I needed to parse a site, but i got an error 403 Forbidden.
Here is a code:
url = 'http://worldagnetwork.com/'
result = requests.get(url)
print(result.content.decode())
Its output:
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx</center>
</body>
</html>
Please, say what the problem is.
![]()
asked Jul 20, 2016 at 19:36
![]()
Толкачёв ИванТолкачёв Иван
1,6993 gold badges10 silver badges13 bronze badges
2
It seems the page rejects GET requests that do not identify a User-Agent. I visited the page with a browser (Chrome) and copied the User-Agent header of the GET request (look in the Network tab of the developer tools):
import requests
url = 'http://worldagnetwork.com/'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
result = requests.get(url, headers=headers)
print(result.content.decode())
# <!doctype html>
# <!--[if lt IE 7 ]><html class="no-js ie ie6" lang="en"> <![endif]-->
# <!--[if IE 7 ]><html class="no-js ie ie7" lang="en"> <![endif]-->
# <!--[if IE 8 ]><html class="no-js ie ie8" lang="en"> <![endif]-->
# <!--[if (gte IE 9)|!(IE)]><!--><html class="no-js" lang="en"> <!--<![endif]-->
# ...
answered Jul 20, 2016 at 19:48
![]()
2
Just add to Alberto’s answer:
If you still get a 403 Forbidden after adding a user-agent, you may need to add more headers, such as referer:
headers = {
'User-Agent': '...',
'referer': 'https://...'
}
The headers can be found in the Network > Headers > Request Headers of the Developer Tools. (Press F12 to toggle it.)
answered Jul 9, 2019 at 5:44
![]()
5
If You are the server’s owner/admin, and the accepted solution didn’t work for You, then try disabling CSRF protection (link to an SO answer).
I am using Spring (Java), so the setup requires You to make a SecurityConfig.java file containing:
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure (HttpSecurity http) throws Exception {
http.csrf().disable();
}
// ...
}
answered May 26, 2018 at 11:31
![]()
AleksandarAleksandar
3,4081 gold badge37 silver badges42 bronze badges
Собственно, проблема следующая:
Postman отрабатывает отлично и возвращает ожидаемый результат
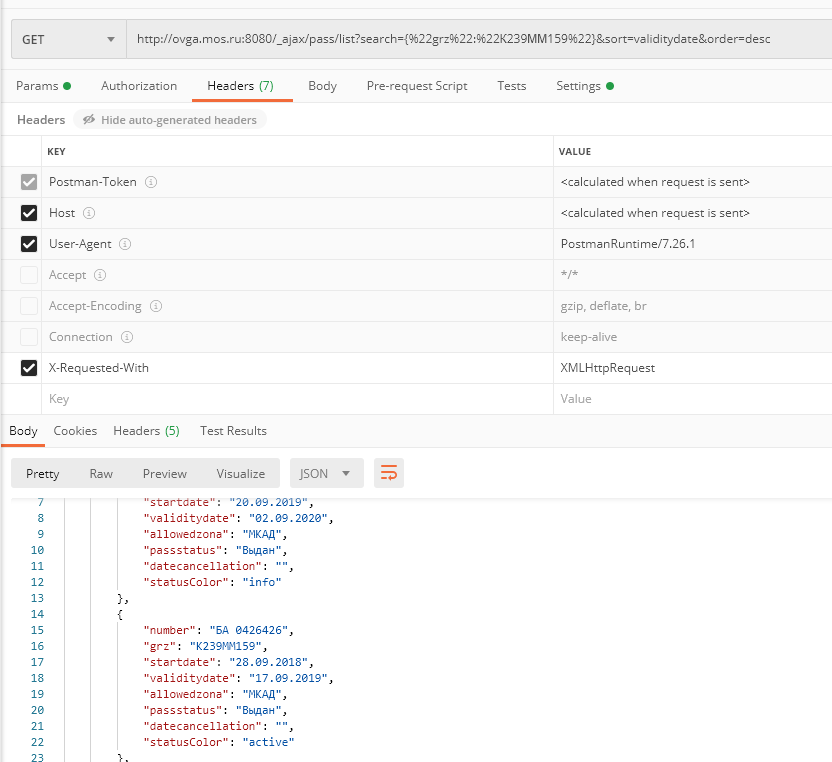
А python на аналогичный запрос выдает 403 код. Хотя вроде как заголовки одинаковые. Что ему, собаке, не хватает?
