Очень часто большие объемы данных, которые подготавливаются для последующего анализа, имеют пропуски. Для того, чтобы можно было использовать алгоритмы машинного обучения, строящие модели по этим данным, в большинстве случаев, необходимо эти пропуски чем-то и как-то заполнить. На вопрос “чем заполнять?” мы не будем отвечать в рамках данного урока, а вот на вопрос “как заполнять?” ответим.
- pandas и отсутствующие данные
- Замена отсутствующих данных
- Удаление объектов/столбцов с отсутствующими данными
Для начала, хочется сказать, что в документации по библиотеке pandas есть целый раздел, посвященный данной тематике.
Для наших экспериментов создадим структуру DataFrame, которая будет содержать пропуски. Для этого импортируем необходимые нам библиотеки.
In [1]: import pandas as pd In [2]: from io import StringIO
После этого создадим объект в формате csv. CSV – это один из наиболее простых и распространенных форматов хранения данных, в котором элементы отделяются друг от друга запятыми, более подробно о нем можете прочитать здесь.
In [3]: data = 'price,count,percentn1,10,n2,20,51n3,30,' In [4]: df = pd.read_csv(StringIO(data))
Полученный объект df – это DataFrame с пропусками.
In [5]: df Out[5]: price count percent 0 1 10 NaN 1 2 20 51.0 2 3 30 NaN
В нашем примере, у объектов с индексами 0 и 2 отсутствуют данные в поле percent. Отсутствующие данные помечаются как NaN. Добавим к существующей структуре еще один объект (запись), у которого будет отсутствовать значение в поле count.
In [6]: df.loc[3] = {'price':4, 'count':None, 'percent':26.3} In [7]: df Out[7]: price count percent 0 1.0 10.0 NaN 1 2.0 20.0 51.0 2 3.0 30.0 NaN 3 4.0 NaN 26.3
Для начала обратимся к методам из библиотеки pandas, которые позволяют быстро определить наличие элементов NaN в структурах. Если таблица небольшая, то можно использовать библиотечный метод isnull. Выглядит это так.
In [8]: pd.isnull(df) Out[8]: price count percent 0 False False True 1 False False False 2 False False True 3 False True False
Таким образом мы получаем таблицу того же размера, но на месте реальных данных в ней находятся логические переменные, которые принимают значение False, если значение поля у объекта есть, или True, если значение в данном поле – это NaN. В дополнение к этому можно посмотреть подробную информацию об объекте, для этого можно воспользоваться методом info().
In [9]: df.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 4 entries, 0 to 3 Data columns (total 3 columns): price 4 non-null float64 count 3 non-null float64 percent 2 non-null float64 dtypes: float64(3) memory usage: 128.0 bytes
В нашем примере видно, что объект df имеет три столбца (count, percent и price), при этом в столбце price все объекты значимы – не NaN, в столбце count – один NaN объект, в поле percent – два NaN объекта. Можно воспользоваться следующим подходом для получения количества NaN элементов в записях.
In [10]: df.isnull().sum() Out[10]: price 0 count 1 percent 2 dtype: int64
Замена отсутствующих данных
Отсутствующие данные объектов можно заменить на конкретные числовые значения, для этого можно использовать метод fillna(). Для экспериментов будем использовать структуру df, созданную в предыдущем разделе.
In [11]: df.isnull().sum() Out[11]: price 0 count 1 percent 2 dtype: int64 In [12]: df Out[12]: price count percent 0 1.0 10.0 NaN 1 2.0 20.0 51.0 2 3.0 30.0 NaN 3 4.0 NaN 26.3 In [13]: df.fillna(0) Out[13]: price count percent 0 1.0 10.0 0.0 1 2.0 20.0 51.0 2 3.0 30.0 0.0 3 4.0 0.0 26.3
Этот метод не изменяет текущую структуру, он возвращает структуру DataFrame, созданную на базе существующей, с заменой NaN значений на те, что переданы в метод в качестве аргумента. Данные можно заполнить средним значением по столбцу.
In [14]: df.fillna(df.mean()) Out[14]: price count percent 0 1.0 10.0 38.65 1 2.0 20.0 51.00 2 3.0 30.0 38.65 3 4.0 20.0 26.30
В зависимости от задачи используется тот или иной метод заполнения отсутствующих элементов, это может быть нулевое значение, математическое ожидание, медиана и т.п. Для замены NaN элементов на конкретные значения, можно использовать интерполяцию, которая реализована в методе interpolate(), алгоритм интерполяции задается через аргументы метода.
