Prerequisite: Pandas.Dataframes in Python
In this article, we will cover how we select rows from a DataFrame based on column values in Python.
The rows of a Dataframe can be selected based on conditions as we do use the SQL queries. The various methods to achieve this is explained in this article with examples.
Importing Dataset for demonstration
To explain the method a dataset has been created which contains data of points scored by 10 people in various games. The dataset is loaded into the Dataframe and visualized first. Ten people with unique player id(Pid) have played different games with different game id(game_id) and the points scored in each game are added as an entry to the table. Some of the player’s points are not recorded and thus NaN value appears in the table.
Note: To get the CSV file used, click here.
Python3
import pandas as pd
df = pd.read_csv(r"__your file path__example2.csv")
print(df)
Output:
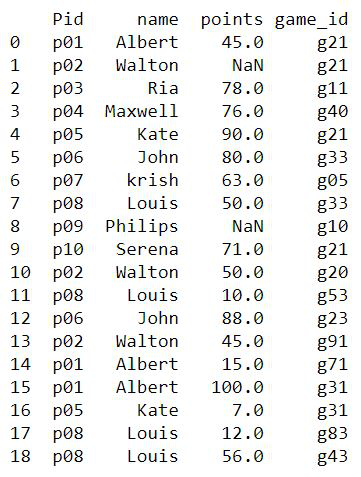
dataset example2.csv
We will select rows from Dataframe based on column value using:
- Boolean Indexing method
- Positional indexing method
- Using isin() method
- Using Numpy.where() method
- Comparison with other methods
Method 1: Boolean Indexing method
In this method, for a specified column condition, each row is checked for true/false. The rows which yield True will be considered for the output. This can be achieved in various ways. The query used is Select rows where the column Pid=’p01′
Example 1: Select rows from a Pandas DataFrame based on values in a column
In this example, we are trying to select those rows that have the value p01 in their column using the equality operator.
Python3
df_new = df[df['Pid'] == 'p01']
print(df_new)
Output

Example 2: Specifying the condition ‘mask’ variable
Here, we will see Pandas select rows by condition the selected rows are assigned to a new Dataframe with the index of rows from the old Dataframe as an index in the new one and the columns remaining the same.
Python3
mask = df['Pid'] == 'p01'
df_new = pd.DataFrame(df[mask])
print(df_new)
Output

Example 3: Combining mask and dataframes.values property
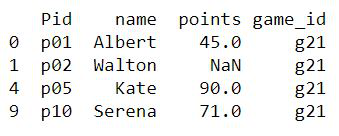
The query here is to Select the rows with game_id ‘g21’.
Python3
mask = df['game_id'].values == 'g21'
df_new = df[mask]
print(df_new)
Output
Method 2: Positional indexing method
The methods loc() and iloc() can be used for slicing the Dataframes in Python. Among the differences between loc() and iloc(), the important thing to be noted is iloc() takes only integer indices, while loc() can take up boolean indices also.
Example 1: Pandas select rows by loc() method based on column values
The mask gives the boolean value as an index for each row and whichever rows evaluate to true will appear in the result. Here, the query is to select the rows where game_id is g21.
Python3
mask = df['game_id'].values == 'g21'
df_new = df.loc[mask]
print(df_new)
Output
Example 2: Pandas select rows by iloc() method based on column values
The query is the same as the one taken above. The iloc() takes only integers as an argument and thus, the mask array is passed as a parameter to the Numpy’s flatnonzero() function that returns the index in the list where the value is not zero (false)
Python3
mask = df['game_id'].values == 'g21'
print("Mask array :", mask)
pos = np.flatnonzero(mask)
print("nRows selected :", pos)
df.iloc[pos]
Output

Method 3: Using dataframe.query() method
The query() method takes up the expression that returns a boolean value, processes all the rows in the Dataframe, and returns the resultant Dataframe with selected rows.
