i have this dataframe:
0 name data
1 alex asd
2 helen sdd
3 alex dss
4 helen sdsd
5 john sdadd
so i am trying to get the most frequent value or values(in this case its values)
so what i do is:
dataframe['name'].value_counts().idxmax()
but it returns only the value: Alex even if it Helen appears two times as well.
asked Feb 2, 2018 at 20:16
![]()
By using mode
df.name.mode()
Out[712]:
0 alex
1 helen
dtype: object
answered Feb 2, 2018 at 20:23
![]()
BENYBENY
316k20 gold badges162 silver badges231 bronze badges
2
To get the n most frequent values, just subset .value_counts() and grab the index:
# get top 10 most frequent names
n = 10
dataframe['name'].value_counts()[:n].index.tolist()
answered Apr 28, 2019 at 6:47
![]()
Jared WilberJared Wilber
5,8791 gold badge31 silver badges35 bronze badges
2
You could try argmax like this:
dataframe['name'].value_counts().argmax()
Out[13]: 'alex'
The value_counts will return a count object of pandas.core.series.Series and argmax could be used to achieve the key of max values.
answered Jun 27, 2018 at 2:57
![]()
Lunar_oneLunar_one
3373 silver badges4 bronze badges
2
df['name'].value_counts()[:5].sort_values(ascending=False)
The value_counts will return a count object of pandas.core.series.Series and sort_values(ascending=False) will get you the highest values first.
answered Sep 11, 2019 at 8:32
![]()
TaieTaie
92513 silver badges29 bronze badges
2
It will give top five most common names:
df['name'].value_counts().nlargest(5)
![]()
Syscall
19.2k10 gold badges36 silver badges52 bronze badges
answered Jan 21, 2022 at 7:25
![]()
Use:
df['name'].mode()
or
df['name'].value_counts().idxmax()
answered Jul 6, 2020 at 9:15
![]()
You can use this to get a perfect count, it calculates the mode a particular column
df['name'].value_counts()
answered Aug 15, 2018 at 5:18
![]()
Here’s one way:
df['name'].value_counts()[df['name'].value_counts() == df['name'].value_counts().max()]
which prints:
helen 2
alex 2
Name: name, dtype: int64
answered Feb 2, 2018 at 20:22
![]()
paultpault
40.8k14 gold badges106 silver badges148 bronze badges
Not Obvious, But Fast
f, u = pd.factorize(df.name.values)
counts = np.bincount(f)
u[counts == counts.max()]
array(['alex', 'helen'], dtype=object)
answered Feb 2, 2018 at 20:34
![]()
piRSquaredpiRSquared
283k57 gold badges469 silver badges620 bronze badges
1
Simply use this..
dataframe['name'].value_counts().nlargest(n)
The functions for frequencies largest and smallest are:
nlargest()for mostfrequent ‘n’ valuesnsmallest()for least frequent ‘n’ values
![]()
answered May 2, 2020 at 20:00
![]()
avineet07avineet07
511 silver badge5 bronze badges
to get top 5:
dataframe['name'].value_counts()[0:5]
answered Jul 2, 2019 at 9:03
![]()
Naomi FridmanNaomi Fridman
2,0632 gold badges25 silver badges36 bronze badges
1
You could use .apply and pd.value_counts to get a count the occurrence of all the names in the name column.
dataframe['name'].apply(pd.value_counts)
answered Feb 2, 2018 at 20:24
![]()
BrianBrian
2,1431 gold badge12 silver badges26 bronze badges
0
To get the top five most common names:
dataframe['name'].value_counts().head()
answered Jul 30, 2019 at 5:41
![]()
pedro_bb7pedro_bb7
1,5093 gold badges12 silver badges28 bronze badges
my best solution to get the first is
df['my_column'].value_counts().sort_values(ascending=False).argmax()
answered Jan 30, 2020 at 15:13
![]()
venergiacvenergiac
7,3792 gold badges47 silver badges70 bronze badges
I had a similar issue best most compact answer to get lets say the top n (5 is default) most frequent values is:
df["column_name"].value_counts().head(n)
answered Mar 12, 2021 at 14:50
![]()
KZiovasKZiovas
3,1451 gold badge22 silver badges45 bronze badges
Identifying the top 5, for example, using value_counts
top5 = df['column'].value_counts()
Listing contents of ‘top_5’
top5[:5]
answered Jun 18, 2021 at 16:53
![]()
2
n is used to get the number of top frequent used items
n = 2
a=dataframe['name'].value_counts()[:n].index.tolist()
dataframe["name"].value_counts()[a]
![]()
Maylo
5725 silver badges16 bronze badges
answered Dec 16, 2020 at 14:10
![]()
Getting top 5 most common lastname pandas:
df['name'].apply(lambda name: name.split()[-1]).value_counts()[:5]
![]()
answered Aug 11, 2021 at 15:34
![]()
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, our basic task is to print the most frequent value in a series. We can find the number of occurrences of elements using the value_counts() method. From that the most frequent element can be accessed by using the mode() method.
Example 1 :
import pandas as pd
series = pd.Series(['g', 'e', 'e', 'k', 's',
'f', 'o', 'r',
'g', 'e', 'e', 'k', 's'])
print("Printing the Original Series:")
