Как работает наш мозг или как смоделировать душу?
Время на прочтение
11 мин
Количество просмотров 51K

Здравствуй, Geektimes! В ранее опубликованной статье, была представлена модель нервной системы, опишу теорию и принципы, которые легли в её основу.
Теория основана на анализе имеющейся информации о биологическом нейроне и нервной системе из современной нейробиологии и физиологии мозга.
Сначала приведу краткую информацию об объекте моделирования, вся информация изложена далее, учтена и использована в модели.
НЕЙРОН
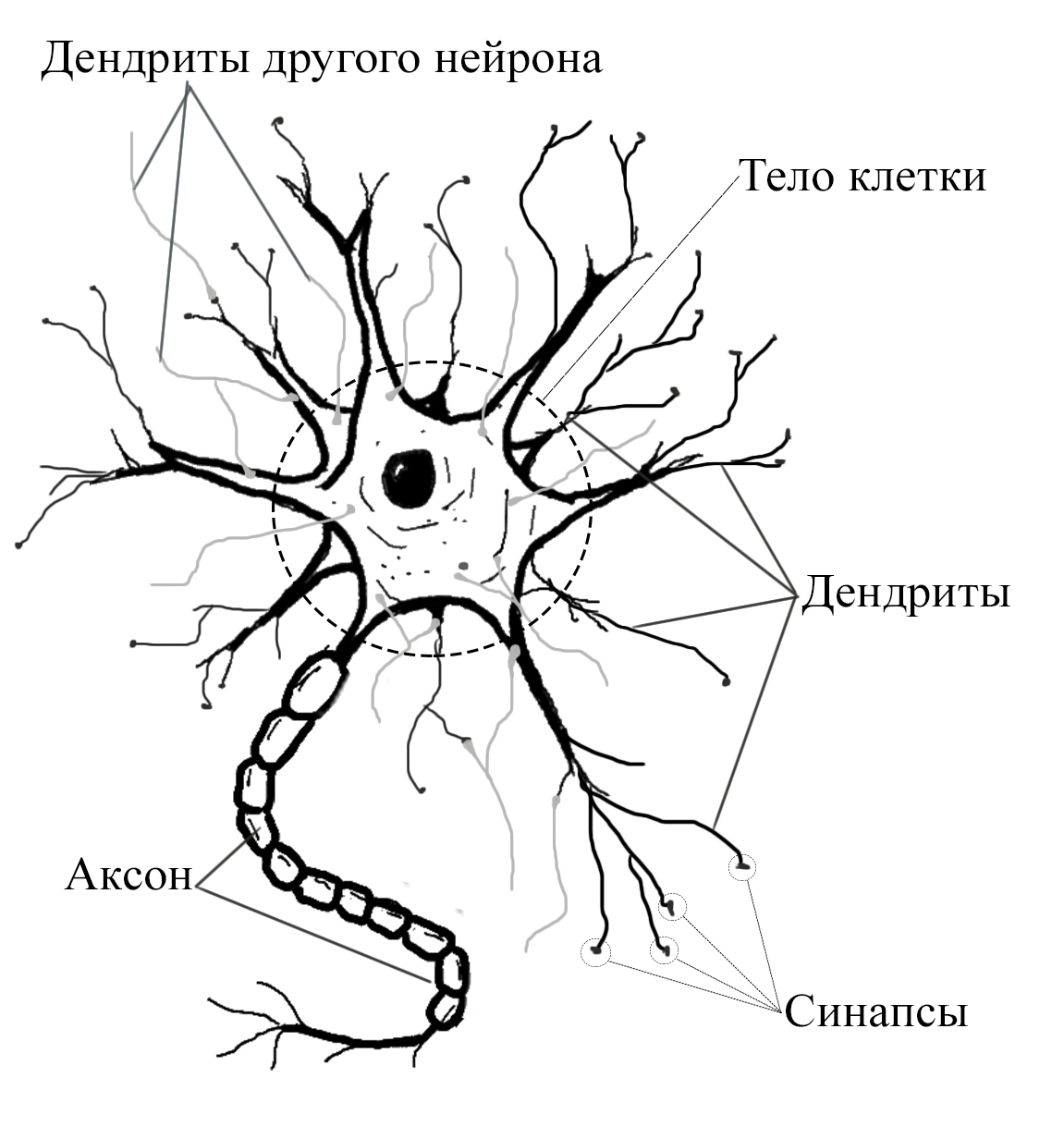
Нейрон является основным функциональным элементом нервной системы, он состоит из тела нервной клетки и её отростков. Существуют два вида отростков: аксоны и дендриты. Аксон – длинный покрытый миелиновой оболочкой отросток, предназначенный для передачи нервного импульса на далекие расстояния. Дендрит – короткий, ветвящийся отросток, благодаря которым происходит взаимосвязь с множеством соседних клеток.
ТРИ ТИПА НЕЙРОНОВ
Нейроны могут сильно отличаться по форме, размерам и конфигурации, не смотря на это, отмечается принципиальное сходство нервной ткани в различных участках нервной системе, отсутствуют и серьезные эволюционные различия. Нервная клетка моллюска Аплизии может выделять такие же нейромедиаторы и белки, что и клетка человека.
В зависимости от конфигурации выделяют три типа нейронов:
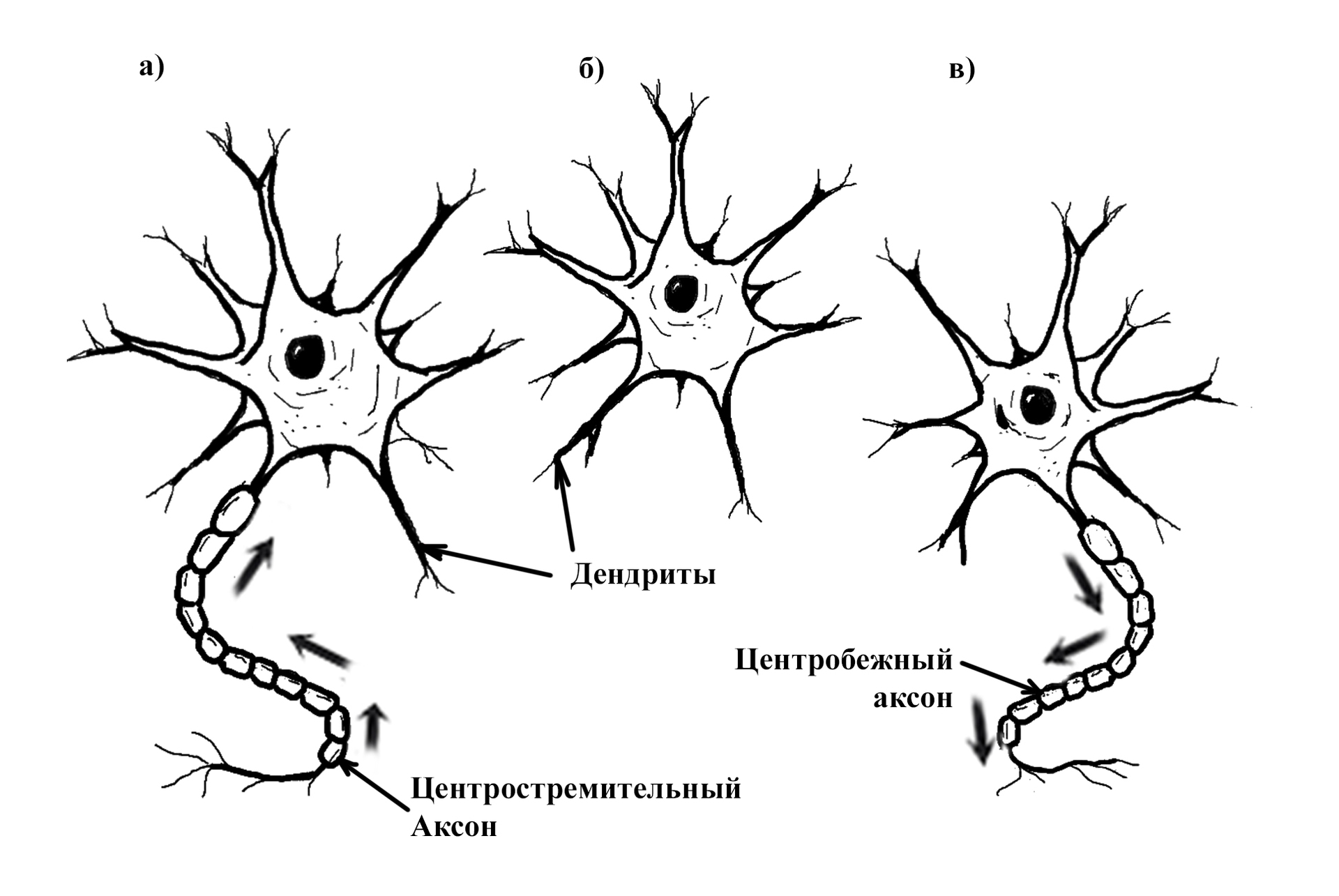
а) рецепторные, центростремительные, или афферентные нейроны, данные нейроны имеют центростремительный аксон, на конце которого имеются рецепторы, рецепторные или афферентные окончания. Эти нейроны можно определить, как элементы, передающие внешние сигналы в систему.
б) интернейроны (вставочные, контактные, или промежуточные) нейроны, не имеющие длинных отростков, но имеющие только дендриты. Таких нейронов в человеческом мозгу больше чем остальных. Данный вид нейронов является основным элементом рефлекторной дуги.
в) моторные, центробежные, или эфферентные, они имеют центростремительный аксон, который имеет эфферентные окончания передающий возбуждение мышечным или железистым клеткам. Эфферентные нейроны служат для передачи сигналов из нервной среды во внешнюю среду.
Обычно в статьях по искусственным нейронным сетям оговаривается наличие только моторных нейронов (с центробежным аксоном), которые связаны в слои иерархической структуры. Подобное описание применимо к биологической нервной системе, но является своего рода частным случаем, речь идет о структурах, базовых условных рефлексов. Чем выше в эволюционном значении нервная система, тем меньше в ней превалируют структуры типа «слои» или строгая иерархия.
ПЕРЕДАЧА НЕРВНОГО ВОЗБУЖДЕНИЯ
Передача возбуждения происходит от нейрона к нейрону, через специальные утолщения на концах дендритов, называемых синапсами. По типу передачи синапсы разделяют на два вида: химические и электрические. Электрические синапсы передают нервный импульс непосредственно через место контакта. Таких синапсов в нервных системах очень мало, в моделях не будут учитываться. Химические синапсы передают нервный импульс посредством специального вещества медиатора (нейромедиатора, нейротрансмиттера), данный вид синапса широко распространен и подразумевает вариативность в работе.
Важно отметить, что в биологическом нейроне постоянно происходят изменения, отращиваются новые дендриты и синапсы, возможны миграции нейронов. В местах контактов с другими нейронами образуются новообразования, для передающего нейрона — это синапс, для принимающего — это постсинаптическая мембрана, снабжаемая специальными рецепторами, реагирующими на медиатор, то есть можно говорить, что мембрана нейрона — это приемник, а синапсы на дендритах — это передатчики сигнала.
СИНАПС
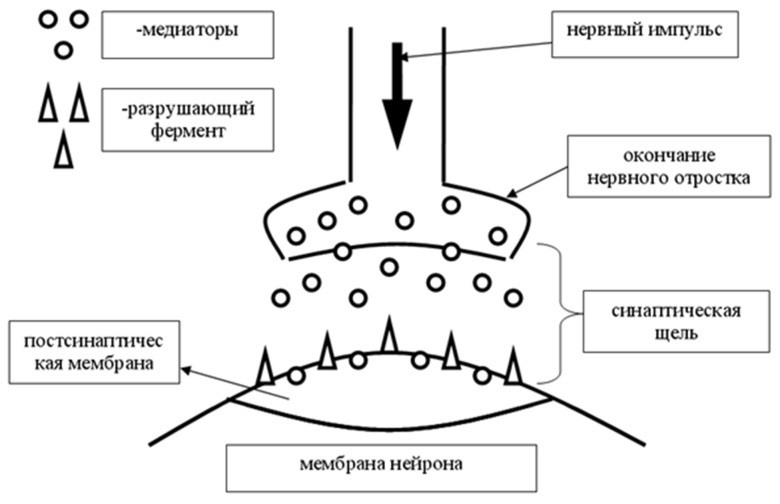
При активации синапса он выбрасывает порции медиатора, эти порции могут варьироваться, чем больше выделится медиатора, тем вероятнее, что принимаемая сигнал нервная клетка будет активирована. Медиатор, преодолевая синоптическую щель, попадает на постсинаптическую мембрану, на которой расположены рецепторы, реагирующие на медиатор. Далее медиатор может быть разрушен специальным разрушающим ферментом, либо поглощен обратно синапсом, это происходит для сокращения времени действия медиатора на рецепторы.
Так же помимо побудительного воздействия существуют синапсы, оказывающие тормозящее воздействие на нейрон. Обычно такие синапсы принадлежат определенным нейронам, которые обозначаются, как тормозящие нейроны.
Синапсов связывающих нейрон с одной и той же целевой клеткой, может быть множество. Для упрощения примем, всю совокупность, оказываемого воздействия одним нейроном, на другой целевой нейрон за синапс с определённой силой воздействия. Главной характеристикой синапса будет, является его сила.
СОСТОЯНИЕ ВОЗБУЖДЕНИЯ НЕЙРОНА
В состоянии покоя мембрана нейрона поляризована. Это означает, что по обе стороны мембраны располагаются частицы, несущие противоположные заряды. В состоянии покоя наружная поверхность мембраны заряжена положительно, внутренняя – отрицательно. Основными переносчиками зарядов в организме являются ионы натрия (Na+), калия (K+) и хлора (Cl-).
Разница между зарядами поверхности мембраны и внутри тела клетки составляет мембранный потенциал. Медиатор вызывает нарушения поляризации – деполяризацию. Положительные ионы снаружи мембраны устремляются через открытые каналы в тело клетки, меняя соотношение зарядов между поверхностью мембраны и телом клетки.
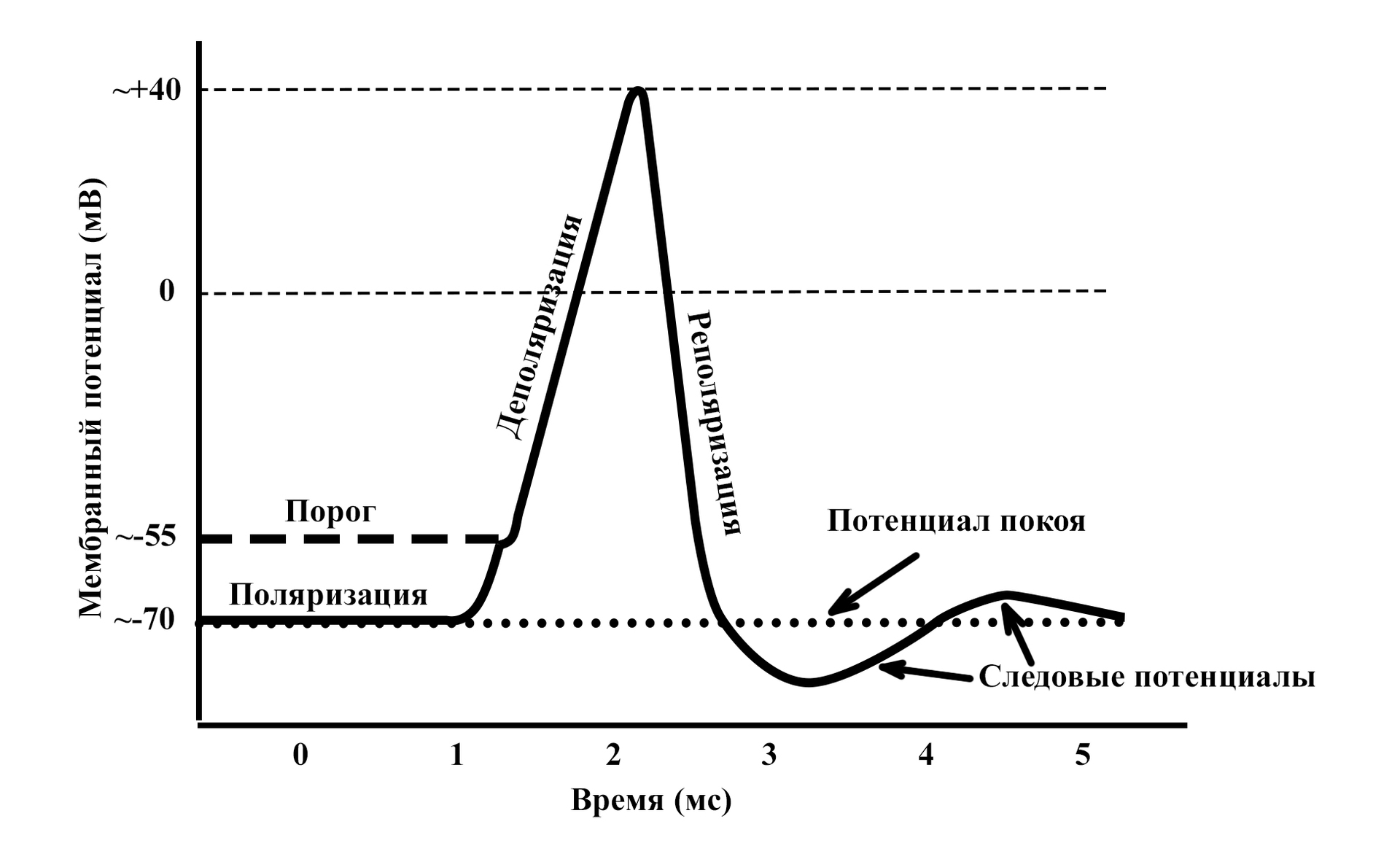
Изменение мембранного потенциала при возбуждении нейрона
Характер изменений мембранного потенциала при активации нервной ткани неизменен. Независимо от того кокой силы воздействия оказывается на нейрон, если сила превышает некоторое пороговое значение, ответ будет одинаков.
Забегая вперед, хочу отметить, что в работе нервной системы имеет значение даже следовые потенциалы (см. график выше). Они не появляются, вследствие каких-то гармонических колебаний уравновешивающих заряды, являются строгим проявлением определённой фазы состояния нервной ткани при возбуждении.
ТЕОРИЯ ЭЛЕКТРОМАГНИТНОГО ВЗАИМОДЕЙСТВИЯ
Итак, далее приведу теоретические предположения, которые позволят нам создавать математические модели. Главная идея заключается во взаимодействии между зарядами формирующихся внутри тела клетки, во время её активности, и зарядами с поверхностей мембран других активных клеток. Данные заряды являются разноименными, в связи этим можно предположить, как будут располагаться заряды в теле клетки под воздействием зарядов других активных клеток.
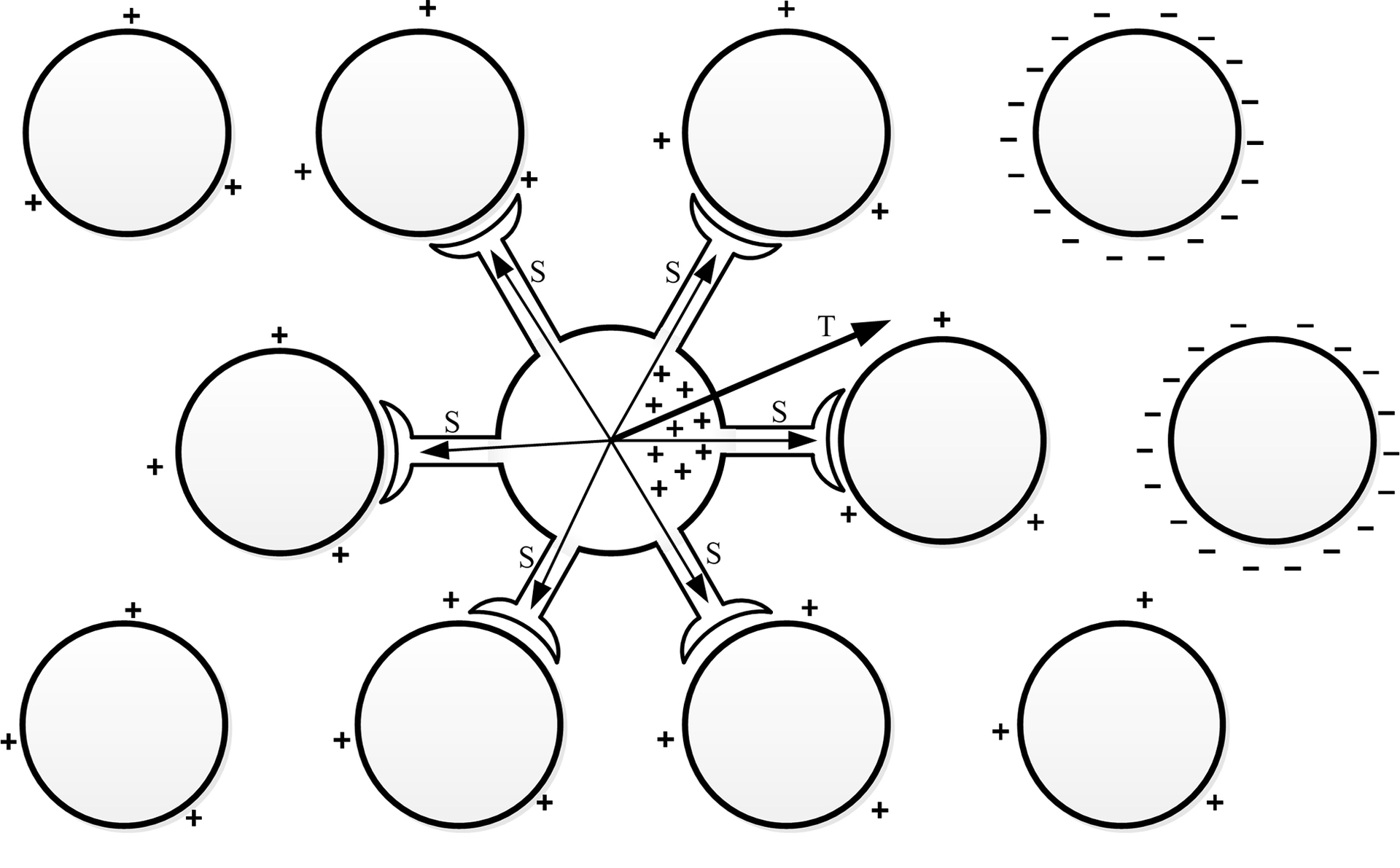
Можно сказать, что нейрон чувствует активность других нейронов на расстоянии, стремится направить распространения возбуждения в направлении других активных участков.
В момент активности нейрона можно рассчитать определённую точку в пространстве, которая определялась бы, как сумма масс зарядов, расположенных на поверхностях других нейронов. Указанную точку назовем точкой паттерна, её месторождение зависит от комбинации фаз активности всех нейронов нервной системы. Паттерном в физиологии нервной системы называется уникальная комбинация активных клеток, то есть можно говорить о влиянии возбуждённых участков мозга на работу отдельного нейрона.
Нужно представлять работу нейрона не просто как вычислителя, а своего рода ретранслятор возбуждения, который выбирает направления распространения возбуждения, таким образом, формируются сложные электрические схемы. Первоначально предполагалось, что нейрон просто избирательно отключает/включает для передачи свои синапсы, в зависимости от предпочитаемого направления возбуждения. Но более детальное изучение природы нейрона, привело к выводам, что нейрон может изменять степень воздействия на целевую клетку через силу своих синапсов, что делает нейрон более гибким и вариативным вычислительным элементом нервной системы.
Какое же направление для передачи возбуждения является предпочтительным? В различных экспериментах связанных с образованием безусловных рефлексов, можно определить, что в нервной системе образуются пути или рефлекторные дуги, которые связывают активируемые участки мозга при формировании безусловных рефлексов, создаются ассоциативные связи. Значит, нейрон должен передавать возбуждения к другим активным участкам мозга, запоминать направление и использовать его в дальнейшем.
Представим вектор начало, которого находится в центре активной клети, а конец направлен в точку паттерна определённую для данного нейрона. Обозначим, как вектор предпочитаемого направления распространения возбуждения (T, trend). В биологическом нейроне вектор Т может проявляться в структуре самой нейроплазмы, возможно, это каналы для движения ионов в теле клетки, или другие изменения в структуре нейрона.
Нейрон обладает свойством памяти, он может запоминать вектор Т, направление этого вектора, может меняться и перезаписываться в зависимости от внешних факторов. Степень с которой вектор Т может подвергается изменениям, называется нейропластичность.
Этот вектор в свою очередь оказывает влияние на работу синапсов нейрона. Для каждого синапса определим вектор S начало, которого находится в центре клетки, а конец направлен в центр целевого нейрона, с которым связан синапс. Теперь степень влияния для каждого синапса можно определить следующим образом: чем меньше угол между вектором T и S, тем больше синапс будет, усиливается; чем меньше угол, тем сильнее синапс будет ослабевать и возможно может прекратить передачу возбуждения. Каждый синапс имеет независимое свойство памяти, он помнит значение своей силы. Указанные значения изменяются при каждой активизации нейрона, под влиянием вектора Т, они либо увеличиваются, либо уменьшаются на определённое значение.
МАТЕМАТИЧЕСКАЯ МОДЕЛЬ
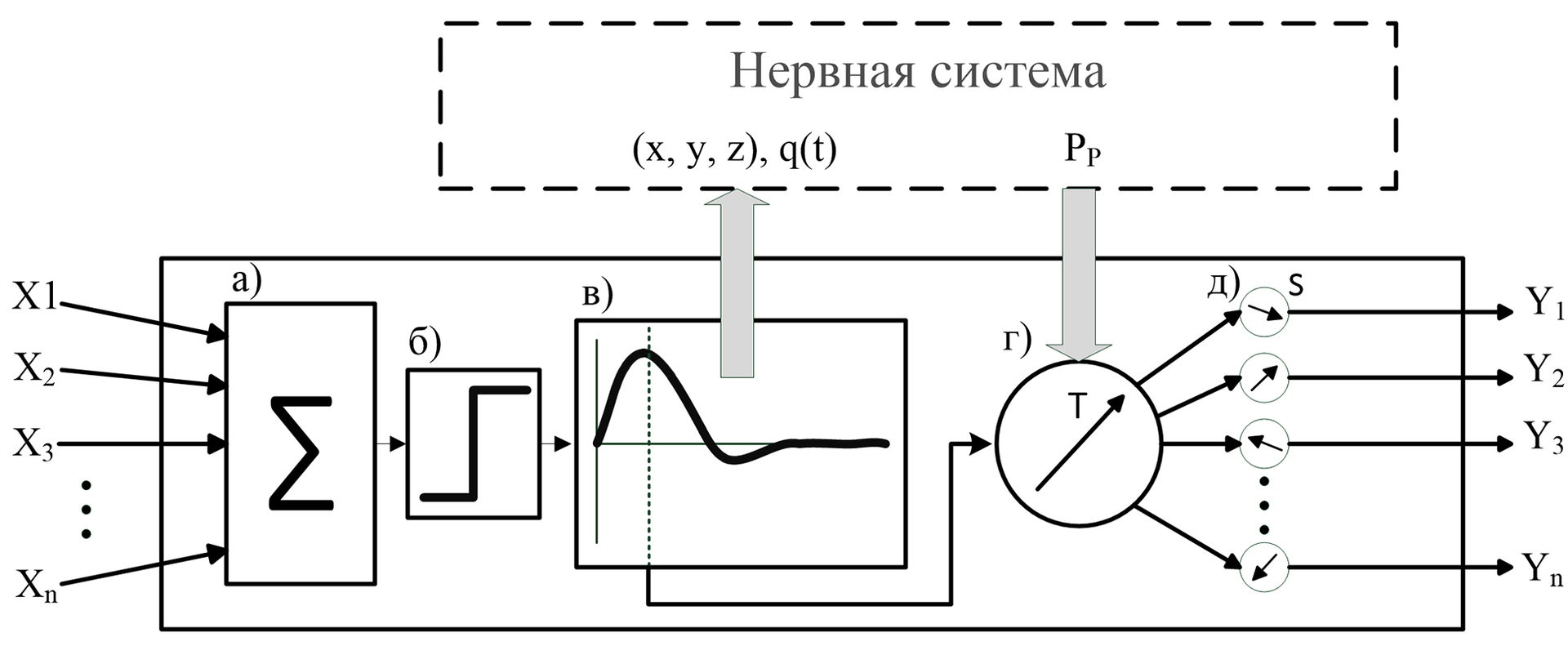
Входные сигналы (x1, x2,…xn) нейрона представляют собой вещественные числа, которые характеризуют силу синапсов нейронов, оказывающих воздействие на нейрон.
Положительное значение входа означает побудительное воздействие, оказываемое на нейрон, а отрицательное значение – тормозящее воздействие.
Для биологического нейрона не имеет значение, откуда поступил возбуждающий его сигнал, результат его активности будет идентичен. Нейрон будет активизирован, когда сумма воздействий на него будет превышать определённое пороговое значение. Поэтому, все сигналы проходят через сумматор (а), а поскольку нейроны и нервная система работают в реальном времени, следовательно, воздействие входов должно оцениваться в короткий промежуток времени, то есть воздействие синапса имеет временный характер.
Результат сумматора проходит пороговую функцию (б), если сумма превосходит пороговое значение, то это приводит к активности нейрона.
При активации нейрон сигнализирует о своей активности системе, передовая информацию о своём положении в пространстве нервной системы и заряде, изменяемом во времени (в).
Через определённое время, после активации нейрон передает возбуждение по всем имеющимся синапсам, предварительно производя пересчет их силы. Весь период активации нейрон перестает реагировать на внешние раздражители, то есть все воздействия синапсов других нейронов игнорируются. В период активации входит так же период восстановления нейрона.
Происходит корректировка вектора Т (г) с учётом значения точки паттерна Pp и уровнем нейропластичности. Далее происходит переоценка значений всех сил синапсов в нейроне(д).
Обратите внимание, что блоки (г) и (д) выполняются параллельно с блоком (в).
ЭФФЕКТ ВОЛНЫ
Если внимательно проанализировать предложенную модель, то можно увидеть, что источник возбуждения должен оказывать большее влияние на нейрон, чем другой удалённый, активный участок мозга. Следовательно возникает вопрос: почему же все равно происходит передача в направлении другого активного участка?
Данную проблему я смог определить, только создав компьютерную модель. Решение подсказал график изменения мембранного потенциала при активности нейрона.
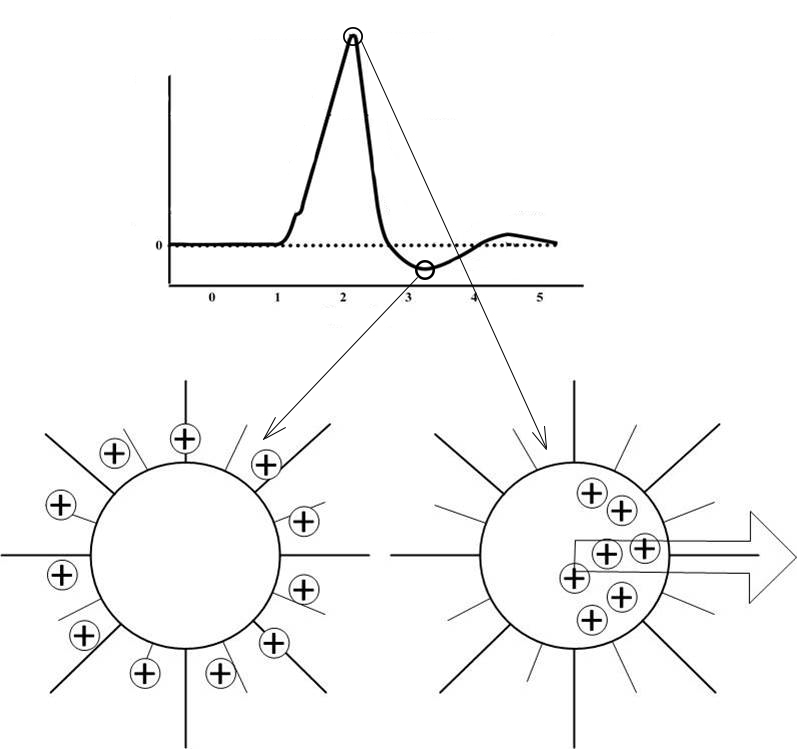
Усиленная реполяризация нейрона, как говорилось ранее, имеет важное значение для нервной системы, благодаря ей создается эффект волны, стремление нервного возбуждения распространятся от источника возбуждения.
При работе с моделью я наблюдал два эффекта, ели пренебречь следовым потенциалом или сделать его недостаточно большим, то возбуждение не распространяется от источников, а в большей степени стремится к локализации. Если сделать следовой потенциал сильно большим, то возбуждение стремится «разбежаться» в разные стороны, не только от своего источника, но и от других.
КОГНИТИВНАЯ КАРТА
Используя теорию электромагнитного взаимодействия, можно объяснить многие явления и сложные процессы, протекающие в нервной системе. К примеру, одним из последних открытий, которое широко обсуждается в науках о мозге, является открытие когнитивных карт в гиппокампе.
Гиппокамп – это отдел мозга, которому отвечает за кратковременную память. Эксперименты на крысах выявили, что определённому месту в лабиринте соответствует своя локализованная группа клеток в гиппокампе, причем, не имеет значение, как животное попадает в это место, все равно будет активирован соответствующий этому месту участок нервной ткани. Естественно, животное должно помнить данный лабиринт, не стоит рассчитывать на топологическое соответствие пространства лабиринта и когнитивной карты.
Каждое место в лабиринте представляется в мозге, как совокупность раздражителей различного характера: запахи, цвет стен, возможные примечательные объекты, характерные звуки и т. д. Указанные раздражители отражаются на коре, различных представительствах органов чувств, в виде всплесков активности в определённых комбинациях. Мозг одновременно обрабатывает информацию в нескольких отделах, зачастую информационные каналы разделяются, одна и та же информация поступает в различные участки мозга.

