В этой статье мы рассмотрим, как с помощью сервиса Labrika обнаружить и исправить на сайте HTML-ошибки. Информация о таких ошибках будет полезна как для владельца веб-ресурса, который контролирует работу своего SEO-специалиста и хочет знать, какие нерешенные проблемы есть на сайте, так и для оптимизаторов, поскольку им нужно оперативно обнаружить и исправить все изъяны, мешающие продвижению ресурса.
HTML (от англ. HyperText Markup Language) — это язык гипертекстовой разметки, который применяется на каждой веб-странице в интернете и состоит из множества элементов (тегов). Как правило, ошибками в коде HTML являются незакрытые или дублированные элементы, неправильный порядок их расположения, неверные атрибуты или их отсутствие.
На примере ниже в коде страницы присутствует закрывающий тег ссылки </a> без открывающего тега <a>:

Для проверки валидности кода (то есть соответствия стандартам HTML) используются специальные инструменты. Они проверяют:
- Синтаксические ошибки: пропущенные символы, ошибки в написании тегов.
- Нарушения вложенности тэгов: незакрытые и неправильно закрытые теги. По правилам теги закрываются так же, как их открыли, только в обратном порядке.
- Соответствие кода указанному DTD (Document Type Definition): правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов.
Как HTML-ошибки влияют на продвижение сайта?
Как отмечал представитель Google Джон Мюллер, валидность кода HTML не является прямым фактором ранжирования, однако критические ошибки в HTML мешают:
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- отображению на мобильных устройствах и кроссбраузерности.
В первую очередь наличие ошибок в коде HTML может привести к тому, что часть контента страницы не будет проиндексирована.
О том, что следует использовать действительный HTML, сказано в Рекомендациях Google для веб-мастеров. Среди авторитетных SEO-источников бытует мнение, что фильтр Google Panda может быть наложен на сайт за большое количество таких ошибок (отдельную статью об алгоритме Google Panda вы можете прочитать на нашем сайте).
Официальные источники Яндекса также сообщают, что подобного рода ошибки на сайте нежелательны, а верстка страниц должна соответствовать принятым стандартам.
Почему важно проверять наличие HTML-ошибок?
Ошибки в коде HTML могут быть критическими и несущественными, которые не ведут к серьезным потерям. Что касается критических, то одни из них отрицательно сказываются на функционировании сайта, а другие — на работе поисковых систем.
Современные браузеры автоматически исправляют 99% критических ошибок при загрузке сайта. Однако некоторые из них браузер исправить не может. Например, если тег <а> для создания ссылки не содержит адреса, то браузер не сможет определить, куда её направить. Или в теге <img> для размещения картинки не указан путь к ней, тогда браузер не сможет её подгрузить. Наличие таких ошибок в коде может привести к серьезным последствиям — например, не загрузятся фото товара или не будет работать корзина.
Поисковые системы также автоматически исправляют часть HTML-ошибок, но у них возникает следующая проблема: если браузеры в состоянии потратить несколько секунд на исправление ошибок, то у поисковых роботов нет такой возможности. Им приходится сканировать сотни миллиардов страниц ежемесячно, поэтому боты не могут тратить время на устранение всех ошибок. Некоторые из них поисковые системы игнорируют, а также могут не включать в индекс содержащие их страницы или проиндексировать только часть контента таких страниц.
Веб-мастера и пользователи просматривают сайты в браузере, где большая часть HTML-ошибок исправляется автоматически, и поэтому не придают им большого значения. Зачастую даже разработчики не исправляют элементарных грубых ошибок в разметке. Это приводит к тому, что критические для поисковых систем ошибки остаются на сайтах и могут стать причиной неправильной индексации страниц. В результате бюджеты на продвижение будут потрачены неэффективно, а источник проблемы так и остается неустановленным.
Как обнаружить HTML-ошибки с помощью сервиса Labrika
Labrika проверяет данные ошибки двумя способами:
- С помощью валидатора W3C, который проверяет наличие всех HTML-ошибок.
- С использованием валидатора Labrika «Критические ошибки HTML». Он устанавливает только те ошибки, которые могут повлиять на сбор данных поисковыми системами или привести к некорректному отображению сайта и нарушениям в его работе. определяет порядка 15 видов таких ошибок.
Отчет » Критические ошибки HTML» вы сможете найти в левом боковом меню в разделе «Технический аудит».
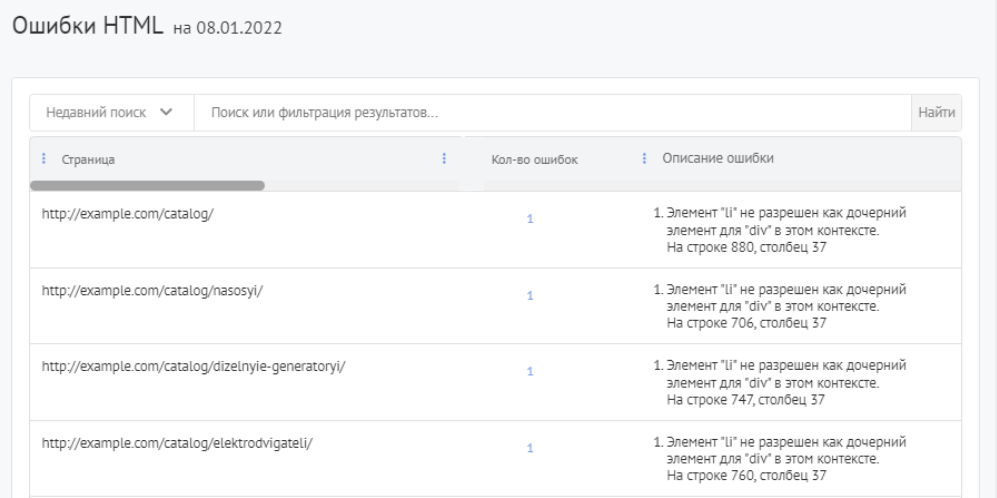
Актуальные данные в отчете вы сможете увидеть после запуска проверки сайта.
Отчет показывает:
- Страницы, которые содержат критические ошибки HTML.
- Количество и описание критических HTML-ошибок на данной странице.
При клике по их числу осуществляется переадресация на валидатор W3C, в котором вы сможете найти подробную информацию обо всех имеющихся в коде страницы ошибках.
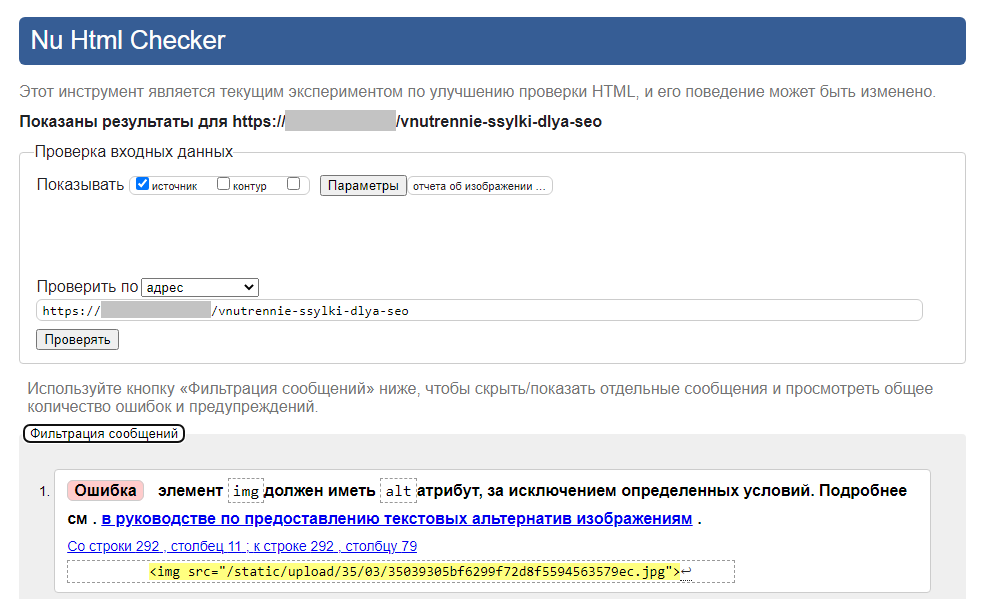
Как исправлять HTML-ошибки?
Критические HTML-ошибки необходимо исправлять в первую очередь, так как поисковые системы могут отреагировать на них отрицательно. Влияние прочих ошибок на продвижение в поиске не доказано.
Если для исправления ошибок требуется передать их список специалисту по верстке, с помощью кнопок в правой части страницы отчета вы можете скачать его данные в формате таблицы Excel или поделиться ссылкой на отчет по HTML-ошибкам с другими пользователями.

После нажатия на значок ссылки появится следующее всплывающее окно:
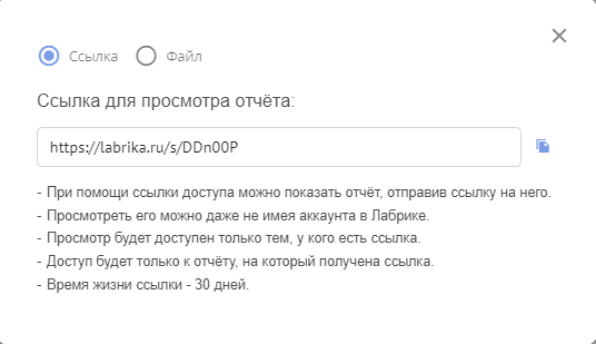
Кнопка, которая расположена справа от ссылки, позволяет скопировать её в буфер обмена. Отчет по ссылке будет доступен даже тем, кто не имеет аккаунта в Labrika.
Для ускорения работы по исправлению HTML-ошибок можно воспользоваться редакторами, которые автоматически создают закрывающие теги для документов HTML (например, Bluefish, Notepad++).
Большинство ошибок, возникающих при валидации кода можно свести к набору типовых вариантов, зная которые легко понять, на что «намекает» валидатор. В качестве образца возьмем расширение HTML Validator для браузера Firefox, предназначенное для проверки кода и рассмотрим список ошибок и замечаний по коду.
Посмотреть все возможные сообщения валидатора можно по адресу http://www.htmlpedia.org/wiki/HTML_Tidy, далее приведены основные ошибки с их описанием и решением. Зеленым цветом выделен корректный вариант, другой цвет используется для обозначения ошибки.
Notice: entity «…» doesn’t end in «;»
Это замечание возникает при использовании спецсимволов вроде < при отсутствии на конце точки с запятой.
 
