
Добавил(а) microsin
Иногда по неизвестным причинам некоторые команды русскоязычной версии Windows выводят русский текст в нечитаемой кодировке, кракозябрами.
Например, команда help выводит нормальный текст:

Но при этом подсказка telnet выводит в ответ кракозябры.

Так может происходить, к примеру, если текущая кодировка консоли 866, а утилита telnet.exe почему-то выводит текст в кодировке 1251. Вывести текст в нужной кодировке поможет команда chcp, которая устанавливает нужную кодировку.
Вот так можно посмотреть текущую кодировку консоли:
c:Documents and Settingsuser>chcp Текущая кодовая страница: 866 c:Documents and Settingsuser>
А вот так можно поменять кодировку на 1251, после чего вывод подсказки telnet будет отображаться нормально:
c:Documents and Settingsuser>chcp 1251 Текущая кодовая страница: 1251 c:Documents and Settingsuser>

К сожалению, заранее угадать, в какой кодировке выводится текст, невозможно, поэтому проще попробовать установить командой chcp разные кодировки, чтобы добиться правильного отображения русского текста. Обычно используются кодировки 866 (кодировка русского текста DOS), 1251 (кодировка русского текста Windows), 65001 (UTF-8).
[Шрифт cmd.exe]
Иногда кракозябры можно убрать, если выбрать в свойствах окна cmd.exe шрифт Lucida Console (по умолчанию там стоит «Точечные шрифты»).
[Ссылки]
1. Универсальный декодер — конвертер кириллицы.
Время чтение: 4 минуты
2014-01-19
Как корректно отобразить Русский текст в CMD. Проблемы с кодировкой могут возникнуть, например, при выполнении Bat файла, когда нужно вывести в консоль русский текст и при других обстоятельствах, о которых речь пойдёт далее.
Рассмотрим пример: когда нужно вывести в консоль Русский текст, скажем «Примет мир». Для этого создадим Bat файл с именем «1.bat». Используйте для этого обычный Блокнот Windows (Notepad.exe) Запишем в него следующие строки!
|
@Echo off echo. echo ПРИВЕТ МИР echo. Pause |
Для тех, кто не понял или не в курсе, строчки «echo.» я добавил специально, что бы были отступы, от строки «Примет мир»
Теперь запускаем файл 1.bat и результат будет такого вида.
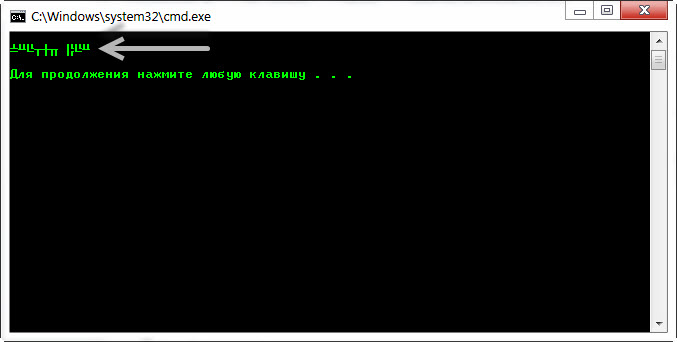
Как видим проблема с кодировкой в cmd на лицо. И произошло это по следующей причине.
Стандартный блокнот Windows сохранил Bat файл в кодировке «1251» а консоль вывела его в кодировки «866». Вот от сюда все проблемы!
Решения проблемы с кодировкой в CMD. 1 Способ.
Для решения проблемы нужно просто использовать текстовой редактор, с помощью которого можно сохранить текст в кодировке «866». Для этих целей прекрасно подходит «Notepad++» (Ссылку для загрузки Вы можете найти в моём Twitter-e).
Скачиваем и устанавливаем на свой компьютер «Notepad++».
