Взлом шифра Виженера с помощью частотного криптоанализа
Время на прочтение
8 мин
Количество просмотров 134K

«Представьте себе такую ситуацию… Как-то раз, уходя со службы около часу ночи (руководитель должен подавать хороший пример), вы замечаете торчащий в дверях измятый клочок бумаги… Бумага отменная, слегка пахнет мускусом; почерк явно женский и веет от него этаким французским шармом. Теперь, по здравом размышлении, новая сотрудница мисс Хари начинает казаться вам, пожалуй, немножко слишком экзотичной. Ее французский акцент, неизменное черное платье для коктейля, нитка черного жемчуга, подчеркивающая декольте, и этот будоражащий запах мускуса, наполняющий комнату, когда она входит… Она говорит, что работала раньше в региональном вычислительном центре Мак-Дональда в Киокаке. Что-то тут не так. Подождите… Неужели мисс Хари шпионит в пользу знаменитой французской фирмы И Бей Эм? А эта записка — шифровка, в которой все секреты вашего новейшего чудо-компилятора? Чтобы уличить мисс Хари, записку нужно расшифровать. Но как?»
На Хабре уже пару раз мелькали статьи о книге Чарльза Уэзерелла «Этюды для программистов». Перед вами фрагмент одного из самых интересных, на мой взгляд, этюдов — «Секреты фирмы», основной задачей в котором является взлом шифра Виженера. Не так давно я реализовал этот этюд, и в моей статье я расскажу о том, как я это сделал и что в итоге получилось.
Задача
Автор предлагает нам написать программу, которая позволит взломать шифр Виженера, а точнее, одну из его модификаций. Текст шифруется следующим образом. Составляется таблица, т. н. квадрат Виженера: сверху и по левому краю записывается алфавит, затем в первую строку помещается некоторая перестановка исходного алфавита, во вторую — эта же перестановка, циклически сдвинутая на одну позицию, и так далее. В результате мы получаем таблицу, которая сопоставляет каждой паре символов какой-то символ.

Затем выбирается ключевое слово и многократно записывается под исходным текстом. Наконец, каждая пара (символ исходного текста; символ ключевого слова под ним) шифруется с помощью таблицы соответствующим этой паре символом. Например, фраза «звезда забега» будет зашифрована с помощью ключа «багаж» и приведенной выше таблицы так:

Идея решения
Рассмотрим обратный квадрат Виженера, то есть таблицу, которая сопоставляет паре (символ зашифрованного текста; символ ключевого слова) символ исходного текста.

Договоримся называть дистанцией между двумя символами разность их позиций в алфавите: например, дистанция между ‘а’ и ‘в’ — это 2. Тогда можно заметить, что если дистанция между i-м и j-м символами ключевого слова равна d, то дистанция между соответствующими символами исходного текста составляет -d. Следовательно, если нам удастся найти ключевое слово, то мы сможем свести шифр Виженера к шифру простой замены: каждая буква исходного текста будет заменена на другую, при этом соответствие букв будет взаимно-однозначным. Взломать такой шифр не составит труда.
Остается найти ключевое слово. Пусть нам известно, что длина ключевого слова — L символов. Тогда текст можно разбить на L групп, каждая из которых будет зашифрована с помощью одного символа ключевого слова, т. е. это будет шифр простой замены. При этом используемые перестановки алфавита будут отличаться лишь сдвигом, равным с точностью до знака дистанции между соответствующими символами ключевого слова. Используя методы частотного криптоанализа, мы сможем определить эти сдвиги.
Таким образом, программа будет состоять из трех частей:
1) Определение длины ключевого слова
2) Поиск ключевого слова
3) Поиск перестановки алфавита и расшифровка текста
Длина ключевого слова
Длину ключевого слова проще всего найти, используя метод индекса совпадений. Этот метод был предложен Уильямом Фридманом в 1922 году для взлома оригинального шифра Виженера, но он сработает и в нашем случае. Метод основан на том факте, что вероятность совпадения двух случайных букв в некотором достаточно длинном тексте (индекс совпадений) — это постоянная величина. Таким образом, если разбить текст на L групп символов, каждая из которых зашифрована шифром простой замены (напомню, это и означает, что L — длина ключевого слова), то индексы совпадений для каждой из групп будут довольно близки к теоретическому значению этой величины; для всех других разбиений индексы совпадений будут гораздо ниже. Индекс совпадений можно посчитать по формуле
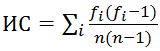
(fi — количество i-х букв алфавита в тексте, а n — его длина)
Ниже, например, приведены индексы совпадений для текста, зашифрованного с помощью ключа «проект» (6 символов).

Таким образом, для определения длины ключевого слова нужно посчитать индексы совпадений для разбиения текста на L = 1, 2,… групп, а затем выбрать из полученных величин первую, значительно превосходящую большинство остальных. Но… тут есть небольшая хитрость. Что если текст зашифрован с использованием ключа, который можно разделить на несколько похожих частей? Снизу приведена таблица индексов совпадений для того же текста, что и в первом примере, но зашифрованного с помощью ключа «космос» (те же 6 символов). Как же определить длину ключа в таком случае?

Я поиграл с различными способами и выяснил, что проще всего выбрать необходимый индекс так: нужно взять первый индекс, для которого справедливо: 1.06*ИС > ИСi, i = 1, 2,… Умножения на 1.06 в большинстве случаев хватает, чтобы настоящий ИС стал превосходить «кратные» ИС (в нашем примере это индексы при L = 12 и 18), но недостаточно для того, чтобы ложные индексы (при L = 3, 9 и 15) превзошли настоящие.
Конечно, мой способ не дает 100% результат. Более того, если текст зашифрован с помощью слова, состоящего из одинаковых частей (например, «тартар»), то длина ключевого слова в любом случае будет определена неверно (если, конечно, мы хотим найти осмысленное ключевое слово): нет никакой разницы между шифрованием ключом «тартар» и «тар». Поэтому важно дать пользователю возможность изменять длину ключа в ходе работы программы: к примеру, не подошла 6, значит, стоит попробовать 3 или 12.
К счастью, для зашифрованной записки из книги все определяется довольно просто. Взглянув на таблицу индексов совпадений, можно с уверенностью сказать, что длина ключевого слова — 7 символов.

Ключевое слово
Теперь, когда длина ключа найдена, можно приступить к поиску самого ключевого слова. Сперва нужно определить вероятности различных сдвигов между группами, на которые мы разбили шифр (напомню, что каждая группа зашифрована с помощью некоторой перестановки алфавита, при этом перестановки отличаются лишь сдвигом каждой буквы на несколько позиций в алфавите). Для нахождения вероятностей сдвигов я воспользовался идеей, предложенной переводчиками «Этюдов». Если опустить все математические выкладки, она заключается в следующем. Для каждой группы мы считаем количество символов x (x = ‘а’, ‘б’, …, ‘я’) в ней и на основании информации о частоте букв в русском языке оцениваем вероятность того, что символу x шифра соответствует символ y (y = ‘а’, ‘б’, …, ‘я’) исходного текста. Сопоставляя полученные таблицы вероятностей для различных групп, мы можем вычислить вероятности сдвигов r (r = 1, 2, …, 32) между этими группами. В результате мы получаем таблицу, показывающую, какова вероятность сдвига r между группами i и j для любых двух групп и любого сдвига.
Найти само ключевое слово можно двумя способами. Первый способ — это найти наилучшую конфигурацию сдвигов, используя (только) полученную таблицу. Полный перебор занял бы очень много времени, поэтому я пошел другим путем. Я искал ключ следующим образом. Возьмем любое слово подходящей длины и вычислим его характеристику — сумму вероятностей сдвигов между каждыми двумя символами в нем (сдвиги между символами ключевого слова и между буквами перестановок в различных группах шифра совпадают с точностью до знака). Теперь внесем небольшое изменение в исследуемое слово. Если после изменения характеристика слова стала лучше, то мы запоминаем новое слово, в противном же случае забываем новое слово и возвращаемся к старому. Внося таким образом случайные изменения, мы довольно быстро найдем лучшее слово.
Проблема заключается лишь в том, что наилучшее слово далеко не всегда является ключевым. Тесты показали, что уже для текстов из 1024 символов ключ и лучшее слово зачастую различаются на один символ. Например, лучшее слово для записки из книги — «федиска». Не знаю я такого слова! Для более коротких текстов ключ определяется совершенно неверно. Поэтому от поиска ключа на основании только таблицы пришлось отказаться.
Второй способ поиска ключа простой и неинтересный, зато эффективный. Мы берем словарь и вычисляем характеристику каждого подходящего слова (для повышения скорости работы программы я разделил слова по их длинам). Лучшее слово мы берем в качестве ключевого. Такой метод работает корректно даже для коротких (400-500 символов) текстов, но у него есть очевидный недостаток: если ключевого слова нет в словаре, то программа ни при каких условиях не сработает верно.
Впрочем, если ключ в словаре есть, второй метод гораздо эффективнее первого. Поэтому в своей программе я использовал его. Этот метод сразу же дал правильное (как выяснилось позднее) ключевое слово — «редиска».
Перестановка алфавита
Имея ключевое слово, мы можем модифицировать текст так, что он окажется зашифрован шифром простой замены. Для этого необходимо циклически сдвинуть символы L-ой группы (L = 2, 3, …, длина ключа) на дистанцию между первой и L-ой буквами ключевого слова влево по алфавиту. После внесения этих изменений нам остается найти, какие буквы исходного текста соответствуют символам шифротекста.
Попробуем сделать это тем же способом, каким мы искали ключевое слово без словаря. Возьмем любую таблицу соответствий между символами исходного и зашифрованного текстов (например, предположим, что букве ‘а’ соответствует буква ‘а’, букве ‘б’ — ‘б’, и т. д.) и расшифруем текст с её помощью. Посчитаем количество всевозможных биграмм (сочетаний по 2 буквы) в полученном тексте. Сравнив результат с эталонной таблицей, вычислим характеристику полученного текста (я вычислял характеристику так:
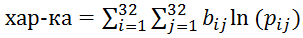
(b_ij — количество биграмм в «расшифрованном» тексте, а p_ij — вероятность встречи определенной биграммы в русском языке)
Затем будем вносить случайные изменения в таблицу соответствий и на каждом шаге вычислять новую характеристику. Если новая характеристика оказывается лучше (больше) старой, запоминаем изменения, иначе откатываем их. В результате у нас получается правильная таблица соответствий букв, и мы можем восстановить исходный текст!
Насколько быстро работает этот алгоритм поиска перестановок? Ниже приведен график зависимости характеристики перестановок от числа итераций для зашифрованной записки из книги (для других текстов графики получаются аналогичными). На горизонтальной оси откладывается число итераций, на вертикальной — характеристика полученного текста. Изменения характеристики происходят рывками при каждом нахождении лучшей таблицы, поэтому для наглядности график представляет из себя интерполированные точки, в которых происходили изменения. Когда линия графика становится прямой и горизонтальной, правильная таблица перестановок найдена.

