В силу первого предположения, а -1 принадлежит Н и а _1 *а = е. Тогда а- 1 *а*Ь -1 = а _1 *с или Ь -1 = а _1 *с, что означает существование обратного элемента любого элемента Н.
Таким образом, необходимым и достаточным условием того, что непустое подмножество Н элементов группы G образует подгруппу, является выполнение для любых двух элементов а и Ь из Н следующих условий:
Кроме того, следует отметить, что единичный элемент подгруппы всегда совпадает с единичным элементом исходной группы [8].
Очевидно, что подмножество <е>любой группы G, состоящее только из единичного элемента, а также сама группа G удовлетворяют условиям образования подгруппы. Такие подгруппы называются тривиальными подгруппами.
Пусть Н — подгруппа группы G, a g — произвольный фиксированный элемент G. Множество
называется правым смежным классом группы G по подгруппе Н, порождаемым элементом g. Аналогично множество
называется левым смежным классом группы G по подгруппе Н, порождаемым элементом g.
В случае некоммутативной группы G число левых смежных классов группы G по подгруппе Н совпадает с числом правых смежных классов. При этом в общем случае никакой левый смежный класс не совпадает ни с каким правым смежным классом. Исключение составляют так называемые нормальные делители — подгруппы, для любого элемента которых H*g = g*H [10].
Очевидно, что если G — абелева группа, то ее левые смежные классы по подгруппе Н совпадают с правыми. Условимся в случае абелевой группы обозначать смежные классы группы G по подгруппе Н в форме соотношения (2.14).
Пусть Н — подгруппа некоторой конечной группы G.
по подгруппе Н равны: gi*hj = gi*hk. Тогда умножение слева на g;
1 дает равенство hj = hk. Но это противоречит определению подгруппы.
равны: gi*hj = gk*hs. Умножение справа на hj— 1 дает равенство g; = gk*hs*hj
Пусть Н = hn> — подгруппа конечной группы G. Пусть g n ) как векторном пространстве GF n (q).
Таким образом, векторное подпространство GF k (q) кода С разбивает исходное векторное пространство GF n (q) на непересекающиеся смежные классы, определяемые следующим образом:
где а — элемент GF n (q), порождающий смежный класс.
Как было показано в предыдущем пункте этого подпараграфа, число элементов каждого смежного класса совпадает с числом кодовых слов кода С. Иными словами, каждый смежный класс а + С содержит q k элементов. Число всех непересекающихся смежных классов определяется соотношением (2.15) и имеет значение q n
Таким образом, векторное пространство GF n (q) можно представить как объединение множеств:
где a s ), s = 0,1. q n
k — 1 — элементы GF n (q), образующие все различные
(не пересекающиеся) смежные классы.
Будем считать, что в соотношении (2.16) а(°) = 0. Тогда смежный класс а(°) + + С совпадает с кодом С.
Как было показано в предыдущем пункте этого подпараграфа, каждый смежный класс вида (2.16) может быть порожден q k различными элементами (векторами) векторного пространства GF n (q).
Пример 2.1.7. Рассмотрим построение отличных от исходного кода смежных классов двоичного линейного (6, 3)-кода С из примера 2.1.4.
Множество всех кодовых слов в данном случае содержит восемь элементов (векторов) векторного пространства GF 6 (2), которые можно представить в виде двоичных последовательностей длиной не более шести двоичных символов:
Число элементов (векторов) каждого смежного класса соответствует числу q k = 8 кодовых слов кода С.
Пусть, например, а = 000001. Тогда смежный класс а + С будет состоять из следующих элементов (векторов):
Нетрудно проверить, что то же множество векторов может быть получено при а = 001100, 010010, 011111, 100111,101010,110100,111001. То есть при любом другом отличном от исходного порождающего элемента а значении, принадлежащем указанному смежному классу.
Согласно соотношению (2.16), число не пересекающихся смежных классов в этом случае: q n
k = 8 (в следующем примере мы укажем их все). Все остальные (отличные от самого кода С) смежные классы могут быть получены, например, при следующих значениях порождающего элемента а:
При этом каждый смежный класс может быть образован, помимо указанных, семью другими значениями вектора а из GF 6 (2), принадлежащими тому же смежному классу.
Любой элемент (вектор) каждого смежного класса, как и сам смежный класс, может быть получен восемью различными способами как а + с для восьми различных значений порождающего элемента а и всех восьми кодовых слов с кода С. Например, элемент 111001 рассмотренного выше в этом примере смежного класса, порожденного элементом а = 000001, может быть получен как а + с для значений а = 000001, 001100, 010010, 011111, 100111, 101010, 110100, 111001 и с = 111000, 110101, 101011, 100110, 011110, 010011, 001101, 000000 соответственно.
4. Пусть С — линейный (л, к)-код над GF(q) и v = с + е — вектор принятого сообщения.
Как было показано выше в этом подпараграфе, вектор v всегда принадлежит одному из q n
k не пересекающихся смежных классов вида (2.16). При отсутствии ошибок вектор v принадлежит смежному классу, совпадающему с кодом С. При ненулевом векторе ошибок вектор i/оказывается в другом смежном классе а + С (пока будем считать, что вес вектора ошибок не превосходит максимального числа t исправляемых кодом ошибок).
Принимая вектор е за порождающий элемент смежного класса е + С, по известному вектору v мы можем определить q k возможных значений вектора е. Очевидно, наиболее вероятным является значение е наименьшего веса.
Элемент (вектор) минимального веса в смежном классе а + С называется лидером смежного класса а + С.
Если в смежном классе а + С несколько векторов имеют минимальный вес, то в качестве лидера смежного класса выбирается любой из них. Таким образом, вектор ошибок принимается равным лидеру смежного класса, которому принадлежит принятый вектор v.
В этом случае аппаратная реализация декодера основана на так называемом табличном методе и требует хранения в памяти устройства всех смежных классов и их лидеров. Подобного рода декодер даже при небольшой длине кода требует значительных аппаратных затрат. Например, для рассмотренного в примерах 2.1.4 и 2.1.7 двоичного линейного (6, 3)-кода требуется хранить в памяти декодера q n
k = 8 смежных классов по q k = 8 двоичных векторов длины п = 6 символов.
Однако табличный декодер может быть несколько упрощен.
Пусть Н — проверочная матрица линейного (л, /с)-кода С. Тогда матрица-строка s(y) = у-Н т размера 1 х к называется синдромом вектора у.
Пусть у = v = с + е — вектор принятого сообщения. Тогда, в силу соотношения (2.10), s(y) = s(e) и, стало быть, равенство нулю s(v) означает принадлежность вектора v коду С. Это в свою очередь означает отсутствие ошибок вектора v. Пока будем считать, что вес вектора ошибок не превосходит максимального числа t исправляемых кодом ошибок. К этому вопросу мы еще вернемся ниже, в конце этого подпараграфа.
Пусть С — линейный (л, к)-код над GF(q), а у и z — два вектора векторного пространства GF n (q).
Очевидно, что s(y) = s(z) тогда и только тогда, когда у-Н т = z-H T или (у — z) х х Н т = 0. Это означает, что вектор у — z принадлежит С. Тогда y-z = Ck- некоторое кодовое слово кода С. Последнее равенство выполняется и в том случае,
если у = а + CiVz = а + Cj, где с,- — су = с*, а — некоторый вектор GF n (q). Равенство синдромов векторов у и z означает принадлежность обоих векторов одному смежному классу.
Таким образом, в силу равенства синдромов s(v) и s(e), вектор v принятого сообщения и вектор ошибок е всегда принадлежат одному смежному классу и по известному синдрому s(v) можно однозначно определить лидер соответствующего смежного класса.
Теперь мы можем описать один из возможных алгоритмов декодирования линейных кодов.
- 1. Определить синдром s(v) принятого сообщения v.
- 2. По известному синдрому s[v) определить соответствующий лидер смежного класса, синдром которого совпадает с s(v).
- 3. Определить исходное кодовое слово с согласно соотношению (2.13) как c-v-e.
Аппаратная реализация декодера в этом случае требует хранения q k синдромов длины п — к (/-ичных символов и q k соответствующих им лидеров смежных классов длины п q-ичных символов в памяти устройства.
Такой метод декодирования называется декодированием линейных кодов по лидерам смежных классов.
Пример 2.1.8. Рассмотрим снова двоичный линейный (6, 3)-код из примеров 2.1.4 и 2.1.7.
В таблице 2.1 показаны смежные классы, лидеры смежных классов и соответствующие им синдромы рассматриваемого кода. Во избежание громоздкости элементы смежных классов представлены соответствующими десятичными значениями. Жирным шрифтом выделены значения лидеров смежных классов.
Лидер смежного класса
< 1, 12, 18,31,39, 42, 52, 57 >
< 2, 15, 17, 28, 36,41,55, 58 >
< 4, 9, 23, 26, 34,47, 49, 60 >
- 001010
- 010100
- 100001
Нетрудно убедиться в том, что синдром любого элемента каждого смежного класса совпадает с синдромом лидера этого смежного класса.
Как видно из таблицы 2.1, в данном случае лидеры смежных классов представлены всеми возможными двоичными векторами веса 1. Эти векторы определены однозначно (в каждом смежном классе только один такой вектор). Таким образом, в случае одиночной ошибки существует единственным образом определяемый синдром, позволяющий однозначно определить вектор ошибки. Поэтому рассмотренный линейный (6,3)-код позволяет гарантированно исправлять одиночную ошибку.
Кроме того, в одном (последнем) смежном классе три лидера веса 2. Это позволяет с небольшой (1/3) вероятностью декодировать двойную ошибку (при условии, что вероятности всех векторов принимаемых сообщений с двойной ошибкой равны).
Очевидно, избыточность рассмотренного в примерах 2.1.4, 2.1.7 и 2.1.8 двоичного линейного (6, 3)-кода немного превышает накладываемые на него корректирующие свойства, так как помимо достаточных для декодирования лидеров смежных классов веса 1 в одном из смежных классов имеют место лидеры веса 2.
Если в качестве лидеров q n
k смежных классов кода удается взять векторы веса t и менее и только их, то код называется совершенным кодом. Если же в качестве лидеров q n
k смежных классов кода удается взять все необходимые для исправления не менее t ошибок векторы веса t и менее, а также несколько векторов веса t + 1, то код называется квазисовершенным кодом.
