План урока:
Понятие выборки и генеральной совокупности
Среднее арифметическое выборки
Упорядоченный ряд и таблица частот
Размах выборки
Мода выборки
Медиана выборки
Ошибки в статистике
Понятие выборки и генеральной совокупности
Слово статистика, образованное от латинского status(состояние дел), появилось только в 1746 году, когда его употребил немец Готфрид Ахенвалль. Однако ещё в Древнем Китае проводились переписи населения, в ходе которых правители собирали информацию о своих владениях и жителях, проживающих в них.
В основе любого статистического исследования лежит массив информации, который называют выборкой данных. Покажем это на примере. Пусть в классе, где учится 20 учеников, проводился тест по математике, содержавший 25 вопросов. В результате учащиеся показали следующие результаты:

Ряд чисел, приведенный во второй строке таблицы (12, 19, 19, 14, 17, 16, 18, 20, 15, 25, 13, 20, 25, 16, 17, 12, 24, 13, 21, 13), будет выборкой. Также ее могут называть рядом данных или выборочной совокупностью.

В примере с классом выборка состоит из 20 чисел. Эту величину (количество чисел в ряду) называют объемом выборки. Каждое отдельное число в ряду именуют вариантой выборки.
В примере со школьным классом в выборку попали все его ученики. Это позволяет точно определить, насколько хорошо учащиеся написали математический тест. Однако иногда необходимо проанализировать очень большие группы населения, состоящие из десятков и даже сотен миллионов человек. Например, необходимо узнать, какая часть населения страны курит. Опросить каждого жителя государства невозможно, поэтому в ходе исследования опрашивают лишь его малую часть. В этом случае статистики выделяют понятие генеральная совокупность.

Так, если с помощью опроса 10 тысяч человек ученые делают выводы о распространении курения в России, то все российское население будет составлять генеральную совокупность исследования, а опрошенные 10 тысяч людей вместе образуют выборку.
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Размах выборки
Следующий важная характеристика ряда данных – это размах выборки.

Если выборка представлена в виде упорядоченного ряда данных, то достаточно вычесть из последнего числа ряда первое число. Так, размах выборки результатов теста в классе равен:
25 – 12 = 13,
так как самые лучшие ученики смогли решить все 25 заданий, а наихудший учащийся ответил правильно только на 13 вопросов.
Размах выборки характеризует стабильность, однородность исследуемых свойств. Например, пусть два спортсмена-стрелка в ходе соревнований производят по 5 выстрелов по круговой мишени, где за попадание начисляют от 0 до 10 очков. Первый стрелок показал результаты 8, 9, 9, 8, 9 очков. Второй же спортсмен в своих попытках показал результаты 7, 10, 10, 6, 10. Средние арифметические этих рядов равны:
(8+9+9+8+9):5 = 43:5 = 8,6;
(7+10+10+6+10):5 = 43:5 = 8,6.
Получается, что в среднем оба стрелка стреляют одинаково точно, однако первый спортсмен демонстрирует более стабильные результаты. У его выборки размах равен
9 – 8 = 1,
в то время как размах выборки второго спортсмена равен
10 – 6 = 4.
Размах выборки может быть очень важен в метеорологии. Например, в Алма-Ате и Амстердаме средняя температура в течение года почти одинакова и составляет 10°С. Однако в Алма-Ате в январе и феврале иногда фиксируются температуры ниже -30°С, в то время как в Амстердаме за всю историю наблюдений она никогда не падала ниже -20°С.
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Медиана выборки
Иногда, например, при расчете средней зарплаты, среднее арифметическое не вполне адекватно отражает ситуацию. Это происходит из-за наличия в выборке чисел, очень сильно отличающихся от среднего. Так, из-за огромных зарплат некоторых начальников большинство рядовых сотрудников компаний обнаруживают, что их зарплата ниже средней. В таких случаях целесообразно использовать такую характеристику, как медиану ряда. Это такое значение, которое делит ряд данных пополам. В упорядоченном ряде 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25 медианой будет равна 12, так как именно она находится в середине ряда:

Однако таким образом можно найти только медиану ряда, в котором находится нечетное количество чисел. Если же их количество четное, то за медиану условно принимают среднее арифметическое двух средних чисел. Так, для ряда 2, 3, 6, 8, 8, 12, 15, 15, 18, 19, 25, 30, содержащего 12 чисел, медиана будет равна среднему значению 12 и 15, которые занимают 6-ое и 7-ое место в ряду:


