Это небольшая заметка-памятка о том, как вводить нестандартные символы в HTML и CSS код.
Unicode и HTML
В HTML есть несколько способов включить символ в текст документа. Помимо непосредственного ввода символа можно использовать ссылки (character references). Ссылки могут быть десятичными, шестнадцатеричными или именованными.
Десятичные символьные ссылки
Возьмём произвольный символ Unicode, например, тильду (~). Её можно ввести с клавиатуры, но мы попробуем сделать это с помощью десятичной ссылки.
Код символа в таблице: U+007E.
Переводим в десятичный формат: 7E16 = 7*16 + 14 = 12610
Чтобы отобразить символ в HTML документе, нужно поместить его код между «&#» и «;».
<span>Это тильда: ~</span>
Шестнадцатеричные символьные ссылки
Аналогично десятичному представлению можно использовать шестнадцатеричное, добавим большую или малую латинскую «x» (икс) перед шестнадцатеричным кодом символа.
<span>Это тоже тильда: ~</span>
Через числовые ссылки можно сослаться на любой символ таблицы Unicode, за исключением символов с кодами U+0000 и U+000D, перманентно не определённых символов, суррогатов (U+D800–U+DFFF) и управляющих символов помимо пробельных.
Именованные символьные ссылки
В начале было слово.. (с)
А в нашем случае был метаязык SGML (Standard Generalized Markup Language), на котором определялись языки разметки документов. HTML до версии 4 включительно был приложением SGML, а XML является подмножеством SGML.
В частности, SGML помимо декларативной разметки и описания типов документов (document type definition, DTD), обладал механизмом строковой подстановки, когда некоторая последовательность символов заменяется при обработке некоторой другой последовательностью (для обеспечения переносимости нестандартных символов).
В SGML строки, для которых определены подстановки, назывались entities (иногда их переводят как «объекты», Википедия называет их «символ-мнемоника»). После того, как entities объявлен, на него можно ссылаться в любом месте документа, используя его имя, перед которым ставится символ «&», а после которого — точка с запятой. Точка с запятой может быть опущена, если за ссылкой на entities следует пробел или конец записи.
В HTML определено много entities для специальных символов, вроде валют и математических знаков, а также для отображения символов, имеющих специальное значение для HTML (например, < и >). Их описание можно найти на официальном сайте консорциума. Для HTML 4 пример описания дроби 3/4 (U+00BE) выглядит так:
<!ENTITY frac34 CDATA "¾" -- vulgar fraction three quarters
= fraction three quarters, U+00BE ISOnum -->
Затем символ можно использовать в документе:
<span>Платформа 9¾</span>
Такое описание выглядит нагляднее, но по факту просто заменяется на:
<span>Платформа 9¾</span>
Unicode и CSS
В CSS тоже можно обращаться к символам через их коды, но формат записи отличается от HTML. Код символа предваряется обратным слешем ().
.test1:after {
content: "7E";
}
<span class="test1">Это всё та же тильда:</span>
Подобным образом можно заэкранировать символ, имеющий специальное значение в CSS-разметке, например, кавычку:
.test2:after {
content: ""Hello"";
}
<span class="test2">Он сказал:</span>
Однако, если мы захотим написать «примерно 15км», то есть «~15км», такой код не сработает:
.test3:after {
content: "7E15км";
}
<span class="test3">Расстояние:</span>
Поскольку символы, которые могут быть интерпретированы как шестнадцатеричные цифры (0-9, a-f, A-F), будут восприняты как часть кода символа. Есть два способа исправить ситуацию: поставить пробел после кода символа (этот первый пробел не будет отображён при выводе) или использовать 6-циферный код символа.
.test4:after {
content: "7E 15км"; /* или "0007E15км" */
}
Сводная табличка в качестве резюме:
| Формат | Описание |
| HTML | |
| &#A9; | Десятичная ссылка (decimal numeric character reference) |
| © | Шестнадцатеричная ссылка (hexadecimal numeric character reference) |
| © | Именованная ссылка (мнемоника, HTML entity, named character reference) |
| CSS | |
| A9 | Если после идёт символ из диапазона 0-9, a-f, A-F, перед ними нужен пробел |
| 000A9 | Код символа должен содержать ровно 6 символов, пробел после не нужен |
Ссылки
- Character entity references in HTML 4 (in HTML 5)
- Character references in HTML 4 (in HTML 5)
- Using character escapes in markup and CSS
Мнемоники и коды Unicode в HTML
Для того, чтобы браузер мог правильно отобразить на экране монитора текст веб-страницы, необходимо сообщить ему используемую на странице кодировку.
Делается это при помощи служебного тега <meta> и его атрибута charset, в качестве
значения которого и указывается требуемая кодировка. Практически все современные сайты используют кодировку
UTF-8 из набора символов Unicode. Поэтому, во-избежание появления
«кракозябр» при
отображении веб-страницы браузером, следует использовать служебный элемент «meta» в виде
<meta charset=«UTF-8»
>.
Кроме того, не все символы обычного текста браузер может вывести на экран напрямую. Например, символы < и
> имеют в
HTML специальный смысл, т.к. они являются важнейшей составляющей синтаксиса языка. Когда интерпретатор
браузера встречает их в коде, то он видит в них не просто символы текста, а в первую очередь метки начала и конца тега. Поэтому, если нам нужно вывести
на экран конструкцию, например, открывающего тега <span>, то мы должны каким-то образом сообщить браузеру,
что он видит перед собою не открывающий тег, а всего лишь простой текст.
Обычно в таких случаях символы заменяются (кодируются) специальными последовательностями обычных символов, называемыми
мнемониками, либо их числовым представлением в виде десятичного или шестнадцатеричного кода
Unicode.
Мнемоника HTML (от др.-греч.
искусство запоминания ) – это легко запоминающаяся буквенная конструкция вида
&abcd;, обозначающая буквенный код символа и вставляющаяся непосредственно в
html-код веб-страницы.
Мнемоники довольно популярны среди профессиональных html-верстальщиков, поскольку они образованы от соответствующих
английских слов и легко запоминаются человеком. Однако область их применения сильно ограничена, чего не скажешь о числовых кодах стандарта
Unicode.
Юникод
(от англ. Unicode) – стандарт кодирования символов, представляющий знаки почти
всех письменных языков мира.
Применение стандарта Unicode позволяет закодировать большое число символов из разных
письменностей, что дает возможность веб-программистам использовать на одной и той же странице сразу несколько языков, а также множество различных
математических и специальных символов.
Для мнемоники конструкция начинается с символа амперсанда &,
после чего следует некоторая последовательность обычных символов и завершающая точка с запятой ;.
Если используется Unicode, то сперва также пишется символ амперсанда &, однако
затем следует # и десятичный код Юникода либо
#x и шестнадцатеричный код Юникода данного символа. Заканчивается конструкция
опять же точкой с запятой ;.
Таким образом, если нам нужно, чтобы браузер вывел на экран конструкцию, например, того же тега <span>,
следует в коде использовать вместо знаков < и > их коды.
Данная ситуация показана в примере №1.
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Использование кодов символов</title> </head> <body> Здесь мы тегов не увидим <span></span>.<br> А вот здесь мы видим тег <span>.<br> Это тоже тег <span>.<br> И это тег <span>. </body> </html>
Пример №1. Замещение символов их кодами
Стандарт Unicode в JavaScript
Числовые коды Unicode можно использовать и в коде JavaScript, т.к. при написании
программ на данном языке используется кодировка UTF-16, а строки представляют собой не
что иное, как последовательности 16-битных значений без знака. Благодаря этому программисты могут использовать в своем
коде как символы своего родного языка (хотя это и не принято), так и различные другие символы, отсутствующие на клавиатуре (см. пример №2).
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Юникод в JavaScript</title>
</head>
<body>
<!-- Заполним при помощи скрипта -->
<p id="p_1"></p>
<script>
//Здесь вместо некоторых символов пишем коды Юникода
//Чтобы конструкция не сработала, экранируем еще одним слешем
//Запустите пример и посмотрите результат
var u00B5='\u00B5 - это символ µ!';
//Находим абзац по его id
var p1=document.getElementById('p_1');
//Вставляем в него значение переменной
p1.innerHTML=µ;
</script>
<p>
Вне JavaScript следует использовать правила HTML!!!<br>
Выводим тот же символ µ.
</p>
</body>
</html>
Пример №2. Использование числовых кодов Unicode в JavaScript
Как видно из примера, для того, чтобы записать в коде JavaScript вместо символа его числовой код
в кодировке UTF-16, следует использовать конструкцию uXXXX (экранируется числовой
код Юникода из четырех цифр в шестнадцатеричной системе счисления).
Стандарт Unicode в PHP
Следует помнить, что в PHP отсутствует встроенная поддержка Unicode, т.е.
язык поддерживает только 256 различных символов, каждому из которых соответствует один байт. Поэтому, для работы с
многобайтовыми кодировками вроде «UTF-8», которая используется нами при верстке веб-страниц, следует отдавать
предпочтение специальным функциям и расширениям для работы с многобайтовыми строками. Все они собраны в официальном справочнике в разделе
«Поддержка языков и кодировок» -> «Многобайтовые строки».
Что касается функций для работы с однобайтовыми строками, то их нужно искать в разделе «Обработка текста». При этом
отметим, что некоторые функции одинаково полезны как для работы с однобайтовыми, так и многобайтовыми строками.