Активация нейронов места в зависимости от положения в лабиринте (активность разных нейронов показана разным цветом). источник
Гиппокамп расположен в центре мозга, вся кара и её области удалены от него, на одинаковые расстояния. Если определить для каждой уникальной комбинации раздражителей точку масс зарядов поверхностей нейронов, то можно увидеть, что указанные точки будут различны, и будут находиться примерно в центре мозга. К этим точкам будет стремиться и распространятся возбуждение в гиппокампе, формируя устойчивые участки возбуждения. Более того, поочередная смена комбинаций раздражителей, будет приводить к смещению точки паттерна. Участки когнитивной карты будут ассоциативно связываться друг с другом последовательно, что приведет к тому, что животное, помещенное в начало знакомого ей лабиринта, может вспомнить весь последующий путь.
Заключение
У многих возникнет вопрос, где в данной работе предпосылки к элементу разумности или проявления высшей интеллектуальной деятельности?
Важно отметить, что феномен человеческого поведения, есть следствие функционирования биологической структуры. Следовательно, чтобы имитировать разумное поведение, необходимо хорошо понимать принципы и особенности функционирования биологических структур. К сожалению, в науке биологии пока не представлен четкий алгоритм: как работает нейрон, как понимает, куда необходимо отращивать свои дендриты, как настроить свои синапсы, что бы в нервной системе смог сформироваться простой условный рефлекс, на подобие тех, которые демонстрировал и описывал в своих работах академик И.П. Павлов.
С другой стороны в науке об искусственном интеллекте, в восходящем (биологическом) подходе, сложилось парадоксальная ситуация, а именно: когда используемые в исследованиях модели основаны на устаревших представлениях о биологическом нейроне, консерватизм, в основе которого берётся персептрон без переосмысления его основных принципов, без обращения к биологическому первоисточнику, придумывается все более хитроумные алгоритмы и структуры, не имеющих биологических корней.
Конечно, никто не уменьшает достоинств классических нейронных сетей, которые дали множество полезных программных продуктов, но игра с ними не является путем к созданию интеллектуально действующей системы.
Более того, не редки заявления, о том, что нейрон подобен мощной вычислительной машине, приписывают свойство квантовых компьютеров. Из-за этой сверхсложности, нервной системе приписывается невозможность её повторения, ведь это соизмеримо с желанием смоделировать человеческую душу. Однако, в реальности природа идет по пути простоты и элегантности своих решений, перемещение зарядов на мембране клетки может служить, как для передачи нервного возбуждения, так и для трансляции информации о том, где происходит данная передача.
Несмотря на то, что указанная работа демонстрирует, как образуются элементарные условные рефлексы в нервной системе, она приближает к пониманию того, что такое интеллект и разумная деятельность.
Существуют еще множество аспектов работы нервной системы: механизмы торможения, принципы построения эмоций, организация безусловных рефлексов и обучение, без которых невозможно построить качественную модель нервной системы. Есть понимание, на интуитивном уровне, как работает нервная система, принципы которой возможно воплотить в моделях.
Создание первой модели помогли отработать и откорректировать представление об электромагнитном взаимодействии нейронов. Понять, как происходит формирование рефлекторных дуг, как каждый отдельный нейрон понимает, каким образом ему настроить свои синапсы для получения ассоциативных связей.
На данный момент я начал разрабатывать новую версию программы, которая позволит смоделировать многие другие аспекты работы нейрона и нервной системы.
Прошу принять активное участие в обсуждении выдвинутых здесь гипотез и предположений, так как я могу относиться к своим идеям предвзято. Ваше мнение очень важно для меня.
Модель(Windows PC) + туториал
Модель(Windows PC) Скачать
В предыдущей главе мы ознакомились с такими понятиями, как искусственный интеллект, машинное обучение и искусственные нейронные сети.
В этой главе я детально опишу модель искусственного нейрона, расскажу о подходах к обучению сети, а также опишу некоторые известные виды искусственных нейронных сетей, которые мы будем изучать в следующих главах.
Упрощение
В прошлой главе я постоянно говорил о каких-то серьезных упрощениях. Причина упрощений заключается в том, что никакие современные компьютеры не могут быстро моделировать такие сложные системы, как наш мозг. К тому же, как я уже говорил, наш мозг переполнен различными биологическими механизмами, не относящиеся к обработке информации.
Нам нужна модель преобразования входного сигнала в нужный нам выходной. Все остальное нас не волнует. Начинаем упрощать.
Биологическая структура → схема
В предыдущей главе вы поняли, насколько сложно устроены биологические нейронные сети и биологические нейроны. Вместо изображения нейронов в виде чудовищ с щупальцами давайте просто будем рисовать схемы.
Вообще говоря, есть несколько способов графического изображения нейронных сетей и нейронов. Здесь мы будем изображать искусственные нейроны в виде кружков.
Вместо сложного переплетения входов и выходов будем использовать стрелки, обозначающие направление движения сигнала.
Таким образом искусственная нейронная сеть может быть представлена в виде совокупности кружков (искусственных нейронов), связанных стрелками.

Электрические сигналы → числа
В реальной биологической нейронной сети от входов сети к выходам передается электрический сигнал. В процессе прохода по нейронной сети он может изменяться.

Электрический сигнал всегда будет электрическим сигналом. Концептуально ничего не изменяется. Но что же тогда меняется? Меняется величина этого электрического сигнала (сильнее/слабее). А любую величину всегда можно выразить числом (больше/меньше).
В нашей модели искусственной нейронной сети нам совершенно не нужно реализовывать поведение электрического сигнала, так как от его реализации все равно ничего зависеть не будет.
На входы сети мы будем подавать какие-то числа, символизирующие величины электрического сигнала, если бы он был. Эти числа будут продвигаться по сети и каким-то образом меняться. На выходе сети мы получим какое-то результирующее число, являющееся откликом сети.
Для удобства все равно будем называть наши числа, циркулирующие в сети, сигналами.
Синапсы → веса связей
Вспомним картинку из первой главы, на которой цветом были изображены связи между нейронами – синапсы. Синапсы могут усиливать или ослаблять проходящий по ним электрический сигнал.

Давайте характеризовать каждую такую связь определенным числом, называемым весом данной связи. Сигнал, прошедший через данную связь, умножается на вес соответствующей связи.
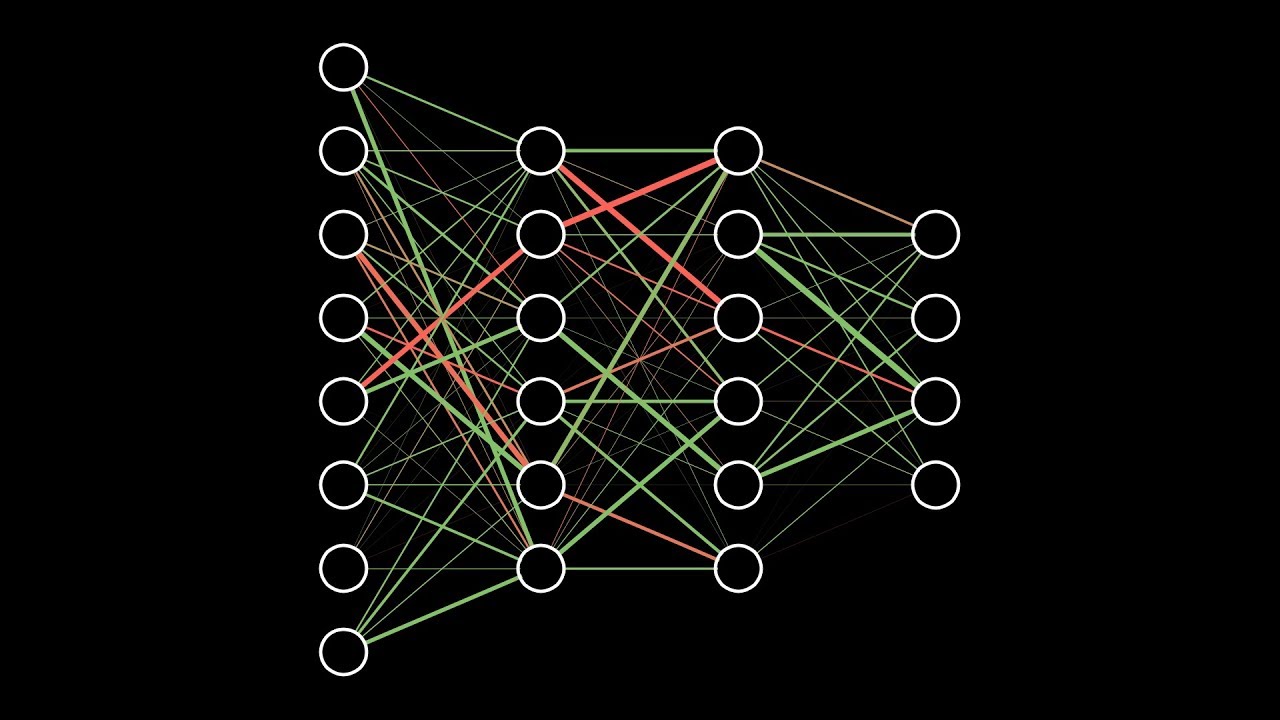
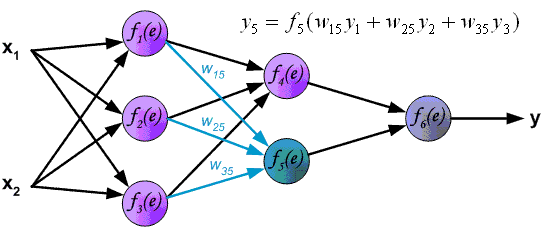
Это ключевой момент в концепции искусственных нейронных сетей, я объясню его подробнее. Посмотрите на картинку ниже. Теперь каждой черной стрелке (связи) на этой картинке соответствует некоторое число ( w_i ) (вес связи). И когда сигнал проходит по этой связи, его величина умножается на вес этой связи.

На приведенном выше рисунке вес стоит не у каждой связи лишь потому, что там нет места для обозначений. В реальности у каждой ( i )-ой связи свой собственный ( w_i )-ый вес.
Искусственный нейрон
Теперь мы переходим к рассмотрению внутренней структуры искусственного нейрона и того, как он преобразует поступающий на его входы сигнал.
На рисунке ниже представлена полная модель искусственного нейрона.

Не пугайтесь, ничего сложного здесь нет. Давайте рассмотрим все подробно слева направо.
Входы, веса и сумматор
У каждого нейрона, в том числе и у искусственного, должны быть какие-то входы, через которые он принимает сигнал. Мы уже вводили понятие весов, на которые умножаются сигналы, проходящие по связи. На картинке выше веса изображены кружками.
Поступившие на входы сигналы умножаются на свои веса. Сигнал первого входа ( x_1 ) умножается на соответствующий этому входу вес ( w_1 ). В итоге получаем ( x_1w_1 ). И так до ( n )-ого входа. В итоге на последнем входе получаем ( x_nw_n ).
Теперь все произведения передаются в сумматор. Уже исходя из его названия можно понять, что он делает. Он просто суммирует все входные сигналы, умноженные на соответствующие веса:
[ x_1w_1+x_2w_2+cdots+x_nw_n = sumlimits^n_{i=1}x_iw_i ]
Результатом работы сумматора является число, называемое взвешенной суммой.
Взвешенная сумма (Weighted sum) (( net )) — сумма входных сигналов, умноженных на соответствующие им веса.
[ net=sumlimits^n_{i=1}x_iw_i ]
Роль сумматора очевидна – он агрегирует все входные сигналы (которых может быть много) в какое-то одно число – взвешенную сумму, которая характеризует поступивший на нейрон сигнал в целом. Еще взвешенную сумму можно представить как степень общего возбуждения нейрона.
Пример
Для понимания роли последнего компонента искусственного нейрона – функции активации – я приведу аналогию.
Давайте рассмотрим один искусственный нейрон. Его задача – решить, ехать ли отдыхать на море. Для этого на его входы мы подаем различные данные. Пусть у нашего нейрона будет 4 входа:
- Стоимость поездки
- Какая на море погода
- Текущая обстановка с работой
- Будет ли на пляже закусочная
Все эти параметры будем характеризовать 0 или 1. Соответственно, если погода на море хорошая, то на этот вход подаем 1. И так со всеми остальными параметрами.
Если у нейрона есть четыре входа, то должно быть и четыре весовых коэффициента. В нашем примере весовые коэффициенты можно представить как показатели важности каждого входа, влияющие на общее решение нейрона. Веса входов распределим следующим образом:
- 5
- 4
- 1
- 1
Нетрудно заметить, что очень большую роль играют факторы стоимости и погоды на море (первые два входа). Они же и будут играть решающую роль при принятии нейроном решения.
Пусть на входы нашего нейрона мы подаем следующие сигналы:
- 1
- 0
- 0
- 1
Умножаем веса входов на сигналы соответствующих входов:
- 5
- 0
- 0
- 1
Взвешенная сумма для такого набора входных сигналов равна 6:
[ net=sumlimits^4_{i=1}x_iw_i = 5 + 0 + 0 + 1 =6 ]
Все классно, но что делать дальше? Как нейрон должен решить, ехать на море или нет? Очевидно, нам нужно как-то преобразовать нашу взвешенную сумму и получить ответ.
Вот на сцену выходит функция активации.
Функция активации
Просто так подавать взвешенную сумму на выход достаточно бессмысленно. Нейрон должен как-то обработать ее и сформировать адекватный выходной сигнал. Именно для этих целей и используют функцию активации.
Она преобразует взвешенную сумму в какое-то число, которое и является выходом нейрона (выход нейрона обозначим переменной ( out )).
Для разных типов искусственных нейронов используют самые разные функции активации. В общем случае их обозначают символом ( phi(net) ). Указание взвешенного сигнала в скобках означает, что функция активации принимает взвешенную сумму как параметр.
Функция активации (Activation function) (( phi(net) )) — функция, принимающая взвешенную сумму как аргумент. Значение этой функции и является выходом нейрона (( out )).
[ out=phi(net) ]
Далее мы подробно рассмотрим самые известные функции активации.
Функция единичного скачка
Самый простой вид функции активации. Выход нейрона может быть равен только 0 или 1. Если взвешенная сумма больше определенного порога ( b ), то выход нейрона равен 1. Если ниже, то 0.
Как ее можно использовать? Предположим, что мы поедем на море только тогда, когда взвешенная сумма больше или равна 5. Значит наш порог равен 5:
[ b=5 ]
В нашем примере взвешенная сумма равнялась 6, а значит выходной сигнал нашего нейрона равен 1. Итак, мы едем на море.
Однако если бы погода на море была бы плохой, а также поездка была бы очень дорогой, но имелась бы закусочная и обстановка с работой нормальная (входы: 0011), то взвешенная сумма равнялась бы 2, а значит выход нейрона равнялся бы 0. Итак, мы никуда не едем.
В общем, нейрон смотрит на взвешенную сумму и если она получается больше его порога, то нейрон выдает выходной сигнал, равный 1.
Графически эту функцию активации можно изобразить следующим образом.

На горизонтальной оси расположены величины взвешенной суммы. На вертикальной оси — значения выходного сигнала. Как легко видеть, возможны только два значения выходного сигнала: 0 или 1. Причем 0 будет выдаваться всегда от минус бесконечности и вплоть до некоторого значения взвешенной суммы, называемого порогом. Если взвешенная сумма равна порогу или больше него, то функция выдает 1. Все предельно просто.
Теперь запишем эту функцию активации математически. Почти наверняка вы сталкивались с таким понятием, как составная функция. Это когда мы под одной функцией объединяем несколько правил, по которым рассчитывается ее значение. В виде составной функции функция единичного скачка будет выглядеть следующим образом:
[ out(net) = begin{cases} 0, net < b \ 1, net geq b end{cases} ]
В этой записи нет ничего сложного. Выход нейрона (( out )) зависит от взвешенной суммы (( net )) следующим образом: если ( net ) (взвешенная сумма) меньше какого-то порога (( b )), то ( out ) (выход нейрона) равен 0. А если ( net ) больше или равен порогу ( b ), то ( out ) равен 1.
Сигмоидальная функция
На самом деле существует целое семейство сигмоидальных функций, некоторые из которых применяют в качестве функции активации в искусственных нейронах.
Все эти функции обладают некоторыми очень полезными свойствами, ради которых их и применяют в нейронных сетях. Эти свойства станут очевидными после того, как вы увидите графики этих функций.
Итак… самая часто используемая в нейронных сетях сигмоида — логистическая функция.

График этой функции выглядит достаточно просто. Если присмотреться, то можно увидеть некоторое подобие английской буквы ( S ), откуда и пошло название семейства этих функций.
А вот так она записывается аналитически:
[ out(net)=frac{1}{1+exp(-a cdot net)} ]
Что за параметр ( a )? Это какое-то число, которое характеризует степень крутизны функции. Ниже представлены логистические функции с разным параметром ( a ).

Вспомним наш искусственный нейрон, определяющий, надо ли ехать на море. В случае с функцией единичного скачка все было очевидно. Мы либо едем на море (1), либо нет (0).
Здесь же случай более приближенный к реальности. Мы до конца полностью не уверены (в особенности, если вы параноик) – стоит ли ехать? Тогда использование логистической функции в качестве функции активации приведет к тому, что вы будете получать цифру между 0 и 1. Причем чем больше взвешенная сумма, тем ближе выход будет к 1 (но никогда не будет точно ей равен). И наоборот, чем меньше взвешенная сумма, тем ближе выход нейрона будет к 0.
Например, выход нашего нейрона равен 0.8. Это значит, что он считает, что поехать на море все-таки стоит. Если бы его выход был бы равен 0.2, то это означает, что он почти наверняка против поездки на море.
Какие же замечательные свойства имеет логистическая функция?
- она является «сжимающей» функцией, то есть вне зависимости от аргумента (взвешенной суммы), выходной сигнал всегда будет в пределах от 0 до 1
- она более гибкая, чем функция единичного скачка – ее результатом может быть не только 0 и 1, но и любое число между ними
- во всех точках она имеет производную, и эта производная может быть выражена через эту же функцию
Именно из-за этих свойств логистическая функция чаще всего используются в качестве функции активации в искусственных нейронах.
Гиперболический тангенс
Однако есть и еще одна сигмоида – гиперболический тангенс. Он применяется в качестве функции активации биологами для более реалистичной модели нервной клетки.
Такая функция позволяет получить на выходе значения разных знаков (например, от -1 до 1), что может быть полезным для ряда сетей.
Функция записывается следующим образом:
[ out(net) = tanhleft(frac{net}{a}right) ]
В данной выше формуле параметр ( a ) также определяет степень крутизны графика этой функции.
А вот так выглядит график этой функции.

Как видите, он похож на график логистической функции. Гиперболический тангенс обладает всеми полезными свойствами, которые имеет и логистическая функция.
Что мы узнали?
Теперь вы получили полное представление о внутренней структуре искусственного нейрона. Я еще раз приведу краткое описание его работы.
У нейрона есть входы. На них подаются сигналы в виде чисел. Каждый вход имеет свой вес (тоже число). Сигналы на входе умножаются на соответствующие веса. Получаем набор «взвешенных» входных сигналов.
Далее этот набор попадает в сумматор, которой просто складывает все входные сигналы, помноженные на веса. Получившееся число называют взвешенной суммой.
Затем взвешенная сумма преобразуется функцией активации и мы получаем выход нейрона.
Сформулируем теперь самое короткое описание работы нейрона – его математическую модель:
Математическая модель искусственного нейрона с ( n ) входами:
[ out=phileft(sumlimits^n_{i=1}x_iw_iright) ]
где
( phi ) – функция активации
( sumlimits^n_{i=1}x_iw_i ) – взвешенная сумма, как сумма ( n ) произведений входных сигналов на соответствующие веса.
Виды ИНС
Мы разобрались со структурой искусственного нейрона. Искусственные нейронные сети состоят из совокупности искусственных нейронов. Возникает логичный вопрос – а как располагать/соединять друг с другом эти самые искусственные нейроны?
Как правило, в большинстве нейронных сетей есть так называемый входной слой, который выполняет только одну задачу – распределение входных сигналов остальным нейронам. Нейроны этого слоя не производят никаких вычислений.
А дальше начинаются различия…
Однослойные нейронные сети
В однослойных нейронных сетях сигналы с входного слоя сразу подаются на выходной слой. Он производит необходимые вычисления, результаты которых сразу подаются на выходы.
Выглядит однослойная нейронная сеть следующим образом:

На этой картинке входной слой обозначен кружками (он не считается за слой нейронной сети), а справа расположен слой обычных нейронов.
Нейроны соединены друг с другом стрелками. Над стрелками расположены веса соответствующих связей (весовые коэффициенты).
Однослойная нейронная сеть (Single-layer neural network) — сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
Многослойные нейронные сети
Такие сети, помимо входного и выходного слоев нейронов, характеризуются еще и скрытым слоем (слоями). Понять их расположение просто – эти слои находятся между входным и выходным слоями.

Такая структура нейронных сетей копирует многослойную структуру определенных отделов мозга.

Название скрытый слой получил неслучайно. Дело в том, что только относительно недавно были разработаны методы обучения нейронов скрытого слоя. До этого обходились только однослойными нейросетями.
Многослойные нейронные сети обладают гораздо большими возможностями, чем однослойные.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Многослойная нейронная сеть (Multilayer neural network) — нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
Сети прямого распространения
Можно заметить одну очень интересную деталь на картинках нейросетей в примерах выше.
Во всех примерах стрелки строго идут слева направо, то есть сигнал в таких сетях идет строго от входного слоя к выходному.
Сети прямого распространения (Feedforward neural network) (feedforward сети) — искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
Однако никто не запрещает сигналу идти и в обратную сторону.
Сети с обратными связями
В сетях такого типа сигнал может идти и в обратную сторону. В чем преимущество?
Дело в том, что в сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах.
А в сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).

Возможность сигналов циркулировать в сети открывает новые, удивительные возможности нейронных сетей. С помощью таких сетей можно создавать нейросети, восстанавливающие или дополняющие сигналы. Другими словами такие нейросети имеют свойства кратковременной памяти (как у человека).
Сети с обратными связями (Recurrent neural network) — искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
Обучение нейронной сети
Теперь давайте чуть более подробно рассмотрим вопрос обучения нейронной сети. Что это такое? И каким образом это происходит?
Что такое обучение сети?
Искусственная нейронная сеть – это совокупность искусственных нейронов. Теперь давайте возьмем, например, 100 нейронов и соединим их друг с другом. Ясно, что при подаче сигнала на вход, мы получим что-то бессмысленное на выходе.
Значит нам надо менять какие-то параметры сети до тех пор, пока входной сигнал не преобразуется в нужный нам выходной.
Что мы можем менять в нейронной сети?
Изменять общее количество искусственных нейронов бессмысленно по двум причинам. Во-первых, увеличение количества вычислительных элементов в целом лишь делает систему тяжеловеснее и избыточнее. Во-вторых, если вы соберете 1000 дураков вместо 100, то они все-равно не смогут правильно ответить на вопрос.
Сумматор изменить не получится, так как он выполняет одну жестко заданную функцию – складывать. Если мы его заменим на что-то или вообще уберем, то это вообще уже не будет искусственным нейроном.
Если менять у каждого нейрона функцию активации, то мы получим слишком разношерстную и неконтролируемую нейронную сеть. К тому же, в большинстве случаев нейроны в нейронных сетях одного типа. То есть они все имеют одну и ту же функцию активации.
Остается только один вариант – менять веса связей.
Обучение нейронной сети (Training) — поиск такого набора весовых коэффициентов, при котором входной сигнал после прохода по сети преобразуется в нужный нам выходной.
Такой подход к термину «обучение нейронной сети» соответствует и биологическим нейросетям. Наш мозг состоит из огромного количества связанных друг с другом нейросетей. Каждая из них в отдельности состоит из нейронов одного типа (функция активации одинаковая). Мы обучаемся благодаря изменению синапсов – элементов, которые усиливают/ослабляют входной сигнал.
Однако есть еще один важный момент. Если обучать сеть, используя только один входной сигнал, то сеть просто «запомнит правильный ответ». Со стороны будет казаться, что она очень быстро «обучилась». И как только вы подадите немного измененный сигнал, ожидая увидеть правильный ответ, то сеть выдаст бессмыслицу.
В самом деле, зачем нам сеть, определяющая лицо только на одном фото. Мы ждем от сети способности обобщать какие-то признаки и узнавать лица и на других фотографиях тоже.
Именно с этой целью и создаются обучающие выборки.
Обучающая выборка (Training set) — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит обучение сети.
После обучения сети, то есть когда сеть выдает корректные результаты для всех входных сигналов из обучающей выборки, ее можно использовать на практике.
Однако прежде чем пускать свежеиспеченную нейросеть в бой, часто производят оценку качества ее работы на так называемой тестовой выборке.
Тестовая выборка (Testing set) — конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит оценка качества работы сети.
Мы поняли, что такое «обучение сети» – подбор правильного набора весов. Теперь возникает вопрос – а как можно обучать сеть? В самом общем случае есть два подхода, приводящие к разным результатам: обучение с учителем и обучение без учителя.
Обучение с учителем
Суть данного подхода заключается в том, что вы даете на вход сигнал, смотрите на ответ сети, а затем сравниваете его с уже готовым, правильным ответом.
Важный момент. Не путайте правильные ответы и известный алгоритм решения! Вы можете обвести пальцем лицо на фото (правильный ответ), но не сможете сказать, как это сделали (известный алгоритм). Тут такая же ситуация.
Затем, с помощью специальных алгоритмов, вы меняете веса связей нейронной сети и снова даете ей входной сигнал. Сравниваете ее ответ с правильным и повторяете этот процесс до тех пор, пока сеть не начнет отвечать с приемлемой точностью (как я говорил в 1 главе, однозначно точных ответов сеть давать не может).
Обучение с учителем (Supervised learning) — вид обучения сети, при котором ее веса меняются так, чтобы ответы сети минимально отличались от уже готовых правильных ответов.
Где взять правильные ответы?
Если мы хотим, чтобы сеть узнавала лица, мы можем создать обучающую выборку на 1000 фотографий (входные сигналы) и самостоятельно выделить на ней лица (правильные ответы).
Если мы хотим, чтобы сеть прогнозировала рост/падение цен, то обучающую выборку надо делать, основываясь на прошлых данных. В качестве входных сигналов можно брать определенные дни, общее состояние рынка и другие параметры. А в качестве правильных ответов – рост и падение цены в те дни.
И так далее…
Стоит отметить, что учитель, конечно же, не обязательно человек. Дело в том, что порой сеть приходится тренировать часами и днями, совершая тысячи и десятки тысяч попыток. В 99% случаев эту роль выполняет компьютер, а точнее, специальная компьютерная программа.
Обучение без учителя
Обучение без учителя применяют тогда, когда у нас нет правильных ответов на входные сигналы. В этом случае вся обучающая выборка состоит из набора входных сигналов.
Что же происходит при таком обучении сети? Оказывается, что при таком «обучении» сеть начинает выделять классы подаваемых на вход сигналов. Короче говоря – сеть начинает кластеризацию.
Например, вы демонстрируете сети конфеты, пирожные и торты. Вы никак не регулируете работу сети. Вы просто подаете на ее входы данные о данном объекте. Со временем сеть начнет выдавать сигналы трех разных типов, которые и отвечают за объекты на входе.
Обучение без учителя (Unsupervised learning) — вид обучения сети, при котором сеть самостоятельно классифицирует входные сигналы. Правильные (эталонные) выходные сигналы не демонстрируются.
Выводы
В этой главе вы узнали все о структуре искусственного нейрона, а также получили полное представление о том, как он работает (и о его математической модели).
Более того, вы теперь знаете о различных видах искусственных нейронных сетей: однослойные, многослойные, а также feedforward сети и сети с обратными связями.
Вы также ознакомились с тем, что представляет собой обучение сети с учителем и без учителя.
Вы уже знаете необходимую теорию. Последующие главы – рассмотрение конкретных видов нейронных сетей, конкретные алгоритмы их обучения и практика программирования.
Вопросы и задачи
Материал этой главы надо знать очень хорошо, так как в ней содержатся основные теоретические сведения по искусственным нейронным сетям. Обязательно добейтесь уверенных и правильных ответов на все нижеприведенные вопросы и задачи.
Опишите упрощения ИНС по сравнению с биологическими нейросетями.
Из каких элементов состоит искусственный нейрон?
Что такое взвешенная сумма? Какой компонент искусственного нейрона ее вычисляет?

