The purpose of this wiki is to explain the reason why SAP BusinessObjects Analysis, edition for Microsoft Office (AO) shows the message «Size limit of result set exceeded» in some scenarios and also to provide details about the memory consumption and what to do when working with huge reports.
Please note that Analysis for Office is a reporting tool, hence it is not suitable for mass data extraction but for data analysis.
1 — Analysis for Office is showing the message «Size limit of result set exceeded»
When the report retrieves too much data from the backend, one of the three scenarios below may occur:
- The message «Size limit of result set exceeded» is displayed in AO instead of the data, see also note 1656983.

- It takes too much time to display the data = performance issue.
- An error/exception occurs in AO, which is related to «out of memory».

2 — Default limit of 500.000 data cells
In Analysis for Office, there is a default limit of 500.000 data cells for the result set. This limit exists because of a memory limitation in .NET framework explained in section #4.
When the report retrieves too much data from the backend and ends up reaching the limit of data cells, the message «Size limit of result set exceeded» will be shown in AO instead of the expected data.
3 — Changing the default limit of the result set in Analysis for Office
SAP does not recommend to change the result set default limit of Analysis for Office.
- However, it is possible to change the default limit.
- You can define the limit of data cells on client side or in BW backend system.
- Note that when connected directly to HANA system, it is not possible to define the limit in HANA side like when connected to BW system. In this case, AO will use the value defined in client side only.
3.1 — Result size Configuration on Client using parameter ResultSetSizeLimit
- You can change result size with the DataSourceConfiguration parameter ResultSetSizeLimit.
- In AO Administrator’s Guide the parameter is described as following:
- This setting defines the maximum number of data cells that are loaded from the server for one data source.
- If a data source contains data for more cells than defined here, a message displays.
- The standard value for this setting is empty and the maximum number of cells is 500000.
- If you set the parameter to a specific number greater than or equal to 0, you define the maximum number of cells with this value.
- If you set the parameter to -1, the setting uses the values defined in the BW system.
- In AO 2.x, the settings are maintained in the file system and not in the registry like in AO 1.x versions.
- The ResultSetSizeLimit setting can be maintained in Ao_app.config (located in %PROGRAMDATA%SapCof) or Ao_user_roaming.config (located in %APPDATA%SapCof).
- When scheduling Analysis workbooks, the ResultSetSizeLimit setting is maintained in AO_BiPrecalculation.config (located in Analysis Precalculation installation folder).
- Please follow note 2083067 — How to maintain settings for Analysis Office 2.x to set ResultSetSizeLimit parameter.
- The value of the ResultSetSizeLimit setting is defined as below by default:
|
ResultSetSizeLimit value |
information |
|---|---|
| <!—default: value=»500000″ —> <ResultSetSizeLimit /> |
This is Comment Line. The default value for this setting is empty. It means this setting will use the default value 500000 for the maximum number of cells. |
| <ResultSetSizeLimit value=»400000″ /> | The parameter can be set to a specific number to define the maximum number of data cells with this value. The example is changing the ResultSetSizeLimit to 400.000 data cells. |
| <ResultSetSizeLimit value=»-1″ /> |
The parameter can be set to -1 so that the setting uses the values defined in the BW System (see section 3.2). |
3.2 — Result size configuration in BW System using parameter BICS_DA_RESULT_SET_LIMIT_MAX
- If you set the ResultSetSizeLimit parameter to -1, the setting uses the values defined in the BW system.
- In BW system, the parameter is set in the RSADMIN table for object BICS_DA_RESULT_SET_LIMIT_MAX (see note 1656983).
- In BW/4HANA system, the safety parameters are part of the SPRO customizing (transaction SPRO -> SAP BW/4HANA -> Analysis -> Settings for BICS interface and clients) and should be maintained using the customizing. If case of RSADMIN set in parallel, the RSADMIN parameter value has higher priority.
- The performance issue occurs because of the amount of data cells that is being retrieved from the backend. If the report is huge and shows too much data, it will take a time to be displayed.
- The «out of memory» error occurs because there is a limit of memory that a process can allocate in a 32-bit environment. This limit is not related to Analysis for Office and it is not possible to change it.
- When a query is executed in AO, objects are created in the main memory of the Frontend for each cell of the result set. Regardless of the number of cells, AO itself allocate additional memory as a kind of baseline from the starting point on (about 100 megabytes).
- Independently of the memory capacity in the Frontend, in a 32 Bit environment, a process can allocate a maximum of approximately 2 gigabytes (GB). The .NET framework itself has an overhead of 600-800 megabytes (MB). So the maximum memory allocation of the EXCEL.EXE process is approximately 1,2 (GB) before getting an out of memory exception on the Frontend.
- Also see note 1729141 — Analysis Office: Front End Memory Consumption
5 — How to avoid the «Size limit of result set exceeded» message, the «out of memory» exception and the performance issue
- The SAP recommendation is to not change the default limitation of 500.000 data cells in Analysis for Office.
- If any of the scenarios explained on this page is occurring, the recommendation is to evaluate whether the report can be changed to display less data.
- This can be done by adding more filters and mandatory variables, for example.
- If it is really necessary to execute huge reports for data analysis and change the ResultSetSizeLimit setting, we recommend to use the 64 Bit version of MS Office and the 64 Bit version of Analysis, edition for MS Office since more memory can be allocated in this case.
- Also, see note 1703279 — General performance recommendations Analysis Office.
6 — Debugging / FAQ
6.1 — I changed the value of the ResultSetSizeLimit setting. How do I know whether Analysis for Office is using the value that I defined?
- Reproduce the scenario in Analysis for Office recording a backend trace (Settings > Support > «Enable BW Server Tracing»);
- In the BW system, go to transaction RSTT and enter the trace;
- Click on display;
- Select the program module BICS_PROV_GET_RESULT_SET and click on «Parameters»;
- Check the tag <I_MAX_DATA_CELLS>, this is the value that Analysis Office is using for the limit of the result set size.
6.2 — I confirmed that Analysis Office is using the value that I defined for the limit of the result set but still I am getting message «Size limit of result set exceeded». Why?
The report is retrieving more data cells than the value defined for the result set size limit.
Follow the steps below in order to know exactly how many data cells are being retrieved from the backend:
- Run transaction SE37 and enter function module BICS_PROV_GET_RESULT_SET;
-
Set an external breakpoint line 94:
IF e_state = cl_rsbolap_qv_result_set=>c_state_data. * Result set size e_n_rows = l_r_rs_rows_axis->n_sx_axis-setxx_size. e_n_columns = l_r_rs_columns_axis->n_sx_axis-setxx_size. l_n_data_cells = e_n_columns * e_n_rows. ENDIF. * provide the max data cell value to the result set object in context. l_r_result_set->set_max_data_cells( i_max_data_cells ). IF i_max_data_cells = 0 OR i_max_data_cells >= l_n_data_cells. - Reproduce the scenario in Analysis for Office;
- Check the value in >> l_n_data_cells
This value is the number of data cells that Analysis for Office is trying to retrieve from the backend.
In case everything is in place according to this Wiki page but the scenario is not working as expected and you want to create an SAP incident for further analysis, please check and provide the following:
-
Is the scenario reproducible in the latest version of Analysis for Office?
