Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
Для того, чтобы полноценно обрабатывать тексты в bash-скриптах с помощью sed и awk, просто необходимо разобраться с регулярными выражениями. Реализации этого полезнейшего инструмента можно найти буквально повсюду, и хотя устроены все регулярные выражения схожим образом, основаны на одних и тех же идеях, в разных средах работа с ними имеет определённые особенности. Тут мы поговорим о регулярных выражениях, которые подходят для использования в сценариях командной строки Linux.

Этот материал задуман как введение в регулярные выражения, рассчитанное на тех, кто может совершенно не знать о том, что это такое. Поэтому начнём с самого начала.

Что такое регулярные выражения
У многих, когда они впервые видят регулярные выражения, сразу же возникает мысль, что перед ними бессмысленное нагромождение символов. Но это, конечно, далеко не так. Взгляните, например, на это регулярное выражение
^([a-zA-Z0-9_-.+]+)@([a-zA-Z0-9_-.]+).([a-zA-Z]{2,5})$
На наш взгляд даже абсолютный новичок сходу поймёт, как оно устроено и зачем нужно  Если же вам не вполне понятно — просто читайте дальше и всё встанет на свои места.
Если же вам не вполне понятно — просто читайте дальше и всё встанет на свои места.
Регулярное выражение — это шаблон, пользуясь которым программы вроде sed или awk фильтруют тексты. В шаблонах используются обычные ASCII-символы, представляющие сами себя, и так называемые метасимволы, которые играют особую роль, например, позволяя ссылаться на некие группы символов.
Типы регулярных выражений
Реализации регулярных выражений в различных средах, например, в языках программирования вроде Java, Perl и Python, в инструментах Linux вроде sed, awk и grep, имеют определённые особенности. Эти особенности зависят от так называемых движков обработки регулярных выражений, которые занимаются интерпретацией шаблонов.
В Linux имеется два движка регулярных выражений:
- Движок, поддерживающий стандарт POSIX Basic Regular Expression (BRE).
- Движок, поддерживающий стандарт POSIX Extended Regular Expression (ERE).
Большинство утилит Linux соответствуют, как минимум, стандарту POSIX BRE, но некоторые утилиты (в их числе — sed) понимают лишь некое подмножество стандарта BRE. Одна из причин такого ограничения — стремление сделать такие утилиты как можно более быстрыми в деле обработки текстов.
Стандарт POSIX ERE часто реализуют в языках программирования. Он позволяет пользоваться большим количеством средств при разработке регулярных выражений. Например, это могут быть специальные последовательности символов для часто используемых шаблонов, вроде поиска в тексте отдельных слов или наборов цифр. Awk поддерживает стандарт ERE.
Существует много способов разработки регулярных выражений, зависящих и от мнения программиста, и от особенностей движка, под который их создают. Непросто писать универсальные регулярные выражения, которые сможет понять любой движок. Поэтому мы сосредоточимся на наиболее часто используемых регулярных выражениях и рассмотрим особенности их реализации для sed и awk.
Регулярные выражения POSIX BRE
Пожалуй, самый простой шаблон BRE представляет собой регулярное выражение для поиска точного вхождения последовательности символов в тексте. Вот как выглядит поиск строки в sed и awk:
$ echo "This is a test" | sed -n '/test/p'
$ echo "This is a test" | awk '/test/{print $0}'
Поиск текста по шаблону в sed

Поиск текста по шаблону в awk
Можно заметить, что поиск заданного шаблона выполняется без учёта точного места нахождения текста в строке. Кроме того, не имеет значение и количество вхождений. После того, как регулярное выражение найдёт заданный текст в любом месте строки, строка считается подходящей и передаётся для дальнейшей обработки.
Работая с регулярными выражениями нужно учитывать то, что они чувствительны к регистру символов:
$ echo "This is a test" | awk '/Test/{print $0}'
$ echo "This is a test" | awk '/test/{print $0}'
Регулярные выражения чувствительны к регистру
Первое регулярное выражение совпадений не нашло, так как слово «test», начинающееся с заглавной буквы, в тексте не встречается. Второе же, настроенное на поиск слова, написанного прописными буквами, обнаружило в потоке подходящую строку.
В регулярных выражениях можно использовать не только буквы, но и пробелы, и цифры:
$ echo "This is a test 2 again" | awk '/test 2/{print $0}'
Поиск фрагмента текста, содержащего пробелы и цифры
Пробелы воспринимаются движком регулярных выражений как обычные символы.
Специальные символы
При использовании различных символов в регулярных выражениях надо учитывать некоторые особенности. Так, существуют некоторые специальные символы, или метасимволы, использование которых в шаблоне требует особого подхода. Вот они:
.*[]^${}+?|()
Если один из них нужен в шаблоне, его нужно будет экранировать с помощью обратной косой черты (обратного слэша) — .
Например, если в тексте нужно найти знак доллара, его надо включить в шаблон, предварив символом экранирования. Скажем, имеется файл myfile с таким текстом:
There is 10$ on my pocketЗнак доллара можно обнаружить с помощью такого шаблона:
$ awk '/$/{print $0}' myfile
Использование в шаблоне специального символа
Кроме того, обратная косая черта — это тоже специальный символ, поэтому, если нужно использовать его в шаблоне, его тоже надо будет экранировать. Выглядит это как два слэша, идущих друг за другом:
$ echo " is a special character" | awk '/\/{print $0}'
Экранирование обратного слэша
Хотя прямой слэш и не входит в приведённый выше список специальных символов, попытка воспользоваться им в регулярном выражении, написанном для sed или awk, приведёт к ошибке:
$ echo "3 / 2" | awk '///{print $0}'
Неправильное использование прямого слэша в шаблоне
Если он нужен, его тоже надо экранировать:
$ echo "3 / 2" | awk '///{print $0}'
Экранирование прямого слэша
Якорные символы
Существуют два специальных символа для привязки шаблона к началу или к концу текстовой строки. Символ «крышка» — ^ позволяет описывать последовательности символов, которые находятся в начале текстовых строк. Если искомый шаблон окажется в другом месте строки, регулярное выражение на него не отреагирует. Выглядит использование этого символа так:
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}'
$ echo "likegeeks website" | awk '/^likegeeks/{print $0}'
Поиск шаблона в начале строки
Символ ^ предназначен для поиска шаблона в начале строки, при этом регистр символов так же учитывается. Посмотрим, как это отразится на обработке текстового файла:
$ awk '/^this/{print $0}' myfile
Поиск шаблона в начале строки в тексте из файла
При использовании sed, если поместить крышку где-нибудь внутри шаблона, она будет восприниматься как любой другой обычный символ:
$ echo "This ^ is a test" | sed -n '/s ^/p'
Крышка, находящаяся не в начале шаблона в sed
В awk, при использовании такого же шаблона, данный символ надо экранировать:
$ echo "This ^ is a test" | awk '/s ^/{print $0}'
Крышка, находящаяся не в начале шаблона в awk
С поиском фрагментов текста, находящихся в начале строки мы разобрались. Что, если надо найти нечто, расположенное в конце строки?
В этом нам поможет знак доллара — $, являющийся якорным символом конца строки:
$ echo "This is a test" | awk '/test$/{print $0}'
Поиск текста, находящегося в конце строки
В одном и том же шаблоне можно использовать оба якорных символа. Выполним обработку файла myfile, содержимое которого показано на рисунке ниже, с помощью такого регулярного выражения:
$ awk '/^this is a test$/{print $0}' myfile
Шаблон, в котором использованы специальные символы начала и конца строки
Как видно, шаблон среагировал лишь на строку, полностью соответствующую заданной последовательности символов и их расположению.
Вот как, пользуясь якорными символами, отфильтровать пустые строки:
$ awk '!/^$/{print $0}' myfile
В данном шаблоне использовал символ отрицания, восклицательный знак — !. Благодаря использованию такого шаблона выполняется поиск строк, не содержащих ничего между началом и концом строки, а благодаря восклицательному знаку на печать выводятся лишь строки, которые не соответствуют этому шаблону.
Символ «точка»
Точка используется для поиска любого одиночного символа, за исключением символа перевода строки. Передадим такому регулярному выражению файл myfile, содержимое которого приведено ниже:
$ awk '/.st/{print $0}' myfile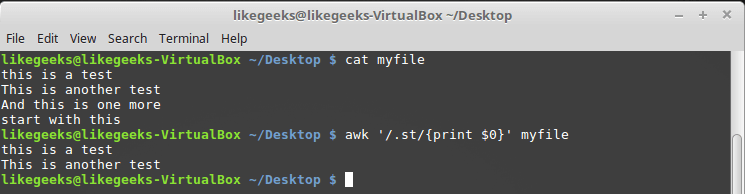
Использование точки в регулярных выражениях
Как видно по выведенным данным, шаблону соответствуют лишь первые две строки из файла, так как они содержат последовательность символов «st», предварённую ещё одним символом, в то время как третья строка подходящей последовательности не содержит, а в четвёртой она есть, но находится в самом начале строки.
Классы символов
Точка соответствует любому одиночному символу, но что если нужно более гибко ограничить набор искомых символов? В подобной ситуации можно воспользоваться классами символов.
Благодаря такому подходу можно организовать поиск любого символа из заданного набора. Для описания класса символов используются квадратные скобки — []:
$ awk '/[oi]th/{print $0}' myfile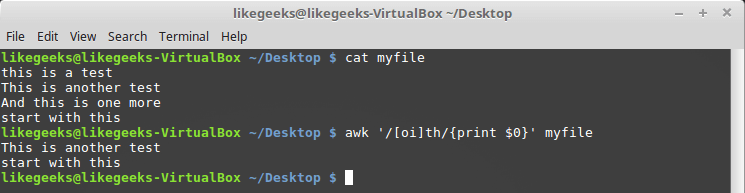
Описание класса символов в регулярном выражении
Тут мы ищем последовательность символов «th», перед которой есть символ «o» или символ «i».