Удаление объектов/столбцов с отсутствующими данными
Довольно часто используемый подход при работе с отсутствующими данными – это удаление записей (строк) или полей (столбцов), в которых встречаются пропуски. Для того, чтобы удалить все объекты, которые содержат значения NaN воспользуйтесь методом dropna() без аргументов.
In [15]: df.dropna() Out[15]: price count percent 1 2.0 20.0 51.0
Вместо записей, можно удалить поля, для этого нужно вызвать метод dropna с аргументом axis=1.
In [16]: df.dropna() Out[16]: price count percent 1 2.0 20.0 51.0 In [17]: df.dropna(axis=1) Out[17]: price 0 1.0 1 2.0 2 3.0 3 4.0
pandas позволяет задать порог на количество не-NaN элементов. В приведенном ниже примере будут удалены все столбцы, в которых количество не-NaN элементов меньше трех.
In [18]: df.dropna(axis = 1, thresh=3) Out[18]: price count 0 1.0 10.0 1 2.0 20.0 2 3.0 30.0 3 4.0 NaN
P.S.
Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.

<<< Урок 3. Доступ к данным в структурах pandas

Есть несколько стратегий индикации пропусков в данных
Использование некоего значения-индикатора
К примеру, можно использовать число -9999 или редко встречающееся сочетание битов. Более часто встречающийся способ — условное обозначение через NaN. NaN — это специальное значение, определенное спецификацией IEEE для чисел с плавающей точкой и используется во многих ЯП.
У метода есть ограничения. Во-первых использование значений индикаторов может привести к дополнительным не оптимизированным расчетам. Во-вторых NaN доступен не для всех типов данных.
Использование масок
Можно создать отдельный булевый массив, индицирующий пропущенные значения. В ряде языков выделяется отдельный бит для разметки пропусков в массиве данных локально. Оба подхода влекут за собой перерасход памяти.
Как это реализовано в Pandas?
Pandas построена на NumPy, в котором отсутствует понятие пропуска для всех данных кроме данных с плавающей точкой. NumPy поддерживает маски, но использование такого подходжа в Pandas влечет значительные накладные расходы на хранение, вычисление и поддержку кода.
В итоге в Pandas используется:
-
индикаторы-числа
-
NaN из Numpy
-
None из Python
Объект None
None — объект python. Его нельзя использовать в NumPy и во всех производных массивах Pandas. None используется только в массивах с типом object. Когда мы создаем массив, используя None, автоматически создается массив с типом object.
Тип object означает, что NumPy не смог установить тип объектов массива, единственное что он знает — это то, что это объекты python. Операции с такими массивами будут производится на уровне языка python, т.е. со всеми накладными расходами, присущими языку с динамической типизацией. Оптимизация NumPy работать не будет.
Кроме того, функции агрегирования по массиву, например, massive.sum() или massive.min() выбросят ошибку, так как операции между численным значением и значением None не определены
Объект NaN
Объект NaN определяет отсутствие числового значения с плавающей точкой. Это вызывает некоторые проблемы — если NaN попадает в массив, все данные приводятся к числам с плавающей точкой. Кроме того, все операции с NaN приводят к NaN, в том числе и функции агрегирования.
Не забудьте, что для вызова объекта NaN нужен NumPy
Nan и None
Pandas преобразует None в NaN, если оба будут встречены в одном массиве. Естественно, осуществляется и повышающее преобразование с приведением всех непустых числовых значений к числу с плавающей точкой, а всех остальных к NaN.
pd.Series([1, np.nan, 3, None])
>>> 0 1.0
... 1 NaN
... 2 3.0
... 3 NaN
... dtype: float64
x = pd.Series([1, 2, 3], dtype='int8')
x
>>> 0 1
... 1 2
... 2 3
... dtype: int8
x[0] = None
x
>>> 0 NaN
... 1 2.0
... 2 3.0
... dtype: float64
Правила повышающих преобразований типов в Pandas (строки всегда хранятся как object)
| Typeclass | Conversion When Storing NAN | NAN Sentinel Value |
|---|---|---|
floating |
No change | np.nan |
object |
No change | None or np.nan |
integer |
Cast to float64 |
np.nan |
boolean |
Cast to object |
None or np.nan |
Операции над пустыми значениями
В Pandas доступно несколько методов:
-
isnull() — генерирует булеву маску для отсутствующих значений
-
notnull() — тоже для непустых
-
dropna() — фильтрация данных по отсутствующим значениям
-
fillna() — замена пропусков с возвратом копии
Методы доступны как для объектов Series так и для dataFrame (с выбором измерения).