- What is the value of the setting ResultSetSizeLimit?
- If ResultSetSizeLimit is set to -1, what is the value of BICS_DA_RESULT_SET_LIMIT_MAX in RSADMIN table?
-
Record and attach to the incident the TRACE files of the scenario reproduced in the latest version of Analysis for Office by following the instructions of SAP note 2129389. Do not forget to select the «Enable BW Server Tracing» check box.
-
Attach to the incident a document with screenshots showing the step-by-step to reproduce the scenario in details, including the technical name of the objects involved;
-
Attach to the incident the files Ao_app.config and Ao_user_roaming.config;
-
Make sure that the following connections are open on the system:
— SAP NI Connection (note 1718597)
— R/3 Support (note 812732) - Make sure there is valid user and password information in the secure area (see note 1773689).
Link to this page: https://wiki.scn.sap.com/wiki/x/IIh9Gg
<<< Вернуться в основной раздел «QlikView — краткий учебник»
Contents
- 1 Анализ Множеств (Set Analysis) в QlikView
- 1.1 Что такое множество в QlikView?
- 2 Синтаксис анализа множеств (Set Analysis) в QlikView
- 2.1 Идентификаторы множества
- 2.2 Операторы множества
- 2.3 Модификаторы множества
- 2.3.1 Модификаторы множества с операторами множества
- 2.3.2 Модификаторы множества с помощью назначений с неявными операторами множества
- 2.3.3 Модификаторы множества с расширениями со знаком доллара
- 2.3.4 Модификаторы множества с расширенными поисками
- 2.3.5 Модификаторы множества с неявными определениями значений поля
- 2.4 Синтаксис для множеств
- 2.5 Использование переменных в Set Analysis
- 2.6 Использование функций в модификаторе Set Analysis (QlikView)
- 2.7 Видео-материалы по Set Analysis в QlikView
- 3 Где и в каких случаях используется Set Analysis в QlikView на практике?
- 4 Большая картинка по анализу множеств в QlikView (Set Analysis)
- 5 Примеры Set Analysis в QlikView
- 6 Сложные примеры по Set Analysis в QlikView
- 7 Литература по SET ANALYSIS
Анализ Множеств (Set Analysis) — одна из основ для построения сложных приложений QlikView. В этой статье рассматриваются инструменты управления Set Analysis.
Что такое множество в QlikView?
Представим, что наше приложение состоит из таблицы фактов и нескольких измерений (схема «Звезда»). Пусть все данные таблицы фактов разделены на два уровня с помощью измерения «Уровни данных»:
- 1 уровень «Первоначально загруженные данные» — это факты, которые были загружены из источников данных;
- 2 уровень «Обработанные данные» — это данные, которые были получены из первичных данных в ходе тех или иных вычислений.
Допустим, что нам нужно отобразить на графике «Выручка от продаж» («Выручка от продаж» — это элемент измерения «Статьи»), при этом данные необходимо получить с уровня «Первоначально загруженные данные». Т.е. фактически нам необходимо работать с ограниченным набором данных из таблицы фактов. Вот тут то нам и приходит на помощь такой инструмент, как множества.
Итак, множество — это ограниченный набор данных, который мы задаем с помощью специального синтаксиса.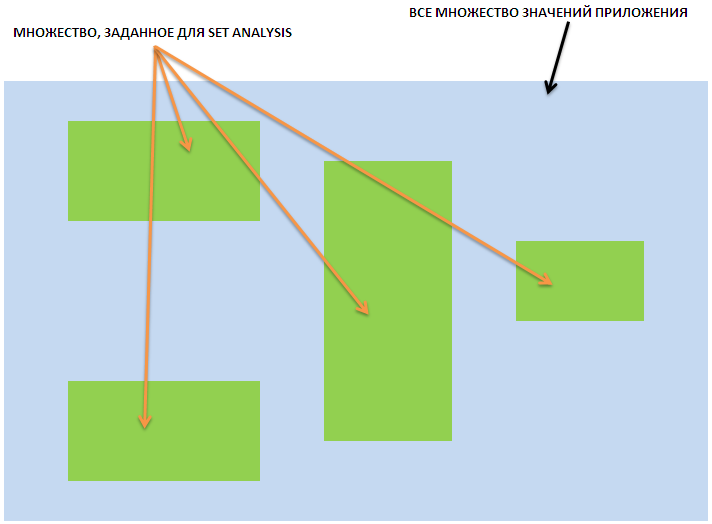
Анализ множеств (Set Analysis) позволяет обрабатывать ограниченный набор данных, на которые не влияют текущие выбранные данные (фильтры, которые мы применили к данным в нашем приложении).
Фактически, множества задают контекст в expression, в разрезе которого мы анализируем данные.

Синтаксис анализа множеств (Set Analysis) в QlikView
Множества описываются в QlikView при помощи фигурных скобок {}.
Пример записи множества:
|
sum({<region= {‘Ярославская область’,‘Владимирская область’}, productgroup={‘Ноутбуки’,‘Телефоны’,‘Планшеты’}>} Sales) |

Далее описываются основные синтаксические элементы, которые используются для задания или модификации множества.
Идентификаторы множества
Знак 0 — описывает пустое множество.
Знак 1 — описывает полное множество всех записей в приложении.
Знак $ — представляет записи текущей выборки.
Рассмотрим выражения, которые можно формировать с помощью идентификаторов:
Выражение {$} указывает на текущую выборку.
Выражение {1-$} обозначает отрицание текущей выборки, т.е. множество, которое образуется путем исключения из всех значений приложения текущей выборки.
Выражение {$1} представляет предыдущую выборку, т.е. эквивалентно нажатию кнопки «Назад».
Выражение {$_1}, {$_2} … {$_N} представляет следующие выборки, т.е. на один, два … N шагов вперед, т.е. эквивалентно нажатию кнопки «Вперед». В уведомлениях Назад и Вперед может быть использовано любое целое без знака. Выражение {$_0} представляет текущую выборку.
Выражение {1} игнорируется текущая выборка (за множество данных берутся все строки приложения). Измерение не игнорируется.
Выражение {1} Total — игнорируется и текущая выборка, и измерение.
Выражение {MyBookMark} — множество содержит набор значений, которое образуется фильтрами, сохраненными в закладке «MyBookmark» приложения QlikView.
Group – Название группы, альтернативное состояние (Alternate State)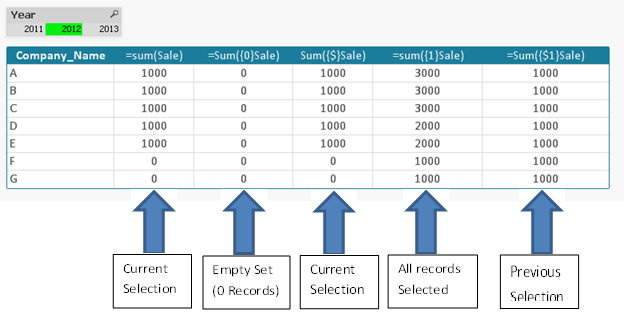
Операторы множества
Над множествами можно производить операции, которые описываются операторами. В результате применения операторов над операндами (множествами) образуется новое множество. В QlikView используются следующие типы операторов:
+ Union (Объединение). Оператор объединения множеств. Т.е. множество записей A + множество записей B = множество записей C.
