Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
- от Яндекса;
- от Google.
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
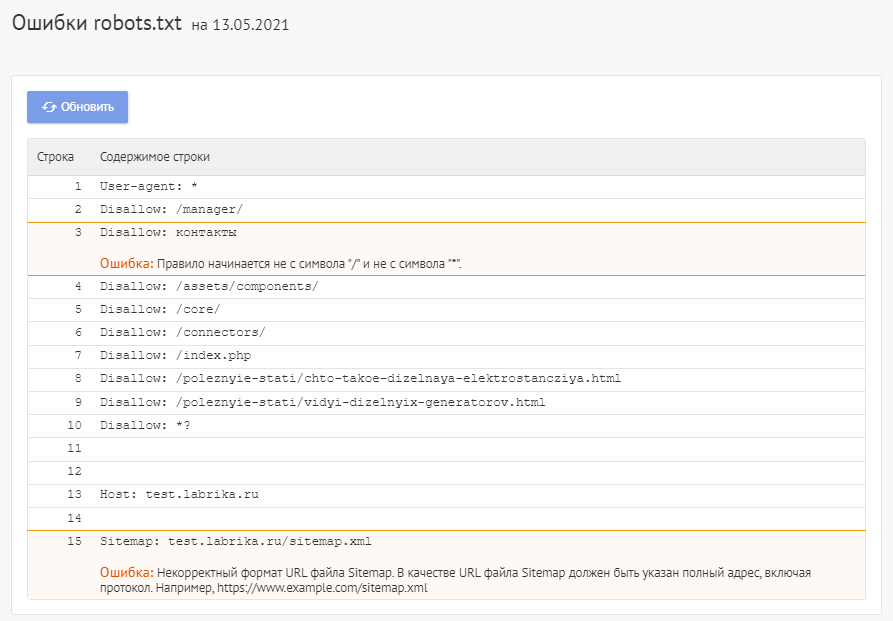
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.
Если робот Google не сможет получить доступ к вашей странице из-за правила в файле robots.txt, то она, скорее всего, не появится в результатах поиска Google, а если и появится, то без описания.
1. Проверьте, заблокирована ли страница в файле robots.txt
Если вы подтвердили право собственности на сайт в Search Console, сделайте следующее:
- Откройте инструмент проверки URL.
- Проверьте URL страницы, представленный в результате поиска Google.Должен быть выбран ресурс Search Console, который содержит этот URL.
- Найдите статус в разделе результатов проверки Индексирование страниц. Если там значится Заблокировано в файле robots.txt, то проблема подтверждена. Как ее устранить, описано далее.
Если вы не подтвердили право собственности на сайт в Search Console, сделайте следующее:
- Выполните поиск валидатора для файла robots.txt.
- Введите в валидаторе URL страницы, описание которой отсутствует. Это должен быть URL, указанный в результатах поиска Google.
- Если валидатор сообщает, что доступ к странице для робота Google запрещен, то проблема подтверждена. Как ее устранить, описано далее.
2. Измените правило
- Чтобы узнать, какое правило блокирует доступ к странице и где находится файл robots.txt, воспользуйтесь валидатором для robots.txt.
- Измените или удалите правило:
- Если вы пользуетесь сервисом веб-хостинга (например, если ваш сайт построен на Wix, Joomla или Drupal), мы не можем предоставить вам точное руководство по обновлению вашего файла robots.txt. Причина в том, что для каждого сервиса хостинга инструкции будут разными. Чтобы узнать, как разблокировать доступ Google к странице или сайту, поищите нужные сведения в документации своего хостинг-провайдера. Советуем выполнить поиск по запросу «robots.txt название_провайдера» или «открыть Google доступ к странице название_провайдера«. Пример: robots.txt Wix.
