Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
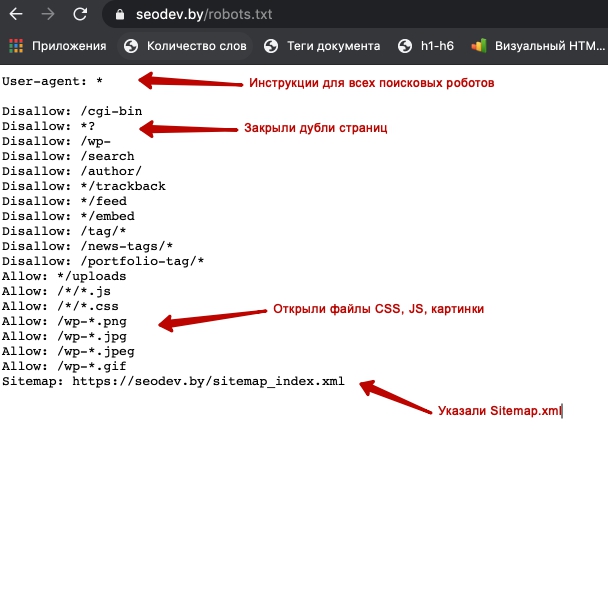
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
- от Яндекса;
- от Google.
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
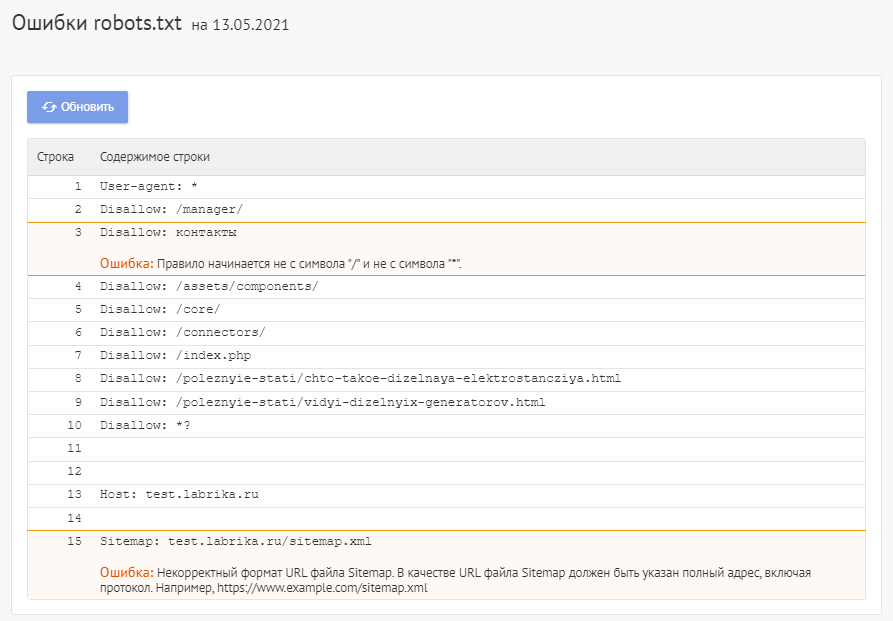
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.
Вкратце о диагностике сайта
Фатальные
- Сайт закрыт к индексации в файле robots.txt
- Не удалось подключиться к серверу из-за ошибки DNS
- Главная страница сайта возвращает ошибку
- Обнаружены нарушения или проблемы с безопасностью
Критичные
- Долгий ответ сервера
- Большое количество неработающих внутренних ссылок
Возможные проблемы
- Главная страница перенаправляет на другой сайт
- Отсутствуют теги <title>
- Ошибки в файле robots.txt
- Не найден файл robots.txt
- Отсутствуют мета-теги <description>
- Некорректное отображение несуществующих файлов и страниц
- В файле robots.txt задана противоречивая директива Host
- В файле robots.txt не задана директива Host
- Большое количество страниц-дублей
- Нет используемых роботом файлов Sitemap
- Обнаружены ошибки в файлах Sitemap
- Файлы Sitemap давно не обновлялись
Рекомендации
- Не задана региональная принадлежность сайта
- Сайт не оптимизирован для мобильных устройств
- Ошибка счётчика Яндекс.Метрики
- Сайт не зарегистрирован в Яндекс.Справочнике
- Отсутствует файл favicon на сайте
- Отсутствуют быстрые ссылки
Вкратце о диагностике сайта
В этой статье мы подробно опишем большинство самых популярных проблем, которые выдает диагностика сайта от Яндекса. Напомним, что раздел диагностики находится в Yandex Webmaster на второй вкладке в левом меню.
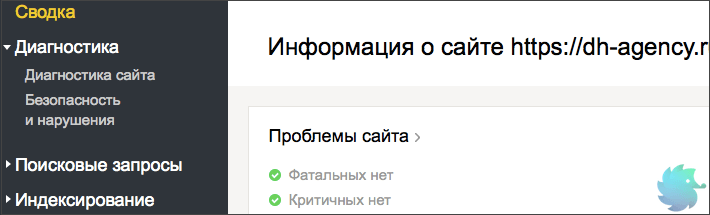
Краткую информацию о наличии проблем возможно найти в левом верхнем блоке на главной странице Вебмастера.
Прежде, чем рассказывать о каждой проблеме отдельно, поясним общую информацию. Яндекс разделил все ошибки на 4 вида:
-
Фатальные — то есть, те, которые несовместимы с отображением сайта в поисковой выдаче. Наличие таких ошибок, скорее всего, приведет к полному исключению сайта из поиска. Среди них — запрет индексации, различного рода санкции со стороны поисковиков, серьезное нарушение безопасности или неработоспособность сайта;
-
Критичные — то есть, те, которые серьезно затрудняют удобство пользования сайтом, его корректную работу или индексацию. Наличие таких ошибок вряд ли приведет к исключению ресурса из поисковой выдачи, но может сильно снизить видимость;
-
Возможные — то есть, те, которые влияют на удобство пользователей, отображение и корректную индексацию. Подобные ошибки стоит устранить для улучшения сайта и повышения видимости в органической выдаче. В общем списке сайтов Вебмастера возможные проблемы обозначаются серым восклицательным знаком.

-
Рекомендации — носят исключительно рекомендательный характер. Обычно направлены на улучшение сайта или отображения.

Фатальные проблемы
Решать фатальные проблемы нужно немедленно, иначе они приведут к исключению сайта из поисковой выдачи. Подобные ошибки справедливы не только для Яндекса, но и для всех остальных поисковых систем. Ниже мы опишем каждую из них в отдельности, а так же предложим варианты решения.
Сайт закрыт к индексации в файле robots.txt

«При последнем обращении к файлу robots.txt было обнаружено, что сайт закрыт для индексации. Убедитесь в корректности файла robots.txt, иначе сайт может полностью пропасть из поиска.» © Яндекс Вебмастер
Очень серьезная, но легко решаемая проблема. Причиной ее появления может стать банальная ошибка в синтаксисе файла robots.txt или ненамеренный запрет индексации. Зачастую такую ошибку можно увидеть у новых сайтов, так как разработчики обычно закрывают ресурс для индексации и не всега открывают обратно.
Поправить это очень просто. Открываем свой robots.txt по ссылке ваш_домен/robots.txt и проверяем содержимое. Если в нем расположен код следующего содержания:
User-agent: *
Disallow: /
или
User-agent: Yandex
Disallow: /
То, просто заменяем его на шаблонные инструкции для Вашей CMS или прописываем уникальные вручную.
Подробнее о настройке файла robots.txt
Не удалось подключиться к серверу из-за ошибки DNS

«При попытке скачать данные с сайта не удалось подключиться к серверу из-за ошибки DNS. Если роботы не смогут получить доступ к серверу, сайт может полностью пропасть из поиска. Возможно, пользователи также не могут попасть на сайт.» © Яндекс Вебмастер
Данная проблема решается уже не так быстро, как предыдущая. Суть ее проста. Индексирующий робот Яндекса попросту не смог получить доступ к сайту. То есть, корректная индексация уже невозможна. Если краулер, при повторных обращениях, будет продолжать получать ошибку, то сайт рано или поздно исключат из поиска.
В данном конкретном случае, лучше всего будет обратиться к разработчикам сайта или хост-провайдеру (регистратору доменного имени.) Если Вы не профессионал, то можете потерять много драгоценного времени в попытках разобраться в произошедшем. Помните, что фатальные ошибки нужно решать незамедлительно.
Главная страница сайта возвращает ошибку

«При обращении к главной странице сайта не удалось получить HTTP-код 200 OK. Поскольку страница недоступна для робота, она может быть исключена из результатов поиска.» © Яндекс Вебмастер
При обращении к главной странице сайта робот ожидает ответ 200 ОК. Только при его получении продолжается корректная индексация.
Если Вы столкнулись с вышеупомянутой проблемой, то вот несколько причин ее появления.
-
Неверно настроен ответ главной страницы. К примеру, главная может отдавать 404 Not Found или 403. Что для нее не корректно. Определить ответ можно в Яндекс Вебмастере, при помощи инструмента «проверка ответа сервера«;
-
Для главной страницы может быть настроен 301 редирект;
-
Главная страница сайта может технически отсутствовать, что редкость.
Решается проблема путем проверки наличия страницы и ее ответа. Для разработчиков сайта устранить данную ошибку не составит никакого труда.
Обнаружены нарушения или проблемы с безопасностью