— Exclusion (Исключение). Оператор вычитание одного множества записей из другого множества записей. Т.е. множество записей A — множество записей B = множество записей D.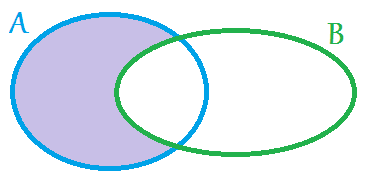
* Intersection (Пересечение). Оператор, который образует множество, которое принадлежит каждому множеству, над которым выполняется данная операция. Т.е. множество записей A * множество записей B = множество записей E.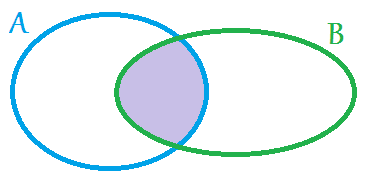
/ Symmetric difference XOR (Исключающее ИЛИ). Образуется множество, которое не содержит общих записей двух множеств. Т.е. множество записей A / множество записей B = множество записей F.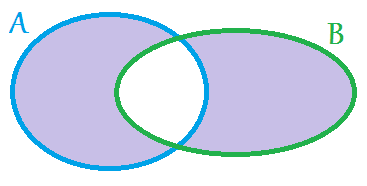
Примеры:
- Выражение {1-$} описывает все записи приложения, исключая текущую выборку.
- Выражение {$*MyBookMark} описывает множество, образованное текущей выборкой и закладкой «MyBookMark».
- Выражение {-($+MyBookMark)} описывает множество всех значений в приложении, исключая множество значений, образованное текущей выборкой и закладкой «MyBookMark».
Модификаторы множества
Множество может быть изменено дополнительной или переобозначенной выборкой. Подобное изменение может быть записано в выражении множества. Модификатор состоит из одного или нескольких имен полей, за каждым из которых следует выборка, которая должна быть составлена на основе поля и заключена в < и >. Например: <Year={2007,2008},Region={‘Владимирская область’}>.
Имена и значения полей могут цитироваться как обычно. Например: <[Регион продаж]={‘Московская область’, ‘Ленинградская область’}>.
Существует несколько способов определения выборки:
1) Первый случай (редко используется) — это выборка, основанная на выбранных значениях другого поля.
Например: <[Дата заказа] = [Дата поставки]>. Данный модификатор возьмет выбранные значения из [Дата поставки] и применит их в качестве выборки к [Дата заказа]. Если присутствует множество уникальных значений (больше пары сотен), то данная операция потребует ресурсов CPU, поэтому ее следует избегать.
2) Наиболее распространенным случаем является второй — выборка, основанная на списке значений полей, заключенном в фигурные скобки, значения разделены запятыми.
Например: <Year = {2007, 2008}>. Здесь фигурные скобки определяют множество элементов, в котором элементы могут быть либо значениями полей, либо поисками значений полей. Поиск всегда определяется использованием двойных кавычек. Например, <Ingredient = {‘*чеснок*’}> выберет все ингредиенты, где есть подстрока ‘чеснок’. Поиски чувствительны к регистру, а также выполняются для всех исключенных значений.
Пустые множества элементов, которые заданы явно, например <Product = {}>, или которые заданы неявно, например <Product = {‘Perpetuum Mobile’}>, означают, что продукция отсутствует, поэтому результатом будет множество записей, не связанных с каким-либо продуктом. Обратите внимание, что данное множество может быть достигнуто с помощью обычных выборок, кроме случаев, когда выборка сделана в другом поле.
3) При необходимости для принудительного исключения определенных значений поля требуется использовать знак ‘~’ (тильда) перед именем поля.
4) Модификатор множества может использоваться на идентификаторе множества или сам по себе. Он не может использоваться на выражении множества. При использовании на идентификаторе множества модификатор должен быть записан сразу после идентификатора множества. Например: {$<Year = {2007, 2008}>}. При использовании модификатора самого по себе он интерпретируется как изменение текущей выборки.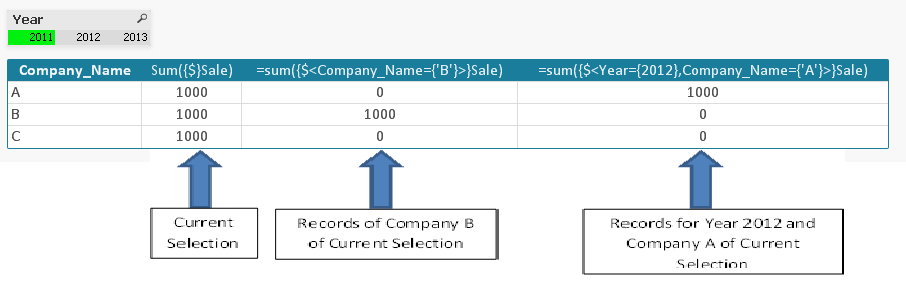
Примеры:
- sum({1<Region= {‘Владимирская область’} >} Sales) данное выражение возвращает продажи для региона ‘Владимирская область’, при этом текущая выборка игнорируется.
- sum({$1<Region = >} Sales) возвращает продажи для текущей выборки, при этом выборка по измерению ‘Region’ удаляется.
- sum({<Region = >} Sales) возвращает то же самое, что и в примере sum({$} Sales). Если в модификаторе отсутствует указанное множество, то используется знак $.
- sum({$<Year = {‘2013′,’2014′,’2015’}, Region = {‘Ярославская область’,’Владимирская область’,’Смоленская область’}>} Sales) возвращает продажи для текущей выборки, но с новыми выборками в по измерениям «Year» и «Region».
- sum({$<~Ingredient = {‘*чеснок*’}>} Sales) возвращает продажи для текущей выборки, но с принудительным исключением все ингредиентов, содержащих подстроку ‘чеснок’.
- sum({$<Year = {‘201*’,’199*’}>} Sales) возвращает продажи для текущей выборки, но по измерению Year берутся все года, которые начинаются на ‘201*’ и на ‘199*’, т.е. в измерении ‘Year’ выбраны диапазоны 1990-1999 и 2010-2019 (все года, которые больше текущего, могут содержать прогнозные данные, если Ваша модель это предполагает).
- sum($<Year = {‘>$2001<2007’}>} Sales) данный пример возвращает продажи для текущей выборки, но года берутся в диапазоне ‘больше 2001 года’ и ‘меньше 2007 года’.
Внимание: <Region = > не эквивалентно выражению <Region = {}>, т.к. в первом случае фильтры будут сброшены (выборка по региону будет сброшена), а во втором случае выражение будет интерпретироваться как ‘взять все записи, у которых Region является пустым полем (регион отсутствует)’.
Модификаторы множества с операторами множества
Выборка в поле может быть определена с помощью операторов множества при работе с различными множествами элементов.
Например, модификатор <Year = {’20*’, 1997} — {2000}> выберет все года, начиная с «20» в дополнение к «1997», кроме«2000».