Проще говоря, у совершенных кодов избыточности «ровно столько, сколько нужно» для исправления не менее чем t ошибок кодового слова.
Возвращаясь к примеру 2.1.4, отметим, что в случае двоичного линейного
- (5,3)-кода вообще нельзя определить однозначно лидеры смежных классов веса
- 1. Пусть, например, проверочная матрица (5,3)-кода имеет вид:
Тогда порождающая матрица:
В этом случае лидер смежного класса веса 1 будет однозначно определен только в одном смежном классе, отличном от смежного класса самого кода. В двух других смежных классах будет по два лидера веса 1. В смежном классе, совпадающем с кодом, также будут два лидера веса 2. Таким образом, данный код не может исправлять одиночную ошибку кодового слова.
Этот вывод подтверждается неравенством (2.5), так как минимальное расстояние (5, 3)-кода равно двум и, следовательно, ни одно целое положительное значение t исправляемых кодом ошибок данному неравенству не удовлетворяет.
Таким образом, при длине информационного сообщения к = 3 двоичных символа и длине проверочной последовательности г=п-к = 2 символа код вообще не позволяет исправлять одиночную ошибку кодового слова, а при длине г — 3 символа уже оказывается не совершенным (хотя и квазисовершенным).
Следует отметить, что совершенные коды, равно как и квазисовершенные, для некоторых значений п и к вообще могут не существовать [10]. Далее мы рассмотрим несколько видов кодов из класса линейных кодов, конструкция которых часто позволяет получить квазисовершенный или даже совершенный код.
Выше мы считали, что вес вектора ошибок не превосходит значение t исправляемых кодом ошибок, так как восстановление исходного кодового слова возможно только в этом случае. В противном случае исходное кодовое слово и принятый вектор могут попасть в один смежный класс, и восстановление кодового слова будет невозможно. Таким образом, число ошибок, превышающее корректирующую способность кода, приводит к ошибочному декодированию.
Если же число ошибок превосходит t и принятый вектор попадает в смежный класс, отличный от смежного класса кода, то декодирование возможно лишь с некоторой (обычно небольшой) вероятностью. При этом возможны два способа декодирования:
- — декодирование любого полученного кодового слова в ближайшее кодовое слово;
- — декодирование только кодовых слов, число ошибок которых не превосходит максимально возможное для данного кода число ошибок t, если число ошибок превышает t, происходит отказ от декодирования.
В первом случае декодер называется полным декодером, а во втором — неполным декодером.
Очевидно, что по сравнению с неполным декодером полный декодер чаще декодирует неправильно. Поэтому полный декодер используется обычно только в тех случаях, когда лучше «угадывать» сообщение, чем вообще не иметь никакой оценки.
В силу указанных особенностей мы будем рассматривать только неполные декодеры.
Метод декодирования линейных кодов по лидерам смежных классов является общим для всех линейных кодов. При этом вполне очевидно, что этот метод связан с трудоемким процессом определения лидеров смежных классов.
Например, для линейного (31, 26)-кода над GF(2) требуется определить 32 смежных класса по 67108864 вектора длины 31 в каждом и найти лидеры каждого смежного класса.
Таким образом, метод декодирования линейных кодов по лидерам смежных классов в общем случае не является приемлемым.
Однако мы можем заранее определить некоторый удобный метод декодирования и на его основе построить линейный код специального вида.
Корректирующие коды «на пальцах»
Корректирующие (или помехоустойчивые) коды — это коды, которые могут обнаружить и, если повезёт, исправить ошибки, возникшие при передаче данных. Даже если вы ничего не слышали о них, то наверняка встречали аббревиатуру CRC в списке файлов в ZIP-архиве или даже надпись ECC на планке памяти. А кто-то, может быть, задумывался, как так получается, что если поцарапать DVD-диск, то данные всё равно считываются без ошибок. Конечно, если царапина не в сантиметр толщиной и не разрезала диск пополам.
Как нетрудно догадаться, ко всему этому причастны корректирующие коды. Собственно, ECC так и расшифровывается — «error-correcting code», то есть «код, исправляющий ошибки». А CRC — это один из алгоритмов, обнаруживающих ошибки в данных. Исправить он их не может, но часто это и не требуется.
Давайте же разберёмся, что это такое.
Для понимания статьи не нужны никакие специальные знания. Достаточно лишь понимать, что такое вектор и матрица, как они перемножаются и как с их помощью записать систему линейных уравнений.
Внимание! Много текста и мало картинок. Я постарался всё объяснить, но без карандаша и бумаги текст может показаться немного запутанным.
Каналы с ошибкой
Разберёмся сперва, откуда вообще берутся ошибки, которые мы собираемся исправлять. Перед нами стоит следующая задача. Нужно передать несколько блоков данных, каждый из которых кодируется цепочкой двоичных цифр. Получившаяся последовательность нулей и единиц передаётся через канал связи. Но так сложилось, что реальные каналы связи часто подвержены ошибкам. Вообще говоря, ошибки могут быть разных видов — может появиться лишняя цифра или какая-то пропасть. Но мы будем рассматривать только ситуации, когда в канале возможны лишь замены нуля на единицу и наоборот. Причём опять же для простоты будем считать такие замены равновероятными.
Ошибка — это маловероятное событие (а иначе зачем нам такой канал вообще, где одни ошибки?), а значит, вероятность двух ошибок меньше, а трёх уже совсем мала. Мы можем выбрать для себя некоторую приемлемую величину вероятности, очертив границу «это уж точно невозможно». Это позволит нам сказать, что в канале возможно не более, чем ошибок. Это будет характеристикой канала связи.
Для простоты введём следующие обозначения. Пусть данные, которые мы хотим передавать, — это двоичные последовательности фиксированной длины. Чтобы не запутаться в нулях и единицах, будем иногда обозначать их заглавными латинскими буквами (, , , …). Что именно передавать, в общем-то неважно, просто с буквами в первое время будет проще работать.
Кодирование и декодирование будем обозначать прямой стрелкой (), а передачу по каналу связи — волнистой стрелкой (). Ошибки при передаче будем подчёркивать.
Например, пусть мы хотим передавать только сообщения и . В простейшем случае их можно закодировать нулём и единицей (сюрприз!):
Передача по каналу, в котором возникла ошибка будет записана так:
Цепочки нулей и единиц, которыми мы кодируем буквы, будем называть кодовыми словами. В данном простом случае кодовые слова — это и .
Код с утроением
Давайте попробуем построить какой-то корректирующий код. Что мы обычно делаем, когда кто-то нас не расслышал? Повторяем дважды:
Правда, это нам не очень поможет. В самом деле, рассмотрим канал с одной возможной ошибкой:
Какие выводы мы можем сделать, когда получили ? Понятно, что раз у нас не две одинаковые цифры, то была ошибка, но вот в каком разряде? Может, в первом, и была передана буква . А может, во втором, и была передана .
То есть, получившийся код обнаруживает, но не исправляет ошибки. Ну, тоже неплохо, в общем-то. Но мы пойдём дальше и будем теперь утраивать цифры.
Проверим в деле:
Получили . Тут у нас есть две возможности: либо это и было две ошибки (в крайних цифрах), либо это и была одна ошибка. Вообще, вероятность одной ошибки выше вероятности двух ошибок, так что самым правдоподобным будет предположение о том, что передавалась именно буква . Хотя правдоподобное — не значит истинное, поэтому рядом и стоит вопросительный знак.
Если в канале связи возможна максимум одна ошибка, то первое предположение о двух ошибках становится невозможным и остаётся только один вариант — передавалась буква .
Про такой код говорят, что он исправляет одну ошибку. Две он тоже обнаружит, но исправит уже неверно.
Это, конечно, самый простой код. Кодировать легко, да и декодировать тоже. Ноликов больше — значит передавался ноль, единичек — значит единица.
Если немного подумать, то можно предложить код исправляющий две ошибки. Это будет код, в котором мы повторяем одиночный бит 5 раз.
Расстояния между кодами
Рассмотрим поподробнее код с утроением. Итак, мы получили работающий код, который исправляет одиночную ошибку. Но за всё хорошее надо платить: он кодирует один бит тремя. Не очень-то и эффективно.
И вообще, почему этот код работает? Почему нужно именно утраивать для устранения одной ошибки? Наверняка это всё неспроста.
Давайте подумаем, как этот код работает. Интуитивно всё понятно. Нолики и единички — это две непохожие последовательности. Так как они достаточно длинные, то одиночная ошибка не сильно портит их вид.
Пусть мы передавали , а получили . Видно, что эта цепочка больше похожа на исходные , чем на . А так как других кодовых слов у нас нет, то и выбор очевиден.
Но что значит «больше похоже»? А всё просто! Чем больше символов у двух цепочек совпадает, тем больше их схожесть. Если почти все символы отличаются, то цепочки «далеки» друг от друга.
Можно ввести некоторую величину , равную количеству различающихся цифр в соответствующих разрядах цепочек и . Эту величину называют расстоянием Хэмминга. Чем больше это расстояние, тем меньше похожи две цепочки.
Например, , так как все цифры в соответствующих позициях равны, а вот .
Расстояние Хэмминга называют расстоянием неспроста. Ведь в самом деле, что такое расстояние? Это какая-то характеристика, указывающая на близость двух точек, и для которой верны утверждения:
- Расстояние между точками неотрицательно и равно нулю только, если точки совпадают.
- Расстояние в обе стороны одинаково.
- Путь через третью точку не короче, чем прямой путь.
Достаточно разумные требования.
Математически это можно записать так (нам это не пригодится, просто ради интереса посмотрим):
- .
Предлагаю читателю самому убедиться, что для расстояния Хэмминга эти свойства выполняются.
Окрестности
Таким образом, разные цепочки мы считаем точками в каком-то воображаемом пространстве, и теперь мы умеем находить расстояния между ними. Правда, если попытаться сколько нибудь длинные цепочки расставить на листе бумаги так, чтобы расстояния Хэмминга совпадали с расстояниями на плоскости, мы можем потерпеть неудачу. Но не нужно переживать. Всё же это особое пространство со своими законами. А слова вроде «расстояния» лишь помогают нам рассуждать.
