tags>
<duration value="10">10 часов</duration>
<url lang="ru">https://ru.hexlet.io/courses/bootstrap_basic</url>
<url lang="en">https://hexlet.io/courses/bootstrap_basic</url>
</course>
В стандарте XPath существует еще несколько функций, но цель статьи — показать принципы работы тех или иных механизмов, а не дать исчерпывающую документацию по всему языку.
Отличия от CSS-селекторов
Если вы писали на JavaScript, то знаете, что элементы можно искать с помощью CSS-селекторов, используя методы querySelector() или querySelectorAll(). Почему же разработчики иногда ищут элементы внутри HTML именно с помощью XPath?
Дело в концепции поиска элементов. Используя CSS, можно идти только в глубину без возможности обратиться к родительским элементам. В отличие от CSS, XPath позволяет в любой момент обращаться и к дочерним, и к родительским элементам.
Если вы хотите подробнее изучить поиск по HTML с помощью XPath, рекомендуем обратиться к статье Introduction to using XPath in JavaScript.
С помощью CSS нельзя найти все элементы div, внутри которых есть ссылки — можно найти сами ссылки, но не их родителей. XPath позволяет это сделать простым сочетанием div[a]. Постепенно ситуация меняется: в CSS появился селектор :has(), но он поддерживается еще не всеми новыми версиями браузеров. Со временем это изменится, но пока реальность именно такая.
Другой пример — поиск элементов по тексту внутри них. С этой задачей CSS никогда не справится, так как такой цели у него нет. XPath, как мы изучили, умеет это делать с помощью функции text().
Кому нужен Xpath
Если коротко, Xpath нужен всем, кто работает с XML.
Чтобы разобраться подробнее, изучим несколько примеров:
SEO-специалисты. Специалисты по продвижению часто обрабатывают большие массивы данных и вытаскивают информацию со страниц сайта.
Например, для них критичны мета-теги — дополнительная информация, в которой содержатся иконки сайтов, название страницы, описание и так далее. Эту информацию SEO-специалист может автоматически парсить с помощью запросов в XPath.
Тестировщики. При работе с Front-end тестировщики часто проверяют тот или иной вывод информации на странице — для этого они выбирают отдельные элементы с нужной страницы. Это можно делать через XPath и DevTools, встроенный в браузеры на основе Chromium.
Разработчики. Они часто используют парсеры — это скрипты, которые ищут нужную информацию на страницах одного или нескольких сайтов. Например, мы хотим сравнить стоимость одного и того же товара в разных магазинах. Для такой задачи можно написать скрипт, который пройдется по всем нужным сайтам, сравнит цены и вернет данные. В этом случае для поиска информацию на странице можно использовать XPath.
Это лишь часть сценариев, в которых пригождается язык XPath — на самом деле, их десятки.
Заключение
В этой статье мы рассмотрели, где встречается XML и кому он может пригодиться. Мы научились составлять базовые запросы и изучили часто используемые конструкции XPath:
- Абсолютные и относительные пути
- Предикаты
- Поиск по атрибутам
- Операторы сравнения
- Функции
Также теперь вы знаете, что поиск по HTML с помощью XPath может быть эффективнее поиска с помощью CSS-селекторов.
В этой статье мы постарались дать знания, которые помогут справиться с большинством задач. Но это далеко не все возможности XPath — это более глубокий язык, чем представлено в статье. Как и с другими технологиями, тут важно набить руку. Чем больше вы практикуетесь, тем более точные и полезные запросы пишете.

When it comes to parsing web-scraped HTML content, there are multiple techniques to select the data we want.
For simple text parsing, regular expression can be used, but HTML is designed to be a machine-readable text structure. We can take advantage of this fact and use special path languages like CSS selectors and XPath to extract data in a much more efficient and reliable way!
You are probably familiar with CSS selectors from the style sheet documents (.css) however, XPath goes beyond that and implements full document navigation in its own unique syntax.
Parsing HTML with CSS Selectors
For parsing using CSS selectors see the CSS version of this article

In this article, we’ll be taking a deep look at this unique path language and how can it be used to extract needed details from modern, complex HTML documents. We’ll start with a quick introduction and expression cheatsheet and explore concepts using an interactive XPath tester.
Finally, we’ll wrap up by covering XPath implementations in various programming languages and some common idioms and tips when it comes to XPath in web scraping. Let’s dive in!
What is Xpath?
XPath stands for «XML Path Language» which essentially means it’s a query language that described a path from point A to point B for XML/HTML type of documents.
Other path languages you might know of are CSS selectors which usually describe paths for applying styles, or tool-specific languages like jq which describe paths for JSON-type documents.
For HTML parsing, Xpath has some advantages over CSS selectors:
- Xpath can traverse HTML trees in every direction and is location-aware.
- Xpath can transform results before returning them.
- Xpath is easily extendable with additional functionality.
Before we dig into Xpath let’s have a quick overview of HTML itself and how it enables xpath language to find anything with the right instructions.
HTML Overview
HTML (HyperText Markup Language) is designed to be easily machine-readable and parsable. In other words, HTML follows a tree-like structure of nodes and their attributes, which we can easily navigate programmatically.
Let’s start off with a small example page and illustrate its structure:
<head>
<title>
</title>
</head>
<body>
<h1>Introduction</h1>
<div>
<p>some description text: /p>
<a class="link" href="https://example.com">example link</a>
</div>
</body>
In this basic example of a simple web page, we can see that the document already resembles a data tree. Let’s go a bit further and illustrate this:

Here we can wrap our heads around it a bit more easily: it’s a tree of nodes and each node can also have properties attached to them like keyword attributes (like class and href) and natural attributes such as text.
Now that we’re familiar with HTML let’s familiarize ourselves with Xpath itself!
Xpath Syntax Overview
Xpath selectors are usually referred to as «xpaths» and a single xpath indicates a destination from the root to the desired endpoint. It’s a rather unique path language, so let’s start off with a quick glance over basic syntax.
Average xpath selector in web scraping often looks something like this:
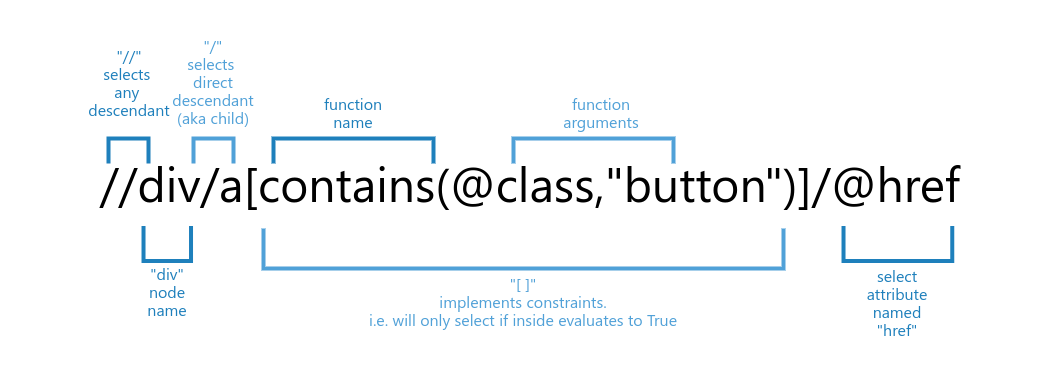
In this example, XPath would select href attribute of an <a> node that has a class «button» which is also directly under <div> node:
<div>
<a class=»button» href=»http://scrapfly.io»>ScrapFly</a>
</div>
Xpath selectors are made up of multiple expressions joined together into a single string. Let’s see the most commonly used expressions in this XPath cheat sheet:
| expression | description |
|---|---|
/node |
selects a direct child that matches node name. |
//node |
selects any descendant — child, grandchild, gran-grandchild etc. |
* |
wildcard can be used instead of node name |
@ |
selects an attribute of a node e.g. a/@href will select value of href attribute of an a node |
text() |
selects text value of a node |
[] |
selector constraint — can be used to filter out nodes that do no match some condition |
parent or .. |
select current nodes parent e.g. /div/a/.. will select div element |
self or . |
select current node (this is useful as argument in xpath function, we’ll cover more later) |
following-sibling::node |
selects all following siblings of type, e.g. following-sibling::div will select all div siblings below the current node |
preceding-sibling::node |
selects all preceding siblings of type, e.g. preceding-sibling::div will select all div siblings below the current node |
function() |
calls registered xpath function e.g. /a/text() will return text value of a node |
This XPath cheatsheet might be a lot to take in — so, let’s solidify this knowledge with some real-life examples.
Basic Navigation
When writing xpaths the first thing we should be aware of is that all xpaths have to have a root (aka point A) and final target (aka point B). Knowing this and xpath axis syntax, we can start describing our selector path:
<div>
<p class=»socials»>
Follow us on
<a href=»https://twitter.com/@scrapfly_dev»>Twitter!</a>
</p>
</div>
Here, our simple xpath simply describes a path from the root to the a node.
All we used is / direct child syntax, however with big documents direct xpaths are often unreliable as any changes to the tree structure or order will break our path.
It’s better to design our xpaths around some smart context. For example, here we can see that this <a> node is under <p class="socials"> node — we can infer strong sense that these two will most likely go together:
<div>
<p class=»socials»>
Follow us on
<a href=»https://twitter.com/@scrapfly_dev»>Twitter!</a>
</p>
</div>
With this xpath, we get rid a lot of structure dependency in favor of context. Generally, modern websites have much more stable contexts than structures, and finding the right balance between context and structure is what creates reliable xpaths!
Further, we can combine constrains option ([]) with value testing functions such as contains() to make our xpath even more reliable:
<div>
<p class=»socials»>
Follow us on
<a href=»https://twitter.com/@scrapfly_dev»>Twitter!</a>
</p>
</div>
Using XPath contains() text function, we can filter out any results that don’t contain a piece of text.
Xpath functions are very powerful and not only they can check for truthfulness but also modify content during runtime:
<div>
<p class=»socials»>
Follow us on
<a href=»https://twitter.com/@scrapfly_dev»>Twitter!</a>
or connect with us on
<a href=»https://www.linkedin.com/company/scrapfly/»>Linkedin</a>
</p>
</div>
Here, we’ve added concat() function, which joins all provided arguments into a single value and only then perform our match check.
Navigating Complex Structures
Sometimes tree complexity outgrows context based selectors and we have to implement some complex structure checks. For that, xpath has powerful tree navigation features that allow to select ancestors and siblings of any level:
<div>
<span>For price contact </span>
<a>Sales department </a>
<div>
<span>total: </span>
</div>
<span>166.00$</span>
<span>*taxes apply</span>
</div>
In this example, we find a text containing the phrase «total», navigate up to its parent and get the first following sibling using XPath.
Other times, we need to use position-based predicates and even combine multiple XPaths to reliably parse HTML data:
<div>
<span>items: </span>
<span>(taxes not included)</span>
<span>166.00$</span>
<span>25.00$</span>
<span>*taxes apply</span>
<div>
<span>addons:</span>
<span>0.5$</span>
</div>
</div>
In this example, we used position() function to select only siblings that are in specific range. We also combined to xpaths using the | operator (for or operation or operator can being used) to fully retrieve all pricing info.
As you can see, xpaths can be very powerful and parse almost any html structure if we get creative with path logic!
Extending Functions
Xpath in most clients can be extended with additional functions, and some clients even come with pre-registered non-standard functions.