Решение
Добавьте в конце спецсимвола точку с запятой.
Notice: numeric character reference «…» doesn’t end in ‘;’
Возникает при использовании числовых спецсимволов вроде — когда в конце забыли добавить точку с запятой.
™
™
Решение
Добавьте в конце спецсимвола точку с запятой.
unescaped & or unknown entity «&…»
Символ амперсанда (&) часто применяется в адресах ссылок (атрибут href тега <a>), поскольку он разделяет несколько параметров. Однако амперсанд зарезервирован для спецсимволов вроде поэтому в ссылках необходимо указывать & вместо &.
<a href=»http://www.htmlbook.ru/content/?id=30&text=1″>Ссылка</a>
<a href=»http://www.htmlbook.ru/content/?id=30&text=1″>Ссылка</a>
Решение
Замените & на &.
missing </…>
Отсутствует обязательный закрывающий тег.
<head><title>Заголовок</title></head>
<head><title>Заголовок</head>
Решение
Добавьте закрывающий тег.
missing </aaa> before <bbb>
Ошибка возникает при нарушении порядка тегов, когда блочный тег располагается внутри встроенного. В данном случае блочный тег <bbb> находится внутри встроенного тега <aaa>.
<p><span>Текст</span></p>
<span><p>Текст</p></span>
Решение
Поменяйте расположение тегов — перенесите встроенный тег внутрь блочного.
discarding unexpected <…>
Обнаружен открывающий или закрывающий тег, у которого нет пары. Подобная ошибка возникает в двух случаях: есть открывающий тег, но нет закрывающего; имеется закрывающий тег, которому не соответствует открывающий.
<div><div>Текст</div></div>
<div>Текст</div></div>
<div><div>Текст</div>
Решение
В зависимости от ситуации добавьте или удалите открывающий или закрывающий тег.
Notice: nested emphasis …
Контейнер содержит аналогичный тег физического форматирования, который не должен повторяться.
<p><b>Текст</b></p>
<p><b><b>Текст</b></b></p>
Решение
Удалите один из тегов.
replacing unexpected … by </…>
Закрывающий тег не соответствует открывающему тегу.
<p><b>Текст</b></p>
<p><b>Текст</span></p>
Решение
Замените открывающий или закрывающий тег на парный.
… isn’t allowed in <…> elements
Обнаружены теги, которые запрещено размещать внутри указанных элементов.
<head><title>Заголовок</title></head>
<head><body>Текст</body></head>
Решение
Переместите HTML-элемент в правильный раздел.
missing <…>
Нет обязательного тега в структуре элементов. Ошибка, к примеру, может возникнуть при формировании таблицы, когда пропущен тег <tr> и сразу же после <table> следует <td>.
<ol><li>Список</li></ol>
<ol>Список</ol>
Решение
Проверить правильность вложения тегов в текущем элементе и наличие обязательных элементов.
Notice: inserting implicit <…>
Сообщение возникает из-за предыдущей ошибки на странице.
Решение
Исправьте предыдущие ошибки.
Insert missing <title> element
В коде не вставлен тег <title>.
<head><title>Заголовок</title></head>
<head></head>
Решение
Добавьте контейнер <title>.
Multiple <frameset> elements
Тег <frameset> используется в документе более одного раза без вложения. Допускается вставлять несколько элементов <frameset>, но вложенных один в другой.
<frameset …><frame …>
<frameset …><frame …></frameset>
</frameset>
<frameset …><frame …></frameset>
<frameset …><frame …></frameset>
Решение
Используйте вложенные теги <frameset>.
<…> is not approved by W3C
Указанный тег не входит в спецификацию HTML.
<span style=»white-space: nowrap;»>текст без переносов</span>
<nobr>текст без переносов</nobr>
Решение
Удалите тег или замените его подходящим эквивалентом.
Error: <…> is not recognized!
Тег не распознан и не входит в спецификацию HTML.
Правильно: <p>Текст</p>
Неверно: <p><adres>Текст</adres></p>
Решение
Удалите неизвестный тег.
Trimming Empty Tag
Контейнер пустой или содержит только пробел.
<p>Текст</p>
<p> </p>
<p></p>
Решение
Удалите тег или добавьте внутрь контейнера текст.
<a> is probably intended as </a>
В закрывающем теге <a> отсутствует слэш.
<a href=»http://htmlbook.ru»>Ссылка на сайт</a>
<a href=»http://htmlbook.ru»>Ссылка на сайт<a>
Решение
Добавьте слэш к закрывающему тегу.
… shouldn’t be nested
Некоторые теги вроде <form> не могут содержать сами себя. Это сообщение также возникает из-за предыдущей ошибки.
<form action=»gb.php» name=»guestbook»></form>
<form action=»gb2.php» name=»guestbook2″></form>
<form action=»gb.php» name=»guestbook»>
<form action=»gb2.php» name=»guestbook2″></form>
</form>
Решение
Удалите вложенные теги или исправьте предыдущую ошибку.
Text found after closing </body>-tag
Теги или текст добавляется после закрывающего тега </body>.
<html>
<head><title>Заголовок</title></head>
<body><p>Основной текст</p></body>
</html>
<html>
<head><title>Заголовок</title></head>
<body><p>Основной текст</p></body>
<b>Привет!</b>
</html>
Решение
Удалите текст после тега </body> или перенесите этот тег в конец текста.
Adjacent hyphens within comment
Комментарии в коде HTML определяются конструкцией вида <!— комментарий —>. Если в тексте комментария подряд идет два и более дефиса, возникает ошибка.
<!— Комментарий — заголовок —>
<!— комментарий —>
<!— Комментарий — тело документа —>
Решение
Удалите лишние дефисы.
SYSTEM, PUBLIC, W3C, DTD, EN must be upper case
Элемент <!DOCTYPE> указан неверно, в частности следующие атрибуты необходимо писать в верхнем регистре: SYSTEM, PUBLIC, W3C, DTD, EN.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01 Transitional//EN» «http://www.w3.org/TR/html4/loose.dtd»>
<!doctype html public «-//w3c//dtd html 4.01 Transitional//en» «http://www.w3.org/TR/html4/loose.dtd»>
Решение
Пишите <!DOCTYPE> корректно.
Warning: missing <!DOCTYPE> declaration
Не указан элемент <!DOCTYPE>.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01//EN» «http://www.w3.org/TR/html4/strict.dtd»>
<html>
<head>
<title>Заголовок</title>
</head>
<body>
<p>Основной текст</p>
</body>
</html>
<html>
<head>
<title>Untitled Document</title>
</head>
<body>
</body>
</html>
Решение
Поместите элемент <!DOCTYPE> в самую первую строку кода документа.
Too much <…>-elements
Повторяется тег, который в коде должен быть только один. К таким тегам относится <html>, <head>, <title> и <body>.
<head>
<title>Заголовок</title>
</head>
<head>
<title>Заголовок</title>
<title>Название статьи</title>
</head>
Решение
Удалите повторяющийся тег.
<…> inserting «…» attribute
Не указан обязательный атрибут для данного тега.
<style type=»text/css»>
<style>
Решение
Проверьте тег и добавьте недостающие атрибуты.
… attribute … lacks value
Атрибут тега не содержит обязательное значение или оно написано с синтаксической ошибкой.
<a href=»link.html»>Ссылка</a>
<a href>Ссылка</a>
Решение
Проверьте атрибуты тега и добавьте недостающие значения.
… attribute «…» has invalid value «…»
Атрибут содержит некорректное значение. Ошибка проявляется в тех случаях, когда в значении вместо текста пишется число и наоборот. Так, атрибуты id и name должны начинаться с символа ([A-Za-z]) и могут содержать цифры ([0-9]), дефис (-), подчеркивание (_), двоеточие (:) и точку (.). Значение ширины и высоты в атрибутах тегов не должно содержать ничего, кроме цифр ([0-9]) и процентов (%).
<div id=»layer1″>Слой 1</div>
<img src=»images/pic.gif» width=»200″ height=»120″>
<div id=»2layer»>Слой 2</div>
<img src=»images/pic.gif» width=»200px» height=»120px»>
Решение
Проверьте атрибут тега и измените его значение.
<…> missing > for end of tag
Ошибка может возникать в двух случаях: некорректно написан тег, что происходит, когда забыли добавить закрывающую скобку и применение > вместо использования спецсимвола.
<p>Пример текста</p>
<p>Для случая 0<p рассмотрим следующий пример.</p>
<p Пример текста</p>
<p>Для случая 0<p рассмотрим следующий пример.</p>
Решение
Вставьте отсутствующую закрывающую скобку.
Замените < на <.
<…> proprietary attribute «…»
Тег содержит атрибут, специфичный только для браузера Internet Explorer или другого и не входящий в спецификацию. Примером является атрибут height тега <table>.
Список всех атрибутов, входящих в спецификацию HTML приведен по адресу http://www.w3.org/TR/html4/index/attributes.html
<table style=»height: 100%»>
<table height=»100%»>
Решение
Список наиболее характерных атрибутов тегов приведен в табл. 14.1.
| Тег | Устаревший атрибут | Стандартный атрибут |
|---|---|---|
| <body> | marginwidth=0, marginheight=0, leftmargin=0, topmargin=0 | style=»margin: 0″ |
| <table> | height=100% | style=»height: 100%» |
| <table> | nowrap | style=»white-space: nowrap» или <td nowrap> |
| <td> | background=»abc.gif» | style=»background-image:url(abc.gif)» |
… proprietary attribute value «…»
Значение атрибута не входит в спецификацию HTML и является специфичным для браузера Internet Explorer или другого. Например, значение align=»absmiddle» тега <img> недопустимо.
<p><img src=»hello.gif» alt=»Привет» align=»middle»></p>
<p><img src=»hello.gif» alt=»Привет» style=»vertical-align: middle»></p>
<p><img src=»hello.gif» alt=»Привет» align=»absmiddle»></p>
Решение
Используйте стандартные значения атрибутов тегов или используйте стилевой эквивалент.
… dropping value «…» for repeated attribute «…»
Атрибут применяется в теге больше одного раза.
<img src=»image.jpg»>
<img src=»image.jpg» src=»image.jpg»>
Решение
Удалите повторяющийся атрибут.
… unexpected or duplicate quote mark
Отсутствует открывающая или закрывающая кавычка в атрибуте тега.
<img src=»image.jpg»>
<img src=image.jpg»>
Решение
Добавьте парную кавычку к значению атрибута.
… attribute with missing trailing quote mark
Тег содержит атрибут, в котором задано неверное количество кавычек.
<p id=»my_id»>
<p id=»my_id»»>
Решение
Добавьте или удалите одну из кавычек.
… id and name attribute value mismatch
Ошибка возникает, когда значения атрибутов id и name не совпадают между собой, что приводит к конфликту при обращении к свойствам элемента через скрипты.
<a name=»elm» id=»elm»>
<a id=»elm»>
<a name=»abcdef» id=»db1″>
Решение
Удалите один из атрибутов или сделайте значения атрибутов name и id одинаковыми.
Notice: replacing <…> by <…>
Ошибка возникает в следующих случаях:
- неверный порядок тегов;
- добавлен лишний закрывающий тег;
- имеется открывающий тег без наличия обязательного закрывающего.
<p>Текст</p><br>
<p>Текст</p></p>
<p>abc<br><table>…</table></p>
Решение
Измените порядок тегов или удалите один из открывающих или закрывающих тегов.
… anchor «…» already defined
Значения атрибута name у различных тегов совпадает между собой. Значение name должно быть уникальным.
<form name=»my_form1″ action=»test1.php»></form>
<form name=»my_form2″ action=»test2.php»></form>
<form name=»my_form» action=»test1.php»></form>
<form name=»my_form» action=»test2.php»></form>
Решение
Выберите другое имя или измените предыдущие имена таким образом, чтобы они не совпадали.
<…> is probably intended as </…>
Тег повторяется дважды в коде HTML, тогда как подобный тег не должен содержать сам себя.
<em>Привет, мир!</em>
<em>Привет<em>, мир!</em></em>
Решение
Удалите один из тегов.
<…> lacks «…» attribute
Требуется обязательный атрибут тега, который, тем не менее, отсутствует.
<form action=»my_action.php»>
<form>
Решение
Добавьте недостающий атрибут к тегу.
В этой статье мы рассмотрим, как с помощью сервиса Labrika обнаружить и исправить на сайте HTML-ошибки. Информация о таких ошибках будет полезна как для владельца веб-ресурса, который контролирует работу своего SEO-специалиста и хочет знать, какие нерешенные проблемы есть на сайте, так и для оптимизаторов, поскольку им нужно оперативно обнаружить и исправить все изъяны, мешающие продвижению ресурса.
HTML (от англ. HyperText Markup Language) — это язык гипертекстовой разметки, который применяется на каждой веб-странице в интернете и состоит из множества элементов (тегов). Как правило, ошибками в коде HTML являются незакрытые или дублированные элементы, неправильный порядок их расположения, неверные атрибуты или их отсутствие.
На примере ниже в коде страницы присутствует закрывающий тег ссылки </a> без открывающего тега <a>:
Для проверки валидности кода (то есть соответствия стандартам HTML) используются специальные инструменты. Они проверяют:
- Синтаксические ошибки: пропущенные символы, ошибки в написании тегов.
- Нарушения вложенности тэгов: незакрытые и неправильно закрытые теги. По правилам теги закрываются так же, как их открыли, только в обратном порядке.
- Соответствие кода указанному DTD (Document Type Definition): правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов.
Как отмечал представитель Google Джон Мюллер, валидность кода HTML не является прямым фактором ранжирования, однако критические ошибки в HTML мешают:
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- отображению на мобильных устройствах и кроссбраузерности.
В первую очередь наличие ошибок в коде HTML может привести к тому, что часть контента страницы не будет проиндексирована.
О том, что следует использовать действительный HTML, сказано в Рекомендациях Google для веб-мастеров. Среди авторитетных SEO-источников бытует мнение, что фильтр Google Panda может быть наложен на сайт за большое количество таких ошибок (отдельную статью об алгоритме Google Panda вы можете прочитать на нашем сайте).
Официальные источники Яндекса также сообщают, что подобного рода ошибки на сайте нежелательны, а верстка страниц должна соответствовать принятым стандартам.
Почему важно проверять наличие HTML-ошибок?
Ошибки в коде HTML могут быть критическими и несущественными, которые не ведут к серьезным потерям. Что касается критических, то одни из них отрицательно сказываются на функционировании сайта, а другие — на работе поисковых систем.
Современные браузеры автоматически исправляют 99% критических ошибок при загрузке сайта. Однако некоторые из них браузер исправить не может. Например, если тег <а> для создания ссылки не содержит адреса, то браузер не сможет определить, куда её направить. Или в теге <img> для размещения картинки не указан путь к ней, тогда браузер не сможет её подгрузить. Наличие таких ошибок в коде может привести к серьезным последствиям — например, не загрузятся фото товара или не будет работать корзина.
Поисковые системы также автоматически исправляют часть HTML-ошибок, но у них возникает следующая проблема: если браузеры в состоянии потратить несколько секунд на исправление ошибок, то у поисковых роботов нет такой возможности. Им приходится сканировать сотни миллиардов страниц ежемесячно, поэтому боты не могут тратить время на устранение всех ошибок. Некоторые из них поисковые системы игнорируют, а также могут не включать в индекс содержащие их страницы или проиндексировать только часть контента таких страниц.
Веб-мастера и пользователи просматривают сайты в браузере, где большая часть HTML-ошибок исправляется автоматически, и поэтому не придают им большого значения. Зачастую даже разработчики не исправляют элементарных грубых ошибок в разметке. Это приводит к тому, что критические для поисковых систем ошибки остаются на сайтах и могут стать причиной неправильной индексации страниц. В результате бюджеты на продвижение будут потрачены неэффективно, а источник проблемы так и остается неустановленным.
Как обнаружить HTML-ошибки с помощью сервиса Labrika
Labrika проверяет данные ошибки двумя способами:
- С помощью валидатора W3C, который проверяет наличие всех HTML-ошибок.
- С использованием валидатора Labrika «Критические ошибки HTML». Он устанавливает только те ошибки, которые могут повлиять на сбор данных поисковыми системами или привести к некорректному отображению сайта и нарушениям в его работе. определяет порядка 15 видов таких ошибок.
Отчет » Критические ошибки HTML» вы сможете найти в левом боковом меню в разделе «Технический аудит».
Актуальные данные в отчете вы сможете увидеть после запуска проверки сайта.
Отчет показывает:
- Страницы, которые содержат критические ошибки HTML.
- Количество и описание критических HTML-ошибок на данной странице.
При клике по их числу осуществляется переадресация на валидатор W3C, в котором вы сможете найти подробную информацию обо всех имеющихся в коде страницы ошибках.
Как исправлять HTML-ошибки?
Критические HTML-ошибки необходимо исправлять в первую очередь, так как поисковые системы могут отреагировать на них отрицательно. Влияние прочих ошибок на продвижение в поиске не доказано.
Если для исправления ошибок требуется передать их список специалисту по верстке, с помощью кнопок в правой части страницы отчета вы можете скачать его данные в формате таблицы Excel или поделиться ссылкой на отчет по HTML-ошибкам с другими пользователями.
После нажатия на значок ссылки появится следующее всплывающее окно:
Кнопка, которая расположена справа от ссылки, позволяет скопировать её в буфер обмена. Отчет по ссылке будет доступен даже тем, кто не имеет аккаунта в Labrika.
Для ускорения работы по исправлению HTML-ошибок можно воспользоваться редакторами, которые автоматически создают закрывающие теги для документов HTML (например, Bluefish, Notepad++).
- Назад
- Обзор: Introduction to HTML
- Далее
Написать HTML — здорово, но как понять, где ошибка, когда что-то не работает? В этой статье описаны несколько инструментов, которые помогают искать и исправлять ошибки в HTML.
| Что нужно знать: | Базовые знания HTML на уровне Начало работы с HTML, Основы редактирования текста в HTML, и Создание гиперссылок. |
|---|---|
| Чему вы научитесь: | Искать проблемы в HTML с помощью инструментов отладки. |
Отладка — это не страшно
Во время написания какого-нибудь кода, обычно все идёт хорошо, пока не появляется тот момент, когда вы совершаете ошибку. Итак, ваш код не работает, или работает не так, как вы задумывали. Если вы попытаетесь скомпилировать неработающую программу на языке Rust, компилятор укажет на ошибку:
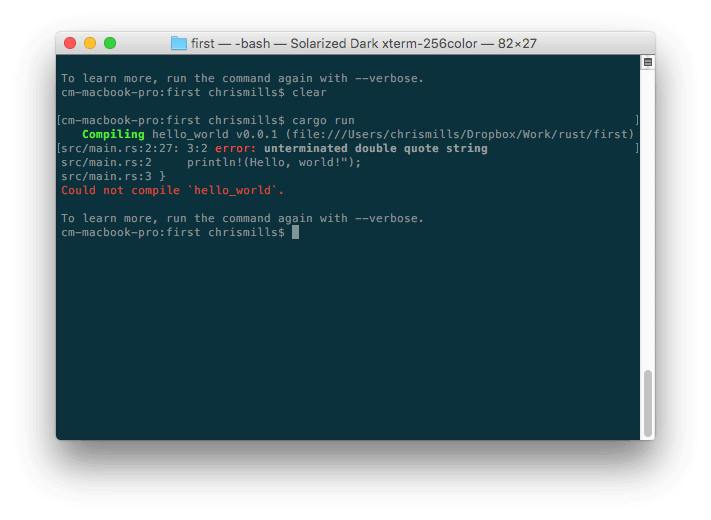 В данном случае, сообщение об ошибке понять относительно просто — «unterminated double quote string». Если вы внимательно посмотрите на
В данном случае, сообщение об ошибке понять относительно просто — «unterminated double quote string». Если вы внимательно посмотрите на println!(Hello, world!"); , то заметите, что здесь отсутствует двойная кавычка. Разумеется, сообщения об ошибках могут становиться куда более сложными для понимания по мере роста вашего кода, и даже самые простые случаи могут показаться пугающими для тех, кто ничего не знает о Rust.
Но не бойтесь отладки! Чтобы комфортно писать и отлаживать любой код, нужно понимать язык и его инструменты.
HTML и отладка
HTML не так сложен к пониманию, как Rust. HTML не компилируется в какую-либо другую форму перед тем, как браузер проанализирует это и покажет результат (он является интерпретируемым, а не компилируемым). Синтаксис HTML элементов намного понятнее, чем у «настоящих языков программирования», таких как Rust, JavaScript, или Python (en-US). Способ, которым браузеры читают HTML более толерантен, чем у языков программирования, интерпретирующих свой код строже. Это одновременно и плохо, и хорошо.
Толерантный код
Так что же означает толерантный? В общих чертах, когда вы напортачили в коде, есть два типа ошибок, с которыми вы столкнётесь:
- Синтаксические ошибки (Syntax errors): Это ошибки в правильности написания, как это было выше, в примере с Rust. Такие обычно легко исправлять, в той мере, в какой вы знакомы с синтаксисом языка и знаете, что означают сообщения об ошибках.
- Логические ошибки (Logic errors): Это ошибки, появляющиеся в том случае, если синтаксис корректен, но код не выполняет своего предназначения, то есть программа выполняется неверно. Такие исправлять сложнее, чем синтаксические, поскольку не выводится сообщений, указывающих место, где вы ошиблись.
HTML не страдает от синтаксических ошибок, потому что браузер читает код толерантно, в том смысле, что страницы могут отображаться даже если синтаксические ошибки присутствуют. Браузеры имеют встроенные правила по интерпретации неверно написанной разметки, и вы можете запустить что-либо, даже если вы имели в виду другое. Это может стать настоящей проблемой!
Примечание: На заметку: HTML читается толерантно, потому что когда веб только появился, было решено позволить людям публиковать контент даже при условии некорректностей в коде, так как это куда более важно, чем уверенность в абсолютно верном синтаксисе. Веб не был бы сейчас так популярен, если бы относился к новичкам строго.
Активное обучение: Знакомство с толерантным кодом
Время изучить природу толерантного кода в HTML.
- Для начала, скачайте наш пример отладки и сохраните локально. Эта демонстрация намеренно написана с ошибками, которые нам предстоит обнаружить.
- Далее, откройте её в браузере. Вы увидите нечто вроде этого :