Пойдём дальше. Раз мы заговорили о расстоянии, то можно ввести такое понятие как окрестность. Как известно, окрестность какой-то точки — это шар определённого радиуса с центром в ней. Шар? Какие ещё шары! Мы же о кодах говорим.
Но всё просто. Ведь что такое шар? Это множество всех точек, которые находятся от данной не дальше, чем некоторое расстояние, называемое радиусом. Точки у нас есть, расстояние у нас есть, теперь есть и шары.
Так, скажем, окрестность кодового слова радиуса 1 — это все коды, находящиеся на расстоянии не больше, чем 1 от него, то есть отличающиеся не больше, чем в одном разряде. То есть это коды:
Да, вот так странно выглядят шары в пространстве кодов.
А теперь посмотрите. Это же все возможные коды, которые мы получим в канале в одной ошибкой, если отправим ! Это следует прямо из определения окрестности. Ведь каждая ошибка заставляет цепочку измениться только в одном разряде, а значит удаляет её на расстояние 1 от исходного сообщения.
Аналогично, если в канале возможны две ошибки, то отправив некоторое сообщение , мы получим один из кодов, который принадлежит окрестности радиусом 2.
Тогда всю нашу систему декодирования можно построить так. Мы получаем какую-то цепочку нулей и единиц (точку в нашей новой терминологии) и смотрим, в окрестность какого кодового слова она попадает.
Сколько ошибок может исправить код?
Чтобы код мог исправлять больше ошибок, окрестности должны быть как можно шире. С другой стороны, они не должны пересекаться. Иначе если точка попадёт в область пересечения, непонятно будет, к какой окрестности её отнести.
В коде с удвоением между кодовыми словами и расстояние равно 2 (оба разряда различаются). А значит, если мы построим вокруг них шары радиуса 1, то они будут касаться. Это значит, точка касания будет принадлежать обоим шарам и непонятно будет, к какому из них её отнести.
Именно это мы и получали. Мы видели, что есть ошибка, но не могли её исправить.
Что интересно, точек касания в нашем странном пространстве у шаров две — это коды и . Расстояния от них до центров равны единице. Конечно же, в обычно геометрии такое невозможно, поэтому рисунки — это просто условность для более удобного рассуждения.
В случае кода с утроением, между шарами будет зазор.
Минимальный зазор между шарами равен 1, так как у нас расстояния всегда целые (ну не могут же две цепочки отличаться в полутора разрядах).
В общем случае получаем следующее.
Этот очевидный результат на самом деле очень важен. Он означает, что код с минимальным кодовым расстоянием будет успешно работать в канале с ошибками, если выполняется соотношение
Полученное равенство позволяет легко определить, сколько ошибок будет исправлять тот или иной код. А сколько код ошибок может обнаружить? Рассуждения такие же. Код обнаруживает ошибок, если в результате не получится другое кодовое слово. То есть, кодовые слова не должны находиться в окрестностях радиуса других кодовых слов. Математически это записывается так:
Рассмотрим пример. Пусть мы кодируем 4 буквы следующим образом.
Чтобы найти минимальное расстояние между различными кодовыми словами, построим таблицу попарных расстояний.
| A | B | C | D | |
|---|---|---|---|---|
| A | — | 3 | 3 | 4 |
| B | 3 | — | 4 | 3 |
| C | 3 | 4 | — | 3 |
| D | 4 | 3 | 3 | — |
Минимальное расстояние , а значит , откуда получаем, что такой код может исправить до ошибок. Обнаруживает же он две ошибки.
Чтобы декодировать полученное сообщение, посмотрим, к какому символу оно ближе всего.
Минимальное расстояние получилось для символа , значит вероятнее всего передавался именно он:
Итак, этот код исправляет одну ошибку, как и код с утроением. Но он более эффективен, так как в отличие от кода с утроением здесь кодируется уже 4 символа.
Таким образом, основная проблема при построении такого рода кодов — так расположить кодовые слова, чтобы они были как можно дальше друг от друга, и их было побольше.
Для декодирования можно было бы использовать таблицу, в которой указывались бы все возможные принимаемые сообщения, и кодовые слова, которым они соответствуют. Но такая таблица получилась бы очень большой. Даже для нашего маленького кода, который выдаёт 5 двоичных цифр, получилось бы варианта возможных принимаемых сообщений. Для более сложных кодов таблица будет значительно больше.
Попробуем придумать способ коррекции сообщения без таблиц. Мы всегда сможем найти полезное применение освободившейся памяти.
Интерлюдия: поле GF(2)
Для изложения дальнейшего материала нам потребуются матрицы. А при умножении матриц, как известно мы складываем и перемножаем числа. И тут есть проблема. Если с умножением всё более-менее хорошо, то как быть со сложением? Из-за того, что мы работаем только с одиночными двоичными цифрами, непонятно, как сложить 1 и 1, чтобы снова получилась одна двоичная цифра. Значит вместо классического сложения нужно использовать какое-то другое.
Введём операцию сложения как сложение по модулю 2 (хорошо известный программистам XOR):
Умножение будем выполнять как обычно. Эти операции на самом деле введены не абы как, а чтобы получилась система, которая в математике называется полем. Поле — это просто множество (в нашем случае из 0 и 1), на котором так определены сложение и умножение, чтобы основные алгебраические законы сохранялись. Например, чтобы основные идеи, касающиеся матриц и систем уравнений по-прежнему были верны. А вычитание и деление мы можем ввести как обратные операции.
Множество из двух элементов с операциями, введёнными так, как мы это сделали, называется полем Галуа GF(2). GF — это Galois field, а 2 — количество элементов.
У сложения есть несколько очень полезных свойств, которыми мы будем пользоваться в дальнейшем.
Это свойство прямо следует из определения.
А в этом можно убедиться, прибавив к обеим частям равенства. Это свойство, в частности означает, что мы можем переносить в уравнении слагаемые в другую сторону без смены знака.
Проверяем корректность
Вернёмся к коду с утроением.
Для начала просто решим задачу проверки, были ли вообще ошибки при передаче. Как видно, из самого кода, принятое сообщение будет кодовым словом только тогда, когда все три цифры равны между собой.
Пусть мы приняли вектор-строку из трёх цифр. (Стрелочки над векторами рисовать не будем, так как у нас почти всё — это вектора или матрицы.)
Математически равенство всех трёх цифр можно записать как систему:
Или, если воспользоваться свойствами сложения в GF(2), получаем
В матричном виде эта система будет иметь вид
Транспонирование здесь нужно потому, что — это вектор-строка, а не вектор-столбец. Иначе мы не могли бы умножать его справа на матрицу.
Будем называть матрицу проверочной матрицей. Если полученное сообщение — это корректное кодовое слово (то есть, ошибки при передаче не было), то произведение проверочной матрицы на это сообщение будет равно нулевому вектору.
Умножение на матрицу — это гораздо более эффективно, чем поиск в таблице, но у нас на самом деле есть ещё одна таблица — это таблица кодирования. Попробуем от неё избавиться.
Кодирование
Итак, у нас есть система для проверки
Её решения — это кодовые слова. Собственно, мы систему и строили на основе кодовых слов. Попробуем теперь решить обратную задачу. По системе (или, что то же самое, по матрице ) найдём кодовые слова.
Правда, для нашей системы мы уже знаем ответ, поэтому, чтобы было интересно, возьмём другую матрицу:
Соответствующая система имеет вид:
Чтобы найти кодовые слова соответствующего кода нужно её решить.
В силу линейности сумма двух решений системы тоже будет решением системы. Это легко доказать. Если и — решения системы, то для их суммы верно
что означает, что она тоже — решение.
Поэтому если мы найдём все линейно независимые решения, то с их помощью можно получить вообще все решения системы. Для этого просто нужно найти их всевозможные суммы.
Выразим сперва все зависимые слагаемые. Их столько же, сколько и уравнений. Выражать надо так, чтобы справа были только независимые. Проще всего выразить .
Если бы нам не так повезло с системой, то нужно было бы складывая уравнения между собой получить такую систему, чтобы какие-то три переменные встречались по одному разу. Ну, или воспользоваться методом Гаусса. Для GF(2) он тоже работает.
Чтобы получить все линейно независимые решения, приравниваем каждую из зависимых переменных к единице по очереди.
Всевозможные суммы этих независимых решений (а именно они и будут кодовыми векторами) можно получить так:
где равны либо нулю или единице. Так как таких коэффициентов два, то всего возможно сочетания.
Но посмотрите! Формула, которую мы только что получили — это же снова умножение матрицы на вектор.
Строчки здесь — линейно независимые решения, которые мы получили. Матрица называется порождающей. Теперь вместо того, чтобы сами составлять таблицу кодирования, мы можем получать кодовые слова простым умножением на матрицу:
Найдём кодовые слова для этого кода. (Не забываем, что длина исходных сообщений должна быть равна 2 — это количество найденных решений.)
Итак, у нас есть готовый код, обнаруживающий ошибки. Проверим его в деле. Пусть мы хотим отправить 01 и у нас произошла ошибка при передаче. Обнаружит ли её код?
А раз в результате не нулевой вектор, значит код заподозрил неладное. Провести его не удалось. Ура, код работает!
Для кода с утроением, кстати, порождающая матрица выглядит очень просто:
Подобные коды, которые можно порождать и проверять матрицей называются линейными (бывают и нелинейные), и они очень широко применяются на практике. Реализовать их довольно легко, так как тут требуется только умножение на константную матрицу.
Ошибка по синдрому
Ну хорошо, мы построили код обнаруживающий ошибки. Но мы же хотим их исправлять!
Для начала введём такое понятие, как вектор ошибки. Это вектор, на который отличается принятое сообщение от кодового слова. Пусть мы получили сообщение , а было отправлено кодовое слово . Тогда вектор ошибки по определению
Но в странном мире GF(2), где сложение и вычитание одинаковы, будут верны и соотношения:
В силу особенностей сложения, как читатель сам может легко убедиться, в векторе ошибки на позициях, где произошла ошибка будет единица, а на остальных ноль.
Как мы уже говорили раньше, если мы получили сообщение с ошибкой, то . Но ведь векторов, не равных нулю много! Быть может то, какой именно ненулевой вектор мы получили, подскажет нам характер ошибки?