Вычислите взвешенную сумму нейрона (рисунок выше)
Что такое функция активации?
Запишите математическую модель искусственного нейрона.
Чем отличаются однослойные и многослойные нейронные сети?
В чем отличие feedforward сетей от сетей с обратными связями?
Что такое обучающая выборка? В чем ее смысл?
Что понимают под обучением сети?
Что такое обучение с учителем и без него?
При помощи множества анимаций на примере задачи распознавания цифр и модели перцептрона дано наглядное введение в процесс обучения нейросети.
Статьи на тему, что такое искусственный интеллект, давно написаны. А вот математическая сторона медали 
Продолжаем серию первоклассных иллюстративных курсов 3Blue1Brown (смотрите наши предыдущие обзоры по линейной алгебре и матанализу) курсом по нейронным сетям.
Первое видео посвящено структуре компонентов нейронной сети, второе – ее обучению, третье – алгоритму этого процесса. В качестве задания для обучения взята классическая задача распознавания цифр, написанных от руки.
Детально рассматривается многослойный перцептрон – базисная (но уже достаточно сложная) модель для понимания любых более современных вариантов нейронных сетей.
1. Компоненты нейронной сети
Цель первого видео состоит в том, чтобы показать, что собой представляет нейронная сеть. На примере задачи распознавания цифр визуализируется структура компонентов нейросети. Видео имеет русские субтитры.
Постановка задачи распознавания цифр
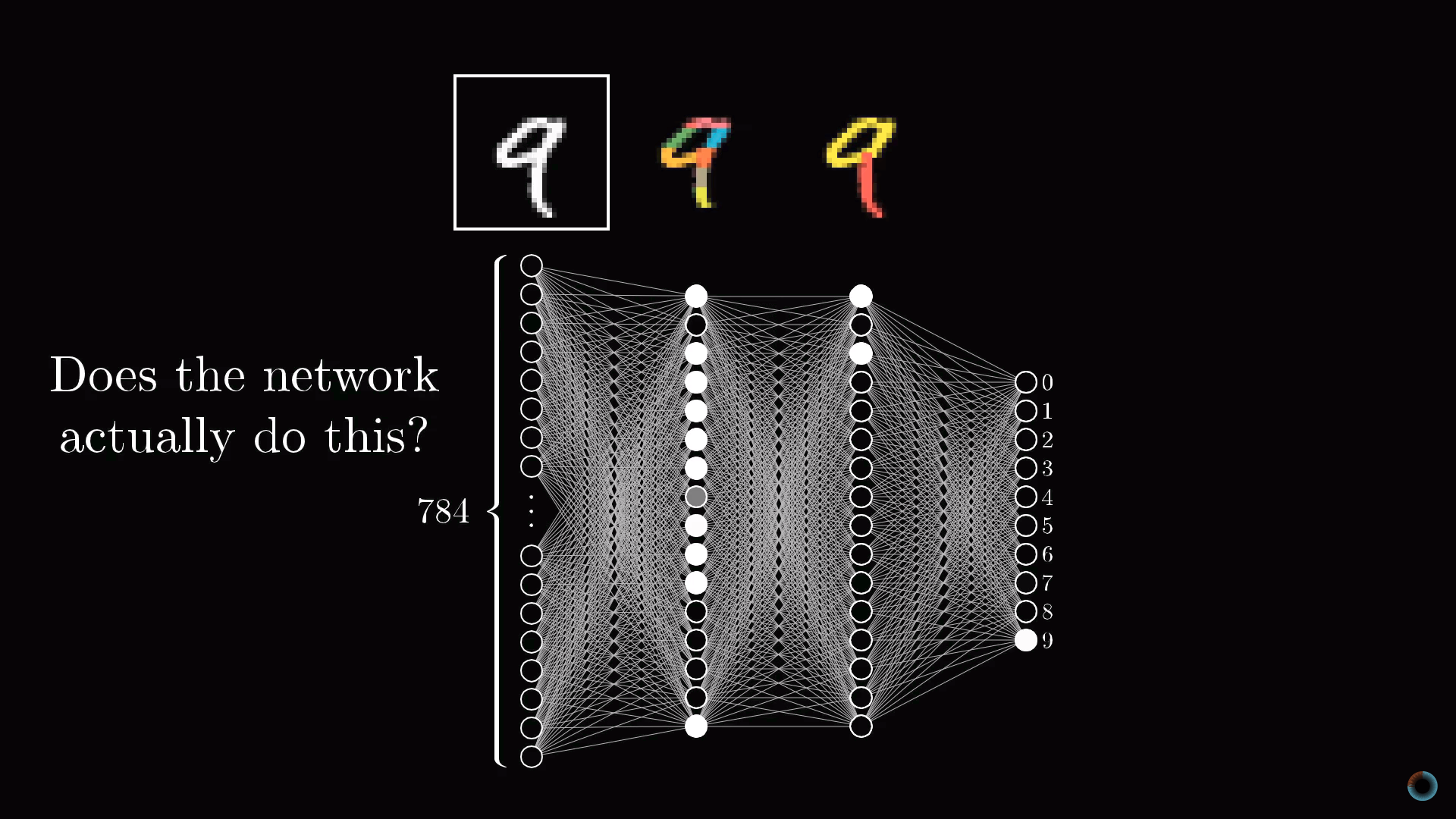
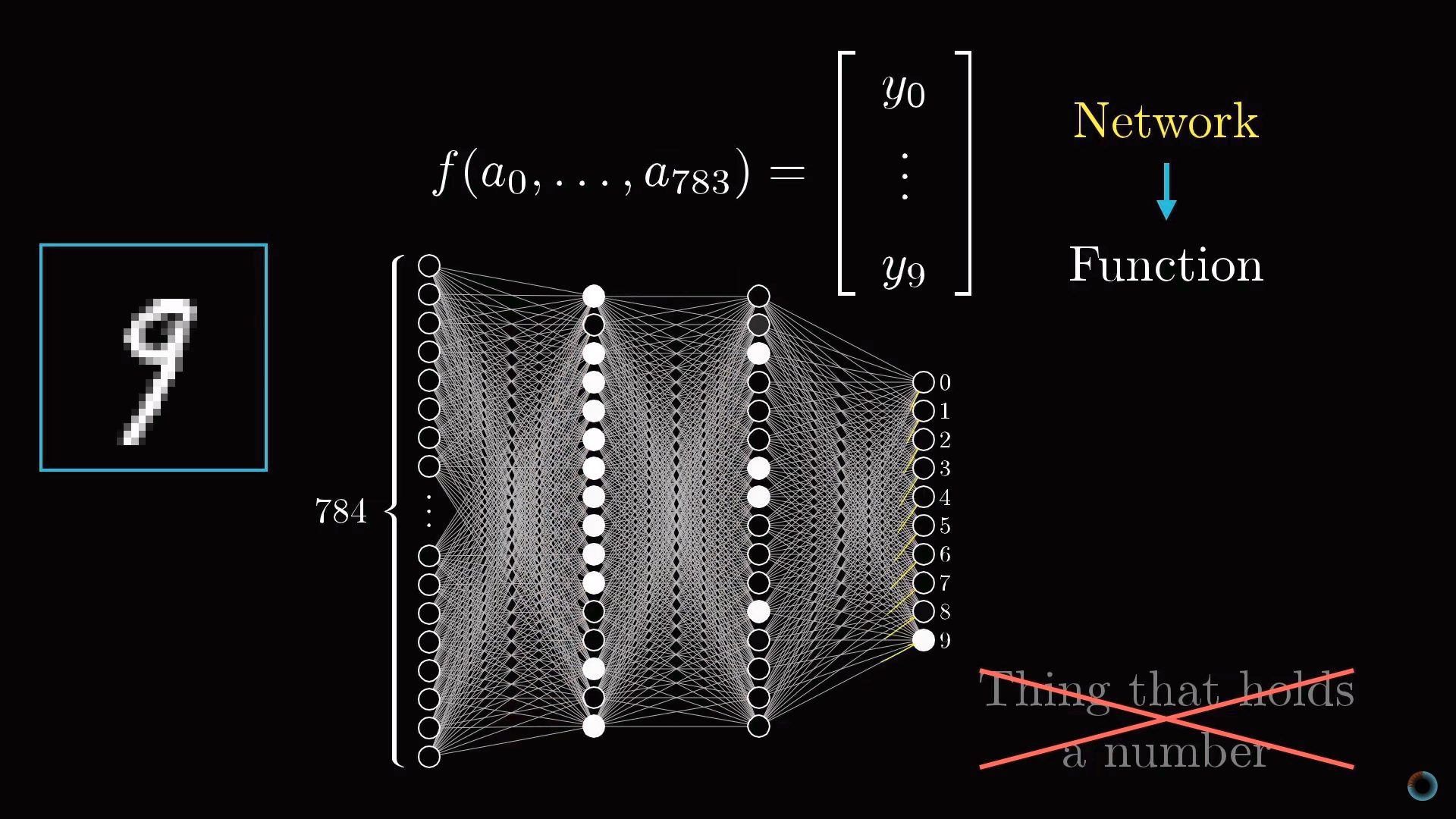
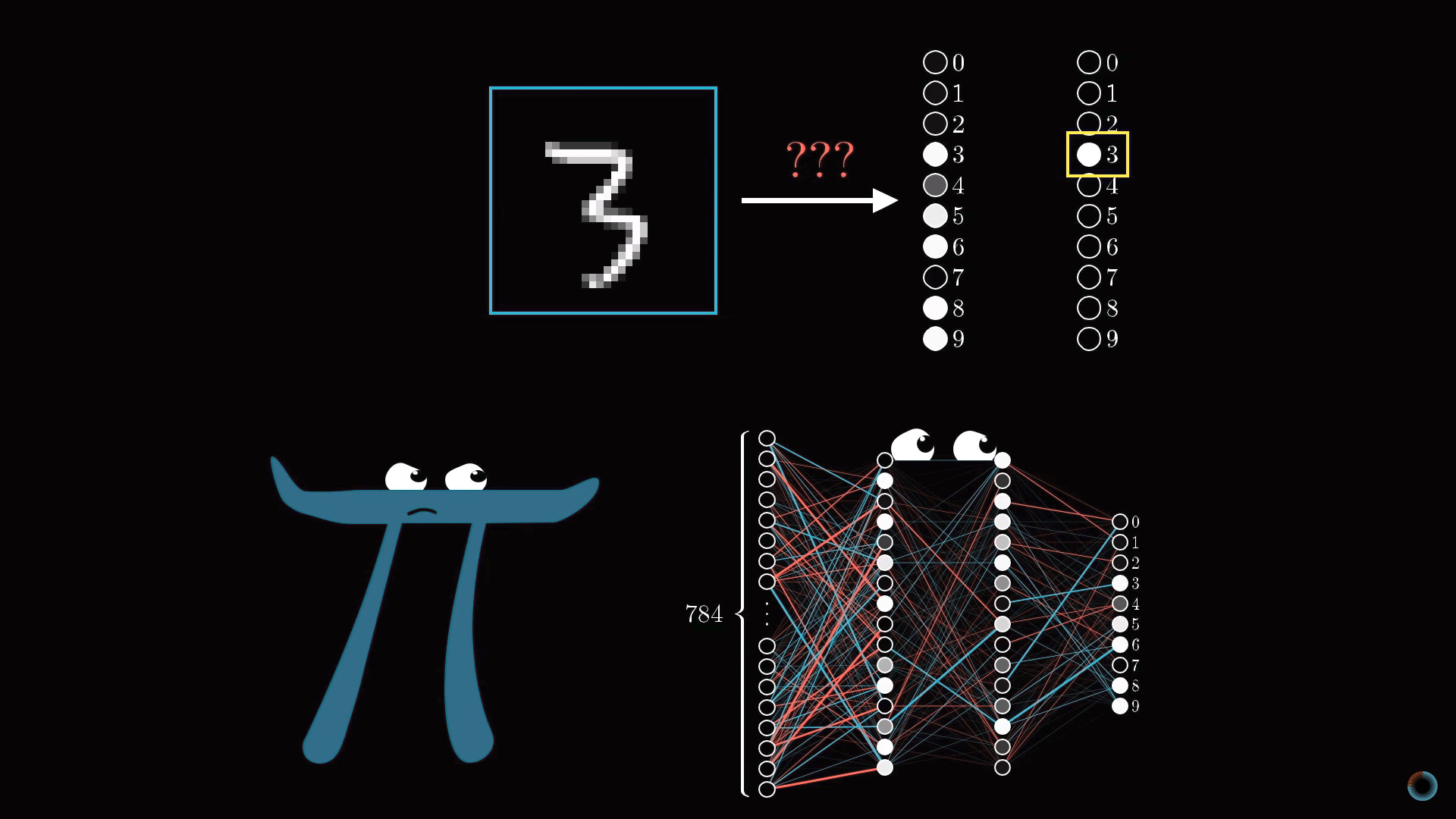
Представим, у вас есть число 3, изображенное в чрезвычайно низком разрешении 28х28 пикселей. Ваш мозг без труда узнает это число.
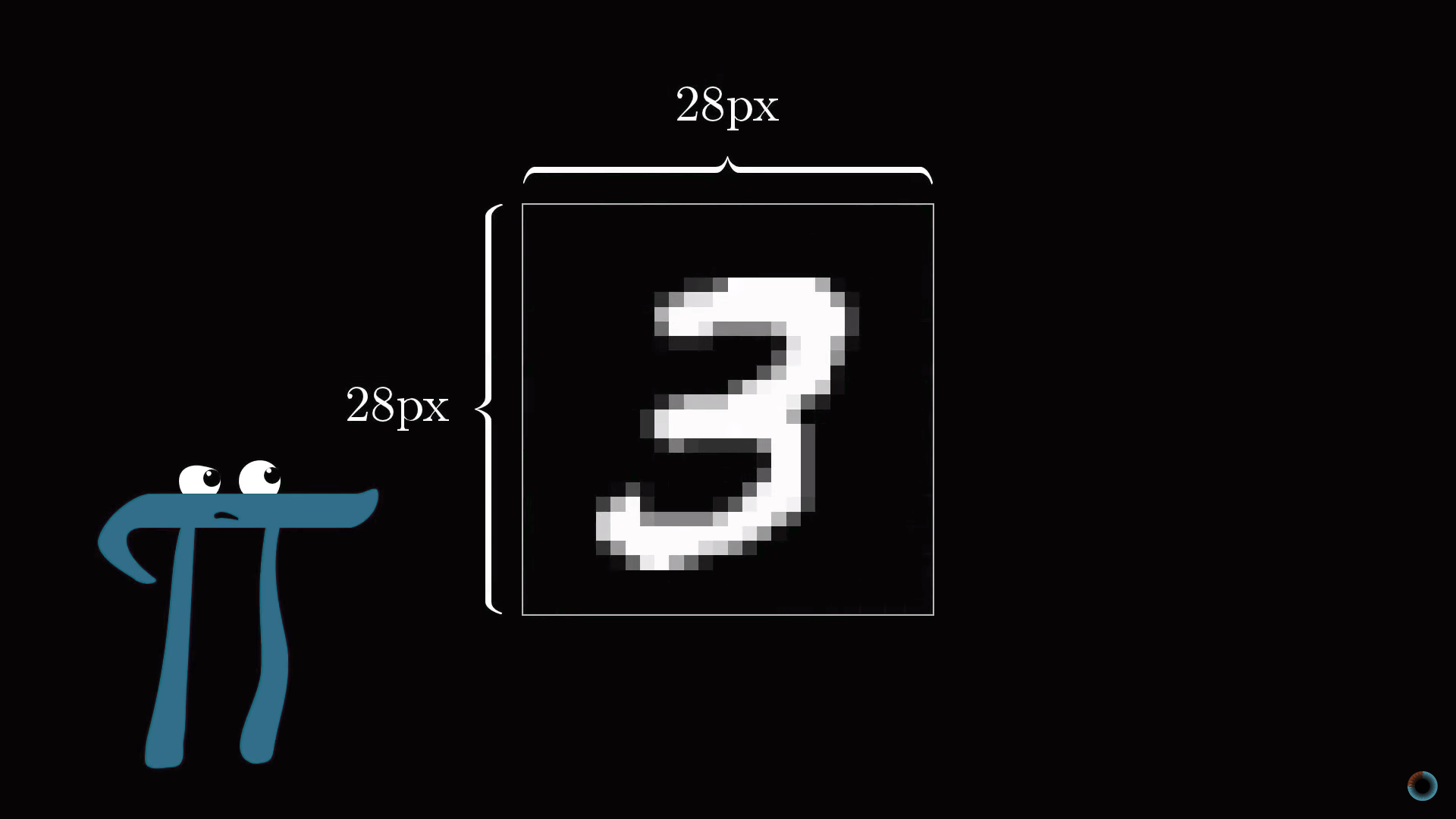
С позиций вычислительной техники удивительно, насколько легко мозг осуществляет эту операцию, при том что конкретное расположение пикселей сильно разнится от одного изображения к другому. Что-то в нашей зрительной коре решает, что все тройки, как бы они ни были изображены, представляют одну сущность. Поэтому задача распознавания цифр в таком контексте воспринимается как простая.
Но если бы вам предложили написать программу, которая принимает на вход изображение любой цифры в виде массива 28х28 пикселей и выдает на выходе саму «сущность» – цифру от 0 до 9, то эта задача перестала бы казаться простой.
Как можно предположить из названия, устройство нейросети в чем-то близко устройству нейронной сети головного мозга. Пока для простоты будем представлять, что в математическом смысле в нейросетях под нейронами понимается некий контейнер, содержащий число от нуля до единицы.
Активация нейронов. Слои нейросети
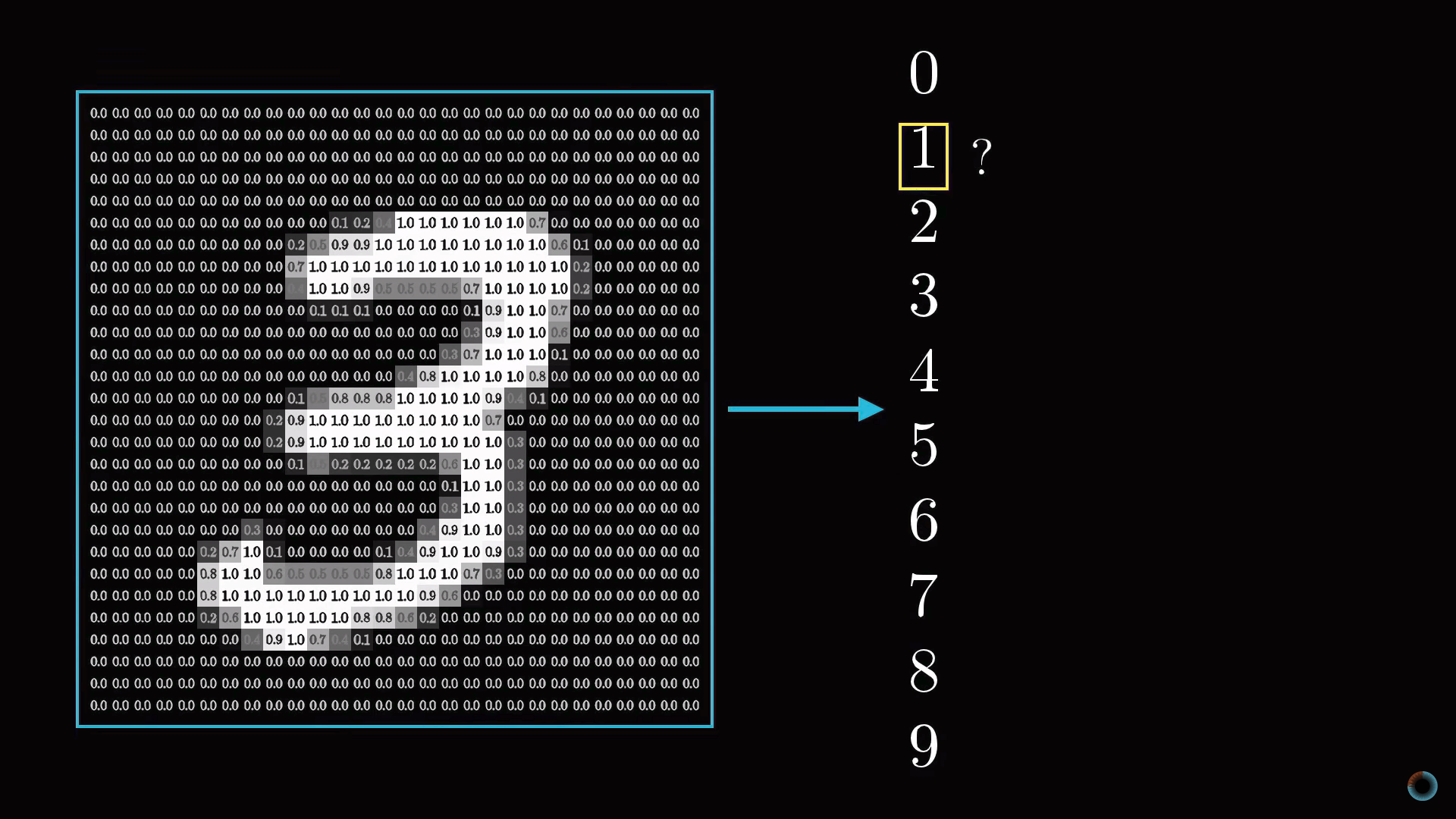
Так как наша сетка состоит из 28х28=784 пикселей, пусть есть 784 нейрона, содержащие различные числа от 0 до 1: чем ближе пиксель к белому цвету, тем ближе соответствующее число к единице. Эти заполняющие сетку числа назовем активациями нейронов. Вы можете себе представлять это, как если бы нейрон зажигался, как лампочка, когда содержит число вблизи 1 и гас при числе, близком к 0.

Описанные 784 нейрона образуют первый слой нейросети. Последний слой содержит 10 нейронов, каждый из которых соответствует одной из десяти цифр. В этих числах активация это также число от нуля до единицы, отражающее насколько система уверена, что входное изображение содержит соответствующую цифру.
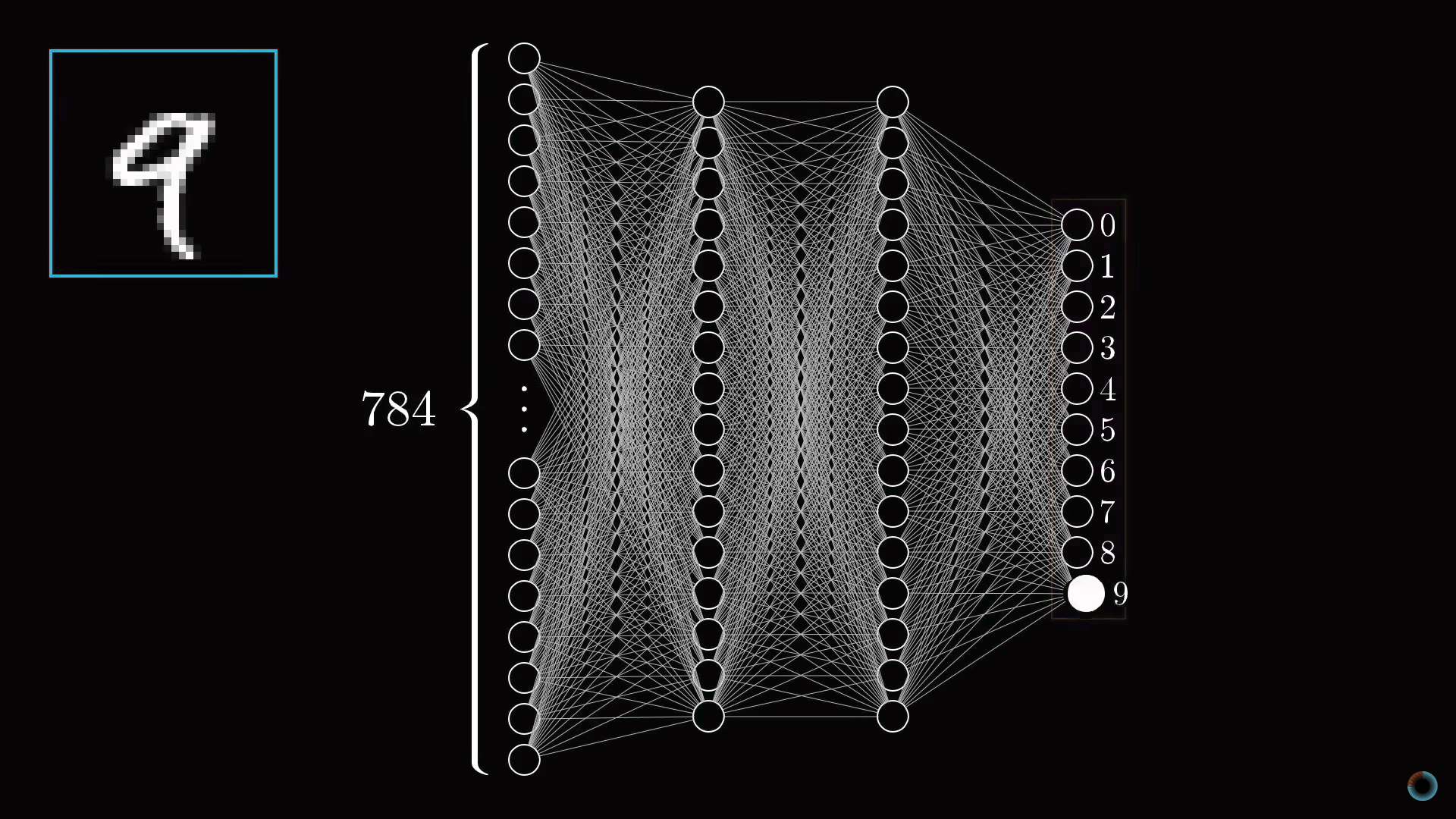
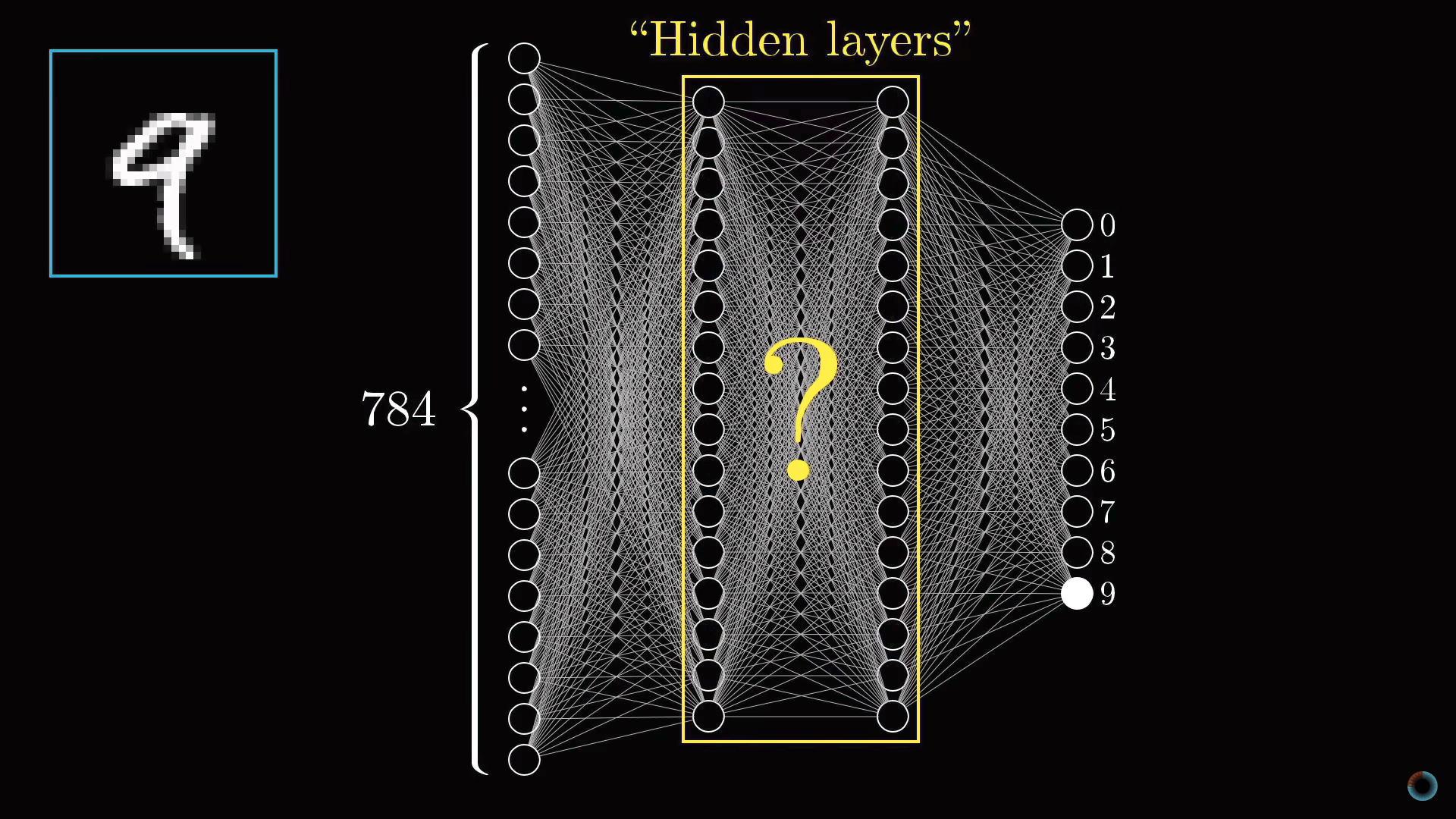
Также есть пара средних слоев, называемых скрытыми, к рассмотрению которых мы вскоре перейдем. Выбор количества скрытых слоев и содержащихся в них нейронов произволен (мы выбрали 2 слоя по 16 нейронов), однако обычно они выбираются из определенных представлений о задаче, решаемой нейронной сетью.
Принцип работы нейросети состоит в том, что активация в одном слое определяет активацию в следующем. Возбуждаясь, некоторая группа нейронов вызывает возбуждение другой группы. Если передать обученной нейронной сети на первый слой значения активации согласно яркости каждого пикселя картинки, цепочка активаций от одного слоя нейросети к следующему приведет к преимущественной активации одного из нейронов последнего слоя, соответствующего распознанной цифре – выбору нейронной сети.
Назначение скрытых слоев
Прежде чем углубляться в математику того, как один слой влияет на следующий, как происходит обучение и как нейросетью решается задача распознавания цифр, обсудим почему вообще такая слоистая структура может действовать разумно. Что делают промежуточные слои между входным и выходным слоями?
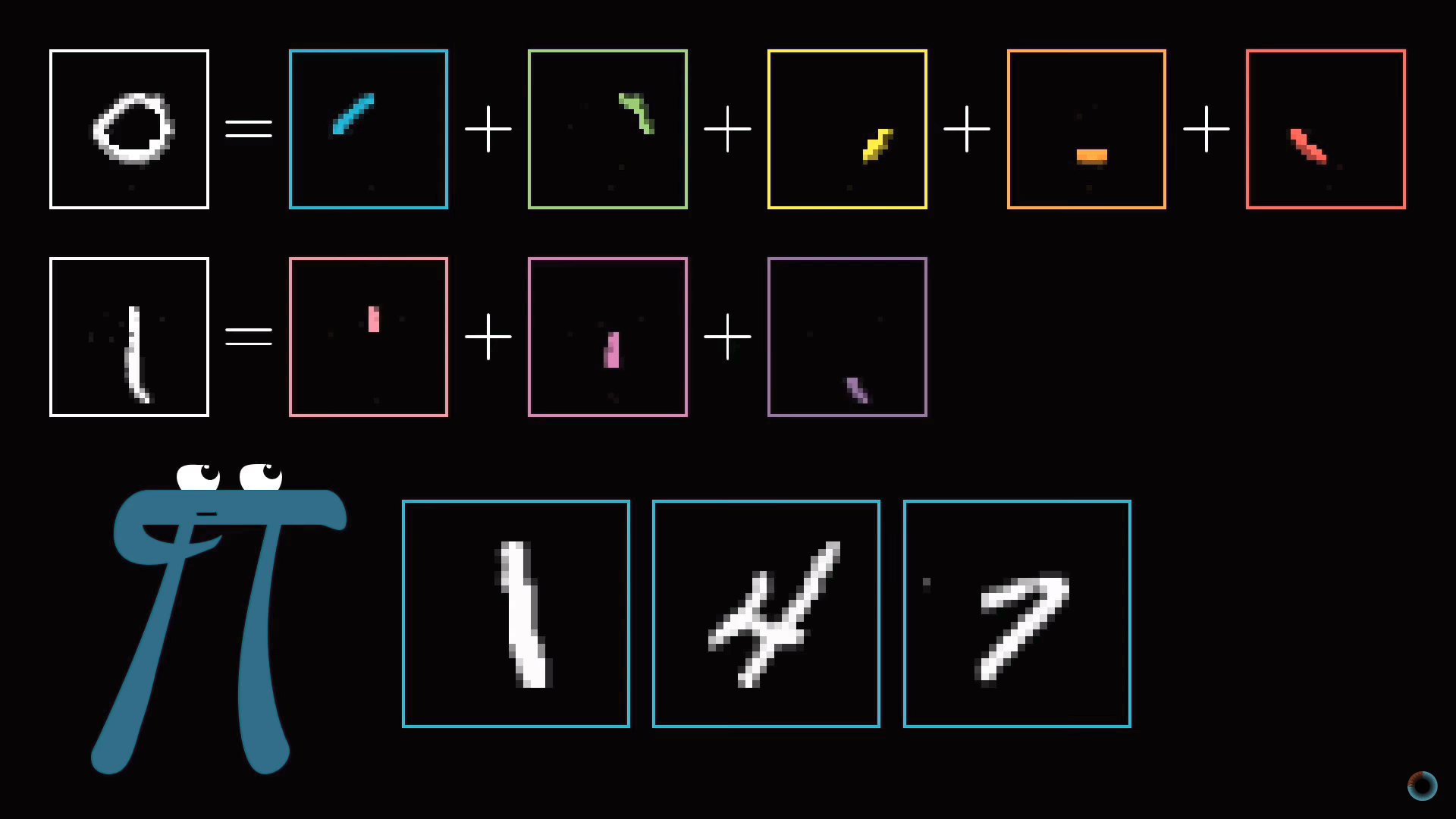
Слой образов фигур
В процессе распознавания цифр мы сводим воедино различные компоненты. Например, девятка состоит из кружка сверху и линии справа. Восьмерка также имеет кружок вверху, но вместо линии справа, у нее есть парный кружок снизу. Четверку можно представить как три определенным образом соединенные линии. И так далее.
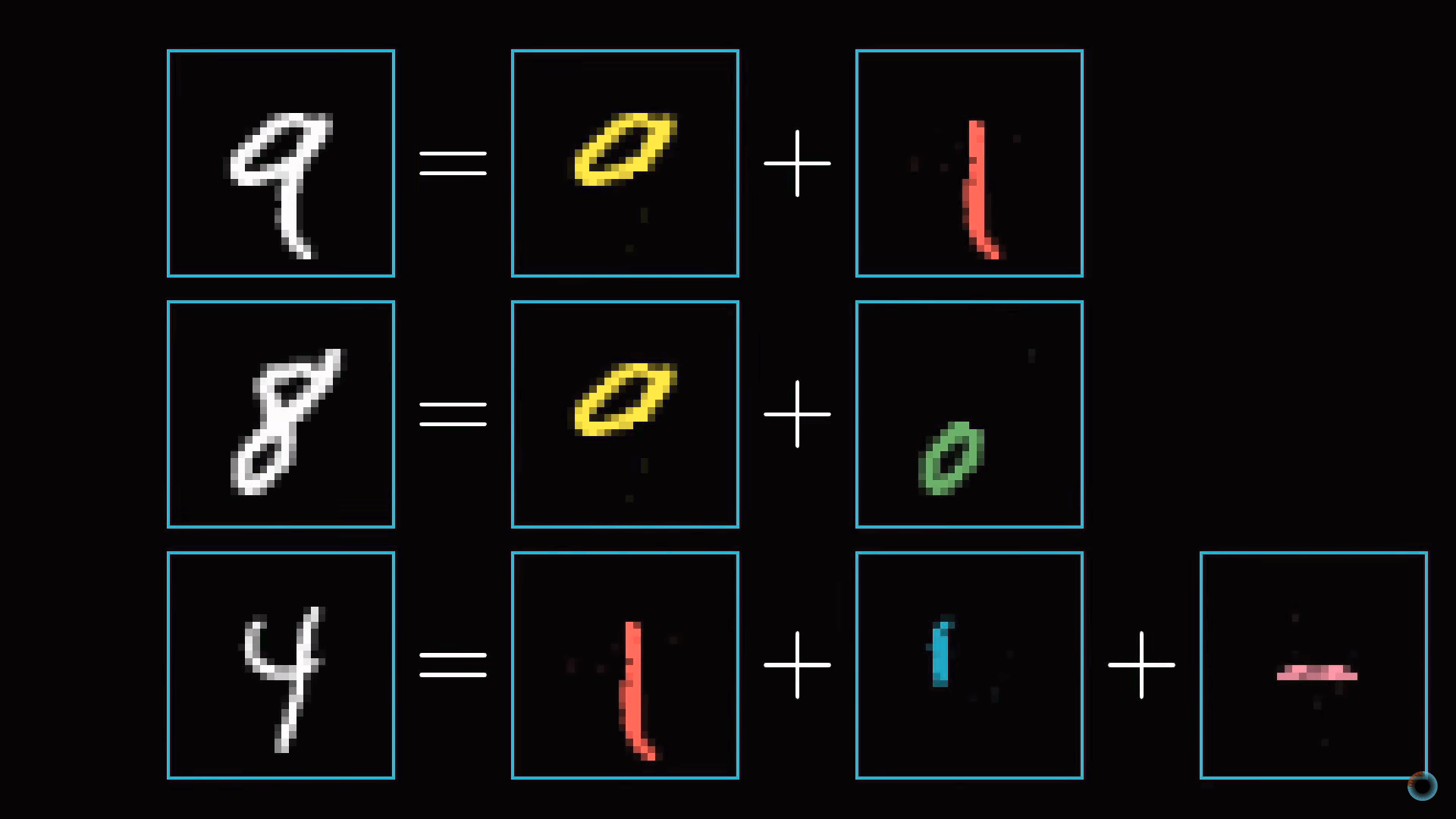
В идеализированном случае можно ожидать, что каждый нейрон из второго слоя соотносится с одним из этих компонентов. И, когда вы, например, передаете нейросети изображение с кружком в верхней части, существует определенный нейрон, чья активация станет ближе к единице. Таким образом, переход от второго скрытого слоя к выходному соответствует знаниям о том, какой набор компонентов какой цифре соответствует.
Слой образов структурных единиц
Задачу распознавания кружка так же можно разбить на подзадачи. Например, распознавать различные маленькие грани, из которых он образован. Аналогично длинную вертикальную линию можно представить как шаблон соединения нескольких меньших кусочков. Таким образом, можно надеяться, что каждый нейрон из первого скрытого слоя нейросети осуществляет операцию распознавания этих малых граней.
Таким образом введенное изображение приводит к активации определенных нейронов первого скрытого слоя, определяющих характерные малые кусочки, эти нейроны в свою очередь активируют более крупные формы, в результате активируя нейрон выходного слоя, ассоциированной определенной цифре.
Будет ли так действовать нейросеть или нет, это другой вопрос, к которому вы вернемся при обсуждении процесса обучения сети. Однако это может служить нам ориентиром, своего рода целью такой слоистой структуры.
С другой стороны, такое определение граней и шаблонов полезно не только в задаче распознавания цифр, но и вообще задаче определения образов.