For example, in Python’s lxml (and it’s based packages like parsel) we can easily register new functions like this:
from lxml import etree
def myfunc(context, *args):
return True
xpath_namespace = etree.FunctionNamespace(None)
xpath_namespace['myfunc'] = myfunc
Other language clients follow a similar process.
Xpath Clients
Almost every programming language contains some sort of xpath client for XML file parsing. Since HTML is just a subset of XML we can safely use xpath in almost every modern language!
Xpath in Python
In Python there are multiple packages that implement xpath functionality, however most of them are based on lxml package which is a pythonic binding of libxml2 and libxslt C language libraries. This means Xpath selectors in Python are blazing fast, as it’s using powerful C components under the hood.
While lxml is a great wrapper, it lacks a lot of modern API usability features used in web scraping. For this, lxml based packages parsel (used by scrapy) and pyquery provide a richer feature set.
Example usage with parsel:
from parsel import Selector
html = """
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1 class="title">Page header by <a href="#">company</a></h1>
<p>This is the first paragraph</p>
<p>This is the second paragraph</p>
</body>
</html>
"""
sel = Selector(html)
sel.xpath("//p").getall()
# [
# "<p>This is the first paragraph</p>",
# "<p>This is the second paragraph</p>",
# ]
Other tool recommendations:
- cssselect — converts css selectors to xpath selectors
- parsel-cli — real time REPL for testing css/xpath selectors
Xpath in PHP
In PHP most popular xpath processor is Symphony’s DomCrawler:
use SymfonyComponentDomCrawlerCrawler;
$html = <<<'HTML'
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1 class="title">Page header by <a href="#">company</a></h1>
<p>This is the first paragraph</p>
<p>This is the second paragraph</p>
</body>
</html>
HTML;
$crawler = new Crawler($html);
$crawler->filterXPath('//p');
Other tool recommendations:
- css-selector — converts css selectors to xpath selectors
Xpath in Javascript
Javascript supports xpath natively, you can read more about it on MDN’s Introduction to Using Xpath in Javascript
Other tool recommendations:
- jQuery — extra syntax sugar and helpers for xpath querying.
- cash — lightweight, modern jQuery alternative.
Xpath in Other Languages
Most other languages have some sort of XPath client as XML parsing is an important data exchange feature. Meaning, we can parse web-scraped content in the language of our choice!
For example, C# supports XPath natively as well, you can read more about it over at the official documentation so does Objecive C and other low-level languages.
While some languages might not have first-party XPath clients it’s very likely there’s a community package. For example, Go language has community packages for xpath in xml, html and even json.
Xpath in Browser Automation
Browser automation tools support XPath without any additional Javascript packages.
To access XPath in Selenium we can use by.XPath selector. For example, for Selenium in Python:
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://httpbin.org/html")
element = driver.find_element(By.XPATH, '//p')
To access XPath in Playwright we can use the locator functionality which take either CSS selectors or XPath as the argument. For example in Playwright and Python:
from playwright.sync_api import sync_playwright
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=False)
context = browser.new_context(viewport={"width": 1920, "height": 1080})
page = context.new_page()
page.goto("http://httpbin.org/html")
paragraphs = page.locator("//p") # this can also take CSS selectors
To access XPath in Puppeteer we can use the $ and $$ methods. For example in Puppeteer in Javascript:
const puppeteer = require('puppeteer')
const browser = await puppeteer.launch();
let page = await browser.newPage();
await page.goto('http://httpbin.org/html');
await page.$("//p");
FAQ
To wrap this introduction up let’s take a look at some frequently asked questions regarding HTML parsing using XPath selectors:
Is XPATH faster than CSS selectors?
Many CSS selector libraries convert CSS selectors to XPATH because it’s faster and more powerful. That being said it depends on each individual library and complexity of the selector itself. Some XPATH selectors which use broad selection paths like // can be very expensive computationally.
My xpath selects more data than it should
XPATH broad selector paths like // are global rather than relative. To make them relative we must add the relativity marker . -> .//
How to match nodes by multiple names?
To match nodes by multiple names we can use wildcard selector together with a name check condition: //*[contains("p h1 head", name())] — will select h1, p and head nodes.
How to select select elements between two nodes?
If we know two nodes like text headers we can select text between with clever use of preceding-sibling notation:
//h2[@id="faq"]//following-sibling::p[(preceding-sibling::h2[1])[@id="faq"]] — this xpath selects all paragraph nodes under h2 tag with id faq and not elements under other h2 nodes.
<div>
<span>items: </span>
<span>(taxes not included)</span>
<span>166.00$</span>
<span>25.00$</span>
<span>*taxes apply</span>
<div>
<span>addons:</span>
<span>0.5$</span>
</div>
</div>
Summary
In this article, we’ve introduced ourselves with xpath query language. We’ve discovered that HTML documents are data trees with nodes and attributes which can be machine parsed efficiently.
We glanced over the most commonly used XPath syntax and functions and explored common HTML parsing scenarios and best practices using our interactive XPath tester.
Xpath is a very powerful and flexible path language that is supported in many low-level and high-level languages: Python, PHP, Javascript etc. — so, whatever stack you’re using for web-scraping, XPath can be your to-go tool for HTML parsing!
For more XPath help we recommend visiting Stackoverflow’s #xpath tag and see our data parsing tag for more articles on data parsing.
xPath это такой язык запросов, который позволяет среди множества элементов веб-страницы найти нужный, — и обратиться к нему, чтобы достать необходимые данные:
- Заголовок и описание.
- Названия статей с количеством просмотров.
- Список ссылок.
- Цены на товары.
- Изображения и т. п.
xPath поддерживают платные инструменты для парсинга (например, Screaming Frog Seo Spider), его выражения можно использовать в программировании на JavaScript, PHP и Python, и даже сделать простой бесплатный парсер прямо в Google Таблицах. Разбираемся, как именно — на трех практических примерах.
Когда начинаешь изучать большинство видео/статей по теме, начинает взрываться мозг — кажется, что все это очень сложно и подвластно только крутым технарям/хакерам. На самом деле все 200 встроенных функций xPath (как сообщает туториал W3C) знать совсем не обязательно, и на практике освоить язык получается гораздо проще. Процесс напоминает привычное ориентирование в папках и файлах в компьютере, а сами выражения xPath — адреса вроде «C:Program Files (x86)R-Studio».
1. Сбор и проверка заголовков и метатегов
Работа с заголовками (h1) и метатегами (title и description, реже keywords) — одна из составляющих поисковой оптимизации сайта. SEO-специалист (маркетолог, предприниматель) может проверять эти текстовые фрагменты на наличие, по длине, вхождениям определенных запросов. Если нужна массовая проверка, лучше воспользоваться специальным парсером (например, от Promopult или Click.ru), но небольшую задачу можно легко решить прямо в Google Spreadsheets.
Подготовка таблицы и разбор синтаксиса IMPORTXML
Начать можно с дизайна самой таблицы. Допустим, в первой колонке (A) будут ссылки на страницы, а правее уже результаты, извлеченные данные: H1, тайтл, дескрипшн, ключевые слова.
Тогда стоит первую строку отдать под заголовки (если планируются десятки ссылок, не помешает «Вид → Закрепить → 1 строку»), в A2 указать URL (можно пока любой — для проверки работоспособности) и приступить к написанию первой функции. (А так как текстовые фрагменты довольно длинные, можно заодно выделить все ячейки, нажать «Формат → Перенос текста → Переносить по словам».)
 Начало работы с парсер-таблицей. В качестве примера разберем заголовки и метатеги главной страницы Webartex — это такая платформа для работы с блогерами и сайтами.
Начало работы с парсер-таблицей. В качестве примера разберем заголовки и метатеги главной страницы Webartex — это такая платформа для работы с блогерами и сайтами.
Для импорта данных с сайтов (в форматах HTML, XML, CSV) в Google Таблицах есть функция IMPORTXML. Она принимает такие аргументы:
- Полный адрес веб-страницы с указанием протокола (например, «https://»). Можно передать сам URL в кавычках или адрес ячейки, где он лежит.
- Непосредственно запрос xPath — тоже в кавычках, так как это тоже текстовая строка.
- locale — локальный код для указания языка и региона, необязательный параметр, по умолчанию используются настройки самого документа.
Читайте также: 20+ продвинутых функций Google Таблиц (Spreadsheets)
Составление функций для импорта XML с разными запросами xPath
Для парсинга H1 получится довольно просто: =IMPORTXML(A2;»//h1″).
«//» это оператор для выбора так называемого корневого узла — откуда нужно будет сразу взять данные или же «плясать» дальше (к дочернему элементу, соседнему или др.). В данном случае не нужно прописывать длинный путь, указывать дополнительные параметры — тег <h1> такой один единственный (как правило, но может быть и несколько заголовков первого уровня, тогда запрос «//h1» выгрузит их в несколько строк).
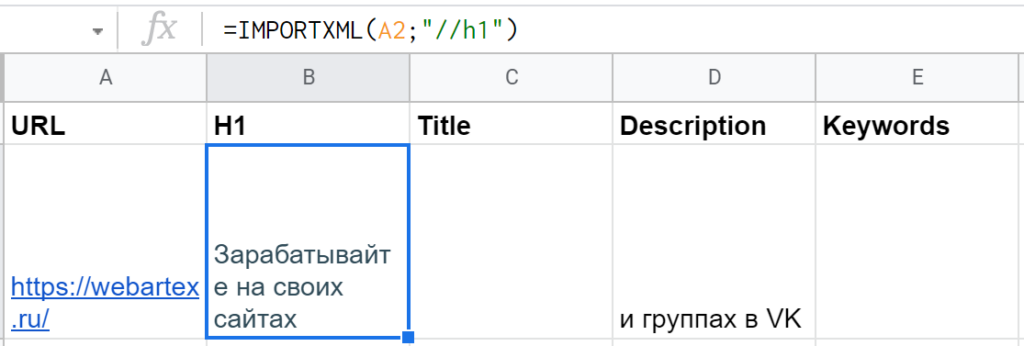 Вот что вернула функция IMPORTXML с «https://webartex.ru» по запросу «//h1»
Вот что вернула функция IMPORTXML с «https://webartex.ru» по запросу «//h1»
Правда, есть нюанс — часть заголовка первого уровня оказывается в ячейке D2, а там нужны совсем другие данные. Все из-за тега <br>, который внутри <h1> используется для перевода строки. Решение — функция самого xPath «normalize-space()«, в которую нужно упаковать текст из H1. Дополненная функция получается такой: =IMPORTXML(A2;»normalize-space(//h1)»)
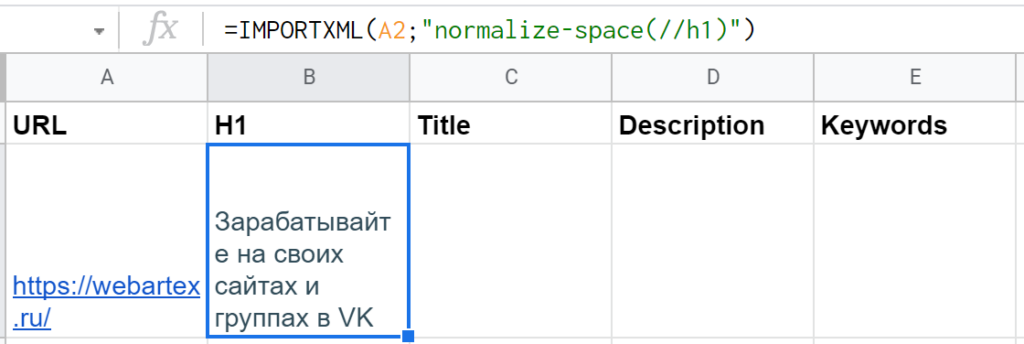 xPath-локатор работает корректно, можно идти дальше
xPath-локатор работает корректно, можно идти дальше
В ячейке C2 — по тому же принципу, только выражение xPath, соответственно, будет «//title».