Назовём результат умножения на проверочную матрицу синдромом:
И заметим следующее
Это означает, что для ошибки синдром будет таким же, как и для полученного сообщения.
Разложим все возможные сообщения, которые мы можем получить из канала связи, по кучкам в зависимости от синдрома. Тогда из последнего соотношения следует, что в каждой кучке будут вектора с одной и той же ошибкой. Причём вектор этой ошибки тоже будет в кучке. Вот только как его узнать?
А очень просто! Помните, мы говорили, что у нескольких ошибок вероятность ниже, чем у одной ошибки? Руководствуясь этим соображением, наиболее правдоподобным будет считать вектором ошибки тот вектор, у которого меньше всего единиц. Будем называть его лидером.
Давайте посмотрим, какие синдромы дают всевозможные 5-элементные векторы. Сразу сгруппируем их и подчеркнём лидеров — векторы с наименьшим числом единиц.
В принципе, для корректирования ошибки достаточно было бы хранить таблицу соответствия синдрома лидеру.
Обратите внимание, что в некоторых строчках два лидера. Это значит для для данного синдрома два паттерна ошибки равновероятны. Иными словами, код обнаружил две ошибки, но исправить их не может.
Лидеры для всех возможных одиночных ошибок находятся в отдельных строках, а значит код может исправить любую одиночную ошибку. Ну, что же… Попробуем в этом убедиться.
Вектор ошибки равен , а значит ошибка в третьем разряде. Как мы и загадали.
Ура, всё работает!
Что же дальше?
Чтобы попрактиковаться, попробуйте повторить рассуждения для разных проверочных матриц. Например, для кода с утроением.
Логическим продолжением изложенного был бы рассказ о циклических кодах — чрезвычайно интересном подклассе линейных кодов, обладающим замечательными свойствами. Но тогда, боюсь, статья уж очень бы разрослась.
Если вас заинтересовали подробности, то можете почитать замечательную книжку Аршинова и Садовского «Коды и математика». Там изложено гораздо больше, чем представлено в этой статье. Если интересует математика кодирования — то поищите «Теория и практика кодов, контролирующих ошибки» Блейхута. А вообще, материалов по этой теме довольно много.
Надеюсь, когда снова будет свободное время, напишу продолжение, в котором расскажу про циклические коды и покажу пример программы для кодирования и декодирования. Если, конечно, почтенной публике это интересно.
http://studref.com/365851/tehnika/dekodirovanie_lineynyh_kodov
http://habr.com/ru/post/328202/
Понятие синдрома
Обнаружение и
исправление ошибок кодом Хэмминга
сводится к определению и последующему
анализу синдрома.
Синдромом называется
совокупность элементов, которые
получены суммированием по модулю 2
принятых проверочных элементов и
проверочных элементов, вычисленных по
принятым информационным элементам.
Вычисление производится по тому же
правилу, которое применяется для их
определения на передающей стороне.
Для определения
проверочных элементов b1,
b2,…,
br
на передающей
стороне пользуются операторами R1,
…, Rr,
bi=Ri{aj},
где аj
— множество информационных элементов
данной кодовой комбинации. На приемной
стороне по принятой совокупности
информационных элементов {
аj
*} вычисляются
с помощью тех же операторов Ri
(они должны быть обязательно известны
и на приемной стороне) новые проверочные
элементы b‘i=
Ri{aj*}
(знак *
означает принятые элементы кодовой
комбинации, которые из-за ошибок в канале
могут отличаться от переданных). Далее
принятые проверочные элементы (т.е.
имеющиеся в принятой кодовой комбинации)
b1*,
b2*,…,
br*
складываются по модулю 2 с вычисленными
проверочными элементами b‘1,
b‘2,
…, b‘r:
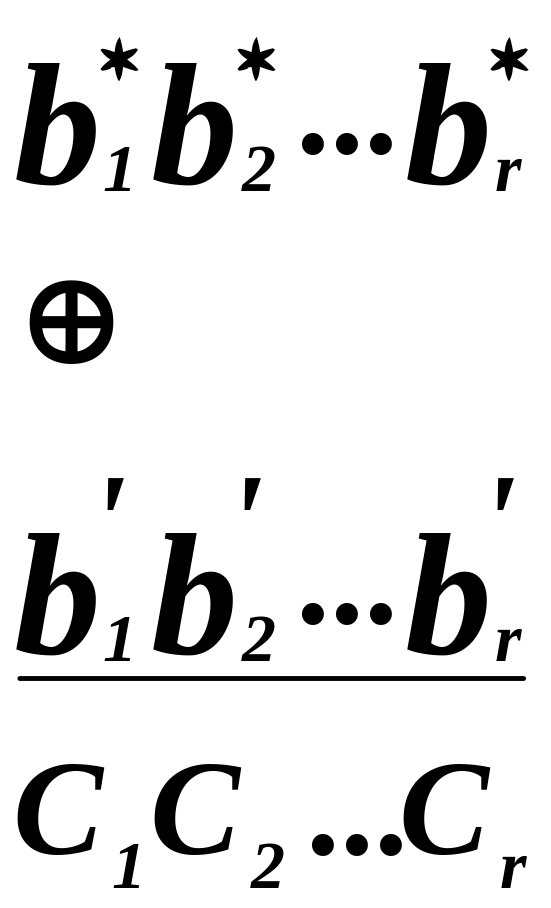
В результате
сложения получается некоторая кодовая
комбинация, которую называют синдромом
или вектором ошибки.
Допустим, что все
информационные элементы кодовой
комбинации приняты верно, тогда {аj}
= {аj*}
и, значит, {bi*}
= {bi},
т. е. проверочные элементы, вычисленные
по {аj*},
такие же, как на передающей стороне.
Если при приеме проверочных элементов
также не произошло ошибок, то
![]()
В этом случае все
разряды синдрома будут представлены
нулями:
С1С2…Сr![]()
00…0.
Если где-то произошла
ошибка, то в составе синдрома появятся
единицы. Это и есть способ обнаружения
ошибок кодом Хэмминга. Поскольку код
Хэмминга имеет минимальное кодовое
расстояние do=3,
то это означает, что код может исправлять
одну ошибку, т. е. указать номер позиции
в кодовой комбинации, где произошла
ошибка (что для двоичных кодов достаточно,
т.к. в этом случае кодовый элемент на
указанной позиции просто меняется на
противоположный). В одном из вариантов
кода Хэмминга между видом синдрома и
номером ошибочного разряда имеется
однозначное соответствие: двоичное
число синдрома представляет собой
условный номер (в десятичной системе)
того разряда в кодовой комбинации, где
произошла ошибка.
Построение кода Хэмминга
Рассмотрим пример
построения кода Хэмминга, в котором
между видом синдрома и номером ошибочного
разряда имеется однозначное соответствие:
двоичное число синдрома представляет
собой условный номер (в десятичной
системе) того разряда в кодовой
комбинации, где произошла ошибка.
Для этого, сопоставляя
двоичное число, которое представляет
синдром, с номером позиции элементов
множеств {аj}
и {bi},
в которых произошла ошибка (учитываем,
что ошибка может произойти и в
информационном, и в проверочном разрядах),
найдем вид операторов {Ri}.
Предположим, что
требуется сформировать код при условии,
что кодовая комбинация содержит 5
информационных символов (k=5)
и код должен исправлять однократную
ошибку, т.е. ошибку в одном разряде
(tИ=1).
Определим требуемое расстояние Хэмминга
и число проверочных разрядов:
![]()
Будем считать, что
d0=3.
Найдем число проверочных разрядов:
![]()
Получили, что для
обеспечения требуемого расстояния
Хэмминга d0=3
кодовая комбинация должна содержать 4
проверочных элемента (элементы b1b2b3b4),
т.е. код вида (9,5).
Появление единицы
в синдроме происходит следующим
образом:
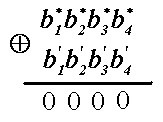
Если синдром имеет
такой вид, то кодовая комбинация не
имеет ошибки ни в одном разряде. Если
синдром имеет вид 0001, то будем считать,
что произошла ошибка в первом разряде
в проверочном элементе b4′.
Синдром вида 0010 свяжем с ошибкой во
втором разряде в проверочном элементе
b3′.
Синдром вида 0100 свяжем с ошибкой в
четвертом разряде в проверочном элементе
b2′
(т.к. в
десятичном коде 0100 соответствует числу
4). Синдром
вида 1000 свяжем с ошибкой в восьмом
разряде в проверочном элементе b1′
(т.к. в десятичном коде 1000 соответствует
числу  .
.
Т.о. одна единица в синдроме соответствует
ошибке в одном из проверочных элементов,
а проверочные элементы будут располагаться
в 1, 2, 4 и 8 разрядах кодовой комбинации.
Появление большего
числа единиц в синдроме будет связано
с ошибками в информационных элементах
{аj}.
Информационные элементы кодовой
комбинации будут располагаться в 3, 5,
6, 7, 9 разрядах.
Запишем вид
синдрома, соответствующий ошибке в
каждом разряде кодовой комбинации в
виде таблицы:
|
Число, соответствующее коде |
Элементы синдрома |
Элементы кодовой комбинации с ошибками |
|||
|
С1 |
С2 |
С3 |
С4 |
||
|
1 |
0 |
0 |
0 |
1 |
b4 |
|
2 |
0 |
0 |
1 |
0 |
b3 |
|
3 |
0 |
0 |
1 |
1 |
a1 |
|
4 |
0 |
1 |
0 |
0 |
b2 |
|
5 |
0 |
1 |
0 |
1 |
a2 |
|
6 |
0 |
1 |
1 |
0 |
a3 |
|
7 |
0 |
1 |
1 |
1 |
a4 |
|
8 |
1 |
0 |
0 |
0 |
b1 |
|
9 |
1 |
0 |
0 |
1 |
a5 |
|
10 |
1 |
0 |
1 |
0 |
a6 |
|
11 |
1 |
0 |
1 |
1 |
a7 |
|
12 |
1 |
1 |
0 |
0 |
a8 |
|
13 |
1 |
1 |
0 |
1 |
a9 |
|
14 |
1 |
1 |
1 |
0 |
a10 |
|
15 |
1 |
1 |
1 |
1 |
a11 |
Т.о. всем элементам
кодовой комбинации поставлено в
соответствие значение синдрома, которое
при переводе в десятичный код, соответствует
номеру разряда этого элемента. Таблица
составлена до 15 разряда, т.к. именно это
число позволяет записать двоичная
комбинация из 4-х элементов. Т.к. в примере
кодовая комбинация состоит из 9 элементов
будем пользоваться первыми девятью
строками таблицы.