Вернемся к примеру с математическим тестом в школе. Так как его сдавали 20 учеников, а 20 – четное число, то для расчета медианы следует найти среднее арифметическое 10-ого и 11-ого числа в упорядоченном ряде
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Эти места занимают числа 17 и 17 (выделены жирным шрифтом). Медиана ряда будет равна
(17+17):2 = 34:2 = 17.
Три приведенные основные статистические характеристики выборки, а именно среднее арифметическое, мода и медиана, называются мерами центральной тенденции. Они позволяют одним числом указать значение, относительно которого группируются все числа ряда.
Рассмотрим для наглядности ещё один пример. Врач в ходе диспансеризации измерил вес мальчиков в классе. В результате он получил 10 значений (в кг):
39, 41, 67, 36, 60, 58, 46, 44, 39, 69.
Найдем среднее арифметическое, размах, моду и медиану для этого ряда.
Решение. Сначала перепишем ряд в упорядоченном виде:
36, 39, 39, 41, 44, 46, 58, 60, 67, 69.
Так как в ряде 10 чисел, то объем выборки равен 10. Найдем среднее арифметическое. Для этого сложим все числа в ряде и поделим их на объем выборки (то есть на 10):
(36+39+39+41+44+46+58+60+67+69):10 =
= 499:10 = 49,9 кг.
Размах выборки равен разнице между наибольшей и наименьшей вариантой в ней. Самый тяжелый мальчик весит 69 кг, а самый легкий – 36 кг, а потому размах ряда равен
69 – 36 = 33 кг.
В упорядоченном ряде только одно число, 39, встречается дважды, а все остальные числа встречаются по одному разу. Поэтому мода ряда будет равна 39 кг.
В выборке 10 чисел, а это четное число. Поэтому для нахождения медианы надо найти два средних по счету значение найти их среднее. На 5-ом и 6-ом месте в ряде находятся числа 44 и 46. Их среднее арифметическое равно
(44+46):2 = 90:2 = 45 кг.
Поэтому и медиана ряда будет равна 45 кг.
Ошибки в статистике
Статистика является очень мощным инструментом для исследований во всех областях человеческой деятельности. Однако иногда ее иронично называют самой точной из лженаук. Известно и ещё одно высказывание, приписываемое политику Дизраэли, согласно которому существует просто ложь, наглая ложь и статистика. С чем же связана такая репутация этой дисциплины?
Дело в том, что некоторые люди и организации часто манипулируют данными статистики, чтобы убедить других в своей правоте или преимуществах товара, которые они продают. Требуются определенные навыки, чтобы правильно пользоваться статистикой. Одна из самых распространенных ошибок – это неправильный выбор выборки.
В 1936 году перед президентскими выборами в США был проведен телефонный опрос, который показал, что с большим преимуществом победу должен одержать Альфред Лендон. Однако на выборах Франклин Рузвельт набрал почти вдвое больше голосов. Ошибка была связана с тем, что в те годы телефон могли позволить себе только богатые люди, которые в большинстве своем поддерживали Лендона. Однако бедные люди (а их, конечно же, больше, чем богатых) голосовали за Рузвельта.
Ещё один пример – это агитация в конце XIX века в США к службе на флоте. Пропагандисты в своей рекламе указывали, что, согласно статистике, смертность на флоте во время войны (испано-американской) составляет 0,09%, в то время как среди населения Нью-Йорка она равнялась 0,16%. Получалось, что служить на флоте в военное время безопаснее, чем жить мирной жизнью. Однако на самом деле причина таких цифр заключается в том, что во флот всегда отбирали молодых мужчин с хорошим здоровьем, которые не могли умереть от «старческих» болезней, в то время как в население Нью-Йорка входят больные и старые люди.
При указании среднего значения исследователь может использовать разные характеристики – среднее арифметическое, медиана, мода. При этом почти всегда среднее арифметическое несколько больше медианы. Именно поэтому большинство людей, узнающих о средней зарплате в стране, удивляются, так как они столько не зарабатывают. Правильнее ориентироваться на медианную зарплату.
Ну и наконец, нельзя забывать, что любая статистика может показать только корреляцию между двумя величинами, но это не всегда означает причинно-следственную связь. Так, известно, что чем больше в городе продается мороженого, тем больше в это же время людей тонет на пляжах. Означает ли это, что поедание мороженого увеличивает риск во время плавания? Нет. Дело в том, что оба этих показателя, продажи мороженого и количество утонувших, зависят от третьей величины – температуры в городе. Чем жарче на улице, тем большее количество людей ходят на пляж и тем больше мороженого продается в магазинах.
Рядом данных называют результаты измерения, перечисленные в порядке их получения. Каждый из результатов называется вариантой измерения.
Например, результаты написания контрольной работы по математике для класса из 20 человек можно представить в виде следующего ряда данных: 3, 4, 4, 5, 3, 4, 3, 3, 3, 5, 5, 4, 5, 4, 5, 3, 3, 3, 4, 3. Эту же информацию можно представить в
виде таблицы:

Кратность варианты — количество её повторений в ряду данных. В нашем ряду оценка «3» появилась 9 раз, поэтому её кратность равна 9.
Понятно, что таблица распределения отображает данные более наглядно и компактно.
Числовые характеристики данных
Объём измерения — количество всех данных этого измерения. Одна из наиболее важных характеристик варианты — это её частота. Частота варианты показывает долю этой
варианты в ряду распределения. Она вычисляется по формуле:
частота =кратность варианты/объём измерения
В нашем примере частота варианты «4» равна .
Это означает, что оценка 4 составляет 0,3 всех полученных оценок.
Размах измерения — разность между максимальной и минимальной вариантами этого измерения. В нашем примере максимальная варианта равна 5, минимальная — 3, значит, размах равен .
Мода измерения — варианта, которая в измерении встретилась чаще других. В приведённом выше примере чаще всех встретилась оценка 3, значит, она и будет модой этого распределения.
Медиана распределения — это центральное число в упорядоченном ряду данных, если в ряду нечётное количество чисел, или полусумма двух центральных, если в ряду чётное количество чисел.
Например, для ряда распределения 1, 2, 3, 6, 9, объём измерения которого равен 5, медианой распределения будет третье число этого ряда, то есть 3.
Для ряда распределения 7, 3, 2, 1 с объёмом измерения, равным 4, медианой будет полусумма двух центральных чисел данного ряда, то есть число, равное .
Для нахождения медианы распределения необходимо
1. Упорядочить ряд распределения по возрастанию или по убыванию: .
2. Если объём измерения нечётный, то есть , то получим следующую ситуацию:
![]()
В этом случае медианой является число .
3. Если объём измерения чётный, то есть , то имеем
![]()
В этом случае медианой является число — .
Среднее ряда (среднее арифметическое) — сумма всех чисел ряда, делённая на их количество. Если имеется таблица распределения, то можно
1) умножить каждую варианту на её кратность;
2) просуммировать полученные значения;
3) разделить результат на объём измерения. Например, для ряда распределения 2, 4, б, 8, у которого объём измерения равен 4, среднее значение равно
Задача 1. Даны результаты измерения веса школьников 9 класса: 55, 53, 56, 48, 45, 56, 49, 52, 53, 49, 50, 56, 45, 52, 56, 45, 45, 48, 55, 52, 43, 48, 52, 49, 50, 45, 48, 45, 50, 53.
а) Постройте таблицу распределения данных.
б) Найдите объём измерения.
в) Найдите размах ряда.
г) Найдите частоту появления каждого веса в указанном ряду.
д) Найдите медиану, моду и среднее указанного ряда.
Решение.
а) Наименьшее число в ряду — 43, оно встречается в ряду один раз, значит, его кратность равна 1. Следующее по величине — число 45, оно встречается шесть раз, значит, его кратность равна 6. Далее 48, оно встречалось 4 раза, значит, его кратность равна 4.
Продолжая аналогично, заполним таблицу:
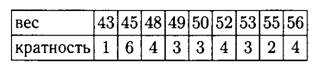
б) Найти объём измерения можем несколькими способами.
1- й способ.
Посчитаем количество чисел в ряду, получим 30.
2- й способ.
Сложим кратности всех вариант:
Ответ: 30.
в) Наибольшее значение в ряду 56, наименьшее — 43, значит, размах равен
Ответ: 13.