А вот для загрузки дескрипшна в соседнюю ячейку D2 нельзя указать просто «//description», потому что такого отдельного тега нет. Эти данные лежат в теге <meta>, у которого есть дополнительный параметр (атрибут) — «name» со значением «description«.
Если в запросе xPath нужно указать не просто элементы веб-страницы, а элементы с конкретным атрибутом, то соответствующие условия указываются в квадратных скобках. Название атрибута пишется с собакой «@», а его значение передается через одинарные кавычки. Если нужно проверить эквивалентность, то условие записывается просто как «атрибут = значение».
То есть для решения этой задачи нужно указать элемент так: «//meta[@name=’description’]».
 Шпаргалка: из чего состоят HTML-элементы, из которых уже состоят веб-страницы (иллюстрация из курса Hexlet по основам HTML, CSS и веб-дизайна).
Шпаргалка: из чего состоят HTML-элементы, из которых уже состоят веб-страницы (иллюстрация из курса Hexlet по основам HTML, CSS и веб-дизайна).
Однако если оставить такое выражение, то функция IMPORTXML вернет значение #N/A — значит, нет данных для импорта. Хотя путь к элементу указан верно. Дело в том, что внутри этого тега <meta> нет ничего — результат соответствующий.
Это хорошо видно, если открыть исходный код страницы (например, через сочетание клавиш Ctrl + U в Google Chrome). У <meta> нет закрывающего тега </meta>, как это бывает у многих других, получается, нет и внутреннего содержания. Нужные данные лежат в другом атрибуте — @content.
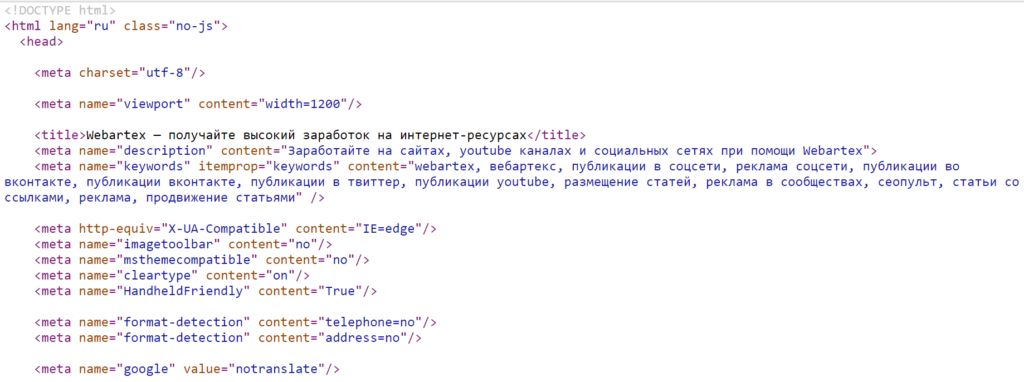 Исходный код страницы Webartex, на которых хорошо видно устройство тегов <meta>
Исходный код страницы Webartex, на которых хорошо видно устройство тегов <meta>
Решение — дополнить запрос xPath, через «/» указав путь к конкретному атрибуту выбранного элемента. В данном случае вся формула будет такой: =IMPORTXML(A2;»//meta[@name=’description’]/@content»)
Если нужно указать не корневой элемент (узел), а его параметр или вложенный тег, тогда уже используется одинарный слеш, а не двойной. По аналогии с URL страниц сайтов или адресами файлов и папок операционной системы.
По такому же принципу составляется запрос для метатега с ключевыми словами — «//meta[@name=’keywords’]/@content». Если все ок, то, значит, можно протягивать формулы ниже, а в столбец URL добавлять новые адреса.
 Результаты после запуска всех функций. Все формулы написаны верно, данные собираются корректно, все работает нормально.
Результаты после запуска всех функций. Все формулы написаны верно, данные собираются корректно, все работает нормально.
Если нужно, аналогичным образом можно извлекать и другие данные: подзаголовки H2—H6, метатеги для разметки OpenGraph и Viewport, robots и др.
Читайте также: Микроразметка на сайте: что это, для чего нужно и как внедрить
Бонус: оценка полученных метатегов и заголовков
Допустим, нужно проверить, находится ли длина title и description в пределах нормы. Для этого можно воспользоваться функцией гугл-таблиц ДЛСТР (LEN). Она работает довольно просто: на входе текстовая строка, на выходе — число символов.
Согласно рекомендациям из блога Promopult, отображаемая длина тайтла в Google — до 50-55, а в Яндексе — до 45-55. Поэтому желательно не писать его слишком длинным, по крайней мере в первых 45–55 символах должна быть законченная мысль, самое главное о странице.
Чтобы не создавать дополнительных ячеек с цифрами по количеству символов, можно прописать формулу LEN в условном форматировании. Выделить третий столбец C, кликнуть в меню на «Формат → Условное форматирование», выбрать в списке «Правила форматирования» вариант «Ваша формула». И туда уже прописать, допустим, =LEN($C$2:$C)>55. А цвет, например, желтый, который как бы будет сигнализировать: «Тут надо посмотреть!».
В данном примере строка C2 пожелтеет, так как длина title составляет 59 знаков, а не 55. Но в принципе вся ключевая мысль, призыв к действию, умещается в лимит, так что все нормально.
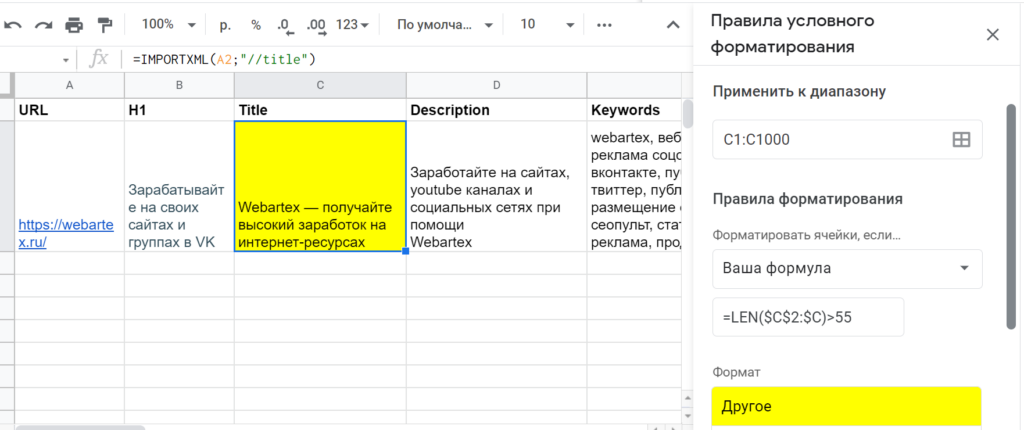 Настройка условного форматирования Google Таблиц для подсвечивания тайтлов, длина которых больше рекомендуемой
Настройка условного форматирования Google Таблиц для подсвечивания тайтлов, длина которых больше рекомендуемой
По такому же алгоритму можно сделать оценку description. В вышеупомянутой статье blog.promopult.ru сказано: лучше, чтобы вся важная информация метаописания умещалась в 100-120 символов.
А еще там есть рекомендация не указывать в метатеге keywords больше 10 ключевых слов. Но чтобы проверить это, нужен не подсчет длины, а количества самих слов, разделенных запятыми.
В гугл-таблицах нет специальной функции, которая считает количество вхождений определенных символов в текстовую строку, но эту задачу можно решить через условное форматирование с помощью такой формулы: =COUNTA(SPLIT($E$2:$E;»,»))>10. Небольшой ликбез:
- SPLIT — разделяет текст по определенным символам и выводит в разные ячейки. Два обязательных параметра: 1) собственно, текст, который нужно разделить, или ссылку на ячейку с таковым 2) один или несколько символов в кавычках, по которым как раз и нужно разделять текст.
- СЧЁТЗ (COUNTA) подсчитывает количество значений в наборе данных: принимает неограниченное число аргументов (значений и диапазонов). В данном случае забирает на вход результаты SPLIT, выдающей массив текстовых значений, и подсчитывает их общее число.
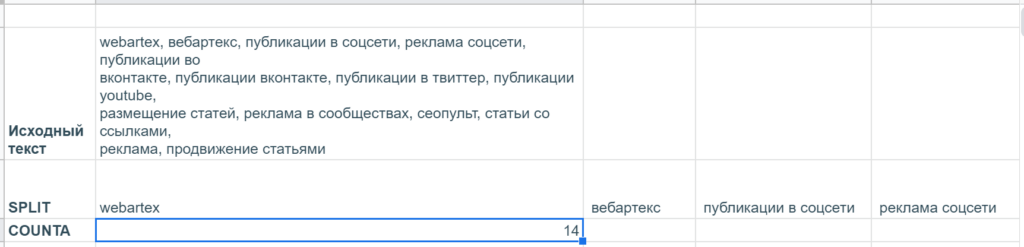 А вот так работают эти функции отдельно (конечно, все результаты SPLIT не поместились, функция располагает их в строке, поэтому они уходят далеко вправо).
А вот так работают эти функции отдельно (конечно, все результаты SPLIT не поместились, функция располагает их в строке, поэтому они уходят далеко вправо).
Получилось, что количество keywords на странице webartex.ru составляет 14, а не 10 штук, значит, их лучше подсократить. Яндекс может использовать этот метатег при ранжировании страницы, но большое количество ключевых слов может, наоборот, привести к пессимизации, исключению из индекса.
«Поисковое продвижение» — бесплатный видеокурс по SEO в обучающем центре CyberMarketing. В программе структура поисковой выдачи, санкции поисковых систем, инструменты для сбора семантического ядра и другие важные темы. Преподаватель — Евгений Костин, руководитель департамента продаж системы Promopult.
2. Парсинг ссылок из топ-10 поисковика
Допустим, нужно регулярно мониторить топ Яндекса по определенному запросу, чтобы узнать, попал ли туда конкретный сайт и на какую позицию. Можно с помощью xPath извлечь все ссылки с органической выдачи, а благодаря текстовым функциям Google Таблиц уже искать совпадения с названием нужного сайта.
Поиск и анализ нужных элементов через DevTools
В качестве примера — запрос «отложенный постинг». Для начала нужно в браузере Chrome перейти на соответствующую страницу, кликнуть правой кнопкой на один из элементов, который нужно будет извлечь (пусть это будет ссылка ниже заголовка), и нажать на «Просмотреть код» (горячие клавиши — Ctrl + Shift +I). Тогда откроются «Инструменты разработчика» (Chrome DevTools) с кодом этого элемента.
В коде документа сразу можно заметить древовидную структуру. На самом верху — корневой тег <html>, внутри на одном уровне <head> и <body>, затем <body> раскрывается на десятки <div> и <script>, а в некоторых <div> еще другие <div> с <ul>, <li>, <h2> и т. п. Написание xPath-запроса напоминает квест: нужно правильно описать искомый элемент и путь к нему.
 Так выглядит просмотр кода нужного элемента в Chrome DevTools. (И было бы удобно кликнуть еще раз правой кнопкой, потом выбрать Copy и Copy XPath, затем вставить этот код в соответствующую функцию Таблиц, но, увы, как правило, так не работает. Приходится разбираться.)
