Мнемоники и коды Unicode в HTML
Для того, чтобы браузер мог правильно отобразить на экране монитора текст веб-страницы, необходимо сообщить ему используемую на странице кодировку.
Делается это при помощи служебного тега <meta> и его атрибута charset, в качестве
значения которого и указывается требуемая кодировка. Практически все современные сайты используют кодировку
UTF-8 из набора символов Unicode. Поэтому, во-избежание появления
«кракозябр» при
отображении веб-страницы браузером, следует использовать служебный элемент «meta» в виде
<meta charset=«UTF-8»
>.
Кроме того, не все символы обычного текста браузер может вывести на экран напрямую. Например, символы < и
> имеют в
HTML специальный смысл, т.к. они являются важнейшей составляющей синтаксиса языка. Когда интерпретатор
браузера встречает их в коде, то он видит в них не просто символы текста, а в первую очередь метки начала и конца тега. Поэтому, если нам нужно вывести
на экран конструкцию, например, открывающего тега <span>, то мы должны каким-то образом сообщить браузеру,
что он видит перед собою не открывающий тег, а всего лишь простой текст.
Обычно в таких случаях символы заменяются (кодируются) специальными последовательностями обычных символов, называемыми
мнемониками, либо их числовым представлением в виде десятичного или шестнадцатеричного кода
Unicode.
Мнемоника HTML (от др.-греч.
искусство запоминания ) – это легко запоминающаяся буквенная конструкция вида
&abcd;, обозначающая буквенный код символа и вставляющаяся непосредственно в
html-код веб-страницы.
Мнемоники довольно популярны среди профессиональных html-верстальщиков, поскольку они образованы от соответствующих
английских слов и легко запоминаются человеком. Однако область их применения сильно ограничена, чего не скажешь о числовых кодах стандарта
Unicode.
Юникод
(от англ. Unicode) – стандарт кодирования символов, представляющий знаки почти
всех письменных языков мира.
Применение стандарта Unicode позволяет закодировать большое число символов из разных
письменностей, что дает возможность веб-программистам использовать на одной и той же странице сразу несколько языков, а также множество различных
математических и специальных символов.
Для мнемоники конструкция начинается с символа амперсанда &,
после чего следует некоторая последовательность обычных символов и завершающая точка с запятой ;.
Если используется Unicode, то сперва также пишется символ амперсанда &, однако
затем следует # и десятичный код Юникода либо
#x и шестнадцатеричный код Юникода данного символа. Заканчивается конструкция
опять же точкой с запятой ;.
Таким образом, если нам нужно, чтобы браузер вывел на экран конструкцию, например, того же тега <span>,
следует в коде использовать вместо знаков < и > их коды.
Данная ситуация показана в примере №1.
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>Использование кодов символов</title> </head> <body> Здесь мы тегов не увидим <span></span>.<br> А вот здесь мы видим тег <span>.<br> Это тоже тег <span>.<br> И это тег <span>. </body> </html>
Пример №1. Замещение символов их кодами
Стандарт Unicode в JavaScript
Числовые коды Unicode можно использовать и в коде JavaScript, т.к. при написании
программ на данном языке используется кодировка UTF-16, а строки представляют собой не
что иное, как последовательности 16-битных значений без знака. Благодаря этому программисты могут использовать в своем
коде как символы своего родного языка (хотя это и не принято), так и различные другие символы, отсутствующие на клавиатуре (см. пример №2).
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Юникод в JavaScript</title>
</head>
<body>
<!-- Заполним при помощи скрипта -->
<p id="p_1"></p>
<script>
//Здесь вместо некоторых символов пишем коды Юникода
//Чтобы конструкция не сработала, экранируем еще одним слешем
//Запустите пример и посмотрите результат
var u00B5='\u00B5 - это символ µ!';
//Находим абзац по его id
var p1=document.getElementById('p_1');
//Вставляем в него значение переменной
p1.innerHTML=µ;
</script>
<p>
Вне JavaScript следует использовать правила HTML!!!<br>
Выводим тот же символ µ.
</p>
</body>
</html>
Пример №2. Использование числовых кодов Unicode в JavaScript
Как видно из примера, для того, чтобы записать в коде JavaScript вместо символа его числовой код
в кодировке UTF-16, следует использовать конструкцию uXXXX (экранируется числовой
код Юникода из четырех цифр в шестнадцатеричной системе счисления).
Стандарт Unicode в PHP
Следует помнить, что в PHP отсутствует встроенная поддержка Unicode, т.е.
язык поддерживает только 256 различных символов, каждому из которых соответствует один байт. Поэтому, для работы с
многобайтовыми кодировками вроде «UTF-8», которая используется нами при верстке веб-страниц, следует отдавать
предпочтение специальным функциям и расширениям для работы с многобайтовыми строками. Все они собраны в официальном справочнике в разделе
«Поддержка языков и кодировок» -> «Многобайтовые строки».
Что касается функций для работы с однобайтовыми строками, то их нужно искать в разделе «Обработка текста». При этом
отметим, что некоторые функции одинаково полезны как для работы с однобайтовыми, так и многобайтовыми строками.
Таблицы мнемоник и числовых кодов стандарта Unicode
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| < | < | < | < | меньше |
| > | > | > | > | больше |
| & | & | & | & | амперсанд |
| « | " | " | " | двойная кавычка |
| » | ' | ' | ' | одинарная кавычка |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| | неразрывный пробел | |||
|   | средний пробел | |||
|   | длинный пробел | |||
|   | узкий пробел | |||
| | ­ | | | мягкий перенос |
| ‑ | ” | ‑ | неразрывный дефис | |
| – | – | – | – | среднее тире |
| — | — | — | — | длинное тире |
| . | . | . | точка | |
| , | , | , | запятая | |
| ; | ; | ; | точка с запятой | |
| : | : | : | двоеточие | |
| … | … | … | … | многоточие |
| ? | ? | ? | вопросительный знак | |
| ǃ | ǃ | ǃ | восклицательный знак | |
| # | # | # | «решетка» | |
| * | * | * | «звездочка» | |
| @ | @ | @ | «собачка» | |
| & | & | & | & | амперсанд |
| № | № | № | знак номера | |
| § | § | § | § | параграф |
| ¶ | ¶ | ¶ | ¶ | абзац |
| • | • | • | • | маркер списка (середина строки) |
| ‣ | ‣ | ‣ | треугольный маркер списка | |
| ‘ | ‘ | ‘ | ‘ | одиночная верхняя левая кавычка |
| ’ | ’ | ’ | ’ | одиночная верхняя правая кавычка |
| ‚ | ‚ | ‚ | ‚ | одиночная нижняя правая кавычка |
| “ | “ | “ | “ | двойная верхняя левая кавычка |
| „ | „ | „ | „ | двойная нижняя правая кавычка |
| « | « | « | « | двойная левая угловая кавычка (рус) |
| » | » | » | » | двойная правая угловая кавычка (рус) |
| ́ | ́ | ́ | знак ударения | |
| ‘ | ' | ' | апостроф | |
| ´ | ´ | ´ | ´ | акут |
| ˆ | ˆ | ˆ | ˆ | акцент |
| ˜ | ˜ | ˜ | ˜ | малая тильда |
| ¦ | ¦ | ¦ | ¦ | вертикальный пунктир |
| ( | ( | ( | круглая скобка влево | |
| ) | ) | ) | круглая скобка вправо | |
| 〈 | ⟨ | 〈 | 〈 | угловая скобка влево |
| 〉 | ⟩ | 〉 | 〉 | угловая скобка вправо |
| ‹ | ‹ | ‹ | ‹ | угловая скобка влево (вариант) |
| › | › | › | › | угловая скобка вправо (вариант) |
| [ | [ | [ | квадратная скобка влево | |
| ] | ] | ] | квадратная скобка вправо | |
| / | / | / | слеш | |
| \ | \ | обратный слеш | ||
| ⁄ | ⁄ | ⁄ | ⁄ | косая дробная черта (знак деления) |
| ǀ | ǀ | ǀ | вертикальная черта | |
| ǁ | ǁ | ǁ | двойная вертикальная черта | |
| ‾ | ‾ | ‾ | ‾ | надчеркивание |
| ¯ | ¯ | ¯ | ¯ | макрон |
| ✓ | ✓ | ✓ | галочка | |
| ✔ | ✔ | ✔ | жирная галочка | |
| ✕ | ✕ | ✕ | косой крест | |
| ✖ | ✖ | ✖ | жирный косой крест | |
| ✗ | ✗ | ✗ | рукописный крест | |
| ✘ | ✘ | ✘ | жирный рукописный крест |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| Α | Α | Α | заглавная альфа | |
| Β | Β | Β | заглавная бета | |
| Γ | Γ | Γ | заглавная гамма | |
| Δ | Δ | Δ | заглавная дельта | |
| Ε | Ε | Ε | заглавная эпсилон | |
| Ζ | Ζ | Ζ | заглавная дзета | |
| Η | Η | Η | заглавная эта | |
| Θ | Θ | Θ | заглавная тета | |
| Ι | Ι | Ι | заглавная йота | |
| Κ | Κ | Κ | заглавная каппа | |
| Λ | Λ | Λ | заглавная лямбда | |
| Μ | Μ | Μ | заглавная мю | |
| Ν | Ν | Ν | заглавная ню | |
| Ξ | Ξ | Ξ | заглавная кси | |
| Ο | Ο | Ο | заглавная омикрон | |
| Π | Π | Π | заглавная пи | |
| Ρ | Ρ | Ρ | заглавная ро | |
| Σ | Σ | Σ | заглавная сигма | |
| Τ | Τ | Τ | заглавная тау | |
| Υ | Υ | Υ | заглавная ипсилон | |
| Φ | Φ | Φ | заглавная фи | |
| Χ | Χ | Χ | заглавная хи | |
| Ψ | Ψ | Ψ | заглавная пси | |
| Ω | Ω | Ω | заглавная омега | |
| α | α | α | альфа | |
| β | β | β | бета | |
| γ | γ | γ | гамма | |
| δ | δ | δ | дельта | |
| ε | ε | ε | эпсилон | |
| ζ | ζ | ζ | дзета | |
| η | η | η | эта | |
| θ | θ | θ | тета | |
| ι | ι | ι | йота | |
| κ | κ | κ | каппа | |
| λ | λ | λ | лямбда | |
| μ | μ | μ | мю | |
| ν | ν | ν | ню | |
| ξ | ξ | ξ | кси | |
| ο | ο | ο | омикрон | |
| π | π | π | пи | |
| ρ | ρ | ρ | ро | |
| ς | ς | ς | окончательная сигма | |
| σ | σ | σ | сигма | |
| τ | τ | τ | тау | |
| υ | υ | υ | ипсилон | |
