Most of us have a habit of downloading many types of stuff (songs, files, etc) from the internet and that is why we may often find we have downloaded the same mp3 files, PDF files, and other extensions. Your disk spaces are unnecessarily wasted by Duplicate files and if you want the same files on a different location you can always set up a soft link or hard link that doesn’t eat the space unnecessarily and store the data in only one location on your disk. This will end up eating your system space unnecessarily and manually locating this duplicate file is quite a tough job. So there are some good tools in Linux for locating duplicate files and removing them to free up your system space by scanning your system, no matter you’re using Linux on your desktop or on a server.
Note: Whenever you’re trying a new tool make sure to first try it on a test directory where deleting files will not be a problem
Method 1: Using FSlint.
FSlint is a tool that helps us to search and remove unnecessary duplicate files, empty directories, temp files, or files with incorrect names completely and free up the disk space on your Linux system. FSlint provides a convenient GUI by default, but it also has CLI modes for various functions which are quite convenient for new users of Linux.
Install fslint in Linux using the following commands:
sudo apt-get install fslint

Fslint Interface
When the FSlint interface will be open you will find that by default, FSlint interface is opened with the Duplicates panel being selected and your home directory is set as the default search path, You will find other several numbers options to choose from like: installed packages, bad names, name clashes, temp files, empty directories, Bad IDs, etc.
Steps to use:
Step 1: First choose the task that you want to perform from the left panel like I am choosing the Duplicates panel option, you can choose the other panel too.
Step 2: Choose the Search Path where you want to perform the task
Step 3: Click on the Find option to locate the files.

Some directories may not be displayed/deleted due to permission issues
Once you get duplicate files (according to the option you choose), you can select and delete them. There is an Advanced search parameter where you can rule can be defined to exclude certain file types or directories which you don’t want to include in the search.

Advanced search parameters
Method 2: Using Fdupe.
Fdupe is another duplicate file removal tool residing within specified directories like fslint but unlike fslint, Fdupe is a command-line interface tool.It is a free and open-source tool written in C. Fdupe uses several modes of searching, they are:
- By size
- Comparing full or partial MD5 signatures and by comparing each byte.
- Byte-by-byte comparison
Install fdupe in Linux using the following commands:
sudo apt install fdupes
After installation simply run the fdupes command followed by the path to a directory that you want to scan.

Duplicate files being displayed
This tool will not automatically delete anything, it will just show you a list of all the duplicate files. You can then delete the duplicate files according to your choice.
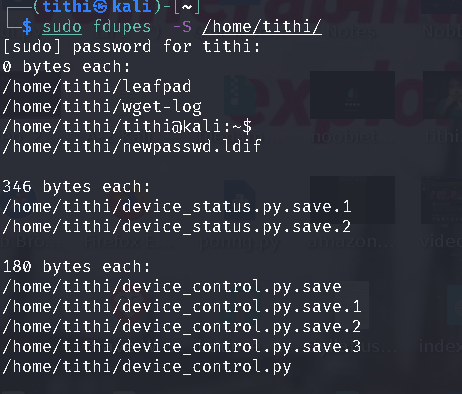
The size of the duplicate files is calculated by -S option:
At last, if you want to delete all duplicates you can use the -d option like the given screenshot:

fdupes -d /path/to/directory
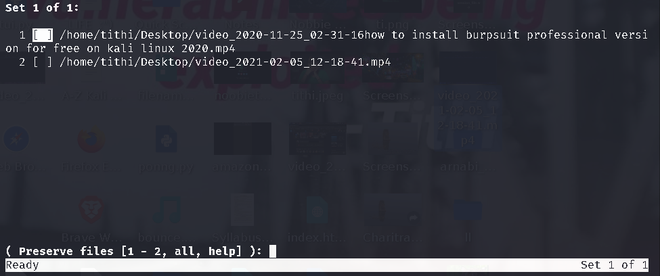
In the above screenshots, we can see the -d command showing all the duplicate files within the folder and giving you the option to select the file which you want to keep(preserve files option), by giving you the option to either delete files one by one or select a range to delete it or all at once. Even If you want to delete all files without asking and preserve the first one, you can use the -N option.
For more option see the help option of fdupes by typing fdupes -h:

fdupes help
Last Updated :
02 Jan, 2023
Like Article
Save Article
Дубликаты файлов могут появляться при сохранении резервных копий на диск, одновременном редактировании нескольких версий одного и того же файла или при изменении структуры каталогов. Одни и те же файлы могут быть сохранены несколько раз с различными именами или в разных папках и только засоряют дисковое пространство.
Охота на них каждый раз может стать большой проблемой. Но к счастью существует маленькая утилита которая может сберечь ваше время потраченное на поиск и уничтожение дубликатов файлов на компьютере — FSLint. Она написана на Python. Время навести порядок и удалить старые файлы.
