Если вы знаете URL нужной страницы, то задача очень простая. Просто введите этот URL в после поиска в ВебАрхиве. В календаре будут видны сохранения этого URL. Если ничего не покажет, значит данный URL никогда не был сохранен.
Если URL не известен, то по ключевым словам найти будет крайне сложно. У Веб-Архива есть поиск по тексту, но он настолько плохо работает, что покажет единичные результаты вхождения на очень древних сохраненных страницах. Но чаще не найдет ничего, как сильно не сужай параметры в поиске.
Если ключевые слова содержатся в ЧПУ, то можно открыть таблицу сохраненных урлов:
https://web.archive.org/web/*/habr.com/*
Внимание, у больших сайтов таблица будет загружаться долго, подгрузит лишь 100 000 урлов. Дождитесь загрузки таблицы. Сверху справа над таблицей после её подгрузки можно ввести часть ЧПУ которая отфильтрует результаты.
О том, как работает ВебАрхив и как работать с его инструментами можно посмотреть видео здесь:
Как работать с Веб-Архивом
Поиск в веб-архиве сайтов по нужной тематике!
A
На сайте с 14.09.2010
Offline
17
29 августа 2011, 09:34
6167
Добрый день коллеги форумчане!
Сейчас делаю новый сайт и мне необходимо огромное количество уникального контента.
Самому писать очень долго, а покупать несколько тысяч статей тоже не хочется, поэтому решился поискать материал в веб-архиве.
Проблема состоит в том, что не знаю как найти в архиве сайты по нужной тематике ?
На сайте dnhunter нашел недавно освобожденные домены, но уникальных статей на них нет, один плагиат. Проверяю плагиат с помощью Advego и Etxt.
Существует какой-нибудь сервис для поиска по веб-архиву по ключевым словам или по тематике?

На сайте с 26.05.2011
Offline
119
29 августа 2011, 10:43
#1
alfacasting, На какую тематику будет написан ресурс?

На сайте с 12.12.2010
Offline
108
29 августа 2011, 10:51
#2
Иными словами, всё надо, но работать не хочу. ТС, так и спросил бы, дайте кнопку бабло.
A
На сайте с 14.09.2010
Offline
17
29 августа 2011, 10:59
#3
Filan:
alfacasting, На какую тематику будет написан ресурс?
Тематика — туризм и путешествия
alfacasting добавил 29.08.2011 в 15:01
webeditor:
Иными словами, всё надо, но работать не хочу. ТС, так и спросил бы, дайте кнопку бабло.
Нет, дело не в том, что работать не хочу. А в том, что написание нескольких тысяч статей займет как минимум пару лет. Я всегда ищу легкие способы.
S
На сайте с 29.01.2006
Offline
404
29 августа 2011, 11:05
#4
мне необходимо огромное количество уникального контента
уникальных статей на них нет, один плагиат
Думал, один такой умный?

На сайте с 03.09.2007
Offline
114
29 августа 2011, 11:18
#5
alfacasting:
Я всегда ищу легкие способы.
Самый легкий способ — заказать рерайт и не парить себе мозги.
DV
На сайте с 01.05.2010
Offline
644
29 августа 2011, 11:25
#6
Ой, зря вы эту тему завели… Я когда пришёл, тоже такой умный был 😂
Мигом осадили.
A
На сайте с 14.09.2010
Offline
17
29 августа 2011, 11:44
#7
DenisVS:
Ой, зря вы эту тему завели… Я когда пришёл, тоже такой умный был 😂
Мигом осадили.
Почему зря?
Сегодня утром уже таким способом нашел две статьи — уникальные на 100 %.
А то , что здесь люди не знают способ или знают, но не хотят говорить — это уже другой вопрос.
S
На сайте с 29.01.2006
Offline
404
29 августа 2011, 11:48
#8
alfacasting,
Сегодня утром уже таким способом нашел две статьи
А долго искал? Может, быстрее было написать или отрерайтить?
A
На сайте с 14.09.2010
Offline
17
29 августа 2011, 11:58
#9
Scaryer:
alfacasting,
А долго искал? Может, быстрее было написать или отрерайтить?