| φ | φ | φ | фи | |
| χ | χ | χ | хи | |
| ψ | ψ | ψ | пси | |
| ω | ω | ω | омега |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| + | + | + | + | плюс |
| − | − | − | − | минус |
| = | = | = | равно | |
| ± | ± | ± | ± | плюс-минус |
| × | × | × | × | знак умножения |
| ÷ | ÷ | ÷ | ÷ | знак деления |
| ⋅ | ⋅ | ⋅ | ⋅ | оператор «точка» (середина строки) |
| ∗ | ∗ | ∗ | ∗ | оператор «звёздочка» (середина строки) |
| ∼ | ∼ | ∼ | ∼ | оператор «тильда» |
| ¹ | ¹ | ¹ | ¹ | верхний индекс «1» |
| ² | ² | ² | ² | верхний индекс «2» |
| ³ | ³ | ³ | ³ | верхний индекс «3» |
| ½ | ½ | ½ | ½ | «одна вторая» |
| ⅓ | ⅓ | ⅓ | ⅓ | «одна треть» |
| ¼ | ¼ | ¼ | ¼ | «одна четвёртая» |
| ¾ | ¾ | ¾ | ¾ | «три четверти» |
| № | № | № | знак номера | |
| % | % | % | процент | |
| ‰ | ‰ | ‰ | ‰ | промилле |
| ° | ° | ° | ° | градусы |
| ′ | ′ | ′ | ′ | штрих (минуты, футы) |
| ″ | ″ | ″ | ″ | двойной штрих (секунды, дюймы) |
| µ | µ | µ | µ | микро |
| π | π | π | π | Пи |
| ƒ | ƒ | ƒ | ƒ | знак функции |
| ∫ | ∫ | ∫ | ∫ | интеграл |
| ∬ | ∬ | ∬ | двойной интеграл | |
| ∭ | ∭ | ∭ | тройной интеграл | |
| ∮ | ∮ | ∮ | интеграл по контуру | |
| ∅ | ∅ | ∅ | ∅ | пустое множество |
| ⌀ | ⌀ | ⌀ | диаметр | |
| ø | ø | ø | ø | латинская o диагонально перечёркнутая |
| Ø | Ø | Ø | Ø | латинская заглавная O диагонально перечёркнутая |
| √ | √ | √ | √ | радикал |
| ∛ | ∛ | ∛ | корень третьей степени | |
| ∜ | ∜ | ∜ | корень четвертой степени | |
| ∝ | ∝ | ∝ | ∝ | пропорционально |
| ∞ | ∞ | ∞ | ∞ | бесконечность |
| ∟ | ∟ | ∟ | прямой угол | |
| ∠ | ∠ | ∠ | ∠ | угол |
| ⊥ | ⊥ | ⊥ | ⊥ | ортогонально (перпендикулярно) |
| ∴ | ∴ | ∴ | ∴ | знак «cледовательно» |
| ∀ | ∀ | ∀ | ∀ | любой (для всех) |
| ∂ | ∂ | ∂ | ∂ | частичный дифференциал |
| ∃ | ∃ | ∃ | ∃ | существует |
| ∄ | ∄ | ∄ | не существует | |
| ∆ | ∆ | ∆ | инкремент | |
| ∇ | ∇ | ∇ | ∇ | оператор набла |
| ∈ | ∈ | ∈ | ∈ | элемент из (принадлежит) |
| ∉ | ∉ | ∉ | ∉ | не элемент из (не принадлежит) |
| ∋ | ∋ | ∋ | ∋ | содержит в качестве члена |
| ∌ | ∌ | ∌ | не содержит в качестве члена | |
| ⊂ | ⊂ | ⊂ | ⊂ | подмножество |
| ⊃ | ⊃ | ⊃ | ⊃ | включает в себя |
| ⊄ | ⊄ | ⊄ | ⊄ | не включает в себя |
| ⊆ | ⊆ | ⊆ | ⊆ | подмножество или эквивалентно |
| ⊇ | ⊇ | ⊇ | ⊇ | включает в себя или эквивалентно |
| ∋ | ∋ | ∋ | ∋ | содержит как член |
| ∏ | ∏ | ∏ | ∏ | знак произведения |
| ∑ | ∑ | ∑ | ∑ | знак суммирования |
| ≅ | ≅ | ≅ | ≅ | приблизительно равно |
| ≈ | ≈ | ≈ | ≈ | почти равно |
| ≠ | ≠ | ≠ | ≠ | не равно |
| ≡ | ≡ | ≡ | ≡ | идентично |
| ≤ | ≤ | ≤ | ≤ | меньше или равно |
| ≥ | ≥ | ≥ | ≥ | больше или равно |
| ¬ | ¬ | ¬ | ¬ | логическое Не |
| ∧ | ∧ | ∧ | ∧ | логическое И |
| ∨ | ∨ | ∨ | ∨ | логическое ИЛИ |
| ⊕ | ⊕ | ⊕ | ⊕ | «плюс в круге» (прямая сумма) |
| ⊗ | ⊗ | ⊗ | ⊗ | «умножение в круге» (векторное произведение, стрела от наблюдателя) |
| ʘ | ʘ | ʘ | точка в круге (стрела к наблюдателю) |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ℠ | ℠ | ℠ | знак обслуживания | |
| ™ | ™ | ™ | ™ | товарный знак (TradeMark) |
| ® | ® | ® | ® | знак регистрации товарного знака |
| © | © | © | © | знак защиты авторского права (copyright) |
| ¤ | ¤ | ¤ | ¤ | валюта |
| ¢ | ¢ | ¢ | ¢ | цент |
| $ | $ | $ | доллар | |
| € | € | $ | $ | евро |
| £ | £ | £ | £ | фунт |
| ¥ | ¥ | ¥ | ¥ | иена |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ❶ | ❶ | ❶ | белая цифра 1 в черном круге | |
| ❷ | ❷ | ❷ | белая цифра 2 в черном круге | |
| ❸ | ❸ | ❸ | белая цифра 3 в черном круге | |
| ❹ | ❹ | ❹ | белая цифра 4 в черном круге | |
| ❺ | ❺ | ❺ | белая цифра 5 в черном круге | |
| ❻ | ❻ | ❻ | белая цифра 6 в черном круге | |
| ❼ | ❼ | ❼ | белая цифра 7 в черном круге | |
| ❽ | ❽ | ❽ | белая цифра 8 в черном круге | |
| ❾ | ❾ | ❾ | белая цифра 9 в черном круге | |
| ❿ | ❿ | ❿ | белая цифра 10 в черном круге | |
| ⓪ | ⓪ | ⓪ | черная цифра 0 в белом круге | |
| ① | ① | ① | черная цифра 1 в белом круге | |
| ② | ② | ② | черная цифра 2 в белом круге | |
| ③ | ③ | ③ | черная цифра 3 в белом круге | |
| ④ | ④ | ④ | черная цифра 4 в белом круге | |
| ⑤ | ⑤ | ⑤ | черная цифра 5 в белом круге | |
| ⑥ | ⑥ | ⑥ | черная цифра 6 в белом круге | |
| ⑦ | ⑦ | ⑦ | черная цифра 7 в белом круге | |
| ⑧ | ⑧ | ⑧ | черная цифра 8 в белом круге | |
| ⑨ | ⑨ | ⑨ | черная цифра 9 в белом круге | |
| ⑩ | ⑩ | ⑩ | черная цифра 10 в белом круге | |
| ⑪ | ⑪ | ⑪ | черная цифра 11 в белом круге | |
| ⑫ | ⑫ | ⑫ | черная цифра 12 в белом круге | |
| ⑬ | ⑬ | ⑬ | черная цифра 13 в белом круге | |
| ⑭ | ⑭ | ⑭ | черная цифра 14 в белом круге | |
| ⑮ | ⑮ | ⑮ | черная цифра 15 в белом круге | |
| ⑯ | ⑯ | ⑯ | черная цифра 16 в белом круге | |
| ⑰ | ⑰ | ⑰ | черная цифра 17 в белом круге | |
| ⑱ | ⑱ | ⑱ | черная цифра 18 в белом круге | |
| ⑲ | ⑲ | ⑲ | черная цифра 19 в белом круге | |
| ⑳ | ⑳ | ⑳ | черная цифра 20 в белом круге | |
| Ⅰ | Ⅰ | Ⅰ | римская цифра 1 | |
| Ⅱ | Ⅱ | Ⅱ | римская цифра 2 | |
| Ⅲ | Ⅲ | Ⅲ | римская цифра 3 | |
| Ⅳ | Ⅳ | Ⅳ | римская цифра 4 | |
| Ⅴ | Ⅴ | Ⅴ | римская цифра 5 | |
| Ⅵ | Ⅵ | Ⅵ | римская цифра 6 | |
| Ⅶ | Ⅶ | Ⅶ | римская цифра 7 | |
| Ⅷ | Ⅷ | Ⅷ | римская цифра 8 | |
| Ⅸ | Ⅸ | Ⅸ | римская цифра 9 | |
| Ⅹ | Ⅹ | Ⅹ | римская цифра 10 | |
| Ⅺ | Ⅺ | Ⅺ | римская цифра 11 | |
| Ⅻ | Ⅻ | Ⅻ | римская цифра 12 | |
| Ⅼ | Ⅼ | Ⅼ | римская цифра 50 | |
| Ⅽ | Ⅽ | Ⅽ | римская цифра 100 | |
| Ⅾ | Ⅾ | Ⅾ | римская цифра 500 | |
| Ⅿ | Ⅿ | Ⅿ | римская цифра 1000 |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ← | ← | ← | ← | влево |
| ↑ | ↑ | ↑ | ↑ | вверх |
| → | → | → | → | направо |
| ↓ | ↓ | ↓ | ↓ | вниз |
| ↔ | ↔ | ↔ | ↔ | влево-вправо |
| ↕ | ↕ | ↕ | вверх-вниз | |
| ↖ | ↖ | ↖ | вверх-влево | |
| ↗ | ↗ | ↗ | вверх-вправо | |
| ↘ | ↘ | ↘ | вниз-вправо | |
| ↙ | ↙ | ↙ | вниз-влево | |
| ⇄ | ⇄ | ⇄ | Стрелка направо над стрелкой налево | |
| ⇅ | ⇅ | ⇅ | Стрелка вверх слева от стрелки вниз | |
| ⇆ | ⇆ | ⇆ | Стрелка налево над стрелкой направо | |
| ⇇ | ⇇ | ⇇ | Парные стрелки налево | |
| ↚ | ↚ | ↚ | зачеркнутая влево | |
| ↛ | ↛ | ↛ | зачеркнутая вправо | |
| ⇠ | ⇠ | ⇠ | штриховая влево | |
| ⇡ | ⇡ | ⇡ | штриховая вверх | |
| ⇢ | ⇢ | ⇢ | штриховая вправо | |
| ⇣ | ⇣ | ⇣ | штриховая вниз | |
| ⤌ | ⤌ | ⤌ | с двойным штрихом влево | |
| ⤍ | ⤍ | ⤍ | с двойным штрихом вправо | |
| ⤎ | ⤎ | ⤎ | с тройным штрихом влево | |
| ⤏ | ⤏ | ⤏ | с тройным штрихом вправо | |
| ⤑ | ⤒ | ⤑ | точечная вправо | |
| ↜ | ↜ | ↜ | волнистая влево | |
| ↝ | ↝ | ↝ | волнистая вправо | |
| ↞ | ↞ | ↞ | двуглавая влево | |
| ↟ | ↟ | ↟ | двуглавая вверх | |
| ↠ | ↠ | ↠ | двуглавая вправо | |
| ↡ | ↡ | ↡ | двуглавая вниз | |
| ↩ | ↩ | ↩ | с крючком влево | |
| ↪ | ↪ | ↪ | с крючком вправо | |
| ↫ | ↫ | ↫ | с петлей влево | |
| ↬ | ↬ | ↬ | с петлей вправо | |
| ↮ | ↮ | ↮ | зачеркнутая вправо-влево | |
| ↯ | ↯ | ↯ | зигзагообразная вниз | |
| ↰ | ↰ | ↰ | вверх и влево | |
| ↱ | ↱ | ↱ | вверх и вправо | |
| ↲ | ↲ | ↲ | вниз и влево | |
| ↳ | ↳ | ↳ | вниз и вправо | |
| ⤴ | ⤴ | ⤴ | изогнутая вправо и вверх | |
| ⤵ | ⤵ | ⤵ | изогнутая вправо и вниз | |
| ⤶ | ⤶ | ⤶ | изогнутая вниз и влево | |
| ⤷ | ⤷ | ⤷ | изогнутая вниз и вправо | |
| ↶ | ↶ | ↶ | против часовой сверху | |
| ↷ | ↷ | ↷ | по часовой сверху | |
| ↺ | ↺ | ↺ | против часовой снизу с разрывом | |
| ↻ | ↻ | ↻ | по часовой снизу с разрывом | |
| ⟲ | ⟲ | ⟲ | против часовой с малым разрывом | |
| ⟳ | ⟳ | ⟳ | по часовой с малым разрывом | |
| ⥀ | ⥀ | ⥀ | против часовой | |
| ⥁ | ⥁ | ⥁ | по часовой | |
| ⇦ | ⇦ | ⇦ | плоская влево | |
| ⇧ | ⇧ | ⇧ | плоская вверх | |
| ⇨ | ⇨ | ⇨ | плоская вправо | |
| ⇩ | ⇩ | ⇩ | плоская вниз | |
| ⇳ | ⇳ | ⇳ | плоская вверх-вниз | |
| ⏎ | ⏎ | ⏎ | символ возврата | |
| ⇪ | ⇪ | ⇪ | плоская (вариант) | |
| ⇫ | ⇫ | ⇫ | плоская (вариант) | |
| ⇬ | ⇬ | ⇬ | плоская (вариант) | |
| ⇭ | ⇭ | ⇭ | плоская (вариант) | |
| ⇮ | ⇮ | ⇮ | плоская (вариант) | |
| ⇯ | ⇯ | ⇯ | плоская (вариант) | |
| ⇰ | ⇰ | ⇰ | плоская (вариант) | |
| ⇐ | ⇐ | ⇐ | двойная влево | |
| ⇑ | ⇑ | ⇑ | двойная вверх | |
| ⇒ | ⇒ | ⇒ | двойная вправо | |
| ⇓ | ⇓ | ⇓ | двойная вниз | |
| ⇔ | ⇔ | ⇔ | двойная влево-вправо | |
| ⇕ | ⇕ | ⇕ | двойная вверх-вниз | |
| ⇖ | ⇖ | ⇖ | двойная вверх-влево | |
| ⇗ | ⇗ | ⇗ | двойная вверх-вправо | |
| ⇘ | ⇘ | ⇘ | двойная вниз-вправо | |
| ⇙ | ⇙ | ⇙ | двойная вниз-влево | |
| ⇍ | ⇍ | ⇍ | двойная зачеркнутая влево | |
| ⇎ | ⇎ | ⇎ | двойная зачеркнутая влево-вправо | |
| ⇏ | ⇏ | ⇏ | двойная зачеркнутая вправо | |
| ⤆ | ⤆ | ⤆ | двойная влево | |
| ⤇ | ⤇ | ⤇ | двойная вправо | |
| ⤊ | ⤊ | ⤊ | тройная вверх | |
| ⤋ | ⤋ | ⤋ | тройная вниз | |
| ⟰ | F0; | ⟰ | четвертная вверх | |
| ⟱ | F1; | ⟱ | четвертная вниз | |
| ⥢ | ⥢ | ⥢ | влево | |
| ⥣ | ⥣ | ⥣ | вверх | |
| ⥤ | ⥤ | ⥤ | вправо | |
| ⥥ | ⥥ | ⥥ | вниз | |
| ➧ | ➧ | ➧ | вправо (вариант) | |
| ➨ | ➨ | ➨ | вправо (вариант) | |
| ➩ | ➩ | ➩ | вправо (вариант) | |
| ➪ | ➪ | ➪ | вправо (вариант) | |
| ➫ | ➫ | ➫ | вправо (вариант) | |
| ➬ | ➬ | ➬ | вправо (вариант) | |
| ➭ | ➭ | ➭ | вправо (вариант) | |
| ➮ | ➮ | ➮ | вправо (вариант) | |
| ➯ | ➯ | ➯ | вправо (вариант) | |
| ➱ | ➲ | ➱ | вправо (вариант) | |