Кроме того, для dropna() ожно задать дополнительные параметры. how=’any’ задан по дефолту, можно переопределить как ‘all’ — будут отбрасываться только полностью пустые строки/столбцы. thresh задает минимальное значение непустых значений, выше которого строки/столбцы не отбрасываются.
Для fillna() доступно несколько аргументов. method=’ffill’ и method=’bfill’ определяют какими значениями будут заполняться пропуски (предыдущими или последующими в массиве).
Подробнее fillna() и dropna()
Missing Data can occur when no information is provided for one or more items or for a whole unit. Missing Data is a very big problem in a real-life scenarios. Missing Data can also refer to as NA(Not Available) values in pandas. In DataFrame sometimes many datasets simply arrive with missing data, either because it exists and was not collected or it never existed. For Example, Suppose different users being surveyed may choose not to share their income, some users may choose not to share the address in this way many datasets went missing.

In Pandas missing data is represented by two value:
- None: None is a Python singleton object that is often used for missing data in Python code.
- NaN : NaN (an acronym for Not a Number), is a special floating-point value recognized by all systems that use the standard IEEE floating-point representation
Pandas treat None and NaN as essentially interchangeable for indicating missing or null values. To facilitate this convention, there are several useful functions for detecting, removing, and replacing null values in Pandas DataFrame :
- isnull()
- notnull()
- dropna()
- fillna()
- replace()
- interpolate()
In this article we are using CSV file, to download the CSV file used, Click Here.
Checking for missing values using isnull() and notnull()
In order to check missing values in Pandas DataFrame, we use a function isnull() and notnull(). Both function help in checking whether a value is NaN or not. These function can also be used in Pandas Series in order to find null values in a series.
Checking for missing values using isnull()
In order to check null values in Pandas DataFrame, we use isnull() function this function return dataframe of Boolean values which are True for NaN values.
Code #1:
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.isnull()
Output: 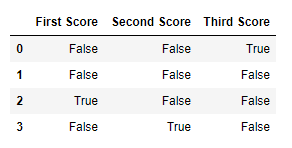
Code #2:
Python
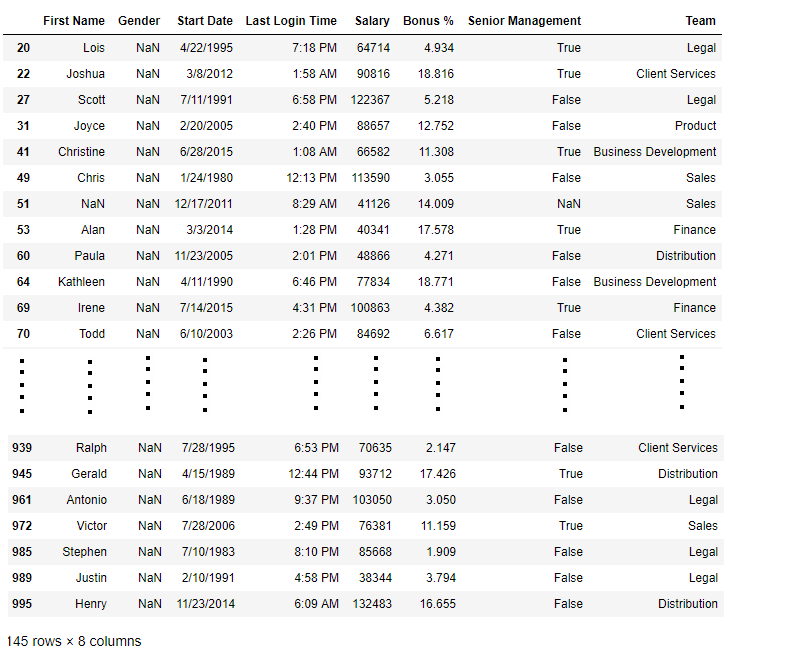
import pandas as pd
data = pd.read_csv("employees.csv")
bool_series = pd.isnull(data["Gender"])
data[bool_series]
Output: As shown in the output image, only the rows having Gender = NULL are displayed.