Я пробовал и рерайтить и самому писать и переводить с других языков, но на хорошую статью уходит целый день с утра до ночи. На следующий день уже нет желания этим заниматься. Это очень выматывает.
Нет, искал не долго. За 30 минут нашел 2 сайта, на каждом по одной уникальной статье. И в течении часа они уже были на моем сайте с картинками. Поэтому этот способ самый быстрый по наполнению. Ведь не просто так я его выбрал ?!
S
На сайте с 29.01.2006
Offline
404
29 августа 2011, 12:04
#10
За 30 минут нашел 2 сайта, на каждом по одной уникальной статье.
Тогда хорошо.
Поэтому этот способ самый быстрый по наполнению.
Если удастся найти ещё несколько тысяч статей;-)
Как добыть уникальный контент из вебархива
Февраль 16, 2015 18 комментариев
![]()
Всем привет =) Сегодня хочется вам рассказать, как можно совершенно бесплатно добывать уникальный контент для своих проектов! Сразу скажу, этот способ я подглядел на одном из форумов, но немного модифицировал его под себя, чем и хочу поделиться с читателями.
Для начала пару слов о WebArchive. Это глобальный архив интернет сайтов. Боты вебархива периодически обходят глобальную паутину и сохраняют на свои сервера все что смогли найти. Потом это все хранится для потомков 😉
Адрес ВебАрхива — http://archive.org/web/ На главной странице, на момент написания статьи, написано — 452 billion web pages saved over time. По-русски говоря, 452 миллиарда страниц закачал себе этот сервис. Этим мы и будем пользоваться.
Суть этого метода проста — мы ищем уже неработающие сайты, которые были закачаны вебархивом и стараемся найти там уникальные статьи, которые уже давно не в индексе поисковых систем.
Итак, поехали, первый способ, прочитанный на форуме:
Идем сюда — nic.ru
Скачиваем список освобождающихся доменов в зоне .ru Можно брать и другие зоны, но там не так много доменов…
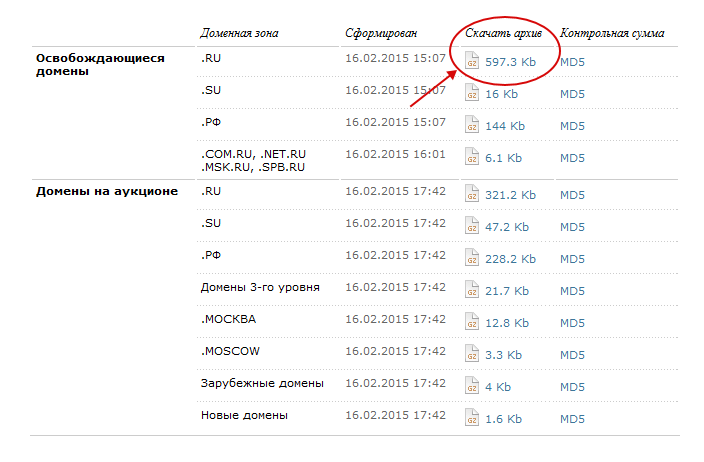
Полученный файл открываем с помощью Excel и жмем «ctrl+F», в поиске вводим ключевое слово, в моем примере это «Forex».