- Если у вас есть возможность вносить изменения непосредственно в файл robots.txt, удалите правило или обновите его иным образом с учетом синтаксиса robots.txt.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Robots.txt — это текстовый файл, который показывает поисковым роботам, как сканировать ваш сайт. Он защищает сайт и сервер от перегрузки из-за запросов поисковых роботов.
Если вы хотите заблокировать работу поисковых роботов, важно убедиться в корректности настроек. Это особенно важно, если вы используете динамические URL или другие методы, которые в теории генерируют бесконечное количество страниц.

В этом гайде рассматриваются самые распространенные проблемы с файлом robots.txt, их влияние на сайт и ранжирование в поисковой выдаче, а также способы решения.
Но для начала поговорим подробнее о robots.txt и его альтернативах.
Что такое файл robots.txt
Robots.txt — это файл в простом текстовом формате. Он размещается в корневом каталоге сайта (самый верхний каталог в иерархии). Если файл размещен в другом каталоге, поисковые роботы будут его игнорировать. Несмотря на всю мощь robots.txt, выглядит он как простой текстовый документ. А создать его можно за пару секунд в любом текстовом редакторе.
Выполнять функции robots.txt могут и его альтернативы. Например, метатеги. Их можно размещать в код отдельной страницы.
Можно использовать и HTTP-заголовок X-Robots-Tag, который задает настройки на уровне страницы.
Что делает robots.txt
Файл robots.txt можно использовать для множества целей. Вот несколько самых популярных.
Блокировка сканирования поисковыми роботами определенных страниц
Они все еще могут появляться в поисковой выдаче, но без текстового описания. Контент не в формате HTML тоже не будет сканироваться.
Блокировка медиафайлов для отображения в результатах поиска
Под медиафайлами понимаются изображения, видео и аудиофайлы. Если для файла предусмотрен общий доступ, он будет отображаться, но приватный контент не попадет в поисковую выдачу.

Блокировка файлов ресурсов с неважными внешними скриптами
Если у страницы заблокирован файл ресурсов, поисковые роботы посчитают, что его не существовало вовсе. Это может сказаться на индексировании.
Использование robots.txt не позволит полностью запретить отображение страницы в результатах поиска. Для этого придется добавить метатег noindex в верхнюю часть страницы.
Насколько опасны ошибки с Robots.txt
Ошибки в robots.txt приводят к определенным последствиям, но обычно не трагичным. А приведение файла в порядок позволит быстро и полностью восстановиться.
Как отмечает сам Google, у поисковых роботов достаточно гибкие алгоритмы. Поэтому незначительные ошибки в файле robots.txt никак не сказываются на их работе. В худшем случае неправильная или неподдерживаемая директива будет проигнорирована. Но если вы знаете, что в файле есть ошибки, их стоит исправить.
Шесть главных ошибок robots.txt
Если ранжирование сайта в поисковой выдаче изменилось странным образом, стоит проверить файл robots.txt. Рассмотрим шесть популярных ошибок подробно.
Ошибка № 1. Robots.txt находится не в корневом каталоге
Поисковые роботы могут найти файл robots.txt только если он расположен в корневом каталоге. Поэтому домен, например, .ru, и название файла robots.txt в URL должна разделять одна косая черта.
Если есть дополнительная папка, скорее всего, поисковые роботы не увидят файл. Сайт в этом случае функционирует так, как будто файла robots.txt нет совсем.
Чтобы исправить эту ошибку, перенесите robots.txt в корневой каталог. Для этого потребуется доступ к серверу. Некоторые системы управления содержимым по умолчанию загружают файл в подпапку с медиафайлами или подобные. Чтобы файл попал в нужное место, придется обойти эту настройку.
Ошибка № 2. Неправильное использование символа-джокера или символа подстановки
Символ-джокер — это символ, используемый для замены других символов или их последовательностей. Robots.txt поддерживает два символа-джокера:
- Звездочка, или астериск (*). Она представляет любые варианты допустимого символа. Своего рода аналог карты джокера.