Так выглядит просмотр кода нужного элемента в Chrome DevTools. (И было бы удобно кликнуть еще раз правой кнопкой, потом выбрать Copy и Copy XPath, затем вставить этот код в соответствующую функцию Таблиц, но, увы, как правило, так не работает. Приходится разбираться.)
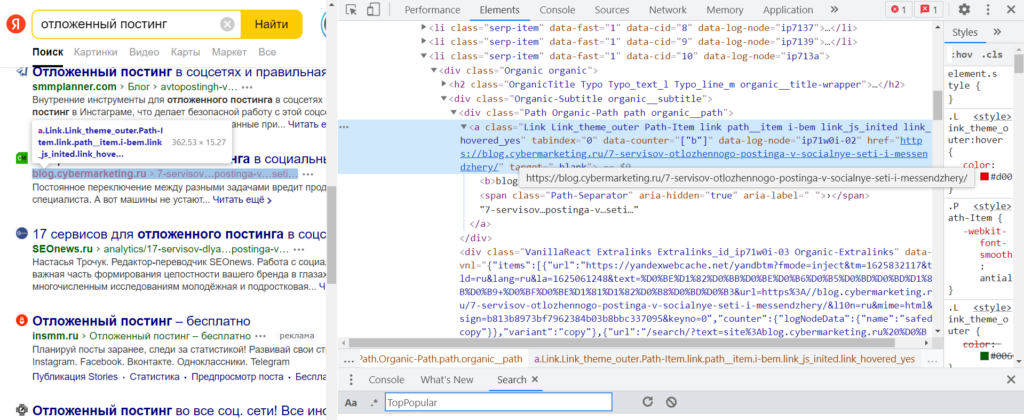
Напоминаем: страница состоит из элементов, а каждый элемент включает тег и содержание (что между открывающим и закрывающим тегом), а еще в открывающем теге может быть дополнительная информация: атрибуты и их значения. В данном случае необходимые данные — ссылка на страницу, которая попала в топ Яндекса — находятся в значении атрибута «href» тега <a>, у которого еще есть атрибут «class» со значением «Link Link_theme_outer Path-Item link path__item i-bem link_js_inited«
(А этот тег <a> находится внутри тега <div> с атрибутом «class» и значением «Path Organic-Path path organic__path»… но весь путь писать нет смысла, если сам <a> достаточно уникальный и правильно находится.)
Фрагмент кода (на скриншоте он не помещается целиком):
<div class="Path Organic-Path path organic__path"><a class="Link Link_theme_outer Path-Item link path__item i-bem link_js_inited" tabindex="0" data-counter="["b"]" data-log-node="ip71w0i-02" href="https://blog.cybermarketing.ru/7-servisov-otlozhennogo-postinga-v-socialnye-seti-i-messendzhery/" target="_blank"><b>blog.cybermarketing.ru</b><span class="Path-Separator" aria-hidden="true" aria-label=" ">›</span>7-servisov…postinga-v…seti…</a></div>
Но прежде чем писать запрос xPath, стоит проверить — действительно ли все нужные элементы имеют соответствующие атрибуты и значения. «href», понятно, будет везде разный, а вот что насчет «class» со значением «Link Link_theme_outer Path-Item link path__item i-bem link_js_inited»?
Для этого в окне «Инструменты разработчика» нужно нажать «Ctrl + F» и внизу появится поле «Find by string, selector, or xPath». Если вставить эту большую и страшную строку, видно, что подсвечивается с десяток элементов.
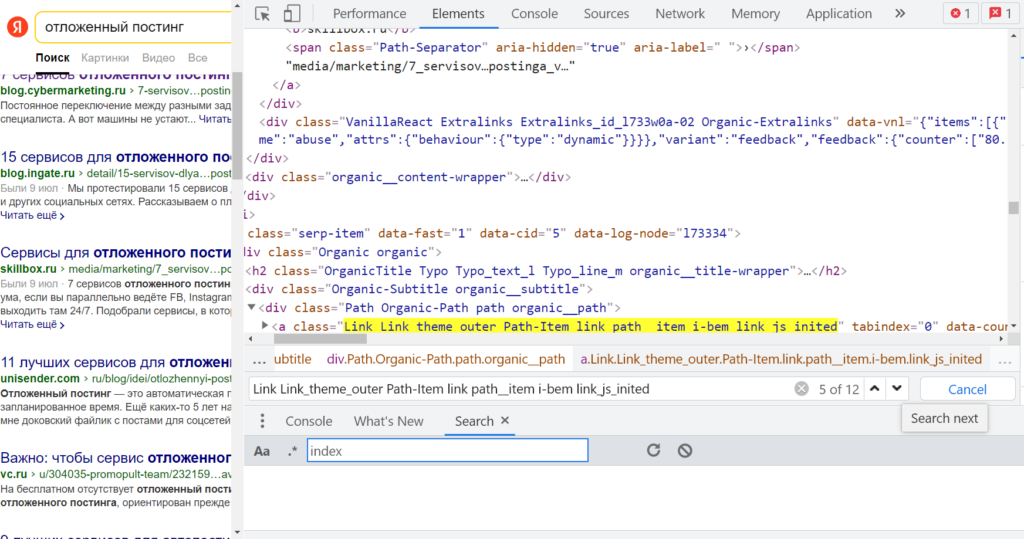 В процессе поиска нужного значения в коде через Chrome DevTools. Вроде все хорошо, и подсвечиваются нужные элементы с необходимыми ссылками…
В процессе поиска нужного значения в коде через Chrome DevTools. Вроде все хорошо, и подсвечиваются нужные элементы с необходимыми ссылками…
Ссылка из блока быстрых ответов не попадает — отлично, иначе она бы дублировалась. Но есть нюанс — и органическая, и платная выдача имеет такое же значение атрибута «class» тега <a>. Но их можно развести через дополнительное условие (все рекламные ссылки начинаются с «http://yabs.yandex.ru/»).
Читайте также: Чем отличается контекстная реклама от таргетированной
Написание xPath-локатора с учетом изученных элементов и их параметров
Вспоминаем: «//» — это оператор, который выбирает так называемый корневой узел — элемент для непосредственного извлечения данных или тот, от которого нужно будет дальше «плясать». Значит, нужно начать с «//a». Но если оставить так, то загрузятся все <a> со страницы, а для решения задачи нужны конкретные. То есть нужно указать, что нужен элемент <a> с атрибутом @class, у которого есть конкретное значение.
Делаем, как это уже было с метатегом дескрипшн из предыдущего раздела: атрибут с собакой, значение в одинарных кавычках, все условие в квадратных скобках → //a[@class=’Link Link_theme_outer Path-Item link path__item i-bem link_js_inited’] Можно проверить работоспособность запроса сразу же в «Инструментах разработчика» — в поле «Find by string, selector, or xPath». Вроде все работает.
Если перенести в Google Таблицы, формула получится такой: =IMPORTXML(«https://yandex.ru/search/?lr=45&text=отложенный постинг&p=0″;»//a[@class=’Link Link_theme_outer Path-Item link path__item i-bem link_js_inited’]») Но результат — #N/A!, нет данных для импорта.
Ах, да — как и в случае с description и keywords, искомые данные лежат в другом атрибуте. То есть нужно продолжить путь с помощью «/@href». Но функция снова не может импортировать данные.
 Вроде все написано правильно, но импорт данных не работает…
Вроде все написано правильно, но импорт данных не работает…
На самом деле в атрибуте это не один такой класс с длинным названием, а несколько, которые разделены пробелами. Возможно, поэтому IMPORTXML не может найти данные по условию [@class=’]. Решение — искать не полное совпадение, а часть значения атрибута с помощью функции contains.
Если взять начало «Link Link_theme_outer Path-Item», то поиск по документу в DevTools выдает те же элементы, ничего лишнего не подмешивается. Значит, можно написать запрос таким образом: «//a[contains(@class,’Link Link_theme_outer Path-Item’)]»
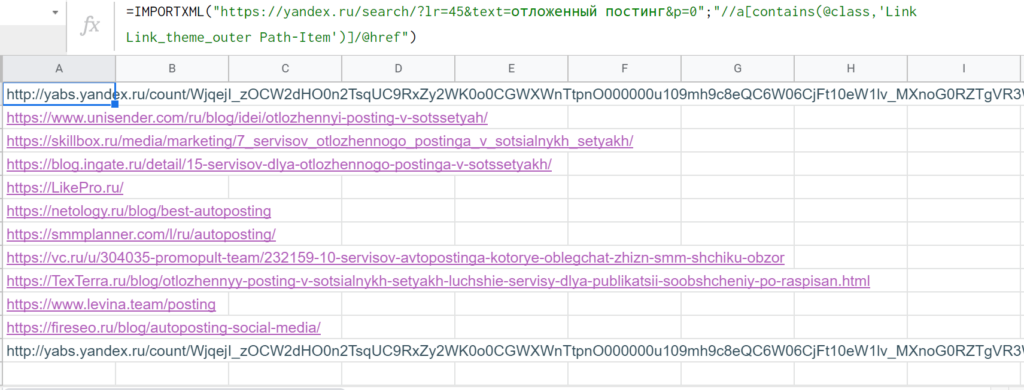 Вставили в IMPORTXML такой запрос xPath — все заработало.
Вставили в IMPORTXML такой запрос xPath — все заработало.
Функция contains через запятую принимает два аргумента: название параметра, где нужно искать вхождение, и текстовую строку, которую нужно искать. В данном случае нужно указать @class, но можно любой другой атрибут (или text(), если требуется найти вхождения во внутреннее содержание элемента). Альтернативой может стать другая функция starts-with — она ищет не в любом месте, а в начале строки. В данном случае результат такой же при «//a[starts-with(@class,’Link Link_theme_outer Path-Item’)]/@href».
Осталось только исключить из списка ссылки из контекстной рекламы, ведь нужна только органическая выдача. Для этого требуется указать два условия: чтобы взять все @href в теге <a> с классом, содержащим «Link Link_theme_outer Path-Item», но в то же время, чтобы в этих @href не было ссылок, где URL включает «yabs.yandex.ru». Решение — дополнить запрос xPath таким образом: «//a[contains(@class,’Link Link_theme_outer Path-Item’) and not(contains(@href,’yabs.yandex.ru’))]/@href»
Что здесь нового: логический оператор «and» указывает, что должны быть выполнены оба условия, а функция not() выполняет другую логическую операцию — отрицание. contains() внутри нее возвращает TRUE, когда находит в ссылке «yabs.yandex.ru», но в списке таковые как раз не нужны, поэтому TRUE надо превратить в FALSE. А логическое «И» работает только, когда оба условия — TRUE. Поэтому на выходе желаемый результат.