Также интересно взглянуть на графики зависимости номера итерации от номера успешного изменения таблицы перестановок (слева) и характеристики текста от номера изменения таблицы (справа).
Мы видим, что характеристика текста изменяется с каждым изменением таблицы перестановок более-менее линейно, а число попыток, необходимых для нахождения нового успешного изменения таблицы растет довольно быстро. Зависимость характеристики текста от числа итераций похожа на логарифмическую. Действительно, по нижним графикам видно, что если x — число итераций, y — характеристика и t — номер успешного изменения таблицы, то x∼e^t, y∼t, следовательно, y∼ln(x). Логарифм растет довольно медленно, но его рост не ограничен асимптотами, поэтому на нахождение правильной таблицы соответствий уходит довольно большое, но не бесконечное количество работы. Впрочем, тесты показывают, что 10 — 12 тысяч итераций всегда достаточно.
Заключение
После реализации описанных алгоритмов и добавления графического интерфейса получилась вот такая программа:
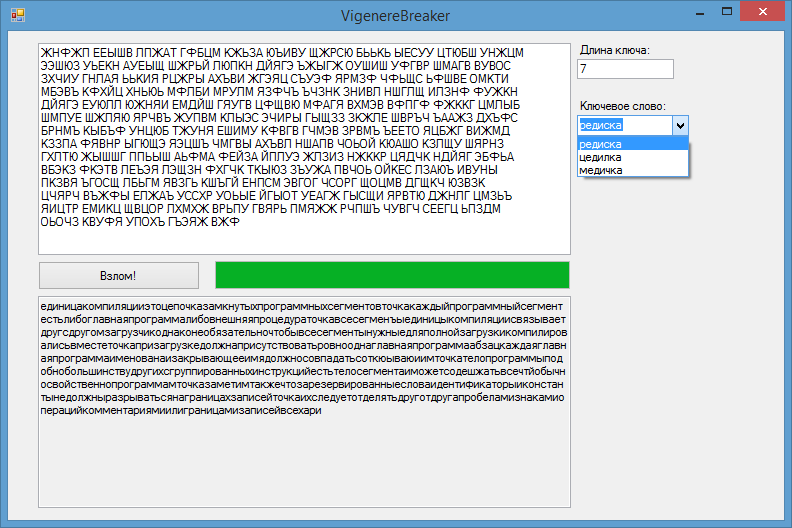
Программа успешно расшифровывает тексты длиной 400-500 символов и больше, время работы не превышает 10 секунд. Я думаю, это неплохой результат.
UPD Вот ссылка на мою программу. Я делал её в Visual Studio 2012 и использовал Windows Forms, так что перед запуском убедитесь, что у вас установлен соответствующий распространяемый пакет и .net Framework 4. В программе можно зашифровать текст (для этого введите текст в верхнюю часть формы и ключевое слово; если ключевое слово не будет введено, оно будет выбрано случайным образом) или взломать шифр (для этого введите шифротекст и нажмите «Взлом!»; если при этом будут указаны длина ключевого слова или само ключевое слово, эти данные будут использованы для расшифровки, в противном случае программа подберет их сама).
![]()
Загрузить PDF
![]()
Загрузить PDF
Шифр Виженера — это метод шифровки, в котором используются различные «шифры Цезаря» на основе букв в ключевом слове. В шифре Цезаря каждую букву абзаца необходимо поменять местами с определенным количеством букв, чтобы заменить исходную букву. Например, в латинском алфавите А становится D, B становится Е, С становится F. Шифр Виженера построен на методе использования различных шифров Цезаря в различных частях сообщения. В этой статье мы расскажем вам, как им пользоваться.
-

1
Скачайте из интернета квадрат Виженера или найдите, как он выглядит, и сделайте его самостоятельно.
-
2
Придумайте ключевое слово короче фразы или фраз, которые вы хотите зашифровать. Например, в этой статье мы будем использовать слово:
LIME
-
3
Запишите сообщение без пробелов. Мы возьмем фразу «wikiHow is the best» и запишем ее как:
WIKIHOWISTHEBEST
-
4
Запишите ключевое слово под сообщением, чтобы каждая буква стояла строго под соответствующей буквой сообщения. Повторяйте это слово (без пробелов) до конца сообщения. В нашем примере это будет:
WIKIHOWISTHEBEST
LIMELIMELIMELIME
-
5
Укоротите ключевое слово, чтобы оно помещалось во фразу, если это необходимо. В нашем примере, слово
LIME
подходит по количеству букв для ключевой фразы, поэтому сокращать его не нужно. Однако возьмем фразу «wikiHow is the best of the best», тогда получится:
WIKIHOWISTHEBESTOFTHEBEST
LIMELIMELIMELIMELIMELIMEL
-
6
Перейдите к ряду первой буквы в ключевом слове в квадрате Видженера и найдите колонку с первой буквой изначального сообщения, а затем найдите точку пересечения ряда и колонки. В нашем примере это ряд, обозначенный L, и колонка, обозначенная W. Буква на их пересечении будет первой буквой вашего зашифрованного сообщения.
-
7
Продолжайте делать то же самое для всех букв фразы по порядку, пока не зашифруете ее целиком. Первая буква, которую мы получили в предыдущем шаге, —буква H, вторая — Q и так далее. В итоге получится фраза:
HQWMSWIMDBTIMMEX
Реклама







-
1
Чтобы расшифровать текст, выполните описанные выше действия в обратном порядке.
-
2
Найдите ряд, обозначенный первой буквой ключевого слова. Найдите в нем первую букву зашифрованной фразы. Посмотрите, в какой колонке она находится: буква, которой обозначена эта колонка, и будет первой буквой расшифрованного сообщения.
-
3
Продолжайте делать то же самое для всех букв фразы по порядку, пока не расшифруете ее целиком.
Реклама



Советы
- Дважды перепроверьте, чтобы убедиться в правильности кодировки. Если вы неправильно закодируете текст, его невозможно будет правильно расшифровать, а понять, что в нем есть ошибка, без проверки очень сложно.
- Если использовать соответствующее программное обеспечение для графического программирования и тщательно все проверять, процесс можно автоматизировать.
- Если вы дадите кому-то зашифрованный текст, для расшифровки потребуется ключевое слово. Сообщите его человеку шепотом по секрету или зашифруйте с помощью шифра Цезаря. Имейте в виду, что на сегодняшний день этот шифр не является абсолютно надежным, и его можно взломать автоматически.
- В интернете есть средства расшифровки кода Виженера, которые вы можете найти и использовать.
- Если вы используете большой квадрат Виженера, включающий пунктуацию и пробелы, шифр будет сложнее расшифровать, особенно если ключевое слово или ключевая фраза имеют такую же или бо́льшую длину, чем сообщение.
- Еще один путь усложнить шифр — сначала зашифровать исходное сообщение другим способом (например, перестановочным шифром), а уже полученный результат закодировать с помощью шифра Виженера. Даже если шифр Виженера расшифруют, на выходе получится лишь бессмысленный набор букв. Не применяйте к исходному сообщению шифр Цезаря вместо перестановочного шифра, так как в этом случае оба шага шифрования можно будет объединить в один, и шифровка будет не очень надежной.
- Чем чаще ваше ключевое слово или фраза повторяются, тем легче расшифровать текст. Ключ должен быть как можно длиннее.
Реклама
Предупреждения
- Этот шифр ненадежен (как и любой другой), и его можно легко взломать. По современным стандартам шифр Виженера является очень ненадежным. Не используйте его для чего-либо действительно секретного. Для лучшей шифровки используйте AES и RSA. Однако этот шифр можно использовать с одноразовым ключом (случайная фраза такой же длины, как и текст, которая используется только раз) — если ключ хранить в секрете, расшифровка будет не такой простой.
Реклама
Об этой статье
Эту страницу просматривали 213 597 раз.
Была ли эта статья полезной?
Привет, Вы узнаете про шифр вижинера , Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
шифр вижинера , настоятельно рекомендую прочитать все из категории Шифры в криптографии.
Шифр Виженера это метод шифрования буквенного текста с использованием ключевого слова.
Этот метод является простой формой многоалфавитной замены. Шифр Виженера изобретался многократно. Впервые этот метод описал Джованни-Баттиста Беллазо (Giovan Battista Bellaso) в книге La cifra del. Sig. Giovan Battista Bellasо в 1553 году , однако в 19 веке получил имя Блеза Виженера , швейцарского дипломата. Метод прост для понимания и реализации, он является недоступным для простых методов криптоанализа.
Шифровани
Квадрат Виженера или таблица Виженера, может быть использована для заширования и расшифрования.
В шифре Цезаря каждая буква алфавита сдвигается на несколько позиций; например в шифре Цезаря при сдвиге +3, A стало бы D, B стало бы E и так далее. Шифр Виженера состоит из последовательности нескольких шифров Цезаря с различными значениями сдвига. Для зашифрования может использоваться таблица алфавитов, называемая квадрат Виженера. Применительно к латинскому алфавиту таблица Виженера составляется из строк по 26 символов, причем каждая следующая строка сдвигается на несколько позиций. Таким образом, в таблице получается 26 различных шифров Цезаря. На разных этапах кодировки шифр Виженера использует различные алфавиты из этой таблицы. На каждом этапе шифрования используются различные алфавиты, выбираемые в зависимости от символа ключевого слова. Например, предположим, что исходный текст имеет вид:
ATTACKATDAWN
Человек, посылающий сообщение, записывает ключевое слово(«LEMON») циклически до тех пор, пока его длина не будет соответствовать длине исходного текста:
LEMONLEMONLE
Первый символ исходного текста A зашифрован последовательностью L, которая является первым символом ключа. Первый символ L шифрованного текста находится на пересечении строки L и столбца A в таблице Виженера. Точно так же для второго символа исходного текста используется второй символ ключа; т.е. второй символ шифрованного текста X получается на пересечении строки E и столбца T. Остальная часть исходного текста шифруется подобным способом.
Пример
Исходный текст: ATTACKATDAWN
Ключ: LEMONLEMONLE
Зашифрованный текст: LXFOPVEFRNHR
Дешифрования
Расшифрование производится следующим образом: находим в таблице Виженера строку, соответствующую первому символу ключевого слова; в данной строке находим первый символ зашифрованного текста. Столбец, в котором находится данный символ, соответствует первому символу исходного текста. Следующие символы зашифрованного текста расшифровываются подобным образом.
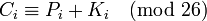
Из наблюдения за частотой совпадения следует:
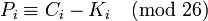