- Значок доллара $. Обозначает конец URL, позволяет добавлять правила к последней части URL, например, файловое расширение.
При использовании символов-джокеров стоит придерживаться минимализма. Они могут потенциально наложить ограничения на большую часть сайта. Неправильное использование астерикса может привести к блокировке поискового робота. Чтобы решить проблему с неправильным символом-джокером, нужно его найти и переместить или удалить.
Ошибка № 3. Тег noindex в robots.txt
Эта ошибка часто встречается у сайтов, которым уже несколько лет. Google в сентябре 2019 года перестал выполнять команды метатега noindex в файле robots.txt.

Если ваш файл был создан до этой даты или содержит метатег noindex, скорее всего, страницы будут индексироваться Google.
Чтобы решить проблему, примените альтернативный метод. Вы можете добавить метатег robots в элемент страницы <head>, чтобы остановить индексацию.
Ошибка № 4. Блокировка скриптов и страниц стилей
Ограничение доступа к внутреннему JavaScript коду и Cascading Style Sheets (CSS) для поисковых роботов кажется логичным шагом. Однако поисковым роботам Google требуется доступ к CSS и JavaScript файлам, чтобы корректно сканировать HTML и PHP страницы.
Если страницы сайта странно отображаются в поисковой выдаче, проверьте, не заблокирован ли доступ поискового робота к этим внутренним файлам. Удалите соответствующую строку из файла robots.txt.
Если же вам нужна блокировка определенных файлов, вставьте исключение, которое даст поисковым роботам доступ только к нужным материалам.
Ошибка № 5. Отсутствует ссылка на файл sitemap.xml
Этот пункт относится к SEO больше всего. Файл sitemap.xml дает роботам информацию о структуре сайта и его главных страницах. Поэтому есть смысл добавить его в файл robots.txt. Его поисковые роботы Google сканируют в первую очередь.
Строго говоря, это не ошибка, и в большинстве случаев отсутствие ссылки на sitemap в robots.txt не должно влиять на функциональность и внешний вид сайта. Но если вы хотите улучшить продвижение, дополните файл robots.txt
Ошибка № 6. Доступ к страницам в разработке
Запрет сканирования поисковыми роботами рабочих страниц — серьезная ошибка. Как и предоставление им доступа к страницам, находящимся в разработке. Включите запрещающие инструкции в файл robots.txt, если сайт находится на реконструкции. Тогда пользователи не увидят «сырой» вариант.
Кстати, не забудьте убрать соответствующую строчку из файла, когда закончите. Это довольно распространенная ошибка, которая не позволит поисковым роботам правильно сканировать и индексировать сайт
Если ваш сайт еще находится в разработке, но вы видите реальный трафик, или, наоборот, запущенный сайт плохо ранжируется, проверьте строчку User-Agent в файле robots.txt.
User-Agent: *
Disallow: /
Наличие косой черты в строке Disallow делает сайт невидимым для поисковых роботов. Корректируйте строку в соответствии с нужным вам эффектом.
Как восстановиться после ошибок в robots.txt
Если ошибка в файле robots.txt повлияла на отображение в поисковой выдаче, самое главное — скорректировать файл и подтвердить, что новые правила дают нужный эффект. Проверить это можно с помощью инструментов для сканирования, например, Screaming Frog.

Когда убедитесь, что robots.txt работает верно, запросите повторное сканирование поисковыми роботами. В этом поможет Google Search Console. Добавьте обновленный файл sitemap и запросите повторное сканирование страниц, которые пострадали.
К сожалению, нет конкретного срока, в который поисковый робот проведет сканирование и страницы начнут нормально отображаться в поисковой выдаче. Все, что остается — быстро выполнить необходимые шаги и ждать, когда поисковый робот просканирует сайт.
Профилактика важнее всего
Ошибки с файлом robots.txt решаются относительно просто, но лучшим лекарством от них станет профилактика. Редактируйте файл аккуратно, привлекая опытных разработчиков, дважды все проверяйте и, если это актуально, послушайте мнение второго специалиста.