Example 1: Pandas select rows by Dataframe.query() method based on column values
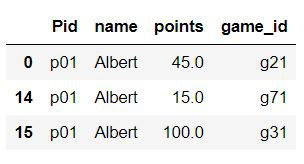
Select rows where the name=”Albert”
Python3
df.query('name=="Albert"')
Output
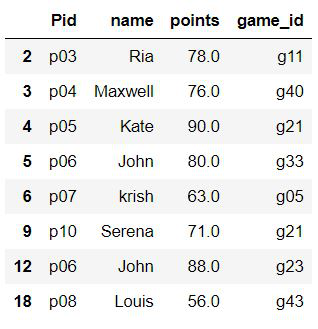
Example 2: Select rows based on iple column conditions
This example is to demonstrate that logical operators like AND/OR can be used to check multiple conditions. we are trying to select rows where points>50 and the player is not Albert.
Python3
df.query('points>50 & name!="Albert"')
Output
Method 3: Using isin() method
This method of Dataframe takes up an iterable or a series or another Dataframe as a parameter and checks whether elements of the Dataframe exist in it. The rows that evaluate to true are considered for the resultant.
Example 1: Pandas select rows by isin() method based on column values
Select rows whose column value is in an iterable array
Select the rows where players are Albert, Louis, and John.
Python3
li = ['Albert', 'Louis', 'John']
df[df.name.isin(li)]
Output
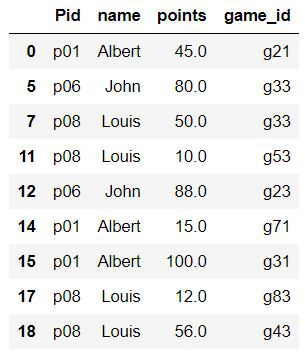
Example 2: Select rows where the column does not equal a value
The tiled symbol (~) provides the negation of the expression evaluated. Here, we are selecting rows where points>50 and players are not Albert, Louis, and John.
Python3
li = ['Albert', 'Louis', 'John']
df[(df.points > 50) & (~df.name.isin(li))]
Output
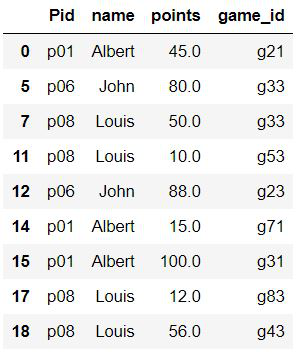
Method 4: Using Numpy.where() method
The Numpy’s where() function can be combined with the pandas’ isin() function to produce a faster result. The numpy.where() is proved to produce results faster than the normal methods used above.
Example: Pandas select rows by np.where() method based on column values
Python3
import numpy as np
df_new = df.iloc[np.where(df.name.isin(li))]
Output:
Method 5: Comparison with other methods
Example 1
In this example, we are using a mixture of NumPy and pandas method
Python3
import numpy as np
% % timeit
df_new = df.iloc[np.where(df.name.isin(li))]
Output:
756 µs ± 132 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Example 2
In this example, we are using only the Pandas method
Python3
%%timeit
li=['Albert','Louis','John']
df[(df.points>50)&(~df.name.isin(li))]
Output
1.7 ms ± 307 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Last Updated :
07 Jul, 2022
Like Article
Save Article
17 авг. 2022 г.
читать 2 мин
Вы можете использовать один из следующих методов для выбора строк в pandas DataFrame на основе значений столбца:
Метод 1: выберите строки, где столбец равен определенному значению
df.loc[df['col1'] == value]
Способ 2: выберите строки, где значение столбца находится в списке значений
df.loc[df['col1']. isin([value1, value2, value3, ...])]
