Notepad++ стал моим первым профессиональным инструментом в веб-разработке и создании сайтов.
И не потому что там есть множество инструментов для работы с исходным кодом, и не из-за обилия плагинов для Notepad++.
Всё проще — в те далёкие времена уроков по веб-дизайну было не так много, а Notepad++ был приведён в статейке по которой я упражнялся. Это было что-то вроде hello-world для HTML. ?
Ещё тогда меня удивил аскетичный интерфейс утилиты и обилие пунктов меню. И до сих пор Notepad++ это самый навороченный текстовый редактор, которым я ежедневно пользуюсь.

В Notepad++, среди прочего, большое внимание уделяется собственному языку регулярных выражений.
Зная как обозначить запрос специальными поисковыми операторами, в Notepad++ можно реализовывать довольно серьезные задачи и работать с большими массивами данных.
Регулярные выражения могут использоваться в Notepad++ для множества логических операция: сортировка строк, удаление дубликатов, поиск и замена как отдельных символов, так и целых логических конструкций. По сути горизонт возможностей такого функционала не ограничен и зависит только от вашей фантазии по его применению.
Я позволил себе отсортировать регулярные выражения для Notepad++ в порядке их надобности и популярности использования. ?
n — Перенос Enter. Что особенно приятно, может использоваться не только для поиска, но и для замены. Например, благодаря этому регулярному выражению, и двум кликам, вы можете поменять построчный список на список через запятую, и наоборот.
t — Табуляция. Означает то же, что и действие клавиши Tab. Очень полезно, если вы комбинируете работу в excel и notepad++. Знаки tab по умолчанию переносятся как колонки таблицы.

nr — Выражение для поиска пустых строк.
s — Пробел. В большинстве случаем вы можете искать просто введя символ пробела в поле поиска Notepad++, однако в составе сложных регулярных выражений пригодится это обозначение. Например, конструкция ^s*$ найдёт все строки с пробелом.
^ и $ — Символы начала и конца соответственно.
d — Этим регулярным выражением в Notepad++ можно обозначить любую цифру. Учитывайте, что под цифрой подразумевается «единичный экземпляр», а не всё число. Например, применив эту комбинацию в тексте с числом 789, последовательно найдутся все три цифры (7, 8, 9) в этом числе.
.(точка) и .*(точка со звёздочкой) — Любой символ и любая последовательность оных соответственно.
D — Также найдутся любые символы, но не цифры.
[a-z], [A-Z], [a-Z], [0-9] — На мой взгляд, всё и так понятно, но я поясню. Такие регулярные выражения в квадратных скобках означают последовательность букв или цифр, и регистр искомого выражения.
Примеры и применение регулярных выражений в Notepad++
Согласитесь, весь этот список на вид звучит довольно нудно и напоминает что-то среднее между высшей математикой и программированием. ? Мне стоит привести примеры использования регулярных выражений и символов Notepad++.
Удалить пустые строки в Notepad++
Удалить пустые строки с помощью текстового редактора Notepad++ просто — выше я уже писал регулярное выражение для этого — nr . Его необходимо ввести в окне поиска и замены. При этом поле Замены оставьте пустым. Все пустые строки удалятся из документа, их место займут данные располагающиеся ниже.

Либо, что конечно же проще, если ваше выражение больше никаких условий не требует, воспользуйтесь пунктом в меню. Edit => Line Operations => Remove empty lines. Там же есть и пункт для удаления пустых строк с пробелом: Containing Blank Characters.
Удалить всё после символа / перед символом в строке в Notepad++
Регулярное выражение удаление всех данных в строке до определенного символа, или их группы я часто использую, например, при сортировке маркетинговых баз с e-mail.
Для того чтобы в Notepad++ удалить всё в строке перед определенным символом, используйте комбинацию .+(искомая-часть). Давайте я разберу подробнее. Например, у нас есть txt файл с почтовыми адресами коллег, по одному адресу в столбик. Кроме того в этой же строке могут содержаться и ФИО человека через пробел, табирование, или через запятую.
Выглядит это вот так:
nastya@mail.ru Анастасия Евгеньевна Петрова
pasha@yandex.ru Павел Иванов Юрлица
vasya@notepad-plus-plus.ru Василий Павлович Работа
И таких контактов с списке у нас 500. Для того чтобы отделить домены, нам понадобится 2 действия в Notepad++, удалить всё в строках до определенного символа, а затем удалить всё в строках после.
Первая регулярное выражение для нас будет .+(@), в поле замены оставляем пустым.
Результат
mail.ru Анастасия Евгеньевна Петрова
yandex.ru Павел Иванов Юрлица
notepad-plus-plus.ru Василий Павлович Работа
Второе регулярное выражение Notepad для удаления после символа, можно сконфигурировать по доменному суффиксу, запрос будет (.ru.+)$.
yandex
notepad-plus-plus
Удалить дубликаты строк в Notepad++
Удаление дубликатов строк в Notepad++ это вообще отдельная большая тема. Мало кто знает как сконфигурировать поисковой запрос в текстовом редакторе и удалить повторяющиеся строки исключительно через Notepad++, не прибегая к помощи плагинов и сторонних расширений.
Но я — знаю ?. Чтобы удалить построчное дублирование в Notepad, используйте эту фразу:
^(.*?)$s+?^(?=.*^1$)