После запуска «Notepad++» запишете в документ те же строки, которые мы уже ранние записывали в стандартный блокнот.
|
@Echo off echo. echo ПРИВЕТ МИР echo. Pause |
Теперь осталось сохранить документ с именем «2.bat» в правильной кодировке. Для этого идём в меню «Кодировки > Кодировки > Кириллица > OEM-866»
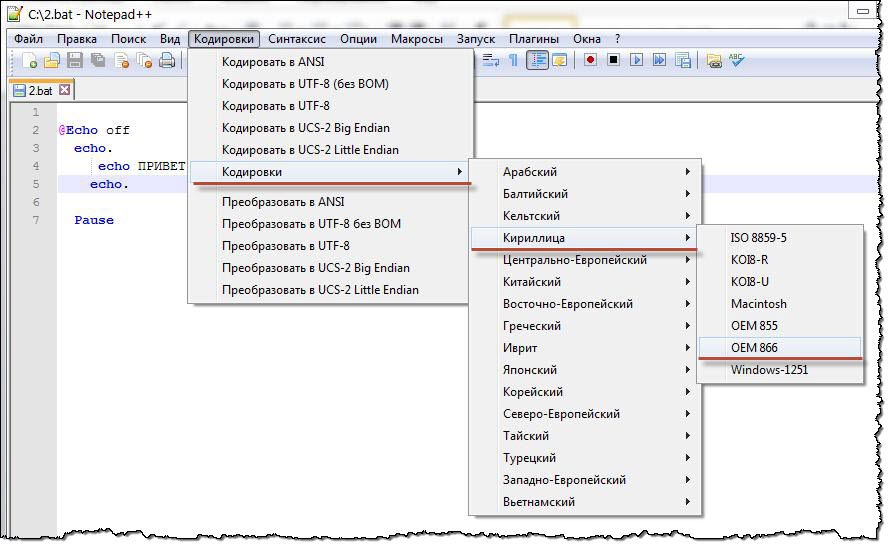
и теперь сохраняем файл с именем «2.bat» и запускаем его! Поле запуска результат на лицо.
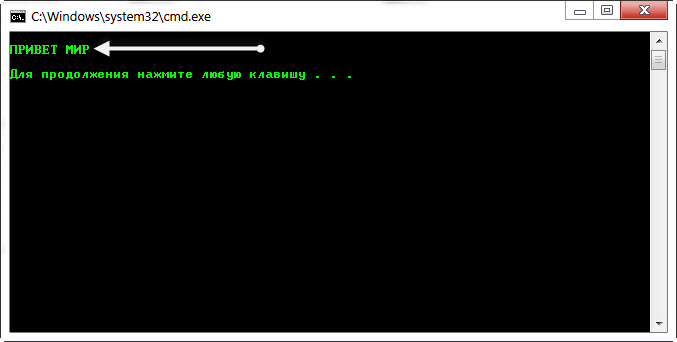
Как видим, текст на Русском в CMD отобразился, как положено.
Решения проблемы с кодировкой в CMD. 2 Способ.
Теперь рассмотрим ещё одну ситуацию, когда могут возникнуть проблемы с кодировкой в CMD.
Допустим, ситуация требует сохранить результат выполнения той или иной команды в обычный «TXT» файл. В приделах этого поста возьмём для примера команду «HELP».
Задача: Сохранить справку CMD в файл «HelpCMD.txt. Для этого создайте Bat файл и запишите в него следующие строки.
|
@Echo off Help > C:HelpCMD.txt Pause |
После выполнения Bat файла в корне диска «C:» появится файл «HelpCMD.txt» и вместо справки получится вот что:
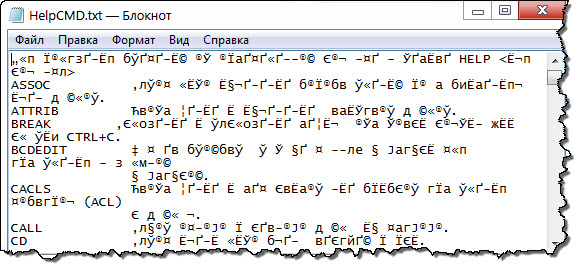
Естественно, такой вариант не кому не понравится и что бы сохранить справку в понятном для человека виде, допишите в Bat файл строку.