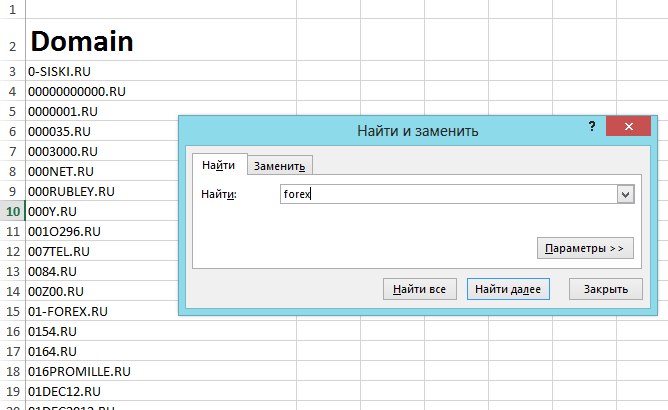
Нажали «найти все» и перед нами появился список нужных ячеек
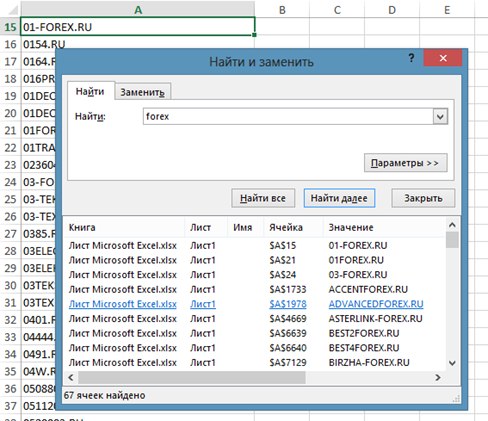
Теперь нужно получить из этого списка сайты в архиве.
Первый вариант — бесплатный сервис, проверяет только 30 ссылок за раз

Но этого вполне хватает, ведь по вашей теме не будет слишком много доменов, да и можно проверять пачками.
Второй вариант, это купить недорогую прогу, которая проверяет по 2000 ссылок за пару минут. Купить можно на форуме.
Вот и все, найденные страницы в вебархиве, через сервис или программу, мы мониторим уже глазками и ищем в куче файлов страницу со статьями или главную. Обязательно проверяйте домен на работоспособность, так как владельцы могли уже успеть продлить его.
Сервис показывает количество документов в вебархиве, цифры ниже 10 нас не интересуют. Старайтесь проверять как можно бОльшие цифры. К примеру, недавно я нашел сайт в вебархиве, нужной мне тематики, с 22000 документов, ох я и накопал оттуда хороших статеек!
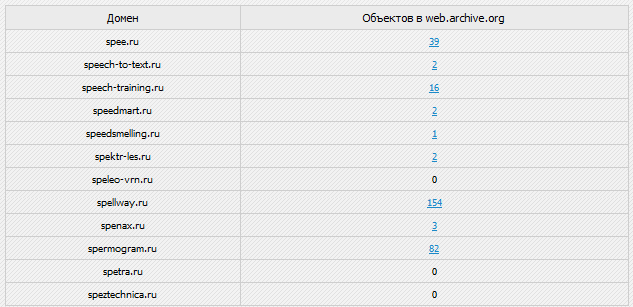
Вот так выглядят файлы в вебархиве.
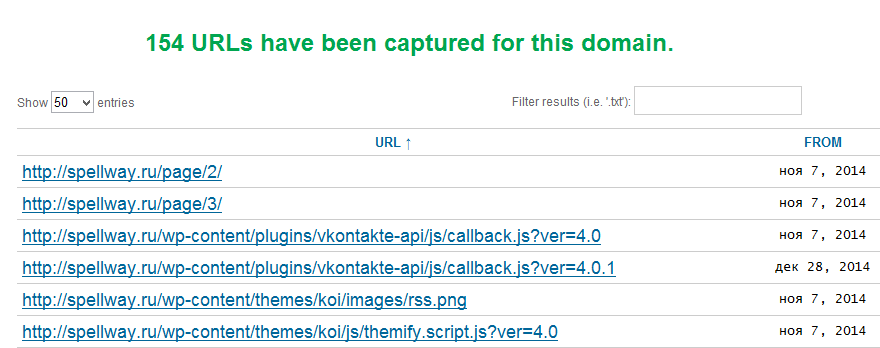
Стараемся попасть на сайте на главную страницу или найти карту сайта. Далее методично открываем статьи и проверяем их на уникальность. Я делаю это антиплагиатором от eTXT.
Второй способ, которым ищу именно я. Суть остается прежней, просто я беру домены ТУТ.
Самый жирный плюс этого сервиса в том, что мы можем пройтись по разным датам, а не качать домены освобождающиеся только в один день. Чем дальше по датам мы уходим, тем больше вероятность того, что домены не продлили.