Теперь определим
{Ri}
— операторы формирования проверочных
элементов по информационным элементам.
При этом учтем, что единственное линейное
преобразование, которое можно совершать
над информационными элементами, — это
суммирование (в данном случае суммирование
по модулю 2).
Построим
алгоритм
оператора R1
так, чтобы он включал в себя информационные
элементы, ошибка в которых приводила
бы к появлению единицы «1» в младшем
разряде синдрома (С4).
Наличие «1» в младшем разряде С4
соответствует
проверочному элементу b4.
Кроме того, эта «1» есть в синдромах с
номерами 3, 5, 7, 9, 11, 13, 15, что соответствует
информационным элементам а1,
а2,
a4,
a5,
a7,
а9,
a11.
Таким образом,
![]()
Для девятиразрядной
кодовой комбинации
![]()
Если в одном из
этих элементов произойдет ошибка, то
это неизбежно приведет к изменению
b4.
Для формирования
проверочного элемента b3,
в синдроме которого единица стоит
на второй позиции (второй разряд),
отбираем информационные элементы,
имеющие «1» во втором разряде своих
синдромов, т. е. a1,
а3,
а4,
а6,
а7,
а10,
а11:
![]()
Для девятиразрядной
кодовой комбинации
![]()
Для формирования
проверочного элемента b2,
в синдроме которого единица стоит
на третьей позиции (третий разряд),
отбираем информационные элементы,
имеющие «1» в третьем разряде своих
синдромов, т. е. a2,
а3,
а4,
а8,
а9,
а10,
а11:
![]()
Для девятиразрядной
кодовой комбинации
![]()
Для формирования
проверочного элемента b1,
в синдроме которого единица стоит
на четвертой позиции (четвертый разряд),
отбираем информационные элементы,
имеющие «1» в четвертом разряде своих
синдромов, т. е. a5,
а6,
а7,
а8,
а9,
а10,
а11:
![]()
Для девятиразрядной
кодовой комбинации
![]()
Пример
Имеется комбинация
информационных элементов 11001. Для кода
Хэмминга построить разрешенную комбинацию
кода (9,5) и показать, что данный код
исправляет однократную ошибку.
Воспользуемся
проверочной матрицей приведенной выше.
Имеем:
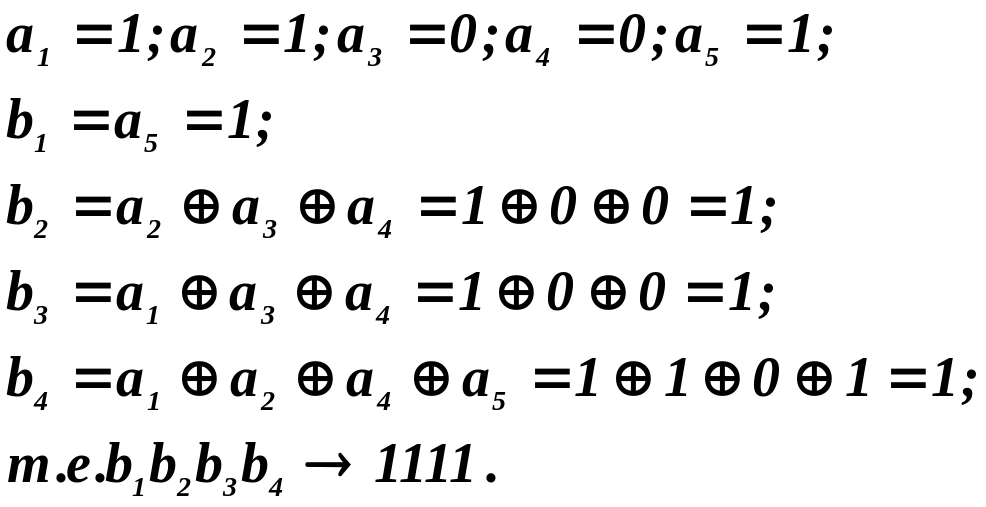
Разрешенная
комбинация имеет вид 11001 1111.
Пусть произошла
ошибка в элементе а3,
т. е. приняли комбинацию 11101 1111. Проверим,
исправляется ли ошибка. Для этого
вычислим по информационной части
принятой кодовой комбинации новые
проверочные разряды:
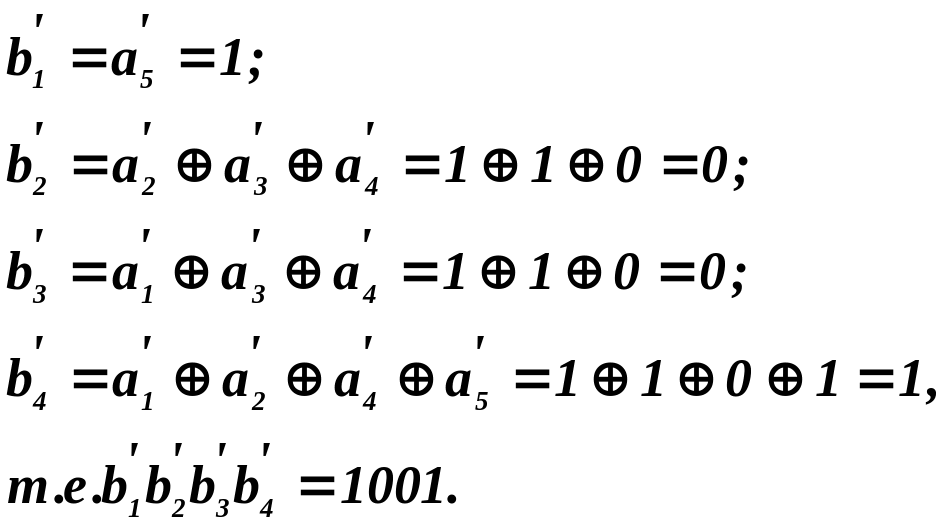
Найдем синдром
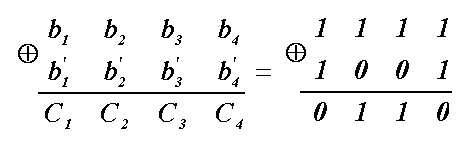
0110
– в десятичной системе есть число 6. На
6-м условном номере согласно таблице
стоит информационный элемент а3.
Следовательно, значение принятого
элемента а’3
нужно исправить: вместо «1» поставить
«0». В результате кодовая комбинация
принята правильно: 11001.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
A syndrome is a set of medical signs and symptoms which are correlated with each other and often associated with a particular disease or disorder.[1] The word derives from the Greek σύνδρομον, meaning «concurrence».[2]: 1818 When a syndrome is paired with a definite cause this becomes a disease.[3] In some instances, a syndrome is so closely linked with a pathogenesis or cause that the words syndrome, disease, and disorder end up being used interchangeably for them. This substitution of terminology often confuses the reality and meaning of medical diagnoses.[3] This is especially true of inherited syndromes. About one third of all phenotypes that are listed in OMIM are described as dysmorphic, which usually refers to the facial gestalt. For example, Down syndrome, Wolf–Hirschhorn syndrome, and Andersen–Tawil syndrome are disorders with known pathogeneses, so each is more than just a set of signs and symptoms, despite the syndrome nomenclature. In other instances, a syndrome is not specific to only one disease. For example, toxic shock syndrome can be caused by various toxins; another medical syndrome named as premoter syndrome can be caused by various brain lesions; and premenstrual syndrome is not a disease but simply a set of symptoms.
If an underlying genetic cause is suspected but not known, a condition may be referred to as a genetic association (often just «association» in context). By definition, an association indicates that the collection of signs and symptoms occurs in combination more frequently than would be likely by chance alone.[2]: 167
Syndromes are often named after the physician or group of physicians that discovered them or initially described the full clinical picture. Such eponymous syndrome names are examples of medical eponyms. Recently, there has been a shift towards naming conditions descriptively (by symptoms or underlying cause) rather than eponymously, but the eponymous syndrome names often persist in common usage.
The defining of syndromes has sometimes been termed syndromology, but it is usually not a separate discipline from nosology and differential diagnosis generally, which inherently involve pattern recognition (both sentient and automated) and differentiation among overlapping sets of signs and symptoms. Teratology (dysmorphology) by its nature involves the defining of congenital syndromes that may include birth defects (pathoanatomy), dysmetabolism (pathophysiology), and neurodevelopmental disorders.
Subsyndromal[edit]
When there are a number of symptoms suggesting a particular disease or condition but does not meet the defined criteria used to make a diagnosis of that disease or condition. This can be a bit subjective because it is ultimately up to the clinician to make the diagnosis. This could be because it has not advanced to the level or passed a threshold or just similar symptoms cause by other issues. Subclinical is synonymous since one of its definitions is «where some criteria are met but not enough to achieve clinical status»;[4] but subclinical is not always interchangeable since it can also mean «not detectable or producing effects that are not detectable by the usual clinical tests»;[5] i.e., asymptomatic.