Таблицы мнемоник и числовых кодов стандарта Unicode
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| < | < | < | < | меньше |
| > | > | > | > | больше |
| & | & | & | & | амперсанд |
| « | " | " | " | двойная кавычка |
| » | ' | ' | ' | одинарная кавычка |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| | неразрывный пробел | |||
|   | средний пробел | |||
|   | длинный пробел | |||
|   | узкий пробел | |||
| | ­ | | | мягкий перенос |
| ‑ | ” | ‑ | неразрывный дефис | |
| – | – | – | – | среднее тире |
| — | — | — | — | длинное тире |
| . | . | . | точка | |
| , | , | , | запятая | |
| ; | ; | ; | точка с запятой | |
| : | : | : | двоеточие | |
| … | … | … | … | многоточие |
| ? | ? | ? | вопросительный знак | |
| ǃ | ǃ | ǃ | восклицательный знак | |
| # | # | # | «решетка» | |
| * | * | * | «звездочка» | |
| @ | @ | @ | «собачка» | |
| & | & | & | & | амперсанд |
| № | № | № | знак номера | |
| § | § | § | § | параграф |
| ¶ | ¶ | ¶ | ¶ | абзац |
| • | • | • | • | маркер списка (середина строки) |
| ‣ | ‣ | ‣ | треугольный маркер списка | |
| ‘ | ‘ | ‘ | ‘ | одиночная верхняя левая кавычка |
| ’ | ’ | ’ | ’ | одиночная верхняя правая кавычка |
| ‚ | ‚ | ‚ | ‚ | одиночная нижняя правая кавычка |
| “ | “ | “ | “ | двойная верхняя левая кавычка |
| „ | „ | „ | „ | двойная нижняя правая кавычка |
| « | « | « | « | двойная левая угловая кавычка (рус) |
| » | » | » | » | двойная правая угловая кавычка (рус) |
| ́ | ́ | ́ | знак ударения | |
| ‘ | ' | ' | апостроф | |
| ´ | ´ | ´ | ´ | акут |
| ˆ | ˆ | ˆ | ˆ | акцент |
| ˜ | ˜ | ˜ | ˜ | малая тильда |
| ¦ | ¦ | ¦ | ¦ | вертикальный пунктир |
| ( | ( | ( | круглая скобка влево | |
| ) | ) | ) | круглая скобка вправо | |
| 〈 | ⟨ | 〈 | 〈 | угловая скобка влево |
| 〉 | ⟩ | 〉 | 〉 | угловая скобка вправо |
| ‹ | ‹ | ‹ | ‹ | угловая скобка влево (вариант) |
| › | › | › | › | угловая скобка вправо (вариант) |
| [ | [ | [ | квадратная скобка влево | |
| ] | ] | ] | квадратная скобка вправо | |
| / | / | / | слеш | |
| \ | \ | обратный слеш | ||
| ⁄ | ⁄ | ⁄ | ⁄ | косая дробная черта (знак деления) |
| ǀ | ǀ | ǀ | вертикальная черта | |
| ǁ | ǁ | ǁ | двойная вертикальная черта | |
| ‾ | ‾ | ‾ | ‾ | надчеркивание |
| ¯ | ¯ | ¯ | ¯ | макрон |
| ✓ | ✓ | ✓ | галочка | |
| ✔ | ✔ | ✔ | жирная галочка | |
| ✕ | ✕ | ✕ | косой крест | |
| ✖ | ✖ | ✖ | жирный косой крест | |
| ✗ | ✗ | ✗ | рукописный крест | |
| ✘ | ✘ | ✘ | жирный рукописный крест |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| Α | Α | Α | заглавная альфа | |
| Β | Β | Β | заглавная бета | |
| Γ | Γ | Γ | заглавная гамма | |
| Δ | Δ | Δ | заглавная дельта | |
| Ε | Ε | Ε | заглавная эпсилон | |
| Ζ | Ζ | Ζ | заглавная дзета | |
| Η | Η | Η | заглавная эта | |
| Θ | Θ | Θ | заглавная тета | |
| Ι | Ι | Ι | заглавная йота | |
| Κ | Κ | Κ | заглавная каппа | |
| Λ | Λ | Λ | заглавная лямбда | |
| Μ | Μ | Μ | заглавная мю | |
| Ν | Ν | Ν | заглавная ню | |
| Ξ | Ξ | Ξ | заглавная кси | |
| Ο | Ο | Ο | заглавная омикрон | |
| Π | Π | Π | заглавная пи | |
| Ρ | Ρ | Ρ | заглавная ро | |
| Σ | Σ | Σ | заглавная сигма | |
| Τ | Τ | Τ | заглавная тау | |
| Υ | Υ | Υ | заглавная ипсилон | |
| Φ | Φ | Φ | заглавная фи | |
| Χ | Χ | Χ | заглавная хи | |
| Ψ | Ψ | Ψ | заглавная пси | |
| Ω | Ω | Ω | заглавная омега | |
| α | α | α | альфа | |
| β | β | β | бета | |
| γ | γ | γ | гамма | |
| δ | δ | δ | дельта | |
| ε | ε | ε | эпсилон | |
| ζ | ζ | ζ | дзета | |
| η | η | η | эта | |
| θ | θ | θ | тета | |
| ι | ι | ι | йота | |
| κ | κ | κ | каппа | |
| λ | λ | λ | лямбда | |
| μ | μ | μ | мю | |
| ν | ν | ν | ню | |
| ξ | ξ | ξ | кси | |
| ο | ο | ο | омикрон | |
| π | π | π | пи | |
| ρ | ρ | ρ | ро | |
| ς | ς | ς | окончательная сигма | |
| σ | σ | σ | сигма | |
| τ | τ | τ | тау | |
| υ | υ | υ | ипсилон | |
| φ | φ | φ | фи | |
| χ | χ | χ | хи | |
| ψ | ψ | ψ | пси | |
| ω | ω | ω | омега |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| + | + | + | + | плюс |
| − | − | − | − | минус |
| = | = | = | равно | |
| ± | ± | ± | ± | плюс-минус |
| × | × | × | × | знак умножения |
| ÷ | ÷ | ÷ | ÷ | знак деления |
| ⋅ | ⋅ | ⋅ | ⋅ | оператор «точка» (середина строки) |
| ∗ | ∗ | ∗ | ∗ | оператор «звёздочка» (середина строки) |
| ∼ | ∼ | ∼ | ∼ | оператор «тильда» |
| ¹ | ¹ | ¹ | ¹ | верхний индекс «1» |
| ² | ² | ² | ² | верхний индекс «2» |
| ³ | ³ | ³ | ³ | верхний индекс «3» |
| ½ | ½ | ½ | ½ | «одна вторая» |
| ⅓ | ⅓ | ⅓ | ⅓ | «одна треть» |
| ¼ | ¼ | ¼ | ¼ | «одна четвёртая» |
| ¾ | ¾ | ¾ | ¾ | «три четверти» |
| № | № | № | знак номера | |
| % | % | % | процент | |
| ‰ | ‰ | ‰ | ‰ | промилле |
| ° | ° | ° | ° | градусы |
| ′ | ′ | ′ | ′ | штрих (минуты, футы) |
| ″ | ″ | ″ | ″ | двойной штрих (секунды, дюймы) |
| µ | µ | µ | µ | микро |
| π | π | π | π | Пи |
| ƒ | ƒ | ƒ | ƒ | знак функции |
| ∫ | ∫ | ∫ | ∫ | интеграл |
| ∬ | ∬ | ∬ | двойной интеграл | |
| ∭ | ∭ | ∭ | тройной интеграл | |
| ∮ | ∮ | ∮ | интеграл по контуру | |
| ∅ | ∅ | ∅ | ∅ | пустое множество |
| ⌀ | ⌀ | ⌀ | диаметр | |
| ø | ø | ø | ø | латинская o диагонально перечёркнутая |
| Ø | Ø | Ø | Ø | латинская заглавная O диагонально перечёркнутая |
| √ | √ | √ | √ | радикал |
| ∛ | ∛ | ∛ | корень третьей степени | |
| ∜ | ∜ | ∜ | корень четвертой степени | |
| ∝ | ∝ | ∝ | ∝ | пропорционально |
| ∞ | ∞ | ∞ | ∞ | бесконечность |
| ∟ | ∟ | ∟ | прямой угол | |
| ∠ | ∠ | ∠ | ∠ | угол |
| ⊥ | ⊥ | ⊥ | ⊥ | ортогонально (перпендикулярно) |
| ∴ | ∴ | ∴ | ∴ | знак «cледовательно» |
| ∀ | ∀ | ∀ | ∀ | любой (для всех) |
| ∂ | ∂ | ∂ | ∂ | частичный дифференциал |
| ∃ | ∃ | ∃ | ∃ | существует |
| ∄ | ∄ | ∄ | не существует | |
| ∆ | ∆ | ∆ | инкремент | |
| ∇ | ∇ | ∇ | ∇ | оператор набла |
| ∈ | ∈ | ∈ | ∈ | элемент из (принадлежит) |
| ∉ | ∉ | ∉ | ∉ | не элемент из (не принадлежит) |
| ∋ | ∋ | ∋ | ∋ | содержит в качестве члена |
| ∌ | ∌ | ∌ | не содержит в качестве члена | |
| ⊂ | ⊂ | ⊂ | ⊂ | подмножество |
| ⊃ | ⊃ | ⊃ | ⊃ | включает в себя |
| ⊄ | ⊄ | ⊄ | ⊄ | не включает в себя |
| ⊆ | ⊆ | ⊆ | ⊆ | подмножество или эквивалентно |
| ⊇ | ⊇ | ⊇ | ⊇ | включает в себя или эквивалентно |
| ∋ | ∋ | ∋ | ∋ | содержит как член |
| ∏ | ∏ | ∏ | ∏ | знак произведения |
| ∑ | ∑ | ∑ | ∑ | знак суммирования |
| ≅ | ≅ | ≅ | ≅ | приблизительно равно |
| ≈ | ≈ | ≈ | ≈ | почти равно |
| ≠ | ≠ | ≠ | ≠ | не равно |
| ≡ | ≡ | ≡ | ≡ | идентично |
| ≤ | ≤ | ≤ | ≤ | меньше или равно |
| ≥ | ≥ | ≥ | ≥ | больше или равно |
| ¬ | ¬ | ¬ | ¬ | логическое Не |
| ∧ | ∧ | ∧ | ∧ | логическое И |
| ∨ | ∨ | ∨ | ∨ | логическое ИЛИ |
| ⊕ | ⊕ | ⊕ | ⊕ | «плюс в круге» (прямая сумма) |
| ⊗ | ⊗ | ⊗ | ⊗ | «умножение в круге» (векторное произведение, стрела от наблюдателя) |
| ʘ | ʘ | ʘ | точка в круге (стрела к наблюдателю) |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ℠ | ℠ | ℠ | знак обслуживания | |
| ™ | ™ | ™ | ™ | товарный знак (TradeMark) |
| ® | ® | ® | ® | знак регистрации товарного знака |
| © | © | © | © | знак защиты авторского права (copyright) |
| ¤ | ¤ | ¤ | ¤ | валюта |
| ¢ | ¢ | ¢ | ¢ | цент |
| $ | $ | $ | доллар | |
| € | € | $ | $ | евро |
| £ | £ | £ | £ | фунт |
| ¥ | ¥ | ¥ | ¥ | иена |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ❶ | ❶ | ❶ | белая цифра 1 в черном круге | |
| ❷ | ❷ | ❷ | белая цифра 2 в черном круге | |
| ❸ | ❸ | ❸ | белая цифра 3 в черном круге | |
| ❹ | ❹ | ❹ | белая цифра 4 в черном круге | |
| ❺ | ❺ | ❺ | белая цифра 5 в черном круге | |
| ❻ | ❻ | ❻ | белая цифра 6 в черном круге | |
| ❼ | ❼ | ❼ | белая цифра 7 в черном круге | |
| ❽ | ❽ | ❽ | белая цифра 8 в черном круге | |
| ❾ | ❾ | ❾ | белая цифра 9 в черном круге | |
| ❿ | ❿ | ❿ | белая цифра 10 в черном круге | |
| ⓪ | ⓪ | ⓪ | черная цифра 0 в белом круге | |
| ① | ① | ① | черная цифра 1 в белом круге | |
| ② | ② | ② | черная цифра 2 в белом круге | |
| ③ | ③ | ③ | черная цифра 3 в белом круге | |
| ④ | ④ | ④ | черная цифра 4 в белом круге | |
| ⑤ | ⑤ | ⑤ | черная цифра 5 в белом круге | |
| ⑥ | ⑥ | ⑥ | черная цифра 6 в белом круге | |
| ⑦ | ⑦ | ⑦ | черная цифра 7 в белом круге | |
| ⑧ | ⑧ | ⑧ | черная цифра 8 в белом круге | |
| ⑨ | ⑨ | ⑨ | черная цифра 9 в белом круге | |
| ⑩ | ⑩ | ⑩ | черная цифра 10 в белом круге | |
| ⑪ | ⑪ | ⑪ | черная цифра 11 в белом круге | |
| ⑫ | ⑫ | ⑫ | черная цифра 12 в белом круге | |
| ⑬ | ⑬ | ⑬ | черная цифра 13 в белом круге | |
| ⑭ | ⑭ | ⑭ | черная цифра 14 в белом круге | |
| ⑮ | ⑮ | ⑮ | черная цифра 15 в белом круге | |
| ⑯ | ⑯ | ⑯ | черная цифра 16 в белом круге | |
| ⑰ | ⑰ | ⑰ | черная цифра 17 в белом круге | |
| ⑱ | ⑱ | ⑱ | черная цифра 18 в белом круге | |
| ⑲ | ⑲ | ⑲ | черная цифра 19 в белом круге | |