«Сайт может угрожать безопасности пользователя, или на нём были обнаружены нарушения правил поисковой системы. Наличие этой проблемы негативно сказывается на положении сайта в результатах поиска.» © Яндекс Вебмастер
Одна из самых сложно решаемых проблем. Причин ее появления может быть множество. Вот основные из них:
-
Сайт был взломан и на нем находится вредоносный код. Это может быть вирусный рекламный баннер, вставки iframe, различного рода трояны, а так же множество другой гадости;
-
Сбор, обработка или передача данных пользователей сделана насколько некорректно, что индексирующий робот заподозрил в этом мошеннические намерения;
-
Сайт не соответствует правилам поисковой системы. То есть, имеет запрещенный контент, обманывает или вводит в заблуждение пользователей, подменяет материал и т.д.;
Стоит сказать, что данная проблема может появляться у очень молодых сайтов из-за темного прошлого доменного имени. Обязательно проверяйте домен перед покупкой.
Однако, не стоит беспокоиться и переделывать сайт, если Вы уверены в его корректной работе. Подобное сообщение может появляться по ошибке. Если это так, то оно автоматически пропадет через несколько обновлений.
Критичные проблемы
На критичные проблемы стоит сразу обратить внимание и начать искать решение. Их появление скорее всего не приведет к исключению из поиска, однако может серьезно повлиять на видимость сайта.
Долгий ответ сервера

«При обращении к серверу среднее время ответа превышает 3 секунды. Долгая загрузка страниц затрудняет работу с сайтом.» © Яндекс Вебмастер
Это одна из основных причин неполной (некорректной) индексации. Робот отводит на каждый сайт определенное количество секунд, после чего переходит к следующем ресурсу. Если ответ сервера слишком долгий, то времени на загрузку страниц может просто не остаться.
Что бы решить эту проблему, необходимо обратиться к администратору сервера или хост-провайдеру. Возможно, Вашему сайту просто не хватает выделенных для работы ресурсов.
Если данное сообщение появилось, а потом пропало без видимых причин, не стоит его игнорировать. Обязательно проверьте скорость ответа сервера, а так же параметры загрузки сайта. Наличие подобной проблемы влияет на индексацию вне зависимости от того, есть сообщение в Вебмастере или его нету.
Большое количество неработающих внутренних ссылок

«На сайте не работает значительное число внутренних ссылок. Это может затруднять навигацию пользователям.» © Яндекс Вебмастер
Причиной возникновения подобной проблемы может служить некорректный перенос разделов, страниц или сайта в целом. Так же, к этому может привести сбой в работе каталога, фильтра, пагинации или другого блока связанного со ссылками.
Определить точное количество неработающих ссылок и увидеть детали можно в разделе «Внутренние ссылки» Яндекс Вебмастера.
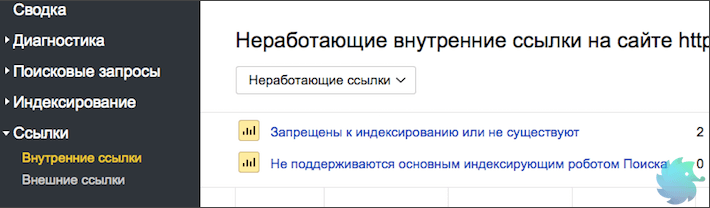
В этом блоке подробно описываются причины, поэтому Вам останется только устранить проблемы внутри сайта.
Возможные проблемы
Несмотря на название, возможные проблемы все же являются серьезными изъянами с точки зрения SEO. Они не приведут к исключению ресурса из поиска, а так же слабо повлияют на позиции и видимость. Однако их устранение может привести к подъему поискового трафика и более лояльному отношению поисковиков.
Главная страница перенаправляет на другой сайт

«При обращении к главной странице робот получает перенаправление на другой сайт, что делает невозможным её индексирование.» © Яндекс Вебмастер
Данную проблему Яндекс относит к разделу «Возможные», однако с нашей точки зрения это серьезная ошибка. Речь сейчас не идет о перенаправлении на зеркала или «склейку». Только редирект на сторонний сайт.
При корректном обращении к главной странице краулер должен получать ответ 200 ОК, что означает, что страница доступна пользователям и ее можно индексировать. В случае получения 301 Redirect, робот не только отправляется на сторонний ресурс, но и получает тревожный сигнал, что сайт мог быть взломан или вводит пользователей в заблуждение. То есть, Вы уже рискуете попасть под фильтры безопасности.
Сразу проверьте ответ сервера, если это будет не 200 ОК — ищите и устраняйте причину. В случае получения 301 Redirect рекомендуем заглянуть в файл .htaccess и проверить его на наличие редиректа.
Отсутствуют теги <title>

«Значительная часть страниц не содержит тег <title>, или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.» © Яндекс Вебмастер
Очень серьезное упущение с точки зрения поискового продвижения. Заголовки <title></title> являются одним из основных факторов внутренней оптимизации, которые влияют на ранжирование страницы.
Ранее этому заголовку мы посвятили полноценную статью. В ней разложено по полочкам все, что нужно знать о данном теге с точки зрения SEO.
Безусловно, Яндекс самостоятельно выберет текст для ссылки при построении поисковой выдачи и без сниппета Вы не останетесь, однако Ваша конкурентоспособность с точки зрения SEO сильно упадет.
Ошибки в файле robots.txt

«Файл robots.txt содержит ошибки. Это может привести к некорректному обходу и индексированию сайта.» © Яндекс Вебмастер
Данный файл представляет из себя список инструкций для индексирующего робота. Именно в нем определяется, что нужно загружать в базу, а что игнорировать. Находится он в корневой папке сайта и доступен по адресу www.ваш_домен.ru/robots.txt.
Большинство ошибок в robots.txt, обычно, связаны с синтаксисом прописываемых в нем инструкций. Лишняя точка, слэш или пробел могут привести к некорректному распознанию команды.
Поэтому, при появлении данной проблемы сразу открывайте свой роботс и начинайте проверять синтаксис. В этом деле Вам может помочь сервис «Анализ robots.txt» находящийся во вкладке «Инструменты» Яндекс Вебмастера.
Подробнее об ошибках и настройке файла robots.txt
Не найден файл robots.txt

«Робот не смог получить доступ к файлу robots.txt при последнем обращении. Из-за отсутствия параметров индексирования и инструкций в поиск могут попасть нежелательные страницы.» © Яндекс Вебмастер
Суть проблемы понятна из названия. Что бы решить ее, необходимо просто добавить robots.txt в корневой каталог Вашего сайта. Сделать это можно через FTP или при помощи различного рода плагинов.
Если Вы используете популярную CMS, то мы готовы предложить шаблонные решения. Однако, обратите внимание, что шаблоны инструкций не гарантируют корректность индексации и отсутствие мусора. У каждого сайта будут свои особенности и подводные камни.
Подробнее о настройке файла robots.txt
Отсутствуют мета-теги <description>

«Значительная часть страниц сайта не содержит мета-тег <description>, или он некорректно заполнен. Это может негативно повлиять на представление сайта в результатах поиска.» © Яндекс Вебмастер
Это одна из самых распространенных проблем, с которой сталкивается практически каждый SEO специалист. Для ее решения необходимо просто добавить недостающие <description>.
Узнать полный список страниц с отсутствующими тегами Вы можете перейдя по ссылке «Ознакомьтесь» в описании проблемы.
Отсутствие meta тега <description> сильно влияет на корректность отображения сниппетов. Поэтому тянуть с решением проблемы не стоит.
Если подобная ошибка появилась у Интернет-магазина, сайта-каталога или другого крупного ресурса, то для ее решения есть стандартные плагины, которые формируют meta description автоматически. Пользоваться такими плагинами мы советуем в крайнем случае, так как результат работы не всегда удовлетворителен.
Подробнее о description и правилах заполнения
Некорректное отображение несуществующих файлов и страниц

«Вероятно, на сайте некорректно настроен возврат HTTP-кода 404 Not Found, что может негативно сказаться на индексировании сайта роботом. Настройте возврат кода 404 на запрос несуществующих страниц.» © Яндекс Вебмастер
Проще говоря, у Вас попросту отсутствует или некорректно работает страница 404. Что бы разобраться в этом, необходимо перейти на несуществующий раздел. Сделать это можно введя любой некорректный URL, к примеру «ваш_домен.ру/none12345».
Если Вы видите перед собой неизвестную ошибку, белый экран, сообщение хост-провайдера или другую информацию, которая к сайту не относится — у Вас просто нету данной страницы. Шаблон для нее необходимо сделать в CMS сайта. Это напрямую относится к разработке и дизайну сайта, поэтому работы стоит поручить верстальщику.
Если Вы видите оформленную страницу 404 своего сайта, тогда проблема в ответе сервера. Нужно понимать, что надпись «404 — страница не найдена» не означает, что сайт действительно отдает «404 Not Found», скорее всего, результатом будет 200 ОК.
Проверить ответ сервера Вы можете в разделе «Проверка ответов сервера» во вкладке «Инструменты» Яндекс Вебмастера.
Создание страницы 404 Not Found и настройка ответа сервера полностью зависят от конкретного сайта, поэтому сделать пошаговую инструкцию просто невозможно.
Подробнее о странице 404 с точки зрения SEO
В файле robots.txt задана противоречивая директива Host