Теперь содержимое кода будет такое.
|
@Echo off chcp 1251 >nul Help > C:HelpCMD.txt Pause |
После выполнения «Батника» результат будет такой:
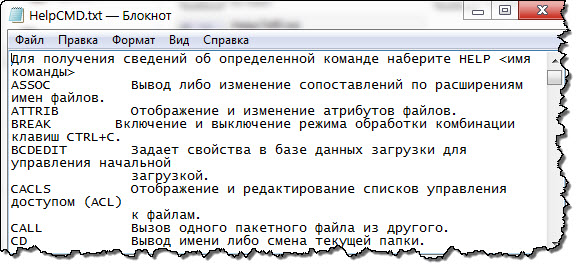
Вот так на много лучше, правда?
Пожалуй, на этом я закончу пост. Добавить больше нечего. Если у Вас имеются какие-то соображения по данной теме, буду рад Вашему комментарию к посту.
Дополнительно из комментариев то Garric
Автор очень хорошо описал принцип. ! Но это неудобно.
Нужно бы добавить. Если автор добавит это в статью то это будет Good.
Создаём файл .reg следующего содержания:
——
Windows Registry Editor Version 5.00
[HKEY_CLASSES_ROOT.batShellNew]
«FileName»=»BATНастроенная кодировка.bat»
——
Выполняем.
——
Топаем в %SystemRoot%SHELLNEW
Создаём там файл «BATНастроенная кодировка.bat»
Открываем в Notepad++
Вводим любой текст. (нужно!) Сохраняемся.
Удаляем текст. Меняем кодировку как сказано в статье. Сохраняемся.
———-
Щёлкаем правой кнопкой мыши по Рабочему столу. Нажимаем «Создать» — «Пакетный файл Windows».
Переименовываем. Открываем в Notepad++. Пишем батник.
В дальнейшем при работе с файлом не нажимаем ничего кроме как просто «Сохранить». Никаких «Сохранить как».
Как я боролся с кодировками в консоли
Время на прочтение
6 мин
Количество просмотров 169K
В очередной раз запустив в Windows свой скрипт-информер для СамИздат-а и увидев в консоли «загадочные символы» я сказал себе: «Да уже сделай, наконец, себе нормальный кросс-платформенный логгинг!»
Об этом, и о том, как раскрасить вывод лога наподобие Django-вского в Win32 я попробую рассказать под хабра-катом (Всё ниженаписанное применимо к Python 2.x ветке)
Задача первая. Корректный вывод текста в консоль
Симптомы
До тех пор, пока мы не вносим каких-либо «поправок» в проинициализировавшуюся систему ввода-вывода и используем только оператор print с unicode строками, всё идёт более-менее нормально вне зависимости от ОС.
«Чудеса» начинаются дальше — если мы поменяли какие-либо кодировки (см. чуть дальше) или воспользовались модулем logging для вывода на экран. Вроде бы настроив ожидаемое поведение в Linux, в Windows получаешь «мусор» в utf-8. Начинаешь править под Win — вылезает 1251 в консоли…
Теоретический экскурс
За параметры преобразования символов и вывода их в консоль отвечают сразу несколько параметров:
- Кодировка по-умолчанию модуля
sys—sys.getdefaultencoding() - Предпочитаемая кодировка для текущей локали —
locale.getpreferredencoding() - Кодировка стандартных потоков
sys.stdout, sys.stderr - Кое-какую смуту вносит и кодировка самого файла, но договоримся, что у нас всё унифицировано и все файлы в utf-8 и содержат корректный заголовок
- «Бонусом» идёт любовь стандартных потоков выдавать исключения, если, даже при корректно установленной кодировке, не найдётся нужного символа при печати unicode строки
Ищем решение
Очевидно, чтобы избавиться от всех этих проблем, надо как-то привести их к единообразию.