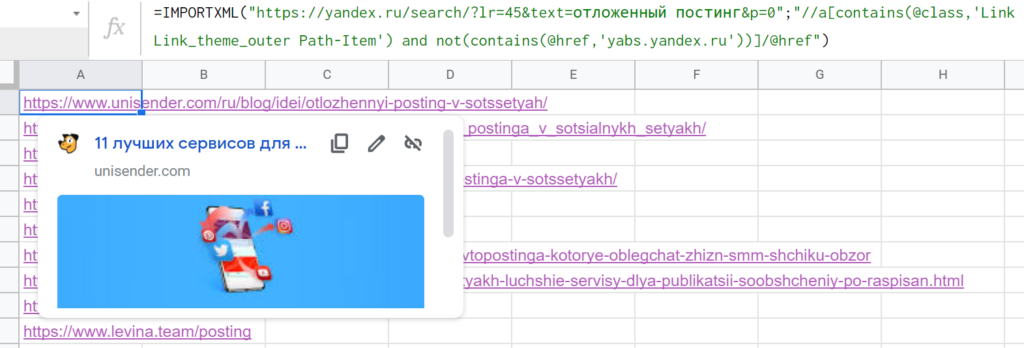 Выражение работает корректно: в списке URL’s органической выдачи, без рекламных ссылок и колдунщиков
Выражение работает корректно: в списке URL’s органической выдачи, без рекламных ссылок и колдунщиков
Кстати, вместо <a> с классом, включающим «Link Link_theme_outer Path-Item», можно взять другую ссылку — с заголовков страниц. То есть составить запрос так: «//a[contains(@class, ‘OrganicTitle-Link’) and not (contains(@href, ‘yabs.yandex.ru’))]/@href» (ну и, конечно, вместо второй функции contains можно взять start-with, в данном случае все рекламные ссылки будут начинаться одинаково, с «http://yabs.yandex.ru»).
А если захочется парсить не первую страницу, а, допустим, вторую, то достаточно в URL — первом аргументе функции IMPORTXML — увеличить значение параметра &p (в конце ссылки) с нуля до единицы. То есть изменить адрес на «https://yandex.ru/search/?lr=45&text=отложенный постинг&p=1».
Читайте также: Исчерпывающий гид по поисковым операторам Google и Яндекса
3. Выгрузка статистики по популярным статьям в блоге
Допустим, автору (редактору, маркетологу или блогеру) хочется следить за популярными материалами в других медиа, чтобы черпать идеи по новым темам уже для своего ресурса. Можно делать это вручную — заходить на каждый сайт, скроллить, тратить время на поиск соответствующего блока — или собирать такие данные в таблицу. Рассмотрим, как это можно делать, на примере сайта Yagla (не самый посещаемый тематический ресурс, но интересный вариант с точки зрения освоения языка xPath).
Изучение сайта и подходящих элементов
На сайте yagla.ru много разных блоков, но для этих целей больше подходят два: «Обсуждаемое» (в самом верху) и «Самые читаемые статьи за последние 3 недели» чуть пониже. Информации по просмотрам нет, но есть количество комментариев (чтобы узнать просмотры, нужно открывать конкретную страницу, но, если нужно, можно с помощью дополнительных IMPORTXML загружать данные и по каждой из них).
Для начала: кликнуть правой кнопкой мыши на один из нужных заголовков в вышеперечисленных блоках, выбрать «Просмотреть код». Chrome DevTools подсвечивают тег <p> с атрибутом @class равным «small-post__title». Но если ввести это значение в поле «Find by string, selector, or xPath» видно, что оно есть и у материалов другого блока «Примеры роста конверсий, заказов и прибыли», который не нужно импортировать.
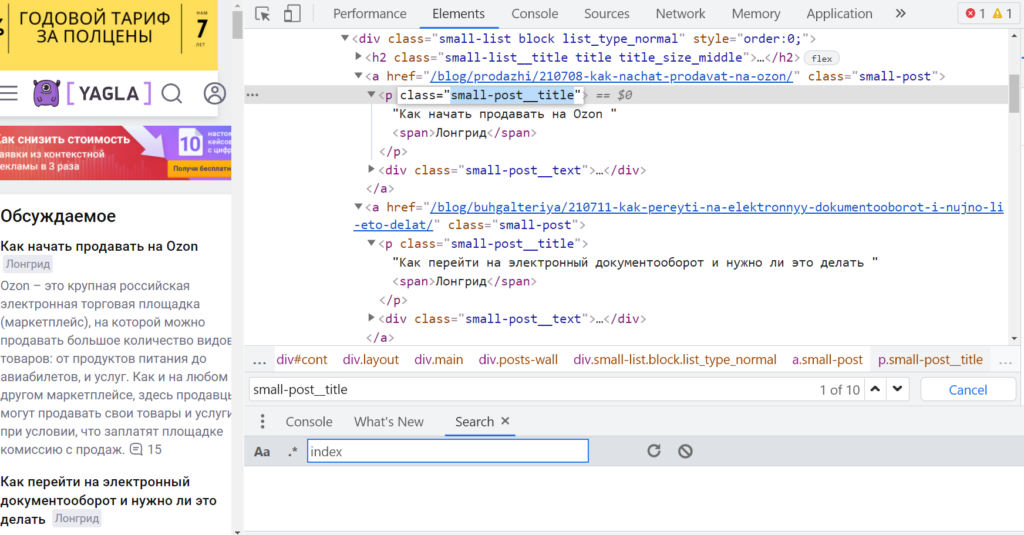 Начинаем изучать элементы главной страницы сайта в «Инструменты разработчика» Google Chrome
Начинаем изучать элементы главной страницы сайта в «Инструменты разработчика» Google Chrome
Родительский элемент, в который вложен вышеупомянутый <p>, — это <a> с классом ‘small-post‘. Но он еще более неуникальный, на странице таких 40 штук. Соседний (на одном и том же уровне) с <a> элемент — <h2> с классом «small-list__title title title_size_middle» тоже найден на странице в количестве четырех штук.
Но ведь можно прописать путь к элементу не только по значению атрибута, но и его содержанию, тексту.
Читайте также: Чек-лист: как проверить верстку
Составление запроса xPath
Обратиться к элементу можно и так — «//*[text()=’Обсуждаемое ‘]», чтобы взять только тот, где текст полностью соответствует строке ‘Обсуждаемое’. Сам тег в таком случае тоже прописывать необязательно.
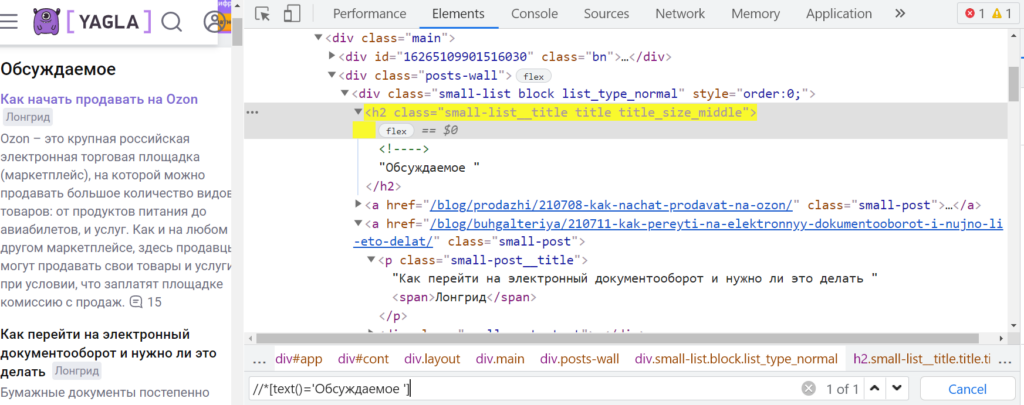 Проверка первой части запроса xPath в DevTools показывает, что все ищется верно
Проверка первой части запроса xPath в DevTools показывает, что все ищется верно
Но при написании дальнейшего пути не получится как обычно продолжить с одинарным слешем, ведь нужен не потомок этого элемента, а элемент того же уровня — «сосед» («брат», «сестра»). В таких случаях нужен специальный оператор — ‘following-sibling::’. В итоге выражение xPath получится таким: «//*[text()=’Обсуждаемое ‘]/following-sibling::a/p». (Дополнительно указывать классы для <a> и <p> нет необходимости, так как других похожих вариантов путей нет.)
Таким же способом можно составить выражение для загрузки данных из другого блока: «//*[text()=’Самые читаемые статьи за последние 3 недели ‘]/following-sibling::a/p»
Базовая настройка и оформление таблицы
Как вариант. В ячейку A1 положить заголовок «Обсуждаемое», а ниже — в A2 — уже написать функцию: =IMPORTXML(«https://yagla.ru/»;»//*[text()=’Обсуждаемое ‘]/following-sibling::a/p»). Затем оставить необходимое пространство (если ячейки будут заняты, функция не сможет отобразить результаты), A5 отдать под следующий заголовок, а в A6 — вторую формулу: =IMPORTXML(«https://yagla.ru/»;»//*[text()=’Самые читаемые статьи за последние 3 недели ‘]/following-sibling::a/p»)
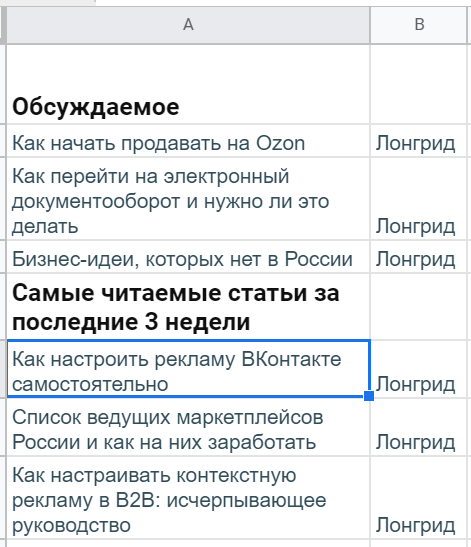 Такая вот таблица с популярными материалами получается в итоге
Такая вот таблица с популярными материалами получается в итоге
Внутри искомого <p> есть еще <span> с указанием формата, поэтому IMPORTXML требуется дополнительный столбец справа. (Так как эта информация излишняя, можно просто выделить все ячейки B, кликнуть правой кнопкой и выбрать «Скрыть столбец».)
‘following-sibling::’ — это одна из осей, основы запросов языка xPath. Есть и другие, например, ‘child::’ — возвращает множество потомков на один уровень ниже; ‘attribute::’ — выдает, соответственно, атрибуты; ‘parent::’ — ищет родительский узел. И с частью этих осей мы уже знакомы, просто для наиболее распространенных действуют сокращения. Так, child:: вообще прописывать необязательно, а attrubute:: заменяется на ‘@’.
Бонус: прокачка мини-парсера в Google Spreadsheets
Допустим, названия статей мало, нужны еще и просмотры, которых нет на главной странице. Тогда придется немного усовершенствовать гугл-таблицу. Разберем на примере блока «Обсуждаемое» — с другим все будет так же.
Для начала нужно выгрузить URL’s материалов. Как обычно ссылки лежат в атрибутах @href тега <a>, так что достаточно просто поменять концовку выражения xPath: «//*[text()=’Обсуждаемое ‘]/following-sibling::a/@href».
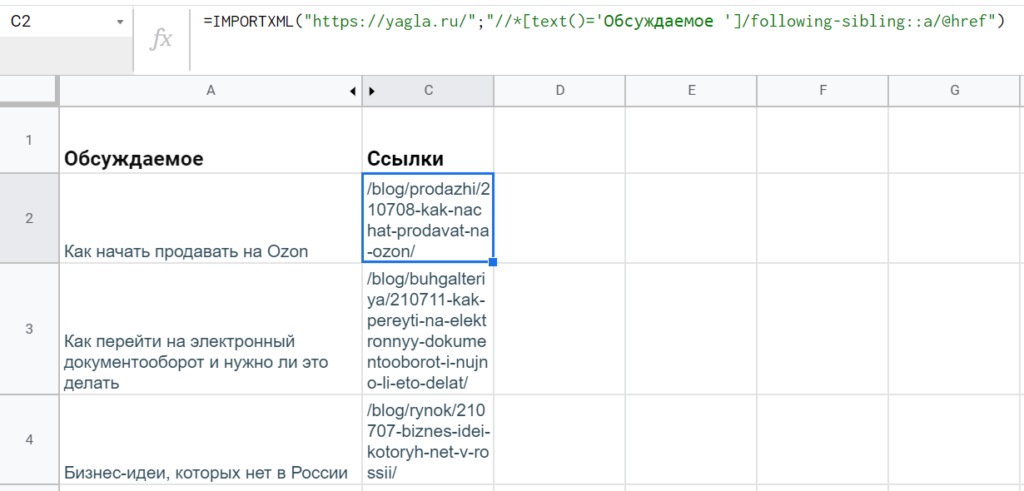 Все работает — в таблице появились ссылки на статьи.