«В директиве Host указан домен, где аналогичные указания в файле robots.txt отсутствуют. Чтобы указания директивы Host были учтены, идентичные директивы должны присутствовать в файлах robots.txt всех зеркал сайта.» © Яндекс Вебмастер
Суть проблемы в следующем. Есть два зеркала. У обоих есть файл robots.txt, в котором указаны различные параметры инструкции HOST.
Решение очень простое. Необходимо указать во всех HOST одно главное зеркало. Это нужно, что бы у робота не оставалось сомнений, какое из зеркал основное.
Бывает так, что файл robots.txt один и инструкции попросту не могут различаться. В таком случае нужно подождать и сообщение пропадет.
В файле robots.txt не задана директива Host

«Для корректного определения главного зеркала сайта рекомендуется задать соответствующую директиву Host в файлах robots.txt всех зеркал сайта. В случае ее отсутствия главное зеркало может быть выбрано автоматически.» © Яндекс Вебмастер
Помимо прочих инструкций в файле robots.txt для агента Яндекса необходимо указывать директиву host. Пример директивы приведен на рисунке ниже.

Синтаксис ее крайне прост. Сначала пишется служебное слово «Host:», далее через пробел вставляется главное зеркало сайта. При этом нужно учесть, что протокол http не пишется. Добавляется только https при его наличии. Убедитесь, что зеркало выставленное в Яндекс Вебмастере и других host (у сайтов-зеркал) соответствует указываемому в robots.txt. В противном случае Вы получите ошибку, о которой говорится выше.
Подробнее о директиве host
Большое количество страниц дублей

«На сайте обнаружено большое количество одинаковых страниц, это усложняет индексирование сайта. Проверьте, правильно ли настроены редиректы и корректно ли составлен файл robots.txt.» © Яндекс Вебмастер
Достаточно серьезная проблема, которая для решения, зачастую, требует квалифицированной помощи программиста. Страницы-дубли, по сути, представляют собой различные URL, которые ведут на одну и ту же страницу. (Реже, это несколько абсолютно одинаковых html файлов с разными URL)
Когда индексирующий робот попадает на сайт, он старается обойти все доступные URL адреса и загрузить по ним уникальный контент. Если робот переходит по адресу и «видит» уже загруженную ранее страницу, то он исключает ее из поиска как дубликат, при этом теряя драгоценное время обхода.
Определить наличие дублей возможно в Яндекс Вебмастере. Необходимо зайти в раздел «Индексирование» -> «Страницы в поиске» -> «Исключенные страницы». Тут будут представлены все исключенные из поиска разделы, в том числе и по причине дублирования. Для того, что бы долго не искать, можно настроить фильтр по статусу. (нажать на значок воронки рядом с заголовком)

После того, как все страницы будут отсортированы, Вы сможете увидеть имеющиеся дубликаты, о которых знает Яндекс.
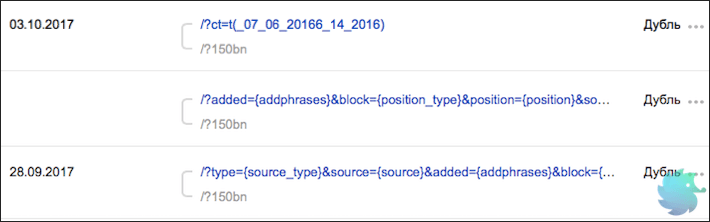
Для решения данной проблемы необходимо, в первую очередь, определить причину появления дублей. Их может быть несколько.
-
При создании страницы, в CMS генерируется технический адрес, который обычно имеет вид «post=3333&action=edit» или любой другой не ЧПУ. Вы не хотите видеть подобный URL и создаете для страницы человекочитаемый адрес. Таким образом статья становится доступна по 2 адресам. В этом случае необходимо скрыть все технические адреса в robots.txt при помощи маски;
-
На сайте имеются динамические URL, которые дополняются различными префиксами в зависимости от выбранных параметров, поиска, сортировки и т.д. Их так же необходимо скрывать при помощи маски в robots или отказаться от динамических URL;
-
Во время настройки рекламы, для получения данных о клиенте и источнике, часто используются дублирующие ссылки с параметрами. Такие URL нужно сразу закрывать в robots.txt во избежание попадания в индекс;
-
Некоторые системы управления могут отображать страницу по нескольким человекочитаемым URL. К примеру, страница может быть доступна по всем 3-м адресам: «/page1/», «/page1.php», «/page1.html». Исключаются подобные дубли так же при помощи маски.
После того, как дубли будут закрыты для индексации, предупреждение пропадет автоматически. Но, не стоит думать, что это произойдет в первую неделю. Подобное сообщение может держаться месяцами.
Нет используемых роботом файлов Sitemap

«Робот не использует ни одного файла Sitemap. Это может негативно сказаться на скорости индексирования новых страниц сайта. Если корректные файлы Sitemap уже добавлены в очередь на обработку, сообщение автоматически исчезнет с началом их использования.» © Яндекс Вебмастер
Это длинное сообщение описывает всего лишь отсутствие sitemap.xml. Что бы поправить ситуацию нужно просто создать данный файл и разместить его в корневом каталоге Вашего сайта. Ранее мы подробно рассказывали, как это сделать.
После создания необходимо зайти в Яндекс Вебмастер -> «Индексирование» — > «Файлы Sitemap» -> «Добавить карту». В этом же разделе возможно отследить корректность индексации и в случае необходимости обновить.
После того, как робот увидит sitemap сообщение о проблеме пропадет автоматически.
Обнаружены ошибки в файлах Sitemap

«В одном или нескольких файлах Sitemap обнаружены ошибки, которые могут повлиять на обработку файлов индексирующим роботом.» © Яндекс Вебмастер
В случае возникновения данной проблемы воспользуйтесь сервисом анализа sitemap.xml, который находится прямо в Яндекс Вебмастере. («Инструменты»-> «Анализ файлов Sitemap»).
Если ошибку не удается выявить, проще всего создать новую карту сайта. Как это сделать, подробно описывали ранее.
Если sitemap генерируется при помощи плагинов, обратите внимание на поля, которые находятся в итоговом файле. В отличии от Google, Яндекс не воспринимает инструкцию <image:image> и может сообщать об ошибке.
Файлы Sitemap давно не обновлялись

«В файлах Sitemap не обнаружено никаких изменений с undefined. Проверьте, не нужно ли обновить файлы Sitemap.»© Яндекс Вебмастер
Тут все просто. Необходимо обновить все имеющиеся на сайте файлы sitemap.xml. Причем сделать это нужно корректно. Вот лишь несколько ошибок, которые допускают при обновлении карты сайта.
-
Даты изменения страниц не соответствуют реальному обновлению страниц. Подобная ошибка происходит в тот момент, когда Вы используете online сервис. В таком случае все даты изменения могут быть одинаковыми и не соответствовать фактическим. Это заставляет поисковую систему повторно загружать один и тот же материал, что приводит к пустой трате времени;
-
Все страницы имеют один и тот же приоритет. В таком случае данный параметр sitemap.xml просто перестает иметь какой-либо смысл;
-
Вероятная частота изменения не соответствует действительной. Не стоит писать, что Ваши страницы обновляются каждый час. Обмануть поисковую систему не удастся и преимущества Вы не получите, но вот возможность корректного указания частоты обновления утратите.
Подробнее о создании sitemap.xml
Рекомендации
Этот раздел носит исключительно информационный характер, однако мы советуем соблюсти все его требования.
Не задана региональная принадлежность сайта

«В разделе «Региональность» регион сайта не задан явно, это может осложнить ранжирование. Если ваш сайт интересен пользователям вне зависимости от региона, выберите в разделе вариант «Нет региона».» © Яндекс Вебмастер
У данной проблемы есть две стороны медали. С одной — присвоение региона не является обязательной процедурой и Яндекс сам может определить его. С другой — если регион определен некорректно, то Вы можете получить нерелевантный трафик или же вообще лишиться его.
Поэтому мы настоятельно рекомендуем присваивать регион каждому сайту. Стоит отметить, что есть ряд ресурсов, которые не имеют региональной привязки. В таком случае необходимо сообщить Яндексу, что региона Вы не имеете.
Подробнее о том, как выбрать и присвоить регион.
Сайт не оптимизирован для мобильных

«По результатам работы алгоритма, определяющего, насколько сайт подходит для мобильных устройств, сайт не удалось признать оптимизированным.» © Яндекс Вебмастер
Сегодня эта проблема должна находиться уже среди критичных. Поисковые системы не раз говорили о том, что будут занижать сайты не имеющие мобильной версии. С каждым годом процентное соотношение трафика с мобильных устройств растет, поэтому мобильная адаптация должна быть у всех.
Насколько корректно Ваш сайт адаптирован под мобильные телефоны и планшеты Вы можете определить с помощью официального сервиса Яндекса — «Проверка мобильных страниц» . Располагается он в разделе «Инструменты» Яндекс Вебмастера.
Ошибка счётчика Яндекс.Метрики

«Яндекс.Метрика помогает отслеживать источники трафика, получать детальную статистику о посещаемости и качестве страниц сайта, а также анализировать видеозаписи действий посетителей.» © Яндекс Вебмастер
Тут все просто. Скорее всего код Яндекс Метрики был установлен некорректно или не на все страницы.
Если Вы зайдете в счетчики и увидите красный значок слева от сайта — данные в Метрику не поступают. Нажмите на него.