Checking for missing values using notnull()
In order to check null values in Pandas Dataframe, we use notnull() function this function return dataframe of Boolean values which are False for NaN values.
Code #3:
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.notnull()
Output:
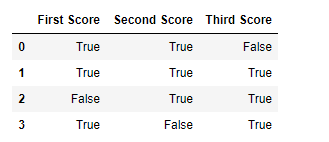
Code #4:
Python
import pandas as pd
data = pd.read_csv("employees.csv")
bool_series = pd.notnull(data["Gender"])
data[bool_series]
Output: As shown in the output image, only the rows having Gender = NOT NULL are displayed.
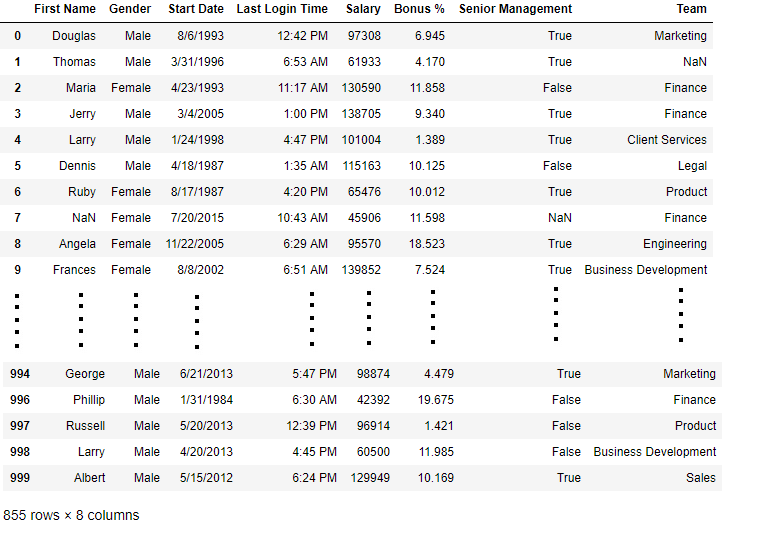
Filling missing values using fillna(), replace() and interpolate()
In order to fill null values in a datasets, we use fillna(), replace() and interpolate() function these function replace NaN values with some value of their own. All these function help in filling a null values in datasets of a DataFrame. Interpolate() function is basically used to fill NA values in the dataframe but it uses various interpolation technique to fill the missing values rather than hard-coding the value.
Code #1: Filling null values with a single value
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(0)
Output:
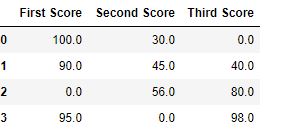
Code #2: Filling null values with the previous ones
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(method ='pad')
Output:
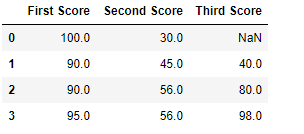
Code #3: Filling null value with the next ones
