17 авг. 2022 г.
читать 1 мин
Вы можете использовать функцию Duplicated () для поиска повторяющихся значений в кадре данных pandas.
Эта функция использует следующий базовый синтаксис:
#find duplicate rows across all columns
duplicateRows = df[df.duplicated ()]
#find duplicate rows across specific columns
duplicateRows = df[df.duplicated(['col1', 'col2'])]
В следующих примерах показано, как использовать эту функцию на практике со следующими пандами DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'points': [10, 10, 12, 12, 15, 17, 20, 20],
'assists': [5, 5, 7, 9, 12, 9, 6, 6]})
#view DataFrame
print(df)
team points assists
0 A 10 5
1 A 10 5
2 A 12 7
3 A 12 9
4 B 15 12
5 B 17 9
6 B 20 6
7 B 20 6
Пример 1. Поиск повторяющихся строк во всех столбцах
В следующем коде показано, как найти повторяющиеся строки во всех столбцах DataFrame:
#identify duplicate rows
duplicateRows = df[df.duplicated ()]
#view duplicate rows
duplicateRows
team points assists
1 A 10 5
7 B 20 6
Есть две строки, которые являются точными копиями других строк в DataFrame.
Обратите внимание, что мы также можем использовать аргумент keep=’last’ для отображения первых повторяющихся строк вместо последних:
#identify duplicate rows
duplicateRows = df[df.duplicated (keep='last')]
#view duplicate rows
print(duplicateRows)
team points assists
0 A 10 5
6 B 20 6
Пример 2. Поиск повторяющихся строк в определенных столбцах
В следующем коде показано, как найти повторяющиеся строки только в столбцах «команда» и «точки» в DataFrame:
#identify duplicate rows across 'team' and 'points' columns
duplicateRows = df[df.duplicated(['team', 'points'])]
#view duplicate rows
print(duplicateRows)
team points assists
1 A 10 5
3 A 12 9
7 B 20 6
Есть три строки, в которых значения столбцов «команда» и «очки» являются точными копиями предыдущих строк.
Пример 3. Поиск повторяющихся строк в одном столбце
В следующем коде показано, как найти повторяющиеся строки только в столбце «команда» DataFrame:
#identify duplicate rows in 'team' column
duplicateRows = df[df.duplicated(['team'])]
#view duplicate rows
print(duplicateRows)
team points assists
1 A 10 5
2 A 12 7
3 A 12 9
5 B 17 9
6 B 20 6
7 B 20 6
Всего имеется шесть строк, в которых значения в столбце «команда» являются точными копиями предыдущих строк.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как удалить повторяющиеся строки в Pandas
Как удалить повторяющиеся столбцы в Pandas
Как выбрать столбцы по индексу в Pandas
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, we will be discussing how to find duplicate rows in a Dataframe based on all or a list of columns. For this, we will use Dataframe.duplicated() method of Pandas.
Syntax : DataFrame.duplicated(subset = None, keep = ‘first’)
Parameters:
subset: This Takes a column or list of column label. It’s default value is None. After passing columns, it will consider them only for duplicates.
keep: This Controls how to consider duplicate value. It has only three distinct value and default is ‘first’.
- If ‘first’, This considers first value as unique and rest of the same values as duplicate.
- If ‘last’, This considers last value as unique and rest of the same values as duplicate.
- If ‘False’, This considers all of the same values as duplicates.
Returns: Boolean Series denoting duplicate rows.
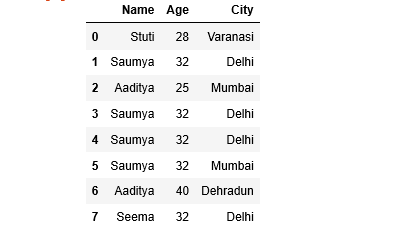
Let’s create a simple dataframe with a dictionary of lists, say column names are: ‘Name’, ‘Age’ and ‘City’.
Python3
import pandas as pd
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
df
Output :
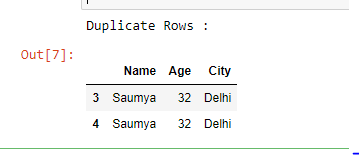
Example 1: Select duplicate rows based on all columns.