Если он не станет зеленым, то просто переустановите счетчик. Для этого нужно:
-
Перейти в настройки нажав на значок шестеренки в правой части экрана;
-
Переходим на вкладку «Код счетчика» и копируем его;
-
Открываем шаблон, который формирует страницы сайта и вставляем в него код;
-
Переходим в метрику и нажимаем на красный кружок со стрелочкой. Он должен стать зеленым.
В случае, если Вы уверены, что код размещен правильно, но данные так и не поступают — обратитесь в службу поддержки или подробно ознакомьтесь с процессом установки счетчика.
Сайт не зарегистрирован в Яндекс.Справочнике

«Сайт не добавлен в Яндекс.Справочник. Если у вас есть офисы или филиалы, добавьте их в справочник, чтобы улучшить внешний вид сайта в поиске и региональное ранжирование. Если офисов и филиалов нет, явно укажите «Нет региона» в подразделе «Вебмастер» раздела настройки региональности.» © Яндекс Вебмастер
С точки зрения SEO, регистрация сайта в Яндекс Справочнике может дополнить сниппет такой полезной информацией, как телефон, адрес и режим работы. По брендовым запросам справа от сниппета начнет появляться карта с адресом и подробной информацией о фирме. Такие сниппеты любят пользователи, поэтому стоить уделить 15 минут на регистрацию.
Зарегистрироваться проще некуда. Это совершенно бесплатно.
-
Заходим в Яндекс Аккаунт и переходим по ссылке: https://yandex.ru/sprav/add/;
-
Вводим информацию о компании и нажимаем «Добавить организацию»;
-
Ожидаем одобрения модераторов. (Обычно проблем с этим не возникает)
После успешной модерации информация появится в выдаче через несколько обновлений.
Отсутствует файл favicon на сайте

«Не найден файл с изображением, которое должно отображаться во вкладке браузера и может быть показано возле названия сайта в поиске.» © Яндекс Вебмастер
Файл favicon.ico это небольшая картинка, которая отображается во вкладке браузера.

Favicon имеет расширение .ico и располагается в корневой папке сайта или шаблона.
Кроме отображения во вкладке, данное изображение присутствует в поисковой выдаче рядом со ссылкой на сайт. Именно поэтому о нем сообщает Яндекс.
Сделать favicon очень просто. Для этого нужно создать рисунок квадратной формы, после чего воспользоваться одним из множество online генераторов. Примеры таких сервисов:
-
http://pr-cy.ru/favicon/
-
http://www.favicon.ru
-
http://www.favicon.by
-
Множество других.
Скачайте получившийся файл, назовите его favicon.ico и разместите в корневой папке сайта. Несколько раз обновите браузер и Ваше изображение появится во вкладке рядом с доменом. В поисковой выдаче favicon обновится в течение 2-3 недель.
Отсутствуют быстрые ссылки

«В некоторых случаях в результатах поиска возможно отображение быстрых ссылок в сниппете сайта, что улучшает его видимость и количество переходов. Ссылки формируются полностью автоматически, роботы регулярно оценивают возможность показа быстрых ссылок.» © Яндекс Вебмастер
Это исключительно информационное сообщение, так как напрямую повлиять на вывод быстрых ссылок Вы не можете. Напомним, что последние располагаются под основным сниппетом сайта в органической выдаче. На рисунке ниже приведен пример быстрых ссылок для сайта компании Apple.
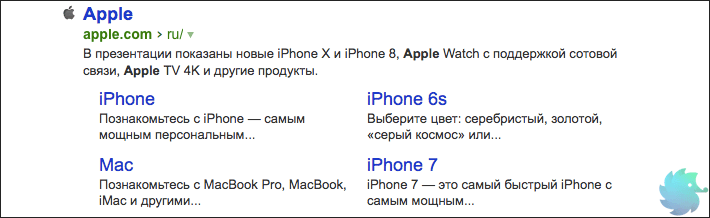
Но, несмотря на то, что напрямую влияния Вы не имеете, возможно «помочь» роботу определить быстрые ссылки. Делается это путем создания корректной древовидной структуры сайта. То есть, выделить основные разделы, сгруппировать в них подразделы и корректно связать все перелинковкой.
В этом случае Яндекс сможет с большей вероятностью определить основные разделы и сформировать блок быстрых ссылок.
Загрузка…
Возможные проблемы — Вебмастер. Справка
Раздел содержит решения часто встречающихся проблем категории «Возможные», выявленных при диагностике сайта в
Вебмастере. Проблемы этой группы могут влиять на качество и скорость индексирования страниц сайта.
Совет. Настройте уведомления о результатах проверки сайта.
- Не найден файл robots.txt
- Обнаружены ошибки в файле robots.txt
- Нет используемых роботом файлов Sitemap
- Обнаружены ошибки в файлах Sitemap
- Некорректно настроено отображение несуществующих или удаленных файлов и страниц
- Отсутствуют элемент title и метатег description
- На страницах есть одинаковые заголовки и описания
- Файл favicon недоступен для робота
Несколько раз в сутки индексирующий робот запрашивает файл robots.txt и обновляет информацию о нем в своей базе. Если при очередном обращении робот не может загрузить файл, в
Вебмастере появляется соответствующее предупреждение.
В сервисе проверьте доступность файла robots.txt. Если файл по-прежнему недоступен, добавьте его. Если вы не можете сделать это самостоятельно, обратитесь к хостинг-провайдеру или регистратору доменного имени. После добавления файла данные в Вебмастере обновляются в течение нескольких дней.
Проверьте файл robots.txt вашего сайта. Чтобы исправить ошибки, посмотрите описания директив.
Файл Sitemap является вспомогательным инструментом при индексировании сайта, он позволяет регулярно сообщать роботу о появлении новых страниц на сайте. Данное предупреждение появляется, если робот не использует ни одного файла Sitemap для сайта.
Чтобы робот начал использовать созданный файл, добавьте его в Вебмастер и дождитесь обработки файла роботом. Обычно на это требуется до двух недель. После этого предупреждение пропадет.
Проверьте файл Sitemap вашего сайта. Проверка может выявить ошибку «Неизвестный тег». Она сообщает, что файл содержит неподдерживаемые Яндексом элементы.
Такие элементы игнорируются роботом при обработке Sitemap, но данные из поддерживаемых элементов учитываются. Поэтому менять содержимое файла необязательно. Подробнее о поддерживаемых элементах Sitemap.
Вероятно, на сайте некорректно настроен возврат HTTP-кода 404 (ресурс не найден/Not Found). В таком случае поисковый робот может при переходе на сайт по любой ссылке получить ответ 200 ОК и проиндексировать несуществующую страницу. Это приведет к большому количеству дублированных страниц, что усложнит и замедлит индексирование сайта и увеличит нагрузку на сервер.
Чтобы проверить ответ сервера, воспользуйтесь инструментом Проверка состояния страницы. Введите адрес несуществующей на вашем сайте страницы. Можно использовать произвольный набор букв и цифр, например https://example.com/kugbkkrfck.
Если настроить рекомендуемый код ответа 404 нет возможности:
-
Настройте любой другой код 4xx, кроме 429.

Не рекомендуем использовать коды ответа 429 и 5xx, так как они сообщают роботу, что сервер испытывает затруднения. Это может привести к замедлению индексирования сайта.
-
Используйте директиву noindex или настройте редирект 301.
При использовании
noindexи редиректа 301 уведомления об ошибке могут появляться в Вебмастере, но страницы в поиск не попадут и на позиции сайта это не повлияет. Эти способы наименее предпочтительны, так как увеличивают нагрузку на сервер и замедляют индексирование сайта.