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, 45, 56, np.nan],
'Third Score':[np.nan, 40, 80, 98]}
df = pd.DataFrame(dict)
df.fillna(method ='bfill')
Output:
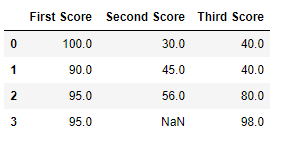
Code #4: Filling null values in CSV File
Python
import pandas as pd
data = pd.read_csv("employees.csv")
data[10:25]
Output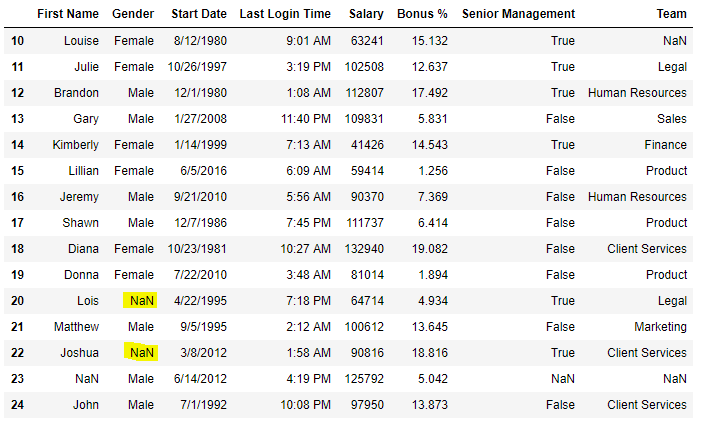
Now we are going to fill all the null values in Gender column with “No Gender”
Python
import pandas as pd
data = pd.read_csv("employees.csv")
data["Gender"].fillna("No Gender", inplace = True)
data
Output:
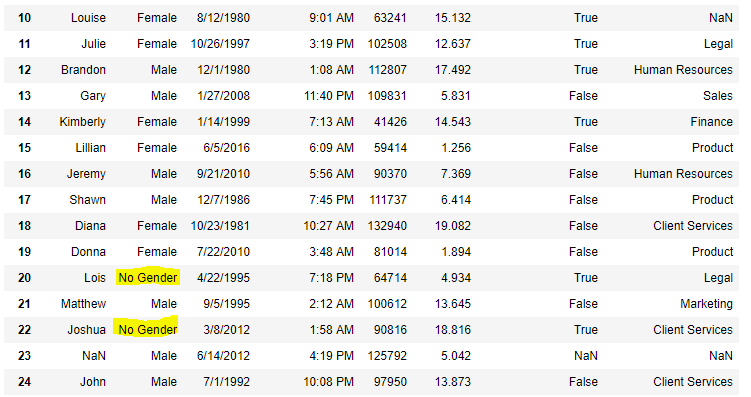
Code #5: Filling a null values using replace() method
Python
import pandas as pd
data = pd.read_csv("employees.csv")
data[10:25]
Output:
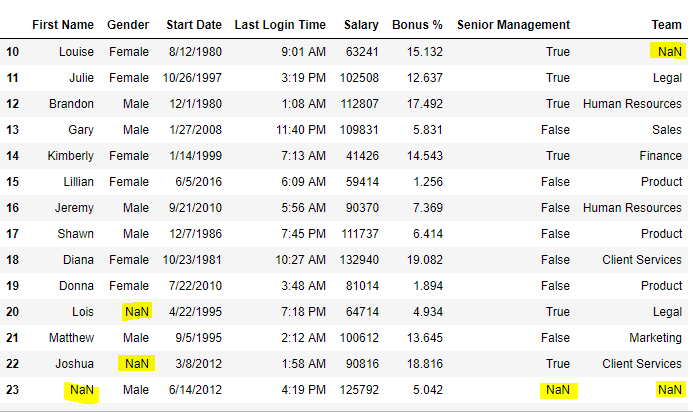
Now we are going to replace the all Nan value in the data frame with -99 value.
Python
import pandas as pd
data = pd.read_csv("employees.csv")
data.replace(to_replace = np.nan, value = -99)
Output:
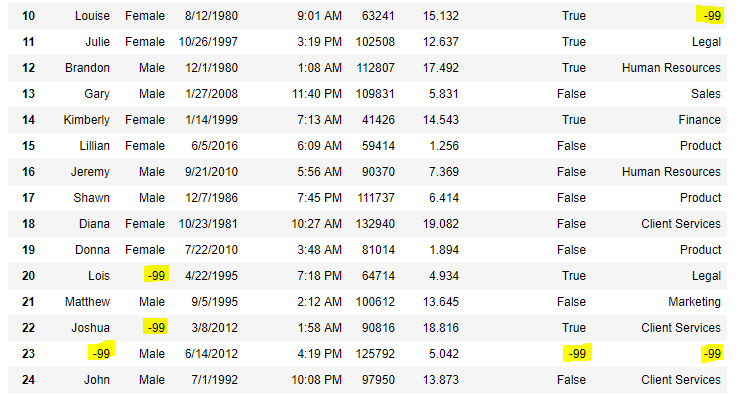
Code #6: Using interpolate() function to fill the missing values using linear method.
Python
import pandas as pd
df = pd.DataFrame({"A":[12, 4, 5, None, 1],
"B":[None, 2, 54, 3, None],
"C":[20, 16, None, 3, 8],
"D":[14, 3, None, None, 6]})
df
Output: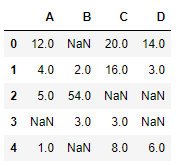
Let’s interpolate the missing values using Linear method. Note that Linear method ignore the index and treat the values as equally spaced.