И не только для распознавания цифр и образов, но и других интеллектуальных задач, которые можно разбить на слои абстракции. Например, для распознавания речи из сырого аудио выделяются отдельные звуки, слоги, слова, затем фразы, более абстрактные мысли и т. д.
Определение области распознавания
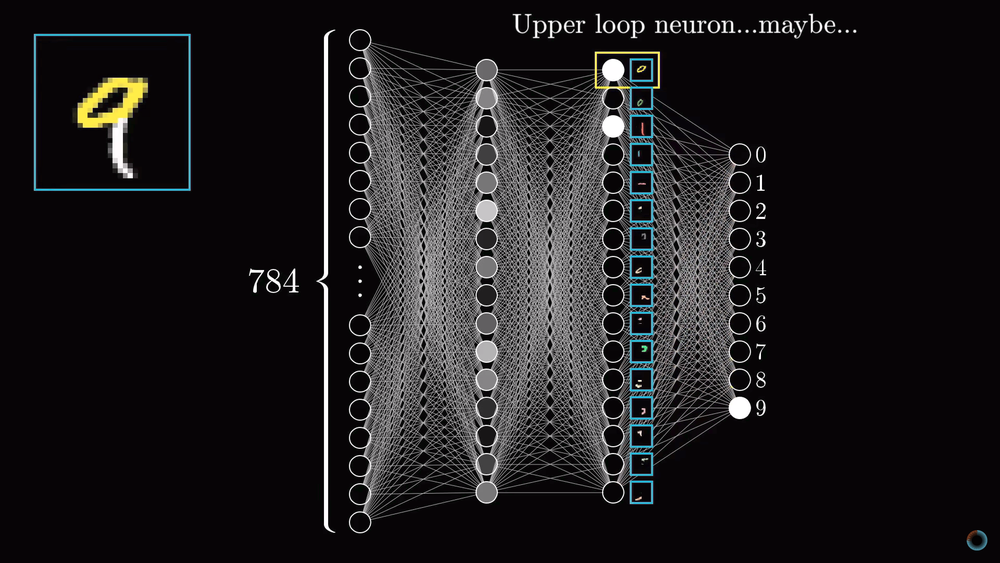
Для конкретики представим теперь, что цель отдельного нейрона в первом скрытом слое это определить, содержит ли картинка грань в отмеченной на рисунке области.
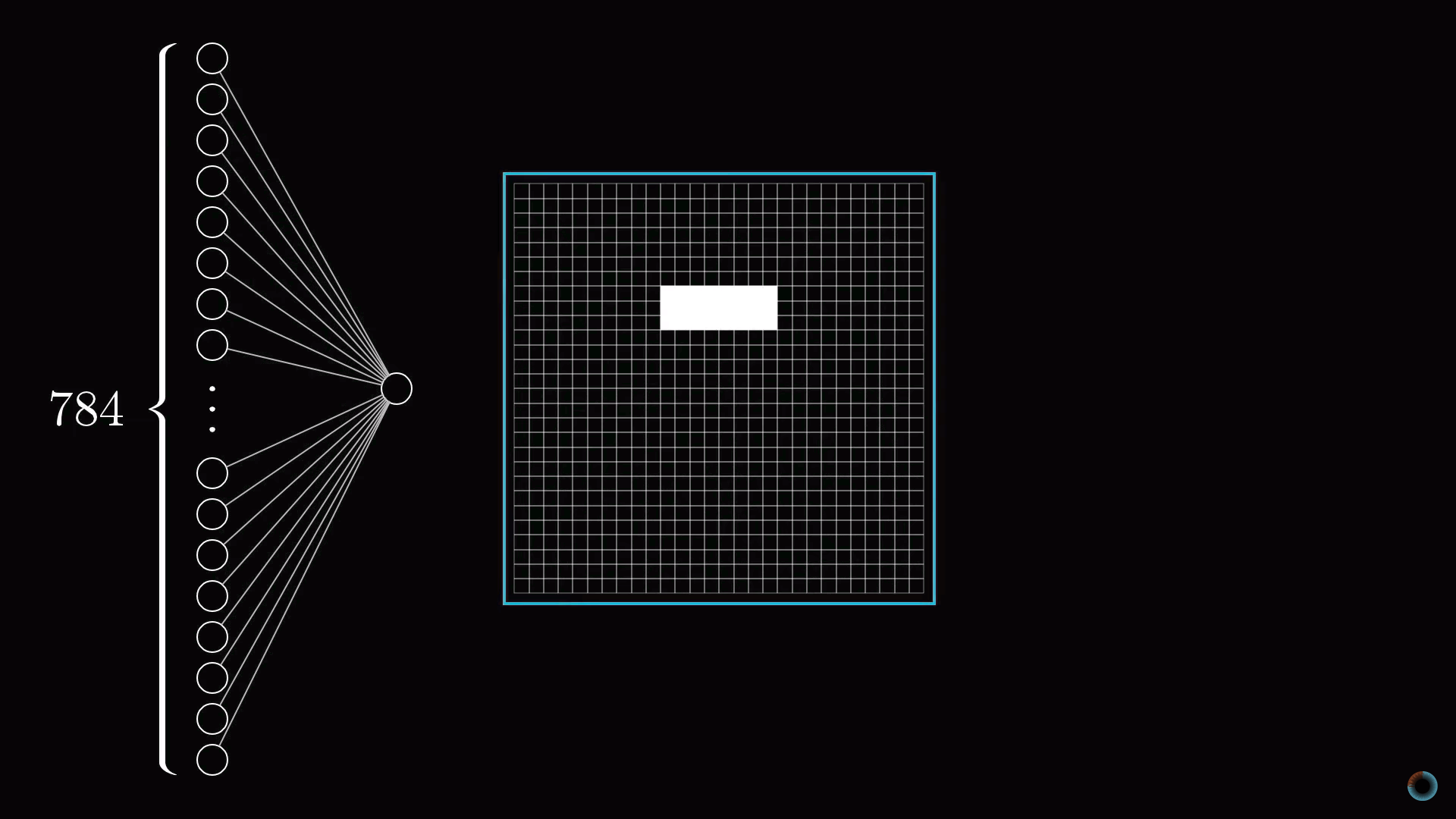
Первый вопрос: какие параметры настройки должны быть у нейросети, чтобы иметь возможность обнаружить этот шаблон или любой другой шаблон из пикселей.
Назначим числовой вес wi каждому соединению между нашим нейроном и нейроном из входного слоя. Затем возьмем все активации из первого слоя и посчитаем их взвешенную сумму согласно этим весам.
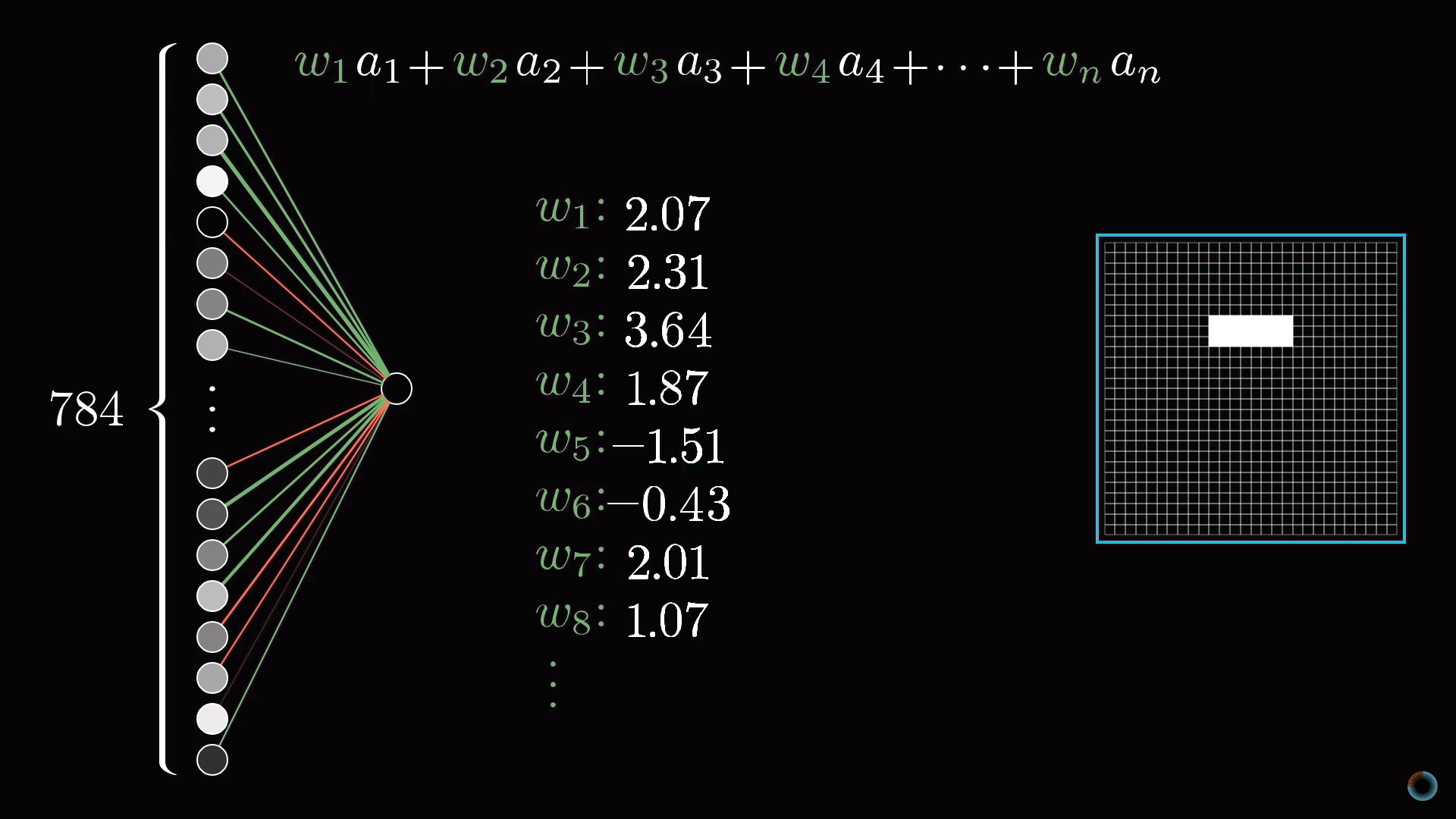
Так как количество весов такое же, как и число активаций, им также можно сопоставить аналогичную сетку. Будем обозначать зелеными пикселями положительные веса, а красными – отрицательные. Яркость пикселя будет соответствовать абсолютному значению веса.
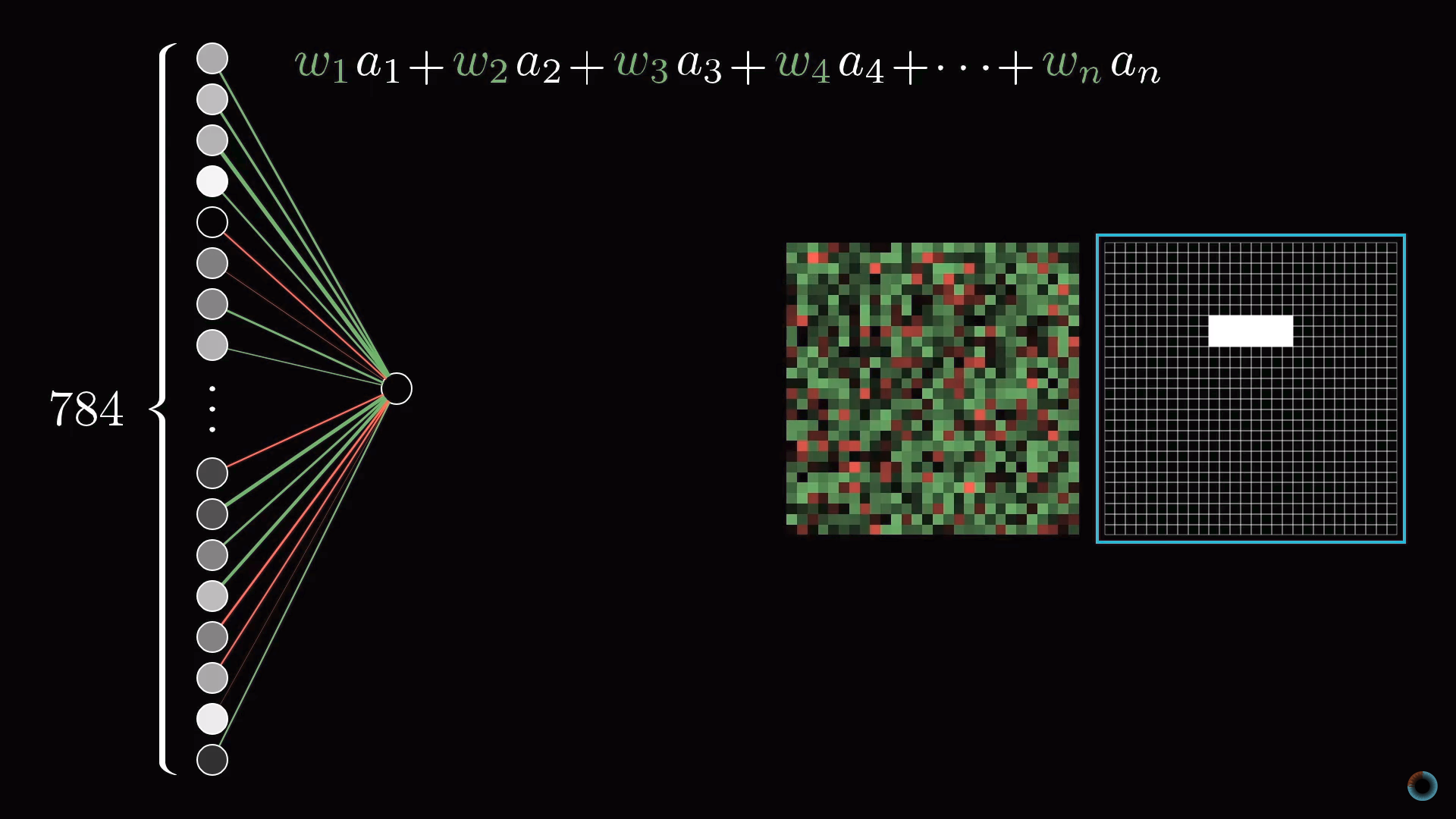
Теперь, если мы установим все веса равными нулю, кроме пикселей, соответствующих нашему шаблону, то взвешенная сумма сведется к суммированию значений активаций пикселей в интересующей нас области.
Если же вы хотите, определить есть ли там именно ребро, вы можете добавить вокруг зеленого прямоугольника весов красные весовые грани, соответствующие отрицательным весам. Тогда взвешенная сумма для этого участка будет максимальной, когда средние пиксели изображения в этой части ярче, а окружающих их пиксели темнее.

Масштабирование активации до интервала [0, 1]
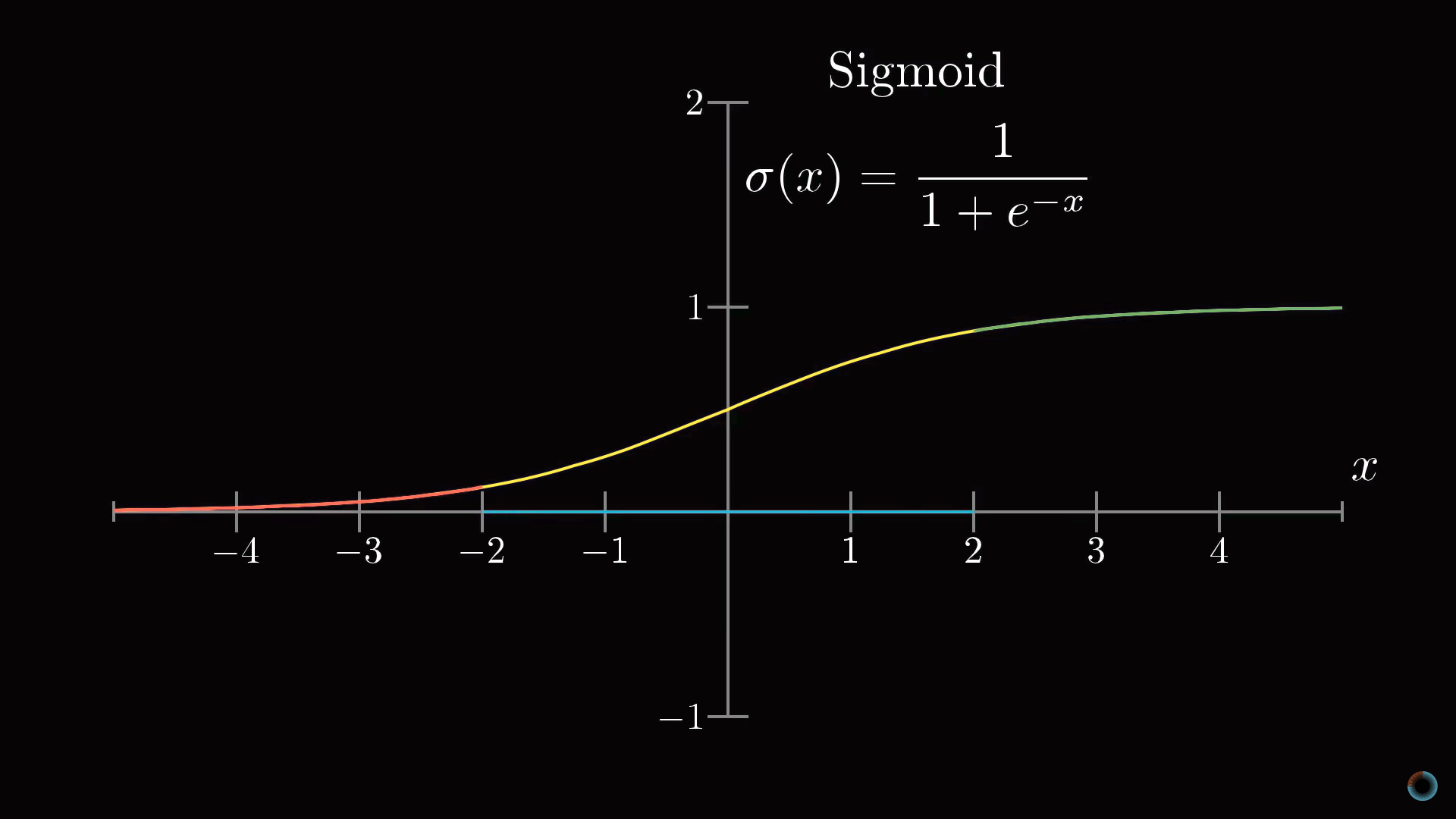
Вычислив такую взвешенную сумму, вы можете получить любое число в широком диапазоне значений. Для того, чтобы оно попадало в необходимый диапазон активаций от 0 до 1, разумно использовать функцию, которая бы «сжимала» весь диапазон до интервала [0, 1].