Элемент title и метатег description помогают сформировать корректное описание сайта в результатах поиска. Подробно см. раздел Отображение заголовка и описания сайта в результатах поиска.
Если элементы или один из них отсутствуют на вашем сайте, добавьте их в HTML-код страниц и сохраните изменения. Если элементы уже размещены, дождитесь, пока робот переобойдет страницы. После этого сообщение об ошибке исчезнет.
Подробно
Эта проблема отображается, если заголовок или описание повторяется на значительной доле страниц сайта. Когда title и description отражают контент страницы, информативны и привлекательны, пользователям удобнее находить ответы в поисковой выдаче.
Посмотрите примеры страниц с повторяющимися заголовками или описаниями, которые обнаружил Вебмастер при обходе сайта роботом. Чтобы исправить их, следуйте рекомендациям по:
-
написанию title;
-
составлению description.
Проблема перестанет отображаться, когда робот узнает об изменениях на сайте. Чтобы это произошло быстрее, отправьте наиболее важные страницы на переобход или настройте обход страниц со счетчиком Метрики.
Если эта проблема отображается для вашего сайта, значит Небольшая картинка, которая отображается в сниппете в результатах поиска Яндекса, рядом с адресом сайта в адресной строке браузера, около названия сайта в Избранном или в Закладках браузера.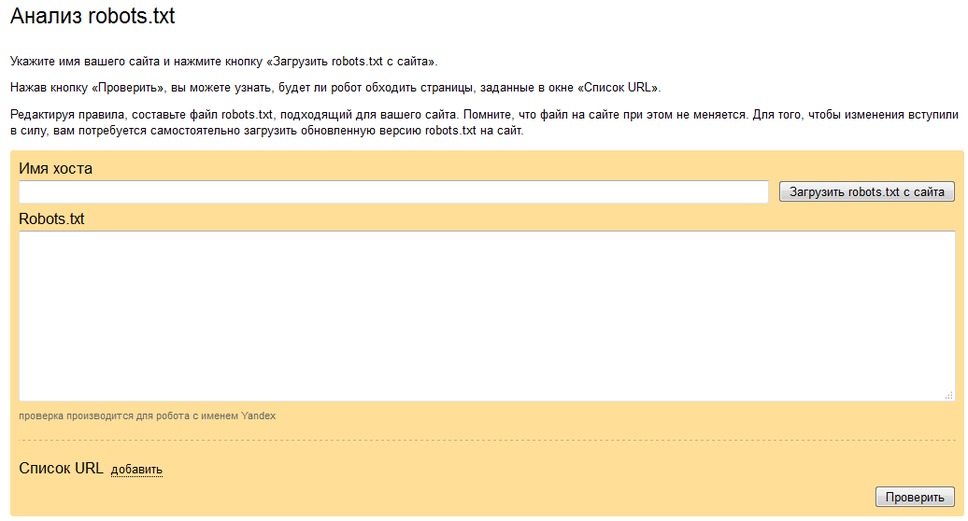 «}}»> не отображается в результатах поиска. В Вебмастере на странице Диагностика → Диагностика сайта (блок Возможные проблемы) посмотрите причину, по которой робот не смог загрузить файл и следуйте указаниям:
«}}»> не отображается в результатах поиска. В Вебмастере на странице Диагностика → Диагностика сайта (блок Возможные проблемы) посмотрите причину, по которой робот не смог загрузить файл и следуйте указаниям:
| Ошибка | Решение |
|---|---|
| Файл отвечает HTTP-кодом, отличным от 200 OK | Проверьте ответ сервера. Ответ должен соответствовать 200 OK. Другие статусы ответа см. в разделе Проверка ответа сервера. |
| Файл перенаправляет на другой адрес | |
| Неправильный тип данных | Проверьте значение параметра type в ссылке на файл. Он должен соответствовать формату файла. |
Как установить фавиконку
Чтобы ваш вопрос быстрее попал к нужному специалисту, уточните тему:
Посмотрите рекомендации. Если файл доступен для робота и загружается в Вебмастере, но проблема продолжает отображаться, заполните форму:
Если файл доступен для робота и загружается в Вебмастере, но проблема продолжает отображаться, заполните форму:
Посмотрите рекомендации выше. Если файл добавлен больше 2 недель назад, но сообщение не пропадает, заполните форму:
Посмотрите рекомендации выше. Если ошибок в файле нет, но сообщение продолжает отображаться, заполните форму:
Посмотрите рекомендации выше. Если ответ сервера соответствует 200 ОК и значение параметра type соответствует формату файла, но сообщение продолжает отображаться, заполните форму:
настройка, статусы, ошибки индексации и способы их исправления — Топвизор–Журнал
 txt
txtПодробный SEO-гайд по Отчёту об индексировании Google Search Console. Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Перевод с сайта onely.com.
В Отчёте вы можете получить данные о сканировании и индексации всех URL-адресов, которые Google смог обнаружить на вашем сайте. Он поможет отследить, добавлен ли сайт в индекс, и проинформирует о технических проблемах со сканированием и индексацией.
Но перед тем, как говорить об Отчёте, вспомним все этапы индексации страницы в Google.
Как проходит индексация в Google
Чтобы страница ранжировалась в поиске и показывалась пользователям, она должна быть обнаружена, просканирована и проиндексирована.
Обнаружение
Перед тем, как просканировать страницу, Google должен её обнаружить. Он может сделать это несколькими способами.
Наиболее распространённые — с помощью внутренних или внешних ссылок или через карту сайта (файл Sitemap.xml).
Сканирование
Суть сканирования состоит и том, что поисковые системы изучают страницу и анализируют её содержимое.
Главный аспект в этом вопросе — краулинговый бюджет, который представляет собой лимит времени и ресурсов, который поисковая система готова «потратить» на сканирование вашего сайта.
Что такое «краулинговый бюджет, как его проверить и оптимизировать
Индексация
В процессе индексации Google оценивает качество страницы и добавляет её в индекс — базу данных, где собраны все страницы, о которых «знает» Google.
В этот этап включается и рендеринг, который помогает Google видеть макет и содержимое страницы. Собранная информация даёт поисковой системе понимание, как показывать страницу в результатах поиска.
Некоторые страницы могут содержать контент низкого качества или быть дублями. Если поисковые системы их увидят, это может негативно отразится на всём сайте.
Поэтому важно в процессе создания стратегии индексации решить, какие страницы должны и не должны быть проиндексированы.
Ранжирование
Только проиндексированные страницы могут появиться в результатах поиска и ранжироваться.
Google определяет, как ранжировать страницу, основываясь на множестве факторов, таких как количество и качество ссылок, скорость страницы, удобство мобильной версии, релевантность контента и др.
Теперь перейдём к Отчёту.
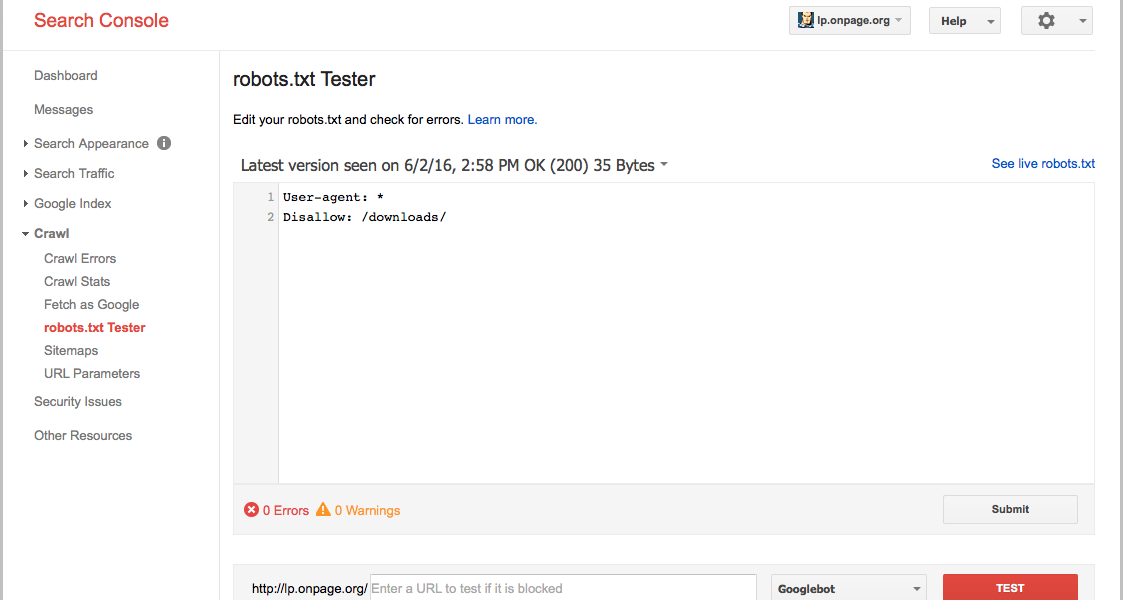
Как пользоваться Отчётом об индексировании в Google Search Console
Чтобы просмотреть Отчёт, авторизуйтесь в своём аккаунте Google Search Console. Затем в меню слева выберите «Покрытие» в секции «Индекс»:
Как найти Отчёт об индексировании в Google Search Console
Перед вами Отчёт. Отметив галочками любой из статусов или все сразу, вы сможете выбрать то, что хотите визуализировать на графике:
Статусы URL на странице Отчёта
Вы увидите четыре статуса URL-адресов:
- Ошибка — критическая проблема сканирования или индексации.
- Без ошибок, есть предупреждения — URL-адреса проиндексированы, но содержат некоторые некритичные ошибки.
- Страница без ошибок — страницы проиндексированы корректно.
- Исключено — страницы, которые не были проиндексированы из-за проблем (это самый важный раздел, на котором нужно сфокусироваться).