Usage[edit]
General medicine[edit]
In medicine, a broad definition of syndrome is used, which describes a collection of symptoms and findings without necessarily tying them to a single identifiable pathogenesis. Examples of infectious syndromes include encephalitis and hepatitis, which can both have several different infectious causes.[6] The more specific definition employed in medical genetics describes a subset of all medical syndromes.[citation needed]
Psychiatry and psychopathology[edit]
Psychiatric syndromes often called psychopathological syndromes (psychopathology refers both to psychic dysfunctions occurring in mental disorders, and the study of the origin, diagnosis, development, and treatment of mental disorders).[citation needed]
In Russia those psychopathological syndromes are used in modern clinical practice and described in psychiatric literature in the details: asthenic syndrome, obsessive syndrome, emotional syndromes (for example, manic syndrome, depressive syndrome), Cotard’s syndrome, catatonic syndrome, hebephrenic syndrome, delusional and hallucinatory syndromes (for example, paranoid syndrome, paranoid-hallucinatory syndrome, Kandinsky-Clérambault’s syndrome also known as syndrome of psychic automatism, hallucinosis), paraphrenic syndrome, psychopathic syndromes (includes all personality disorders), clouding of consciousness syndromes (for example, twilight clouding of consciousness, amential syndrome also known as amentia, delirious syndrome, stunned consciousness syndrome, oneiroid syndrome), hysteric syndrome, neurotic syndrome, Korsakoff’s syndrome, hypochondriacal syndrome, paranoiac syndrome, senestopathic syndrome, encephalopathic syndrome.[7][8]
Some examples of psychopathological syndromes used in modern Germany are psychoorganic syndrome, depressive syndrome, paranoid-hallucinatory syndrome, obsessive-compulsive syndrome, autonomic syndrome, hostility syndrome, manic syndrome, apathy syndrome.[9]
Münchausen syndrome, Ganser syndrome, neuroleptic-induced deficit syndrome, olfactory reference syndrome are also well-known.[citation needed]
History[edit]
The most important psychopathological syndromes were classified into three groups ranked in order of severity by German psychiatrist Emil Kraepelin (1856—1926). The first group, which includes the mild disorders, consists of five syndromes: emotional, paranoid, hysterical, delirious, and impulsive.[10] The second, intermediate, group includes two syndromes: schizophrenic syndrome and speech-hallucinatory syndrome.[10] The third includes the most severe disorders, and consists of three syndromes: epileptic, oligophrenic and dementia.[10] In Kraepelin’s era, epilepsy was viewed as a mental illness; Karl Jaspers also considered «genuine epilepsy» a «psychosis», and described «the three major psychoses» as schizophrenia, epilepsy, and manic-depressive illness.[11]
Medical genetics[edit]
In the field of medical genetics, the term «syndrome» is traditionally only used when the underlying genetic cause is known. Thus, trisomy 21 is commonly known as Down syndrome.[citation needed]
Until 2005, CHARGE syndrome was most frequently referred to as «CHARGE association». When the major causative gene (CHD7) for the condition was discovered, the name was changed.[12] The consensus underlying cause of VACTERL association has not been determined, and thus it is not commonly referred to as a «syndrome».[13]
Other fields[edit]
In biology, «syndrome» is used in a more general sense to describe characteristic sets of features in various contexts. Examples include behavioral syndromes, as well as pollination syndromes and seed dispersal syndromes.[citation needed]
In orbital mechanics and astronomy, Kessler syndrome refers to the effect where the density of objects in low Earth orbit (LEO) is high enough that collisions between objects could cause a cascade in which each collision generates space debris that increases the likelihood of further collisions.
In quantum error correction theory syndromes correspond to errors in code words which are determined with syndrome measurements, which only collapse the state on an error state, so that the error can be corrected without affecting the quantum information stored in the code words.
Naming[edit]
There is no set common convention for the naming of newly identified syndromes. In the past, syndromes were often named after the physician or scientist who identified and described the condition in an initial publication. These are referred to as «eponymous syndromes». In some cases, diseases are named after the patient who initially presents with symptoms,[14] or their home town (Stockholm syndrome). There have been isolated cases of patients being eager to have their syndromes named after them, while their physicians are hesitant.[15] When a syndrome is named after a person, there is some difference of opinion as to whether it should take the possessive form or not (e.g. Down syndrome vs. Down’s syndrome). North American usage has tended to favor the non-possessive form, while European references often use the possessive.[16] A 2009 study demonstrated a trend away from the possessive form in Europe in medical literature from 1970 through 2008.[16]
History[edit]
Avicenna, in The Canon of Medicine (published 1025), pioneered the idea of a syndrome in the diagnosis of specific diseases.[17] The concept of a medical syndrome was further developed in the 17th century by Thomas Sydenham.[18]
Underlying cause[edit]
Even in syndromes with no known etiology, the presence of the associated symptoms with a statistically improbable correlation normally leads the researchers to hypothesize that there exists an unknown underlying cause for all the described symptoms.[citation needed]
See also[edit]
- List of syndromes
- Toxidrome
- Symptom
- Sequence (medicine)
References[edit]
- ^ The British Medical Association Illustrated Medical Dictionary. London: Dorling Kindersley. 2002. pp. 177, 536. ISBN 9780751333831. OCLC 51643555.
- ^ a b Dorland’s Illustrated Medical Dictionary (32nd ed.). Philadelphia, PA: Saunders/Elsevier. 2012. ISBN 9781416062578. OCLC 706780870.
- ^ a b Calvo, F; Karras, BT; Phillips, R; Kimball, AM; Wolf, F (2003). «Diagnoses, Syndromes, and Diseases: A Knowledge Representation Problem». AMIA Annu Symp Proc. 2003: 802. PMC 1480257. PMID 14728307.
- ^ «subclinical — Wiktionary». en.wiktionary.org. Retrieved 2021-01-29.
- ^ «Definition of Subclinical». www.merriam-webster.com. Retrieved 2021-01-29.
- ^ Slack, R. C. B. (2012). «Infective syndromes». In Greenwood, D.; Barer, M.; Slack, R.; Irving, W. (eds.). Medical Microbiology (18th ed.). Churchill Livingstone. pp. 678–688. ISBN 978-0-7020-4089-4.
- ^ Дмитриева, Т. Б.; Краснов, В. Н.; Незнанов, Н. Г.; Семке, В. Я.; Тиганов, А. С. (2011). Психиатрия: Национальное руководство [Psychiatry: The National Manual] (in Russian). Moscow: ГЭОТАР-Медиа. pp. 306–330. ISBN 978-5-9704-2030-0.
- ^ Сметанников, П. Г. (1995). Психиатрия: Краткое руководство для врачей [Psychiatry: A Brief Guide for Physicians] (in Russian). Saint Petersburg: СПбМАПО. pp. 86–119. ISBN 5-85077-025-9.
- ^ P. Pichot (2013). Clinical Psychopathology Nomenclature and Classification. Springer. p. 157. ISBN 978-1-4899-5049-9.
- ^ a b c Cole, S. J. (1922). «The Forms in which Insanity Expresses Itself [Die Erscheinungsformen des Irreseins]. (Arb. für Psychiat., München, Bd. ii, 1921.) Kraepelin, Emil». The British Journal of Psychiatry. Royal College of Psychiatrists. 68 (282): 296. doi:10.1192/bjp.68.282.295. ISSN 0007-1250.
- ^ Ghaemi S. N. (2009). «Nosologomania: DSM & Karl Jaspers’ critique of Kraepelin». Philosophy, Ethics, and Humanities in Medicine. 4: 10. doi:10.1186/1747-5341-4-10. PMC 2724409. PMID 19627606.
- ^ «#214800 — CHARGE Syndrome». Johns Hopkins University. Retrieved 2014-02-15.
- ^ «#192350 — VATER Association». Johns Hopkins University. Retrieved 2014-02-15.
- ^ McCusick, Victor (1986). Mendelian Inheritance in Man (7th ed.). Baltimore: Johns Hopkins University Press. pp. xxiii–xxv.
- ^ Teebi, A. S. (2004). «Naming of a syndrome: The story of «Adam Wright» syndrome». American Journal of Medical Genetics. 125A (3): 329–30. doi:10.1002/ajmg.a.20460. PMID 14994249. S2CID 8439955.
- ^ a b Jana, N; Barik, S; Arora, N (2009). «Current use of medical eponyms—a need for global uniformity in scientific publications». BMC Medical Research Methodology. 9: 18. doi:10.1186/1471-2288-9-18. PMC 2667526. PMID 19272131.
- ^ Lenn Evan Goodman (2003), Islamic Humanism, p. 155, Oxford University Press, ISBN 0-19-513580-6.
- ^ Natelson, Benjamin H. (1998). Facing and fighting fatigue: a practical approach. New Haven, Conn: Yale University Press. pp. 30. ISBN 0-300-07401-8.
External links[edit]
![]()
Look up syndrome in Wiktionary, the free dictionary.
- Whonamedit.com — a repository of medical eponyms
Дислексия
Вы в курсе, что объединяет таких разных людей, как Уолт Дисней, Альберт Эйнштейн, Мэрилин Монро и Уинстон Черчилль? Значит, вам знаком диагноз дислексия – частичное специфическое расстройство навыков чтения. Если доверять биографам, все эти знаменитости испытывали очень серьезные сложности с чтением, то есть были дислексиками. К слову, биографии перечисленных личностей подтверждают, что можно прожить яркую жизнь, несмотря на обидный детский ярлык «не такого как все». В этой статье разберемся, как дислексики воспринимают текст и можно ли корректировать неспособность к чтению.

Общие сведения
Дислексия обусловлена недоразвитием или выпадением психических функций, реализующих процесс чтения. Согласно официальной статистике расстройство встречается у примерно 5% детей с нормальным уровнем интеллекта. На каждую девочку с дислексией приходится 4 мальчика-дислексика. Расстройство может выглядеть как синдром, когда нарушение чтения сопровождается частичным расстройством письма (дисграфией), или проявляться самостоятельно.
Причины дислексии
Человек с дислексией не способен корректно распознавать буквы. Речь дислексика несвязна, неправильно оформлена с грамматической точки зрения, отличается скудостью словарного запаса. Расстройство может быть обусловлено биологическими и социальными причинами.
Биологические факторы
Большинство специалистов склоняются к тому, что в большинстве случаев дислексия развивается под влиянием патологий биологического характера в пренатальном периоде:
- поражение ЦНС вследствие внутриутробной интоксикации или иммунного конфликта;
- гипоксия мозга плода в утробе матери, патологии развития пуповины, родовая асфиксия;
- инфекционное поражение мозга;
- травматизация во время сложных родов.
Получите консультацию прямо сейчас!
Позвонив сейчас, даже если у вас не стоит остро вопрос об оказании психиатрической помощи или лечения — вы однозначно получите развернутую консультацию.
Социальные факторы
Социальные факторы легче поддаются коррекции, что отличает их от биологических.