Вы можете установить утилиту из официальных репозиториев большинства дистрибутивов Linux. Давайте рассмотрим пример для Ubuntu. Сначала обновите списки пакетов:
sudo apt update
Затем установите утилиту:
sudo apt install fslint
После завершения установки вы можете запустить утилиту из главного меню:
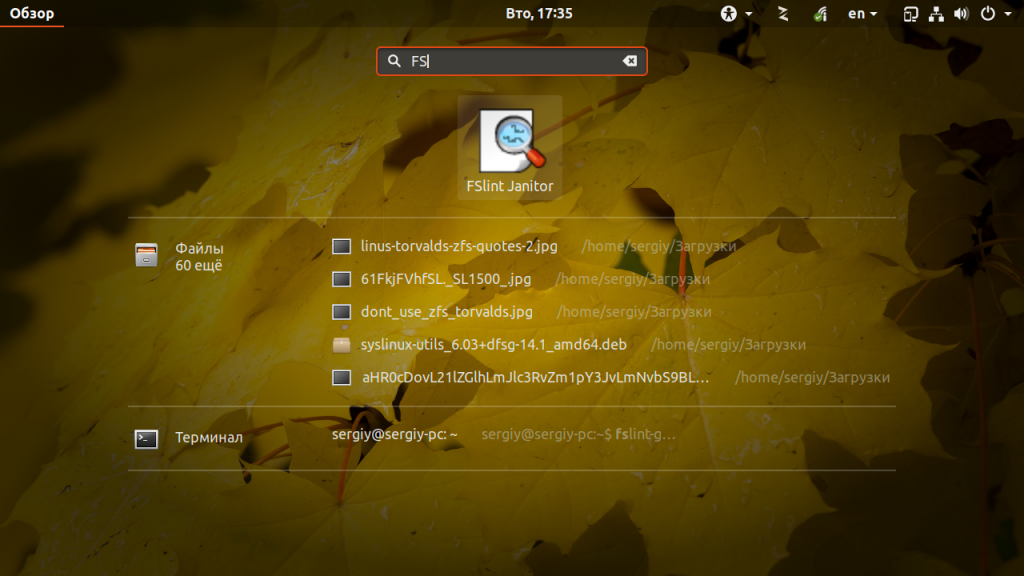
В главном окне программы можно выбрать различные варианты поиска неисправностей файловой системы. По умолчанию выбран Поиск дубликатов, ещё вам предстоит настроить папки, в которых будет выполнятся поиск, по умолчанию добавлена только домашняя папка:
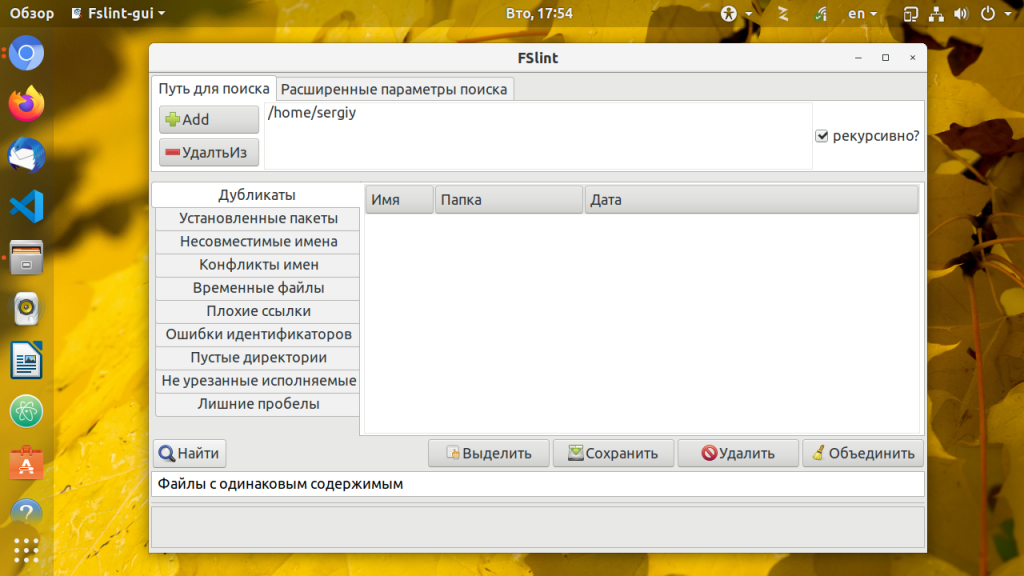
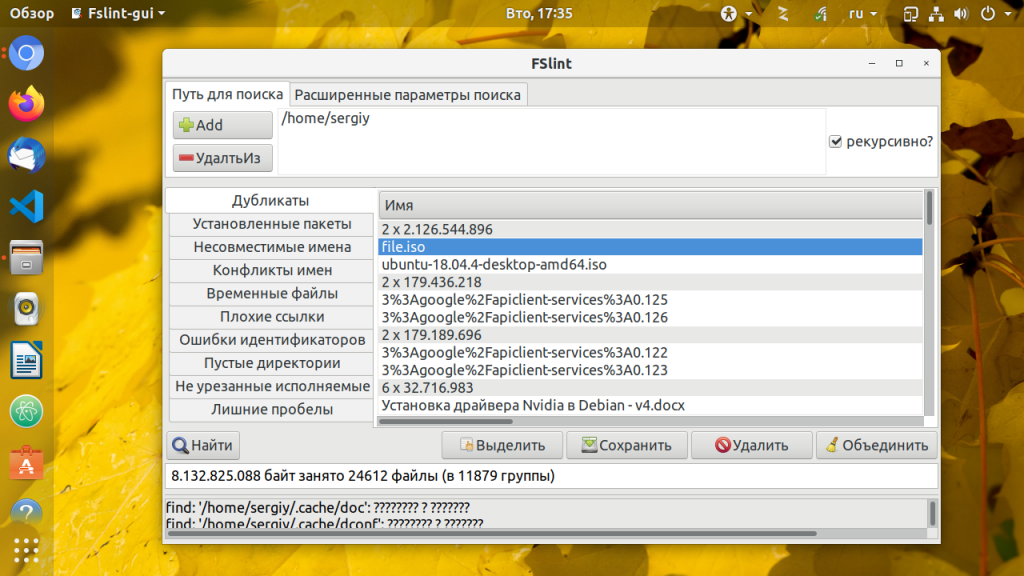
После того как вы выберите каталоги, запустите поиск дубликатов Linux. Для этого надо нажать кнопку Поиск. Утилита сразу же начнёт выводить обнаруженные дубликаты файлов:
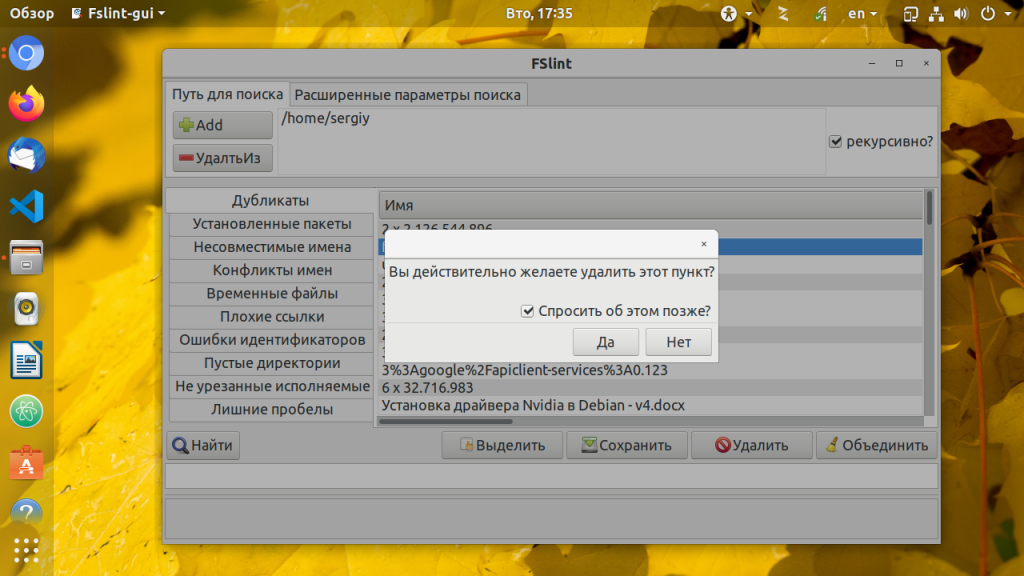
Когда поиск завершится вы сможете удалить файлы, которые вам не нужны, для этого выделите их мышью и нажмите кнопку Удалить. Программа спросит подтверждения действия и удалит файл:
Также вы можете объединить файлы дубликаты с помощью жесткой ссылки. По нажатию кнопки Объединить, утилита объединяет все файлы кроме выделенных. Кроме того, утилита позволяет искать несовместимые имена файлов, временные файлы, плохие ссылки, пустые директории и многое другое. Поэкспериментируйте с ней если будет желание.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Об авторе
![]()
Основатель и администратор сайта losst.ru, увлекаюсь открытым программным обеспечением и операционной системой Linux. В качестве основной ОС сейчас использую Ubuntu. Кроме Linux, интересуюсь всем, что связано с информационными технологиями и современной наукой.
Я всегда резервирую файлы конфигурации или любые файлы где-нибудь на своем жестком диске перед редактированием или изменением, поэтому я могу восстановить их из резервной копии, если случайно сделал что-то неправильно.
Но проблема в том, что я периодически забываю удалить эти файлы, и мой жесткий диск заполняется большим количеством дубликатов файлов через определенный промежуток времени.
Мне иногда лень удалить старые файлы или просто боюсь, что могу удалить важные файлы.
Если вы похожи на меня и делаете по несколько резервных копий одинаковых файлов в разных каталогах, вы можете найти и удалить дубликаты файлов, используя приведенные ниже инструменты в Unix-подобных операционных системах.
Предупреждение:
Будьте осторожны при удалении дубликатов. Если вы не будете осторожны, это приведет к случайной потере данных. Я советую вам быть очень внимательными при использовании этих инструментов.
Для целей этого руководства я собираюсь уделить внимание трем утилитам, а именно:
-
Rdfind,
-
Fdupes,
-
FSlint.
Эти три утилиты бесплатны, с открытым исходным кодом и работают в большинстве Unix-подобных операционных систем.
Rdfind, означает redundant data find, что переводится как — поиск избыточных данных, и представляет собой бесплатную утилиту с открытым исходным кодом для сквозного поиска дубликатов файлов в корне и/или внутри каталогов и подкаталогов. Он сравнивает файлы на основе их содержимого, а не по именам файлов. Rdfind использует алгоритм ранжирования для классификации оригинальных и повторяющихся файлов. Если у вас есть два или более одинаковых файла, Rdfind достаточно умен, чтобы найти исходный файл, и рассматривает остальные файлы как дубликаты. Как только он найдет дубликаты, он сообщит об этом вам. Вы можете либо удалить их, либо заменить их жесткими ссылками или символьными (мягкими) ссылками.
Rdfind доступен в AUR. Таким образом, вы можете установить его в системах на базе Arch, используя любую вспомогательную программу AUR, такую как Yay, как показано ниже:
$ yay -S rdfind
В Debian, Ubuntu, Linux Mint:
$ sudo apt-get install rdfind
В Fedora:
$ sudo dnf install rdfind
В RHEL, CentOS:
$ sudo yum install epel-release $ sudo yum install rdfind
После установки просто запустите команду Rdfind вместе с указанием пути к каталогу в котором будет производиться поиск дубликатов файлов.
$ rdfind ~/Downloads

Как видно из приведенного выше снимка экрана, команда Rdfind сканирует каталог ~/Downloads и сохраняет результаты в файле с именем results.txt в текущем рабочем каталоге. Вы можете просмотреть имя возможных дубликатов файлов в файле results.txt.
$ cat results.txt # Automatically generated # duptype id depth size device inode priority name DUPTYPE_FIRST_OCCURRENCE 1469 8 9 2050 15864884 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test5.regex DUPTYPE_WITHIN_SAME_TREE -1469 8 9 2050 15864886 1 /home/sk/Downloads/tor-browser_en-US/Browser/TorBrowser/Tor/PluggableTransports/fte/tests/dfas/test6.regex [...] DUPTYPE_FIRST_OCCURRENCE 13 0 403635 2050 15740257 1 /home/sk/Downloads/Hyperledger(1).pdf DUPTYPE_WITHIN_SAME_TREE -13 0 403635 2050 15741071 1 /home/sk/Downloads/Hyperledger.pdf # end of file
Просмотрев файл results.txt, вы можете легко найти дубликаты. Вы можете удалить дубликаты вручную.