Модификаторы множества с помощью назначений с неявными операторами множества
Необходимо образовать выборку на текущей выборке и добавить несколько значений.
Например, выражение <Year = Year + {2007, 2008}> можно получить с помощью выражения <Year += {2007, 2008}>. Т.е. оператор назначения неявно определяет объединение. Также неявные «пересечения», «исключения» и «Исключающее ИЛИ» могут быть определены с помощью “*=”, “–=” и “/=”.
Модификаторы множества с расширениями со знаком доллара
В выражениях множества могут использоваться переменные и другие множества со знаком доллара.
Примеры:
- sum({$<Year = {$(#vLastYear)}>} Sales) возвращает продажи для предыдущего года в отношении текущей выборки. Здесь переменная vLastYear, содержащая соответствующий год, используется в множестве со знаком доллара.
- sum({$<Year = {$(#=Only(Year)-1)}>} Sales) возвращает продажи для предыдущего года в отношении текущей выборки. Здесь множество со знаком доллара используется для расчета предыдущего года.
Модификаторы множества с расширенными поисками
Для определения множеств могут использоваться расширенные поиски с помощью подстановочных знаков и агрегирований.
Примеры:
- sum({$–1<Product = {‘*Internal*’, ‘*Domestic*’}>} Sales) возвращает продажи для текущей выборки, за исключением продуктов с подстрокой «Internal» или «Domestic» в имени продукта.
- sum({$<Customer = {‘=Sum({1<Year = {2015}>} Sales ) > 1000000’}>} Sales) возвращает продажи для текущей выборки, но с новой выборкой в поле «Customer»: только клиенты с общими продажами более 1000000 за 2015 год.
Модификаторы множества с неявными определениями значений поля
Существует дополнительный способ определения множества значений поля, используя вложенное определение множества.
В подобных случаях должны использоваться функции элемента P() и E(), представляющие множество элементов возможных значений и исключенные значения поля, соответственно. В скобках можно указать одно выражение множества и одно поле.
Например: P({1} Customer). Эти функции не могут использоваться в других выражениях.
Примеры:
- sum({$<Customer = P({1<Product={‘Shoe’}>} Customer)>} Sales) возвращает продажи для текущей выборки, но только тех клиентов, которые когда-то покупали продукт «Shoe». Здесь функция элемента P( ) возвращает список возможных клиентов, подразумеваемых выборкой «Shoe» в поле Product.
- sum({$<Customer = P({1<Product={‘Shoe’}>})>} Sales) то же, что и в примере выше. Если в функции элемента поле опущено, функция вернет возможные значения для поля, указанного во внешнем назначении.
- sum({$<Customer = P({1<Product={‘Shoe’}>} Supplier)>} Sales) возвращает продажи для текущей выборки, но только клиентов, поставлявших когда-либо продукт «Shoe». Здесь функция элемента P( ) возвращает список возможных поставщиков, подразумеваемых выборкой «Shoe» в поле Продукция. Список поставщиков затем используется в качестве выборки в поле Клиент.
- sum({$<Customer = E({1<Product={‘Shoe’}>})>} Sales) возвращает продажи для текущей выборки, но только клиентов, никогда не покупавших продукт «Shoe». Здесь функция элемента E( ) возвращает список клиентов, исключенных выборкой «Shoe» в поле Продукция.
Синтаксис для множеств
Полный синтаксис (не включая дополнительное использование стандартных скобок для определения последовательности) выглядит следующим образом:
- set_expression ::= {set_entity {set_operator set_entity}}
- set_entity ::= set_identifier [set_modifier]
- set_identifier ::= 1 | $ | $N | $_N | bookmark_id | bookmark_name
- set_operator ::= + | — | * | /
- set_modifier ::= <field_selection {,field_selection}>
- field_selection ::= field_name [ = | += | ¬–= | *= | /= ] element_set_expression
- element_set_expression ::= element_set {set_operator element_set}
- element_set ::= [field_name] | {element_list} | element_function
- element_list ::= element {, element}
- element_function ::= (P|E) ([set_expression] [field_name])
- element ::= field_value| «search_mask»
Использование переменных в Set Analysis
Зададим переменные в скрипте загрузки данных:
|
SET vYearMin = 2004; SET vYearMax = 2014; SET vYearCurr = 2015; |
В диаграммах можно задать следующие формулы с применением Set Analysis:
|
=SUM({$ <Год = {‘>=$(vYearMin)<=$(vYearMax)’}>} Продажи) |
Данное выражение вычисляет продажи, которые соответствуют текущей выборке, при этом значение измерения Год будет задано в интервале от vYearMin до vYearMax (т.е. от 2004 года до 2014 года включительно).
|
=SUM({$ <Год = {‘$(vYearCurr)’}>} Продажи) |
Данное выражение вычисляет продажи, которые соответствуют текущей выборке, при этом значение измерения Год равно vYearCurr (т.е. 2015).
Использование функций в модификаторе Set Analysis (QlikView)
|
sum( {$<Year = {$(=Only(Year)—1)}>} Sales ) |
Данное выражение возвращает число продаж за предыдущий год по отношению к выбранному году. Год должен быть выбран в единственном числе, иначе выражение не рассчитается.
Видео-материалы по Set Analysis в QlikView
Где и в каких случаях используется Set Analysis в QlikView на практике?