- Сейчас документ выглядит не особо хорошо; Давайте посмотрим в код и выясним почему (Показано только тело документа):
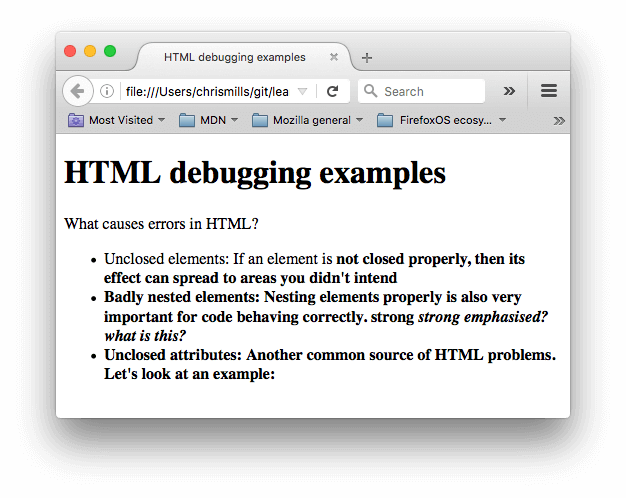
<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasised?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> - Рассмотрим проблемы:
- У параграфа и элемента списка не закрыты теги. На изображении выше видно, что разметка не пострадала, так как браузеру легко сделать вывод о том, где заканчивается один элемент и начинается другой.
- Первый
<strong>элемент также не имеет закрывающего тега. Это уже более проблематично, так как сложно сказать, где элемент должен заканчиваться. На деле, весь оставшийся текст был выделен жирным. - Следующая часть нарушает правила вложенности:
<strong>strong <em>strong emphasised?</strong> what is this?</em>. В этом случае код тоже сложно проинтерпретировать по причине, описанной выше. - В атрибуте
hrefотсутствует закрывающая двойная кавычка. Это послужило причиной крупной проблемы — ссылка не воспроизвелась вовсе.
- Сейчас же посмотрим, как браузер сгенерировал собственную разметку, в противовес исходной разметке документа. Чтобы сделать это, воспользуемся инструментами разработчика. Если вы не знакомы с инструментами разработчика, потратьте несколько минут на Обзор инструментов разработки в браузерах.
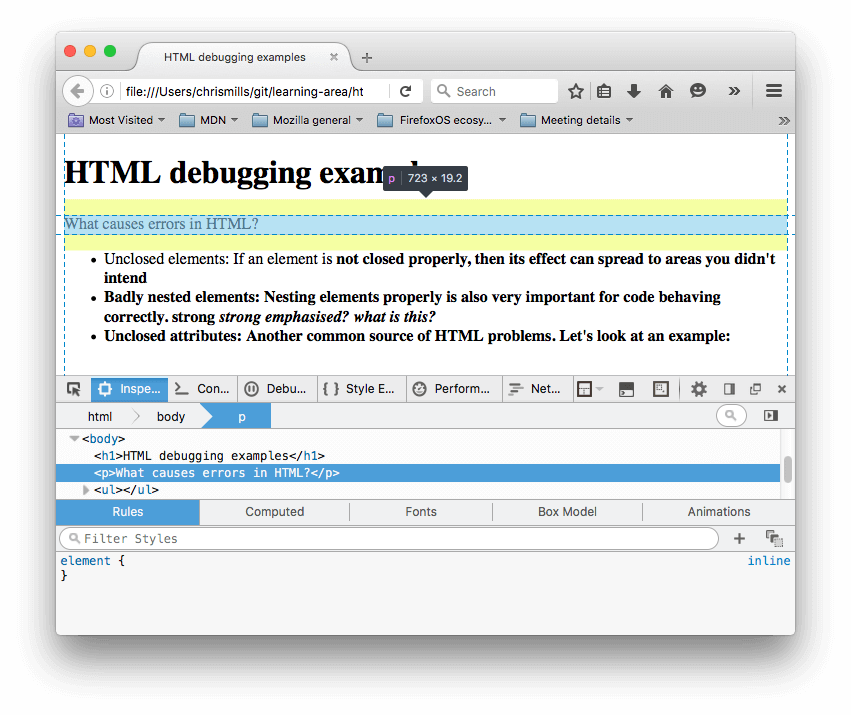
- В DOM инспекторе вы можете увидеть как сгенерировалась новая разметка:

- Используя DOM инспектор, давайте рассмотрим детали нашего кода, чтобы увидеть, как браузер пытается исправить наши ошибки в HTML (мы обозреваем в Firefox; другой современный браузер должен выдать те же результаты):
- Параграфы и элементы списка получены с закрывающими тегами.
- Было неочевидно, где элемент
<strong>должен был закрыться, так что браузер обернул каждый отдельный блок текста своими собственными тегами strong, причём до самого низа документа! - Некорректная вложенность была исправлена браузером следующим образом:
<strong>strong <em>strong emphasised?</em> </strong> <em> what is this?</em> - Ссылка с отсутствующими двойными кавычками была удалена насовсем. Последний элемент списка будет выглядеть так:
<li> <strong>Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
Валидация HTML
Из примера выше ясно, что стоит проверять валидность HTML. В простом примере сверху можно просто просмотреть весь код и найти ошибки, но как быть с огромными, сложными страницами?
Лучше всего проверить страницу в сервисе валидации разметки. Его создал и поддерживает W3C — организация, которая занимается спецификациями HTML, CSS и других веб-технологий. Сервис проверит ваш HTML и составит отчёт по ошибкам в нем.
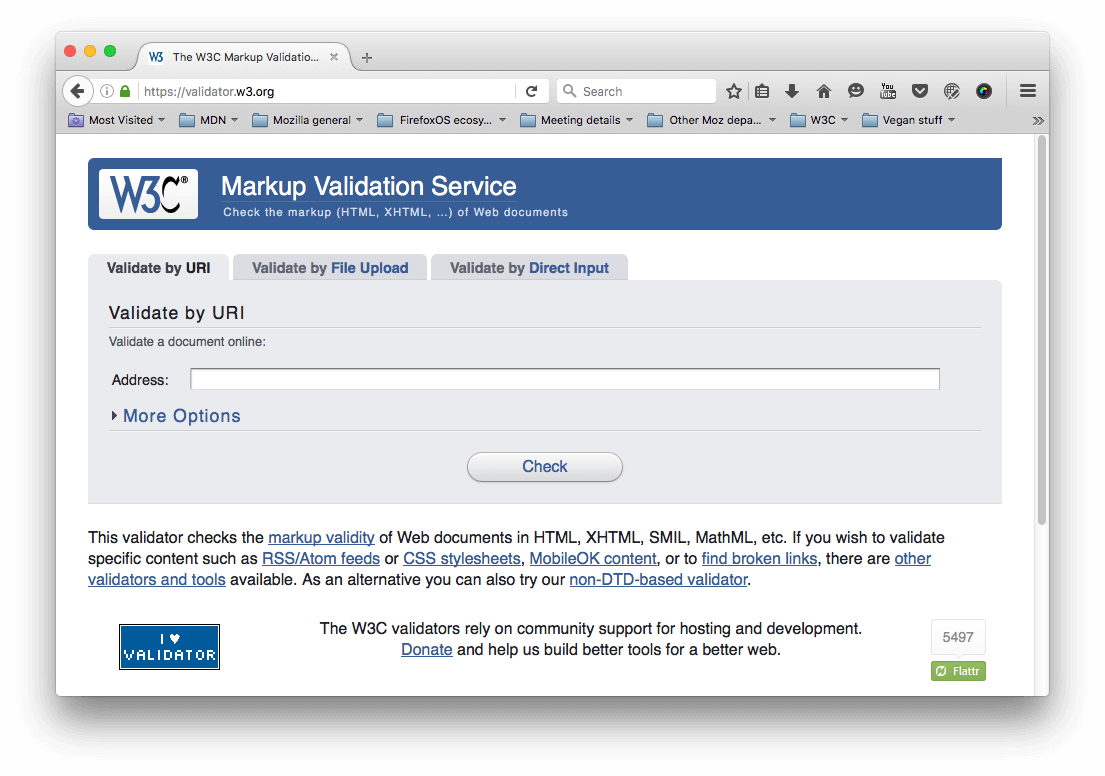
HTML можно проверить по адресу, загрузив файл или напрямую ввести код HTML.
Активное обучение: Валидируем HTML-документ
Попробуем проверить документ-пример.
- Откройте сервис валидации разметки в браузере.
- Перейдите в режим Validate by Direct Input.
- Скопируйте весь код документа (не только body) и вставьте в место для ввода.
- Нажмите на Check (проверить).
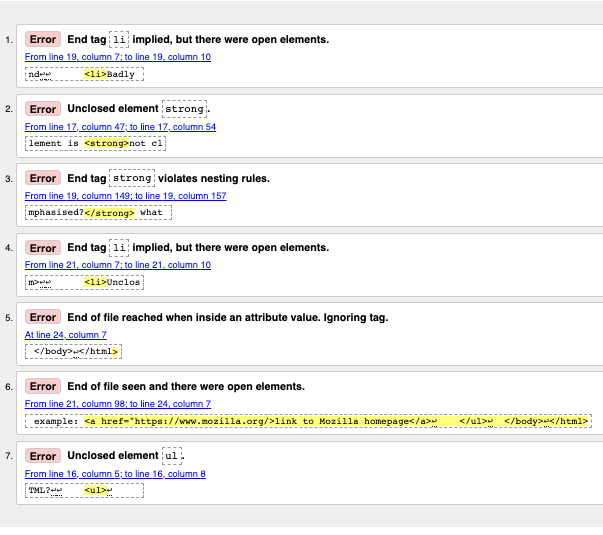
Вы увидите список ошибок и другую информацию.
Работа с сообщениями об ошибках
Обычно сразу ясно, что значат сообщения, но иногда приходится постараться, чтобы понять, в чем дело. Сейчас мы пройдёмся по всем ошибкам и разберём, что они значат. Обратите внимание, что в сообщениях указаны строка и столбец кода, чтобы ошибки было проще искать.
- «End tag
liimplied, but there were open elements» (2 instances): Нет явного закрывающего тега, хотя браузер догадывается, где он должен быть. Сообщение указывает на строку после той, на которой ожидался закрывающий тег, но вы найдёте нужное место. - «Unclosed element
strong«: Это очень простая ошибка — элемент<strong>не закрыт, и сообщение указывает прямо на открывающий тег. - «End tag
strongviolates nesting rules»: Элемент неправильно вложен — на этом уровне нет парного открывающего тега. - «End of file reached when inside an attribute value. Ignoring tag»: Загадочное сообщение. Дело в том, что где-то (скорее всего, в конце документа) неправильно прописано свойство элемента, и конец файла оказался внутри этого свойства. В браузере не видно ссылки — скорее всего, проблема рядом с ней.
- «End of file seen and there were open elements»: Файл закончился, но некоторые элементы не закрыты. Сообщение указывает на конец файла, в данном случае не закрыт элемент
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
Примечание: Свойство без закрывающей кавычки может проглотить закрывающий тег — браузер считает его частью значения этого свойства.
- «Unclosed element
ul«: Странно, ведь элемент<ul>закрыт. Настоящая проблема всё там же — элемент<a>не закрыт из-за недостающей кавычки в свойстве.
Если некоторые ошибки кажутся вам странными, начните исправление с остальных и проверьте документ ещё раз. Иногда одна ошибка ломает большую часть документа.
Когда вы увидите эту надпись, в вашем документе больше нет ошибок:
![]()
Заключение
Теперь вы умеете отлаживать HTML. С новыми знаниями вам будет проще разобраться и в отладке более сложных языков — например, CSS и JavaScript. На этом мы заканчиваем вводный модуль курса HTML — время попробовать свои силы в упражнениях.
- Назад
- Обзор: Introduction to HTML
- Далее
В этом модуле
Большинство ошибок, возникающих при валидации кода можно свести к набору типовых вариантов, зная которые легко понять, на что «намекает» валидатор. В качестве образца возьмем расширение HTML Validator для браузера Firefox, предназначенное для проверки кода и рассмотрим список ошибок и замечаний по коду.
Посмотреть все возможные сообщения валидатора можно по адресу http://www.htmlpedia.org/wiki/HTML_Tidy, далее приведены основные ошибки с их описанием и решением. Зеленым цветом выделен корректный вариант, другой цвет используется для обозначения ошибки.
Notice: entity «…» doesn’t end in «;»
Это замечание возникает при использовании спецсимволов вроде < при отсутствии на конце точки с запятой.
 