Кроме того, вы можете использовать опцию -dryrun для поиска всех дубликатов в заданном каталоге без изменения чего-либо и вывода сводки в вашем терминале:
$ rdfind -dryrun true ~/Downloads
Когда вы найдете дубликаты, вы можете заменить их либо жесткимим ссылками, либо символьными ссылками.
Чтобы заменить все дубликаты на жесткие ссылки, запустите:
$ rdfind -makehardlinks true ~/Downloads
Чтобы заменить все дубликаты символьными (мягкими) ссылками, запустите:
$ rdfind -makesymlinks true ~/Downloads
У вас могут быть пустые файлы в каталоге, вы можете их проигнорировать. Для этого используйте параметр -ignoreempty, как показано ниже:
$ rdfind -ignoreempty true ~/Downloads
Если вам больше не нужны дубликаты файлов, просто удалите их вместо замены жесткими или символьными ссылками.
Чтобы удалить все дубликаты, просто запустите:
$ rdfind -deleteduplicates true ~/Downloads
Если вы не хотите игнорировать пустые файлы и удалять их вместе со всеми дубликатами, запустите:
$ rdfind -deleteduplicates true -ignoreempty false ~/Downloads
Для получения дополнительной информации можно посмотреть раздел справки:
$ rdfind --help
Или man:
$ man rdfind
Fdupes — еще одна утилита командной строки для идентификации и удаления дубликатов файлов в указанных каталогах и подкаталогах. Это бесплатная утилита с открытым исходным кодом, написанная на языке программирования C. Fdupes идентифицирует дубликаты, сравнивая размеры файлов, частичные подписи MD5, полные подписи MD5 и, наконец, выполняет побайтового сравнение.
Подобно утилите Rdfind, Fdupes обладает большим функционалом для выполнения операций:
Fdupes по умолчанию доступен в репозиториях большинства дистрибутивов Linux.
На Arch Linux и его вариантах, таких как Antergos, Manjaro Linux, установите его с помощью Pacman, как показано ниже:
$ sudo pacman -S fdupes
В Debian, Ubuntu, Linux Mint:
$ sudo apt-get install fdupes
В Fedora:
$ sudo dnf install fdupes
В RHEL, CentOS:
$ sudo yum install epel-release $ sudo yum install fdupes
Использование Fdupes довольно просто. Просто запустите следующую команду, чтобы найти дубликаты файлов в каталоге, например, ~/Downloads:
$ fdupes ~/Downloads
Пример вывода:
/home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf
Как вы можете видеть, имеется дубликат файла в каталоге /home/test/Downloads/. Он показывает только дубликаты из родительского каталога. Как просмотреть дубликаты из подкаталогов? Просто используйте параметр -r, как показано ниже:
$ fdupes -r ~/Downloads
Теперь вы увидите дубликаты из каталога /home/test/Downloads/ и его подкаталогов.
Fdupes также может найти дубликаты сразу в нескольких каталогах:
$ fdupes ~/Downloads ~/Documents/test
Вы можете искать в нескольких каталогах, при этом в одном и в подкаталогах:
$ fdupes ~/Downloads -r ~/Documents/test
Вышеупомянутая команда выполняет поиск дубликатов в каталоге ~/Downloads и в каталоге ~/Documents/test с его подкаталогами.
Иногда вам может понадобиться узнать размер дубликатов в каталоге. Если это так, используйте параметр -S, как показано ниже:
$ fdupes -S ~/Downloads 403635 bytes each: /home/sk/Downloads/Hyperledger.pdf /home/sk/Downloads/Hyperledger(1).pdf
Аналогично, чтобы просмотреть размер дубликатов в каталогах и подкаталогах, используйте параметр -Sr.
Мы можем исключить пустые и скрытые файлы из поиска, используя -n и -A соответственно:
$ fdupes -n ~/Downloads $ fdupes -A ~/Downloads
Первая команда исключает файлы с нулевой длиной из поиска, последняя исключает скрытые файлы при поиске дубликатов в указанном каталоге.
Чтобы просмотреть общую информацию о дублированных файлах, используйте параметр -m:
$ fdupes -m ~/Downloads 1 duplicate files (in 1 sets), occupying 403.6 kilobytes
Чтобы удалить все дубликаты, используйте опцию -d.
$ fdupes -d ~/Downloads
Пример вывода:
[1] /home/sk/Downloads/Hyperledger Fabric Installation.pdf [2] /home/sk/Downloads/Hyperledger Fabric Installation(1).pdf Set 1 of 1, preserve files [1 - 2, all]:
Эта команда предложит вам сохранить файлы и удалить все остальные дубликаты. Просто введите любое число, чтобы сохранить соответствующий файл и удалить оставшиеся файлы. Будьте внимательны при использовании этой опции. Вы можете удалить исходные файлы, если не будете внимательны.
Если вы хотите сохранить первый файл в каждом наборе дубликатов и удалить остальные, не запрашивая каждый раз, используйте параметр -dN (не рекомендуется).
$ fdupes -dN ~/Downloads
Чтобы удалить дубликаты, по мере их встречи, используйте флаг -I.
$ fdupes -I ~/Downloads
Более подробную информацию о Fdupes см. в разделе справки и в справочных страницах.
$ fdupes --help $ man fdupes
FSlint — это еще одна утилита для поиска дубликатов файлов, которую я время от времени использую, чтобы избавиться от ненужных дубликатов файлов и освободить место на диске в моей системе Linux. В отличие от двух других утилит, FSlint имеет режимы GUI и CLI. Таким образом, это более удобный инструмент для новичков. FSlint не только находит дубликаты, но и плохие символьные ссылки, плохие имена, временные файлы, плохие IDS, пустые каталоги и не защищенные двоичные файлы и т.д.
