-
31.01.2013, 00:15
#1

Senior Member
Некорректный конфиг nginx
После последнего обновления ISPmanager появилась возможность указывать расширения файлов, которые будут обрабатываться nginx’ом.
Для проверки добавил для домена txt. Получил следующий конфиг:
Код:
if ($host ~* ^((.*).twilightradio.ru)$) { set $subdomain ../$1; } location ~* ^.+.(jpg|jpeg|gif|png|svg|js|css|mp3|ogg|mpe?g|avi|zip|gz|bz2?|rar|swf)$ { root $root_path/$subdomain; access_log /var/www/nginx-logs/intervision isp; access_log /var/www/httpd-logs/twilightradio.ru.access.log ; error_page 404 = @fallback; expires 360d; } location / { proxy_pass http://127.0.0.1:81; proxy_redirect http://127.0.0.1:81/ /; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Real-IP $remote_addr; } location ~* ^/(webstat|awstats|webmail|myadmin|pgadmin)/ { proxy_pass http://127.0.0.1:81; proxy_redirect http://127.0.0.1:81/ /; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Real-IP $remote_addr; } location @fallback { proxy_pass http://127.0.0.1:81; proxy_set_header Host $host; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Real-IP $remote_addr; } location ~* ^.+.(jpg|jpeg|gif|png|svg|js|css|mp3|ogg|mpeg|avi|zip|gz|bz2|rar|swf|txt)$ { root $root_path/$subdomain; access_log /var/www/nginx-logs/intervision isp; access_log /var/www/httpd-logs/twilightradio.ru.access.log ; error_page 404 = @fallback; } include /usr/local/ispmgr/etc/nginx.inc; }Два раза указание расширения это как-то странно
-
01.02.2013, 22:19
#2
Senior Member
Кроме того, c ошибками создается дефолтный конфиг (если при создании www домена, например, не указывать во вкладке nginx никаких расширений)
Код:
server_name localproject.ru www.localproject.ru; location ~* ^.+.(jpg|jpeg|gif|png|svg|js|css|mp3|ogg|mpe?g|avi|zip|gz|bz2?|rar|swf)$ {странные знаки вопроса в расширении mpeg и bz2
-
22.03.2014, 19:56
#3
Member
-
22.03.2014, 23:28
#4
Senior Member
Это регулярное выражение, а не опечатка.
-
23.03.2014, 09:20
#5
ISPsystem team
Сообщение от intervision
странные знаки вопроса в расширении mpeg и bz2
Да, как уже отметил nyanhost — вопросительные знаки это регулярное выражение. Они нужны для обработки расширений
mpe?g — mpg и mpeg
bz2? — bz и bz2
Можно также добавить например
html? — htm и html
-
23.03.2014, 15:21
#6
Member
Аааа! Как хитро! Не баг это значит, а фича
))
Тогда другой вопрос!
Как сделать так, чтобы в конфиге домена по умолчанию было включено браузерное кеширование?!
Сейчас мне приходится в конфиге nginx каждого домена дописывать «expires 30d;» чтобы получилось вот так:Код:
location ~* ^.+.(jpg|jpeg|gif|png|svg|js|css|mp3|ogg|mpe?g|avi|zip|gz|bz2?|rar|swf)$ { expires 30d; }Только после этого браузер начинает кешировать файлы сайта. Пробовал также править location в nginx.conf , чтобы для вех доменов браузерное кеширование было включено по умолчанию, но оттуда включить его не удалось (видимо, приоритетен конфиг домена).
Хотелось бы, чтобы это было «по умолчанию», а не руками конфиг каждого домена править Как это сделать??? Буду очень благодарен за ответ!Ps
У меня ISP manager 5 и ось Debian 7.4
-
23.03.2014, 22:27
#7
-
24.03.2014, 00:49
#8
Member
Последний раз редактировалось Racter; 24.03.2014 в 00:51.
-
24.03.2014, 10:33
#9
ISPsystem team
Можно попробовать еще использовать директиву NgStaticRegexp в файле конфигурации ISPmanager.
NgStaticRegexp — регулярное выражение, позволяющее задать файлы, которые будет отдавать Nginx, например, NgStaticRegexp «~* ^.+.(jpg|jpeg|gif|png|svg|js|css|mp3|ogg|mpe?g|avi |zip|gz|bz2?|rar)$»
если не поможет, то только плагин писать.
-
25.03.2014, 12:33
#10
Member
Либо я что-то делаю не так, либо NgStaticRegexp в ispmanager 5 не работает принципиально.
Добавил в конце конфига
NgStaticRegexp «~* ^.+.(test|mpe?g|avi|zip|gz|bz2?)$» {
expires 30d;
}
После этого
killall coreПосле этого при создании нового домена = нуль изменений.
ps
Неужели вопрос браузерного кеширования так не популярен? Неужели его никто не включает, или все довольствуются прописыванием его руками?!


 ))
))
Помогая пользователям NGINX с разрешением проблемных ситуаций, мы поняли, что большинство из них часто совершает одни и те же ошибки конфигурации. Более того, подобные ситуации вполне могут возникнуть даже у самих инженеров NGINX! В этой статье рассмотрим 10 наиболее распространенных ошибок и объясним как их исправить.
- Недостаточное количество файловых дескрипторов;
- Директива error_log off;
- Отсутствие keepalive-соединения с вышестоящими серверами;
- Упущение механизмов наследования директив;
- Директива proxy_buffering;
- Неправильное использование директивы if;
- Чрезмерные проверки работоспособности;
- Незащищенный доступ к метрикам;
- Использование ip_hash, когда весь трафик поступает из одного и того же блока /24 CIDR;
- Игнорирование преимуществ вышестоящих групп.
Ошибка №1: Недостаточное количество файловых дескрипторов на воркера
Директива worker_connections задает максимальное количество одновременных подключений, которое может быть открыто для рабочего процесса NGINX (значение по умолчанию 512). Здесь учитываются не только клиентские, но и все типы подключений (например, соединения с прокси-серверами). Важно помнить, что существует еще одно ограничение на количество одновременных подключений, которые могут быть открыты воркером: ограничение операционной системы на максимальное количество файловых дескрипторов (FDS), выделенных для каждого процесса. В современных дистрибутивах UNIX ограничение по умолчанию равно 1024.
Для всех развертываний NGINX, кроме самых маленьких, ограничение в 512 подключений на воркера может быть недостаточным. На самом же деле, дефолтный файл nginx.conf, который мы распространяем с двоичными файлами NGINX с открытым исходным кодом и NGINX Plus, увеличивает это значение до 1024.
Распространенной ошибкой при конфигурации является неувеличение количества FDs как минимум вдвое по сравнению со значением worker_connections. Исправить ситуацию можно, установив это значение с помощью директивы worker_rlimit_nofile в основном контексте конфигурации.
Больше FD требуется по следующей причине: каждое соединение рабочего процесса NGINX с клиентом или вышестоящим сервером потребляет файловый дескриптор. Когда NGINX действует как веб-сервер, требуется один FD для соединения и один FD непосредственно для каждого обслуживаемого файла, то есть минимум два FD на клиента (стоит отметить, что большинство веб-страниц создаются из множества файлов). Когда NGINX используется в качестве прокси-сервера, требуется по одному дескриптору для подключения к клиенту и вышестоящему серверу и, возможно, третий FD для файла, используемого для временного хранения ответа сервера. NGINX может функционировать как веб-сервер для кэшированных ответов и как прокси-сервер, если кэш пуст или истек.
NGINX также использует FD на каждый файл журнала и пару FD для связи с мастер-процессом, но обычно эти цифры невелики по сравнению с количеством файловых дескрипторов, используемых для подключений и файлов.
UNIX предлагает несколько способов задать необходимое количество FDs для каждого процесса:
- Команда ulimit, если вы запускаете NGINX из shell;
- Переменные манифеста init script или systemd если вы запускаете NGINX как сервис;
- Файл /etc/security/limits.conf.
Стоит отметить, что данный метод зависит от того, как вы запускаете NGINX, тогда как worker_rlimit_nofile работает независимо от этого.
Плюс ко всему, с помощью команды операционной системы sysctl fs.file-max вы можете установить общесистемное ограничение на количество FDs. Общего объема должно хватить, но стоит проверить, что максимальное количество файловых дескрипторов, задействованных в рабочих процессах NGINX (*worker_rlimit_nofile worker_connections), значительно ниже, чем fs.file‑max**. В случае если вдруг NGINX станет использовать все доступные ресурсы (например, во время DoS-атаки), даже возможность выполнить вход в систему для устранения проблем станет невозможна.
Ошибка №2: Директива error_log off
Распространенная ошибка заключается в убежденности, что директива error_log off отключает ведение журнала. Фактически, в отличие от директивы access_log, error_log не включает режим off. Если вы включаете директиву error_log off в конфигурацию, NGINX создает файл лога ошибок с именем off в каталоге по умолчанию для файлов конфигурации NGINX (обычно это /etc/nginx).
Мы не рекомендуем отключать журнал ошибок, поскольку он является жизненно важным источником информации при отладке любых проблем связанных с NGINX. Однако, если объем хранилища ограничен настолько, что его дисковое пространство может быть вот-вот исчерпано общим количеством данных, отключение ведения журнала ошибок вполне имеет смысл. Включите эту директиву в основной контекст конфигурации:
error_log /dev/null emerg;Обратите внимание, что эта директива работает только после проверки данной конфигурации со стороны NGINX. Таким образом, каждый раз при запуске NGINX или перезагрузке конфигурации, она будет по умолчанию зарегистрирована в журнале ошибок (обычно это /var/log /nginx/error.log) до тех пор, пока конфигурация не будет проверена. Чтобы изменить каталог журнала, включите параметр -e <error_log_location> в команде nginx.
Ошибка №3: Отсутствие keepalive-соединения с вышестоящими серверами
По умолчанию NGINX открывает новое соединение с вышестоящим (бэкенд) сервером для каждого нового входящего запроса. Это безопасно, но не очень эффективно, поскольку NGINX и сервер должны обмениваться тремя пакетами для установления соединения и тремя-четырьмя для его завершения.
При больших объемах трафика открытие нового соединения для каждого запроса может значительно истощить системные ресурсы и сделать невозможным открытие соединений. Причина заключается в следующем: для каждого соединения кортеж из адреса источника, порта источника, адреса назначения и порта назначения должен быть уникальным. Для подключений из NGINX к вышестоящему серверу три элемента (первый, третий и четвертый) являются фиксированными, оставляя в качестве переменной только порт источника. Когда соединение закрывается, сокет Linux находится в состоянии TIME-WAIT в течение двух минут, что при больших объемах трафика увеличивает вероятность исчерпания пула доступных исходных портов. Если это произойдет, NGINX не сможет открывать новые подключения к вышестоящим серверам.
Выход из ситуации включить keepalive-соединение между NGINX и вышестоящими серверами – таким образом, вместо того, чтобы закрываться при завершении запроса, соединение остается открытым для использования для дополнительных запросов. Это одновременно снижает вероятность исчерпания исходных портов и увеличивает производительность.