Важно, чтобы все галочки в поиске у вас были включены. И зациклить поиск, и применять регулярные выражения, тогда Notepad++ точно сработает как надо, и удалит из документа дубли строк.
Второй способ избавится от дублирования строк
Второй способ удалить дубликаты строк с помощью Notepad++ абсолютно не элегантен, но функционален при ежедневном использовании. Навигатор по репозиторию дополнений встроен прямо в ваш Notepad. Просто ставим плагин через меню Plugins => Plugin manager.
Нужный нам плагин называется TextFx Characters.
Не слишком сложно, правда? Устанавливаются плагины автоматически, нужно будет только перезагрузить утилиту. Жмёте установить и активировать.
Функционал плагина местами дублирует многие регулярные выражения в Notepad++, а по-моему мнению собственно на них и основан.
Настройка для удаления дубликатов строк находится в меню: Textfx => Tools => Sort Lines insensetive.
Не забудьте выделить данные в редакторе, перед тем как нажимать.
Notepad++: плагины и альтернативы.
Для начала про плагины. Как вы поняли, в Notepad++ система плагинов весьма интуитивна и встроена в редактор. Но, кроме того, существует и множество других дополнений от сторонних авторов — в этом одна из прелестей freeware софта. Пожалуй, я как-нибудь выложу их обзор, если вам будет интересна тема Notepad и эта статья придётся по вкусу.
Что касается альтернатив, Notepad++ любят за регулярные выражения, легкость, простоту и бесплатность. Такое сочетание вообще, пожалуй, единственное в этом кластере, потому лично я не вижу прямых конкурентов и альтернатив для Notepad.

Но если посмотреть на нишу шире, можно вспомнить про AkelPad (тоже текстовый редактор), Textmate, LeafPad, Sublime Text, Atom, Brackets…Так можно дойти и до моего любимого Adobe Dreamweaver. Однако, всё это по сути уже не то. Notepad++ неповторим, аскетичен, и по своему прекрасен, и очень в духе софта былых времён. ?
P.S. Если вам была полезна эта статья, оставьте коммент, и я буду знать что двигаюсь в правильном направлении. Или задавайте вопросы! welcome ⬇️⬇️⬇️
Debian, Linux, Ubuntu
 Как найти дубликаты строк в текстовом файле
Как найти дубликаты строк в текстовом файле
- 19.08.2021
- 3 357
- 0
- 6
- 6
- 0