display(series)
freq = series.value_counts()
print("Printing the frequency")
display(freq)
print("Printing the most frequent element of series")
display(series.mode());
Output :
Example 2 : Replacing the every element except the most frequent element with None.
import pandas as pd
series = pd.Series(['g', 'e', 'e', 'k', 's',
'f', 'o', 'r',
'g', 'e', 'e', 'k', 's'])
freq = series.value_counts()
series[~series.isin(freq .index[:1])] = None
print(series)
Output :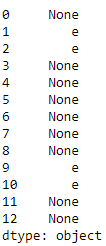
Last Updated :
18 Aug, 2020
Like Article
Save Article
In this tutorial, we will look at how to get the most frequent value in pandas column with the help of some examples.
How to get the most frequent value in a pandas series?
The most frequent value in a pandas series is basically the mode of the series. You can get the mode by using the pandas series mode() function. The following is the syntax:
# get mode of a pandas column df['Col'].mode()
It returns the modes of the series in sorted order.
You can also use the pandas value_counts() function with the idxmax() function to return the value with the highest count. The following is the syntax:
# most frequent value in a pandas column df['Col'].value_counts().idxmax()
Let’s look at some examples of getting the mode in a pandas column.
First, let’s create a dataframe with a categorical field that we will be using throughout this tutorial.
import pandas as pd
# create a dataframe
df = pd.DataFrame({
'Name': ['Steve', 'Varun', 'Maya', 'Jones', 'Emily', 'Stuart', 'Karen'],
'Team': ['Red', 'Blue', 'Blue', 'Red', 'Green', 'Green', 'Blue']
})
# display the dataframe
print(df)
Output:
Name Team 0 Steve Red 1 Varun Blue 2 Maya Blue 3 Jones Red 4 Emily Green 5 Stuart Green 6 Karen Blue
The dataframe df stores the names and the team information of students for a science project. The column “Team” is a categorical field with values representing the team assigned to the corresponding student.
1. Most frequent value with mode()
Mode is a descriptive statistic that is equal to the most frequent value in the dataset. Let’s apply the pandas series mode() function to get the most frequent value in the “Team” column, which essentially tells us which team has the most students.
# most frequent value in Team df['Team'].mode()
Output:
0 Blue dtype: object
It returns a pandas series with the mode of the column. You can see that we get “Blue” as the mode since it is the most frequent value in the “Team” column.
Note that you can also apply the mode() function on a pandas dataframe to get the mode of each column.
2. Most frequent value with value_counts()
The pandas value_counts() function is used to get the count of each unique value in a pandas series. You can use it to get the counts and then extract the value with the most counts using idxmax() function. For example –
# most frequent value in Team df['Team'].value_counts().idxmax()
Output:
'Blue'
We get the value with the highest value count in the “Team” column.
Note that this method only gives a single value as output even if there are more than one modes present.
What happens if we have two values that are most frequent?
Let’s find out what the above two methods give when we have a tie for the most frequent value.
For this, let’s modify the dataframe so that we have two modes in the “Team” column. Here we modify the “Team” value for “Jones” from “Red” to “Green”.
# change Jones' team to Green df.at[3, 'Team'] = 'Green' # display the dataframe print(df)
Output:
Name Team 0 Steve Red 1 Varun Blue 2 Maya Blue 3 Jones Green 4 Emily Green 5 Stuart Green 6 Karen Blue
You can see that now we have two modes – “Blue” and “Green” both occurring three times in the “Team” column.
Now, let’s find the mode of the “Team” with the mode() function.
# most frequent value in Team df['Team'].mode()
Output:
0 Blue 1 Green dtype: object
We get both the modes in the returned series.
Let’s check what we get with the value_counts() and idxmax() method.
# most frequent value in Team df['Team'].value_counts().idxmax()
Output:
'Green'
We get only one of the two modes. This happened because idxmax() returns only one value – “If multiple values equal the maximum, the first row label with that value is returned.”
Thus, it’s recommended that you use the pandas series `mode()` function to get the most frequent value in a pandas series.
With this, we come to the end of this tutorial. The code examples and results presented in this tutorial have been implemented in a Jupyter Notebook with a python (version 3.8.3) kernel having pandas version 1.0.5
Subscribe to our newsletter for more informative guides and tutorials.
We do not spam and you can opt out any time.
-