Часто для такого масштабирования используется логистическая функция сигмоиды. Чем больше абсолютное значение отрицательного входного числа, тем ближе выходное значение сигмоиды к нулю. Чем больше значение положительного входного числа, тем ближе значение функции к единице.
Таким образом, активация нейрона это по сути мера того, насколько положительна соответствующая взвешенная сумма. Чтобы нейрон не активировался при малых положительных числах, можно добавить к взвешенной сумме некоторое отрицательное число – сдвиг (англ. bias), определяющий насколько большой должна быть взвешенная сумма, чтобы активировать нейрон.
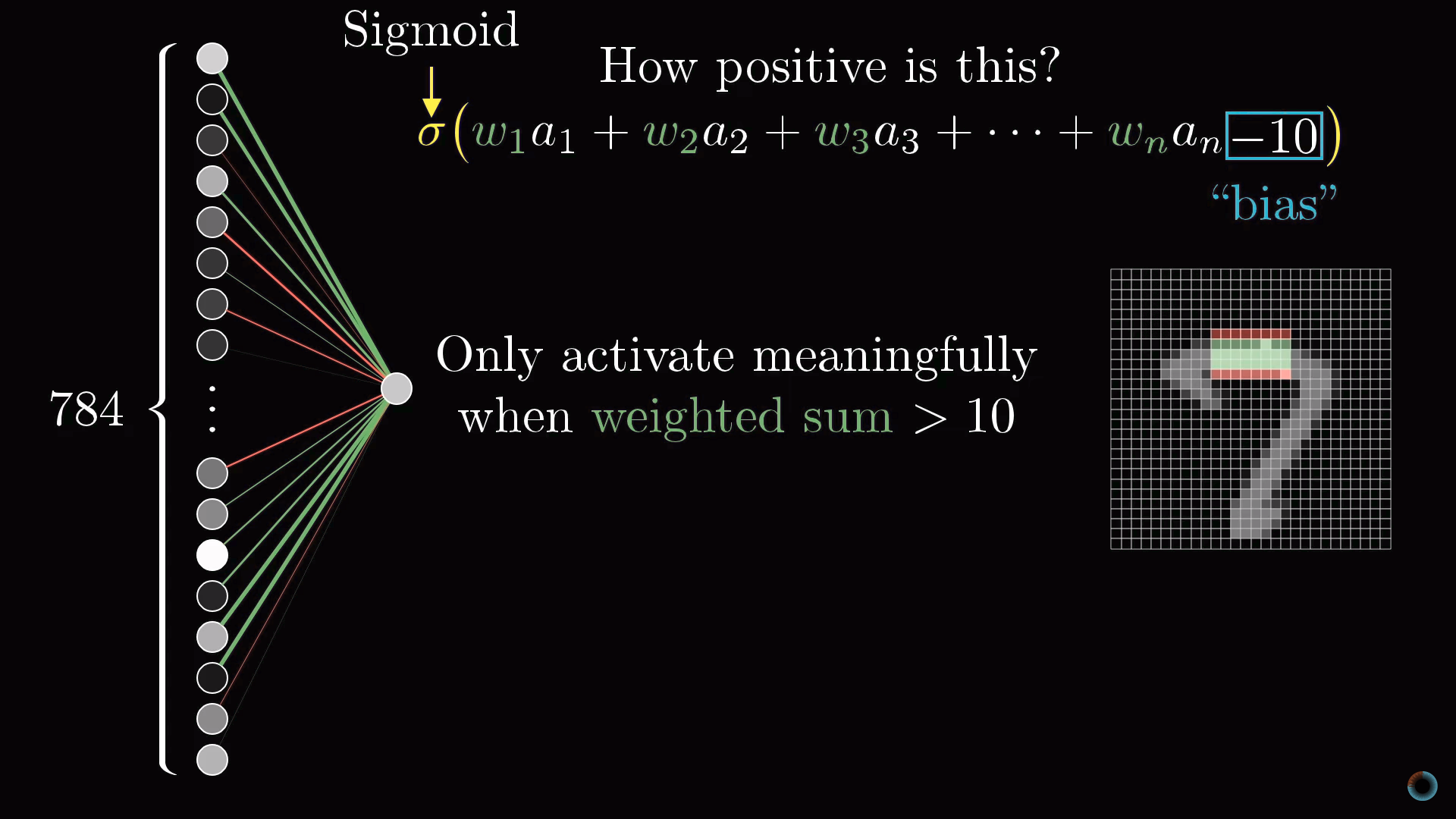
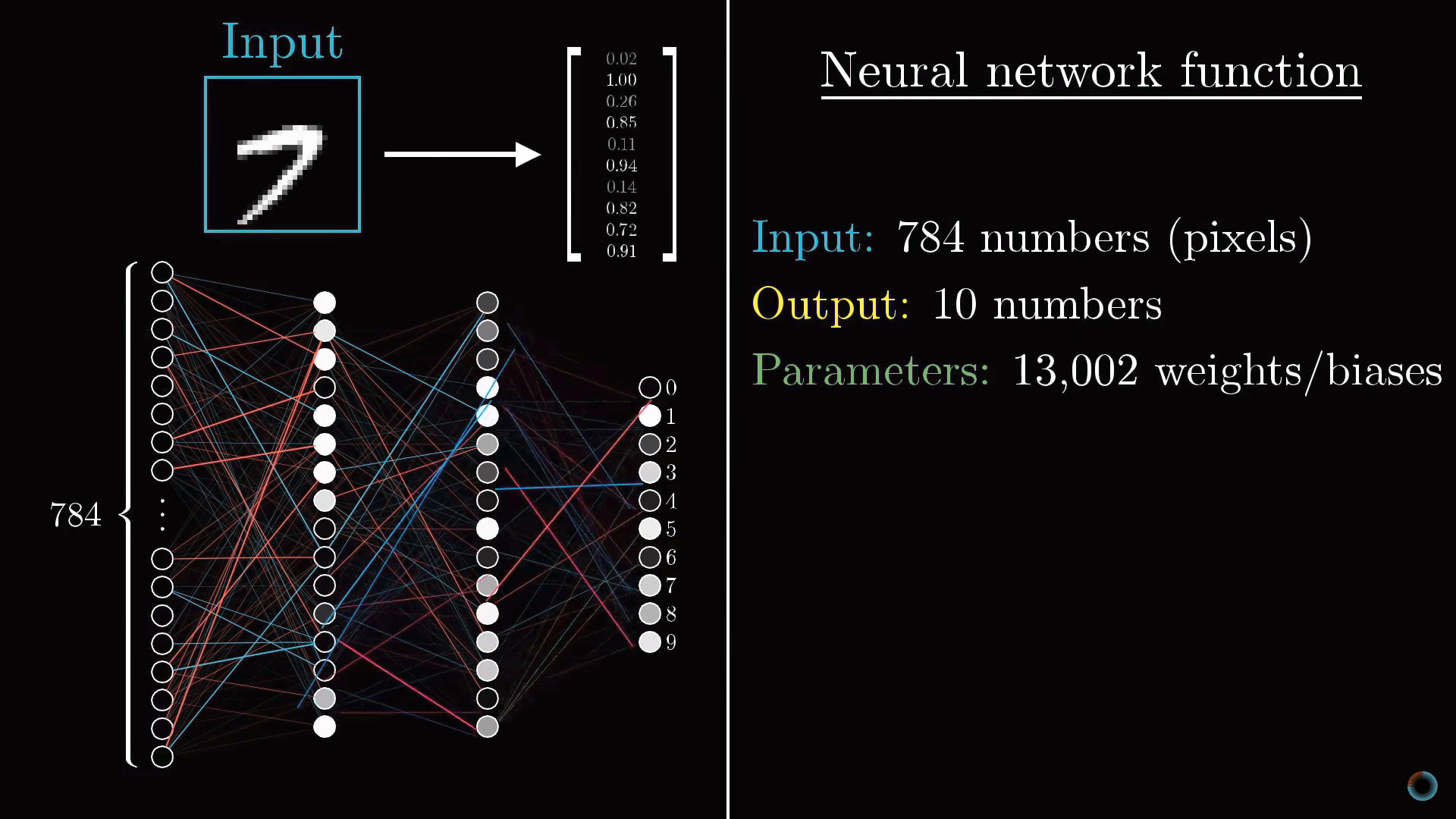
Разговор пока шел только об одном нейроне. Каждый нейрон из первого скрытого слоя соединен со всеми 784 пиксельными нейронами первого слоя. И каждое из этих 784 соединений будет иметь свой ассоциированный с ним вес. Также у каждого из нейронов первого скрытого слоя есть ассоциированный с ним сдвиг, добавляемый к взвешенной сумме перед «сжатием» этого значения сигмоидой. Таким образом, для первого скрытого слоя имеется 784х16 весов и 16 сдвигов.
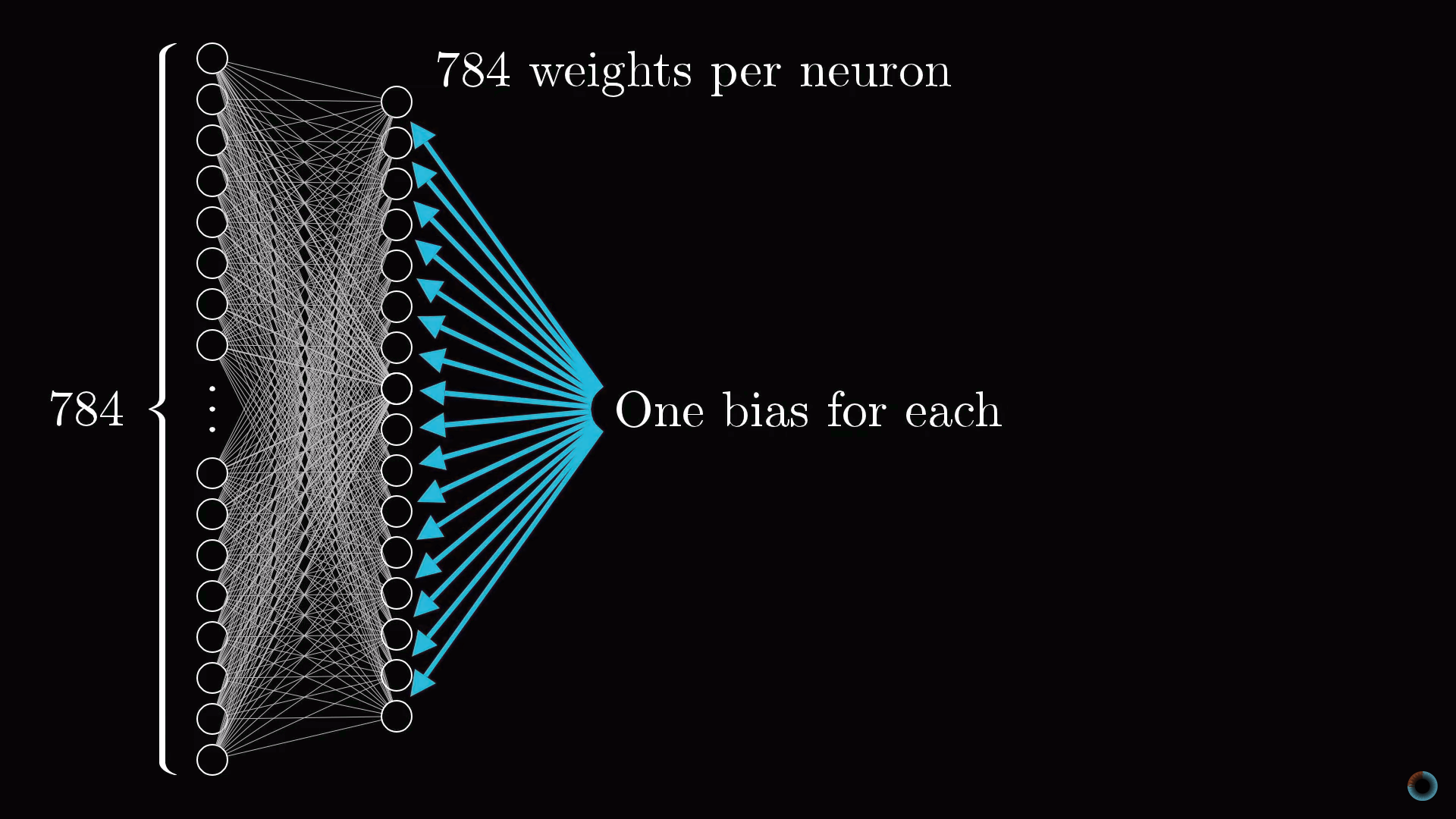
Соединение между другими слоями также содержат веса и сдвиги, связанные с ними. Таким образом, для приведенного примера в качестве настраиваемых параметров выступают около 13 тыс. весов и сдвигов, определяющих поведение нейронной сети.
Обучить нейросеть задаче распознавания цифр значит заставить компьютер найти корректные значения для всех этих чисел так, чтобы это решило поставленную задачу. Представьте себе настройку всех этих весов и сдвигу вручную. Это один из действенных аргументов, чтобы трактовать нейросеть как черный ящик – мысленно отследить совместное поведение всех параметров практически невозможно.
Описание нейросети в терминах линейной алгебры
Обсудим компактный способ математического представления соединений нейросети. Объединим все активации первого слоя в вектор-столбец. Все веса объединим в матрицу, каждая строка которой описывает соединения между нейронами одного слоя с конкретным нейроном следующего (в случае затруднений посмотрите описанный нами курс по линейной алгебре). В результате умножения матрицы на вектор получим вектор, соответствующий взвешенным суммам активаций первого слоя. Сложим матричное произведение с вектором сдвигов и обернем функцией сигмоиды для масштабирования интервалов значений. В результате получим столбец соответствующих активаций.
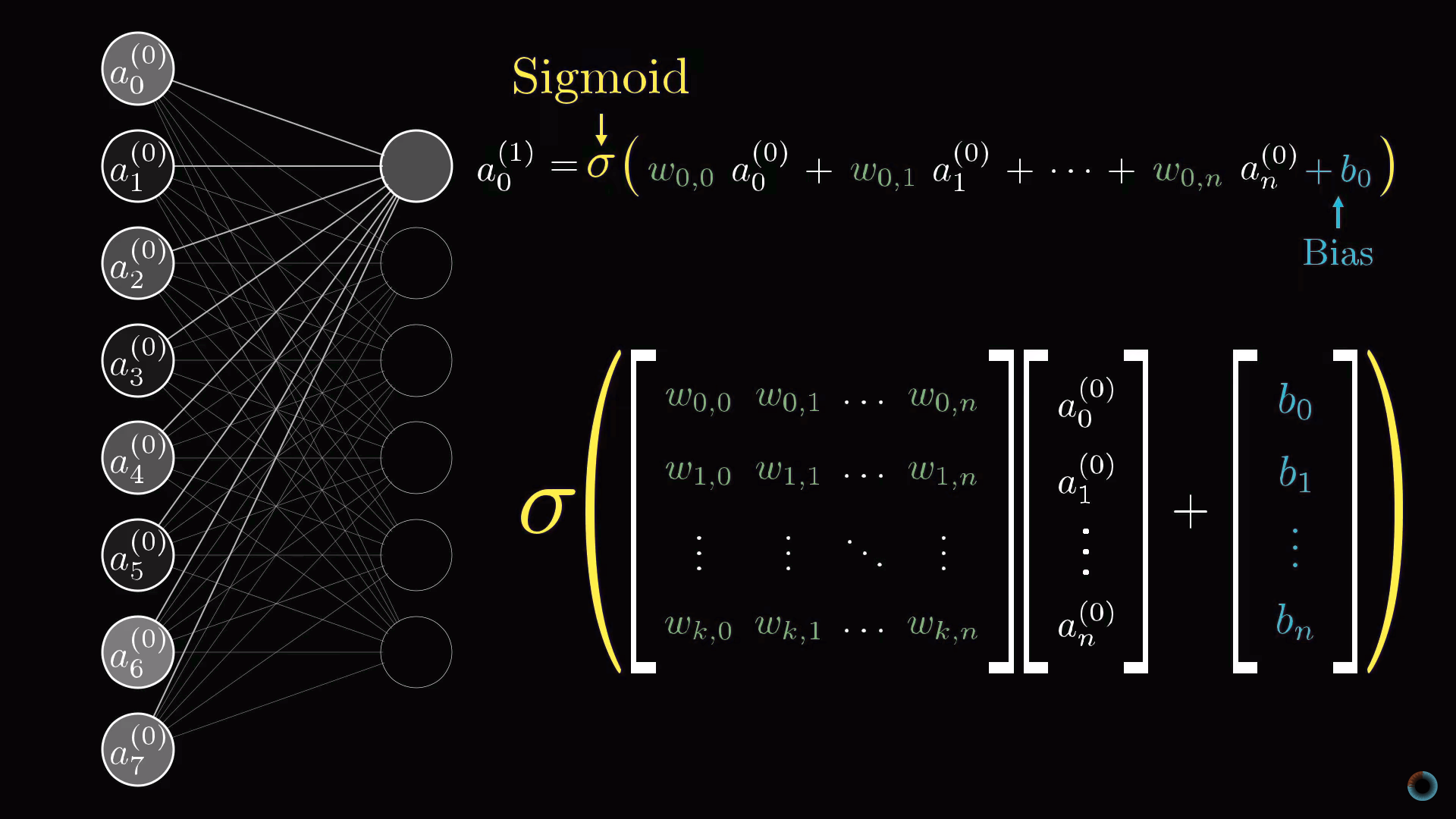
Очевидно, что вместо столбцов и матриц, как это принято в линейной алгебре, можно использовать их краткие обозначения. Это делает соответствующий программный код и проще, и быстрее, так как библиотеки машинного обучения оптимизированы под векторные вычисления.
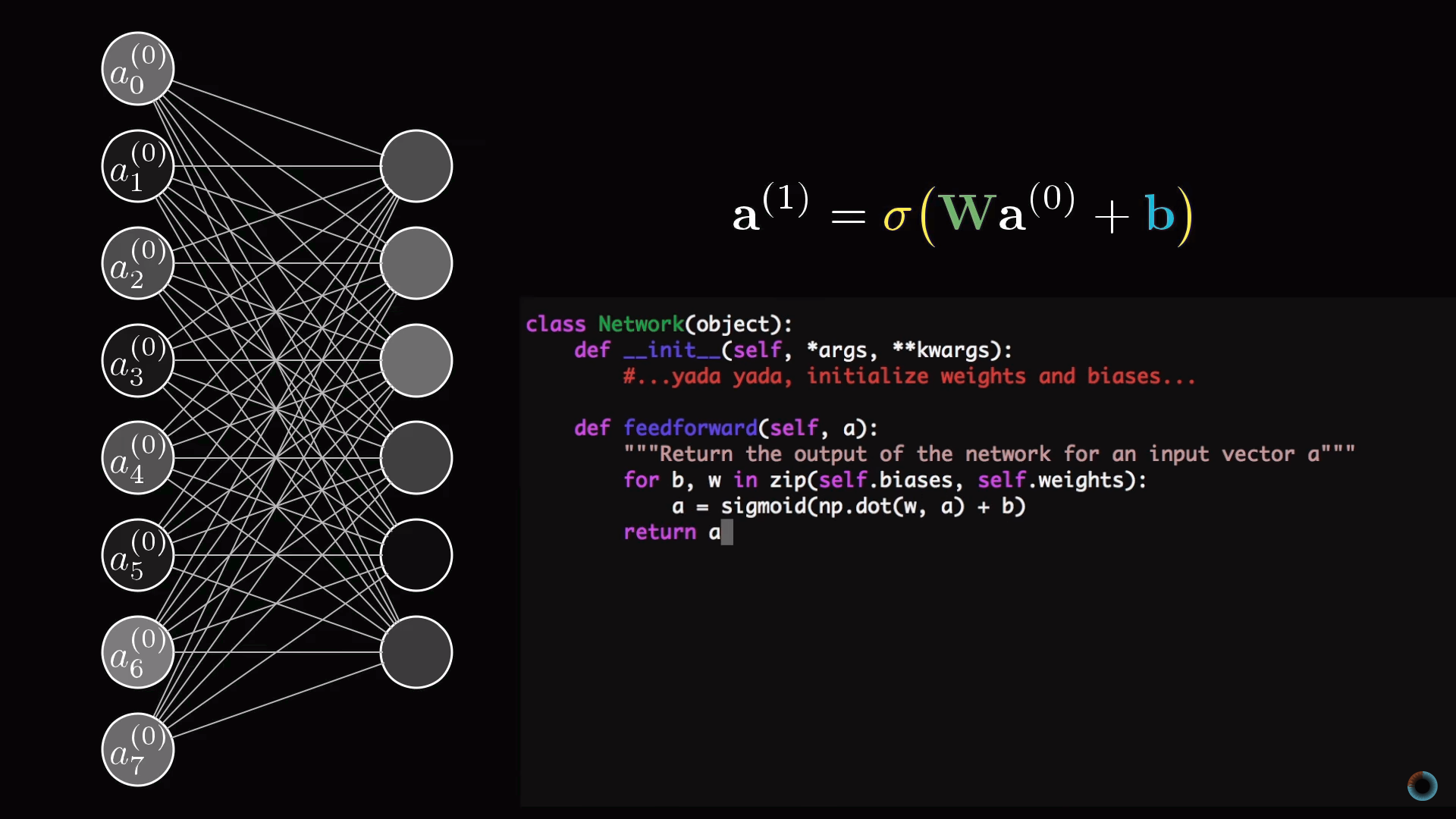
Уточнение об активации нейронов
Настало время уточнить то упрощение, с которого мы начали. Нейронам соответствуют не просто числа – активации, а функции активации, принимающие значения со всех нейронов предыдущего слоя и вычисляющие выходные значения в интервале от 0 до 1.
Фактически вся нейросеть это одна большая настраиваемая через обучения функция с 13 тысячами параметров, принимающая 784 входных значения и выдающая вероятность того, что изображение соответствует одной из десяти предназначенных для распознавания цифр. Тем не менее, не смотря на свою сложность, это просто функция, и в каком-то смысле логично, что она выглядит сложной, так как если бы она была проще, эта функция не была бы способна решить задачу распознавания цифр.
В качестве дополнения обсудим, какие функции активации используются для программирования нейронных сетей сейчас.
Дополнение: немного о функциях активации. Сравнение сигмоиды и ReLU
Затронем кратко тему функций, используемых для «сжатия» интервала значений активаций. Функция сигмоиды является примером, подражающим биологическим нейронам и она использовалась в ранних работах о нейронных сетях, однако сейчас чаще используется более простая ReLU функция, облегчающая обучение нейросети.
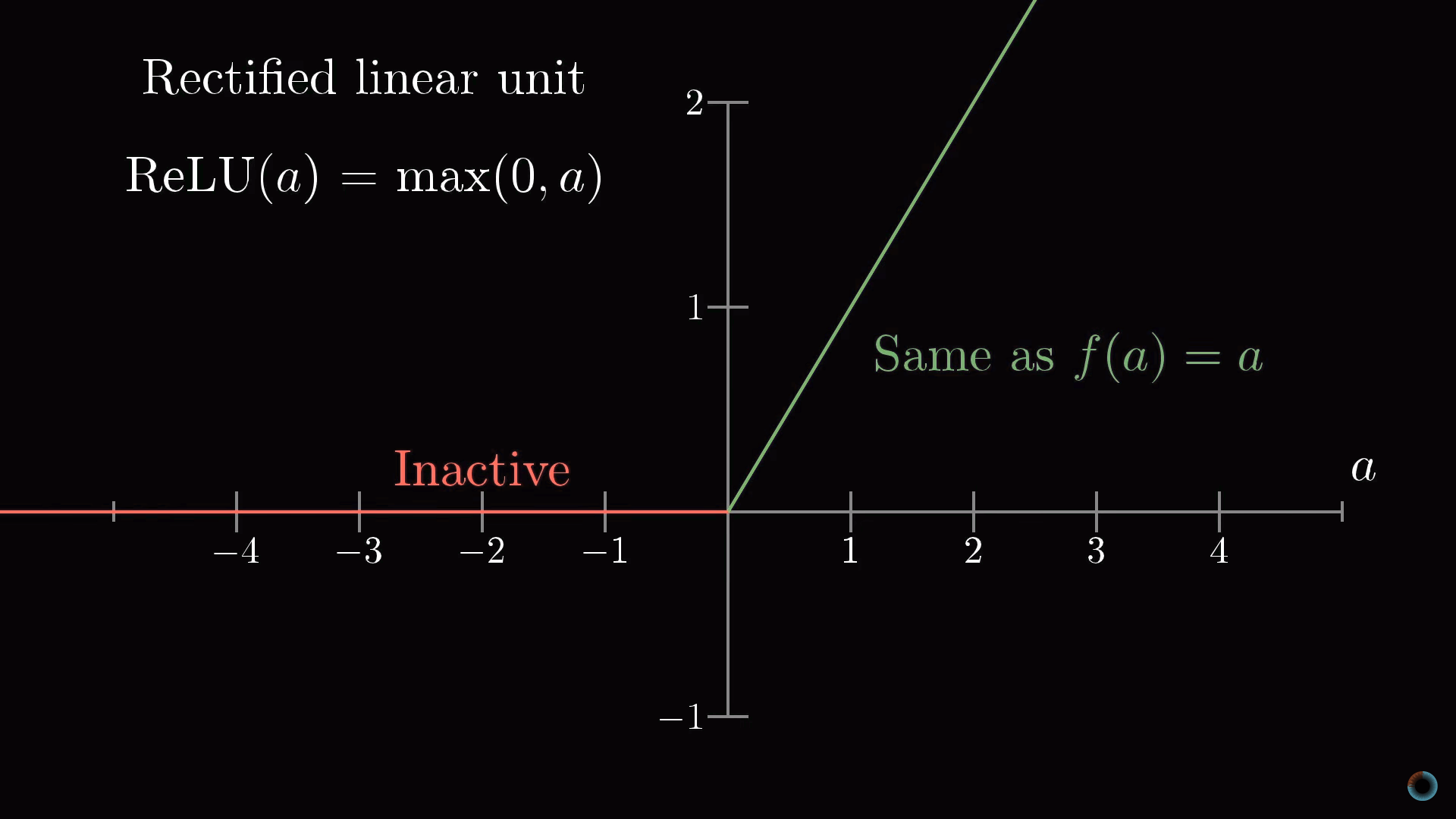
Функция ReLU соответствует биологической аналогии того, что нейроны могут находиться в активном состояни либо нет. Если пройден определенный порог, то срабатывает функция, а если не пройден, то нейрон просто остается неактивным, с активацией равной нулю.
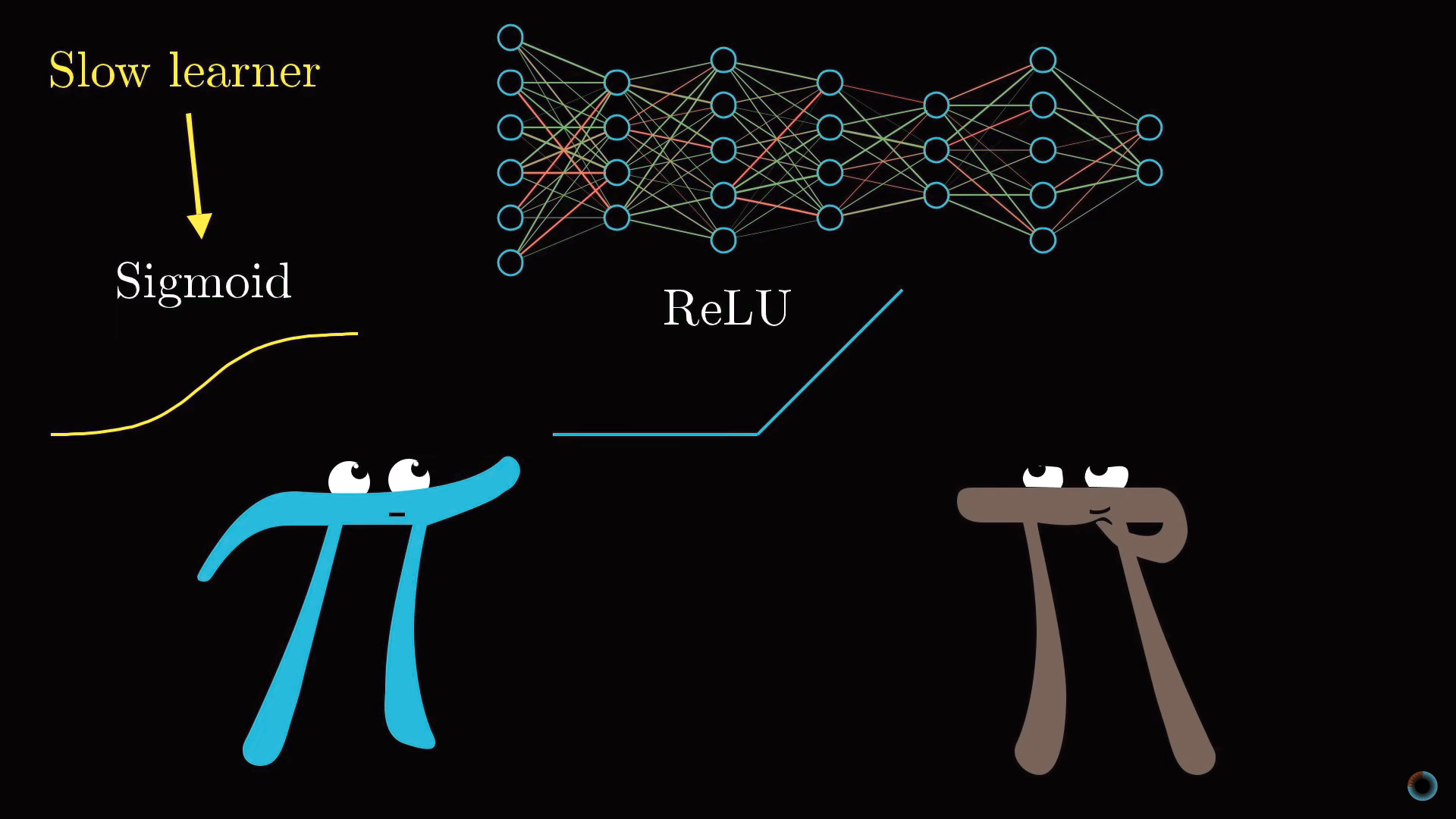
Оказалось, что для глубоких многослойных сетей функция ReLU работает очень хорошо и часто нет смысла использовать более сложную для расчета функцию сигмоиды.
2. Обучение нейронной сети для распознавания цифр
Возникает вопрос: как описанная в первом уроке сеть находит соответствующие веса и сдвиги только исходя из полученных данных? Об этом рассказывает второй урок.
В общем виде алгоритм состоит в том, чтобы показать нейросети множество тренировочных данных, представляющих пары изображений записанных от руки цифр и их абстрактных математических представлений.
В общих чертах
В результате обучения нейросеть должна правильным образом различать числа из ранее не представленных, тестовых данных. Соответственно в качестве проверки обучения нейросети можно использовать отношение числа актов корректного распознавания цифр к количеству элементов тестовой выборки.
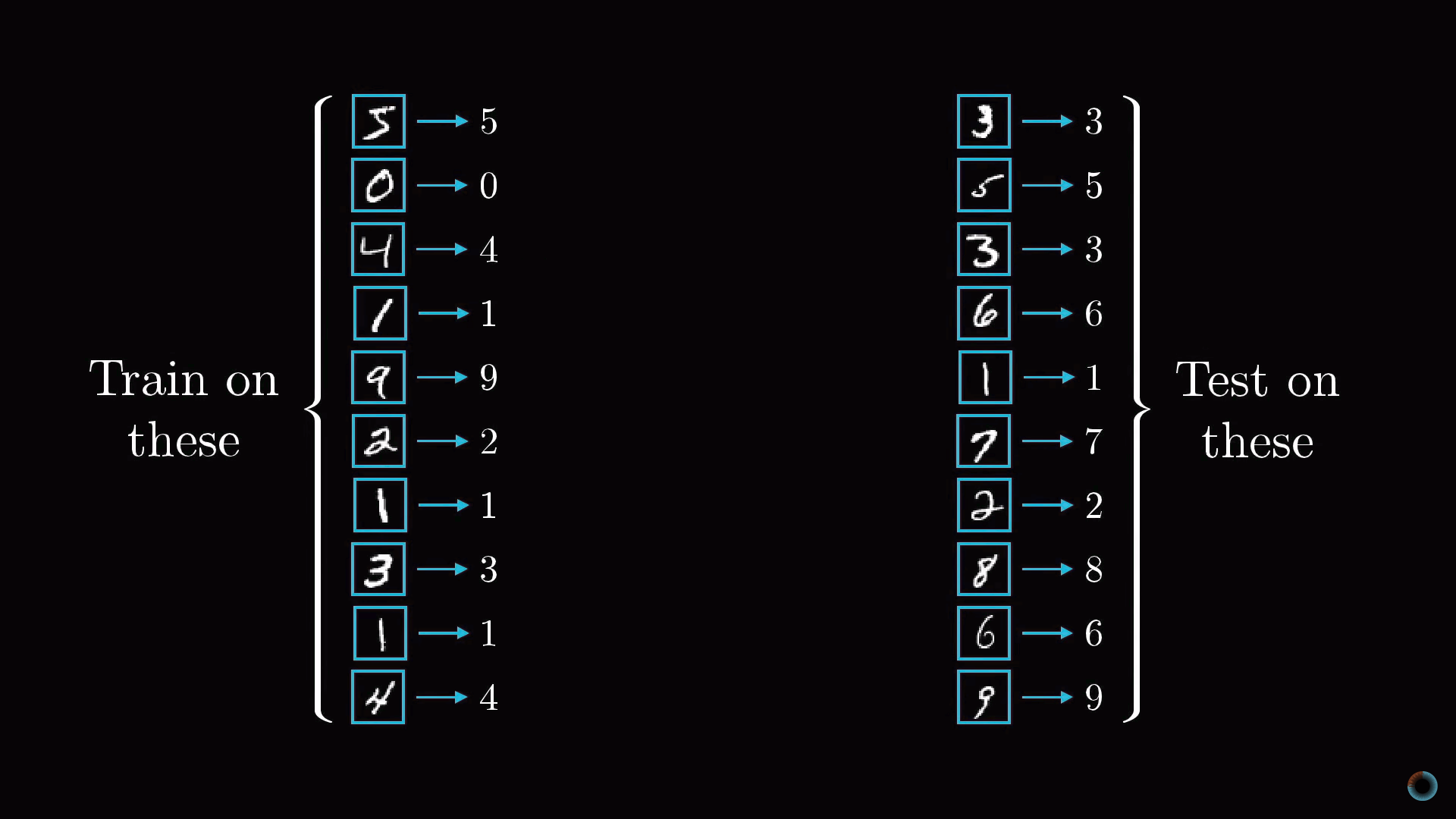
Откуда берутся данные для обучения? Рассматриваемая задача очень распространена, и для ее решения создана крупная база данных MNIST, состоящая из 60 тыс. размеченных данных и 10 тыс. тестовых изображений.

Функция стоимости
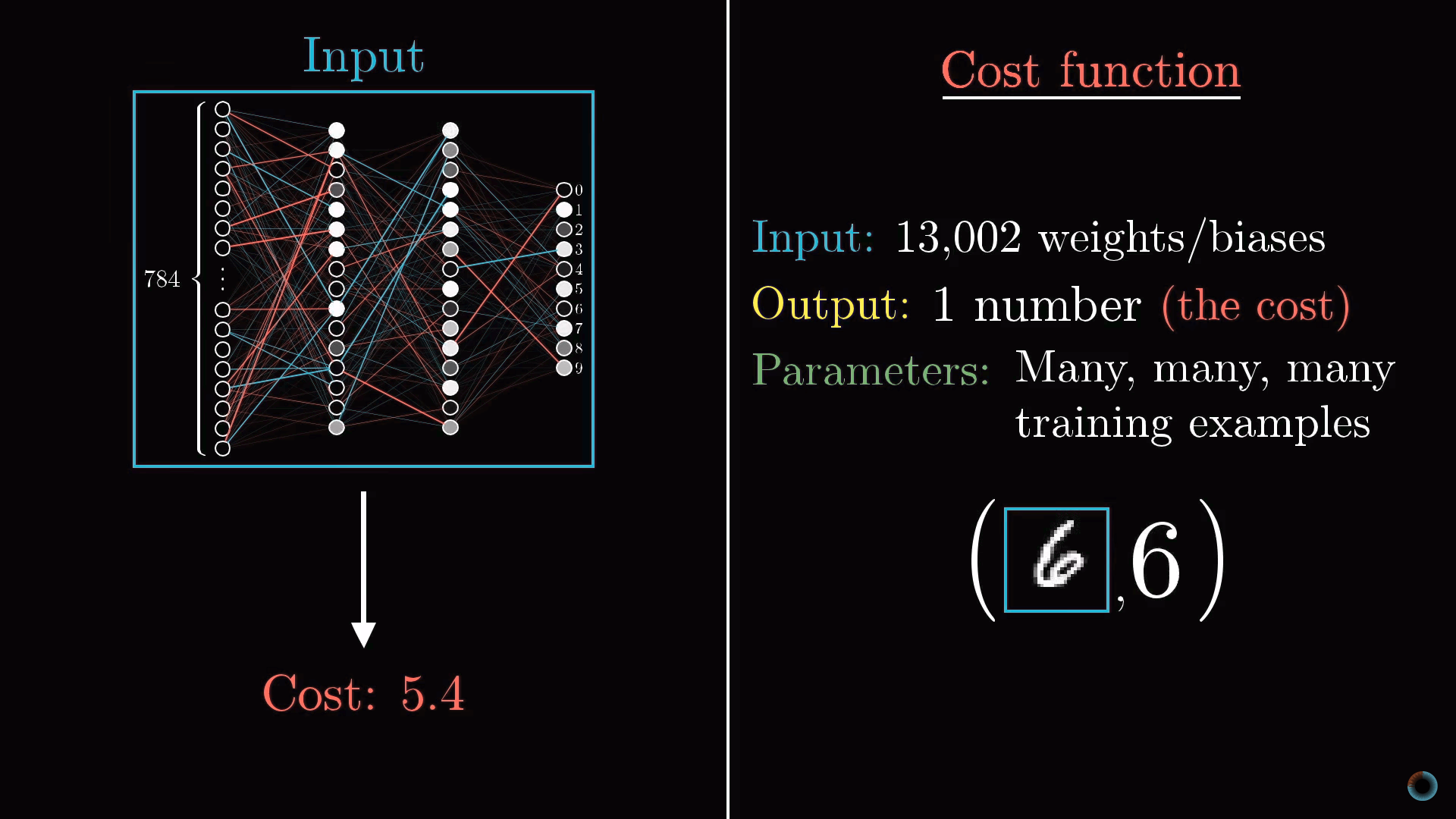
Концептуально задача обучения нейросети сводится к нахождению минимума определенной функции – функции стоимости. Опишем что она собой представляет.
Как вы помните, каждый нейрон следующего слоя соединен с нейроном предыдущего слоя, при этом веса этих связей и общий сдвиг определяют его функцию активации. Для того, чтобы с чего-то начать мы можем инициализировать все эти веса и сдвиги случайными числами.
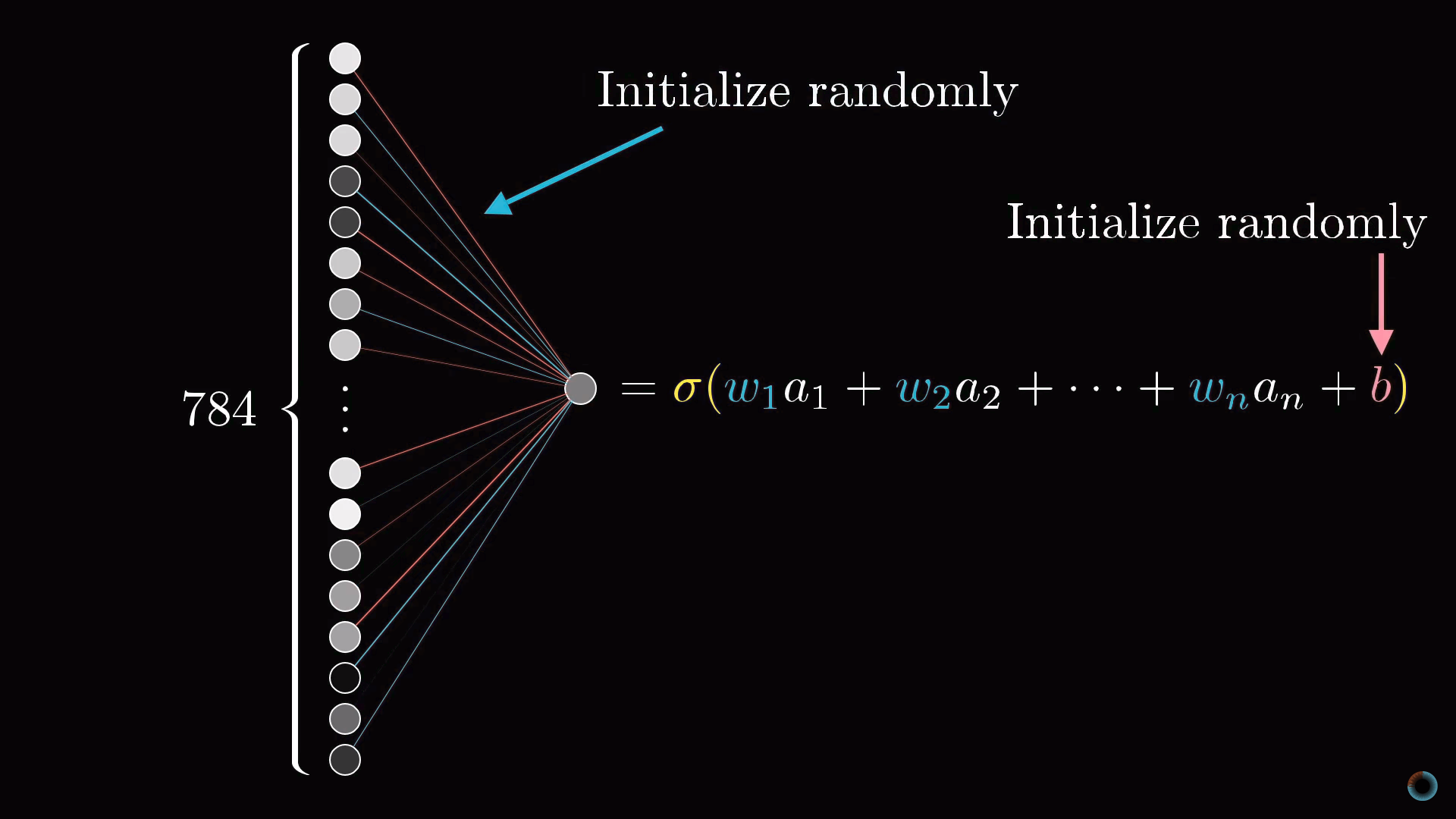
Соответственно в начальный момент необученная нейросеть в ответ на изображение заданного числа, например, изображение тройки, выходной слой выдает совершенно случайный ответ.
Чтобы обучать нейросеть, введем функцию стоимости (англ. cost function), которая будет как бы говорить компьютеру в случае подобного результата: «Нет, плохой компьютер! Значение активации должно быть нулевым у всех нейронов кроме одного правильного».
Задание функции стоимости для распознавания цифр
Математически эта функция представляет сумму квадратов разностей между реальными значениями активации выходного слоя и их же идеальными значениями. Например, в случае тройки активация должна быть нулевой для всех нейронов, кроме соответствующего тройке, у которого она равна единице.