Чтобы включить keepalive-соединения:
- Включите директиву keepalive в каждый блок upstream{}, чтобы задать количество ожидающих соединений keepalive с вышестоящими серверами, сохраненных в кэше каждого рабочего процесса.
Обратите внимание, что директива keepalive не ограничивает общее количество подключений к вышестоящим серверам, которые может открыть рабочий процесс NGINX – это распространенное заблуждение. Таким образом параметр keepalive не обязательно должен быть большим, как может показаться на первый взгляд.
Мы рекомендуем установить значение, в два раза превышающее количество серверов, перечисленных в блоке upstream{}. Этого хватит для того, чтобы NGINX поддерживал непрерывные соединения со всеми серверами и вышестоящие серверы могли обрабатывать новые входящие соединения.
Также обратите внимание, что когда вы указываете алгоритм балансировки нагрузки в блоке upstream{} ‑ с помощью директивы hash, ip_hash, least_conn, least_time или random – директива должна отображаться над директивой keepalive. Это одно из редких исключений из общего правила, согласно которому порядок директив в конфигурации NGINX не имеет значения.
- В блоке location{}, который перенаправляет запросы в вышестоящую группу, включите следующие директивы вместе с proxy_pass:
proxy_http_version 1.1;
proxy_set_header "Connection" "";По умолчанию NGINX использует HTTP/1.0 для подключений к вышестоящим серверам и соответственно добавляет заголовок Connection: close к запросам, которые он пересылает на серверы. В результате, каждое соединение закрывается по завершении запроса, несмотря на наличие директивы keepalive в блоке upstream{}.
Директива proxy_http_version говорит NGINX использовать HTTP/1.1 вместо дефолтного параметра, а директива proxy_set_header удаляет значение close из заголовка Connection.
Ошибка №4: Упущение механизмов наследования директив
Директивы NGINX наследуются с предыдущего уровня конфигурации, или “сверху-вниз”: дочерний контекст, будучи вложенным в другой контекст (родительский), наследует настройки директив, входящих в родительский уровень. Например, все блоки server{} и location{} в контексте http{} наследуют значение директив, входящих в уровень http, а директива в блоке server{} наследуется всеми дочерними блоками location{}. Однако, когда одна и та же директива включена как в родительский контекст, так и в его дочерний контекст, значения не суммируются – вместо этого значение в дочернем контексте перекрывает родительское значение.
Ошибочным будет забыть о “правиле перекрытия” для директив массива, которые могут быть включены не только в нескольких контекстах, но и несколько раз в пределах данного контекста. Данные примеры включают proxy_set_header и add_header – наличие “add” в имени второго позволяет особенно легко забыть о правиле перекрытия.
Рассмотрим, как работает наследование на примере add_header:
http {
add_header X-HTTP-LEVEL-HEADER 1;
add_header X-ANOTHER-HTTP-LEVEL-HEADER 1;
server {
listen 8080;
location / {
return 200 "OK";
}
}
server {
listen 8081;
add_header X-SERVER-LEVEL-HEADER 1;
location / {
return 200 "OK";
}
location /test {
add_header X-LOCATION-LEVEL-HEADER 1;
return 200 "OK";
}
location /correct {
add_header X-HTTP-LEVEL-HEADER 1;
add_header X-ANOTHER-HTTP-LEVEL-HEADER 1;
add_header X-SERVER-LEVEL-HEADER 1;
add_header X-LOCATION-LEVEL-HEADER 1;
return 200 "OK";
}
}
}Для сервера, прослушивающего порт 8080, нет директив add_header ни в блоках server{}, ни в location{}. Таким образом, наследование происходит напрямую, и мы видим два заголовка в контексте http{}:
% curl -is localhost:8080
HTTP/1.1 200 OK
Server: nginx/1.21.5
Date: Mon, 21 Feb 2022 10:12:15 GMT
Content-Type: text/plain
Content-Length: 2
Connection: keep-alive
X-HTTP-LEVEL-HEADER: 1
X-ANOTHER-HTTP-LEVEL-HEADER: 1
OKДля сервера, прослушивающего порт 8081, существует директива add_header в блоке server{}, но не в его дочернем location/ блоке. Заголовок, определенный в блоке server{}, переопределяет два заголовка, определенных в контексте http{}:
% curl -is localhost:8081
HTTP/1.1 200 OK
Server: nginx/1.21.5
Date: Mon, 21 Feb 2022 10:12:20 GMT
Content-Type: text/plain
Content-Length: 2
Connection: keep-alive
X-SERVER-LEVEL-HEADER: 1
OKВ дочернем блоке location /test есть директива add_header, и она перекрывает как заголовок из родительского блока server{}, так и два заголовка из контекста http{}:
% curl -is localhost:8081/test
HTTP/1.1 200 OK
Server: nginx/1.21.5
Date: Mon, 21 Feb 2022 10:12:25 GMT
Content-Type: text/plain
Content-Length: 2
Connection: keep-alive
X-LOCATION-LEVEL-HEADER: 1
OKЕсли мы хотим, чтобы блок location{} сохранял заголовки, определенные в его родительских контекстах, вместе с любыми заголовками, определенными локально, мы должны переопределить родительские заголовки в блоке location{}. Это как раз то, что мы сделали в блоке location /correct:
% curl -is localhost:8081/correct
HTTP/1.1 200 OK
Server: nginx/1.21.5
Date: Mon, 21 Feb 2022 10:12:30 GMT
Content-Type: text/plain
Content-Length: 2
Connection: keep-alive
X-HTTP-LEVEL-HEADER: 1
X-ANOTHER-HTTP-LEVEL-HEADER: 1
X-SERVER-LEVEL-HEADER: 1
X-LOCATION-LEVEL-HEADER: 1
OKОшибка №5: Директива proxy_buffering off
Буферизация прокси-сервера включена по умолчанию в NGINX (proxy_buffering в режиме on). Буферизация прокси-сервера означает, что NGINX сохраняет ответ с сервера во внутренних буферах по мере его поступления и не начинает отправлять данные клиенту до тех пор, пока весь ответ не будет буферизован. Буферизация помогает оптимизировать производительность при работе с медленными клиентами – поскольку NGINX буферизует свой ответ столько времени, сколько требуется клиенту для его получения, прокси-сервер может получить свой ответ быстро и вернуться к работе с другими запросами.
Когда буферизация прокси отключена, NGINX буферизует только первую часть ответа сервера, прежде чем начать отправлять его клиенту, в буфере, размер которого по умолчанию составляет одну страницу памяти (4 КБ или 8 КБ в зависимости от операционной системы). Обычно этого места вполне достаточно для заголовка ответа. Далее NGINX тут же отправляет ответ клиенту по мере его получения, оставляя сервер бездействовать пока NGINX сможет принять следующий сегмент ответа.
Вот почему мы крайне удивлены тем, как часто мы видим отключение proxy_buffering в конфигурациях. Вероятно, это предназначено для уменьшения задержки, с которой сталкиваются клиенты. Позитивный эффект от этого очень незначителен, а вот побочных эффектов целое множество: при отключенной буферизации прокси-сервера ограничение скорости и кэширование не работают, и даже если они настроены, производительность снижается.
Существует лишь небольшое количество вариантов использования, в которых отключение буферизации прокси-сервера может иметь смысл (например, “длинный запрос”), поэтому мы настоятельно не рекомендуем изменять значение по умолчанию. Дополнительные сведения см. в Руководстве администратора NGINX Plus.
Ошибка №6: Неправильное использование директивы if
Директиву if сложно использовать, особенно в блоках location{}. Она не всегда функционирует, как вы ожидаете, и даже может привести к сбоям в сегментах. На самом деле, это настолько сложный вопрос, что в NGINX Wiki есть статья под названием If is Evil — почитайте, чтобы подробно изучить и разобраться как избежать данной проблемы.
В общем говоря, единственными директивами, которые вы всегда можете безопасно использовать в блоке if{}, являются return и rewrite. В следующем примере if используется для обнаружения запросов, которые включают заголовок X‑Test (это может быть любое условие, которое вы хотите проверить). NGINX возвращает ошибку 430 («Поля заголовка запроса слишком велики»), перехватывает ее в именованном локейшне @error_430 и отправляет запрос в группу upstream b.
location / {
error_page 430 = @error_430;
if ($http_x_test) {
return 430;
}
proxy_pass http://a;
}
location @error_430 {
proxy_pass b;
}Для этого и многих других применений if часто можно полностью избежать директивы. В следующем примере, запрос включает заголовок X‑Test, блок map{} присваивает переменной $upstream_name значение b, и запрос перенаправляется в вышестоящую группу с этим именем.
map $http_x_test $upstream_name {
default "b";
"" "a";
}
# ...
location / {
proxy_pass http://$upstream_name;
}Ошибка №7: Чрезмерные проверки работоспособности
Довольно часто несколько виртуальных серверов настраиваются на прокси-запросы к одной и той же вышестоящей группе (другими словами, для включения идентичной директивы proxy_pass в несколько блоков server{}). Ошибка данной ситуации заключается в том, чтобы включать директиву health_check в каждый блок server{}. Это лишь создает дополнительную нагрузку на вышестоящие серверы, не предоставляя никакой дополнительной информации.
Исправление ситуации довольно очевидно и состоит в том, чтобы оставить только одну проверку работоспособности для каждого блока upstream{}. Здесь мы определяем проверку работоспособности для вышестоящей группы под именем b в именованном локейшене, вместе с соответствующими тайм-аутами и настройками заголовка.
location / {
proxy_set_header Host $host;
proxy_set_header "Connection" "";
proxy_http_version 1.1;
proxy_pass http://b;
}
location @health_check {
health_check;
proxy_connect_timeout 2s;
proxy_read_timeout 3s;
proxy_set_header Host example.com;
proxy_pass http://b;
}В сложных конфигурациях это поможет еще больше упростить управление, сгруппировав все на одном виртуальном сервере вместе с API NGINX Plus и панелью мониторинга, как в этом примере.
server {
listen 8080;
location / {
# …
}
location @health_check_b {
health_check;
proxy_connect_timeout 2s;
proxy_read_timeout 3s;
proxy_set_header Host example.com;
proxy_pass http://b;
}
location @health_check_c {
health_check;
proxy_connect_timeout 2s;
proxy_read_timeout 3s;
proxy_set_header Host api.example.com;
proxy_pass http://c;
}
location /api {
api write=on;
# directives limiting access to the API (see 'Mistake 8' below)
}
location = /dashboard.html {
root /usr/share/nginx/html;
}
}Для дополнительной информации о проверке работоспособности серверов HTTP, TCP, UDP и gRPC см. в Руководстве администратора NGINX Plus.
Ошибка №8: Незащищенный доступ к метрикам
Основные показатели работы NGINX доступны в модуле Stub Status. Для NGINX Plus вы также можете собрать гораздо более обширный набор показателей с помощью API NGINX Plus. Включите сбор метрик с помощью директивы stub_status или api в блок server{} или location{}, который станет URL, обеспечивающим доступ к метрикам. (Для API NGINX Plus будет необходимо настроить зоны общей памяти для объектов NGINX – виртуальных серверов, вышестоящих групп, кэшей и т. д. – данные которых вам необходимо учитывать; см. инструкции в Руководстве администратора NGINX Plus.)