Решение
Добавьте в конце спецсимвола точку с запятой.
Notice: numeric character reference «…» doesn’t end in ‘;’
Возникает при использовании числовых спецсимволов вроде — когда в конце забыли добавить точку с запятой.
™
™
Решение
Добавьте в конце спецсимвола точку с запятой.
unescaped & or unknown entity «&…»
Символ амперсанда (&) часто применяется в адресах ссылок (атрибут href тега <a>), поскольку он разделяет несколько параметров. Однако амперсанд зарезервирован для спецсимволов вроде поэтому в ссылках необходимо указывать & вместо &.
<a href=»http://www.htmlbook.ru/content/?id=30&text=1″>Ссылка</a>
<a href=»http://www.htmlbook.ru/content/?id=30&text=1″>Ссылка</a>
Решение
Замените & на &.
missing </…>
Отсутствует обязательный закрывающий тег.
<head><title>Заголовок</title></head>
<head><title>Заголовок</head>
Решение
Добавьте закрывающий тег.
missing </aaa> before <bbb>
Ошибка возникает при нарушении порядка тегов, когда блочный тег располагается внутри встроенного. В данном случае блочный тег <bbb> находится внутри встроенного тега <aaa>.
<p><span>Текст</span></p>
<span><p>Текст</p></span>
Решение
Поменяйте расположение тегов — перенесите встроенный тег внутрь блочного.
discarding unexpected <…>
Обнаружен открывающий или закрывающий тег, у которого нет пары. Подобная ошибка возникает в двух случаях: есть открывающий тег, но нет закрывающего; имеется закрывающий тег, которому не соответствует открывающий.
<div><div>Текст</div></div>
<div>Текст</div></div>
<div><div>Текст</div>
Решение
В зависимости от ситуации добавьте или удалите открывающий или закрывающий тег.
Notice: nested emphasis …
Контейнер содержит аналогичный тег физического форматирования, который не должен повторяться.
<p><b>Текст</b></p>
<p><b><b>Текст</b></b></p>
Решение
Удалите один из тегов.
replacing unexpected … by </…>
Закрывающий тег не соответствует открывающему тегу.
<p><b>Текст</b></p>
<p><b>Текст</span></p>
Решение
Замените открывающий или закрывающий тег на парный.
… isn’t allowed in <…> elements
Обнаружены теги, которые запрещено размещать внутри указанных элементов.
<head><title>Заголовок</title></head>
<head><body>Текст</body></head>
Решение
Переместите HTML-элемент в правильный раздел.
missing <…>
Нет обязательного тега в структуре элементов. Ошибка, к примеру, может возникнуть при формировании таблицы, когда пропущен тег <tr> и сразу же после <table> следует <td>.
<ol><li>Список</li></ol>
<ol>Список</ol>
Решение
Проверить правильность вложения тегов в текущем элементе и наличие обязательных элементов.
Notice: inserting implicit <…>
Сообщение возникает из-за предыдущей ошибки на странице.
Решение
Исправьте предыдущие ошибки.
Insert missing <title> element
В коде не вставлен тег <title>.
<head><title>Заголовок</title></head>
<head></head>
Решение
Добавьте контейнер <title>.
Multiple <frameset> elements
Тег <frameset> используется в документе более одного раза без вложения. Допускается вставлять несколько элементов <frameset>, но вложенных один в другой.
<frameset …><frame …>
<frameset …><frame …></frameset>
</frameset>
<frameset …><frame …></frameset>
<frameset …><frame …></frameset>
Решение
Используйте вложенные теги <frameset>.
<…> is not approved by W3C
Указанный тег не входит в спецификацию HTML.
<span style=»white-space: nowrap;»>текст без переносов</span>
<nobr>текст без переносов</nobr>
Решение
Удалите тег или замените его подходящим эквивалентом.
Error: <…> is not recognized!
Тег не распознан и не входит в спецификацию HTML.
Правильно: <p>Текст</p>
Неверно: <p><adres>Текст</adres></p>
Решение
Удалите неизвестный тег.
Trimming Empty Tag
Контейнер пустой или содержит только пробел.
<p>Текст</p>
<p> </p>
<p></p>
Решение
Удалите тег или добавьте внутрь контейнера текст.
<a> is probably intended as </a>
В закрывающем теге <a> отсутствует слэш.
<a href=»http://htmlbook.ru»>Ссылка на сайт</a>
<a href=»http://htmlbook.ru»>Ссылка на сайт<a>
Решение
Добавьте слэш к закрывающему тегу.
… shouldn’t be nested
Некоторые теги вроде <form> не могут содержать сами себя. Это сообщение также возникает из-за предыдущей ошибки.
<form action=»gb.php» name=»guestbook»></form>
<form action=»gb2.php» name=»guestbook2″></form>
<form action=»gb.php» name=»guestbook»>
<form action=»gb2.php» name=»guestbook2″></form>
</form>
Решение
Удалите вложенные теги или исправьте предыдущую ошибку.
Text found after closing </body>-tag
Теги или текст добавляется после закрывающего тега </body>.
<html>
<head><title>Заголовок</title></head>
<body><p>Основной текст</p></body>
</html>
<html>
<head><title>Заголовок</title></head>
<body><p>Основной текст</p></body>
<b>Привет!</b>
</html>
Решение
Удалите текст после тега </body> или перенесите этот тег в конец текста.
Adjacent hyphens within comment
Комментарии в коде HTML определяются конструкцией вида <!— комментарий —>. Если в тексте комментария подряд идет два и более дефиса, возникает ошибка.
<!— Комментарий — заголовок —>
<!— комментарий —>
<!— Комментарий — тело документа —>
Решение
Удалите лишние дефисы.
SYSTEM, PUBLIC, W3C, DTD, EN must be upper case
Элемент <!DOCTYPE> указан неверно, в частности следующие атрибуты необходимо писать в верхнем регистре: SYSTEM, PUBLIC, W3C, DTD, EN.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01 Transitional//EN» «http://www.w3.org/TR/html4/loose.dtd»>
<!doctype html public «-//w3c//dtd html 4.01 Transitional//en» «http://www.w3.org/TR/html4/loose.dtd»>
Решение
Пишите <!DOCTYPE> корректно.
Warning: missing <!DOCTYPE> declaration
Не указан элемент <!DOCTYPE>.
<!DOCTYPE HTML PUBLIC «-//W3C//DTD HTML 4.01//EN» «http://www.w3.org/TR/html4/strict.dtd»>
<html>
<head>
<title>Заголовок</title>
</head>
<body>
<p>Основной текст</p>
</body>
</html>
<html>
<head>
<title>Untitled Document</title>
</head>
<body>
</body>
</html>
Решение
Поместите элемент <!DOCTYPE> в самую первую строку кода документа.
Too much <…>-elements
Повторяется тег, который в коде должен быть только один. К таким тегам относится <html>, <head>, <title> и <body>.
<head>
<title>Заголовок</title>
</head>
<head>
<title>Заголовок</title>
<title>Название статьи</title>
</head>
Решение
Удалите повторяющийся тег.
<…> inserting «…» attribute
Не указан обязательный атрибут для данного тега.
<style type=»text/css»>
<style>
Решение
Проверьте тег и добавьте недостающие атрибуты.
… attribute … lacks value
Атрибут тега не содержит обязательное значение или оно написано с синтаксической ошибкой.
<a href=»link.html»>Ссылка</a>
<a href>Ссылка</a>
Решение
Проверьте атрибуты тега и добавьте недостающие значения.
… attribute «…» has invalid value «…»
Атрибут содержит некорректное значение. Ошибка проявляется в тех случаях, когда в значении вместо текста пишется число и наоборот. Так, атрибуты id и name должны начинаться с символа ([A-Za-z]) и могут содержать цифры ([0-9]), дефис (-), подчеркивание (_), двоеточие (:) и точку (.). Значение ширины и высоты в атрибутах тегов не должно содержать ничего, кроме цифр ([0-9]) и процентов (%).
<div id=»layer1″>Слой 1</div>
<img src=»images/pic.gif» width=»200″ height=»120″>
<div id=»2layer»>Слой 2</div>
<img src=»images/pic.gif» width=»200px» height=»120px»>
Решение
Проверьте атрибут тега и измените его значение.
<…> missing > for end of tag
Ошибка может возникать в двух случаях: некорректно написан тег, что происходит, когда забыли добавить закрывающую скобку и применение > вместо использования спецсимвола.
<p>Пример текста</p>
<p>Для случая 0<p рассмотрим следующий пример.</p>
<p Пример текста</p>
<p>Для случая 0<p рассмотрим следующий пример.</p>
Решение
Вставьте отсутствующую закрывающую скобку.
Замените < на <.
<…> proprietary attribute «…»
Тег содержит атрибут, специфичный только для браузера Internet Explorer или другого и не входящий в спецификацию. Примером является атрибут height тега <table>.
Список всех атрибутов, входящих в спецификацию HTML приведен по адресу http://www.w3.org/TR/html4/index/attributes.html
<table style=»height: 100%»>
<table height=»100%»>
Решение
Список наиболее характерных атрибутов тегов приведен в табл. 14.1.
Табл. 14.1. Замена нестандартных атрибутов тегов
| Тег | Устаревший атрибут | Стандартный атрибут |
|---|---|---|
| <body> | marginwidth=0, marginheight=0, leftmargin=0, topmargin=0 | style=»margin: 0″ |
| <table> | height=100% | style=»height: 100%» |
| <table> | nowrap | style=»white-space: nowrap» или <td nowrap> |
| <td> | background=»abc.gif» | style=»background-image:url(abc.gif)» |
… proprietary attribute value «…»
Значение атрибута не входит в спецификацию HTML и является специфичным для браузера Internet Explorer или другого. Например, значение align=»absmiddle» тега <img> недопустимо.
<p><img src=»hello.gif» alt=»Привет» align=»middle»></p>
<p><img src=»hello.gif» alt=»Привет» style=»vertical-align: middle»></p>
<p><img src=»hello.gif» alt=»Привет» align=»absmiddle»></p>
Решение
Используйте стандартные значения атрибутов тегов или используйте стилевой эквивалент.
… dropping value «…» for repeated attribute «…»
Атрибут применяется в теге больше одного раза.
<img src=»image.jpg»>
<img src=»image.jpg» src=»image.jpg»>
Решение
Удалите повторяющийся атрибут.
… unexpected or duplicate quote mark
Отсутствует открывающая или закрывающая кавычка в атрибуте тега.
<img src=»image.jpg»>
<img src=image.jpg»>
Решение
Добавьте парную кавычку к значению атрибута.
… attribute with missing trailing quote mark
Тег содержит атрибут, в котором задано неверное количество кавычек.
<p id=»my_id»>
<p id=»my_id»»>
Решение
Добавьте или удалите одну из кавычек.
… id and name attribute value mismatch
Ошибка возникает, когда значения атрибутов id и name не совпадают между собой, что приводит к конфликту при обращении к свойствам элемента через скрипты.
<a name=»elm» id=»elm»>
<a id=»elm»>
<a name=»abcdef» id=»db1″>
Решение
Удалите один из атрибутов или сделайте значения атрибутов name и id одинаковыми.
Notice: replacing <…> by <…>
Ошибка возникает в следующих случаях:
- неверный порядок тегов;
- добавлен лишний закрывающий тег;
- имеется открывающий тег без наличия обязательного закрывающего.
<p>Текст</p><br>
<p>Текст</p></p>
<p>abc<br><table>…</table></p>
Решение
Измените порядок тегов или удалите один из открывающих или закрывающих тегов.
… anchor «…» already defined
Значения атрибута name у различных тегов совпадает между собой. Значение name должно быть уникальным.
<form name=»my_form1″ action=»test1.php»></form>
<form name=»my_form2″ action=»test2.php»></form>
<form name=»my_form» action=»test1.php»></form>
<form name=»my_form» action=»test2.php»></form>
Решение
Выберите другое имя или измените предыдущие имена таким образом, чтобы они не совпадали.
<…> is probably intended as </…>
Тег повторяется дважды в коде HTML, тогда как подобный тег не должен содержать сам себя.
<em>Привет, мир!</em>
<em>Привет<em>, мир!</em></em>
Решение
Удалите один из тегов.
<…> lacks «…» attribute
Требуется обязательный атрибут тега, который, тем не менее, отсутствует.
<form action=»my_action.php»>
<form>
Решение
Добавьте недостающий атрибут к тегу.
 Для начала немного теории. Валидность HTML – это соответствие кодов html и каскадных таблиц стилей CSS неким стандартам, которые задает нам Консорциум Всемирной Паутины (W3C – World Wide Web Consortium). На производстве – ГОСТ, в русском языке – грамматика, а в интернете – валидность. Страницы сайта, прошедшего проверку на соответствие стандартам W3C будут правильно отображаться в современных браузерах, вырастет скорость загрузки и как следствие — маленький плюсик при ранжировании в поисковой выдаче.
Для начала немного теории. Валидность HTML – это соответствие кодов html и каскадных таблиц стилей CSS неким стандартам, которые задает нам Консорциум Всемирной Паутины (W3C – World Wide Web Consortium). На производстве – ГОСТ, в русском языке – грамматика, а в интернете – валидность. Страницы сайта, прошедшего проверку на соответствие стандартам W3C будут правильно отображаться в современных браузерах, вырастет скорость загрузки и как следствие — маленький плюсик при ранжировании в поисковой выдаче.
Проверить валидность HTML кода сайта можно официальным валидатором стандарта W3C.
 Здесь мы видим три вкладки проверки:
Здесь мы видим три вкладки проверки:
- Validate by URL – по URL адресу;
- Validate by File Upload – загруженного файла;
- Validate by Direct Input — непосредственно HTML кода страницы сайта.
Начните проверку по URL с главной страницы своего сайта (блога), а затем проверьте отдельные страницы, на которых вставлены какие-либо скрипты или блоки (голосование, различные сервисы, фотогалереи и т. д.).
Перед проверкой нажмите на кнопку «More Options» и выберите параметры отображения ошибок.

- Show Source – с выводом исходного (с ошибками) кода;
- Validate error pages – проверка страниц вывода ошибок (404 страница);
- Show Outline – вывод строки с ошибкой;
- Verbose Output — отображение заголовков, передаваемых сайтом браузеру: дата изменения документа, его размер и тип, параметры сервера;
- Clean up Markup with HTML Tidy – вывод правильного кода (по версии html Tidy), которым можно заменить неправильный. Полезная функция, должна здорово помочь при исправлении ошибок. По моим наблюдениям, работает только с мелкими ошибками – пропущена кавычка, не закрыт тег, и т. д.
- List messages Sequentially – вывод ошибок и предупреждений по порядку;
- Group Error Messages bu Type – вывод ошибок и предупреждений в группах по типу.
Рассмотрим на конкретном примере как найти на блоге и исправить найденные валидатором ошибки и предупреждения.
После проверки этой моей страницы валидатор выдал предупреждение на линии 252 и ошибку на линии 263.
 После перевода этой абракадабры можно понять, что для устранения предупреждения на линии 252 рекомендуется заменить символ «<» (в куске кода выделен красным цветом) на амперсанд «&«. Опустимся на линию 252 приведенного HTML кода нашей страницы ниже.
После перевода этой абракадабры можно понять, что для устранения предупреждения на линии 252 рекомендуется заменить символ «<» (в куске кода выделен красным цветом) на амперсанд «&«. Опустимся на линию 252 приведенного HTML кода нашей страницы ниже.

Сразу становится понятным то, что это код поиска вирусов онлайн от Dr.Web, включенный мной в пост в HTML редакторе.

1. Как и было рекомендовано символ «<» заменяем на амперсанд «&«. 2. Проделываем аналогичную операцию с закрывающим символом «>» на линии 263. Проводим перепроверку страницы валидатором.