Если есть возможность, протестируйте изменения в песочнице, прежде чем применять их на реальном сервере.
Песочница — специально выделенная (изолированная) среда для безопасного исполнения компьютерных программ.
Это позволит избежать непроизвольных ошибок. И помните, если самое страшное уже случилось, не поддавайтесь панике. Проанализируйте проблему, внесите необходимые изменения в файл robots.txt и отправьте запрос на повторное сканирование. Скорее всего, нескольких дней будет достаточно, чтобы вернуться на прежние позиции в поисковой выдаче.
Содержание
В статье о том, зачем и как закрыть сайт от индексации в robots.txt, что можно скрыть и как проверить, что вы всё сделали правильно.
Зачем закрывать сайт от индексации
Когда поисковые роботы просканировали и проиндексировали страницы сайта, они начинают показываться в поисковых системах. Это значит, что пользователи могут находить сайт по конкретным поисковым запросам в Google, Яндексе и других поисковых системах.
При этом сайт может состоять из множества разных страниц, и некоторые из них пользователям и поисковым системам видеть не нужно. Например, служебные страницы, дубли страниц и другой малополезный контент. Страницы с таким контентом поисковые системы могут и сами «выбрасывать» из индекса или понижать их позиции, но тогда это может отразиться на ранжировании всего сайта.
Кроме того, стоит учитывать и краулинговый бюджет сайта — лимит на количество страниц сайта, которые поисковые роботы смогут обойти за сутки. И этот лимит может тратиться на неважные страницы сайта, в то время как важные целевые страницы могут долго быть непроиндексированными. Подробнее об этом мы писали в статье «Как оптимизировать краулинговый бюджет».
Что можно закрыть от индексации
Дубль
Это страницы сайта, которые отличаются URL‑адресом, но содержат одинаковый или практически одинаковый контент. Дубли могут привести к таким последствиям, как:
-
снижение скорости индексирования новых страниц. Индексирующий робот может медленнее доходить до новых страниц, из‑за того что будет обходить дубли;
-
поисковая система «склеит» дубли и сама выберет среди них основную страницу. При этом есть риск, что эта выбранная страница не будет вашей целевой;
-
в индексе останутся все дубли. Тогда все они могут конкурировать между собой, «моргать» в выдаче и т. д. Это может влиять на положение сайта в поиске.
Подробнее про дубли в Яндекс.Справке
Документ для скачивания
В некоторых случаях может быть нужно закрыть от индексации документы, например в формате pdf, docx и т. п. С помощью robots.txt это можно сделать.
С одной стороны, когда документы можно скачать из выдачи, не переходя на сайт, это может приводить к потере трафика, с другой стороны, может, наоборот, положительно повлиять на посещаемость сайта. Исходите из стратегии и пользы для вашего проекта.
Страницы, которые находятся в разработке
Если на странице нет контента или есть, но он дублирует другую страницу, если на странице идёт редизайн или доработка и мы пока не хотим её выкатывать и в других подобных случаях можно запретить её индексацию.
Если оставить такие страницы доступными для индексации, то ПС может сама понизить или исключить их из индекса, что может сказаться на оценке сайта в целом.
Техническая страница
Все служебные, технические страницы не содержат полезного контента для пользователей или вовсе могут быть пустыми. Поэтому их стоит закрыть от индексации.
Такими страницами, в зависимости от конкретного сайта и особенностей проекта, могут быть: страницы регистрации, авторизации, результаты поиска по страницам сайта, Личный кабинет, Корзина, Избранное и т. д.
Папка
Файлы сайта обычно распределяются по папкам, например по категориям, каталогам, разделам, подразделам и т. д. Если какой‑то раздел на сайте устарел целиком, то можно скрыть от индексации всю папку, а не только отдельные страницы.