Некоторые из показателей представляют собой конфиденциальную информацию, которая может быть использована для атаки на ваш веб-сайт или приложение, на которое происходит проксирование через NGINX, и ошибка, которую мы иногда видим в пользовательских конфигурациях, заключается в невозможности ограничить доступ к соответствующему URL-адресу. Рассмотрим некоторые из способов защиты метрик. В первых примерах мы будем использовать stub_status.
Благодаря нижеизложенной конфигурации, метрики станут доступны любому интернет пользователю (используйте http://example.com/basic_status).
server {
listen 80;
server_name example.com;
location = /basic_status {
stub_status;
}
}Защитите данные с помощью базовой HTTP-аутентификации
Чтобы защитить метрики паролем с помощью базовой аутентификации HTTP, включите директивы auth_basic и auth_basic_user_file. В файле (в данном случае .htpasswd) перечислены имена пользователей и пароли клиентов, которые могут войти в систему, чтобы просмотреть показатели:
server {
listen 80;
server_name example.com;
location = /basic_status {
auth_basic “closed site”;
auth_basic_user_file conf.d/.htpasswd;
stub_status;
}
}Защитите метрики с помощью директив allow и deny
Если вы не хотите, чтобы пользователям приходилось вводить имя и пароль, и вы знаете IP-адреса, с которых они будут получать доступ к метрикам, другим вариантом является директива allow. Вы можете указать отдельные адреса IPv4 и IPv6, а также диапазоны CIDR. Директива **deny all** запрещает доступ с любых других адресов.
server {
listen 80;
server_name example.com;
location = /basic_status {
allow 192.168.1.0/24;
allow 10.1.1.0/16;
allow 2001:0db8::/32;
allow 96.1.2.23/32;
deny all;
stub_status;
}
}Объедините оба метода
А что если понадобится объединить оба метода? Мы можем разрешить клиентам получать доступ к метрикам с определенных адресов без пароля и по-прежнему требовать входа для клиентов, поступающих с остальных адресов. Для этого мы используем директиву satisfy any. Она позволяет NGINX разрешить доступ клиентам, которые либо входят в систему с помощью учетных данных базовой HTTP-аутентификации, либо используют предварительно утвержденный IP-адрес. Для дополнительной безопасности вы можете установить значение satisfy to all, чтобы требовать входа в систему от людей, которые приходят с конкретных адресов.
server {
listen 80;
server_name monitor.example.com;
location = /basic_status {
satisfy any;
auth_basic “closed site”;
auth_basic_user_file conf.d/.htpasswd;
allow 192.168.1.0/24;
allow 10.1.1.0/16;
allow 2001:0db8::/32;
allow 96.1.2.23/32;
deny all;
stub_status;
}
}С NGINX Plus вы используете те же методы для ограничения доступа в конечной точке API NGINX Plus (http://monitor.example.com:8080/api/ в следующем примере), так же, как и панель мониторинга активности в реальном времени на http://monitor.example.com/dashboard.html.
Эта конфигурация разрешает доступ без пароля только клиентам, поступающим из сети 96.1.2.23/32 или локального хоста. Поскольку директивы определены на уровне server{}, одни и те же ограничения применяются как к API, так и к панели мониторинга. В качестве дополнительного примечания параметр write=on для api означает, что эти клиенты могут использовать API для внесения изменений в конфигурацию.
Дополнительные сведения о настройке API и панели мониторинга см. в Руководстве администратора NGINX Plus.
server {
listen 8080;
server_name monitor.example.com;
satisfy any;
auth_basic “closed site”;
auth_basic_user_file conf.d/.htpasswd;
allow 127.0.0.1/32;
allow 96.1.2.23/32;
deny all;
location = /api/ {
api write=on;
}
location = /dashboard.html {
root /usr/share/nginx/html;
}
}Ошибка №9: Использование ip_hash, когда весь трафик поступает из одного и того же блока /24 CIDR
Алгоритм ip_hash балансирует нагрузку на трафик между серверами в блоке upstream{} на основе хэша IP-адреса клиента. Ключ хеширования — это первые три октета адреса IPv4 или полностью адрес IPv6. Метод обеспечивает сохранение сеанса, что означает, что запросы от клиента всегда передаются на один и тот же сервер, за исключением случаев, когда сервер недоступен.
Предположим, что мы развернули NGINX в качестве обратного прокси-сервера в виртуальной частной сети, настроенной на высокую доступность. Мы размещаем различные файерволы, маршрутизаторы, балансировщики нагрузки и шлюзы перед NGINX для приема трафика из различных источников (внутренняя сеть, партнерские сети, Интернет и т. д.) и передаем его в NGINX для обратного проксирования на вышестоящие серверы. Так выглядит начальная конфигурация NGINX:
http {
upstream {
ip_hash;
server 10.10.20.105:8080;
server 10.10.20.106:8080;
server 10.10.20.108:8080;
}
server {# …}
}Важно отметить, что здесь есть одна загвоздка: все “перехватывающие” устройства находятся в одной и той же сети 10.10.0.0/ 24, поэтому для NGINX это выглядит так, что весь трафик поступает с адресов в этом диапазоне CIDR. Помните, что алгоритм ip_hash хэширует первые три октета адреса IPv4. В нашем развертывании первые три октета одинаковы – 10.10.0 – для каждого клиента, поэтому хэш одинаков для всех них, и нет никаких оснований для распределения трафика на разные серверы.
Исправить ситуацию можно, воспользовавшись алгоритмом хэширования с переменной $binary_remote_addr в качестве хэш-ключа. Эта переменная фиксирует полный адрес клиента, конвертируя его в двоичное представление, которое составляет 4 байта для адреса IPv4 и 16 байт для адреса IPv6. Теперь хэш отличается для каждого перехватывающего устройства, и балансировка нагрузки работает должным образом.
Мы также включаем параметр consistent для использования метода хэширования ketama вместо параметра по умолчанию. Это значительно уменьшает количество ключей, которые переназначаются на другой вышестоящий сервер при изменении набора серверов, что обеспечивает более высокий коэффициент попадания в кэш для серверов кэширования.
http {
upstream {
hash $binary_remote_addr consistent;
server 10.10.20.105:8080;
server 10.10.20.106:8080;
server 10.10.20.108:8080;
}
server {# …}
}Ошибка №10: Игнорирование преимущества вышестоящих групп
Предположим, вы используете NGINX в качестве обратного прокси‑сервера для одного серверного приложения на базе NodeJS, прослушивающего порт 3000. Общая конфигурация может выглядеть следующим образом:
http {
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host;
proxy_pass http://localhost:3000/;
}
}
}Все довольно просто, не так ли? Директива proxy_pass указывает NGINX куда отправлять запросы от клиентов. Все, что нужно сделать NGINX, это преобразовать имя хоста в адрес IPv4 или IPv6. Как только соединение установлено, NGINX пересылает запросы на этот сервер.
Ошибка здесь может заключается в предположении, что, поскольку существует только один сервер – и, следовательно, нет причин настраивать балансировку нагрузки, – бессмысленно создавать блок upstream{}. На самом же деле, блок upstream{} открывает несколько функций по повышению производительности, отраженных в этой конфигурации:
http {
upstream node_backend {
zone upstreams 64K;
server 127.0.0.1:3000 max_fails=1 fail_timeout=2s;
keepalive 2;
}
server {
listen 80;
server_name example.com;
location / {
proxy_set_header Host $host;
proxy_pass http://node_backend/;
proxy_next_upstream error timeout http_500;
}
}
}Директива zone устанавливает зону общей памяти, в которой все рабочие процессы NGINX на хосте могут получать доступ к информации о конфигурации и состоянии вышестоящих серверов. Несколько вышестоящих групп могут совместно использовать эту зону. Благодаря NGINX Plus эта зона также позволяет использовать API NGINX Plus для изменения серверов в вышестоящей группе и настройки отдельных серверов без перезапуска NGINX. Дополнительные сведения см. в Руководстве администратора NGINX Plus.
Директива server содержит несколько параметров, которые вы можете использовать для настройки поведения сервера. В этом примере мы изменили настройки NGINX чтобы выявить, какой из серверов недоступен и не может принимать запросы. Сервер принимается за неработоспособный если попытка связи завершается неудачей хотя бы один раз в течение каждого 2-секундного периода (по умолчанию это один раз в 10-секундный период).
Мы объединяем этот параметр с директивой proxy_next_upstream, чтобы настроить то, что NGINX считает неудачной попыткой связи. Таким образом, он станет передавать запросы следующему серверу в вышестоящей группе. К условиям ошибки и тайм-аута по умолчанию мы добавляем http_500, чтобы NGINX рассматривал код ошибки HTTP 500 (внутренняя ошибка сервера) с вышестоящего сервера как неудачную попытку.
Директива keepalive задает количество незанятых keepalive-подключений к вышестоящим серверам, сохраненных в кэше каждого рабочего процесса. Мы уже обсуждали преимущества такого шага в Ошибке №3: Отсутствие соединения с вышестоящими серверами.
Благодаря NGINX Plus можно настроить дополнительные функции с помощью вышестоящих групп:
- Как мы упоминали выше, NGINX Open Source преобразует имена хостов серверов в IP-адреса только один раз, во время запуска. Параметр resolve для директивы server позволяет NGINX Plus отслеживать изменения IP-адресов, соответствующих доменному имени вышестоящего сервера, и автоматически изменять конфигурацию вышестоящего сервера без необходимости перезагрузки.
Параметр service дополнительно позволяет NGINX Plus использовать записи DNS SRV, которые включают информацию о номерах портов, весе и приоритетах. Это имеет решающее значение в микросервисах, где номера портов часто назначаются динамически.
Дополнительные сведения о разрешении адресов серверов см. в разделе Использование DNS для обнаружения служб с помощью NGINX и NGINX Plus в нашем блоге.
- Параметр slow_start в директиве server позволяет NGINX Plus постепенно увеличивать объем запросов, отправленных на сервер, признанный исправным и доступным для приема запросов. Это предотвратит внезапный поток запросов, которые могут перегрузить сервер и снова привести к сбою.
Директива queue позволяет NGINX Plus размещать запросы в очереди в случае невозможности выбрать вышестоящий сервер для обслуживания запроса, вместо того, чтобы немедленно возвращать клиенту сообщение об ошибке.
Ресурсы:
- Gixy, анализатор конфигурации NGINX на GitHub
- NGINX Amplify, который включает в себя инструмент Analyzer
Присоединяйтесь к нашему телеграмм-каналу DevOps FM.
Nginx – очень популярный веб-сервер в наши дни.
В этой статье мы расскажем вам о некоторых распространенных ошибках при работе веб-сервера Nginx и возможных решениях.
Это не полный список.
Если вы все еще не можете устранить ошибку, попробовав предложенные решения, пожалуйста, проверьте логи сервера Nginx в каталоге /var/log/nginx/ и поищите в Google, чтобы отладить проблему.