Квадрат Виженера, или таблица Виженера, также известная как tabula recta, может быть использована для шифрования и расшифровывания.
Криптоанализ Шифра Виженера
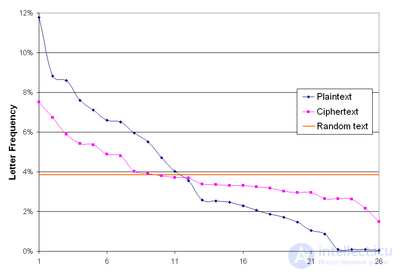
Шифр Виженера «размывает» характеристики частот появления символов в тексте.
Шифр Виженера «размывает» характеристики частот появления символов в тексте, но некоторые особенности появления символов в тексте остаются. Главный недостаток шифра Виженера состоит в том, что его ключ повторяется. Поэтому простой криптоанализ шифра может быть построен в два этапа:
- Поиск длины ключа. Можно анализировать распределение частот в зашифрованном тексте с различным прореживанием. То есть брать текст, включающий каждую 2-ю букву зашифрованного текста, потом каждую 3-ю и т. д. Как только распределение частот букв будет сильно отличаться от равномерного (например, по энтропии), то можно говорить о найденной длине ключа.
- Криптоанализ. Совокупность l шифров Цезаря (где l — найденная длина ключа), которые по отдельности легко взламываются.
Тесты Фридмана и Касиски могут помочь определить длину ключа.
Тест Касиски и определение с его помощью длины ключа и Индекса совпадений
Чарльз Беббидж был первым, кто разработал алгоритм атаки на шифр Виженера в 1854 году. Стимулом к разработке алгоритма послужил обмен письмами с Джоном Х. Б. Твейтсом. Он заявил, что создал новый шифр, и отправил его в «Journal of the Society of the Arts»; когда Беббидж показал, что шифр Твейтса является лишь частным случаем шифра Виженера, Твейтс предложил ему его взломать. Беббидж расшифровал текст, который оказался поэмой «The Vision of Sin» Альфреда Теннисона, зашифрованной ключевым словом Emily — именем жены поэта. Но он не опубликовал свое открытие. Поэтому данный алгоритм назван в честь Фридриха Вильгельма Касиски, офицера прусской армии, который независимо от Беббиджа разработал такой же алгоритм в 1863 году. И только в XX веке, когда ученые исследовали заметки Беббиджа, появилась информация о первом изобретателе этого алгоритма.[12]
Вначале определим понятие индекса совпадения  данного текста. Пусть рассматривается текст
данного текста. Пусть рассматривается текст  , соответствующий алфавиту, состоящему из
, соответствующий алфавиту, состоящему из  букв. Пусть
букв. Пусть  — длина этого текста. Обозначим через
— длина этого текста. Обозначим через  число вхождений буквы с номером
число вхождений буквы с номером  в текст . Тогда индекс совпадения текста определяется как
в текст . Тогда индекс совпадения текста определяется как
 .
.
Эмпирически проверено, что индекс совпадения длинных осмысленных английских текстов, таких как «Моби Дик» Меллвила, приблизительно равен 0,065. При этом, конечно, в тексте оставляют только 26 букв английского алфавита. В то же время абсолютно случайный достаточно длинный текст на 26 буквах, в котором все буквы встречаются приблизительно одинаковое число раз, равен 0,038. Замечено, что чем «осмысленнее» текст, тем выше его индекс совпадения. Это обстоятельство как раз и помогает вычислять длину ключа в шифре Виженера.
Пусть  — исходный текст, в котором
— исходный текст, в котором  — его
— его  -я буква, а
-я буква, а  — его шифровка по Виженеру. Если применяется обычный сдвиг, то есть длина ключа
— его шифровка по Виженеру. Если применяется обычный сдвиг, то есть длина ключа  , то должно выполняться равенство
, то должно выполняться равенство  , поскольку изменяются только номера букв, но не числа их вхождений. Так как
, поскольку изменяются только номера букв, но не числа их вхождений. Так как  — осмысленный (по предположению) текст, то значение
— осмысленный (по предположению) текст, то значение  , будет приблизительно равно стандартному значению
, будет приблизительно равно стандартному значению  , для данного языка. Рассматривается пример обычного английского языка, поэтому
, для данного языка. Рассматривается пример обычного английского языка, поэтому  . Конечно, вряд ли шифр Виженера будет в общем случае получен ключом длины 1. Поэтому последовательно вычисляются следующие индексы совпадения:
. Конечно, вряд ли шифр Виженера будет в общем случае получен ключом длины 1. Поэтому последовательно вычисляются следующие индексы совпадения:






до тех пор, пока не получится  .
.
Это может свидетельствовать о том, что длина ключа равна  , хотя и может оказаться ложным следом.
, хотя и может оказаться ложным следом.
Действительно, если длина ключа равна , то текст  будет получен из
будет получен из  сдвигом, следовательно, сохранит
сдвигом, следовательно, сохранит  , а текст , в свою очередь, является случайной выборкой осмысленного текста, следовательно, должен сохранить его статистические характеристики, в частности индекс совпадения . Об этом говорит сайт https://intellect.icu . Если индекс совпадения некоторого языка неизвестен, то использование теста Касиски также возможно. Нужно не сравнивать полученные значения индексов совпадения со стандартным значением, а смотреть, когда этот индекс резко возрастет. Это может сигнализировать о найденной длине ключа. Конечно, речь идет о расшифровке осмысленных и одновременно достаточно длинных текстов. Впрочем, понятие осмысленности для формальных языков — понятие непростое.
, а текст , в свою очередь, является случайной выборкой осмысленного текста, следовательно, должен сохранить его статистические характеристики, в частности индекс совпадения . Об этом говорит сайт https://intellect.icu . Если индекс совпадения некоторого языка неизвестен, то использование теста Касиски также возможно. Нужно не сравнивать полученные значения индексов совпадения со стандартным значением, а смотреть, когда этот индекс резко возрастет. Это может сигнализировать о найденной длине ключа. Конечно, речь идет о расшифровке осмысленных и одновременно достаточно длинных текстов. Впрочем, понятие осмысленности для формальных языков — понятие непростое.
Другим применением теста Касиски является проверка сохранения частот встречающихся букв при шифровании. Пусть  — зашифрованный текст, причем алгоритм шифрования неизвестен. Если известно, что использовался обычный английский алфавит и значение близко к 0,065, то это дает основание полагать, что использовался шифр, сохраняющий частоты. Возможно, что это шифр простой замены. В ситуации, когда значение далеко от 0,065, можно предположить, что использовался шифр, не сохраняющий частоты, или же текст был бессмысленным, или же использовался другой алфавит и т.п. Одним словом, что-то оказалось не так и необходим более глубокий анализ.
— зашифрованный текст, причем алгоритм шифрования неизвестен. Если известно, что использовался обычный английский алфавит и значение близко к 0,065, то это дает основание полагать, что использовался шифр, сохраняющий частоты. Возможно, что это шифр простой замены. В ситуации, когда значение далеко от 0,065, можно предположить, что использовался шифр, не сохраняющий частоты, или же текст был бессмысленным, или же использовался другой алфавит и т.п. Одним словом, что-то оказалось не так и необходим более глубокий анализ.
Однако вернемся к шифру Виженера. Пусть определили правильно длину ключа, равную . Теперь нужно найти сам ключ.
Гистограмма, построенная по стандартным частотам букв в языке, имеет свои отличительные особенности. Они объясняются крайне неравномерным использованием букв в английском языке. Эта неравномерность как раз и позволяет эффективно применять частотный анализ.

Прежде всего, обращают на себя внимание «пики», соответствующие буквам A, E, H, I, N, O, R, S, T, и «пеньки», соответствующие J, Q, X, Z. При этом некоторые «пики» стоят рядом, даже есть целая тройка: R, S, T. Все вместе дает весьма специфический рельеф.
Если используется сдвиг на 4, то картина изменяется циклически:
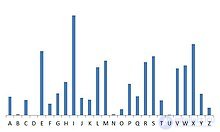
Наблюдается циклический сдвиг рельефа на 4 единицы. Если не знать величину сдвига, то ее нетрудно восстановить, руководствуясь здравым смыслом.
Роторные машины[править | править код]
Можно усовершенствовать шифр Виженера, рассматривая в качестве повторяющегося ключа комбинацию произвольных замен:  . Это означает, что единицы исходного текста преобразуются в
. Это означает, что единицы исходного текста преобразуются в  единицы
единицы  соответственно в
соответственно в  и т.д.
и т.д.
При взломе такого шифра, как и в случае шифра Виженера, вначале нужно определить длину ключа . Это можно делать с использованием теста Касиски так же, как в описанном случае. Далее для определения подстановок можно применить частотный анализ.
Частотный анализ
Как только длина ключа становится известной, зашифрованный текст можно записать во множество столбцов, каждый из которых соответствует одному символу ключа. Каждый столбец состоит из исходного текста, который зашифрован шифром Цезаря; ключ к шифру Цезаря является всего-навсего одним символом ключа для шифра Виженера, который используется в этом столбце. Используя методы, подобные методам взлома шифра Цезаря, можно расшифровать зашифрованный текст. Усовершенствование теста Касиски, известное как метод Кирхгофа, заключается в сравнении частоты появления символов в столбцах с частотой появления символов в исходном тексте для нахождения ключевого символа для этого столбца. Когда все символы ключа известны, криптоаналитик может легко расшифровать шифрованный текст, получив исходный текст. Метод Кирхгофа не применим, когда таблица Виженера скремблирована, вместо использования обычной алфавитной последовательности, хотя тест Касиски и тесты совпадения все еще могут использоваться для определения длины ключа для этого случая.
Упоминания в литературе
В 1881 году Жюль Верн написал роман Жангада. В данном романе автор использовал для зашифровки документа шифр Виженера. В качестве зашифрованного текста, автор использует следующий документ:

По ходу истории герои находят фрагмент расшифрованного слова к этому документу: ОРТЕГА Герои догадались, что это имя может обозначать подпись в конце документа. Таким образом выходит:

Следовательно, ключ — 432513. Зная ключ, можно легко перевести данный документ:

Варианты Шифра Вижинера
Существует, конечно, много других легкозапоминающихся квадратов, которые могут применяться в качестве основы для многоалфавитной системы так же, как и квадрат Виженера. Одним из наиболее известных является квадрат Бофора. Его строками являются строки квадрата Виженера, записанные в обратном порядке. Он назван в честь адмирала сэра Френсиса Бофора — создателя шкалы для определения скорости ветра. Если в квадрате Виженера первая строка и столбец указывают на строки и столбцы соответственно, то в квадрате Бофора этим целям служат первая строка и последний столбец.[14]
Вариант running key (бегущий ключ) шифра Виженера когда-то был невзламываемым. Эта версия использует в качестве ключа блок текста, равный по длине исходному тексту. Так как ключ равен по длине сообщению, то методы, предложенные Фридманом и Касиски, не работают (так как ключ не повторяется). В 1920 году Фридман первым обнаружил недостатки этого варианта. Проблема с running key шифра Виженера состоит в том, что криптоаналитик имеет статистическую информацию о ключе (учитывая, что блок текста написан на известном языке) и эта информация будет отражаться в шифрованном тексте. Если ключ действительно случайный, его длина равна длине сообщения и он использовался единожды, то шифр Виженера теоретически будет невзламываемым, фактически этот вариант будет уже шифром Вернама-Виженера, для которого доказана абсолютная криптостойкость.
Несмотря на очевидную стойкость шифра Виженера, он широко не использовался в Европе. Большее распространение получил шифр Гронсфельда, созданный графом Гронсфельдом, идентичный шифру Виженера, за исключением того, что он использовал только 10 различных алфавитов (соответствующих цифрам от 0 до 9). Преимущество шифра Гронсфельда состоит в том, что в качестве ключа используется не слово, а цифровая последовательность, которая повторяется до тех пор, пока не станет равной длине шифруемого сообщения. Шифр Гронсфельда широко использовался по всей Германии и Европе, несмотря на его недостатки.
Реализация Шифра Вижинера
JavaScript
//Можно скопировать и вставить весь этот код - в консоль браузера. var a = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"; //Строка алфавита var m = "ATTACKATDAWN"; //Сообщение var k = "LEMON"; //Ключ function Vizhener( m, k, mode ){//(encrypt/decrypt) for "Gronsfeld" + "Vizhener" + "Beaufort" + "Shifted Atbash" //m - сообщение или шифротекст (может быть и ключ, если шифр Бофора), //k - ключ (или сообщение/шифротекст, если шифр Бофора), //mode - режим: // Шифрование: "encrypt" (по умолчанию), // Дешифрование: "decrypt" (mode === 'decrypt'), // Шифрование-дешифрование по таблице сдвинутого атбаша: (mode==='shifted_atbash') // Извлечение цифр из ключа шифра Гронсфельда: "gronsfeld" или "gronsfeld_encrypt", "gronsfeld decrypt". var maxlength = Math.max(m.length, k.length); var r = ''; //Пустой результат for(i=0; i<maxlength; i++){ //encrypt/decrypt //Vizhener - encrypt/decrypt one forumula (encrypt - by default; decrypt - when (mode === 'decrypt') ) var mi = a.indexOf( m[ ( (i>=m.length) ?i%m.length :i ) ] ); //подгон сообщения/шифротекста - к ключу (если меньше) var ki_s = k[ ( (i>=k.length) ?i%k.length :i ) ]; //подгон ключа к сообщению/шифротексту (если короткий) var ki = (typeof mode !== 'undefined' && mode.indexOf('gronsfeld') !== -1) ? parseInt( ki_s ): a.indexOf( ki_s ); //вычитание при дешифровании, либо сложение. ki = ( (typeof mode !== 'undefined' && mode.indexOf('decrypt') !== -1) ?(-ki) :ki ); c = a[ ( ( ( a.length + ( mi + ki ) ) % a.length ) ) ]; //символ по таблице Виженера. c = (mode === 'shifted_atbash') ? a[a.length-1-a.indexOf(c)] : c; //Атбаш символа или символ. r += c; //Добавить символ к результату. } return r; //вернуть строку результата } //Тесты: //1. Шифр Гронсфельда. (Урезанная версия шифра Виженера). //Параметры: m - сообщение/шифротекст, k - ключ (только цифр), mode - "encrypt/decrypt" console.log( 'nn1. Шифр Гронсфельда (Урезанная версия шифра Виженера c цифровым ключом):' , 'n'+ 'm = ', 'GRONSFELD', ' - сообщение' , 'n'+ 'k = ', '2015', '- ключ' , 'n'+ 'Шифр Гронсфельда - шифрование: ' , Vizhener( 'GRONSFELD', '2015', 'gronsfeld' ) //выдаст IRPSUFFQF - шифр Гронсфельда , 'n'+ 'Шифр Гронсфельда - дешифрование: ' , Vizhener( Vizhener('GRONSFELD', '2015', 'gronsfeld'), '2015', 'gronsfeld decrypt' ) //выдаст GRONSFELD - из шифра Гронсфельда , 'n'+ 'Сравнение с сообщением: ', "( decrypted === m )" , ( Vizhener( Vizhener( 'GRONSFELD', '2015', 'gronsfeld'), '2015', 'gronsfeld_decrypt' ) === 'GRONSFELD' ) //m? true ); //2. Также, вместо цифр, в шифре Гронсфельда - возможно и указание букв. //Тогда, шифром Гронсфельда будет обычный шифр Виженера, но с ограничением символов на ключ. //Например, при всех возможных цифрах в ключе "0123456789", ключ может быть только из букв "ABCDEFGHIJ" //Получить его - можно так: var Gronsfeld_key = '2015'; var Vizhener_key = Gronsfeld_key.split('').map(function(x){return a[parseInt(x)]}).join(''); //CABF //И наоборот: var Gronsfeld_key2 = Vizhener_key.split('').map(function(x){return a.indexOf(x)}).join(''); //2015 //Вот они, в консоли: console.log( 'n2. Конвертация ключа Гронсфельда - в ключ Виженера:' , 'nGronsfeld_key', Gronsfeld_key , 'n'+'в Vizhener_key', Vizhener_key , 'n'+'и назад:', Gronsfeld_key2 ); //3. Тогда шифрование-дешифрование шифра Гронсфельда - есть работа с шифром Виженера: console.log( "n3. Шифр Гронсфельда - с ключом Виженера, по таблице Виженера:" , 'n'+ 'm = ', 'GRONSFELD', ' - сообщение' , 'n'+ 'k = ', Vizhener_key, '- ключ' , 'n'+ 'Шифр Гронсфельда - шифрование: ' , Vizhener( 'GRONSFELD', Vizhener_key ) //выдаст IRPSUFFQF - шифр Бофора , 'n'+ 'Шифр Гронсфельда - дешифрование:' , Vizhener( Vizhener( 'GRONSFELD', Vizhener_key ), Vizhener_key, 'decrypt' ) //выдаст GRONSFELD - из шифра Бофора. , 'n'+ 'Сравнение с сообщением: ', "( decrypted === m )" , ( Vizhener( Vizhener( 'GRONSFELD', Vizhener_key ), Vizhener_key, 'decrypt' ) === 'GRONSFELD' ) //'GRONSFELD'? true ); //4. Шифр Виженера (полная версия): //Параметры: m - сообщение/шифротекст, k - ключ, mode - "encrypt"/"decrypt" console.log( 'n4. Шифр Виженера (полная версия):' , 'n'+ 'm = ', m, ' - сообщение' , 'n'+ 'k = ', k, '- ключ' , 'n'+ 'Шифр Виженера - шифрование: ', Vizhener( m, k ) //выдаст LXFOPVEFRNHR - шифр Виженера , 'n'+ 'Шифр Виженера - дешифрование: ' , Vizhener( Vizhener(m, k), k, 'decrypt' ) //выдаст ATTACKATDAWN - из шифра Виженера , 'n'+ 'Сравнение с сообщением: ', "( decrypted === m )" , ( Vizhener( Vizhener( m, k, 'encrypt'), k, 'decrypt' ) === m ) //m? true ); //5. Шифр Бофора - через шифр Виженера (там другая таблица и шифротекст - сдвинутый атбаш по строкам). //Параметры: m - ключ, k - сообщение/шифротекст, mode - 'decrypt' (только дешифрование) //Особенность шифра Бофора - в том, что дешифрование представляет из себя повторное шифрование шифротекста - тем же ключом. //То есть - одна и та же операция. console.log( "n5. Шифр Бофора (в талбице - атбаш по строкам):" , 'n'+ 'm = ', m, ' - сообщение' , 'n'+ 'k = ', k, '- ключ' , 'n'+ 'Шифр Бофора - шифрование по таблице Виженера: ' , Vizhener( k, m, 'decrypt' ) //выдаст LLTOLBETLNPR - шифр Бофора , 'n'+ 'Шифр Бофора - дешифрование по таблице Виженера:' , Vizhener( k, Vizhener( k, m, 'decrypt' ), 'decrypt' ) //выдаст ATTACKATDAWN - из шифра Бофора. , 'n'+ 'Сравнение с сообщением: ', "( decrypted === m )" , ( Vizhener( k, Vizhener( k, m, 'decrypt' ), 'decrypt' ) === m ) //m? true ); //6. Сдвинутый атбаш - через шифр Виженера (там другая таблица и шифротекст - атбаш, сдвинутый и по строкам по столбцам). //Параметры: m или k - сообщение/шифротекст и ключ (или наоборот), mode - 'shifted_atbash'(только encrypt + атбаш к результату) //Мало того, что одна и та же операция (дешифрование - есть шифрование шифротекста), но к тому же она еще и коммутативна. //То есть, здесь, n-ные буквы (сообщения/шифротекста) и ключа - могут быть поменяны местами, давая тот же результат. //Именно этим, сдвинутый атбаш - и приближается к шифру Вернама, //так как при дешифровании шифром Вернама - операции XOR не важно где именно байты ключа, а где - байты шифротекста. console.log( "n6. Сдвинутый атбаш (в таблице атбаш, сдвинутый и по строкам и по столбцам):" , 'n'+ 'm = ', m, ' - сообщение' , 'n'+ 'k = ', k, '- ключ' , 'n'+ 'Сдвинутый атбаш - шифрование по таблице Виженера: ' , Vizhener( m, k, 'shifted_atbash' ) //выдаст OCULKEVUIMSI - шифр сдвинутого атбаша. , 'Тест коммутативности замены: ' , Vizhener( k, m, 'shifted_atbash' ) //То же самое, не важно где ключ, а где сообщение. , 'n'+ 'Сдвинутый атбаш - дешифрование по таблице Виженера: ' , Vizhener( Vizhener( k, m, 'shifted_atbash' ), k, 'shifted_atbash' ) //выдаст ATTACKATDAWN - из шифра сдвинутого атбаша. , 'Тест коммутативности замены: ' , Vizhener( k, Vizhener( k, m, 'shifted_atbash' ), 'shifted_atbash' ) //То же самое, не важно где ключ, а где шифротекст. , 'n'+ 'Сравнение с сообщением: ' , "( decrypted === m )" , ( Vizhener( k, Vizhener( k, m, 'shifted_atbash' ), 'shifted_atbash' ) === m ) //m? true , 'n'+ 'Коммутативность замены: ' , ( (Vizhener( m, k, 'shifted_atbash') === Vizhener( k, m, 'shifted_atbash')) && ( Vizhener( Vizhener( k, m, 'shifted_atbash' ), k, 'shifted_atbash' ) === Vizhener( k, Vizhener( k, m, 'shifted_atbash' ), 'shifted_atbash' ) ) ) //Коммутативность? true );
Вау!! 😲 Ты еще не читал? Это зря!
- симметричные шифры ,
На этом все! Теперь вы знаете все про шифр вижинера , Помните, что это теперь будет проще использовать на практике. Надеюсь, что теперь ты понял что такое шифр вижинера
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Шифры в криптографии