| ➲ | ➳ | ➲ | вправо (вариант) | |
| ➳ | ➴ | ➳ | вправо (вариант) | |
| ➴ | ➵ | ➴ | стрела вниз-вправо (вариант) | |
| ➵ | ➶ | ➵ | вправо (вариант) | |
| ➶ | ➷ | ➶ | стрела вверх-вправо (вариант) | |
| ➷ | ➸ | ➷ | стрела вниз-вправо (вариант) | |
| ➸ | ➹ | ➸ | вправо (вариант) | |
| ➹ | ➺ | ➹ | стрела вверх-вправо (вариант) | |
| ➺ | ➻ | ➺ | вправо (вариант) | |
| ➻ | ➼ | ➻ | вправо (вариант) | |
| ➼ | ➽ | ➼ | вправо (вариант) | |
| ➽ | ➾ | ➽ | вправо (вариант) | |
| ➾ | ➿ | ➾ | вправо (вариант) | |
| ➔ | ➔ | ➔ | вправо (вариант) | |
| ➘ | ➘ | ➘ | вниз-вправо (вариант) | |
| ➙ | ➙ | ➙ | вправо (вариант) | |
| ➚ | ➚ | ➚ | вверх-вправо (вариант) | |
| ➛ | ➛ | ➛ | вправо (вариант) | |
| ➜ | ➜ | ➜ | вправо (вариант) | |
| ➝ | ➝ | ➝ | вправо (вариант) | |
| ➞ | ➞ | ➞ | вправо (вариант) | |
| ➟ | ➟ | ➟ | вправо (вариант) | |
| ➠ | ➠ | ➠ | вправо (вариант) | |
| ➡ | ➡ | ➡ | вправо (вариант) | |
| ➢ | ➢ | ➢ | вправо (вариант) | |
| ➣ | ➣ | ➣ | вправо (вариант) | |
| ➤ | ➤ | ➤ | вправо (вариант) | |
| ➥ | ➥ | ➥ | изогнутая вниз и вправо (вариант) | |
| ➦ | ➦ | ➦ | изогнутая вверх и вправо (вариант) | |
| ◄ | ◄ | ◄ | треугольник влево | |
| ▲ | ▲ | ▲ | треугольник вверх | |
| ► | ► | ► | треугольник вправо | |
| ▼ | ▼ | ▼ | треугольник вниз |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ♈ | ♈ | ♈ | Овен | |
| ♉ | ♉ | ♉ | Телец | |
| ♊ | ♊ | ♊ | Близнецы | |
| ♋ | ♋ | ♋ | Рак | |
| ♌ | ♌ | ♌ | Лев | |
| ♍ | ♍ | ♍ | Дева | |
| ♎ | ♎ | ♎ | Весы | |
| ♏ | ♏ | ♏ | Скорпион | |
| ♐ | ♐ | ♐ | Стрелец | |
| ♑ | ♑ | ♑ | Казерог | |
| ♒ | ♒ | ♒ | Водолей | |
| ♓ | ♓ | ♓ | Рыбы | |
| ⛎ | ⛎ | ⛎ | Змееносец | |
| ☿ | ☿ | ☿ | Меркурий | |
| ♀ | ♀ | ♀ | Венера (женское начало) | |
| ♁ | ♁ | ♁ | Земля | |
| ♂ | ♂ | ♂ | Марс (мужское начало) | |
| ♃ | ♃ | ♃ | Юпитер | |
| ♄ | ♄ | ♄ | Сатурн | |
| ♅ | ♅ | ♅ | Уран | |
| ♆ | ♆ | ♆ | Нептун | |
| ♇ | ♇ | ♇ | Плутон |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ☼ | ☼ | ☼ | солнечно | |
| ☁ | ☁ | ☁ | облачно | |
| 🌁 | 🌁 | 🌁 | туманно | |
| 🌂 | 🌂 | 🌂 | закрытый зонт | |
| 🌃 | 🌃 | 🌃 | звездная ночь | |
| 🌄 | 🌄 | 🌄 | восход над горами | |
| 🌅 | 🌅 | 🌅 | восход | |
| 🌆 | 🌆 | 🌆 | город в сумерках | |
| 🌇 | 🌇 | 🌇 | закат над домами | |
| 🌈 | 🌈 | 🌈 | радуга | |
| 🌉 | 🌉 | 🌉 | мост ночью | |
| 🌊 | 🌊 | 🌊 | волна | |
| 🌋 | 🌋 | 🌋 | вулкан | |
| 🌌 | 🌌 | 🌌 | млечный путь | |
| ☂ | ☂ | ☂ | возможен дождь | |
| ☔ | ☂ | ☔ | дождливо | |
| ☃ | ☃ | ☃ | снежно | |
| ☽ | ☽ | ☽ | растущая луна | |
| ☾ | ☾ | ☾ | стареющая луна | |
| 🌑 | 🌑 | 🌑 | новолуние | |
| 🌓 | 🌓 | 🌓 | первая четверть луны | |
| 🌔 | 🌔 | 🌔 | почти полная растущая луна | |
| 🌕 | 🌕 | 🌕 | полная луна | |
| 🌙 | 🌙 | 🌙 | полумесяц | |
| 🌛 | 🌛 | 🌛 | первая четверть луны с лицом | |
| ☀ | ☀ | ☀ | солнечное затмение | |
| ☊ | ☊ | ☊ | восходящий узел | |
| ☋ | ☋ | ☋ | нисходящий узел | |
| ☌ | ☌ | ☌ | соединение | |
| ☍ | ☍ | ☍ | противостояние |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ♔ | ♔ | ♔ | белый король | |
| ♕ | ♕ | ♕ | белый ферзь | |
| ♖ | ♖ | ♖ | белая ладья | |
| ♗ | ♗ | ♗ | белый слон | |
| ♘ | ♘ | ♘ | белый конь | |
| ♙ | ♙ | ♙ | белая пешка | |
| ♚ | ♚ | ♚ | черный король | |
| ♛ | ♛ | ♛ | черный ферзь | |
| ♜ | ♜ | ♜ | черная ладья | |
| ♝ | ♝ | ♝ | черный слон | |
| ♞ | ♞ | ♞ | черный конь | |
| ♟ | ♟ | ♟ | черная пешка | |
| ♤ | ♤ | ♤ | незакрашенная пика | |
| ♡ | ♡ | ♡ | незакрашенная черва | |
| ♢ | ♢ | ♢ | незакрашенная бубна | |
| ♧ | ♧ | ♧ | незакрашенная трефа | |
| ♠ | ♠ | ♠ | пика | |
| ♥ | ♥ | ♥ | черва | |
| ♦ | ♦ | ♦ | бубна | |
| ♣ | ♣ | ♣ | трефа | |
| ♩ | ♩ | ♩ | четвертная нота | |
| ♪ | ♪ | ♪ | восьмая нота | |
| ♫ | ♫ | ♫ | связанные восьмые ноты | |
| ♬ | ♬ | ♬ | шестнадцатая нота | |
| ♭ | ♭ | ♭ | знак бемоль | |
| ♮ | ♮ | ♮ | знак бекар | |
| ♯ | ♯ | ♯ | знак диез |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ☺ | ☺ | ☺ | незакрашенный веселый | |
| ☻ | ☻ | ☻ | закрашенный веселый | |
| ☹ | ☹ | ☹ | незакрашенный хмурый | |
| 😁 | 😁 | 😁 | ухмыляющийся | |
| 😂 | 😂 | 😂 | со слезами радости | |
| 😃 | 😃 | 😃 | улыбающийся с открытым ртом | |
| 😄 | 😄 | 😄 | улыбающийся с открытым ртом | |
| 😅 | 😅 | 😅 | улыбающийся в холодном поту | |
| 😆 | 😆 | 😆 | улыбающийся с открытым ртом и закрытыми глазами | |
| 😇 | 😇 | 😇 | улыбающийся с нимбом над головой | |
| 😈 | 😈 | 😈 | злорадно улыбающийся с рогами | |
| 😉 | 😉 | 😉 | подмигивающий | |
| 😊 | 😊 | 😊 | улыбающийся с закрытым ртом | |
| 😋 | 😋 | 😋 | смакующий | |
| 😌 | 😌 | 😌 | расслабленный | |
| 😍 | 😍 | 😍 | улыбающийся с глазами-сердечками | |
| 😎 | 😎 | 😎 | улыбающийся в солнечных очках | |
| 😏 | 😏 | 😏 | усмехающийся | |
| 😐 | 😐 | 😐 | нейтральный | |
| 😒 | 😒 | 😒 | неодобряющий | |
| 😓 | 😓 | 😓 | в холодном поту | |
| 😔 | 😔 | 😔 | задумчивый | |
| 😖 | 😖 | 😖 | с выражением стыда | |
| 😘 | 😘 | 😘 | посылающий поцелуй | |
| 😚 | 😚 | 😚 | целующийся с закрытыми глазами | |
| 😜 | 😜 | 😜 | подмигивающий с высунутым языком | |
| 😝 | 😝 | 😝 | с крепко закрытыми глазами и высунутым языком | |
| 😞 | 😞 | 😞 | разочарованный | |
| 😠 | 😠 | 😠 | злой | |
| 😡 | 😡 | 😡 | надувший губы | |
| 😢 | 😢 | 😢 | плачущий | |
| 😣 | 😣 | 😣 | с упрямым выражением лица | |
| 😤 | 😤 | 😤 | чихающий | |
| 😥 | 😥 | 😥 | разочарованный | |
| 😨 | 😧 | 😨 | с выражением страха | |
| 😩 | 😨 | 😩 | утомленный | |
| 😪 | 😩 | 😪 | сонный | |
| 😫 | 😪 | 😫 | усталый | |
| 😭 | 😬 | 😭 | громко плачущий | |
| 😰 | 😯 | 😰 | с открытым ртом в холодном поту | |
| 😱 | 😰 | 😱 | кричащий от страха | |
| 😲 | 😱 | 😲 | удивленный | |
| 😵 | 😴 | 😵 | головокружение | |
| 😶 | 😵 | 😶 | без рта | |
| 😷 | 😶 | 😷 | в медицинской маске | |
| 😸 | 😷 | 😸 | ухмыляющийся кот | |
| 😹 | 😸 | 😹 | кот со слезами радости | |
| 😺 | 😹 | 😺 | улыбающийся кот с открытым ртом | |
| 😻 | 😺 | 😻 | улыбающийся кот с глазами-сердечками | |
| 😼 | 😻 | 😼 | кот с кривой улыбкой | |
| 😽 | 😼 | 😽 | кот, целующийся с закрытыми глазами | |
| 😾 | 😽 | 😾 | кот, надувший губы | |
| 😿 | 😾 | 😿 | плачущий кот | |
| 🙀 | 😿 | 🙀 | усталый кот | |
| 🙅 | 🙅 | 🙅 | стоп, не нравится | |
| 🙆 | 🙆 | 🙆 | приветствует двумя руками | |
| 🙈 | 🙈 | 🙈 | обезьяна, закрывающая глаза от страха | |
| 🙉 | 🙉 | 🙉 | обезьяна, закрывающая уши | |
| 🙊 | 🙊 | 🙊 | обезьяна, держащая рот на замке | |
| 🙋 | 🙋 | 🙋 | человек, привлекающий внимание | |
| 🙌 | 🙌 | 🙌 | человек, поднимающий руки в восторге | |
| 🙍 | 🙍 | 🙍 | нахмурившийся человек | |
| 🙎 | 🙎 | 🙎 | человек с надутыми губами | |
| 🙏 | 🙏 | 🙏 | человек, сложивший ладошки |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ❦ | ❦ | ❦ | сердечко с завитушкой | |
| ❧ | ❧ | ❧ | сердечко с завитушкой, повернутое вправо | |
| ☙ | ☙ | ☙ | сердечко с завитушкой, повернутое влево | |
| ❣ | ❣ | ❣ | восклицательный знак в виде сердца | |
| ❤ | ❤ | ❤ | закрашенное сердце | |
| ❥ | ❥ | ❥ | закрашенное сердце, повернутое вправо | |
| ♡ | ♡ | ♡ | незакрашенная черва | |
| ♥ | ♥ | ♥ | закрашенная черва | |
| 💓 | 💓 | 💓 | бьющееся сердце | |
| 💔 | 💔 | 💔 | разбитое сердце | |
| 💕 | 💕 | 💕 | два сердца | |
| 💖 | 💖 | 💖 | игристое сердце | |
| 💗 | 💗 | 💗 | растущее сердце | |
| 💘 | 💘 | 💘 | сердце, пронзенное стрелой | |
| 💙 | 💙 | 💙 | сердце, заштрихованное горизонтально | |
| 💚 | 💚 | 💚 | сердце, заштрихованное сверху направо | |
| 💛 | 💛 | 💛 | сердце, заштрихованное сверху налево | |
| 💜 | 💜 | 💜 | сердце, заштрихованное вертикально | |
| 💝 | 💝 | 💝 | сердце с бантиком | |
| 💞 | 💞 | 💞 | вращающиеся сердца | |
| 💟 | 💟 | 💟 | декоративное сердце | |
| 🏩 | 🏩 | 🏩 | отель для влюбленных | |
| 💌 | 💌 | 💌 | любовное письмо | |
| 💑 | 💑 | 💑 | влюбленная пара | |
| 💐 | 💐 | 💐 | букет | |
| ✤ | ✤ | ✤ | цветок (вариант) | |
| ✥ | ✥ | ✥ | цветок (вариант) | |
| ✻ | ✻ | ✻ | цветок (вариант) | |
| ✼ | ✼ | ✼ | цветок (вариант) | |
| ✽ | ✽ | ✽ | цветок (вариант) | |
| ✾ | ✾ | ✾ | цветок (вариант) | |
| ✿ | ❀ | ✿ | цветок (вариант) | |
| ❀ | ❁ | ❀ | цветок (вариант) | |
| ❁ | ❂ | ❁ | цветок (вариант) | |
| 🌼 | 🌼 | 🌼 | цветок (вариант) | |
| ☘ | ☘ | ☘ | трилистник | |
| 🍀 | 🍀 | 🍀 | клевер | |
| ⚘ | ⚘ | ⚘ | цветок | |
| 🌷 | 🌷 | 🌷 | тюльпан | |
| 🌸 | 🌸 | 🌸 | цветок вишни | |
| 🌹 | 🌹 | 🌹 | роза | |
| 🌺 | 🌺 | 🌺 | гибискус | |
| 🌻 | 🌻 | 🌻 | подсолнечник |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ★ | ★ | ★ | закрашенная звезда | |
| ☆ | ☆ | ☆ | незакрашенная звезда | |
| ⚝ | ⚝ | ⚝ | звезда со скругленными концами | |
| ✡ | ✡ | ✡ | звезда Давида | |
| ✪ | ✪ | ✪ | звезда в закрашенном круге | |
| ⍟ | ⍟ | ⍟ | закрашенная звезда в круге | |
| ✫ | ✫ | ✫ | звезда с незакрашенным кружком | |
| ✭ | ✭ | ✭ | обведенная закрашенная звезда | |
| ✯ | ✯ | ✯ | вращающаяся звезда | |
| ✰ | ✰ | ✰ | незакрашенная звезда с тенью | |
| ✱ | ✱ | ✱ | жирная 6-конечная звездочка | |
| ✲ | ✲ | ✲ | 6-конечная звездочка с кружком | |
| ✳ | ✳ | ✳ | 8-конечная звездочка (снежинка) | |
| ✴ | ✴ | ✴ | 8-конечная звездочка с закрашенным кружком | |
| ✵ | ✵ | ✵ | 8-конечная вращающаяся звезда | |
| ✶ | ✶ | ✶ | 6-конечная закрашенная звезда | |
| ✷ | ✷ | ✷ | 8-конечная закрашенная звезда | |
| ✸ | ✸ | ✸ | жирная 8-конечная закрашенная звезда | |
| ✹ | ✹ | ✹ | жирная 12-конечная закрашенная звезда | |