Картинка
Помимо закрытия страниц сайта, можно также закрыть от индексации отдельный тип контента, например все картинки определённого формата или фотографии.
Если вы размещаете информативные и полезные изображения, закрывать их от индексации нежелательно.
Ссылка
С помощью robots.txt мы не можем запретить индексацию одной ссылки. Чтобы робот не переходил по ссылкам на странице, мы можем закрыть от индексации страницу, на которой размещена ссылка, или страницу, на которую она ведёт.
Чтобы скрыть от индексирования конкретную ссылку, Яндекс рекомендует использовать атрибут rel.
Блок на сайте
Мы не можем закрывать в robots.txt отдельные блоки на странице.
Запретить индексирование части текста в Яндексе можно с помощью тега noindex, но Google данный тег не поддерживает.
Как запретить индексацию в robots.txt
Файл robots.txt — это текстовый документ формата .txt, в котором прописаны специальные правила (директивы) для поисковых роботов. Они помогают управлять индексацией сайта.
С помощью этих правил можно указать поисковым роботам, какие страницы и файлы сайта не должны присутствовать в поисковой выдаче, а какие, наоборот, должны.
В файле robots.txt можно:
-
разрешить или запретить индексацию страниц или разделов сайта;
-
указать ссылку на карту сайта Sitemap.xml;
-
заблокировать показ изображений, видеороликов и аудиофайлов в результатах поиска.
В robots.txt мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
Если у сайта есть robots.txt, то обычно он хранится он в корневой папке сайта — там, куда загружаются каталоги и другие файлы.
Кроме того, на некоторых сайтах robots.txt можно найти по ссылке site.ru/robots.txt, где site.ru — это ваш сайт. Например, https://topvisor.com/robots.txt.
Если файла нет, значит, скорее всего, сейчас для индексации доступны все страницы сайта и у поисковых роботов нет специальных указаний.
Поэтому файл нужно создать самостоятельно. Сделать это можно в Блокноте или другом текстовом редакторе. В файле нужно прописать специальные директивы, о которых расскажем ниже.
После этого сохраняем документ в формате .txt с названием robots и загружаем в корневую папку сайта.
Основные директивы robots.txt
-
User‑Agent — обязательная директива, которая говорит, какому именно поисковому роботу адресуются указанные ниже правила. В документе эта директива может повторяться несколько раз — с неё начинается каждая новая группа правил для конкретного бота.
В файле эта строка будет выглядеть так:
User‑agent:
После двоеточия мы прописываем название бота, к которому будут обращены последующие правила.
Чаще всего используем такие:
- * — когда обращаемся ко всем поисковым роботам;
- Googlebot — когда обращаемся к роботам Google;
- Yandex — когда обращаемся к роботам Яндекса.
Записи в файле будут выглядеть так:
User‑agent: * или: User‑agent: Yandex или: User‑agent: Googlebot
Список User‑agent поисковых роботов Google
Список User‑agent поисковых роботов Яндекса
Перед каждой новой директивой User‑agent, которую вы прописываете в документе, необходимо ставить дополнительный пропуск строки.
Например, если бы нам нужно было закрыть весь сайт от индексации для Яндекса и Google, мы бы написали так:
User‑agent: Googlebot Disallow: / User‑agent: Yandex Disallow: /
-
Disallow — этой директивой мы можем запретить роботу индексировать определённые разделы сайта, страницы или файлы. Здесь могут закрываться от индексации, например:
-
технические страницы: страницы регистрации, авторизации и др., у интернет‑магазинов это могут быть страницы «Корзина», «Избранное» и др.;
-
страницы сортировок, которые изменяют вид отображения информации;
-
страницы внутреннего поиска и т. д.
-
Правила указания директивы такие:
-
Сначала указываем саму директиву и двоеточие. Например: Disallow:
-
После этого указываем раздел или страницу в корневой папке текущего сайта без указания самого домена. Например: /ru/marketing/.