Содержание
- Unable to connect/Refused to Connect
- The Connection Has Timed Out
- 404 Not Found
- 403 Forbidden
- 500 Internal Server Error
- Nginx показывает страницу по умолчанию
- 504 Gateway time-out
- Размер памяти исчерпан
- PR_END_OF_FILE_ERROR
- Resource temporarily unavailable
- Два файла виртуального хоста для одного и того же сайта
- PHP-FPM Connection reset by peer
- Утечки сокетов Nginx
- Заключение
Unable to connect/Refused to Connect
Если при попытке получить доступ к вашему сайту вы видите следующую ошибку:
Firefox can’t establish a connection to the server at www.example.com
или
www.example.com refused to connect
или
The site can't be reached, www.example.com unexpectedly closed the connection.
Это может быть потому, что:
- Nginx не запущен. Вы можете проверить состояние Nginx с помощью sudo systemctl status nginx. Запустите Nginx с помощью sudo systemctl start nginx. Если Nginx не удается запустить, запустите sudo nginx -t, чтобы выяснить, нет ли ошибок в вашем конфигурационном файле. И проверьте логи (sudo journalctl -eu nginx), чтобы выяснить, почему он не запускается.
- Брандмауэр блокирует порты 80 и 443. Если вы используете брандмауэр UFW на Debian/Ubuntu, выполните sudo ufw allow 80,443/tcp, чтобы открыть TCP порты 80 и 443. Если вы используете Firewalld на RHEL/CentOS/Rocky Linux/AlmaLinux, выполните sudo firewall-cmd –permanent –add-service={http,https}, затем sudo systemctl reload firewalld, чтобы открыть TCP порты 80 и 443.
- Fail2ban. Если ваш сервер использует fail2ban для блокировки вредоносных запросов, возможно, fail2ban запретил ваш IP-адрес. Выполните команду sudo journalctl -eu fail2ban, чтобы проверить, не заблокирован ли ваш IP-адрес. Вы можете добавить свой IP-адрес в список fail2ban ignoreip, чтобы он больше не был забанен.
- Nginx не прослушивает нужный сетевой интерфейс. Например, Nginx не прослушивает публичный IP-адрес сервера.
The Connection Has Timed Out
Это может означать, что ваш сервер находится в автономном режиме или Nginx работает неправильно.
Однажды у меня возникла проблема нехватки памяти, из-за чего Nginx не смог запустить рабочие процессы.
Если вы увидите следующее сообщение об ошибке в файле /var/log/nginx/error.log, вашему серверу не хватает памяти:
fork() failed while spawning "worker process" (12: Cannot allocate memory)
404 Not Found
404 not found означает, что Nginx не может найти ресурсы, которые запрашивает ваш веб-браузер.
🌐 Как создать пользовательскую страницу ошибки 404 в NGINX
Причина может быть следующей:
- Корневой каталог web не существует на вашем сервере. В Nginx корневой веб-каталог настраивается с помощью директивы root, например, так: root /usr/share/nginx/linuxbabe.com/;. Убедитесь, что файлы вашего сайта (HTML, CSS, JavaScript, PHP) хранятся в правильном каталоге.
- PHP-FPM не запущен. Вы можете проверить статус PHP-FPM с помощью sudo systemctl status php7.4-fpm (Debian/Ubuntu) или sudo systemctl status php-fpm.
- Вы забыли включить директиву try_files $uri /index.php$is_args$args; в конфигурационный файл сервера Nginx. Эта директива необходима для обработки PHP-кода.
- На вашем сервере нет свободного дискового пространства. Попробуйте освободить немного дискового пространства. Вы можете использовать утилиту ncdu (sudo apt install ncdu или sudo dnf install ncdu), чтобы узнать, какие каталоги занимают огромное количество дискового пространства.
403 Forbidden
Эта ошибка означает, что вам не разрешен доступ к ресурсам запроса.
Возможный сценарий включает:
- Администратор сайта блокирует публичный доступ к запрашиваемым ресурсам с помощью белого списка IP-адресов или других методов.
- На сайте может использоваться брандмауэр веб-приложения, например ModSecurity, который обнаружил атаку вторжения, поэтому заблокировал запрос.
Некоторые веб-приложения могут показывать другое сообщение об ошибке, когда происходит запрет 403. Оно может сказать вам, что “secure connection failed, хотя причина та же.
500 Internal Server Error
Это означает, что в веб-приложении произошла какая-то ошибка.
Это может быть следующее
- Сервер базы данных не работает. Проверьте состояние MySQL/MariaDB с помощью sudo systemctl status mysql. Запустите его с помощью sudo systemctl start mysql. Запустите sudo journalctl -eu mysql, чтобы выяснить, почему он не запускается. Процесс MySQL/MariaDB может быть завершен из-за проблем с нехваткой памяти.
- Вы не настроили Nginx на использование PHP-FPM, поэтому Nginx не знает, как выполнять PHP-код.
- Если ваше веб-приложение имеет встроенный кэш, вы можете попробовать очистить кэш приложения, чтобы исправить эту ошибку.
- Ваше веб-приложение может создавать свой собственный журнал ошибок. Проверьте этот файл журнала, чтобы отладить эту ошибку.
- Возможно, в вашем веб-приложении есть режим отладки. Включите его, и вы увидите более подробные сообщения об ошибках на веб-странице. Например, вы можете включить режим отладки в почтовом сервере хостинг-платформы Modoboa, установив DEBUG = True в файле /srv/modoboa/instance/instance/settings.py.
- PHP-FPM может быть перегружен. Проверьте журнал PHP-FPM (например, /var/log/php7.4-fpm.log). Если вы обнаружили предупреждение [pool www] seems busy (возможно, вам нужно увеличить pm.start_servers, или pm.min/max_spare_servers), вам нужно выделить больше ресурсов для PHP-FPM.
- Иногда перезагрузка PHP-FPM (sudo systemctl reload php7.4-fpm) может исправить ошибку.
Nginx показывает страницу по умолчанию
Если вы пытаетесь настроить виртуальный хост Nginx и при вводе доменного имени в веб-браузере отображается страница Nginx по умолчанию, это может быть следующее
- Вы не использовали реальное доменное имя для директивы server_name в виртуальном хосте Nginx.
- Вы забыли перезагрузить Nginx.
504 Gateway time-out
Это означает, что апстрим, такой как PHP-FPM/MySQL/MariaDB, не может обработать запрос достаточно быстро.
Вы можете попробовать перезапустить PHP-FPM, чтобы временно исправить ошибку, но лучше начать настраивать PHP-FPM/MySQL/MariaDB для более быстрой работы.
Вот конфигурация InnoDB в моем файле /etc/mysql/mariadb.conf.d/50-server.cnf.
Это очень простая настройка производительности.
innodb_buffer_pool_size = 1024M innodb_buffer_pool_dump_at_shutdown = ON innodb_buffer_pool_load_at_startup = ON innodb_log_file_size = 512M innodb_log_buffer_size = 8M #Improving disk I/O performance innodb_file_per_table = 1 innodb_open_files = 400 innodb_io_capacity = 400 innodb_flush_method = O_DIRECT innodb_read_io_threads = 64 innodb_write_io_threads = 64 innodb_buffer_pool_instances = 3
Где:
- InnoDB buffer pool size должен быть не менее половины вашей оперативной памяти. (Для VPS с небольшим объемом оперативной памяти я рекомендую установить размер буферного пула на меньшее значение, например 400M, иначе ваш VPS будет работать без оперативной памяти).
- InnoDB log file size должен составлять 25% от размера буферного пула.
- Установите потоки ввода-вывода для чтения и записи на максимум (64).
- Заставьте MariaDB использовать 3 экземпляра буферного пула InnoDB. Количество экземпляров должно соответствовать количеству ядер процессора в вашей системе.
- После сохранения изменений перезапустите MariaDB.
После сохранения изменений перезапустите MariaDB.
sudo systemctl restart mariadb
Вы также можете установить более длительное значение тайм-аута в Nginx, чтобы уменьшить вероятность тайм-аута шлюза.
Отредактируйте файл виртуального хоста Nginx и добавьте следующие строки в блок server {…}.
proxy_connect_timeout 600; proxy_send_timeout 600; proxy_read_timeout 600; send_timeout 600;
Если вы используете Nginx с PHP-FPM, то установите для параметра fastcgi_read_timeout большее значение, например 300 секунд.
По умолчанию это 60 секунд.
location ~ .php$ {
try_files $uri /index.php$is_args$args;
include snippets/fastcgi-php.conf;
fastcgi_split_path_info ^(.+.php)(/.+)$;
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
fastcgi_read_timeout 300;
}
Затем перезагрузите Nginx.
sudo systemctl reload nginx
PHP-FPM также имеет максимальное время выполнения для каждого скрипта.
Отредактируйте файл php.ini.
sudo nano /etc/php/7.4/fpm/php.ini
Вы можете увеличить это значение до 300 секунд.
max_execution_time = 300
Затем перезапустите PHP-FPM
sudo systemctl restart php7.4-fpm
Размер памяти исчерпан
Если вы видите следующую строку в журнале ошибок Nginx, это означает, что PHP достиг лимита памяти в 128 МБ.
PHP Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 57134520 bytes)
Вы можете отредактировать файл php.ini (/etc/php/7.4/fpm/php.ini) и увеличить лимит памяти PHP.
memory_limit = 512M
Затем перезапустите PHP7.4-FPM.
sudo systemctl restart php7.4-fpm
Если ошибка все еще существует, скорее всего, в вашем веб-приложении плохой PHP-код, который потребляет много оперативной памяти.
PR_END_OF_FILE_ERROR
- Вы настроили Nginx на перенаправление HTTP-запросов на HTTPS, но в Nginx нет блока сервера, обслуживающего HTTPS-запросы.
- Может быть, Nginx не запущен?
- Иногда основной бинарник Nginx запущен, но рабочий процесс может не работать и завершиться по разным причинам. Для отладки проверьте логи ошибок Nginx (/var/log/nginx/error.log).
Resource temporarily unavailable
Некоторые пользователи могут найти следующую ошибку в файле логов ошибок Nginx (в разделе /var/log/nginx/).
connect() to unix:/run/php/php7.4-fpm.sock failed (11: Resource temporarily unavailable)
Обычно это означает, что на вашем сайте много посетителей и PHP-FPM не справляется с обработкой огромного количества запросов.
Вы можете изменить количество дочерних процессов PHP-FPM, чтобы он мог обрабатывать больше запросов.
Отредактируйте файл PHP-FPM www.conf.
(Путь к файлу зависит от дистрибутива Linux).
sudo /etc/php/7.4/fpm/pool.d/www.conf
По умолчанию конфигурация дочернего процесса выглядит следующим образом:
pm = dynamic pm.max_children = 5 pm.start_servers = 2 pm.min_spare_servers = 1 pm.max_spare_servers = 3
Приведенная выше конфигурация означает.
- PHP-FPM динамически создает дочерние процессы. Нет фиксированного количества дочерних процессов.