Все работает — в таблице появились ссылки на статьи.
Правда, ссылки не полные, а относительные — нужно превратить их в URL’s с названием домена. Решить задачу можно с помощью текстовой функции гугл-таблиц — СЦЕПИТЬ (CONCATENATE). Она работает просто: принимает на вход несколько строк, а возвращает объединенный текст.
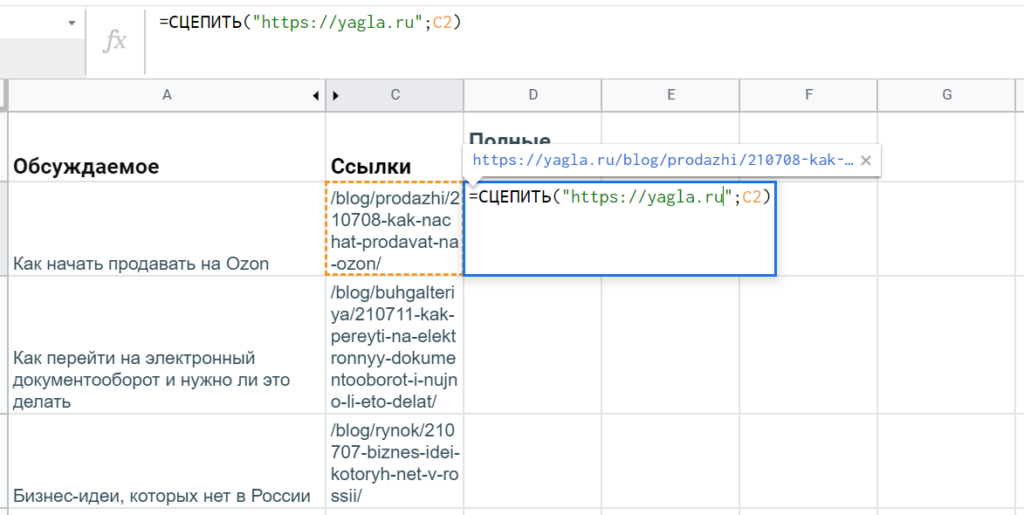 В отдельном столбце можно дополнить выгруженные относительные ссылки до полных путей
В отдельном столбце можно дополнить выгруженные относительные ссылки до полных путей
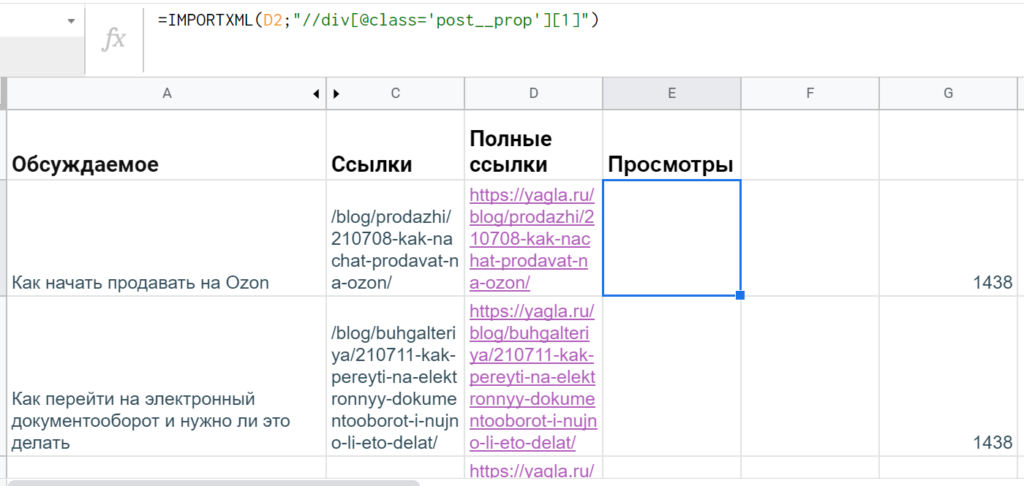
Дальше уже к каждой странице сделать отдельные запросы xPath, чтобы извлечь данные со счетчика просмотров. Если посмотреть через DevTools, таковые находятся в теге <div> c атрибутом @class равным ‘post__prop‘. Однако элемент есть и наверху, и внизу, а в таблице нужен один. В такой ситуации в квадратных скобках указывается индекс, порядковый номер (если говорить терминами xPath — предикат).
Судя по шпаргалкам и справочникам, кажется, что нужно просто написать «//div[@class=’post__prop’][1]», но в таблице все равно оказываются два значения — да еще и с лишними пустыми ячейками.
 Пока что получился такой некрасивый результат
Пока что получился такой некрасивый результат
Однако эксперты Stackoverflow разъясняют, что такой синтаксис работает только для последовательности узлов, а если нужен корневой элемент, то понадобятся дополнительные скобки: «(//div[@class=’post__prop’])[1]».
А лишние ячейки появляются из-за того, что внутри этого div есть еще теги. Чтобы почистить данные, понадобится применить функцию text(). Итоговая формула в гугл-таблицах получается такой: =IMPORTXML(D2;»(//div[@class=’post__prop’])[1]/text()»)
Остается только протянуть ее ниже — для всех строк с выгруженными URL статей.
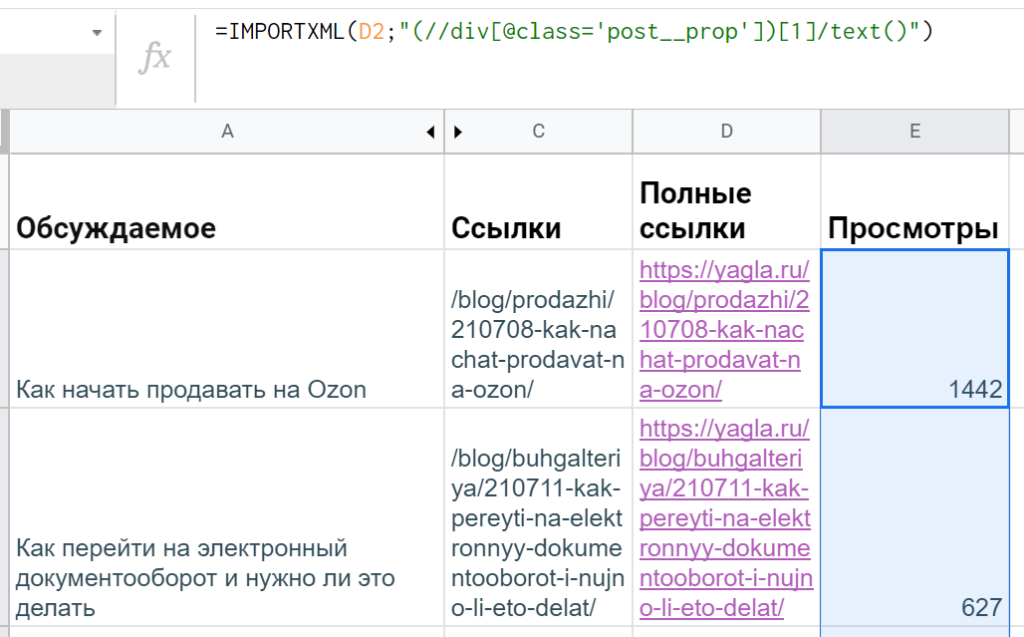 Доработанная таблица с выгрузкой просмотров
Доработанная таблица с выгрузкой просмотров
Читайте также: Где вести блог, если нет своего сайта: 10 платформ для личного и корпоративного блогинга
Подытожим
xPath в гугл-таблицах — мощная штука, однако подходит только для решения относительно простых задач.
Так, при наличии большого количества формул типа IMPORTHTML, IMPORTDATA, IMPORTFEED и IMPORTXML результаты могут грузиться очень долго — а польза парсинга как раз в том, что можно быстро добывать свежие данные. К тому же, например, статистику Яндекс.Вордстат не получится извлечь через xPath — для работы нужна авторизация, да и даже при ручном сборе сервис может замучать капчей.
Поэтому для более серьезных задач по продвижению/оптимизации нужны профессиональные инструменты, например, Promopult. Там большой выбор решений для SEO- и PPC-специалистов: парсинг Wordstat и метатегов, сбор поисковых подсказок и кластеризация запросов, поиск и генерация объявлений и др. Один запрос стоит от 0.01 руб.
- Что такое XPath
- Терминология XPath и отношение узлов
- Синтаксис
- Предикаты
- Как парсить данные с помощью Google Spreadsheets
- Синтаксис XPath-запроса для Google Spreadsheets
- Распространённые выражения
- Разметка Open Graph
- Извлечь ссылки, которые содержат слово по шаблону
- Извлечь ссылки на профили в соцсетях
- Спарсить количество проиндексированных страниц в Яндексе
- Спарсить количество контента на странице
- Спарсить код ответа сервера
- Как парсить данные с помощью XPath и Screaming Frog
- Несколько полезных кастомных функций Screaming Frog
Занимаясь поисковой оптимизацией сайта, специалисты часто сталкиваются с необходимостью извлечь данные не с одной страницы, а с нескольких за раз. Для этого удобно использовать XPath (XML Path Language) – декларативный язык запросов к элементам XML или XHTML документа. В этой статье я расскажу о базовых элементах и покажу несколько примеров их применения.
Что такое XPath
XPath или XML Path – это язык запросов, который можно использовать для поиска узлов (элементов) в документах XML (Extensible Markup Language).
Языки разметки HTML и XML следуют аналогичным правилам структуры и формата. Поэтому XPath также можно использовать для запросов к HTML-документам.
Проще говоря, для поиска и обработки элементов в HTML-документах мы можем использовать особый синтаксис XPath, чтобы следовать структуре и иерархии страницы.
Терминология XPath и отношение узлов
В XPath есть семь типов узлов: элементы, атрибуты, текст, пространство имён, инструкции по обработке, комментарии и узлы документов.
XML-документы рассматриваются как деревья узлов. Самый верхний элемент дерева называется корневым элементом.
Связи между узлами бывают Parent, Children, Siblings, Ancestors, Descendant – подробнее о связях читайте в справке. Мы можем выделить 2 главные связи:
- Связь Parent (родитель) – у каждого элемента и атрибута есть один родитель. Так, в следующем примере элемент ‹book› является родителем по отношению к элементам ‹title›, ‹author›, ‹year› и ‹price›:

- Связь Children (ребёнок) – узлы элементов могут иметь ноль, одного или нескольких дочерних элементов. Так, элементы ‹title›, ‹author›, ‹year› и ‹price› являются дочерними элементами элемента ‹book›.