Фильтры «Все обработанные страницы» vs «Все отправленные страницы»
В верхнем углу вы можете отфильтровать, какие страницы хотите видеть:
Фильтр отображаемых страниц
«Все обработанные страницы» показываются по умолчанию. В этот фильтр включены все URL-адреса, которые Google смог обнаружить любым способом.
Фильтр «Все отправленные страницы» включает только URL-адреса, добавленные с помощью файла Sitemap.
Так что когда открываете Отчёт, убедитесь, что смотрите нужные данные.
Проверка статусов URL
Чтобы увидеть подробную информацию о проблемах, обнаруженных для каждого статуса, посмотрите «Сведения» под графиком:
Раздел «Сведения»
Тут показан статус, тип проблемы и количество затронутых страниц. Обратите внимание на столбец «Проверка» — после исправления ошибки, вы можете попросить Google проверить URL повторно.
Например, если кликнуть на первую строку со статусом «Предупреждение», то вверху появится кнопка «Проверить исправление»:
Проверка исправлений
Вы также можете увидеть динамику каждого статуса: увеличилось, уменьшилось или осталось на том же уровне количество URL-адресов в этом статусе.
Если в «Сведениях» кликнуть на любой статус, вы увидите количество адресов, связанных с ним. Кроме того, вы сможете посмотреть, когда каждая страница была просканирована (но помните, что эта информация может быть неактуальна из-за задержек в обновлении отчётов).
Подробная информация о сканировании в Сведениях
Что учесть при использовании отчёта
- Всегда проверяйте, смотрите ли вы отчёт по всем обработанным или по всем отправленным страницам. Разница может быть очень существенной.
- Отчёт может показывать изменения с задержкой. После публикации контента подождите несколько дней, пока страницы просканируются и проиндексируются.
- Google пришлёт уведомления на электронную почту, если увидит какие-то критичные проблемы с сайтом.
- Стремитесь к индексации канонической версии страницы, которую вы хотите показывать пользователям и поисковым ботам.
- В процессе развития сайта, на нём будет появляться больше контента, так что ожидайте увеличения количества проиндексированных страниц в Отчёте.
Как часто смотреть Отчёт
Обычно достаточно делать это раз в месяц.
Но если вы внесли значимые изменения на сайте, например, изменили макет страницы, структуру URL или сделали перенос сайта, мониторьте Отчёт чаще, чтобы вовремя поймать негативное влияние изменений.
Рекомендую делать это хотя бы раз в неделю и обращать особое внимание на статус «Исключено».
Дополнительно: инструмент проверки URL
В Search Console есть ещё один инструмент, который даст ценную информацию о сканировании и индексации страниц вашего сайта — Инструмент проверки URL.
Он находится в самом верху страницы в GSC:
Инструмент проверки URL
Просто вставьте URL, который вы хотите проверить, в эту строку и увидите данные по нему.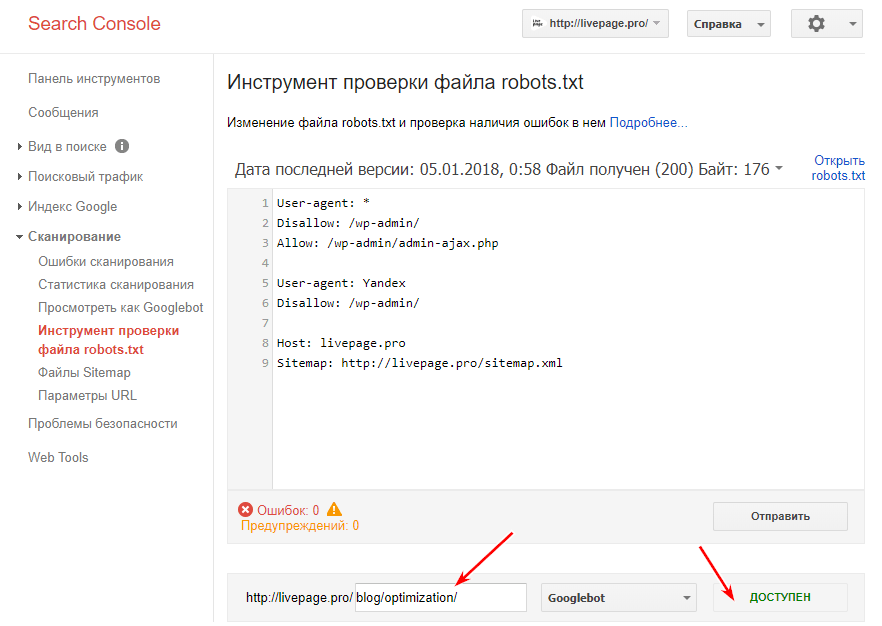 Например:
Например:
Результат проверки URL
Инструментом можно пользоваться для того, чтобы:
- проверить статус индексирования URL, и обнаружить возможные проблемы;
- узнать, индексируется ли URL;
- просмотреть проиндексированную версию URL;
- запросить индексацию, например, если страница изменилась;
- посмотреть загруженные ресурсы, например, такие как JavaScript;
- посмотреть, какие улучшения доступны для URL, например, реализация структурированных данных или удобство для мобильных.
Если в Отчёте об индексировании обнаружены какие-то проблемы со страницами, используйте Инструмент, чтобы тщательнее проверить их и понять, что именно нужно исправить.
Статус «Ошибка»
Под этим статусом собраны URL, которые не были проиндексированы из-за ошибок.
Если вы видите проблему с пометкой «Отправлено», то это может касаться только URL, которые были отправлены через карту сайту.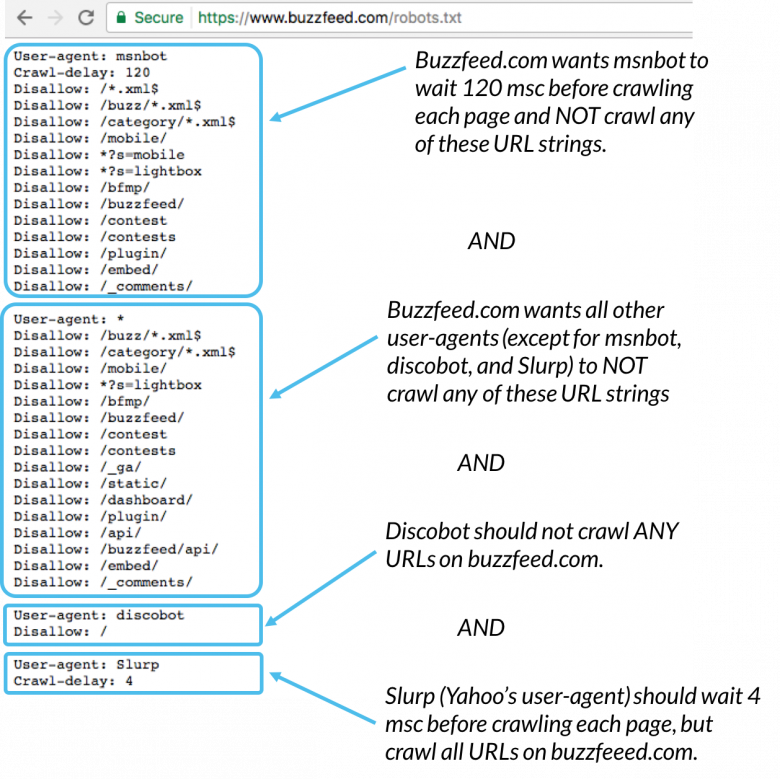 Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Ошибка сервера (5xx)
Эта проблема говорит об ошибке сервера со статусом 5xx, например, 502 Bad Gateway или 503 Service Unavailable.
Советую регулярно проверять этот раздел и следить, нет ли у Googlebot проблем с индексацией страниц из-за ошибки сервера.
Что делать. Нужно связаться с вашим хостинг-провайдером, чтобы исправить эту проблему или проверить, не вызваны ли эти ошибки недавними обновлениями и изменениями на сайте.
Как исправить ошибки сервера — рекомендации Google
Ошибка переадресации
Редиректы перенаправляют поисковых ботов и пользователей со старого URL на новый. Обычно они применяются, если старый адрес изменился или страницы больше не существует.
Ошибки переадресации могут указывать на такие проблемы:
- цепочка редиректов слишком длинная;
- обнаружен циклический редирект — страницы переадресуют друг на друга;
- редирект настроен на страницу, URL которой превышает максимальную длину;
- в цепочке редиректов найден пустой или ошибочный URL.