В это сервисе все проще — выбираем дату, жмем Ctrl+A — копируем все что есть на странице и вставляем в NotePad++, так же жмем Ctrl+F и вводим нужный нам ключ и жмем — Найти ВСЕ в текущем документе.
После поиска это выглядит так:
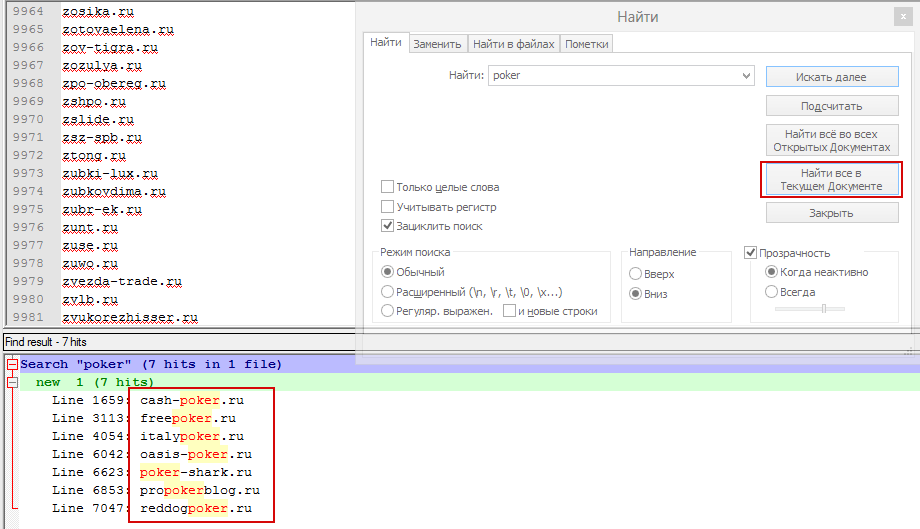
Вот и все =) Советую вам не париться с эксель и работать в нотпаде, а так же юзать сервис доменов по датам. Данным способом я нашел больше сотни отличных и уникальных статей на нужную мне тематику. На эти статьи, если бы я их заказал, у меня бы ушла не одна тысяча рублей… Всем благ и большого профита!
15 минут назад, vituson сказал:
В вебархиве часто битые страницы, отсутствуют картинки, разные версии сайта и т.д. Лучше восстанавливать полные версии дроп-сайтов через сервис mydrop. Тут немного про этот сервис есть — https://sitedrop.ru/
Сомневаюсь, что сервисы качественно восстановят. Достаточно знать немного примеров комбинации find и sed, чтоб почистить самостоятельно.
Примеры:
1. Убираем различные блоки, в том числе счётчики и прочий мусор:
find site.ru/ -type f -name '*.html' -exec sed -i '/<p align="left">/,/</p>/d' {} ;
2. Убираем битую ссылку:
find site.ru/ -type f -iname '*.html' -exec sed -i 's|<img height=1 width=1 border=0 src="http://www.googleadservices.com/pagead/conversion/1058209190/imp.gif?value=1&label=pageview&script=0">||g' {} ;
3. Считаем сколько однотипных файлов в каталоге:
find . -type f -name "*.html" | wc -l
4. Если нужно добавить текст в конец каждой строки:
sed 's/^/echo "test" | mail -s "test"/' file
5. Если нужно перекодировать из CP1251 в UTF8:
ПЕРЕКОДИРОВАТЬ РЕКУРСИВНО ИЗ CP1251 В UTF8
find . -name '*.*' -exec enconv -L russian -x UTF-8 {} ;
for FILE in $(find gsbeton.ru -name '*.html'); do mv $FILE{,.orig} && iconv -c -t UTF8 $FILE.orig -o $FILE; done
удаление файлов *.orig:
for FILE in $(find forexmoscow.ru -name '*.orig'); do rm $FILE; done
Игнорировать непонятные символы:
iconv -c
6. Если нужно добавить текст в конец каждого файла:
for FILE in $(find site.ru -name '*.html?.*'); do echo "</tr></table></body></html>">> $FILE; done
Спиcки битых и внешних ссылок выгружает программа Screaming Frog SEO Spider. Если на сайте тысячи битых ссылок, можно автозаменой в блокноте типа notepad++ подставить вышеуказанные команды и получиться список команд на удаление всех ненужных ссылок. Я так одному клиенту целых пол года делал сетку сателлитов из Вебархива. А для массовых замен по всем файлам отлично подходят Notepad++, Doublecmd и CodeLobsterIDE !