Дмитрий Михайлович Беляев
Эксперт по предмету «Информатика»
Задать вопрос автору статьи
Общие сведения о шифре Виженера
Замечание 1
Шифром Виженера является способ полиалфавитного шифрования буквенных текстов с применением ключевого слова. Данный метод считается упрощенной формой многоалфавитной замены.
Шифр Виженера, по сути, был изобретен несколько раз. Впервые данный метод был описан Джованом Баттистой Беллазо в его книге, выпущенной в 1553 году. Тем не менее, в девятнадцатом веке он был назван именем Блеза Виженера, который был французским дипломатом. Метод является простым для понимания и реализации, и его невозможно взломать при помощи простых методик криптографического анализа.
В шифре Цезаря все буквы алфавита должны сдвигаться на определенное количество позиций. К примеру, в шифре Цезаря, если выбран сдвиг плюс три позиции, то буква A стала бы D, а буква B стала бы E и дальше аналогично. Шифр Виженера составлен из очередности ряда шифров Цезаря с разными величинами сдвига. Для зашифровки текста можно использовать таблицу алфавитов, именуемую квадратом или таблицей Виженера.
![]()
Сдай на права пока
учишься в ВУЗе
Вся теория в удобном приложении. Выбери инструктора и начни заниматься!
Получить скидку 3 000 ₽
Относительно латинского алфавита таблица Виженера должна составляться из строк по двадцать шесть символов, при этом каждая последующая строчка должна сдвигаться на некоторое число позиций. Это означает, что в таблице получится двадцать шесть разных шифров Цезаря. На всех этапах шифровки должны использоваться разные алфавиты, которые могут выбираться в зависимости от буквы ключевого слова. К примеру, имеем следующий исходный текст:
ATTACKATDAWN
Пользователь, который посылает сообщение, должен записать ключевое слово, например, «LEMON» циклически до тех пор, пока его длина не сравняется с длиной исходного текста:
LEMONLEMONLE
Первый символ исходного текста A шифруется последовательностью L, являющейся первой буквой ключа. Первый символ L зашифрованного текста расположен на пересечении строки L и столбца A в таблице Виженера. Таким же образом для второй буквы исходного текста должен использоваться второй символ ключа; то есть второй символ зашифрованного текста X расположен на пересечении строки E и столбца T. Оставшаяся часть исходного текста должна шифроваться аналогичным методом. Таким образом получаем:
«Взлом шифра Виженера» 👇
- Исходный текст: ATTACKATDAWN.
- Используемый ключ: LEMONLEMONLE.
- Шифрованный текст: LXFOPVEFRNHR.
Расшифровка должна производиться следующим образом:
- Нужно найти в таблице Виженера строку, которая соответствует первому символу ключевого слова. В этой строке следует найти первый символ зашифрованного текста.
- Столбец, в котором расположен данный символ, будет соответствовать первому символу исходного текста.
- Последующие символы зашифрованного текста подвергаются расшифровке аналогичным образом.
Взлом шифра Виженера
Шифр Виженера как бы размывает параметры частот возникновения символов в тексте, но отдельные особенности использования символов в тексте остаются. Основным недостатком шифра Виженера является тот факт, что его ключ повторяется. Это означает, что простой криптоанализ шифра может содержать следующие этапы:
- Этап поиска длины ключа. Следует выполнить анализ распределения частот в зашифрованном тексте с разным прореживанием. То есть, нужно брать текст, который включает каждую вторую букву зашифрованного текста, потом каждую третью и так далее. Когда распределение частот букв начнет сильно отличаться от равномерного (например, по энтропии), то это означает определение длины ключа.
- Этап криптоанализа. Набор l-шифров Цезаря, где l является найденной длиной ключа, может по отдельности легко поддаваться взлому.
Тесты Фридмана и Касиски способны оказать помощь в определении длины ключа. В 1863-ем году Фридрих Касиски стал первым, кто сделал публикацию успешного алгоритма атаки на шифр Виженера. Но следует отметить, что Чарльз Беббидж создал данный алгоритм еще в 1854-ом году. В то время когда Беббидж пытался взломать шифр Виженера, Джон Холл Брок Твейтс предложил новый шифр в «Journal of the Society of the Arts». А когда Беббидж доказал, что шифр Твейтса представляет собой только частный случай шифра Виженера, Твейтс предложил ему его взломать. Беббидж сумел расшифровать текст, который оказался поэмой «The Vision of Sin» Альфреда Теннисона, зашифрованной при помощи ключевого слова Emily. Это было имя жены поэта.
Тест Касиски базируется на том факте, что отдельные слова, такие как «the», могут шифроваться при помощи одинаковых символов, что может приводить к повторению групп символов в зашифрованном тексте. К примеру, сообщение, зашифрованное ключом ABCDEF, может не всегда одинаково шифровать слово «crypto»:
- Ключ: ABCDEF AB CDEFA BCD EFABCDEFABCD.
- Исходный текст: CRYPTO IS SHORT FOR CRYPTOGRAPHY.
- Зашифрованный текст: CSASXT IT UKSWT GQU GWYQVRKWAQJB.
Зашифрованный текст в этом варианте не будет повторять последовательности символов, соответствующие повторным последовательностям исходного текста. В этом зашифрованном тексте имеется ряд повторяющихся сегментов, которые могут позволить криптоаналитику определить длину ключа:
- Ключ: ABCDAB CD ABCDA BCD ABCDABCDABCD.
- Исходный текст: CRYPTO IS SHORT FOR CRYPTOGRAPHY.
- Зашифрованный текст: CSASTP KV SIQUT GQU CSASTPIUAQJB.
Более длинные сообщения могут сделать тест более точным, поскольку они включают в себя больше повторяющихся сегментов зашифрованного текста.
Тест Фридмана (иногда именуемый каппа-тестом) изобрел Вильям Фридман в 1920-ом году. Фридманом использовался индекс совпадения, измеряющий частоты повторения символов, для того чтобы взломать шифр. Зная вероятность Kp того, что пара случайно отобранных символов текста совпадает (примерно 0,067 для английского языка) и вероятность совпадения пары случайно отобранных символов алфавита Kr (примерно 1 / 26 = 0,0385 для английского языка), можно оценить длину ключа как:

Рисунок 1.
Наблюдения за частотой совпадения показали, что:

Рисунок 2.
где :
- С является размером алфавита,
- N является длинной текста,
- ni является наблюдаемыми частотами повторения символов зашифрованного текста.
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Теория криптоанализа
шифра Виженера
Рассмотрим шифр
модульного гаммирования с уравнением
bi
= (ai+
yi)
mod n, для
которого гамма является периодической
последовательностью знаков алфавита.
Такая гамма обычно получается периодическим
повторением некоторого ключевого слова.
Например, ключевое слово KEY дает гамму
KEYKEYKEY… . Рассмотрим задачу вскрытия
такого шифра по тексту одной криптограммы
достаточной длины.
Пусть μ — длина
ключевого слова. Обычно криптоанализ
шифра Виженера проводится в два этапа.
На первом этапе определяется число μ,
на втором этапе — само ключевое слово.
Для определения
числа μ применяется так называемый тест
Казиски, названный в честь Ф. Казиски,
применившего его в 1863 г. Тест основан
на простом наблюдении о том, что два
одинаковых отрезка открытого текста,
отстоящих друг от друга на расстоянии,
кратном μ, будут одинаково зашифрованы.
В силу этого в шифр-тексте ищутся
повторения длины, не меньшей трех, и
расстояния между ними. Обратим внимание
на то, что случайно такие одинаковые
отрезки могут появиться в тексте с
достаточно малой вероятностью.
Пусть d1,d2,…
— найденные расстояния между повторениями
и d — наибольший общий делитель этих
чисел. Тогда μ должно делить d. Чем больше
повторений имеет текст, тем более
вероятно, что μ совпадает с d. Для уточнения
значения μ, можно использовать так
называемый индекс совпадения, введенный
в практику У. Фридманом в 1920 г.
Для строки х =
(x1,…,,xm)
длины т, составленной из букв алфавита
А, индексом совпадения в х, обозначаемым
Ic(х)
будем называть вероятность того, что
две случайно выбранные буквы из х
совпадают.
Пусть A = { ai,…,
an
}. Будем отождествлять буквы алфавита
с числами, так что a1
≡ 0,…, an-1
≡ n
— 2, аn
= n
-1.
Теорема.
Индекс
совпадения в х вычисляется по формуле

