Instead of using regex, it is generally better to parse the string as a datetime.datetime object:
In [140]: datetime.datetime.strptime("11/12/98","%m/%d/%y")
Out[140]: datetime.datetime(1998, 11, 12, 0, 0)
In [141]: datetime.datetime.strptime("11/12/98","%d/%m/%y")
Out[141]: datetime.datetime(1998, 12, 11, 0, 0)
You could then access the day, month, and year (and hour, minutes, and seconds) as attributes of the datetime.datetime object:
In [143]: date.year
Out[143]: 1998
In [144]: date.month
Out[144]: 11
In [145]: date.day
Out[145]: 12
To test if a sequence of digits separated by forward-slashes represents a valid date, you could use a try..except block. Invalid dates will raise a ValueError:
In [159]: try:
.....: datetime.datetime.strptime("99/99/99","%m/%d/%y")
.....: except ValueError as err:
.....: print(err)
.....:
.....:
time data '99/99/99' does not match format '%m/%d/%y'
If you need to search a longer string for a date,
you could use regex to search for digits separated by forward-slashes:
In [146]: import re
In [152]: match = re.search(r'(d+/d+/d+)','The date is 11/12/98')
In [153]: match.group(1)
Out[153]: '11/12/98'
Of course, invalid dates will also match:
In [154]: match = re.search(r'(d+/d+/d+)','The date is 99/99/99')
In [155]: match.group(1)
Out[155]: '99/99/99'
To check that match.group(1) returns a valid date string, you could then parsing it using datetime.datetime.strptime as shown above.
Given a string, the task is to write a Python program to extract date from it.
Input : test_str = "gfg at 2021-01-04" Output : 2021-01-04 Explanation : Date format string found. Input : test_str = "2021-01-04 for gfg" Output : 2021-01-04 Explanation : Date format string found.
Method #1 : Using re.search() + strptime() methods
In this, the search group for a particular date is fed into search(), and strptime() is used to feed in the format to be searched.
Python3
import re
from datetime import datetime
test_str = "gfg at 2021-01-04"
print("The original string is : " + str(test_str))
match_str = re.search(r'd{4}-d{2}-d{2}', test_str)
res = datetime.strptime(match_str.group(), '%Y-%m-%d').date()
print("Computed date : " + str(res))
Output
The original string is : gfg at 2021-01-04 Computed date : 2021-01-04
Method #2: Using python-dateutil() module
This is another way to solve this problem. In this inbuilt Python library python-dateutil, The parse() method can be used to detect date and time in a string.
Python3
from dateutil import parser
test_str = "gfg at 2021-01-04"
print("The original string is : " + str(test_str))
res = parser.parse(test_str, fuzzy=True)
print("Computed date : " + str(res)[:10])
Output:
The original string is : gfg at 2021-01-04 Computed date : 2021-01-04
Method #3: Using string manipulation
Approach
We can use string manipulation to search for the date format string in the input string.
Algorithm
1. Split the input string into words.
2. Iterate through the words and check if each word matches the date format string.
3. If a match is found, return the date format string.
Python3
test_str = "gfg at 2021-01-04"
words = test_str.split()
for word in words:
if len(word) == 10 and word[4] == "-" and word[7] == "-":
print(word)
break
Time complexity: O(n)
Auxiliary Space: O(1)
METHOD 4:Using Split and Join
APPROACH:
This approach first splits the string into a list of words, then extracts the last word which is the date, and finally splits the date using ‘-‘ and joins it again using ‘-‘.
ALGORITHM:
1.Split the input string by space character, which gives a list of two elements: the text “gfg” and the date string “2021-01-04”.
2.Get the last element of the list (i.e., the date string) using indexing.
3.Split the date string by “-” character, which gives a list of three elements: the year, month, and day.
4.Join the elements of the list with “-” character using the join() method to get the final date string.
Python3
string = 'gfg at 2021-01-04'
date = "-".join(string.split()[-1].split("-"))
print("Computed date:", date)
Output
Computed date: 2021-01-04
Time complexity: O(n), where n is the length of the string.
Space complexity: O(n).
METHOD 5:Using Regular Expression
APPROACH:
The program extracts the date from a given string using regular expression.
ALGORITHM:
1.Import the re module.
2.Define the input string.
3.Use the re.findall() method with a regular expression pattern to extract the date from the string.
4.Print the extracted date.
Python3
import re
string = 'gfg at 2021-01-04'
date = re.findall('d{4}-d{2}-d{2}', string)[0]
print("Computed date:", date)
Output
Computed date: 2021-01-04
Time Complexity: The time complexity of the program depends on the size of the input string and the efficiency of the regular expression pattern. In the worst case, the time complexity is O(n), where n is the length of the input string.
Space Complexity: The space complexity of the program is O(1), as it only stores the extracted date in a variable.