Piyush is a data professional passionate about using data to understand things better and make informed decisions. He has experience working as a Data Scientist in the consulting domain and holds an engineering degree from IIT Roorkee. His hobbies include watching cricket, reading, and working on side projects.
View all posts

Вы можете просто использовать pd.Series.mode и извлечь первое значение:
res = s.mode().iloc[0]
Это не обязательно неэффективно. Как всегда, проверьте свои данные, чтобы узнать, что подходит.
import numpy as np, pandas as pd
from scipy.stats.mstats import mode
from collections import Counter
np.random.seed(0)
s = pd.Series(np.random.randint(0, 100, 100000))
def jez_np(s):
_, idx, counts = np.unique(s, return_index=True, return_counts=True)
index = idx[np.argmax(counts)]
val = s[index]
return val
def pir(s):
i, r = s.factorize()
return r[np.bincount(i).argmax()]
%timeit s.mode().iloc[0] # 1.82 ms
%timeit pir(s) # 2.21 ms
%timeit s.value_counts().index[0] # 2.52 ms
%timeit mode(s).mode[0] # 5.64 ms
%timeit jez_np(s) # 8.26 ms
%timeit Counter(s).most_common(1)[0][0] # 8.27 ms
jpp
27 авг. 2018, в 12:15
Поделиться
Используйте value_counts и выберите первое значение по index:
val = s.value_counts().index[0]
Или Counter.most_common:
from collections import Counter
val = Counter(s).most_common(1)[0][0]
Или решение numpy:
_, idx, counts = np.unique(s, return_index=True, return_counts=True)
index = idx[np.argmax(counts)]
val = s[index]
jezrael
27 авг. 2018, в 12:25
Поделиться
pandas.factorize и numpy.bincount
Это очень похоже на ответ @jezrael Numpy. Разница заключается в использовании factorize а не numpy.unique
-
factorizeвозвращает целочисленную факторизацию и уникальные значения -
bincountподсчитывает, сколько из каждого уникального значения -
argmaxопределяет, какойargmaxили фактор является наиболее частым - Используйте позицию bin, возвращаемого из
argmaxчтобы ссылаться на наиболее частое значение из массива уникальных значений
i, r = s.factorize()
r[np.bincount(i).argmax()]
3
piRSquared
27 авг. 2018, в 13:25
Поделиться
from scipy import stats
import pandas as pd
x=[1,5,3,3,3,5,2,1,8,10,2,3,3,3]
data=pd.DataFrame({"values":x})
print(stats.mode(data["values"]))
output:-ModeResult(mode=array([3], dtype=int64), count=array([6]))
ramakrishnareddy
27 авг. 2018, в 13:02
Поделиться
Ещё вопросы
- 1Автоматизация NonEnglish сайт, используя WebDriver
- 0Установка высоты абсолютно позиционированного элемента div по высоте его содержимого
- 0ошибка: my_texture не называет тип
- 1Python — динамически изменять количество аргументов
- 0Как получить пост в Facebook (поиск по ключевым словам) с помощью API
- 1Оптимальный способ использовать tkinter и openpyxl для перебора электронной таблицы?
- 0Асинхронный обратный вызов не был вызван в течение тайм-аута — модульное тестирование службы Typescript & Angular $ http
- 0Combobox не применяется в поле выбора
- 0несколько условий внутри функции щелчка не работает
- 0плагин проверки jquery, условный удаленный вызов не работает должным образом
- 0file_get_contents на время ожидания при запуске на том же сервере, что и цель
- 1ASP.NET MVC 4 передача значений между списками
- 0AngularJS устанавливает заголовки SSL
- 0Array push — изменить имя на ключ
- 1Как заставить Jetty Maven плагин v9.1.x * не * развертывать зависимые военные артефакты?
- 0G ++ с Mountain Lion поддерживает -msse4.2?
- 1Как я могу определить базовый тип в объектном типе dtype?
- 1Заменить поля объекта
- 1Нажмите на ссылку, используя селен вебдрайвер
- 1установка переменных среды для настройки учетных данных хранилища данных из Java
- 0Как связать JavaScript при наведении на элемент, чтобы изменить изображение элемента и отобразить блок третьего элемента