Получается, что для одного изображения мы можем определить одно текущее значение функции стоимости. Если нейросеть обучена, это значения будет небольшим, в идеале стремящимся к нулю, и наоборот: чем больше значение функции стоимости, тем хуже обучена нейросеть.
Таким образом, чтобы впоследствии определить, насколько хорошо произошло обучение нейросети, необходимо определить среднее значение функции стоимости для всех изображений обучающей выборки.
Это довольно трудная задача. Если наша нейросеть имеет на входе 784 пикселя, на выходе 10 значений и требует для их расчета 13 тыс. параметров, то функция стоимости является функцией от этих 13 тыс. параметров, выдает одно единственное значение стоимости, которое мы хотим минимизировать, и при этом в качестве параметров выступает вся обучающая выборка.
Как изменить все эти веса и сдвиги, чтобы нейросеть обучалась?
Градиентный спуск
Для начала вместо того, чтобы представлять функцию с 13 тыс. входных значений, начнем с функции одной переменной С(w). Как вы, наверное, помните из курса математического анализа, для того, чтобы найти минимум функции, нужно взять производную.
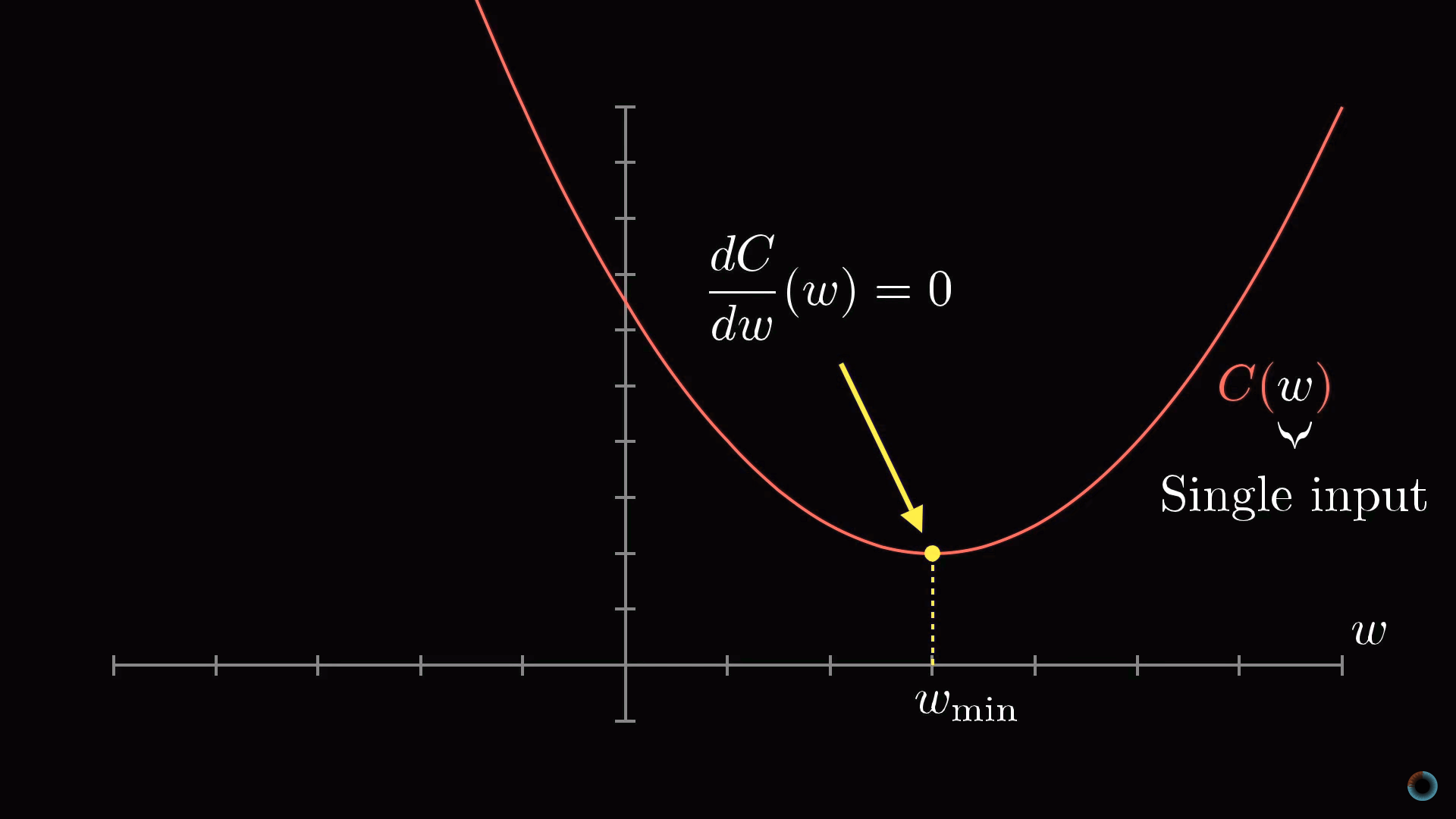
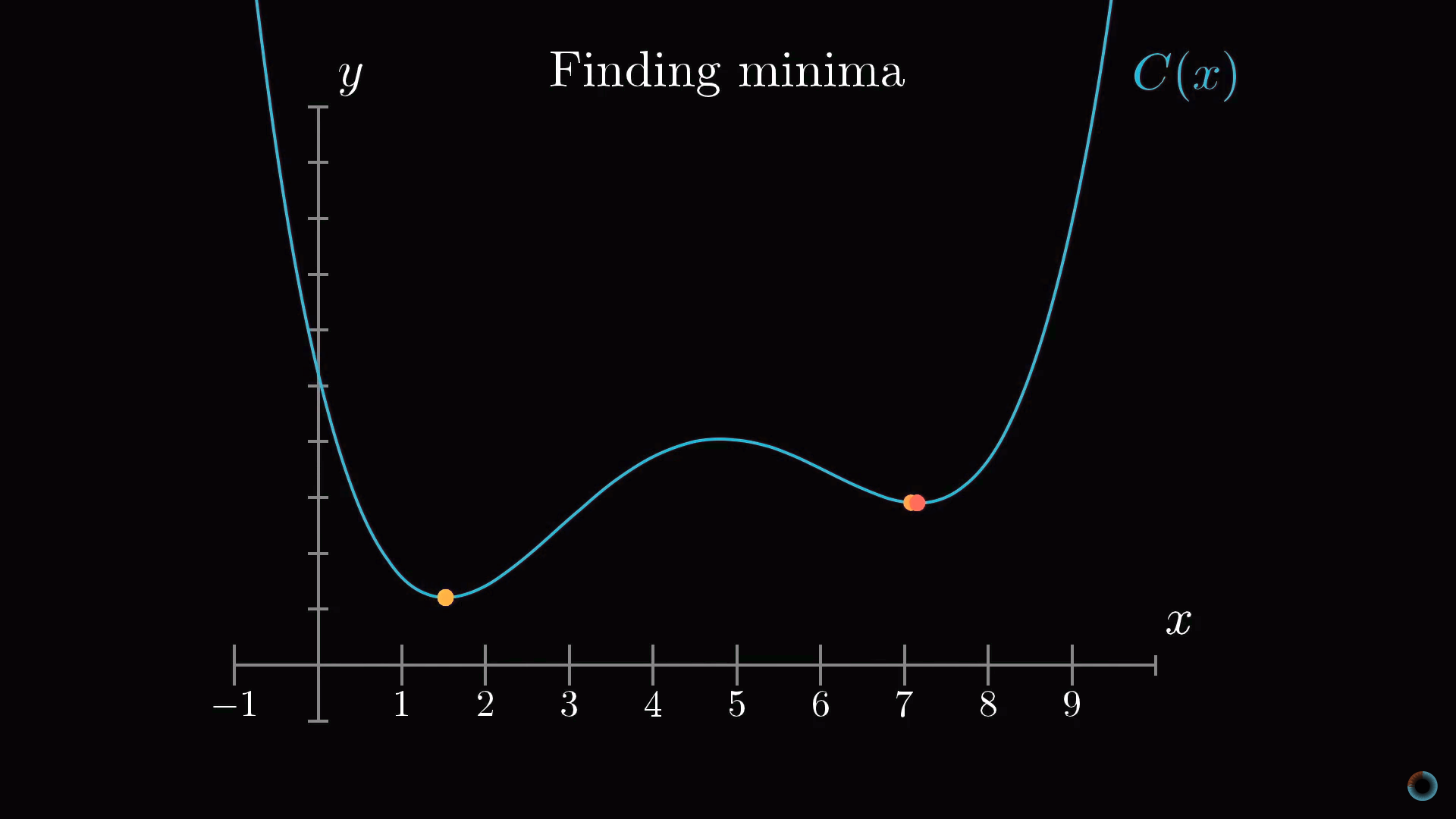
Однако форма функции может быть очень сложной, и одна из гибких стратегий состоит в том, чтобы начать рассмотрение с какой-то произвольной точки и сделать шаг в направлении уменьшения значения функции. Повторяя эту процедуру в каждой следующей точке, можно постепенно прийти к локальному минимуму функции, как это делает скатывающийся с холма мяч.
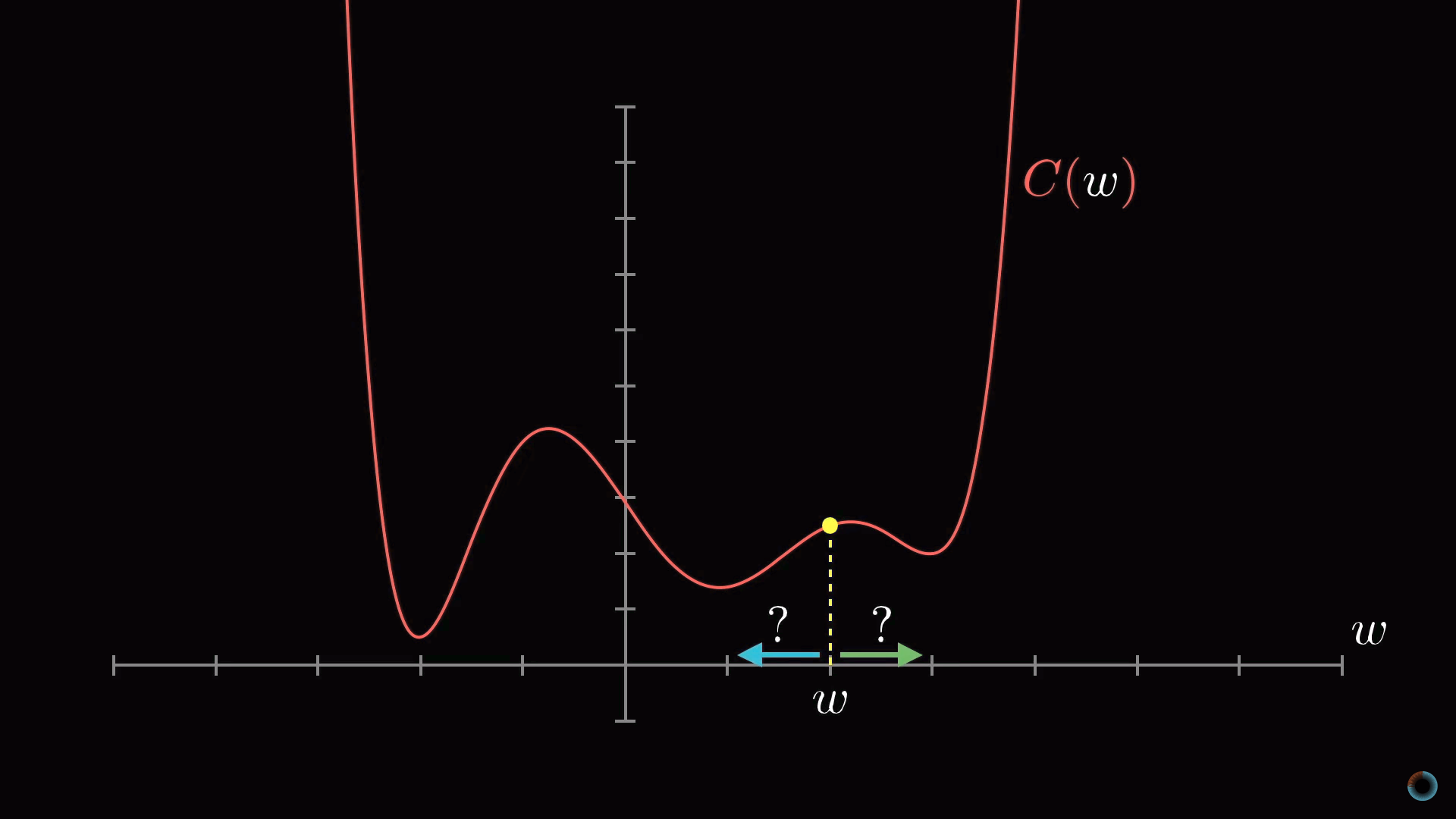
Как на приведенном рисунке показано, что у функции может быть множество локальных минимумов, и то, в каком локальном минимуме окажется алгоритм зависит от выбора начальной точки, и нет никакой гарантии, что найденный минимум является минимальным возможным значением функции стоимости. Это нужно держать в уме. Кроме того, чтобы не «проскочить» значение локального минимума, нужно менять величину шага пропорционально наклону функции.
Чуть усложняя эту задачу, вместо функции одной переменной можно представить функцию двух переменных с одним выходным значением. Соответствующая функция для нахождения направления наиболее быстрого спуска представляет собой отрицательный градиент -∇С. Рассчитывается градиент, делается шаг в направлении -∇С, процедура повторяется до тех пор, пока мы не окажемся в минимуме.
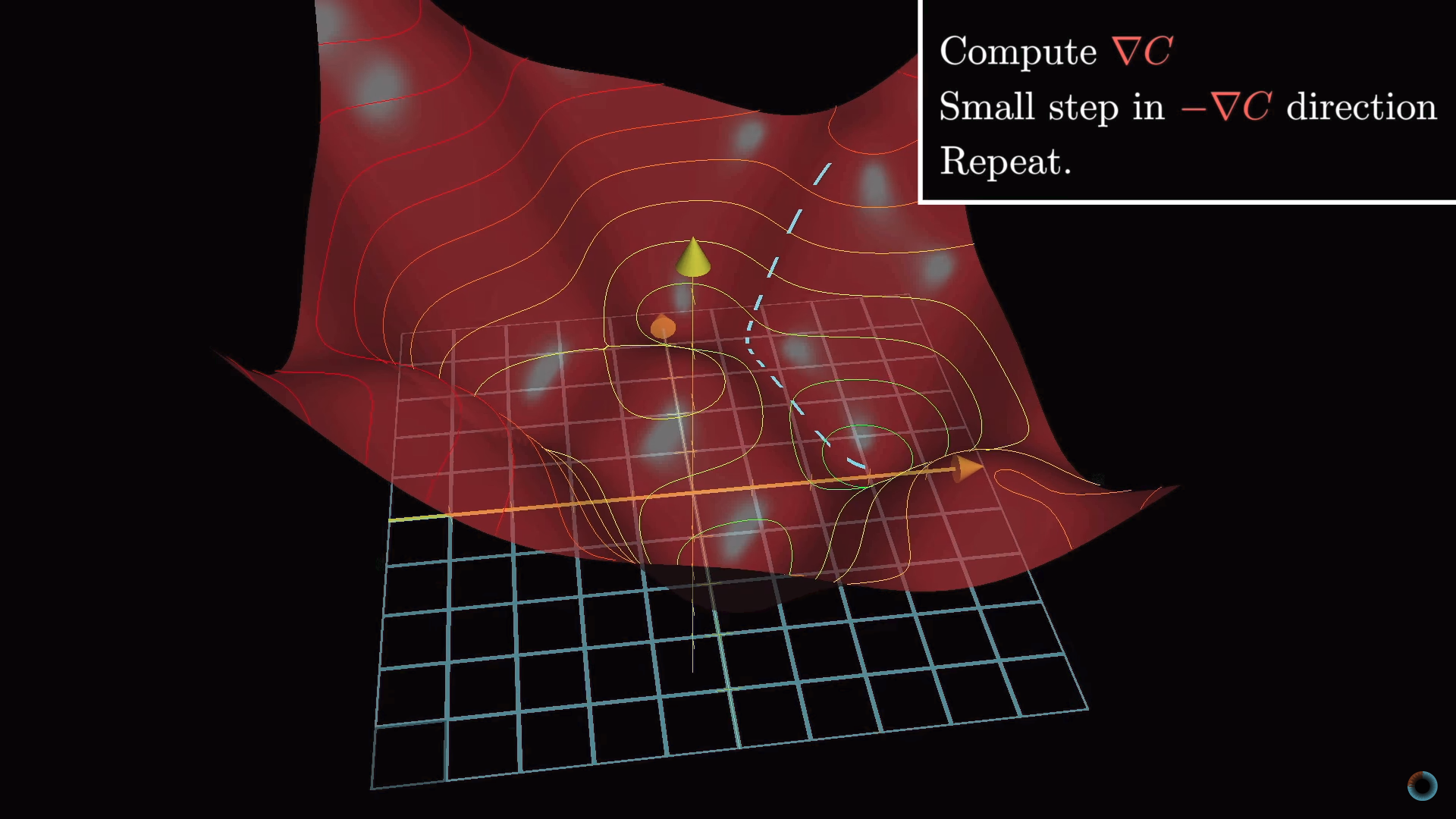
Описанная идея носит название градиентного спуска и может быть применена для нахождения минимума не только функции двух переменных, но и 13 тыс., и любого другого количества переменных. Представьте, что все веса и сдвиги образуют один большой вектор-столбец w. Для этого вектора можно рассчитать такой же вектор градиента функции стоимости и сдвинуться в соответствующем направлении, сложив полученный вектор с вектором w. И так повторять эту процедуру до тех пор, пока функция С(w) не прийдет к минимуму.

Компоненты градиентного спуска
Для нашей нейросети шаги в сторону меньшего значения функции стоимости будут означать все менее случайный характер поведения нейросети в ответ на обучающие данные. Алгоритм для эффективного расчета этого градиента называется метод обратного распространения ошибки и будет подробно рассмотрен в следующем разделе.
Для градиентного спуска важно, чтобы выходные значения функции стоимости изменялись плавным образом. Именно поэтому значения активации имеют не просто бинарные значения 0 и 1, а представляют действительные числа и находятся в интервале между этими значениями.
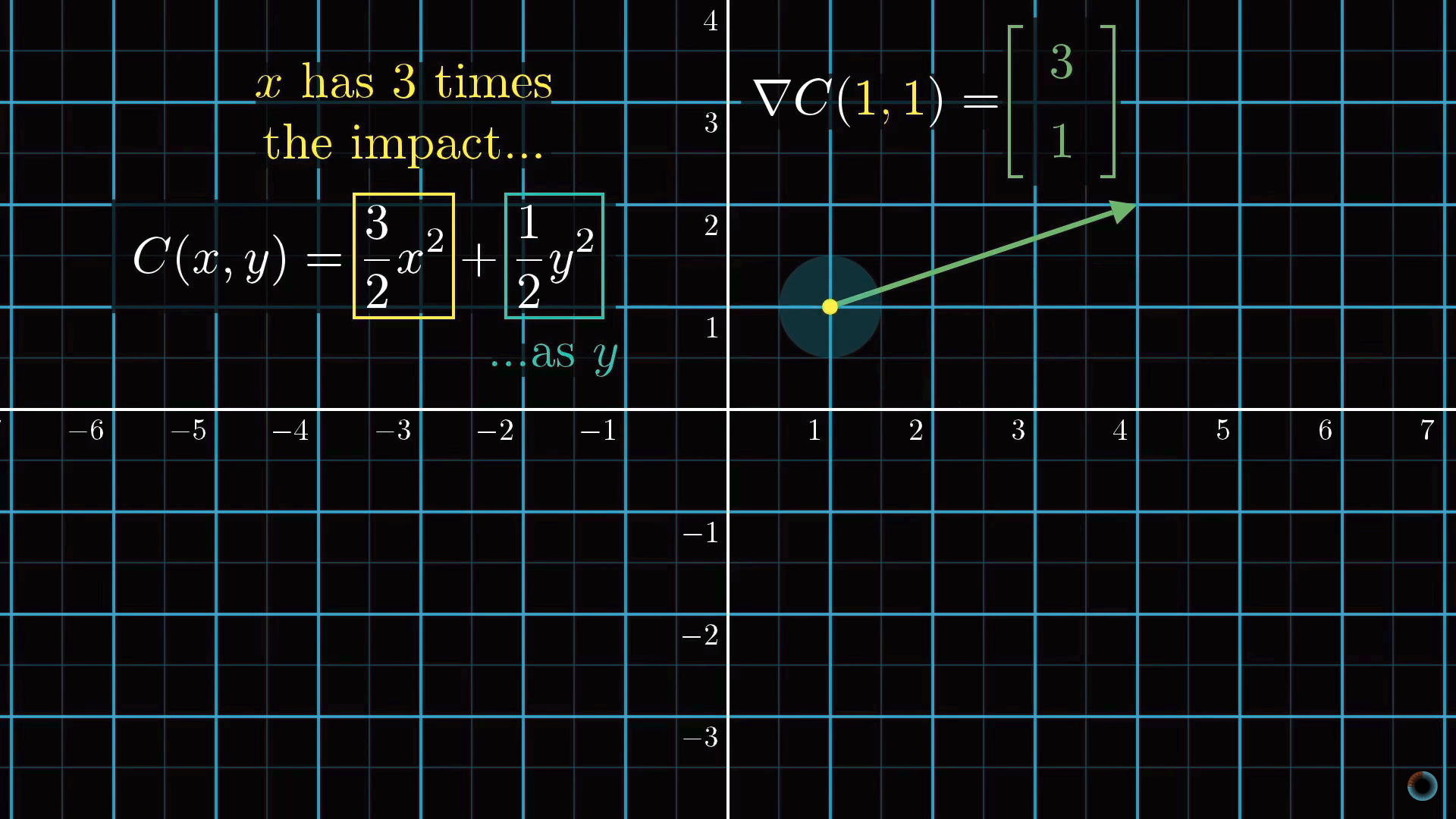
Каждый компонент градиента сообщает нам две вещи. Знак компонента указывает на направление изменения, а абсолютная величина – на влияние этого компонента на конечный результат: одни веса вносят больший вклад в функцию стоимости, чем другие.
Проверка предположения о назначении скрытых слоев
Обсудим вопрос того, насколько соответствуют слои нейросети нашим ожиданиям из первого урока. Если визуализировать веса нейронов первого скрытого слоя обученной нейросети, мы не увидим ожидавшихся фигур, которые бы соответствовали малым составляющим элементам цифр. Мы увидим гораздо менее ясные паттерны, соответствующие тому как нейронная сеть минимизировала функцию стоимости.
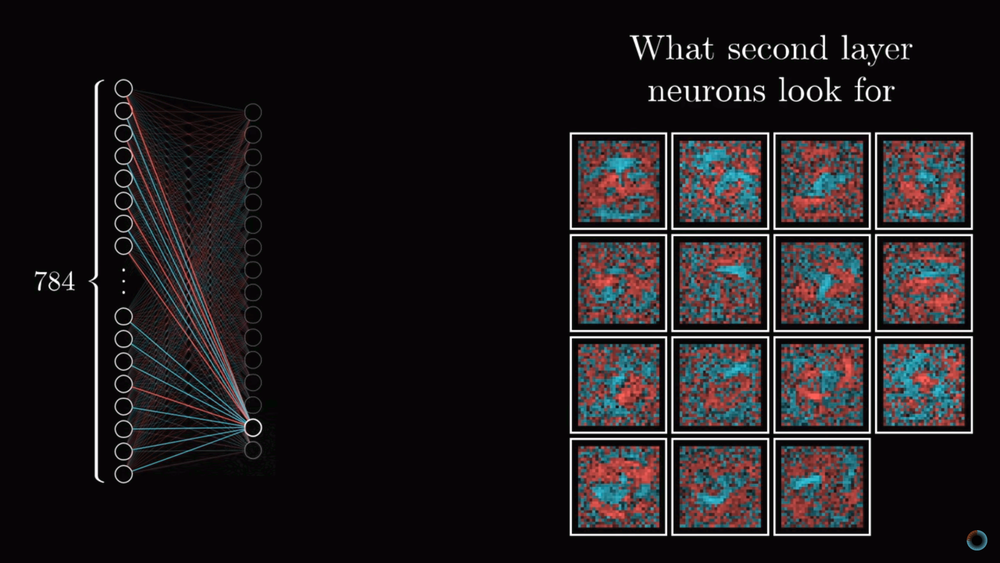
С другой стороны возникает вопрос, что ожидать, если передать нейронной сети изображение белого шума? Можно было бы предположить, что нейронная сеть не должна выдать никакого определенного числа и нейроны выходного слоя не должны активироваться или, если и активироваться, то равномерным образом. Вместо этого нейронная сеть в ответ на случайное изображение выдаст вполне определенное число.
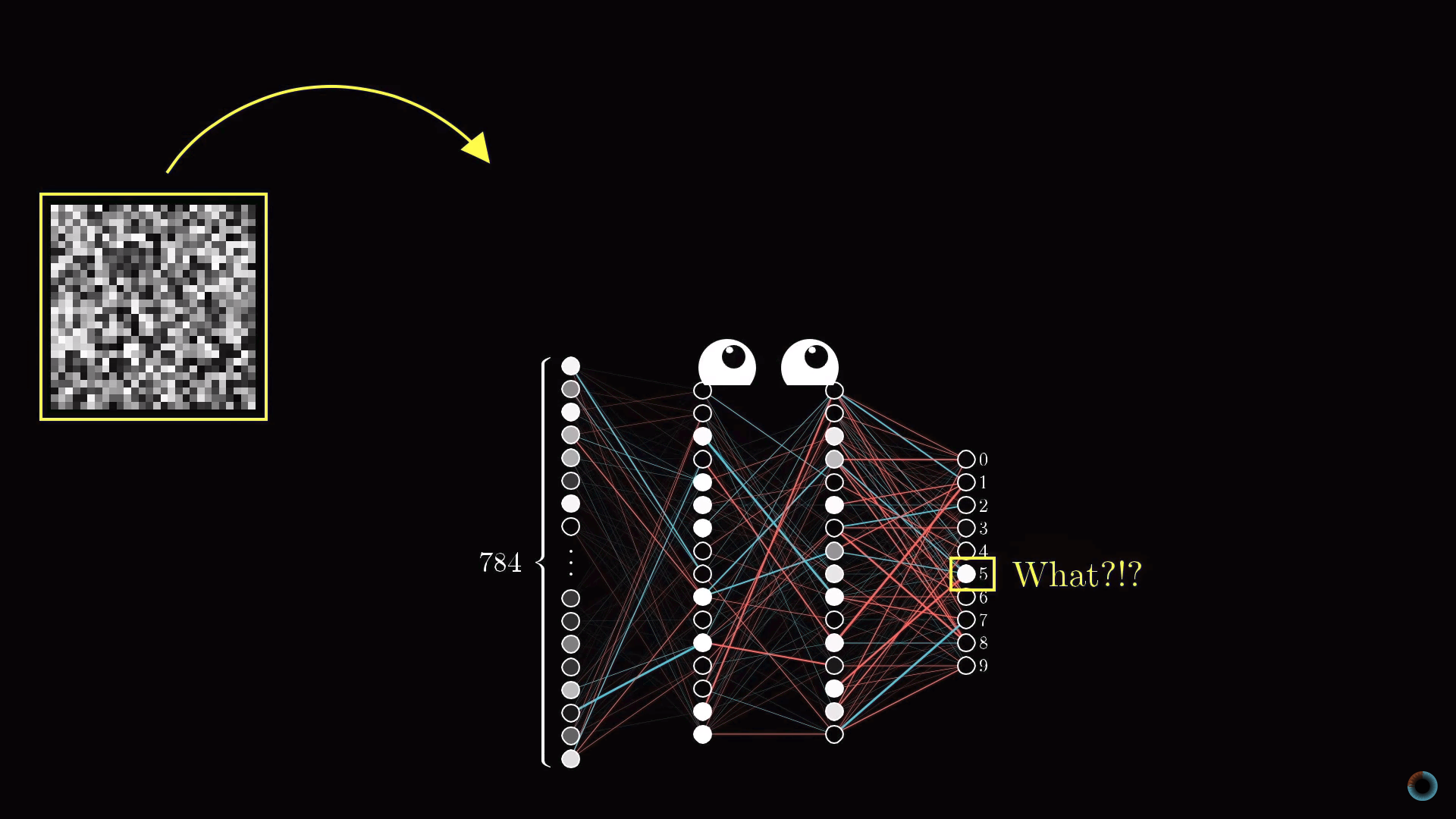
Хотя нейросеть выполняет операции распознавания цифр, она не имеет никаких представлений о том, как они пишутся. На самом деле такие нейросети это довольно старая технология, разработанная в 80-е-90-е годы. Однако понять работу такого типа нейросети очень полезно, прежде чем разбираться в современных вариантах, способных решать различные интересные проблемы. Но, чем больше вы копаетесь в том, что делают скрытые слои нейросети, тем менее интеллектуальной кажется нейросеть.
Обучение на структурированных и случайных данных
Рассмотрим пример современной нейросети для распознавания различных объектов реального мира.

Что произойдет, если перемешать базу данных таким образом, чтобы имена объектов и изображения перестали соответствовать друг другу? Очевидно, что так как данные размечены случайным образом, точность распознавания на тестовой выборке будет никудышной. Однако при этом на обучающей выборке вы будете получать точность распознавания на том же уровне, как если бы данные были размечены верным образом.
Миллионы весов этой конкретной современной нейросети будут настроены таким образом, чтобы в точности определять соответствие данных и их маркеров. Соответствует ли при этом минимизация функции стоимости каким-то паттернам изображений и отличается ли обучение на случайно размеченных данных от обучения на неверно размеченных данных?
Если вы обучаете нейросеть процессу распознавания на случайным образом размеченных данных, то обучение происходит очень медленно, кривая стоимости от количества проделанных шагов ведет себя практически линейно. Если же обучение происходит на структурированных данных, значение функции стоимости снижается за гораздо меньшее количество итераций.
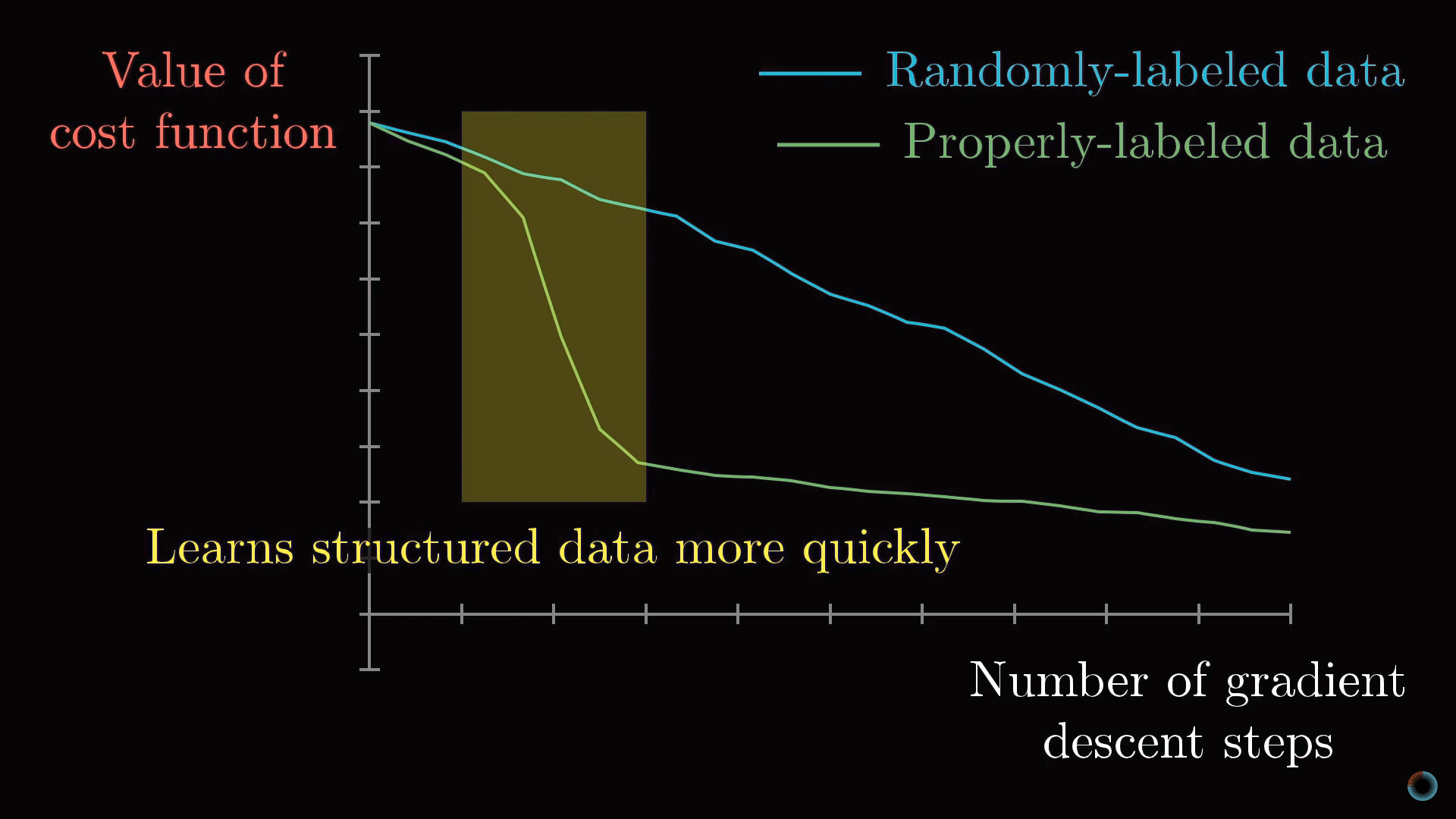
3. Метод обратного распространения ошибки
Обратное распространение это ключевой алгоритм обучения нейронной сети. Обсудим вначале в общих чертах, в чем заключается метод.
Управление активацией нейрона
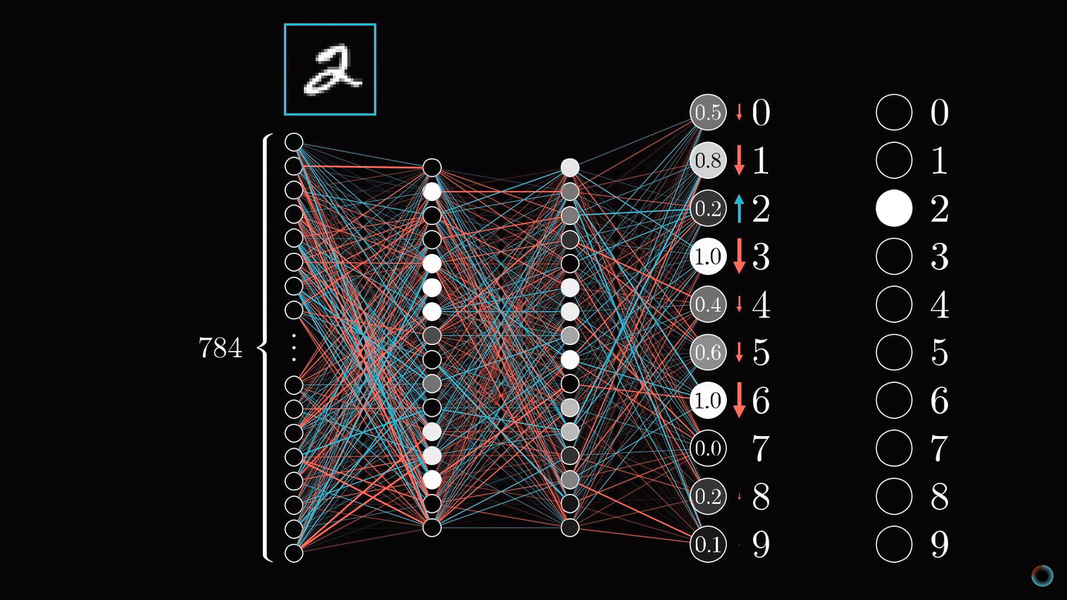
Каждый шаг алгоритма использует в теории все примеры обучающей выборки. Пусть у нас есть изображение двойки и мы в самом начале обучения: веса и сдвиги настроены случайно, и изображению соответствует некоторая случайная картина активаций выходного слоя.
Мы не можем напрямую изменить активации конечного слоя, но мы можем повлиять на веса и сдвиги, чтобы изменить картину активаций выходного слоя: уменьшить значения активаций всех нейронов, кроме соответствующего 2, и увеличить значение активации необходимого нейрона. При этом увеличение и уменьшение требуется тем сильнее, чем дальше текущее значение отстоит от желаемого.
Варианты настройки нейросети
Сфокусируемся на одном нейроне, соответствующем активации нейрона двойки на выходном слое. Как мы помним, его значение является взвешенной суммой активаций нейронов предыдущего слоя плюс сдвиг, обернутые в масштабирующую функцию (сигмоиду или ReLU).
Таким образом, чтобы повысить значение этой активации, мы можем:
- Увеличить сдвиг b.
- Увеличить веса wi.
- Поменять активации предыдущего слоя ai.
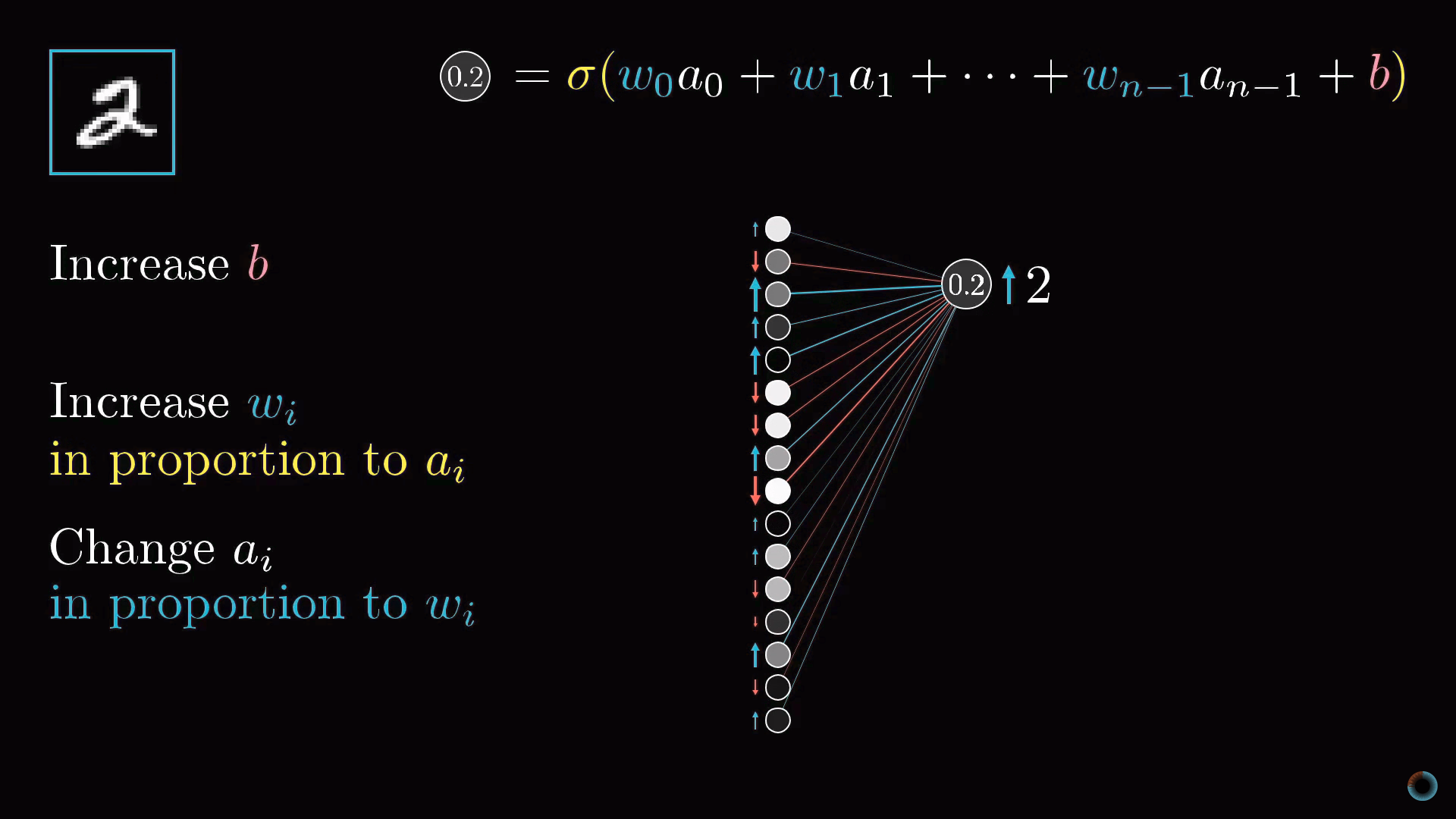
Из формулы взвешенной суммы можно заметить, что наибольший вклад в активацию нейрона оказывают веса, соответствующие связям с наиболее активированными нейронами. Стратегия, близкая к биологическим нейросетям заключается в том, чтобы увеличивать веса wi пропорционально величине активаций ai соответствующих нейронов предыдущего слоя. Получается, что наиболее активированные нейроны соединяются с тем нейроном, который мы только хотим активировать наиболее «прочными» связями.
Другой близкий подход заключается в изменении активаций нейронов предыдущего слоя ai пропорционально весам wi . Мы не можем изменять активации нейронов, но можем менять соответствующие веса и сдвиги и таким образом влиять на активацию нейронов.
Обратное распространение
Предпоследний слой нейронов можно рассматривать аналогично выходному слою. Вы собираете информацию о том, как должны были бы измениться активации нейронов этого слоя, чтобы изменились активации выходного слоя.
Важно понимать, что все эти действия происходят не только с нейроном, соответствующим двойке, но и со всеми нейронами выходного слоя, так как каждый нейрон текущего слоя связан со всеми нейронами предыдущего.
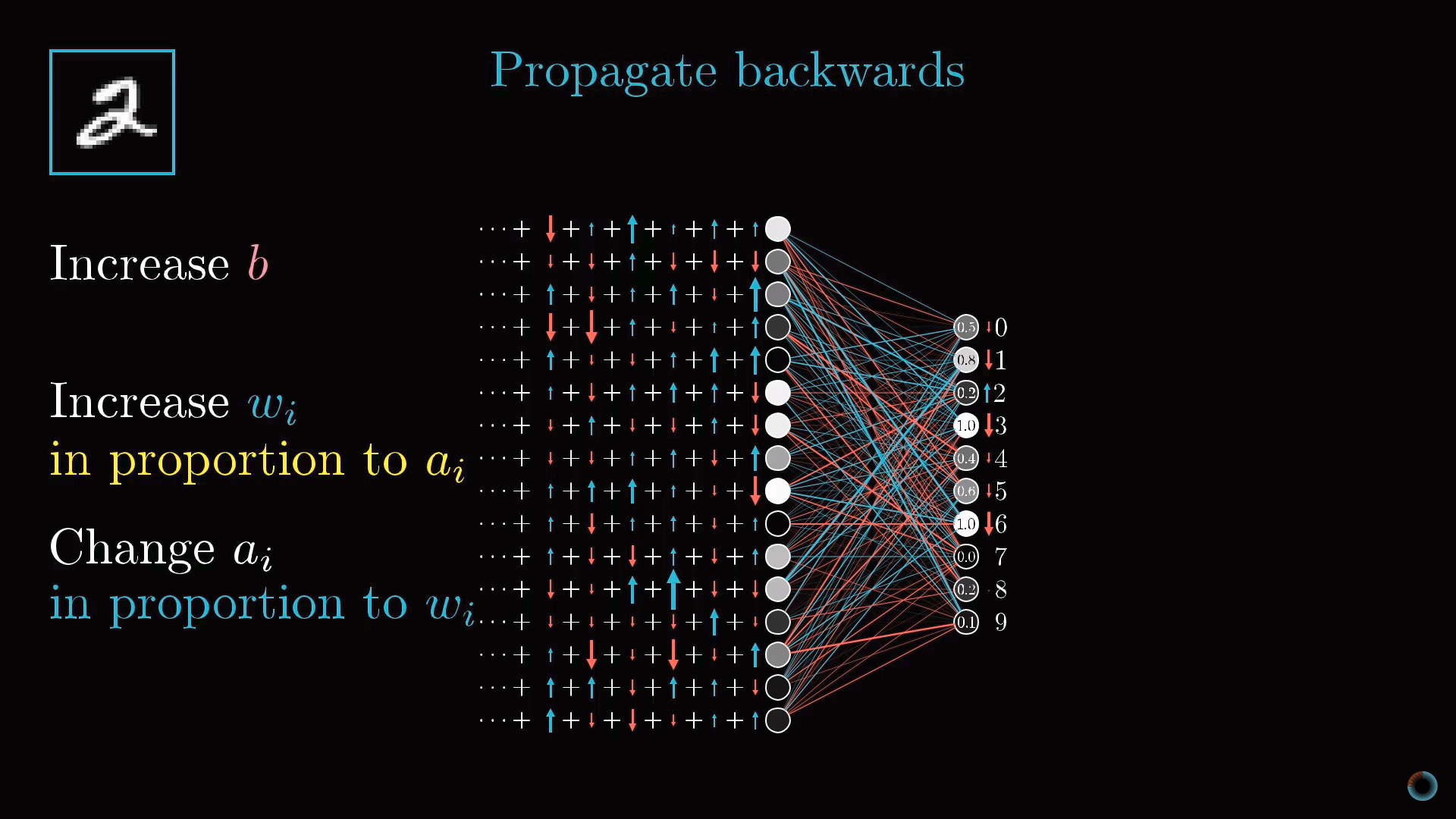
Просуммировав все эти необходимые изменения для предпоследнего слоя, вы понимаете, как должен измениться второй с конца слой. Далее рекурсивно вы повторяете тот же процесс для определения свойств весов и сдвигов всех слоев.
Классический градиентный спуск
В результате вся операция на одном изображении приводит к нахождению необходимых изменений 13 тыс. весов и сдвигов. Повторяя операцию на всех примерах обучающей выборки, вы получаете значения изменений для каждого примера, которые далее вы можете усреднить для каждого параметра в отдельности.
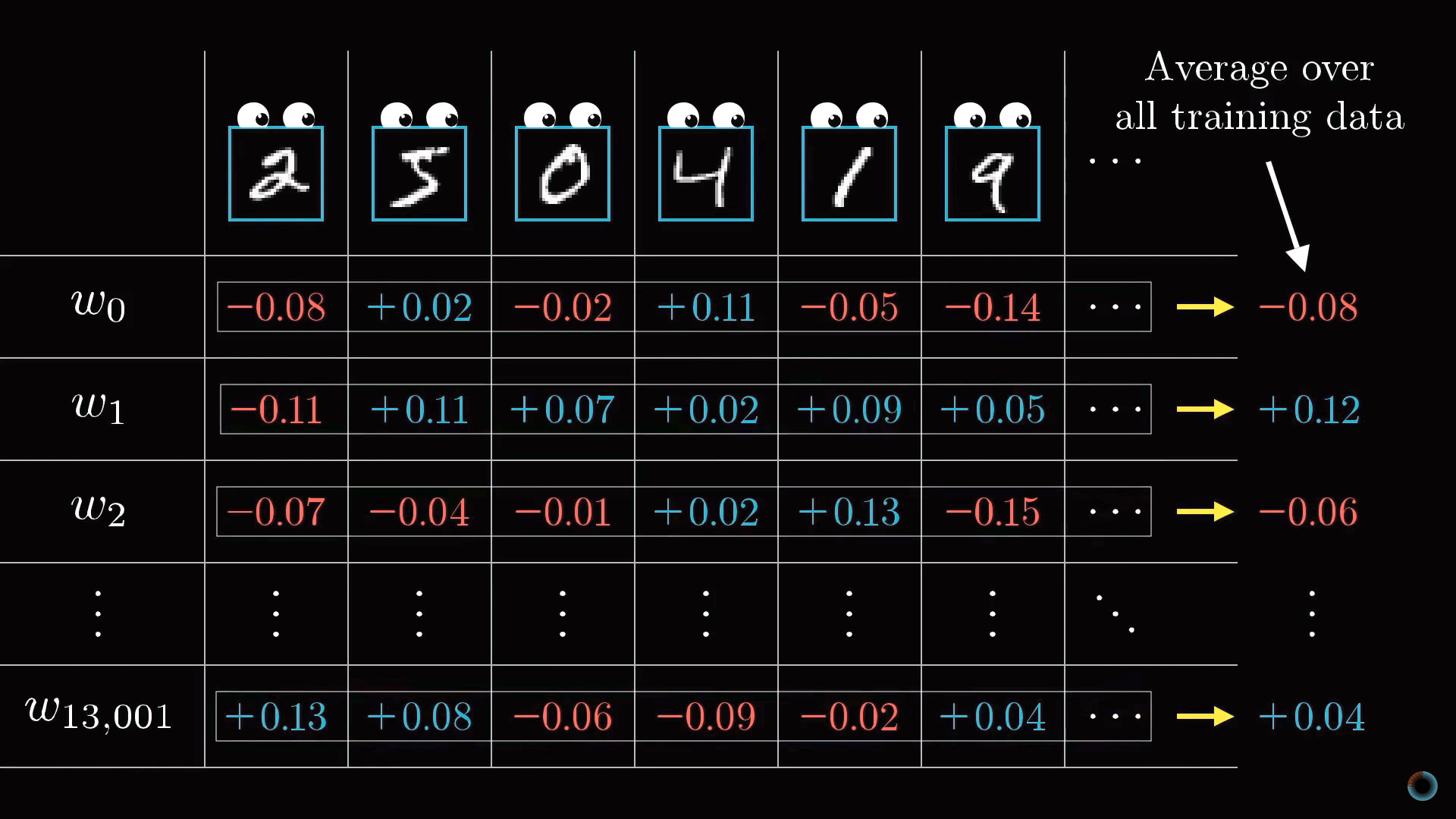
Результат этого усреднения представляет вектор столбец отрицательного градиента функции стоимости.
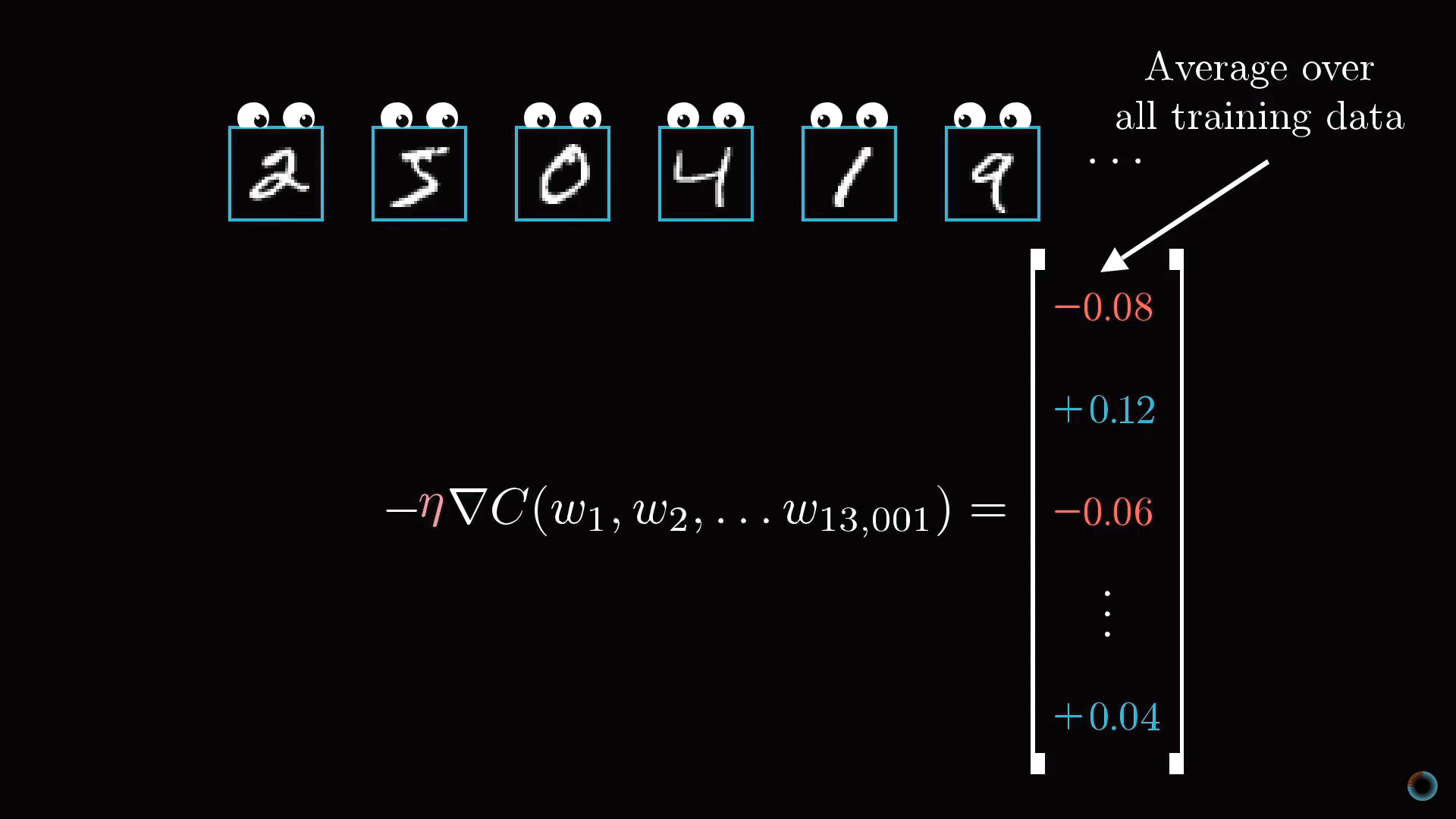
Стохастический градиентный спуск
Рассмотрение всей совокупности обучающей выборки для расчета единичного шага замедляет процесс градиентного спуска. Поэтому обычно делается следующее.
Случайным образом данные обучающей выборки перемешиваются и разделяются на подгруппы, например, по 100 размеченных изображений. Далее алгоритм рассчитывает шаг градиентного спуска для одной подгруппы.