| ⑳ | ⑳ | ⑳ | черная цифра 20 в белом круге | |
| Ⅰ | Ⅰ | Ⅰ | римская цифра 1 | |
| Ⅱ | Ⅱ | Ⅱ | римская цифра 2 | |
| Ⅲ | Ⅲ | Ⅲ | римская цифра 3 | |
| Ⅳ | Ⅳ | Ⅳ | римская цифра 4 | |
| Ⅴ | Ⅴ | Ⅴ | римская цифра 5 | |
| Ⅵ | Ⅵ | Ⅵ | римская цифра 6 | |
| Ⅶ | Ⅶ | Ⅶ | римская цифра 7 | |
| Ⅷ | Ⅷ | Ⅷ | римская цифра 8 | |
| Ⅸ | Ⅸ | Ⅸ | римская цифра 9 | |
| Ⅹ | Ⅹ | Ⅹ | римская цифра 10 | |
| Ⅺ | Ⅺ | Ⅺ | римская цифра 11 | |
| Ⅻ | Ⅻ | Ⅻ | римская цифра 12 | |
| Ⅼ | Ⅼ | Ⅼ | римская цифра 50 | |
| Ⅽ | Ⅽ | Ⅽ | римская цифра 100 | |
| Ⅾ | Ⅾ | Ⅾ | римская цифра 500 | |
| Ⅿ | Ⅿ | Ⅿ | римская цифра 1000 |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ← | ← | ← | ← | влево |
| ↑ | ↑ | ↑ | ↑ | вверх |
| → | → | → | → | направо |
| ↓ | ↓ | ↓ | ↓ | вниз |
| ↔ | ↔ | ↔ | ↔ | влево-вправо |
| ↕ | ↕ | ↕ | вверх-вниз | |
| ↖ | ↖ | ↖ | вверх-влево | |
| ↗ | ↗ | ↗ | вверх-вправо | |
| ↘ | ↘ | ↘ | вниз-вправо | |
| ↙ | ↙ | ↙ | вниз-влево | |
| ⇄ | ⇄ | ⇄ | Стрелка направо над стрелкой налево | |
| ⇅ | ⇅ | ⇅ | Стрелка вверх слева от стрелки вниз | |
| ⇆ | ⇆ | ⇆ | Стрелка налево над стрелкой направо | |
| ⇇ | ⇇ | ⇇ | Парные стрелки налево | |
| ↚ | ↚ | ↚ | зачеркнутая влево | |
| ↛ | ↛ | ↛ | зачеркнутая вправо | |
| ⇠ | ⇠ | ⇠ | штриховая влево | |
| ⇡ | ⇡ | ⇡ | штриховая вверх | |
| ⇢ | ⇢ | ⇢ | штриховая вправо | |
| ⇣ | ⇣ | ⇣ | штриховая вниз | |
| ⤌ | ⤌ | ⤌ | с двойным штрихом влево | |
| ⤍ | ⤍ | ⤍ | с двойным штрихом вправо | |
| ⤎ | ⤎ | ⤎ | с тройным штрихом влево | |
| ⤏ | ⤏ | ⤏ | с тройным штрихом вправо | |
| ⤑ | ⤒ | ⤑ | точечная вправо | |
| ↜ | ↜ | ↜ | волнистая влево | |
| ↝ | ↝ | ↝ | волнистая вправо | |
| ↞ | ↞ | ↞ | двуглавая влево | |
| ↟ | ↟ | ↟ | двуглавая вверх | |
| ↠ | ↠ | ↠ | двуглавая вправо | |
| ↡ | ↡ | ↡ | двуглавая вниз | |
| ↩ | ↩ | ↩ | с крючком влево | |
| ↪ | ↪ | ↪ | с крючком вправо | |
| ↫ | ↫ | ↫ | с петлей влево | |
| ↬ | ↬ | ↬ | с петлей вправо | |
| ↮ | ↮ | ↮ | зачеркнутая вправо-влево | |
| ↯ | ↯ | ↯ | зигзагообразная вниз | |
| ↰ | ↰ | ↰ | вверх и влево | |
| ↱ | ↱ | ↱ | вверх и вправо | |
| ↲ | ↲ | ↲ | вниз и влево | |
| ↳ | ↳ | ↳ | вниз и вправо | |
| ⤴ | ⤴ | ⤴ | изогнутая вправо и вверх | |
| ⤵ | ⤵ | ⤵ | изогнутая вправо и вниз | |
| ⤶ | ⤶ | ⤶ | изогнутая вниз и влево | |
| ⤷ | ⤷ | ⤷ | изогнутая вниз и вправо | |
| ↶ | ↶ | ↶ | против часовой сверху | |
| ↷ | ↷ | ↷ | по часовой сверху | |
| ↺ | ↺ | ↺ | против часовой снизу с разрывом | |
| ↻ | ↻ | ↻ | по часовой снизу с разрывом | |
| ⟲ | ⟲ | ⟲ | против часовой с малым разрывом | |
| ⟳ | ⟳ | ⟳ | по часовой с малым разрывом | |
| ⥀ | ⥀ | ⥀ | против часовой | |
| ⥁ | ⥁ | ⥁ | по часовой | |
| ⇦ | ⇦ | ⇦ | плоская влево | |
| ⇧ | ⇧ | ⇧ | плоская вверх | |
| ⇨ | ⇨ | ⇨ | плоская вправо | |
| ⇩ | ⇩ | ⇩ | плоская вниз | |
| ⇳ | ⇳ | ⇳ | плоская вверх-вниз | |
| ⏎ | ⏎ | ⏎ | символ возврата | |
| ⇪ | ⇪ | ⇪ | плоская (вариант) | |
| ⇫ | ⇫ | ⇫ | плоская (вариант) | |
| ⇬ | ⇬ | ⇬ | плоская (вариант) | |
| ⇭ | ⇭ | ⇭ | плоская (вариант) | |
| ⇮ | ⇮ | ⇮ | плоская (вариант) | |
| ⇯ | ⇯ | ⇯ | плоская (вариант) | |
| ⇰ | ⇰ | ⇰ | плоская (вариант) | |
| ⇐ | ⇐ | ⇐ | двойная влево | |
| ⇑ | ⇑ | ⇑ | двойная вверх | |
| ⇒ | ⇒ | ⇒ | двойная вправо | |
| ⇓ | ⇓ | ⇓ | двойная вниз | |
| ⇔ | ⇔ | ⇔ | двойная влево-вправо | |
| ⇕ | ⇕ | ⇕ | двойная вверх-вниз | |
| ⇖ | ⇖ | ⇖ | двойная вверх-влево | |
| ⇗ | ⇗ | ⇗ | двойная вверх-вправо | |
| ⇘ | ⇘ | ⇘ | двойная вниз-вправо | |
| ⇙ | ⇙ | ⇙ | двойная вниз-влево | |
| ⇍ | ⇍ | ⇍ | двойная зачеркнутая влево | |
| ⇎ | ⇎ | ⇎ | двойная зачеркнутая влево-вправо | |
| ⇏ | ⇏ | ⇏ | двойная зачеркнутая вправо | |
| ⤆ | ⤆ | ⤆ | двойная влево | |
| ⤇ | ⤇ | ⤇ | двойная вправо | |
| ⤊ | ⤊ | ⤊ | тройная вверх | |
| ⤋ | ⤋ | ⤋ | тройная вниз | |
| ⟰ | F0; | ⟰ | четвертная вверх | |
| ⟱ | F1; | ⟱ | четвертная вниз | |
| ⥢ | ⥢ | ⥢ | влево | |
| ⥣ | ⥣ | ⥣ | вверх | |
| ⥤ | ⥤ | ⥤ | вправо | |
| ⥥ | ⥥ | ⥥ | вниз | |
| ➧ | ➧ | ➧ | вправо (вариант) | |
| ➨ | ➨ | ➨ | вправо (вариант) | |
| ➩ | ➩ | ➩ | вправо (вариант) | |
| ➪ | ➪ | ➪ | вправо (вариант) | |
| ➫ | ➫ | ➫ | вправо (вариант) | |
| ➬ | ➬ | ➬ | вправо (вариант) | |
| ➭ | ➭ | ➭ | вправо (вариант) | |
| ➮ | ➮ | ➮ | вправо (вариант) | |
| ➯ | ➯ | ➯ | вправо (вариант) | |
| ➱ | ➲ | ➱ | вправо (вариант) | |
| ➲ | ➳ | ➲ | вправо (вариант) | |
| ➳ | ➴ | ➳ | вправо (вариант) | |
| ➴ | ➵ | ➴ | стрела вниз-вправо (вариант) | |
| ➵ | ➶ | ➵ | вправо (вариант) | |
| ➶ | ➷ | ➶ | стрела вверх-вправо (вариант) | |
| ➷ | ➸ | ➷ | стрела вниз-вправо (вариант) | |
| ➸ | ➹ | ➸ | вправо (вариант) | |
| ➹ | ➺ | ➹ | стрела вверх-вправо (вариант) | |
| ➺ | ➻ | ➺ | вправо (вариант) | |
| ➻ | ➼ | ➻ | вправо (вариант) | |
| ➼ | ➽ | ➼ | вправо (вариант) | |
| ➽ | ➾ | ➽ | вправо (вариант) | |
| ➾ | ➿ | ➾ | вправо (вариант) | |
| ➔ | ➔ | ➔ | вправо (вариант) | |
| ➘ | ➘ | ➘ | вниз-вправо (вариант) | |
| ➙ | ➙ | ➙ | вправо (вариант) | |
| ➚ | ➚ | ➚ | вверх-вправо (вариант) | |
| ➛ | ➛ | ➛ | вправо (вариант) | |
| ➜ | ➜ | ➜ | вправо (вариант) | |
| ➝ | ➝ | ➝ | вправо (вариант) | |
| ➞ | ➞ | ➞ | вправо (вариант) | |
| ➟ | ➟ | ➟ | вправо (вариант) | |
| ➠ | ➠ | ➠ | вправо (вариант) | |
| ➡ | ➡ | ➡ | вправо (вариант) | |
| ➢ | ➢ | ➢ | вправо (вариант) | |
| ➣ | ➣ | ➣ | вправо (вариант) | |
| ➤ | ➤ | ➤ | вправо (вариант) | |
| ➥ | ➥ | ➥ | изогнутая вниз и вправо (вариант) | |
| ➦ | ➦ | ➦ | изогнутая вверх и вправо (вариант) | |
| ◄ | ◄ | ◄ | треугольник влево | |
| ▲ | ▲ | ▲ | треугольник вверх | |
| ► | ► | ► | треугольник вправо | |
| ▼ | ▼ | ▼ | треугольник вниз |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ♈ | ♈ | ♈ | Овен | |
| ♉ | ♉ | ♉ | Телец | |
| ♊ | ♊ | ♊ | Близнецы | |
| ♋ | ♋ | ♋ | Рак | |
| ♌ | ♌ | ♌ | Лев | |
| ♍ | ♍ | ♍ | Дева | |
| ♎ | ♎ | ♎ | Весы | |
| ♏ | ♏ | ♏ | Скорпион | |
| ♐ | ♐ | ♐ | Стрелец | |
| ♑ | ♑ | ♑ | Казерог | |
| ♒ | ♒ | ♒ | Водолей | |
| ♓ | ♓ | ♓ | Рыбы | |
| ⛎ | ⛎ | ⛎ | Змееносец | |
| ☿ | ☿ | ☿ | Меркурий | |
| ♀ | ♀ | ♀ | Венера (женское начало) | |
| ♁ | ♁ | ♁ | Земля | |
| ♂ | ♂ | ♂ | Марс (мужское начало) | |
| ♃ | ♃ | ♃ | Юпитер | |
| ♄ | ♄ | ♄ | Сатурн | |
| ♅ | ♅ | ♅ | Уран | |
| ♆ | ♆ | ♆ | Нептун | |
| ♇ | ♇ | ♇ | Плутон |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ☼ | ☼ | ☼ | солнечно | |
| ☁ | ☁ | ☁ | облачно | |
| 🌁 | 🌁 | 🌁 | туманно | |
| 🌂 | 🌂 | 🌂 | закрытый зонт | |
| 🌃 | 🌃 | 🌃 | звездная ночь | |
| 🌄 | 🌄 | 🌄 | восход над горами | |
| 🌅 | 🌅 | 🌅 | восход | |
| 🌆 | 🌆 | 🌆 | город в сумерках | |
| 🌇 | 🌇 | 🌇 | закат над домами | |
| 🌈 | 🌈 | 🌈 | радуга | |
| 🌉 | 🌉 | 🌉 | мост ночью | |
| 🌊 | 🌊 | 🌊 | волна | |
| 🌋 | 🌋 | 🌋 | вулкан | |
| 🌌 | 🌌 | 🌌 | млечный путь | |
| ☂ | ☂ | ☂ | возможен дождь | |
| ☔ | ☂ | ☔ | дождливо | |
| ☃ | ☃ | ☃ | снежно | |
| ☽ | ☽ | ☽ | растущая луна | |
| ☾ | ☾ | ☾ | стареющая луна | |
| 🌑 | 🌑 | 🌑 | новолуние | |
| 🌓 | 🌓 | 🌓 | первая четверть луны | |
| 🌔 | 🌔 | 🌔 | почти полная растущая луна | |
| 🌕 | 🌕 | 🌕 | полная луна | |
| 🌙 | 🌙 | 🌙 | полумесяц | |
| 🌛 | 🌛 | 🌛 | первая четверть луны с лицом | |
| ☀ | ☀ | ☀ | солнечное затмение | |
| ☊ | ☊ | ☊ | восходящий узел | |
| ☋ | ☋ | ☋ | нисходящий узел | |
| ☌ | ☌ | ☌ | соединение | |
| ☍ | ☍ | ☍ | противостояние |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ♔ | ♔ | ♔ | белый король | |
| ♕ | ♕ | ♕ | белый ферзь | |
| ♖ | ♖ | ♖ | белая ладья | |
| ♗ | ♗ | ♗ | белый слон | |
| ♘ | ♘ | ♘ | белый конь | |
| ♙ | ♙ | ♙ | белая пешка | |
| ♚ | ♚ | ♚ | черный король | |
| ♛ | ♛ | ♛ | черный ферзь | |
| ♜ | ♜ | ♜ | черная ладья | |
| ♝ | ♝ | ♝ | черный слон | |
| ♞ | ♞ | ♞ | черный конь | |
| ♟ | ♟ | ♟ | черная пешка | |
| ♤ | ♤ | ♤ | незакрашенная пика | |
| ♡ | ♡ | ♡ | незакрашенная черва | |
| ♢ | ♢ | ♢ | незакрашенная бубна | |
| ♧ | ♧ | ♧ | незакрашенная трефа | |
| ♠ | ♠ | ♠ | пика | |
| ♥ | ♥ | ♥ | черва | |
| ♦ | ♦ | ♦ | бубна | |
| ♣ | ♣ | ♣ | трефа | |
| ♩ | ♩ | ♩ | четвертная нота | |
| ♪ | ♪ | ♪ | восьмая нота | |
| ♫ | ♫ | ♫ | связанные восьмые ноты | |
| ♬ | ♬ | ♬ | шестнадцатая нота | |
| ♭ | ♭ | ♭ | знак бемоль | |
| ♮ | ♮ | ♮ | знак бекар | |
| ♯ | ♯ | ♯ | знак диез |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ☺ | ☺ | ☺ | незакрашенный веселый | |
| ☻ | ☻ | ☻ | закрашенный веселый | |
| ☹ | ☹ | ☹ | незакрашенный хмурый | |
| 😁 | 😁 | 😁 | ухмыляющийся | |
| 😂 | 😂 | 😂 | со слезами радости | |
| 😃 | 😃 | 😃 | улыбающийся с открытым ртом | |
| 😄 | 😄 | 😄 | улыбающийся с открытым ртом | |
| 😅 | 😅 | 😅 | улыбающийся в холодном поту | |
| 😆 | 😆 | 😆 | улыбающийся с открытым ртом и закрытыми глазами | |
| 😇 | 😇 | 😇 | улыбающийся с нимбом над головой | |
| 😈 | 😈 | 😈 | злорадно улыбающийся с рогами | |
| 😉 | 😉 | 😉 | подмигивающий | |
| 😊 | 😊 | 😊 | улыбающийся с закрытым ртом | |