Анализ множеств (Set Analysis) очень часто требуется при работе с визуализацией данных. Если в скриптах можно использовать те же выражения «where», то при проектировании диаграмм крайне необходимо понимание как задается и используется множество. Ниже приведен краткий пример настройки круговой диаграммы с отображением доли выручки от продаж по продуктам: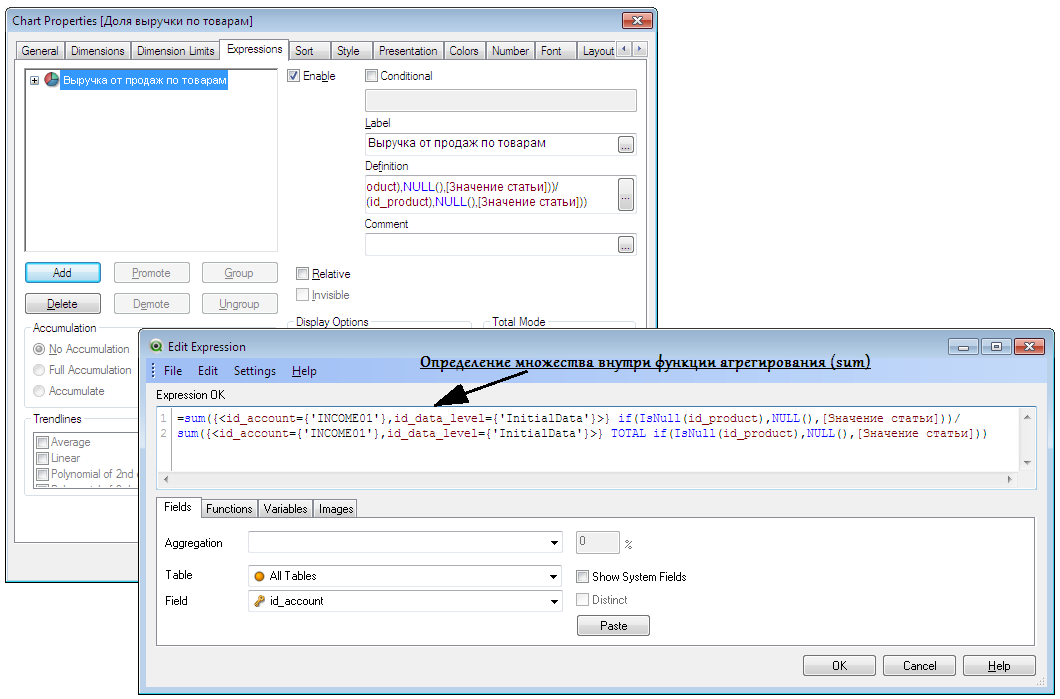
Большая картинка по анализу множеств в QlikView (Set Analysis)

Примеры Set Analysis в QlikView
|
Count ({$<[Academic Year] = {‘2011/2’} > }DISTINCT [Visitors Count]) Count({$<[Academic Year]={‘2011/2’}>}DISTINCT [Visitors Count])/Count( total{$<[Year Code]={‘2011/2’},[Service Type] = , [Visit Category] = ,[Visit Subject] = , [Academic Year]= , Month = , MonthYear= >} DISTINCT [All Students Count]) Count (DISTINCT [Visitors Count]) Count (DISTINCT [Visitors Count])/Count ( {$< [Year Code] ={«=$(vTest)» }, [Academic Year] = , [Service Type] = , [Visit Category] = , [Visit Subject] = , Month= , MonthYear= >}DISTINCT([All Students Count])) Count({<[Visitors Count]=P({<[Service Type]={‘ASC’}>}[Visitors Count])>*<[Visitors Count]=P({<[Service Type]={‘UniDesk’}>}[Visitors Count])>} distinct [VisitorsCount]) Count({<[Visitors Count]=P({<[Service Type]={‘ASC’}>}[Visitors Count])>*< [Visitors Count]=P({<[Service Type]={‘UniDesk’}>}[Visitors Count])>} distinct [Visitors Count])/ Count ( {$< [Year Code] ={«=$(vTest)» }, [Academic Year] = , [Service Type] = , [Visit Category] = , [Visit Subject] = , Month= , MonthYear= >} DISTINCT([All Students Count])) count({<[Visit Subject]=[Visit Subject]—[Associate Visit Subject], [Academic Year]= {«$(vMarketTest)»}>}distinct([Associate Student])) |
Сложные примеры по Set Analysis в QlikView
|
=sum({<Дата={«<=$(=Today())»}>} [Количество]) =sum({<Дата={«>=$(=Date(‘$(пПериод1)’))»}>*<Дата={«<=$(=Date(‘$(пПериод2)’))»}>} [Количество]) =sum({<Дата=[АльтернативноеСостояние0]::Дата>+<Дата=[АльтернативноеСостояние1]::Дата>+<Дата=[АльтернативноеСостояние2]::Дата>+<Дата=[АльтернативноеСостояние3]::Дата>} [Количество]) =sum({<Дата={«>=$(=Date(‘$(пПериод1)’))»}>*<Дата={«<=$(=Date(‘$(пПериод2)’))»}>*<[Клиент ID]={$(=Concat({$} DISTINCT chr(39)&[КлиентПоКаналуПродаж ID]&chr(39),‘,’))}>} [Сумма]) |
Литература по SET ANALYSIS
- Анализ множеств в QlikView — описание (Set Analysis).pdf
- Обучающая презенташка — QlikView Set Analysis.pdf
<<< Вернуться в основной раздел «QlikView — краткий учебник»
Acid_Firewood написал(а):
Приветствую, коллега.
По 1002 не совсем понял. В чем принципиальное отличие HRP1002 от прочих словарских таблиц? Буду благодарен за тыканье носом.
1002 инфотип имеет еще дополнительную таблицу HRT1002 в которой можно сохранять строки переменной длины. HR350 в помощь, там про табличные инфотипы все детально описано, и как работать с ними в рантайме в том числе.
Acid_Firewood написал(а):
По текстовым расширениям сегодня гляну.
По разным языкам — думаю, это не корректное предложение. У стандартной функции <HR_READ_INFOTYPE> нет входного параметра для языка, в макросе <RP-READ-INFOTYPE> — тоже. А если читать таблицы с инфотипом прямыми селектами — это совсем плохо.
Да, и есть риск запутаться или забыть какой язык для каких целей был использован.
Гм, а вот про APPEND включения к таблицам и структурам я как-то забыл совсем. Как-то на INCLUDE включениях зациклился.
Думаю, это самый лучший вариант.
Так как, если мне память не изменяет, длина APPEND структуры не суммируется с общей длинной расширяемого словарского объекта и при активации система ругаться не должна. Это тоже сегодня обязательно проверю…
Спасибо
Да текстовые таблицы к инфотипам не применимы ![]() из начального поста я не понял что требуется работать только с раширением инфотипов. Но честно говоря APPEND структуры к инфотипам тоже не применимы так как, инфотип с учетом расширения не может быть больше 1000 символов (2000 для юникод систем), так как это жестко заабаплено в транзакциях PA2030 etc, переменная CRELP, PRELP имеют в описании: PRELP(1000).
из начального поста я не понял что требуется работать только с раширением инфотипов. Но честно говоря APPEND структуры к инфотипам тоже не применимы так как, инфотип с учетом расширения не может быть больше 1000 символов (2000 для юникод систем), так как это жестко заабаплено в транзакциях PA2030 etc, переменная CRELP, PRELP имеют в описании: PRELP(1000). ![]() помните об этом когда расширяете инфотипы. Технически их больше и можно сделать но все что выше 1000 тупо обрежется и данные будут кривые.
помните об этом когда расширяете инфотипы. Технически их больше и можно сделать но все что выше 1000 тупо обрежется и данные будут кривые.
Анализ множеств, более известный как Set Analysis, – основа основ для работы с QlikView. Именно по этой причине я решил перевести данную инфографику и помочь начинающим разработчикам Qlik в не легком деле покорения вершин Клика.
Анализ множеств: шпаргалка
Под вдохновением от одного из авторов книги QlikView 11 for Developers решил для вас перевести полезную шпаргалку по анализу множеств. Конечно, в ней представлены самые основы. По сути, это – компас по использованию анализа множеств. В конце инфографики вы найдете список полезных ресурсов по Set Analysis.