Изменено 2 октября 2019 пользователем softuser
Добавил примеры
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:https://www.iphones.ru/
Где https://www.iphones.ru/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

Во Всемирном архиве интернета хранятся старые версии очень многих сайтов за разные даты (с начала 90-ых по настоящее время). На данный момент в России этот сайт заблокирован.
3. Кэш Яндекса, почему бы и нет

К сожалению, нет способа добрать до кэша Яндекса по прямой ссылке. Поэтому приходиться набирать адрес страницы в поисковой строке и из контекстного меню ссылки на результат выбирать пункт Сохраненная копия. Если результат поиска в кэше Google вас не устроил, то этот вариант обязательно стоит попробовать, так как версии страниц в кэше Яндекса могут отличаться.
4. Кэш Baidu, пробуем азиатское
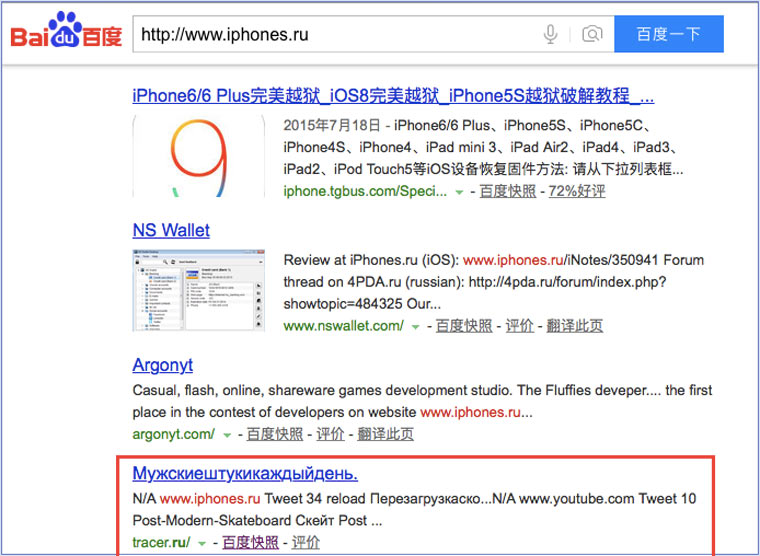
Когда ищешь в кэше Google статьи удаленные с habrahabr.ru, то часто бывает, что в сохраненную копию попадает версия с надписью «Доступ к публикации закрыт». Ведь Google ходит на этот сайт очень часто! А китайский поисковик Baidu значительно реже (раз в несколько дней), и в его кэше может быть сохранена другая версия.
Иногда срабатывает, иногда нет. P.S.: ссылка на кэш находится сразу справа от основной ссылки.
5. CachedView.com, специализированный поисковик
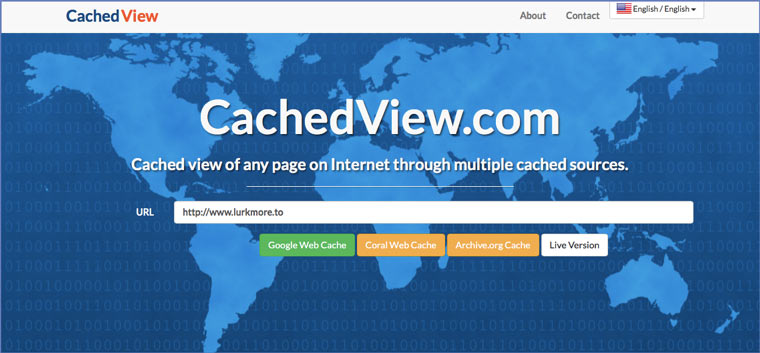
На этом сервисе можно сразу искать страницы в кэше Google, Coral Cache и Всемирном архиве интернета. У него также еcть аналог cachedpages.com.