Как видим, предупреждение и ошибка исчезли, наш документ проверку на валидность прошел. Наслаждаемся чувством умиротворения от качественно проделанной работы.
Довольно часто, почти всегда, ошибки кроются в плагинах. В этих случаях ошибку найти не так просто, и я рекомендую воспользоваться инструментом «поиск» файл менеджера Total Commander. Как использовать этот инструмент файл менеджера я уже писал в статье «Внешние ссылки» и повторяться здесь не буду.
Многим блогерам, особенно тем, кто плотно не знаком с HTML, будет трудно понять чего нам говорит валидатор. Для облегчения понимания сути ошибки и ее исправления скачайте шпаргалку — подсказку по ссылке — на скачивание шпаргалки, где описаны самые распространенные ошибки HTML кода и способы их исправления. Если, несмотря на все усилия, ошибку в коде плагина, скрипта, и т.п., устранить не удается, откажитесь от него и замените подобным с валидным кодом.
Sorry! This document can not be checked.

Такой грозной надписью вас известит сервис, если он не сможет проверить сайт на валидность HTML сода. Причиной этому может быть конфликт плагинов. В моем случае помогло простое обновление WordPress. Можете использовать проверку валидности непосредственно HTML кода страницы блога на вкладке Validate by Direct Input.
В следующей статье «Валидность CSS» мы рассмотрим, как выполнить проверку и исправление ошибок CSS каскадных таблиц стилей. P.S. По многочисленным просьбам читателей публикую здесь валидный код блока кнопок поделиться в социальных сетях от Яндекса:
<script type="text/javascript" src="http://yandex.st/share/share.js" charset="utf-8"></script> <script type="text/javascript"><!-- document.write('</p> <p> </p> <p> </p> <p> </p> <p> </p> <p> </p> <p> </p> <p> </p> <div class="yashare-auto-init" data-yashareL10n="ru" data-yashareType="button" data-yashareQuickServices="yaru,vkontakte,facebook,twitter,odnoklassniki,moimir,lj,friendfeed,moikrug,gplus,blogger"></div> <p> </p> <p> </p> <p> </p> <p> </p> <p> </p> <p> </p> <p> </p> <p>'); --></script>
Именно этот блок вы видите в конце каждой моей статьи. Нажмите на кнопки, чтобы проверить, работают ли :-).
Просмотров 1.2к. Опубликовано 19.12.2022
Обновлено 19.12.2022
Каждый сайт, который создает компания, должен отвечать принятым стандартам. В первую очередь затем, чтобы он попадал в поисковую выдачу и был удобен для пользователей. Если код страниц содержит ошибки, неточности, он становится “невалидным”, то есть не соответствующим требованиям. В результате интернет-ресурс не увидят пользователи или информация на нем будет отображаться некорректно.
В этой статье рассмотрим, что такое валидность, какие могут быть ошибки в HTML-разметке и как их устранить.
Содержание
- Что такое HTML-ошибка валидации и зачем она нужна
- Чем опасны ошибки в разметке
- Как проверить ошибки валидации
- Предупреждения
- Ошибки
- Пример прохождения валидации для страницы сайта
- Как исправить ошибку валидации
- Плагины для браузеров, которые помогут найти ошибки в коде
- Коротко о главном
Что такое HTML-ошибка валидации и зачем она нужна
Под понятием “валидация” подразумевается процесс онлайн-проверки HTML-кода страницы на соответствие стандартам w3c. Эти стандарты были разработаны Организацией всемирной паутины и стандартов качества разметки. Сама организация продвигает идею унификации сайтов по HTML-коду — чтобы каждому пользователю, вне зависимости от браузера или устройства, было удобно использовать ресурс.
Если код отвечает стандартам, то его называют валидным. Браузеры могут его прочитать, загрузить страницы, а поисковые системы легко находят страницу по соответствующему запросу.
Чем опасны ошибки в разметке
Ошибки валидации могут разными — видимыми для глаза простого пользователя или такими, которые можно засечь только с помощью специальных программ. В первом случае кроме технических проблем, ошибки в разметке приводят к негативному пользовательскому опыту.
К наиболее распространённым последствиям ошибок в коде HTML-разметки также относят сбои в нормальной работе сайта и помехи в продвижении ресурса в поисковых системах.
Рассмотрим несколько примеров, как ошибки могут проявляться при работе:
- Медленно подгружается страница
Согласно исследованию Unbounce, более четверти пользователей покидают страницу, если её загрузка занимает более 3 секунд, ещё треть уходит после 6 секунд;
- Не видна часть текстовых, фото и видео-блоков
Эта проблема делает контент для пользователей неинформативным, поэтому они в большинстве случаев уходят со страницы, не досмотрев её до конца;
- Страница может остаться не проиндексированной
Если поисковый робот распознает недочёт в разметке, он может пропустить страницу и прервать её размещение в поисковых системах;
- Разное отображение страниц на разных устройствах
Например, на компьютере или ноутбуке страница будет выглядеть хорошо, а на мобильных гаджетах половина кнопок и изображений будет попросту не видна.
Из-за этих ошибок пользователь не сможет нормально работать с ресурсом. Единственное решение для него — закрыть вкладку и найти нужную информацию на другом сайте. Так количество посетителей сайта постепенно уменьшается, он перестает попадать в поисковую выдачу — в результате ресурс становится бесполезным и пропадает в пучине Интернета.
Как проверить ошибки валидации
Владельцы ресурсов используют 2 способа онлайн-проверки сайтов на наличие ошибок — технический аудит или использование валидаторов.
Первый случай подходит для серьёзных проблем и масштабных сайтов. Валидаторами же пользуются ежедневно. Наиболее популярный — сервис The W3C Markup Validation Service. Он сканирует сайт и сравнивает код на соответствие стандартам W3C. Валидатор выдаёт 2 типа несоответствий разметки стандартам W3C: предупреждения и ошибки.
Давайте рассмотрим каждый из типов чуть подробнее.
Предупреждения
Предупреждения отмечают незначительные проблемы, которые не влияют на работу ресурса. Они появляются из-за расхождений написания разметки со стандартами W3C.
Тем не менее, предупреждения всё равно нужно устранять, так как из-за них сайт может работать медленнее — например, по сравнению с конкурентами с такими же сайтами.
Примером предупреждения может быть указание на отсутствие тега alt у изображения.
Ошибки
Ошибки — это те проблемы, которые требуют обязательного устранения.
Они представляют угрозу для корректной работы сайта: например, из-за них могут скрываться разные блоки — текстовые, фото, видео. А в некоторых более запущенных случаях содержимое страницы может вовсе не отображаться, и сам ресурс не будет загружаться. Поэтому после проверки уделять внимание ошибкам с красными отметками нужно в первую очередь.
Распространённым примером ошибки может быть отсутствие тега <!DOCTYPE html> в начале страницы, который помогает информации преобразоваться в разметку.
Пример прохождения валидации для страницы сайта
Рассмотрим процесс валидации на примере сайта avavax.ru, который создали на WordPress.
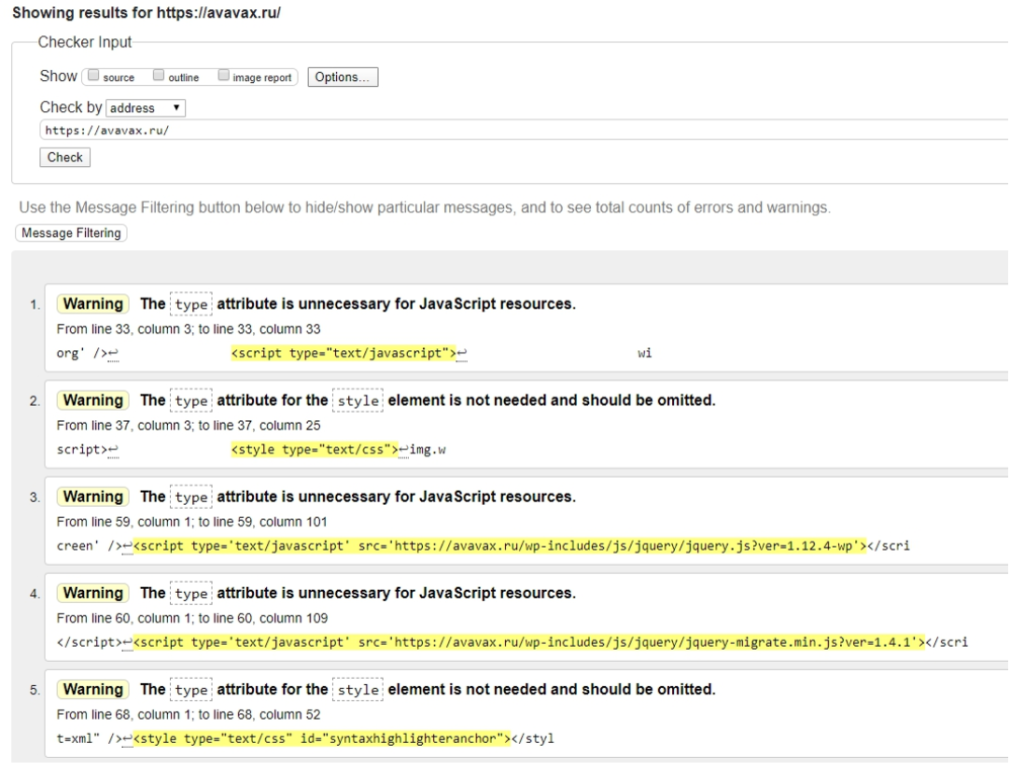
В результате проверки валидатор выдал 17 замечаний. После анализа отчета их можно свести к 3 основным:
- атрибут ‘text/javascript’ не требуется при подключении скрипта;
- атрибут ‘text/css’ не требуется при подключении стиля;
- у одного из элементов section нет внутри заголовка h1-h6.
Первое и второе замечания генерирует сам движок WordPress, поэтому разработчикам не нужно их убирать. Третье же замечание предполагает, что каждый блок текста должен иметь заголовок, даже если это не всегда необходимо или видно для читателя.
Решить проблемы с предупреждениями для стилей и скриптов можно через добавление кода в файл темы function.php.
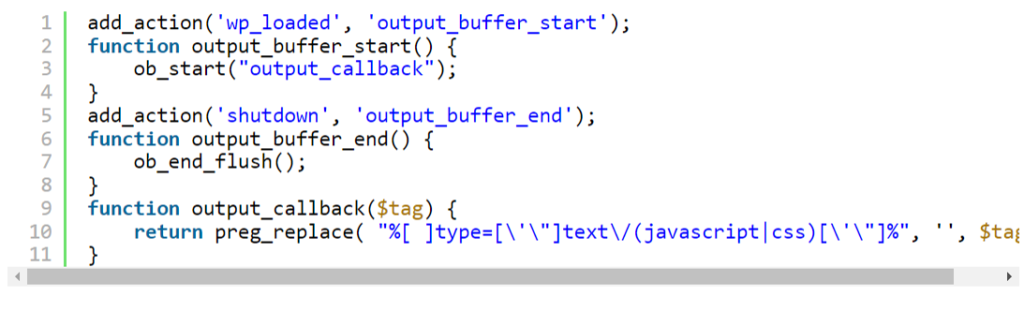
Для этого на хук wp_loaded нужно повесить функцию output_buffer_start(), которая загрузит весь генерируемый код html в буфер. При выводе в буфер вызывается функция output_callback($tag), которая просматривает все теги, находит нежелательные атрибуты с помощью регулярных выражений и заменяет их пробелами. Затем на хук ‘shutdown вешается функция output_buffer_end(), которая возвращает обработанное содержимое буфера.
Для исправления семантики на сайте нужно использовать заголовки. Валидатор выдаёт предупреждение на секцию about, которая содержит фото и краткий текст. Валидатор требует, чтобы в каждой секции был заголовок. Для исправления предупреждения нужно добавить заголовок, но сделать это так, чтобы его не было видно пользователям:
- Добавить заголовок в код: <h3>Обо мне</h3>
Отключить отображение заголовка:
1 #about h3 {
2 display: none;
3 }
После этой части заголовок будет в коде, но валидатор его увидит, а посетитель — нет.
За 3 действия удалось убрать все предупреждения, чтобы качество кода устроило валидатор. Это подтверждается зелёной строкой с надписью: “Document checking completed. No errors or warnings to show”.
Как исправить ошибку валидации
Всё зависит от того, какими техническими знаниями обладает владелец ресурса. Он может сделать это сам, вручную. Делать это нужно постепенно, разбирая ошибку за ошибкой. Но нужно понимать, что если при проверке валидатором было выявлено 100 проблем — все 100 нужно обязательно решить.
Поэтому если навыков и знаний не хватает, лучше привлечь сторонних специалистов для улучшения качества разметки. Это могут быть как фрилансеры, так и профессиональные веб-агентства. При выборе хорошего специалиста, результат будет гарантироваться в любом случае, но лучше, чтобы в договоре оказания услуг будут чётко прописаны цели проведения аудита и гарантии решения проблем с сайтом.
Если объём работ большой, выгоднее заказать профессиональный аудит сайта. С его помощью можно обнаружить разные виды ошибок, улучшить внешний вид и привлекательность интернет-ресурса для поисковых ботов, обычных пользователей, а также повысить скорость загрузки страниц, сделать качественную верстку и избавиться от переспама.
Плагины для браузеров, которые помогут найти ошибки в коде
Для поиска ошибок валидации можно использовать и встроенные в браузеры плагины. Они помогут быстро находить неточности еще на этапе создания кода.
Для каждого браузера есть свой адаптивный плагин:
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- HTML5 Editor для Opera.
С помощью этих инструментов можно не допускать проблем, которые помешают нормальному запуску сайта. Плагины помогут оценить качество внешней и внутренней оптимизации, контента и другие характеристики.
Коротко о главном
Валидация — процесс выявления проблем с HTML-разметкой сайта и ее соответствия стандартам W3C. Это унифицированные правила, с помощью которых сайт может нормально работать и отображаться и для поисковых роботов, и для пользователей.
Проверку ресурса можно проводить тремя путями: валидаторами, специалистам полномасштабного аудита и плагинами в браузере. В большинстве случаев валидатор — самое удобное и быстрое решение для поиска проблем. С его помощью можно выявить 2 типа проблем с разметкой — предупреждения и ошибки.
Работать необходимо сразу с двумя типами ошибок. Даже если предупреждение не приведет к неисправности сайта, оставлять без внимания проблемные блоки нельзя, так как это снизит привлекательность ресурса в глазах пользователя. Ошибки же могут привести к невозможности отображения блоков на сайте, понижению сайта в поисковой выдаче или полному игнорированию ресурса со стороны поискового бота.
Даже у крупных сайтов с миллионной аудиторией, например, Яндекс.Дзен или ВКонтакте, есть проблемы с кодом. Но комплексный подход к решению проблем помогает устранять серьёзные моменты своевременно. Нужно развивать сайт всесторонне, чтобы получить результат от его существования и поддержки. Если самостоятельно разобраться с проблемами не получается, не стоит “доламывать” — лучше обратиться за помощью к профессионалам, например, агентствам по веб-аудиту.
Наличие ошибок в коде страницы сайта всегда влечет за собой негативные последствия – от ухудшения позиций в ранжировании до жалоб со стороны пользователей. Ошибки валидации могут наблюдаться как на главной, так и на иных веб-страницах, их наличие свидетельствует о том, что ресурс является невалидным. Некоторые проблемы замечают даже неподготовленные пользователи, другие невозможно обнаружить без предварительного аудита, анализа. О том, что такое ошибки валидации и как их обнаружить, мы сейчас расскажем.