Классы оказываются очень кстати, если выполняется поиск слов, которые могут начинаться как с прописной, так и со строчной буквы:
$ echo "this is a test" | awk '/[Tt]his is a test/{print $0}'
$ echo "This is a test" | awk '/[Tt]his is a test/{print $0}'
Поиск слов, которые могут начинаться со строчной или прописной буквы
Классы символов не ограничены буквами. Тут можно использовать и другие символы. Нельзя заранее сказать, в какой ситуации понадобятся классы — всё зависит от решаемой задачи.
Отрицание классов символов
Классы символов можно использовать и для решения задачи, обратной описанной выше. А именно, вместо поиска символов, входящих в класс, можно организовать поиск всего, что в класс не входит. Для того, чтобы добиться такого поведения регулярного выражения, перед списком символов класса нужно поместить знак ^. Выглядит это так:
$ awk '/[^oi]th/{print $0}' myfile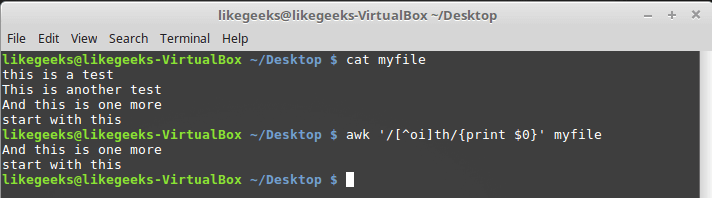
Поиск символов, не входящих в класс
В данном случае будут найдены последовательности символов «th», перед которыми нет ни «o», ни «i».
Диапазоны символов
В символьных классах можно описывать диапазоны символов, используя тире:
$ awk '/[e-p]st/{print $0}' myfile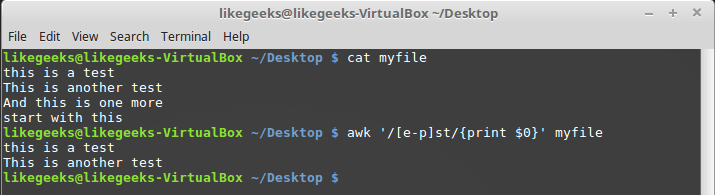
Описание диапазона символов в символьном классе
В данном примере регулярное выражение реагирует на последовательность символов «st», перед которой находится любой символ, расположенный, в алфавитном порядке, между символами «e» и «p».
Диапазоны можно создавать и из чисел:
$ echo "123" | awk '/[0-9][0-9][0-9]/'
$ echo "12a" | awk '/[0-9][0-9][0-9]/'
Регулярное выражение для поиска трёх любых чисел
В класс символов могут входить несколько диапазонов:
$ awk '/[a-fm-z]st/{print $0}' myfile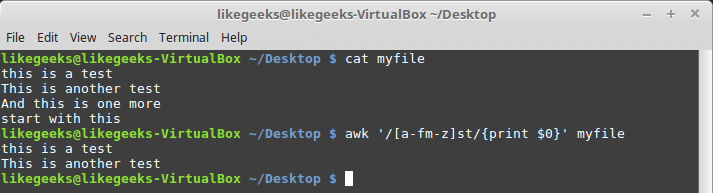
Класс символов, состоящий из нескольких диапазонов
Данное регулярное выражение найдёт все последовательности «st», перед которыми есть символы из диапазонов a-f и m-z.
Специальные классы символов
В BRE имеются специальные классы символов, которые можно использовать при написании регулярных выражений:
[[:alpha:]]— соответствует любому алфавитному символу, записанному в верхнем или нижнем регистре.[[:alnum:]]— соответствует любому алфавитно-цифровому символу, а именно — символам в диапазонах0-9,A-Z,a-z.[[:blank:]]— соответствует пробелу и знаку табуляции.[[:digit:]]— любой цифровой символ от0до9.[[:upper:]]— алфавитные символы в верхнем регистре —A-Z.[[:lower:]]— алфавитные символы в нижнем регистре —a-z.[[:print:]]— соответствует любому печатаемому символу.[[:punct:]]— соответствует знакам препинания.[[:space:]]— пробельные символы, в частности — пробел, знак табуляции, символыNL,FF,VT,CR.
Использовать специальные классы в шаблонах можно так:
$ echo "abc" | awk '/[[:alpha:]]/{print $0}'
$ echo "abc" | awk '/[[:digit:]]/{print $0}'
$ echo "abc123" | awk '/[[:digit:]]/{print $0}'
Специальные классы символов в регулярных выражениях
Символ «звёздочка»
Если в шаблоне после символа поместить звёздочку, это будет означать, что регулярное выражение сработает, если символ появляется в строке любое количество раз — включая и ситуацию, когда символ в строке отсутствует.
$ echo "test" | awk '/tes*t/{print $0}'
$ echo "tessst" | awk '/tes*t/{print $0}'
Использование символа * в регулярных выражениях
Этот шаблонный символ обычно используют для работы со словами, в которых постоянно встречаются опечатки, или для слов, допускающих разные варианты корректного написания:
$ echo "I like green color" | awk '/colou*r/{print $0}'
$ echo "I like green colour " | awk '/colou*r/{print $0}'
Поиск слова, имеющего разные варианты написания
В этом примере одно и то же регулярное выражение реагирует и на слово «color», и на слово «colour». Это так благодаря тому, что символ «u», после которого стоит звёздочка, может либо отсутствовать, либо встречаться несколько раз подряд.
Ещё одна полезная возможность, вытекающая из особенностей символа звёздочки, заключается в комбинировании его с точкой. Такая комбинация позволяет регулярному выражению реагировать на любое количество любых символов:
$ awk '/this.*test/{print $0}' myfile
Шаблон, реагирующий на любое количество любых символов
В данном случае неважно сколько и каких символов находится между словами «this» и «test».
Звёздочку можно использовать и с классами символов:
$ echo "st" | awk '/s[ae]*t/{print $0}'
$ echo "sat" | awk '/s[ae]*t/{print $0}'
$ echo "set" | awk '/s[ae]*t/{print $0}'
Использование звёздочки с классами символов
Во всех трёх примерах регулярное выражение срабатывает, так как звёздочка после класса символов означает, что если будет найдено любое количество символов «a» или «e», а также если их найти не удастся, строка будет соответствовать заданному шаблону.
Регулярные выражения POSIX ERE
Шаблоны стандарта POSIX ERE, которые поддерживают некоторые утилиты Linux, могут содержать дополнительные символы. Как уже было сказано, awk поддерживает этот стандарт, а вот sed — нет.
Тут мы рассмотрим наиболее часто используемые в ERE-шаблонах символы, которые пригодятся вам при создании собственных регулярных выражений.
▍Вопросительный знак
Вопросительный знак указывает на то, что предшествующий символ может встретиться в тексте один раз или не встретиться вовсе. Этот символ — один из метасимволов повторений. Вот несколько примеров:
$ echo "tet" | awk '/tes?t/{print $0}'
$ echo "test" | awk '/tes?t/{print $0}'
$ echo "tesst" | awk '/tes?t/{print $0}'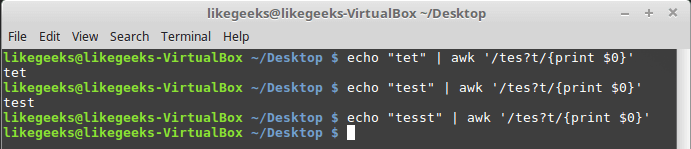
Вопросительный знак в регулярных выражениях
Как видно, в третьем случае буква «s» встречается дважды, поэтому на слово «tesst» регулярное выражение не реагирует.
Вопросительный знак можно использовать и с классами символов:
$ echo "tst" | awk '/t[ae]?st/{print $0}'
$ echo "test" | awk '/t[ae]?st/{print $0}'
$ echo "tast" | awk '/t[ae]?st/{print $0}'
$ echo "taest" | awk '/t[ae]?st/{print $0}'
$ echo "teest" | awk '/t[ae]?st/{print $0}'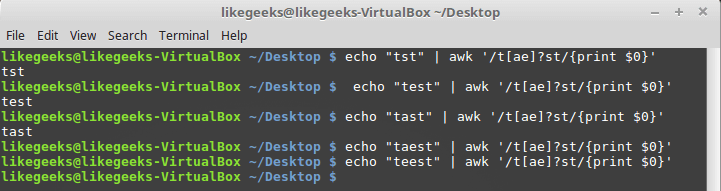
Вопросительный знак и классы символов
Если символов из класса в строке нет, или один из них встречается один раз, регулярное выражение срабатывает, однако стоит в слове появиться двум символам и система уже не находит в тексте соответствия шаблону.
▍Символ «плюс»
Символ «плюс» в шаблоне указывает на то, что регулярное выражение обнаружит искомое в том случае, если предшествующий символ встретится в тексте один или более раз. При этом на отсутствие символа такая конструкция реагировать не будет:
$ echo "test" | awk '/te+st/{print $0}'
$ echo "teest" | awk '/te+st/{print $0}'
$ echo "tst" | awk '/te+st/{print $0}'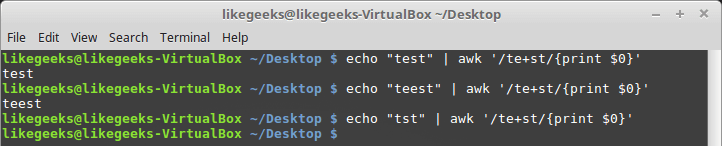
Символ «плюс» в регулярных выражениях
В данном примере, если символа «e» в слове нет, движок регулярных выражений не найдёт в тексте соответствий шаблону. Символ «плюс» работает и с классами символов — этим он похож на звёздочку и вопросительный знак:
$ echo "tst" | awk '/t[ae]+st/{print $0}'
$ echo "test" | awk '/t[ae]+st/{print $0}'
$ echo "teast" | awk '/t[ae]+st/{print $0}'
$ echo "teeast" | awk '/t[ae]+st/{print $0}'
Знак «плюс» и классы символов
В данном случае если в строке имеется любой символ из класса, текст будет сочтён соответствующим шаблону.