6. Archive.is, для собственного кэша
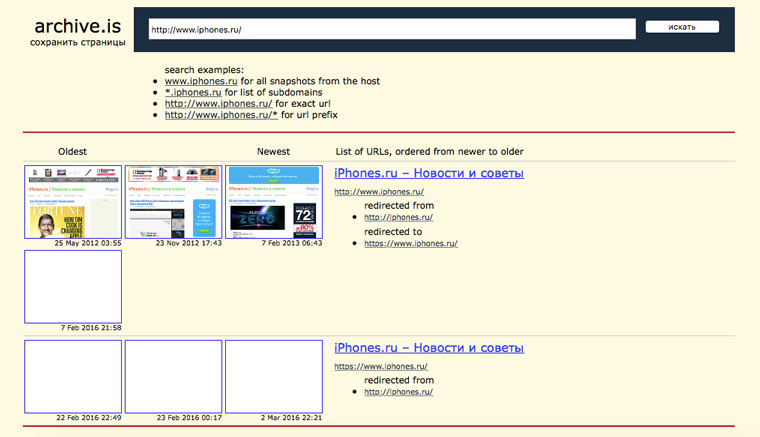
Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса. Там есть даже несколько сохраненных копий iPhones.ru.
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com, перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari.
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
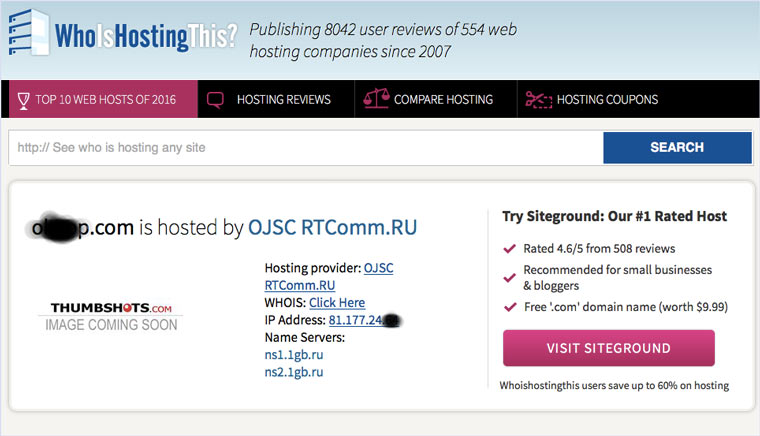
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:
После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
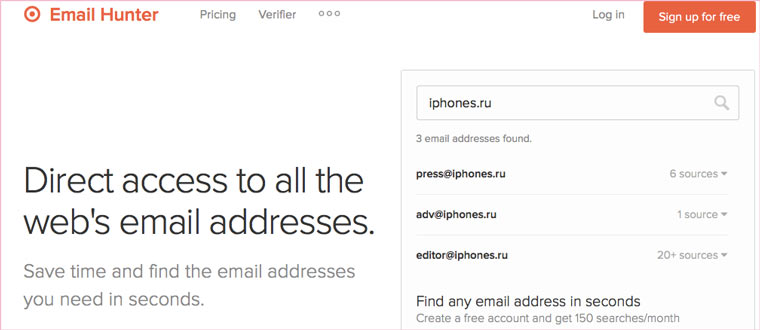
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com:
О других методах поиска читайте в статье 12 способов найти владельца сайта и узнать про него все.
А о сборе информации про людей читайте в статьях 9 сервисов для поиска информации в соцсетях и 15 фишек для сбора информации о человеке в интернете.

 (30 голосов, общий рейтинг: 4.80 из 5)
(30 голосов, общий рейтинг: 4.80 из 5)
🤓 Хочешь больше? Подпишись на наш Telegram.
![]()
iPhones.ru
Сервисы и трюки, с которыми найдётся ВСЁ. Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход. Всё, что попадает в интернет,…
- Google,
- полезный в быту софт,
- хаки
![]()