| ✺ | ✺ | ✺ | 16-конечная звездочка с закрашенным кружком | |
| 🌟 | 🌟 | 🌟 | светящаяся звезда | |
| 🌠 | 🌠 | 🌠 | падающая звезда |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| 🐚 | F41A; | 🐚 | закрученная раковина | |
| 🐌 | F40C; | 🐌 | улитка | |
| 🐍 | F40D; | 🐍 | змея | |
| 🐛 | F41B; | 🐛 | гусеница | |
| 🐜 | F41C; | 🐜 | муравей | |
| 🐝 | F41D; | 🐝 | пчела | |
| 🐞 | F41E; | 🐞 | божья коровка | |
| 🐟 | F41F; | 🐟 | рыба | |
| 🐠 | F420; | 🐠 | тропическая рыба | |
| 🐡 | F421; | 🐡 | иглобрюхая рыба | |
| 🐬 | F42C; | 🐬 | дельфин | |
| 🐳 | F433; | 🐳 | кит выпускающий струю | |
| 🐙 | F419; | 🐙 | осьминог | |
| 🐢 | F422; | 🐢 | черепаха | |
| 🐧 | F427; | 🐧 | пингвин | |
| 🐦 | F426; | 🐦 | птица | |
| 🐔 | F414; | 🐔 | курица | |
| 🐣 | F423; | 🐣 | вылупившийся цыпленок | |
| 🐤 | F424; | 🐤 | цыпленок | |
| 🐥 | F425; | 🐥 | цыпленок в анфас | |
| 🐨 | F428; | 🐨 | коала | |
| 🐩 | F429; | 🐩 | пудель | |
| 🐫 | F42B; | 🐫 | двугорбый верблюд | |
| 🐎 | F40E; | 🐎 | лошадь | |
| 🐑 | F411; | 🐑 | овца | |
| 🐒 | F412; | 🐒 | обезьяна | |
| 🐗 | F417; | 🐗 | кабан | |
| 🐘 | F418; | 🐘 | слон | |
| 🐭 | F42D; | 🐭 | мордочка мыши | |
| 🐮 | F42E; | 🐮 | морда коровы | |
| 🐯 | F42F; | 🐯 | морда тигра | |
| 🐰 | F430; | 🐰 | морда кролика | |
| 🐱 | F431; | 🐱 | морда кота | |
| 🐴 | F434; | 🐴 | морда лошади | |
| 🐵 | F435; | 🐵 | морда обезьяны | |
| 🐶 | F436; | 🐶 | морда собаки | |
| 🐷 | F437; | 🐷 | морда свиньи | |
| 🐸 | F438; | 🐸 | морда лягушки | |
| 🐹 | F439; | 🐹 | морда хомяка | |
| 🐺 | F43A; | 🐺 | морда волка | |
| 🐻 | F43B; | 🐻 | морда медведя | |
| 🐼 | F43C; | 🐼 | морда панды |
| Символ | Мнемоника | 16-ный код Unicode | 10-ный код Unicode | Описание |
|---|---|---|---|---|
| ✂ | ✂ | ✂ | ножницы | |
| ✁ | ✁ | ✁ | ножницы с верхним лезвием | |
| ✃ | ✃ | ✃ | ножницы с нижним лезвием | |
| ✄ | ✄ | ✄ | незакрашенные ножницы | |
| ☎ | ☎ | ☎ | телефон | |
| ☏ | ☏ | ☏ | незакрашенный телефон | |
| ✆ | ✆ | ✆ | знак телефона | |
| ✉ | ✉ | ✉ | конверт | |
| ✏ | ✏ | ✏ | карандаш | |
| ✎ | ✎ | ✎ | карандаш, напрвленный вправо-вниз | |
| ✐ | ✐ | ✐ | карандаш, напрвленный вправо-вверх | |
| ✑ | ✑ | ✑ | незакрашенное острие пера | |
| ✒ | ✒ | ✒ | закрашенное острие пера | |
| 📌 | 📌 | 📌 | канцелярская кнопка | |
| 📍 | 📍 | 📍 | булавка | |
| 📎 | 📎 | 📎 | скрепка | |
| 📏 | 📏 | 📏 | линейка | |
| 📐 | 📐 | 📐 | треугольная линейка | |
| ✈ | ✈ | ✈ | самолет | |
| 🚀 | 🚀 | 🚀 | ракета | |
| 🚃 | 🚃 | 🚃 | вагон | |
| 🚄 | 🚄 | 🚄 | высокоскоростной поезд | |
| 🚇 | 🚇 | 🚇 | метро | |
| 🚉 | 🚉 | 🚉 | станция | |
| 🚌 | 🚌 | 🚌 | автобус | |
| 🚏 | 🚏 | 🚏 | остановка автобуса | |
| 🚑 | 🚒 | 🚑 | скорая помощь | |
| 🚒 | 🚓 | 🚒 | пожарная машина | |
| 🚓 | 🚔 | 🚓 | полицейская машина | |
| 🚕 | 🚖 | 🚕 | такси | |
| 🚗 | 🚘 | 🚗 | автомобиль | |
| 🚙 | 🚚 | 🚙 | джип | |
| 🚚 | 🚛 | 🚚 | грузовик | |
| 🚢 | 🚢 | 🚢 | корабль | |
| 🚤 | 🚤 | 🚤 | катер | |
| 🚥 | 🚥 | 🚥 | горизонтальный светофор | |
| 🚧 | 🚧 | 🚧 | предупреждающие огни | |
| 🚨 | 🚨 | 🚨 | полицейская мигалка | |
| 🚩 | 🚩 | 🚩 | треугольный флаг на стойке | |
| 🚪 | 🚪 | 🚪 | дверь | |
| 🚫 | 🚫 | 🚫 | не входить | |
| 🚬 | 🚬 | 🚬 | знак курения | |
| 🚭 | 🚭 | 🚭 | курить запрещено | |
| 🚲 | 🚲 | 🚲 | велосипед | |
| 🚶 | 🚶 | 🚶 | пешеход | |
| 🚹 | 🚹 | 🚹 | мужская уборная | |
| 🚺 | 🚺 | 🚺 | женская уборная | |
| 🚻 | 🚻 | 🚻 | уборная | |
| 🚼 | 🚼 | 🚼 | знак с ребенком | |
| ♿ | ♿ | ♿ | для инвалидов | |
| 🚽 | 🚽 | 🚽 | туалет | |
| 🚾 | 🚾 | 🚾 | женский туалет | |
| 🛀 | 🛀 | 🛀 | ванна | |
| ⛽ | ⛽ | ⛽ | знак заправки | |
| 🍴 | 🍴 | 🍴 | вилка и нож | |
| 🏠 | 🏠 | 🏠 | дом | |
| 💻 | 💻 | 💻 | персональный компьютер | |
| 🌴 | 🌴 | 🌴 | пальма |
Этот восхитительный Юникод
Время на прочтение
27 мин
Количество просмотров 78K

Перед вами обновляемый список самых замечательных «вкусностей» Юникода, а также пакетов и ресурсов
Юникод — это потрясающе! До его появления международная коммуникация была изнурительной: каждый определял свой отдельный расширенный набор символов в верхней половине ASCII (так называемые кодовые страницы). Это порождало конфликты. Просто подумайте, что немцам приходилось договариваться с корейцами, где чья кодовая страница. К счастью, появился Юникод и ввёл общий стандарт. Юникод 8.0 охватывает более 120 000 символов из более 129 письменностей. И современные, и древние, и до сих пор не расшифрованные. Юникод поддерживает текст слева направо и справа налево, наложение символов и включает самые разные культурные, политические, религиозные символы и эмодзи. Юникод потрясающе человечен, а его возможности сильно недооцениваются.
Содержание
- Краткое введение
- Какие символы входят в Стандарт Юникод?
- Кодировки символов Юникода
- Поговорим о цифрах
- Суррогатные пары UTF-16
- Вычисление суррогатных пар
- Композиция и декомпозиция
- Мифы о Юникоде
- Прикладные кодировки Юникода
- Исходный код
- Список удивительных символов
- Специальные символы
- Идентификаторы переменных могут включать пробелы!
- Модификаторы
- Коллизии преобразований в верхнем регистре
- Коллизии преобразований в нижнем регистре
- Причуды и устранение неполадок
- Сопоставления одного ко многим
- Отличные пакеты и библиотеки
- Эмодзи
- Многообразие
- Переменные и методы с креативными названиями
- Скрипт рекурсивного переименования тегов HTML
- Шрифты Юникода
- Дополнительные ресурсы
- Более глубокое исследование самого Юникода
- Общая карта
- Карта основной многоязычной плоскости
- Блоки Юникода
- Принципы Стандарта Юникод
- Версии Юникода
Краткое введение
Какие символы входят в Стандарт Юникод?
Стандарт Юникод определяет коды для символов основных современных языков. Это европейские алфавитные письменности, ближневосточные письменности справа налево и многие письменности Азии.
Стандарт также содержит знаки пунктуации, диакритические знаки, математические символы, технические символы, стрелки, дингбаты, эмодзи и т. д. Он предоставляет коды для диакритических знаков, изменяющих знаки символов, такие как тильда (~). Они используются в сочетании с основными для представления акцентированных символов (например, ñ). В целом, Юникод версии 9.0 предоставляет коды для 128 172 символов из мировых алфавитов, наборов идеограмм и коллекций символов.
Большинство символов общего пользования помещаются в первые 64K кодовых точек, область кодового пространства, которая называется основной многоязычной плоскостью, или BMP для краткости. Есть ещё шестнадцать других дополнительных плоскостей, доступных для кодирования других символов, с более чем 850 000 неиспользуемых кодовых точек. Они могут пригодиться для добавления новых символов в будущие версии стандарта.
Стандарт Юникод также резервирует кодовые точки для частного использования. Вендоры или конечные пользователи могут назначать их в своих собственных системах для своих символов или использовать со специализированными шрифтами. На BMP находится 6400 кодовых точек для частного использования и ещё 131 068 дополнительных кодовых точек частного использования, если 6400 недостаточно для конкретных приложений.
Кодировки символов Юникода
Стандарты кодирования символов определяют не только идентичность каждого символа и его числовое значение или кодовую точку, но и то, как это значение представлено в битах.
Стандарт Юникод определяет три формы кодирования, которые позволяют передавать одни и те же данные: это байт, слово и двойное слово (то есть 8, 16 или 32 бит на единицу кода). Все три формы кодируют один и тот же общий набор символов и могут быть эффективно преобразованы друг в друга без потери данных. Консорциум Юникод полностью одобряет использование любой из этих форм кодирования в качестве согласованного способа реализации Стандарта Юникод.
UTF-8 популярен для HTML и подобных протоколов. UTF-8 — это способ преобразования всех символов Юникода в кодировку переменной байтовой длины. Его преимущество в том, что символы Юникода, соответствующие знакомому набору ASCII, имеют те же байтовые значения, что и ASCII, а символы Юникода, преобразованные в UTF-8, могут использоваться с большим количеством существующего программного обеспечения без серьёзной доработки ПО.
UTF-16 популярен во многих средах, где необходимо сбалансировать эффективный доступ к символам с экономичным хранением. Он достаточно компактен, и все часто используемые символы помещаются в один 16-битный кодовый блок, в то время как все остальные символы доступны через пары 16-битных кодовых блоков.
UTF-32 полезен там, где объём памяти не вызывает беспокойства, но требуется доступ к символам по единому коду фиксированной ширины. Здесь каждый символ Юникода кодируется в одном 32-разрядном кодовом блоке.
Все три формы кодирования требуют для каждого символа не более 4 байт (или 32 бит).
Поговорим о цифрах
Набор символов Юникода разделён на 17 основных сегментов (плоскостей), которые далее делятся на блоки. В каждой плоскости есть место для 65 536 (216) кодовых точек, что создаёт в сумме 1 114 112 кодовых точек. Есть две «плоскости частного использования» (№ 16 и № 17), которые выделяются для использования на усмотрение компаний/пользователей. В них 131 072 кодовые точки.