Что делать. Проверьте и исправьте редиректы каждой затронутой страницы.
Доступ к отправленному URL заблокирован в файле robots.txt
Эти страницы есть в файле Sitemap, но заблокированы в файле robots.txt.
Robots.txt — это файл, который содержит инструкции для поисковых роботов о том, как сканировать ваш сайт. Чтобы URL был проиндексирован, Google нужно для начала его просканировать.
Что делать. Если вы видите такую ошибку, перейдите в файл robots.txt и проверьте настройку директив. Убедитесь, что страницы не закрыты через noindex.
Страница, связанная с отправленным URL, содержит тег noindex
По аналогии с предыдущей ошибкой, эта страница была отправлена на индексацию, но она содержит директиву noindex в метатеге или в заголовке ответа HTTP.
Что делать. Если страница должна быть проиндексирована, уберите noindex.
Отправленный URL возвращает ложную ошибку 404
Ложная ошибка 404 означает, что страница возвращает статус 200 OK, но её содержимое может указывать на ошибку. Например, страница пустая или содержит слишком мало контента.
Например, страница пустая или содержит слишком мало контента.
Что делать. Проверьте страницы с ошибками и посмотрите, есть ли возможность изменить контент или настроить редирект.
Отправленный URL возвращает ошибку 401 (неавторизованный запрос)
Ошибка 401 Unauthorized означает, что запрос не может быть обработан, потому что необходимо залогиниться под правильными user ID и паролем.
Что делать. Googlebot не может индексировать страницы, скрытые за логинами. Или уберите необходимость авторизации или подтвердите авторизацию Googlebot, чтобы он мог получить доступ к странице.
Отправленный URL не найден (ошибка 404)
Ошибка 404 говорит о том, что запрашиваемая страница не найдена, потому что была изменена или удалена. Такие страницы есть на каждом сайте и наличие их в малом количестве обычно ни на что не влияет. Но если пользователи будут находить такие страницы, это может отразиться негативно.
Что делать. Если вы увидели эту проблему в отчёте, перейдите на затронутые страницы и проверьте, можете ли вы исправить ошибку. Например, настроить 301-й редирект на рабочую страницу.
Например, настроить 301-й редирект на рабочую страницу.
Дополнительно убедитесь, что файл Sitemap не содержит URL, которые возвращают какой-либо другой код состояния HTTP кроме 200 OK.
При отправке URL произошла ошибка 403
Код состояния 403 Forbidden означает, что сервер понимает запрос, но отказывается авторизовывать его.
Что делать. Можно либо предоставить доступ анонимным пользователям, чтобы робот Googlebot мог получить доступ к URL, либо, если это невозможно, удалить URL из карты сайта.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Страница может быть непроиндексирована из-за других ошибок 4xx, которые не описаны выше.
Что делать. Чтобы понять, о какой именно ошибке речь, используйте Инструмент проверки URL. Если устранить ошибку невозможно, уберите URL из карты сайта.
Статус «Без ошибок, есть предупреждения»
URL без ошибок, но с предупреждениями, были проиндексированы, но могут требовать вашего внимания. Тут обычно случается две проблемы.
Тут обычно случается две проблемы.
Проиндексировано, несмотря на блокировку в файле robots.txt
Обычно эти страницы не должны быть проиндексированы, но скорее всего Google нашёл ссылки, указывающие на них, и посчитал их важными.
Что делать. Проверьте эти страницы. Если они всё же должны быть проиндексированы, то обновите файл robots.txt, чтобы Google получил к ним доступ. Если не должны — поищите ссылки, которые на них указывают. Если вы хотите, чтобы URL были просканированы, но не проиндексированы, добавьте директиву noindex.
Страница проиндексирована без контента
URL проиндексированы, но Google не смог прочитать их контент. Это может быть из-за таких проблем:
- Клоакинг — маскировка контента, когда Googlebot и пользователи видят разный контент.
- Страница пустая.
- Google не может отобразить страницу.
- Страница в формате, который Google не может проиндексировать.