Это не в точности настоящий градиент для функции стоимости, который требует всех данных обучающей выборки, но, так как данные выбраны случайным образом, они дают хорошую аппроксимацию, и, что важно, позволяют существенно повысить скорость вычислений.
Если построить кривую обучения такого модернизированного градиентного спуска, она будет похожа не на равномерный целенаправленный спуск с холма, а на петляющую траекторию пьяного, но делающего более быстрые шаги и приходящего также к минимуму функции.
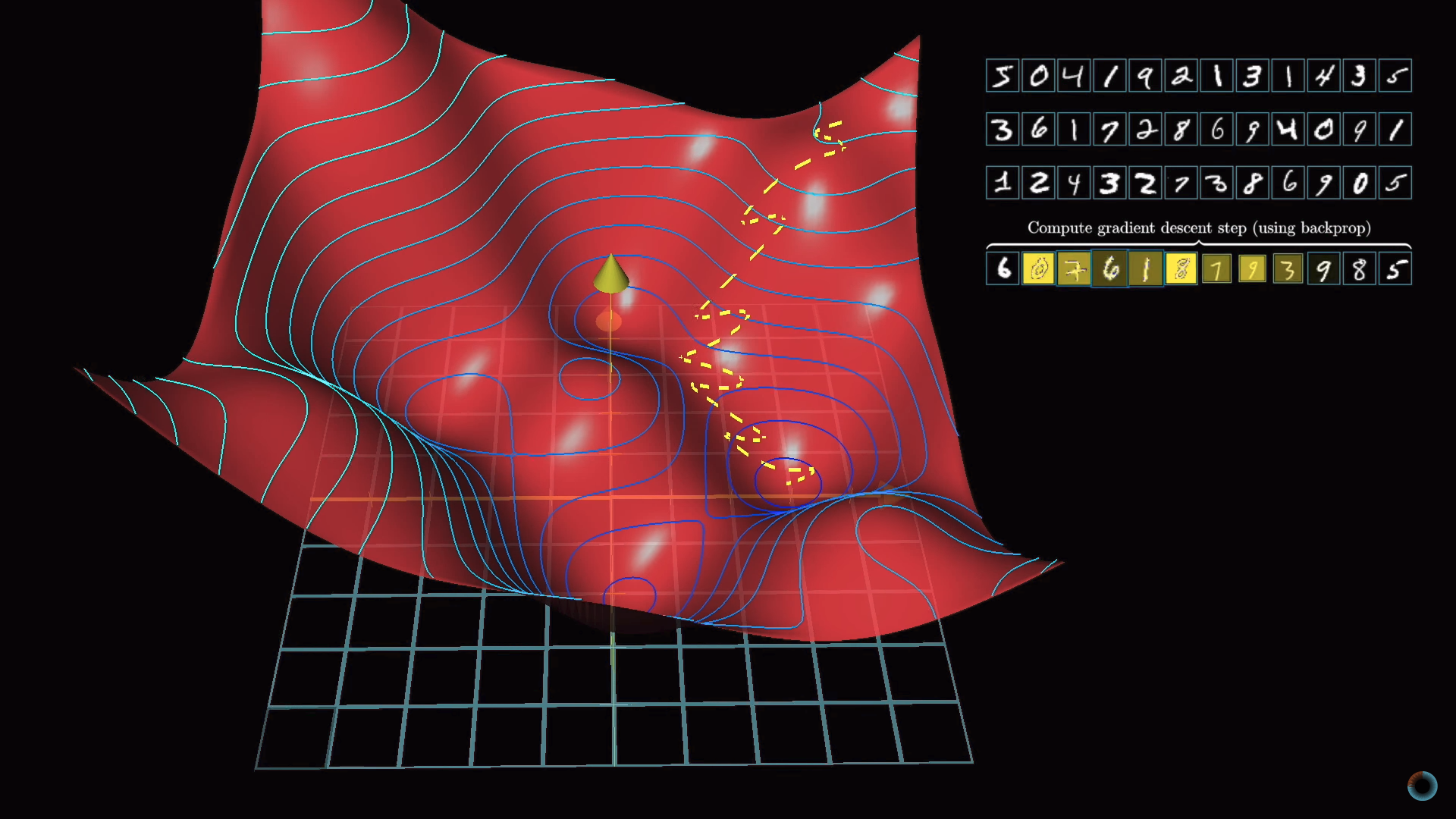
Такой подход называется стохастическим градиентным спуском.
Дополнение. Математическая составляющая обратного распространения
Разберемся теперь немного более формально в математической подоплеке алгоритма обратного распространения.
Примитивная модель нейронной сети
Начнем рассмотрение с предельно простой нейросети, состоящей из четырех слоев, где в каждом слое всего по одному нейрону. Соответственно у сети есть три веса и три сдвига. Рассмотрим, насколько функция чувствительна к этим переменным.
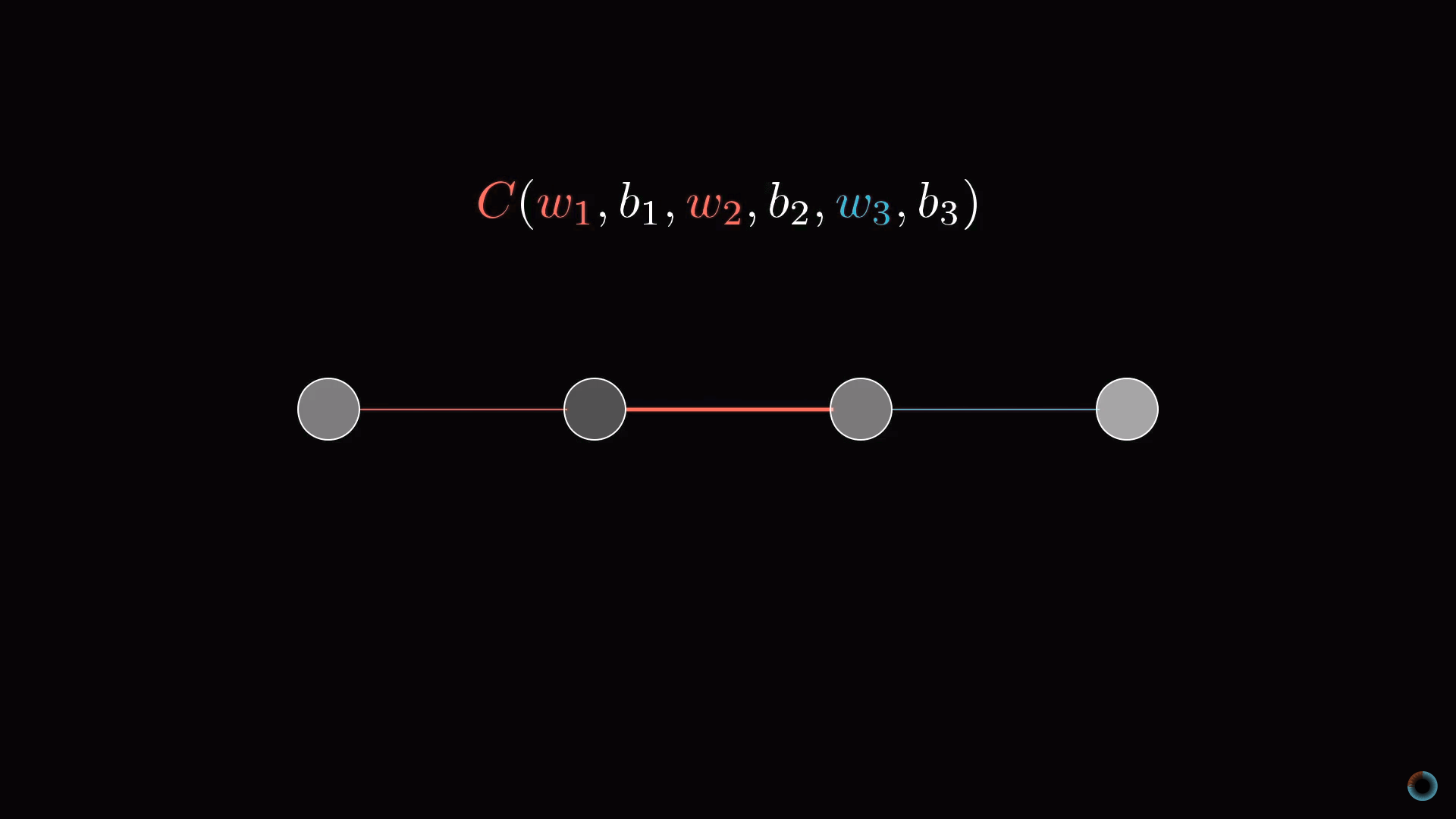
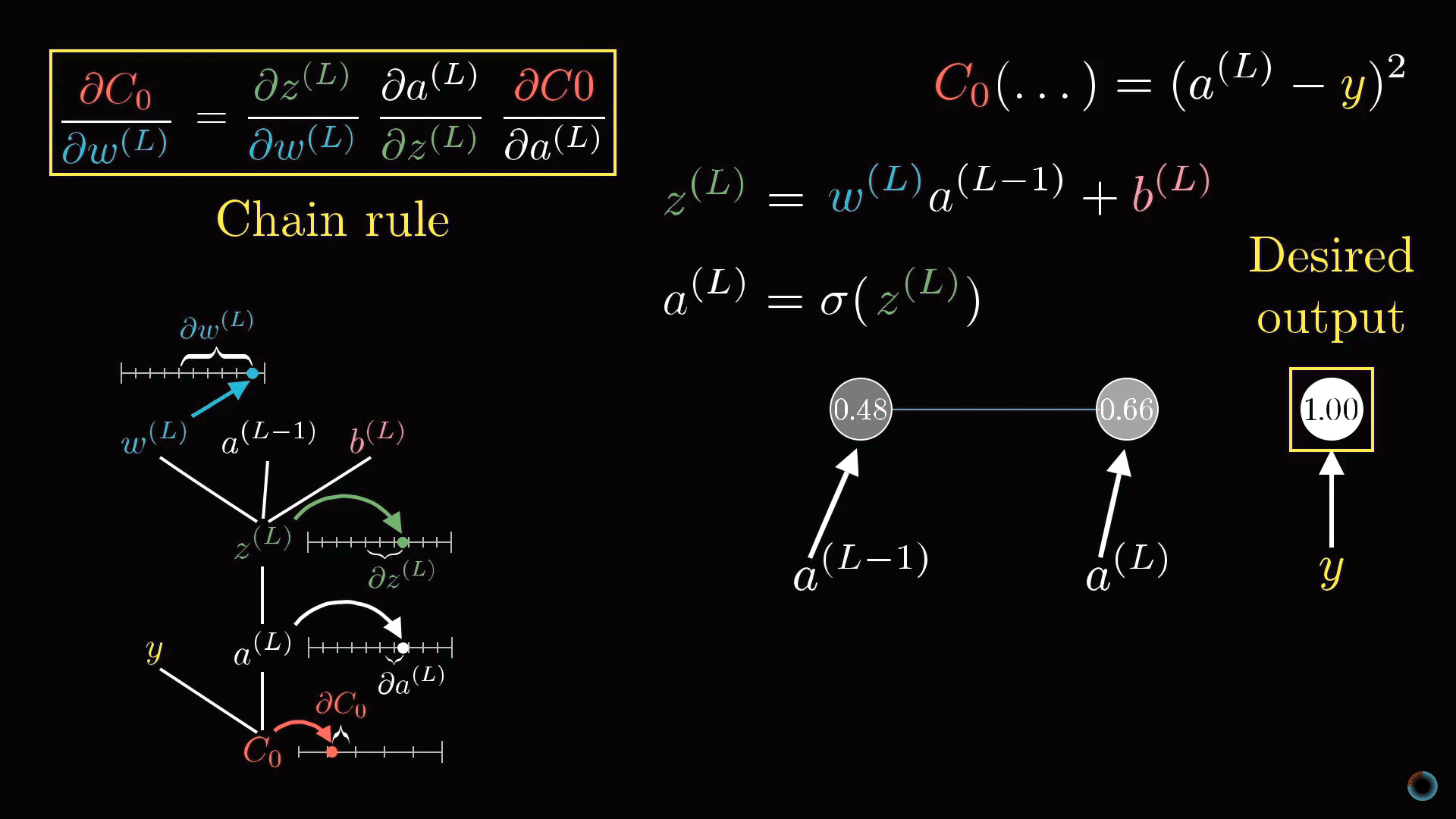
Начнем со связи между двумя последними нейронами. Обозначим последний слой L, предпоследний L-1, а активации лежащих в них рассматриваемых нейронов a(L), a(L-1).
Функция стоимости
Представим, что желаемое значение активации последнего нейрона, данное обучающим примеров это y, равное, например, 0 или 1. Таким образом, функция стоимости определяется для этого примера как
C0 = (a(L) — y)2.
Напомним, что активация этого последнего нейрона задается взвешенной суммой, а вернее масштабирующей функцией от взвешенной суммы:
a(L) = σ(w(L)a(L-1) + b(L)).
Для краткости взвешенную сумму можно обозначить буквой с соответствующим индексом, например z(L):
a(L) = σ(z(L)).
Рассмотрим как в значении функции стоимости сказываются малые изменения веса w(L). Или математическим языком, какова производная функции стоимости по весу ∂C0/∂w(L)?
Можно видеть, что изменение C0 зависит от изменения a(L), что в свою очередь зависит от изменения z(L), которое и зависит от w(L). Соответственно правилу взятия подобных производных, искомое значение определяется произведением следующих частных производных:
∂C0/∂w(L) = ∂z(L)/∂w(L) • ∂a(L)/∂z(L) • ∂C0/∂a(L).
Определение производных
Рассчитаем соответствующие производные:
∂C0/∂a(L) = 2(a(L) — y)
То есть производная пропорциональна разнице между текущим значением активации и желаемым.
Средняя производная в цепочке является просто производной от масштабирующей функции:
∂a(L)/∂z(L) = σ'(z(L))
И наконец, последний множитель это производная от взвешенной суммы:
∂z(L)/∂w(L) = a(L-1)
Таким образом, соответствующее изменение определяется тем, насколько активирован предыдущий нейрон. Это соотносится с упоминавшейся выше идеей, что между загорающимися вместе нейронами образуется более «прочная» связь.
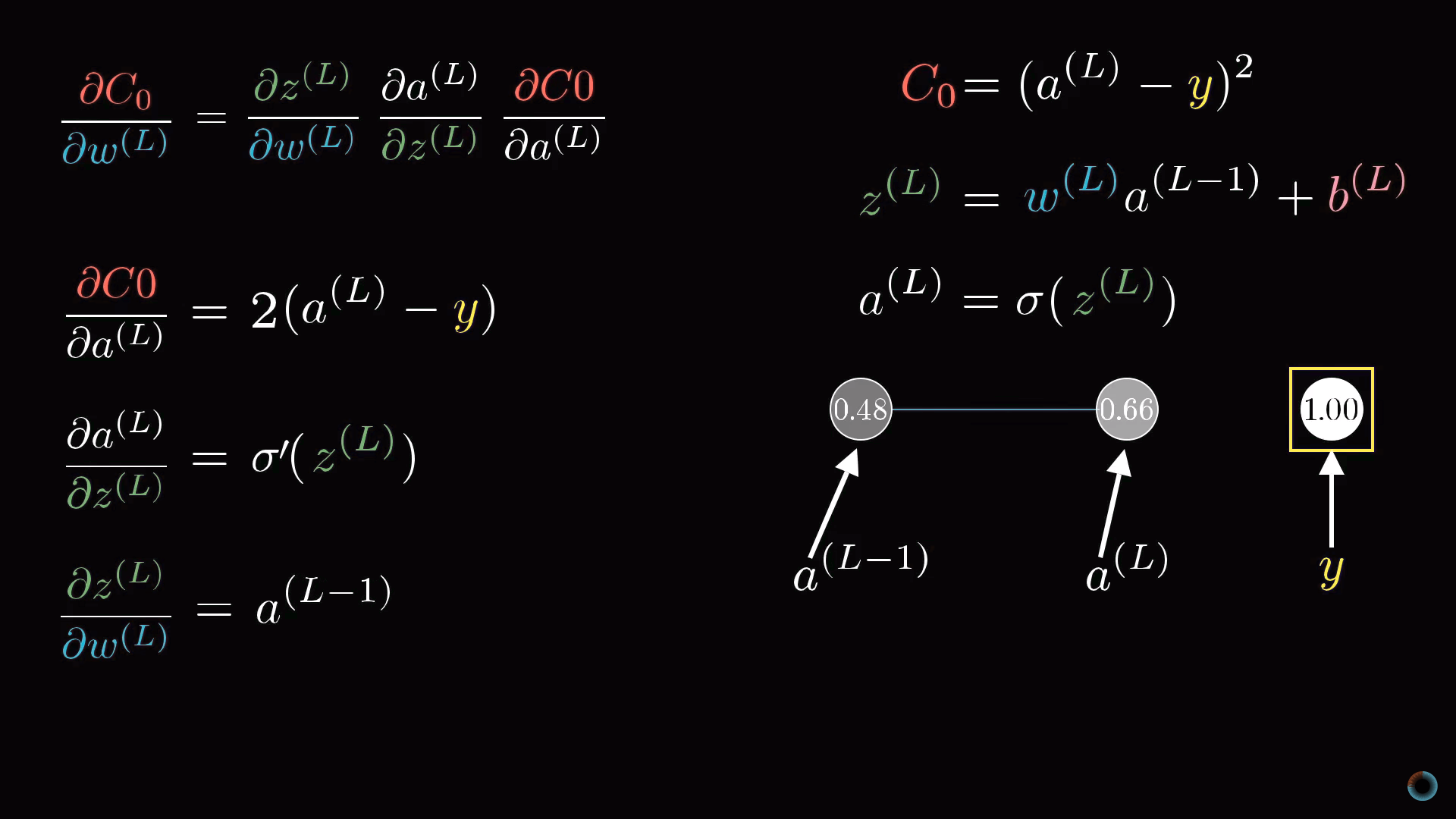
Конечное выражение:
∂C0/∂w(L) = 2(a(L) — y) σ'(z(L)) a(L-1)
Обратное распространение
Напомним, что определенная производная лишь для стоимости отдельного примера обучающей выборки C0. Для функции стоимости С, как мы помним, нужно производить усреднение по всем примерам обучающей выборки:
∂C/∂w(L) = 1/n Σ ∂Ck/∂w(L)
 Полученное усредненное значение для конкретного w(L) является одним из компонентов градиента функции стоимости. Рассмотрение для сдвигов идентично приведенному рассмотрению для весов.
Полученное усредненное значение для конкретного w(L) является одним из компонентов градиента функции стоимости. Рассмотрение для сдвигов идентично приведенному рассмотрению для весов.
Получив соответствующие производные, можно продолжить рассмотрение для предыдущих слоев.
Модель со множеством нейронов в слое
Однако как осуществить переход от слоев, содержащих по одному нейрону к исходно рассматриваемой нейросети. Все будет выглядеть аналогично, просто добавится дополнительный нижней индекс, отражающий номер нейрона внутри слоя, а у весов появятся двойные нижние индексы, например, jk, отражающие связь нейрона j из одного слоя L с другим нейроном k в слое L-1.
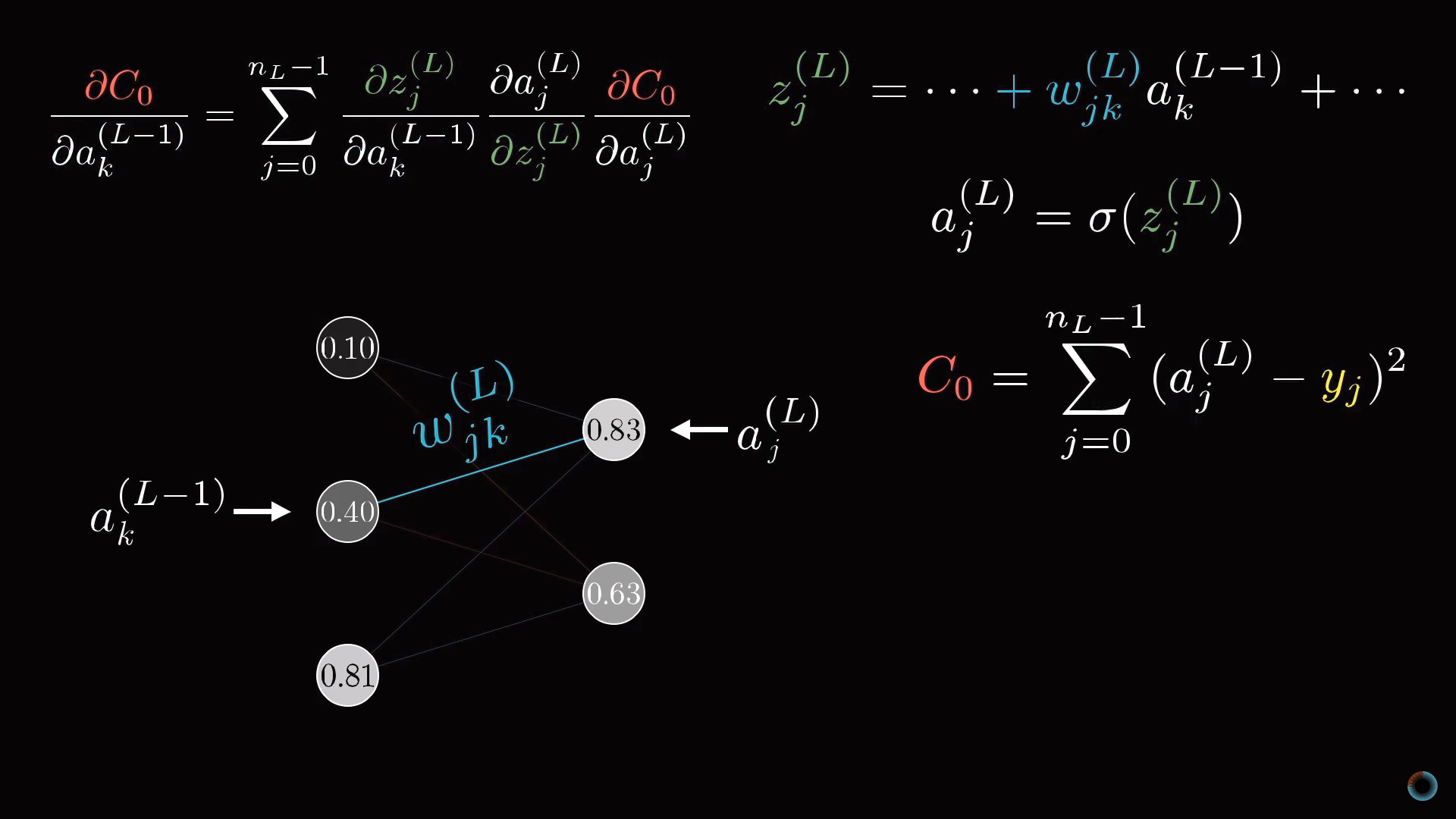
Конечные производные дают необходимые компоненты для определения компонентов градиента ∇C.