Способ 3: выбор строк на основе условий нескольких столбцов
df.loc[(df['col1'] == value) &(df['col2'] < value)]
В следующем примере показано, как использовать каждый метод со следующими пандами DataFrame:
import pandas as pd
#create DataFrame
df = pd.DataFrame({'team': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
'points': [5, 7, 7, 9, 12, 9, 9, 4],
'rebounds': [11, 8, 10, 6, 6, 5, 9, 12],
'blocks': [4, 7, 7, 6, 5, 8, 9, 10]})
#view DataFrame
df
team points rebounds blocks
0 A 5 11 4
1 A 7 8 7
2 B 7 10 7
3 B 9 6 6
4 B 12 6 5
5 C 9 5 8
6 C 9 9 9
7 C 4 12 10
Метод 1: выберите строки, где столбец равен определенному значению
В следующем коде показано, как выбрать каждую строку в DataFrame, где столбец «точки» равен 7:
#select rows where 'points' column is equal to 7
df.loc[df['points'] == 7]
team points rebounds blocks
1 A 7 8 7
2 B 7 10 7
Способ 2: выберите строки, где значение столбца находится в списке значений
В следующем коде показано, как выбрать каждую строку в DataFrame, где столбец «точки» равен 7, 9 или 12:
#select rows where 'points' column is equal to 7
df.loc[df['points']. isin([7, 9, 12])]
team points rebounds blocks
1 A 7 8 7
2 B 7 10 7
3 B 9 6 6
4 B 12 6 5
5 C 9 5 8
6 C 9 9 9
Способ 3: выбор строк на основе условий нескольких столбцов
В следующем коде показано, как выбрать каждую строку в DataFrame, где столбец «команда» равен «B», а столбец «очки» больше 8:
#select rows where 'team' is equal to 'B' and points is greater than 8
df.loc[(df['team'] == 'B') &(df['points'] > 8)]
team points rebounds blocks
3 B 9 6 6
4 B 12 6 5
Обратите внимание, что возвращаются только две строки, в которых команда равна «B», а «очки» больше 8.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как выбрать строки по индексу в Pandas
Как выбрать уникальные строки в Pandas
Как выбрать строки, в которых значение появляется в любом столбце в Pandas
There are several ways to select rows from a Pandas dataframe:
- Boolean indexing (
df[df['col'] == value] ) - Positional indexing (
df.iloc[...]) - Label indexing (
df.xs(...)) df.query(...)API
Below I show you examples of each, with advice when to use certain techniques. Assume our criterion is column 'A' == 'foo'
(Note on performance: For each base type, we can keep things simple by using the Pandas API or we can venture outside the API, usually into NumPy, and speed things up.)
Setup
The first thing we’ll need is to identify a condition that will act as our criterion for selecting rows. We’ll start with the OP’s case column_name == some_value, and include some other common use cases.
Borrowing from @unutbu:
import pandas as pd, numpy as np
df = pd.DataFrame({'A': 'foo bar foo bar foo bar foo foo'.split(),
'B': 'one one two three two two one three'.split(),
'C': np.arange(8), 'D': np.arange(8) * 2})
1. Boolean indexing
… Boolean indexing requires finding the true value of each row’s 'A' column being equal to 'foo', then using those truth values to identify which rows to keep. Typically, we’d name this series, an array of truth values, mask. We’ll do so here as well.
mask = df['A'] == 'foo'
We can then use this mask to slice or index the data frame
df[mask]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
This is one of the simplest ways to accomplish this task and if performance or intuitiveness isn’t an issue, this should be your chosen method. However, if performance is a concern, then you might want to consider an alternative way of creating the mask.
2. Positional indexing
Positional indexing (df.iloc[...]) has its use cases, but this isn’t one of them. In order to identify where to slice, we first need to perform the same boolean analysis we did above. This leaves us performing one extra step to accomplish the same task.
mask = df['A'] == 'foo'
pos = np.flatnonzero(mask)
df.iloc[pos]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
3. Label indexing
Label indexing can be very handy, but in this case, we are again doing more work for no benefit
df.set_index('A', append=True, drop=False).xs('foo', level=1)
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
4. df.query() API
pd.DataFrame.query is a very elegant/intuitive way to perform this task, but is often slower. However, if you pay attention to the timings below, for large data, the query is very efficient. More so than the standard approach and of similar magnitude as my best suggestion.
df.query('A == "foo"')
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
My preference is to use the Boolean mask
Actual improvements can be made by modifying how we create our Boolean mask.
mask alternative 1
Use the underlying NumPy array and forgo the overhead of creating another pd.Series
mask = df['A'].values == 'foo'
I’ll show more complete time tests at the end, but just take a look at the performance gains we get using the sample data frame. First, we look at the difference in creating the mask
%timeit mask = df['A'].values == 'foo'
%timeit mask = df['A'] == 'foo'
5.84 µs ± 195 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
166 µs ± 4.45 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Evaluating the mask with the NumPy array is ~ 30 times faster. This is partly due to NumPy evaluation often being faster. It is also partly due to the lack of overhead necessary to build an index and a corresponding pd.Series object.