| 😋 | 😋 | 😋 | смакующий | |
| 😌 | 😌 | 😌 | расслабленный | |
| 😍 | 😍 | 😍 | улыбающийся с глазами-сердечками | |
| 😎 | 😎 | 😎 | улыбающийся в солнечных очках | |
| 😏 | 😏 | 😏 | усмехающийся | |
| 😐 | 😐 | 😐 | нейтральный | |
| 😒 | 😒 | 😒 | неодобряющий | |
| 😓 | 😓 | 😓 | в холодном поту | |
| 😔 | 😔 | 😔 | задумчивый | |
| 😖 | 😖 | 😖 | с выражением стыда | |
| 😘 | 😘 | 😘 | посылающий поцелуй | |
| 😚 | 😚 | 😚 | целующийся с закрытыми глазами | |
| 😜 | 😜 | 😜 | подмигивающий с высунутым языком | |
| 😝 | 😝 | 😝 | с крепко закрытыми глазами и высунутым языком | |
| 😞 | 😞 | 😞 | разочарованный | |
| 😠 | 😠 | 😠 | злой | |
| 😡 | 😡 | 😡 | надувший губы | |
| 😢 | 😢 | 😢 | плачущий | |
| 😣 | 😣 | 😣 | с упрямым выражением лица | |
| 😤 | 😤 | 😤 | чихающий | |
| 😥 | 😥 | 😥 | разочарованный | |
| 😨 | 😧 | 😨 | с выражением страха | |
| 😩 | 😨 | 😩 | утомленный | |
| 😪 | 😩 | 😪 | сонный | |
| 😫 | 😪 | 😫 | усталый | |
| 😭 | 😬 | 😭 | громко плачущий | |
| 😰 | 😯 | 😰 | с открытым ртом в холодном поту | |
| 😱 | 😰 | 😱 | кричащий от страха | |
| 😲 | 😱 | 😲 | удивленный | |
| 😵 | 😴 | 😵 | головокружение | |
| 😶 | 😵 | 😶 | без рта | |
| 😷 | 😶 | 😷 | в медицинской маске | |
| 😸 | 😷 | 😸 | ухмыляющийся кот | |
| 😹 | 😸 | 😹 | кот со слезами радости | |
| 😺 | 😹 | 😺 | улыбающийся кот с открытым ртом | |
| 😻 | 😺 | 😻 | улыбающийся кот с глазами-сердечками | |
| 😼 | 😻 | 😼 | кот с кривой улыбкой | |
| 😽 | 😼 | 😽 | кот, целующийся с закрытыми глазами | |
| 😾 | 😽 | 😾 | кот, надувший губы | |
| 😿 | 😾 | 😿 | плачущий кот | |
| 🙀 | 😿 | 🙀 | усталый кот | |
| 🙅 | 🙅 | 🙅 | стоп, не нравится | |
| 🙆 | 🙆 | 🙆 | приветствует двумя руками | |
| 🙈 | 🙈 | 🙈 | обезьяна, закрывающая глаза от страха | |
| 🙉 | 🙉 | 🙉 | обезьяна, закрывающая уши | |
| 🙊 | 🙊 | 🙊 | обезьяна, держащая рот на замке | |
| 🙋 | 🙋 | 🙋 | человек, привлекающий внимание | |
| 🙌 | 🙌 | 🙌 | человек, поднимающий руки в восторге | |
| 🙍 | 🙍 | 🙍 | нахмурившийся человек | |
| 🙎 | 🙎 | 🙎 | человек с надутыми губами | |
| 🙏 | 🙏 | 🙏 | человек, сложивший ладошки |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ❦ | ❦ | ❦ | сердечко с завитушкой | |
| ❧ | ❧ | ❧ | сердечко с завитушкой, повернутое вправо | |
| ☙ | ☙ | ☙ | сердечко с завитушкой, повернутое влево | |
| ❣ | ❣ | ❣ | восклицательный знак в виде сердца | |
| ❤ | ❤ | ❤ | закрашенное сердце | |
| ❥ | ❥ | ❥ | закрашенное сердце, повернутое вправо | |
| ♡ | ♡ | ♡ | незакрашенная черва | |
| ♥ | ♥ | ♥ | закрашенная черва | |
| 💓 | 💓 | 💓 | бьющееся сердце | |
| 💔 | 💔 | 💔 | разбитое сердце | |
| 💕 | 💕 | 💕 | два сердца | |
| 💖 | 💖 | 💖 | игристое сердце | |
| 💗 | 💗 | 💗 | растущее сердце | |
| 💘 | 💘 | 💘 | сердце, пронзенное стрелой | |
| 💙 | 💙 | 💙 | сердце, заштрихованное горизонтально | |
| 💚 | 💚 | 💚 | сердце, заштрихованное сверху направо | |
| 💛 | 💛 | 💛 | сердце, заштрихованное сверху налево | |
| 💜 | 💜 | 💜 | сердце, заштрихованное вертикально | |
| 💝 | 💝 | 💝 | сердце с бантиком | |
| 💞 | 💞 | 💞 | вращающиеся сердца | |
| 💟 | 💟 | 💟 | декоративное сердце | |
| 🏩 | 🏩 | 🏩 | отель для влюбленных | |
| 💌 | 💌 | 💌 | любовное письмо | |
| 💑 | 💑 | 💑 | влюбленная пара | |
| 💐 | 💐 | 💐 | букет | |
| ✤ | ✤ | ✤ | цветок (вариант) | |
| ✥ | ✥ | ✥ | цветок (вариант) | |
| ✻ | ✻ | ✻ | цветок (вариант) | |
| ✼ | ✼ | ✼ | цветок (вариант) | |
| ✽ | ✽ | ✽ | цветок (вариант) | |
| ✾ | ✾ | ✾ | цветок (вариант) | |
| ✿ | ❀ | ✿ | цветок (вариант) | |
| ❀ | ❁ | ❀ | цветок (вариант) | |
| ❁ | ❂ | ❁ | цветок (вариант) | |
| 🌼 | 🌼 | 🌼 | цветок (вариант) | |
| ☘ | ☘ | ☘ | трилистник | |
| 🍀 | 🍀 | 🍀 | клевер | |
| ⚘ | ⚘ | ⚘ | цветок | |
| 🌷 | 🌷 | 🌷 | тюльпан | |
| 🌸 | 🌸 | 🌸 | цветок вишни | |
| 🌹 | 🌹 | 🌹 | роза | |
| 🌺 | 🌺 | 🌺 | гибискус | |
| 🌻 | 🌻 | 🌻 | подсолнечник |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ★ | ★ | ★ | закрашенная звезда | |
| ☆ | ☆ | ☆ | незакрашенная звезда | |
| ⚝ | ⚝ | ⚝ | звезда со скругленными концами | |
| ✡ | ✡ | ✡ | звезда Давида | |
| ✪ | ✪ | ✪ | звезда в закрашенном круге | |
| ⍟ | ⍟ | ⍟ | закрашенная звезда в круге | |
| ✫ | ✫ | ✫ | звезда с незакрашенным кружком | |
| ✭ | ✭ | ✭ | обведенная закрашенная звезда | |
| ✯ | ✯ | ✯ | вращающаяся звезда | |
| ✰ | ✰ | ✰ | незакрашенная звезда с тенью | |
| ✱ | ✱ | ✱ | жирная 6-конечная звездочка | |
| ✲ | ✲ | ✲ | 6-конечная звездочка с кружком | |
| ✳ | ✳ | ✳ | 8-конечная звездочка (снежинка) | |
| ✴ | ✴ | ✴ | 8-конечная звездочка с закрашенным кружком | |
| ✵ | ✵ | ✵ | 8-конечная вращающаяся звезда | |
| ✶ | ✶ | ✶ | 6-конечная закрашенная звезда | |
| ✷ | ✷ | ✷ | 8-конечная закрашенная звезда | |
| ✸ | ✸ | ✸ | жирная 8-конечная закрашенная звезда | |
| ✹ | ✹ | ✹ | жирная 12-конечная закрашенная звезда | |
| ✺ | ✺ | ✺ | 16-конечная звездочка с закрашенным кружком | |
| 🌟 | 🌟 | 🌟 | светящаяся звезда | |
| 🌠 | 🌠 | 🌠 | падающая звезда |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| 🐚 | F41A; | 🐚 | закрученная раковина | |
| 🐌 | F40C; | 🐌 | улитка | |
| 🐍 | F40D; | 🐍 | змея | |
| 🐛 | F41B; | 🐛 | гусеница | |
| 🐜 | F41C; | 🐜 | муравей | |
| 🐝 | F41D; | 🐝 | пчела | |
| 🐞 | F41E; | 🐞 | божья коровка | |
| 🐟 | F41F; | 🐟 | рыба | |
| 🐠 | F420; | 🐠 | тропическая рыба | |
| 🐡 | F421; | 🐡 | иглобрюхая рыба | |
| 🐬 | F42C; | 🐬 | дельфин | |
| 🐳 | F433; | 🐳 | кит выпускающий струю | |
| 🐙 | F419; | 🐙 | осьминог | |
| 🐢 | F422; | 🐢 | черепаха | |
| 🐧 | F427; | 🐧 | пингвин | |
| 🐦 | F426; | 🐦 | птица | |
| 🐔 | F414; | 🐔 | курица | |
| 🐣 | F423; | 🐣 | вылупившийся цыпленок | |
| 🐤 | F424; | 🐤 | цыпленок | |
| 🐥 | F425; | 🐥 | цыпленок в анфас | |
| 🐨 | F428; | 🐨 | коала | |
| 🐩 | F429; | 🐩 | пудель | |
| 🐫 | F42B; | 🐫 | двугорбый верблюд | |
| 🐎 | F40E; | 🐎 | лошадь | |
| 🐑 | F411; | 🐑 | овца | |
| 🐒 | F412; | 🐒 | обезьяна | |
| 🐗 | F417; | 🐗 | кабан | |
| 🐘 | F418; | 🐘 | слон | |
| 🐭 | F42D; | 🐭 | мордочка мыши | |
| 🐮 | F42E; | 🐮 | морда коровы | |
| 🐯 | F42F; | 🐯 | морда тигра | |
| 🐰 | F430; | 🐰 | морда кролика | |
| 🐱 | F431; | 🐱 | морда кота | |
| 🐴 | F434; | 🐴 | морда лошади | |
| 🐵 | F435; | 🐵 | морда обезьяны | |
| 🐶 | F436; | 🐶 | морда собаки | |
| 🐷 | F437; | 🐷 | морда свиньи | |
| 🐸 | F438; | 🐸 | морда лягушки | |
| 🐹 | F439; | 🐹 | морда хомяка | |
| 🐺 | F43A; | 🐺 | морда волка | |
| 🐻 | F43B; | 🐻 | морда медведя | |
| 🐼 | F43C; | 🐼 | морда панды |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ✂ | ✂ | ✂ | ножницы | |
| ✁ | ✁ | ✁ | ножницы с верхним лезвием | |
| ✃ | ✃ | ✃ | ножницы с нижним лезвием | |
| ✄ | ✄ | ✄ | незакрашенные ножницы | |
| ☎ | ☎ | ☎ | телефон | |
| ☏ | ☏ | ☏ | незакрашенный телефон | |
| ✆ | ✆ | ✆ | знак телефона | |
| ✉ | ✉ | ✉ | конверт | |
| ✏ | ✏ | ✏ | карандаш | |
| ✎ | ✎ | ✎ | карандаш, напрвленный вправо-вниз | |
| ✐ | ✐ | ✐ | карандаш, напрвленный вправо-вверх | |
| ✑ | ✑ | ✑ | незакрашенное острие пера | |
| ✒ | ✒ | ✒ | закрашенное острие пера | |
| 📌 | 📌 | 📌 | канцелярская кнопка | |
| 📍 | 📍 | 📍 | булавка | |
| 📎 | 📎 | 📎 | скрепка | |
| 📏 | 📏 | 📏 | линейка | |
| 📐 | 📐 | 📐 | треугольная линейка | |
| ✈ | ✈ | ✈ | самолет | |
| 🚀 | 🚀 | 🚀 | ракета | |
| 🚃 | 🚃 | 🚃 | вагон | |
| 🚄 | 🚄 | 🚄 | высокоскоростной поезд | |
| 🚇 | 🚇 | 🚇 | метро | |
| 🚉 | 🚉 | 🚉 | станция | |
| 🚌 | 🚌 | 🚌 | автобус | |
| 🚏 | 🚏 | 🚏 | остановка автобуса | |
| 🚑 | 🚒 | 🚑 | скорая помощь | |
| 🚒 | 🚓 | 🚒 | пожарная машина | |
| 🚓 | 🚔 | 🚓 | полицейская машина | |
| 🚕 | 🚖 | 🚕 | такси | |
| 🚗 | 🚘 | 🚗 | автомобиль | |
| 🚙 | 🚚 | 🚙 | джип | |
| 🚚 | 🚛 | 🚚 | грузовик | |
| 🚢 | 🚢 | 🚢 | корабль | |
| 🚤 | 🚤 | 🚤 | катер | |
| 🚥 | 🚥 | 🚥 | горизонтальный светофор | |
| 🚧 | 🚧 | 🚧 | предупреждающие огни | |
| 🚨 | 🚨 | 🚨 | полицейская мигалка | |
| 🚩 | 🚩 | 🚩 | треугольный флаг на стойке | |
| 🚪 | 🚪 | 🚪 | дверь | |
| 🚫 | 🚫 | 🚫 | не входить | |
| 🚬 | 🚬 | 🚬 | знак курения | |
| 🚭 | 🚭 | 🚭 | курить запрещено | |
| 🚲 | 🚲 | 🚲 | велосипед | |
| 🚶 | 🚶 | 🚶 | пешеход | |
| 🚹 | 🚹 | 🚹 | мужская уборная | |
| 🚺 | 🚺 | 🚺 | женская уборная | |
| 🚻 | 🚻 | 🚻 | уборная | |
| 🚼 | 🚼 | 🚼 | знак с ребенком | |
| ♿ | ♿ | ♿ | для инвалидов | |
| 🚽 | 🚽 | 🚽 | туалет | |
| 🚾 | 🚾 | 🚾 | женский туалет | |
| 🛀 | 🛀 | 🛀 | ванна | |
| ⛽ | ⛽ | ⛽ | знак заправки | |
| 🍴 | 🍴 | 🍴 | вилка и нож | |
| 🏠 | 🏠 | 🏠 | дом | |
| 💻 | 💻 | 💻 | персональный компьютер | |
| 🌴 | 🌴 | 🌴 | пальма |
Верите вы или нет, но существует формат изображений, встроенных в браузер. Этот формат позволяет загружать изображения до того, как они понадобились, обеспечивает рендеринг изображения на обычных или retina экранах и позволяет добавлять к изображениям CSS. ОК, это не совсем правда. Это не формат изображения, хотя все остальное остается в силе. Используя его, вы можете создавать иконки, независимые от разрешения, не требующие время на загрузку и стилизуемые с помощью CSS.