Here, We do not pass any argument, therefore, it takes default values for both the arguments i.e. subset = None and keep = ‘first’.
Python3
import pandas as pd
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
duplicate = df[df.duplicated()]
print("Duplicate Rows :")
duplicate
Output :
Example 2: Select duplicate rows based on all columns.
If you want to consider all duplicates except the last one then pass keep = ‘last’ as an argument.
Python3
import pandas as pd
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
duplicate = df[df.duplicated(keep = 'last')]
print("Duplicate Rows :")
duplicate
Output :

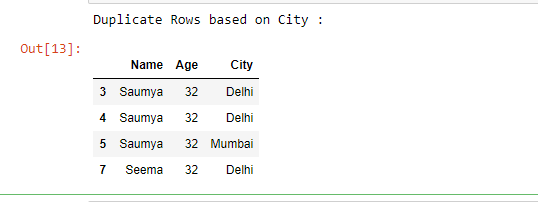
Example 3: If you want to select duplicate rows based only on some selected columns then pass the list of column names in subset as an argument.
Python3
import pandas as pd
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
duplicate = df[df.duplicated('City')]
print("Duplicate Rows based on City :")
duplicate
Output :
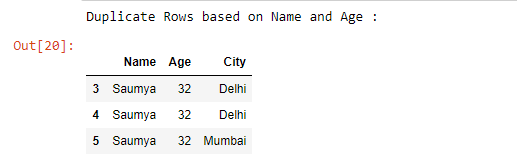
Example 4: Select duplicate rows based on more than one column name.
Python3
import pandas as pd
employees = [('Stuti', 28, 'Varanasi'),
('Saumya', 32, 'Delhi'),
('Aaditya', 25, 'Mumbai'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Delhi'),
('Saumya', 32, 'Mumbai'),
('Aaditya', 40, 'Dehradun'),
('Seema', 32, 'Delhi')
]
df = pd.DataFrame(employees,
columns = ['Name', 'Age', 'City'])
duplicate = df[df.duplicated(['Name', 'Age'])]
print("Duplicate Rows based on Name and Age :")
duplicate
Output :
Last Updated :
16 Feb, 2022
Like Article
Save Article
Approach #1
Here’s one vectorized approach inspired by this post—
def group_duplicate_index(df):
a = df.values
sidx = np.lexsort(a.T)
b = a[sidx]
m = np.concatenate(([False], (b[1:] == b[:-1]).all(1), [False] ))
idx = np.flatnonzero(m[1:] != m[:-1])
I = df.index[sidx].tolist()
return [I[i:j] for i,j in zip(idx[::2],idx[1::2]+1)]
Sample run —
In [42]: df
Out[42]:
param_a param_b param_c
1 0 0 0
2 0 2 1
3 2 1 1
4 0 2 1
5 2 1 1
6 0 0 0
In [43]: group_duplicate_index(df)
Out[43]: [[1, 6], [3, 5], [2, 4]]
Approach #2
For integer numbered dataframes, we could reduce each row to a scalar each and that lets us work with a 1D array, giving us a more performant one, like so —
def group_duplicate_index_v2(df):
a = df.values
s = (a.max()+1)**np.arange(df.shape[1])
sidx = a.dot(s).argsort()
b = a[sidx]
m = np.concatenate(([False], (b[1:] == b[:-1]).all(1), [False] ))
idx = np.flatnonzero(m[1:] != m[:-1])
I = df.index[sidx].tolist()
return [I[i:j] for i,j in zip(idx[::2],idx[1::2]+1)]
Runtime test
Other approach(es) —
def groupby_app(df): # @jezrael's soln
df = df[df.duplicated(keep=False)]
df = df.groupby(df.columns.tolist()).apply(lambda x: tuple(x.index)).tolist()
return df
Timings —
In [274]: df = pd.DataFrame(np.random.randint(0,10,(100000,3)))
In [275]: %timeit group_duplicate_index(df)
10 loops, best of 3: 36.1 ms per loop
In [276]: %timeit group_duplicate_index_v2(df)
100 loops, best of 3: 15 ms per loop
In [277]: %timeit groupby_app(df) # @jezrael's soln
10 loops, best of 3: 25.9 ms per loop
In this Python Pandas tutorial, we will learn how to Find Duplicates in Python DataFrame using Pandas. Also, we will cover these topics.