И вот тут начинается самое интересное:
# -*- coding: utf-8 -*-
>>> import sys
>>> import locale
>>> print sys.getdefaultencoding()
ascii
>>> print locale.getpreferredencoding() # linux
UTF-8
>>> print locale.getpreferredencoding() # win32/rus
cp1251
# и самое интересное:
>>> print sys.stdout.encoding # linux
UTF-8
>>> print sys.stdout.encoding # win32
cp866
Ага! Оказывается «система» у нас живёт вообще в ASCII. Как следствие — попытка по-простому работать с вводом/выводом заканчивается «любимым» исключением UnicodeEncodeError/UnicodeDecodeError.
Кроме того, как замечательно видно из примера, если в linux у нас везде utf-8, то в Windows — две разных кодировки — так называемая ANSI, она же cp1251, используемая для графической части и OEM, она же cp866, для вывода текста в консоли. OEM кодировка пришла к нам со времён DOS-а и, теоретически, может быть также перенастроена специальными командами, но на практике никто этого давно не делает.
До недавнего времени я пользовался распространённым способом исправить эту неприятность:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ==============
# Main script file
# ==============
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# или
import locale
sys.setdefaultencoding(locale.getpreferredencoding())
# ...
И это, в общем-то, работало. Работало до тех пор, пока пользовался print-ом. При переходе к выводу на экран через logging всё сломалось.
Угу, подумал я, раз «оно» использует кодировку по-умолчанию, — выставлю-ка я ту же кодировку, что в консоли:
sys.setdefaultencoding(sys.stdout.encoding or sys.stderr.encoding)
Уже чуть лучше, но:
- В Win32 текст печатается кракозябрами, явно напоминающими cp1251
- При запуске с перенаправленным выводом опять получаем не то, что ожидалось
- Периодически, при попытке напечатать текст, где есть преобразованный в unicode символ типа ① (
①), «любезно» добавленный автором в какой-нибудь заголовок, снова получаемUnicodeEncodeError!
Присмотревшись к первому примеру, нетрудно заметить, что так желаемую кодировку «cp866» можно получить только проверив атрибут соответствующего потока. А он далеко не всегда оказывается доступен.
Вторая часть задачи — оставить системную кодировку в utf-8, но корректно настроить вывод в консоль.
Для индивидуальной настройки вывода надо переопределить обработку выходных потоков примерно так:
import sys
import codecs
sys.stdout = codecs.getwriter('cp866')(sys.stdout,'replace')
Этот код позволяет убить двух зайцев — выставить нужную кодировку и защититься от исключений при печати всяких умляутов и прочей типографики, отсутствующей в 255 символах cp866.
Осталось сделать этот код универсальным — откуда мне знать OEM кодировку на произвольном сферическом компе? Гугление на предмет готовой поддержки ANSI/OEM кодировок в python ничего разумного не дало, посему пришлось немного вспомнить WinAPI
UINT GetOEMCP(void); // Возвращает системную OEM кодовую страницу как число
UINT GetANSICP(void); // то же для ANSI кодовой странцы
… и собрать всё вместе:
# -*- coding: utf-8 -*-
import sys
import codecs
def setup_console(sys_enc="utf-8"):
reload(sys)
try:
# для win32 вызываем системную библиотечную функцию
if sys.platform.startswith("win"):
import ctypes
enc = "cp%d" % ctypes.windll.kernel32.GetOEMCP() #TODO: проверить на win64/python64
else:
# для Linux всё, кажется, есть и так
enc = (sys.stdout.encoding if sys.stdout.isatty() else
sys.stderr.encoding if sys.stderr.isatty() else
sys.getfilesystemencoding() or sys_enc)
# кодировка для sys
sys.setdefaultencoding(sys_enc)
# переопределяем стандартные потоки вывода, если они не перенаправлены
if sys.stdout.isatty() and sys.stdout.encoding != enc:
sys.stdout = codecs.getwriter(enc)(sys.stdout, 'replace')
if sys.stderr.isatty() and sys.stderr.encoding != enc:
sys.stderr = codecs.getwriter(enc)(sys.stderr, 'replace')
except:
pass # Ошибка? Всё равно какая - работаем по-старому...