Если правило касается страницы, ставим полный относительный адрес. В начале должен идти знак «/». Например, /ru/marketing/57‑free‑seo‑tools.
Если закрываем весь каталог, то в конце строки должен стоять слеш «/».
Например, чтобы запретить роботам Яндекса индексацию всего раздела «Маркетинг» в Топвизор‑Журнале, мы бы написали в robots.txt так:
User‑agent: Yandex Disallow: /ru/marketing/
-
Allow — директива указывает поисковому роботу, какие разделы сайта можно индексировать. Обычно используется для указания подправила директивы Disallow, например, когда мы хотим разрешить сканирование какой‑то страницы или каталога внутри закрытого директивой Disallow раздела.
User‑agent: Yandex Disallow: /catalog/ Allow: /catalog/auto/ # запрещает скачивать страницы, начинающиеся с '/catalog/', # но разрешает скачивать страницы, начинающиеся с '/catalog/auto/'
Если в документе одновременно указаны директивы Allow и Disallow для одного и того же элемента, то предпочтение отдаётся директиве Allow — элемент будет проиндексирован.
О директиве Disallow и Allow у Яндекса
О директиве Disallow и Allow у Google
Дополнительно
При указании пути к разделу, странице или файлам может использоваться спецсимвол «*».
Он означает любую (в том числе пустую) последовательность символов. Может ставиться как префикс в начале адреса или как суффикс в конце.
Например:
Disallow: /catalog/*/shopinfo — запрещает индексацию любых страниц в разделе catalog, в URL которых есть shopinfo.
Disallow: *shopinfo — запрещает индексацию всех страниц, содержащих в URL “shopinfo”, например: /ru/marketing/shopinfo.
Подробнее о спецсимволах и правилах их использования в Яндексе
Спецсимволы работают в том числе и с директивой Allow.
-
Sitemap — в robots.txt мы можем указать путь к карте сайта (Sitemap.xml) и таким образом помочь поисковому роботу просканировать страницы сайта.
Путь указывается через директиву Sitemap, а сам путь должен быть полным, с указанием домена, как в браузере:
Sitemap: https://site.com/sitemaps1.xml
Если карт сайта несколько, директиву можно повторять несколько раз с новой строки.
Директива считается межсекционной: поисковые роботы увидят путь к карте сайта вне зависимости от места в файле robots.txt, где он указан.
О директиве Sitemap в Яндекс.Справке
О директиве Sitemap в Google Справке
-
Clean‑param для Яндекса — директива позволяет запретить поисковым роботам индексировать страницы с динамическими параметрами, например с GET‑параметрами или UTM‑метками и т. д.
Яндекс предупреждает, что если не закрыть страницы с параметрами через Clean‑param, то в поиске могут появиться многочисленные дубли страниц, что может негативно отразиться на ранжировании.
Синтаксис и правила оформления:
-
файл должен называться robots.txt;
-
размер файла не больше 500 КБ;
-
на сайте должен быть только один такой файл;
-
файл размещён в корневом каталоге сайта, но не в подкаталоге. Нужно вот так: https://www.example.com/robots.txt, а так нельзя: https://example.com/pages/robots.txt;
-
файл отдаёт ответ сервера 200 OK.
Подробные правила оформления robots.txt у Яндекса.
Подробные правила оформления robots.txt у Google.
Дополнительно про файл robots.txt:
-
есть директивы, которые одни ПС воспринимают, а другие нет. Например, Clean‑param для Яндекса;
-
те страницы, которые вы запретили в файле, всё равно могут быть проиндексированы. Например, Google говорит, что страницы могут попасть в индекс, если поисковый робот нашёл их по ссылке с других сайтов или страниц. Чтобы полностью скрыть информацию от краулеров, стоит использовать другие способы, например метатег robots и HTTP‑заголовок X‑Robots‑Tag и др.