- How to identify duplicates in Python DataFrame
- How to find duplicate values in Python DataFrame
- How to find duplicates in a column in Python DataFrame
- How to Count duplicate rows in Pandas DataFrame
- In this Program, we will discuss how to find duplicates in Pandas DataFrame.
- To do this task we can use In Python built-in function such as DataFrame.duplicate() to find duplicate values in Pandas DataFrame.
- In Python DataFrame.duplicated() method will help the user to analyze duplicate values and it will always return a boolean value that is True only for specific elements.
Syntax:
Here is the Syntax of DataFrame.duplicated() method
DataFrame.duplicated
(
subset=None,
keep='first'
)- It consists of few parameters
- Subset: This parameter takes a column of labels and should be used for duplicates checks and by default its value is None.
- keep: This parameter specifies the occurrence of the value which has to be marked as duplicate. It has three distinct values‘ first’, ‘last’, ‘False’, and by default, it takes the ‘First’ value as an argument.
Example:
Let’s understand a few examples based on these function
Source Code:
import pandas as pd
new_list = [('Australia', 9, 'Germany'),
('China', 14, 'France'), ('Paris', 77, 'switzerland'),
('Australia',9, 'Germany'), ('China', 88, 'Russia'),
('Germany', 77, 'Bangladesh')]
result= pd.DataFrame(new_list, columns=['Country_name', 'Value', 'new_count'])
new_output = result[result.duplicated()]
print("Duplicated values",new_output)In the above code, we have selected duplicate values based on all columns. Now we have created a DataFrame object in which we have assigned a list ‘new_list’ and columns as an argument. After that to find duplicate values in Pandas DataFrame we use the df. duplicated() function.

Another example to find duplicates in Python DataFrame
In this example, we want to select duplicate rows values based on the selected columns. To perform this task we can use the DataFrame.duplicated() method. Now in this Program first, we will create a list and assign values in it and then create a dataframe in which we have to pass the list of column names in subset as a parameter.
Source Code:
import pandas as pd
student_info = [('George', 78, 'Australia'),
('Micheal', 189, 'Germany'),
('Oliva', 140, 'Malaysia'),
('James', 95, 'Uganda'),
('James', 95, 'Uganda'),
('Oliva', 140, 'Malaysia'),
('Elijah', 391, 'Japan'),
('Chris', 167, 'China')
]
df = pd.DataFrame(student_info,
columns = ['Student_name', 'Student_id', 'Student_city'])
new_duplicate = df[df.duplicated('Student_city')]
print("Duplicate values in City :")
print(new_duplicate)In the above code Once you will print ‘new_duplicate’ then the output will display the duplicate row values which are present in the given list.
Here is the output of the following given code

Also, Read: Python Pandas CSV Tutorial
How to identify duplicates in Python DataFrame
- Here we can see how to identify Duplicates value in Pandas DataFrame by using Python.
- In Pandas library, DataFrame class provides a function to identify duplicate row values based on columns that is DataFrame.duplicated() method and it always return a boolean series denoting duplicate rows with true value.
Example:
Let’s take an example and check how to identify duplicate row values in Python DataFrame
import pandas as pd
df = pd.DataFrame({'Employee_name': ['George','John', 'Micheal', 'Potter','James','Oliva'],'Languages': ['Ruby','Sql','Mongodb','Ruby','Sql','Python']})
print("Existing DataFrame")
print(df)
print("Identify duplicate values:")
print(df.duplicated())In the above example, we have set duplicated values in the Pandas DataFrame and then apply the method df. duplicated() it will check the condition if duplicate values are present in the dataframe then it will display ‘true’. if duplicate values do not exist in DataFrame then it will show the ‘False’ boolean value.
You can refer to the below Screenshot

Read: How to get unique values in Pandas DataFrame
Another example to identify duplicates row value in Pandas DataFrame
In this example, we will select duplicate rows based on all columns. To do this task we will pass keep= ‘last’ as an argument and this parameter specifies all duplicates except their last occurrence and it will be marked as ‘True’.