г) Для каждой варианты делим её кратность на объём измерения (на 30), результаты пишем в таблицу.
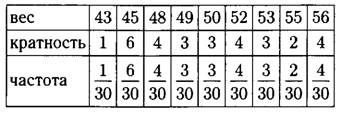
д) В данном ряду 30 чисел, значит, медиана равна полусумме 15-го и 16-го чисел в упорядоченном ряду.
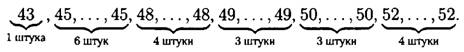
Как видно из такой записи чисел, от 43 до 49 — 14 чисел, значит, 15-ое и 16-ое числа равны 50, и значит, медиана равна
Мода — то значение, которое встречается чаще всех, то есть то, у которого больше кратность. Из таблицы распределения находим, что наибольшую кратность имеет число 45, значит, мода равна 45.
Для нахождения среднего необходимо найти сумму всех чисел ряда и разделить ее на количество этих чисел. Сумму можно найти просто складывая подряд все числа ряда. А можно поступить иначе: каждую варианту умножить на её кратность и сложить полученные результаты. Имеем:
.
Осталось разделить полученную сумму на количество всех чисел: .
Ответ: медиана: 50; мода: 45; среднее: 50,1.
Задача 2. Пятерых учеников попросили подсчитать, сколько времени (в минутах) они тратят на дорогу от дома до школы. Получили следующие результаты: 5,15,10,15,20.
1) На сколько среднее значение этого ряда меньше его размаха?
2) На сколько мода этого ряда больше медианы?
3) Найдите процентную частоту значения 10.
Решение.
1) Среднее ряда: , размах:
. Искомое значение равно
.
Ответ: 2.
2) Найдём медиану. Расположим числа в порядке возрастания: 5, 10, 15, 15, 20. Медианой этого набора будет третье число в упорядоченном ряду, то есть 15.
В данном ряду число 15 встретилось 2 раза, остальные — по одному разу. Мода ряда равна 15. Мода и медиана этого ряда равны, значит, ответ 0.
Ответ: 0.
3) Кратность значения 10 равна 1, объём измерения равен 5 (всего 5 чисел). Частота значения 10 равна , процентная частота равна
.
Ответ: 20.
Задача 3. Имеется 4 группы породистых котов. Для некоторого соревнования отбирают котов с длиной шерсти не менее 8 см.
Известно следующее:
1) в первой группе наибольшая длина шерсти равна 10 см;
2) во второй группе средняя длина шерсти равна 8 см;
3) в третьей группе мода длины шерсти равна 8 см;
4) в четвёртой группе медиана длины шерсти равна 9 см.
В какой из групп хотя бы половина котов гарантированно подходит по длине шерсти?
Решение.
1) Из того, что наибольшая длина шерсти равна 10 см, не следует никакой другой информации, то есть ничего не можем сказать про остальных котов этой группы.
2) Рассмотрим для примера группу котов с длиной шерсти 7 см, 7 см и 10 см. Среднее равно , но в этой группе нет половины котов, удовлетворяющих требованиям.
3) Рассмотрим для примера группу котов с шерстью длиной 8 см, 8 см, 7 см, б см, 5 см. Мода равна 8, но опять же нет половины котов, удовлетворяющих требованиям.
4) Если медиана равна 9 см, то есть половина котов с шерстью меньшей или равной длины и половина — с большей или равной длины. Значит, в этой группе найдётся половина котов с шерстью длиной не менее 8 см.
Ответ: 4.
Задача 4. По статистике автозавода из 1000 машин в среднем 20 бракованных. Сколько бракованных машин следует ожидать, если завод собирается выпустить 300 500 машин?
Решение.
Если из 1000 машин 20 бракованных, то частота появления бракованной машины равна . То есть доля бракованных машин будет равна 0,02, тогда из 300 500 машин будет
бракованных.
Ответ: 6010.
Содержание материала
- Среднее арифметическое
- Видео
- Среднее арифметическое
- Межквартильный размах
- Мода выборки
- Размах, полученный из процентилей
- Что такое процентили
- Применение процентилей
- Статистические характеристики
- Упорядоченный ряд и таблица частот
- Как определить размах числового ряда?
- Мода и медиана
- Бонус: Вебинары с нашего курса по подготовке к ЕГЭ
- ЕГЭ Теория вероятности
Среднее арифметическое
Вероятно, большинство из вас использовало такую важную описательную статистику, как среднее.
Среднее — очень информативная мера «центрального положения» наблюдаемой переменной, особенно если сообщается ее доверительный интервал. Исследователю нужны такие статистики, которые позволяют сделать вывод относительно популяции в целом. Одной из таких статистик является среднее.
Доверительный интервал для среднего представляет интервал значений вокруг оценки, где с данным уровнем доверия, находится «истинное» (неизвестное) среднее популяции.
Например, если среднее выборки равно 23, а нижняя и верхняя границы доверительного интервала с уровнем p=.95 равны 19 и 27 соответственно, то можно заключить, что с вероятностью 95% интервал с границами 19 и 27 накрывает среднее популяции.
Если вы установите больший уровень доверия, то интервал станет шире, поэтому возрастает вероятность, с которой он «накрывает» неизвестное среднее популяции, и наоборот.
Хорошо известно, например, что чем «неопределенней» прогноз погоды (т.е. шире доверительный интервал), тем вероятнее он будет верным. Заметим, что ширина доверительного интервала зависит от объема или размера выборки, а также от разброса (изменчивости) данных. Увеличение размера выборки делает оценку среднего более надежной. Увеличение разброса наблюдаемых значений уменьшает надежность оценки.
Вычисление доверительных интервалов основывается на предположении нормальности наблюдаемых величин. Если это предположение не выполнено, то оценка может оказаться плохой, особенно для малых выборок.
При увеличении объема выборки, скажем, до 100 или более, качество оценки улучшается и без предположения нормальности выборки.
Довольно трудно «ощутить» числовые измерения, пока данные не будут содержательно обобщены. Диаграмма часто полезна в качестве отправной точки. Мы можем также сжать информацию, используя важные характеристики данных. В частности, если бы мы знали, из чего состоит представленная величина, или если бы мы знали, насколько широко рассеяны наблюдения, то мы бы смогли сформировать образ этих данных.
Среднее арифметическое, которое очень часто называют просто «среднее», получают путем сложения всех значений и деления этой суммы на число значений в наборе.
Это можно показать с помощью алгебраической формулы. Набор n наблюдений переменной X можно изобразить как X1, X2, X3, …, Xn. Например, за X можно обозначить рост индивидуума (см), X1 обозначит рост 1-го индивидуума, а Xi — рост i-го индивидуума. Формула для определения среднего арифметического наблюдений  (произносится «икс с чертой»):
(произносится «икс с чертой»):
 = (Х1 + Х2 + … + Xn) / n
= (Х1 + Х2 + … + Xn) / n
Можно сократить это выражение:

где  (греческая буква «сигма») означает «суммирование», а индексы внизу и вверху этой буквы означают, что суммирование производится от i = 1 до i = n. Это выражение часто сокращают еще больше:
(греческая буква «сигма») означает «суммирование», а индексы внизу и вверху этой буквы означают, что суммирование производится от i = 1 до i = n. Это выражение часто сокращают еще больше:
 или
или 
Видео
Среднее арифметическое
Понятие среднего значения часто используется в повседневной жизни.
Примеры:
- средняя зарплата жителей страны;
- средний балл учащихся;
- средняя скорость движения;
- средняя производительность труда.
Речь идет о среднем арифметическом — результате деления суммы элементов выборки на их количество.
Среднее арифметическое — это результат деления суммы элементов выборки на их количество.

Вернемся к нашему примеру

Узнаем сколько в среднем мы тратили в каждом из шести дней:

Межквартильный размах
В статистике для анализа выборки часто прибегают к другому показателю вариации – межквартильному размаху. Квартиль – это то значение, которые делит ранжированные (отсортированные) данные на части, кратные одной четверти, или 25%. Так, 1-й квартиль – это значение, ниже которого находится 25% совокупности. 2-й квартиль делит совокупность данных пополам (то бишь медиана), ну и 3-й квартиль отделяет 25% наибольших значений. Так вот межквартильный размах – это разница между 3-м и 1-м квартилями. У данного показателя есть одно неоспоримое преимущество: он является робастным, т.е. не зависит от аномальных отклонений.
Наглядное отображение размаха вариации и межкварительного расстояния производят с помощью диаграммы «ящик с усами».
Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны. Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Размах, полученный из процентилей
Что такое процентили
Предположим, что мы расположим наши данные упорядоченно от самой маленькой величины переменной X и до самой большой величины. Величина X, до которой расположен 1% наблюдений (и выше которой расположены 99% наблюдений), называется первым процентилем.
Величина X, до которой находится 2% наблюдений, называется 2-м процентилем, и т. д.
Величины X, которые делят упорядоченный набор значений на 10 равных групп, т. е. 10-й, 20-й, 30-й,…, 90 и процентили, называются децилями. Величины X, которые делят упорядоченный набор значений на 4 равные группы, т.е. 25-й, 50-й и 75-й процентили, называются квартилями. 50-й процентиль — это медиана.
Применение процентилей
Мы можем добиться такой формы описания рассеяния, на которую не повлияет выброс (аномальное значение), исключая экстремальные величины и определяя размах остающихся наблюдений.
Межквартильный размах — это разница между 1-м и 3-м квартилями, т.е. между 25-м и 75-м процентилями. В него входят центральные 50% наблюдений в упорядоченном наборе, где 25% наблюдений находятся ниже центральной точки и 25% — выше.
Интердецильный размах содержит в себе центральные 80% наблюдений, т. е. те наблюдения, которые располагаются между 10-м и 90-м процентилями.
Мы часто используем размах, который содержит 95% наблюдений, т.е. он исключает 2,5% наблюдений снизу и 2,5% сверху. Указание такого интервала актуально, например, для осуществления диагностики болезни. Такой интервал называется референтный интервал, референтный размах или нормальный размах.
Статистические характеристики
К основным статистическим характеристикам выборки данных…
Какая еще такая «выборка»!?
Под словом «выборка» подразумевается просто данные, которые ты собираешься исследовать.
Дальше на примерах будет все понятно.
Так вот к основным статистическим характеристикам выборки данных относятся:
- объем выборки,
- размах выборки,
- среднее арифметическое,
- мода,
- медиана,
- частота,
- относительная частота.
Стоп-стоп-стоп! Сколько новых слов! Давай обо всем по порядку.
Упорядоченный ряд и таблица частот
В ряде данных в таблице 1 числа приведены в произвольном порядке. Перепишем ряд так, чтобы все числа шли в неубывающем порядке, то есть от самого маленького к самому большому:
12, 12, 13, 13, 13, 14, 15, 16, 16, 17, 17, 18, 19, 19, 20, 20, 21, 24, 25, 25.
Такую запись называют упорядоченным рядом данных.

Его характеристики ничем не отличаются от изначальной выборки, однако с ним удобнее работать. С его помощью можно видеть, что ни одному ученику не удалось набрать 22 или 23 балла на тесте, но сразу двое учащихся дали 25 правильных ответов. На основе упорядоченного ряда данных несложно составить таблицу частот, в которой будет указано, как часто та или иная варианта выборки встречается в ряде. Выглядеть она будет так:

При составлении этой таблицы мы исключили из нее те варианты количества набранных баллов, частота которых равна нулю (от 0 до 12, 22 и 23).Заметим, что сумма чисел в нижней строке таблицы частот должна равняться объему выборки. Действительно,
2+3+1+1+2+2+1+2+2+1+1+2 = 20.
С помощью таблицы частот можно быстрее посчитать среднее арифметическое выборки. Для этого каждую варианту надо умножить на ее частоту, после чего сложить полученные результаты и поделить их на объем выборки:
(12•2+13•3+14•1+15•1+16•2+17•2+18•1+19•2+20•2+21•1+24•1+25•2):20 =
(24+39+14+15+32+34+18+38+40+42+24+50):20 = 349:20 = 17,45.
Как определить размах числового ряда?
Среднее арифметическое, размах, мода и медиана
- Средним арифметическим ряда чисел называется частное от деления суммы этих чисел на число слагаемых. …
- Размахом ряда чисел называется разность между наибольшим и наименьшим из этих чисел. …
- Модой ряда чисел называется число, которое встречается в данном ряду чаще других.
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану

Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186

Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190

Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2

По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Бонус: Вебинары с нашего курса по подготовке к ЕГЭ
Этот вебинар по родственной математической статистике теме — теории вероятности.
А вот наша статья о теории вероятности.
ЕГЭ Теория вероятности
Что вы узнаете на этом уроке?
20% урока — теория.
- Мы разберём, что такое вероятность;
- Узнаем, что можно называть случайным событием;
- Рассмотрим, на какие типы можно разделить события:
- Что такое совместные и несовместные события;
- Что такое зависимые и независимые события;
- Выучим формулы, которые нужно применять для разных типов событий.
80% урока — решение задач
- Мы решим 54 задачи на первом уроке и ещё 22 (посложнее) на втором;
- Отработаем все 6 типов задач, которые могут встретиться в ЕГЭ:
Теги
Ряд
распределения
— это последовательность чисел с указанием
качественного
или количественного значения признака
и частоты его встречаемости.
Виды
рядов распределения
классифицируются
по разным принципам.
По
степени упорядоченности ряды
делят на:
-
неупорядоченные
-
упорядоченные
Неупорядоченный
ряд
— это такой ряд, в котором значения
признака записаны
в порядке поступления вариантов при
исследовании.
Пример:
При исследовании роста группы студентов
были записаны его значения
в см (175,170,168,173,179).
Упорядоченный
ряд —
это ряд, полученный из неупорядоченного
в котором значения признака перезаписаны
в порядке возрастания или убывания.
Упорядоченный ряд называется
ранжированным, а процедура
ранжирования
(
упорядочивания ) называется сортировкой.
Пример:
( Рост 168,170,173,175,179 )
По
виду признака ряды распределения делятся
на:
-
атрибутивные
-
вариационные.
Атрибутивный
ряд
— это ряд, составленный на основе
качественного признака.
Вариационный
ряд
— это ряд, составленный на основе
количественного признака.
Вариационные
ряды подразделяются на дискретные,
непрерывные
и интервальные.
Вариационные
дискретные, непрерывные и интервальные
ряды названы
по соответствующему признаку, который
лежит в основе составления
ряда. Например, ряд по размеру обуви
является дискретным по
массе тела — непрерывным.
Способы
представления рядов в
практической и научной медицине делятся
на три группы:
-
Табличное
представление; -
Аналитическое
представление (в виде формулы); -
Графическое
представление.
1.
Простейшая таблица представляет собой
два столбца или две строки, в одной из
которых записаны значения признака xi
в упорядоченном виде, а в другой —
относительная или абсолютная частота
его встречаемости ni,
fi.
Пример:
табличное представление оценок в группе
xi
и
числа их получивших студентов ni.
-
xi
5
4
3
2
ni
3
8
2
—
2.
Графическое представление рядов основано
на табличных
данных. Графики строят в прямоугольной
системе координат,
где по горизонтали всегда откладывают
значения признака хi
,
а по вертикали
абсолютную или относительную частоту
ni
.
Основные
способы представления графиков:
-
Диаграмма
в отрезках. -
Гистограмма
-
Полигон
частот. -
Вариационная
( частотная
)
кривая.
Диаграмма
в отрезках
— это график представления ряда в виде
вертикальных прямых-отрезков,
положение которых на горизонтали
определяется значением признака,
а длина отрезка пропорциональна его
абсолютной или относительной частоте.
Пример:
диаграмма в отрезках для
оценок успеваемости группы.
n i
i
8
3
2
5 4 3 2 XI
Обычно
диаграммы в отрезках строят для дискретно
заданных признаков при
небольшом числе вариантов.
Гистограмма
— это график в виде ступенчатой фигуры
из примыкающих друг
к другу прямоугольников, основаниями
которых являются интервалы значений
признаков, а высоты прямоугольников
пропорциональны частоте
или частости ( количеству объектов,
попавших в интервал ). Площади
прямоугольников соответствуют численности
групп, в данном интервале.
Гистограммы
— это графики интервальных рядов. Их
строят преимущественно
для больших объемов совокупностей.
Пример:
Гистограмма нормального распределения
эритроцитов в крови человека.
По горизонтали — диаметр
клеток хi
(мк),
по вертикали — частота ni
числа клеток
в интервале.
n i
i
2
4 6 8 10 12 xi
Полигон
(многоугольник) частот
— график ряда, представленный ломаной
линией
точки — вершины которой соответствуют
серединам интервалов, а высота точки
над горизонталью пропорциональна
частоте или частости.
Полигоны
строят для непрерывных и дискретных
вариационных рядов в тех
случаях, когда в интервалах выделены
средние значения признака. Полигоны
предпочтительнее
гистограмм при
непрерывных рядах распределения
Пример:
полигон
частот на основе гистограммы
распределения эритроцитов
в крови человека.
n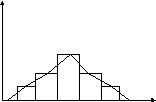 i
i
2
4 6 8 10 12
xi
Вариационная
(частотная) кривая
— график ряда, полученный при условии,
что объем совокупности, стремится к
бесконечности ( N→∞
),
а длина самого
интервала стремится к нулю ( Δх→0
).
Для
практических статистических расчетов
в качестве стандартов выделено четыре
группы частотных распределений:
-
Прямоугольное
распределение. -
Колоколообразное
унимодальное (одновершинное)
распределение. -
Бимодальное
(двухвершинное) распределение. -
Экспоненциальное
распределение:
-
нарастающее,
-
убывающее.

ni
xi
xi
xi
xi
Прямоугольному
распределению подчиняются случайные
равновероятные
события.
Колоколообразному
симметричному распределению
подчиняется широкий класс
явлений ( показатели умственного
и физического развития, рост,
масса, и др ).
На практике наиболее часто встречается
симметричное унимодальное распределение,
поэтому его классическая форма называется
нормальным распределением.
Бимодальному
распределению соответствует, например
успеваемость
студентов имеющих и
не имеющих большого перерыва в учебе.
Экспоненциально
убывающему распределению
соответствует распределение
доходов в капиталистическом
обществе, ( частота
убывает при возрастании дохода
).
Соседние файлы в папке Медицинская физика
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Мода и медиана
Модой ряда чисел называется число, наиболее часто встречающееся в данном ряду.
Обратимся снова к нашему примеру со сборной по футболу:
Чему в данном примере равна мода? Какое число наиболее часто встречается в этой выборке?
Все верно, это число ( displaystyle 181), так как два игрока имеют рост ( displaystyle 181) см; рост же остальных игроков не повторяется.
Тут все должно быть ясно и понятно, да и слово знакомое, правда?
Перейдем к медиане, ты ее должен знать из курса геометрии. Но мне не сложно напомнить, что в геометрии медиана (в переводе с латинского- «средняя») — отрезок внутри треугольника, соединяющий вершину треугольника с серединой противоположной стороны.
Ключевое слово – СЕРЕДИНА. Если ты знал это определение, то тебе легко будет запомнить, что такое медиана в статистике.
Медианой ряда чисел с нечетным числом членов называется число, которое окажется посередине, если этот ряд упорядочить (проранжировать, т.е. расположить значения в порядке убывания или возрастания).
Медианой ряда чисел с четным числом членов называется среднее арифметическое двух чисел, записанных посередине, если этот ряд упорядочить.
Ну что, вернемся к нашей выборке футболистов?
Ты заметил в определении медианы важный момент, который нам еще здесь не встречался? Конечно, «если этот ряд упорядочить»!
Для того, чтобы в ряду чисел был порядок, можно расположить значения роста футболистов как в порядке убывания, так и в порядке возрастания. Мне удобней выстроить этот ряд в порядке возрастания (от самого маленького к самому большому).
Вот, что у меня получилось:
Так, ряд упорядочили, какой еще есть важный момент в определении медианы? Правильно, четное и нечетное количество членов в выборке.
Заметил, что для четного и нечетного количества даже определения отличаются? Да, ты прав, не заметить – сложно. А раз так, то нам надо определиться, четное у нас количество игроков в нашей выборке или нечетное?
Все верно – игроков ( displaystyle 11), значит, количество нечетное! Теперь можем применять к нашей выборке менее заковыристое определение медианы для нечетного количества членов в выборке.
Ищем число, которое оказалось посередине в нашем упорядоченном ряду:
Ну вот, чисел у нас ( displaystyle 11), значит, по краям остается по пять чисел, а рост ( displaystyle 183) см будет медианой в нашей выборке.
Не так уж и сложно, правда?
Частота и относительная частота
Частота представляет собой число повторений, сколько раз за какой-то период происходило некоторое событие, проявлялось определенное свойство объекта либо наблюдаемый параметр достигал данной величины.
То есть частота определяет то, как часто повторяется та или иная величина в выборке.
Разберемся на нашем примере с футболистами. Перед нами вот такой вот упорядоченный ряд:
![]()
Частота – это число повторений какой-либо величины параметра. В нашем случае, это можно считать вот так. Сколько игроков имеет рост ( 176)?
Все верно, один игрок. Таким образом, частота встречи игрока с ростом ( 176) в нашей выборке равна ( 1).
Сколько игроков имеет рост ( 178)? Да, опять же один игрок. Частота встречи игрока с ростом ( 178) в нашей выборке равна ( 1).
Задавая такие вопросы и отвечая на них, можно составить вот такую табличку:
Ну вот, все довольно просто. Помни, что сумма частот должна равняться количеству элементов в выборке (объему выборки).
То есть в нашем примере: ( 1+1+1+2+1+1+1+1+1+1=11)
Перейдем к следующей характеристике – относительная частота.
Относительная частота – это отношение частоты к общему числу данных в ряду. Как правило, относительная частота выражается в процентах.
Обратимся опять к нашему примеру с футболистами. Частоты для каждого значения мы рассчитали, общее количество данных в ряду мы тоже знаем ( left( n=11 right)) .
Рассчитываем относительную частоту для каждого значения роста и получаем вот такую табличку:
А теперь сам составь таблицы частот и относительных частот для примера с 9-классниками, решающими задачи.