Next, we’ll look at the timing for slicing with one mask versus the other.
mask = df['A'].values == 'foo'
%timeit df[mask]
mask = df['A'] == 'foo'
%timeit df[mask]
219 µs ± 12.3 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
239 µs ± 7.03 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
The performance gains aren’t as pronounced. We’ll see if this holds up over more robust testing.
mask alternative 2
We could have reconstructed the data frame as well. There is a big caveat when reconstructing a dataframe—you must take care of the dtypes when doing so!
Instead of df[mask] we will do this
pd.DataFrame(df.values[mask], df.index[mask], df.columns).astype(df.dtypes)
If the data frame is of mixed type, which our example is, then when we get df.values the resulting array is of dtype object and consequently, all columns of the new data frame will be of dtype object. Thus requiring the astype(df.dtypes) and killing any potential performance gains.
%timeit df[m]
%timeit pd.DataFrame(df.values[mask], df.index[mask], df.columns).astype(df.dtypes)
216 µs ± 10.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
1.43 ms ± 39.6 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
However, if the data frame is not of mixed type, this is a very useful way to do it.
Given
np.random.seed([3,1415])
d1 = pd.DataFrame(np.random.randint(10, size=(10, 5)), columns=list('ABCDE'))
d1
A B C D E
0 0 2 7 3 8
1 7 0 6 8 6
2 0 2 0 4 9
3 7 3 2 4 3
4 3 6 7 7 4
5 5 3 7 5 9
6 8 7 6 4 7
7 6 2 6 6 5
8 2 8 7 5 8
9 4 7 6 1 5
%%timeit
mask = d1['A'].values == 7
d1[mask]
179 µs ± 8.73 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Versus
%%timeit
mask = d1['A'].values == 7
pd.DataFrame(d1.values[mask], d1.index[mask], d1.columns)
87 µs ± 5.12 µs per loop (mean ± std. dev. of 7 runs, 10000 loops each)
We cut the time in half.
mask alternative 3
@unutbu also shows us how to use pd.Series.isin to account for each element of df['A'] being in a set of values. This evaluates to the same thing if our set of values is a set of one value, namely 'foo'. But it also generalizes to include larger sets of values if needed. Turns out, this is still pretty fast even though it is a more general solution. The only real loss is in intuitiveness for those not familiar with the concept.
mask = df['A'].isin(['foo'])
df[mask]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
However, as before, we can utilize NumPy to improve performance while sacrificing virtually nothing. We’ll use np.in1d
mask = np.in1d(df['A'].values, ['foo'])
df[mask]
A B C D
0 foo one 0 0
2 foo two 2 4
4 foo two 4 8
6 foo one 6 12
7 foo three 7 14
Timing
I’ll include other concepts mentioned in other posts as well for reference.
Code Below
Each column in this table represents a different length data frame over which we test each function. Each column shows relative time taken, with the fastest function given a base index of 1.0.
res.div(res.min())
10 30 100 300 1000 3000 10000 30000
mask_standard 2.156872 1.850663 2.034149 2.166312 2.164541 3.090372 2.981326 3.131151
mask_standard_loc 1.879035 1.782366 1.988823 2.338112 2.361391 3.036131 2.998112 2.990103
mask_with_values 1.010166 1.000000 1.005113 1.026363 1.028698 1.293741 1.007824 1.016919
mask_with_values_loc 1.196843 1.300228 1.000000 1.000000 1.038989 1.219233 1.037020 1.000000
query 4.997304 4.765554 5.934096 4.500559 2.997924 2.397013 1.680447 1.398190
xs_label 4.124597 4.272363 5.596152 4.295331 4.676591 5.710680 6.032809 8.950255
mask_with_isin 1.674055 1.679935 1.847972 1.724183 1.345111 1.405231 1.253554 1.264760
mask_with_in1d 1.000000 1.083807 1.220493 1.101929 1.000000 1.000000 1.000000 1.144175
You’ll notice that the fastest times seem to be shared between mask_with_values and mask_with_in1d.