import requests
from pprint import pprint
url = 'http://ovga.mos.ru:8080/_ajax/pass/list?search={%22grz%22:%22К239ММ159%22}&sort=validitydate&order=desc'
headers = {"X-Requested-With": "XMLHttpRequest",
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/54.0.2840.99 Safari/537.36',
}
response = requests.get(url, headers)
pprint(response)
<Response [403]>-
Вопрос заданболее двух лет назад
-
2505 просмотров
Ты не все заголовки передал. Postman по-умолчанию генерирует некоторые заголовки самостоятельно, вот так подключается нормально:
headers = {
'Host': 'ovga.mos.ru',
'User-Agent': 'Magic User-Agent v999.26 Windows PRO 11',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'X-Requested-With': 'XMLHttpRequest'
}
url = 'http://ovga.mos.ru:8080/_ajax/pass/list?search={"grz":"К239ММ159"}&sort=validitydate&order=desc'
response = requests.get(url, headers=headers)<Response [200]>
Пригласить эксперта
-
Показать ещё
Загружается…
28 мая 2023, в 00:03
8000 руб./за проект
27 мая 2023, в 23:03
10000 руб./за проект
27 мая 2023, в 22:55
1000 руб./за проект
Минуточку внимания
Уведомления
- Начало
- » Python для новичков
- » Requests: 403 в питоне, OK в браузере
#1 Фев. 15, 2017 15:13:27
Requests: 403 в питоне, OK в браузере
wallet
R
Попробовал, то же самое. Пока удалось продвинутся только со ссылками на сторонние сайты благодаря удалению слэша в адресе. Member area почему-то для меня по-прежнему закрыта.
Код полностью:
#! python3 import requests, bs4, os, re, random, time, pyperclip myheader = {'user-agent': 'Mozilla Firefox/51.0.1', 'Referer':'https://www.volodaily.com/'} loginpage='https://www.volodaily.com:443/login' payload={'cjfm_do_login_nonce':'cc12226939','do_login':'','login_form_user_login':'blah','login_form_user_pass':'blah','redirect_url':'https://www.volodaily.com/issues','remember_me':'on'} image='https://s3.amazonaws.com/dailyvolo/wp-content/uploads/2016/05/03164021/oceanflavor-by-Igor-Koshelev.jpg' with requests.Session() as s: logged = s.post(loginpage, headers=myheader, data=payload) mycookies = logged.cookies print(mycookies) print('Login page responce: ' + str(logged)) err = s.get(image, headers=myheader, cookies=mycookies) print('Amazon link avail: ' + str(err)) membersonly = s.get('https://www.volomagazine.com', headers=myheader, cookies=mycookies) print('Members only area avail: ' + str(membersonly))
Login page responce: <Response [200]> Amazon link avail: <Response [200]> Members only area avail: <Response [403]>
Офлайн
- Пожаловаться
#2 Фев. 15, 2017 15:21:02
Requests: 403 в питоне, OK в браузере
Слэш в конце пришлось удалить по рекомендациям отсюда http://stackoverflow.com/questions/19909127/python-requests-403-on-post
Говорят, нужно скармливать именно файл, а не каталог.
А ещё там же говорят, что 403 — это не 401, и сделано именно для защиты:
403 means the server is refusing to respond it and authentication won’t make a difference. Sure, there’s a chance whoever implemented it doesn’t know the difference, but it’s also likely that they are tracking something else and trying to prevent automated access like you’re trying to do.
Но, я уверен, что и на это можно найти обход… только как?
Отредактировано m0rtal (Фев. 15, 2017 15:23:07)
Офлайн
- Пожаловаться
#3 Фев. 15, 2017 16:27:30
Requests: 403 в питоне, OK в браузере
Ещё немного поправили: User-Agent большими буквами. Но всё равно не помогает.
Офлайн
- Пожаловаться
#4 Фев. 15, 2017 16:42:29
Requests: 403 в питоне, OK в браузере
У меня вот так получилось картинку слить —
# -*- coding: UTF-8 -*- from robobrowser import RoboBrowser USER_AGENT = 'Mozilla/5.0 (compatible; ABrowse 0.4; Syllable)' browser = RoboBrowser(user_agent=USER_AGENT, parser='html.parser') LOGIN = 'логин' PASSWORD = 'пароль' browser.open('https://www.volodaily.com/login/') form = browser.get_form(action='https://www.volodaily.com:443/login/') form['login_form_user_login'] = LOGIN form['login_form_user_pass'] = PASSWORD browser.submit_form(form) browser.open('https://www.volodaily.com/ocean-flavor-by-igor-koshelev/') url = 'https://s3.amazonaws.com/dailyvolo/wp-content/uploads/2016/05/03164021/oceanflavor-by-Igor-Koshelev.jpg' headers = {'Referer':'https://www.volodaily.com/ocean-flavor-by-igor-koshelev/'} image = browser.session.get(url , headers=headers, stream=True) with open('Igor-Koshelev.jpg', 'wb') as file: file.write(image.content) print('ok')
И действительно, пока headers не прописал amasonaws отдавал xml с ошибкой.