FSlint доступен в AUR, поэтому вы можете установить его с помощью любых инструментов AUR.
$ yay -S fslint
В Debian, Ubuntu, Linux Mint:
$ sudo apt-get install fslint
В Fedora:
$ sudo dnf install fslint
В RHEL, CentOS:
$ sudo yum install epel-release $ sudo yum install fslint
Как только он будет установлен, запустите его из меню или панели запуска приложений.
Вот как выглядит FSlint GUI.
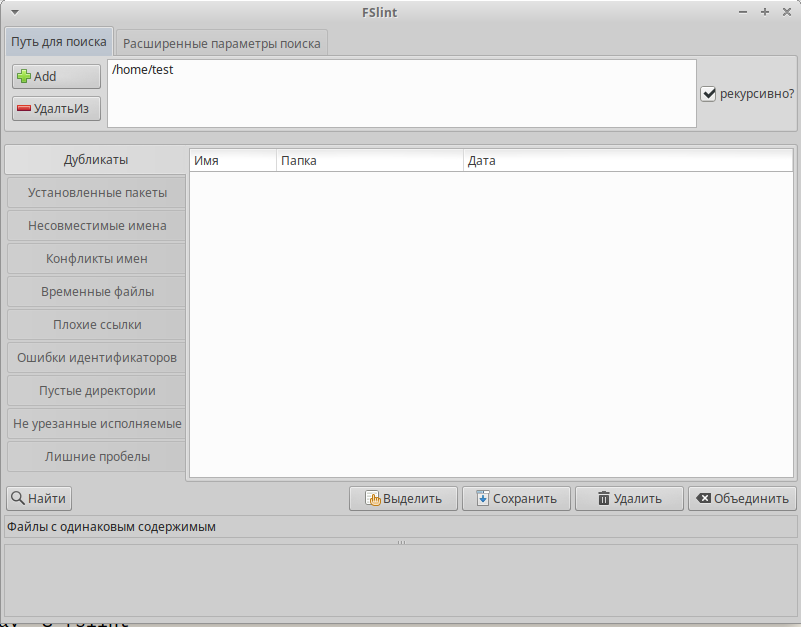
Как вы видете, интерфейс FSlint удобен и понятен. На вкладке Путь поиска добавьте путь к каталогу, который вы хотите отсканировать, и нажмите кнопку «Найти» в левом нижнем углу, чтобы найти дубликаты. Проверьте параметр рекурсивно для рекурсивного поиска дубликатов в каталогах и подкаталогах. FSlint быстро сканирует данный каталог и выведет их.
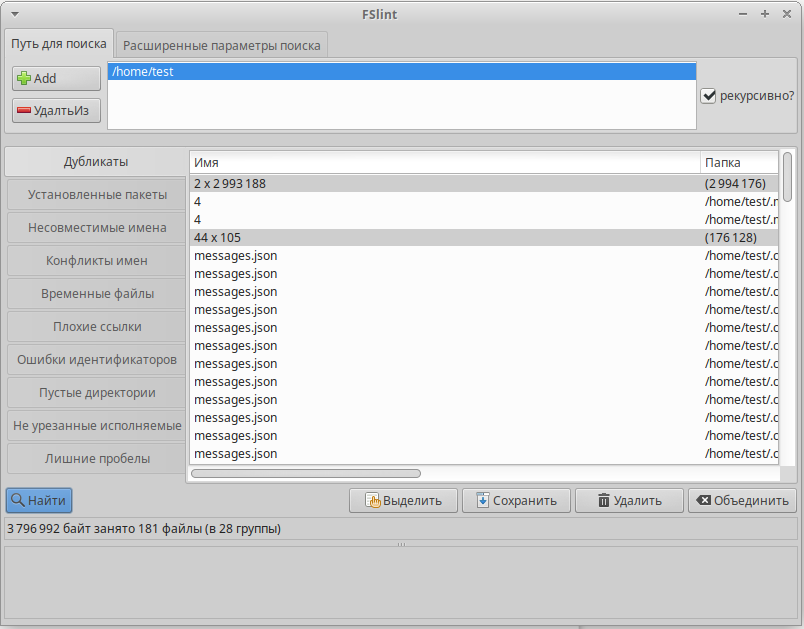
В списке выберите дубликаты, которые вы хотите очистить, и выберите действие, например, удалить,объединить, сохранить.
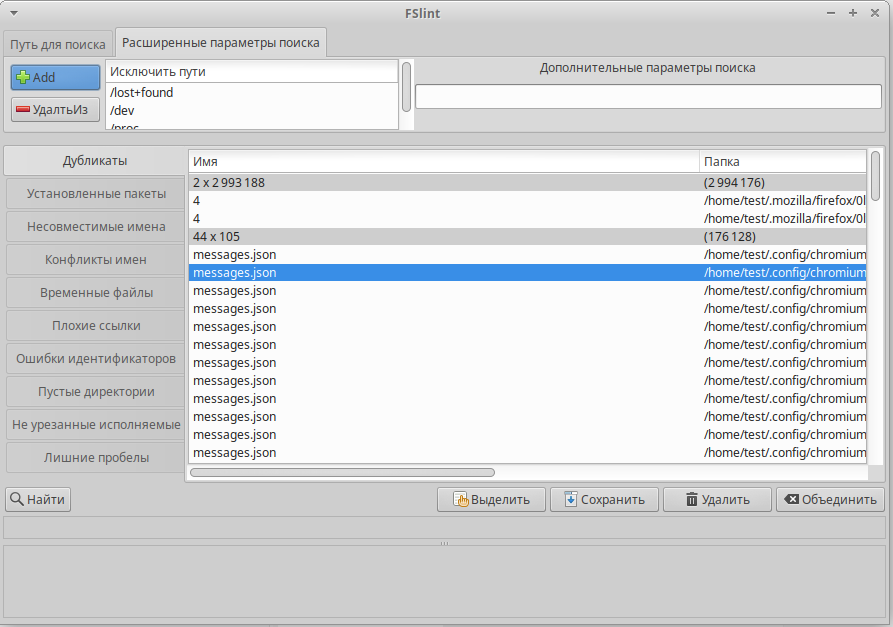
На вкладке Расширенные параметры поиска вы можете указать пути для исключения во время поиска дубликатов.