Python
df.interpolate(method ='linear', limit_direction ='forward')
Output:
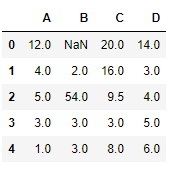
As we can see the output, values in the first row could not get filled as the direction of filling of values is forward and there is no previous value which could have been used in interpolation.
Dropping missing values using dropna()
In order to drop a null values from a dataframe, we used dropna() function this function drop Rows/Columns of datasets with Null values in different ways.
Code #1: Dropping rows with at least 1 null value.
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df
Output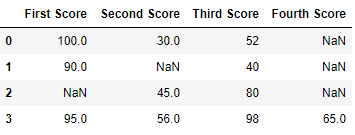
Now we drop rows with at least one Nan value (Null value)
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, 90, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, 40, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna()
Output: 
Code #2: Dropping rows if all values in that row are missing.
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df
Output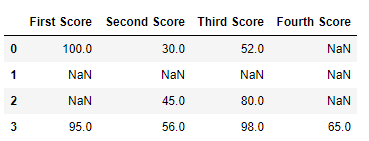
Now we drop a rows whose all data is missing or contain null values(NaN)
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[np.nan, np.nan, np.nan, 65]}
df = pd.DataFrame(dict)
df.dropna(how = 'all')
Output:
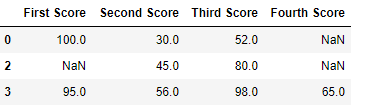
Code #3: Dropping columns with at least 1 null value.
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
df = pd.DataFrame(dict)
df
Output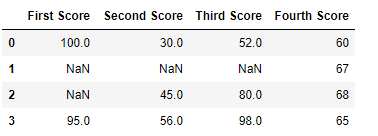
Now we drop a columns which have at least 1 missing values
Python
import pandas as pd
import numpy as np
dict = {'First Score':[100, np.nan, np.nan, 95],
'Second Score': [30, np.nan, 45, 56],
'Third Score':[52, np.nan, 80, 98],
'Fourth Score':[60, 67, 68, 65]}
df = pd.DataFrame(dict)
df.dropna(axis = 1)
Output :
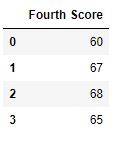
Code #4: Dropping Rows with at least 1 null value in CSV file
Python
import pandas as pd
data = pd.read_csv("employees.csv")
new_data = data.dropna(axis = 0, how ='any')
new_data
Output:
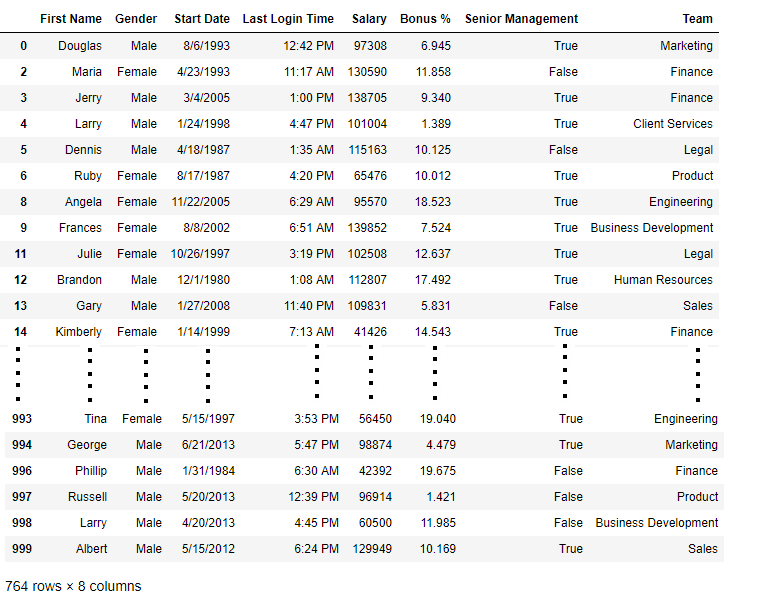
Now we compare sizes of data frames so that we can come to know how many rows had at least 1 Null value
Python
print("Old data frame length:", len(data))
print("New data frame length:", len(new_data))
print("Number of rows with at least 1 NA value: ", (len(data)-len(new_data)))
Output :
Old data frame length: 1000 New data frame length: 764 Number of rows with at least 1 NA value: 236
Since the difference is 236, there were 236 rows which had at least 1 Null value in any column.