res.T.plot(loglog=True)

Functions
def mask_standard(df):
mask = df['A'] == 'foo'
return df[mask]
def mask_standard_loc(df):
mask = df['A'] == 'foo'
return df.loc[mask]
def mask_with_values(df):
mask = df['A'].values == 'foo'
return df[mask]
def mask_with_values_loc(df):
mask = df['A'].values == 'foo'
return df.loc[mask]
def query(df):
return df.query('A == "foo"')
def xs_label(df):
return df.set_index('A', append=True, drop=False).xs('foo', level=-1)
def mask_with_isin(df):
mask = df['A'].isin(['foo'])
return df[mask]
def mask_with_in1d(df):
mask = np.in1d(df['A'].values, ['foo'])
return df[mask]
Testing
res = pd.DataFrame(
index=[
'mask_standard', 'mask_standard_loc', 'mask_with_values', 'mask_with_values_loc',
'query', 'xs_label', 'mask_with_isin', 'mask_with_in1d'
],
columns=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
dtype=float
)
for j in res.columns:
d = pd.concat([df] * j, ignore_index=True)
for i in res.index:a
stmt = '{}(d)'.format(i)
setp = 'from __main__ import d, {}'.format(i)
res.at[i, j] = timeit(stmt, setp, number=50)
Special Timing
Looking at the special case when we have a single non-object dtype for the entire data frame.
Code Below
spec.div(spec.min())
10 30 100 300 1000 3000 10000 30000
mask_with_values 1.009030 1.000000 1.194276 1.000000 1.236892 1.095343 1.000000 1.000000
mask_with_in1d 1.104638 1.094524 1.156930 1.072094 1.000000 1.000000 1.040043 1.027100
reconstruct 1.000000 1.142838 1.000000 1.355440 1.650270 2.222181 2.294913 3.406735
Turns out, reconstruction isn’t worth it past a few hundred rows.
spec.T.plot(loglog=True)

Functions
np.random.seed([3,1415])
d1 = pd.DataFrame(np.random.randint(10, size=(10, 5)), columns=list('ABCDE'))
def mask_with_values(df):
mask = df['A'].values == 'foo'
return df[mask]
def mask_with_in1d(df):
mask = np.in1d(df['A'].values, ['foo'])
return df[mask]
def reconstruct(df):
v = df.values
mask = np.in1d(df['A'].values, ['foo'])
return pd.DataFrame(v[mask], df.index[mask], df.columns)
spec = pd.DataFrame(
index=['mask_with_values', 'mask_with_in1d', 'reconstruct'],
columns=[10, 30, 100, 300, 1000, 3000, 10000, 30000],
dtype=float
)
Testing
for j in spec.columns:
d = pd.concat([df] * j, ignore_index=True)
for i in spec.index:
stmt = '{}(d)'.format(i)
setp = 'from __main__ import d, {}'.format(i)
spec.at[i, j] = timeit(stmt, setp, number=50)
Pandas DataFrame.query() method is used to query the rows based on the expression (single or multiple column conditions) provided and returns a new DataFrame. In case you wanted to update the existing referring DataFrame use inplace=True argument.
In this article, I will explain the syntax of the Pandas DataFrame query() method and several working examples like query with multiple conditions and query with string contains to new few.
Related:
- pandas.DataFrame.filter() – To filter rows by index and columns by name.
- pandas.DataFrame.loc[] – To select rows by indices label and column by name.
- pandas.DataFrame.iloc[] – To select rows by index and column by position.
- pandas.DataFrame.apply() – To custom select using lambda function.
1. Quick Examples of pandas query()
If you are in hurry, below are quick examples of how to use pandas.DataFrame.query() method.