FSlint предоставляет набор служебных программ CLI для поиска дубликатов в вашей системе:
Все эти утилиты доступны в каталоге /usr/share/fslint/fslint/.
Например, чтобы найти дубликаты в заданном каталоге, выполните следующие действия:
$ /usr/share/fslint/fslint/findup ~/Downloads/
Аналогично, чтобы найти пустые каталоги:
$ /usr/share/fslint/fslint/finded ~/Downloads/
Чтобы получить более подробную информацию о каждой утилите, например findup, выполните:
$ /usr/share/fslint/fslint/findup --help
Для получения дополнительной информации о FSlint см. раздел справки и справочные страницы.
$ /usr/share/fslint/fslint/fslint --help $ man fslint
Теперь вы знаете три инструмента для поиска и удаления ненужных дубликатов файлов в Linux. Среди этих трех инструментов я часто использую Rdfind. Это не означает, что две другие утилиты неэффективны, но до сих пор я доволен Rdfind. Выбор за вами
Is it possible to find duplicate files on my disk which are bit to bit identical but have different file-names?
![]()
Jeff Schaller♦
65.9k35 gold badges108 silver badges245 bronze badges
asked Apr 4, 2013 at 13:18
![]()
8
fdupes can do this. From man fdupes:
Searches the given path for duplicate files. Such files are found by comparing file sizes and MD5 signatures, followed by a byte-by-byte comparison.
In Debian or Ubuntu, you can install it with apt-get install fdupes. In Fedora/Red Hat/CentOS, you can install it with yum install fdupes. On Arch Linux you can use pacman -S fdupes, and on Gentoo, emerge fdupes.
To run a check descending from your filesystem root, which will likely take a significant amount of time and memory, use something like fdupes -r /.
As asked in the comments, you can get the largest duplicates by doing the following:
fdupes -r . | {
while IFS= read -r file; do
[[ $file ]] && du "$file"
done
} | sort -n
This will break if your filenames contain newlines.
![]()
answered Apr 4, 2013 at 13:24
![]()
Chris DownChris Down
121k23 gold badges264 silver badges262 bronze badges
9
Another good tool is fslint:
fslint is a toolset to find various problems with filesystems,
including duplicate files and problematic filenames
etc.Individual command line tools are available in addition to the GUI and to access them, one can change to, or add to
$PATH the /usr/share/fslint/fslint directory on a standard install. Each of these commands in that directory have a
—help option which further details its parameters.findup - find DUPlicate files
On debian-based systems, youcan install it with:
sudo apt-get install fslint
You can also do this manually if you don’t want to or cannot install third party tools. The way most such programs work is by calculating file checksums. Files with the same md5sum almost certainly contain exactly the same data. So, you could do something like this:
find / -type f -exec md5sum {} ; > md5sums
awk '{print $1}' md5sums | sort | uniq -d > dupes
while read -r d; do echo "---"; grep -- "$d" md5sums | cut -d ' ' -f 2-; done < dupes
Sample output (the file names in this example are the same, but it will also work when they are different):
$ while read -r d; do echo "---"; grep -- "$d" md5sums | cut -d ' ' -f 2-; done < dupes
---
/usr/src/linux-headers-3.2.0-3-common/include/linux/if_bonding.h
/usr/src/linux-headers-3.2.0-4-common/include/linux/if_bonding.h
---
/usr/src/linux-headers-3.2.0-3-common/include/linux/route.h
/usr/src/linux-headers-3.2.0-4-common/include/linux/route.h
---
/usr/src/linux-headers-3.2.0-3-common/include/drm/Kbuild
/usr/src/linux-headers-3.2.0-4-common/include/drm/Kbuild
---
This will be much slower than the dedicated tools already mentioned, but it will work.
answered Apr 4, 2013 at 16:00
![]()
terdon♦terdon
231k64 gold badges438 silver badges653 bronze badges
3
I thought to add a recent enhanced fork of fdupes, jdupes, which promises to be faster and more feature rich than fdupes (e.g. size filter):
jdupes . -rS -X size-:50m > myjdups.txt
This will recursively find duplicated files bigger than 50MB in the current directory and output the resulted list in myjdups.txt.
Note, the output is not sorted by size and since it appears not to be build in, I have adapted @Chris_Down answer above to achieve this:
jdupes -r . -X size-:50m | {
while IFS= read -r file; do
[[ $file ]] && du "$file"
done
} | sort -n > myjdups_sorted.txt
answered Nov 23, 2017 at 17:27
![]()
1
Short answer: yes.
Longer version: have a look at the wikipedia fdupes entry, it sports quite nice list of ready made solutions. Of course you can write your own, it’s not that difficult — hashing programs like diff, sha*sum, find, sort and uniq should do the job. You can even put it on one line, and it will still be understandable.
answered Apr 4, 2013 at 13:25
![]()
peterphpeterph
30.3k2 gold badges69 silver badges75 bronze badges
If you believe a hash function (here MD5) is collision-free on your domain:
find $target -type f -exec md5sum '{}' + | sort | uniq --all-repeated --check-chars=32
| cut --characters=35-
Want identical file names grouped? Write a simple script not_uniq.sh to format output:
#!/bin/bash
last_checksum=0
while read line; do
checksum=${line:0:32}
filename=${line:34}
if [ $checksum == $last_checksum ]; then
if [ ${last_filename:-0} != '0' ]; then
echo $last_filename
unset last_filename
fi
echo $filename
else
if [ ${last_filename:-0} == '0' ]; then
echo "======="
fi
last_filename=$filename
fi
last_checksum=$checksum
done
Then change find command to use your script:
chmod +x not_uniq.sh
find $target -type f -exec md5sum '{}' + | sort | not_uniq.sh
This is basic idea. Probably you should change find if your file names containing some characters. (e.g space)
![]()
Wayne Werner
11.4k8 gold badges29 silver badges42 bronze badges
answered Apr 13, 2013 at 15:39
![]()
reithreith
3842 silver badges10 bronze badges
1
Wikipedia once had an article with a list of available open source software for this task, but it’s now been deleted.