▍Фигурные скобки
Фигурные скобки, которыми можно пользоваться в ERE-шаблонах, похожи на символы, рассмотренные выше, но они позволяют точнее задавать необходимое число вхождений предшествующего им символа. Указывать ограничение можно в двух форматах:
n —число, задающее точное число искомых вхожденийn, m —два числа, которые трактуются так: «как минимум n раз, но не больше чем m».
Вот примеры первого варианта:
$ echo "tst" | awk '/te{1}st/{print $0}'
$ echo "test" | awk '/te{1}st/{print $0}'
Фигурные скобки в шаблонах, поиск точного числа вхождений
В старых версиях awk нужно было использовать ключ командной строки --re-interval для того, чтобы программа распознавала интервалы в регулярных выражениях, но в новых версиях этого делать не нужно.
$ echo "tst" | awk '/te{1,2}st/{print $0}'
$ echo "test" | awk '/te{1,2}st/{print $0}'
$ echo "teest" | awk '/te{1,2}st/{print $0}'
$ echo "teeest" | awk '/te{1,2}st/{print $0}'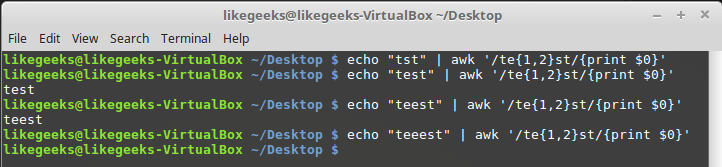
Интервал, заданный в фигурных скобках
В данном примере символ «e» должен встретиться в строке 1 или 2 раза, тогда регулярное выражение отреагирует на текст.
Фигурные скобки можно применять и с классами символов. Тут действуют уже знакомые вам принципы:
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}'
$ echo "test" | awk '/t[ae]{1,2}st/{print $0}'
$ echo "teest" | awk '/t[ae]{1,2}st/{print $0}'
$ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'
Фигурные скобки и классы символов
Шаблон отреагирует на текст в том случае, если в нём один или два раза встретится символ «a» или символ «e».
▍Символ логического «или»
Символ | — вертикальная черта, означает в регулярных выражениях логическое «или». Обрабатывая регулярное выражение, содержащее несколько фрагментов, разделённых таким знаком, движок сочтёт анализируемый текст подходящим в том случае, если он будет соответствовать любому из фрагментов. Вот пример:
$ echo "This is a test" | awk '/test|exam/{print $0}'
$ echo "This is an exam" | awk '/test|exam/{print $0}'
$ echo "This is something else" | awk '/test|exam/{print $0}'
Логическое «или» в регулярных выражениях
В данном примере регулярное выражение настроено на поиск в тексте слов «test» или «exam». Обратите внимание на то, что между фрагментами шаблона и разделяющим их символом | не должно быть пробелов.
Группировка фрагментов регулярных выражений
Фрагменты регулярных выражений можно группировать, пользуясь круглыми скобками. Если сгруппировать некую последовательность символов, она будет восприниматься системой как обычный символ. То есть, например, к ней можно будет применить метасимволы повторений. Вот как это выглядит:
$ echo "Like" | awk '/Like(Geeks)?/{print $0}'
$ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'
Группировка фрагментов регулярных выражений
В данных примерах слово «Geeks» заключено в круглые скобки, после этой конструкции идёт знак вопроса. Напомним, что вопросительный знак означает «0 или 1 повторение», в результате регулярное выражение отреагирует и на строку «Like», и на строку «LikeGeeks».
Практические примеры
После того, как мы разобрали основы регулярных выражений, пришло время сделать с их помощью что-нибудь полезное.
▍Подсчёт количества файлов
Напишем bash-скрипт, который подсчитывает файлы, находящиеся в директориях, которые записаны в переменную окружения PATH. Для того, чтобы это сделать, понадобится, для начала, сформировать список путей к директориям. Сделаем это с помощью sed, заменив двоеточия на пробелы:
$ echo $PATH | sed 's/:/ /g'
Команда замены поддерживает регулярные выражения в качестве шаблонов для поиска текста. В данном случае всё предельно просто, ищем мы символ двоеточия, но никто не мешает использовать здесь и что-нибудь другое — всё зависит от конкретной задачи.
Теперь надо пройтись по полученному списку в цикле и выполнить там необходимые для подсчёта количества файлов действия. Общая схема скрипта будет такой:
mypath=$(echo $PATH | sed 's/:/ /g')
for directory in $mypath
do
done
Теперь напишем полный текст скрипта, воспользовавшись командой ls для получения сведений о количестве файлов в каждой из директорий:
#!/bin/bash
mypath=$(echo $PATH | sed 's/:/ /g')
count=0
for directory in $mypath
do
check=$(ls $directory)
for item in $check
do
count=$[ $count + 1 ]
done
echo "$directory - $count"
count=0
done
При запуске скрипта может оказаться, что некоторых директорий из PATH не существует, однако, это не помешает ему посчитать файлы в существующих директориях.
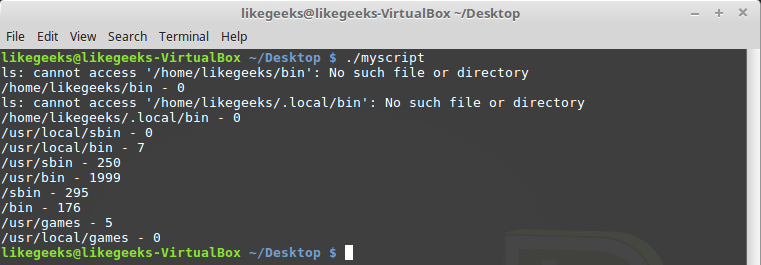
Подсчёт файлов
Главная ценность этого примера заключается в том, что пользуясь тем же подходом, можно решать и куда более сложные задачи. Какие именно — зависит от ваших потребностей.
▍Проверка адресов электронной почты
Существуют веб-сайты с огромными коллекциями регулярных выражений, которые позволяют проверять адреса электронной почты, телефонные номера, и так далее. Однако, одно дело — взять готовое, и совсем другое — создать что-то самому. Поэтому напишем регулярное выражение для проверки адресов электронной почты. Начнём с анализа исходных данных. Вот, например, некий адрес:
username@hostname.com
Имя пользователя, username, может состоять из алфавитно-цифровых и некоторых других символов. А именно, это точка, тире, символ подчёркивания, знак «плюс». За именем пользователя следует знак @.
Вооружившись этими знаниями, начнём сборку регулярного выражения с его левой части, которая служит для проверки имени пользователя. Вот что у нас получилось:
^([a-zA-Z0-9_-.+]+)@Это регулярное выражение можно прочитать так: «В начале строки должен быть как минимум один символ из тех, которые имеются в группе, заданной в квадратных скобках, а после этого должен идти знак @».
Теперь — очередь имени хоста — hostname. Тут применимы те же правила, что и для имени пользователя, поэтому шаблон для него будет выглядеть так:
([a-zA-Z0-9_-.]+)Имя домена верхнего уровня подчиняется особым правилам. Тут могут быть лишь алфавитные символы, которых должно быть не меньше двух (например, такие домены обычно содержат код страны), и не больше пяти. Всё это значит, что шаблон для проверки последней части адреса будет таким:
.([a-zA-Z]{2,5})$Прочесть его можно так: «Сначала должна быть точка, потом — от 2 до 5 алфавитных символов, а после этого строка заканчивается».
Подготовив шаблоны для отдельных частей регулярного выражения, соберём их вместе:
^([a-zA-Z0-9_-.+]+)@([a-zA-Z0-9_-.]+).([a-zA-Z]{2,5})$Теперь осталось лишь протестировать то, что получилось:
$ echo "name@host.com" | awk '/^([a-zA-Z0-9_-.+]+)@([a-zA-Z0-9_-.]+).([a-zA-Z]{2,5})$/{print $0}'
$ echo "name@host.com.us" | awk '/^([a-zA-Z0-9_-.+]+)@([a-zA-Z0-9_-.]+).([a-zA-Z]{2,5})$/{print $0}'
Проверка адреса электронной почты с помощью регулярных выражений
То, что переданный awk текст выводится на экран, означает, что система распознала в нём адрес электронной почты.
Итоги
Если регулярное выражение для проверки адресов электронной почты, которое встретилось вам в самом начале статьи, казалось тогда совершенно непонятным, надеемся, сейчас оно уже не выглядит бессмысленным набором символов. Если это действительно так — значит данный материал выполнил своё предназначение. На самом деле, регулярные выражения — это тема, которой можно заниматься всю жизнь, но даже то немногое, что мы разобрали, уже способно помочь вам в написании скриптов, которые довольно продвинуто обрабатывают тексты.
В этой серии материалов мы обычно показывали очень простые примеры bash-скриптов, которые состояли буквально из нескольких строк. В следующий раз рассмотрим кое-что более масштабное.
Уважаемые читатели! А вы пользуетесь регулярными выражениями при обработке текстов в сценариях командной строки?