Офлайн
- Пожаловаться
#5 Фев. 15, 2017 16:43:53
Requests: 403 в питоне, OK в браузере
m0rtal
Ещё немного поправили: User-Agent большими буквами. Но всё равно не помогает.
Вместо “Mozilla Firefox” пишите просто “Mozilla”
Офлайн
- Пожаловаться
#6 Фев. 15, 2017 16:45:54
Requests: 403 в питоне, OK в браузере
Добавил полную строку User-Agent отсюда, вроде пошло. Редко ещё бывает 403, но пока не системно, буду разбираться.
Спасибо!
Отредактировано m0rtal (Фев. 15, 2017 16:52:48)
Офлайн
- Пожаловаться
#7 Фев. 16, 2017 01:57:11
Requests: 403 в питоне, OK в браузере
m0rtal
Добавил полную строку User-Agent отсюда, вроде пошло.
Свой браузер можно было посмотреть в заголовках запроса в Firebug или HttpFox.
Отредактировано py.user.next (Фев. 16, 2017 01:57:45)
Офлайн
- Пожаловаться
#8 Фев. 20, 2017 07:32:45
Requests: 403 в питоне, OK в браузере
py.user.next
Можно было, но честно говоря глазами в выдаче не нашёл.
Офлайн
- Пожаловаться
#9 Фев. 20, 2017 12:57:39
Requests: 403 в питоне, OK в браузере
m0rtal
Можно было, но честно говоря глазами в выдаче не нашёл.
Там вкладка “заголовки”, вот в ней.
Офлайн
- Пожаловаться
#10 Фев. 20, 2017 12:59:37
Requests: 403 в питоне, OK в браузере
py.user.next
Там вкладка “заголовки”, вот в ней.
Теперь нашёл ))
Офлайн
- Пожаловаться
- Начало
- » Python для новичков
- » Requests: 403 в питоне, OK в браузере
Summary
TL;DR: requests raises a 403 while requesting an authenticated Github API route, which otherwise succeeds while using curl/another python library like httpx
Was initially discovered in the ‘ghexport’ project; I did a reasonable amount of debugging and created this repo before submitting this issue to PyGithub, but thats a lot to look through, just leaving it here as context.
It’s been hard to reproduce, the creator of ghexport (where this was initially discovered) didn’t have the same issue, so I’m unsure of the exact reason
Expected Result
requests succeeds for the authenticated request
Actual Result
Request fails, with:
{'message': 'Must have push access to repository', 'documentation_url': 'https://docs.github.com/rest/reference/repos#get-repository-clones'}
failed
Traceback (most recent call last):
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 47, in <module>
main()
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 44, in main
make_request(requests.get, url, headers)
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 31, in make_request
resp.raise_for_status()
File "/home/sean/.local/lib/python3.9/site-packages/requests/models.py", line 941, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
Reproduction Steps
Apologies if this is a bit too specific, but otherwise requests works great on my system and I can’t find any other way to reproduce this — Is a bit long as it requires an auth token
Go here and create a token with scopes like:

I’ve compared this to httpx, where it doesn’t fail:
#!/usr/bin/env python3 from typing import Callable, Any import requests import httpx # extract status/status_code from the requests/httpx item def extract_status(obj: Any) -> int: if hasattr(obj, "status"): return obj.status if hasattr(obj, "status_code"): return obj.status_code raise TypeError("unsupported request object") def make_request(using_verb: Callable[..., Any], url: str, headers: Any) -> None: print("using", using_verb.__module__, using_verb.__qualname__, url) resp = using_verb(url, headers=headers) status = extract_status(resp) print(str(resp.json())) if status == 200: print("succeeded") else: print("failed") resp.raise_for_status() def main(): # see https://github.com/seanbreckenridge/pygithub_requests_error for token scopes auth_token = "put your auth token here" headers = { "Authorization": "token {}".format(auth_token), "User-Agent": "requests_error", "Accept": "application/vnd.github.v3+json", } # replace this with a URL you have access to url = "https://api.github.com/repos/seanbreckenridge/albums/traffic/clones" make_request(httpx.get, url, headers) make_request(requests.get, url, headers) if __name__ == "__main__": main()
That outputs:
using httpx get https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
{'count': 15, 'uniques': 10, 'clones': [{'timestamp': '2021-04-12T00:00:00Z', 'count': 1, 'uniques': 1}, {'timestamp': '2021-04-14T00:00:00Z', 'count': 1, 'uniques': 1}, {'timestamp': '2021-04-17T00:00:00Z', 'count': 1, 'uniques': 1}, {'timestamp': '2021-04-18T00:00:00Z', 'count': 2, 'uniques': 2}, {'timestamp': '2021-04-23T00:00:00Z', 'count': 9, 'uniques': 5}, {'timestamp': '2021-04-25T00:00:00Z', 'count': 1, 'uniques': 1}]}