- Содержание статьи
- Описание
- Ищем дубликаты
- Добавить комментарий
Описание
Иногда возникает необходимость найти все дублирующиеся строчки в каком-либо текстовом файле, что в ОС Linux делается очень легко
Ищем дубликаты
Для поиска дубликатов строк в текстовом файле можно воспользоваться следующей командой:
sort filename.txt | uniq -dГде filename.txt — это название текстового файла в котором мы ищем дубликаты строк.
В случае, если в данном файле есть одинаковые строки, в консоль будут выведены эти строки и можно будет вручную их убрать из файла.
Имеется два текстовых файла содержащие строки: file_0.txt и file_1.txt. Количество строк может быть разным. Длина строк может быть разной. Файлы содержат большое количество строк. Необходимо эффективно вывести в другой файл строки, которые содержатся одновременно в двух файлах.
Пример:
Содержимое файла file_0.txt:
file_0.txt
j43j72h531
b2x891ow52
rr35986z77
x77jm9lp7g
q0pprcp52yawc10
wh3h476m2u
e7h0cv6rh5
5l7i700939
l3ri0p8p2f
l1h14no300
Содержимое файла file_1.txt:
file_1.txt
l1h14no300
j2615a2e0y
815555v33h
q0pprcp52yawc10
2vhhh0ugxv
rc2jl8lhdl
79qn640321
b2x891ow52
Необходимое содержимое файла file_2.txt после работы программы/команды:
file_2.txt
b2x891ow52
q0pprcp52yawc10
l1h14no300
Я пытался это сделать с помощью CMD команды findstr но в выводе получал почему-то не все совпадающие строки, хотя их наличие я проверял вручную. На процессоре i5-8400 скорость сравнения 100’000 строк в одном и 100’000 в другом файле меня вполне устраивает: 10-15 секунд.
Подскажите команду CMD/PowerShell или программу, чтобы сделать задуманное.
Если вы не используете jQuery в своем коде, этот ответ для вас
Феликс Клинг отлично справился с написанием ответа для людей, использующих jQuery для AJAX, я решил предоставить альтернативу для людей, которые этого не делают.
То, с чем вы столкнулись
Это краткое резюме «Объяснение проблемы» из другого ответа, если вы не уверены, прочитав это, прочитайте это.
A в AJAX означает асинхронность. Это означает, что отправка запроса (или, скорее, получение ответа) вынимается из обычного потока выполнения. В вашем примере .send немедленно возвращается, а следующий оператор return result; выполняется до того, как функция, которую вы передали, когда был вызван обратный вызов success .
Это означает когда вы возвращаетесь, слушатель, который вы определили, еще не выполнил, что означает, что возвращаемое вами значение не было определено.
Вот простая аналогия
Возвращаемое значение a — undefined так как часть a=5 еще не выполнена. AJAX действует так, вы возвращаете значение до того, как сервер получил возможность сообщить вашему браузеру, что это за значение.
Одним из возможных решений этой проблемы является код повторно активно , сообщая вашей программе, что делать, когда расчет завершен.
Это называется CPS . В основном, мы передаем getFive действие, которое необходимо выполнить, когда оно завершается, мы сообщаем нашему кодексу, как реагировать, когда событие завершается (например, наш вызов AJAX или в этом случае время ожидания).
Который должен предупредить «5» на экране. (Fiddle) .
Возможные решения
Существуют два способа решения этой проблемы:
- Сделать AJAX синхронный вызов (позволяет называть его SJAX).
- Реструктурируйте свой код для правильной работы с обратными вызовами.
1. Синхронный AJAX — Не делайте этого !!
Что касается синхронного AJAX, не делайте этого! Ответ Феликса вызывает некоторые веские аргументы в пользу того, почему это плохая идея. Подводя итог, он заморозит браузер пользователя, пока сервер не вернет ответ и не создаст очень плохой пользовательский интерфейс. Вот еще краткое резюме из MDN о том, почему:
XMLHttpRequest поддерживает как синхронную, так и асинхронную связь. В общем, однако, асинхронные запросы должны быть предпочтительнее синхронных запросов по причинам производительности.
Короче говоря, синхронные запросы блокируют выполнение кода . . это может вызвать серьезные проблемы .
Если вы имеете , вы можете передать флаг: Вот как это сделать:
2. Код реструктуризации
Пусть ваша функция принимает обратный вызов. В примере код foo может быть сделан для принятия обратного вызова. Мы сообщим нашему кодексу, как отреагировали , когда foo завершает работу.
Итак:
Становится:
Здесь мы передали анонимную функцию, но мы могли бы так же легко передать ссылку на существующую , чтобы он выглядел следующим образом:
Для получения дополнительной информации о том, как выполняется этот вид обратного вызова, проверьте ответ Felix.
Теперь давайте определим сам foo, чтобы действовать соответственно
(скрипка)
Теперь мы сделали нашу функцию foo принять действие, которое будет выполняться, когда AJAX завершится успешно, мы можем продолжить это, проверив, не является ли статус ответа не 200 и действует соответственно (создайте обработчик сбоя и т. д.). Эффективное решение нашей проблемы.
Если вам все еще трудно понять это , прочитайте руководство по началу работы AJAX в MDN.
Notepad++ — поиск одинаковых вещей, которые находятся в строке дважды
Я хотел бы знать, есть ли способ поиска файла для двух вещей в одной строке. Например, если я хочу найти строку с » variable > = «и «variable>=». Проблема в том, что я не знаю, что такое «переменная» (ну, в файле много разных переменных, и я ищу проверку дубликатов переменных в одной строке).
может кто-нибудь помочь мне с этим?
2 ответов
у вас есть несколько вариантов.
в любом случае перед началом:
- откройте диалоговое окно» найти «(Ctrl + f) или» заменить » (если вы знаете, что вы хотите сделать дальше),
- выберите переключатель «регулярное выражение»в левом нижнем углу диалогового окна.
- здесь, я буду предполагать, что вы ищете дубликаты шаблонов, таких как variable >= something или hour >= NUM .
- кроме того, я в группе как можно больше, так что вы можете позже смогу замените путем держать, или бросать прочь, любую часть как нужно.
(1) Явное Найти
вы знаете дубликаты, и вы можете найти их явно, например:
или, для «час», просто замените слово «переменная» на слово «час»:
объяснение:
каждый набор скобок, слева направо, — это группа. Поэтому, вы будете иметь следование:
Группа 1: ((variable)s*>=s*S+) : находит строку, начинающуюся с» variable», за которой следует s (пробел) и * означает любое количество пробелов (следовательно, вы можете иметь «variable>=» или » variable> переменная».
Группа 3: (.*) : что-нибудь между двумя дубликатами вы найдете. Это позволяет сделать что-то с этим дополнительным текстом, если он существует.
Предупреждение, если есть трипликаты (или больше), это будет потребитель шаблоны в середине, делая group1 и group4 содержат только первый и последний дубликаты. Если вы хотите найти последовательные дубликаты, то измените эту часть на (.*?) ; the ? делает его не жадным, т. е. найдет минимум . (ничего).
4 группа: (s*>=s*S+) : наконец, это дублировать. Причина его дубликат, потому что узор такой же, как и группы 1, Кроме того, он использует , это просто способ сказать, что находится в группе 2. В данном случае это слово «переменная».
вторая картина для «часа» по мере того как вы увидите идентична, за исключением того, что он ищет «час», а не»переменную».
(2) Найти Неизвестные Повторяющиеся Узоры
С небольшими изменениями, вы можете искать любые дубликаты одного и того же шаблона:
объяснение:
это идентично поиску дубликатов с явно известными именами. Разница здесь заключается в использовании w+ (любые буквы и слова), а не слово «переменная»/»час».
w+ : w соответствует любому символу слова (включая прописные, строчные и цифры, но не знаки препинания или другие символы). The + снова так сказать, по крайней мере, один. Поэтому, с w+ вы найдете любые буквы слова.
Как удалить дубликаты строк в Notepad++