Как проверить запрет
После создания из загрузки файла на сайт убедитесь, что он существует, размещён в корневом каталоге сайта и без проблем открывается. Для проверки введите в строку браузера адрес сайта с указанием файла в формате https://site.ru/robots.txt.
После этого можно проверить файл в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Яндекс.Вебмастер
В Вебмастере открываем «Инструменты» → «Анализ robots.txt». Обычно содержимое файла сразу будет отображаться в строке. Если нет, копируем из браузера и вставляем сюда. Затем нажимаем кнопку «Проверить»:

Если в файле будут ошибки, Вебмастер подскажет, как их исправить.
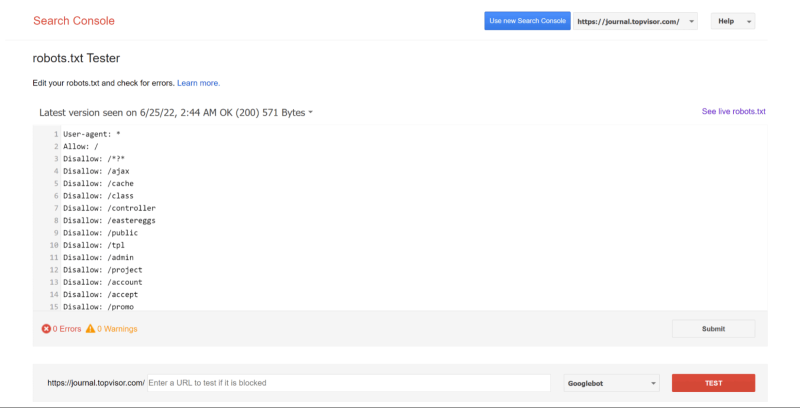
Google Search Console
Для того чтобы проверить файл robots.txt с помощью валидатора Google, необходимо:
1. Зайти в аккаунт Google Search Console.
2. Перейти в инструмент проверки robots.txt.
3. В открывшемся окне вы увидите уже подгруженную информацию из файла. Если нет, вставьте её из браузера.
GSC покажет, есть ли в файле ошибки и как их исправить.
Краткий конспект
На сайте может быть необходимо скрыть некоторые страницы, например:
-
служебные страницы или дубли;
-
неважные, неактуальные или малополезные страницы.
Закрывать от индексации можно как сайт полностью, так и отдельные страницы, файлы, изображения.
В robots.txt с помощью специальных директив мы обычно закрываем страницы массово: весь каталог, конкретные типы страниц, страницы или файлы с определёнными характеристиками.
После создания правил для индексирования сайта в robots.txt важно его проверить. Сделать это можно бесплатно в панелях веб‑мастеров Яндекс.Вебмастер и Google Search Console.
Поисковые роботы Яндекса перестают учитывать пустую директиву Allow как запрещающий сигнал в robots.txt.
Часто индексирующий робот не может получить доступ к сайтам из-за установленного по ошибке в robots.txt запрета на посещение всех страниц. Часть этих ошибок связана с использованием пустой директивы Allow:
User-agent: * Allow:
Ранее робот интерпретировал это правило как полностью запрещающее, что делало сайт недоступным для посещения роботов, и такие сайты не могли показываться в результатах поиска. Когда же владельцы сайтов намеренно хотели запретить посещение сайтов, они обычно четко прописывали команду запрета.
Поэтому мы решили изменить обработку роботом такой директивы — сейчас она игнорируется при обнаружении в robots.txt. Если на вашем сайте намеренно используются пустое правило Allow в robots.txt, то для того, чтобы робот корректно учитывал запрет, правило нужно изменить на директиву Disallow:
Disallow: *
Или
Disallow: /
Проверить, что разрешено, а что запрещено в robots.txt можно в Яндекс.Вебмастере. Рекомендуем обратить особое внимание на пустые значения для Allow — если нужно запретить индексирование, то их быть не должно.


Теперь ограничения в robots.txt работают еще надёжнее
Команда Поиска