I don’t have much experience with JavaScript but i’m trying to create a tag system which, instead of using @ or #, would use /.
var start = /#/ig; // @ Match
var word = /#(w+)/ig; //@abc Match
How could I use a / instead of the #. I’ve tried doing var slash = '/' and adding + slash +, but that failed.
![]()
ajp15243
7,6841 gold badge32 silver badges38 bronze badges
asked May 20, 2013 at 19:44
![]()
1
You can escape it like this.
///ig; // Matches /
or just use indexOf
if(str.indexOf("/") > -1)
answered May 20, 2013 at 19:46
![]()
Ben McCormickBen McCormick
25.1k12 gold badges51 silver badges71 bronze badges
2
You need to escape the / with a .
///ig // matches /
answered May 20, 2013 at 19:46
![]()
djechlindjechlin
58.9k34 gold badges161 silver badges288 bronze badges
You can escape it by preceding it with a (making it /), or you could use new RegExp('/') to avoid escaping the regex.
See example in JSFiddle.
'/'.match(///) // matches /
'/'.match(new RegExp('/') // matches /
answered Sep 26, 2019 at 20:13
![]()
If you want to use / you need to escape it with a
var word = //(w+)/ig;
answered May 20, 2013 at 19:46
![]()
epascarelloepascarello
203k20 gold badges193 silver badges234 bronze badges
In regular expressions, «/» is a special character which needs to be escaped (AKA flagged by placing a before it thus negating any specialized function it might serve).
Here’s what you need:
var word = //(w+)/ig; // /abc Match
Read up on RegEx special characters here: http://www.regular-expressions.info/characters.html
answered May 20, 2013 at 19:47
![]()
Kirk HKirk H
4312 silver badges6 bronze badges
1
You can also work around special JS handling of the forward slash by enclosing it in a character group, like so:
const start = /[/]/g;
"/dev/null".match(start) // => ["/", "/"]
const word = /[/](w+)/ig;
"/dev/null".match(word) // => ["/dev", "/null"]
answered Feb 22, 2018 at 19:22
![]()
nupanicknupanick
6858 silver badges12 bronze badges
2
I encountered two issues related to the foregoing, when extracting text delimited by and /, and found a solution that fits both, other than using new RegExp, which requires \\ at the start. These findings are in Chrome and IE11.
The regular expression
/\(.*)//g
does not work. I think the // is interpreted as the start of a comment in spite of the escape character. The regular expression (equally valid in my case though not in general)
/b/\(.*)/b/g
does not work either. I think the second / terminates the regular expression in spite of the escape character.
What does work for me is to represent / as x2F, which is the hexadecimal representation of /. I think that’s more efficient and understandable than using new RegExp, but of course it needs a comment to identify the hex code.
answered Oct 31, 2014 at 1:47
![]()
Forward Slash is special character so,you have to add a backslash before forward slash to make it work
$patterm = "/[0-9]{2}+(?:-|.|/)+[a-zA-Z]{3}+(?:-|.|/)+[0-9]{4}/";
where / represents search for /
In this way you
answered Feb 7, 2018 at 7:24
![]()
For me, I was trying to match on the / in a date in C#. I did it just by using (/):
string pattern = "([0-9])([0-9])?(/)([0-9])([0-9])?(/)(d{4})";
string text = "Start Date: 4/1/2018";
Match m = Regex.Match(text, pattern);
if (m.Success)
{
Console.WriteLine(match.Groups[0].Value); // 4/1/2018
}
else
{
Console.WriteLine("Not Found!");
}
JavaScript should also be able to similarly use (/).
answered Sep 20, 2018 at 16:11
![]()
vapcguyvapcguy
7,0131 gold badge55 silver badges50 bronze badges
3
Перевод второй части статьи «Regular Expressions Demystified: RegEx isn’t as hard as it looks». Первую часть читайте здесь.

3. Повторное совпадение для поиска
дублирующихся символов
Это реальная задача,
которую я пытался решить, и для решения
которой углубился в изучение регулярных
выражений. Собственно, это и привело к
написанию данной статьи.
Представьте, что перед
вами стоит следующая задача. У вас есть
строка. Определите, есть ли в ней
повторяющиеся символы.
Вот решение, с помощью
которого можно найти дубликаты, идущие
сразу после первого вхождения символа:
let e=/(w)1/;
e.test("abc"); //false
e.test("abb"); //true
Шаблон в этом выражении
не находит совпадений в строке «abc»,
поскольку в ней нет последовательно
расположенных повторяющихся символов.
Поэтому здесь test возвращает false.
Но в строке «abb» есть
совпадение с шаблоном — «bb» — поэтому
возвращается true.
Давайте, испробуйте
это в своей консоли в DevTool!
Разобьем это выражение
на понятные кусочки.
Обратный слэш
Я пока ничего не говорил
об обратном слэше (бэкслэш, обратная
косая черта), который появился в предыдущем
разделе. Тем, кто уже занимался
программированием, этот символ может
быть вполне понятен, а начинающим я
поясню.
В языке регулярных
выражений обратный слэш имеет особое
значение. Он меняет значение символа,
следующего за ним.
Что означает сочетание
символов n, встречающееся в строке? Да,
это новая строка. Здесь у нас нечто
похожее.
Фактически, n это то,
что вы используете в качестве шаблона
при поиске новой строки. Обратный слэш
экранирует обычное значение символа
«n» и придает ему новый смысл — теперь
это символ новой строки.
- d — условное
обозначение цифр. Совпадает с любой
одной цифрой. - D — условное
обозначение нецифровых символов.
Совпадает с любым символом, кроме тех,
которые совпадают с d. - s — условное
обозначение пробелов (а также новой
строки или таба). - S — антоним s,
обозначает все, кроме пробелов. - w — условное
обозначение букв и цифр. Совпадает с
a-z, A-Z, 0–9 и символом подчеркивания. - W — антоним w.
Запоминание и повторный
поиск совпадений
Мы начали этот раздел с решения для
поиска повторяющихся символов. Шаблон
в выражении /(w)1/ находит совпадение в
строке «abb». Это демонстрирует использование
памяти и повторного вызова внутри
регулярных выражений.
Обратите внимание на использование
круглых скобок в этом формате (выражение).
Строка, совпадающая с выражением внутри
скобок, запоминается для дальнейшего
использования.
1 запоминает и использует совпадение
с первым выражением в скобках. Аналогично,
2 запоминает и использует совпадение
с выражением во втором наборе скобок.
И так далее.
Опишем наше выражение (w)1 простыми
словами:
«Найди любой буквенно-цифровой
символ в данной строке. Запомни его как
1. Проверь, появляется ли этот символ
еще раз, справа от первого».
Приложение 1 — пары букв,
идущих в обратном порядке
Допустим, нам нужно найти пары символов,
находящихся рядом друг с другом и
расположенных в обратном порядке. Как
в «abba»: символы в «ab» идут в алфавитном
порядке, а в «ba» – в обратном алфавитном
порядке.
Вот наше выражение:
let e=/(w)(w)21/;
e.test("aabb"); //false
e.test("abba"); //true
e.test("abab"); //false
Первая часть в скобках — (w) — совпадает
с «а» и запоминается как 1 (первая
переменная). Вторая часть в скобках
совпадает с «b» и запоминается как вторая
переменная, 2. Далее в нашем выражении
идет переменная 2, а за ней — переменная
1. Из всех проверяемых строк только
строка «abba» совпадает с указанным
шаблоном.
Приложение 2 — отсутствие
дубликатов
А сейчас давайте поищем последовательность
символов, в которой не окажется двойных
букв. Т.е., после любого символа НЕ должен
идти такой же символ.
Вот наше решение:
let e=/^(w)(?!1)$/;
e.test("a"); //true
e.test("ab"); //false
e.test("aa"); //false
Не совсем то, чего нам бы хотелось, но
близко. Средний кейс не должен возвращать
false. Но здесь мы добавили еще несколько
символов, которые нужно объяснить. Нас
ждет еще одна встреча с самым сильным
мушкетером.
Возвращение вопросительного
знака
Помните историю о трех мушкетерах из
первой части статьи? Скромный вопросительный
знак на самом деле самый мощный
манипулятор, способный заставить другие
символы повиноваться его приказам.
Вопросительный и восклицательный
знак, заключенные в скобки, называются
look ahead, опережающей проверкой. Точнее,
негативной опережающей проверкой.
Шаблон a(?!b) совпадает с «а», только если
после «а» НЕ идет «b».
А вот (?=) это позитивная опережающая
проверка (positive look ahead). Шаблон a(?=b) совпадает
с «а» только если после «а» следует «b».
В решении, которое у нас было, шаблон
(w)(?!1) предполагал поиск символа, за
которым НЕ идет такой же символ. Но,
таким образом, мы искали только
один символ. Нам нужно
применить группирование, чтобы вести
поиск 1 или более вхождений неповторяющихся
символов. Здесь нам поможет знак плюс
(+).
let e=/^((w)(?!1))+$/;
e.test("madam"); //false
e.test("maam"); //false
Кажется, не сработало. Тут дело в
следующем. Если мы группируем шаблон
при помощи второй пары круглых скобок,
переменная 1 больше не представляет
(w), теперь она представляет выражение
в более высокоуровневой паре скобок,
которая группирует шаблон. Поэтому
проверки провалены.
Нам необходимо исключение из запоминания
скобочной группы. Вопросительный знак
с двоеточием (?:), поставленный после
скобки, указывает на то, что эти скобки
поставлены только для применения к ним
квантификатора (знака +) и запоминать
их не нужно.
let e=/^(?:(w)(?!1))+$/;
e.test("madam"); //true
e.test("maam"); //false
В этот раз первая скобочная пара не
запоминается (благодаря ?:), поэтому 1
помнит совпадение, возвращаемое w.