Ошибка валидации, что это такое?
Для написания страниц используется HTML – стандартизированный язык разметки, применяемый в веб-разработке. HTML, как любой другой язык, имеет специфические особенности синтаксиса, грамматики и т. д. Если во время написания кода правила не учитываются, то после запуска сайта будут появляться различные виды проблем. Если HTML-код ресурса не соответствует стандарту W3C, то он является невалидным, о чем мы писали выше.
Почему ошибки валидации сайта оказывают влияние на ранжирование, восприятие?
Наличие погрешностей в коде – проблема, с которой необходимо бороться сразу после обнаружения. Поисковые системы «читают» HTML-код, если он некорректный, то процесс индексации и ранжирования может быть затруднен. Поисковые роботы должны понимать, каким является ресурс, что он предлагает, какие запросы использует. Особо критичны такие ситуации для ресурсов, имеющих большое количество веб-страниц.
Как проверить ошибки валидации?

Для этой работы используется либо технический аудит сайта, либо валидаторы, которые ищут проблемы автоматически. Одним из самых популярных является сервис The W3C Markup Validation Service, выполняющий сканирование с оглядкой на World Wide Web Consortium (W3C). Рассматриваемый валидатор предлагает три способа, с помощью которых можно осуществить проверку сайта:
- ввод URL-адреса страниц, которые необходимо просканировать;
- загрузка файла страницы;
- ввод части HTML-кода, нуждающегося в проверке.
После завершения проверки вы получите развернутый список выявленных проблем, дополненных описанием, ссылками на стандарты W3C. По ходу анализа вы увидите слабые места со ссылками на правила, что позволит самостоятельно исправить проблему.
Существуют другие сервисы, позволяющие выполнить проверку валидности кода:
- Dr. Watson. Проверяет скорость загрузки страниц, орфографию, ссылки, а также исходный код;
- InternetSupervision.com. Отслеживает производительность сайта, проверяет доступность HTML.
Плагины для браузеров, которые помогут найти ошибки в коде
Решить рассматриваемую задачу можно с помощью плагинов, адаптированных под конкретный браузер. Можно использовать следующие инструменты (бесплатные):
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- Validate HTML для Firefox.
После проверки нужно решить, будете ли вы устранять выявленные ошибки. Многие эксперты акцентируют внимание на том, что поисковые системы сегодня уделяют больше внимания качеству внешней/внутренней оптимизации, контенту, другим характеристикам. Однако валидность нельзя оставлять без внимания, ведь если даже обнаруженные проблемы не будут мешать поисковым ботам, то они точно начнут раздражать посетителей сайта.
Как исправить ошибку валидации?

В первую очередь нужно сосредоточить внимание на слабых местах, связанных с контентом – это то, что важно для поисковых систем. Если во время сканирования было выявлено более 25 проблем, то их нельзя игнорировать из-за ряда причин:
- частичная индексация;
- медленная загрузка;
- баги, возникающие во время непосредственной коммуникации пользователя с ресурсом.
Например, игнорирование ошибок может привести к тому, что некоторые страницы не будут проиндексированы. Для решения рассматриваемой проблемы можно привлечь опытного фрилансера, однако лучшее решение – заказ услуги в веб-агентстве, что позволит исправить, а не усугубить ситуацию.
Технический и SEO-аудит
Выявление ошибок – первый шаг, ведь их еще нужно будет устранить. При наличии большого пула проблем целесообразно заказать профессиональный аудит сайта. Он поможет найти разные виды ошибок, повысит привлекательность ресурса для поисковых ботов, обычных пользователей: скорость загрузки страниц, верстка, переспам, другое.
В заключение
На всех сайтах наблюдаются ошибки валидации – их невозможно искоренить полностью, но и оставлять без внимания не стоит. Например, если провести проверку сайтов Google или «Яндекс», то можно увидеть ошибки, однако это не означает, что стоит вздохнуть спокойно и закрыть глаза на происходящее. Владелец сайта должен ставить во главу угла комплексное развитие, при таком подходе ресурс будет наполняться, обновляться и «лечиться» своевременно. Если проблем мало, то можно попробовать устранить их своими силами или с помощью привлечения стороннего частного специалиста. В остальных случаях лучше заказать услугу у проверенного подрядчика.

 Здравствуйте, дорогие читатели. Сожалею, что так долго не писал, решил немного заняться новым проектом и на 2 месяца забросил этот сайт
Здравствуйте, дорогие читатели. Сожалею, что так долго не писал, решил немного заняться новым проектом и на 2 месяца забросил этот сайт  . Исправляюсь, по вашим многочисленным просьбам пишу статью про валидность сайта валидность HTML кода и как проверить сайт на валидность и исправить ошибки.
. Исправляюсь, по вашим многочисленным просьбам пишу статью про валидность сайта валидность HTML кода и как проверить сайт на валидность и исправить ошибки.
Проверить сайт на валидность важно по нескольким причинам:
- выявить ошибки и устранить их
- для каждого пользователя ( зависит от его браузера и версии ) страница может отображаться по-разному. Браузеры смогут отобразить страницу с небольшими огрехами, но каждый отобразит по-своему.
- если браузеры могут автоматически исправить маленькие недочеты, то поисковые системы замечают любую погрешность. К примеру на западе поисковики серьезно относятся к валидности сайтов, у нас уже тоже не исключение.
Всему этому необходимо следовать. А задает эти нормы W3C Консорциум Всемирной паутины ( World Wide Web Consortium ).
Проверка HTML кода на валидность
W3C предоставляет для всех вебмастеров валидатор html кода, чтобы проверить валидность сайта.

Validate by URI — проверка по URL
Validate by File Upload — проверить загружаемый файл
Validate by Direct Input — вставка и проверка участка кода
Нажимаем кнопку Check и появятся результаты. По умолчанию настройки определяются автоматически, но если вы подгоняете под другой тип, то используйте свои.

Подмечу, что часто достаточно исправить 1 или пару ошибок, чтобы сайт полностью соответствовал правилам. ( Например, в этом случае достаточно было сделать 1 исправление в 1 файле, чтобы пропало 5 ошибок ).
Далее будет выведен список ошибок и их решение.

Все на английском, правда в валидаторе есть полезная опция «Clean up Markup with HTML-Tidy», ниже расскажу о ней.
Также можно будет выбрать дополнительные опции при проверке на валидность:
- Show Source – отобразить исходный код вашей страницы
- Show Outline – показать строку, где есть ошибки
- Validate error pages – проверить страницы ошибок, например 404 — страницы не существует
- List Messages Sequentially – показать ошибки и предупреждения списком, последовательно
- Group Error Messages by Type – группировать ошибки с общими признаками
- Clean up Markup with HTML Tidy — программа HTML Tidy выводит исправленный код, не входит в состав W3C validator, поэтому не гарантируется полная корректность
Исправление ошибок валидности
Теперь попытаемся разобраться как исправлять ошибки.
1. Копируем строчку с ошибкой ( … не копируем, это продолжение кода )
2. Определяем в каком файле она находится. Открываем сайт, CTRL + U просматриваем исходный код страницы и ищем ошибку CTRL + F. Часто ошибка не связана с файлами шаблона, она может находиться в файлах плагинов, либо в подпапках вашего шаблона, поэтому нужны некоторые знания
3. Далее открываем файл и при помощи записи под ошибкой, либо при помощи программы HTML Tidy ( включаем опцию вверху страницы валидатора), в таком случае ищем уже исправленный код ( просто копируйте код на 2-3 символа до красного выделения ). И исправляем.
Часто встречаемые ошибки валидации
Тег noindex
Пример:
<noindex> <a rel=»nofollow» href=»…» >…</a></noindex>
Ошибка валидатора: You have used the element named above in your document, but the document type you are using does not define an element of that name
Пояснение: noindex — не входит официальную спецификацию тега языка гипертекстовой разметки веб-страниц HTML. Также полезно знать, что ЯНДЕКС учитывает, как и Google, Yahoo и Bing, rel=»nofollow»
Правильно:
<a rel=»nofollow» href=»…» >…</a>
Пример:
<a href="index.php?pid=1&id=2">...</a>
Ошибка валидатора: Unknown entity…
Пояснение: использовать & вместо &
Правильно:
<a href="index.php?pid=1&id=2">...</a>
Неверная вложенность
Пример:
<strong><li>...</strong></li>
Ошибка валидатора: Missing </ tagli>
Пояснение: элементы должны быть закрыты в обратном порядке их открытию
Правильно:
<strong><lili
Чувствительность DOCTYPE к регистру
Пример:
<!doctype html public "-//w3c//dtd xhtml 1.0 transitional//en" "http://www.w3.org/tr/xhtml1/dtd/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" >
Ошибка валидатора: Missing DOCTYPE
Пояснение: DOCTYPE зависим к регистру
Правильно:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="<a>http://www.w3.org/1999/xhtml</a>" >
Не прописан закрывающий «/»
Пример:
…style.css" type="text/css" media="screen">
Пояснение: «пустые элементы», как img или br, должны заканчиваться»/» c пробелом перед этим
Правильно:
…style.css» type=»text/css» media=»screen» />
Тэги прописаны в верхнем регистре
Пример:
<STRONG><LI>...</LI></STRONG>
Ошибка валидатора: There is no such element…
Пояснение: в XHTML документах все элементы и атрибуты должны быть в нижнем регистре, т.к. этот язык регистрозависим и для него <li> и < разные тэгиLI>
Правильно:
<strong><li>...</li></strong>
Значения атрибутов прописаны без кавычек
Пример:
<style type=text/css>...</style>
Ошибка валидатора: Missing » »
Пояснение: значения атрибутов пишутся вместе с кавычками
Правильно:
<style type="text/css">...</style>
У img отсутствует атрибут alt
Пример:
<img src="/image/1.png" height="10" width="10" alt="" title="">
Ошибка валидатора: required attribute «alt» not specified
Пояснение: у тега img атрибут alt должен быть всегда, значение можно оставить пустым, если картинка используется для оформления
Правильно:
<img src="/image/1.png" height="10" width="10" alt="" title="">
В итоге вы сможете исправить ошибки сайта и сделать сайт валидным.
Просмотров 7.7к. Опубликовано 19.12.2022
Обновлено 19.12.2022
Каждый сайт, который создает компания, должен отвечать принятым стандартам. В первую очередь затем, чтобы он попадал в поисковую выдачу и был удобен для пользователей. Если код страниц содержит ошибки, неточности, он становится “невалидным”, то есть не соответствующим требованиям. В результате интернет-ресурс не увидят пользователи или информация на нем будет отображаться некорректно.
В этой статье рассмотрим, что такое валидность, какие могут быть ошибки в HTML-разметке и как их устранить.
Содержание
- Что такое HTML-ошибка валидации и зачем она нужна
- Чем опасны ошибки в разметке
- Как проверить ошибки валидации
- Предупреждения
- Ошибки
- Пример прохождения валидации для страницы сайта
- Как исправить ошибку валидации
- Плагины для браузеров, которые помогут найти ошибки в коде
- Коротко о главном
Что такое HTML-ошибка валидации и зачем она нужна
Под понятием “валидация” подразумевается процесс онлайн-проверки HTML-кода страницы на соответствие стандартам w3c. Эти стандарты были разработаны Организацией всемирной паутины и стандартов качества разметки. Сама организация продвигает идею унификации сайтов по HTML-коду — чтобы каждому пользователю, вне зависимости от браузера или устройства, было удобно использовать ресурс.
Если код отвечает стандартам, то его называют валидным. Браузеры могут его прочитать, загрузить страницы, а поисковые системы легко находят страницу по соответствующему запросу.
Чем опасны ошибки в разметке
Ошибки валидации могут разными — видимыми для глаза простого пользователя или такими, которые можно засечь только с помощью специальных программ. В первом случае кроме технических проблем, ошибки в разметке приводят к негативному пользовательскому опыту.
К наиболее распространённым последствиям ошибок в коде HTML-разметки также относят сбои в нормальной работе сайта и помехи в продвижении ресурса в поисковых системах.
Рассмотрим несколько примеров, как ошибки могут проявляться при работе:
- Медленно подгружается страница
Согласно исследованию Unbounce, более четверти пользователей покидают страницу, если её загрузка занимает более 3 секунд, ещё треть уходит после 6 секунд;
- Не видна часть текстовых, фото и видео-блоков
Эта проблема делает контент для пользователей неинформативным, поэтому они в большинстве случаев уходят со страницы, не досмотрев её до конца;
- Страница может остаться не проиндексированной
Если поисковый робот распознает недочёт в разметке, он может пропустить страницу и прервать её размещение в поисковых системах;
- Разное отображение страниц на разных устройствах
Например, на компьютере или ноутбуке страница будет выглядеть хорошо, а на мобильных гаджетах половина кнопок и изображений будет попросту не видна.
Из-за этих ошибок пользователь не сможет нормально работать с ресурсом. Единственное решение для него — закрыть вкладку и найти нужную информацию на другом сайте. Так количество посетителей сайта постепенно уменьшается, он перестает попадать в поисковую выдачу — в результате ресурс становится бесполезным и пропадает в пучине Интернета.
Как проверить ошибки валидации
Владельцы ресурсов используют 2 способа онлайн-проверки сайтов на наличие ошибок — технический аудит или использование валидаторов.
Первый случай подходит для серьёзных проблем и масштабных сайтов. Валидаторами же пользуются ежедневно. Наиболее популярный — сервис The W3C Markup Validation Service. Он сканирует сайт и сравнивает код на соответствие стандартам W3C. Валидатор выдаёт 2 типа несоответствий разметки стандартам W3C: предупреждения и ошибки.
Давайте рассмотрим каждый из типов чуть подробнее.
Предупреждения
Предупреждения отмечают незначительные проблемы, которые не влияют на работу ресурса. Они появляются из-за расхождений написания разметки со стандартами W3C.
Тем не менее, предупреждения всё равно нужно устранять, так как из-за них сайт может работать медленнее — например, по сравнению с конкурентами с такими же сайтами.
Примером предупреждения может быть указание на отсутствие тега alt у изображения.
Ошибки
Ошибки — это те проблемы, которые требуют обязательного устранения.
Они представляют угрозу для корректной работы сайта: например, из-за них могут скрываться разные блоки — текстовые, фото, видео. А в некоторых более запущенных случаях содержимое страницы может вовсе не отображаться, и сам ресурс не будет загружаться. Поэтому после проверки уделять внимание ошибкам с красными отметками нужно в первую очередь.
Распространённым примером ошибки может быть отсутствие тега <!DOCTYPE html> в начале страницы, который помогает информации преобразоваться в разметку.
Пример прохождения валидации для страницы сайта
Рассмотрим процесс валидации на примере сайта avavax.ru, который создали на WordPress.
В результате проверки валидатор выдал 17 замечаний. После анализа отчета их можно свести к 3 основным:
- атрибут ‘text/javascript’ не требуется при подключении скрипта;
- атрибут ‘text/css’ не требуется при подключении стиля;
- у одного из элементов section нет внутри заголовка h1-h6.
Первое и второе замечания генерирует сам движок WordPress, поэтому разработчикам не нужно их убирать. Третье же замечание предполагает, что каждый блок текста должен иметь заголовок, даже если это не всегда необходимо или видно для читателя.
Решить проблемы с предупреждениями для стилей и скриптов можно через добавление кода в файл темы function.php.
Для этого на хук wp_loaded нужно повесить функцию output_buffer_start(), которая загрузит весь генерируемый код html в буфер. При выводе в буфер вызывается функция output_callback($tag), которая просматривает все теги, находит нежелательные атрибуты с помощью регулярных выражений и заменяет их пробелами. Затем на хук ‘shutdown вешается функция output_buffer_end(), которая возвращает обработанное содержимое буфера.
Для исправления семантики на сайте нужно использовать заголовки. Валидатор выдаёт предупреждение на секцию about, которая содержит фото и краткий текст. Валидатор требует, чтобы в каждой секции был заголовок. Для исправления предупреждения нужно добавить заголовок, но сделать это так, чтобы его не было видно пользователям:
- Добавить заголовок в код: <h3>Обо мне</h3>
Отключить отображение заголовка:
1 #about h3 {
2 display: none;
3 }
После этой части заголовок будет в коде, но валидатор его увидит, а посетитель — нет.
За 3 действия удалось убрать все предупреждения, чтобы качество кода устроило валидатор. Это подтверждается зелёной строкой с надписью: “Document checking completed. No errors or warnings to show”.
Как исправить ошибку валидации
Всё зависит от того, какими техническими знаниями обладает владелец ресурса. Он может сделать это сам, вручную. Делать это нужно постепенно, разбирая ошибку за ошибкой. Но нужно понимать, что если при проверке валидатором было выявлено 100 проблем — все 100 нужно обязательно решить.
Поэтому если навыков и знаний не хватает, лучше привлечь сторонних специалистов для улучшения качества разметки. Это могут быть как фрилансеры, так и профессиональные веб-агентства. При выборе хорошего специалиста, результат будет гарантироваться в любом случае, но лучше, чтобы в договоре оказания услуг будут чётко прописаны цели проведения аудита и гарантии решения проблем с сайтом.
Если объём работ большой, выгоднее заказать профессиональный аудит сайта. С его помощью можно обнаружить разные виды ошибок, улучшить внешний вид и привлекательность интернет-ресурса для поисковых ботов, обычных пользователей, а также повысить скорость загрузки страниц, сделать качественную верстку и избавиться от переспама.
Плагины для браузеров, которые помогут найти ошибки в коде
Для поиска ошибок валидации можно использовать и встроенные в браузеры плагины. Они помогут быстро находить неточности еще на этапе создания кода.
Для каждого браузера есть свой адаптивный плагин:
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- HTML5 Editor для Opera.
С помощью этих инструментов можно не допускать проблем, которые помешают нормальному запуску сайта. Плагины помогут оценить качество внешней и внутренней оптимизации, контента и другие характеристики.
Коротко о главном
Валидация — процесс выявления проблем с HTML-разметкой сайта и ее соответствия стандартам W3C. Это унифицированные правила, с помощью которых сайт может нормально работать и отображаться и для поисковых роботов, и для пользователей.
Проверку ресурса можно проводить тремя путями: валидаторами, специалистам полномасштабного аудита и плагинами в браузере. В большинстве случаев валидатор — самое удобное и быстрое решение для поиска проблем. С его помощью можно выявить 2 типа проблем с разметкой — предупреждения и ошибки.
Работать необходимо сразу с двумя типами ошибок. Даже если предупреждение не приведет к неисправности сайта, оставлять без внимания проблемные блоки нельзя, так как это снизит привлекательность ресурса в глазах пользователя. Ошибки же могут привести к невозможности отображения блоков на сайте, понижению сайта в поисковой выдаче или полному игнорированию ресурса со стороны поискового бота.
Даже у крупных сайтов с миллионной аудиторией, например, Яндекс.Дзен или ВКонтакте, есть проблемы с кодом. Но комплексный подход к решению проблем помогает устранять серьёзные моменты своевременно. Нужно развивать сайт всесторонне, чтобы получить результат от его существования и поддержки. Если самостоятельно разобраться с проблемами не получается, не стоит “доламывать” — лучше обратиться за помощью к профессионалам, например, агентствам по веб-аудиту.
Зачем нужен валидный код и как устранить ошибки валидации
Валидация является одним из самых важных аспектов хорошего веб-дизайна. Давайте рассмотрим, что это такое и как проверить HTML код на валидность. В качестве примера возьмем самую распространенную систему управления контентом (CMS) – WordPress. После чего мы поделимся перечнем ошибок, с которыми столкнулись на практике и, самое главное, предложим свои, проверенные, методы по их устранению.
Зачем необходима проверка на валидность сайта
Проще говоря, проверка веб-страницы позволит определить, соответствует ли она стандартам, разработанным Консорциумом Всемирной паутины (W3C). Обычно это делается путем проверки отдельных страниц на валидность с помощью онлайн-сервиса проверки от W3C.
Подобно правилам грамматики на разных языках, есть также правила в программировании. Проверка позволяет увидеть, соответствует ли страница этим правилам, а в случае наличия ошибок и предупреждений будут предоставлены рекомендации по их устранению. Подробнее о необходимости такой проверки рассмотрим ниже.
На что влияет валидность сайта
Вы когда-нибудь задумывались о том, как браузеры “читают” веб-страницу? У них есть “двигатели” для анализа кода и преобразования его в визуальный вид для людей. К сожалению, у каждого браузера есть собственный механизм обработки кода, и это может привести к отображению ваших страниц по-разному.
Некорректная веб-страница может быть прочитана браузерами по-разному. Это приведет к тому, что ваши посетители, возможно, даже не смогут правильно увидеть контент страницы в своих браузерах. Валидация в дальнейшем позволит исправить почти все основные различия и делает вашу веб-страницу доступной для чтения почти всеми веб-браузерами (чаще всего исключением становится Internet Explorer старых версий). Отсюда и появился термин “кроссбраузерная верстка” – т. е. верстка, которая одинаково хороша (совместима) для всех популярных браузеров.
А как же это повлияет на SEO? Важно понимать, что роботы поисковых систем любят семантические веб-страницы. Семантическая верстка, согласно данным Википедии, – это подход к созданию веб-страниц на языке HTML, основанный на использовании HTML тегов в соответствии с их семантикой (предназначением). Кроме того, структурная семантическая веб-страница позволяет поисковым роботам более точно определять значимость, как отдельных элементов веб-страницы, так и всего текста в целом. По заверению Google, валидный код никак не влияет на ранжирование страниц. Но при этом наличие ошибок в коде способно негативно повлиять на сканирование микроразметки и адаптированностью под мобильные устройства.
Так что, если в SEO-аудите вы встретите рекомендации по устранению ошибок, выявленных в процессе валидации, то лучше их исправить, а как это сделать мы вам расскажем.
Инструменты проверки для вашего сайта
Понимая необходимость отсутствия ошибок валидации на страницах сайта, давайте рассмотрим, как осуществить поиск данных ошибок.
Существует множество бесплатных сервисов для проверки сайта, такие как Markup Validation Service W3C, Web Page Analyzer, Browsershots и другие.
Служба проверки HTML разметки W3C, вероятно, является самым простым и популярным инструментом для проверки валидности веб-страницы. Используя этот инструмент, вы можете обнаружить ошибки валидации, начиная от отсутствующих атрибутов ALT для ваших IMG-тегов и заканчивая размещением элементов блок-уровня внутри встроенных элементов (например, <p> внутри <span>).
Вы можете оценить HTML код, указав адрес своей веб-страницы, загрузив файл HTML или вставив HTML код напрямую.