В этой статье я опишу основы Unicode (далее — Юникод) и некоторые интересные вещи, которые вы можете сделать с его помощью.
Что такое Юникод?
Юникод это возможность корректно отображать буквы и знаки пунктуации из различных языков на одной страницы. Он невероятно полезен: пользователи смогут работать с вашим сайтом по всему миру и он будет показывать то, что вы хотите — это может быть французский язык с диакритическими знаками или Kanji.
Юникод продолжает развиваться: сейчас актуальна версия 8.0 в которой более 120 тысяч символов (в оригинальной статье, опубликованной в начале 2014 года, речь шла о версии 6.3 и 110 тысячах символов).
Кроме букв и цифр, в Юникоде есть и другие символы и иконки. В последних версиях в их число вошли эмодзи, которые вы можете видеть в месседжере iOS.
Страницы HTML создаются из последовательности символов Юникода и при отсылке по сети они конвертируются в байты. Каждая буква и каждый символ любого языка имеют свой уникальный код и кодируются при сохранении файла.
При использовании системы кодирования UTF-8 вы можете напрямую вставлять в текст символы Юникода, но также можно добавлять их в текст, указывая цифровую символьную ссылку. Например, ♥ это символ сердечка и вы можете вывести этот символ, просто добавив код в разметку ♥.
Эту числовую ссылку можно задавать как в десятичном формате, так и в шестнадцатеричном. Десятичный формат требует добавления в начале буквы x, запись ♥ даст то же самое сердечко (♥), что и предыдущий вариант. (2665 это шестнадцатеричный вариант 9829).
Если вы добавляете символ Юникода с помощью CSS, то вы можете использовать только шестнадцатеричные значения.
Некоторые наиболее часто используемые символы Юникода имеют более запоминаемые текстовые имена или аббревиатуры вместо цифровых кодов — это, например, амперсанд (& — &). Такие символы называются мнемоники в HTML, их полный список есть в Википедии.
Почему вам стоит использовать Юникод?
Хороший вопрос, вот несколько причин:
- Чтобы использовать корректные символы из разных языков.
- Для замены иконок.
- Для замены иконок, подключаемых через
@font-face. - Для задания CSS-классов
Корректные символы
Первая из причин не требует никаких дополнительных действий. Если HTML сохранен в формате UTF-8 и его кодировка передана по сети как UTF-8, все должно работать как надо.
Должно. К сожалению, не все браузеры и устройства поддерживают все символы Юникода одинаково (точнее, не все шрифты поддерживают полный набор символов). Например, недавно добавленные символы эмодзи поддерживаются не везде.
Для поддержки UTF-8 в HTML5 добавьте <meta charset=utf-8> (при отсутствии доступа к настройкам сервера стоит добавить также <meta http-equiv= "Content-Type" content="text/html; charset=utf-8">). При старом доктайпе используется (<meta http-equiv="content-type" content="text/html; charset=UTF-8" />).
Иконки
Вторая причина использования Юникода это наличие большого количества полезных символов, которые можно использовать в качестве иконок. Например, ▶, ≡ и ♥.
Их очевидный плюс в том, что вам не надо никаких дополнительных файлов, чтобы добавить их на страницу, а, значит, ваш сайт будет быстрее. Вы также можете изменить их цвет или добавить тень с помощью CSS. А добавив переходы (css transition) вы сможете плавно менять цвет иконки при наведении на нее без каких-либо дополнительных изображений.
Предположим, что я хочу подключить индикатор рейтинга со звездами на свою страницу. Я могу сделать это так:
<span>★ ★ ★ ☆ ☆</span>
Получится следующий результат:
 Образец рейтинга в Firefox
Образец рейтинга в Firefox
Но если вам не повезет, вы увидите что-то вроде этого:
 Тот же рейтинг на BlackBerry 9000
Тот же рейтинг на BlackBerry 9000
Так бывает, если используемые символы отсутствуют в шрифте браузера или устройства (к счастью, эти звездочки поддерживаются отлично и старые телефоны BlackBerry являются здесь единственным исключением).
Если символ Юникода отсутствует, на его месте могут быть разные символы от пустого квадрата (□) до ромба со знаком вопроса (�).
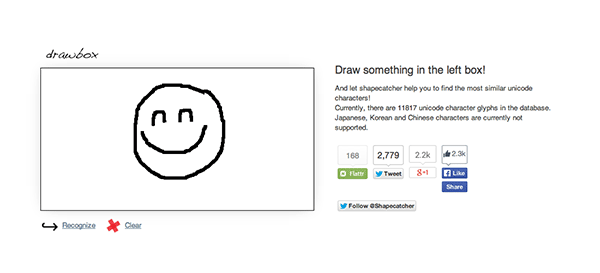
А как найти символ Юникода, который может подойти для использования в вашем дизайне? Вы можете поискать его на сайте типа Unicodinator, просматривая имеющиеся символы, но есть и лучший вариант. Shapecatcher — этот отличный сайт позволяет вам нарисовать искомую иконку, после чего предлагает вам список похожих символов Юникода.
Использование Юникода с @font-face иконками
Если вы используете иконки, подключаемые с внешним шрифтом через @font-face, символы Юникода можно использовать в качестве запасного варианта. Таким образом вы можете показать похожий символ Юникода на тех устройствах или в браузерах, где @font-face не поддерживается:

Слева иконки Font Awesome в Chrome, а справа замещающие их символы Юникода в Opera Mini.
Многие инструменты для подбора @font-face используют диапазон символов Юникода из области для частного использования (private use area). Проблема этого подхода в том, что если @font-face не поддерживается, пользователю передаются коды символов без какого-либо смысла.
Использование символов из области для частного использования может также вынудить Internet Explorer 8 перейти в режим совместимости, а это сродни открытию портала в ад и призванию отвратительных монстров из старых IE (подробнее эта проблема описана в статье Джереми Кита).
IcoMoon отлично подходит для создания наборов иконок в @font-face и позволяет выбрать в качестве основы для иконки подходящий символ Юникода.
Но будьте внимательны — некоторые браузеры и устройства не любят отдельные символы Юникода при их использовании с @font-face. Имеет смысл проверить поддержку символов Юникода с помощью Unify — это приложение поможет вам определить, насколько безопасно использование символа в наборе иконок @font-face.
Поддержка символов Юникода
Основная проблема с использованием символов Юникода в качестве запасного варианта это плохая поддержка в скринридерах (опять-таки, некоторые сведения об этом можно найти на Unify), поэтому важно осторожно выбирать используемые символы.
Если ваша иконка это просто декоративный элемент рядом с текстовой меткой, читаемым скринридером, вы можете особо не волноваться. Но если иконка расположена отдельно, стоит добавить скрытую текстовую метку, чтобы помочь пользователям скринридеров. Даже если символ Юникода будет считан скринридером, есть вероятность, что он будет сильно отличен от своего предназначения. Например, ≡ (≡) в качестве иконки-гамбургера будет считан VoiceOver на iOS как “идентичный”.
Юникод в названиях CSS-классов
То, что Юникод можно использовать в названиях классов и в таблицах стилей известно с 2007 года. Именно тогда Джонатан Снук написал об использовании символов Юникода во вспомогательных классов при верстке скругленных углов. Особого распространения эта идея не получила, но о возможности использовать Юникод в названиях классов (спецсимволы или кириллицу) знать стоит.
Выбор шрифтов
Совсем немногие шрифты поддерживают полный набор символов Юникода, поэтому при выборе шрифта сразу проверяйте наличие нужных вам символов.
Из шрифтов с полной поддержкой Юникода наиболее известны Noto, поддерживающий Юникод версии 6.2 и GNU Unifont (версия Юникода 8.0.01).
Много иконок в Segoe UI Symbol или Arial Unicode MS. Эти шрифты есть и на PC и на Mac; в Lucida Grande также достаточное количество символов Юникода. Вы можете добавить эти шрифты в декларацию font-family, чтобы обеспечить наличие максимального количества символов Юникода для пользователей, у которых эти шрифты установлены.
Определение поддержки Юникода
Было бы очень удобно иметь возможность проверить наличие того или иного символа Юникода, но нет гарантированного способа сделать это.
В Modernizr есть проверка поддержки эмодзи — но она работает проверкой одного пикселя и поэтому даст неправильный результат, если в нужном символе этот пиксель не используется. Да и сама проверка наличия отдельного символа не скажет ничего о поддержке остальных ста тысяч.
Проверяйте. И обеспечивайте запасные варианты, чтобы пользователь всегда мог понять, что происходит при отсутствии нужного символа.
Юникод в письмах
Юникод можно использовать не только на веб-страницах, но и в письмах.
Но здесь есть та же проблема: некоторые почтовые клиенты и некоторые устройства поддерживают нужные символы, а некоторые нет. Небольшое тестирование, позволяющее определить уровень поддержки символов, было проведено Campaign Monitor.
Символы Юникода могут быть эффективны при наличии поддержки. Например, эмодзи в теме письма выделяет его на фоне остальных в почтовом ящике.