Благодаря этому мы можем использовать
плюс ко всей группе, чтобы искать по
всей последовательности символов. Если
выразить эту конструкцию простыми
словами, мы как бы говорим:
«Ищи символ. Проверь, не следует ли
за ним еще один такой же символ. Проделай
это для всех символов в строке, от начала
до конца».
Повторение
- w – представляет все буквенно-цифровые
символы. То же самое, но в верхнем
регистре (W) означает любой символ,
кроме букв и цифр. - () – выражение в круглых скобках
запоминается для дальнейшего
использования. - 1 – запоминает и использует
совпадение с первой скобочной группой. - 2 – то же самое для второй скобочной
группы. И так далее. - a(?!b) – комбинация скобок, вопросительного
и восклицательного знаков называется
негативной опережающей проверкой (look
ahead). Этот шаблон даст совпадение с «а»,
только если после «а» НЕ идет «b». - a(?=b) – обратная сторона медали. Этот
шаблон даст совпадение с «а», только
если после «а» ИДЕТ «b». - (?:a) – «забывчивое» группирование.
Ищет «а», но не запоминает его. Вы не
сможете повторно использовать найденное
совпадение при помощи 1.
4. Чередующаяся последовательность
Наш новый usecase прост. Наш шаблон должен
совпадать со строкой, в которой
используются только два символа. Эти
два символа должны сменять друг друга
по всей длине строки, как, например, в
строках «abab» и «xyxyx».
Придумать такой шаблон было непросто,
я предпринял несколько попыток, и все
неудачные. Но вот
этот ответ направил меня на верный
путь.
Вот решение:
let e=/^(S)(?!1)(S)(12)*$/;
e.test("abab"); //true
e.test("$#$#"); //true
e.test("#$%"); //false
e.test("$ $ "); //false
e.test("xyxyx"); //false
Здесь вы можете подумать: «Ну все, с
меня хватит!» Но погодите, дождитесь
«ага!»-момента! Вы в трех шагах от золотой
жилы, сейчас не время прекращать копать.
Прежде чем приступить к разбору,
давайте посмотрим на результаты тестов.
«abab» совпадает, «$#$#» тоже совпадает.
«#$%» не совпадает, здесь добавлен
третий символ.
«$ $ » не совпадает, потому что хоть
чередование и соблюдено, здесь использован
символ пробела, а S исключает пробелы
из шаблона.
В общем, все хорошо, за исключением
того, что по строке «xyxyx» мы получили
false. Наш шаблон не знает, что делать с
последним «х». Но мы с этим разберемся.
Давайте посмотрим, какие инструменты
мы применили, и вскоре нам все станет
понятно.
По кусочку за раз
Большая часть кусочков вам уже знакомы.
S это антоним s, используется для поиска
любого символа кроме пробела.
Теперь давайте пошагово опишем шаблон
/^(S)(?!1)(S)(12)*$/ простыми словами.
- Начать с начала строки /^.
- Искать любой символ, не являющийся
пробелом (S). - Запомнить его как 1.
- Проверить, не следует ли за первым
символом еще один такой же символ
(?!1). Вы помните,
это негативная опережающая проверка. - Если все в порядке, искать следующий
символ (S). - Запомнить его как 2.
- Далее искать 0 или больше пар
первых двух совпадений (12)*. - Искать этот паттерн до конца
строки $/.
Применяем это к нашим тестовым случаям.
«abab» и «$#$#» совпадают с описанным
шаблоном.
Хвостовая часть
Давайте исправим выражение, чтобы
шаблон охватывал и «xyxyx». Как мы знаем,
проблема в последнем «х». Для «xyxy» у нас
уже есть решение. Все, что нам нужно, это
шаблон, говорящий «Ищи возможное
вхождение первого символа».
Как обычно, начнем с готового решения.
let e=/^(S)(?!1)(S)(12)*1?$/;
e.test("xyxyx"); //true
e.test("$#$#$"); //true
Вопросительный знак после шаблона
(символа или группы символов) означает
0 или 1 вхождение этого шаблона. Этот
знак не жадный.
В нашем случае 1? означает 0 или 1
вхождение первого символа, запомненного
по первой скобочной группе.
Все просто.
Повторение
- S — представляет любой символ за
исключением пробела. - а* — астериск (звездочка) указывает
на 0 или более вхождений предыдущего
символа. В данном случае — 0 или больше
букв «а». - a(?!b) — негативная опережающая
проверка. Дает совпадение с «а», только
если за «а» НЕ идет «b». Например,
совпадает с «а» в «аа», «ах», «а$», но не
в «ab». - s — одинарный пробел.
- a(?=b) — позитивная опережающая
проверка. Дает совпадение с «а», если
после «а» идет « b». - ^ab*$ — возможно, вы подумали, что
этот шаблон совпадает с 0 или большим
числом вхождений «ab», но на самом деле
это буква «а», за которой следует 0 или
больше букв «b». Например, этот шаблон
найдет совпадение в «abbb», «а» и «ab», но
не в «abab». - ^(ab)*$ — а вот здесь речь идет о 0 или
большем числе вхождений пары «ab». Этот
шаблон совпадет с пустой строкой «»»»,
«ab» и «abab», но не с «abb». - а? — ? означает 0 или 1 вхождение
предыдущего символа или шаблона. - 1? — означает 0 или 1 вхождение
первого запомненного совпадения.
5. Проверка email-адреса
Регулярные выражения сами по себе не
могут справиться с проверкой email-адресов.
Кто-то может даже сказать, что в этом
случае регулярные выражения не стоит
использовать, поскольку они никогда не
смогут охватить 100% адресов.
Только представьте все многообразие
доменных имен. А также подумайте о
включении различных символов внутри
адресов, например, точек и знаков «плюс».
Email-адреса следует проверять дважды.
Один раз на стороне клиента, чтобы помочь
пользователям избежать опечаток в
указании адреса. Начните с указания
типа семантического тега input:
<input type='email'>.
Некоторые браузеры автоматически
проверяют его без всяких дополнительных
сценариев во фронтенде.
А потом адрес нужно проверить еще раз
на сервере, путем отправки подтверждающего
email-а.
RegEx для Email
Теперь вы, вероятно, хотите увидеть
сам шаблон проверки? Попробуйте поискать
регулярное выражение для email-адреса.
Один
такой результат занимает больше целой
страницы. Так что я даже пытаться не
буду. Такие длинные регулярные выражения
генерируются компьютерами при помощи
специальных билдеров. Это не для простых
смертных вроде меня.

6. Проверка надежности пароля
Если любите кофе, самое время налить
себе чашечку, да покрепче. Мы подобрались
к последней части нашей статьи, причем
самой длинной.
В ней мы разберем совсем немного новых
операторов и шаблонов. Но будем
использовать много уже известных. Как
обычно, самое короткое и оптимизированное
решение прибережем на закуску.
Перейдем к нашей задаче. Помните
случай, когда вам лишь с нескольких
попыток удалось подобрать пароль,
соответствующий всем требованиям?
«Слабый», «хороший», «сильный», «очень
сильный». Вот такую проверку мы и
создадим.
Наш пароль должен:
- состоять как минимум из 4 символов,
- содержать как минимум одну букву
в нижнем регистре, - содержать как минимум одну букву
в верхнем регистре, - содержать как минимум одну цифру,
- содержать как минимум один символ.
Длина строки
Давайте сначала проверим, есть ли в
пароле как минимум 4 символа. Это довольно
просто, можно же использовать .length, да
и все. Но нееет, мы не ищем легких путей.
//выражение, содержащее только lookahead
//не охватывает ни одного символа
e1=/^(?=.{4,})$/;
e1.test("abc") //false
e1.test("abcd") //false
//после lookahead
//идет шаблон для охвата нужных символов.
e2=/^(?=.{4,}).*$/;
e2.test("abc") //false
e2.test("abcd") //true
- (?=) вы помните по разделу с поиском
дубликатов букв. Это использование
опережающей проверки. Само по себе оно
не охватывает никаких символов. - Точка — интересный знак. Она
обозначает любой символ. - {4,} — означает как минимум 4
предшествующих символа, без верхнего
лимита. - d{4} — ищет точно 4 цифры.
- w{4,20} — ищет от 4 до 20 буквенно-цифровых
символов.
Давайте переведем выражение /^(?=.{4,})$/
на человеческий язык.
«Начни с начала строки. Посмотри,
есть ли впереди как минимум 4 символа.
Не запоминай совпадение. Вернись в
начало и проверь, кончается ли там
строка».
Звучит неправильно, верно? По крайней
мере последняя часть.
Вот почему мы сделали вариант
/^(?=.{4,}).*$/. То есть, добавили к предыдущему
дополнительную точку и звездочку. Это
читается следующим образом:
«Начни с начала строки. Посмотри,
есть ли впереди как минимум 4 символа.
Не запоминай совпадение. Вернись к
началу. Охвати все символы при помощи
.* и посмотри, достигнут ли конец строки».
Вот теперь выражение приобрело смысл,
не так ли?
Вот почему строка «abc» не проходит
проверку, а «abcd» проходит.
Как минимум одна цифра
Это будет легко.
e=/^(?=.*d+).*$/
e.test(""); //false
e.test("a"); //false
e.test("8"); //true
e.test("a8b"); //true
e.test("ab890"); //true
- «Начни с начала строки – /^.
- Посмотри, есть ли впереди 0 или
больше любых символов – ?=.*. - Проверь, следует ли за ними 1 или
больше цифр – d+. - Если есть совпадение, вернись к
началу (потому что это была опережающая
проверка). Охвати все символы в строке
до конца строки – .*$/».