- 1Вывод процесса трубопровода в новый процесс
- 1Бревна переворачиваются слишком быстро [дубликаты]
- 1Добавление минут к метке времени в python
- 0Как я могу обновить несколько строк MySQL?
- 1Генерация случайного изображения JPG из консольного приложения
- 1Как можно нарисовать гауссиан отдельно от примерки в питоне?
- 1Как справиться с игровым потоком?
- 1Функция module.exports не является функцией
- 0использование PHP регулярных выражений для удаления атрибутов из элементов HTML-тегов
- 1Как разбить строку на слова?
- 1CasperJS — методы DOM не выполняются внутри функцииvalu ()
- 1Обязательны ли определения типов для пакетов npm только на компьютере разработчика?
- 0Получение cookie на той же странице
- 0Идентификатор возвращает 0 для API отдыха с Go
- 0Проверка Javascript перед сохранением информации
- 1стеки Java и очевидное бессмысленное упражнение
- 0Как создать ассоциативный массив php из грязных данных
- 1Как очистить анимацию добавления / удаления панели действий?
- 1Создание словаря из панда данных
- 1TypeError: done не является функцией
- 0Добавление коробки количества к списку товаров magento
- 0PHP-скрипт не выполняется на сервере Apache
- 1Создание экземпляра класса в цикле и его обновление
- 0push () в глубокий массив
- 0SFINAE выбор перегрузки для имеет или не имеет оператора <<?
- 0Div открывается вертикально, когда страница загружается с помощью JavaScript и CSS
- 0Joomla — Самый эффективный способ заставить внешние ссылки без http: // быть внешними
- 0Как вставить массивы со значениями объектов в MySQL, используя для или foreach в JavaScript (nodejs)?
- 1Шаблон посетителя, почему это полезно?
На чтение 6 мин Просмотров 1.7к. Опубликовано 07.09.2022
В этом руководстве по Pandas вы узнаете, как подсчитать количество вхождений данных или значений в столбце. В науке о данных бывают случаи, когда нам нужно определить, как часто определенное значение встречается в определенном столбце DataFrame. Это может произойти, например, когда вы хотите сравнить только небольшой диапазон потенциальных значений. Если вы хотите подсчитать количество повторяющихся или повторяющихся значений в столбце, это еще один пример. Кроме того, нам может потребоваться подсчитать наблюдения, которые составляют фактор, или, например, нам нужно знать долю мужчин и женщин в сборе данных.
Содержание
- Как использовать среднюю функцию Pandas
- Пример 1. Подсчет частоты столбцов с помощью функции Value_Counts()
- Пример 2. Подсчет частоты столбцов с помощью функции GroupBy.Counts()
- Пример 3. Подсчет частоты столбцов с помощью функции GroupBy.Size()
- Пример 4. Подсчет частоты столбца путем создания таблицы частот для определенной строки
- Заключение
Как использовать среднюю функцию Pandas
Нам нужно определить частоту подсчета данных/значений или элементов в одном или нескольких столбцах Pandas DataFrame. Есть несколько способов сделать это. Мы обсудим несколько методов подсчета появления или частоты элементов или значений в столбце DataFrame.
Пример 1. Подсчет частоты столбцов с помощью функции Value_Counts()
Метод value_counts() в Pandas возвращает серию с частотой уникальных значений. Результирующий ряд по умолчанию находится в порядке убывания и лишен каких-либо значений NA. Объект «pandas.Series» подходит для использования с этой функцией (value_counts()). С помощью этого метода можно получить частоту значений в одном столбце, поскольку объекты Pandas DataFrame представляют собой группу объектов Series. Сначала мы должны создать DataFrame, чтобы продемонстрировать этот пример. Функция «pandas.DataFrame()» используется для создания DataFrame. Таким образом, мы должны сначала импортировать пакет Pandas.