Last Updated :
23 Apr, 2023
Like Article
Save Article
You can run a date parser on all subtexts of your text and pick the first date. Of course, such solution would either catch things that are not dates or would not catch things that are, or most likely both.
Let me provide an example that uses dateutil.parser to catch anything that looks like a date:
import dateutil.parser
from itertools import chain
import re
# Add more strings that confuse the parser in the list
UNINTERESTING = set(chain(dateutil.parser.parserinfo.JUMP,
dateutil.parser.parserinfo.PERTAIN,
['a']))
def _get_date(tokens):
for end in xrange(len(tokens), 0, -1):
region = tokens[:end]
if all(token.isspace() or token in UNINTERESTING
for token in region):
continue
text = ''.join(region)
try:
date = dateutil.parser.parse(text)
return end, date
except ValueError:
pass
def find_dates(text, max_tokens=50, allow_overlapping=False):
tokens = filter(None, re.split(r'(S+|W+)', text))
skip_dates_ending_before = 0
for start in xrange(len(tokens)):
region = tokens[start:start + max_tokens]
result = _get_date(region)
if result is not None:
end, date = result
if allow_overlapping or end > skip_dates_ending_before:
skip_dates_ending_before = end
yield date
test = """Adelaide was born in Finchley, North London on 12 May 1999. She was a
child during the Daleks' abduction and invasion of Earth in 2009.
On 1st July 2058, Bowie Base One became the first Human colony on Mars. It
was commanded by Captain Adelaide Brooke, and initially seemed to prove that
it was possible for Humans to live long term on Mars."""
print "With no overlapping:"
for date in find_dates(test, allow_overlapping=False):
print date
print "With overlapping:"
for date in find_dates(test, allow_overlapping=True):
print date
The result from the code is, quite unsurprisingly, rubbish whether you allow overlapping or not. If overlapping is allowed, you get a lot of dates that are nowhere to be seen, and if if it is not allowed, you miss the important date in the text.
With no overlapping:
1999-05-12 00:00:00
2009-07-01 20:58:00
With overlapping:
1999-05-12 00:00:00
1999-05-12 00:00:00
1999-05-12 00:00:00
1999-05-12 00:00:00
1999-05-03 00:00:00
1999-05-03 00:00:00
1999-07-03 00:00:00
1999-07-03 00:00:00
2009-07-01 20:58:00
2009-07-01 20:58:00
2058-07-01 00:00:00
2058-07-01 00:00:00
2058-07-01 00:00:00
2058-07-01 00:00:00
2058-07-03 00:00:00
2058-07-03 00:00:00
2058-07-03 00:00:00
2058-07-03 00:00:00
Essentially, if overlapping is allowed:
- «12 May 1999» is parsed to 1999-05-12 00:00:00
- «May 1999» is parsed to 1999-05-03 00:00:00 (because today is the 3rd day of the month)
If, however, overlapping is not allowed, «2009. On 1st July 2058» is parsed as 2009-07-01 20:58:00 and no attempt is made to parse the date after the period.
We must first understand some regular expression fundamentals as we will use them. There are various ways to declare patterns in regular expressions, which might make them appear complex but are pretty simple. Regular expressions are patterns that can be used to match strings that adhere to that pattern. You need to read the following article to learn how regular expressions operate.
You may commonly extract dates from a given text when learning to code. If you are automating a Python script and need to extract specific numerical figures from a CSV file, if you are a data scientist and need to separate complex date from given patterns, or if you are a Python enthusiast who wants to learn more about strings and numerical data types, you will undoubtedly find this helpful article.
It is expected that you are familiar with regular expression fundamentals moving forward.
Example 1
Only the basic notations will be used to create a regex pattern for dates. We aim to match dates that have the elements day, month, year, or day, month, and year, with the elements day and month having two digits and the element year having four digits. Now let’s build the pattern piece by piece.
d will match digits, as you would have guessed. We need to supply the number 2 within to match strings that have precisely 2 digits. Therefore, «d2» will match any string that only has 2 digits. The pattern for the day, the month, and the year is d2, d2, and d4, respectively. These three must be joined together with a ‘/’ or ‘-‘.
The latest regex pattern is «d2» followed by «d2» and «d4».
Now that the problematic portion is finished, the remaining task is easy.