I will add that the GUI version of fslint is very interesting, allowing to use mask to select which files to delete — very useful to clean duplicated photos.
On Linux you can use:
- FSLint: http://www.pixelbeat.org/fslint/
- FDupes: https://en.wikipedia.org/wiki/Fdupes
- DupeGuru: https://www.hardcoded.net/dupeguru/
- Czkawka: https://qarmin.github.io/czkawka/
FDupes and DupeGuru work on many systems (Windows, Mac and Linux). I’ve not checked FSLint or Czkawka.
![]()
Toby Speight
8,1242 gold badges25 silver badges47 bronze badges
answered Jan 29, 2014 at 11:01
![]()
4
I had a situation where I was working in an environment where I couldn’t install new software, and had to scan >380 GB of JPG and MOV files for duplicates. I developed the following POSIX awk script to process all of the data in 72 seconds (as opposed to the find -exec md5sum approach, that took over 90 minutes to run):
https://github.com/taltman/scripts/blob/master/unix_utils/find-dupes.awk
You call it as follows:
ls -lTR | awk -f find-dupes.awk
It was developed on a FreeBSD shell environment, so might need some tweaks to work optimally in a GNU/Linux shell environment.
answered Jan 10, 2021 at 3:04
![]()
2
Here’s my take on that:
find -type f -size +3M -print0 | while IFS= read -r -d '' i; do
echo -n '.'
if grep -q "$i" md5-partial.txt; then echo -e "n$i ---- Already counted, skipping."; continue; fi
MD5=`dd bs=1M count=1 if="$i" status=noxfer | md5sum`
MD5=`echo $MD5 | cut -d' ' -f1`
if grep "$MD5" md5-partial.txt; then echo "n$i ---- Possible duplicate"; fi
echo $MD5 $i >> md5-partial.txt
done
It’s different in that it only hashes up to first 1 MB of the file.
This has few issues / features:
- There might be a difference after first 1 MB so the result rather a candidate to check. I might fix that later.
- Checking by file size first could speed this up.
- Only takes files larger than 3 MB.
I use it to compare video clips so this is enough for me.
answered Jun 2, 2017 at 1:50
![]()
Ondra ŽižkaOndra Žižka
8699 silver badges15 bronze badges
I realize this is necro but it is highly relevant. I had asked a similar question on Find duplicate files based on first few characters of filename and what was a presented was a solution to use some awk script.
I use it for mod conflict cleanup, useful in Forge packs 1.14.4+ because Forge now disabled mods that are older instead of FATAL crashing and letting you know of the duplicate.
#!/bin/bash
declare -a names
xIFS="${IFS}"
IFS="^M"
while true; do
awk -F'[-_ ]' '
NR==FNR {seen[tolower($1)]++; next}
seen[tolower($1)] > 1
' <(printf "%sn" *.jar) <(printf "%sn" *.jar) > tmp.dat
IDX=0
names=()
readarray names < tmp.dat
size=${#names[@]}
clear
printf 'nPossible Dupesn'
for (( i=0; i<${size}; i++)); do
printf '%st%s' ${i} ${names[i]}
done
printf 'nWhich dupe would you like to delete?nEnter # to delete or q to quitn'
read n
if [ $n == 'q' ]; then
exit
fi
if [ $n -lt 0 ] || [ $n -gt $size ]; then
read -p "Invalid Option: present [ENTER] to try again" dummyvar
continue
fi
#clean the carriage return n from the name
IFS='^M'
read -ra TARGET <<< "${names[$n]}"
unset IFS
#now remove the first element from the filesystem
rm "${TARGET[0]}"
echo "removed ${TARGET[0]}" >> rm.log
done
IFS="${xIFS}"
I recommend saving it as «dupes.sh» to your personal bin or /usr/var/bin
answered Nov 5, 2020 at 15:42
![]()
You can find duplicate with this command:
time find . ! -empty -type f -print0 | xargs -0 -P"$(nproc)" -I{} md5sum "{}" | sort | uniq -w32 -dD
answered Jul 30, 2021 at 21:17
![]()
BensuperpcBensuperpc
6015 silver badges9 bronze badges
For free open-source Linux duplicate file finders, there is a new kid on the block and it’s even in a trendy language, Rust.
It is called Czkawka (which apparently means hiccup)
So it does have an unpronounceable name unless you speak Polish.
It is based very much on some of the ideas in FSlint (which can now be difficult to make work as it is no longer maintained and uses the now deprecated Python 2.x).
Czkawka has both GUI and CLI versions and is reported to be faster than FSlint and Fdupes.
There is also a Githup repo For those that want to fork it just to change the name.
answered Dec 20, 2021 at 18:05
![]()
Jay MJay M
1255 bronze badges
On Linux, you can use the following tools to find duplicate files.
https://github.com/adrianlopezroche/fdupes
https://github.com/arsenetar/dupeguru
https://github.com/jbruchon/jdupes
https://github.com/pauldreik/rdfind
https://github.com/pixelb/fslint (Python 2.x)
https://github.com/sahib/rmlint
https://github.com/qarmin/czkawka (Rust)
![]()
answered Nov 19, 2021 at 5:55
![]()
AkhilAkhil
1,1622 gold badges13 silver badges29 bronze badges
I have a largish music collection and there are some duplicates in there. Is there any way to find duplicate files. At a minimum by doing a hash and seeing if two files have the same hash.