Last Updated :
09 Feb, 2023
Like Article
Save Article
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
Фильтрация значений и подготовка данных для анализа
—
Python: Pandas
В библиотеке Pandas реализованы различные подходы, чтобы индексировать элементы. Можно обращаться к ним по порядковому номеру или по метке. При этом есть задачи, в которых нужно отсеивать элементы по условию с использованием специальных масок. В данной задаче указание конкретных интервалов для индексов не всегда подходит.
Для таких задач в Pandas реализован гибкий алгоритм фильтрации. В нем сложность масок определяется только фантазией аналитика и правилами логической арифметики. В этом уроке мы познакомимся с инструментами Pandas для подготовки и первичного анализа данных.
Использование булевых масок
Для работы нам понадобится датасет с недельными показателями кликов на сайтах четырех магазинов:
import pandas as pd
df_clicks = pd.read_csv('./data/Cite_clicks_week.csv', index_col=0)
print(df_clicks)
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 1319.0 -265.0 319.0 NaN
# 2 NaN 267.0 333.0 344.0
# 3 283.0 NaN 274.0 283.0
# 4 328.0 364.0 328.0 NaN
# 5 391.0 355.0 373.0 337.0
# 6 445.0 -418.0 1409.0 445.0
# 7 481.0 NaN 481.0 409.0
Среди показателей есть NaN-значения, которые указывают на пропуски в данных. Также есть отрицательные значения и показатели, которые существенно выше всех остальных. Это вполне обычная ситуация.
Такие значения могут влиять на точность анализа данных и даже на возможность его проведения. Поэтому аналитику приходится находить их и исправлять.
Структура DataFrame поддерживает операции среза последовательных элементов в данных по аналогии со стандартными списками:
print(df_clicks[1:5])
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 2 NaN 267.0 333.0 344.0
# 3 283.0 NaN 274.0 283.0
# 4 328.0 364.0 328.0 NaN
# 5 391.0 355.0 373.0 337.0
Чтобы извлечь конкретные строки, можно использовать булевы маски. Это массивы значений True и False. Строка берется, если по ее порядковому номеру в булевой маске стоит значение True:
print(df_clicks[[True, True, False, True, False, True, False]])
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 1319.0 -265.0 319.0 NaN
# 2 NaN 267.0 333.0 344.0
# 4 328.0 364.0 328.0 NaN
# 6 445.0 -418.0 1409.0 445.0
Чтобы извлечь конкретные столбцы в срезе, используется метод loc(), в параметры которого передается срез и массив меток столбцов:
print(df_clicks.loc[1:5, ['SHOP1']])
# => SHOP1
# day
# 1 1319.0
# 2 NaN
# 3 283.0
# 4 328.0
# 5 391.0
print(df_clicks.loc[1:5, ['SHOP1', 'SHOP3']])
# => SHOP1 SHOP3
# day
# 1 1319.0 319.0
# 2 NaN 333.0
# 3 283.0 274.0
# 4 328.0 328.0
# 5 391.0 373.0
Для больших таблиц будет неудобно вручную задавать булевы маски, как мы это делали в примерах выше. В Pandas получить маску можно с помощью логических операторов, примененных к данным:
print(df_clicks['SHOP1'] < 300)
# => day
# 1 False
# 2 False
# 3 True
# 4 False
# 5 False
# 6 False
# 7 False
# Name: SHOP1, dtype: bool
Чтобы получить нужные строки согласно булевой маске, достаточно передать ее в качестве индекса в DataFrame:
print(df_clicks[df_clicks['SHOP1'] < 300])
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 3 283.0 NaN 274.0 283.0
Выбор нужных столбцов в таблице осуществляется по аналогии с примером выше:
print(df_clicks.loc[df_clicks['SHOP1'] < 300, ['SHOP1', 'SHOP3']])
# => SHOP1 SHOP3
# day
# 3 283.0 274.0
Поиск пропусков в данных
Одной из существенных проблем в данных являются пропуски. Многие функции агрегации, обработки и даже простые арифметические операции не могут быть выполнены при их наличии. Чтобы обнаружить пропуски, в Pandas используют метод isna():
print(df_clicks[df_clicks['SHOP1'].isna()])
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 2 NaN 267.0 333.0 344.0
Для поиска строк, которые не содержат пропуски, можно использовать оператор тильда для логического отрицания исходной булевой маски:
print(df_clicks[~df_clicks['SHOP1'].isna()])
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 1319.0 -265.0 319.0 NaN
# 3 283.0 NaN 274.0 283.0
# 4 328.0 364.0 328.0 NaN
# 5 391.0 355.0 373.0 337.0
# 6 445.0 -418.0 1409.0 445.0
# 7 481.0 NaN 481.0 409.0
Данный метод применим не только к столбцам, но и ко всей таблице:
print(df_clicks.isna())
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 False False False True
# 2 True False False False
# 3 False True False False
# 4 False False False True
# 5 False False False False
# 6 False False False False
# 7 False True False False
Замена пропусков на определенные значения
Когда мы находим пропуски в данных, это помогает контролировать их качество. Но часто приходится не только их находить, но и исправлять.