Source Code:
import pandas as pd
employee_name = [('Chris', 178, 'Australia'),
('Hemsworth', 987, 'Newzealand'),
('George', 145, 'Switzerland'),
('Micheal',668, 'Malaysia'),
('Elijah', 402, 'England'),
('Elijah',402, 'England'),
('William',389, 'Russia'),
('Hayden', 995, 'France')
]
df = pd.DataFrame(employee_name,
columns = ['emp_name', 'emp_id', 'emp_city'])
new_val = df[df.duplicated(keep = 'last')]
print("Duplicate Rows :")
print(new_val)In the above code first, we have imported the Pandas library and then create a list of tuples in which we have assigned the row’s value along with that create a dataframe object and pass keep=’last’ as an argument. Once you will print the ‘new_val’ then the output will display the duplicate rows which are present in the Pandas DataFrame.
Here is the execution of the following given code

Read: Crosstab in Python Pandas
How to find duplicate values in Python DataFrame
- Let us see how to find duplicate values in Python DataFrame.
- Now we want to check if this dataframe contains any duplicates elements or not. To do this task we can use the combination of df.loc() and df.duplicated() method.
- In Python the loc() method is used to retrieve a group of rows columns and it takes only index labels and DataFrame.duplicated() method will help the user to analyze duplicate values in Pandas DataFrame.
Source Code:
import pandas as pd
df=pd.DataFrame(data=[[6,9],[18,77],[6,9],[26,51],[119,783]],columns=['val1','val2'])
new_val = df.duplicated(subset=['val1','val2'], keep='first')
new_output = df.loc[new_val == True]
print(new_output)
In the above code first, we have created a dataframe object in which we have assigned column values. Now we want to replace duplicate values from the given Dataframe by using the df. duplicated() method.
Here is the implementation of the following given code

Read: Groupby in Python Pandas
How to find duplicates in a column in Python DataFrame
- In this program, we will discuss how to find duplicates in a specific column by using Pandas DataFrame.
- By using the DataFrame.duplicate() method we can find duplicates value in Python DataFrame.
Example:
Let’s take an example and check how to find duplicates values in a column
Source Code:
import pandas as pd
Country_name = [('Uganda', 318),
('Newzealand', 113),
('France',189),
('Australia', 788),
('Australia', 788),
('Russia', 467),
('France', 189),
('Paris', 654)
]
df = pd.DataFrame(Country_name,
columns = ['Count_name', 'Count_id'])
new_val = df[df.duplicated('Count_id')]
print("Duplicate Values")
print(new_val)Here is the output of the following given code

Read: Python Pandas Drop Rows
How to Count duplicate rows in Pandas DataFrame
- Let us see how to Count duplicate rows in Pandas DataFrame.
- By using df.pivot_table we can perform this task. In Python the pivot() function is used to reshaped a Pandas DataFrame by given column values and this method can handle duplicate values for one pivoted pair.
- In Python, the pivot_table() is used to count the duplicates in a Single Column.
Source Code:
import pandas as pd
df = pd.DataFrame({'Student_name' : ['James', 'Potter', 'James',
'William', 'Oliva'],
'Student_desgination' : ['Python developer', 'Tester', 'Tester', 'Q.a assurance', 'Coder'],
'City' : ['Germany', 'Australia', 'Germany',
'Russia', 'France']})
new_val = df.pivot_table(index = ['Student_desgination'], aggfunc ='size')
print(new_val)In the above code first, we will import a Pandas module then create a DataFrame object in which we have assigned key-value pair elements and consider them as column values.
You can refer to the below Screenshot for counting duplicate rows in DataFrame

You may also like to read the following tutorials on Pandas.
- How to Convert Pandas DataFrame to a Dictionary
- Convert Integers to Datetime in Pandas
- Check If DataFrame is Empty in Python Pandas
- Python Pandas Write DataFrame to Excel
- How to Add a Column to a DataFrame in Python Pandas
- Convert Pandas DataFrame to NumPy Array
- How to Set Column as Index in Python Pandas
- Add row to Dataframe Python Pandas
In this Python Pandas tutorial, we have learned how to Find Duplicates in Python DataFrame using Pandas. Also, we have covered these topics.