Синтаксис
Рассмотрим базовый синтаксис XPath:
| Синтаксис | Что означает |
|---|---|
| nodename | Выбирает все узлы с именем «nodename» |
| / | Выбирает из корневого узла |
| // | Выбирает узлы в документе из текущего узла, которые соответствуют выделению, независимо от того, где они находятся |
| . | Выбирает текущий узел |
| .. | Выбирает родителя текущего узла |
| @ | Выбирает атрибуты |
Существуют два вида указания пути к нужному элементу – абсолютный и относительный.
В абсолютном пути используется полный XPath-запрос от корневого тега HTML до конкретного элемента. Ключевой характеристикой является то, что он начинается с одинарной косой черты (/), обозначающей корневой узел.
Например:
Есть текст «Drappier Rose Brut» в ссылке.
Абсолютный путь будет следующим:
/html[1]/body[1]/div[@class='wu_body']/div[1]/div[1]/main[1]/div[1]/section[1]/div[2]/div[1]/a[1]/div[1]
Относительный XPath начинается с выбранного вами узла, который не обязательно должен быть корневым.
Он начинается с двойной косой черты (//), и преимущество его использования в том, что вам не нужно прописывать абсолютный путь XPath.
Для этого же примера относительный XPath будет следующим:
//div[@class='w2_index__slider-mon--elem-name']
Как видите, выполнять запросы с помощью относительного пути намного проще, а запись намного короче.
Предикаты
Предикаты помогают сделать выборку в наборе узлов на основе некоторого условия. Вот несколько основных:
| Предикат | Что означает |
|---|---|
| //a[1] | Выбирает первый элемент, который является дочерним элементом ‹a› |
| //a[last()] | Выбирает последний элемент из всех элементов ‹a› |
| //a[@class] | Выбирает все элементы ‹a› с атрибутом class |
| //a[@class=’offer’] | Выбирает все элементы ‹a›, у которых есть атрибут class со значением «offer». |
Полный список выражений и предикатов можно посмотреть в справке.
Как парсить данные с помощью Google Spreadsheets
С помощью функции importxml в таблицах Google можно парсить метаданные, заголовки, наименования товаров, цены, почту и многое другое. Рассмотрим самые популярные и полезные функции и их применение.
Синтаксис XPath-запроса для Google Spreadsheets
IMPORTXML(URL,"XPath_выражение")
, где
- URL – это URL-адрес страницы, включая протокол (например, http://). Значение URL должно быть указано в кавычках или быть ссылкой на ячейку, содержащую соответствующий текст.
- XPath_выражение – запрос XPath, выполняемый для структурированных данных.
Распространённые выражения
| XPath | Значение импорта |
|---|---|
| //h1 | Спарсить заголовок страницы (h2-h6 по аналогии) |
| //title | Спарсить Title страницы |
| //meta[@name=’description’]/@content | Спарсить Description страницы |
| //a/@href | Выгрузка всех ссылок с сайта |
| //link[@rel=’canonical’]/@href | Спарсить каноникал страницы |
| //meta[@name=’robots’]/@content | Спарсить значения тега robots на странице |
| //link[@rel=’amphtml’]/@href | URL-адрес AMP |
Разметка Open Graph
Open Graph используется Facebook, LinkedIn и Pinterest, так что это ещё одна причина убедиться в правильной реализации разметки.
| XPath | Значение импорта |
|---|---|
| //meta[@property=’og:title’]/@content | OG Title |
| //meta[@property=’og:description’]/@content | OG Description |
| //meta[@property=’og:type’]/@content | OG Type |
| //meta[@property=’og:url’]/@content | OG URL |
| //meta[@property=’og:image’]/@content | OG Image |
| //meta[@property=’og:site_name’]/@content | OG Site Name |
| //meta[@property=’og:locale’]/@content | OG Locale |
Пример использования – нам нужно узнать значение тега Title для разметки Open Graph.

Спарсить URL из Sitemap
Формула:
=ImportXML(URL;"//url/loc")
Пример использования:

Спарсить внутренние и внешние ссылки страницы
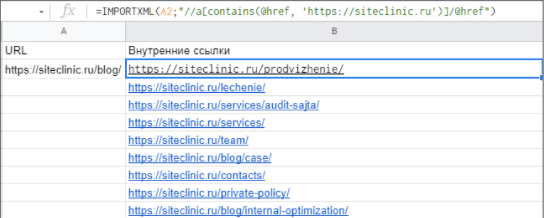
- Формула для парса внутренних ссылок:
=ImportXML(URL;"//a[contains(@href, 'доменное_имя')]/@href")
Пример:

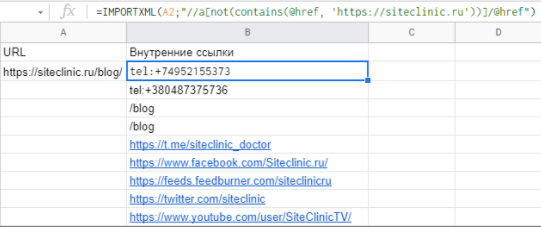
- Формула для парса внешних ссылок:
=ImportXML(URL;"//a[not(contains(@href, 'доменное_имя'))]/@href")
Пример:

Замечание!
В этих примерах на странице реализованы внутренние ссылки с относительным URL, поэтому для точного результата нужно в примере с внешними ссылками отфильтровать значения по протоколу https:// и убрать значения с относительными URL в таблицу с внутренними ссылками.
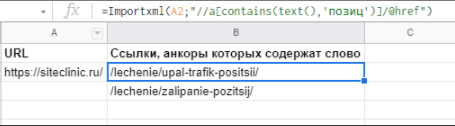
Извлечь ссылки, которые содержат слово по шаблону
Формула:
=Importxml(A2;"//a[contains(text(),'Шаблон текста')]/@href")
Пример:
Извлечь ссылки на профили в соцсетях
Формула:
=IMPORTXML(URL;"//a[contains(@href, 'vk.com/') or contains(@href, 'twitter.com/') or contains(@href, 'facebook.com/') or contains(@href, 'instagram.com/') or contains(@href, 'youtube.com/')]/@href")
Пример:

Спарсить количество проиндексированных страниц в Яндексе
Алгоритм:
Поисковый запрос такого типа [site:siteclinic.ru] показывает количество проиндексированных страниц в выдаче.
Эти данные лежат в теге ‹div› с классом serp-adv__found.
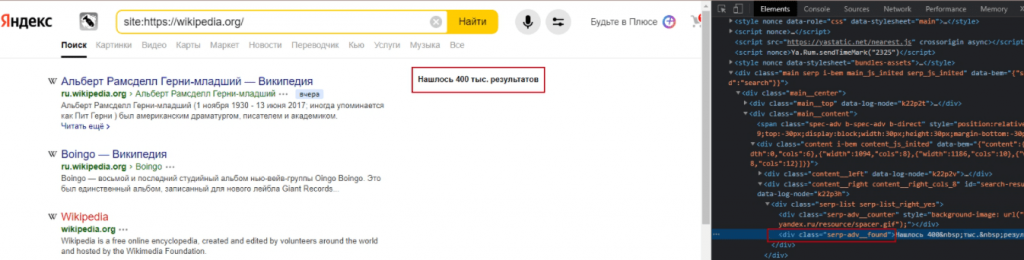
Поэтому для извлечения данных используем формулу:
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(importxml(CONCATENATE("https://yandex.ru/search/?text=site%3A";"ссылка на сайт");"//div[@class='serp-adv__found']");"Нашлось ";"");" результатов";"");" результата";"");" ";"");"Нашлась";"");"результат";"");"Нашёлся";"");"тыс.";"000")
Пример:
![]()
Спарсить количество контента на странице
К примеру, нужно узнать соотношение текста на странице блога к количеству кода на странице – таким образом можно узнать, какие статьи желательно доработать, так как там мало контента.
Пример:

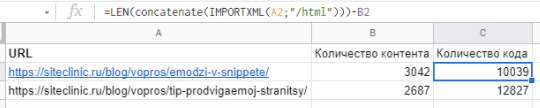
Формула:
=LEN(concatenate(IMPORTXML(A2;"//article/div";"//h1")))
– формула, позволяющая узнать количество текстового контента на странице
=LEN(concatenate(IMPORTXML(A2;"/html")))-B2
– формула, позволяющая узнать количество кода на странице, при этом в ячейке B2 мы находим количество текстового контента на странице
Спарсить код ответа сервера
Формула:
=SUBSTITUTE(importxml(concatenate("https://bertal.ru/index.php?a9132898/";A2);"//div[@id='otv']/b");"HTTP/1.1 ";"")
где A2 – это URL страницы.
Пример:

Чтобы выбрать определённый user-agent, замените первую ссылку на следующую:
https://bertal.ru/index.php?a9133026/ – Google Bot
https://bertal.ru/index.php?a9133032/ – Yandex Bot
Как парсить данные с помощью XPath и Screaming Frog
Screaming Frog SEO Spider – это SEO-краулер, при помощи которого можно парсить свой ресурс, а также ресурсы конкурентов.
После скачивания и установки программы нужно купить лицензию, так как нужная нам опция доступна только для лицензированных пользователей.
Custom Extraction – это пользовательская функция извлечения, которая позволяет вам парсить любые данные из HTML веб-страницы, используя CSSPath, XPath и регулярное выражение. Извлечение выполняется на основе статического HTML, возвращённого из URL-адресов с ответом 200 ОК, просканированных парсером. Также можно переключиться в режим рендеринга JavaScript, чтобы извлечь данные из визуализированного HTML.
После открытия Screaming Frog выполните следующие шаги для начала извлечения данных:
1. Нажмите Configuration > Custom > Extraction.
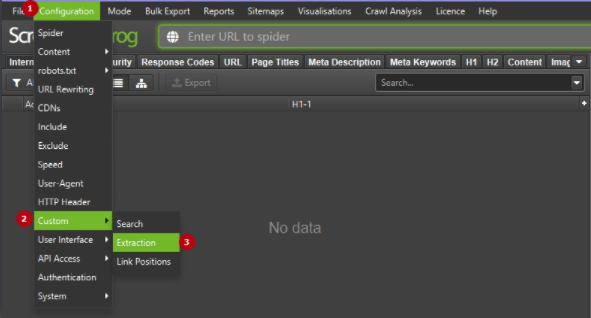
Вы перейдёте в пользовательскую конфигурацию извлечения, которая позволяет вам настроить до 100 отдельных «экстракторов»-правил. Чтобы добавить новые правила, кликните по кнопке Add – появится новое поле для задания правил.
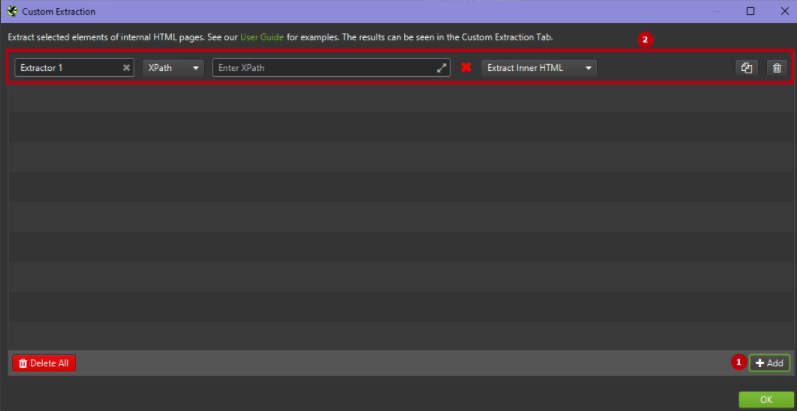
2. Выберите метод извлечения XPath.