Первая плоскость называется основной многоязычной плоскостью или BMP. Она содержит кодовые точки от U+0000 до U+FFFF, то есть наиболее часто используемые символы. Остальные шестнадцать плоскостей (U+010000 → U+10FFFF) называются дополнительными или астральными.
Суррогатные пары UTF-16
Символы вне основной плоскости, как тетраграмматон, означающий центр (U+1D306), можно закодировать в UTF-16 только двумя 16-битными кодовыми единицами: 0xD834 0xDF06. Это называется суррогатной парой. Обратите внимание, что суррогатная пара представляет только один символ.
Первая кодовая единица суррогатной пары всегда находится в диапазоне от 0xD800 до 0xDBFF и называется верхней частью пары.
Вторая кодовая единица суррогатной пары всегда находится в диапазоне от 0xDC00 до 0xDFFF и называется нижней частью пары.
Матиас Байненс
Суррогатная пара: представление одного абстрактного символа, состоящего из последовательности двух 16-разрядных кодовых единиц, где первое значение пары является верхней суррогатной кодовой единицей, а второе — нижней суррогатной кодовой единицей. Суррогатные пары используются только в UTF-16.
Unicode 8.0 Глава 3.8 − Суррогаты
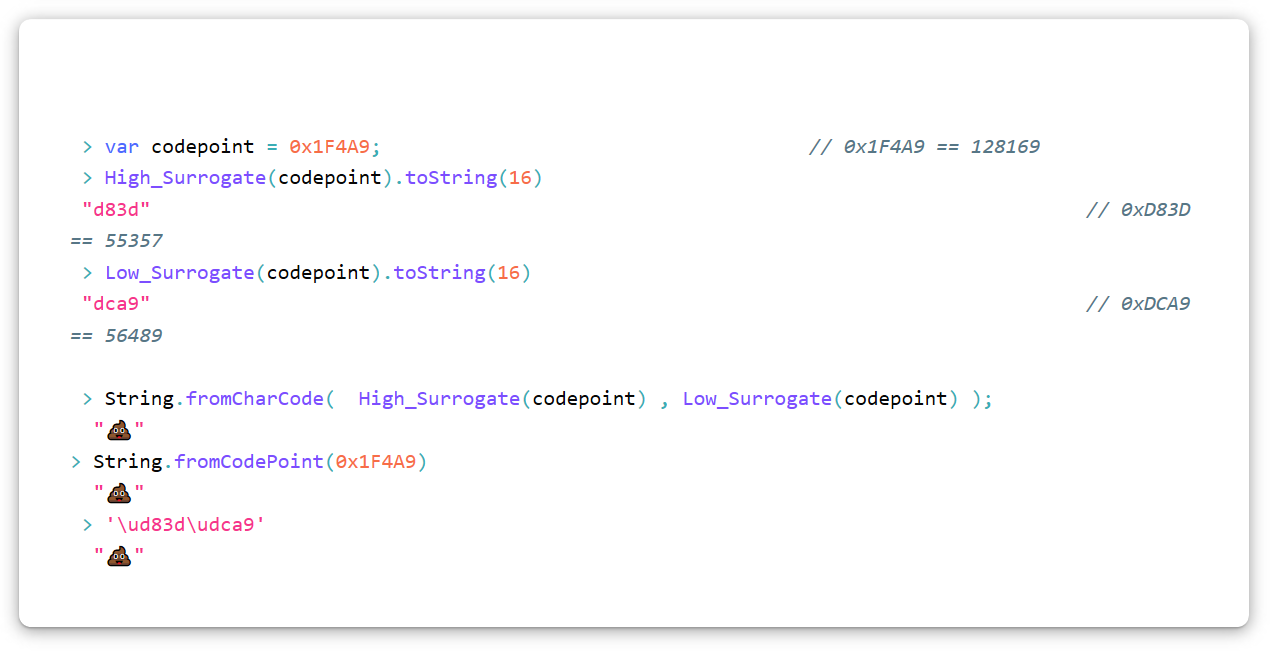
Вычисление суррогатных пар
Юникодовский символ «Куча дерьма» (U+1F4A9) в UTF-16 придётся кодировать как суррогатную пару, т. е. два суррогата. Чтобы преобразовать любую кодовую точку в суррогатную пару, используйте такой алгоритм (на JavaScript). Имейте в виду, что мы используем шестнадцатеричную нотацию.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 };
var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
// Reverses The Conversion
var Code_Point = function(High_Surrogate, Low_Surrogate){
return (High_Surrogate - 0xD800) * 0x400 + Low_Surrogate - 0xDC00 + 0x10000;
};
Композиция и декомпозиция
Юникод включает в себя механизм для изменения формы символа, который значительно расширяет поддерживаемый набор глифов. Это касается комбинируемых диакритических знаков. Они вставляются после главного знака. На один и тот же знак можно наложить несколько комбинируемых диакритических знаков. Юникод также содержит предварительно составленные версии большинства таких комбинаций для нормального использования.
Некоторые последовательности символов также можно представить в виде одного символа, который называется предварительно составленным символом (precomposed character), он же составной символ (composite character). Например, символ [ü] можно закодировать как единственную кодовую точку U+00FC или как базовый символ U+0075 (u), за которым следует несамостоятельный знак U+0308 (¨). Стандарт Юникод кодирует составные символы для совместимости с установленными стандартами, такими как Latin 1, который включает в себя множество составных символов, таких как [ü] и [ñ].
Составные символы можно разложить для согласованности или анализа. Например, при сортировке имён по алфавиту символ [ü] можно разложить на [u], за которым следует несамостоятельный знак [¨]. После такой декомпозиции алгоритму проще работать с последовательностью символов. Это позволяет упростить сортировку в языках, где модификаторы символов не влияют на алфавитный порядок. Стандарт Юникод устанавливает порядок декомпозиции для всех составных символов. Он также определяет формы нормализации для обеспечения уникальных представлений символов.
Мифы о Юникоде
Из слайдов презентации Марка Дэвиса «Мифы Юникода».
- Юникод — это просто 16-битный код. — Некоторые ошибочно полагают, что Юникод — это просто 16-битный код, в котором каждый символ занимает 16 бит, и поэтому существует 65 536 возможных символов. На самом деле это не совсем так. Это самый распространённый миф о Юникоде, так что если вы тоже так думали раньше, не расстраивайтесь.
- Можно взять для своих нужд любую кодовую точку, которая не используется. — Нет. Когда-нибудь это место займёт другой символ. Вместо этого используйте плоскости для частного использования или области без символов в каждой плоскости, где по стандарту не будет никаких символов.
- Каждая кодовая точка Юникода представляет символ. — Нет. Есть много точек без символов (FFFE, FFFF, 1FFFE и др.) Кроме того, суррогатные кодовые точки, приватные и неиспользуемые кодовые точки, а также управляющие/форматирующие «символы» (RLM, ZWNJ и др.)
- В Юникоде заканчивается место. — Если бы оно заполнялось линейно, то закончилось бы в 2140 году. Но место не заполняется линейно. Планы на будущее см. здесь.
- Все знаки сопоставляются один к одному. — Нет. Возможны варианты:
- Один ко многим: (β → SS)
- С учётом контекста: (…Σ ←→ …ς и в то же время …ΣΤ… ←→ …στ…)
- С учётом локали: (I ←→ ı и в то же время İ ←→ i)
Прикладные кодировки Юникода
Исходный код
Список удивительных символов

Совместный доступ к документу может быстро превратить редактирование в письменную рэп-битву, ведущуюся все более запутанной расстановкой управляющих от U+202a до U+202e
Специальные символы
Консорциум Unicode опубликовал диаграмму общей пунктуации, где можете найти более подробную информацию.
Подожди… что я только что прочитал?
Идентификаторы переменных могут включать пробелы!
U+3164 Заполнитель хангыль отображается в виде широкого пробела. Если символ явно не поддерживается в рендеринге, то отображается как полностью невидимый (и не занимает место, т. е. «нулевой ширины»). Это означает, что вы никогда не увидите уродливый символ замены символов (�).
Я пока не уверен, почему U+3164 указано вести себя таким образом. Интересно, что U+3164 был добавлен в Юникод в версии 1.1 (1993) — так что у специалистов Консорциума было много времени, чтобы его продумать. Во всяком случае, вот несколько примеров.
> var ᅟ = 'foo';
undefined
> ᅟ
'foo'
> var ㅤ= alert;
undefined
> var foo = 'bar'
undefined
> if ( foo ===ㅤ`baz` ){} // alert
undefined
> var varㅤfooㅤu{A60C}ㅤπ = 'bar';
undefined
> varㅤfooㅤꘌㅤπ
'bar'**Примечание:** я тестировал рендеринг U+3164 на Ubuntu и OS X со следующими параметрами: `node`, `php`, `ruby`, `python3.5`, `scala`, `vim`, `cat`, `chrome`+`github gist’. Atom — единственная система, которая терпит неудачу, (некорректно) отображая пустые поля. Мне ещё предстоит проверить код в Emacs и Sublime. Насколько я понимаю, Консорциум Юникод не будет переназначать или переименовывать символы или кодовые точки, но его можно убедить изменить свойства символов, таких как ID_Start и ID_Continue.
Модификаторы
Объединитель нулевой ширины (ZWJ) является непечатным символом в компьютерном наборе некоторых сложных шрифтов, таких как арабский или любой индийский шрифт. При помещении между двумя символами, которые в противном случае не были бы связаны, ZWJ заставляет их печататься в объединённой форме.
Разъединитель нулевой ширины (ZWNJ) — это непечатный символ в компьютерных наборах письменностей с лигатурами. При размещении между двумя символами, которые в противном случае были бы соединены в лигатуру, ZWNJ заставляет их печататься в их окончательной и первоначальной формах, соответственно. Действует как пробел, но используется в том случае, когда желательно удерживать слова рядом друг с другом или соединить слово с его морфемой.
> 'a'
"a"
> 'au{0308}'
"ä"
> 'au{20DE}u{0308}'
"a⃞̈"
> 'au{20DE}u{0308}u{20DD}'
"a⃞̈⃝"
// Modifying Invisible Characters
> 'u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}'
""
> 'u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}'.length
10Коллизии преобразований в верхнем регистре
Коллизии преобразований в нижнем регистре
Причуды и устранение неполадок
- Длина строки обычно определяется по количеству кодовых точек. Это означает, что суррогатные пары будут считаться двумя символами. На символ может быть наложено нескольких диакритических знаков:
a + ̈ == ̈a. Это увеличивает длину строки, производя только один символ. - Аналогично, обращение строки часто становится нетривиальной задачей. Опять же, суррогатные пары и диакритические знаки следует обращать вместе. ES Reverser предлагает довольно хорошее решение.
- Сопоставления верхнего и нижнего регистра не всегда совпадают. Они могут выражаться и такими отношениями:
- Один ко многим: (ß → SS )
- С учётом контекста: (…Σ ←→ …ς и …ΣΤ… ←→ …στ… )
- С учётом локали: ( I ←→ ı и İ ←→ i )
Сопоставления одного ко многим
Большинство нижеприведенных символов выражают свои сопоставления «один ко многим» в верхнем регистре, а другие в нижнем. В принципе, список можно разделить на две части.
Отличные пакеты и библиотеки
- PhantomScript — :ghost: :flashlight: Выполнение невидимого JavaScript и социальная инженерия
- ESReverser — Обращение строк на JavaScript с учётом Юникода.
- mimic — Некорректное использование Юникода
- python-ftfy — Пытается создать максимальную корректное и цельное представление текста, поступившего в Юникоде.
- vim-troll-stopper — Защита вашего кода от юникод-троллей.
Эмодзи
- Диаграмма эмодзи от Консорциума Юникод
- Emojipedia — Информация о конкретном эмодзи, новостной блог.
- emojitracker — Использование эмодзи в реальном времени в Twitter.
- World Translation Foundation — Исследование, продвижение, а также словарь эмодзи.
- Can I Emoji? — Отображает текущее состояние нативной поддержки эмодзи в iOS, Android и Windows.
- Как зарегистрировать доменное имя с эмодзи
Многообразие
Консорциум Unicode приложил огромные усилия для лучшего отражения человеческого многообразия (diversity), включая культурные практики. Вот отчёт Консорциума о многообразии.
Теперь доступны эмодзи для разных гендерных ситуаций, включая однополые семьи, держащиеся руки и поцелуи. Последний функционал — это составные последовательности эмодзи. Основные примеры:
Кроме того, эмодзи теперь поддерживают модификаторы цвета кожи.
В Юникоде версии 8.0 (середина 2015 года) появилось пять символов-модификаторов символов для оттенков человеческой кожи. Эти символы основаны на шести оттенках по шкале Фицпатрика, признанного стандарта в дерматологии (в интернете много примеров этой шкалы, таких как FitzpatrickSkinType.pdf). Точные оттенки зависят от реализации.
Отчёт Консорциума Unicode о многообразии
Просто выбирайте нужный эмодзи, указав один из модификаторов цвета кожи
u{1F466}u{1F3FE}.
+
→

Переменные и методы с креативными названиями
Примеры на JavaScript (ES6)
Обычно символы, обозначенные свойством ID_START, можно ставить в начале названия переменной. Символы, обозначенные свойством ID_CONTINUE, можно ставить после первого символа в имени переменной.