Вам понадобится плагин TextFX. Раньше он был включен в более старые версии Notepad ++, но если у вас есть более новая версия, вы можете добавить плагин из меню, перейдя в Plugins → Plugin Manager → Show Plugin Manager → Available tab → TextFX → Install. В некоторых случаях его также можно найти введя TextFX, но это одно и то же.
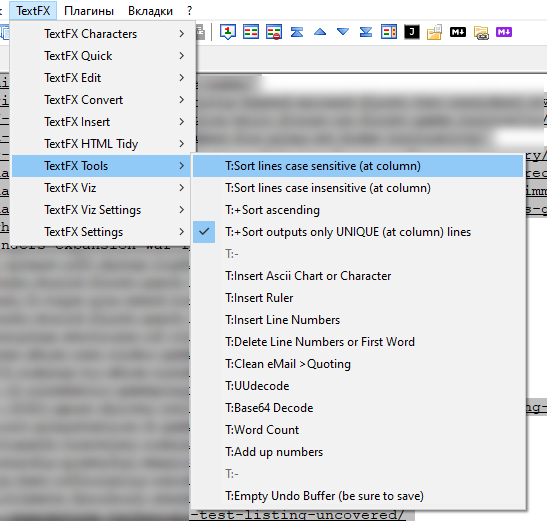
Теперь необходимые флажки и кнопки появятся в меню: TextFX → Инструменты TextFX.
Убедитесь, что установлен флажок «sort lines case sensitive». Затем выберите блок текста (Ctrl + A, чтобы выделить весь документ). Наконец, нажмите sort lines case sensitive (Сортировать строки с учетом регистра) или sort lines case insensitive (Сортировать строки без учета регистра).
При помощи поиска и замены по регулярным выражениям
Выполните поиск с заменой для поиска
Это оставляет из всех повторяющихся строк последнее вхождение в файле.
Для этого не требуется сортировка, и повторяющиеся строки могут находиться в любом месте файла!
Вам нужно проверить параметры «Регулярное выражение» и обязательно удалите отметку с опции поиска “и новые строки”.
Вот подробный вид окна поиска для удаления дубликатов строк в Notepad++:
I have multiple email addresses. I need to find and delete all (including found one). Is this possible in notepad++?
example:epshetsky@test.com,
rek4@test.com,
rajesh1239@test.com,
mohanraj@test.com,
sam@test.com,
nithin@test.com,
midhunvintech@test.com,
karthickgm27@test.com,
rajesh1239@test.com,
mohanraj@test.com,
nithin@test.com,
I need results back like
epshetsky@test.com,
rek4@test.com,
sam@test.com,
nithin@test.com,
midhunvintech@test.com,
karthickgm27@test.com,
How to do in notepad++?