Инструмент Screaming Frog SEO Spider предоставляет три метода парсинга данных с веб-сайтов – CSS Path, XPath и Regex. В данной статье мы будем использовать XPath.
При использовании XPath для сбора HTML-данных вы можете точно выбрать, что извлекать, используя раскрывающиеся фильтры:
- Extract HTML Element – извлекает выбранный элемент и всё его внутреннее HTML-содержимое.
- Extract Inner HTML – извлекает внутреннее HTML-содержимое выбранного элемента. Если выбранный элемент содержит другие элементы HTML, они будут включены.
- Extract Text – извлекает текстовое содержимое выбранного элемента и текстовое содержимое любых подэлементов.
- Function Value – извлекает результат предоставленной функции, например, count(//h1), чтобы найти количество тегов h1 на странице.
3. Добавьте выражение XPath.
Далее вам нужно будет ввести своё выражение XPath в соответствующие поля экстрактора. Быстрый и простой способ определить соответствующий путь XPath данных, которые вы хотите спарсить – это просто открыть веб-страницу в браузере Google Chrome и «просмотреть код» элемента HTML, который вы хотите спарсить (ПКМ по нужному элементу > Просмотреть код).
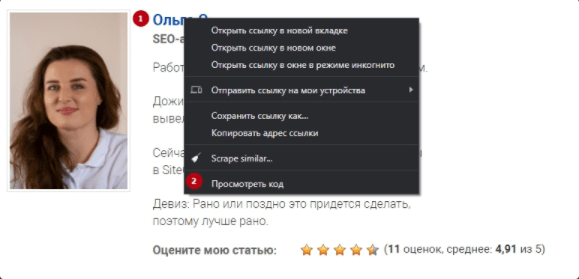
Затем откроется панель разработчика с выделенным элементом, щёлкните правой кнопкой мыши и скопируйте соответствующий путь селектора XPath.
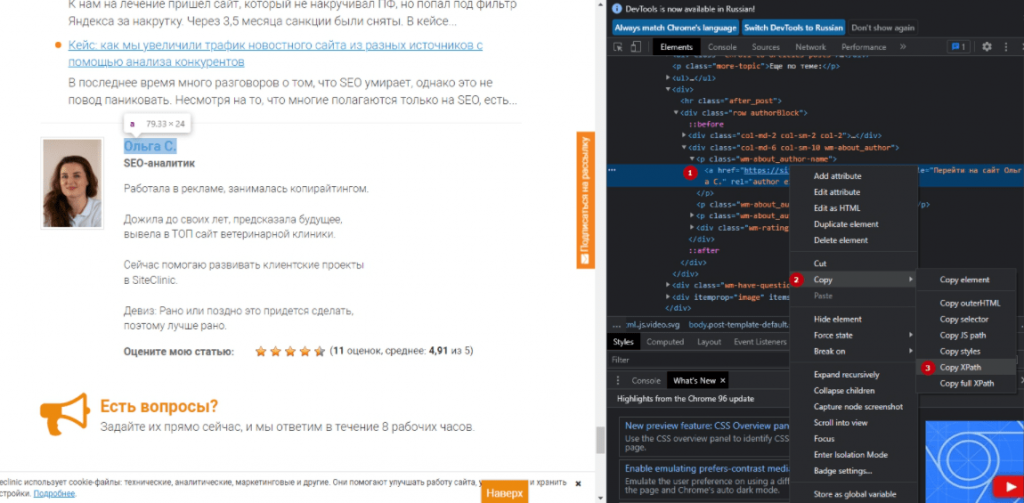
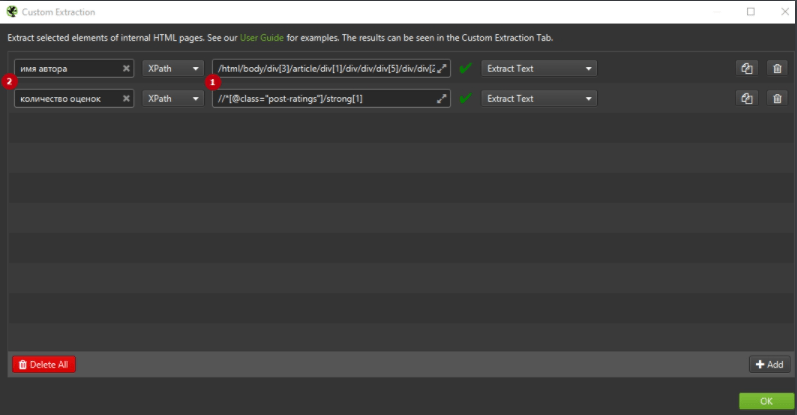
Например, вы можете начать собирать «авторов» статей в блогах и количество оценок статьи, которые они получили. Возьмём в качестве примера сайт https://siteclinic.ru/.
Откройте любой пост в блоге в браузере Google Chrome, щёлкните правой кнопкой мыши и «просмотрите код элемента» по имени автора и количеству оценок, которые находятся в инструментах разработчика. Скопируйте соответствующий путь XPath и вставьте его в соответствующее поле экстрактора в SEO Spider, укажите любое название правила.
4. Запустите сканирование сайта.
Затем введите адрес веб-сайта в поле URL-адреса вверху и нажмите «Пуск», чтобы просканировать сайт.

После окончания сканирования перейдите во вкладку Custom Extraction.
Здесь мы можем видеть, что добавились такие поля, как «имя автора 1» и «количество оценок 1». Это и есть нужные нам поля.
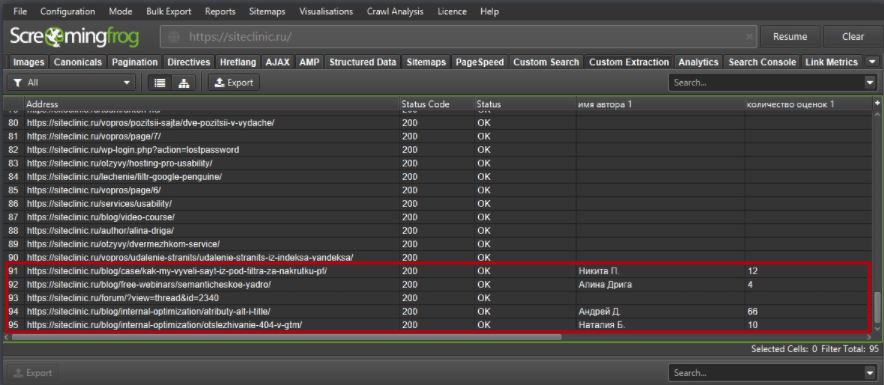
Несколько полезных кастомных функций Screaming Frog
1. Заголовки
По умолчанию Screaming Frog парсит только h1 и h2, но если вы хотите спарсить h3, XPath:
//h3
– спарсить все h3 на странице
/descendant::h3[1]
– спарсить первый заголовок h3 на странице
/descendant::h3[position() >= 0 and position() <= 4]
– спарсить первые 4 h3 на странице
count(//h3)
– спарсить количество заголовков h3 на странице
Примечание. В этом случае поле «Extract Inner HTML» в крайнем правом раскрывающемся списке окна Custom Extraction необходимо изменить на «Function Value», чтобы это выражение работало правильно.
string-length(//h3)
– длина строки h3 на странице
Примечание. В этом случае поле «Extract Inner HTML» в крайнем правом раскрывающемся списке окна Custom Extraction необходимо изменить на «Function Value», чтобы это выражение работало правильно.
2. Hreflang
//*[@hreflang]
– спарсить содержимое всех элементов hreflang
Примечание. В этом случае поле «Extract Inner HTML» в крайнем правом раскрывающемся списке окна Custom Extraction необходимо изменить на «Extract HTML Element», чтобы это выражение работало правильно.
//*[@hreflang]/@hreflang
– спарсить конкретное значение в атрибуте Hreflang
3. Метатеги социальных сетей
Здесь мы парсим различные значения из метатегов социальных сетей, такие как Title, Description, Type и т. д.
//meta[starts-with(@property, 'og:title')]/@content //meta[starts-with(@property, 'og:description')]/@content //meta[starts-with(@property, 'og:type')]/@content //meta[starts-with(@property, 'og:site_name')]/@content //meta[starts-with(@property, 'og:image')]/@content //meta[starts-with(@property, 'og:url')]/@content //meta[starts-with(@property, 'fb:page_id')]/@content //meta[starts-with(@property, 'fb:admins')]/@content //meta[starts-with(@property, 'twitter:title')]/@content //meta[starts-with(@property, 'twitter:description')]/@content //meta[starts-with(@property, 'twitter:account_id')]/@content //meta[starts-with(@property, 'twitter:card')]/@content //meta[starts-with(@property, 'twitter:image:src')]/@content //meta[starts-with(@property, 'twitter:creator')]/@content
4. Почта E-mail
//a[starts-with(@href, 'mailto')]
– парсит все email-адреса на странице
5. Iframes
//iframe/@src
– спарсить содержимое всех тегов iframe на странице
//iframe[contains(@src ,'www.youtube.com/embed/')]
– извлечёт содержимое только тех тегов iframe, в которые встроено видео YouTube
6. Ссылки
//a[contains(.,'SEO')]/@href
– извлечь все ссылки на странице, в анкоре которых написано «SEO»
Примечание. Предыдущее выражение регистрозависимо, поэтому если у вас есть ссылки с анкорами «SEO» и «Seo», тогда используйте следующее выражение:
/a[contains(translate(., 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'Seo')]/@href
Выводы
Таким образом, мы показали, как можно спарсить практически любую интересующую информацию с сайта. Эти формулы будут полезны как для короткого постраничного анализа, так и для извлечения нужной информации на больших проектах.
Если вы хотите получить полный список ошибок и более глубокий анализ состояния сайта, обращайтесь к нам ↓
Заказать аудит сайта
Еще по теме:
- 11 полезных расширений для SEO-специалиста в Google Chrome
- Группировка запросов по методу подобия ТОПов: описание, кластеризаторы
- Отслеживание отправки форм на сайте с помощью GTM
- Отслеживание кликов в Google Analytics c помощью Google Tag Manager
- Новый функционал SEOlib превосходит все ожидания?
Подготовили подборку из 11 SEO-расширений в Chrome, которые используем в повседневной работе, со скриншотами и описанием плюсов/минусов каждого. Такие плагины будут полезны в работе и SEO-специалисту,…
Преимущества кластеризации по методу ТОПов Недостатки кластеризации по методу ТОПов Почему нужно использовать автоматическую кластеризацию? Какие есть виды кластеризации? Какие есть сервисы для автоматической кластеризации?…
Ранее мы уже писали о том, как установить и настроить Google Tag Manager на сайт, а также как с его помощью настроить отслеживание кликов. В…
В данной статье мы рассмотрим, как настроить отслеживание кликов по любому элементу на сайте в Google Analytics с помощью Google Tag Manager (далее GTM). Если…
Сегодня подробно поговорим про новую функцию анализа топов одного из самых популярных сервисов на просторах SEO. Как это выглядит Как добавить функцию «Анализ ТОП(а)» Отчет…

SEO-аналитик
В SEO нравится возможность работать в различных ситуациях.
Всегда привлекала командная работа.
Увлекаюсь хореографией, настолками, сериалами и фильмами, чуть-чуть играю в волейбол и настольный теннис.
Девиз: Человек сам прокладывает свой путь
Есть вопросы?
Задайте их прямо сейчас, и мы ответим в течение 8 рабочих часов.