// How convenient! var π = Math.PI; // Sometimes, you just have to use the Bad Parts of JavaScript: var ಠ_ಠ = eval; // Code, Y U NO WORK?! var ლ_ಠ益ಠ_ლ = 42; // How about a JavaScript library for functional programming? var λ = function() {}; // Obfuscate boring variable names for great justice var u006Cu006Fu006Cu0077u0061u0074 = 'heh'; // …or just make up random ones var Ꙭൽↈⴱ = 'huh'; // While perfectly valid, this doesn’t work in most browsers: var foou200Cbar = 42; // This is *not* a bitwise left shift (`<<`): var 〱〱 = 2; // This is, though: 〱〱 << 〱〱; // 8 // Give yourself a discount: var price_9̶9̶_89 = 'cheap'; // Fun with Roman numerals var Ⅳ = 4; var Ⅴ = 5; Ⅳ + Ⅴ; // 9 // Cthulhu was here var Hͫ̆̒̐ͣ̊̄ͯ͗͏̵̗̻̰̠̬͝ͅE̴̷̬͎̱̘͇͍̾ͦ͊͒͊̓̓̐_̫̠̱̩̭̤͈̑̎̋ͮͩ̒͑̾͋͘Ç̳͕̯̭̱̲̣̠̜͋̍O̴̦̗̯̹̼ͭ̐ͨ̊̈͘͠M̶̝̠̭̭̤̻͓͑̓̊ͣͤ̎͟͠E̢̞̮̹͍̞̳̣ͣͪ͐̈T̡̯̳̭̜̠͕͌̈́̽̿ͤ̿̅̑Ḧ̱̱̺̰̳̹̘̰́̏ͪ̂̽͂̀͠ = 'Zalgo';А вот некоторые юникодовские классы CSS от Дэвида Уолша.
<!-- place this within the document head --> <meta charset="UTF-8" /> <!-- error message --> <div class="ಠ_ಠ">You do not have access to this page.</div> <!-- success message --> <div class="">Your changes have been saved successfully!</div>.ಠ_ಠ { border: 1px solid #f00; } . { background: lightgreen; }Скрипт рекурсивного переименования тегов HTML
Если вы хотите переименовать все свои HTML-теги в нечто невидимое, вот скрипт, который вам нужен.
Только обратите внимание, что HTML поддерживает не все символы Юникода.
// U+1160 HANGUL JUNGSEONG FILLER transformAllTags('ᅠ'); // An actual HTML element node designed to look like a comment node, using the U+01C3 LATIN LETTER RETROFLEX CLICK // <ǃ-- name="viewport" content="width=device-width"></ǃ--> transformAllTags('ǃ--'); // or even <ᅠ⃝ transformAllTags('u{1160}u{20dd}'); // and for a bonus, all existing tag names will have each character ensquared. h⃞t⃞m⃞l⃞ transformAllTags(); function transformAllTags (newName){ // querySelectorAll doesn't actually return an array. Array.from(document.querySelectorAll('*')) .forEach(function(x){ transformTag(x, newName); }); } function wonky(str){ return str.split('').join('u{20de}') + 'u{20de}'; } function transformTag(tagIdOrElem, tagType){ var elem = (tagIdOrElem instanceof HTMLElement) ? tagIdOrElem : document.getElementById(tagIdOrElem); if(!elem || !(elem instanceof HTMLElement))return; var children = elem.childNodes; var parent = elem.parentNode; var newNode = document.createElement(tagType||wonky(elem.tagName)); for(var a=0;a<elem.attributes.length;a++){ newNode.setAttribute(elem.attributes[a].nodeName, elem.attributes[a].value); } for(var i= 0,clen=children.length;i<clen;i++){ newNode.appendChild(children[0]); //0...always point to the first non-moved element } newNode.style.cssText = elem.style.cssText; parent.replaceChild(newNode,elem); }Вот что он поддерживает:
function testBegin(str){ try{ eval(`document.createElement( '${str}' );`) return true; } catch(e){ return false; } } function testContinue(str){ try{ eval(`document.createElement( 'a${str}' );`) return true; } catch(e){ return false; } }А вот некоторые результаты:
// Test if dashes can start an HTML Tag > testBegin('-') < false > testContinue('-') < true > testBegin('ᅠ-') // Prepend dash with U+1160 HANGUL JUNGSEONG FILLER < trueШрифты Юникода
Ни один шрифт TrueType или OpenType не способен охватить все символы UTF-8, поскольку есть жёсткое ограничение на 65 535 символов в шрифте. Если у нас более 1,1 миллиона глифов UTF-8, то для полного покрытия придётся делать семейство шрифтов.
- https://en.wikipedia.org/wiki/Unicode_font#List_of_Unicode_fonts
- https://www.unifont.org/fontguide/
Дополнительные ресурсы
- «Абсолютный минимум, который каждый разработчик должен обязательно, совершенно точно знать о Юникоде и наборах символов» — Джоэл Спольски
- «Что каждый программист обязательно, совершенно точно должен знать о кодировках и наборах символов для работы с текстом»
- Список рекомендованной литературы от Консорциума Юникод
- Space Yourself — руководство по интервалам от Smashing Magazine
- «У JavaScript проблема Юникода»
- Креативные юзернеймы и захват учётной записи Spotify
Более глубокое исследование самого Юникода
- Shapecatcher — нарисуйте символ, который вы ищете.
- Похожие символы Юникода
- База данных символов Юникода
- Дампы базы Codepoints.net
- Список блоков в пространстве Юникода
- Таблицы символов Юникода
- Таблицы регистров в Юникоде
- Таблица нормализации для Юникода
- FAQ по Юникоду
Общая карта
Карта основной многоязычной плоскости
Каждое нумерованное поле представляет собой 256 кодовых точек.

Китайские, японские и корейские (ККЯ) письменности объединены одним цветом как символы ККЯ (CJK). В процессе, который называется унификацией Хань, распознаются общие символы и составляется список «унифицированных идеограмм ККЯ».
Блоки Юникода
Стандарт Юникод объединяет группы символов в блоки. Вот полный список блоков по всем 17-ти плоскостям.
Принципы Стандарта Юникод
Стандарт Юникод устанавливает следующие фундаментальные принципы:
- Универсальность — каждую когда-либо используемую письменную систему следует уважать и представить в стандарте.
- Логический порядок — в двунаправленном тексте символы хранятся в логическом порядке, а не в соответствии с представлением.
- Эффективность — документация должна быть эффективной и полной.
- Унификация — если разные культуры или языки используют один и тот же символ, он должен быть включен только один раз. Это ведёт к следующему пункту.
- Символы, а не глифы — кодируются только символы, а не глифы. В двух словах, глифы являются фактической графической репрезентацией.
- Динамическая композиция — новые символы могут быть составлены из других, уже стандартизированных символов. Например, символ [Ä] может состоять из символа [A] и символа диерезиса [¨].
- Семантика — включённые символы должны быть чётко определены и отличаться от других.
- Стабильность — однажды определённые, символы никогда не будут удалены, а их кодовые точки никогда не будут переназначены. В случае ошибки кодовая точка считается устаревшей.
- Обычный текст — символы в стандарте являются текстом, они никогда не могут быть разметкой или метасимволами.
- Конвертируемость — любая другая используемая кодировка должна иметь возможность быть представленной в терминах кодировки Юникода.
Источник: описание принципов c codepoints.net.
Версии Юникода
- Версия 11.0 (черновик)
- Версия 10.0 (последняя версия, опубликована 20.06.2017 г.)
- Версия 9.0
- Версия 8.0
- Версия 7.0
- Версия 6.3
- Версия 6.2
- Версия 6.1
- Версия 6.0
- Версия 5.2
- Версия 5.1
- Версия 5.0 (недоступна)
- Версия 4.0.1
- Версия 4.0

Верите вы или нет, но существует формат изображений, встроенных в браузер. Этот формат позволяет загружать изображения до того, как они понадобились, обеспечивает рендеринг изображения на обычных или retina экранах и позволяет добавлять к изображениям CSS. ОК, это не совсем правда. Это не формат изображения, хотя все остальное остается в силе. Используя его, вы можете создавать иконки, независимые от разрешения, не требующие время на загрузку и стилизуемые с помощью CSS.
В этой статье я опишу основы Unicode (далее — Юникод) и некоторые интересные вещи, которые вы можете сделать с его помощью.
Что такое Юникод?
Юникод это возможность корректно отображать буквы и знаки пунктуации из различных языков на одной страницы. Он невероятно полезен: пользователи смогут работать с вашим сайтом по всему миру и он будет показывать то, что вы хотите — это может быть французский язык с диакритическими знаками или Kanji.
Юникод продолжает развиваться: сейчас актуальна версия 8.0 в которой более 120 тысяч символов (в оригинальной статье, опубликованной в начале 2014 года, речь шла о версии 6.3 и 110 тысячах символов).
Кроме букв и цифр, в Юникоде есть и другие символы и иконки. В последних версиях в их число вошли эмодзи, которые вы можете видеть в месседжере iOS.
Страницы HTML создаются из последовательности символов Юникода и при отсылке по сети они конвертируются в байты. Каждая буква и каждый символ любого языка имеют свой уникальный код и кодируются при сохранении файла.
При использовании системы кодирования UTF-8 вы можете напрямую вставлять в текст символы Юникода, но также можно добавлять их в текст, указывая цифровую символьную ссылку. Например, ♥ это символ сердечка и вы можете вывести этот символ, просто добавив код в разметку ♥.
Эту числовую ссылку можно задавать как в десятичном формате, так и в шестнадцатеричном. Десятичный формат требует добавления в начале буквы x, запись ♥ даст то же самое сердечко (♥), что и предыдущий вариант. (2665 это шестнадцатеричный вариант 9829).
Если вы добавляете символ Юникода с помощью CSS, то вы можете использовать только шестнадцатеричные значения.
Некоторые наиболее часто используемые символы Юникода имеют более запоминаемые текстовые имена или аббревиатуры вместо цифровых кодов — это, например, амперсанд (& — &). Такие символы называются мнемоники в HTML, их полный список есть в Википедии.
Почему вам стоит использовать Юникод?
Хороший вопрос, вот несколько причин:
- Чтобы использовать корректные символы из разных языков.
- Для замены иконок.
- Для замены иконок, подключаемых через
@font-face. - Для задания CSS-классов
Корректные символы
Первая из причин не требует никаких дополнительных действий. Если HTML сохранен в формате UTF-8 и его кодировка передана по сети как UTF-8, все должно работать как надо.
Должно. К сожалению, не все браузеры и устройства поддерживают все символы Юникода одинаково (точнее, не все шрифты поддерживают полный набор символов). Например, недавно добавленные символы эмодзи поддерживаются не везде.
Для поддержки UTF-8 в HTML5 добавьте <meta charset=utf-8> (при отсутствии доступа к настройкам сервера стоит добавить также <meta http-equiv= "Content-Type" content="text/html; charset=utf-8">). При старом доктайпе используется (<meta http-equiv="content-type" content="text/html; charset=UTF-8" />).
Иконки
Вторая причина использования Юникода это наличие большого количества полезных символов, которые можно использовать в качестве иконок. Например, ▶, ≡ и ♥.
Их очевидный плюс в том, что вам не надо никаких дополнительных файлов, чтобы добавить их на страницу, а, значит, ваш сайт будет быстрее. Вы также можете изменить их цвет или добавить тень с помощью CSS. А добавив переходы (css transition) вы сможете плавно менять цвет иконки при наведении на нее без каких-либо дополнительных изображений.
Предположим, что я хочу подключить индикатор рейтинга со звездами на свою страницу. Я могу сделать это так:
<span>★ ★ ★ ☆ ☆</span>
Получится следующий результат:
 Образец рейтинга в Firefox
Образец рейтинга в Firefox
Но если вам не повезет, вы увидите что-то вроде этого:
 Тот же рейтинг на BlackBerry 9000
Тот же рейтинг на BlackBerry 9000
Так бывает, если используемые символы отсутствуют в шрифте браузера или устройства (к счастью, эти звездочки поддерживаются отлично и старые телефоны BlackBerry являются здесь единственным исключением).
Если символ Юникода отсутствует, на его месте могут быть разные символы от пустого квадрата (□) до ромба со знаком вопроса (�).
А как найти символ Юникода, который может подойти для использования в вашем дизайне? Вы можете поискать его на сайте типа Unicodinator, просматривая имеющиеся символы, но есть и лучший вариант. Shapecatcher — этот отличный сайт позволяет вам нарисовать искомую иконку, после чего предлагает вам список похожих символов Юникода.
Использование Юникода с @font-face иконками
Если вы используете иконки, подключаемые с внешним шрифтом через @font-face, символы Юникода можно использовать в качестве запасного варианта. Таким образом вы можете показать похожий символ Юникода на тех устройствах или в браузерах, где @font-face не поддерживается:

Слева иконки Font Awesome в Chrome, а справа замещающие их символы Юникода в Opera Mini.
Многие инструменты для подбора @font-face используют диапазон символов Юникода из области для частного использования (private use area). Проблема этого подхода в том, что если @font-face не поддерживается, пользователю передаются коды символов без какого-либо смысла.
Использование символов из области для частного использования может также вынудить Internet Explorer 8 перейти в режим совместимости, а это сродни открытию портала в ад и призванию отвратительных монстров из старых IE (подробнее эта проблема описана в статье Джереми Кита).
IcoMoon отлично подходит для создания наборов иконок в @font-face и позволяет выбрать в качестве основы для иконки подходящий символ Юникода.
Но будьте внимательны — некоторые браузеры и устройства не любят отдельные символы Юникода при их использовании с @font-face. Имеет смысл проверить поддержку символов Юникода с помощью Unify — это приложение поможет вам определить, насколько безопасно использование символа в наборе иконок @font-face.
Поддержка символов Юникода
Основная проблема с использованием символов Юникода в качестве запасного варианта это плохая поддержка в скринридерах (опять-таки, некоторые сведения об этом можно найти на Unify), поэтому важно осторожно выбирать используемые символы.
Если ваша иконка это просто декоративный элемент рядом с текстовой меткой, читаемым скринридером, вы можете особо не волноваться. Но если иконка расположена отдельно, стоит добавить скрытую текстовую метку, чтобы помочь пользователям скринридеров. Даже если символ Юникода будет считан скринридером, есть вероятность, что он будет сильно отличен от своего предназначения. Например, ≡ (≡) в качестве иконки-гамбургера будет считан VoiceOver на iOS как “идентичный”.
Юникод в названиях CSS-классов
То, что Юникод можно использовать в названиях классов и в таблицах стилей известно с 2007 года. Именно тогда Джонатан Снук написал об использовании символов Юникода во вспомогательных классов при верстке скругленных углов. Особого распространения эта идея не получила, но о возможности использовать Юникод в названиях классов (спецсимволы или кириллицу) знать стоит.
Выбор шрифтов
Совсем немногие шрифты поддерживают полный набор символов Юникода, поэтому при выборе шрифта сразу проверяйте наличие нужных вам символов.
Из шрифтов с полной поддержкой Юникода наиболее известны Noto, поддерживающий Юникод версии 6.2 и GNU Unifont (версия Юникода 8.0.01).
Много иконок в Segoe UI Symbol или Arial Unicode MS. Эти шрифты есть и на PC и на Mac; в Lucida Grande также достаточное количество символов Юникода. Вы можете добавить эти шрифты в декларацию font-family, чтобы обеспечить наличие максимального количества символов Юникода для пользователей, у которых эти шрифты установлены.
Определение поддержки Юникода
Было бы очень удобно иметь возможность проверить наличие того или иного символа Юникода, но нет гарантированного способа сделать это.
В Modernizr есть проверка поддержки эмодзи — но она работает проверкой одного пикселя и поэтому даст неправильный результат, если в нужном символе этот пиксель не используется. Да и сама проверка наличия отдельного символа не скажет ничего о поддержке остальных ста тысяч.
Проверяйте. И обеспечивайте запасные варианты, чтобы пользователь всегда мог понять, что происходит при отсутствии нужного символа.
Юникод в письмах
Юникод можно использовать не только на веб-страницах, но и в письмах.
Но здесь есть та же проблема: некоторые почтовые клиенты и некоторые устройства поддерживают нужные символы, а некоторые нет. Небольшое тестирование, позволяющее определить уровень поддержки символов, было проведено Campaign Monitor.
Символы Юникода могут быть эффективны при наличии поддержки. Например, эмодзи в теме письма выделяет его на фоне остальных в почтовом ящике.
Заключение
Эта статья затрагивает лишь основы Юникода. Надеюсь, она окажется полезной и поможет вам лучше понять Юникод и эффективно применять его.
Список ссылок
- “Пуленепробиваемые” иконочные шрифты
- Символы Юникода в теме письма
- IcoMoon (Генератор набора иконок @font-face на основе Юникода)
- Shape Catcher (Инструмент для распознавания символов Юникода)
- Unicodinator(таблица символов Юникода)
- Unify (Проверка поддержки символов Юникода в браузерах)
- Unitools (Коллекция инструментов для работы с Юникодом)
Кодирование строк
Кодирование строк


![]()
Чтобы компьютер смог отобразить передаваемые ему символы, они должны быть представлены в конкретной кодировке. Навряд ли найдется человек, который никогда не сталкивался с кракозябрами: открываешь интернет-страницу, а там – набор непонятных знаков; хочешь прочесть книгу в текстовом редакторе, а вместо слов получаешь сплошные знаки вопроса. Причина заключается в неверной процедуре декодирования текста (если сильно упростить, то программа пытается представить американцу, например, букву «Щ», осуществляя поиск в английском алфавите).
Возникают вопросы: что происходит, кто виноват? Ответ не будет коротким.
1. Компьютер – человек
Так сложилось, что компьютерная техника оперирует единицами и нулями. На вашей же клавиатуре представлено не менее 100 клавиш. Все, что вы вводите при печати, в итоге преобразуется в те самые бинарные величины.
В этом суть кодировки. ПК запоминает любые буквы, числа и знаки в виде определенного значения из единиц и нулей. Для примера: английская буква «Y» в двоичном коде выглядит как «0b1011001», а в шестнадцатеричном как «0x59».
Для осмысленного диалога пользователя и компьютера требуется двусторонний переводчик:
– «человеческие» строки необходимо перекодировать в байты;
– «компьютерную» речь требуется преобразовать в воспринимаемые пользователем осмысленные структуры.
В языке Python за это отвечают функции encode / decode. Важно кодировать и декодировать сообщение в одинаковой кодировке, чтобы не столкнуться с проблемой бессмысленных наборов символов.
Так как первые вычислительные машины были малоемкими, для представления в их памяти всего набора требуемых знаков хватало 7 бит (или 128 символов). Сюда входил весь английский алфавит в верхнем и нижнем регистрах, цифры, знаки, вспомогательные символы.

Поначалу этого вполне хватало. Кодировка получила имя ASCII (читается как «аски» или «эски»). В Пайтоне вы и сегодня можете посмотреть на символы ASCII. Для этого имеется встроенный модуль string.
import string
print(string.ascii_letters)
print(string.digits)
print(string.punctuation)
Результат выполнения кода
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
0123456789
!"#$%&'()*+,-./:;<=>?@[]^_`{|}~С другими свойствами модуля можете ознакомиться самостоятельно.
Время шло, компьютеризация общества ширилась, 128 символов стало не хватать. Оставшийся последний 8-ой бит также выделили для кодирования (а это еще 128 знаков). В итоге появилось большое количество кодировок (кириллическая, немецкая и т.п.). Такая ситуация привела к проблемам. Уже в то время англичанин, получающий электронное письмо из России, мог увидеть не русские буквы, а набор непонятных закорючек.
Потребовалось указание кодировок в заголовках документов.
3. Юникод-стандарт
Как вы считаете, сколько нужно символов, чтобы хватило всем и навсегда? 10_000? Конечно, нет. Уже сегодня более 100_000 знаков имеет свое числовое представление. И это не предел. Люди постоянно придумывают новые «буквы».
Откройте свой телефон и создайте пустое сообщение. Зайдите в раздел «смайликов». Да их тут больше сотни! И это не картинки в большинстве своем. Они являются символами определенной кодировки. Если вы застали времена, когда SMS-технологии только начинали развиваться, то этих самых «смайлов» было не более десятка. Лет через 10 их количество станет «неприличным».
Упомянутая выше кодировка ASCII в своем расширенном варианте породила большое количество новых. Основная беда: имея 128 вариантов обозначить символ, мы никак не сумеем внедрить туда буквы других языков. В частности, какой-нибудь символ под номером 201 в кириллице даст совсем не русскую букву, если отослать его в Румынию. Следовательно, говоря кому-то «посмотри на 201-ый символ» мы не даем никакой гарантии, что собеседник увидит то же.
Для решения задачи был разработан стандарт Unicode. Отметим, что это не определенная кодировка, а именно набор правил. Суть юникода – связь символа и определенного числа без возможного повторения. Если мы кого-то попросим показать символ, скрытый под номером «1000», то в любой точке планеты он будет одним и тем же графическим элементом.

Всего в Unicode стандарте на сегодня имеется место под более чем 1,1 млн знаков:
- UTF-8 – кодировка символов юникод в двоичном виде. Использует от 1 до 4 байт. Так как наиболее часто используемые символы занимают 1 байт (в частности, аски-символы), то UTF-8 оптимальна для английского текста, но не для азиатского.
- UTF-16 используется для кодирования 2-мя или 4-мя байтами. Считается удобным способом для пользователей азиатских стран с иероглифическим письмом.
- UTF-32 представляет все символы при помощи 4 байт. Используется редко, так как потребляет много памяти. Тем не менее, быстро работает при наличии мощностей.
4. Кодирование и декодирование строк
Пользователям Python 3 версии повезло. Все символы и документы заранее приводятся к кодировке UTF-8. И если где-то в коде вы напишете строку «Ёжик в тумане» или «אֱלִיעֶזֶר וְהַגֶזֶר», то будьте уверены, они не превратятся в абракадабру и не приведут к ошибкам.
Тем не менее, строковые методы decode / encode не потеряли свою актуальность. По умолчанию все преобразования осуществляются в кодировке UTF-8, но никто не мешает задать нужную вам.
Пример – Интерактивный режим
>>> 'Ёжик'.encode()
b'xd0x81xd0xb6xd0xb8xd0xba'
>>> 'Ёжик в тумане'.encode().decode()
'Ёжик в тумане'
>>> 'Ёжик в тумане'.encode().decode('utf-16')
'臐뛐룐뫐퀠₲苑菑볐냐뷐뗐'Поясним полученные результаты и принцип работы этих методов.
Задача encode() – представить строку в виде объекта типа bytes (предваряется литералом b). Если знак относится к ASCII, то его байтовое представление будет выглядеть как оригинальный символ. В случае когда он выходит за пределы ASCII, то заменяется байтовым представлением (x — эскейп-последовательность для обозначения 16-ричных чисел в языке Python).
Пример — интерактивный режим
>>> 'Python'.encode()
b'Python'
>>> 'Пайтон'.encode()
B'xd0x9fxd0xb0xd0xb9xd1x82xd0xbexd0xbd'Метод decode() преобразует последовательность байтов в привычную нам строку. Если задать другую кодировку, то можем получить либо неожиданный результат (как в последнем примере, где русские слова превратились в набор корейских иероглифов), либо ошибку UnicodeDecodeError, если в требуемой кодировке нет такого сочетания байтов или они выходят за ее границы.
Читайте также
5. Инструментарий для работы с кодировками
В Python встроено большое разнообразие функций и методов для работы с кодированием-декодированием строк. Часть из них менее актуальна, но на практике могут встречаться.
Перечислим те, которые вам могут понадобиться, а затем опробуем их на практике:
6. Практические примеры
Для усвоения материала попрактикуемся в применении изученного.
А. Функция ascii
Примеры – Интерактивный режим
>>> ascii(12)
'12'
>>> ascii('cat')
"'cat'"
>>> ascii('шапка')
"'\u0448\u0430\u043f\u043a\u0430'"Экранирование русского слова связано с тем, что ни один из символов не включен в стандартный набор знаков ascii (т.е. не имеет 1-байтового представления).
Б. Применение функции str для получения строк
Примеры – Интерактивный режим
>>> str(123)
'123'
>>> str(b'xd0x9fxd0xb0xd0xb9xd1x82xd0xbexd0xbd', 'utf8')
'Пайтон'В. Функция bytes
Превращает в объект bytes не только строки или числа, но и последовательности чисел (каждое из которых соответствует определенному символу).
Примеры – Интерактивный режим
>>> bytes('well done', 'ascii')
b'well done'
>>> bytes('Юта', 'utf16')
b'xffxfe.x04Bx040x04'
>>> bytes((80, 77, 99, 101))
b'PMce'Г. Модуль unicodedata
Позволяет узнать имя любого юникод-символа, а также отобразить его по имени. С другими свойствами можете ознакомиться самостоятельно.
Примеры – Интерактивный режим
>>> import unicodedata
>>> unicodedata.name('Я')
'CYRILLIC CAPITAL LETTER YA'
>>> unicodedata.lookup('GIRL')
'????'
>>> unicodedata.lookup('Trigram for Heaven')
'☰'Задачи по темам
Решаем задачи и отвечаем на вопросы по теме «Целые числа»: работаем с типом данных int
Решаем задачи и отвечаем на вопросы по теме «Числа с плавающей точкой»: работаем с типом данных float
Решаем задачи и отвечаем на вопросы по теме «Логический тип данных»: работаем с типом данных bool
Строки как тип данных в Python. Основные методы и свойства строк. Примеры работы со строками, задачи с решениями.
Д. Отображение любого Юникод-символа
Функция chr() может принимать числа любой стандартной системы счисления (десятичной, двоичной, восьмеричной или шестнадцатеричной).
Функция ord() возвращает десятичное число, соответствующее символу юникод. Если требуется, мы это число можем преобразовать к любому иному основанию.
Примеры – Интерактивный режим
>>> chr(0o144)
'd'
>>> chr(0b1100100)
'd'
>>> chr(0x64)
'd'
>>> chr(100)
'd'
>>> ord('d')
100Также попробуем немного экзотики. Если какой-то из символов не отображается, у вас нет шрифта в системе, который поддерживает эти знаки.
Примеры – Интерактивный режим
>>> chr(0x131B0) # Египетский иероглиф
????
>>> chr(0x1F5A4) # Черное сердечко
'????'
>>> chr(0x265E) # Черный конь
'♞'
>>> chr(0x111E1) # Сингальское число 1
????
>>> chr(0x4E78) # Китайский иероглиф
'乸'Воспользовавшись базой данных символов юникод, вы сумеете просмотреть все доступные варианты на сегодняшний день с указанием имени, кода, принадлежности.
Как вам материал?


Читайте также
From Wikipedia, the free encyclopedia
Web pages authored using HyperText Markup Language (HTML) may contain multilingual text represented with the Unicode universal character set. Key to the relationship between Unicode and HTML is the relationship between the «document character set», which defines the set of characters that may be present in an HTML document and assigns numbers to them, and the «external character encoding», or «charset», used to encode a given document as a sequence of bytes.
In RFC 1866, the initial HTML 2.0 standard, the document character set was defined as ISO-8859-1 (later HTML standard defaults to Windows-1252 encoding). It was extended to ISO 10646 (which is basically equivalent to Unicode) by RFC 2070. It does not vary between documents of different languages or created on different platforms. The external character encoding is chosen by the author of the document (or the software the author uses to create the document) and determines how the bytes used to store and/or transmit the document map to characters from the document character set. Characters not present in the chosen external character encoding may be represented by character entity references.
The relationship between Unicode and HTML tends to be a difficult topic for many computer professionals, document authors, and web users alike. The accurate representation of text in web pages from different natural languages and writing systems is complicated by the details of character encoding, markup language syntax, font, and varying levels of support by web browsers.
HTML document characters[edit]
Web pages are typically HTML or XHTML documents. Both types of documents consist, at a fundamental level, of characters, which are graphemes and grapheme-like units, independent of how they manifest in computer storage systems and networks.
An HTML document is a sequence of Unicode characters. More specifically, HTML 4.0 documents are required to consist of characters in the HTML document character set : a character repertoire wherein each character is assigned a unique, non-negative integer code point. This set is defined in the HTML 4.0 DTD, which also establishes the syntax (allowable sequences of characters) that can produce a valid HTML document. The HTML document character set for HTML 4.0 consists of most, but not all, of the characters jointly defined by Unicode and ISO/IEC 10646: the Universal Character Set (UCS).
Like HTML documents, an XHTML document is a sequence of Unicode characters. However, an XHTML document is an XML document, which, while not having an explicit «document character» layer of abstraction, nevertheless relies upon a similar definition of permissible characters that cover most, but not all, of the Unicode/UCS character definitions. The sets used by HTML and XHTML/XML are slightly different, but these differences have little effect on the average document author.
Regardless of whether the document is HTML or XHTML, when stored on a file system or transmitted over a network, the document’s characters are encoded as a sequence of bit octets (bytes) according to a particular character encoding. This encoding may either be a Unicode Transformation Format, like UTF-8, that can directly encode any Unicode character, or a legacy encoding, like Windows-1252, that cannot. However, even when using encodings that do not support all Unicode characters, the encoded document may make use of numeric character references. For example, ☺ (☺) is used to indicate a smiling face character in the Unicode character set.
Character encoding[edit]
In order to support all Unicode characters without resorting to numeric character references, a web page must have an encoding covering all of Unicode. The most popular is UTF-8, where the ASCII characters, such as English letters, digits, and some other common characters are preserved unchanged against ASCII. This makes HTML code (such as <br> and </div>) unchanged compared to ASCII. Characters outside the ASCII range are stored in 2–4 bytes. It is also possible to use UTF-16 where most characters are stored as two bytes with varying endianness, which is supported by modern browsers but less commonly used.
Numeric character references[edit]
In order to work around the limitations of legacy encodings, HTML is designed such that it is possible to represent characters from the whole of Unicode inside an HTML document by using a numeric character reference: a sequence of characters that explicitly spell out the Unicode code point of the character being represented. A character reference takes the form &#N;, where N is either a decimal number for the Unicode code point, or a hexadecimal number, in which case it must be prefixed by x. The characters that compose the numeric character reference are universally representable in every encoding approved for use on the Internet.[citation needed]
The support for hexadecimal in this context is more recent, so older browsers might have problems displaying characters referenced with hexadecimal numbers – but they will probably have a problem displaying Unicode characters above code point 255 anyway. To ensure better compatibility with older browsers, it is still a common practice to convert the hexadecimal code point into a decimal value (for example 合 instead of 合).[citation needed]
Named character entities[edit]
In HTML 4, there is a standard set of 252 named character entities for characters — some common, some obscure — that are either not found in certain character encodings or are markup sensitive in some contexts (for example angle brackets and quotation marks). Although any Unicode character can be referenced by its numeric code point, some HTML document authors prefer to use these named entities instead, where possible, as they are less cryptic and were better supported by early browsers.
Character entities can be included in an HTML document via the use of entity references, which take the form &EntityName;, where EntityName is the name of the entity. For example, —, much like — or —, represents U+2014: the em dash character «—» even if the character encoding used doesn’t contain that character.
For the full list, see: List of XML and HTML character entity references.
Character encoding determination[edit]
In order to correctly process HTML, a web browser must ascertain which Unicode characters are represented by the encoded form of an HTML document. In order to do this, the web browser must know what encoding was used.
Encoding information[edit]
When a document is transmitted via a MIME message or a transport that uses MIME content types such as an HTTP response, the message may signal the encoding via a Content-Type header, such as Content-Type: text/html; charset=UTF-8. Other external means of declaring encoding are permitted but rarely used. If the document uses a Unicode encoding, the encoding info might also be present in the form of a byte order mark (BOM). Finally, the encoding can be declared via the HTML syntax. For the text/html serialisation then, as long as the page is encoded in an extension of ASCII (such as UTF-8, and thus, not if the page is using UTF-16), a meta element, like <meta http-equiv="content-type" content="text/html; charset=UTF-8"> or (starting with HTML5) <meta charset="UTF-8"> can be used. For HTML pages serialized as XML, then declaration options is to either rely on the encoding default (which for XML documents is UTF-8), or to use an XML encoding declaration. The meta attribute plays no role in HTML served as XML.
Encoding defaults[edit]
An encoding default applies when there is no external or internal encoding declaration and also no byte order mark. While the encoding default for HTML pages served as XML is required to be UTF-8, the encoding default for a regular Web page (that is: for HTML pages serialized as text/html) varies depending on the localization of the browser. For a system set up mainly for Western European languages, it will generally be Windows-1252. For Cyrillic alphabet locales, the default is typically Windows-1251. For a browser from a location where legacy multi-byte character encodings are prevalent, some form of auto-detection is likely to be applied.
Encoding trends[edit]
Because of the legacy of 8-bit text representations in programming languages and operating systems and the desire to avoid burdening users with the need to understand the nuances of encoding, many text editors used by HTML authors are unable or unwilling to offer a choice of encodings when saving files to disk and often do not even allow input of characters beyond a very limited range. Consequently, many HTML authors are unaware of encoding issues and may not have any idea what encoding their documents actually use. Misunderstandings, such as the belief that the encoding declaration affects a change in the actual encoding (whereas it is actually just a label that could be inaccurate), is also a reason for this editor attitude. Another factor contributing in the same direction, is the arrival of UTF-8 – which greatly diminishes the need for other encodings, and thus modern editors tends to default, as recommended by the HTML5 specification,[1] to UTF-8.
Byte order mark/Unicode sniffing[edit]
For both serializations of HTML (content-type «text/html» and content/type «application/xhtml+xml»), the byte order mark (BOM) is an effective way to transmit encoding information within an HTML document. For UTF-8, the BOM is optional, while it is a must for the UTF-16 and the UTF-32 encodings. (Note: UTF-16 and UTF-32 without the BOM are formally known under different names, they are different encodings, and thus needs some form of encoding declaration – see UTF-16BE, UTF-16LE, UTF-32LE and UTF-32BE.) The use of the BOM character (U+FEFF) means that the encoding automatically declares itself to any processing application. Processing applications need only look for an initial 0x0000FEFF, 0xFEFF or 0xEFBBBF in the byte stream to identify the document as UTF-32, UTF-16 or UTF-8 encoded respectively. No additional metadata mechanisms are required for these encodings since the byte-order mark includes all of the information necessary for processing applications. In most circumstances, the byte-order mark character is handled by editing applications separately from the other characters so there is little risk of an author removing or otherwise changing the byte order mark to indicate the wrong encoding (as can happen when the encoding is declared in English/Latin script). If the document lacks a byte-order mark, the fact that the first non-blank printable character in an HTML document is supposed to be «<» (U+003C) can be used to determine a UTF-8/UTF-16/UTF-32 encoding.
Encoding overriding[edit]
Many HTML documents are served with inaccurate encoding information, or no encoding information at all. In order to determine the encoding in such cases, many browsers allow the user to manually select an encoding name from a list. They may also employ an encoding auto-detection algorithm that works in concert with or – in the case of the BOM and in case of HTML served as XML – against the manual override.
For HTML documents which are text/html serialized, manual override may apply to all documents, or only those for which the encoding cannot be ascertained by looking at declarations and/or byte patterns. The fact that the manual override is present and widely used hinders the adoption of accurate encoding declarations on the Web; therefore the problem is likely to persist. But note that Internet Explorer, Chrome and Safari – for both XML and text/html serializations – do not permit the encoding to be overridden whenever the page includes the BOM.[2]
For HTML documents serialized with the preferred XML label – application/xhtml+xml, manual encoding override is not permitted. To override the encoding of such an XML document would mean that the document stopped being XML, as it is a fatal error for XML documents to have an encoding declaration with detectable errors. Currently, Gecko browsers such as Firefox, abide to this rule, whereas the bulk of the other common browsers that support HTML as XML, such as Webkit browsers (Chrome/Safari) [3] do allow the encoding of XHTML documents to be manually overridden.
Web browser support[edit]
Many browsers are only capable of displaying a small subset of the full Unicode repertoire. Here is how your browser displays various Unicode code points:
| Character | HTML char ref | Unicode name | What your browser displays |
|---|---|---|---|
| U+0041 | A or A
|
Latin capital letter A | A |
| U+00DF | ß or ß
|
Latin small letter Sharp S | ß |
| U+00FE | þ or þ
|
Latin small letter Thorn | þ |
| U+0394 | Δ or Δ
|
Greek capital letter Delta | Δ |
| U+017D | Ž or Ž
|
Latin capital letter Z with háček | Ž |
| U+0419 | Й or Й
|
Cyrillic capital letter Short I | Й |
| U+05E7 | ק or ק
|
Hebrew letter Qof | ק |
| U+0645 | م or م
|
Arabic letter Meem | م |
| U+0E57 | ๗ or ๗
|
Thai digit 7 | ๗ |
| U+1250 | ቐ or ቐ
|
Ge’ez syllable Qha | ቐ |
| U+3042 | あ or あ
|
Hiragana letter A (Japanese) | あ |
| U+53F6 | 叶 or 叶
|
CJK Unified Ideograph-53F6 (Simplified Chinese «Leaf») | 叶 |
| U+8449 | 葉 or 葉
|
CJK Unified Ideograph-8449 (Traditional Chinese «Leaf») | 葉 |
| U+B5AB | 떫 or 떫
|
Hangul syllable Tteolp (Korean «Ssangtikeut Eo Rieulbieup») | 떫 |
| U+16A0 | ᚠ or ᚠ
|
Runic letter Fehu | ᚠ |
| U+0D37 | ഷ or ഷ
|
Malayalam letter ഷ (ṣha) | ഷ |
| U+1F602 | 😂 or 😂
|
Face with Tears of Joy emoji | 😂 |
| To display all of the characters above, you may need to install one or more large multilingual fonts, like Code2000. |
Some web browsers, such as Mozilla Firefox, Opera, Safari and Internet Explorer (from version 7 on), are able to display multilingual web pages by intelligently choosing a font to display each individual character on the page. They will correctly display any mix of Unicode blocks, as long as appropriate fonts are present in the operating system.
Older browsers, such as Netscape Navigator 4.77 and Internet Explorer 6, can only display text supported by the current font associated with the character encoding of the page, and may misinterpret numeric character references as being references to code values within the current character encoding, rather than references to Unicode code points. When you are using such a browser, it is unlikely that your computer has all of those fonts, or that the browser can use all available fonts on the same page. As a result, the browser will not display the text in the examples above correctly, though it may display a subset of them. Because they are encoded according to the standard, though, they will display correctly on any system that is compliant and does have the characters available. Further, those characters given names for use in named entity references are likely to be more commonly available than others.
For displaying characters outside the Basic Multilingual Plane, such as the Gothic letter faihu, which is a variant of the runic letter fehu in the table above, some systems (like Windows 2000) need manual adjustments of their settings.
Frequency of usage[edit]
According to internal data from Google’s web index, in December 2007 the UTF-8 Unicode encoding became the most frequently used encoding on web pages, overtaking both ASCII (US) and 8859-1/1252 (Western European).[4]
See also[edit]
- Help file for using special characters on Wikipedia
- Character encodings in HTML
- Charset detection
- Unicode character reference (wikibooks)
References[edit]
- ^ Ian Hickson (2011). «HTML5». Retrieved 17 September 2011.
Authors are encouraged to use UTF-8. Conformance checkers may advise authors against using legacy encodings. [RFC3629] Authoring tools should default to using UTF-8 for newly created documents. [RFC3629]
- ^ «12897 – In some parsers, UTF-8 BOM trumps the HTTP charset attribute (Encoding sniffing algorithm)». www.w3.org. Retrieved 2023-03-09.
- ^ «66189 – XML parser doesn’t emit FATAL ERROR for all, detectable encoding errors». bugs.webkit.org. Retrieved 2023-03-09.
- ^ Mark Davis: Moving to Unicode 5.1 Official Google blog, 5 May 2008
External links[edit]
- Unicode in XML and other Markup Languages — a W3C & Unicode Consortium joint publication that describes issues and provides guidelines relating to Unicode in markup languages
- Latin-1, «Special», and Mathematical, Greek and Symbolic named character entity definitions for HTML 4.01
- UnicodeMap.org — Browse Unicode characters, ranges, and other information
- SIL’s freeware fonts, editors and documentation
- Alan Wood’s Unicode Resources — Unicode fonts and information.
- http://www.phon.ucl.ac.uk/home/wells/ipa-unicode.htm The International Phonetic Alphabet in Unicode
- http://www.alanwood.net/unicode/cjk_compatibility_ideographs.html CJK Compatibility Ideographs
- http://www.unicode.org/charts/ Unicode character charts; hexadecimal numbers only; PDF files showing all characters independent of browser capabilities
- Table of Unicode characters from 1 to 65535 Archived 2007-11-03 at the Wayback Machine — shows how they look in one’s browser
- Web tool that converts «special» characters (such as Chinese characters) to Unicode numeric character references
- Multi-lingual web pages and Unicode — how to fix display problems
- w3.org via web.archive.org — Original HTML5 Citation Reference saved via Wayback Machine