- Создается не более 5 дочерних процессов.
- При запуске PHP-FPM запускаются 2 дочерних процесса.
- Есть как минимум 1 незанятый процесс.
- Максимум 3 неработающих процесса.
pm = dynamic pm.max_children = 20 pm.start_servers = 8 pm.min_spare_servers = 4 pm.max_spare_servers = 12
Убедитесь, что у вас достаточно оперативной памяти для запуска дополнительных дочерних процессов.
Сохраните и закройте файл.
Затем перезапустите PHP-FPM. (Возможно, вам потребуется изменить номер версии).
sudo systemctl restart php7.4-fpm
Чтобы следить за состоянием PHP-FPM, вы можете включить страницу status .
Найдите следующую строку в файле PHP-FPM www.conf.
Обратите внимание, что
;pm.status_path = /status
Уберите точку с запятой, чтобы включить страницу состояния PHP-FPM.
Затем перезапустите PHP-FPM.
sudo systemctl restart php7.4-fpm
Затем отредактируйте файл виртуального хоста Nginx.
Добавьте следующие строки.
Директивы allow и deny используются для ограничения доступа.
Только IP-адреса из “белого списка” могут получить доступ к странице состояния.
location ~ ^/(status|ping)$ {
allow 127.0.0.1;
allow your_other_IP_Address;
deny all;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_index index.php;
include fastcgi_params;
#fastcgi_pass 127.0.0.1:9000;
fastcgi_pass unix:/run/php/php7.4-fpm.sock;
}
Сохраните и закройте файл. Затем протестируйте конфигурацию Nginx.
sudo nginx -t
Если проверка прошла успешно, перезагрузите Nginx, чтобы изменения вступили в силу.
sudo systemctl reload nginx
В файле PHP-FPM www.conf дается хорошее объяснение того, что означает каждый параметр.
Если PHP-FPM очень занят и не может обслужить запрос немедленно, он поставит его в очередь.
По умолчанию может быть не более 511 ожидающих запросов, определяемых параметром listen.backlog.
listen.backlog = 511
Если вы видите следующее значение на странице состояния PHP-FPM, это означает, что в очереди еще не было ни одного запроса, т.е. ваш PHP-FPM может быстро обрабатывать запросы.
listen queue: 0 max listen queue: 0
Если в очереди 511 ожидающих запросов, это означает, что ваш PHP-FPM очень загружен, поэтому вам следует увеличить количество дочерних процессов.
Вам также может понадобиться изменить параметр ядра Linux net.core.somaxconn, который определяет максимальное количество соединений, разрешенных к файлу сокетов в Linux, например, к файлу сокетов PHP-FPM Unix.
По умолчанию его значение равно 128 до ядра 5.4 и 4096 начиная с ядра 5.4.
$ sysctl net.core.somaxconn net.core.somaxconn = 128
Если у вас сайт с высокой посещаемостью, вы можете использовать большое значение.
Отредактируйте файл /etc/sysctl.conf.
sudo nano /etc/sysctl.cnf
Добавьте следующие две строки.
net.core.somaxconn = 20000 net.core.netdev_max_backlog = 65535
Сохраните и закройте файл. Затем примените настройки.
sudo sysctl -p
Примечание: Если ваш сервер имеет достаточно оперативной памяти, вы можете выделить фиксированное количество дочерних процессов для PHP-FPM, как показано ниже.
Два файла виртуального хоста для одного и того же сайта
Если вы запустите sudo nginx -t и увидите следующее предупреждение.
nginx: [warn] conflicting server name "example.com" on [::]:443, ignored nginx: [warn] conflicting server name "example.com" on 0.0.0.0:443, ignored
Это означает, что есть два файла виртуальных хостов, содержащих одну и ту же конфигурацию server_name.
Не создавайте два файла виртуальных хостов для одного сайта.
PHP-FPM Connection reset by peer
В файле логов ошибок Nginx отображается следующее сообщение.
recv() failed (104: Connection reset by peer) while reading response header from upstream
Это может быть вызвано перезапуском PHP-FPM.
Если он перезапущен вручную самостоятельно, то вы можете игнорировать эту ошибку.
Утечки сокетов Nginx
Если вы обнаружили следующее сообщение об ошибке в файле /var/log/nginx/error.log, значит, у вашего Nginx проблема с утечкой сокетов.
2021/09/28 13:27:41 [alert] 321#321: *120606 open socket #16 left in connection 163 2021/09/28 13:27:41 [alert] 321#321: *120629 open socket #34 left in connection 188 2021/09/28 13:27:41 [alert] 321#321: *120622 open socket #9 left in connection 213 2021/09/28 13:27:41 [alert] 321#321: *120628 open socket #25 left in connection 217 2021/09/28 13:27:41 [alert] 321#321: *120605 open socket #15 left in connection 244 2021/09/28 13:27:41 [alert] 321#321: *120614 open socket #41 left in connection 245 2021/09/28 13:27:41 [alert] 321#321: *120631 open socket #24 left in connection 255 2021/09/28 13:27:41 [alert] 321#321: *120616 open socket #23 left in connection 258 2021/09/28 13:27:41 [alert] 321#321: *120615 open socket #42 left in connection 269 2021/09/28 13:27:41 [alert] 321#321: aborting
Вы можете перезапустить ОС, чтобы решить эту проблему.
Если это не помогает, вам нужно скомпилировать отладочную версию Nginx, которая покажет вам отладочную информацию в логах.
Заключение
Надеюсь, эта статья помогла вам исправить распространенные ошибки веб-сервера Nginx.
см. также:
- 🌐 Как контролировать доступ на основе IP-адреса клиента в NGINX
- 🐉 Настройка http-сервера Kali Linux
- 🌐 Как парсить логи доступа nginx
- 🌐 Ограничение скорости определенных URL-адресов с Nginx
- 🛡️ Как использовать обратный прокси Nginx для ограничения внешних вызовов внутри веб-браузера
- 🔏 Как настроить Nginx с Let’s Encrypt с помощью ACME на Ubuntu
- 🌐 Как собрать NGINX с ModSecurity на Ubuntu сервере
При разработке веб-сайтов и веб-приложений можно столкнуться с ошибкой 500 internal server error. Сначала она может испугать и ввести в заблуждение, поскольку обычно веб-сервер выдает более конкретные ошибки, в которых указана точная причина проблемы, например, превышено время ожидания, неверный запрос или файл не найден, а тут просто сказано что, обнаружена внутренняя ошибка.
Но не все так страшно и в большинстве случаев проблема вполне решаема и очень быстро. В этой статье мы разберем как исправить ошибку Internal server error в Nginx.
Дословно Internal server error означает внутренняя ошибка сервера. И вызвать её могут несколько проблем. Вот основные из них:
- Ошибки в скрипте на PHP — одна из самых частых причин;
- Превышено время выполнения PHP скрипта или лимит памяти;
- Неправильные права на файлы сайта;
- Неверная конфигурация Nginx.
А теперь рассмотрим каждую из причин более подробно и разберем варианты решения.
1. Ошибка в скрипте PHP
Мы привыкли к тому, что если в PHP скрипте есть ошибки, то сразу же видим их в браузере. Однако на производственных серверах отображение сообщений об ошибках в PHP отключено, чтобы предотвратить распространение информации о конфигурации сервера для посторонних. Nginx не может отобразить реальную причину ошибки, потому что не знает что за ошибка произошла, а поэтому выдает универсальное сообщение 500 internal server error.
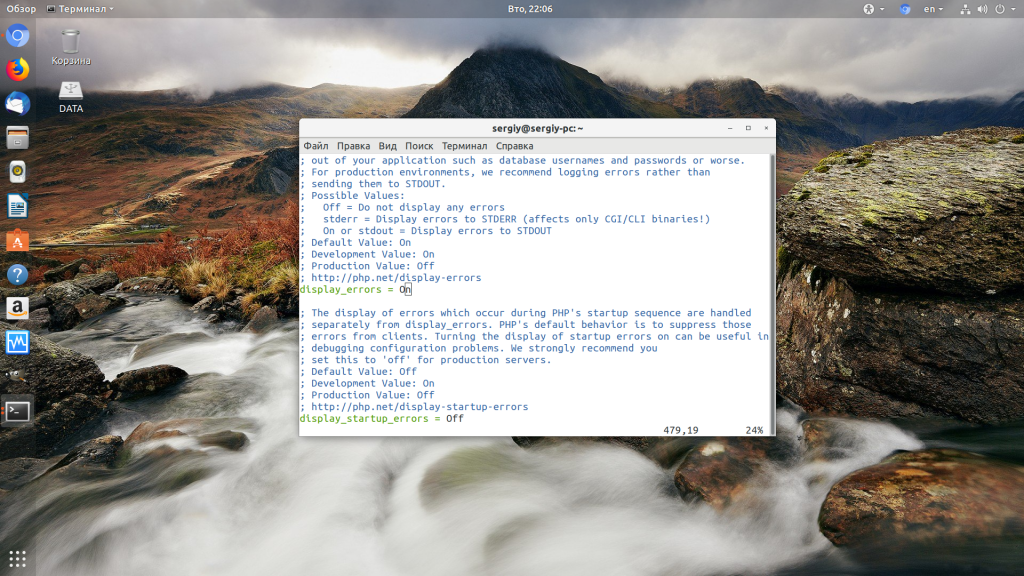
Чтобы исправить эту ошибку, нужно сначала понять где именно проблема. Вы можете включить отображение ошибок в конфигурационном файле php изменив значение строки display_errors с off на on. Рассмотрим на примере Ubuntu и PHP 7.2:
vi /etc/php/7.2/php.ini
display_errors = On
Перезапустите php-fpm:
sudo systemctl restart php-fpm
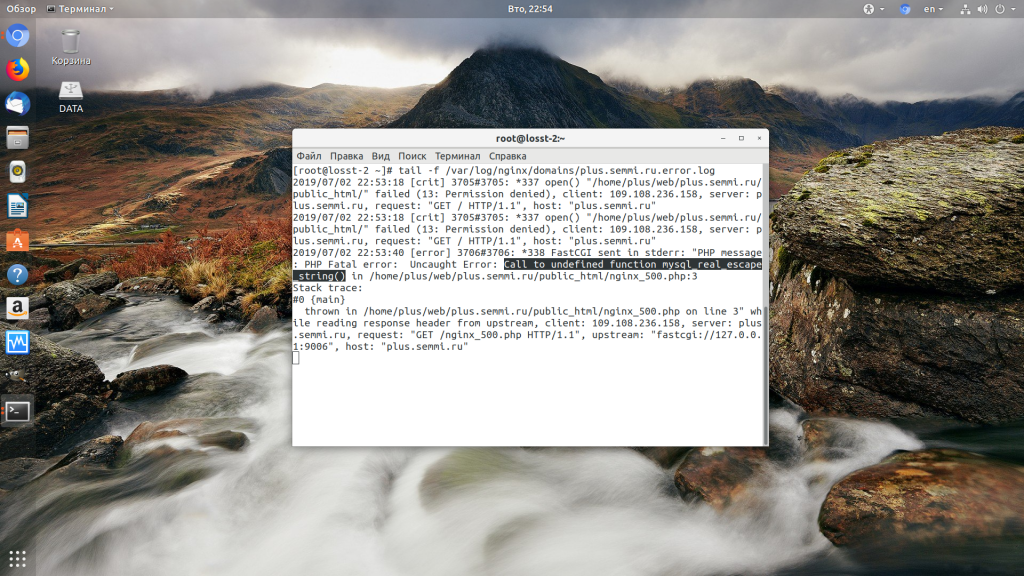
Затем обновите страницу и вы увидите сообщение об ошибке, из-за которого возникла проблема. Далее его можно исправить и отключить отображение ошибок, тогда все будет работать. Ещё можно посмотреть сообщения об ошибках PHP в логе ошибок Nginx. Обычно он находится по пути /var/log/nginx/error.log, но для виртуальных доменов может настраиваться отдельно. Например, смотрим последние 100 строк в логе:
tail -n 100 -f /var/log/nginx/error.log
Теперь аналогично, исправьте ошибку и страница будет загружаться нормально, без ошибки 500.
2. Превышено время выполнения или лимит памяти
Это продолжение предыдущего пункта, так тоже относится к ошибкам PHP, но так, как проблема встречается довольно часто я решил вынести её в отдельный пункт. В файле php.ini установлены ограничения на время выполнения скрипта и количество оперативной памяти, которую он может потребить. Если скрипт потребляет больше, интерпретатор PHP его убивает и возвращает сообщение об ошибке.
Также подобная ошибка может возникать, если на сервере закончилась свободная оперативная память.
Если же отображение ошибок отключено, мы получаем error 500. Обратите внимание, что если время ожидания было ограничено в конфигурационном файле Nginx, то вы получите ошибку 504, а не HTTP ERROR 500, так что проблема именно в php.ini.
Чтобы решить проблему увеличьте значения параметров max_execution_time и memory_limit в php.ini:
sudo vi /etc/php/7.2/php.ini
max_execution_time 300
memory_limit 512M
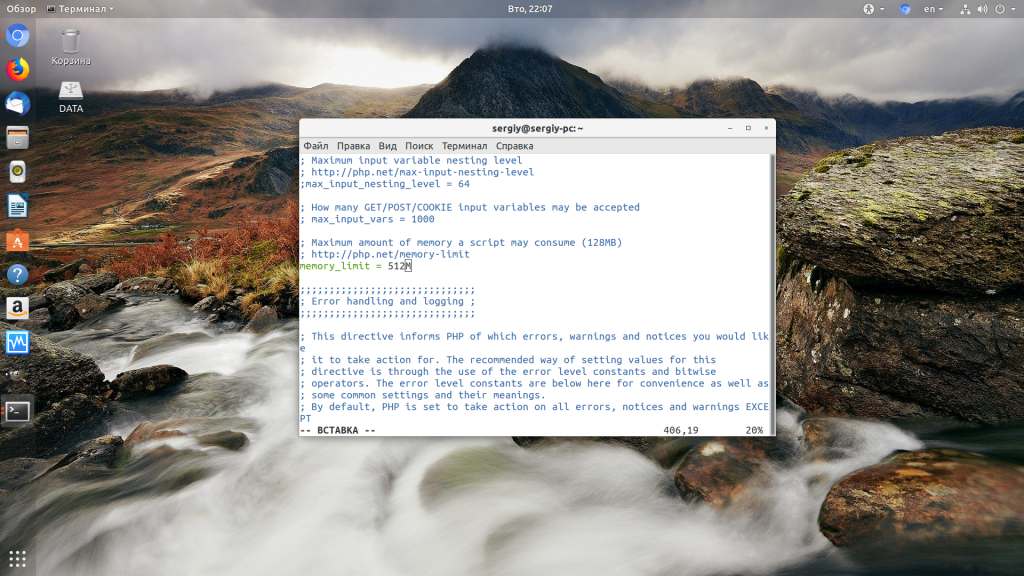
Также проблема может быть вызвана превышением других лимитов установленных для скрипта php. Смотрите ошибки php, как описано в первом пункте. После внесения изменений в файл перезапустите php-fpm:
sudo systemctl restart php-fpm
3. Неверные права на файлы
Такая ошибка может возникать, если права на файлы, к которым обращается Nginx установлены на правильно. Сервисы Nginx и php-fpm должны быть запущены от имени одного и того же пользователя, а все файлы сайтов должны принадлежать этому же пользователю. Посмотреть от имени какого пользователя запущен Nginx можно командой:
nginx -T | grep user
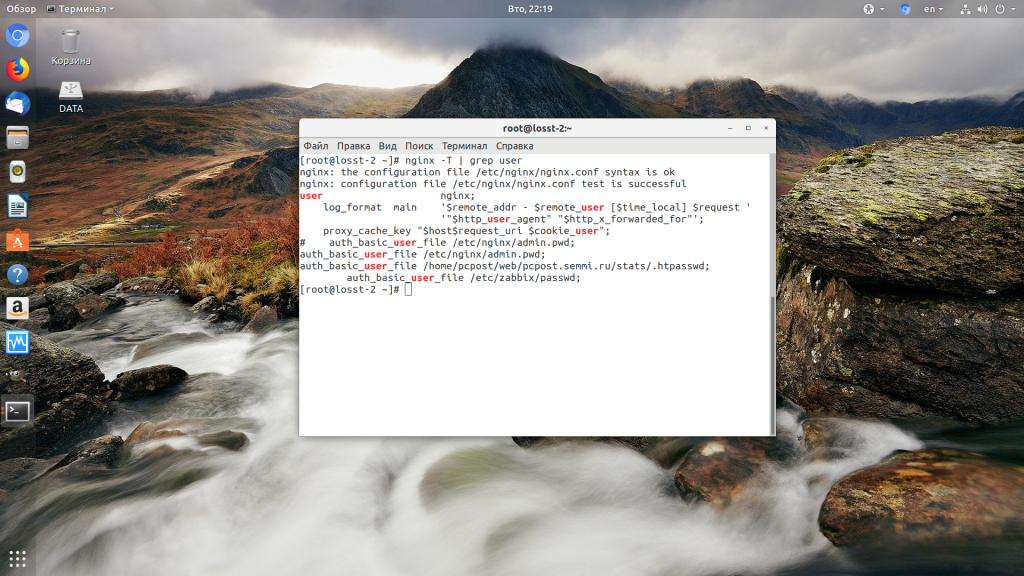
Чтобы узнать от какого пользователя запущен php-fpm посмотрите содержимое конфигурационного файла используемого пула, например www.conf:
sudo vi /etc/php-fpm.d/www.conf
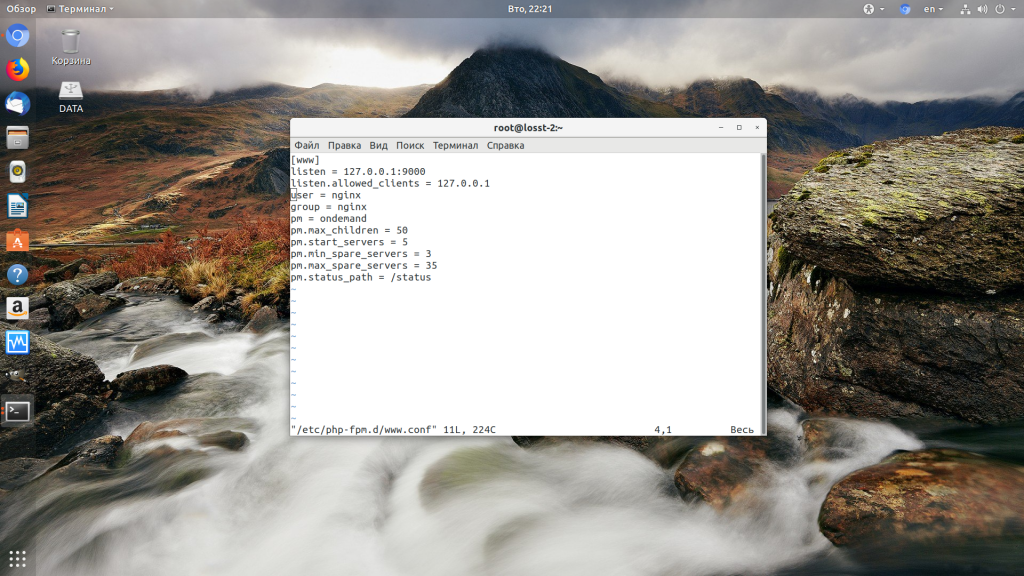
В моем случае это пользователь nginx. Теперь надо убедится, что файлы сайта, к которым вы пытаетесь обратиться принадлежат именно этому пользователю. Для этого используйте команду namei:
namei -l /var/www/site
Файлы сайта должны принадлежать пользователю, от имени которого запущены сервисы, а по пути к каталогу с файлами должен быть доступ на чтение для всех пользователей. Если файлы принадлежат не тому пользователю, то вы можете все очень просто исправить:
sudo chown nginx:nginx -R /var/www/site
Этой командой мы меняем владельца и группу всех файлов в папке на nginx:nginx. Добавить права на чтение для всех пользователей для каталога можно командой chmod. Например:
sudo chmod o+r /var/www/
Далее все должно работать. Также, проблемы с правами может вызывать SELinux. Настройте его правильно или отключите:
setenforce 0
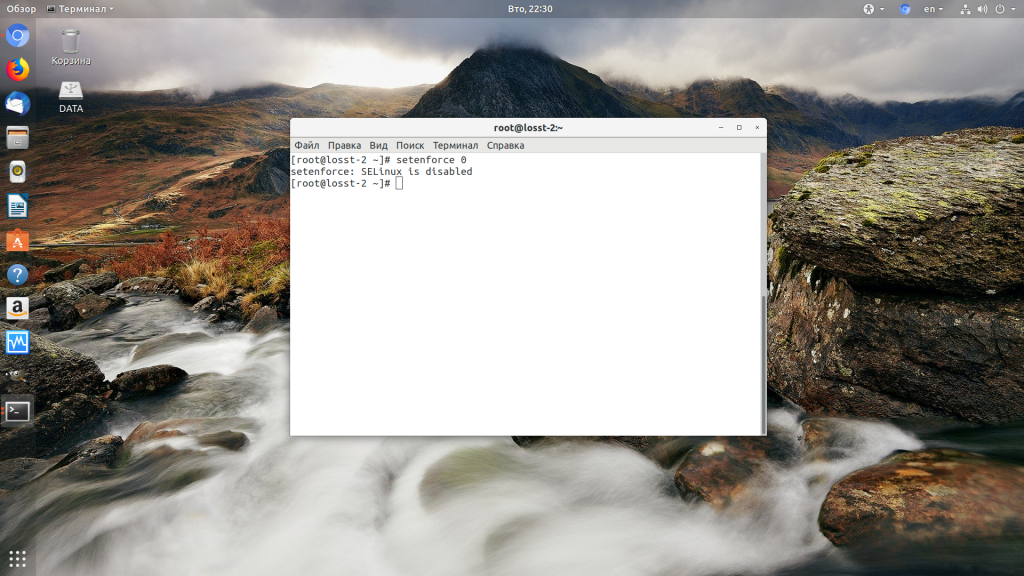
Выводы
В этой статье мы разобрали что делать если на вашем сайте встретилась ошибка 500 internal server error nginx. Как видите проблема вполне решаема и в большинстве случаев вам помогут действия описанные в статье. А если не помогут, напишите свое решение в комментариях!

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
I am new to nginx. I try to learn using search www and stackoverflow. Mostly I get help to understand how to build my nginx configuration.
I have my domain as www.mysite.com. Everything; landing page, the error and server error must be redirect to default index.html. I also define my access and error log. All this done (below code) inside the /etc/nginx/conf.d/default.conf.
I need to redirect (proxy_pass) /admin, /user and anything related to them. Example the /admin has also different folder like /admin/login/. I need to everything after /admin must be redirected. The same goes also for the /user as well.
1) Looking at my code am I redirect the location /admin and location /user correctly?
2) I also use try_files $uri $uri/ =404; in redirection. which also redirects the 404 to default index.html. Am I doing right?
3) I am also denying access to some file and folder. Am I doing right?
My main question is How to correct my nginx configuration if it is wrong? So to understand the correct nginx configuration I divide my question to 3 different question above. I hope I didnt brake stackoverflow how to ask question guidelines.
Thank you.
UPDATE:
server {
charset UTF-8;
listen 80;
listen [::]:80;
server_name www.mysite.com;
access_log /var/log/nginx/host.access.log main;
error_log /var/log/nginx/host.error.log main;
# define a root location variable and assign a value
set $rootLocation /usr/share/nginx/html;
# define www.mysite.com landing page to the static index.html page
location / {
root rootLocation;
index index.html index.htm;
}
# define error page to the static index.html page
error_page 404 /index.html;
location = /index.html {
root rootLocation;
internal;
}
# redirect server error pages to the static index.html page
error_page 500 502 503 504 /index.html;
location = /index.html {
root rootLocation;
internal;
}
# redirect www.mysite.com/admin to localhost
# /admin or /admin/ or /admin/**** must be redirect to localhost
location /admin {
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header Host $http_host;
proxy_pass "http://127.0.0.1:3000";
}
# redirect www.mysite.com/user to localhost
# /user or /user/ or /user/**** must be redirect to localhost
location /user {
proxy_set_header X-Forwarded-For $remote_addr;
proxy_set_header Host $http_host;
proxy_pass "http://127.0.0.1:3001";
}
}
Здравствуйте!
Возникла проблема с конфигурацией nginx 1.14. Работаю в Open server panel. в папке domain создал два сайта test.ru и testsite.ru. Там же в папке domain создал папку catalog. В этой папке создал 2 папки test и testsite.и в них индексные файлы index.php
Конфиг для обоих сайтов такой:
server {
listen 127.0.0.1:80;
server_name testsite.ru;
index index.php;
charset utf-8;
add_header 'Access-Control-Allow-Origin' '*';
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS';
add_header 'Access-Control-Allow-Headers' 'DNT,User-Agent,X-Requested-With,If-Modified-Since,Cache-Control,Content-Type,Range';
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
ssl_certificate "%sprogdir%/userdata/config/server.crt";
ssl_certificate_key "%sprogdir%/userdata/config/server.key";
location / {
root "F:ServerOSPaneldomainscatalogtestsite";
#try_files $uri $uri/ /index.php$is_args$args;
try_files $uri $uri/ /index.php?$query_string;
location ~ .php$ {
try_files $uri =404;
# if (!-e $document_root$document_uri){return 404;}
fastcgi_pass backend;
fastcgi_index index.php;
fastcgi_buffers 4 64k;
fastcgi_connect_timeout 1s;
fastcgi_ignore_client_abort off;
fastcgi_next_upstream timeout;
fastcgi_read_timeout 5m;
fastcgi_send_timeout 5m;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param DOCUMENT_URI $document_uri;
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param HTTPS $https;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param REQUEST_URI $request_uri;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $host;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param SERVER_SOFTWARE nginx;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param SCRIPT_NAME $fastcgi_script_name;
fastcgi_param TMP "%sprogdir%/userdata/temp";
fastcgi_param TMPDIR "%sprogdir%/userdata/temp";
fastcgi_param TEMP "%sprogdir%/userdata/temp";
}
}
}При переходе на testsite.ru показывает 404. То же самое и для test.ru. Если меняю название папки в catalog test на 2test и правлю в конфиге root на «F:ServerOSPaneldomainscatalog2test»; все фурычит. То же самое и для второго сайта. Что за магия? В чем ошибка?
Nginx – очень популярный веб-сервер в наши дни.
В этой статье мы расскажем вам о некоторых распространенных ошибках при работе веб-сервера Nginx и возможных решениях.
Это не полный список.
Если вы все еще не можете устранить ошибку, попробовав предложенные решения, пожалуйста, проверьте логи сервера Nginx в каталоге /var/log/nginx/ и поищите в Google, чтобы отладить проблему.
Содержание
- Unable to connect/Refused to Connect
- The Connection Has Timed Out
- 404 Not Found
- 403 Forbidden
- 500 Internal Server Error
- Nginx показывает страницу по умолчанию
- 504 Gateway time-out
- Размер памяти исчерпан
- PR_END_OF_FILE_ERROR
- Resource temporarily unavailable
- Два файла виртуального хоста для одного и того же сайта
- PHP-FPM Connection reset by peer
- Утечки сокетов Nginx
- Заключение
Unable to connect/Refused to Connect
Если при попытке получить доступ к вашему сайту вы видите следующую ошибку:
Firefox can’t establish a connection to the server at www.example.com
или
www.example.com refused to connect
или
The site can't be reached, www.example.com unexpectedly closed the connection.
Это может быть потому, что:
- Nginx не запущен. Вы можете проверить состояние Nginx с помощью sudo systemctl status nginx. Запустите Nginx с помощью sudo systemctl start nginx. Если Nginx не удается запустить, запустите sudo nginx -t, чтобы выяснить, нет ли ошибок в вашем конфигурационном файле. И проверьте логи (sudo journalctl -eu nginx), чтобы выяснить, почему он не запускается.
- Брандмауэр блокирует порты 80 и 443. Если вы используете брандмауэр UFW на Debian/Ubuntu, выполните sudo ufw allow 80,443/tcp, чтобы открыть TCP порты 80 и 443. Если вы используете Firewalld на RHEL/CentOS/Rocky Linux/AlmaLinux, выполните sudo firewall-cmd –permanent –add-service={http,https}, затем sudo systemctl reload firewalld, чтобы открыть TCP порты 80 и 443.
- Fail2ban. Если ваш сервер использует fail2ban для блокировки вредоносных запросов, возможно, fail2ban запретил ваш IP-адрес. Выполните команду sudo journalctl -eu fail2ban, чтобы проверить, не заблокирован ли ваш IP-адрес. Вы можете добавить свой IP-адрес в список fail2ban ignoreip, чтобы он больше не был забанен.
- Nginx не прослушивает нужный сетевой интерфейс. Например, Nginx не прослушивает публичный IP-адрес сервера.
The Connection Has Timed Out
Это может означать, что ваш сервер находится в автономном режиме или Nginx работает неправильно.
Однажды у меня возникла проблема нехватки памяти, из-за чего Nginx не смог запустить рабочие процессы.
Если вы увидите следующее сообщение об ошибке в файле /var/log/nginx/error.log, вашему серверу не хватает памяти:
fork() failed while spawning "worker process" (12: Cannot allocate memory)
404 Not Found
404 not found означает, что Nginx не может найти ресурсы, которые запрашивает ваш веб-браузер.
🌐 Как создать пользовательскую страницу ошибки 404 в NGINX
Причина может быть следующей:
- Корневой каталог web не существует на вашем сервере. В Nginx корневой веб-каталог настраивается с помощью директивы root, например, так: root /usr/share/nginx/linuxbabe.com/;. Убедитесь, что файлы вашего сайта (HTML, CSS, JavaScript, PHP) хранятся в правильном каталоге.
- PHP-FPM не запущен. Вы можете проверить статус PHP-FPM с помощью sudo systemctl status php7.4-fpm (Debian/Ubuntu) или sudo systemctl status php-fpm.
- Вы забыли включить директиву try_files $uri /index.php$is_args$args; в конфигурационный файл сервера Nginx. Эта директива необходима для обработки PHP-кода.
- На вашем сервере нет свободного дискового пространства. Попробуйте освободить немного дискового пространства. Вы можете использовать утилиту ncdu (sudo apt install ncdu или sudo dnf install ncdu), чтобы узнать, какие каталоги занимают огромное количество дискового пространства.
403 Forbidden
Эта ошибка означает, что вам не разрешен доступ к ресурсам запроса.
Возможный сценарий включает:
- Администратор сайта блокирует публичный доступ к запрашиваемым ресурсам с помощью белого списка IP-адресов или других методов.
- На сайте может использоваться брандмауэр веб-приложения, например ModSecurity, который обнаружил атаку вторжения, поэтому заблокировал запрос.
Некоторые веб-приложения могут показывать другое сообщение об ошибке, когда происходит запрет 403. Оно может сказать вам, что “secure connection failed, хотя причина та же.
500 Internal Server Error
Это означает, что в веб-приложении произошла какая-то ошибка.
Это может быть следующее
- Сервер базы данных не работает. Проверьте состояние MySQL/MariaDB с помощью sudo systemctl status mysql. Запустите его с помощью sudo systemctl start mysql. Запустите sudo journalctl -eu mysql, чтобы выяснить, почему он не запускается. Процесс MySQL/MariaDB может быть завершен из-за проблем с нехваткой памяти.
- Вы не настроили Nginx на использование PHP-FPM, поэтому Nginx не знает, как выполнять PHP-код.
- Если ваше веб-приложение имеет встроенный кэш, вы можете попробовать очистить кэш приложения, чтобы исправить эту ошибку.
- Ваше веб-приложение может создавать свой собственный журнал ошибок. Проверьте этот файл журнала, чтобы отладить эту ошибку.
- Возможно, в вашем веб-приложении есть режим отладки. Включите его, и вы увидите более подробные сообщения об ошибках на веб-странице. Например, вы можете включить режим отладки в почтовом сервере хостинг-платформы Modoboa, установив DEBUG = True в файле /srv/modoboa/instance/instance/settings.py.
- PHP-FPM может быть перегружен. Проверьте журнал PHP-FPM (например, /var/log/php7.4-fpm.log). Если вы обнаружили предупреждение [pool www] seems busy (возможно, вам нужно увеличить pm.start_servers, или pm.min/max_spare_servers), вам нужно выделить больше ресурсов для PHP-FPM.
- Иногда перезагрузка PHP-FPM (sudo systemctl reload php7.4-fpm) может исправить ошибку.
Nginx показывает страницу по умолчанию
Если вы пытаетесь настроить виртуальный хост Nginx и при вводе доменного имени в веб-браузере отображается страница Nginx по умолчанию, это может быть следующее
- Вы не использовали реальное доменное имя для директивы server_name в виртуальном хосте Nginx.