В функции pd.DataFrame() мы использовали словарь Python для создания нашего DataFrame. Мы присвоили столбцам в нашем DataFrame метки «X» и «Y». Мы отображаем наш DataFrame «df», используя метод print().

Во вновь созданном DataFrame «df» есть два столбца — столбец «X» хранит целые значения (1, 1, 4, 3, 5, 1, 4, 3, 5, 4), а столбец «Y» хранит строковые значения («q», «r», «t», «q», «q», «t», «r», «q», «t», «r»). Вы можете заметить, что в данных обоих столбцов есть повторение. Мы можем использовать функцию value_counts() для вычисления частоты данных в определенном столбце. Подсчитаем частоту данных в столбце «Y».

Функция вернула серию с количеством различных значений. Значение «q» встречается 4 раза, а значения «r» и «t» встречаются 3 раза в столбце «y». Давайте также подсчитаем уникальные значения в столбце X.

Видно, что значения «1» и «4» встречаются в столбце «X» 3 раза, а значения «3» и «5» встречаются 2 раза.
Пример 2. Подсчет частоты столбцов с помощью функции GroupBy.Counts()
В этом примере мы группируем строки по столбцам с помощью функции Pandas DataFrame.groupby() и используем метод count() для определения количества различных значений для каждой группы, игнорируя значения None и NaN. Давайте сначала создадим DataFrame, где мы применим функцию groupby.counts().

Мы использовали словарь Pandas для создания нашего DataFrame после импорта модуля Pandas. Имена наших столбцов указаны как «col1» и «col2».

В столбце «col1» у нас есть целые данные (8, 6, 5, 8, 8, 7, 7, 9, 5, 7). В столбце «col2» у нас есть строковые данные («мальчик», «мальчик», «девочка», «мальчик», «мальчик», «девочка», «девочка», «девочка», «мальчик», » мальчик«). Теперь мы применяем функцию groupby.counts() для вычисления частоты значений в каждом столбце.

Для проведения расчетов мы разделили данные на различные группы с помощью функции groupby(). Затем применяется функция count() для подсчета частот различных значений в указанном столбце DataFrame. Значение «5» встречается 2 раза. Значения «6» и «9» встречаются один раз. Тогда как значения «7» и «8» встречаются 2 раза в столбце «col1». Теперь давайте применим функцию groupby.count() к столбцу «col2».

Функция определила частоту значений «мальчик» и «девочка» как 6 и 4 раза соответственно.
Пример 3. Подсчет частоты столбцов с помощью функции GroupBy.Size()
С помощью этого метода можно подсчитать частоту элементов в отдельных столбцах. Чтобы получить объект DataFrame с подсчетом частоты, мы можем применить метод count() к объекту DataFrame, сгруппированному по одному столбцу. Во-первых, создается DataFrame, который содержит хотя бы один повторяющийся столбец, чтобы мы могли использовать функцию count() для определения частоты значений. Сначала мы импортируем модуль Pandas перед созданием DataFrame. Затем с помощью функции pd.DataFrame() мы создаем наш DataFrame.

В предыдущем DataFrame у нас есть два столбца — столбец «имя» со значениями («Алекс», «Джек», «Алекс», «Али», «Джек», «Джек», «Алекс», «Алекс», «Али», «Алекс», «Али», «Али», «Джек», «Алекс») и столбец «оценка», который содержит оценки отдельных лиц («А», «А», «В», » В«, «В», «В», «А», «С», «А», «С», «С», «С», «А», «Б»). Теперь, чтобы найти количество частот этих столбцов, мы используем функцию groupby.size(). Целое число, представляющее количество элементов в этом объекте, может быть получено с помощью атрибута размера. Если серия дает количество строк и если DataFrame возвращает общее количество строк, умноженное на количество столбцов.

Это показывает, что есть два случая, когда «Алекс» имеет оценку «А». Также есть два случая, когда «Алекс» имеет оценку «B» и «C». «Али» встречалось 1 раз с оценками «А» и «В», а 2 раза со значением оценки «С». «Валет» встречался два раза с оценками «А» и «В».
Пример 4. Подсчет частоты столбца путем создания таблицы частот для определенной строки
Мы можем применить метод crosstab() для определения частот в Pandas DataFrame.

Теперь давайте предположим, что нам нужно создать DataFrame с подробной информацией о поле, возрасте и буквенной оценке десяти разных учеников.
Мы создали необходимый DataFrame с тремя столбцами — столбец оценок («A», «B», «A», «B», «C», «B», «B», «C», «A», » А«), столбец возраста (17, 19, 18, 17, 19, 17, 18, 18, 17, 19) и столбец пола («Ж», «М», «Ж», «М», «Ж», «Ж», «М», «М», «Ж», «Ж»). Теперь мы используем функцию crosstab() для создания таблицы частот. Таблицу перекрестных таблиц, созданную методом crosstab(), можно использовать для отображения частоты появления различных групп данных.

Внутри функции pd.crosstab() мы указали столбец «оценка» в параметре индекса для расчета частоты данных в столбце и указали параметр столбцов как «частота» для хранения возвращаемых значений/частот данных группы.
Заключение
В этом руководстве по Pandas мы обсудили, как подсчитывать количество вхождений данных или значений в столбце Pandas DataFrame. Мы попытались научить, как использовать функции «value_counts()» и «groupby()» вместе с атрибутами «size()» и «count()» для подсчета частоты данных в указанном столбце. Мы также увидели, как подсчитать частоту столбца, создав таблицу частот с помощью функции crosstab().