Задача вторая. Раскрашиваем вывод
Насмотревшись на отладочный вывод Джанги в связке с werkzeug, захотелось чего-то подобного для себя. Гугление выдаёт несколько проектов разной степени проработки и удобности — от простейшего наследника logging.StreamHandler, до некоего набора, при импорте автоматически подменяющего стандартный StreamHandler.
Попробовав несколько из них, я, в итоге, воспользовался простейшим наследником StreamHandler, приведённом в одном из комментов на Stack Overflow и пока вполне доволен:
class ColoredHandler( logging.StreamHandler ):
def emit( self, record ):
# Need to make a actual copy of the record
# to prevent altering the message for other loggers
myrecord = copy.copy( record )
levelno = myrecord.levelno
if( levelno >= 50 ): # CRITICAL / FATAL
color = 'x1b[31;1m' # red
elif( levelno >= 40 ): # ERROR
color = 'x1b[31m' # red
elif( levelno >= 30 ): # WARNING
color = 'x1b[33m' # yellow
elif( levelno >= 20 ): # INFO
color = 'x1b[32m' # green
elif( levelno >= 10 ): # DEBUG
color = 'x1b[35m' # pink
else: # NOTSET and anything else
color = 'x1b[0m' # normal
myrecord.msg = (u"%s%s%s" % (color, myrecord.msg, 'x1b[0m')).encode('utf-8') # normal
logging.StreamHandler.emit( self, myrecord )
Однако, в Windows всё это работать, разумеется, отказалось. И если раньше можно было «включить» поддержку ansi-кодов в консоли добавлением «магического» ansi.dll из проекта symfony куда-то в недра системных папок винды, то, начиная (кажется) с Windows 7 данная возможность окончательно «выпилена» из системы. Да и заставлять юзера копировать какую-то dll в системную папку тоже как-то «не кошерно».
Снова обращаемся к гуглу и, снова, получаем несколько вариантов решения. Все варианты так или иначе сводятся к подмене вывода ANSI escape-последовательностей вызовом WinAPI для управления атрибутами консоли.
Побродив некоторое время по ссылкам, набрёл на проект colorama. Он как-то понравился мне больше остального. К плюсам именно этого проекта ст́оит отнести, что подменяется весь консольный вывод — можно выводить раскрашенный текст простым print u"x1b[31;40mЧто-то красное на чёрномx1b[0m" если вдруг захочется поизвращаться.
Сразу замечу, что текущая версия 0.1.18 содержит досадный баг, ломающий вывод unicode строк. Но простейшее решение я привёл там же при создании issue.