К ним относятся:
- недостаток общения у ребенка;
- погрешности в обучении и воспитании (педагогическая запущенность);
- двуязычие (дети-билингвы могут путать символы из разных языков);
- слишком ранее начало обучения;
- дефицит социально-эмоциональных контактов, отдаление от матери (синдром госпитализма).
Люди, подвергавшиеся жесткой критике из-за их особенности в детстве, впоследствии страдают от низкой самооценки и нуждаются в психологической помощи.
Влияние дислексии
Орфография
Образование
Чтение
Здоровье
Жизнь
Карьера
Самооценка
Математика
Патогенез
Чтение – это психофизиологический процесс, при котором одновременно задействуется несколько систем-анализаторов: зрительная, речезвуковая, речедвигательная. Сбои в работе систем нарушают единство процесса. Если с точки зрения психолингвистики механизм дислексии следует рассматривать как частичную задержку развития психических функций, то с когнитивной – это нарушение одного или нескольких познавательных процессов (внимания, восприятия, памяти, осмысливания). И одно, и другое приводит к трудностям с чтением и обучаемостью.
Наши преимущества

Высокая квалификация специалистов
Более 200 сертифицированных профессионалов со стажем от 10 лет

Круглосуточный выезд на дом
Звоните в любое время и наши специалисты помогут вам

Полная анонимность
Гарантируем полную конфиденциальность, пациентов не ставят на диспансерный учет

Программа «Двойной диагноз»
Комплексное лечение зависимости и психического расстройства

VIP отделение
Повышенный уровень комфорта и полное уединение
Классификация
Специалисты выделяют шесть форм дислексии – в соответствии с механизмом, который нарушен. Каждая из форм требует особого внимания специалистов и семьи.
оптическая
зеркальное чтение, перескакивание на соседнюю строку, сложности с различием похожих символов («о» и «е», «b»и «d»);
фонематическая
самая распространенная проблема (искажение структуры слов, перестановка слогов);
аграмматическая
ошибки в построении речевых отрезков («пойдем дом», «белый птица»);
семантическая
беглое чтение на фоне абсолютного непонимания смысла;
мнестическая
трудности распознавания букв во время артикуляции (отсутствие понимания связки между звуками и буквами);
тактильная
типична для слабовидящих (сложности с пространственным распознаванием).

Симптомы дислексии
Расстройство выявляется в возрасте 6-10 лет. У дислексиков не получается сопоставлять звуки и буквы, поэтому показатели техники чтения у них намного хуже, чем у сверстников. Параллельно могут наблюдаться грубые ошибки письма.
Дислексия негативно влияет на процесс формирования личности. Неудачи в школе на уроках чтения могут способствовать развитию мнительности, тревожности, проявлению других аффективных реакций.
Фонематическая дислексия
Фонематическая форма дислексии вызвана недоразвитием процессов восприятия, связанных с анализом и объединением составных частей слов в единое целое. Симптомы проявляются в виде замены и смешивания звуков, близких по акустическим или артикуляционным признакам («том» — «дом», «ток» — «кот»), а также с искажением структуры языковых единиц.
Семантическая дислексия
Семантическую форму дислексии (так называемое механическое чтение)следует воспринимать как затрудненное понимание синтаксических связей. Также это результат бедности словарного запаса. Пациент понимает слова только в отрыве от текста, поэтому не может зафиксировать смысл прочитанного.
Аграмматическая дислексия
В аграмматической форме дислексии симптоматика связана с погрешностями в построении речевых конструкций. Во время чтения пациент неправильно применяет падежи, окончания, может путать времена. Аграмматическая дислексия предполагает допущение аналогичных проявлений и в устной речи.
Мнестическая дислексия
Симптомы при мнестической форме дислексии обусловлены неспособностью связывать визуальную форму символа с ее акустическим эквивалентом. Пациенту сложно соотнести звук и обозначающий его печатный (рукописный) знак. Попросту говоря, он не запоминает букв.
Оптическая дислексия
Оптическая форма дислексии выражается как чтение задом наперед, предполагает сложности с фокусированием взгляда на нужной строке. Оптическую дислексию объясняют недостаточной сформированностью зрительно-пространственных представлений.
Тактильная дислексия
Тактильная форма дислексия присуща людям с тяжелыми пороками зрения и проявляется в виде смешения тактильно сходных символов при чтении по Брайлю. Пациент может путать буквы, соскальзывать со строки, пропускать речевые единицы, искажая смысл прочитанного.
Диагностика
Дислексия может быть диагностирована только при определенных условиях:
- отсутствие диагностированной умственной отсталости;
- отсутствие патологий слуха и зрения;
- отсутствие расстройств психики, напрямую влияющих на способность читать;
- не ранее, чем через 2 года от начала активного обучения;
- ребенку подходит выбранный метод обучения чтению, стимулирует его учиться;
- сложности возникают только в ходе выполнения заданий, связанных с чтением.
Чтобы обследовать ребенка, можно прийти к логопеду, нейропсихологу, детскому неврологу. Специалисты клиники Исаева консультируют по проблемам дислексии и дискалькулии, общего недоразвития речи, нарушений темпа психического развития, дефицита внимания. Обследование охватывает сбор анамнеза, оценку состояния артикуляционного аппарата, проверку моторики. С помощью специальных тестов врач проводит диагностику устной и письменной речи, а также нейропсихологическую диагностику.
Взрослому человеку официальный диагноз дислексия впервые должен поставить врач-психиатр. Запишитесь на прием к платному психиатру клиники доктора Исаева.

Коррекция и лечение дислексии в клинике Исаева
Если обнаружить признаки дислексии в дошкольном возрасте, это дает возможность оперативно и эффективно корректировать проблему. Чтобы приступить к коррекции, необходимо исключить другие расстройства, которые могут коррелироваться с нарушениями речевых процессов. Для лечения расстройства необходима помощь дефектолога, клинического психолога, нейропсихолога.
В клинике неврозов доктора Исаева к преодолению проблемы подходят комплексно, с применением современных методик и с учетом оценки всего спектра нарушений речи и психики у пациента. Не следует упускать из виду, что спутниками дислексии и дисграфии могут быть сидром дефицита внимания, гиперактивность, стрессы, несформированность высших психических функций. В клинике работают квалифицированные врачи, которые успешно лечат сложные когнитивные расстройства. Чтобы обратиться к компетентному специалисту, позвоните по номеру +7 (495) 463-09-45.
Варианты лечения
- Консультация специалиста
от 4000 ₽ за прием - Стационарное лечение
от 6000 ₽ за сутки - Реабилитация
от 2900 ₽ за сутки
- у нас организована круглосуточная «горячая линия», обратившись на которую, вам ответят на вопросы, связанные с лечением ваших заболеваний, организуют прием у доктора;
- у нас организован круглосуточный прием доктора психиатра, что позволяет оказать неотложную помощь в любое время;
- консультация доктора психиатра – это комплексная первичная помощь пациенту, она длится до 2-х часов и призвана не только ответить на ваши вопросы, но и поставить или уточнить диагноз, назначить лечение и указать вектор ваших дальнейших действий;
- на данном этапе вы получаете достаточно четкий план и прогноз по вашему заболеванию.
Вам необходимо сделать этот первый шаг, если вы начали чувствовать дискомфорт или наблюдаете изменения у ваших близких людей!
от 4000 ₽
- это самая эффективная помощь при любых видах психиатрических проблем;
- для некоторых диагнозов данный вид лечения безальтернативен ввиду тяжести ситуации и серьезности оказываемой терапии;
- мы организовали стационарное лечение в клинике исходя из принципов «фокусировки на интересах пациента»;
- мы предоставляем круглосуточный мониторинг основных показателей, надзор за состоянием пациента;
- мы предоставляем комфортные палаты с четырехразовым питанием;
- мы предоставляем нашу клиническую базу высококвалифицированных докторов-практиков, методик и лучших препаратов;
- мы сделали стоимость приемлемой, удобной и демократичной.
Одна неделя стационара может заменить до трех-четырех месяцев «домашнего лечения»! Приблизьте себя к результату!
от 6000 ₽
- в реабилитации мы применяем индивидуальный подход к каждому пациенту и составляем персонализированный план реабилитации;
- реабилитация в наших центрах базируется на концепции терапевтического сообщества;
- с реабилитантами работают квалифицированные специалисты в области наркологии и психиатрии, которые ежедневно проводят лекции и занимаются их психообразованием;
- мы помогаем сформировать устойчивые здоровые привычки и наработать навыки для успешной адаптации в обществе;
- в стоимость включено трехразовое питание и все для комфортной жизни. Есть возможность одноместного размещения;
- мы предоставляем дополнительные услуги, которые могут помочь в реабилитации: йога, спортивный зал, бассейн, массаж и т.д.;
- мы создаем благоприятную и дружественную реабилитационную атмосферу, где вы получите поддержку и понимание.
Чем раньше вы обратитесь к специалистам и начнете реабилитацию, тем быстрее и качественнее вы придете к видимым положительным результатам и начнёте жить здоровую счастливую жизнь!
от 2900 ₽
Часто задаваемые вопросы
Почему реабилитация необходима пациентам с двойным диагнозом?
Современная клиническая психология делает акцент на необходимости реабилитации пациентов с психическими расстройствами и психологическими проблемами. В основе некоторых заболеваний лежит нарушение психофизиологических процессов, поэтому лечение без реабилитации не принесет стойкого ожидаемого результата. В нашем центре успешно применяются современные программы медикосоциальной реабилитации для самых разных групп пациентов.
Дислексия проходит с годами?
Без коррекции и грамотного лечения проблема не проходит с возрастом. Детская дислексия – это всегда неуверенность в себе, социальная тревожность, депрессия вплоть до мыслей о суициде во взрослом возрасте. Помогут только направленная коррекция расстройства при условии психологической поддержки, а также работа с семейной системой. Обратитесь за помощью в клинику Исаева.
Можно ведь просто взять справку для школы и жить спокойно. Не зря же говорят, что дислексия – это болезнь гениев?
Действительно, есть исследования на тему того, что дети-дислексики обладают незаурядным умственным потенциалом. Но рассчитывать на спокойную жизнь ребенка-школьника со справкой не стоит. Под негативным давлением реальных обстоятельств ребенок может быстро утратить врожденную способность к освоению мира. Заботливые и ответственные родители обязательно воспользуются профессиональной помощью, чтобы вырастить из дислексика в первую очередь счастливого, а возможно и гениального человека.