# Query Rows using DataFrame.query()
df2=df.query("Courses == 'Spark'")
#Using variable
value='Spark'
df2=df.query("Courses == @value")
#inpace
df.query("Courses == 'Spark'",inplace=True)
#Not equals, in & multiple conditions
df.query("Courses != 'Spark'")
df.query("Courses in ('Spark','PySpark')")
df.query("`Courses Fee` >= 23000")
df.query("`Courses Fee` >= 23000 and `Courses Fee` <= 24000")
If you are a learner, Let’s see with sample data and run through these examples and explore the output to understand better. First, let’s create a pandas DataFrame from Dict.
import pandas as pd
import numpy as np
technologies= {
'Courses':["Spark","PySpark","Hadoop","Python","Pandas"],
'Fee' :[22000,25000,23000,24000,26000],
'Duration':['30days','50days','30days', None,np.nan],
'Discount':[1000,2300,1000,1200,2500]
}
df = pd.DataFrame(technologies)
print(df)
Note that the above DataFrame also contains None and Nan values on Duration column that I would be using in my examples below to select rows that has None & Nan values or select ignoring these values.
3. Using DataFrame.query()
Following is the syntax of DataFrame.query() method.
# query() method syntax
DataFrame.query(expr, inplace=False, **kwargs)
expr– expression takes conditions to query rowsinplace– Defaults toFalse. When set toTrue, it updates the referring DataFrame andquery()method returnsNone.**kwargs– Keyword arguments that works with eval()
DataFrame.query() takes condition in expression to select rows from a DataFrame. This expression can have one or multiple conditions.
# Query all rows with Courses equals 'Spark'
df2=df.query("Courses == 'Spark'")
print(df2)
Yields below output.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
In case you wanted to use a variable in the expression, use @ character.
# Query Rows by using Python variable
value='Spark'
df2=df.query("Courses == @value")
print(df2)
If you notice the above examples return a new DataFrame after filtering the rows. if you wanted to update the existing DataFrame use inplace=True
# Replace current esisting DataFrame
df.query("Courses == 'Spark'",inplace=True)
print(df)
If you wanted to select based on column value not equals then use != operator.
# not equals condition
df2=df.query("Courses != 'Spark'")
Yields below output.
Courses Courses Fee Duration Discount
1 PySpark 25000 50days 2300
2 Hadoop 23000 30days 1000
3 Python 24000 None 1200
4 Pandas 26000 NaN 2500
4. Select Rows Based on List of Column Values
If you have values in a python list and wanted to select the rows based on the list of values, use in operator, it’s like checking a value contains in a list of string values.
# Query Rows by list of values
print(df.query("Courses in ('Spark','PySpark')"))
Yields below output.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
1 PySpark 25000 50days 2300
You can also write with a list of values in a python variable.
# Query Rows by list of values
values=['Spark','PySpark']
print(df.query("Courses in @values"))
To select rows that are not in a list of column values can be done using not in operator.
# Query Rows not in list of values
values=['Spark','PySpark']
print(df.query("Courses not in @values"))
If you have column names with special characters using column name surrounded by tick ` character .
# Using columns with special characters
print(df.query("`Courses Fee` >= 23000"))
5. Query with Multiple Conditions
In Pandas or any table-like structures, most of the time we would need to select the rows based on multiple conditions by using multiple columns, you can do that in Pandas DataFrame as below.
# Query by multiple conditions
print(df.query("`Courses Fee` >= 23000 and `Courses Fee` <= 24000"))
Yields below output. Alternatively, you can also use pandas loc with multiple conditions.
Courses Courses Fee Duration Discount
2 Hadoop 23000 30days 1000
3 Python 24000 None 1200
6. Query Rows using apply()
pandas.DataFrame.apply() method is used to apply the expression row-by-row and return the rows that matched the values. The below example returns every match when Courses contains a list of specified string values.
# By using lambda function
print(df.apply(lambda row: row[df['Courses'].isin(['Spark','PySpark'])]))
Yields below output. A lambda expression is used with pandas to apply the function for each row.