где fi
— число вхождений буквы ai
в х, I Є
Zn.
Доказательство.
Будем вычислять Iс(х)
как отношение числа благоприятных
исходов к общему числу исходов.
Благоприятным является исход, при
котором на выбранных двух позициях в х
расположены одинаковые буквы. Общее
число исходов равно, очевидно, С2m
. Число благоприятных исходов есть
![]()
В самом деле,
переупорядочим буквы в х таким образом,
чтобы сначала шли fa1
букв а1
затем — fa2
букв а2
и т.д.(4):

Теперь заметим,
что при случайном выборе мест (i
и j)
в строке х
благоприятными
являются следующие исходы:

В случае (а1)
мы можем выбрать пару букв а, из набора
(3) С2fa1
способами, в случае (а2)
пару букв а2
из (3) — С2fa2
способами
и т. д.
Таким образом,
общее число благоприятных исходов
выражается величиной (2), а индекс
совпадения в х
— формулой

и, следовательно,
формулой (1).
Пусть х
— строка
осмысленного текста (например,
английского). Допустим, как и ранее, что
буквы в х
появляются
на любом месте текста с соответствующими
вероятностями р0,…,рn-1
независимо
друг от друга, где рi
— вероятность
появления буквы i
в осмысленном
тексте, i Є Zn
В такой модели открытого текста
вероятность того, что две случайно
выбранные буквы из х
совпадают
с i Є
Zn
равна p2i
следовательно,
![]()
Взяв за основу
значения вероятностей рi
для открытых
текстов на английском языке, получаем
приближение
![]() .
.
Тем самым для английских текстовх
можно
пользоваться следующим приближением
для индекса совпадения: Ic(x)
≈ 0,066.
Аналогичные
приближения можно получить и для других
языков. Так, для русского языка получаем
приближение: Iс(x)
≈ 0,053.
Приведем значения
индексов совпадения для ряда европейских
языков:
Таблица 7. Индексы
совпадения европейских языков
|
Язык |
Русский |
Англ |
Франц |
Нем |
Итал |
Испан |
|
Ic(x) |
0,0529 |
0,0662 |
0,0778 |
0,0762 |
0,0738 |
0,0775 |
Рассуждения,
использованные при выводе формулы (4),
остаются, очевидно, справедливыми и в
случае, когда х
результат
зашифрования некоторого открытого
текста простой заменой. В этом случае
вероятности рi
переставляются
местами, но сумма
![]()
остается
неизменной.
Предположим, что
х —
реализация независимых испытаний
случайной
величины, имеющей
равномерное распределение на Zn.
Тогда индекс совпадения вычисляется
по формуле

Вернемся к вопросу
об определении числа μ. Пусть y = y1
y2
…yn
— данный
шифр-текст. Выпишем его с периодом μ:

и обозначим столбцы
получившейся таблицы через Y↓1,…,
Y↓μ.
Если μ это
истинная длина
ключевого слова, то каждый столбец Y↓i,
i Є
1, μ, представляет
собой участок открытого текста,
зашифрованный простой заменой,
определяемой подстановкой

для некоторого s
Є 0, n-l (числа
берутся по модулю n).
В силу сказанного
выше, (для английского языка) Iс(Y↓i)
≈ 0,066 при
любом i.
С другой стороны, если μ
отлично от
длины ключевого слова, то столбцы Y↓i
будут более
«случайными», поскольку они являются
результатом зашифрования фрагментов
открытого текста некоторым многоалфавитным
шифром. Тогда Iс(Y↓i)
будет ближе
(для английского языка) к числу 1/28 ≈
0,038
Заметная разница
значений Iс(x)
для осмысленных
открытых текстов и случайных
последовательностей букв (для английского
языка — 0,066 и 0,038, для русского языка —
0,053 и 0,030) позволяет в большинстве случаев
установить точное значение μ.
Предположим, что
на первом этапе мы нашли длину ключевого
слова μ.
Рассмотрим
теперь вопрос о нахождении самого
ключевого слова. Для его нахождения
можно использовать так называемый
взаимный
индекс совпадения.
Пусть х
= (х1
,…,хп),у
= (у1,…,ут)—
две строки букв алфавита А. Взаимным
индексом совпадения х
и у, обозначаемым
МIс(х,
у), называется
вероятность того, что случайно выбранная
буква из х
совпадает
со случайно выбранной буквой из у.
Пусть f0
f1
…fn
и f10
f11
…f1n-1
— числа
вхождений букв алфавита в х
и у соответственно.
Теорема. Взаимный
индекс совпадения в х и у вычисляется
по формуле (эта
теорема доказывается точно так же, как
и предыдущая теорема.)
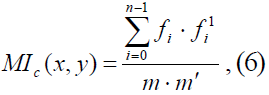
Пусть k = (k1,…,
kμ,)
— истинное ключевое слово. Попытаемся
оценить индексы MIc(Y↓i,
Y↓j)
Для этого напомним,
что Y↓3
является
результатом зашифрования фрагмента
открытого текста простой заменой,
определяемой подстановкой (5) при
некотором s.
Вероятность
того, что Y↓i
и Y↓j
произвольная
пара букв равна 0, имеет вид pn-si*pn-sj
(где ра
— вероятность
появления буквы а в открытом тексте);
вероятность того, что обе буквы есть 1,
равна
pn-si+1*pn-sj+1
и так далее.
На основании этого получаем:
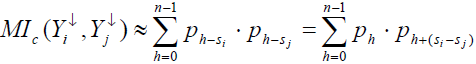
Заметим, что сумма
в правой части последнего равенства
зависит только от разности (si
– sj)mod
n , которую
назовем относительным
сдвигом Y↓i
и Y↓j.
Заметим также, что

поэтому Y↓i
и Y↓j
с относительными
сдвигами s и
п-s имеют
одинаковые взаимные индексы совпадения.
Приведем таблицу значений сумм (7) для
английского языка:
Таблица 8. Взаимный
индекс совпадения при сдвиге s
|
Сдвиг s |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
MI |
0,066 |
0,039 |
0,032 |
0,034 |
0,044 |
0,033 |
0,036 |
|
Сдвиг s |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
MI |
0,039 |
0,034 |
0,034 |
0,038 |
0,045 |
0,039 |
0,043 |
Обратим внимание
на то, что ненулевые «сдвиги» дают
взаимные индексы совпадения, изменяющиеся
в пределах от 0,032 до 0,045, в то время как
при нулевом сдвиге индекс MIc(x,y)
близок к
0,066. Это наблюдение позволяет определить
величины относительных сдвигов si
– sj столбцов
Y↓i
и Y↓j.
Для этого заметим, что при некотором
значении s(i,j)Є0,
n-1столбец Ys(i,j)↓j,
полученный из Y↓j
прибавлением
к каждому его элементу числа S(i,j)
(по модулю
n),
имеет нулевой относительный сдвиг с
Y↓j.
Пусть Y0↓j
, Y1↓j,…,
Yn-1↓j
– результаты
зашифрования Y↓j
каждой из
простых замен (5). Несложно вычислить
взаимные индексы
![]()
(всего, таким
образом, имеется С2μn
значений).
Для этого воспользуемся формулой,
полученной из (6):