Input 1
import re f = open("doc.txt", "r") content = f.read() pattern = "d{2}[/-]d{2}[/-]d{4}" dates = re.findall(pattern, content)
It should be noted that our regex pattern will also extract dates that aren’t legitimate, such 40/32/2019. The final code must be modified to appear as follows:
Input 2
import re f = open("doc.txt", "r") content = f.read() pattern = "d{2}[/-]d{2}[/-]d{4}" dates = re.findall(pattern, content) for date in dates: if "-" in date: day, month, year = map(int, date.split("-")) else: day, month, year = map(int, date.split("/")) if 1 <= day <= 31 and 1 <= month <= 12: print(date) f.close()
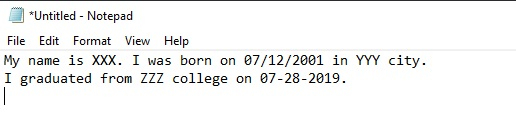
Input Text
For example, if the content of the text file is as follows
My name is XXX. I was born on 07/12/2001 in YYY city. I graduated from ZZZ college on 07-28-2019.
Output
07/04/1998 09-05-2019
Example 2
import datetime from datetime import date import re s = "Jason's birthday is on 2002-07-28" match = re.search(r'd{4}-d{2}-d{2}', s) date = datetime.datetime.strptime(match.group(), '%Y-%m-%d').date() print (date)
Output
2002-07-28
Conclusion
As a result of the conversations above, we discovered various Python functions for extracting date from a given text. The regex module is undoubtedly our personal favorite, though. You may counter that alternative approaches, such as the split() functions, result in speedier execution and more straightforward, more understandable code. However, as previously stated, it does not yield negative values (about method 2), nor does it function for floating-point numbers with no space between them and other characters, such as «25.50k» (about method 2). Furthermore, speed is essentially a useless statistic when it comes to log parsing. You can now understand why, out of all the options on this list, regex is my personal preference.
Last updated on
Feb 10, 2022
In this post you will see how to extract any date with python regular expression:
- Regex Matching Date 10/10/2015
- Regex Matching Date 10-10-15
- Regex Matching Date 1 NOV 2010
- Regular expression Matching Date 10 March 2015
The list of the matched formats:
- 10/10/2015
- 10-10-15
- 1 NOV 2010
- 10 March 2015
You can watch a short video on this article here: python regular expression matching dates
You can be interested in Python project: Python useful tips and reference project
Regex Matching Date 10/10/2015
Regex date format: dd/mm/yyyy
- [d]{1,2} — match one or two digits
- [d]{4} — match exactly 4 digits
- separator is /
import re
# Matching capital letters
str = """COBOL is a compiled English-like computer programming language designed for business use. 122. On 10/10/2015 is a big date unlike 1/11/2010 """
all = re.findall(r"[d]{1,2}/[d]{1,2}/[d]{4}", str)
for s in all:
print(s)
result
10/10/2015
1/11/2010
Regex Matching Date 10-10-15
Regex date format: dd-mm-yy
- [d]{1,2} — match one or two digits
- separator is —
import re
# Matching capital letters
str = """COBOL is a compiled English-like computer programming language designed for business use. 122. On 10-10-15 is a big date unlike 1-11-10 """
all = re.findall(r"[d]{1,2}-[d]{1,2}-[d]{2}", str)
for s in all:
print(s)
result
10-10-15
1-11-10
Regex Matching Date 1 NOV 2010
Regular expression date format: dd MMM yyyy
- [ADFJMNOS]w* — Match big letter from ADFJMNOS followed by another letters
import re
# Matching capital letters
str = """COBOL is a compiled English-like computer programming language designed for business use. 122. On 10 OCT 2015 is a big date unlike 1 NOV 2010 """
all = re.findall(r"[d]{1,2} [ADFJMNOS]w* [d]{4}", str)
for s in all:
print(s)
result
10 OCT 2015
1 NOV 2010
A more precise extraction for this example would be:
r"([d]{1,2}s(JAN|NOV|OCT|DEC)s[d]{4})"
result(if you change the OCT date):
('1 NOV 2010', 'NOV')
Better result for date extraction with this format can be done by using — ?: — check this code below:
all = re.findall(r"([d]{1,2}s(?:JAN|NOV|OCT|DEC)s[d]{4})", str)
result:
1 NOV 2010
Regular expression Matching Date 10 March 2015
Extracting date by Python regex which has full month name:
- [ADFJMNOS]w* — Match big letter from ADFJMNOS followed by another letters
import re
# Matching capital letters
str = """COBOL is a compiled English-like computer programming language designed for business use. 122. On 10 October 2015 is a big date unlike 1 November 2010 """
all = re.findall(r"[d]{1,2} [ADFJMNOS]w* [d]{4}", str)
for s in all:
print(s)
result
10 October 2015
1 November 2010
You can list the words that you want by using this regular expression:
all = re.findall(r"([d]{1,2}s(January|February|March|April|May|June|July|August|September|October|November|December)s[d]{4})", str)
result:
('10 October 2015', 'October')
('1 November 2010', 'November')
if you want your result to be only the dates then you can add — ?: to your middle group:
all = re.findall(r"(d{1,2} (?:January|February|March|April|May|June|July|August|September|October|November|December) d{4})", str)
result:
10 October 2015
1 November 2010