- How to identify duplicates in Python DataFrame
- How to find duplicate values in Python DataFrame
- How to find duplicates in a column in Python DataFrame
- How to Count duplicate rows in Pandas DataFrame

Python is one of the most popular languages in the United States of America. I have been working with Python for a long time and I have expertise in working with various libraries on Tkinter, Pandas, NumPy, Turtle, Django, Matplotlib, Tensorflow, Scipy, Scikit-Learn, etc… I have experience in working with various clients in countries like United States, Canada, United Kingdom, Australia, New Zealand, etc. Check out my profile.
Pandas DataFrame.duplicated() function is used to get/find/select a list of all duplicate rows(all or selected columns) from pandas. Duplicate rows means, having multiple rows on all columns. Using this method you can get duplicate rows on selected multiple columns or all columns. In this article, I will explain these with several examples.
1. Quick Examples of Get List of All Duplicate Items
If you are in a hurry, below are some quick examples of how to get a list of all duplicate rows in pandas DataFrame.
# Below are quick example
# Select duplicate rows except first occurrence based on all columns
df2 = df[df.duplicated()]
# Select duplicate row based on all columns
df2 = df[df.duplicated(keep=False)]
# Get duplicate last rows based on all columns
df2 = df[df.duplicated(keep = 'last')]
# Get list Of duplicate rows using single columns
df2 = df[df['Courses'].duplicated() == True]
# Get list of duplicate rows based on 'Courses' column
df2 = df[df.duplicated('Courses')]
# Get list Of duplicate rows using multiple columns
df2 = df[df[['Courses', 'Fee','Duration']].duplicated() == True]
# Get list of duplicate rows based on list of column names
df2 = df[df.duplicated(['Courses','Fee','Duration'])]
Now, let’s create a DataFrame with a few duplicate rows on all columns. Our DataFrame contains column names Courses, Fee, Duration, and Discount.
import pandas as pd
technologies = {
'Courses':["Spark","PySpark","Python","pandas","Python","Spark","pandas"],
'Fee' :[20000,25000,22000,30000,22000,20000,30000],
'Duration':['30days','40days','35days','50days','40days','30days','50days'],
'Discount':[1000,2300,1200,2000,2300,1000,2000]
}
df = pd.DataFrame(technologies)
print(df)
Yields below output.
Courses Fee Duration Discount
0 Spark 20000 30days 1000
1 PySpark 25000 40days 2300
2 Python 22000 35days 1200
3 pandas 30000 50days 2000
4 Python 22000 40days 2300
5 Spark 20000 30days 1000
6 pandas 30000 50days 2000
2. Select Duplicate Rows Based on All Columns
You can use df[df.duplicated()] without any arguments to get rows with the same values on all columns. It takes defaults values subset=None and keep=‘first’. The below example returns two rows as these are duplicate rows in our DataFrame.
# Select duplicate rows of all columns
df2 = df[df.duplicated()]
print(df2)
Yields below output.
Courses Fee Duration Discount
5 Spark 20000 30days 1000
6 pandas 30000 50days 2000
You can set 'keep=False' in the duplicated function to get all the duplicate items without eliminating duplicate rows.
# Select duplicate row based on all columns
df2 = df[df.duplicated(keep=False)]
print(df2)
Yields below output.
Courses Fee Duration Discount
0 Spark 20000 30days 1000
3 pandas 30000 50days 2000
5 Spark 20000 30days 1000
6 pandas 30000 50days 2000
3. Get List of Duplicate Last Rows Based on All Columns
You want to select all the duplicate rows except their last occurrence, we must pass a keep argument as ”last". For instance, df[df.duplicated(keep='last')].
# Get duplicate last rows based on all columns
df2 = df[df.duplicated(keep = 'last')]
print(df2)
Yields below output.
Courses Fee Duration Discount
0 Spark 20000 30days 1000
3 pandas 30000 50days 2000
4. Get List Of Duplicate Rows Using Single Columns
You want to select duplicate rows based on single columns then pass the column name as an argument.