Если s
равно si
– sj
— (относительному
сдвигу Y↓i
и Y↓j),
то взаимный индекс впадения должен быть
(для английского языка) близок к 0,066, так
как относительный сдвиг Y↓i
и Y↓j
равен нулю. Если же s не равно si
– sj
то взаимный
индекс совпадения должен колебаться в
пределах 0,032 — 0,045.
Используя изложенный
метод, мы сможем связать системой
уравнений относительные сдвиги различных
пар столбцов Y↓i
и Y↓j.
В результате останется 26 (для английского
языка) вариантов для ключевого слова,
из которых можно выбрать наиболее
предпочтительный вариант (если ключевое
слово является осмысленным).
Следует отметить,
что предложенный метод будет эффективным
для не слишком больших значений μ. Это
объясняется тем, что для хороших сближений
индексов совпадения требуются тексты
достаточно большой длины.
Пример
криптоанализа текста:
Задан некоторый
текст зашифрованный шифром Виженера,
требуется определить ключевое слово и
прочитать открытый текст.
Шифрованный текст:
влцдутжбюцхъяррмшбрхцэооэцгбрьцмйфктъъюьмшэсяцпунуящэйтаьэдкцибрьцгбрпачкъуцпъбьсэгкцъгуущарцёэвърюуоюэкааэбрняфукабъарпяъафкъиьжяффнйояфывбнэнфуюгбрьсшьжэтбэёчюъюръегофкбьчябашвёэуъъюаднчжчужцёэвлрнчулбюпцуруньъшсэюъзкцхъяррнрювяспэмасчкпэужьжыатуфуярюравртубурьпэщлафоуфбюацмнубсюкйтаьэдйюнооэгюожбгкбрънцэпотчмёодзцвбцшщвщепчдчдръюьскасэгъппэгюкдойрсрэвоопчщшоказръббнэугнялёкьсрбёуыэбдэулбюасшоуэтъшкрсдугэфлбубуъчнчтртпэгюкиугюэмэгюккъъпэгяапуфуэзьрадзьжчюрмфцхраююанчёчюъыхьъцомэфъцпоирькнщпэтэузуябащущбаыэйчдфрпэцъьрьцъцпоилуфэдцойэдятррачкубуфнйтаьэдкцкрннцюабугюуубурьпйюэъжтгюркующоъуфъэгясуоичщщчдцсфырэдщэъуяфшёчцюйрщвяхвмкршрпгюопэуцчйтаьэдкцибрьцыяжтюрбуэтэбдуящэубъибрювъежагибрбагбрымпуноцшяжцечкфодщоъчжшйуъцхчщвуэбдлдъэгясуахзцэбдэулькнъщбжяцэьрёдъьвювлрнуяфуоухфекьгцчччгэъжтанопчынажпачкъуъмэнкйрэфщэъьбудэндадъярьеюэлэтчоубъцэфэвлнёэгфдсэвэёкбсчоукгаутэыпуббцчкпэгючсаъбэнэфъркацхёваетуфяепьрювържадфёжбьфутощоявьъгупчршуитеачйчирамчюфчоуяюонкяжыкгсцбрясшчйотъъжрсщчл
Для определения
числа букв в данном ключевом слове
применяется так называемый тест Казиски.
Тест основан на простом наблюдении о
том, что два одинаковых отрезка открытого
текста, отстоящих друг от друга на
расстоянии, кратном μ (количество букв
в слове), будут одинаково зашифрованы.
В силу этого в шифротексте ищутся
повторения длины, не меньшей трех, и
расстояния между ними. Необходимо
обратить внимание на то, что случайно
такие одинаковые отрезки могут появиться
в тексте с достаточно малой вероятностью.
В данном тексте
обнаружено четырехкратное повторение
буквосочетания «брь». Выясним расстояние
между ними и найдем наибольший общий
делитель этих расстояний.
В результате
получаем: 35, 85, 510
НОД = 5;
Следовательно, с
определенной долей вероятности можно
заключить, что длина кодового слова
равна 5.
Для подтверждения
гипотезы воспользуемся математической
статистикой для определения длины
ключевого слова. Для этого запишем
шифр-текст в таблицу с 5 столбцами,
предполагая, что длина ключевого слова
равна 5.
Вычислим взаимные
индексы совпадения IC(x)
букв в каждом
из столбцов таблицы, для достоверного
установления длины ключевого слова.
Для этого посчитаем частоту повторения
букв в каждом столбце. Таблица состоит
из 5 столбцов, так как на предыдущем
этапе нами было установлено, что ключевое
слово по НОД может состоять из 5 букв.
|
Y1 |
Y2 |
Y3 |
Y4 |
Y5 |
|
В |
л |
ц |
д |
у |
|
Т |
ж |
б |
ю |
ц |
|
Х |
ъ |
я |
р |
р |
|
М |
ш |
б |
р |
х |
|
Ц |
э |
о |
о |
э |
|
Ц |
г |
б |
р |
ь |
|
Ц |
м |
й |
ф |
к |
|
Т |
ъ |
ъ |
ю |
ь |
|
М |
ш |
э |
с |
я |
|
Ц |
п |
у |
н |
у |
|
Я |
щ |
э |
й |
т |
|
А |
ь |
э |
д |
к |
|
Ц |
и |
б |
р |
ь |
|
Ц |
г |
б |
р |
п |
|
А |
ч |
к |
ъ |
у |
|
Ц |
п |
ъ |
б |
ь |
|
С |
э |
г |
к |
ц |
|
Ъ |
г |
у |
у |
щ |
|
А |
р |
ц |
ё |
э |
|
В |
ъ |
р |
ю |
у |
|
О |
ю |
э |
к |
а |
|
А |
э |
б |
р |
н |
|
Я |
ф |
у |
к |
а |
|
Б |
ъ |
а |
р |
п |
|
Я |
ъ |
а |
ф |
к |
|
Ъ |
и |
ь |
ж |
я |
|
Ф |
ф |
н |
й |
о |
|
Я |
ф |
ы |
в |
б |
|
Н |
э |
н |
ф |
у |
|
Ю |
г |
б |
р |
ь |
|
С |
ш |
ь |
ж |
э |
|
Т |
б |
э |
ё |
ч |
|
Ю |
ъ |
ю |
р |
ъ |
|
Е |
г |
о |
ф |
к |
|
Б |
ь |
ч |
я |
б |
|
А |
ш |
в |
ё |
э |
|
У |
ъ |
ъ |
ю |
а |
|
Д |
н |
ч |
ж |
ч |
|
У |
ж |
ц |
ё |
э |
|
В |
л |
р |
н |
ч |
|
У |
л |
б |
ю |
п |
|
Ц |
у |
р |
у |
н |
|
Ь |
ъ |
ш |
с |
э |
|
Ю |
ъ |
з |
к |
ц |
|
Х |
ъ |
я |
р |
р |
|
Н |
р |
ю |
в |
я |
|
С |
п |
э |
м |
а |
|
С |
ч |
к |
п |
э |
|
У |
ж |
ь |
ж |
ы |
|
А |
т |
у |
ф |
у |
|
Я |
р |
ю |
р |
а |
|
В |
р |
т |
у |
б |
|
У |
р |
ь |
п |
э |
|
Щ |
л |
а |
ф |
о |
|
У |
ф |
б |
ю |
а |
|
Ц |
м |
н |
у |
б |
|
С |
ю |
к |
й |
т |
|
А |
ь |
э |
д |
й |
|
Ю |
н |
о |
о |
э |
|
Г |
ю |
о |
ж |
б |
|
Г |
к |
б |
р |
ъ |
|
Н |
ц |
э |
п |
о |
|
Т |
ч |
м |
ё |
о |
|
Д |
з |
ц |
в |
б |
|
Ц |
ш |
щ |
в |
щ |
|
Е |
п |
ч |
д |
ч |
|
Д |
р |
ъ |
ю |
ь |
|
С |
к |
а |
с |
э |
|
Г |
ъ |
п |
п |
э |
|
Г |
ю |
к |
д |
о |
|
Й |
р |
с |
р |
э |
|
В |
о |
о |
п |
ч |
|
Щ |
ш |
о |
к |
а |
|
З |
р |
ъ |
б |
б |
|
Н |
э |
у |
г |
н |
|
Я |
л |
ё |
к |
ь |
|
С |
р |
б |
ё |
у |
|
Ы |
э |
б |
д |
э |
|
У |
л |
б |
ю |
а |
|
С |
ш |
о |
у |
э |
|
Т |
ъ |
ш |
к |
р |
|
С |
д |
у |
г |
э |
|
Ф |
л |
б |
у |
б |
|
У |
ъ |
ч |
н |
ч |
|
Т |
р |
т |
п |
э |
|
Г |
ю |
к |
и |
у |
|
Г |
ю |
э |
м |
э |
|
Г |
ю |
к |
к |
ъ |
|
Ъ |
п |
э |
г |
я |
|
А |
п |
у |
ф |
у |
|
Э |
з |
ь |
р |
а |
|
Д |
з |
ь |
ж |
ч |
|
Ю |
р |
м |
ф |
ц |
|
Х |
р |
а |
ю |
ю |
|
А |
н |
ч |
ё |
ч |
|
Ю |
ъ |
ы |
х |
ь |
|
Ъ |
ц |
о |
м |
э |
|
Ф |
ъ |
ц |
п |
о |
|
И |
р |
ь |
к |
н |
|
Щ |
п |
э |
т |
э |
|
У |
з |
у |
я |
б |
|
А |
щ |
у |
щ |
б |
|
А |
ы |
э |
й |
ч |
|
Д |
ф |
р |
п |
э |
|
Ц |
ъ |
ь |
р |
ь |
|
Ц |
ъ |
ц |
п |
о |
|
И |
л |
у |
ф |
э |
|
Д |
ц |
о |
й |
э |
|
Д |
я |
т |
р |
р |
|
А |
ч |
к |
у |
б |
|
У |
ф |
н |
й |
т |
|
А |
ь |
э |
д |
к |
|
Ц |
к |
р |
н |
н |
|
Ц |
ю |
а |
б |
у |
|
Г |
ю |
у |
у |
б |
|
У |
р |
ь |
п |
й |
|
Ю |
э |
ъ |
ж |
т |
|
Г |
ю |
р |
к |
у |
|
Ю |
щ |
о |
ъ |
у |
|
Ф |
ъ |
э |
г |
я |
|
С |
у |
о |
и |
ч |
|
Щ |
щ |
ч |
д |
ц |
|
С |
ф |
ы |
р |
э |
|
Д |
щ |
э |
ъ |
у |
|
Я |
ф |
ш |
ё |
ч |
|
Ц |
ю |
й |
р |
щ |
|
В |
я |
х |
в |
м |
|
К |
р |
ш |
р |
п |
|
Г |
ю |
о |
п |
э |
|
У |
ц |
ч |
й |
т |
|
А |
ь |
э |
д |
к |
|
Ц |
и |
б |
р |
ь |
|
Ц |
ы |
я |
ж |
т |
|
Ю |
р |
б |
у |
э |
|
Т |
э |
б |
д |
у |
|
Я |
щ |
э |
у |
б |
|
Ъ |
и |
б |
р |
ю |
|
В |
ъ |
е |
ж |
а |
|
Г |
и |
б |
р |
б |
|
А |
г |
б |
р |
ы |
|
М |
п |
у |
н |
о |
|
Ц |
ш |
я |
ж |
ц |
|
Е |
ч |
к |
ф |
о |
|
Д |
щ |
о |
ъ |
ч |
|
Ж |
ш |
й |
у |
ъ |
|
Ц |
х |
ч |
щ |
в |
|
У |
э |
б |
д |
л |
|
Д |
ъ |
э |
г |
я |
|
С |
у |
а |
х |
з |
|
Ц |
э |
б |
д |
э |
|
У |
л |
ь |
к |
н |
|
Ъ |
щ |
б |
ж |
я |
|
Ц |
э |
ь |
р |
ё |
|
Д |
ъ |
ь |
в |
ю |
|
В |
л |
р |
н |
у |
|
Я |
ф |
у |
о |
у |
|
Х |
ф |
е |
к |
ь |
|
Г |
ц |
ч |
ч |
ч |
|
Г |
э |
ъ |
ж |
т |
|
А |
н |
о |
п |
ч |
|
Ы |
н |
а |
ж |
п |
|
А |
ч |
к |
ъ |
у |
|
Ъ |
м |
э |
н |
к |
|
Й |
р |
э |
ф |
щ |
|
Э |
ъ |
ь |
б |
у |
|
Д |
э |
н |
д |
а |
|
Д |
ъ |
я |
р |
ь |
|
Е |
ю |
э |
л |
э |
|
Т |
ч |
о |
у |
б |
|
Ъ |
ц |
э |
ф |
э |
|
В |
л |
н |
ё |
э |
|
Г |
ф |
д |
с |
э |
|
В |
э |
ё |
к |
б |
|
С |
ч |
о |
у |
к |
|
Г |
а |
у |
т |
э |
|
Ы |
п |
у |
б |
б |
|
Ц |
ч |
к |
п |
э |
|
Г |
ю |
ч |
с |
а |
|
Ъ |
б |
э |
н |
э |
|
Ф |
ъ |
р |
к |
а |
|
Ц |
х |
ё |
в |
а |
|
Е |
т |
у |
ф |
я |
|
Е |
п |
ь |
р |
ю |
|
В |
ъ |
р |
ж |
а |
|
Д |
ф |
ё |
ж |
б |
|
Ь |
ф |
у |
т |
о |
|
Щ |
о |
я |
в |
ь |
|
Ъ |
г |
у |
п |
ч |
|
Р |
ш |
у |
и |
т |
|
Е |
а |
ч |
й |
ч |
|
И |
р |
а |
м |
ч |
|
Ю |
ф |
ч |
о |
у |
|
Я |
ю |
о |
н |
к |
|
Я |
ж |
ы |
к |
г |
|
С |
ц |
б |
р |
я |
|
С |
ш |
ч |
й |
о |
|
Т |
ъ |
ъ |
ж |
р |
|
С |
щ |
ч |
л |
Частота повторения
букв в столбцах:
1 столбец (общее
количество букв m=198)
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
17 |
2 |
10 |
16 |
14 |
7 |
0 |
1 |
1 |
3 |
2 |
1 |
0 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
3 |
4 |
1 |
0 |
1 |
16 |
9 |
14 |
5 |
5 |
23 |
0 |
0 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
5 |
10 |
3 |
2 |
2 |
10 |
11 |
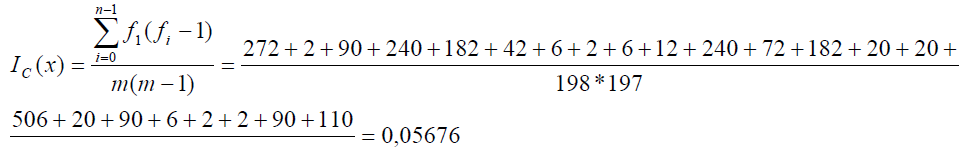
2 столбец (общее
количество букв m=198)
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
2 |
2 |
0 |
7 |
1 |
0 |
0 |
4 |
4 |
5 |
0 |
3 |
11 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
3 |
5 |
2 |
10 |
18 |
0 |
2 |
3 |
14 |
2 |
7 |
9 |
11 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
9 |
26 |
2 |
5 |
14 |
15 |
2 |