Итак, Анализ множеств Qlik в инфографике:
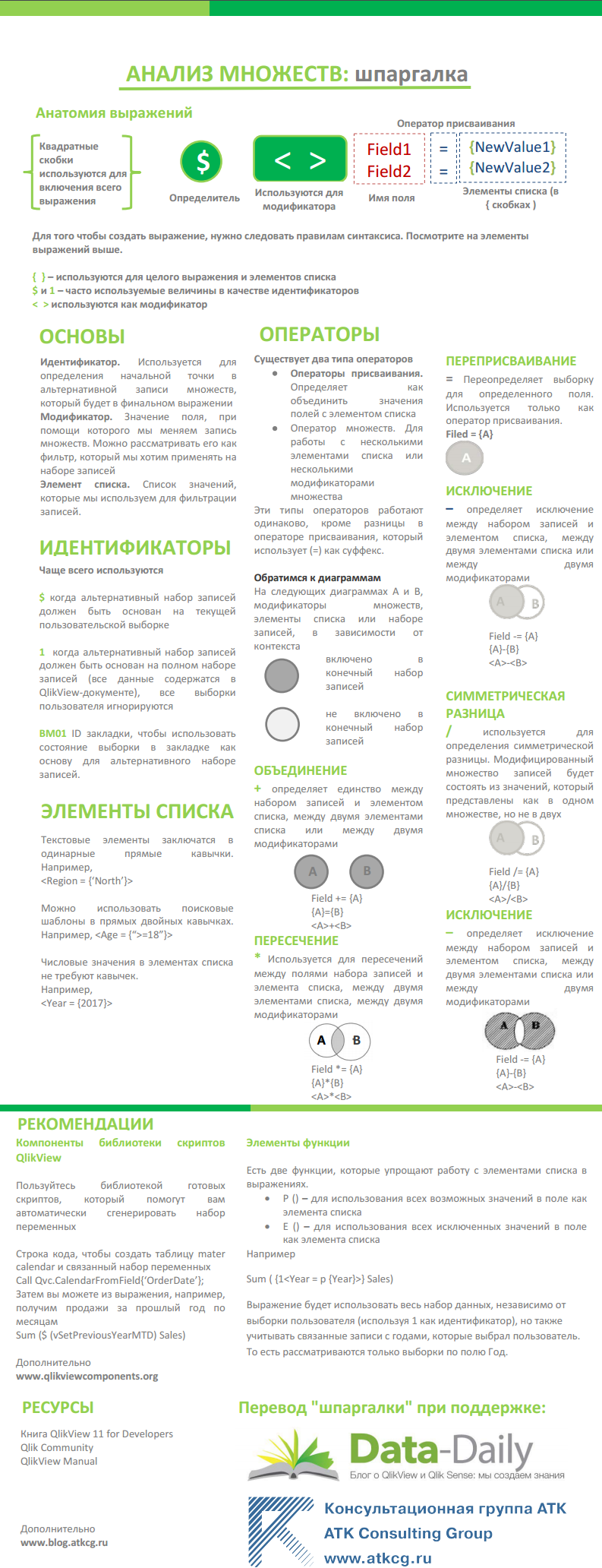
P.s. Чтобы скачать инфографику в PDF, поделитесь этой записью.
![]()
Источник: http://feedproxy.google.com/~r/Data-Daily/~3/FxAlrJG4qUw/
Данный материал является частной записью члена сообщества Club.CNews.
Редакция CNews не несет ответственности за его содержание.
Зачем использовать SetAnalysis
Анализ множеств (Set Analysis) позволяет создать выбор, отличный от активного, в используемой в таблице или графике. Созданная группа позволяют сравнить агрегирование этой группы и группы из текущего выбора.
Эти агрегаты позволяют сравнить, например, продажи текущего месяца и месяца в предыдущем году.
Анализ множеств (Set Analysis) изменяет контекст только для выражения, которое использует его. Другое выражение без какого-либо выбора получит контекст по умолчанию, стандартный выбор или группу альтернативного состояния.
Множества могут использоваться в функциях агрегирования.Функции агрегирования как правило агрегируют множества возможных записей, определенных текущей выборкой. Однако выражением множества может быть определено альтернативное множество записей. Поэтому множество имеет принципиальное сходство с выборкой. В случае использования выражение множества всегда начинается и заканчивается фигурными скобками, например {BM01}.
Анализ множеств применим, как в QlikView, так и в Qlik Sense.
Анализ множества и выражения множества
Анализ множества предлагает способ определения множества (или группы) значений данных, отличных от обычного множества, определяемого текущими выборками.
Обычно при совершении выборки функции агрегирования, такие как Sum, Max, Min, Avg и Count, выполняют агрегирование совершенных выборок: текущие выборки. Ваши выборки автоматически определяют набор данных, в отношении которых выполняется агрегирование. С помощью анализа множества можно определить группу, независимую от текущих выборок. Это может быть полезным в том случае, если необходимо узнать точное значение, например долю продукта на рынке по всем регионам, независимо от текущих выборок.
Анализ множества также очень удобен при выполнении различных сравнений, как, например сравнение продуктов, пользующихся наибольшим спросом с продуктами, пользующимися наименьшим спросом, или сравнение показателей этого года с показателями прошлого года.
Давайте представим, что вы начинаете работать с документом, выбрав в списке 2010 год. В таком случае агрегирования основаны на этой выборке, и в диаграммах показаны значения, относящиеся только к этому году. При выполнении новых выборок диаграммы обновляются соответственно. Агрегирования выполняются в отношении множества возможных записей, определенных текущими выборками. С помощью анализа множества можно определить множество,которое вам интересно и которое не зависит от выборок.
Создание выражений множества
Перед тем как рассматривать различные аспекты примера анализа множества необходимо определить различие между выражением множества и анализом множества:
Определение множества значений поля считается определением выражения множества, тогда как использование выражений множества для анализа данных считается анализом множества. Следовательно, в остальной части данного раздела говорится о выражении множества и его компонентах.
Ниже приведен пример анализа множества: sum( {$<Year={2009}>} Sales ), где {$<Year={2009}>} является выражением множества.
Существует два общих синтаксических правила для выражения множества:
- Выражение множества должно использоваться в функции агрегирования. В этом примере функцией агрегирования является sum(Sales).
- Выражение множества должно быть заключено в скобки {}. В этом примере выражением множества является: {$<Year={2009}>}.
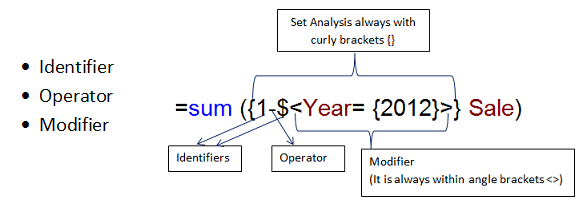
Выражение множества состоит из комбинации следующих частей:
- Identifiers.
Один или несколько идентификаторов определяют отношение между выражением множества и тем, что оценивается в остальной части выражения. Простое выражение множества состоит из одиночного идентификатора, например знака доллара США {$}, что означает все записи в текущей выборке. - Operators.
Если идентификаторов несколько, для обновления множества данных используется один или несколько операторов. Обновление выполняется путем определения способа объединения множеств данных, представленных идентификаторами, для создания подмножества или супермножества, например. - Modifiers.
Для изменения выборки в выражение множества можно добавить один или несколько модификаторов. Модификатор можно использовать самостоятельно или для изменения идентификатора для фильтра множества данных.
Выражения множества можно использовать только в выражениях для диаграмм, но не в выражениях скрипта.
Идентификаторы
Идентификаторы определяют отношение между выражением множества и значениями поля или оцениваемым выражением.