Courses Fee Duration Discount
0 Spark 22000 30days 1000
1 PySpark 25000 50days 2300
8. Other Examples using df[] and loc[]
# Other examples you can try to query rows
df[df["Courses"] == 'Spark']
df.loc[df['Courses'] == value]
df.loc[df['Courses'] != 'Spark']
df.loc[df['Courses'].isin(values)]
df.loc[~df['Courses'].isin(values)]
df.loc[(df['Discount'] >= 1000) & (df['Discount'] <= 2000)]
df.loc[(df['Discount'] >= 1200) & (df['Fee'] >= 23000 )]
# Select based on value contains
print(df[df['Courses'].str.contains("Spark")])
# Select after converting values
print(df[df['Courses'].str.lower().str.contains("spark")])
#Select startswith
print(df[df['Courses'].str.startswith("P")])
Conclusion
In this article, I have explained multiple examples of how to query Pandas DataFrame Rows based on single and multiple conditions, from a list of values (checking column value exists in list of string values) e.t.c. Remember when you query DataFrame Rows, it always returns a new DataFrame with selected rows, in order to update existing df you have to use inplace=True. I hope this article helps you learn Pandas.
Happy Learning !!
Related Articles
- Different Ways to Rename Pandas DataFrame Column
- How to Drop Column From Pandas DataFrame
- Pandas- How to get a Specific Cell Value from DataFrame
- Pandas Filter DataFrame by Multiple Conditions
- Pandas apply map (applymap()) Explained
- Apply Multiple Filters to Pandas DataFrame or Series
- Pandas Filter Rows by Conditions
- Pandas Filter by Column Value
References
- https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.query.html
- https://pandas.pydata.org/docs/reference/api/pandas.eval.html#pandas.eval
В Pandas данные представлены в виде двухмерной таблицы Dataframe. Получение значений отдельной строки из Dataframe является часто встречающейся задачей. В этой статье мы рассмотрим три метода, как это можно сделать.
Для учебного примера создадим датафрейм с информацией по городам:
import pandas as pd
city_data = {
‘Город’:[‘Москва’, ‘Казань’, ‘Владивосток’, ‘Санкт-Петербург’, ‘Калининград’],
‘Дата основания’:[‘1147’, ‘1005’, ‘1860’, ‘1703’, ‘1255’],
‘Площадь’:[‘2511’, ‘516’, ‘331’, ‘1439’, ‘223’],
‘Население’:[‘11,9’, ‘1,2’, ‘0,6’, ‘4,9’, ‘0,4’],
‘Погода’:[‘8’, ‘8’, ’17’, ‘9’, ’12’] }
city_df = pd.DataFrame(city_data)
city_df
Способ 1. Выбор строки по ее индексу в Pandas
Метод iloc() позволяет получить строку по номеру ее индекса. Обратите внимание, что нумерация строк в Pandas начинается с 0. Давайте получим значения строки по городу Владивосток и выведем их, индекс у него 2:
print(city_df.iloc[2])

Способ 2. Выбор строки по условию в столбце Pandas
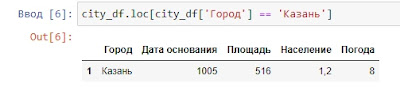
В случае, если вам нужно получить значение строки по определенному условию в столбце, то нам подойдет метод loc(). Давайте отразим значения строки, по условию что город у нас равен «Казань»:
city_df.loc[city_df[‘Город’] == ‘Казань’]
Способ 3. Выбор строки по нескольким условиям в столбцах Pandas
Отбор можно проводить как по одному условию (см. Способ 2), так и по нескольким. Давайте найдем строку с городом, год основания которого 1703, а площадь 1439:
city_df.loc[(city_df[‘Дата основания’] == ‘1703’)&(city_df[‘Площадь’] ==’1439′)]

Обратите внимание на то, что каждое условие должно быть заключено в круглые скобки, а между ними логическое И либо ИЛИ: & или | (Важно!!! Команды and и or в Pandas не работают для отборов, используйте только & или |).
Мы рассмотрели основные варианты получения значения строки в Pandas по условию. Эти знания могут помочь вам получить современную, высокооплачиваемую профессию, к примеру Data Scientist. А для того, чтобы получить все необходимые для этого навыки, пройдите курс «
Data Scientist с нуля до Junior
» от Skillbox.
Спасибо за внимание. Для лучшего понимания материала прикладываю
ноутбук
для этой статьи.