# Get list Of duplicate rows using single columns
df2 = df[df['Courses'].duplicated() == True]
print(df2)
# Get list of duplicate rows based on 'Courses' column
df2 = df[df.duplicated('Courses')]
print(df2)
Yields below output.
Courses Fee Duration Discount
4 Python 22000 40days 2300
5 Spark 20000 30days 1000
6 pandas 30000 50days 2000
5. Get List Of Duplicate Rows Using Multiple Columns
To get/find duplicate rows on the basis of multiple columns, specify all column names as a list.
# Get list Of duplicate rows using multiple columns
df2 = df[df[['Courses', 'Fee','Duration']].duplicated() == True]
print(df2)
# Get list of duplicate rows based on list of column names
df2 = df[df.duplicated(['Courses','Fee','Duration'])]
print(df2)
Yields below output.
Courses Fee Duration Discount
5 Spark 20000 30days 1000
6 pandas 30000 50days 2000
6. Get List Of Duplicate Rows Using Sort Values
Let’s see how to sort the results of duplicated() method. You can sort pandas DataFrame by one or multiple (one or more) columns using sort_values() method.
# Get list Of duplicate rows using sort values
df2 = df[df.duplicated(['Discount'])==True].sort_values('Discount')
print(df2)
Yields below output.
Courses Fee Duration Discount
5 Spark 20000 30days 1000
6 pandas 30000 50days 2000
4 Python 22000 40days 2300
You can use sort_values("Discount") instead to sort after duplicate filter.
# Using sort values
df2 = df[df.Discount.duplicated(keep=False)].sort_values("Discount")
print(df2)
Yields below output.
Courses Fee Duration Discount
0 Spark 20000 30days 1000
5 Spark 20000 30days 1000
3 pandas 30000 50days 2000
6 pandas 30000 50days 2000
1 PySpark 25000 40days 2300
4 Python 22000 40days 2300
7. Complete Example For Get List of All Duplicate Items
import pandas as pd
technologies = {
'Courses':["Spark","PySpark","Python","pandas","Python","Spark","pandas"],
'Fee' :[20000,25000,22000,30000,22000,20000,30000],
'Duration':['30days','40days','35days','50days','40days','30days','50days'],
'Discount':[1000,2300,1200,2000,2300,1000,2000]
}
df = pd.DataFrame(technologies)
print(df)
# Select duplicate rows except first occurrence based on all columns
df2 = df[df.duplicated()]
# Select duplicate row based on all columns
df2 = df[df.duplicated(keep=False)]
print(df2)
# Get duplicate last rows based on all columns
df2 = df[df.duplicated(keep = 'last')]
print(df2)
# Get list Of duplicate rows using single columns
df2 = df[df['Courses'].duplicated() == True]
print(df2)
# Get list of duplicate rows based on 'Courses' column
df2 = df[df.duplicated('Courses')]
print(df2)
# Get list Of duplicate rows using multiple columns
df2 = df[df[['Courses', 'Fee','Duration']].duplicated() == True]
print(df2)
# Get list of duplicate rows based on list of column names
df2 = df[df.duplicated(['Courses','Fee','Duration'])]
print(df2)
# Get list Of duplicate rows using sort values
df2 = df[df.duplicated(['Discount'])==True].sort_values('Discount')
print(df2)
# Using sort values
df2 = df[df.Discount.duplicated(keep=False)].sort_values("Discount")
print(df2)
Conclusion
In this article, you have learned how to get/select a list of all duplicate rows (all or multiple columns) using pandas DataFrame duplicated() method with examples.
Happy Learning !!
Related Articles
- Select Rows From List of Values in Pandas DataFrame
- Set Order of Columns in Pandas DataFrame
- Pandas Add Constant Column to DataFrame
- Rename Index Values of Pandas DataFrame
- Pandas Rename Index of DataFrame
- pandas.DataFrame.drop_duplicates() – Examples
- Pandas.Index.drop_duplicates() Explained
- How to Drop Duplicate Columns in pandas DataFrame
References
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.duplicated.html