Собственно осталось объединить оба пожелания и начать пользоваться вместо традиционных «костылей»:
# -*- coding: utf-8 -*-
import sys
import codecs
import copy
import logging
#: Is ANSI printing available
ansi = not sys.platform.startswith("win")
def setup_console(sys_enc='utf-8', use_colorama=True):
"""
Set sys.defaultencoding to `sys_enc` and update stdout/stderr writers to corresponding encoding
.. note:: For Win32 the OEM console encoding will be used istead of `sys_enc`
"""
global ansi
reload(sys)
try:
if sys.platform.startswith("win"):
#... код, показанный выше
if use_colorama and sys.platform.startswith("win"):
try:
# пробуем подключить colorama для винды и взводим флаг `ansi`, если всё получилось
from colorama import init
init()
ansi = True
except:
pass
class ColoredHandler( logging.StreamHandler ):
def emit( self, record ):
# Need to make a actual copy of the record
# to prevent altering the message for other loggers
myrecord = copy.copy( record )
levelno = myrecord.levelno
if( levelno >= 50 ): # CRITICAL / FATAL
color = 'x1b[31;1m' # red
elif( levelno >= 40 ): # ERROR
color = 'x1b[31m' # red
elif( levelno >= 30 ): # WARNING
color = 'x1b[33m' # yellow
elif( levelno >= 20 ): # INFO
color = 'x1b[32m' # green
elif( levelno >= 10 ): # DEBUG
color = 'x1b[35m' # pink
else: # NOTSET and anything else
color = 'x1b[0m' # normal
myrecord.msg = (u"%s%s%s" % (color, myrecord.msg, 'x1b[0m')).encode('utf-8') # normal
logging.StreamHandler.emit( self, myrecord )
Дальше в своём проекте, в запускаемом файле пользуемся:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from setupcon import setup_console
setup_console('utf-8', False)
#...
# или если будем пользоваться раскрашиванием логов
import setupcon
setupcon.setup_console()
import logging
#...
if setupcon.ansi:
logging.getLogger().addHandler(setupcon.ColoredHandler())
На этом всё. Из потенциальных доработок осталось проверить работоспособность под win64 python и, возможно, добаботать ColoredHandler чтобы проверял себя на isatty, как в более сложных примерах на том же StackOverflow.
Итоговый вариант получившегося модуля можно забрать на dumpz.org
Проблема: в консоли кириллические символы отображаются в неверной кодировке (в народе «кракозябры»):

При этом, если выполнить команду
chcp 866
кириллица становится читаемой только для текущего сеанса. А при перезапуске командной строки кодировка снова сбивается. Если у вас ситуация выглядит так же, то это означает, что неверные параметры кодовой страницы берутся из реестра и решать проблему нужно именно там.
Как установить правильную кодировку в консоли
Запустите редактор реестра:

Откройте раздел HKEY_CURRENT_USERConsole и проверьте значение параметра CodePage (должно быть 866).
В нашем примере на картинке мы видим, что в параметре по какой-то причине указана кодировка 1251, что бесспорно и является причиной появления абракадабры.
Если у вас значение этого параметра отличается от 866, нажмите два раза по параметру CodePage:

Установите переключатель в положение Десятичная.
В поле Значение введите 866.
Нажмите OK:

Перезапустите командную строку (закройте окно и запустите его заново — Win+R, cmd, enter). Вы должны увидеть корректное отображение кириллицы:


Многие скажут — в PowerShell нет таких проблем как в CMD, юникод поддерживается из коробки!
И будут правы:)
Но мне быстрее и проще что-то простое сделать с помощью batch файла.
Мы используем русский язык в Windows.
Windows же использует несколько кодировок для русского языка:
CP1251 — Windows кодировка
CP866 — используется в консольных приложениях
UTF-8 — Юникод
В консоли CMD по умолчанию используется кодировка CP866.
Поэтому для вывода русского текста в cmd, batch файлах необходимо русский текст перекодировать в CP866 кодировку.
Узнать какая кодировка установлена в консоли позволяет команда chcp:
chcp Текущая кодовая страница: 866
Попробуем вывести текст в кодировке CP1251

>test.bat C:Usersvino7>echo "╧ЁютхЁър Ёєёёъюую ч√ър" "╧ЁютхЁър Ёєёёъюую ч√ър"
Изменим кодировку терминала командой:
@echo off chcp 1251 echo "Проверка русского языка"
Выполним скрипт:
test.bat Текущая кодовая страница: 1251 "Проверка русского языка"
Теперь русский выводится правильно.
Варианты установок:
- chcp 1251 — Установить кодировку в CP1251
- chcp 866 — Установить кодировку в CP866
- chcp 65001 — UTF-8
( 1 оценка, среднее 5 из 5 )