Получите консультацию прямо сейчас!
Позвонив сейчас, даже если у вас не стоит остро вопрос об оказании психиатрической помощи или лечения — вы однозначно получите развернутую консультацию.
Статьи по теме

Дискалькулия
Ваш ребенок никак не может «подружиться» с цифрами, учителя считают его ленивым, а одноклассники дразнят? Не спешите делать поспешных выводов об умственных способностях малыша, опускать руки и тем более наказывать…
Подробнее

Расстройства речи
В отдельную категорию психических нарушений выделяют расстройства речи. Они представляют собой не только проблемы с вербальной коммуникацией у пациента, но и патологии в речевой моторике и других смежных областях…
Подробнее

Синдром дефицита внимания и гиперактивности
Подробнее

Умственная отсталость
Олигофрения или умственная отсталость – отклонение врожденного или приобретенного типа. Характеризуется нарушением интеллектуальной сферы, неполноценным развитием психических функций. Одной из особенностей…
Подробнее
Дислексия – это расстройство, связанное с навыками чтения. Из-за проблем с определенными психическими функциями, которые должны участвовать в формировании таких навыков, ребенок может испытывать самые разные сложности при работе с текстом. Чаще всего сложно распознавать отдельные символы, знаки – в результате смысл слов, словосочетаний или предложений не улавливается либо искажается.
Проявляется проблема с детства и при должной коррекции может нивелироваться до уровня, который позволяет комфортно жить и эффективно обучаться. Но если не уделить ей внимания в раннем возрасте, она остается и во взрослом, доставляя немало неудобств. Одновременно с этим важно понимать, что дислексия не определяет сама по себе развитие ребенка – он может эффективно воспринимать информацию благодаря другим каналам, например, хорошо понимать на слух.
Почему возникает дислексия – причины заболевания
В основном причины дислексии имеют нейробиологический характер. Это важно для понимания, потому что нередко от незнания родители и учителя списывают сложности с чтением на «лень» или «невнимательность» ребенка, только запуская ситуацию. Но при таком отклонении определенные зоны мозга отличаются меньшей активностью, а также имеют пониженную плотность.
Дополнительными причинами дислексии (провоцирующими факторами) становятся:
- нарушения, которые влияют на равновесие между двумя полушариями мозга;
- серьезные, тяжелые инфекции, влияющие на мозг – самым распространенными примером является менингит;
- черепно-мозговые травмы;
- осложнения при родах и беременности: от инфекций до асфиксии плода. При беременности ухудшают ситуацию и вредные привычки матери: курение, употребление спиртного, а также наркотических средств.
Серьезное влияние имеют на это отклонение и факторы социального характера. Причем они могут быть абсолютно противоположными по своей направленности. Так, симптомы дислексии могут проявиться и от слишком большой учебной нагрузки, и от запущенности – полного игнорирования развития ребенка. При изоляции, дефиците общения, не очень хорошем окружении ситуация только ухудшается.
Однако напомним, что дислексия – это необязательно болезнь детей из неблагополучных семей. Из-за чисто биологических причин она может проявляться у детей, которые живут в отличных условиях и получают от взрослых достаточно внимания.
Виды дислексии
Прежде чем описать конкретные симптомы недуга, поговорим про виды дислексии. На данный момент их выделяется шесть.
- Фонематическая (акустическая). По классификации дислексии – наиболее распространенная проблема, которая часто встречается у учеников младших классов. При такой проблеме ребята переставляют слоги, искажают структуру слова – например, вместо «кот» читают «ток».
- Аграмматическая. Предполагает ошибки в составлении конструкций, например, человек может неправильно использовать окончания, падежи, времена («белая стол», «я быть голодный»).
- Семантическая. Каждое слово, которое читает человек, он понимает, но в отдельности от всего текста. А собрать слова в предложения либо в другие, еще более сложные конструкции, он не может – поэтому невозможно уловить смысл того, что было прочитано. По этой причине дислексия у взрослых и детей не позволяет получать достаточное количество информации из книг.
- Мнестическая. Это проблема на уровне отдельных букв и звуков, которые не позволяют усвоить или понять все слово целиком.
- Оптическая. Тут отклонения происходят на зрительном уровне. Например, дислексик видит слово задом наперед (зеркально) или же не может удержать взгляд на той строчке, которую читает – глаза постоянно скользят по странице, не позволяя придерживаться нужной последовательности чтения.
- Тактильная. Специфическая дислексия характерна для людей, которые не видят и используют для чтения азбуку Брайля. При этом отклонении буквы, определяемые на ощупь, либо воспринимаются неправильно (их путают с похожими), либо «ускользают» – человек не может удержаться на нужной строчке.
При таких видах дислексии симптомы заболевания будут крайне разнообразны и неоднозначны.
Симптомы по возрастам
Для обнаружения дислексии необходимо знать весь спектр признаков, характерных для этого заболевания. И тут есть сложности, потому что проявлений очень много – более того, многие из них отличаются по возрастам. Начнем с общих моментов, а затем расскажем о том, на что обращать внимание в разном возрасте ребенка.
Общие симптомы дислексии:
- проблемы с концентрацией, вниманием и памятью;
- сложности с ориентацией в пространстве – например, когда ребенок путает право и лево, верх и низ;
- трудности с простыми и более сложными задачами: от выполнения элементарной просьбы – до изучения алфавита, таблицы умножения;
- изменения в последовательности букв, слогов, чисел при записывании, чтении информации;
- неумение хорошо справляться с ручками, карандашами и т.д. Если ребенку надо что-то писать, он неуклюже пользуется инструментом для письма;
- нежелание читать вслух, писать и т.д. Действия, которые даются очень сложно или в которых потом обнаруживается много ошибок, вызывают у детей психологический дискомфорт.
Даже часть из этих признаков – повод для того, чтобы отправиться к врачу и начать разбираться с ситуацией. При этом родителям очень важно не ругать ребенка, не давить на него, заставляя делать то, что у него не получается. Здесь необходим более мягкий и взвешенный подход.
Учитывают не только формы дислексии, но и то, как проблема показывает себя в динамике, в разное время.
В дошкольном возрасте болезнь проявляет себя проблемами в речи, сложностями в изучении, произношении разных слов. Ребенок часто путается, не запоминает даже короткий набор фраз. Ему сложно осваивать базовые навыки чтения, письма, он путает слова и буквы. Все это легко может отразиться и на качестве общения с одноклассниками, сверстниками – оно становится хуже.
В младшем школьном возрасте проблемы проявляются не только на уровне слов и слогов. Ребенку уже сложно запоминать факты, он путается в арифметических знаках. Состояние отражается на освоении новой информации. Продолжаются и проблемы другого характера: поведение становится неловким, импульсивным, нарушается координация движений.
В среднем школьном возрасте диагностика дислексии показывает плохое качество чтения, слабую память. Ребенок так же плохо читает, произносит слова. Трудности вызывают бунт, поэтому школьник отказывается читать и писать, у него возникают сложности с жестами, мимикой, усиливаются проблемы при общении со сверстниками.
В старшем школьном возрасте остаются проблемы с письмом, чтением, запоминанием, воспроизведением информации. Формируется медленная скорость работы, от чего кажется, что подросток «ленив». Более того, проблема распространяется дальше – часто дислексики сложно адаптируются к любым изменениям в жизни.
Симптомы дислексии у взрослых предполагают проблемы с письмом и чтением, при этом добавляются рассеянность, невнимательность. Взрослый с таким недугом часто не умеет планировать свое время – качество жизни снижается.
Диагностика
Для диагностики дислексии ребенка тестируют при помощи разных упражнений. Специалист проверяет особенности долгосрочной и краткосрочной памяти, способности к анализу, уровень концентрации, внимания, логику, интеллект и т.д. Важной частью работы является психологическое обследование – симптоматика дислексии очень разнообразна и требует персонального подхода.
Лечение, коррекция дислексии в Москве

Поставить диагноз «дислексия» могут врачи-дефектологи, психоневрологи. Направить на дополнительное обследование также может логопед, к которому родители часто обращаются, если замечают проблемы с речью или чтением у ребенка.
Специалисты говорят, что двух одинаковых дислексиков не бывает – поэтому лечение дислексии индивидуально. Нередко сложности остаются с человеком на всю жизнь – и тогда важно понимать, как улучшить ее качество, как помочь ребенку справиться с основными жизненными задачами. В иных ситуациях возможна довольно качественная коррекция. Для этих целей подбирается специальная логопедическая программа. Она основывается на виде дислексии, возрасте человека, а также его личных особенностях.
Медикаментозное лечение дислексии остается на данный момент под вопросом.
Профилактические меры
Как только у ребенка обнаружены проблемы с чтением, письмом, запоминанием и другими важными функциями, необходимо тут же обратиться к логопеду, а также обеспечить ему комфортную среду для обучения, начать использовать рекомендованные логопедом упражнения.
Развивающие игры, упор на визуальную информацию в детском возрасте, всестороннее (но не изнуряющее) внимание со стороны взрослых – все это будет хорошей профилактикой заболевания.
Распространенные вопросы и ответы на них
Можно ли вылечить дислексию полностью?
Все зависит от конкретной ситуации. Иногда удается скорректировать проблему до такой степени, что она не влияет на дальнейшую жизнь. Но важно вовремя начать работу.
Кто лечит дислексию?
Мы уже частично ответили на этот вопрос про дислексию, что это такое и как лечить. После постановки диагноза и исключения иных патологий основным лечением занимается логопед по специальной программе.
Дислексия – это всегда проблемы с интеллектом?
Ни в коем случае. Ребенок с дислексией при правильном подходе может не просто получить хорошую профессию, но и стать в ней очень успешным. Достаточно сказать, что дислексиками были такие известные люди, как Стив Джобс, Джон Леннон или миллиардер Ричард Брэнсон.
Дислексия – это ни в коем случае не приговор, но проблема, которая требует тщательного внимания со стороны взрослых. Если они приложат усилия и уделят ей время, ребенок получит шанс на хорошее образование и отличное будущее.
Не нашли ответа на свой вопрос?
Наши специалисты готовы проконсультировать вас по телефону: