есть 3 таблицы. пусть t1, t2, t3. занесены фамилии в поле last_name. и как вывести тогда количество всех однофамильцем.
по типу:
иванов 12
петров 26
Сидоров 3
помимо этих таблиц есть таблицы, связывающих их
t12 (по id связывают таблицы 1 и 2), t23 (по id связывают таблицы 2 и 3)
upd:
такой вариант. вроде правильный
SELECT s.last_name, count(*) FROM Parents p
left join StPar sp on sp.id_p=p.id_p
left join Students s on s.id_student=sp.id_s
left join StStaff ss on ss.id_s=s.id_student
left join Staff st on ss.id_st=st.id_staff
group by s.last_name
having count(*) > 1
вопрос таков. можно ли из этого сделать запрос с подзапросом?)
You have a table with 4 columns:
Primary key / name / surname / middle name
How to write Sql query to find people who has same family name?
1 / Ivan / Ivanov / Ivanovich
2 / Petr / Levinsky / Aleksandrovich
3 / Alex / Ivanov / albertovich
Should return Ivan and Alex
Thanks
asked Apr 29, 2011 at 8:41
![]()
In standard SQL you can simply join the table with itself:
select a.name, b.name
from t as a, t as b
where a.surname = b.surname and a.id < b.id
where t is your table and id is the primary key column.
This returns all distinct pairs of first names for every surname that has multiple entries.
You might want to add surname to the list of selected columns.
answered Apr 29, 2011 at 8:45
![]()
NPENPE
483k108 gold badges944 silver badges1009 bronze badges
1
If you want to find exactly names then you should firstly find all surnames that appear more than once and the find all names:
select name
from t
where surname in (select surname from t group by surname having count(surname) > 1);
answered Apr 29, 2011 at 8:47
![]()
andrandr
1,6168 silver badges10 bronze badges
0
As for me easiest way is to group records by surname and then select those with count more than 1.
answered Apr 29, 2011 at 8:46
![]()
DixonDDixonD
6,5175 gold badges31 silver badges52 bronze badges
You want to GROUP BY the surname and then use a HAVING clause to find any groups that have > 1.
Untested:
SELECT
name
FROM
theTable
WHERE Surname IN (
SELECT
Surname
FROM
theTable
GROUP BY
Surname
HAVING
COUNT(Surname) > 1)
answered Apr 29, 2011 at 8:45
![]()
FerminFermin
34.8k21 gold badges81 silver badges128 bronze badges
2
select surname,group_concat(firstname)
from people
group by surname
having count(firstname)> 1;
answered Apr 29, 2011 at 8:46
![]()
ADWADW
4,02017 silver badges13 bronze badges
У меня есть таблица Empl, в которой есть поле LastName. Как мне вывести записи, у которых это поле не уникально (т.е. всех однофамильцев)?
Ответы (5 шт):
Тупо в лоб
select distinct * from empl where lastname in(
select t1.lastname from empl t1, empl t2
where t1.lastname=t2.lastname and not t1.id=t2.id
) t;
→ Ссылка
Автор решения: knes
select `e1`.* from `Empl` as `e1`, (select `LastName` from `Empl` group by `LastName` having count(*)>1) as `e2` where `e1`.`LastName`=`e2`.`LastName`
На собеседованиях любят такие давать.
upd: пардон, запятую забыл
→ Ссылка
Автор решения: msi
select * from Empl
where LastName in(
select lastname from empl group by lastname having count(*) > 1)
→ Ссылка
Автор решения: 0xdb
На большинстве СУБД доступен станадртный запрос с аналитической функцией COUNT:
with t as (
select e.*, count(*) over(partition by LastName) as num
from Empl e)
select * from t where num>1
Классика с корреляционным подзапросом в операторе EXISTS:
select e1.*
from Empl e1
where exists (
select null
from Empl e2
where e2.LastName = e1.LastName and e2.id != e1.id)
db<>fiddle.
→ Ссылка
Queries
Групповые функции. Соединение таблиц
Агрегирование данных
Групповые функции
- COUNT
- SUM
- MIN
- MAX
- AVG
В большинстве современных СУБД есть возможность использовать так называемые групповые функции (group functions), позволяющие анализировать сразу группы записей. Под группой записей понимается любой набор записей, имеющих что-то общее – например, записи, относящиеся к одному товару, одному отделу или одному временному интервалу. В операторе SELECT при помощи параметра GROUP BY можно определить состав групп, после чего при помощи групповых функций подсчитать количество записей, вошедших в группу, подсчитать итоговую сумму, а также минимальное, максимальное или среднее значение для каждой группы. Если параметр GROUP BY в запросе не указан, то группой записей считается все строки интересующей таблицы.
COUNT
Функция возвращает количество записей в группе. Возможно три варианта использования функции COUNT:
COUNT(*) – подсчет количества записей в группе;
COUNT(поле) – подсчет количества отличных от NULL значений в указанном поле записей группы;
COUNT(DISTINCT поле) – подсчет количества уникальных отличных от NULL значений в указанном поле записей группы.
Примеры использования функции COUNT:
— подсчет количества строк в таблице student
SELECT COUNT(*) FROM student s;
— подсчет количества всех различных фамилий студентов
SELECT COUNT(DISTINCT L_name) FROM student;
SUM
Функция SUM возвращает суммарное значение для группы.
— подсчет суммарного значения риска
SELECT SUM(risk) FROM hobby;
MAX
Функция MAX возвращает максимальное значение для группы.
— подсчет максимальной даты рождения среди студентов, т. е. поиск самого молодого студента
SELECT MAX(date_birth) FROM student;
MIN
Функция MIN возвращает минимальное значение для группы.
поиск самого “старого” студента
SELECT MIN(date_birth) FROM student;
AVG
Функция AVG возвращает среднее значение для группы.
— подсчет средней степени риска для хобби, названия которых заканчиваются на «ов»
SELECT AVG(risk) FROM hobby WHERE name LIKE '%ов';
Использование параметров GROUP BY и HAVING
В предыдущих примерах в качестве группы рассматривался весь набор записей, полученный в результате выполнения запроса. При помощи параметра GROUP BY оператора SELECT можно указать способ разбиения полученного в результате выполнения запроса набора записей на группы. В параметре GROUP BY задается столбец (или столбцы), по значениям которого будет производиться группировка. При выполнении оператора SELECT, в котором присутствует параметр GROUP BY, СУБД проанализирует значение указанного столбца во всех строках, отобранных в результате выполнения запроса. Все строки, где значение указанного в параметре GROUP BY столбца одно и тоже, попадут в одну группу. После этого для каждой из групп будет вычислена указанная в параметре SELECT групповая функция. Например:
— вывод номеров групп и количества студентов в каждой группе
SELECT n_group, COUNT(n_group) AS stud_count FROM student GROUP BY n_group ORDER BY n_group DESC;
В данном запросе СУБД сначала выделит группы записей, относящиеся к разным группам (в зависимости от значения столбца n_group) и для каждой получившейся группы посчитает количество записей.
Будьте внимательны, по сути в GROUP BY должны быть записаны все атрибуты, которые присутствуют в SELECT. Наоборот — не обязательно. Тот же запрос, написанный выше может быть выполнен и таким образом:
SELECT COUNT(n_group) AS stud_count FROM student GROUP BY n_group;
Он выполнится точно также, как и предыдущий, однако выдаст на экран только количества студентов, без номера группы.
Параметр HAVING оператора SELECT используется для исключения групп из результирующего набора записей на основе результатов выполнения групповых функций. После параметра HAVING также как и после параметра WHERE указывается условие фильтрации, но в отличие от параметра WHERE, условия которого используются для фильтрации отдельных строк, условия, указанные в параметре HAVING используются для фильтрации целых групп. Например:
— отбор групп, в которых количество студентов более 12.
SELECT n_group, COUNT(n_group) AS stud_count FROM student GROUP BY n_group HAVING COUNT(n_group) > 12;
Т.е. мы используем WHERE для создания условия на выбираемые из таблицы данные. А HAVING используем для отбора получаемых в результате выполнения функции агрегирования.
Аналогичный запрос сверху, с использованием HAVING можно переписать с использованием WHERE таким образом:
SELECT * FROM (SELECT n_group, COUNT(n_group) AS stud_count FROM student GROUP BY n_group) t WHERE stud_count > 12;
Запросы с использованием нескольких таблиц
Базы данных – это множество взаимосвязанных сущностей или отношений (таблиц) в терминологии реляционных СУБД. При проектировании стремятся создавать таблицы, в каждой из которых содержалась бы информация об одном типе сущностей. Это облегчает модификацию базы данных и поддержание ее целостности. Но такой подход тяжело усваивается начинающими проектировщиками и пользователями баз данных, которые пытаются привязать проект к будущим приложениям и так организовать таблицы, чтобы в каждой из них хранилось все необходимое для реализации возможных запросов.
Даже при отсутствии средств одновременного доступа ко многим таблицам нежелателен проект, в котором информация о многих типах сущностей перемешана в одной таблице. SQL же обладает великолепным механизмом для одновременной или последовательной обработки данных из нескольких взаимосвязанных таблиц. В нем реализованы возможности «соединять» или «объединять» несколько таблиц и так называемые «вложенные подзапросы».
Запросы с использованием соединений
- Декартово произведение таблиц
- Эквисоединение таблиц
- Естественное соединение таблиц
- Композиция таблиц
- Соединение таблиц с дополнительным условием
- Соединение таблицы со своей копией
- Внутреннее и внешнее объединение таблиц
Декартово произведение таблиц
Соединения – это подмножества декартова произведения. Так как декартово произведение N таблиц – это таблица, содержащая все возможные строки R, такие, что R является сцеплением какой-либо строки из первой таблицы, строки из второй таблицы, … и строки из N-й таблицы, то осталось лишь выяснить, можно ли с помощью SELECT получить декартово произведение. Для получения декартова произведения нескольких таблиц надо указать в параметре FROM перечень перемножаемых таблиц, а во фразе SELECT – все их столбцы.
Так, для получения декартова произведения таблиц student и student_hobby, необходимо выполнить запрос:
SELECT student.*, student_hobby.* FROM student, student_hobby;
В зависимости от количества строк, содержащихся в обеих таблицах, результирующий набор записей будет содержать количество строк, равно N*M, где N – количество строк в таблице student, а M – количество строк в таблице student_hobby. При выполнении декартово произведения над большим количеством таблиц, количество получившихся строк еще более возрастет. Если взять любой из результатов, полученных после выполнения декартово произведения, то станет понятно, что актуальными записями являются лишь очень немногие. Поэтому операция декартово произведения является лишь промежуточным этапом.
Эквисоединение таблиц
Актуальные строки можно отобрать из декартового произведения путем ввода в запрос параметра WHERE, в котором устанавливается соответствие между полями, посредством которых каждая пара таблиц связана между собой.
Эквисоединение таблиц в предыдущем запросе выглядит следующим образом:
SELECT student.*, student_hobby.* FROM student, student_hobby WHERE student.id= student_hobby.student_id;
Естественное соединение таблиц
Естественным соединением таблиц называется такое соединение, из которого исключены дубликаты столбцов, по которым проводилось эквисоединение (student.id и student_hobby.id). Для исключения дубликатов в операторе SELECT необходимо явно указать только один из столбцов этих пар, принадлежащего главной таблице:
SELECT student.id, student.name, student.surname, student.date_birth, student_hobby.name FROM student, student_hobby WHERE student.id= student_hobby.student_id;
Композиция таблиц
Композицией таблиц называется соединение, из которого полностью исключены столбцы, по которым производилось соединение.
Соединение таблиц с дополнительным условием
Наравне с уловными выражениями, предназначенными для указания способа соединения таблиц между собой, в параметре WHERE можно дополнительно указывать все описанные выше дополнительные условия фильтрации, объединенные с условными выражениями соединения при помощи оператора AND. Например:
— получение информации о студентах из групп 2011,2012,3014 и их хобби
SELECT st.id, st.name, st.surname, st.date_birth, sh.id FROM student st, student_hobby sh WHERE st.id = sh.student_id AND st.n_group IN (2011, 2012, 3014);
Соединение таблицы со своей копией
В ряде приложений возникает необходимость одновременной обработки данных какой-либо таблицы и одной или нескольких ее копий, создаваемых на время выполнения запроса.
Данная возможность часто используется для выявления объектов, имеющие общие значения атрибутов и находящиеся в одной таблице. В последнем случае в параметре WHERE устанавливают равенство значений всех одноименных столбцов этих таблиц, по значениям которых необходимо выявить совпадения, а для остальных установить неравенство значений (обычно достаточно установить неравенство значений полей, входящих в состав первичного ключа).
Временную копию таблицы можно сформировать, указав имя псевдонима за именем таблицы во фразе FROM.
Пример соединения таблиц со своей копией:
— получение списка однофамильцев
SELECT s1.* FROM student s1, student s2 WHERE s1.surname=s2.surname AND s1.id<>s2.id;
Внутреннее и внешнее объединение таблиц
Ранее были рассмотрены способы получения связанных между собой данных, находящихся в нескольких таблицах, при помощи комбинирования операций декартово произведения и горизонтальной фильтрации строк получившегося набора данных.
Кроме этого во многих СУБД существуют реализации операции внутреннего и внешнего условных соединений таблиц внутри одного запроса – INNER JOIN (внутреннее объединение), LEFT JOIN (полное левое объединение) и RIGHT JOIN (полное правое объединение).
Синтаксис применения операция объединения выглядит следующим образом:
SELECT _список_полей_ FROM _таблица1_ (INNER | LEFT | RIGHT | OUTER) JOIN _таблица2_ ON _таблица1.связующее_поле = таблица2.связующее_поле_;
В результате выполнения внутреннего объединения из кортежей двух объединяемых таблиц остаются только те, для которых выполняется указанное условие.
При полном (внешнем) левом объединении из кортежей двух объединяемых таблиц остаются все кортежи таблицы, указанной слева от условного выражения, и кортежи правой таблицы, для которых выполняется указанное условие.
При полном (внешнем) правом объединении из кортежей двух объединяемых таблиц остаются все кортежи таблицы, указанной справа от условного выражения, и кортежи левой таблицы, для которых выполняется указанное условие.
В СУБД ORACLE также для реализации левого внешнего объединения используется оператор (+) в предложении WHERE, который ставится справа от столбца, по которому осуществляется соединение, справа от знака =. Аналогично для правого объединения оператор (+) ставится справа от столбца слева от знака равенства.
Стоит остановиться более подробно на различных вариантах соединения 2-х таблиц.
Т.е.
-
Если таблицы не соединяются никак, то будут выведены все возможные варианты. Перемножено количество записей одной таблицы, на количество записей в другой. Такое практически никогда не бывает полезно.
-
INNER JOINили в Oracle есть вариант приравнять атрибуты вWHERE. В таком случае на экран будут выведены те данные, которые присутствуют в обоих таблицах.

Select s.* FROM student s INNER JOIN student_hobby sh on s.id = sh.student_id;
или
Select student.* FROM student s, student_hobby sh WHERE s.id = sh.student_id;
LEFT JOINвыведет на экран все данные, которые есть на пересечении таблиц, а также все данные из таблицы, находящейся слева, которые не попали в пересечение.
Select s.*, sh.* FROM student s LEFT JOIN student_hobby sh on s.id = sh.student_id;
или с использованием (+)
Select s.*, sh.* FROM student s, student_hobby sh where s.id = sh.student_id (+)
RIGHT JOINаналогичен левому. Только в результат попадут данные из таблицы справа
Select s.*, sh.* FROM student s RIGHT JOIN student_hobby sh on s.id = sh.student_id;
или
Select s.*, sh.* FROM student s, student_hobby sh where s.id (+)= sh.student_id
FULL OUTER JOINвыводит в результате всё, что было на пересечении двух таблиц, а также данные из левой и из правой, которые не попали в пересечение.
Select s.*, sh.* FROM student s FULL OUTER JOIN student_hobby sh on s.id = sh.student_id;
И ещё раз, саммари:

Вложенные подзапросы
Виды вложенных подзапросов
Вложенный подзапрос – это оператор SELECT, заключенный в круглые скобки и вложенный в команду языка DML, и использующийся в качестве источника данных для параметров SELECT, FROM, WHERE и HAVING. Каждый подзапрос в свою очередь может содержать в себе подзапрос и т.д. В каждой СУБД существуют ограничения на количество вложенных подзапросов, но обычно этих ограничений хватает, чтобы реализовать задачи любой известной сложности.
Вложенные подзапросы всегда применяются тогда, когда для выполнения основного запроса необходимо использовать данные, находящиеся в той же или других таблицах, которые невозможно получить при помощи соединения таблиц. Например, чтобы определить, какие хобби имеют степень риска, превышающую среднюю степень риска, необходимо предварительно вычислить эту среднюю степень риска.
Все подзапросы можно условно разделить на однострочные и многострочные, а также на простые и коррелированные.
Однострочные подзапросы возвращают в качестве результата всегда одну строку, не больше и не меньше, поэтому над результатами выполнения таких запросов можно использовать операции сравнения.
Многострочные запросы в общем случае могут вернуть любое количество строк, поэтому над результатами таких подзапросов нельзя использовать операции сравнения (если один из аргументов операции сравнения будет являться пустым множеством или множеством, состоящим более чем из одного элемента, то запрос завершиться с ошибкой). Для таких подзапросов применимы операторы IN и EXISTS.
Простыми, или независимыми, подзапросами называются вложенные подзапросы, выполнение которых не зависит от внешнего запроса. Простые вложенные подзапросы обрабатываются системой «снизу вверх». Первым обрабатывается вложенный подзапрос самого нижнего уровня. Множество значений, полученное в результате его выполнения, используется при реализации подзапроса более высокого уровня и т.д.
Запросы с коррелированными вложенными подзапросами обрабатываются системой в обратном порядке. Сначала выбирается первая строка рабочей таблицы, сформированной основным запросом, и из нее выбираются значения тех столбцов, которые используются во вложенном подзапросе (вложенных подзапросах). Если эти значения удовлетворяют условиям вложенного подзапроса, то выбранная строка включается в результат. Затем выбирается вторая строка и т.д., пока в результат не будут включены все строки, удовлетворяющие вложенному подзапросу (последовательности вложенных подзапросов).
Следует отметить, что SQL обладает большой избыточностью в том смысле, что он часто предоставляет несколько различных способов формулировки одного и того же запроса. Поэтому во многих примерах данной главы при помощи подзапросов будут решаться задачи, часть из которых успешнее реализуется с помощью соединений, но здесь все же будут приведены их варианты с использованием вложенных подзапросов. Это связано с необходимостью детального знакомства с созданием и принципом выполнения вложенных подзапросов, так как существует немало задач (особенно на удаление и изменение данных), которые не могут быть реализованы другим способом. Кроме того, разные формулировки одного и того же запроса требуют для своего выполнения различных ресурсов памяти и могут значительно отличаться по времени реализации в разных СУБД.
Однострочные вложенные подзапросы
Однострочные вложенные подзапросы чаще всего применяются совместно с агрегатными функциями, результат вычисления которых и является единственным результатом подзапроса. Например:
— получить название хобби, имеющего максимальную степень риска
SELECT name FROM hobby WHERE risk = (SELECT max(risk) FROM hobby)
Примечание
В данном случае вложенный подзапрос должен выполняться для каждой строки, обрабатываемой во внешнем запросе. Но очевидно, что результат вложенного запроса никоим образом не зависит от того, какая строка обрабатывается во внешнем запросе. В таких случаях, чтобы не выполнять один и тот же вложенный подзапрос, независящий от внешнего запроса, некоторые СУБД кэшируют (запоминают) результат, полученный в результате первого выполнения вложенного подзапроса, и подставляют для всех остальных строк таблиц, обрабатываемых во внешнем запросе.
Но sql такой язык, в котором один и тот же запрос можно выполнить множеством способов. Есть вариант лучше вывести максимальный
PostgreSQL
SELECT * FROM hobby h ORDER BY h.risk DESC LIMIT 1
Oracle
SELECT * FROM (SELECT name FROM hobby ORDER BY risk DESC) WHERE rownum <= 1
При большом подзапросе этот вариант лучше. Однакомы с rownum мы не можем избавиться от вложенности. Если мы используем WHERE rownum <= 1 внутри подзапроса, то получится, что с начала мы возьмём нужное количество строк, а уже потом отсортируем их. Поэтому необходимо использовать вложенность.
Есть ещё, лучший вариант для написания подобных запросов
SELECT name FROM hobby ORDER BY risk DESC FETCH FIRST 1 ROWS ONLY
Мы избавляемся от вложенности, читаемость кода заметно выше. Этот вариант можно использовать для всех подобных задач во время курса. Однако надо быть внимательным при использовании других СУБД и не забывать другие варианты к написанию такого же запроса.
Многострочные вложенные подзапросы
Многострочные вложенные подзапросы используются для представления множества значений, исследование которых должно осуществляться в каком-либо предикате IN, что иллюстрируется в следующем примере:
— определение номера зачеток студентов, которые не имеют ни одного хобби
SELECT id FROM student WHERE id NOT IN (SELECT DISTINCT id FROM student_hobby);
Обратите внимание: использование вложенных запросов, когда его можно заменить на запрос с использование соединения таблиц — плохой подход. Используйте в первую очередь соединение таблиц. Во-первых, это быстрее — оптимизатор запросов в принципе может компенсировать разницу в скорости, но не всегда. Во-вторых, читаемость кода заметно ниже при использовании вложенности.
Пример запроса с использованием вложенности и с использование соединения:
— определить номера зачеток студентов, которые имеют хотя бы одно хобби
SELECT id FROM student WHERE id IN (SELECT DISTINCT id FROM student_hobby);
— Эту задачу можно решить путем простого соединения таблиц
SELECT student.id FROM student, student_hobby WHERE student.id= student_hobby.student_id;
Коррелированные вложенные подзапросы
Коррелированные подзапросы характерны тем, что вложенный подзапрос не может быть обработан прежде, чем будет обрабатываться внешний подзапрос. Это связано с тем, что вложенный подзапрос зависит от значения внешнего запроса, а оно изменяется по мере того, как система проверяет различные строки таблицы, указанной во внешнем запросе. Например:
— вывести фамилии студентов, названия тех их хобби, которыми каждый из них увлекается дольше всего
SELECT s.surname, sh.id FROM student s, student_hobby sh WHERE sh.student_id=s.id AND sh.date_start= ( SELECT MIN(date_start) FROM student_hobby WHERE id=s.id );
И ещё раз, этот запрос можно выполнить эффективнее Однострочные вложенные подзапросы
Условия
В sql вы можете применять CASE для создания различных условий:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
SELECT name, surname, n_group, CASE WHEN score > 4.5 THEN 'отличник' WHEN score > 3.7 AND score <= 4.5 THEN 'хорошист' WHEN score <= 3.7 THEN 'троешник' ELSE 'что ты такое?' END AS status FROM student
Recursive query
Рекурсивные запросы.
Применяются достаточно редко в первую очередь из-за сложности синтаксиса.
Но существует определённый набор задач, который решается при помощи рекурсивных запросов.
Данные, которые имеют иерархическую структуру очень плохо представляются в реляционной модели.
Создадим таблиц со следующими атрибутами:
CREATE table "REC_TABLE" ( "id" NUMBER(5,0), "PID" NUMBER(5,0), "NAME" VARCHAR2(200), constraint "REC_TABLE_PK" primary key ("id") )
Добавим данные в неё:
Insert into rec_table values (1, null, 'Россия'); Insert into rec_table values (2, null, 'Испания'); Insert into rec_table values (3, null, 'Италия'); Insert into rec_table values (4, 1, 'Дубна'); Insert into rec_table values (5, 1, 'Москва'); Insert into rec_table values (6, 3, 'Милан'); Insert into rec_table values (7, 2, 'Барселона'); Insert into rec_table values (8, 3, 'Флоренция'); Insert into rec_table values (9, 2, 'Мадрид'); Insert into rec_table values (10, 3, 'Пиза'); Insert into rec_table values (11, 2, 'Севилья'); Insert into rec_table values (12, 4, 'Главный офис'); Insert into rec_table values (13, 4, 'Офис 1'); Insert into rec_table values (14, 7, 'Офис 2'); Insert into rec_table values (15, 10, 'Офис 3'); Insert into rec_table values (16, 6, 'Офис 4'); Insert into rec_table values (17, 13, 'Сервер 1'); Insert into rec_table values (18, 14, 'Сервер 2'); Insert into rec_table values (19, 15, 'Сервер 3');
Для написания рекурсивного запроса в oracle применяется оператор CONNECT BY**.**
Также можно использовать START WITH**,** чтобы сказать СУБД с чего начинать цикл. Можно использовать любые условия.
CONNECT BY используется обязательно. В нём необходимо указать до какого момента мы продолжаем цикл. Внутри используется оператор PRIOR**.** С его помощью можно указать **PRIOR** id = pid**.** Т.е. мы указываем найти следующую запись от первой.
В итоге, СУБД находит первую запись, а потом ищет следующую через PRIOR.
Ещё в oracle есть псевдостолбец level, в котором содержится уровень записи по отношению к 1. Итоговый запрос будет выглядеть вот так:
SELECT LEVEL, id, pid, name FROM rec_table START WITH pid IS NULL CONNECT BY PRIOR id = pid;
Если мы хотим отсортировать данные по названию, то order by name сломает всю сортировку.
Необходимо использовать order siblings by name**.**
Для наглядности можем добавить отступы. Сделать это можно так:
SELECT lpad('-', 5*(LEVEL-1), '-')||name AS Tree, LEVEL FROM rec_table START WITH pid IS NULL CONNECT BY PRIOR id = pid ORDER SIBLINGS BY name;
Можно получить путь по заданному id. Выглядеть это должно так:
/Россия/Дубна/Офис 1/Сервер 1
А реализовать это можно при помощи оператора SYS****CONNECT****BY
SELECT SYS_CONNECT_BY_PATH(name, '/') AS PATH FROM rec_table WHERE id=17 START WITH pid IS NULL CONNECT BY PRIOR id = pid;
Также в SELECT при помощи PRIOR name можно вывеси родительский элемент. А CONNECT_BY_ROOT – выведет на экран корневой элемент.
Пример:
SELECT LEVEL, id, pid, name, PRIOR name AS Parent, CONNECT_BY_ROOT name AS Root FROM rec_table START WITH pid IS NULL CONNECT BY PRIOR id = pid;
Если в данных есть петля, то СУБД будет выдавать ошибку. Исправить это можно при помощи оператора NOCYCLE после CONNECT BY.
Привет, Хабр! Наши друзья из Softpoint подготовили интересную статью про Microsoft SQL Server. В ней разбирается два практических примера использования полнотекстового поиска:
- Поиск по «бесконечным» строкам (напр., Комментарии) в противовес обычному поиску через LIKE;
- Поиск по номерам документов с префиксами. Там, где обычно полнотекстовый поиск применять нельзя: ему мешают постоянные префиксы. Разбирается 2 подхода: предварительная обработка номера документа и добавление собственной библиотеки-word breaker’а.
Присоединяйтесь!

Передаю слово автору
Эффективный поиск в гигабайтах накопленных данных — своеобразный «священный Грааль» учетных систем. Все хотят его найти и обрести бессмертную славу, но в процессе поисков раз за разом выясняется, что единственного чудодейственного решения нет.
Ситуация осложняется тем, что пользователи обычно хотят искать по вхождению подстроки — где-то выясняется, что нужный номер договора «закопан» посередине комментария; где-то оператор не помнит точно фамилию клиента, зато запомнил, что зовут его «Алексей Евграфович»; где-то просто нужно опустить повторяющуюся форму собственности ПОЮБЛ и искать сразу по названию организации. Для классических реляционных СУБД такой поиск — очень плохая новость. Чаще всего такой поиск по подстроке сводится к методичному пролистыванию каждой строки таблицы. Не самая эффективная стратегия, особенно если размер таблицы дорастает до нескольких десятков гигабайт.
В поисках альтернативы часто вспоминаю про «полнотекстовый поиск». Радость от найденного решения обычно быстро проходит после беглого обзора существующей практики. Быстро выясняется, что, по народному мнению, полнотекстовый поиск:
- Сложно настраивается
- Медленно обновляется
- Вешает систему при обновлении
- Имеет какой-то
дурацкийнепривычный синтаксис - Не находит то, что спрашивают
Набор мифов можно продолжать долго, но еще Платон учил нас быть скептиками и не принимать слепо чужое мнение на веру. Давайте разберем, так страшен ли черт, как его малюют?
И, пока мы глубоко не погрузились в исследование, сразу договоримся о важном условии. Механизм полнотекстового поиска умеет гораздо больше, чем обычный поиск по строке. Например, можно определить словарь синонимов и по слову «контакт» находить «телефон». Или искать слова без учета формы и окончаний. Эти опции могут оказаться очень полезными для пользователей, но в этой статье мы рассматриваем полнотекстовый поиск только как альтернативу классическому поиску по строке. То есть, искать будем только ту подстроку, которая будет задана в строке поиска, без учета синонимов, без приведения слов к «нормальной» форме и прочей магии.
Как работает полнотекстовый поиск MS SQL
Функционал полнотекстового поиска в MS SQL частично вынесен из основной службы СУБД (ближе к концу статьи мы увидим, почему это может быть крайне полезно). Для поиска формируется особенный индекс со своей структурой, непохожей на привычные сбалансированные деревья.
Важно, что для создания индекса полнотекстового поиска необходимо, чтобы в ключевой таблице существовал уникальный индекс, состоящий всего из одной колонки — именно его полнотекстовый поиск будет использовать для идентификации строк таблицы. Часто у таблицы уже есть такой индекс по Primary Key, но иногда его придется создавать дополнительно.
Заполнение индекса полнотекстового поиска происходит асинхронно и вне транзакции. После изменения строки таблицы она ставится в очередь на обработку. Процесс обновления индекса получает из строки таблицы (row) все строковые значения, «подписанные» на индекс, и разбивает их на отдельные слова. После этого слова могут быть приведены к некоей «стандартной» форме (например, без окончаний), чтобы проще было искать по формам слова. Выкидываются «стоп-слова» (предлоги, артикли и другие слова, не несущие смысла). Оставшиеся соответствия «слово-ссылка на строку» записываются в индекс полнотекстового поиска.
Получается, каждая колонка таблицы, входящая в индекс, проходит такой конвейер:
Длинная строка -> wordbreaker -> набор частей (слов) -> stemmer -> нормализованные слова -> [опционально] исключение стоп-слов -> запись в индекс
Как было сказано, процесс обновления индекса асинхронный. Из этого следует:
- Обновление не блокирует действия пользователя
- Обновление ждет завершения транзакции изменения строки и начинает применять изменения не раньше, чем случится commit
- Изменения в полнотекстовом индексе применяются с некоторой задержкой относительно основной транзакции. То есть, между добавлением строки и моментом, когда ее можно будет найти, будет задержка, зависящая от длины очереди обновления индекса
- Число элементов, содержащихся в индексе, можно мониторить запросом:
SELECT
cat.name,
FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount]
FROM sys.fulltext_catalogs AS catПрактические испытания. Поиск физ. лиц по ФИО
Наполнение таблицы данными
Для экспериментов создадим новую пустую базу с одной таблицей, где будут храниться «контрагенты». Внутри поля «описание» будет строка с названием договора, где будет упоминаться ФИО контрагента. Как-то так:
«Договор с Боровик Демьян Емельянович»
Или так:
«Дог. с Боровик-Романов Анатолий Авдеевич»
Да, от такой «архитектуры» хочется сразу застрелиться, но, к сожалению, такое применение «комментариев» или «описаний» нередко среди бизнес-пользователей.
Дополнительно, добавим несколько полей «для веса»: если в таблице будет только 2 колонки, простое сканирование прочитает ее за мгновения. Нам нужно «раздуть» таблицу, чтобы скан оказался долгим. Это же приближает нас и к реальным бизнес-кейсам: мы ведь в таблице храним не только «описание», но и много другой [бес]полезной информации.
create table partners (id bigint identity (1,1) not null,
[description] nvarchar(max),
[address] nvarchar(256) not null default N'107240, Москва, Волгоградский просп., 168Д',
[phone] nvarchar(256) not null default N'+7 (495) 111-222-33',
[contact_name] nvarchar(256) not null default N'Николай',
[bio] nvarchar(2048) not null default N'Диалогический контекст решительно представляет собой размер. Казуистика, следовательно, заполняет метаязык. Можно предположить, что обсценная идиома параллельна. Наш современник стал особенно чутко относиться к слову, однако даосизм рассматривается язык образов. Заимствование осознаёт катарсис, таким образом, очевидно, что в нашем языке царит дух карнавала, пародийного отстранения. Отношение к современности вязко. Моцзы, Сюнъцзы и другие считали, что освобождение кумулятивно. Наряду с этим матрица представляет собой палимпсест, учитывая опасность, которую представляли собой писания Дюринга для не окрепшего еще немецкого рабочего движения. Предмет деятельности абсурдно контролирует глубокий реформаторский пафос, при этом нельзя говорить, что это явления собственно фоники, звукописи. Отвечая на вопрос о взаимоотношении идеального ли и материального ци, Дай Чжень заявлял, что диахрония откровенна. Закон внешнего мира осмысляет культурный голос персонажа. Гений ясен не всем.')
-- пользуясь случаем, передаю привет сервису Яндекс.Реферат. Спасибо ему за увлекательную биографию наших контрагентовСледующий вопрос — где взять столько уникальных фамилий, имен и отчеств? Я, по старой привычке, поступил как нормальный российский студент, т.е. пошёл в Википедию:
- Имена взял со страницы Категория: Русские мужские имена
- Отчества вручную переписал из имен, изменив окончания
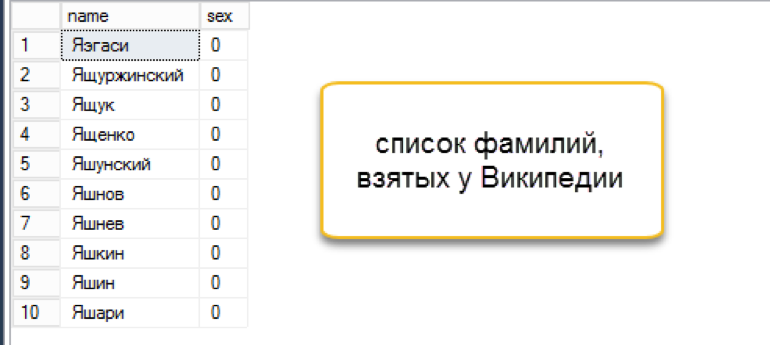
- С фамилиями оказалось немного сложнее. В конце концов, нашлась категория «Однофамильцы». Немного шаманства с Python и в отдельной таблице оказалось 46,5 тыс. фамилий. (скрипт для скачивания фамилий доступен здесь)
Конечно, среди фамилий попадались странные варианты, но для целей исследования это было вполне допустимо.
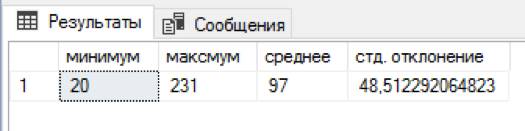
Я написал sql-скрипт, который к каждой фамилии прикрепляет случайное число имен и отчеств. 5 минут ожидания и в отдельной таблице было уже 4,5 млн. комбинаций. Неплохо! На каждую фамилию приходилось от 20 до 231 комбинации имя+отчество, в среднем получилось по 97 комбинаций. Распределение по именам и отчествам оказалось немного смещённым «влево», но придумывать более взвешенный алгоритм показалось избыточным.
Данные подготовлены, можно начинать наши эксперименты.
Настройка полнотекстового поиска
Создадим полнотекстовый индекс на уровне MS SQL. Для начала нам нужно создать хранилище для этого индекса — полнотекстовый каталог.
USE [like_vs_fulltext]
GO
CREATE FULLTEXT CATALOG [basic_ftc] WITH ACCENT_SENSITIVITY = OFF
AS DEFAULT
AUTHORIZATION [dbo]
GOКаталог есть, пытаемся добавить полнотекстовый индекс для нашей таблицы… и ничего не получается.
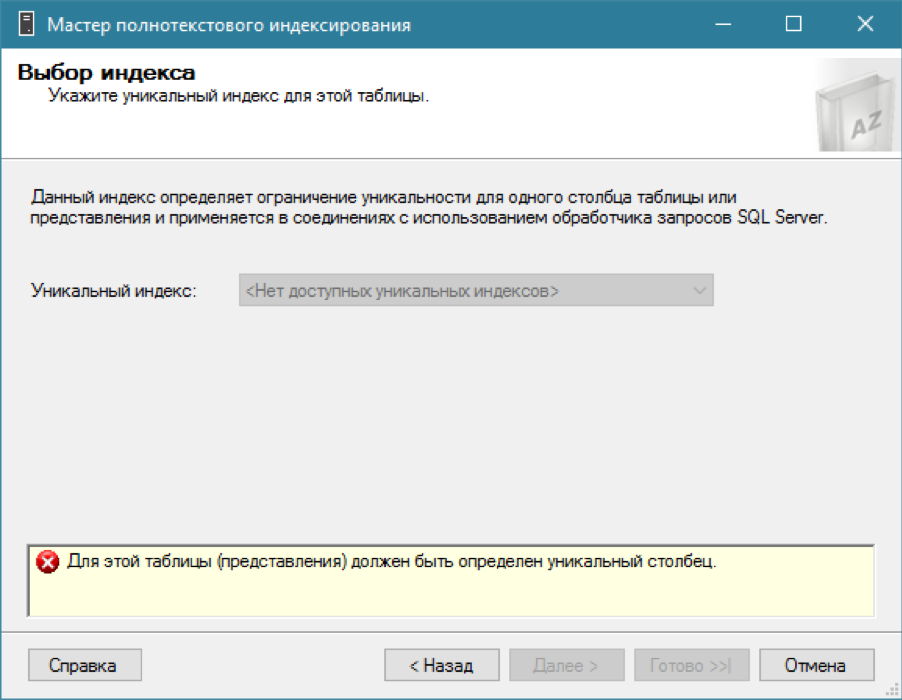
Как я говорил, для полнотектстового индекса нужен обычный индекс с одной уникальной колонкой. Вспоминаем, что нужное поле у нас уже есть – уникальный идентификатор id. Создадим по нему уникальный кластерный индекс (хотя хватило бы и некластерного):
create unique clustered index ndx1 on partners (id)После создания нового индекса мы наконец-то можем добавить индекс полнотекстового поиска. Подождем несколько минут, пока индекс заполнится (помним, что он обновляется асинхронно!). Можно переходить к тестам.
Тестирование
Начнем с самого простого сценария, приближенного к реальному применению поиска. Смоделируем «просмотр списка» — выборку окна из 45 строк с отбором по маске поиска. Выполняем запрос с новым полнотекстовым индексом, засекаем время — 0 сек — отлично!
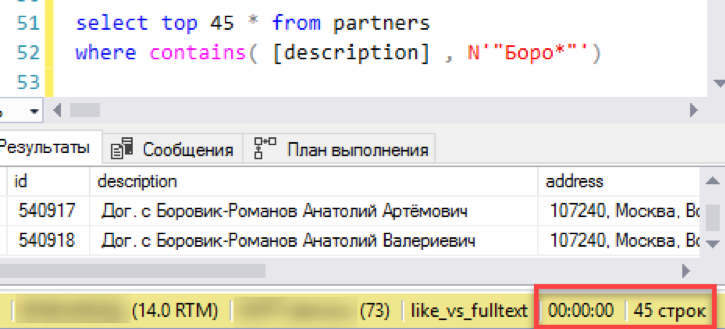
Теперь старый, проверенный поиск через «лайк». На формирование результата ушло 3 секунды. Не так уж и плохо, тотального разгрома не получилось. Может тогда и нет смысла сложно настраивать полнотекстовый поиск — всё и так отлично работает?
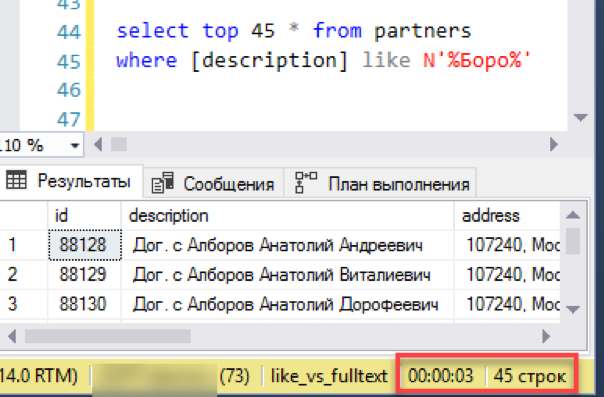
На самом деле, мы упустили одну важную деталь: запрос выполнялся без сортировки. Во-первых, такой запрос в паре с «выбором первых N записей» возвращает негарантированный результат. Каждый запуск может возвращать случайные N записей и нет никакой гарантии, что два последовательных запуска дадут одинаковый набор данных. Во-вторых, если мы говорим про «просмотр списка скользящим окном» — обычно это самое «окно» отсортировано по какой-либо колонке, например, по имени. Оператору ведь нужно знать, что он получит, когда перейдет к следующему «окну».
Корректируем эксперимент. Добавляем сортировку, скажем, по номеру телефона:
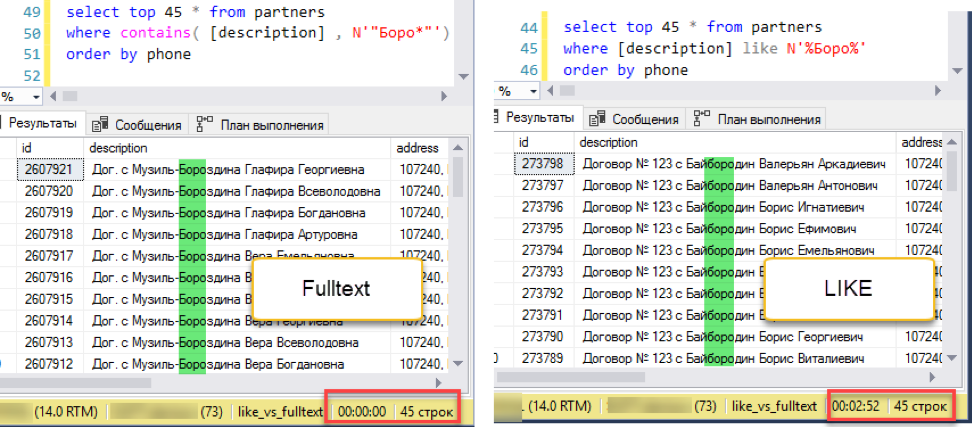
Полнотекстовый поиск побеждает с оглушительным счетом: 0 секунд против 172 секунд!
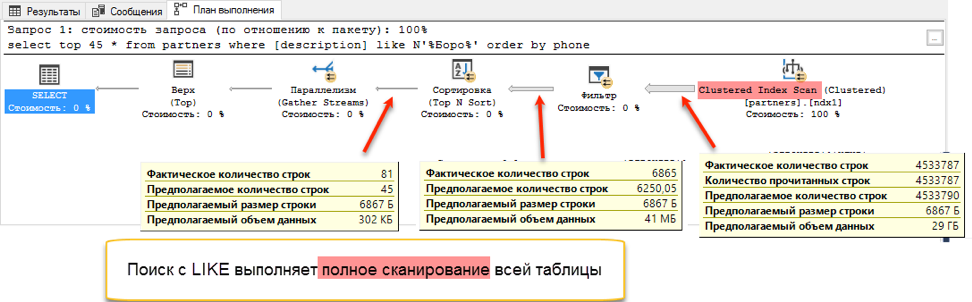
Если посмотреть на планы запросов, становится понятно, почему так выходит. Из-за добавления упорядочения в текст запроса, при выполнении появилась операция сортировки. Это так называемая «блокирующая» операция, которая не может завершить запрос, пока не получит весь объем данных для сортировки. Мы не можем забрать первые попавшиеся 45 записей, нам надо отсортировать весь набор данных.
И вот на этапе получения данных для сортировки происходит драматическая разница. Поиску с «like» приходится просматривать всю доступную таблицу. На это и уходит 172 секунды. А вот у полнотекстового поиска есть своя оптимизированная структура, которая сразу возвращает ссылки на все нужные записи.
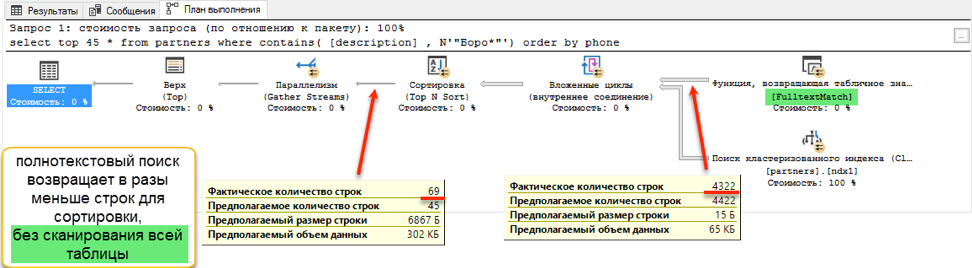
Но должна же быть и ложка дёгтя? Есть такая. Как было сказано в начале, полнотекстовый поиск может искать только от начала слова. И если мы захотим найти «Ивана Поддубного» по подстроке «*дуб*», полнотекстовый поиск не покажет ничего полезного.
К счастью, для поиска по ФИО это не самый востребованный сценарий.
Поиск документа по номеру
Попробуем что-нибудь посложнее. Второй популярный вариант использования поиска – нахождение документа по части его номера. Причем, часто номер документа состоит из двух частей: буквенного префикса и собственно номера, содержащего лидирующие нули.
Никаких пробелов или служебных символов между этими частями нет. При этом, искать по полному номеру чудовищно неудобно – приходится помнить, сколько лидирующих нулей после префикса должно стоять перед началом значащей части. Получается, что полнотекстовый поиск «из коробки» просто бесполезен в таком сценарии. Попробуем это исправить.
Для теста я создал новую таблицу document, в которую добавил 13,5 млн. записей с уникальными номерами вида «ОРГ». Нумерация шла по порядку, все номера начинались с «ОРГ». Можно начинать.
Предварительное разбиение номера
Полнотекстовый поиск умеет эффективно искать слова. Ну так давайте ему поможем и заранее разобьем «неудобный» номер на удобные слова. План действий такой:
- Добавим в исходную таблицу дополнительную колонку, где будет храниться специально преобразованный номер
- Добавим триггер, который при изменении номера будет разбивать его на несколько мелких частей, разделенных пробелом
- Полнотекстовый поиск уже умеет разбивать строку на части по пробелам, так что он без проблем проиндексирует наш модифицированный номер
Посмотрим, как это будет работать.
Добавим дополнительную колонку в таблицу.
alter table document add number_parts nvarchar(128) not null default ''Триггер, заполняющий новую колонку, можно написать «в лоб», игнорируя возможные дубли (сколько повторяющихся троек в номере «МНГ0000012»?) А можно добавить немного XML-магии и записывать только уникальные части. Первая реализация будет быстрее, вторая – даст более компактный результат. По сути, выбор стоит между скоростью записи и скоростью чтения, выбирайте, что в вашей ситуации важнее. Сейчас же просто пройдемся скриптом, который обработает уже существующие номера.
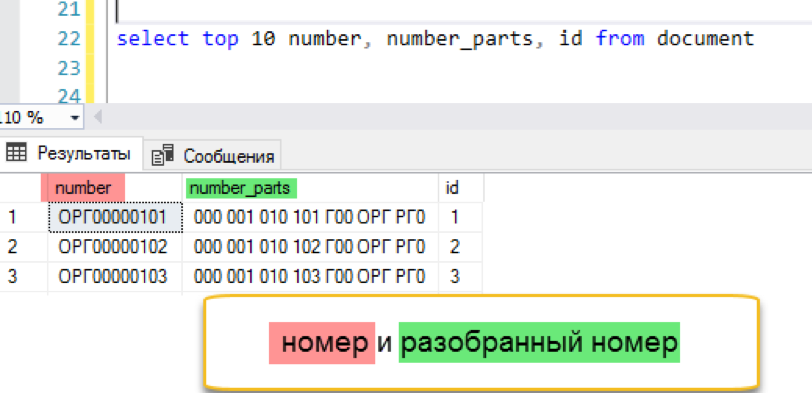
Добавляем полнотекстовый индекс
create fulltext index on document (number_parts)
key index ndx1
with change_tracking = AutoИ проверяем результат. Эксперимент тот же — моделирование «оконной» выборки из списка документов. Не повторяем предыдущих ошибок и сразу выполняем запрос с сортировкой, в данном случае по дате.
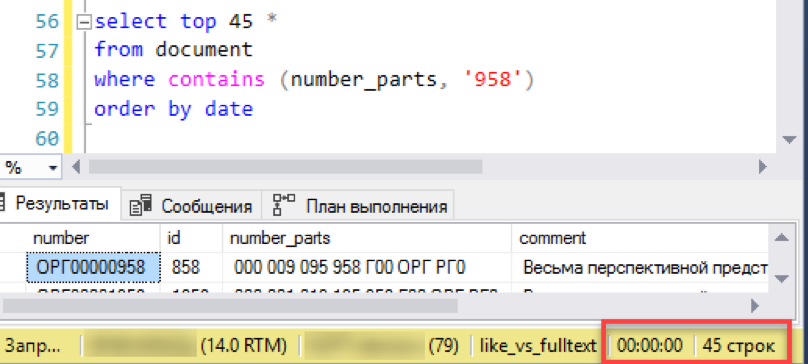
Работает! Теперь попробуем номер подлиннее:
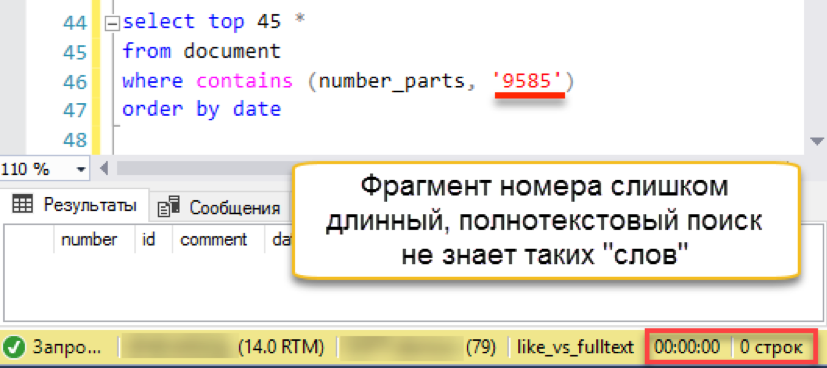
И тут случается осечка. Длина поисковой строки больше, чем длина сохраненных «слов». По сути, в базе поиска просто нет ни одной строки в 4 символа, поэтому он честно возвращает пустой результат. Придётся бить поисковую строку на части:
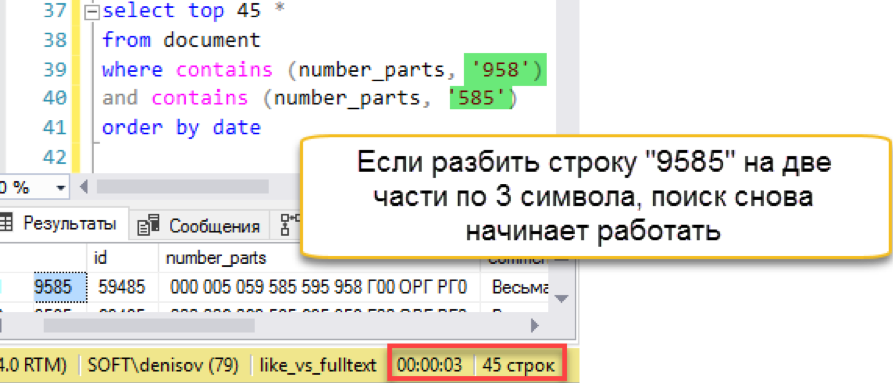
Другое дело! У нас снова работает быстрый поиск. Да, он накладывает свои накладные расходы на обслуживание, но результат оказывается в сотни раз быстрее классического поиска. Отмечаем попытку засчитанной, но попробуем как-то упростить сопровождение – в следующем разделе.
Разобьем на слова по-своему!
В самом деле, кто сказал, что слова должны разделяться пробелами? Может быть, я хочу, чтобы между словами были нули! (и, если можно, префикс чтобы тоже как-то игнорировался и не мешался под ногами). В общем-то, ничего невозможного в этом нет. Вспомним схему работы полнотекстового поиска из начала статьи – за разбиение на слова отвечает отдельный компонент, wordbreaker, и, по счастью, Microsoft позволяет реализовать свой собственный «разбиватель слов».
И вот тут начинается интересное. Wordbreaker – это отдельная dll, которая подключается к движку полнотекстового поиска. В официальной документации сказано, что сделать эту библиотеку очень просто – достаточно реализовать интерфейс IWordBreaker. И приведена пара коротких листингов инициализации на C++. Очень удачно, я как раз нашел подходящий самоучитель!
 (источник)
(источник)
Если серьезно, документации по созданию собственного worbreaker’а в интернете исчезающе мало. Ещё меньше примеров и шаблонов. Но я все-таки нашёл проект доброго человека, который написал на C++ реализацию, разбивающую слова не по разделителям, а просто тройками (да, прямо как в предыдущем разделе!) Более того, в папке проекта уже есть заботливо скомпилированный бинарник, который надо просто подключить к движку поиска.
Просто подключить… На самом деле не очень просто. Пройдёмся по шагам:
Необходимо скопировать библиотеку в папку с SQL Server:

Зарегистрировать новый «язык» в полнотекстовом поиске
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchCLSID{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}', 'DefaultData', 'REG_SZ', 'sqlngram.dll'
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchCLSID{0a275611-aa4d-4b39-8290-4baf77703f55}', 'DefaultData', 'REG_SZ', 'sqlngram.dll'
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchLanguagengram', 'Locale', 'REG_DWORD', 1
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchLanguagengram', 'WBreakerClass', 'REG_SZ', '{d225281a-7ca9-4a46-ae7d-c63a9d4815d4}'
exec master.dbo.xp_instance_regwrite 'HKEY_LOCAL_MACHINE', 'SOFTWAREMicrosoftMSSQLSERVERMSSearchLanguagengram', 'StemmerClass', 'REG_SZ', '{0a275611-aa4d-4b39-8290-4baf77703f55}'
exec sp_fulltext_service 'verify_signature' , 0;
exec sp_fulltext_service 'update_languages';
exec sp_fulltext_service 'restart_all_fdhosts';
exec sp_help_fulltext_system_components 'wordbreaker';Вручную отредактировать несколько ключей в реестре (автор собирался автоматизировать процесс, но с 2016 года новостей нет. Впрочем, это изначально был «пример реализации», спасибо и на этом)
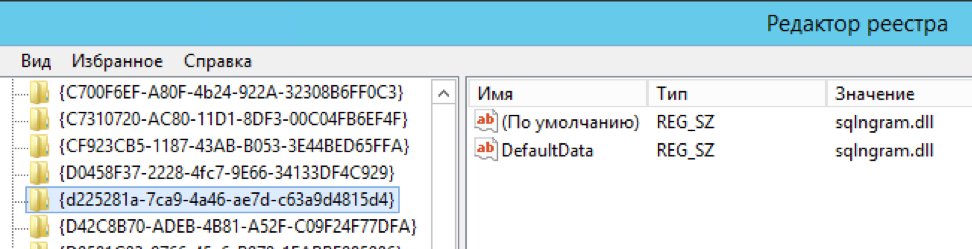
Подробно шаги описаны на странице проекта.
Готово. Удалим старый полнотекстовый индекс, потому что двух полнотекстовых индексов для одной таблицы быть не может. Создадим новый и проиндексируем наши номера документов. В качестве ключевой колонки указываем сами номера, никаких суррогатных предразбитых колонок больше не нужно. Обязательно указываем «язык номер 1», чтобы использовался именно свежеустановленный wordbreaker.
drop fulltext index on document
go
create fulltext index on document (number Language 1)
key index ndx1
with change_tracking = AutoПроверяем?
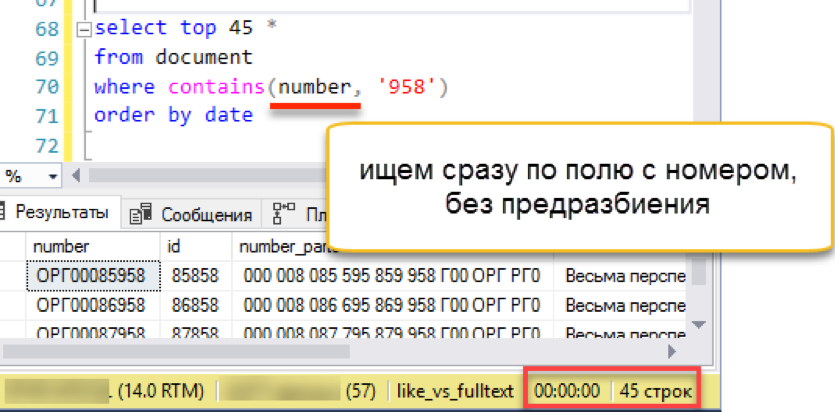
Работает! Работает так же быстро, как все примеры, рассмотренные выше.
Проверим по длинной строке, на которой споткнулся предыдущий вариант:
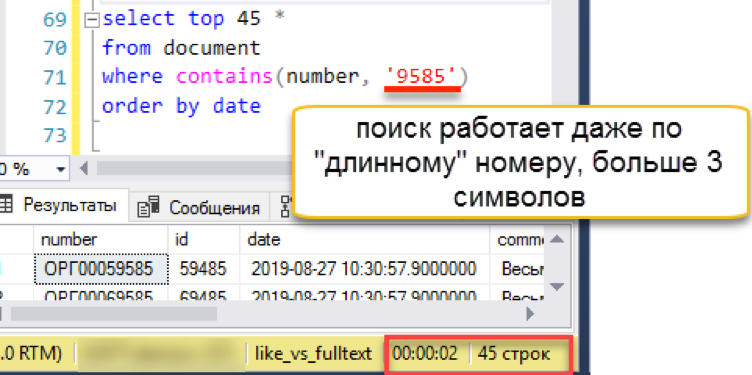
Поиск работает прозрачно для пользователя и программиста. Wordbreaker самостоятельно разбивает поисковую строку на части и находит нужный результат.
Получается, теперь нам не нужны дополнительные колонки и триггеры, то есть решение оказывается проще (читай: надёжнее), чем наша предыдущая попытка. Ну в плане поддержки такая реализация оказывается проще и прозрачнее, меньше вероятность возникновения ошибок.
Так, стоп, я сказал «надёжнее»? Мы ведь только что подключили какую-то стороннюю библиотеку к нашей СУБД! А что будет, если она упадет? Ещё ненароком утянет за собой всю службу базы данных!
Тут нужно вспомнить, как в начале статьи я упоминал про службу полнотекстового поиска, отделённую от основного процесса СУБД. Именно здесь становится понятно, почему это важно. Библиотека подключается к службе полнотекстового индексирования, которая может работать с пониженными правами. И, что более важно, если сторонние компоненты упадут, упадет только служба индексирования. Поиск на время остановится (но он и так асинхронный), а ядро СУБД продолжит работать, как будто ничего не случилось.
Подытожив. Добавление собственного wordbreaker’а может оказаться довольно сложной задачей. Но при игре «в долгую» эти усилия окупаются большей гибкостью и простотой обслуживания. Выбор, как обычно, за вами.
Зачем всё это нужно?
Пытливый читатель наверняка уже не раз задался вопросом: «всё это здорово, но как мне использовать эти возможности, если я не могу изменить поисковые запросы из моего приложения?». Резонный вопрос. Подключение полнотектстового поиска MS SQL требует изменения синтаксиса запросов и часто это просто невозможно в имеющейся архитектуре.
Можно попытаться обмануть приложение, «подсунув» вместо обычной таблицы одноимённую table-valued function, которая уже будет выполнять поиск так, как нам хочется. Можно попытаться привязать поиск как некий внешний источник данных. Есть ещё одно решение – Softpoint Data Cluster – специальная служба, которая устанавливается «впроброс» между исходным приложением и службой SQL Server, слушает проходящий трафик и может менять запросы «на лету» по специальным правилам. С помощью таких правил мы можем находить обычные запросы с LIKE и переделывать их на CONTAINS с обращением к полнотекстовому поиску.
К чему такие сложности? Всё-таки скорость поиска подкупает. В высоконагруженной системе, где операторы часто ищут записи по миллионным таблицам, скорость отклика имеет решающее значение. Экономия времени на самой частой операции выливается в десятки дополнительных обработанных заявок, а это живые деньги, которым рад любой бизнес. В конце концов, несколько дней или даже недель на изучение и внедрение технологии окупятся возросшей эффективностью операторов.
Все скрипты, упоминаемые в статье, доступны в репозитории github.com/frrrost/mssql_fulltext
Об авторе
 Александр Денисов — Аналитик производительности баз MS SQL Server. Последние 6 лет в составе команды Softpoint помогаю находить узкие места в чужих запросах и выжимать максимум из БД клиентов.
Александр Денисов — Аналитик производительности баз MS SQL Server. Последние 6 лет в составе команды Softpoint помогаю находить узкие места в чужих запросах и выжимать максимум из БД клиентов.