Как минимум одна буква в
нижнем регистре
e=/^(?=.*[a-z]+).*$/;
e.test(""); //false
e.test("A"); //false
e.test("a"); //true
Здесь используется тот же шаблон, что и выше. Только вместо d+ используется [a-z]+, то есть набор буквенных символов
от «a» до «z».
Как минимум одна буква в
верхнем регистре
Заменяем [a-z] на [A-Z] и используем то же
самое выражение.
Как минимум один символ
Здесь будет посложнее. Можно поместить
весь список возможных символов в набор.
/^(?=.*[-+=_)(*&^%$#@!~”’:;|}]{[/?.>,<]+).*$/.test(“$”)
Это все возможные символы, экранированные
в нужных местах. Чтобы выразить это
простым языком, понадобятся месяцы.
Так что давайте перейдем к более
простому варианту.
//считает пробел символом
let e1;
e1=/^(?=.*[^a-zA-Z0-9])[ -~]+$/
e1.test("_"); //true
e1.test(" "); //true
//не принимает пробелы
let e2;
e2=/^(?=.*[^a-zA-Z0-9])[!-~]+$/
e2.test(" "); //false
e2.test("_"); //true
//исключение подчеркивания
let e3;
e3=/^(?=.*[W])[!-~]+$/
e3.test("_"); //false
Погодите, что это за ^ появляется снова
в середине непонятно чего? Здесь мы
подобрались к разбору того, почему
невинный (на первый взгляд) знак ^ является
двойным агентом (об этом упоминалось в
первой части).
Внутри набора символов ^ служит для
отрицания этого набора. То есть, шаблон
[^a-z] означает любой символ, не входящий
в набор a-z.
Следовательно, [^a-zA-Z0-9] означает любой
символ, не являющийся буквой в нижнем
или верхнем регистре и не являющийся
цифрой.
Вместо этого длинного набора символов
мы могли бы использовать условное
обозначение W. Но оно включает в себя
символ подчеркивания. Как видите в
третьем наборе из примера, использование
символа подчеркивания при таком раскладе
не проходит проверку.
Диапазон набора символов
Любопытно использование диапазона
[!-~]. Восклицательный знак и тильда на
клавиатуре находятся рядом, но их
значения в ASCII диагонально противоположны.
Помните диапазоны a-z? A-Z? 0–9? Это не
константы. Они, собственно, базируются
на диапазонах их значений в ASCII.
Таблица ASCII
содержит 125 символов. Символы по 31-й нас
не интересуют. Диапазон нужных нам
символов открывает восклицательный
знак (33), а закрывает тильда (~).
Таким образом шаблон [!-~] включает в
себя все символы, буквы и цифры, которые
нам нужны.
Собираем войска
Собрав все это вместе, мы получаем
отличное регулярное выражение:
/^(?=.{5,})(?=.*[a-z]+)(?=.*d+)(?=.*[A-Z]+)(?=.*[^w])[ -~]+$/
Все, собранное воедино, выглядит
пугающе, хотя мы рассмотрели каждую
часть отдельно. Вот тут-то и пригодится
синтаксис для динамического построения
объекта выражения. Мы построим каждый
кусок отдельно и соберем их позже.
//начнем с префикса
let p = "^";
//look ahead
// min 4 символа
p += "(?=.{4,})";
// нижний регистр
p += "(?=.*[a-z]+)";
// верхний регистр
p += "(?=.*[A-Z]+)";
// цифры
p += "(?=.*\d+)";
// символы
p += "(?=.*[^ a-zA-Z0-9]+)";
//конец lookaheads
//финальный охват
p += "[ -~]+";
//суффикс
p += "$";
//Construct RegEx
let e = new RegEx(p);
// tests
e.test("aB0#"); //true
e.test(""); //false
e.test("aB0"); //false
e.test("ab0#"); //false
e.test("AB0#"); //false
e.test("aB00"); //false
e.test("aB!!"); //false
// space is in our control
e.test("aB 0"); //false
e.test("aB 0!"); //true
Если ваши глаза еще не устали, вы могли
заметить две странности в этом коде.
- Во-первых, мы не использовали /^, а
вместо этого использовали просто ^.
Также мы не использовали $/ для конца
строки, заменив это на просто $. Это
потому, что конструктор RegEx автоматически
добавляет начальные и завершающие
слэши. - Во-вторых, для цифр мы использовали
\d вместо обычного d. Это потому, что
переменная «р» это просто обычная
строка внутри парных кавычек. Чтобы
вставить обратный слэш, его самого
нужно экранировать обратным слэшем. В
конструкторе RegEx \d резолвится в d.
7. Заключение
Вот мы и подобрались к концу. Но это
лишь начало пути.
Мы только прикоснулись к поиску
совпадений RegEx при помощи метода test.
Метод exec на основе всего этого возвращает
совпадающие с шаблоном подстроки.
Строчные объекты имеют такие методы
как match, search, replace и split, которые широко
используются в регулярных выражениях.
Надеюсь, эта статья помогла вам лучше разобраться в возможностях RegEx и построении шаблонов.

Продолжим говорить о регулярных выражениях в Python в рамках NLP. Регулярные выражения нужны для поиска подстрок, которые удовлетворяют правилам. Например, нужно найти все слова, которые начинаются с заглавной буквы «А», или все даты в предложении, которое содержит и другие виды чисел. Сегодня мы расскажем об основных символах, которые образуют регулярные выражения: замена, группировка, перечисление символов, а также специальные символы в Python.
Один любой символ или повторять до бесконечности
Когда появляется ситуация, когда мы не знаем какой именно символ используется, то используется точка .. А когда нужно повторить какой символ сколько-то раз, то используется звездочка * (0 или n символов) или плюс + (1 или n символов). Рассмотрите примеры регулярных выражений в Python:
# aa.bb. # Может значить aapbby или aa4bb$
# a.b* # Может значить acbbb или aqb или a,bbbbbb
>>> import re
>>> re.search('aa.bb.', 'aapbby')
<re.Match object; span=(0, 6), match='aapbby'>
>>> re.search('a.b*', 'a,bbbbbb')
<re.Match object; span=(0, 8), match='a,bbbbbb'>
Точка и звездочка могут использоваться вместе .*, тогда это значит любой символ повторяется сколько-то раз. Это удобно, когда вы не помните все выражение, но знаете каким символом он заканчивается. Ниже пример того, как применять такое регулярное выражение в Python.
>>> re.search('<h.*>', '<html>')
<re.Match object; span=(0, 6), match='<html>'>
Но стоит быть очень осторожным с ним, поскольку это регулярное выражение будет смотреть совпадения до конца строки. А это бывает не то, что нужно:
# Вместо <html> совпала вся строка, потому что она оканичается на символ '>'
>>> re.search('<h.*>', '<html>..<li>...</li>')
<re.Match object; span=(0, 20), match='<html>..<li>...</li>'>
Группа символов
Символы могут быть сгруппированы с помощью круглых скобок. К этим группам могут быть применены повторения * или +. Кроме того внутри скобок может использоваться оператор ИЛИ в виде |. Следующие примеры показывают разные регулярные выражения в Python с применением группировок:
# (ac)* # соответсвует acacac или acac
# Знак | соответсвует ИЛИ:
>>> re.search('d(e|i)n', 'den')
<re.Match object; span=(0, 3), match='den'>
>>> re.search('d(e|i)n', 'din')
<re.Match object; span=(0, 3), match='din'>
Перечисление символов
Как мы увидели, использовать .* опасно. Поэтому лучше всего перечислять всевозможные символы внутри квадратных скобок []. Например, не известно какой знак препинания следует дальше, тогда в Python можно регулярное выражение вывести следующим образом:
>>> pattern = 'a[,u]bc' >>> re.search(pattern, 'a,bc') <re.Match object; span=(0, 4), match='a,bc'> >>> re.search(pattern, 'aubc') <re.Match object; span=(0, 4), match='aubc'> >>> re.search(pattern, 'adbc') # Ничего не нашел
Последний пример не соответствует правилу, потому что символ 'd' не указан в []. Также в квадратных скобках можно указывать диапазоны букв и цифры. Например, [a-z] означает все строчные буквы английского алфавита, [A-Z] — все прописные, а [0-9] — все цифры. Ниже приведены примеры регулярных выражения с применением диапазонов на Python.
>>> re.search('[a-z0-5]+', 'asaBR')
<re.Match object; span=(0, 3), match='asa'>
>>> re.search('[a-z0-5]+', 'B612')
<re.Match object; span=(2, 4), match='12'>
Также если внутри квадратных скобок указан символ ^, то это значит «всё, что НЕ совпадает». Например, [^0-9] — любой символ не цифра. Диапазоны кириллических символов задаются в виде [А-Яа-я].
Обратный слэш для пропуска символов
Как в квадратных скобках для регулярного выражения указать знак препинания точку? Ведь точка является специальным правилом, которое обозначает «любой символ». Для таких случаев используется обратный слэш . При использовании перед специальными символами Python интерпретирует их как обычные символы. Поэтому чтобы пропустить также сами квадратные скобки, то и перед ними тоже нужно его поставить. Ниже показаны примеры регулярных выражения с использованием обратного слэша на Python.