Сервис проверит указанные вами данные на ошибки и сформирует отчет с их перечнем и рекомендациями по исправлению.
Условно ошибки и предупреждения можно разделить на два основных типа: шаблонные (связанные с выбранной темой и установленными плагинами) и ошибки, допущенные при оформлении уникального контента.
Проверяя веб-страницу в первый раз, не пугайтесь возможному большому количеству ошибок! Как правило, большинство из них многократно повторяются на анализируемой странице. А это значит, что если убрать ошибку в одном месте шаблона или страницы, то она исчезнет и во всех однотипных.
Откуда берутся ошибки
Огромное количество ошибок связано с используемой темой сайта, а также установленными плагинами. Большинство из нас устанавливает бесплатную тему и плагины, не задумываясь, что в них скрыто. Во многих темах при более глубоком изучении приходится сталкиваться с типичными ошибками.
Как исправить ошибки, и улучшить валидность сайта
Исправить выявленные ошибки можно двумя способами: обратиться к специалистам, заплатив N-ную сумму денег, либо исправить их самостоятельно. Рассмотрим последний вариант на реальных примерах и устраним все неточности, следуя подробным инструкциям.
Важно, резервное копирование.
Перед осуществлением каких-либо изменений в исходном коде сайта необходимо произвести резервное копирование файлов сайта и базы данных. А нужно это для того, чтобы в случае, если после проведенных манипуляций нормальная работа сайта будет нарушена, восстановить его.
Редактирование файлов шаблона темы.
Редактирование исходников можно осуществлять несколькими способами: редактирование файлов по FTP, через файловый менеджер хостинга либо через административную панель WordPress. Мы рекомендуем использовать последний вариант, т. к. он является самым быстрым и простым.
- Warning: The type attribute is unnecessary for JavaScript resources.
Предупреждение. Атрибут “type” элемента <script> не является обязательным для JavaScript ресурсов.

Warning: The type attribute for the style element is not needed and should be omitted.
Предупреждение. Атрибут “type” для элемента <style> не нужен и его следует опустить.

Для устранения данных двух предупреждений необходимо удалить атрибут type=”text/javascript” во всех тегах <script>, а также type=”text/css” во всех тегах <style>. В помощь нам приходит простая функция PHP preg_replace в паре с чудесной возможностью фильтрации данных в WordPress. Код выглядит так:
Вставить данный код необходимо в файл functions. php используемой темы. Для этого авторизуемся в административной панели WordPress, выбираем пункт меню “Внешний вид” -> “Редактор” и справа в списке файлов выбираем интересующий нас файл. Код вставляем в самом конце файла. Нажимаем кнопку “Обновить файл”.

Дополнительно удалим данный атрибут в некоторых файлах вашей WordPress-темы.
В меню “Внешний вид” -> “Редактор” выбираем интересующие нас файлы – index. php, header. php, footer. php. Поиск атрибута будем осуществлять с помощью горячих кнопок поиска Ctrl+F, введя в поисковой панели text/javascript. Выявив такую запись заменяем <script type=”text/javascript”> на <script>, т. е. удаляем непонравившийся атрибут type=”text/javascript” и не забываем нажать кнопку “Обновить файл”.
- Error: The center element is obsolete. Use CSS instead.
Ошибка. Тег <center> устарел. Используйте соответствующие CSS стили.

HTML 5 активно взаимодействует с CSS (язык описания внешнего вида документа, написанного с использованием HTML), поэтому запрет на многие теги и атрибуты, начатый в HTML 4 в пользу стилей, только усилился. Такого рода теги и атрибуты уже не поддерживаются некоторыми браузерами и должны исключаться из кода. Одним из таких тегов является тег <center>, а также атрибут “frameborder” тега <iframe>. При решении данных ошибок нам необходимо будет немного “поколдовать” над нашей Базой данных сайта.
Для этого необходимо зайти в панель управления вашего хостинга, перейти по ссылке в phpMyAdmin и авторизоваться.


Первым делом экспортируем всю базу данных в качестве резервной копии! Для этого нажимаем кнопку “Экспорт” в панели веб-интерфейса для администрирования. Далее выбираем закладку “SQL” для осуществления SQL запросов к базе данных, в нашем случае поиск и замена устаревших тегов и атрибутов. Прописываем следующие запросы:

Рассмотрим более подробно выше представленные SQL запросы.
Первой строчкой заменяем устаревший тег на контейнер <div> и сразу же задаем класс “ag_center”. Данный стилевой класс позволит нам выровнять содержимое контейнера по центру. Для этого заходим в админ панель WordPress, выбираем пункт меню “Внешний вид” -> “Редактор” -> файл style. css нашей темы. В конец файла добавляем следующие строки кода:

Второй строчкой SQL запроса заменяем закрывающийся тег </center> на закрывающийся </div>. А третьей – производим замену атрибут frameborder=”0” на класс “ag_border_zero” элемента <iframe>.
SQL запросы можно оптимизировать, сведя в один, однако проще для понимания и наглядности разбить задачу на несколько запросов, как мы это и сделали. Вам, конечно, могут попасться другие устаревшие теги, которые необходимо будет заменить на универсальный тег <div> и перенести прямое его назначение в стилевой файл.
Перечень тегов, которые более не поддерживаются и должны исключаться из кода:
- Error: The width attribute on the th element is obsolete. Use CSS instead.
Ошибка. Атрибут “width” элемента <th> устарел. Используйте соответствующие CSS стили.

Аналогично предыдущей ошибке, атрибут “width” элемента <th> также является устаревшим. Исправить данную ошибку можно двумя способами — заменить width=”10%” на style=”width:10%;”. Либо, чтобы не описывать каждый раз стиль внутри тега, можно выделить стиль во внешнюю таблицу стилей. Т. е. в элемент <th> добавляем а в файл style. css нашей темы. width_ten_percent . Какой способ проще, выбирать вам!
В случае если данная ошибка несет массовый характер в статьях вашего проекта, воспользуемся поиском и заменой атрибута “width” в панели phpMyAdmin следующим SQL запросом:
После чего необходимо добавить стилевой класс width_ten_percent в файле style. css:
.width_ten_percent
Следует отметить, что при массовой замене устаревших атрибутов на стилевые классы в панеле phpMyAdmin, при наличии уже прописанного класса у элемента (например, <img />), может возникнуть другая ошибка – дублирование атрибута “class”. Подобная ситуация обстоит и с атрибутом “style” (например, <img style=”width: 300px” style=”height: 200px”>). Поэтому, нужно быть уверенным в отсутствии ранее указанного другого атрибута “class” / “style”, либо отказаться от редактирования БД SQL запросами в пользу ручной проверки и редактирования каждой отдельной статьи в редакторе админ панели WordPress.
Для примера, рассмотрим добавление дополнительного класса / свойства атрибута “style”, придерживаясь стилевых правил. Добавим дополнительный класс width_ten_percent к уже имеющемуся color_red (class=”color_red”), и получаем: width_ten_percent” (перечисляем имена классов через пробел). Добавим ширину в 10% к уже имеющемуся style=”color: red;”, в итоге у нас должно получиться так: style=”color: red; width: 10%;” (стилевые свойства разделяются между собой точкой с запятой и пробелом).
Также хотелось бы отметить частое ошибочное использование атрибута “width” для элемента <tr>, атрибута “height” для элемента <td>.
Периодически проверяйте новый контент на наличие данных ошибок, и в случае необходимости повторите процедуру исправления.
| Устаревшие атрибуты | Элемент |
|---|---|
| charset, coords, shape, methods, name, rev, urn | <a> |
| nohref | <area> |
| alink, bgcolor, link, marginbottom, marginheight, marginleft, marginright, margintop, marginwidth, text, vlink | <body> |
| clear | <br> |
| name | <embed> |
| profile | <head> |
| version | <html> |
| longdesc | <iframe> |
| longdesc, lowsrc, name | <img> |
| usemap | <input> |
| charset, methods, rev, target, urn | <link> |
| scheme | <meta> |
| name | <option> |
| archive, classid, code, codebase, codetype, declare, standby | <object> |
| type, valuetype | <param> |
| event, for, language | <script> |
| datapagesize | <table> |
| abbr, axis | <td> и <th> |
Перечень атрибутов, которые более не поддерживаются и должны исключаться из кода:
- Error: Bad value 300px for attribute width on element img: Expected a digit but saw px instead.
Ошибка. Неприемлемое значение “300px” для ширины атрибута в элементе <img>: Ожидалась цифра, но вместо этого прочитал “px”.

Атрибуты элементов являются важной частью HTML разметки. Некоторые атрибуты элементов могут принимать практически любое значение, другие могут принимать только значения определенного типа, а третьи – принимать значение только из заранее определенного набора.
В контексте <img width=”300px” /> атрибутом “width” допускается принимать любое целое положительное число. Необходимо установить допустимое значение для правильной разметки, а именно 285, без указания единицы измерения (px).
Выявленные ошибки могут находиться не только в записях, настройках WordPress темы, но и в содержимом HTML кода виджетов сайдбара. В таких случаях для устранения ошибки заходим в меню “Внешний вид” -> “Виджеты” -> Сайдбар слева (справа/подвал) и в настройках виджета находим ошибочно указанный атрибут “width” удалив единицу измерения (px).

Дополнительно встречается ошибочное указание параметра атрибута “height” элемента <img>.
Использование имени стилевого идентификатора (id=“имя”) более одного раза на одной странице.

Стилевой идентификатор — уникальное имя элемента, которое используется для изменения его стиля и обращения к нему через скрипты. Идентификатор в коде документа должен быть в единственном экземпляре, т. е. встречаться только один раз.
- Имя класса и идентификатора должны обязательно начинаться с латинского символа (A–Z, a–z).
Имя класса и идентификатор должен обязательно начинаться с латинского символа (A–Z, a–z). Может содержать цифры (0–9), символ дефиса (-) и подчеркивания (_), но не в начале слова. Использование русских букв в именах идентификатора недопустимо.
- Ошибочное использование тега noindex по синтаксису.
Тег noindex используется для исключения контента, который необходимо скрыть от поисковой системы Яндекс. Например, дубли элементов навигации. Однако многие используют его неверно:
<noindex>Текст или код, который нужно исключить из индексации</noindex>
Для того, чтобы сделать код с noindex валидным, рекомендуется использовать следующую конструкцию:
- Error: No p element in scope but a p end tag seen.
Отсутствует открывающий или закрывающий тег.

В синтаксисе тегов обычно используются парные теги для обозначения начала и конца элемента. Закрывающий тег похож на открывающий, но содержит слэш (/) внутри угловых скобок и указывается сразу за открывающейся скобкой. Если вы открыли тег в HTML документе, его необходимо закрыть в соответствующем месте. В противном случае, это может вызвать проблемы с корректным отображением элемента в браузере.
- Error: Element p not allowed as child of element span in this context. (Suppressing further errors from this subtree.)
Блочные элементы внутри строчных.

Согласно спецификации блочный элемент запрещено вставлять внутрь строчного. Например, <span><p>Lorem ipsum…</p></span> не пройдёт валидацию, правильно вложить теги наоборот — <p><span>Lorem ipsum…</span></p>.
Наиболее часто используемыми блочными элементами являются:
Встроенные (строчные) элементы:
- Error: An img element must have an alt attribute, except under certain conditions. For details, consult guidance on providing text alternatives for images.
Отсутствует атрибут “alt” у изображения.

Каждое изображение (даже если оно служит для дизайнерских целей) в документе HTML должно иметь атрибут “alt” с описанием содержания картинки. Данный атрибут индексируется поисковыми роботами и используется ими для определения содержимого обнаруженных картинок. А это, в свою очередь, важно как для улучшения релевантности веб-страниц, так и для привлечения на сайт дополнительного трафика из «поиска по картинкам».
Памятка для контент-менеджеров
Для наших контент-менеджеров мы подготовили памятку о том, как правильно оформить веб-страницу, используя валидный код. Делимся ею и с вами, пользуйтесь на здоровье:

Завершение
Результатом кропотливой работы над ошибками мы должны увидеть следующее: Проверка документа завершена. Каких-либо ошибок и предупреждений не выявлено (“Document checking completed. No errors or warnings to show.”).

Что вы думаете о важности валидации? С какими ошибками сталкивались Вы и как их решали? Добавьте к этой статье свои комментарии!
Ошибки W3C: что это такое, как проверить сайт, как их исправить
HTML — это язык разметки сайтов. Браузеры интерпретируют этот язык и отображают в виде сайта на экране. HTML совершенствуется со временем: в него добавляются новые элементы, отвечающие современным технологиям, требованиям безопасности, параметрам новейших устройств. С каждым таким обновлением языка выпускается его новая версия. Сейчас действует пятая версия HTML, или HTML5.
Как у каждого языка, у HTML есть правила написания, которые называются спецификацией. Спецификацию устанавливают профессиональные сообщества специалистов веб-разработки.
Каждый HTML документ в интернете должен соответствовать спецификации актуальной версии языка, то есть чтобы браузеры правильно интерпретировали код сайта, он должен соблюдать правила, описанные в спецификации.
Спецификации HTML5
У HTML5 есть две разновидности спецификаций: от консорциума W3C и от WHATWG. Обе эти организации — международные сообщества специалистов веб-разработки, однако W3C появился раньше и долгое время оставался единственной авторитетной организацией вырабатывавшей стандарты для интернета.
Веб-разработчики и производители браузеров могут выбирать, какие спецификации HTML5 использовать. Но в принципе, это не имеет значения, так как поддерживаются оба стандарта языка. В статье мы будем рассматривать спецификацию W3C.
 Разработка SEO-сайтов с пожизненной гарантиейСоздаем невероятные SEO-сайты, оптимизированные по 69 параметрам уже на этапе разработки
Разработка SEO-сайтов с пожизненной гарантиейСоздаем невероятные SEO-сайты, оптимизированные по 69 параметрам уже на этапе разработки
Валидность кода
Код, соответствующий спецификации называется валидным, то есть правильным. Если в коде есть ошибки, то поисковые роботы при сканировании сайта могут не найти контент, а неправильные или незакрытые теги, битые ссылки запутают роботов — в результате у сайта возникнут проблемы с индексацией. Поэтому сайт, чтобы хорошо работать и индексироваться поисковиками, должен иметь валидный HTML код.
Как проверить валидность кода
Написать на 100% валидный код очень сложно, почти всегда сайт будет содержать какие-то недочеты, особенно если у сайта много страниц, на нем установлены виджеты от сторонних разработчиков, или сайт сделан на готовом шаблоне.
Проверить сайт на ошибки W3C можно с помощью специальных сервисов. В том числе на сайте самого консорциума W3C есть соответствующий раздел. Принцип работы все этих сервисов заключается в одном: вы вводите URL сайта и через некоторое время получаете отчет о валидности html кода.
-
В отчете будет показано, какие нарушения правил спецификации W3C имеются. Нарушения бывают двух типов:
- Error — критическая ошибка w3c. Грубое нарушение правил разметки, выделяется красным цветом.
- Warning — предупреждение, небольшая погрешность в коде. Выделяется желтым и словом Warning.
Предупреждения же являются скорее рекомендациями. Учитывать их или нет, решает разработчик сайта исходя из особенностей шаблона и количества таких предупреждений.
Как исправить ошибки W3C
Валидатор указывает в отчете часть кода, в котором содержится ошибка с указанием конкретной строки HTML кода и пояснение. В пояснении содержится суть ошибки и рекомендация к исправлению.
-
Самые распространенные ошибки:
- Одиночный тег прописан как парный, или наоборот, парный тег не имеет закрывающего тега.
- Отсутствие в теге какого-то атрибута. Например, в теге для изображений должен быть атрибут alt. Его отсутствие валидатор отметит как критическую ошибку.
- У тега прописанные не предназначенные для него атрибуты.
- Неправильная пунктуация в коде. Например, лишняя точка с запятой, и наоборот, ее отсутствие.
- Есть тег, но нет его содержания. Например, в коде прописан заголовок H2, но самого текста заголовка нет.
- Отсутствие слеша “/ ” в самозакрывающемся теге
- Блочные элементы внутри строчных. Например, когда заголовок прописан внутри ссылки. Должно быть наоборот.
Нужен настоящий SEO-сайт и интернет-реклама ? Пишите, звоните:
Наша почта:
Единая справочная: 8 (843) 2-588-132
WhatsApp: +7 (960) 048 81 32
Оставить заявку
7 критических ошибок в коде сайта: как найти за пять минут самостоятельно
Предлагаем рассмотреть критические ошибки в коде страницы сайта, которые оказывают влияние на корректность отображения страницы в браузере и степень ее оптимизации.
Какие ошибки мы отнесем к критическим:
- Открыт ли сайт или страница для индексирования
- <!DOCTYPE>
- Адаптивность
- Наличие viewport
- h1 на странице
- Подзаголовки страницы
- Проверяйте валидность сверстанных страниц
Такие ошибки делают невозможным индексирование страницы поисковыми системами или сильно усложняют его. Также эти ошибки могут повлиять на отображение вашего сайта в различных браузерах.
Для начала мы разберем, как проверить наличие таких ошибок самостоятельно, а в конце я дам несколько рекомендаций какими инструментами воспользоваться для полного анализа сайта и нахождения всех ошибок.
Как посмотреть код верстки страницы?
Что бы посмотреть код страницы откройте любой браузер (в данном случае Google Chrome) и нажмите на клавиатуре клавишу F12 или Ctrl+Shift+I.
Появится небольшой окно, в котором Вы можете увидеть HTML-код.

Посмотрим, какие ошибки мы можем быстро найти на сайте самостоятельно.
1. Открыт ли сайт или страница для индексирования.
Сначала открываем файл ВашДомен/robots. txt и смотрим, не закрыта ли интересующая нас страница от индексирования. User-agent * указывает на робота, для которого действуют перечисленные в robots. txt правила. А вот директива Disallow запрещает индексирование разделов или отдельных страниц сайта. Допустим нас интересует страница ВашДомен/catalog/, если в файле robots. txt видим конструкцию типа Disallow: /catalog/, то ее необходимо удалить, что бы открыть доступ поисковым роботам для индексирования страницы. (так же возможен такой вид Disallow: /, такой код тоже следует удалять – он закрывает для поисковиков весь сайт).
Далее открываем код страницы (способом который описывался выше), нажимаем Ctrl+F, появится поле для поиска.

В него вставляем следующий код
и выполняем поиск, если ничего не найдено, то все нормально, если вы видите такую строку
ее необходимо удалить или заменить на
2. <!DOCTYPE>
Элемент <!DOCTYPE> предназначен для указания типа текущего документа. <!DOCTYPE> описывает, какую версию HTML разметки вы используете в документе. Очень важно что бы <!DOCTYPE> был указан в коде, иначе Ваш код не будет считаться валидным. Также браузеры будут делать свои предположения относительно версии HTML-кода, и в итоге страница будет отображаться не так, как было Вами задумано.

3. Адаптивность
Все меньше пользователей, которые не слышали про адаптивность и не знали бы про ее важность для сайта.
Адаптивный сайт — это стандарт веб-разработки, один из показателей качества интернет-ресурса и внимательного отношения к потребностям пользователей.
Адаптивность сайта — это его обеспечивать правильное отображение сайта на различных устройствах, подключённых к интернету и динамически подстраиваться под заданные размеры окна браузера. Адаптивность при верстке реализуется на практике разными способами. Это:
- Применение гибкого макета на основе сетки (англ. flexible, grid-based layout);
- Работа с медиа-запросами (англ. media queries);
- Bootstrap (front-end framework).
Чтобы проверить адаптивность сайта даже необязательно лезть в его код. Достаточно просто изменить размер окна браузера и наблюдать на поведением элементов на сайте.

Ширина окна 1024 px

Проверить, как ваш сайт отображается на мобильных устройствах, можно с помощью инструмента Google Mobile Friendly (Google Search Console).
Адрес инструмента — https://search. google. com/test/mobile-friendly
Просто вбиваем полный URL в строку и получаем результаты. Обычно проверка занимает меньше минуты.
4. Наличие viewport
Так же необходимо проверить поиском по коду наличие мета-тега
который отвечает за оптимизацию сайта для мобильных устройств.

5. h1 на странице
h1 — тег заголовка. Его наличие и содержание критически важно для улучшения позиций сайта в поисковой выдачи. Заголовок h1 на странице:
Пренебрежительное отношение к важности и уникальности заголовков может вызвать проблемы в индексации, даже вплоть до попадания сайта под фильтры поисковых систем. Тег h1 является одной из главных составляющих SEO, так как предоставляет пользователю информацию о том, про что будет страница, на которую он попал с поиска. Поэтому очень важно добавить основной фокус ключ в заголовок h1, чтобы поисковик и пользователь понимали о чем данная страница.

6. Подзаголовки страницы
Подзаголовки размечаются специальными тегами в коде h2. h6. Цифра соответствует важности заголовка. Зачем это необходимо? Поисковые системы не видят как люди глазами, для них дополнительные заголовки показывают, что это та самая страница и её тоже можно показывать по этому ключевому слову. Заголовки h2-h6 помогают положительно усилить внимание поисковиков к этой странице по этим запросам.
Открываете код страницы, поиск по коду и вы туда вбиваете <h2 и видите, есть ли на странице заголовки h2 или нет. Если h2 нет, не страшно. Потому что мы знаем, что должно быть минимум одно упоминание в этом диапазоне. Если заголовков в диапазоне h2-h6 нет, это плохо. Но если хотя бы один раз есть упоминание ключевого слова, это уже хорошо.

- В тег заголовка заключен логотип страницы. Особенно часто встречается в ряде шаблонов, в том числе и от самых популярных сервисов шаблонов;
- Подзаголовками сверстаны служебные элементы страницы («Корзина», «Авторизация», «Форма обратной связи» и т. д.);
- Подзаголовки не используют ключевые слова;
- Подзаголовки содержат в оформлении стили, которые должны быть вынесены в файлы. css.;
- Пример кода со стилями:
- Пример чистого кода: А еще лучше:
- Указанные ошибки относятся и к тегу заголовка h1.
7. Проверяйте валидность сверстанных страниц
Чтобы сэкономить время и найти больше ошибок используем автоматические сервисы и инструменты.
Всегда пользуйтесь онлайн HTML/CSS валидатором чтобы определить ошибки в вашей разметке. Вот ссылки на сервисы валидации:
- HTML Validator: https://validator. w3.org/
- CSS Validator: https://jigsaw. w3.org/css-validator/ (на практике используется редко, проверять и исправлять обычно стоит, когда другие важные задачи по seo и улучшению сайта сделаны)
- Анализ сайта SiteDozor: https://sitedozor. ru/
SiteDozor — система анализа сайтов, а также продвижения и контроля сайтов. Определить ошибки помогут несколько видов аудитов в системе Sitedozor — как сайта в целом так и отдельных страниц. На выходе Вы получите многостраничный отчет с ошибками и рекомендациями по их исправлению. Плюс великолепный набор инструментов для быстрого решения отдельных вопросов: посмотреть на сайт глазами поисковиков, узнать что «тормозит» страницу, замерить скорость страницы и так далее — более 50 инструментов.
Источники:
https://apollon. guru/seo/validnost-html-koda/
https://advegital. com/academy/glossary/oshibki-w3c-chto-eto-takoe-kak-proverit-sajt-kak-ikh-ispravit. html
https://onvolga. ru/statsozd/2739-7-kriticheskih-oshibok-code-site. html