Потренироваться в описанной задаче распознавания цифр можно при помощи учебного репозитория на GitHub и упомянутого датасета для распознавания цифр MNIST.
Другие материалы по теме:
- Пишем свою нейросеть: пошаговое руководство
- Подборка материалов по нейронным сетям
- Иллюстративный видеокурс по линейной алгебре: 11 уроков
- Введение в глубинное обучение
- Иллюстративный видеокурс математического анализа: 10 уроков
- От новичка до профи в машинном обучении за 3 месяца
Оглавление:
- Что такое искусственные нейронные сети?
- Виды обучения нейронных сетей
- Многослойные нейронные сети и их базовые понятия
- Разбираемся на примере
- Заключение
Что такое искусственные нейронные сети?
Данная статья предназначена для ознакомления читателя с искусственными нейронными сетями (далее ANN – Artificial Neural Network) и базовыми понятиями многослойных нейронных сетей.
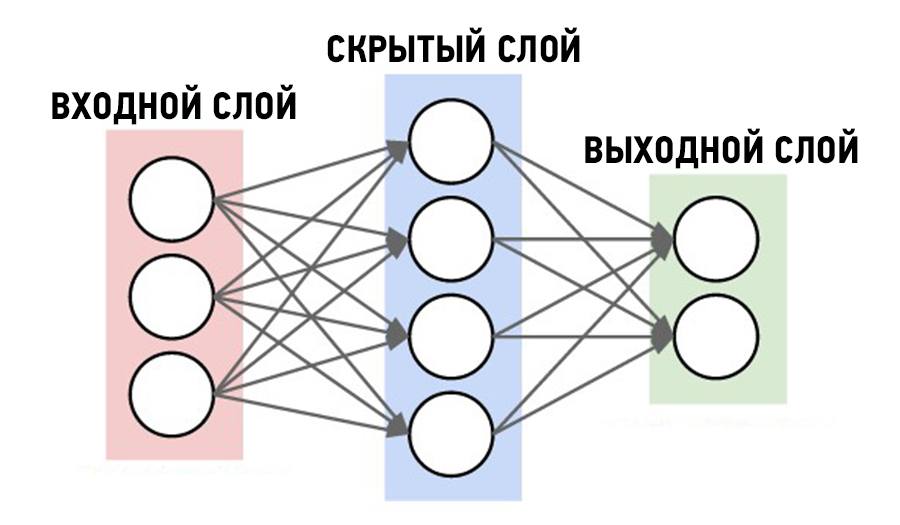
Основным элементом ANN является нейрон. Его основной задачей является перемножение предыдущих значений нейронов или входных значений с соответствующими им весовыми коэффициентами связей между соответствующими нейронами, после активации вычисленного значения.
Основными задачами ANN является классификация, принятие решения, анализ данных, прогнозирование, оптимизация.
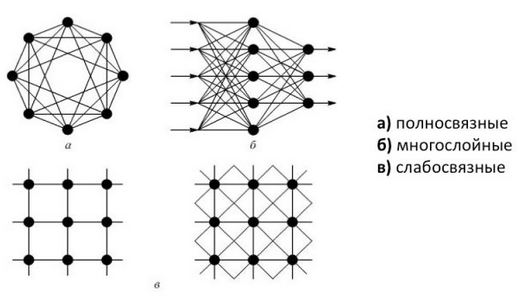
Искусственные нейронные сети категорируются по топологии (полносвязные, многослойные, слабосвязные), способу обучения (с учителем, без учителя, с подкреплением), модели нейронной сети (прямого распространения, рекррентные нейронные сети, сверточные нейронные сети, радиально-базисные функции), а также по типу связей (полносвязные, многослойные, слабосвязные). Такой значительно большой тип категорирования связан с разнообразием задач, которые ставятся перед ANN. Примеры, приведенные в скобках являются одними из самых распространенных типов категорирования, на самом деле их значительно больше.
Виды обучения нейронных сетей
Обучение с учителем
Данный тип обучения является самым простым, за счет того, что нет необходимости в написании алгоритмов самообучения. Для обучения с учителем требуется размеченный и структурированный набор данных для обучения. Под словом «размеченный» подразумевается процесс обозначения верного ответа на конкретный набор входных данных, который мы ожидаем от нейронной сети как результат работы. За счет таких данных нейронная сеть будет ориентироваться на разметку и корректировать процесс обучения за счет определения совершенных ошибок, которые будут определяться из данных разметки и ее предсказанных данных.
Обучение без учителя
Под обучением без учителя подразумевается процесс обучения нейронной сети без какого-либо контроля с нашей стороны. Весь процесс будет протекать за счет нахождения нейронной сетью корреляции в данных, извлечения полезных признаков и их анализа.
Существуют несколько способов обучения без учителя: обнаружение аномалий, ассоциации, автоэнкодеры и кластеризация.
На основе алгоритмов, описанных выше, в процессе обучения будет определяться значение ошибки, допущенной на каждом шаге обучения, за счет чего будет происходить корректировка обучения, следовательно, нейронная сеть обучится. За счет наличия алгоритмов, процесс написания которых занимает много времени и сильно усложняет моделирование нейронной сети, данный тип обучения считается самым сложным.
Обучение с подкреплением
Обучение с подкреплением или частичным вмешательством учителя можно считать золотой серединой в обучении нейронных сетей. Данный тип обучения представляет собой обучение без учителя с периодической его корректировкой. Корректировка обучения происходит тогда, когда нейронная сеть допускает ошибки при обучении.
Многослойные нейронные сети и их базовые понятия
Каждая ANN имеет входной, выходной и скрытые слои. Количество скрытых слоев и их сложность (количество искусственных нейронов) зачастую играют важную роль в процессе обучения, обеспечивая хорошее обучение модели нейронной сети.
Многослойными ANN называются нейронные сети, у которых количество скрытых слоев более одного. Пример многослойной нейронной сети:
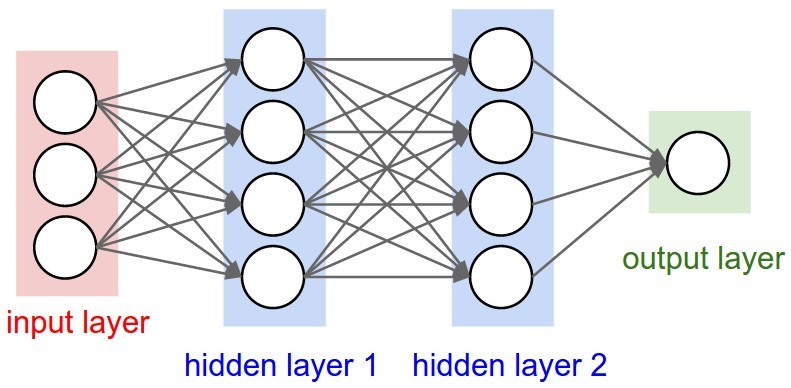
Входной, выходной и скрытые слои, нормализация и зачем все это нужно?
Входной слой дает возможность «скормить» данные, на которых требуется производить обучение. Выходной, в свою очередь, выдает результат работы нейронной сети. Вся суть заключается в скрытых слоях. Повторюсь, количество скрытых слоев и их сложность определяют качество обучения. Объясню на простом примере. Я, при написании модели нейронной сети, которая классифицирует рукописные цифры, смоделировал нейронную сеть из двух скрытых слоев по 30 нейронов в каждом. На вход подавал изображение 28х28 пикселей, но предварительно проведя нормализацию (объясню чуть ниже) входных значений и приведение изображения к виду 784х1, путем расставления всех столбцов в один. Т.е. входными значениями являлись 0 и 1, а если быть точнее — значения из данного диапазона. Так вот эти 0 и 1 оказались на входном слое, т.е. каждый нейрон входного слоя представлял из себя пиксель исходного изображения. Далее следовал скрытый слой, состоящий из 30 нейронов. Так вот, эти 30 нейронов представляют собой 30 участков исходного изображения, а каждый участок в свою очередь содержит какие-либо признаки, характеризующие изображение как определенную цифру. Т.е. чем больше нейронов в скрытых слоях, тем точнее будет представление и градуировка исходного изображения. Будет «плодиться» больше характеристик, по которым нейронная сеть будет классифицировать изображение должным образом.
Вернусь к такому понятию, как нормализация. Она необходима для приведения входных значений к значениям из диапазона 0 и 1. Смысл заключается в том, что нейронная сеть должна явно или с долей вероятности классифицировать изображение, или дать какое-то предсказание. Раз предсказание представляет собой вероятность, то и входные значения должны быть в диапазоне от 0 до 1. Поэтому нормализация, к примеру, значений пикселей изображения, происходит путем деления на 255, т.к. значения пикселей находятся в диапазоне от 0 до 255 и максимальным значением является значение 255.
Весовые коэффициенты
Каждая связь между искусственными нейронами обладает весовым коэффициентом, который постоянно изменяется в процессе обучения и является величиной, которая увеличивает или уменьшает предсказанную вероятность. К примеру, при уменьшении веса связи между 1 и 2 нейроном и увеличении веса между 1 и 3 получим, что, используя сигмоидальную функцию активации, значение на ее выходе в 1-ом случае будет стремиться к 0, а во втором к 1. Т.е. весовые коэффициенты являются своего рода возбудителями искусственных нейронов к прогнозированию.
Функция активация, виды и особенности
Функция активации является нормализующим звеном на каждом слое нейронной сети. Она представляет из себя функцию, которая приводит входное значение к значению от 0 до 1. Одной из самых распространенных функция активации является сигмоидальная функция активации:
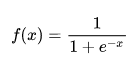
Значение ‘х’ является значением, которое обрабатывается функцией активации. Оно включает в себя алгебраическую сумму произведений значений нейронов на предыдущем слое на соответствующие им связи с тем нейроном, на котором мы производим расчет функции активации, а также нейрон смещения.
Пример вычисления функции активации приведен на рис. 5
Распространенные виды функций активации:
- Активация пороговой функции; функция активирована, если x, не активирована, если х<0
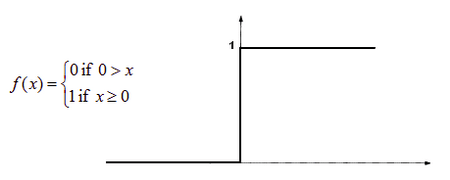
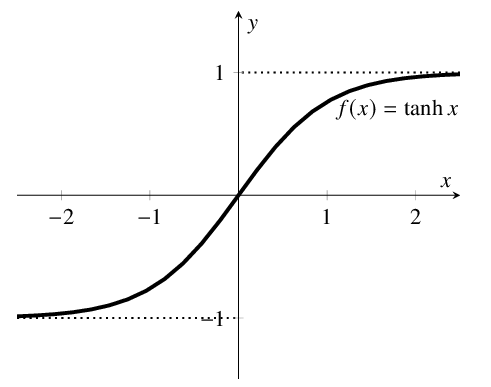
- Гиперболическая касательная функция ошибки; функция нелинейна, ее значения находятся в диапазоне (-1;1)
- ReLu и LeakyReLu; функция ReLu равна при х, при x, а при х<0 равна 0. Отличием LeakyReLu от ReLu является наличие коэффициента, определяющего значение функции при х<0 как ах
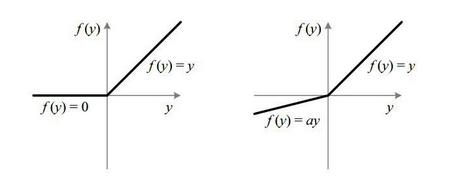
Функция ошибки, виды
Функция ошибки необходима для определения ошибки прогнозирования, допускаемой нейронной сетью на каждом этапе обучения и корректировкой процесса обучения, за счет корректировки весовых значений связей между искусственными нейронами.
Примеры функций ошибок:
- Кросс-энтропия
- Квадратичная (среднеквадратичное отклонение)
- Расстояние Кульбака — Лейблера
- Экспоненциальная
Самая простая и часто используемая функция ошибок (функция потерь) – среднеквадратичное отклонение.
Она вычисляется как половина от алгебраической суммы квадрата разности, прогнозируемого нейронной сетью значения и реальным значением – разметкой данных.
Backpropagation или обратное распространение ошибки
Для корректировки весов на каждом слое нейронной сети необходима метрика для определения ошибки каждого веса, с этой целью был разработан алгоритм обратного распространения ошибки. Он работает следующим образом:
- Вычисляется прогнозируемое нейронной сетью значение на выходе ANN
- Производится расчет функции ошибки, к примеру, среднеквадратичной
- Корректируются веса связей нейронов на последнем слое на основе вычисленной ошибки на выходе
- Происходит расчет ошибки на предпоследнем слое нейронной сети на основании скорректированных весов связей на последнем слое и ошибки на выходе ANN
- Процесс повторяется до первого слоя нейронной сети
Пример работы алгоритма обратного распространения ошибки:
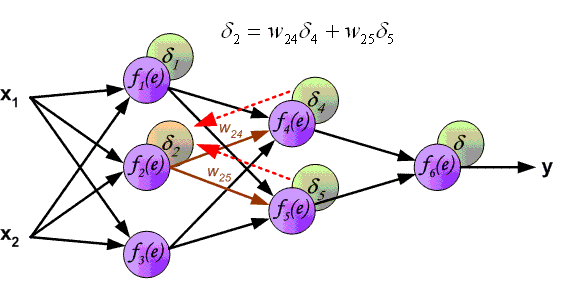
Bias или нейрон смещения
Значение смещения позволяет сместить функцию активации влево или вправо, что может иметь решающее значение для успешного обучения, а также позволяет быть более гибким при выборе решения или прогнозировании.
При наличии нейрона смещения, его значение тоже поступает на вход функции активации, складываясь с алгебраической суммой произведений нейронов и их весовых коэффициентов.
Пример работы нейрона смещения:
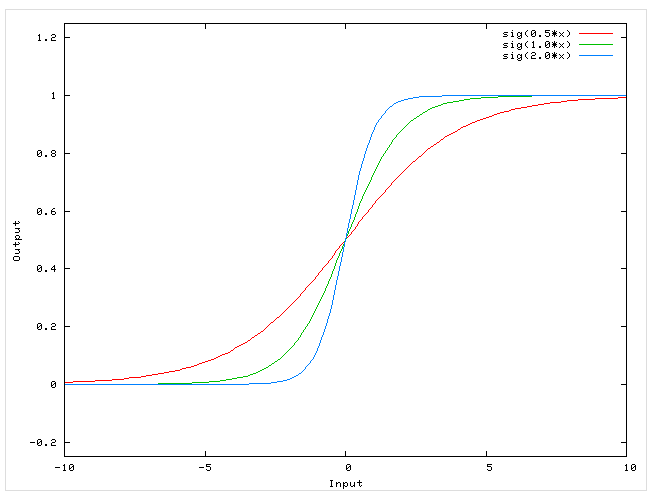
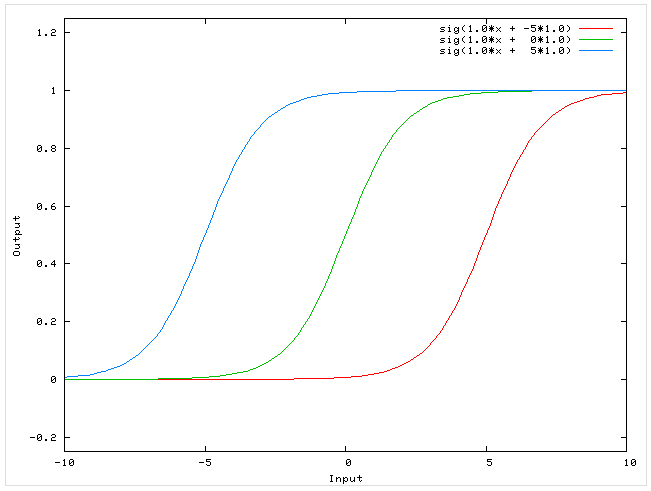
Разбираемся на примере
В данном примере напишем классификатор рукописных цифр на языке программирования С++. Обучающую выборку найдем на официальном сайте MNIST.
В первую очередь импортируем модули:
Определим обучающую выборку ‘dataset’, и загрузим в нее размеченные изображения MNIST.

Создадим входной слой равный 784 нейронам, так как наши изображения равны 28х28 пикселей и мы разложим их в цепочку пикселей 784х1, чтобы подать на вход нейронной сети; два скрытых слоя размера 30 нейронов каждый (размеры скрытых слоев подбирались случайно); выходной слой размером 10 нейронов, так как наша нейросеть будет классифицировать числа в диапазоне 0-9, где первый нейрон будет отвечать за классификацию числа 0, второй за число 1 и так далее до 9.
Необходимо сразу инициализировать наши значения слоев, к примеру 0.

Создадим матрицы весов между входным и 1-м скрытым слоями, 1-м скрытым и 2-м скрытым слоями, 2-м скрытым и выходным слоями, и инициализируем матрицы случайными значениями, как показано на рисунке. На примере значения весов находятся в диапазоне [-1;1].
![Пример весов в диапазоне [-1;1]](https://codeby.school/images/immersion_in_ml_part1/16.png)
Также необходимо создать массивы, которые будут содержать в себе значения алгебраической суммы произведения весов на соответствующие нейроны, как было описано выше в статье, после чего эти значения будут подаваться в функцию активации.
Ниже были созданы массивы ошибок на каждом слое. Для сохранения результатов ошибок на каждом нейроне, были инициализированы количество эпох и скорость обучения (определяет скорость перемещения по функции в поисках минимума во время обучения; необходимо быть осторожным с этим значением, так как если оно будет слишком мало, то, есть вероятность остаться в локальном минимуме, не найдя настоящий минимум функции или наоборот, при слишком большом значении, есть вероятность перескочить главный минимум функции.)
На данном этапе начинается процесс обучения нашей нейронной сети. Внешний цикл определяет количество эпох обучения, а внутренний количество итераций обучения в каждой эпохе.
На рисунке ниже инициализируются значения из обучающей выборки MNIST и занесения их на входной слой нейронной сети, а после происходит инициализация S-величин, о которых было сказано выше, нулями
Ниже происходит подсчет алгебраической суммы значений произведений веса на соответствующий нейрон, а после прохождение их через функцию активации, где в роли функции активации выступает сигмоидальная функция.
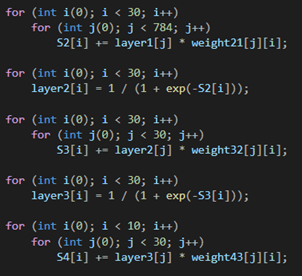
Подсчитав значения на каждом слое, происходит инициализация массивов ошибок, путем заполнения их 0, а также определение ошибок на выходном слое, путем вычитания полученных значений из 1, и последующим умножением на произведение значений нейронов прошедших через функцию активации на выходном слое на разницу между 1 и этими же значениями.
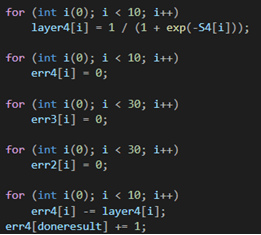
Далее необходимо определить ошибки на каждом слое нейронной сети методом обратного распространения ошибки. К примеру, чтобы найти ошибку на первом нейроне предыдущего слоя от выходного слоя, необходимо найти алгебраическую сумму произведения ошибок нейронов на выходном слое на соответствующие им веса связей с первым нейроном предыдущего слоя и перемножить на произведение значения нейронов на предпоследнем слое на разницу 1 и этих же значений. Таким образом необходимо найти допущенные ошибки нейронной сетью на каждом слое.

После определения ошибок, допущенных нейронной сетью на каждом нейроне, приступаем к корректировке весовых коэффициентов связей между каждым нейроном. Алгоритм корректировки представлен ниже.

Скорректировав веса, определяем максимальное полученное значение на выходном слое, тем самым определим ответ нейронной сети после прохождения через нее изображения.
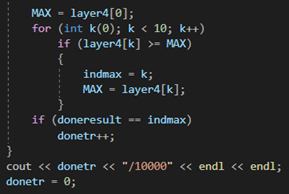
Заключение
В этой статье мы разобрались с базовыми понятиями искусственных нейронных сетей, а именно с такими как: входной, выходной, скрытые слои и их предназначение, весовыми коэффициентами связи между искусственными нейронами, функцией активации и ее предназначением, методами определения ошибки на каждом искусственном, с понятием нейрона смещения и функциями ошибки. В следующей статье мы перейдем к изучению нового класса нейронных сетей, таких как сверточные нейронные сети (CNN).
Желаю всем успехов в изучении!
Нейросеть — это компьютерная программа, способная к обучению. Перед ней можно поставить практически любую задачу. И если сперва показать машине тысячу-другую верных решений, то затем она научится находить правильный ответ самостоятельно. За нейронными сетями стоит сложная математика, при этом модель компьютерной сети построена по принципу работы нервных клеток человека, то есть биологических нейронных сетей. В общем всю эту математику проще всего объяснить в картинках.
Непростое человеческое
Контекст и опыт
Перед вами десять картинок. Человек без труда узнает на всех десяти цифру 6. Для машины же это набор совершенно разных изображений, никак не связанных между собой. Что помогает человеку узнать «шестерку»? Контекст и опыт.
Контекст помогает нам разобрать даже почерк врача: если на месте буквы появляется странный крестик, мы понимаем, что это, видимо, «т» или «к». К сожалению, компьютеры на сегодняшний день мало что смыслят в контексте. Зато опыта они набираются гораздо быстрее людей. Покажите нейронной сети тысячу рукописных цифр, и она научится их различать.

На месте цифр может быть что угодно: кошки, лица, раковые опухоли. Речь идет не обязательно об изображениях: обучить программу можно на биржевых сводках, художественных текстах, аудиозаписях — любых оцифрованных данных. Но прежде, чем обучать, давайте разберемся с матчастью — какие виды структур нейронных сетей существуют.
Виды структур нейросетей
Нейронные сети прямого распространения или FFNN (от английского Feed Forward Neural Networks) имеют две входные клетки и всего одну выходную. Обучение осуществляется по принципу обратного распространения ошибки между вводом и выводом, что предполагает способность сети моделировать связь между входными и выходными слоями, генерируя определенный результат. FFNN применяются для распознавания речи, письменных символов, изображений и компьютерного зрения.
Сети радиально-базисныx функций (RBFN, radial basis function network) обладают такой же структурой, что и предыдущие с той лишь разницей, что для активации применяется радиально-базисная функция. Эта ИНС (искусственная нейронная сеть) находит применение для решения задач аппроксимации, а также классификации и прогноза временных рядов.
Нейронная сеть Хопфилда (HN, Hopfield network) характеризуется симметрией матрицы образующихся связей. Это означает, что смещение, вернее вход и выход данных осуществляется в рамках одного и того же узла. Эта нейронная сеть также имеет название сеть с ассоциативной памятью — в процессе обучения она запоминает определенные шаблоны и впоследствии возвращается к одному из них.
Автоэнкодер (Autoencoder) — сеть прямого распространения, которая умеет восстанавливать входные данные на узле выхода. Подобная структура применяется для классификации данных, сжатия и восстановления информации.
Свёрточные нейронные сети (CNN, convolutional neural networks) основное применение нашли в области распознания изображений. Технология их работы заключается в том, что она считывает изображения небольшими квадратами, потом передает информацию через сверточные слои. Логичным продолжением операции становится подключение FFNN, которые выдают определенный результат на основе полученных данных (так сверточные нейронные сети становятся глубинными). Если на обрабатываемых картинках изображена мышь, то сети констатируют этот факт.
Развёртывающие нейронные сети (DN, deconvolutional networks), как следует из их названия, обладают обратным к CNN действием. Для примера обратимся к помощи уже взятой выше мыши. Если нужно, наоборот, создать или найти картинки с изображением грызуна, для запуска функции активации DN достаточно одного этого слова, вернее, определённого бинарного вектора.
Генеративно-состязательные сети (GAN, Generative Adversarial Network) используются для досконального копирования цифровых данных, например, изображений. Применение GAN нашли в области кибербезопасности. А еще с их помощью можно наложить на фото эффект старения.
Квадратно-гнездовое
Сенсорный слой
Приступим к строительству и обучению нейронных сетей. Разделим изображение на точки (пиксели): 30 по вертикали и 30 по горизонтали. Каждый из пикселей имеет свою яркость. Пусть черные пиксели имеют значение 0, белые — 1, а градации серого дают дробные значения, например 0,4 или 0,8. Эти 900 пикселей — наши первые нейроны, точнее нейроны входного слоя, или сенсоры.

Псевдоживое многослойное
Структура нейросети
Наша нейросеть будет состоять из входного, выходного и двух промежуточных (скрытых) слоев. Входной слой воспринимает рукописные цифры и состоит из 900 нейронов. Выходной слой выдает один из десяти возможных результатов: числа от 0 до 9. Поэтому нейронов в нем будет 10, они называются реагирующими. Промежуточные слои имеют по 15 нейронов, их элементы называются ассоциативными.
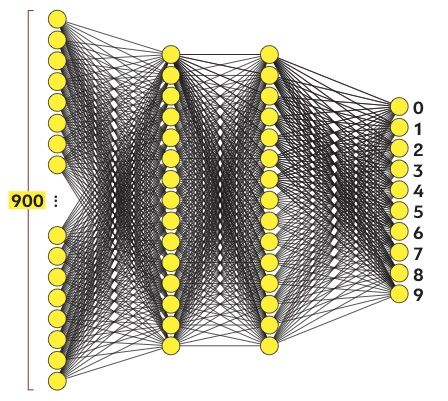
Концептуально нейроны имитируют клетки живого мозга. Как и для настоящих нейронов, для компьютерных тоже важны связи. Каждый нейрон связан со всеми нейронами соседнего слоя.
Тайное искомое
Связи и веса
Посмотрим на первый нейрон промежуточного слоя (назовем его b1). Он связан с каждым из 900 нейронов входного слоя (назовем их a1 — a900). Собственно, нейрон b1 — это математическая формула, длинная, но довольно простая. Она показывает, насколько сильно каждый из сенсоров a1 — a900 влияет на значение b1.
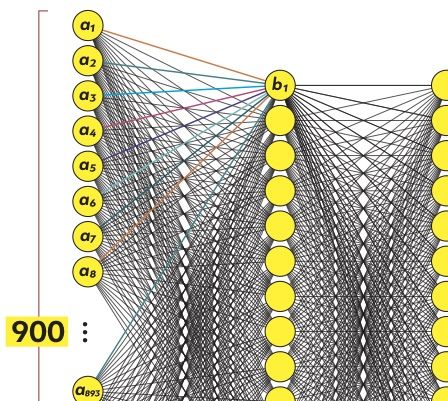
На рисунке связи нейрона b1 имеют разные цвета, чтобы показать: каждый нейрон входящего слоя имеет свой коэффициент, или вес, в общей формуле b1. Эти веса, настроенные оптимальным образом, — вот то тайное знание, которое является результатом глубокого машинного обучения.
Абстрактное обобщенное
Ассоциативные слои
Итак, процесс машинного обучения направлен на то, чтобы придать всем связям внутри искусственной нейронной сети оптимальные веса. Для чего нужны промежуточные слои? Выражаясь очень образно, они помогают машине обобщить накопленный опыт. Проведем мысленный эксперимент. Как мы, люди, узнаем шестерку? Она состоит из кружочка и «хвостика» слева вверху.
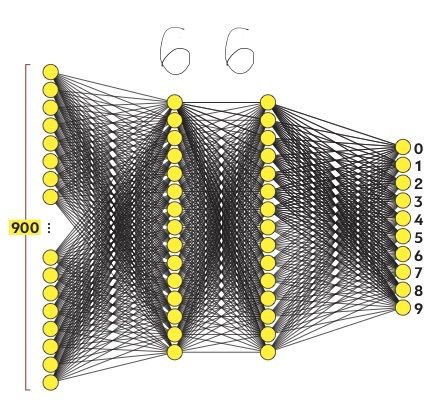
Представим, что предпоследний (второй скрытый) слой нейронной сети разбирается во взаимном расположении кружочков, «хвостиков» и «крючочков», из которых состоят цифры. А первый скрытый слой умеет выделять на картинке сами кружочки и «хвостики» по сочетанию пикселей. Если бы речь шла о человеческой логике, то скрытые слои представляли бы собой разные уровни абстракции и обобщения.
Горящее пороговое
Активация нейронов
Запустим нашу нейросеть: расставим веса в произвольном порядке, покажем сенсорам шестерку и посмотрим, какой из выходных нейронов активируется. Под активацией подразумевается превышение некоего порогового значения. Например, если формула нейрона выдает результат больше 0,8, то он «загорается», или активируется.
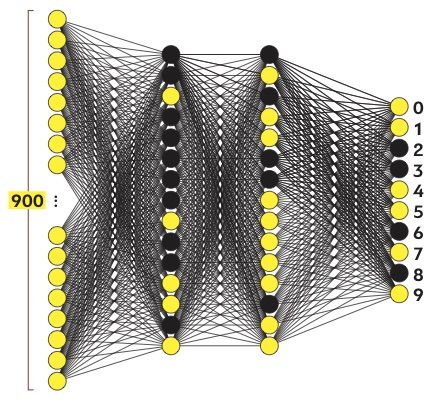
Вполне вероятно, что при первом запуске «загорелось» несколько реагирующих нейронов. Машина «признала» в шестерке и 8, и 2, и 3, и все эти результаты не имеют никакого отношения к истине. Нейросеть еще предстоит обучить.
Остроумное реверсивное
Обратное распространение ошибки
Если бы вес каждой связи искали простым перебором, процесс занял бы вечность. Сокращает путь главное ноу-хау машинного обучения — алгоритм обратного распространения ошибки. Метод обратного распространения позволяет нейронной сети, словно находчивому школьнику, подогнать значения переменных в уравнении, зная правильный ответ.
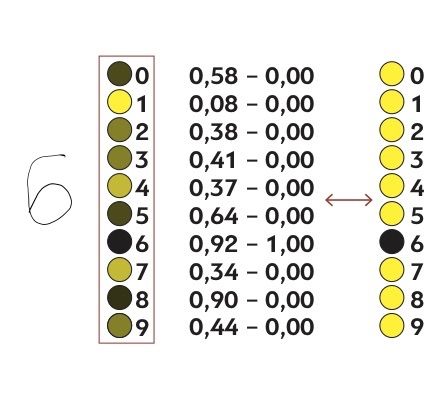
Посмотрим, насколько полученный в первой итерации результат отличается от желаемого. Допустим, нейрон, обозначающий единицу, получил значение 0,08. Это мало, как и должно быть, ведь на входе не единица. Значит, веса для связей, подключенных к этому нейрону, нужно скорректировать совсем немного. А вот нейрон, отвечающий за восьмерку, «загорелся» и показал результат 0,9. Это никуда не годится: восьмерка не шестерка. Значит, связи этого нейрона нуждаются в сильной коррекции.
Теплое быстрое
Градиентный спуск
Говоря чуть более математическим языком, каждый набор нейронов есть функция от множества переменных — весов нейронов, стоящих за ним. Для одного выходного нейрона — того, что отвечает за шестерку, — нам нужно найти максимум этой функции. Для всех остальных — минимумы.
Представьте, что вам нужно найти кошелек, потерявшийся в лесу. Методично прочесать весь лес — практически невыполнимая задача. Но если что-то подсказывает вам направление движения и оставшееся расстояние до кошелька, найти его будет намного проще. Вы сперва разгонитесь до высокой скорости, а подойдя ближе к искомому объекту, замедлитесь и поищете внимательнее. Такая технология поиска в математике называется градиентным спуском. А маячок, на который вы ориентируетесь, появляется благодаря алгоритму обратного распространения ошибки.
Среднее разнообразное
Обучение на датасетах
Посчитав, насколько сильно значения всех нейронов отличаются от желаемых, мы получим суммарную ошибку сети. Найти ее минимум было бы достаточно, если бы мы хотели научить такую сеть отличать шестерку от других цифр. Чтобы машина могла распознавать любую цифру, нужно каждый раз демонстрировать ей датасет (набор data, то есть данных) из десяти цифр и стремиться свести к минимуму среднюю ошибку для всех десяти. Сложность задачи возводится в десятую степень.

Чтобы нейросеть научилась распознавать цифры, написанные разным почерком, нужно продемонстрировать ей множество рукописных цифровых комплектов. И проделать множество вычислений, чтобы найти оптимальные средние значения для всех весов. Это ресурсоемкая задача — как по вычислительной мощности, так и в плане подготовки огромного датасета. Но результат того стоит.
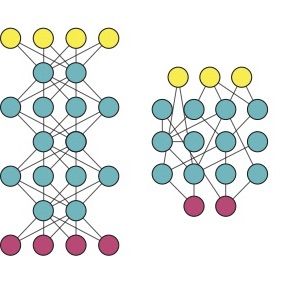
Неизвестное машинное
Неразумная математика
Помните разговор о кружочках и «хвостиках»? Компьютер позволяет визуализировать происходящее на скрытых уровнях нейронной сети, чтобы увидеть… что никаких кружочков там нет. Абстракция и обобщение — человеческие понятия. Нейросеть «мыслит», точнее сказать, работает совершенно по-другому. Это просто математика, а вовсе не разум.
Если показать нашей нейронной сети, скажем, фотографию кота, она с уверенностью скажет, что это три, пять или девять. Для нее весь мир состоит только из цифр, и никакой иной контекст ей неведом.
Наше журнальное объяснение нейронной сети упрощено до предела, а структура давно устарела — таким машинное обучение было в 1960-е. Современным специалистам приходится иметь дело с десятками и сотнями всевозможных параметров, не только весами и количеством слоев. И чем совершеннее становится искусственный интеллект, тем сложнее нам становится понять, что творится глубоко в его «мыслях».
Читайте также максимально простое объяснение, как работает блокчейн:
Как работает блокчейн Максимально простое и полное объяснение
Блокчейн — одна из самых надежных технологий на планете. Его нельзя выключить и практически невозможно взломать. «Цифровой океан» разобрался, как работает блокчейн на примере первой и главной цепочки блоков — Биткойна