В нашем примере sum( {$<Year={2009}>} Sales ) идентификатором является знак доллара $, он означает, что множество записей для оценки состоит из всех записей текущей выборки. Этот набор в дальнейшем фильтруется частью модификатора выражения множества. В более сложном выражении множества два идентификатора можно объединить с помощью оператора.
Множества описываются в QlikView (Qlik Sense) при помощи фигурных скобок {}.
Знак 0 – описывает пустое множество.
Знак 1 – описывает полное множество всех записей в приложении.
Знак $ – представляет записи текущей выборки.
Рассмотрим выражения, которые можно формировать с помощью идентификаторов:
Выражение {$} указывает на текущую выборку.
Выражение {1-$} обозначает отрицание текущей выборки, т.е. множество, которое образуется путем исключения из всех значений приложения текущей выборки.
Выражение {$1} представляет предыдущую выборку, т.е. эквивалентно нажатию кнопки “Назад”.
Выражение {$_1}, {$_2} … {$_N} представляет следующие выборки, т.е. на один, два … N шагов вперед, т.е. эквивалентно нажатию кнопки “Вперед”. В уведомлениях Назад и Вперед может быть использовано любое целое без знака. Выражение {$_0} представляет текущую выборку.
Выражение {1} игнорируется текущая выборка (за множество данных берутся все строки приложения). Измерение не игнорируется.
Выражение{1} Total – игнорируется и текущая выборка, и измерение.
Выражение {BookMark} – множество содержит набор значений, которое образуется фильтрами, сохраненными в закладке “Bookmark” приложения QlikView (Qlik Sense).
Group – Название группы, альтернативное состояние (Alternate State)
Примеры:
- sum({$} Sales)
возвращает продажи для текущей выборки, т.е. тоже самое, что функция sum(Sales); - sum({$1} Sales)
возвращает продажи для предыдущей выборки; - sum({$_2} Sales)
возвращает продажи для второй следующей выборки, т.е. на два шага вперед. Подходит только в случае выполнения двух операций Назад; - sum({1} Sales)
возвращает общий объем продаж в приложении, игнорируется выборка, но не измерение. При использовании в диаграмме, где в качестве измерения присутствует Продукция, каждый продукт получит различное значение; - sum({1} TotalSales)
возвращает общий объем продаж в приложении, игнорируется и выборка, и измерение. Т.е. тоже самое, что функция sum(AllSales); - sum({BM01} Sales)
возвращает продажи для закладки BM01; - sum({MyBookMark} Sales)
возвращает продажи для закладки MyBookMark.; - sum({ServerBM01} Sales)
возвращает продажи для закладки сервера BM01.; - sum({DocumentMyBookmark} Sales)
возвращает продажи для закладки документа MyBookmark.;
Операторы множества
В существующих выражениях множества могут использоваться несколько операторов множества. Все операторы множества используют множества в качестве операндов, как описано выше, и в результате возвращают множество.
+: объединение множеств. Данная бинарная операция возвращает множество, состоящее из записей, принадлежащих любому из двух операндов множества.

A+B
—: Исключение одного множества записей из другого множества записей. Данная бинарная операция возвращает множество записей, принадлежащих первому из двух операндов множества. Также, при использовании в качестве унарного оператора, она возвращает дополнительное множество.

A-B
*: Пересечение множеств. Данная бинарная операция возвращает множество, состоящее из записей, принадлежащих обоим операндам множества.

A*B
/: Исключающее ИЛИ. (члены, принадлежащие только к одному из двух наборов). Данная бинарная операция возвращает множество, состоящее из записей, принадлежащих любому из операндов множества, но не обоим.

AB
Очередность:
1) унарный минус (дополнительно), 2) пересечение и симметрическая разность и 3)Объединение и исключение. Внутри группы выражение оценивается слева на право. Альтернативная очередность может быть определена стандартными скобками, которые могут быть необходимы, так как операторы множества не переключаются. Например, A+(B-C) отлично от (A+B)-C, которое, в свою очередь, отлично от (A-C)+B.
Модификаторы множества
Модификаторы используются для внесения дополнений или изменений в выборку. Подобные изменения могут быть записаны в выражении множества. Модификатор состоит из нескольких имен поля, после каждого указана одна или несколько выборок, которые можно выполнить в поле. Модификаторы начинаются и заканчиваются угловыми скобками <>.
Модификатор множества изменяет выбор предыдущего идентификатора множества. Если отсутствует ссылка на идентификатор множества, состояние текущей выборки будет implicit.
Множество может быть изменено дополнительной или измененной выборкой. Подобное изменение может быть записано в выражении множества. Модификатор состоит из одного или нескольких имен полей, за каждым из которых следует выборка, которая должна быть составлена на основе поля и заключена в <и>. Например: <Year={2007,+2008}, Region={US}>. Имена и значения полей могут цитироваться как обычно. Например: <[SalesRegion]={’Westcoast’, ’SouthAmerica’}>.
Существует несколько способов определения выборки. Простой случай — это выборка, основанная на выбранных значениях другого поля. Например: <OrderDate = DeliveryDate>. Данный модификатор возьмет выбранные значения из Delivery Date и применит их в качестве выборки к OrderDate. Если присутствует множество уникальных значений (больше пары сотен), то данная операция потребует большой загрузки ЦП, поэтому ее следует избегать.
Наиболее распространенным случаем, однако, является выборка, основанная на списке значений полей, заключенном в фигурные скобки, значения разделены запятыми. Например: <Year={2007,2008}>. Здесь фигурные скобки определяют множество элементов, в котором элементы могут быть либо значениями полей, либо поисками значений полей. Поиск всегда определяется использованием двойных кавычек. Например, <Ingredient={«*Garlic*»}> выберет все ингредиенты, включая строку «чеснок».
Поиски чувствительны к регистру, а также выполняются для всех исключенных значений. Пустые множества элементов, явно, например <Product={}>, или не явно, например <Product={«PerpetuumMobile»}> (поиск без проверок), означают продукция отсутствует, т.е. результатом будет множество записей, не связанных с каким-либо продуктом. Обратите внимание, что данное множество может быть достигнуто с помощью обычных выборок, кроме случаев, когда выборка сделана в другом поле, например TransactionID.
Наконец, для полей в режиме логич. «И» существует также возможность принудительного исключения. При необходимости принудительно исключить определенные значения поля потребуется использовать знак «~» (тильда) перед именем поля.
Модификатор множества может использоваться на идентификаторе множества или сам по себе. Он не может использоваться на выражении множества. При использовании на идентификаторе множества модификатор должен быть записан сразу после идентификатора множества. Например: {$<Year={2007,2008}>}. При использовании модификатора самого по себе он интерпретируется как изменение текущей выборки.