Bonus points for also finding files with the same name apart from the extension — I think I have some songs with both mp3 and ogg format versions.
I’m happy using the command line if that is the easiest way.
![]()
asked Sep 8, 2010 at 19:11
![]()
Hamish DownerHamish Downer
19k14 gold badges69 silver badges91 bronze badges
0
I use fdupes for this. It is a commandline program which can be installed from the repositories with sudo apt install fdupes. You can call it like fdupes -r /dir/ect/ory and it will print out a list of dupes. fdupes has also a README on GitHub and a Wikipedia article, which lists some more programs.
![]()
FriendFX
7381 gold badge11 silver badges32 bronze badges
answered Sep 8, 2010 at 19:20
![]()
8
List of programs/scripts/bash-solutions, that can find duplicates and run under nix:
- dupedit: Compares many files at once without checksumming. Avoids comparing files against themselves when multiple paths point to the same file.
- dupmerge: runs on various platforms (Win32/64 with Cygwin, *nix, Linux etc.)
- dupseek: Perl with algorithm optimized to reduce reads.
- fdf: Perl/c based and runs across most platforms (Win32, *nix and probably others). Uses MD5, SHA1 and other checksum algorithms
- freedups: shell script, that searches through the directories you specify. When it finds two identical files, it hard links them together. Now the two or more files still exist in their respective directories, but only one copy of the data is stored on disk; both directory entries point to the same data blocks.
- fslint: has command line interface and GUI.
- liten: Pure Python deduplication command line tool, and library, using md5 checksums and a novel byte comparison algorithm. (Linux, Mac OS X, *nix, Windows)
- liten2: A rewrite of the original Liten, still a command line tool but with a faster interactive mode using SHA-1 checksums (Linux, Mac OS X, *nix)
- rdfind: One of the few which rank duplicates based on the order of input parameters (directories to scan) in order not to delete in «original/well known» sources (if multiple directories are given). Uses MD5 or SHA1.
- rmlint: Fast finder with command line interface and many options to find other lint too (uses MD5), since 18.04 LTS has a
rmlint-guipackage with GUI (may be launched byrmlint --guior from desktop launcher named Shredder Duplicate Finder) - ua: Unix/Linux command line tool, designed to work with find (and the like).
- findrepe: free Java-based command-line tool designed for an efficient search of duplicate files, it can search within zips and jars.(GNU/Linux, Mac OS X, *nix, Windows)
- fdupe: a small script written in Perl. Doing its job fast and efficiently.1
- ssdeep: identify almost identical files using Context Triggered Piecewise Hashing
![]()
N0rbert
96k33 gold badges229 silver badges415 bronze badges
answered Apr 3, 2012 at 1:22
![]()
v2rv2r
9,28711 gold badges49 silver badges52 bronze badges
5
FSlint has a GUI and some other features. The explanation of the duplicate checking algorithm from their FAQ:
1. exclude files with unique lengths
2. handle files that are hardlinked to each other
3. exclude files with unique md5(first_4k(file))
4. exclude files with unique md5(whole file)
5. exclude files with unique sha1(whole file) (in case of md5 collisions).
fslint installation instructions
![]()
Kalle Richter
5,88620 gold badges68 silver badges100 bronze badges
answered Sep 8, 2010 at 19:31
![]()
DominikDominik
7614 silver badges3 bronze badges
3
If your deduplication task is music related, first run the picard application to correctly identify and tag your music (so that you find duplicate .mp3/.ogg files even if their names are incorrect). Note that picard is also available as an Ubuntu package.
That done, based on the musicip_puid tag you can easily find all your duplicate songs.
answered Sep 8, 2010 at 21:46
![]()
ΤΖΩΤΖΙΟΥΤΖΩΤΖΙΟΥ
1,2003 gold badges13 silver badges27 bronze badges
2
Another script that does this job is rmdupe. From the author’s page:
rmdupe uses standard linux commands to search within specified folders for duplicate files, regardless of filename or extension. Before duplicate candidates are removed they are compared byte-for-byte. rmdupe can also check duplicates against one or more reference folders, can trash files instead of removing them, allows for a custom removal command, and can limit its search to files of specified size. rmdupe includes a simulation mode which reports what will be done for a given command without actually removing any files.
answered Apr 22, 2014 at 7:34
![]()
girardengogirardengo
4,9051 gold badge26 silver badges31 bronze badges
I use komparator — sudo apt-get install komparator (Ubuntu 10.04+ ) — as GUI-tool for finding duplicates in manual mode.
answered Dec 29, 2013 at 12:15
![]()
N0rbertN0rbert
96k33 gold badges229 silver badges415 bronze badges
For Music related duplicate identification and deletion Picard and Jaikoz by http://musicbrainz.org/ is the best solution. Jaikoz I believe automatically tags your music based on the data of the song file. You don’t even need the name of the song for it to identify the song and assign all meta data to it. Although the free version can tag only a limited number of songs in one run, but you can run it as many times as you want.
answered Apr 22, 2014 at 7:47
![]()
YathiYathi
2012 silver badges10 bronze badges
Have you tried
finddup
or
finddup -l
I guess it works fine.
![]()
blade19899
26.4k21 gold badges113 silver badges177 bronze badges
answered Jul 5, 2014 at 4:34
![]()
xerostomusxerostomus
8049 silver badges17 bronze badges
dupeGuru has a dedicated mode for music. It is a cross-platform GUI program and, as of today (February 2021), it is in active development, although it is unclear which releases work on which systems. Check its documentation.
answered Feb 23, 2021 at 15:33
![]()
Diego VDiego V
4103 silver badges14 bronze badges