- Вы забыли перезагрузить Nginx.
504 Gateway time-out
Это означает, что апстрим, такой как PHP-FPM/MySQL/MariaDB, не может обработать запрос достаточно быстро.
Вы можете попробовать перезапустить PHP-FPM, чтобы временно исправить ошибку, но лучше начать настраивать PHP-FPM/MySQL/MariaDB для более быстрой работы.
Вот конфигурация InnoDB в моем файле /etc/mysql/mariadb.conf.d/50-server.cnf.
Это очень простая настройка производительности.
innodb_buffer_pool_size = 1024M innodb_buffer_pool_dump_at_shutdown = ON innodb_buffer_pool_load_at_startup = ON innodb_log_file_size = 512M innodb_log_buffer_size = 8M #Improving disk I/O performance innodb_file_per_table = 1 innodb_open_files = 400 innodb_io_capacity = 400 innodb_flush_method = O_DIRECT innodb_read_io_threads = 64 innodb_write_io_threads = 64 innodb_buffer_pool_instances = 3
Где:
- InnoDB buffer pool size должен быть не менее половины вашей оперативной памяти. (Для VPS с небольшим объемом оперативной памяти я рекомендую установить размер буферного пула на меньшее значение, например 400M, иначе ваш VPS будет работать без оперативной памяти).
- InnoDB log file size должен составлять 25% от размера буферного пула.
- Установите потоки ввода-вывода для чтения и записи на максимум (64).
- Заставьте MariaDB использовать 3 экземпляра буферного пула InnoDB. Количество экземпляров должно соответствовать количеству ядер процессора в вашей системе.
- После сохранения изменений перезапустите MariaDB.
После сохранения изменений перезапустите MariaDB.
sudo systemctl restart mariadb
Вы также можете установить более длительное значение тайм-аута в Nginx, чтобы уменьшить вероятность тайм-аута шлюза.
Отредактируйте файл виртуального хоста Nginx и добавьте следующие строки в блок server {…}.
proxy_connect_timeout 600; proxy_send_timeout 600; proxy_read_timeout 600; send_timeout 600;
Если вы используете Nginx с PHP-FPM, то установите для параметра fastcgi_read_timeout большее значение, например 300 секунд.
По умолчанию это 60 секунд.
location ~ .php$ {
try_files $uri /index.php$is_args$args;
include snippets/fastcgi-php.conf;
fastcgi_split_path_info ^(.+.php)(/.+)$;
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
fastcgi_read_timeout 300;
}
Затем перезагрузите Nginx.
sudo systemctl reload nginx
PHP-FPM также имеет максимальное время выполнения для каждого скрипта.
Отредактируйте файл php.ini.
sudo nano /etc/php/7.4/fpm/php.ini
Вы можете увеличить это значение до 300 секунд.
max_execution_time = 300
Затем перезапустите PHP-FPM
sudo systemctl restart php7.4-fpm
Размер памяти исчерпан
Если вы видите следующую строку в журнале ошибок Nginx, это означает, что PHP достиг лимита памяти в 128 МБ.
PHP Fatal error: Allowed memory size of 134217728 bytes exhausted (tried to allocate 57134520 bytes)
Вы можете отредактировать файл php.ini (/etc/php/7.4/fpm/php.ini) и увеличить лимит памяти PHP.
memory_limit = 512M
Затем перезапустите PHP7.4-FPM.
sudo systemctl restart php7.4-fpm
Если ошибка все еще существует, скорее всего, в вашем веб-приложении плохой PHP-код, который потребляет много оперативной памяти.
PR_END_OF_FILE_ERROR
- Вы настроили Nginx на перенаправление HTTP-запросов на HTTPS, но в Nginx нет блока сервера, обслуживающего HTTPS-запросы.
- Может быть, Nginx не запущен?
- Иногда основной бинарник Nginx запущен, но рабочий процесс может не работать и завершиться по разным причинам. Для отладки проверьте логи ошибок Nginx (/var/log/nginx/error.log).
Resource temporarily unavailable
Некоторые пользователи могут найти следующую ошибку в файле логов ошибок Nginx (в разделе /var/log/nginx/).
connect() to unix:/run/php/php7.4-fpm.sock failed (11: Resource temporarily unavailable)
Обычно это означает, что на вашем сайте много посетителей и PHP-FPM не справляется с обработкой огромного количества запросов.
Вы можете изменить количество дочерних процессов PHP-FPM, чтобы он мог обрабатывать больше запросов.
Отредактируйте файл PHP-FPM www.conf.
(Путь к файлу зависит от дистрибутива Linux).
sudo /etc/php/7.4/fpm/pool.d/www.conf
По умолчанию конфигурация дочернего процесса выглядит следующим образом:
pm = dynamic pm.max_children = 5 pm.start_servers = 2 pm.min_spare_servers = 1 pm.max_spare_servers = 3
Приведенная выше конфигурация означает.
- PHP-FPM динамически создает дочерние процессы. Нет фиксированного количества дочерних процессов.
- Создается не более 5 дочерних процессов.
- При запуске PHP-FPM запускаются 2 дочерних процесса.
- Есть как минимум 1 незанятый процесс.
- Максимум 3 неработающих процесса.
pm = dynamic pm.max_children = 20 pm.start_servers = 8 pm.min_spare_servers = 4 pm.max_spare_servers = 12
Убедитесь, что у вас достаточно оперативной памяти для запуска дополнительных дочерних процессов.
Сохраните и закройте файл.
Затем перезапустите PHP-FPM. (Возможно, вам потребуется изменить номер версии).
sudo systemctl restart php7.4-fpm
Чтобы следить за состоянием PHP-FPM, вы можете включить страницу status .
Найдите следующую строку в файле PHP-FPM www.conf.
Обратите внимание, что
;pm.status_path = /status
Уберите точку с запятой, чтобы включить страницу состояния PHP-FPM.
Затем перезапустите PHP-FPM.
sudo systemctl restart php7.4-fpm
Затем отредактируйте файл виртуального хоста Nginx.
Добавьте следующие строки.
Директивы allow и deny используются для ограничения доступа.
Только IP-адреса из “белого списка” могут получить доступ к странице состояния.
location ~ ^/(status|ping)$ {
allow 127.0.0.1;
allow your_other_IP_Address;
deny all;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_index index.php;
include fastcgi_params;
#fastcgi_pass 127.0.0.1:9000;
fastcgi_pass unix:/run/php/php7.4-fpm.sock;
}
Сохраните и закройте файл. Затем протестируйте конфигурацию Nginx.
sudo nginx -t
Если проверка прошла успешно, перезагрузите Nginx, чтобы изменения вступили в силу.
sudo systemctl reload nginx
В файле PHP-FPM www.conf дается хорошее объяснение того, что означает каждый параметр.
Если PHP-FPM очень занят и не может обслужить запрос немедленно, он поставит его в очередь.
По умолчанию может быть не более 511 ожидающих запросов, определяемых параметром listen.backlog.
listen.backlog = 511
Если вы видите следующее значение на странице состояния PHP-FPM, это означает, что в очереди еще не было ни одного запроса, т.е. ваш PHP-FPM может быстро обрабатывать запросы.
listen queue: 0 max listen queue: 0
Если в очереди 511 ожидающих запросов, это означает, что ваш PHP-FPM очень загружен, поэтому вам следует увеличить количество дочерних процессов.
Вам также может понадобиться изменить параметр ядра Linux net.core.somaxconn, который определяет максимальное количество соединений, разрешенных к файлу сокетов в Linux, например, к файлу сокетов PHP-FPM Unix.
По умолчанию его значение равно 128 до ядра 5.4 и 4096 начиная с ядра 5.4.
$ sysctl net.core.somaxconn net.core.somaxconn = 128
Если у вас сайт с высокой посещаемостью, вы можете использовать большое значение.
Отредактируйте файл /etc/sysctl.conf.
sudo nano /etc/sysctl.cnf
Добавьте следующие две строки.
net.core.somaxconn = 20000 net.core.netdev_max_backlog = 65535
Сохраните и закройте файл. Затем примените настройки.
sudo sysctl -p
Примечание: Если ваш сервер имеет достаточно оперативной памяти, вы можете выделить фиксированное количество дочерних процессов для PHP-FPM, как показано ниже.
Два файла виртуального хоста для одного и того же сайта
Если вы запустите sudo nginx -t и увидите следующее предупреждение.
nginx: [warn] conflicting server name "example.com" on [::]:443, ignored nginx: [warn] conflicting server name "example.com" on 0.0.0.0:443, ignored
Это означает, что есть два файла виртуальных хостов, содержащих одну и ту же конфигурацию server_name.
Не создавайте два файла виртуальных хостов для одного сайта.
PHP-FPM Connection reset by peer
В файле логов ошибок Nginx отображается следующее сообщение.
recv() failed (104: Connection reset by peer) while reading response header from upstream
Это может быть вызвано перезапуском PHP-FPM.
Если он перезапущен вручную самостоятельно, то вы можете игнорировать эту ошибку.
Утечки сокетов Nginx
Если вы обнаружили следующее сообщение об ошибке в файле /var/log/nginx/error.log, значит, у вашего Nginx проблема с утечкой сокетов.
2021/09/28 13:27:41 [alert] 321#321: *120606 open socket #16 left in connection 163 2021/09/28 13:27:41 [alert] 321#321: *120629 open socket #34 left in connection 188 2021/09/28 13:27:41 [alert] 321#321: *120622 open socket #9 left in connection 213 2021/09/28 13:27:41 [alert] 321#321: *120628 open socket #25 left in connection 217 2021/09/28 13:27:41 [alert] 321#321: *120605 open socket #15 left in connection 244 2021/09/28 13:27:41 [alert] 321#321: *120614 open socket #41 left in connection 245 2021/09/28 13:27:41 [alert] 321#321: *120631 open socket #24 left in connection 255 2021/09/28 13:27:41 [alert] 321#321: *120616 open socket #23 left in connection 258 2021/09/28 13:27:41 [alert] 321#321: *120615 open socket #42 left in connection 269 2021/09/28 13:27:41 [alert] 321#321: aborting
Вы можете перезапустить ОС, чтобы решить эту проблему.
Если это не помогает, вам нужно скомпилировать отладочную версию Nginx, которая покажет вам отладочную информацию в логах.
Заключение
Надеюсь, эта статья помогла вам исправить распространенные ошибки веб-сервера Nginx.
см. также:
- 🌐 Как контролировать доступ на основе IP-адреса клиента в NGINX
- 🐉 Настройка http-сервера Kali Linux
- 🌐 Как парсить логи доступа nginx
- 🌐 Ограничение скорости определенных URL-адресов с Nginx
- 🛡️ Как использовать обратный прокси Nginx для ограничения внешних вызовов внутри веб-браузера
- 🔏 Как настроить Nginx с Let’s Encrypt с помощью ACME на Ubuntu
- 🌐 Как собрать NGINX с ModSecurity на Ubuntu сервере