Зайдите на эти страницы сами и проверьте, виден ли на них контент. Также проверьте их через Инструмент проверки URL и посмотрите, как их видит Googlebot. После того, как устраните ошибки, или если не обнаружите каких-либо проблем, вы можете запросить у Google повторное индексирование.
Статус «Страница без ошибок»
Здесь показываются страницы, которые корректно проиндексированы. Но на эту часть Отчёта всё равно нужно обращать внимание, чтобы сюда не попали страницы, которые не должны были оказаться в индексе. Тут тоже есть два статуса.
Страница была отправлена в Google и проиндексирована
Это значит, что страницы отправлена через Sitemap и Google её проиндексировал.
Страница проиндексирована, но её нет в файле Sitemap
Это значит, что страница проиндексирована даже несмотря на то, что её нет в Sitemap. Посмотрите, как Google нашёл эту страницу, через Инструмент проверки URL.
Чаще всего страницы в этом статусе — это страницы пагинации, что нормально, учитывая, что их и не должно быть в Sitemap. Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Статус «Исключено»
В этом статусе находятся страницы, которые не были проиндексированы. В большинстве случаев это вызвано теми же проблемами, которые мы обсуждали выше. Единственное различие в том, что Google не считает, что исключение этих страниц вызвано какой-либо ошибкой.
Вы можете обнаружить, что многие URL здесь исключены по разумным причинам. Но регулярный просмотр Отчёта поможет убедиться, что не исключены важные страницы.
Индексирование страницы запрещено тегом noindex
Что делать. Тут то же самое — если страница и не должна быть проиндексирована, то всё в порядке. Если должна — удалите noindex.
Индексирование страницы запрещено с помощью инструмента удаления страниц
У Google есть Инструмент удаления страниц. Как правило с его помощью Google удаляет страницы из индекса не навсегда. Через 90 дней они снова могут быть проиндексированы.
Что делать. Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Заблокировано в файле robots.txt
У Google есть Инструмент проверки файла robots.txt, где вы можете в этом убедиться.
Что делать. Если эти страницы и не должны быть в индексе, то всё в порядке. Если должны — обновите файл robots.txt.
Помните, что блокировка в robots.txt — не стопроцентный вариант закрыть страницу от индексации. Google может проиндексировать её, например, если найдёт ссылку на другой странице. Чтобы страница точно не была проиндексирована, используйте директиву noindex.
Подробнее о блокировке индексирования при помощи директивы noindex
Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос)
Обычно это происходит на страницах, защищённых паролем.
Что делать. Если они и не должны быть проиндексированы, то ничего делать не нужно. Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Страница просканирована, но пока не проиндексирована
Это значит, что страница «ждёт» решения. Для этого может быть несколько причин. Например, с URL нет проблем и вскоре он будет проиндексирован.
Но чаще всего Google не будет торопиться с индексацией, если контент недостаточно качественный или выглядит похожим на остальные страницы сайта.
В этом случае он поставит её в очередь с низким приоритетом и сфокусируется на индексации более важных страниц. Google говорит, что отправлять такие страницы на переиндексацию не нужно.
Что делать. Для начала убедитесь, что это не ошибка. Проверьте, действительно ли URL не проиндексирован, в Инструменте проверки URL или через инструмент «Индексация» в Анализе сайта в Топвизоре. Они показывают более свежие данные, чем Отчёт.
Как исправить ошибку, когда страница просканирована, но не проиндексирована (на английском)
Обнаружена, не проиндексирована
Это значит, что Google увидел страницу, например, в карте сайта, но ещё не просканировал её.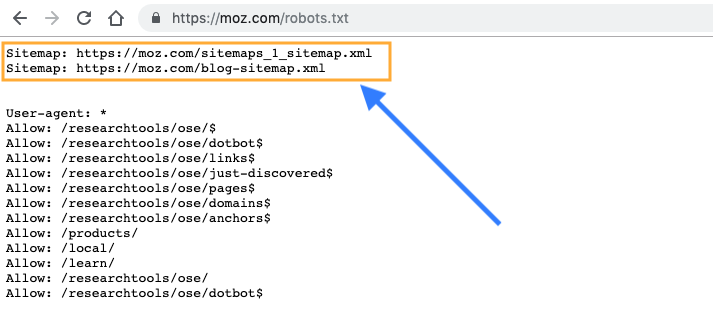 В скором времени страница может быть просканирована.
В скором времени страница может быть просканирована.
Иногда эта проблема возникает из-за проблем с краулинговым бюджетом. Google может посчитать сайт некачественным, потому что ему не хватает производительности или на нём слишком мало контента.
Что такое краулинговый бюджет и как его оптимизировать
Возможно, Google не нашёл каких-либо ссылок на эту страницу или нашёл страницы с большим ссылочным весом и посчитал их более приоритетными для сканирования.
Если на сайте есть более качественные и важные страницы, Google может игнорировать менее важные страницы месяцами или даже никогда их не просканировать.
Вариант страницы с тегом canonical
Эти URL — дубли канонической страницы, отмеченные правильным тегом, который указывает на основную страницу.
Что делать. Ничего, вы всё сделали правильно.
Страница является копией, канонический вариант не выбран пользователем
Это значит, что Google не считает эти страницы каноническими. Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Что делать. Выберите страницу, которая по вашему мнению является канонической, и разметьте дубли с помощью rel=”canonical”.
Страница является копией, канонические версии страницы, выбранные Google и пользователем, не совпадают
Вы выбрали каноническую страницу, но Google решил по-другому. Возможно, страница, которую вы выбрали, не имеет столько внутреннего ссылочного веса, как неканоническая.
Что делать. В этом случае может помочь объединение URL повторяющихся страниц.
Как правильно настроить внутренние ссылки на сайте
Не найдено (404)
URL нет в Sitemap, но Google всё равно его обнаружил. Возможно, это произошло с помощью ссылки на другом сайте или ранее страница существовала и была удалена.
Что делать. Если вы и не хотели, чтобы Google индексировал страницу, то ничего делать не нужно. Другой вариант — поставить 301-й редирект на работающую страницу.
Страница с переадресацией
Эта страница редиректит на другую страницу, поэтому не была проиндексирована. Обычно, такие страницы не требуют внимания.
Что делать. Эти страницы и не должны быть проиндексированы, так что делать ничего не нужно.
Ложная ошибка 404
Обычно это страницы, на которых пользователь видит сообщение «не найдено», но которые не сопровождаются кодом ошибки 404.
Что делать. Для исправления проблемы вы можете:
- Добавить или улучшить контент таких страниц.
- Настроить 301-й редирект на ближайшую альтернативную страницу.
- Настроить сервер, чтобы он возвращал правильный код ошибки 404 или 410.
Страница является копией, отправленный URL не выбран в качестве канонического
Эти страницы есть в Sitemap, но для них не выбрана каноническая страница. Google считает их дублями и канонизировал их другими страницами, которые определил самостоятельно.
Что делать. Выберите и добавьте канонические страницы для этих URL.
Страница заблокирована из-за ошибки 403 (доступ запрещён)
Что делать. Если Google не может получить доступ к URL, лучше закрыть их от индексации с помощью метатега noindex или файла robots.txt.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Сервер столкнулся с ошибкой 4xx, которая не описана выше.
Гайд по ошибкам 4xx и способы их устранения (на английском)
Попробуйте исправить ошибки или оставьте страницы как есть.
Ключевые выводы
- Проверяя данные в Отчёте помните, что не все страницы сайта должны быть просканированы и проиндексированы.
- Закрыть от индексации некоторые страницы может быть так же важно, как и следить за тем, чтобы нужные страницы сайта индексировались корректно.
- Отчёт об индексировании показывает как критичные ошибки, так и неважные, которые не обязательно требуют действий с вашей стороны.
- Регулярно проверяйте Отчёт, но только для того, чтобы убедиться, что всё идёт по плану. Исправляйте только те ошибки, которые не соответствуют вашей стратегии индексации.
Robots.txt — важный файл для правильной работы сайта. Именно здесь сканеры поисковых систем находят информацию о страницах веб-ресурса, которые следует сканировать в первую очередь, а на какие вообще не стоит обращать внимание. Файл robots.txt используется, когда необходимо скрыть некоторые части сайта или весь сайт от поисковых систем. Например, место с личной информацией пользователя или зеркало сайта.
Что делать, если системный аудитор не видит этот файл? Об этом и других проблемах, связанных с файлом robots.txt, читайте в нашей статье.
Как работает файл robots.txt?
robots.txt — это текстовый документ в кодировке UTF-8. Этот файл работает для протоколов http, https и FTP. Тип кодировки очень важен: если файл robots. txt закодирован в другом формате, поисковая система не сможет прочитать документ и определить, какие страницы следует распознавать, а какие нет. Другие требования к файлу robots.txt следующие:
- все настройки в файле актуальны только для сайта, на котором находится robots.txt;
- расположением файла является корневой каталог; URL-адрес должен выглядеть так: https://site.com.ua/robots.txt;
- размер файла не должен превышать 500 Кб.
При сканировании файла robots.txt поисковым роботам предоставляется разрешение на сканирование всех или некоторых веб-страниц; им также может быть запрещено это делать.
Об этом можно здесь.
Коды ответов поисковой системы
Поисковый робот сканирует файл robots.txt и получает следующие ответы:
- 5XX – разметка временной ошибки сервера, при которой сканирование останавливается;
- 4XX — разрешение на сканирование каждой страницы сайта;
- 3XX — перенаправлять до тех пор, пока сканер не получит другой ответ.
После 5 попыток исправлена ошибка 404;
- 2XX – успешное сканирование; все страницы, которые необходимо прочитать, распознаются.
Если при переходе на https://site.com.ua/robots.txt поисковая система не находит или не видит файл, будет ответ «robots.txt не найден».
Причины ответа «robots.txt не найден»
Причины ответа поискового робота «robots.txt не найден» могут быть следующими:
- текстовый файл расположен по другому URL-адресу;
- файл robots.txt не найден на сайте.
Дополнительная информация об этом видео Джона Мюллера из Google.
Обратите внимание! Файл robots.txt находится в каталоге основного домена, а также в поддоменах. Если вы включили поддомены в аудит сайта, файл должен быть доступен; в противном случае сканер сообщит об ошибке о том, что файл robots. txt не найден.
Почему это важно?
Отсутствие исправления ошибки «robots.txt не найден» приведет к некорректной работе поисковых роботов из-за некорректных команд из файла. Это, в свою очередь, может привести к падению рейтинга сайта, некорректным данным о посещаемости сайта. Также, если поисковые системы не увидят robots.txt, будут просканированы все страницы вашего сайта, что нежелательно. В результате вы можете пропустить следующие проблемы:
- перегрузка сервера;
- бесцельное сканирование страниц с одинаковым содержанием поисковыми системами;
- больше времени для обработки запросов посетителей.
От бесперебойной работы файла robots.txt зависит бесперебойная работа вашего веб-ресурса. Поэтому давайте рассмотрим, как исправить ошибки в работе этого тестового документа.
Как исправить файл robots.txt?
Чтобы поисковые роботы правильно реагировали на ваш файл robots.txt, он должен быть правильно отлажен. Проверьте текстовый документ безопасности на наличие следующих ошибок:
- Значения директив перепутаны. Запретить или разрешить должны быть в конце фразы.
- URL-адреса нескольких страниц в одной директиве.
- Опечатки в имени файла robots.txt или прописные буквы, используемые в файле.
- User-agent не указан.
- Отсутствие директивы во фразе: запретить или разрешить.
- Неточный URL: используйте символы $ и /, чтобы указать пробел.
Вы можете проверить файл robots.txt с помощью инструментов проверки поисковых систем. Например, используйте инструмент тестирования Google robots.txt.
Определите, не найден ли Robots.txt, и приступайте к анализу других проблем с ним!
Проверьте не только проблему, но и проведите полный аудит, чтобы выяснить и исправить ваше техническое SEO.
Иван Палий
Эксперт по маркетингу
Иван работает специалистом по продуктовому маркетингу в Sitechecker. Увлекается аналитикой и созданием бизнес-стратегии для продуктов SaaS.
Фейсбук
Линкедин
seo — Что произойдет, если на веб-сайте нет файла robots.txt?
спросил
12 лет, 9 месяцев назад
Изменено
7 месяцев назад
Просмотрено
25 тысяч раз
Если файл robots.txt отсутствует в корневом каталоге веб-сайта, как обстоят дела:
- сайт вообще не индексируется
- сайт индексируется без ограничений
По логике вещей должен быть вторым. Спрашиваю в связи с этим вопросом.
- поисковая оптимизация
- индексирование
- robots.txt
- поисковая система
Целью файла robots.txt является защита сканеров от определенных частей веб-сайта . Его отсутствие должно привести к тому, что весь ваш контент будет проиндексирован.
Из первого комментария к этому мета-вопросу следует, что файл robots.txt существовал, но был недоступен (по какой-либо причине), а не отсутствовал вообще. Этот может вызвать некоторые проблемы у поисковых роботов, но это предположение.
У меня нет файла robots.txt в моем блоге (самостоятельная установка WordPress), и он проиндексирован.
Robots.txt является строго добровольным соглашением среди поисковых систем; они свободны игнорировать его или реализовать любым удобным для себя способом. Тем не менее, за исключением случайных пауков, ищущих адреса электронной почты или тому подобное, они почти все уважают это. Его формат и логика очень, очень просты, а правило по умолчанию — разрешать (поскольку вы можете только или позволяют). Сайт без robots.txt будет полностью проиндексирован.
У меня не было robots.txt на десятках доменов, которые я зарегистрировал, некоторые еще в 1994 году, и у меня никогда не было проблем с их размещением в google/yahoo и т. д.
Даже на моем личном веб-сайте получает 150-200 пользователей в день от Google и не имеет файла robots.txt.
(Мне нравится трехминутная пауза между ответами на вопросы. Затем я получу робот-капчу. Иногда просто не стоит пытаться быть полезным.)
2
robots.txt является необязательным. Если он у вас есть, поисковые роботы, соответствующие стандартам, будут его уважать, если у вас его нет, все, что не запрещено в элементах HTML-META (Википедия), будет доступно для сканирования.
Сайт будет индексироваться без ограничений.
пауки будут следовать за всем, что найдут.
Перед сканированием вашего сайта мы выполнили обращение к файлу robots.txt, чтобы исключить сканирование страниц, которые не предназначены для показа в результатах поиска. Однако при попытке получить доступ к этому файлу ваш сервер вернул ошибку 5xx (недоступен). Чтобы исключить сканирование страниц, указанных в этом файле, оно было отложено.
Возможно, ваш хостинг-провайдер заблокировал доступ для робота Googlebot или были допущены ошибки в настройке брандмауэра.
Примечание. Если вы видите содержимое файла robots.txt, отличающееся от того, что обнаружили роботы Google, попросите своего хостинг-провайдера удалить все правила нашего сервера, которые могут влиять на передачу агентам пользователей разного содержимого вашего файла robots.txt.
Эта информация оказалась полезной?
Как можно улучшить эту статью?