>>> pattern = 'a[,.]]bc' # Это , или . или ] >>> re.search(pattern, r'a]bc') <re.Match object; span=(0, 4), match='a]bc'> >>> re.search(pattern, r'a.bc') <re.Match object; span=(0, 4), match='a.bc'>
В строке обратный слэш тоже имеет особое значение. Он ответственен за специальные символы: n (новая строка), t (отступ), s (пробел) и т.д. Их так же можно перечислять в квадратных скобках. А вот для пропуска самого обратного слэша в Python, требуется повторить его 4 раза. Ведь два слэша значат слэш как обычный символ, а чтобы пропустить его нужно два обычных. Иными словами, это:
>>> re.search('\\', 'abcd')
<re.Match object; span=(2, 3), match='\'>
интерпретируется как это:
regex("\" [пропущенный слэш] пропускает "\" [пропущенный слэш])
В Python строку можно инициализировать как raw (сырую), т.е. в ней обратный слэш будет считаться как обычный символ. Для этого перед строкой указывается r. Взгляните как прописываются пути Windows в Python в виде обычной и сырой строки:
>>> 'C:Useradminpython'
File "<stdin>", line 1
'C:Useradminpython'
SyntaxError: (unicode error) 'unicodeescape' codec can t decode bytes in position 2-3: truncated UXXXXXXXX escape
SyntaxError: invalid syntax
# Ошибка, потому что Python не понимает U
# Чтобы прописать путь, используется \ или r:
>>> path = 'C:\User\admin\python'
>>> raw_path = r'C:\User\admin\python'
Цифры, пробелы, отступы
Использование обратного слэша вместе с некоторыми символами даст новое значение строке. Так, n — новая строка, t — отступ . Есть ещё полезные специальные символы:
- d — любая цифра, эквивалентно использованию
[0-9] - D — любая не цифра, эквивалентно использованию
[^0-9] - s — пробел
- s — не пробел
- w — любой цифробуквенный символ, эквивалентно использованию
[a-zA-Z0-9_] - W — любой не цифробуквенный символ, эквивалентно использованию
[^a-zA-Z0-9_]
>>> re.search('dddd-dd-dd', '2020-05-10')
<re.Match object; span=(0, 10), match='2020-05-10'>
Этот пример на Python показывает, как можно найти даты в предложении с применением специальных символов. Ниже таблица, в который приведены символы для регулярных выражений.
| Символ | Значение | Пример | Совпадения |
| . | Любой одиночный символ (включая числа, пробелы и т. д.). | f.t | fat, fit, fet |
| * | Повторение 0 или более раз | a*b* | aabbb, bbb, ab, aaa |
| + | Повторение 1 или более раз | a+b+ | aabbb, ab, aaabbb |
| [] | Выбор любого символа в скобках | [a-z]* | apes, banana, flu |
| [^] | Любой символ, которого нет в скобках | [^a-z]* | APES,FLU, BANANA |
| () | Группа символов | (a*b)* | aaabaab, abaaab, bab |
| | | Оператор ИЛИ внутри группы символов | b(a|i|e)d | bad, bid, bed |
| Знак пропуска | .|\ | .| | |
| {m,n} | Повторение указанного количества раз от m до n (включительно) | a{2,3}b{2,3} | aabbb, aaabbb,aabb |
| ^ | Указывает, что символ или часть выражения находится в начале строки | ^a | apple, asdf, a |
| $ | Сканировать до конца строки | [A-Z]*[a-z]*$ | ABCabc, zzzyx, Bob |
О том, как применять регулярные выражения в Python для решения реальных Data Science задач, вы узнаете на нашем специализированном курсе «PNLP: NLP – обработка естественного языка с Python» в лицензированном учебном центре обучения и повышения квалификации Data Scientist’ов и IT-специалистов в Москве.
Источники
- https://docs.python.org/3/howto/regex.html
Решил написать шпаргалку по регулярным выражениям. Вдруг я когда-нибудь их подзабуду. Кроме того, этот пост можно считать продолжением к моей серии уроков по Perl.
1. Введение
Пара слов для тех, кто не совсем в курсе, о чем идет речь. Вы видели когда-нибудь маски имен файлов — всякие там *.html, filename.{txt|csv} и тд? Так вот, регулярные выражения — это те же «маски», только более сложные. В умелых руках регулярные выражения могут быть невероятно мощным инструментом. Так или иначе они используются в 95% моих скриптов.
Многие небезосновательно считают, что регулярные выражения — это скорее самостоятельный язык программирования, чем часть какого-либо языка. Регулярные выражения есть в Perl, PHP, Python, JavaScript, конфигурационных файлах Apache… В зависимости от языка, могут иметь место небольшие различия в синтаксисе регулярных выражений, но основные идеи везде одни и те же.
Поэтому, несмотря на то, что все примеры в заметке написаны на Perl, приведенная информация также пригодится программистам, использующим в своей работе любой другой язык. Например, такой код на PHP:
if(preg_match(«/[0123456789]/», $text)) {
// в тексте есть цифры
} else {
// в тексте нет ни одной цифры
}
… и такой — на Perl:
if($text =~ /[0123456789]/) {
# в тексте есть цифры
} else {
# в тексте нет ни одной цифры
}
… делают одно и то же. Как не сложно догадаться по комментариям в коде, здесь идет проверка, содержит ли строка $text хотя бы одну цифру.
2. Простые примеры
Как всегда, учиться будем на примерах. Квадратные скобки в регулярных выражениях означают «здесь должен быть один из перечисленных символов». Например, приведенному выше выражению [0123456789] соответствует любая строка, содержащая хотя бы одну цифру. Аналогично, выражению [abc] соответствует любая строка, содержащая хотя бы одну из первых трех букв латинского алфавита. Чтобы обозначить любой символ, кроме заданных, используется запись [^abcdef], то есть с символом крышки сразу за открывающейся квадратной скобкой.
Пусть нам нужно проверить, содержит ли строка любой символ латинского алфавита. Перечислять все 26 букв не совсем удобно, правда? Специально для таких случаев в регулярных выражениях можно использовать тире в квадратных скобках для обозначения упорядоченного множества символов. Выражению [a-z] будет соответствовать любая строка, содержащая хотя бы одну строчную букву латинского алфавита. По аналогии, приведенный ранее пример с цифрами можно записать более коротко:
if($text =~ /[0-9]/) {
# в тексте есть цифры
} else {
# в тексте нет ни одной цифры
}
И еще пара примеров:
if($text =~ /[a-z0-9]/) {
# в тексте есть цифры и/или строчные буквы
# подходит: abc, ZZaZZ, ===17
# не подходит: EPIC FAIL, @&#^*!@#
}
if($text =~ /[^0-9]/) {
# в тексте есть символы, отличные от цифр
# подходит: abc, 123abc456, 0x1111111111
# не подходит: 123, 123456, 9999999999
}
if($text =~ /[a-zA-Z]/) {
# в тексте есть буквы латинского алфавита
# подходит: ___Abba___, zyx
# не подходит: 0123, ^_^
}
if($text =~ /[a-fA-F0-9]/) {
# текст содержит цифры и буквы от A до F
# подходит: ***777***, DeadC0de, intel, 0_o
# не подходит: Xor, wiki
}
Усложним задачу. Теперь нам нужно проверить не просто наличие или отсутствие определенных символов, а соответствие строки определенному формату. Вот несколько простых примеров:
if($text =~ /num=[0-9]/) {
# подходит: num=1, some_num=000, bebenum=2(&^*
# не подходит: NUM=1, my_num=-1, num=abc
}
if($text =~ /<img src=»[^»]+»>/) {
# подходит:
# zzz<img src=»logo.png»>zzz
# <img src=»http://example.ru/logo.png»>
# не подходит:
# <img src=’logo.png’>
# <img src=»logo.png» />
}
Внимательный читатель поинтересуется, что это за знак плюса стоит в последнем регулярном выражении? Этот символ означает «один или более символов, указанных перед этим плюсом». Почти то же самое обозначает символ звездочка — «от нуля до сколько угодно символов, указанных перед звездочкой». Например, выражению A+ будет соответствовать последовательность из одного и более символов A, а выражению [0-9]* — любое количество цифр, в том числе и ни одной.
Иногда количество символов нужно задать точнее. Это можно сделать с помощью фигурных скобок. Например, выражению [0-9]{8} соответствует любая последовательность из ровно восьми цифр, а выражению [a-z]{3,8} — последовательность, содержащая от 3-х до 8-и символов латинского алфавита.
Число на второй позиции можно не указывать. То есть выражение [a-z]{3,} также может иметь место. Оно означает «не менее трех строчных букв латинского алфавита». Выражение {0,} полностью аналогично звездочке, а {1,} — плюсу. Выражение {0,1} можно записать более коротко, используя знак вопроса.
Пример (не самый простой, зато интересный):
if($text =~ /<img src=[«‘]{1}https?[^»‘]+[«‘]{1} *>/) {
# подходит:
# dfgd<img src=»http://example.ru/logo.png»>dfgdfg
# <img src=’https://null’ >
# не подходит:
# <img src=»logo.png»>
# <img src=»http://bebebe’bebebe»>
}
Если от этого примера у вас закипают мозги, самое время немного попрактиковаться в регулярных выражениях путем написания тестовых программок. Иначе от дальнейшего прочтения у вас будет каша в голове. Если пока что все понятно, идем дальше.
3. Как выдрать кусок строки?