3 столбец (общее
количество букв m=198)
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
9 |
24 |
1 |
1 |
1 |
2 |
4 |
0 |
1 |
0 |
3 |
10 |
0 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
2 |
6 |
17 |
1 |
9 |
1 |
3 |
19 |
0 |
1 |
6 |
14 |
4 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
1 |
8 |
4 |
14 |
23 |
3 |
6 |
 4
4
столбец (общее количество букв m=198)
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
0 |
5 |
8 |
5 |
13 |
0 |
9 |
16 |
0 |
3 |
9 |
15 |
2 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
4 |
9 |
4 |
14 |
27 |
5 |
3 |
13 |
13 |
2 |
0 |
1 |
0 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
2 |
5 |
0 |
0 |
0 |
9 |
2 |

5 столбец (общее
количество букв m=197)
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
15 |
18 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
2 |
9 |
1 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
1 |
6 |
11 |
5 |
5 |
0 |
8 |
19 |
0 |
1 |
6 |
17 |
0 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
4 |
4 |
2 |
13 |
33 |
4 |
9 |

По полученным
индексам совпадения можно сказать, что
длина ключевого слова выбрана верно и
равна 5.
После того как мы
нашли длину ключевого слова произведем
поиск его истинного значения. Для его
нахождения можно использовать так
называемый взаимный индекс совпадения
 .,
.,
где
fi,
fi
1 —
частота
буквы i в столбцах Yi,
Yi1
соответственно;
m, m` — число букв в
столбцах ,Yi,
Yi1
соответственно;
Так как каждый из
столбцов таблицы является результатом
зашифрования фрагмента открытого
текста простой заменой, определяемой
подстановкой, то попытаемся оценить
взаимные индексы совпадения.
Взаимный индекс
совпадения значения ключевого слова
для русского языка должен находиться
в приделах 0,053 – 0,07. И для его вычисления
предварительно необходимо определить
относительный сдвиг всех столбцов
относительно первого.
Сдвиг 2-го столбца
на 6 позиций
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
26 |
2 |
5 |
14 |
15 |
2 |
2 |
2 |
0 |
7 |
1 |
0 |
0 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
4 |
4 |
5 |
0 |
3 |
11 |
3 |
5 |
2 |
10 |
18 |
0 |
2 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
3 |
14 |
2 |
7 |
9 |
11 |
9 |
MIc(Y1,Y26)=
0.05494
Сдвиг 3-го столбца
на 3 позиции
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
23 |
3 |
6 |
9 |
24 |
1 |
1 |
1 |
2 |
4 |
0 |
1 |
0 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
3 |
10 |
0 |
2 |
6 |
17 |
1 |
9 |
1 |
3 |
19 |
0 |
1 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
6 |
14 |
4 |
1 |
8 |
4 |
14 |
MIc(Y1,Y33)=
0.5798
Сдвиг 4-го столбца
на 16 позиций
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
27 |
5 |
3 |
13 |
13 |
2 |
0 |
1 |
0 |
2 |
5 |
0 |
0 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
0 |
9 |
2 |
0 |
5 |
8 |
5 |
13 |
0 |
9 |
16 |
0 |
3 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
9 |
15 |
2 |
4 |
9 |
4 |
14 |
MIc(Y1,Y416)=
0.06068
Сдвиг 5-го столбца
на 3 позиции
|
Обозначение |
а |
б |
в |
г |
д |
е |
ё |
ж |
з |
и |
й |
к |
л |
|
Количество |
33 |
4 |
9 |
15 |
18 |
1 |
1 |
0 |
0 |
1 |
0 |
1 |
0 |
|
Обозначение |
м |
н |
о |
п |
р |
с |
т |
у |
ф |
х |
ц |
ч |
ш |
|
Количество |
2 |
9 |
1 |
1 |
6 |
11 |
5 |
5 |
0 |
8 |
19 |
0 |
1 |
|
Обозначение |
щ |
ъ |
ы |
ь |
э |
ю |
я |
|
Количество |
6 |
17 |
0 |
4 |
4 |
2 |
13 |
MIc(Y1,Y53)=
0.06045
По взаимным
индексам совпадения можно судить что
сдвиги
между столбцами выбраны верно.
Составим уравнения
для определения ключевого слова:
g[1]-g[2]=6
g[1]=g[2]
+ 6 g[2]=g[1]
— 6
g[1]-g[3]=3
g[1]=g[3]
+ 3 g[3]=g[1]
— 3
g[1]-g[4]=16
g[1]=g[4]
+ 16 g[4]=g[1]
— 16
g[1]-g[5]=3
g[1]=g[5]
+ 3 g[5]=g[1]
— 3
Теперь только
необходимо вычислить значение g[1]
g[l]=1: быюсю g[l]=2:
вьятя g[l]=3: гэауа
g[l]=4: дюбфб g[l]=5:
еявхв g[l]=6: ёагцг
g[l]=7: жбдчд g[l]=8:
звеше g[l]=9: игёщё
g[l]=10: йджъж
g[l]=ll: кезыз g[l]=12: лёиьи
g[lj=13: мжйэй
g[l]=14: нзкюк g[l]=15: оилял
g[l]=16: пймам
g[l]=17: pкнбн g[l]=18: «словоサ
g[l]=19: тмпгп
g[l]=20: унрдр g[l]=21: фосес
g[l]=22: xптёт g[l]=23:
цружу g[l]=24: чсфзф
g[l]=25: штхих
g[l]=26: щуцйц g[l]=27: ъфчкч
g[l]=28: ыхшлш
g[l]=29: ьцщмщ g[l]=30: эчънъ
g[l]=31: юшыоы
g[l]=32: ящьпь
Найдено одно
ключевое слово
«СЛОВО»
Расшифруем
зашифрованный текст:
Развебытьздоровымтожесамоечтонебытьбольнымопределенноздоровьеэтонечтобольшеедлянасфизическоездоровьеэтоисостояниеиспособностьиэнергиязаниматьсятемчтонамнеобходимополучатьприэтомудовольствиеивыздоравливатьбезвсякойпомощиздоровьепарадоксальновынеможетенепосредственнозаставитьсебястатьздоровымвамостаетсятольконаблюдатьзатемкакудивительнаяспособностьвашегоорганизмаисцелятьсебяначинаетдействоватьсамасобойивашебогатствоилибедностьжестокостьилидобродетельностьнеимеютздесьповидимомуникакогозначенияздоровьеэтонечтопозитивноеононеозначаетотказотудовольствияздоровьеявляетсяестественнымследствиемнашегообразажизнивзаимоотношенийдиетыокружающейобстановкиздоровьеэтонепредметсобственностиэтопроцессэтоточтомыделаемрезультатнашихмыслейичувствэтообразсуществованияинтересночтонаправлениемедицинскихисследованийвсебольшеибольшеотклоняетсявсторонутойобластикотораядосихпорсчиталасьсферойдеятельностипсихологовисейчасужетруднопровестичеткиеразграничениямеждуфизическимииментальнымифакторамизаболеваний
Вывод:
Ключевое слово верное, текст читается.__