Примеры:
- sum({1<Region={US}>} Sales)
возвращает продажи для региона США, текущая выборка игнорируется; - sum({$<Region=>} Sales)
возвращает продажи для текущей выборки, выборки «Регион» удаляется; - sum({<Region=>} Sales)
возвращает тоже, что и в примере выше. Если множество для изменения отсутствует, используется знак $; - sum({$<Year={2000}, Region={US,SE,DE,UK,FR}>} Sales)
возвращает продажи для текущей выборки, но с новыми выборками в полях «Год» и «Регион»; - sum({$<~Ingredient={“*garlic*”}>} Sales)
возвращает продажи для текущей выборки, но с принудительным исключением всех ингредиентов, содержащих строку «garlic»; - sum({$<Year={“2*”}>} Sales)
возвращает продажи для текущей выборки, но все года начинаются на цифру «2», т.е. в поле «Год» выбран год 2000 и далее; - sum({$<Year={“2*”, ”198*”}>} Sales)
как и выше, но в выборку также включены 80-е года; - sum({$<Year={“>1978$<2004”}>} Sales)
как и выше, но с цифровым поиском с возможностью указания произвольного диапазона;
Модификаторы множества с операторами множества
Выборка в поле может быть определена с помощью операторов множества, как описано выше, при работе с различными множествами элементов. Например, модификатор <Year={«20*»,1997}-{2000}> выберет все года, начиная с «20» в дополнение к «1997», кроме «2000».
Модификаторы множества, использующие назначения с операторами множества implicit
Эта нотация определяет новые выборки, игнорируя текущие выборки в поле. Однако, если требуется основать выборку на текущей выборке в поле и добавить значения поля, например, необходим модификатор <Year = Year + {2007, 2008}>. Простой и эквивалентный способ записать это — <Year += {2007, 2008}>, т. е. оператор назначения неявно определяет объединение. Также неявные пересечения, исключения и симметрические разности могут быть определены с помощью элементов “*=”, “–=” и “/=”.
Примеры:
- sum({$<Product += {OurProduct1,OurProduct2}>} Sales)
возвращает продажи для текущей выборки, но с использованием неявного объединения для добавления продуктов «OurProduct1» и «OurProduct2» в список выбранных продуктов; - sum({$<Year = Year+({“20*”,1997} – {2000})>} Sales)
возвращает продажи для текущей выборки, но с использованием неявного объединения для добавления нескольких годов в выборку: 1997 и все годы, начинающиеся с “20” – за исключением 2000. Обратите внимание, что в случае включения значения 2000 в текущую выборку оно останется включенным и после изменения. Также, как <Year = Year + ({“20*”,1997} – {2000})>; - sum({$<Product *= {OurProduct1}>} Sales)
возвращает продажи для текущей выборки, но только для пересечения выбранных на данный момент продуктов и продукта «OurProduct1»;
Модификаторы множества с расширениями со знаком доллара
В выражениях множества могут использоваться переменные и другие расширения со знаком доллара.
Примеры:
- sum({$<Year = {$(#vLastYear)}>} Sales)
возвращает продажи для предыдущего года в отношении текущей выборки. Здесь переменная vLastYear, содержащая соответствующий год, используется в расширении со знаком доллара.; - sum({$<Year = {$(#=Only(Year)-1)}>} Sales)
возвращает продажи для предыдущего года в отношении текущей выборки. Здесь расширение со знаком доллара используется для расчета предыдущего года;
Модификаторы множества с расширенными поисками
Для определения множеств могут использоваться расширенные поиски с помощью подстановочных знаков и агрегирований.
Примеры:
- sum({$–1<Product = {“*Internal*”, “*Domestic*”}>} Sales)
возвращает продажи для текущей выборки, за исключением продуктов со строкой «Internal» или «Domestic» в имени продукта; - sum({$<Customer = {“=Sum({$<Year={2007}>} Sales)>1000000”}>} Sales)
возвращает продажи для текущей выборки, но с новой выборкой в поле «Клиент»: только клиенты с общими продажами более 1 000 000 за 2007 год;
Модификаторы множества с неявными определениями значений поля
В приведенных выше примерах все значения поля были определены явно или посредством поисков. Однако существует дополнительный способ определения множества значений поля, используя вложенное определение множества.
В подобных случаях должны использоваться функции элемента P() и E(), представляющие множество элементов возможных значений и исключенные значения поля, соответственно. В скобках можно указать одно выражение множества и одно поле. Например: P({1} Customer). Эти функции не могут использоваться в других выражениях.
Примеры:
- sum({$<Customer = P({$<Product = {‘Shoe’}>} Customer)>} Sales)
возвращает продажи для текущей выборки, но только клиентов, покупавших когда — либо продукт «Обувь». Здесь функцияэ лемента P() возвращает список возможных клиентов, подразумеваемых выборкой «Обувь» в поле Продукция; - sum({$<Customer = P({$<Product = {‘Shoe’}>})>} Sales)
то же, что и в примере выше. Если в функции элемента поле опущено, функция вернет возможные значения для поля, указанного во внешнем назначении; - sum({$<Customer=P({$<Product = {‘Shoe’}>} Supplier)>} Sales)
возвращает продажи для текущей выборки, но только клиентов, поставлявших когда — либо продукт «Обувь». Здесь функция элемента P() возвращает список возможных поставщиков, подразумеваемых выборкой «Обувь» в поле Продукция. Список поставщиков затем используется в качестве выборки в поле Клиент; - sum({$<Customer = E({$<Product={‘Shoe’}>})>} Sales)
возвращает продажи для текущей выборки, но только клиентов, никогда не покупавших продукт «Обувь». Здесь функция элемента E() возвращает список клиентов, исключенных выборкой «Обувь» в поле Продукция;
Синтаксис для множеств (QlikView, Qlik Sense)
Таким образом, полный синтаксис (не включая дополнительное использование стандартных скобок для определения последовательности) выглядит следующим образом:
set_expression ::= { set_entity { set_operatorset_entity }}
set_entity ::= set_identifier[ set_modifier ]
set_identifier ::= 1|$|$N|$_N|bookmark_id|bookmark_name
set_operator ::= +|-|*|/
set_modifier ::= $<field_selection{,field_selection}>
field_selection ::= field_name[=|+=|¬–=|*=|/=] element_set_expression
element_set_expression ::= element_set{ set_operator element_set }
element_set ::= [field_name]|{element_list}|element_function
element_list ::= element{,element}
element_function ::= (P|E)([set_expression][field_name])
element ::= field_value| «search_mask»
Примеры
Sum ({$<[Компания]-={‘*Indef*’}+{‘<пустоезначение>’}>}Данные)

Sum({1-$<~[Компания] = {‘*ffff*’}>} Данные)

Sum({$<[Год] *= {‘201*’,2009}-{$(#vCurrentYear)}>}Данные)

Существует дополнительный способ определения множества значений поля, используя вложенное определение множества.
В подобных случаях должны использоваться функции элемента P() и E(), представляющие множество элементов возможных значений и исключенные значения поля, соответственно. В скобках можно указать одно выражение множества и одно поле.
Sum({<[Компания] = P({$<[Рэйтинг]={‘5’}>) [Компания]}>} Данные)

Sum({<[Год] ={‘>=$(vYearMin)<=$(vYearMax)’}Данные)

Свяжитесь с нами
Более подробную информацию Вы можете получить, позвонив в «ФБ Консалт» по тел.: +7 (495) 781–6400 или отправив запрос по электронной почте: info@fbconsult.ru. Специалисты компании с радостью ответят на все интересующие Вас вопросы. Обращайтесь!