В качестве значения, на которое заменяется пропуск, можно взять среднее по всем данным. Чтобы найти среднее, нужно дважды применить метод mean(), поскольку после первого применения получается массив средних для каждого магазина по отдельности:
df_clicks_mean = df_clicks.mean().mean()
print(df_clicks_mean)
# => 366.94
Чтобы заполнить пропуски, используется метод fillna() с параметром, на который происходит замена пропущенных значений:
print(df_clicks.fillna(df_clicks_mean))
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 1319.00000 -265.00000 319.0 366.94881
# 2 366.94881 267.00000 333.0 344.00000
# 3 283.00000 366.94881 274.0 283.00000
# 4 328.00000 364.00000 328.0 366.94881
# 5 391.00000 355.00000 373.0 337.00000
# 6 445.00000 -418.00000 1409.0 445.00000
# 7 481.00000 366.94881 481.0 409.00000
Замена значений в данных согласно условию
Помимо пропусков в данных могут быть значения, которые попали туда по ошибке, были некорректно введены или искажены при записи. Такие случаи называют выбросами.
Анализ данных и поиск выбросов приводит к формированию некоторого условия, которому должны удовлетворять элементы. Если элементы ему не удовлетворяют, то данные значения можно заменить на среднее. Для этого используют метод where():
print(df_clicks.where(df_clicks < 1000, df_clicks_mean))
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 366.94881 -265.00000 319.00000 366.94881
# 2 366.94881 267.00000 333.00000 344.00000
# 3 283.00000 366.94881 274.00000 283.00000
# 4 328.00000 364.00000 328.00000 366.94881
# 5 391.00000 355.00000 373.00000 337.00000
# 6 445.00000 -418.00000 366.94881 445.00000
# 7 481.00000 366.94881 481.00000 409.00000
При работе с Pandas это условие формируется в виде булевой маски. Для удобства ее выносят в отдельную переменную:
mask = (0 < df_clicks) & (df_clicks < 1000)
print(mask)
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 False False True False
# 2 False True True True
# 3 True False True True
# 4 True True True False
# 5 True True True True
# 6 True False False True
# 7 True False True True
print(df_clicks.where(
mask,
df_clicks_mean,
)
)
# => SHOP1 SHOP2 SHOP3 SHOP4
# day
# 1 366.94881 366.94881 319.00000 366.94881
# 2 366.94881 267.00000 333.00000 344.00000
# 3 283.00000 366.94881 274.00000 283.00000
# 4 328.00000 364.00000 328.00000 366.94881
# 5 391.00000 355.00000 373.00000 337.00000
# 6 445.00000 366.94881 366.94881 445.00000
# 7 481.00000 366.94881 481.00000 409.00000
np.where(pd.isnull(df)) returns the row and column indices where the value is NaN:
In [152]: import numpy as np
In [153]: import pandas as pd
In [154]: np.where(pd.isnull(df))
Out[154]: (array([2, 5, 6, 6, 7, 7]), array([7, 7, 6, 7, 6, 7]))
In [155]: df.iloc[2,7]
Out[155]: nan
In [160]: [df.iloc[i,j] for i,j in zip(*np.where(pd.isnull(df)))]
Out[160]: [nan, nan, nan, nan, nan, nan]
Finding values which are empty strings could be done with applymap:
In [182]: np.where(df.applymap(lambda x: x == ''))
Out[182]: (array([5]), array([7]))
Note that using applymap requires calling a Python function once for each cell of the DataFrame. That could be slow for a large DataFrame, so it would be better if you could arrange for all the blank cells to contain NaN instead so you could use pd.isnull.