Символ вертикальной черты (он же «пайп» или просто «палка») в регулярных выражениях означает «или». Например, выражению [a-zA-Z]{20}|[0-9]{25} соответствуют все строки, содержащие 20 символов латинского алфавита или 25 цифр подряд. Обычно этот символ используется совместно с круглыми скобками, предназначенных для группировки частей регулярного выражения. Пример:
if($filename =~ /backup(19|20)[0-9]{2}-[0-9]{2}-[0-9]{2}/) {
# подходит: backup2011-04-01, backup1999-01-13
# не подходит: backup1873-12-12, backup2101-07-07
}
У круглых скобок есть еще одна функция. С их помощью можно выдирать куски соответствующих строк. В PHP результат сохраняется в переменную, указанную третьим аргументом функции preg_match. В Perl совпадения для 1-ой, 2-ой … 9-ой пары скобок сохраняются в переменные $1, $2, …, $9 . Но удобнее использовать такую конструкцию:
if(my ($y, $m, $d) =
$filename =~ /backup([0-9]{4})-([0-9]{2})-([0-9]{2})/) {
print «year = $y, month = $m, day = $dn«;
}
Спрашивается, под каким номером искать совпадение в возвращаемом массиве, если регулярное выражение содержит вложенные скобки? Все просто — совпадения возвращаются в том же порядке, в котором идут открывающиеся скобки. Пример:
my $filename = «./dumps/backup2011-04-01.tgz»;
$filename =~ /backup((20|19)[0-9]{2})-([0-9]{2})-([0-9]{2})/;
print «$1, $2, $3, $4n«;
# выведет: 2011, 20, 04, 01
Иногда нам хотелось бы сгруппировать какую-то часть выражения, но не возвращать ее. Для этого сразу за открывающейся скобкой нужно написать последовательность из знака вопроса и двоеточия. Пример:
if(my ($y, $m, $d) =
$filename =~ /backup((?:20|19)[0-9]{2})-([0-9]{2})-([0-9]{2})/) {
print «year = $y, month = $m, day = $dn«;
}
Также за круглыми скобками может следовать вопросительный знак, плюс или звездочка, означающие, что конструкция, указанная в скобках, необязательна, должна повторяться 1+ раз или должна повторяться 0+ раз соответственно. Использование фигурных скобок вслед за круглыми также допустимо.
4. Начало и конец строки
Часто бывает полезным обозначить в регулярном выражение место, где должна начинаться и/или заканчиваться строка. Первое делается с помощью символа крышки в начале выражения, второе — с помощью знака доллара в конце. Примеры:
if($text =~ /^[1-9][0-9]*/) {
# текст, начинающийся с десятичной цифры
# подходит: 3, 801403, 6543bebebe
# не подходит: 0275, -123, abc11111
}
if($text =~ /^0x[0-9a-fA-F]{1,8}$/) {
# шестнадцатеричное число в C-нотации
# подходит: 0x5f3759df, 0xDEADBEEF
# не подходит: 0x1234xxx, xxx0x5678, xxx0x9ABCxxx
}
Не сложно, правда? Обратите внимание, что при проверке полей веб-форм, аргументов функции перед подстановкой их в SQL-запрос и так далее, обязательно следует проверять всю строку, как это сделано в последнем регулярном выражении.
Примечание: Если кого-нибудь интересует, что это за «магические числа» 0x5f3759df и 0xDEADBEEF, обращайтесь к Википедии.
5. Специальные символы
Помимо названных специальных символов следует также особо отметить точку. Она означает любой символ, кроме символа новой строки. Пример использования:
if(my ($name) = $arg =~ /^—name=(.+)$/) {
print «Hello, $name!n«;
}
По умолчанию регулярные выражения производят так называемый жадный разбор. Другими словами, ищутся совпадения максимальной длины. Когда мы используем точку, с этим могут возникнуть проблемы. Например, нам нужно выдрать некоторый текст из сотни HTML-страниц примерно такого содержания:
<span>Text <em>text</em> text</span><span>Source: http://eax.me/</span>
Следующий код вернет нам не то, что хотелось бы:
# в регулярном выражении содержится слэш, поэтому
# приходится использовать вместо него другой ограничитель
my ($text) = $data =~ m#<span>(.*)</span>#;
print $text;
# выведет наиболее длинное совпадение:
# Text <em>text</em> text</span><span>Source: http://eax.me/
А вот что произойдет, если отключить жадный разбор (внимание на знак вопроса):
my ($text) = $data =~ m#<span>(.*?)</span>#;
print $text;
# выведет первое совпадение:
# Text <em>text</em> text
Да, следующие строки делают одно и то же:
# обычная запись …
$text =~ /([0-9]{4})-([0-9]{2})-([0-9]{2})/;
# на самом деле — лишь сокращение оператора m//
$text =~ m/([0-9]{4})-([0-9]{2})-([0-9]{2})/;
# вместо слэша можно использовать разные скобочки:
$text =~ m{([0—9]{4})—([0—9]{2})—([0—9]{2})};
$text =~ m<([0—9]{4})—([0—9]{2})—([0—9]{2})>;
$text =~ m[([0—9]{4})—([0—9]{2})—([0—9]{2})];
$text =~ m(([0—9]{4})—([0—9]{2})—([0—9]{2}));
# или даже такие символы:
$text =~ m!([0—9]{4})—([0—9]{2})—([0—9]{2})!;
$text =~ m|([0—9]{4})—([0—9]{2})—([0—9]{2})|;
$text =~ m#([0-9]{4})-([0-9]{2})-([0-9]{2})#;
# а также крышку, кавычки, двоеточие, запятую, точку, …
Зачем понадобилось столько способов записи регулярных выражений? Представьте, что выражение содержит слэши, точки, запятые и прочие символы, но не содержит восклицательного знака. Тогда, очевидно, мы не можем использовать для обозначения начала и конца регулярного выражения слэши, точки и так далее, зато восклицательный знак — можем.
Часто в регулярных выражениях приходится использовать обратный слэш. Поставленный перед точкой, скобкой, плюсом, крышкой и другими символами, он означает «следующий символ означает именно символ, а не что-то другое». Например, вот как можно определить расширение файла по его имени:
# экранированная обратным слэшем точка
# означает именно точку, а не «любой символ»
my ($ext) = $fname =~ /.([a-z0-9]+)$/;
print «file name: $fname, extension: $extn«;
Кроме того, обратный слэш используется в следующих обозначениях:
- t — обозначает символ табуляции (tab)
- r и n — символы возврата каретки (return) и новой строки (new line)
- xNN — соответствует символу с ASCII кодом NN, например x41 соответствует заглавной букве A латинского алфавита
- s — соответствует пробелу (space), табуляции, символу новой строки или символу возврата каретки
- d — означает любую цифру (digit), а точнее — то, что считается цифрой в Юникоде (см слайд номер 102 в этой презентации)
- w — означает так называемое «слово» (word), аналог [0-9a-zA-Z_]
В последних трех выражениях запись буквы в верхнем регистре означает отрицание. Например, D соответствует выражению [^0-9], W — выражению [^0-9a-zA-Z_], а S — любому «не пробельному» символу.
Все эти «буквенные» выражения можно использовать внутри квадратных скобок. Например, выражение [a-fd] полностью эквивалентно [a-f0-9].
Особого внимания заслуживают выражения b и B, означающие границу слова (в том же понимании «слова», как и в случае с w) и отсутствие границы слова соответственно. Например, выражению perlb соответствует строка «perl rulez!», но не соответствует «perlmonk». С выражением perlB все с точностью наоборот. Надеюсь, идея ясна.
И еще один пример:
# разбиваем полное имя файла на путь и имя
my($path, $fname) = $full_name =~ /^(.*)/([^/]+)$/;
Он иллюстрирует использование обратного слэша для экранирования символа, который используется для обозначения границ регулярного выражения. В данном примере это — прямой слэш.
6. Модификаторы
Поведение регулярных выражений можно менять с помощью модификаторов. Например, как вы уже могли заметить, соответствие строки регулярному выражению проверяется с учетом регистра символов. Изменить это поведение можно с помощью модификатора /i (case insensitivity):
# выражение
$str =~ s/[a—z]/i;
# полностью аналогично
$str =~ s/[a—zA—Z]/;
По-умолчанию производится поиск только первого совпадения регулярному выражению. Модификатор /g позволяет осуществить глобальный (global) поиск:
# выдираем из HTML-файла все, что выделено жирным
# знак вопроса — для отключения жадного разбора
my @words = $html =~ m#<strong>(.*?)</strong>#g;
# будьте осторожны при использовании /g в скалярном контексте
# подробности здесь: http://koorchik.blogspot.com/2011/07/perl-5.html
print «$_n« for(@words);
Как было сказано выше, точка обозначает любой символ, кроме символа новой строки. Изменить такое поведение можно с помощью модификатора /s:
# выдираем из HTML-файла содержимое статьи,
# которое может содержать далеко не одну и не две строчки
my ($article) = $html =~ m#<div id=»article»>(.*?)</div>#s;
Кстати, если в регулярном выражении нужно обозначить «любой символ» без использования модификатора /s, используйте выражение [dD]. Оно означает «любой символ, являющийся цифрой, или не являющийся цифрой», то есть вообще любой символ.
Наконец, ничто не мешает использовать несколько модификаторов одновременно:
# выдираем из HTML-файла все, что выделено жирным
my @words = $html =~ m#<strong>(.*?)</strong>#gi;
# сработает для <strong>, <STRONG> или даже <StRoNg>
Дополнение: Еще один полезный модификатор — /o. Он означает «компилировать регулярное выражение только один раз». В некоторых случаях этот модификатор может существенно ускорить скрипт. Правда, я не уверен, что он поддерживается где-то, кроме как в Perl. За наводку спасибо товарищу @tanraya.
7. Заключение
Данная заметка не претендует на полноту. Однако в ней перечислены почти все возможности регулярных выражений, которыми мне когда-либо приходилось пользоваться. Я специально умолчал о замене с помощью регулярных выражений (оператор s/// в Perl), модификаторе /e, работе с юникодом и, возможно, нескольких других моментах.
Заметка и так получилась раза в два больше, чем я планировал. Так что, об названных вещах я напишу как-нибудь в другой раз. В качестве источника дополнительной информации я бы рекомендовал man perlrequick (быстрое введение в регулярные выражения) и man perlre (более подробное описание сабжа).
Метки: Perl, PHP, Python.