Заключение
Эта статья затрагивает лишь основы Юникода. Надеюсь, она окажется полезной и поможет вам лучше понять Юникод и эффективно применять его.
Список ссылок
- “Пуленепробиваемые” иконочные шрифты
- Символы Юникода в теме письма
- IcoMoon (Генератор набора иконок @font-face на основе Юникода)
- Shape Catcher (Инструмент для распознавания символов Юникода)
- Unicodinator(таблица символов Юникода)
- Unify (Проверка поддержки символов Юникода в браузерах)
- Unitools (Коллекция инструментов для работы с Юникодом)
Описание кириллицы и способы ее использования
В России имеется свой алфавит и свои особенности написания. Они выражаются в так называемой кириллице, которую используют как для письма в любых видах, так и для регистрации в доменной зоне Российской Федерации.
Современная версия кириллицы представляет собой усовершенствованный вариант алфавита от Кирилла и Мефодия. Именно она и станет предметом изучения статьи.
Немного предыстории
Начало кириллического правописания восходит к IX веку. Инициатором ее создания выступил византийский император Михаил Третий, желавший донести религиозные тексты до верующих. Разработка этой темы была поручена Кириллу и Мефодию.
Теперь немного интересных фактов из истории кириллицы:
Вместе с развитием языка начинается распространение таких книг, как Библия, Евангелие, иные церковнославянские издания. Однако в своем первоначальном виде кириллица не сохранилась. Она претерпела изменения вместе с развитием страны.
Современный алфавит
В своем нынешнем виде кириллический алфавит имеет всего 33 буквы. Современный русский язык стал таковым в результате масштабной орфографической реформы, проведенной в 1917—1918 годах. Целью данных преобразований было упрощение алфавита и более широкий доступ к соответствующей письменности простых граждан. Именно современная версия кириллической азбуки стала основой для ряда неславянских языков на территории бывшего СССР и Монголии. Самым распространенным является гражданский шрифт, которым пользуются большинство граждан России, Украины, Беларуси, Болгарии и многих других.
Кириллица в кодировке
В настоящее время получило распространение использование кириллицы при регистрации сайтов, доменов, различных операторов в Интернете. Некоторые люди задаются вопросом: что такое кириллица в пароле? Это означает, что она записана в вордовском документе или зарегистрирована с помощью определенной кодировки.
На сегодняшний день имеются следующие виды кодировки, применяемые на компьютере:
Каждая из кодировок имеет место в качестве используемой в том или ином документе. Вы можете настроить в документе в соответствующем разделе собственную кодировку. Однако наиболее популярно написание русских символов, настраиваемое через юникод, потому что данная программа установлена на большинстве компьютеров.
Юникодовская кириллица
Последняя, 9 версия программы Юникод установила для данной письменности 5 блоков. Помимо основного кода под названием Cirillic, имеются дополнения в виде Supplement, Extended-A, B, C. Последние 3 варианта кодировки представляют собой расширенную версию кириллицы.
В стандартной кодировке имеются обычные буквы, исторические, дополнительные символы для славянских языков. В расширенных версиях также добавляются такие элементы, как надстрочные буквы, предназначенные для церковнославянского языка, исторические начертания современных букв и некоторые другие старинные буквы.
При этом следует отметить, что юникод не имеет в своем арсенале ударений. Если это необходимо использовать при написании тех или иных документов, то следует делать их составными. Для этого добавляют так называемый U+0301, он же combining acute accent. Его ставят после гласной ударной буквы, это такие, как е, ы, ю, я и некоторые другие гласные, в которых надо поставить ударение.
Достаточно длительное время для юникода было проблемным составлять церковнославянскую письменность, но после версии 5.1 данная проблема практически исчезла и нужные символы были добавлены в качестве используемых.
История данной письменности достаточно интересная и познавательная. Претерпев значительные изменения, она обрела свой нынешний вид и активно используется как в обычном письме, так и в компьютерных программах. Последние предлагают немало вариантов кодировки, каждый из которых подойдет под определенные задачи. Несмотря на относительную простоту, кириллица имеет значительную популярность и применяется даже в неславянских языках в качестве базы для дальнейшего развития.
При этом предпринимаются попытки отказа от кириллической письменности в пользу латиницы, что произвели немало стран бывшего советского пространства. Однако кириллическая письменность продолжает существовать и развиваться. Удачного изучения кириллицы и русского алфавита, в них можно найти много познавательных вещей!
Видео
Из этого видео вы узнаете, что же такое кириллица.
Источник
Кириллица — это какие буквы на клавиатуре
 Русскоязычную раскладку клавиатуры во всем мире называют кириллицей. Она популярна среди носителей языка и узнаваема даже теми, кто никогда не занимался изучением языков славянской группы. Разберемся, какие буквы называются кириллицей, а какие латиницей.
Русскоязычную раскладку клавиатуры во всем мире называют кириллицей. Она популярна среди носителей языка и узнаваема даже теми, кто никогда не занимался изучением языков славянской группы. Разберемся, какие буквы называются кириллицей, а какие латиницей.
Раскладка клавиатуры по-русски
Первая клавиатура создавалась с латинскими символами. Но распространяясь, она обзавелась дополнительными символами других языков, от которых слабо отличалась (например, немецкий). А для других языков и вовсе поменяла свой внешний вид. Яркий тому пример кириллица.

Почему русская раскладка называется кириллицей
Как ни странно, символы на «русской» клавиатуре не являются самой кириллицей, а лишь созданы на основе ее. Кириллица — это старославянская письменность, которая в настоящее время в повседневном письме не используется. Так как кириллица была некогда создана апостолами Кириллом и Мефодием, она стала, по сути, первой письменностью на Руси. В честь нее решили назвать и русскоязычную раскладку на клавиатуре.
Как расположен русский алфавит на клавиатуре
Буквы кириллической раскладки, созданной уже после опытов с Qwerty, расположены не в алфавитном порядке, а в зависимости от частоты их использования. Так как российская раскладка создавалась несколько позднее латинской, то были учтены ошибки последнего опыта.
ВАЖНО! Российская раскладка является более эргономичной и удобной как для простой печати, так и для набора вслепую.

Буквы в ней расположены по следующему принципу:
СПРАВКА! Основным недостатком кириллической раскладки является расположение запятой, которой не досталось отдельной клавиши.
Чтобы ее поставить в тексте, необходимо использовать сразу две клавиши. Некоторые считают, что именно это послужило причиной частого опускания запятых при быстрой электронной переписке.
Переход с кириллицы на латиницу и обратно
В адаптированных компьютерах и ноутбуках перейти на кириллицу не составит труда. Однако если установленная у вас система не предполагает сразу быстрого доступа к русской раскладке, то необходимо будет произвести дополнительные настройки.
СПРАВКА! Аналогично можно будет подключить и любые другие раскладки, что наиболее актуально для тех, кто изучает несколько иностранных языков.
Второй язык клавиатуры — латиница
Латиница часто выступает в роли основной раскладки, так как без ее использования буквально не обойтись. Мало того, что все общение в интернете (URL-адреса сайтов, e-mail) прописываются латиницей, так и операции в той же командной строке набираются именно латинскими буквами.
Если у вас нет в настройках быстрого доступа к кириллице, то придется произвести несколько действий по ее добавлению. Для этого достаточно следовать простому алгоритму.
Справка: в этой же вкладке при необходимости можно изменить язык интерфейса Windows.
Как перейти с кириллицы на латиницу и вернуться назад
 При печати часто требуется смена раскладки, будь то сообщения на иностранных языках, адреса сайтов и электронных почт, а также некоторые специальные символы, которые недоступны на кириллической раскладке (например, квадратные скобки).
При печати часто требуется смена раскладки, будь то сообщения на иностранных языках, адреса сайтов и электронных почт, а также некоторые специальные символы, которые недоступны на кириллической раскладке (например, квадратные скобки).
Сочетание клавиш
Если бы переключение раскладки производилось каждый раз вручную через настройки, то это значительно бы замедлило скорость печати. Поэтому выделили несколько сочетаний клавиш, которые для переключения необходимо нажимать одновременно:
Справка: если вы подключили несколько раскладок, то они будут переключаться по очереди. Поэтому возможно, придется нажать на клавиши несколько раз.
Панель быстрого доступа
Чуть менее быстрый способ изменения раскладки через панель быстрого доступа. Однако он более удобен, если у вас подключено более трех раскладок. Справа в нижней панели есть значок раскладки, представляющий собой 2–3 буквы от названия алфавита (EN — латиница, РУС — кириллица). При нажатии на него левой кнопкой мыши будут отображены все подключенные раскладки. Из них еще одним щелчком вы можете выбрать необходимую.
Источник
LiveInternetLiveInternet
—Рубрики
—Кнопки рейтинга «Яндекс.блоги»
—Поиск по дневнику
—Подписка по e-mail
—Постоянные читатели
—Сообщества
—Статистика
КИРИЛЛИЦА: коды символов для HTML
Если в нерусскоязычную страницу требуется вставить русские буквы или же в русском тексте необходимы старославянские (кириллические) символы, например, буква » ѣ » («ять») (см. страницу «КИРИЛЛИЦА: азбука, буквенное счисление»), то я предложу Вам несколько решений:
1. Рисовать
банально рисуем буквы графикой:
2. Подменять
довольно неплохой результат дает замена недостающих символов другими: например, за букву «ять» сойдет перечеркнутый мягкий знак: Ь, «фиту» нам даст зачеркнутая «О» или цифра ноль: 0; кси-пси-омегу-ижицу и т. п. можно «сотворить» из похожих греческих букв: ξ ψ ω υ (см. коды греческих букв для HTML); «и десятеричное» и та же «ижица» получаются из латиницы: i v; и т. д.
преимущества: текст остается легким и при этом читаемым
3. Кодировать
оказывается, в некоторых unicode-шрифтах есть самые настоящие кириллические юсы-яти-ижицы и т. д., предусмотрен практически полный набор символов (не нашел я разве что только «двугласную» «ia»). Как же вставить в текст «интересные» буквы? Во-первых, необходимо использовать по возможности шрифт, имеющий расширенную таблицу кириллических символов, а во-вторых, на месте «сложных» букв ставить их коды (см. таблицу ниже). Пример использования кодов кириллических букв среди русского текста:
Радѹйсѧ, Свѣтъ нєизрєчєннѡ родившаѧ
преимущества: используются полноценные буквы кириллицы, не их эрзац-заменители из чужих алфавитов.
недостатки: не каждый читатель увидит буквы, не входящие в современную русскую азбуку. В системе должен быть установлен «правильный» шрифт. Отрадно, что один из таких шрифтов становится де-факто стандартным: начиная с MS Office-2000, все «Офисы» внедряют в Windows шрифт Arial Unicode MS, содержащий нужные нам значки.
Таблица символов кириллицы, современного русского алфавита и некоторых знаков:
| буква/знак | название кир. | название рус. | код | ||
| загл. | строчн. | загл. | строчн. | ||
| буквы кириллицы и русского алфавита (вперемешку): | |||||
| А | а | аз | а | А | а |
| Б | б | буки | бэ | Б | б |
| В | в | веди | вэ | В | в |
| Г | г | глаголь | гэ | Г | г |
| Д | д | добро | дэ | Д | д |
| Є | є | есть | — | Є | є |
| Е | е | — | е | Е | е |
| Ё | ё | — | ё | Ё | ё |
| Ж | ж | живете | же | Ж | ж |
| Ѕ | ѕ | зело | — | Ѕ | ѕ |
| З | з | земля | зэ | З | з |
| І | і | и (десятеричное) | — | І | і |
| И | и | иже | и | И | и |
| Й | й | — | и краткое | Й | й |
| К | к | како | ка | К | к |
| Л | л | люди | эль | Л | л |
| М | м | мыслете | эм | М | м |
| Н | н | наш | эн | Н | н |
| О | о | он | о | О | о |
| П | п | покой | пэ | П | п |
| Р | р | рцы | эр | Р | р |
| С | с | слово | эс | С | с |
| Т | т | твердо | тэ | Т | т |
| Ѹ | ѹ | ук | — | Ѹ | ѹ |
| У | у | — | у | У | у |
| Ф | ф | ферт | эф | Ф | ф |
| Х | х | хер | ха | Х | х |
| Ѡ | ѡ | омега | — | Ѡ | ѡ |
| Ц | ц | цы | це | Ц | ц |
| Ч | ч | червь | че | Ч | ч |
| Ш | ш | ша | ша | Ш | ш |
| Щ | щ | ща | ща | Щ | щ |
| Ъ | ъ | ер | твердый знак | Ъ | ъ |
| Ы | ы | еры | ы | Ы | ы |
| Ь | ь | ерь | мягкий знак | Ь | ь |
| Ѣ | ѣ | ять | — | Ѣ | ѣ |
| Э | э | — | э (оборотное) | Э | э |
| Ю | ю | ю | ю | Ю | ю |
| — | — | (й)я | — | — | — |
| Ѥ | ѥ | (й)е | — | Ѥ | ѥ |
| Ѧ | ѧ | юс малый | — | Ѧ | ѧ |
| Я | я | — | я | Я | я |
| Ѫ | ѫ | юс большой | — | Ѫ | ѫ |
| Ѩ | ѩ | йотированный юс малый | — | Ѩ | ѩ |
| Ѭ | ѭ | йотированный юс большой | — | Ѭ | ѭ |
| Ѯ | ѯ | кси | — | Ѯ | ѯ |
| Ѱ | ѱ | пси | — | Ѱ | ѱ |
| Ѳ | ѳ | фита | — | Ѳ | ѳ |
| Ѵ | ѵ | ижица | — | Ѳ | ѳ |
| + дополнительные полезные буквы: | |||||
| Ї | ї | i с двумя точками (крапками), i-умляут | — | Ї | ї |
| Ѿ | ѿ | от | — | Ѿ | ѿ |
| Ѻ | ѻ | омега круглая | — | Ѻ | ѻ |
| ˊ | оксия (прямое (острое) ударение) (?) | ˊ | |||
| ˋ | вария (обратное (тупое) ударение) (?) | ˋ | |||
| а̑ | камора (?) * | ̑ | |||
| ˘ | краткая (знак краткости) | ˘ | |||
| д̾ | ерок (ерик) (?) * | ̾ | |||
| ¨ | две точки (умляут) | ¨ | |||
| ҃ | титло | ҃ | |||
| ¯ | надчеркивание | ¯ | |||
| ˀ | придыхание (?) | ˀ | |||
| а̉ | крюк (?) * | ̉ | |||
| ҄ | смягчение (?) | ҄ | |||
| ҂ | знак тысячи | ҂ |
* ) данные знаки не являются отдельными символами, не занимают место отдельной буквы в тексте, а «наскакивают» на букву, после которой стоят
Итак, как же использовать наши знания «секретных» кодов для создания web-страниц?
Ситуация 1:
Необходим кириллический текст (с «ятями»). Что делать? Можно буквы, совпадающие в русском и кириллическом алфавитах писать русским текстом, а вместо недостающих «ятей» вставлять их коды из вышеприведенной таблицы.
получаем на экране:
ижє хєрѹвімы тайнѡ ѡбразѹющє
Текст остается русским, но содержит «расширенную» кириллицу.
Ситуация 2:
В текст, написанный исключительно латиницей (например, английский) или вообще любым другим языком, отличным от русского, необходимо «вживить» русское слово. Обычно такие страницы предлагается писать в формате Unicode, но есть и такой вариант: писать как обычно, а русское слово набирать из кодов символов, взятых из таблицы выше.
получаем на экране:
In Old Russian, «красный» (krasny) meant both «red» and «beautiful».
Текст остается нерусским, но содержит русские буквы.
ВНИМАНИЕ. ПОСТ НАХОДИТСЯ В СТАДИИ РАЗРАБОТКИ, ДУМАЮ К ВОСКРЕСЕНЬЮ БУДЕТ ГОТОВ ИЛИ. ну сами понимаете. Извините.
Процитировано 4 раз
Понравилось: 1 пользователю
Источник
Кириллица в Юникоде
Начиная с версии Юникода 5.1 для кириллицы выделено четыре раздела:
| название | диапазон кодов (hex) | версия Юникода | ||
|---|---|---|---|---|
| Cyrillic | кириллица | 0400 | 04FF | 1.1 |
| Cyrillic Supplement | кириллица (приложение) | 0500 | 052F | 3.2 |
| Cyrillic Extended-A | кириллица (расширение A) | 2DE0 | 2DFF | 5.1 |
| Cyrillic Extended-B | кириллица (расширение B) | A640 | A69F | 5.1 |
Эти 4 раздела занимают в кодовом пространстве Юникода 432 позиции, из которых 15 пока свободны (не определены). Кроме того, в нижеприведённую большую таблицу включены 3 символа, не входящие в эти 4 раздела (см. «Разное»).
Символы можно разделить на 6 групп:
Содержание
Проблемы и особенности использования
Символы кириллицы в версии Юникода 6.0
В нижеприведённой таблице строчные буквы упорядочены в порядке возрастания их юникодовских номеров (за исключением Ё, поставленной на своём алфавитном месте, и украинской Ґ, перемещённой в конец блока дополнительных знаков для современных славянских языков). Прописные буквы стоят непосредственно перед соответствующими строчными буквами.
Колонка «КР» означает «каноническое разложение» — если ячейка в этом столбце не пуста, то символ можно представить в виде сочетания базового символа и диакритического знака.
Английские названия символов, написанные заглавными буквами (колонка «название») являются частью стандарта Юникода. Названия на других языках, включая русский и прочие языки на кириллической основе, в стандарте юникода не прописаны. При этом для многих символов официальных названий на русском языке нет, а некоторые другие символы имеют разные названия в разных кириллических языках (например, «Ъ» в русском алфавите называется «Твёрдый знак», в церковнославянском — «Еръ», а в болгарском — «Ер голям»).
Источник
Что такое кириллические символы в пароле
В статье рассказывается о том, что такое кириллица в пароле, почему использовать ее нельзя, и из-за чего возникает ошибка с таким содержанием.
Пароль

В наш век цифровых технологий сложно найти человека, который бы не пользовался различными электронными устройствами и гаджетами. И в каждом из них порой возникает необходимость защиты информации от доступа посторонних, и самое удачное решение – это обычный пароль. Также нужен он и для авторизации в программах и интернет-сервисах. И если с именем все понятно, то как понять, что именно его владелец пытается войти в тот же «ВКонтакте»? В этом случае на помощь приходит пароль. Но часто система его не принимает, ругаясь на наличие русских букв. Так что такое кириллица в пароле, и почему ее использование ошибочно?
«Неправильный пароль»
Подобное системное сообщение возникает в случае его ошибочности. К примеру, пользователь случайно ввел не тот символ и не обратил на это внимания. Но порой, казалось бы, все верно, многократно проверено, но войти под своей учетной записью все не выходит. Одна из возможных причин ошибки – это то, что человек забыл сменить раскладку клавиатуры или же использовал в нем кириллический символ. Обычно для удобства пользователей сайт или приложение может об этом предупредить, выдав подсказку, что в кодовой фразе есть буква русского алфавита. Но подобная функциональность встречается не во всех сервисах. Так что мы разобрались с тем, что такое кириллица в пароле.
Для исправления такой ошибки нужно просто быть внимательнее, – проверить, на каком языке вводится информация, и не включена ли клавиша Caps Lock. Ведь к примеру, Planeta и PlAnEtA – совершенно разные пароли, и об этом стоит помнить. Но почему использование наших «родных» букв запрещено?
Универсальность

Разбирая вопрос, что такое кириллица в пароле, нужно упомянуть общее положение дел в компьютерном мире. Все дело в том, что они и Интернет распространены по всем странам, как и их различные сервисы. И большое количество программного обеспечения, названий, документации и прочего переводится на язык нужного региона, но так бывает не всегда и не со всеми. Ведь одно дело – интерфейс программы или сайта, а другое – техническая информация, внутренние файлы настроек и то, что обычному пользователю вовсе не понадобится. Все это составляется на английском языке. Как и с реальной жизнью, в компьютерном мире он тоже является универсальным и международным.
Именно потому в пароле нельзя использовать кириллицу, как и арабские символы с китайскими иероглифами.
В России имеется свой алфавит и свои особенности написания. Они выражаются в так называемой кириллице, которую используют как для письма в любых видах, так и для регистрации в доменной зоне Российской Федерации.
Современная версия кириллицы представляет собой усовершенствованный вариант алфавита от Кирилла и Мефодия. Именно она и станет предметом изучения статьи.
Немного предыстории
Начало кириллического правописания восходит к IX веку. Инициатором ее создания выступил византийский император Михаил Третий, желавший донести религиозные тексты до верующих. Разработка этой темы была поручена Кириллу и Мефодию.
Теперь немного интересных фактов из истории кириллицы:
Вместе с развитием языка начинается распространение таких книг, как Библия, Евангелие, иные церковнославянские издания. Однако в своем первоначальном виде кириллица не сохранилась. Она претерпела изменения вместе с развитием страны.
Современный алфавит
В своем нынешнем виде кириллический алфавит имеет всего 33 буквы. Современный русский язык стал таковым в результате масштабной орфографической реформы, проведенной в 1917—1918 годах. Целью данных преобразований было упрощение алфавита и более широкий доступ к соответствующей письменности простых граждан. Именно современная версия кириллической азбуки стала основой для ряда неславянских языков на территории бывшего СССР и Монголии. Самым распространенным является гражданский шрифт, которым пользуются большинство граждан России, Украины, Беларуси, Болгарии и многих других.
Кириллица в кодировке
В настоящее время получило распространение использование кириллицы при регистрации сайтов, доменов, различных операторов в Интернете. Некоторые люди задаются вопросом: что такое кириллица в пароле? Это означает, что она записана в вордовском документе или зарегистрирована с помощью определенной кодировки.
На сегодняшний день имеются следующие виды кодировки, применяемые на компьютере:
Каждая из кодировок имеет место в качестве используемой в том или ином документе. Вы можете настроить в документе в соответствующем разделе собственную кодировку. Однако наиболее популярно написание русских символов, настраиваемое через юникод, потому что данная программа установлена на большинстве компьютеров.
Юникодовская кириллица
Последняя, 9 версия программы Юникод установила для данной письменности 5 блоков. Помимо основного кода под названием Cirillic, имеются дополнения в виде Supplement, Extended-A, B, C. Последние 3 варианта кодировки представляют собой расширенную версию кириллицы.
В стандартной кодировке имеются обычные буквы, исторические, дополнительные символы для славянских языков. В расширенных версиях также добавляются такие элементы, как надстрочные буквы, предназначенные для церковнославянского языка, исторические начертания современных букв и некоторые другие старинные буквы.
При этом следует отметить, что юникод не имеет в своем арсенале ударений. Если это необходимо использовать при написании тех или иных документов, то следует делать их составными. Для этого добавляют так называемый U+0301, он же combining acute accent. Его ставят после гласной ударной буквы, это такие, как е, ы, ю, я и некоторые другие гласные, в которых надо поставить ударение.
Достаточно длительное время для юникода было проблемным составлять церковнославянскую письменность, но после версии 5.1 данная проблема практически исчезла и нужные символы были добавлены в качестве используемых.
История данной письменности достаточно интересная и познавательная. Претерпев значительные изменения, она обрела свой нынешний вид и активно используется как в обычном письме, так и в компьютерных программах. Последние предлагают немало вариантов кодировки, каждый из которых подойдет под определенные задачи. Несмотря на относительную простоту, кириллица имеет значительную популярность и применяется даже в неславянских языках в качестве базы для дальнейшего развития.
При этом предпринимаются попытки отказа от кириллической письменности в пользу латиницы, что произвели немало стран бывшего советского пространства. Однако кириллическая письменность продолжает существовать и развиваться. Удачного изучения кириллицы и русского алфавита, в них можно найти много познавательных вещей!
Видео
Из этого видео вы узнаете, что же такое кириллица.
Для ввода имени пользователя и пароля разрешается применять следующие символы. Имя пользователя и пароль следует вводить с учетом регистра.
Заглавные латинские буквы: от A до Z (26 символов)
Строчные латинские буквы: от a до z (26 символов)
Цифры от 0 до 9 (10 символов)
Имя пользователя для входа в систему
Пробелы, двоеточия и кавычки не допускаются.
Оно не может состоять только из цифр, и поле нельзя оставлять незаполненным.
Длина ограничивается 32 символами.
Пароль для входа в систему
Максимально допустимая длина пароля для администраторов и супервайзера составляет 32 символа, тогда как для пользователей длина ограничивается 128 символами.
В отношении типов символов, которые могут использоваться для задания пароля, никаких ограничений не установлено. В целях безопасности рекомендуется создавать пароли, содержащие буквы верхнего и нижнего регистров, цифры и другие символы. Чем большее число символов используется в пароле, тем более трудной является задача его подбора для посторонних лиц.
В подразделе [Политика паролей] раздела [Расширенная безопасность] вы можете установить требование в отношении обязательного включения в пароль букв верхнего и нижнего регистров, цифр и других символов, а также минимально необходимое количество символов в пароле. Для получения сведений об определении политики паролей см. Настройка функций расширенной безопасности.
Источник
Юникод для чайников
Время на прочтение
8 мин
Количество просмотров 320K

Сам я не очень люблю заголовки вроде «Покемоны в собственном соку для чайниковкастрюльсковородок», но это кажется именно тот случай — говорить будем о базовых вещах, работа с которыми довольно часто приводить к купе набитых шишек и уйме потерянного времени вокруг вопроса — «Почему же оно не работает?». Если вы до сих пор боитесь иили не понимаете Юникода — прошу под кат.
Зачем?
Главный вопрос новичка, который встречается с впечатляющим количеством кодировок и на первый взгляд запутанными механизмами работы с ними (например, в Python 2.x). Краткий ответ — потому что так сложилось 
Кодировкой, кто не знает, называют способ представления в памяти компьютера (читай — в нулях-единицахчислах) цифр, буков и всех остальных знаков. Например, пробел представляется как 0b100000 (в двоичной), 32 (в десятичной) или 0x20 (в шестнадцатеричной системе счисления).
Так вот, когда-то памяти было совсем немного и всем компьютерам было достаточно 7 бит для представления всех нужных символов (цифры, строчныйпрописной латинский алфавит, куча знаков и так называемые управляемые символы — все возможные 127 номеров были кому-то отданы). Кодировка в это время была одна — ASCII. Шло время, все были счастливы, а кто не был счастлив (читай — кому не хватало знака «©» или родной буквы «щ») — использовали оставшиеся 128 знаков на свое усмотрение, то есть создавали новые кодировки. Так появились и ISO-8859-1, и наши (то есть кириличные) cp1251 и KOI8. Вместе с ними появилась и проблема интерпретации байтов типа 0b1******* (то есть символовчисел от 128 и до 255) — например, 0b11011111 в кодировке cp1251 это наша родная «Я», в тоже время в кодировке ISO-8859-1 это
греческая
немецкая Eszett (подсказывает Moonrise) «ß». Ожидаемо, сетевая коммуникация и просто обмен файлами между разными компьютерами превратились в чёрт-знает-что, несмотря на то, что заголовки типа ‘Content-Encoding’ в HTTP протоколе, email-письмах и HTML-страницах немного спасали ситуацию.
В этот момент собрались светлые умы и предложили новый стандарт — Unicode. Это именно стандарт, а не кодировка — сам по себе Юникод не определяет, как символы будут сохранятся на жестком диске или передаваться по сети. Он лишь определяет связь между символом и некоторым числом, а формат, согласно с которым эти числа будут превращаться в байты, определяется Юникод-кодировками (например, UTF-8 или UTF-16). На данный момент в Юникод-стандарте есть немного более 100 тысяч символов, тогда как UTF-16 позволяет поддерживать более одного миллиона (UTF-8 — и того больше).
Полней и веселей по теме советую почитать у великолепного Джоеля Спольски The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets.
Ближе к делу!
Естественно, есть поддержка Юникода и в Пайтоне. Но, к сожалению, только в Python 3 все строки стали юникодом, и новичкам приходиться убиваться об ошибки типа:
>>> with open('1.txt') as fh:
s = fh.read()
>>> print s
кощей
>>> parser_result = u'баба-яга' # присвоение для наглядности, представим себе, что это результат работы какого-то парсера
>>> parser_result + s
Traceback (most recent call last):
File "<pyshell#43>", line 1, in <module>
parser_result + s
UnicodeDecodeError: 'ascii' codec can't decode byte 0xea in position 0: ordinal not in range(128)
или так:
>>> str(parser_result)
Traceback (most recent call last):
File "<pyshell#52>", line 1, in <module>
str(parser_result)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-3: ordinal not in range(128)
Давайте разберемся, но по порядку.
Зачем кто-то использует Юникод?
Почему мой любимый html-парсер возвращает Юникод? Пусть возвращает обычную строку, а я там уже с ней разберусь! Верно? Не совсем. Хотя каждый из существующих в Юникоде символов и можно (наверное) представить в некоторой однобайтовой кодировке (ISO-8859-1, cp1251 и другие называют однобайтовыми, поскольку любой символ они кодируют ровно в один байт), но что делать если в строке должны быть символы с разных кодировок? Присваивать отдельную кодировку каждому символу? Нет, конечно, надо использовать Юникод.
Зачем нам новый тип «unicode»?
Вот мы и добрались до самого интересного. Что такое строка в Python 2.x? Это просто байты. Просто бинарные данные, которые могут быть чем-угодно. На самом деле, когда мы пишем что-нибудь вроде:
>>> x = 'abcd'
>>> x
'abcd'
интерпретатор не создает переменную, которая содержит первые четыре буквы латинского алфавита, но только последовательность
('a', 'b', 'c', 'd')с четырёх байт, и латинские буквы здесь используются исключительно для обозначения именно этого значения байта. То есть ‘a’ здесь просто синоним для написания ‘x61’, и ни чуточку больше. Например:
>>> 'x61'
'a'
>>> struct.unpack('>4b', x) # 'x' - это просто четыре signed/unsigned char-а
(97, 98, 99, 100)
>>> struct.unpack('>2h', x) # или два short-а
(24930, 25444)
>>> struct.unpack('>l', x) # или один long
(1633837924,)
>>> struct.unpack('>f', x) # или float
(2.6100787562286154e+20,)
>>> struct.unpack('>d', x * 2) # ну или половинка double-а
(1.2926117739473244e+161,)
И всё!
И ответ на вопрос — зачем нам «unicode» уже более очевиден — нужен тип, который будет представятся символами, а не байтами.
Хорошо, я понял чем есть строка. Тогда что такое Юникод в Пайтоне?
«type unicode» — это прежде всего абстракция, которая реализует идею Юникода (набор символов и связанных с ними чисел). Объект типа «unicode» — это уже не последовательность байт, но последовательность собственно символов без какого либо представления о том, как эти символы эффективно сохранить в памяти компьютера. Если хотите — это более высокой уровень абстракции, чем байтовый строки (именно так в Python 3 называют обычные строки, которые используются в Python 2.6).
Как пользоваться Юникодом?
Юникод-строку в Python 2.6 можно создать тремя (как минимум, естественно) способами:
- u»» литерал:
>>> u'abc' u'abc' - Метод «decode» для байтовой строки:
>>> 'abc'.decode('ascii') u'abc' - Функция «unicode»:
>>> unicode('abc', 'ascii') u'abc'
ascii в последних двух примерах указывается в качестве кодировки, что будет использоваться для превращения байтов в символы. Этапы этого превращения выглядят примерно так:
'x61' -> кодировка ascii -> строчная латинская "a" -> u'u0061' (unicode-point для этой буквы)
или
'xe0' -> кодировка c1251 -> строчная кириличная "a" -> u'u0430'
Как из юникод-строки получить обычную? Закодировать её:
>>> u'abc'.encode('ascii')
'abc'
Алгоритм кодирования естественно обратный приведенному выше.
Запоминаем и не путаем — юникод == символы, строка == байты, и байты -> что-то значащее (символы) — это де-кодирование (decode), а символы -> байты — кодирование (encode).
Не кодируется 

Разберем примеры с начала статьи. Как работает конкатенация строки и юникод-строки? Простая строка должна быть превращена в юникод-строку, и поскольку интерпретатор не знает кодировки, от использует кодировку по умолчанию — ascii. Если этой кодировке не удастся декодировать строку, получим некрасивую ошибку. В таком случае нам нужно самим привести строку к юникод-строке, используя правильную кодировку:
>>> print type(parser_result), parser_result
<type 'unicode'> баба-яга
>>> s = 'кощей'
>>> parser_result + s
Traceback (most recent call last):
File "<pyshell#67>", line 1, in <module>
parser_result + s
UnicodeDecodeError: 'ascii' codec can't decode byte 0xea in position 0: ordinal not in range(128)
>>> parser_result + s.decode('cp1251')
u'xe1xe0xe1xe0-xffxe3xe0u043au043eu0449u0435u0439'
>>> print parser_result + s.decode('cp1251')
баба-ягакощей
>>> print '&'.join((parser_result, s.decode('cp1251')))
баба-яга&кощей # Так лучше :)
«UnicodeDecodeError» обычно есть свидетельством того, что нужно декодировать строку в юникод, используя правильную кодировку.
Теперь использование «str» и юникод-строк. Не используйте «str» и юникод строки В «str» нет возможности указать кодировку, соответственно кодировка по умолчанию будет использоваться всегда и любые символы > 128 будут приводить к ошибке. Используйте метод «encode»:
>>> print type(s), s
<type 'unicode'> кощей
>>> str(s)
Traceback (most recent call last):
File "<pyshell#90>", line 1, in <module>
str(s)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-4: ordinal not in range(128)>>> s = s.encode('cp1251')
>>> print type(s), s
<type 'str'> кощей«UnicodeEncodeError» — знак того, что нам нужно указать правильную кодировку во время превращения юникод-строки в обычную (или использовать второй параметр ‘ignore»replace»xmlcharrefreplace’ в методе «encode»).
Хочу ещё!
Хорошо, используем бабу-ягу из примера выше ещё раз:
>>> parser_result = u'баба-яга' #1
>>> parser_result
u'xe1xe0xe1xe0-xffxe3xe0' #2
>>> print parser_result
áàáà-ÿãà #3
>>> print parser_result.encode('latin1') #4
баба-яга
>>> print parser_result.encode('latin1').decode('cp1251') #5
баба-яга
>>> print unicode('баба-яга', 'cp1251') #6
баба-яга
Пример не совсем простой, но тут есть всё (ну или почти всё). Что здесь происходит:
- Что имеем на входе? Байты, которые IDLE передает интерпретатору. Что нужно на выходе? Юникод, то есть символы. Осталось байты превратить в символы — но ведь надо кодировку, правда? Какая кодировка будет использована? Смотрим дальше.
- Здесь важной момент:
>>> 'баба-яга' 'xe1xe0xe1xe0-xffxe3xe0' >>> u'u00e1u00e0u00e1u00e0-u00ffu00e3u00e0' == u'xe1xe0xe1xe0-xffxe3xe0' Trueкак видим, Пайтон не заморачивается с выбором кодировки — байты просто превращаются в юникод-поинты:
>>> ord('а') 224 >>> ord(u'а') 224 - Только вот проблема — 224-ый символ в cp1251 (кодировка, которая используется интерпретатором) совсем не тот, что 224 в Юникоде. Именно из-за этого получаем кракозябры при попытке напечатать нашу юникод-строку.
- Как помочь бабе? Оказывается, что первые 256 символов Юникода те же, что и в кодировке ISO-8859-1latin1, соответственно, если используем её для кодировки юникод-строки, получим те байты, которые вводили сами (кому интересно — Objects/unicodeobject.c, ищем определение функции «unicode_encode_ucs1»):
>>> parser_result.encode('latin1') 'xe1xe0xe1xe0-xffxe3xe0' - Как же получить бабу в юникоде? Надо указать, какую кодировку использовать:
>>> parser_result.encode('latin1').decode('cp1251') u'u0431u0430u0431u0430-u044fu0433u0430' - Способ с пункта #5 конечно не ахти, намного удобней использовать использовать built-in unicode.
На самом деле не всё так плохо с «u»» литералами, поскольку проблема возникает только в консоле. Ведь в случае использования non-ascii символов в исходном файле Пайтон будет настаивать на использовании заголовка типа «# -*- coding: -*-» (PEP 0263), и юникод-строки будут использовать правильную кодировку.
Есть ещё способ использования «u»» для представления, например, кириллицы, и при этом не указывать кодировку или нечитабельные юникод-поинты (то есть «u’u1234’»). Способ не совсем удобный, но интересный — использовать unicode entity codes:
>>> s = u'N{CYRILLIC SMALL LETTER KA}N{CYRILLIC SMALL LETTER O}N{CYRILLIC SMALL LETTER SHCHA}N{CYRILLIC SMALL LETTER IE}N{CYRILLIC SMALL LETTER SHORT I}'
>>> print s
кощей
Ну и вроде всё. Основные советы — не путать «encode»«decode» и понимать различия между байтами и символами.
Python 3
Здесь без кода, ибо опыта нет. Свидетели утверждают, что там всё значительно проще и веселее. Кто возьмется на кошках продемонстрировать различия между здесь (Python 2.x) и там (Python 3.x) — респект и уважуха.
Полезно
Раз уж мы о кодировках, порекомендую ресурс, который время-от-времени помогает побороть кракозябры — http://2cyr.com/decode/?lang=ru.
Ещё раз линк на статью Спольски — The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets.
Unicode HOWTO — официальный документ о том где, как и зачем Юникод в Python 2.x.
Спасибо за внимание. Буду благодарен за замечания в приват.
P.S. Подкинули линк на перевод Спольски — Абсолютный Минимум, который Каждый Разработчик Программного Обеспечения Обязательно Должен Знать о Unicode и Наборах Символов.