Главное об атрибуте rel = «canonical”: что это такое, зачем и где указывать, какие ошибки часто допускают оптимизаторы.
Разбираемся, что нужно знать оптимизатору о работе с каноническими тегами. Материал для начинающих или тех, кто хочет освежить знания в памяти.
В статье:
-
Что такое rel canonical и для чего он нужен
-
Когда нужно прописывать канонический тег
-
Как настроить canonical правильно: 6 способов указать основной URL
Что такое rel canonical и для чего он нужен
Одинаковый контент на разных страницах — плохо, за это следуют санкции. Но есть случаи, когда дубли оправданы. К примеру, одна и та же страница может входить в несколько категорий, один и тот же сайт может быть доступен с www и без, а еще в каталогах товаров есть сортировка и фильтрация.
Страницы могут быть не полностью одинаковыми. К примеру, на одной включен фильтр товаров по сезона, а на другой — сортировка по цене. Тем не менее, от включенных фильтров уникальными они не станут.

В таких случаях нужно указывать, какой вариант страницы роботу считать основным, то есть каноническим, а какие дублями. Для этого придумали канонический тег — rel = «canonical», он решает проблему дублирования контента.
Каноническая страница — это основной URL. Атрибут rel = «canonical» добавляют на страницы-дубли и в нем указывают адрес канонической страницы, чтобы дать боту знать, какую страницу они повторяют.
Зачем указывать основную версию страницы?
Причины указывать canonical:
-
избежать санкций поисковиков за дублирование контента;
-
корректно передавать ссылочный вес на нужную версию сайта и страницы;
-
из контента, доступного по нескольким URL, выбрать страницу, которая будет получать все сигналы и показываться в выдаче;
-
не тратить краулинговый бюджет на дубли.
Краткая информация о канонических URL из первых уст есть в справке Google и Яндекса.
Например, есть страница, доступная по трем адресам:
site.ru/page?id=123
site.ru/blog/category/tema
site.ru/blog/tema
Допустим, мы хотим, чтобы страница site.ru/blog/category/tema ранжировалась в выдаче, получала весь положенный ей ссылочный вес и другие сигналы — считалась канонической.
Тогда эту страницу мы не трогаем, в коде страниц дублей site.ru/page?id=123 и site.ru/blog/tema указываем ее как каноническую. В коды дублей мы добавляем такую строчку:
<link rel="canonical" href="http://site.ru/blog/category/tema"/>Неканонические страницы не попадут в индекс?
Страницы, отмеченные как неканонические, все равно могут попасть в выдачу. Яндекс отмечает:
«Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом».
В Вебмастере у всех страниц появилась пометка «каноническая», «неканоническая» и «каноническая страница не указана». Вы можно посмотреть неканонические страницы, попавшие в выдачу, для этого откройте «Страницы в поиске» и ищите строчки с пометкой «Неканоническая».

Google тоже заявляет, что система признает указанный канонический URL, но не всегда, поскольку тег canonical — рекомендация, а не приказ к действию. Если неканоническая покажется ему релевантнее, она и появится в выдаче.
Но если сеошник указывает этот атрибут, уменьшается риск, что Google сам определит основной не ту версию страницы.
Канонические страницы все равно появляются в поиске чаще и имеют приоритет при показе в выдаче, а ошибки с настройкой canonical могут привести к проблемам в индексировании страниц. Разберем все варианты, когда нужно использовать канонический тег.
Когда нужно прописывать канонический тег
Используйте canonical, когда одинаковый контент доступен по разным URL. Когда дублирующиеся URL создаются системой, фактически сам контент не дублируется — разные URL обслуживают одно содержимое. Тем не менее, это дубли, канонический тег стоит указать. Разберем разные случаи.
Дублирование страниц
Дублирующиеся страницы с похожим содержанием, которые генерируются CMS. Они бывают на всех сайтах интернет-магазинов, где можно настраивать параметры выбора товара. Ссылки для навигации по каталогу, сортировка товаров, фильтрация, ссылки с UTM-метками для отслеживания, другие страницы с GET-параметрами в URL.
К примеру, если в каталоге есть несколько позиций одного дивана, отличающиеся только цветом обивки, можно выбрать самый популярный вариант и указать его каноническим. Все варианты диванов будут доступны пользователям, но ссылочный вес и другие сигналы будут идти на страницу с основным вариантом.
Другой вариант — страница товара подходит сразу под несколько категорий, так что образовываются множественные URL одного предмета. Решение такое же: выбрать популярную в качестве основной и указать ее на остальных дублирующих страницах в rel = «canonical».
Страницы пагинации
Переключение страниц в каталоге рождает дубли. Иногда для всех страниц пагинации указывают первую страницу в качестве канонической — это советуют не делать, потому что тогда проиндексируется только первая страница.

Вариант 1
Если на странице есть «Показать все», страница со всеми вариантами и будет канонической. На каждой из страниц пагинации укажите ее в атрибуте rel = «canonical».
Например, для страницы https:=»» site.ru=»» <=»» a>category1=»» page-2″=»»>https://site.ru/category1/page-2 нужно прописать канонический URL:
<link rel="canonical" href="http://site.ru/category1/show-all">Вариант 2
Если «Показать все» нет, для каждой страницы пагинации советуют указывать эти же страницы как канонические.
Например, на странице https://site.ru/category1/page2 нужно указать каноническую ссылку:
<link rel="canonical" href="http://site.ru/category1/page2">Вариант 3
Есть и другое мнение: если указать canonical страницы саму на себя, все страницы пагинации пойдут в выдачу. Если вы считаете, что плохо, если у разных URL с отличающимся контентом будут одинаковые Title и Description, то не делайте так.
В таком случае не нужно проставлять canonical, а лучше закрыть страницы пагинации в noindex, follow и использовать dissalow в robots для /page. Это значит, что индексировать нельзя, а переходить по ссылкам можно.
<meta name="robots" content="noindex, follow"/>Напомним, что noindex подходит только для Яндекса.
HTTPS, HTTP, www
Один сайт может быть доступен по трем вариантам: http://site.ru и http://www.site.ru и https://www.site.ru. Но поисковые системы будут рассматривать все три как наборы отдельных страниц, если не указать canonical. Из-за чего могут быть проблемы со сканированием и индексацией сайта.
Мобильный URL
Google уже давно переходит на Mobile-First Indexing, то есть при индексировании он ориентируется на мобильную версию сайта.
Представитель Google Джон Мюллер рассказал, что делать с каноническим тегом в этих условиях.
Если у вас есть мобильная версия сайта m.site.ru, обычно у нее указывают rel = «canonical», ведущий на десктопную. А для десктопной используют тег rel=alternate, ведущий на мобильную. Если вы сделали так, ничего менять не надо. Бот распознает мобильную версию как каноническую, даже если в коде канонической указана десктопная. Если и в Sitemap.xml также, то тоже можно не трогать.
URL страны
Бывает, что для конкретной страны у сайта есть несколько версий с разными URL. При этом язык один и контент одинаковый с несущественными отличиями. Тогда нужно выбрать каноническую и сделать отсылки к ней на всех дублях.
Но если речь идет о разных языковых версиях, нужно использовать hreflang, чтобы поисковики выдавали отдельные результаты. Атрибут hreflang нужен для указания дополнительных URL с аналогичным или похожим содержимым на других языках или для отдельных регионов.
Из-за перехода Google на Mobile-First Indexing, нужно правильно настроить hreflang. Десктопные hreflang-теги должны ссылаться на десктопные URL, мобильные — соответственно на мобильные URL. И редиректить пользователей на нужную версию в зависимости от устройства.
Верхний и нижний регистр
Поисковик может посчитать разными два адреса, написанные в разном регистре. При назначении URL система должна применять только нижний регистр, чтобы одни и те же ссылки были действительно одинаковыми.
Материал по теме:
Htaccess для перенаправления верхнего регистра на нижний
Итак, с помощью rel = «canonical» можно указать поисковику, какую страницу считать основной и главной среди дублей, чтобы сканировать ее, индексировать, показывать в выдаче и направлять на нее ссылочный вес. Разберемся, как настраивать тег.
Как настроить canonical правильно: 6 способов указать основной URL
Для использования канонического тега нужно выбрать среди дублей основной URL, вписать его в атрибут:
<link rel="canonical" href="http://site.ru/page/">и добавить ко всем неосновным страницам.
Для добавления есть несколько способов:
С помощью плагина CMS
Большинство CMS имеют встроенную функцию или плагины, которые позволяют автоматизировать настройку канонического URL.
К примеру:
-
настроить canonical на WordPress можно с помощью плагина Yoast SEO;
-
в OpenCart в настройках товара можно задать SEO URL;
-
в Joomla версии от 3 и выше можно включить функцию SEF. Тогда в код технических страниц вида /index.php?option добавится атрибут rel = «canonical» с указанием основной страницы с ЧПУ.
Для примера подробнее рассмотрим WordPress как самую популярную CMS среди наших подписчиков.
Настройка canonical WordPress
Все просто: установите плагин Yoast SEO, чтобы канонические теги добавлялись автоматически.
Настроить теги для конкретной страницы можно в разделе «Дополнительно» («Advanced»), там нужно указать основной URL:

Yoast SEO делает так, что если на странице появляется noindex или nofollow, тег canonical пропадает, чтобы не было проблем с представлением сайта в выдаче.
Если вы не используете CMS и не можете реализовать канонический тег плагинами, можно сделать все иначе.
Прописать между тегами любой HTML-страницы
Основной способ — прописать rel = «canonical» в секцию < head > любой страницы-копии.
Например, если для страницы https://site.ru/*utm_content= канонической будет https://site.ru/, на страницу https://site.ru/*utm_content= нужно добавить код:
<link rel="canonical" href="http://site.ru/">В заголовке HTTP
У PDF и других не HTML документов нет секции < head >, так что использовать предыдущий способ не получится. Если у вас есть доступ к настройкам сервера, можно указать канонический тег в заголовке HTTP с использованием .htaccess или PHP.
При запросе дублирующего файла сервер должен отдавать в заголовке ссылку на оригинальный файл:
Link: <http://example.com/file.pdf>; rel="canonical"К примеру, вы составили руководство, выложили его в блог и отдельно оформили в PDF-файл для скачивания, который разместили в подкаталоге http://site.ru/blog/*. HTTP-заголовок для этого руководства в PDF может выглядеть так:
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <http://site.ru/blog/canonical-tags/>; rel="canonical"
С другими страницами так тоже можно.
В файле Sitemap
Поисковики по умолчанию думают обо всех ссылках в XML-файле как о канонических. У Google есть требование включать в Карту сайта только канонические адреса страниц. Но Карта не свод правил для поисковых ботов, а список рекомендаций, который поисковики могут проигнорировать.
Материал по теме:
Как составить Sitemap
Через 301 редирект
Отвести трафик и ссылочный вес от дублей к канонической страницы можно с помощью 301 редиректа. Этот способ можно использовать, если сайт, к примеру, доступен по нескольким адресам:
https://site.ru/
http://site.ru/
http://www.site.ru/
https://www.site.ru/
Можно выбрать в качестве основного https://site.ru/, а со всех остальных настроить перенаправление.
Материал по теме:
Как настроить 301 редирект самостоятельно
Дополнительный сигнал — ссылки
Представитель Google Джон Мюллер в этом видео перечислял все сигналы, которые поисковик использует для определения канонического адреса.
К примеру, между адресами HTTPS и HTTP Google выберет HTTPS, а еще он может предпочесть привлекательный с его точки зрения URL. В числе сигналов каноникализации числятся ссылки с одной страницы на другую. Если вы указали канонической одну страницу, а по совокупности факторов другая кажется поисковику более подходящей, он не будет вас слушать.
Неправильной настройкой можно навредить индексированию страниц. Разберем несколько типичных ошибок оптимизаторов.
Неправильно указан canonical: популярные ошибки настройки
Использование нескольких канонических ссылок для одной страницы
Для одной страницы нужно указать один канонический адрес. Если указано несколько, бот либо проигнорирует страницу вообще, либо примет к сведению первый указанный URL.
Проверяйте, как плагин CMS реализует canonical, иногда из-за неправильной настройки он может указывать несколько адресов.
Настройка разных канонических URL одной странице
Похожий пункт, но речь идет не о нескольких канонических адресах для одной страницы, а в о разных, указанных разными способами.
Если вы используете несколько способов указать канонический тег, например, в HTTP-заголовке и в секции < head >, ссылка на основную страницу должна быть одна и та же.
Настройка цепочки канонических URL
Бот не будет учитывать канонический адрес, если для страницы, которую вы указали основной, настроена какая-то своя основная страница. Например, для адреса site.ru/1 канонической ссылкой указана site.ru/2, а для нее указана site.ru/3.
Размещение rel = «canonical» не в секции head
Тег rel = «canonical» должен находиться только в секции < head >. Если указать его в < body > документа, боты его проигнорируют. Или даже могут проигнорировать всю страницу.
Лучше перепроверить: даже если вы поставили canonical ближе к началу документа, секция < head > может закрыться раньше, например, из-за вставок JavaScript, контейнеров < iframe > или незакрытых парных тегов. Тогда canonical окажется за пределами < head > в секции < body >.
Указание первой страницы пагинации как канонической
Если для всех страниц пагинации канонической указать первую, бот не проиндексирует остальные. Выше мы писали, как лучше сделать, есть три варианта:
-
сделать канонической страницу «Показать все», если она есть;
-
для каждой страницы поставить ее же URL в качестве канонической, если нет общей страницы.
Но если вы считаете, что наличие всех страниц пагинации в выдаче плохо повлияет из-за повторяющихся Title и Description, не ставьте канонический тег вообще и закройте их для индексации. Используйте noindex, follow для страниц пагинации и для /page укажите disallow в файле robots. Такая настройка означает, что индексировать нельзя, а переходить по ссылкам можно.
Использование канонических URL вместо 301 редиректа
Тег canonical и 301 редирект кажутся похожими — перенаправляют бота на основную страницу. Но не стоит использовать canonical вместо редиректа. Редирект переводит весь трафик на один URL, а при использовании rel = «canonical» страница откроется, будет активной и сможет получать трафик, но не появится в индексе.
Выбор главной как канонической для всех страниц
Ошибкой будет указать главную страницу в качестве канонической для всего сайта. Боты могут проигнорировать все страницы, кроме главной.
Закрытие канонической страницы от индексирования
Если канонический URL закрыт от индексирования или по другой причине недоступен для поискового бота, он не сможет участвовать в формировании выдачи. В этом случае бот возьмет доступный неканонический URL.
Как проверить canonical
Проверить, для каких страниц вы настроили canonical и какие канонические страницы указали, можно с помощью сервиса Screaming Frog SEO Spider.

Узнать, какую страницу Google считает основной для конкретного URL, можно через инструмент проверки URL.
Проверить, как поступил Яндекс, можно в Вебмастере: если вы верно указали каноническую страницу, дубли пропадут из поиска. Посмотрите страницу «Индексирование» — «Страницы в поиске». Если страницу исключили из результатов, она будет в блоке «Исключённые страницы».

Рассказывайте, о каких необходимых вариантах использования canonical мы забыли, и какие еще ошибки настройки вы встречали в своей практике!
Содержание
Если на сайте есть несколько страниц с одинаковым контентом, среди них нужно определить главную страницу — каноническую. Иначе ПС могут вывести в индекс не то, что вы ожидали.
Рассказываем, как работают канонические страницы, в каких случаях их нужно указывать и как это сделать.
Что такое каноническая страница, ссылка и rel canonical
- Каноническая страница —
- основная, наиболее предпочитаемая страница.
- Каноническая ссылка (URL) —
- ссылка, которая ведёт на эту страницу.
- rel=”canonical” —
- атрибут, который указывается в контейнере тега <link>, чтобы указать поисковому роботу: конкретная страница каноническая, то есть главная.
Объясним на примере, как работают канонические страницы. Представим, что страница с одним и тем же контентом доступна по нескольким адресам. Например, товар размещается одновременно в разных категориях. В этом случае образуются несколько страниц с разными URL, но с одинаковым контентом:
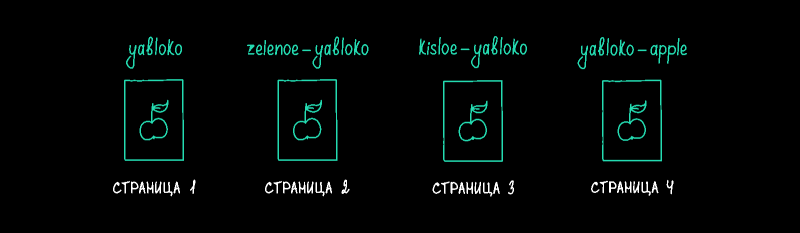
Поисковые системы могут посчитать такие страницы дублями. Это проблема для SEO.
Почему канониклы важны для SEO
Если один и тот же контент доступен на разных страницах сайта, в дальнейшем есть два пути развития событий. Оба неблагоприятны для SEO сайта.
-
ПС определит среди дублей основную страницу, а остальные «склеит» с ней как дубли и удалит из индекса.
При этом не факт, что страница будет выбрана верно, и из индекса может выпасть нужная страница.
Google говорит, что у ПС есть собственные «канонические сигналы», по которым она пытается определить, какой из URL выбрать каноническим. Подробнее — в Справке.
-
Если ПС не определит каноническую страницу автоматически, то может оставить в индексе версии страницы вместе с дублями.
Тогда все они могут конкурировать между собой, «моргать» в выдаче и т. д. Это может влиять на положение сайта в поиске.
Кроме того, индексирующий робот может медленнее доходить до новых страниц из‑за того, что будет обходить дубли.
Подробнее про дубли в Яндекс Справке
Поэтому не стоит надеяться на то, что ПС сами определят каноническую страницу. Лучше напрямую указать роботам, какую из версий страницы мы считаем основной и наиболее предпочитаемой для показа в результатах поиска. Для этого нужно указать ссылку на основную (каноническую) страницу в коде всех дублей:
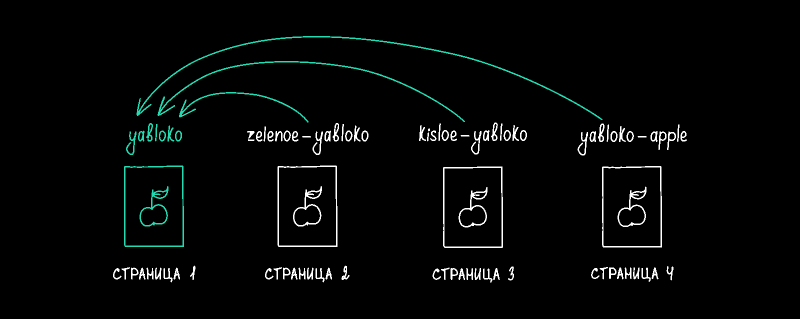
Расскажем, как это делать и в каких ситуациях.
Как настроить rel canonical
Мы будем рассказывать про разные способы указать каноническую страницу, но суть у них одна: мы размещаем ссылку на нужную страницу на её дублях, чтобы поисковики понимали, какую индексировать в первую очередь.
Через атрибут в теге <link>
Нужно разместить следующий код в теге <link> страницы‑дубля, который содержится в блоке <head>:
Код будет выглядеть так:
<link rel="canonical" href="https://site.ru/page/">
где https://site.ru/page/ — ссылка на нужную страницу.
Способ работает только с HTML‑страницами, но не с файлами, например, в формате PDF. Для таких файлов лучше использовать следующий вариант.
Через атрибут в заголовке HTTP
У не‑HTML‑документов нет раздела <head>, поэтому для них используют этот способ.
❗️ Чтобы воспользоваться этой инструкцией, нужно иметь доступ к настройкам сервера.
Нужно разместить запись следующего типа в HTTP‑заголовке файла, который является дублем канонического:
HTTP/1.1 200 OK Content‑Type: application/pdf Link: <http://site.ru/page/file>; rel="canonical"
где 200 OK — код ответа сервера, Content‑Type — тип файла, Link: <https://site.ru/page/file.pdf — ссылка на канонический файл.
В файле Sitemap
Поисковые роботы предполагают, что все ссылки, размещённые в карте сайта, канонические. Google даже требует включать в Sitemap только канонические ссылки.
Узнайте, как создать Sitemap и не только, на нашем бесплатном курсе по SEO
С помощью CMS
В зависимости от того, какую CMS вы используете на своём сайте, добавлять канониклы можно с помощью разных плагинов.
Так, в Wordpress это плагин Yoast SEO, в Joomla — Canonical Url, в 1С‑Bitrix — «Канонические ссылки».
❗️ Про перенаправление через 301‑редирект
Если вы больше не хотите показывать те или иные версии страницы в индексе, можно настроить перенаправление с них на нужные страницы. Тогда первая страница будет отправлять пользователя на вторую.
Отличие от установки канонической страницы в том, что в случае с 301‑м редиректом страница вообще не будет показываться пользователям и в выдаче; а в случае с rel canonical её можно будет увидеть, но при этом она не будет приоритетной для ПС.
Когда нужно настраивать канонический тег
При дублировании страниц
Если вы точно знаете, что на сайте есть дубли страниц, нужно указать, какая из одинаковых страниц главная.
Найти дублирующиеся страницы можно с помощью панелей Яндекс Вебмастер и Google Search Console.
В Вебмастере нужно смотреть раздел «Индексирование» — «Страницы в поиске»: у дублирующихся страниц будет статус «Дубль».
В GSC нужно смотреть пункт с исключёнными страницами в разделе «Покрытие».
В Топвизоре найти дубликаты, а также битые ссылки, редиректы, ошибки загрузки и в тегах можно найти с помощью инструмента «Анализ сайта».
Как удалить 12 тысяч дублей и попасть в ТОП Яндекса за три месяца
На страницах пагинации
Пагинация — это разделение контента на сайте на отдельные страницы. Когда пользователь открывает страницу, контент подгружается не весь сразу, а постранично. При этом образуется несколько страниц: первая, вторая, третья и т. д.
При разделении контента на несколько страниц может образоваться дубль основной страницы.
Представим, что вы хотите разделить товары в категории «Самокаты» на несколько страниц. В таком случае первая страница категории будет иметь адрес «site.ru/samokati/», но в то же время у нас появится и URL первой страницы пагинации — «site.ru/samokati/page1». Эти страницы могут быть восприняты поисковиками как дубли.
Поэтому:
-
настройте постоянный редирект с site.ru/samokati/page1 на site.ru/samokati/;
-
проследите, чтобы ссылка с других страниц на первую вела на site.ru/samokati/, а не на site.ru/samokati/page1.
❗️ Важно
На всех страницах, начиная со второй, ставьте каноникал на первую страницу. Помните, что первая страница — это основная страница категории, а не page1.
Следите за тем, чтобы ссылка с других страниц на первую вела не на page1, а на основную страницу.
Если у сайта есть версии HTTPS, HTTP, www
Если в этом случае не указать canonical, ПС будут рассматривать все три версии сайта как наборы отдельных страниц.
Это может привести к проблемам с индексацией: мы уже рассказывали про распространенные сценарии: либо страницы склеятся и в индексе останется не та, что вам нужна, а остальные удалятся (в том числе и нужная); либо в индексе останутся все страницы, что может привести к каннибализации.
То же касается слешей на конце адресов: site.ru/samokati и site.ru/samokati/.
Ставить завершающий слеш в URL или нет: как лучше для SEO
В мобильном URL
Это особенно актуально для Google, так как он уже давно ориентируется на мобильную версию сайта при индексации.
Вот что можно сделать, если у вас есть отдельная версия сайта, доступная по адресу типа m.site.ru:
-
Укажите в коде мобильной версии сайта rel=”canonical”, который будет вести на десктопную версию.
-
В десктопной версии укажите rel=“alternate” — этот атрибут будет вести на мобильную версию, показывая, что есть альтернативная версия, но не каноническая.
То же касается AMP‑страниц.
В динамических адресах
Когда человек переходит по рекламе, взаимодействует с фильтрами в каталоге, переходит в разные разделы сайта, образуются динамические адреса.
Допустим, мы зашли в раздел самокатов на сайте: site.ru/samokati/. Затем мы начали настраивать фильтры, чтобы увидеть все самокаты бренда «САМ» белого цвета. Получилось вот что:
site.ru/samokati/brand=SAM&color=white.
Таких комбинаций может быть много, поэтому из них нужно выделить главную и проставить в дубликатах ссылки на неё.
Когда не нужно настраивать канонический тег
Для набора сайта верхним и нижним регистром
Даже одни и те же адреса, написанные верхним регистром (ВОТ ТАК) и нижним (вот так), поисковики могут считать разными версиями сайта.
Но чтобы указать системе, что она должна применять только нижний регистр, нужно использовать не rel=”canonical”, а специальные записи в .htaccess‑файле сайта. Можете скопировать код отсюда:
RewriteEngine On
RewriteBase /
# If there are caps, set HASCAPS to true and skip next rule
RewriteRule [A‑Z] — [E=HASCAPS:TRUE,S=1]
# Skip this entire section if no uppercase letters in requested URL
RewriteRule ![A‑Z] — [S=28]
# Replace single occurance of CAP with cap, then process next Rule.
RewriteRule ^([^A]*)A(.*)$ $1a$2
RewriteRule ^([^B]*)B(.*)$ $1b$2
RewriteRule ^([^C]*)C(.*)$ $1c$2
RewriteRule ^([^D]*)D(.*)$ $1d$2
RewriteRule ^([^E]*)E(.*)$ $1e$2
RewriteRule ^([^F]*)F(.*)$ $1f$2
RewriteRule ^([^G]*)G(.*)$ $1g$2
RewriteRule ^([^H]*)H(.*)$ $1h$2
RewriteRule ^([^I]*)I(.*)$ $1i$2
RewriteRule ^([^J]*)J(.*)$ $1j$2
RewriteRule ^([^K]*)K(.*)$ $1k$2
RewriteRule ^([^L]*)L(.*)$ $1l$2
RewriteRule ^([^M]*)M(.*)$ $1m$2
RewriteRule ^([^N]*)N(.*)$ $1n$2
RewriteRule ^([^O]*)O(.*)$ $1o$2
RewriteRule ^([^P]*)P(.*)$ $1p$2
RewriteRule ^([^Q]*)Q(.*)$ $1q$2
RewriteRule ^([^R]*)R(.*)$ $1r$2
RewriteRule ^([^S]*)S(.*)$ $1s$2
RewriteRule ^([^T]*)T(.*)$ $1t$2
RewriteRule ^([^U]*)U(.*)$ $1u$2
RewriteRule ^([^V]*)V(.*)$ $1v$2
RewriteRule ^([^W]*)W(.*)$ $1w$2
RewriteRule ^([^X]*)X(.*)$ $1x$2
RewriteRule ^([^Y]*)Y(.*)$ $1y$2
RewriteRule ^([^Z]*)Z(.*)$ $1z$2
# If there are any uppercase letters, restart at very first RewriteRule in file.
RewriteRule [A‑Z] — [N]
RewriteCond %{ENV:HASCAPS} TRUE
RewriteRule ^/?(.*) /$1 [R=301,L]
Для контента на разных языках
Здесь ни rel=”canonical”, ни 301‑й редирект не подойдут: нужно не перенаправлять пользователей и поисковых роботов на те или иные страницы, а показывать разные результаты выдачи для разных стран, как бы «разделять» контент на разные языки. Для этого используют атрибут hreflang.
Его также вставляют в тег <link> секции <head>. Код будет выглядеть следующим образом:
<link rel="alternate" hreflang="lang_code" href="url_of_page" />
где lang_code — код языка и региона, который соответствует версии страницы (например, ru_rus), а url_of_page — URL‑версии страницы для указанного языка и региона.
Об атрибуте — Справка Google
Как проверить canonical
Чтобы узнать, какая страница считается канонической в Google, нужно воспользоваться инструментом проверки URL.
В Яндекс Вебмастере нужно посмотреть «Индексирование» — «Страницы в поиске». Дубли после указания каноникла отобразятся в разделе «Исключённые из поиска» (но всё ещё будут видны пользователям).
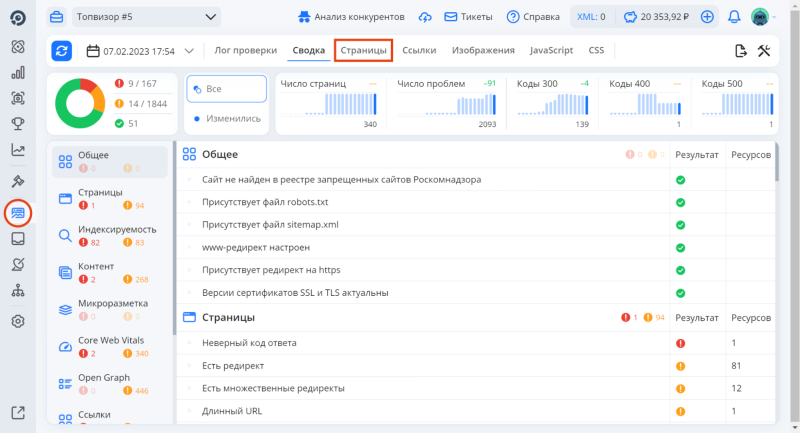
Покажем, как это делать, на примере «Анализа сайта» в Топвизоре.
Чтобы найти страницы с rel canonical:
-
Перейдите в инструмент «Анализ сайта» в левом меню и откройте «Страницы»:
-
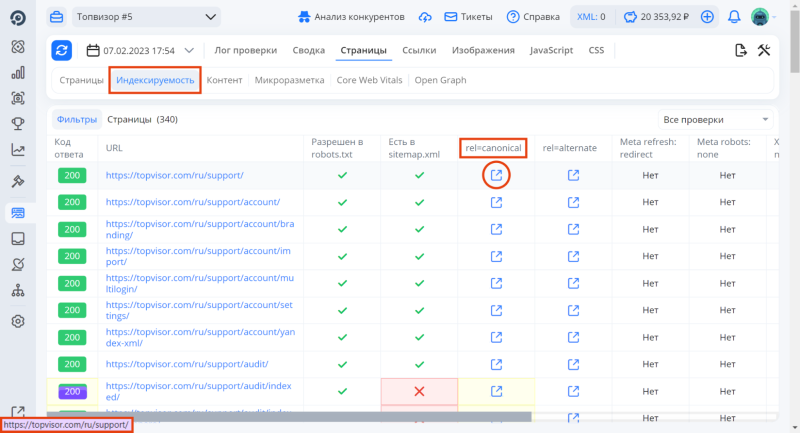
Перейдите в «Индексируемость»; в столбце «rel=canonical» наведите курсор на значок ссылки, чтобы посмотреть, куда ведёт страница. URL отобразится в левом нижнем углу.
Чтобы увидеть дубли:
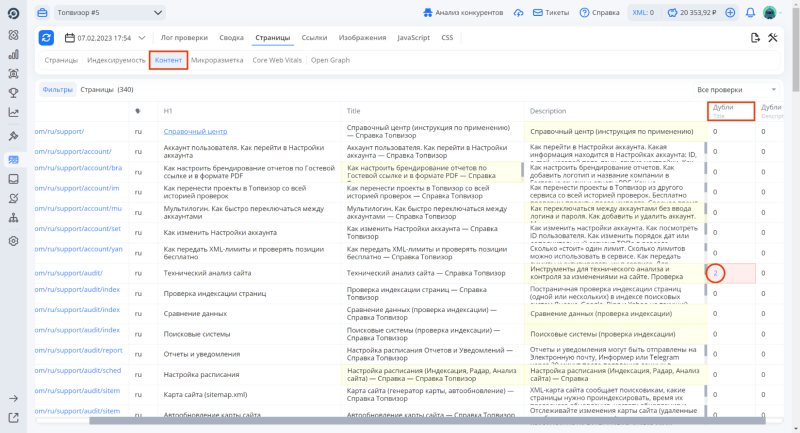
-
Перейдите в «Контент». В столбце «Дубли» у каждой страницы появится кнопка, обозначающая количество таких же страниц.
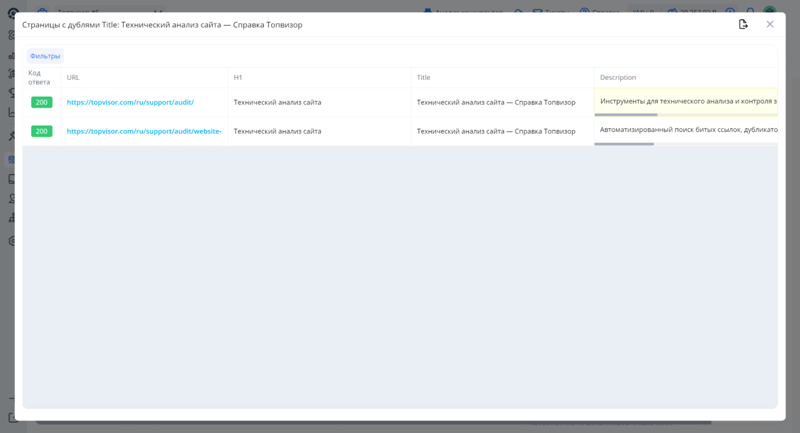
-
Нажмите на количество страниц, чтобы появился полный список дублей конкретной страницы.
❗️ Мы обновили дизайн инструмента «Анализ сайта» и открыли его для альфа‑теста. Теперь аудит стал нагляднее, проще и функциональнее: ищите редиректы и битые ссылки, проверяйте индексируемость, атрибуты и теги.
Чтобы первыми получить доступ к новой версии «Анализа сайта», напишите свой ID в комментариях.
Распространенные ошибки в настройке canonical
-
Страницы заблокированы robots.txt
Если вы блокируете сканирование неканонических адресов в robots.txt, то роботы не увидят канонические страницы.
Если вы блокируете сканирование канонических страниц, вместо них в поиске может участвовать дубль, доступный роботу.
-
Каноническая страница закрыта от индексирования
Бот не будет учитывать такую страницу.
-
Используются и noindex, и rel=»canonical» для одной страницы
Директива noindex не заменяет и не объединяется с rel=”canonical”. noindex нужен для того, чтобы исключать страницы из индекса.
-
Написаны два (или больше) атрибута rel=canonical
На странице не может быть указано несколько канониклов: бот или выберет первый из них, или вовсе проигнорирует указание.
-
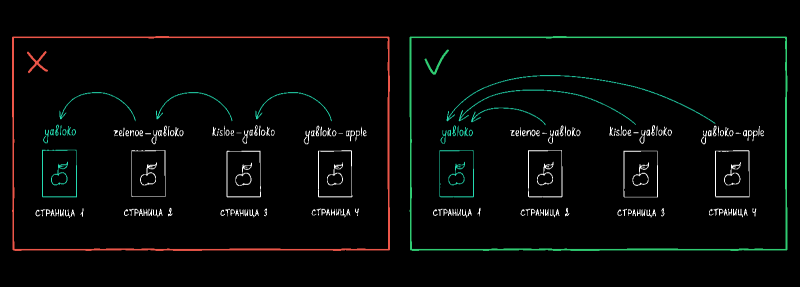
Канонические адреса образовали цепочку
Если вы указали какую‑то страницу канонической, а на ней — перенаправление на какую‑то другую страницу с помощью атрибута rel=”canonical”, бот не будет считать эту страницу канонической.
Запомните эту схему:
-
В написании канонического адреса допущена ошибка
Теги link с атрибутом rel=»canonical» должны содержать абсолютные пути, а не относительные. Нужно указывать, как в браузере: https://site.ru/page/, а не /page/ — чтобы робот понял, куда идти.
-
В атрибуте указана битая ссылка
Если вы указываете на неканонической странице адрес неработающей страницы с кодом состояния 4XX (например, знакомый всем 404 Not Found), робот ничего не поймёт и не отреагирует на указанное.
Битые ссылки на сайте: как найти и исправить
-
В атрибуте указана ссылка на страницу с редиректом
Канонические ссылки указывают ботам на более предпочтительные версии страницы. А редирект говорит им, что нужно учитывать другой адрес. Поэтому тег rel=”canonical” может быть проигнорирован.
-
Канонический адрес указывает на другой домен или поддомен
Ссылка должна указывать только на страницу на этом же сайте.
-
Канонические страницы конфликтуют друг с другом
Например, если на Странице 1 указана канонической Страница 2, но при этом в карте сайта Sitemap.XML стоит ссылка на Страницу 1 — это конфликт канонических страниц.
Поисковый робот, опираясь на карту сайта, может определить Страницу 1 важной и проигнорировать каноникал.
-
Каноническая ссылка ведет на нерелевантную страницу
Содержимое страницы, на которую вы пытаетесь перенаправить поискового бота, должно быть таким же, что и на странице‑дубле.
Если содержимое канонической страницы отличается от содержимого неканонической — например, на момент обхода неканонические страницы более полно отвечают на запрос пользователя, и их контент существенно отличается от канонических, — ПС может не учесть то, что вы указали.
-
Тег rel=canonical использован в другой секции кода
Атрибут тега <link> должен быть только в секции <head>. Если он будет в <body> или где‑то ещё, боты его проигнорируют.
-
Главная выбрана канонической для всех страниц
Тогда боты могут проиндексировать только главную, а все остальные страницы — нет. И в выдаче у вас будет только одна страница.
- Определения каноничности
- Как выглядит атрибут каноникал
- Процесс канонизации
- Почему канониклы важны для SEO
- Случаи, когда каноникал нужен✔️
- Случай, когда можно использовать каноникал👌
- Как указать канонический адрес страницы
- Правила использования канониклов
- Как проверить каноническую страницу
- Ошибки⛔
- Ответы на вопросы
- Какую страницу выбрать канонической?
- Почему Гугл ставит каноникал не мой сайт, а на сторонний ресурс?
- Каноникал или 301 редирект?
- Нужно ли ставить каноникал сам на себя?
- Вывод
Определения каноничности

Каноническая страница — это страница, которую поисковая система считает главной в группе схожих по содержимому.
Каноническая ссылка — это ссылка, которая ведет на каноническую страницу и содержит атрибут rel со значением canonical: <link rel=»canonical» href=»ссылка»/>.
Неканоническая страница — это страница на которой размещен атрибут rel=»canonical» с адресом другой страницы.
Как выглядит атрибут каноникал
Атрибут rel=“canonical” может быть прописан двумя способами:
- <link rel=“canonical” href=“ссылка” /> — в блоке <head> страницы;
- Link: <ссылка>; rel=»canonical» — в HTTP-заголовке.
Какой из этих методов выбрать лучше всего, разберем в главе «Как указать канонический адрес страницы».
Процесс канонизации
Канонизация — это процесс выбора главной страницы среди дублей (одинаковых страниц доступных по разным адресам) и/или среди страниц с похожим контентом.
В подкасте Search Off the Record от 4 ноября 2020 сотрудник Google Мартин Сплитт рассказал, как поисковик обрабатывает канонизацию:
Сначала нужно обнаружить дубликаты, сгруппировать их вместе и отметить, что эти страницы дублируют друг друга. Затем для всех них нужно найти страницу лидера.
И то, как мы это делаем, возможно, так делают большинство людей и другие поисковые системы — сводят контент к хэшу или контрольной сумме, а затем сравнивают контрольные суммы. Это намного проще, чем сравнивать, например, 3 000 слов.
Итак, мы сокращаем содержание до контрольной суммы, потому что не хотим сканировать весь текст и потому что это просто не имеет смысла — это требует больше ресурсов, а результат будет примерно таким же. Мы вычисляем несколько видов контрольных сумм для текстового содержимого страницы, а затем сравниваем их.
На вопрос: «Обнаруживает ли такой метод только точные дубли или частичные тоже?» специалист ответил:
У нас есть несколько алгоритмов, которые пытаются обнаружить и не учитывать шаблонную часть страниц. Так, например, мы исключаем навигацию из расчета контрольной суммы, убираем нижний колонтитул. Тогда у нас остается то, что мы называем центральным элементом, то есть центральное содержимое страницы, что-то вроде самой сути страницы.
После вычисления и сравнения контрольных сумм, те, которые похожи между собой (сильно или частично) мы объединяем в дублирующий кластер.
Далее по словам Мартина, необходимо выбрать один документ из кластера, который и будет показываться в результатах поиска:
Но вычислить какая из них будет ведущей в кластере не так просто. Есть случаи, когда даже людям будет сложно определить, какая именно страница должна отображаться в результатах поиска. Мы используем более 20 сигналов, чтобы решить, какую страницу выбрать как каноническую из дублирующего кластера.
Очевидно, что один из них — это содержание страницы. Но это могут быть и другие сигналы: у какой страницы более высокий PageRank, на каком протоколе страницы (http или https), включена ли страница в карту сайта, перенаправляется ли на другую страницу, проставлен ли атрибут rel=canonical… Каждый из этих сигналов имеет свой вес, а для подсчета весовых коэффициентов мы используем машинное обучение.
После сравнения всех сигналов для всех пар страниц, мы приближаемся к фактическому определению канонической.
Почему канониклы важны для SEO
1) Поисковики не любят дублирующийся контент, потому что он засоряют выдачу. Так же алгоритмам бывает непросто выбрать правильно главную страницу. Атрибут rel=»canonical» подсказывает какой URL стоит индексировать.
Google и Яндекс заявляют, что они не всегда признают указанный канонический адрес. Из-за того, что теги каноничности считаются подсказками, а не директивами (указаниями). Учитываются различные сигналы (были рассмотрены выше). Грамотное использование тегов каноничности помогает снизить риск того, что робот сочтет канонической не ту страницу.
2) Большое количество дублирующегося контента может плохо сказаться на «краулинговом бюджете» вашего сайта. Это значит поисковые системы будут тратить свои ресурсы на сканирование неуникальных страниц вместо того, чтобы находить новый или обновленный контент.
Стоит отметить, что при грамотной настройке, поисковые боты обходят неканонические страницы заметно реже канонических.
Сотрудник Яндекса Платон Щукин подчеркивает:
Поисковой робот может посещать ссылки с неканонических страниц.
Частоту обхода назвать сложно: на планирование и обход страниц влияет очень большое число факторов. И если поисковому роботу уже известны ссылки на те страницы, которые указаны на неканонических адресах, например, из файлов sitemap, робот в любом случае будет обходить их.
3) Атрибут каноничности помогает в консолидации переходов на одинаковые или повторяющиеся страницы. Это необходимо, чтобы собрать всю информацию, которая есть о разных страницах (например, ссылки на них), и связать ее с одним URL.
Например, чтобы ссылки для страницы site.ru/tea/red?gclid=123 объединить со ссылками для site.ru/tea/red.
4) Данные из отчета об эффективности в Google Search Console с 2019 привязаны к каноническим адресам. Это значит, что для получения корректных данных из отчета нужно указать правильные канонические страницы.
5) Проставленные канониклы для каждой страницы помогают защититься от спама, когда конкуренты генерируют мусорные страницы через гет-параметры.
Случаи, когда каноникал нужен✔️
Есть несколько ситуаций, когда атрибут каноникал нужно использовать. В остальных случаях его можно использовать по своему усмотрению (рассмотрим отдельно).
Для страниц-дубликатов

Нередко одна и та же страница может открываться по разным URL-адресам. Это происходит из-за того, что раздел или товар/услуга/публикация может принадлежать нескольким категориям. В этом случае необходимо выбрать один адрес, который будет считаться основным, а для остальных страниц-копий проставить каноникал.
Пример: в интернет-магазине попасть на товарную страницу майки можно тремя способами:
- site.ru/t-shirt/nike/futbolka-sportivnaya/
- site.ru/brands/nike/futbolka-sportivnaya/
- site.ru/t-shirt/kovty/sportivnyye/futbolka-sportivnaya/
В качестве канонического урла можно выбрать любой, однако предпочтительными будут 1-й или 2-й варианты. Т.к. их уровень вложенности адреса меньше, чем у 3-го варианта. (P.S. Исследование факторов рейтинга 2016 года от Backlinko выявило сильную корреляцию между короткими адресами ссылок и высокими позициями в Google).
Также дублями с точки зрения поисковых систем считаются страницы сортировок т.к. порядок вывода содержимого не меняет сам контент. Это страницы вида:
- site.ru/divany/?sort=price_asc
- site.ru/divany/?sort=price_desc
- site.ru/divany/?sort=new
- и т.д.
Еще канониклы стоит использовать в тех случаях, когда после применения фильтров на сайте, содержимое страницы не меняется.
Например, есть страница «сплит-системы» представленная 5 моделями. После применения фильтра «Рекомендуемая площадь охлаждения» со значением «до 30 кв. м» на странице отображаются все те же 5 моделей. Т.е. в данном случае контент не изменился и поэтому стоит проставить каноникл в сторону родительской страницы.
Для страниц с похожим контентом

Если у вас есть похожий контент по разными адресами, то также стоит использовать каноникал. Например, это могут быть товары отличающиеся только цветом или размером. В этом случае выбираем из группы-страниц главную, расставляя канонические ссылки на нее. Такой вариант избавления от похожих страниц стоит применять, когда по ключу «товар+цвет», «товар+размер» нет спроса.

Для мобильных URL-адресов

Если урл адреса для мобильных устройств реализованы на отдельном домене (m.site.ru), то обязательно указывать каноническую ссылку на каждой такой странице в сторону основной (т.е. десктопной).
Для AMP-страниц

Для страниц, созданных по технологии AMP, ситуация точно такая же, что была рассмотрена выше. Для каждой AMP-страницы необходимо указать канонический адрес в сторону основной страницы.

Кстати, для Турбо-страниц, которые являются аналогом технологии AMP, по умолчанию проставляется канонический адрес.

Случай, когда можно использовать каноникал👌
Теперь рассмотрим ситуации, когда канонические адреса применяются в качестве одного из возможных решений технических проблем.
Для динамических адресов
На сайте могут формироваться динамические адреса, путем добавления различных идентификаторов и параметров в результате взаимодействия с фильтрами, за счет спама, переходов по рекламе и т.д.
- site.ru/kitchen/table?material=wood&color=red
- site.ru/kitchen/table?gclid=ABCD
Отсекать такие дубликаты можно с помощью канониклов, блокировки мусорных адресов по маске в robots.txt, с помощью директивы Clean-param для Яндекса (рекомендуется), с помощью инструмента «Параметры URL» для Гугла.
Для копий страниц на многоязычных и мультирегиональных сайтах
Версии одной страницы на разных языках считаются копиями, когда основной контент написан на одном и том же языке, а переведены лишь колонтитулы и прочие незначительные текстовые элементы. В этом случае нужно указать в качестве канонической страницы основную версию.
Использование rel=»canonical» на пагинации
Каноникал на пагинации можно использовать в двух вариациях:
- если существует общая страница, которая содержит весь контент с пагинации, то проставлять канониклы на нее;
- когда на каждой странице пагинации каноникал стоит сам на себя.
Больше информации по оптимизации страниц пагинации читайте в нашей статье.

Пример применения rel=»canonical» на пагинации от Гугла

Пример применения rel=»canonical» на пагинации от интернет-магазина Walmart
Для отдельных страниц печати
Бывает, что страницы печати формируют отдельные страницы, которые бесполезны для поисковых систем. Например:
- site.ru/gotovyy-sertifikat-covid/
- site.ru/gotovyy-sertifikat-covid/print/
Установка каноникала в сторону родительской страницы поможет избежать дублирования.
Для склейки
Использовать канониклы можно для склейки страниц, когда контент одинаковый, а URL-адреса различаются только:
- префиксом www или его отсутствием: https://site.ru и https://www.site.ru
- протоколами http и https: http://site.ru и https:/site.ru
- слешом на конце урла или его отсутствием: site.ru/seo-god/ и site.ru/seo-god
Для индексных страниц
Главная страница сайта может быть открыта по разным адресам:
- site.ru/index.html
- site.ru/index.htm
- site.ru/index.php
- site.ru/default.htm
- и т. д.
Для дублей можно указать каноническую страницу в сторону основной версии.
При разном написание URL-адреса
Например, когда страницы одинаковы по контенту, а отличаются только наличием заглавных букв в адресе:
- site.ru/author/mike/
- site.ru/Author/Mike/
Как указать канонический адрес страницы
Есть 3 основных метода указания канонической страницы. Далее рассмотрим каждый и сравним их.
HTML-код
Самый популярный способ — это использовать тег <link> в разделе <head> HTML-документа:
<link rel=»canonical» href=»ссылка на каноническую страницу» />
При этом необходимо установить каноническую ссылку для всех страниц-дублей.
Http-заголовок
Каноникализация может проводится как для обычных HTML-страниц, так и для электронных документов (PDF, DOC, XLS и т.д.).
Если у вас, например, PDF-файл доступен по разным URL-адресам, то необходимо указать предпочтительный через HTTP-заголовок следующим образом:
Link: <ссылка на каноническую страницу>; rel=»canonical»
Файл Sitemap
Все страницы в карте сайта по умолчанию считаются каноническими. По этой причине в сайтмапе не должно быть дубликатов. Иначе поисковые боты будут путаться в выборе канонического адреса.
Никаких атрибутов для указания канонической страницы использовать не нужно.
Сводная таблица методов
- Для обычного HTML-документа размещайте конструкцию <link rel=»canonical» href=»ссылка»/> непосредственно на странице в разделе <head>.
- Для документа формата .PDF, .DOC и т.д. используйте HTTP-заголовок с атрибутом rel=»canonical».
- Канонический адрес в карте сайта является менее значимым сигналом, чем атрибут rel=»canonical». Поэтому на этот метод рассчитывать не стоит. Главное, чтобы в Sitemap не попадали дубли страниц, дабы не путать поисковые системы.
Установка канониклов на различных CMS и конструкторах
Для различных CMS существуют собственные плагины, которые позволяют настроить канонические URL-адреса, например, для WordPress можно воспользоваться Yoast SEO.
Для OpenCart настройка канониклов производится средствами CMS. Необходимо зайти в настройки товара и задать параметр SEO URL.
В Тильде по умолчанию проставляется каноникал сам на себя, но так же возможно изменить значение атрибута для каждой страницы вручную.
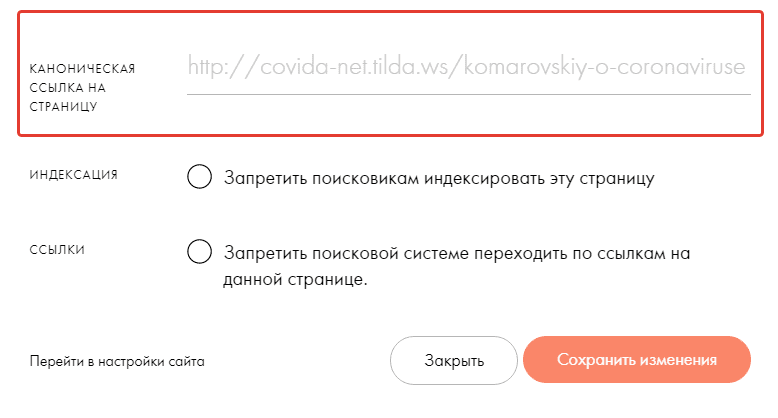
Правила использования канониклов
Джон Мюллер советует использовать только абсолютные URL-адреса:
Вы можете использовать как относительные, так и абсолютные канонические адреса. Я бы рекомендовал использовать последние. Чтобы вы были уверены, что адреса правильно интерпретируются.
В справке Яндекса такая же рекомендация:
Указывайте канонический адрес в пределах одного домена. В качестве канонического адреса задавайте абсолютный путь, например http://example.com/blog/.
✅ Правильно:
<link rel=“canonical” href=“https://site.ru/covid/2021/” />
⛔ Не правильно :
<link rel=“canonical” href=”site.ru/covid/2021/” />
Чек-лист:
- Убедитесь, что вся или большая часть основного контента дублированной страницы также отображается на канонической странице.
- Убедитесь, что rel=canonical указан только 1 раз на странице в разделе <head> или в HTTP-заголовке.
- Убедитесь, что каноническая страница возвращает 200 ОК.
- Убедитесь, что канонический адрес доступен для сканирования и индексирования.
- Убедитесь, что каноническая страница указанная через атрибут rel=canonical совпадает со страницей в файле sitemap.
- Убедитесь, что для группы страниц-копий выбрана единственная каноническая страница.
Как проверить каноническую страницу
Чтобы узнать какую страницу поисковая система определила в качестве канонической нужно воспользоваться специальными отчетами.
Проверка канонической страницы в Google Search Console
C помощью инструмента проверки URL в Google Search Console можно проверить, какой канонический адрес выбрала (или не выбрала) поисковая система. Нужно ввести интересующий URL, отправить запрос и получить в ответ сведения из индекса Гугла. Нас интересует отчет «Покрытие» и его статус.
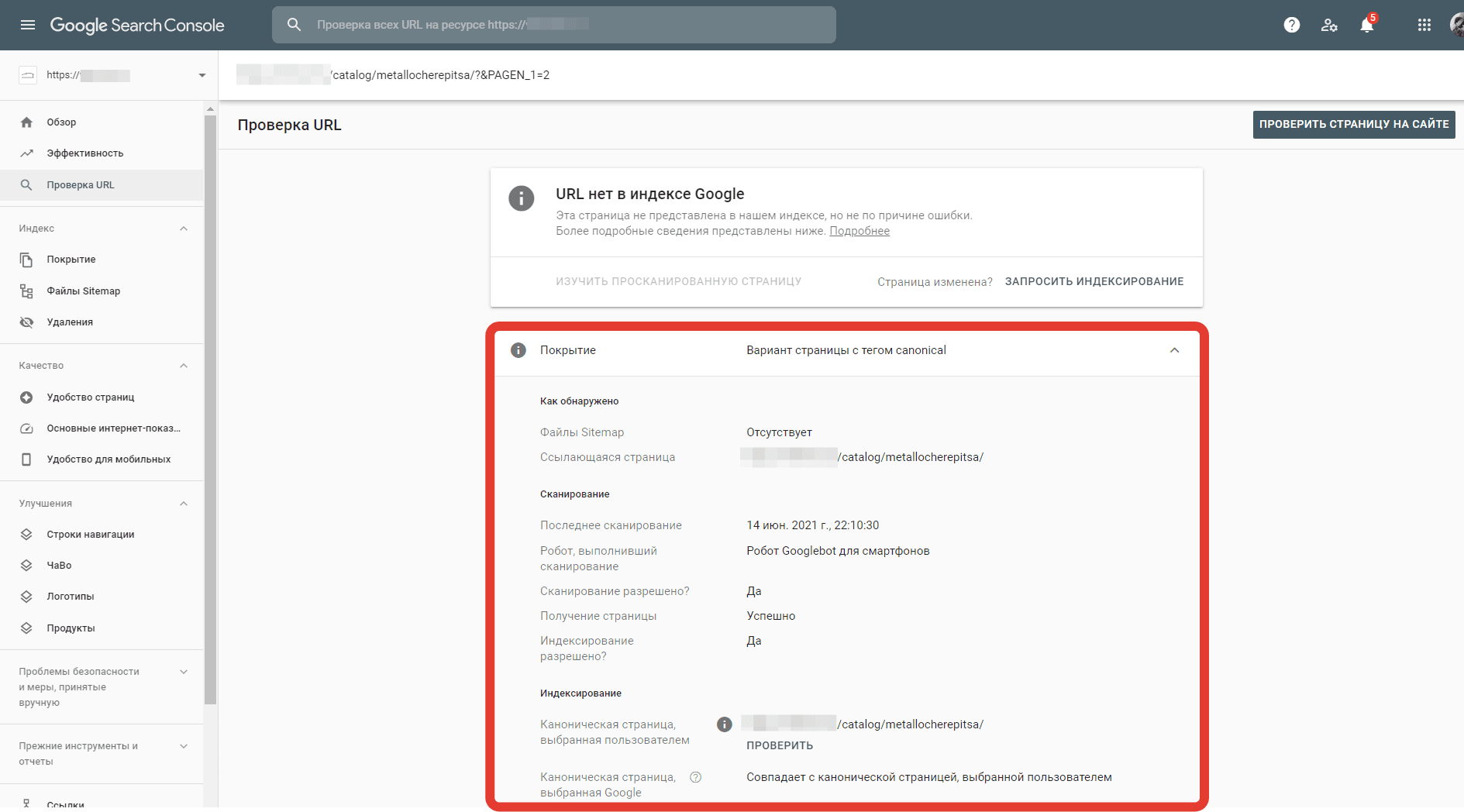
Важно обращать внимание на дату сканирования. Сведения о проверяемой странице могут быть устаревшими. Если это так, то есть смысл отправить каноническую страницу на переиндексацию и дождаться обновления отчета.
Итак, возможны 4 варианта статуса. Далее про каждый подробнее.
Вариант страницы с тегом canonical
Данный статус означает, что проверяемая страница дублирует другую, которую Google считает канонической, и при этом канонический адрес верно указан.
В этом случае никаких дополнительных действий предпринимать не нужно.

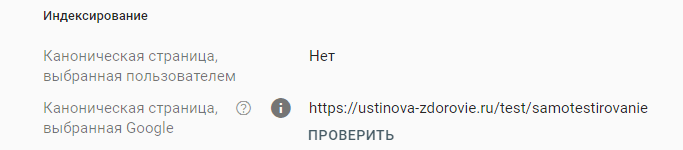
Страница является копией. Канонический вариант не выбран пользователем
Это значит, что у проверяемой страницы есть точные копии и ни одна из них не указана в качестве канонической в явном виде. При этом Google считает анализируемую страницу неканонической. В отчете отображается какую страницу поисковик считает главной.
Если страница выбранная Гуглом вас не устраивает, то стоит указать каноническую страницу в явном виде через HTML-код или HTTP-заголовок. Иначе можно оставить все как есть.
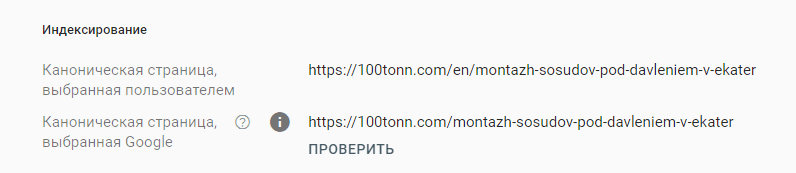
Страница является копией. Канонические версии страницы, выбранные Google и пользователем, не совпадают
Это значит, что для проверяемой страницы указан канонический адрес, но Google считает, что другой URL больше подходит. Поэтому робот не проиндексировал страницу.
В справке Гугла рекомендуют пойти у них на поводу и отметить страницу как неканоническую копию. Однако если вас такой вариант не устраивает, то нужно будет проанализировать почему поисковик выбрал другую страницу (ссылка на абзац про процесс канонизации) и внести правки. Добавить каноническую страницу в карту сайта и удалить из нее дубли, проверить наличие внутренних ссылок на эту страницу, получить на нее внешние ссылки и т.д.
Страница является копией. Отправленный URL не выбран в качестве канонического
Отличие этого отчета от предыдущего в том, что страницы были принудительно отправлены на индексирование и при этом Google их считает копиями. Грубо говоря это отчет можно назвать «Зачем ты просишь меня индексировать неканонические страницы?».
Проверка канонической страницы в Яндекс.Вебмастере
В Яндекс.Вебмастере в разделе «Страницы в поиске» необходимо на вкладке «Последние изменения» отфильтровать интересующую вас страницу по условию «Статус и URL». В отчете будет указано является ли проверяемая страница канонической или нет.
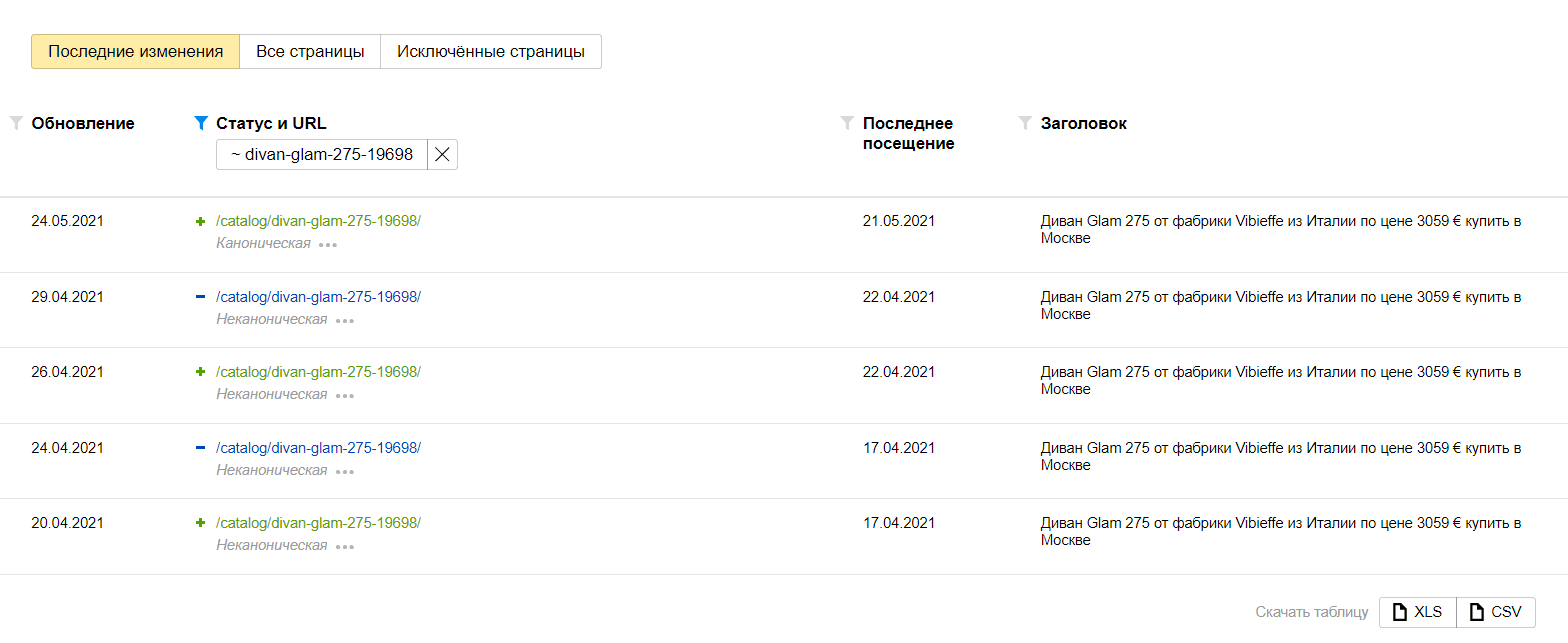
Также возможно скачать данные в .XLS формате и отфильтровать данные по столбцу «status», где выбрать значение «NOT_CANONICAL». Т.о. вы получите весь список канонических страниц, которые не участвуют в поиске.
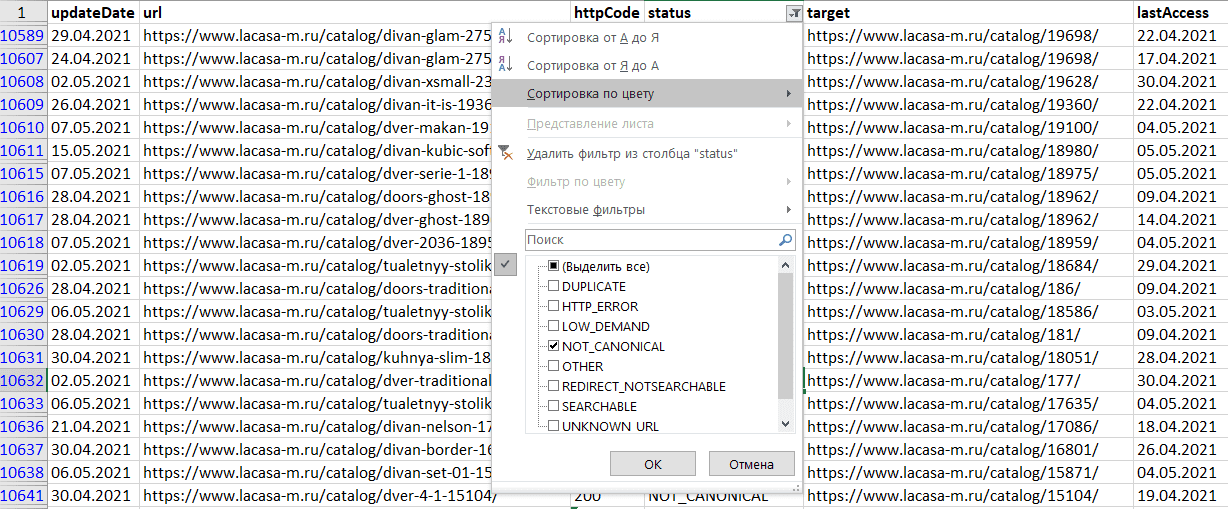
Ошибки⛔
Мы собрали наиболее популярные ошибки, которые могут возникнуть в процессе канонизации.
Блокирование с помощью файла robots.txt
Блокировка неканонических адресов в robots.txt не позволяет поисковыми роботам просканировать их содержимое. Поэтому такие страницы не смогут передавать сигналы, даже если на них установлен атрибут rel=»canonical».
Если в robots.txt была заблокирована каноническая страница, то вместо нее в поиске может участвовать копия, если она доступна для индексации.
Совмещение noindex и rel=»canonical»
Официальный ответ Джона Мюллер о различиях между сигналами noindex и rel=canonical и почему их нельзя совмещать:
Когда Google видит два URL с одного сайта, которые выглядят одинаково, а вы четко сообщаете о своих предпочтениях, то мы стараемся объединить их и обрабатывать как один (более сильный) URL вместо двух. Редиректы, rel=canonical, внутренние и внешние ссылки, файлы Sitemap, heflang и т.д. демонстрируют нам ваши предпочтения, поэтому чем более согласованно они применяются, тем скорее мы им последуем и используем их для канонической версии страницы.
С другой стороны, noindex (один) и директива disallow в файле robots.txt не являются четкими сигналами для каноникализации. Наличие на странице лишь тега noindex не говорит нам, что вы хотите объединить его с чем-то еще и что сигналы необходимо перенаправить. А директива disallow в файле robots.txt еще сложнее для понимания, так как мы не знаем, есть ли на сайте похожие страницы, поэтому не можем использовать данный сигнал для каноникализации.
Отсюда вытекает правило: нельзя смешивать noindex и rel=canonical: для нас это очень противоречивые сигналы. Обычно мы учитываем rel=canonical как более важный сигнал. Однако всякий раз, когда вы полагаетесь на интерпретацию со стороны компьютерного скрипта, вы уменьшаете вес вашего входа. А SEO сводится к передаче компьютерным скриптам информации о ваших предпочтениях.
Ошибка в написании канонического адреса
Речь идет о тех случаях, когда адрес канонической страницы по логике выбран правильно, но допущена ошибка в его написании. Например:
- утрачен слеш в конце урла или наоборот добавлен лишний;
- указан http протокол вместо https или наоборот;
- домен указан с www или без него;
- с ошибкой указан относительный адрес, например <link rel=»canonical» href=»site.ru/catalog/phones/» />.
Битые ссылки
Когда одна или несколько страниц указывают в качестве канонического адреса страницу с кодом состояния 4XX — это считается ошибкой. В этом случае сигналы с неканонических страниц никуда не перейдут.
Ссылки на страницы с редиректом
Канонические ссылки должны вести на наиболее предпочтительную версию страницы. Редирект же указывает на то, что нужно учитывать другой адрес. Из-за этого поисковые системы могут неверно интерпретировать тег или проигнорировать его вовсе.
Канонический адрес указывает на другой домен или поддомен
Эта ситуация актуальна только для Яндекса. Поисковик не учитывает канониклы, если они ведут на другой домен или поддомен.
В блоге Яндекса для вебмастеров сказано:
Стоит отметить, что межхостовый атрибут все ещё не поддерживается, поэтому, если отдельные страницы будут содержать атрибут с такими указаниями, как неканонические, они из поиска не выпадут.
Атрибут каноникал помогает указать оригинал контента. Например, если вы размещаете статью на стороннем ресурсе, но хотите чтобы в результатах поиска отображался основной URL т.е. с вашего сайта. Или у вас на основном домене и поддоменах есть одинаковые страницы (например блог).
Гугл поддерживает междоменные канонические адреса.
Конфликт канонических страниц
Не указывайте разные канонические адреса для страниц копий. Например, в карте сайта один адрес, а с помощью атрибута rel=»canonical» – другой.
Цепочка канонических адресов
Например, для страницы A канонической версией является страница B, а для страницы B указан канонический адрес C. Такие цепочки путают поисковые системы из-за чего атрибут каноникал может быть проигнорирован.
Два атрибута rel=canonical
Каноническая ссылка ведет на не релевантную страницу
301 редирект работает примерно также, как атрибут canonical. Если контент на неканонической и канонической страницах совпадает, то они склеиваются. В противном случае склейки не будет.
Если вы делаете склейку на страницу с совершенно другим контентом, то Google это будет расценивать как soft 404, что приводит к потере 100% PageRank.
Использование rel=canonical в секции <body>
Тег rel=canonical должен быть размещен в разделе <head> или в HTTP-заголовке. В секции <body> он не учитывается.
Ответы на вопросы

Какую страницу выбрать канонической?
Чтобы было проще определиться с выбором канонической страницы, обратите внимание на следующие моменты:
- какая страница из группы дублей индексируется в данный момент;
- посещаемость каждой из страниц;
- наличие внешних/внутренних ссылок и их количество;
- в качестве главной версии лучше выбирать страницу с наименьшей вложенностью URL-адреса
Предпочтительно выбирать в качестве канонической страницы ту, которая уже в индексе, обладает максимальной посещаемостью, наибольшим количеством ссылок и минимальной длинной URL-адреса.
Почему Гугл ставит каноникал не мой сайт, а на сторонний ресурс?
Такое может возникнуть по двум причинам:
- Сайт был взломан и проставлен каноникал в сторону стороннего ресурса. Проверить легко. Заходим в исходной код нужной страницы и смотрим куда ведет каноникал. Если каноническая страница указана верно, то проблема может заключаться в другом.

- Ваш контент скопировал более трастовый сайт и Гугл посчитал его источником материала (пример). В данном случае вы можете подать DMCA запрос на удаление контента.



Каноникал или 301 редирект?
Google и Яндекс могут передавать сигналы ранжирования на другой URL без 301-редиректа.
Джон Мюллер в июне 2021 года поделился своими мнением на этот счет:
Бывают случаи, когда при смене URL страницы технически невозможно поставить 301 редирект.
И для таких случаев есть шанс, что сигналы передадутся аналогично тому, как если бы стоял редирект.
При этом должны выполняться условия:
- Контент должен быть тот же;
- Старая страница должна существовать.
В общем случае лучше использовать 301 редирект, когда это возможно.
Каноникал лучше использовать в ситуациях, описанных в главе «Случаи, когда каноникал нужен».
Нужно ли ставить каноникал сам на себя?
Не обязательно. Т.е. никакого эффекта в ранжировании это не даст. Максимум защитит от появления страниц дубликатов.
Джон Мюллер заявляет, что автореферентные теги каноничности не являются обязательными, однако их применение рекомендуется.
Я рекомендую использовать автореферентные теги каноничности, поскольку это лучше всего помогает нам понять, какую именно страницу вы хотите проиндексировать, или какой адрес должен быть у проиндексированной страницы.
Даже если у вас только одна страница, иногда ее можно вызвать через разные варианты адреса — например, с определенными символами в конце, в верхнем или нижнем регистре, с www или без. Все это можно конкретизировать с помощью тега rel canonical.

Так делают в самом Гугле
В справке Яндекса сказано, что если атрибут rel=»canonical» указывает на страницу, на которой размещен — это не ошибка. Робот просто посчитает ее канонической.

А в Яндексе так не делают
Вывод
rel=“canonical” — это очередной полезный инструмент для поискового продвижения, который помогает решить проблему с дублированием контента, а также с неэффективным расходованием краулингового бюджета. Главное применять канониклы только по назначению и грамотно их настраивать, тогда и будет результат.
Cправка — Search Console
Войти
Справка Google
- Справочный центр
- Сообщество
- Search Console
- Политика конфиденциальности
- Условия предоставления услуг
- Отправить отзыв
Тема отзыва
Информация в текущем разделе Справочного центра
Общие впечатления о Справочном центре Google
- Справочный центр
- Сообщество
Search Console
Неканонические страницы в Поиске
Часто на сайтах присутствуют страницы с разными URL, но с одинаковым или очень похожим содержанием. С помощью атрибута rel=«canonical» вебмастера могут указать, какая страница является «канонической» — предпочтительной для индексации и появления в результатах поиска. Остальные, неканонические версии как правило в поиск не попадают.
Наши исследования показывают, что страницы, размеченные как неканонические могут быть полезны, а их наличие в поиске может влиять на качество и полноту ответа на запрос пользователя. Например, если для темы форума владелец сайта указал канонической страницу с началом ветки, то многие важные и нужные ответы, которые были даны пользователями позже, в поиск не попадают. Другой пример: бывает, что какое-то литературное произведение разбито на страницы и в качестве канонической прописана первая страница. В результате сайт не находится по запросу-цитате, соответствующей тексту за пределами первой странице. Поэтому теперь в поиске неканонические страницы будут появляться чаще.
Они будут показаны в том случае, если они более релевантны запросу и их контент существенно отличался от канонической версии во время сканирования роботом. В Вебмастере такие страницы можно увидеть на странице «Страницы в поиске» с пометкой «Неканоническая». Помимо этого статуса мы начали показывать статусы «Каноническая» и «Каноническая страница не указана» для всех страниц, попавших в поиск.

Если канонические страницы настроены на сайте без ошибок, то никаких дополнительных действий от вебмастера не требуется. Для сайтов, имеющих много неканонических страниц, которые сильно отличались от канонических, возможен прирост количества страниц в Поиске. Впрочем, канонические страницы по-прежнему попадают в поиск гораздо чаще и имеют более высокий приоритет при показе в результатах поиска. Объем трафика для каждого конкретного сайта существенно не изменится.
Команда Поиска
P. S. Подписывайтесь на наши каналы
Блог Яндекса для Вебмастеров
Канал Яндекса о продвижении сайтов на YouTube
Канал для владельцев сайтов в Яндекс.Дзен