succeeded
using requests.api get https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
{'message': 'Must have push access to repository', 'documentation_url': 'https://docs.github.com/rest/reference/repos#get-repository-clones'}
failed
Traceback (most recent call last):
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 48, in <module>
main()
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 45, in main
make_request(requests.get, url, headers)
File "/home/sean/Repos/pygithub_requests_error/minimal.py", line 32, in make_request
resp.raise_for_status()
File "/home/sean/.local/lib/python3.9/site-packages/requests/models.py", line 943, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://api.github.com/repos/seanbreckenridge/albums/traffic/clones
Another thing that may be useful as context is the pdb trace I did here, which was me stepping into where the request was made in PyGithub, and making all the requests manually using the computed url/headers. Fails when I use requests.get but httpx.get works fine:
> /home/sean/.local/lib/python3.8/site-packages/github/Requester.py(484)__requestEncode()
-> self.NEW_DEBUG_FRAME(requestHeaders)
(Pdb) n
> /home/sean/.local/lib/python3.8/site-packages/github/Requester.py(486)__requestEncode()
-> status, responseHeaders, output = self.__requestRaw(
(Pdb) w
/home/sean/Repos/ghexport/export.py(109)<module>()
-> main()
/home/sean/Repos/ghexport/export.py(84)main()
-> j = get_json(**params)
/home/sean/Repos/ghexport/export.py(74)get_json()
-> return Exporter(**params).export_json()
/home/sean/Repos/ghexport/export.py(60)export_json()
-> repo._requester.requestJsonAndCheck('GET', repo.url + '/traffic/' + f)
/home/sean/.local/lib/python3.8/site-packages/github/Requester.py(318)requestJsonAndCheck()
-> *self.requestJson(
/home/sean/.local/lib/python3.8/site-packages/github/Requester.py(410)requestJson()
-> return self.__requestEncode(cnx, verb, url, parameters, headers, input, encode)
> /home/sean/.local/lib/python3.8/site-packages/github/Requester.py(486)__requestEncode()
-> status, responseHeaders, output = self.__requestRaw(
(Pdb) url
'/repos/seanbreckenridge/advent-of-code-2019/traffic/views'
(Pdb) requestHeaders
{'Authorization': 'token <MY TOKEN HERE>', 'User-Agent': 'PyGithub/Python'}
(Pdb) import requests
(Pdb) requests.get("https://api.github.com" + url, headers=requestHeaders).json()
{'message': 'Must have push access to repository', 'documentation_url': 'https://docs.github.com/rest/reference/repos#get-page-views'}
(Pdb) httpx.get("https://api.github.com" + url, headers=requestHeaders).json()
{'count': 0, 'uniques': 0, 'views': []}
(Pdb) httpx succeeded??
System Information
$ python -m requests.help
{
"chardet": {
"version": "3.0.4"
},
"cryptography": {
"version": "3.4.7"
},
"idna": {
"version": "2.10"
},
"implementation": {
"name": "CPython",
"version": "3.9.3"
},
"platform": {
"release": "5.11.16-arch1-1",
"system": "Linux"
},
"pyOpenSSL": {
"openssl_version": "101010bf",
"version": "20.0.1"
},
"requests": {
"version": "2.25.1"
},
"system_ssl": {
"version": "101010bf"
},
"urllib3": {
"version": "1.25.9"
},
"using_pyopenssl": true
}
$ pip freeze | grep -E 'requests|httpx'
httpx==0.16.1
requests==2.25.1
Python:
import requests
cookies = {
'_ALGOLIA': 'xxx',
'wtstp_sid': 'xxx',
'wtstp_eid': 'xxx',
'_dy_c_exps': '',
'_dy_c_att_exps': '',
'_dycnst': 'xxx',
'_dyid': 'xxx',
'.Nop.Customer': 'xxx',
'dy_fs_page': 'www.computeruniverse.net%2Fen%2Fc%2Flaptops-tablet-pcs-pcs%2Flaptops-notebooks',
'_dy_geo': 'KZ',
'_dy_df_geo': 'Kazakhstan',
'_dy_toffset': '0',
'_dyid_server': 'xxx',
'_dycst': 'xxx.',
'__cf_bm': 'xxx',
'cu-edge-hints': xxx',
'_dy_soct': 'xxx',
}
headers = {
'authority': 'www.computeruniverse.net',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-US,en;q=0.9',
'cache-control': 'max-age=0',
'if-modified-since': 'Sat, 17 Dec 2022 03:23:59 GMT',
'sec-ch-ua': '"Opera";v="93", "Not/A)Brand";v="8", "Chromium";v="107"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 OPR/93.0.0.0',
}
params = {
'lang': '1',
'cachecountry': 'KZ',
}
response = requests.get('https://webapi.computeruniverse.net/api/catalog/topmenu/', params=params, cookies=cookies, headers=headers)
print(response.status_code)